Try it yourself in our interactive notebooks:
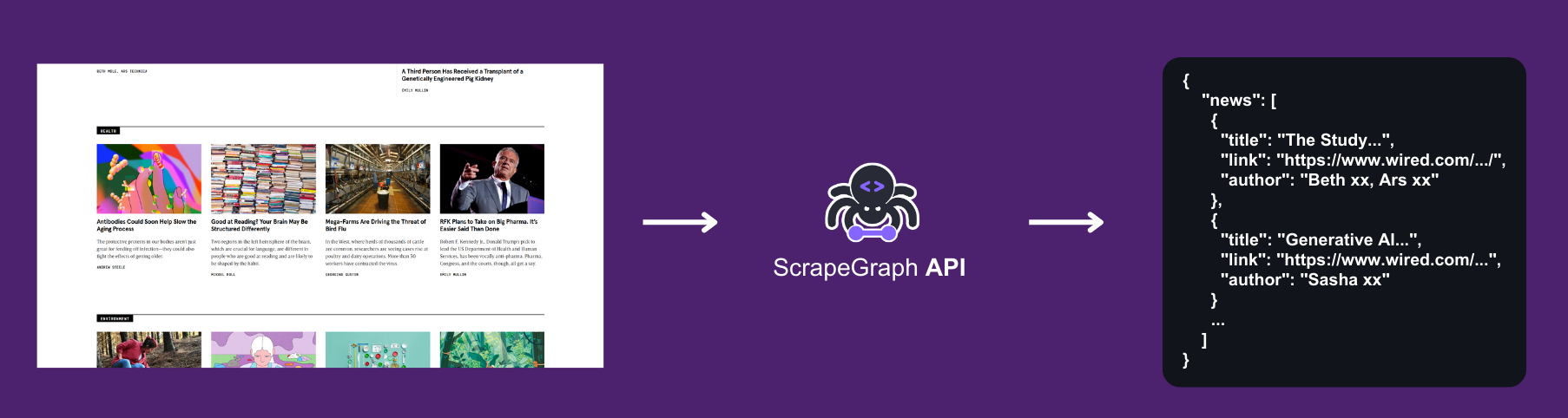
The Goal
We’ll extract the following article information:| Field | Description |
|---|---|
| Category | Article category (e.g., ‘Health’, ‘Environment’) |
| Title | Article headline |
| Link | URL to the full article |
| Author | Writer’s name |
Code Example
Example Output
SmartScraper
Learn more about our AI-powered extraction service
Python SDK
Explore our Python SDK documentation
Have a suggestion for a new example? Contact us with your use case or contribute directly on GitHub.