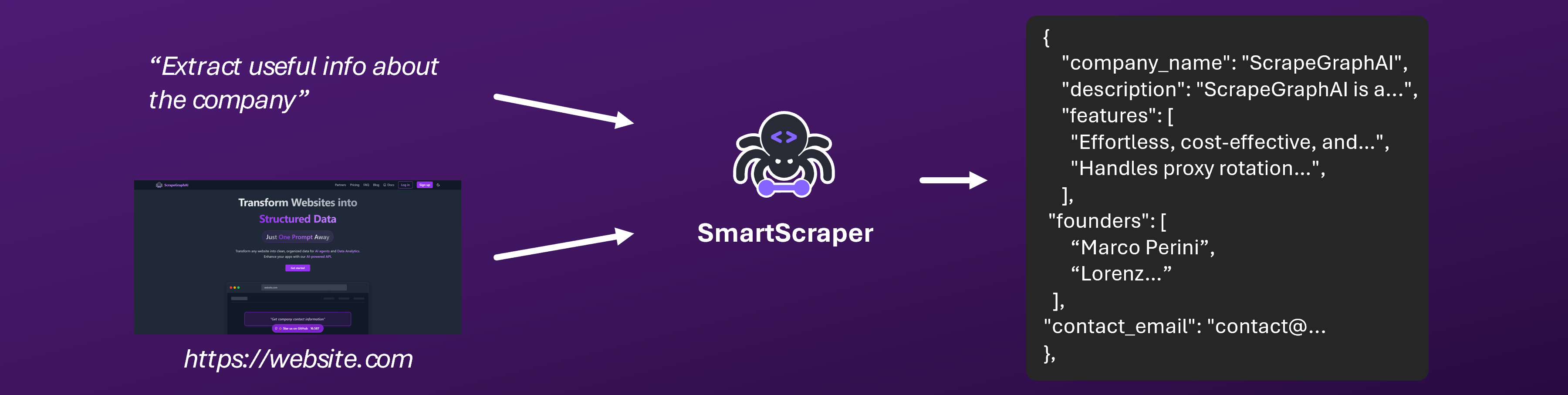
Overview
SmartScraper supports pagination functionality to extract data from multiple pages of a website. This is particularly useful for:- E-commerce product listings
- News article collections
- Job listing aggregations
- Any content spread across multiple pages
Pagination Parameters
Core Parameters
| Parameter | Type | Required | Default | Range | Description |
|---|---|---|---|---|---|
total_pages | integer | No | 1 | 1-10 | Number of pages to scrape |
number_of_scrolls | integer | No | 0 | 0-10 | Number of scrolls per page |
wait_for | integer | No | 0 | 0-30 | Wait time in seconds between actions |
Advanced Parameters
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
pagination_delay | integer | No | 2 | Delay between page requests (seconds) |
scroll_delay | integer | No | 1 | Delay between scrolls (seconds) |
max_items_per_page | integer | No | 100 | Maximum items to extract per page |
Basic Usage
Python SDK
JavaScript SDK
Advanced Pagination Examples
E-commerce Product Scraping
News Article Collection
Job Listing Aggregation
Pagination Strategies
1. Sequential Pagination
For websites with traditional page-based navigation:2. Infinite Scroll Pagination
For websites with infinite scroll or “Load More” buttons:3. Hybrid Approach
Combine both strategies for complex websites:Best Practices
1. Start Small and Scale Up
2. Optimize Prompts for Pagination
3. Handle Rate Limiting
4. Error Handling and Retries
Common Use Cases
E-commerce Scraping
Social Media Monitoring
News Aggregation
Troubleshooting
Common Issues
Pagination Not Working
Pagination Not Working
Problem: Data is only extracted from the first page.Solutions:
- Verify the website supports pagination
- Check if
total_pagesparameter is set correctly - Ensure the URL includes proper pagination parameters
- Try increasing
number_of_scrollsfor infinite scroll sites
Rate Limiting
Rate Limiting
Problem: Requests are being rate limited.Solutions:
- Reduce
total_pagesvalue - Increase
wait_forandpagination_delay - Implement exponential backoff
- Use async clients for better performance
Incomplete Data
Incomplete Data
Problem: Not all expected data is extracted.Solutions:
- Increase
number_of_scrollsfor dynamic content - Add
wait_forparameter for slow-loading pages - Refine your user prompt for better extraction
- Check if the website requires authentication
API Errors
API Errors
Problem: Getting API errors during pagination.Solutions:
- Verify your API key is valid
- Check your API usage limits
- Ensure the website URL is accessible
- Review error messages for specific issues
Performance Optimization
Async Processing
Batch Processing
API Reference
For detailed API documentation, see:Support & Resources
Pagination Examples
Complete pagination examples with code
API Reference
Detailed API documentation
Community
Join our Discord community
GitHub
Check out our open-source projects
Need Help?
Contact our support team for assistance with pagination or any other questions!