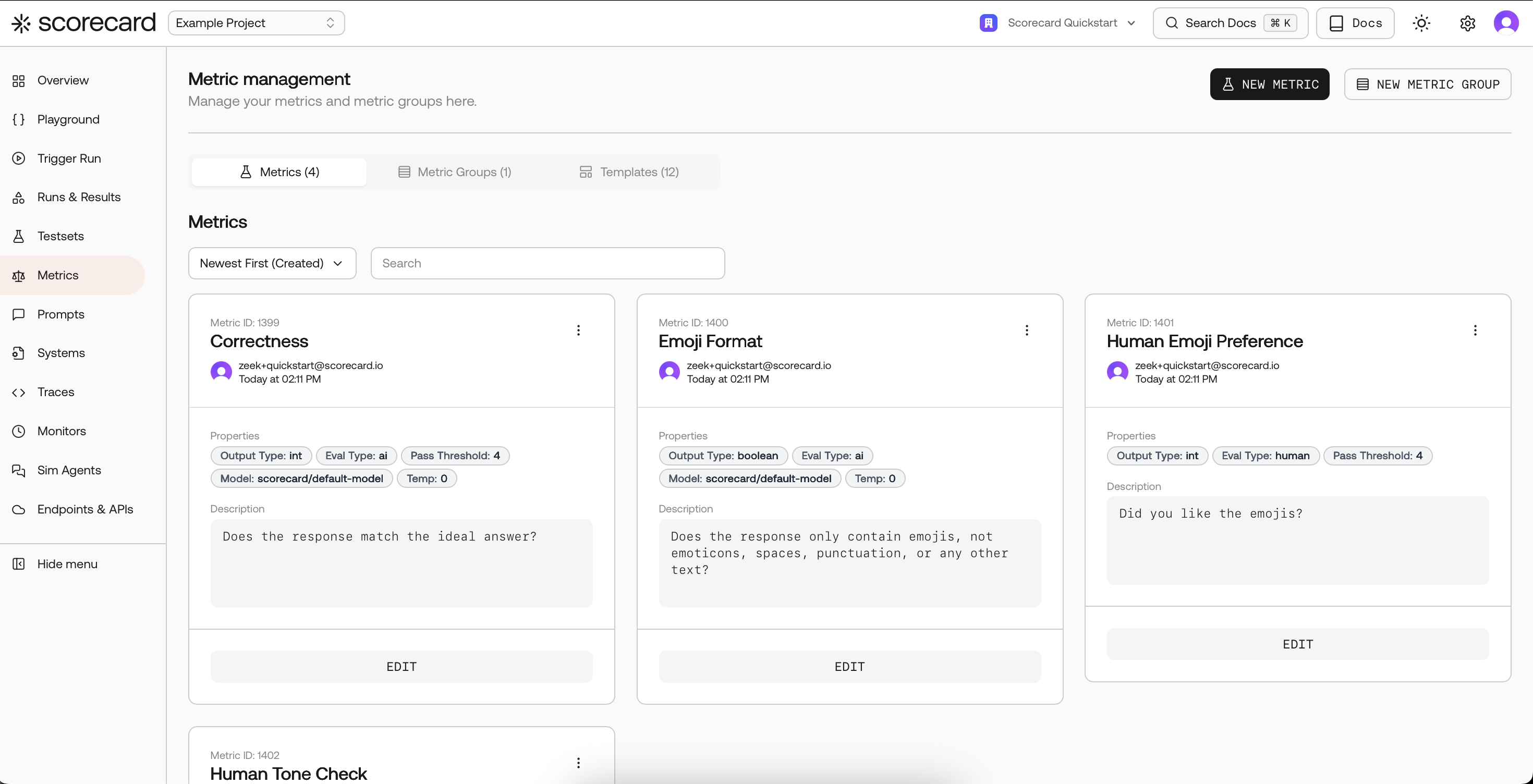
Metrics page with Metrics, Groups, and Templates tabs.
1
Open Metrics and explore templates
Go to your project’s Metrics page. Start fast by copying a proven template, then tailor the guidelines to your domain.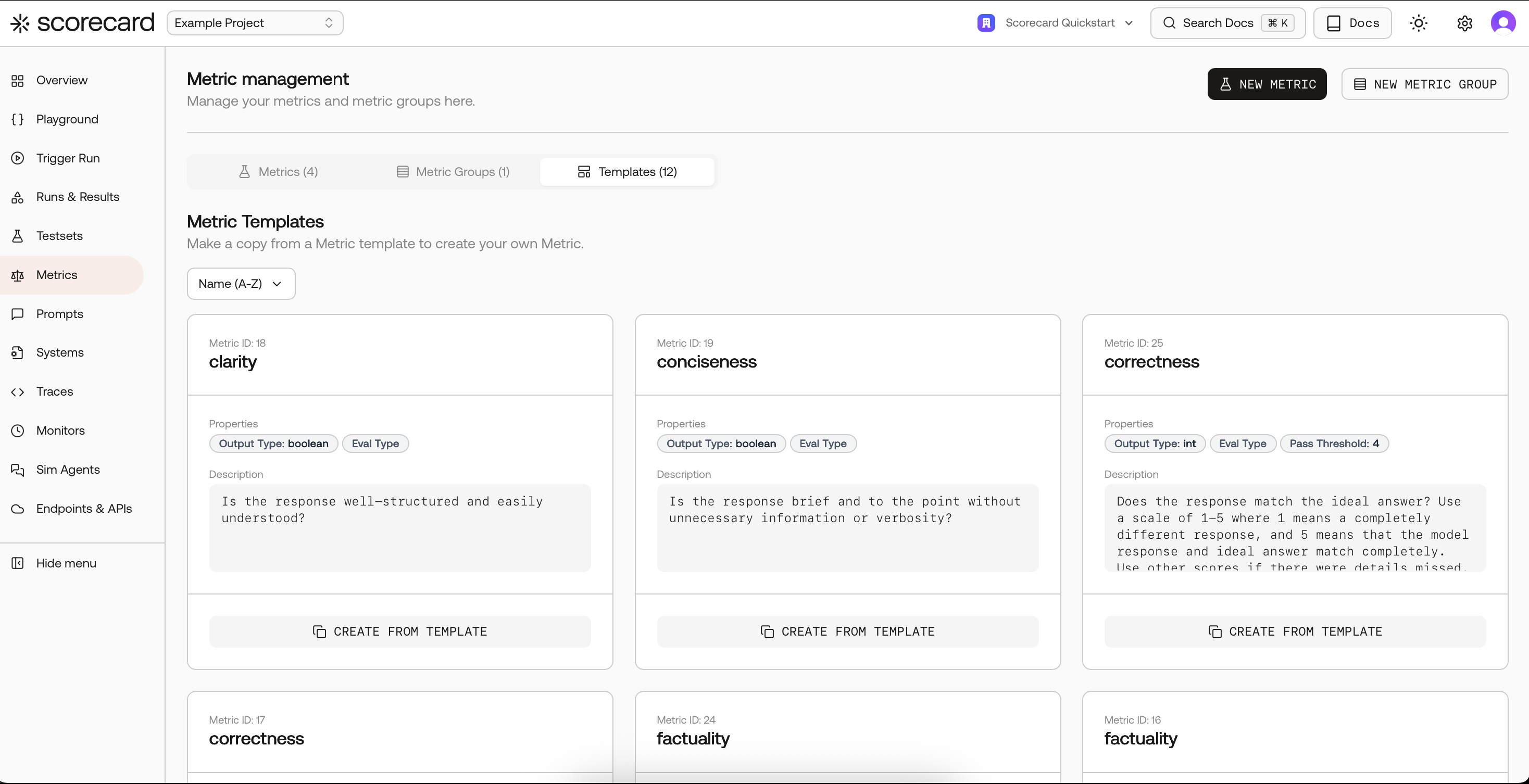
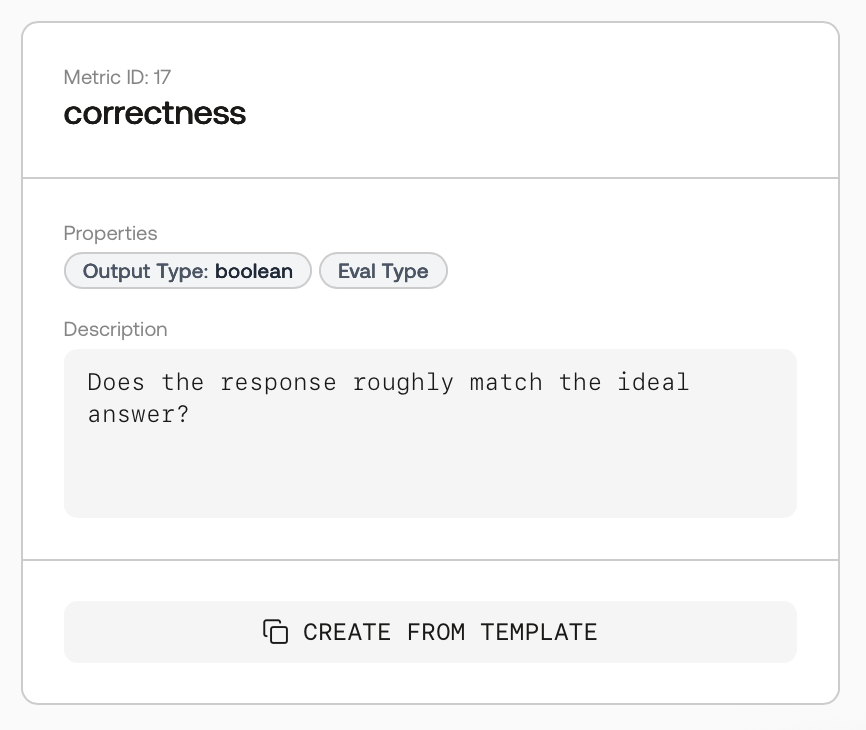
Templates list with Create from Template.
Template details with description and output type.
2
Create your first metric (AI‑scored)
You can also create a metric from scratch. Provide a name, description, clear guidelines, and choose an Evaluation Type and Output Type.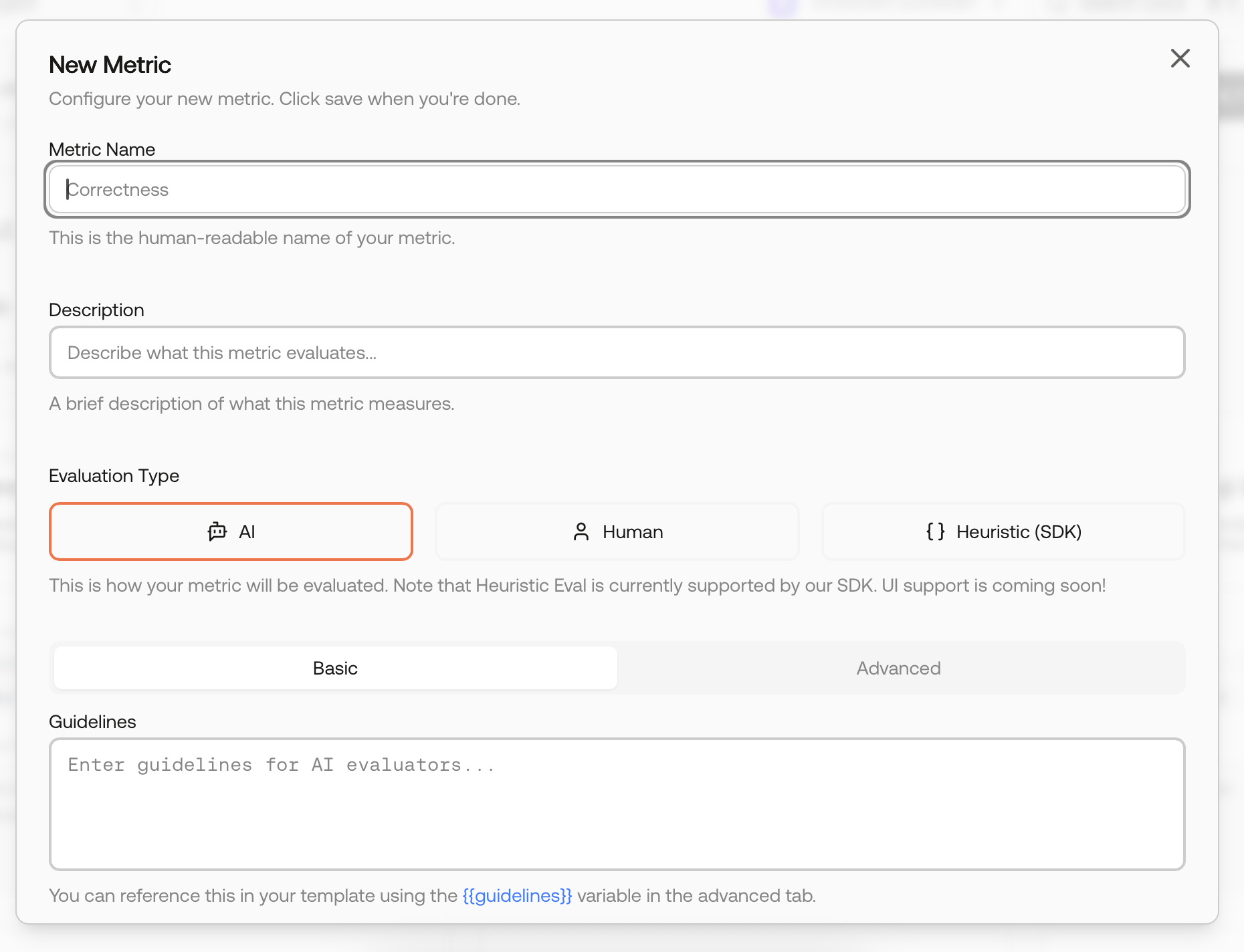
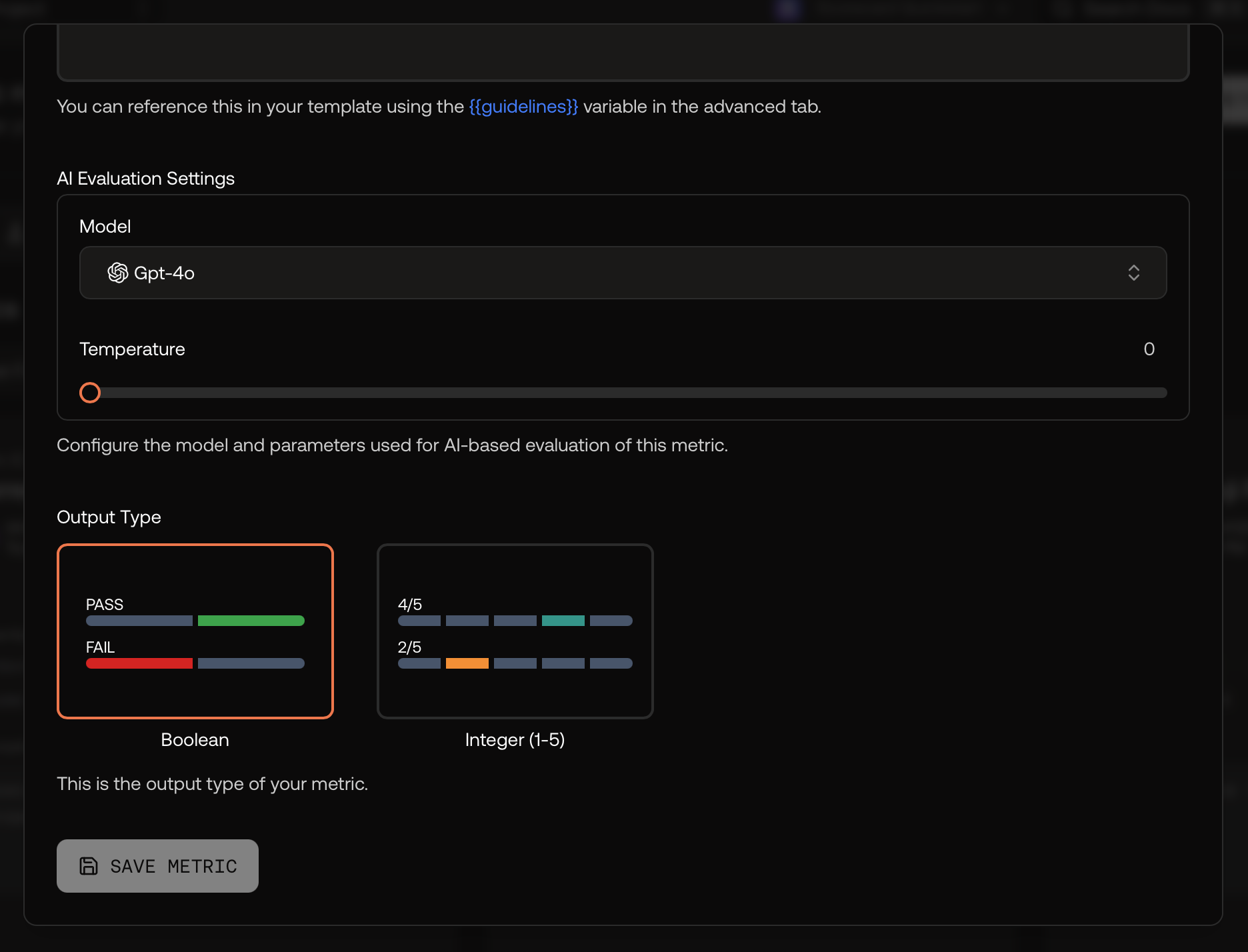
 For AI‑scored metrics, pick the evaluator model and keep temperature low for repeatability.
For AI‑scored metrics, pick the evaluator model and keep temperature low for repeatability.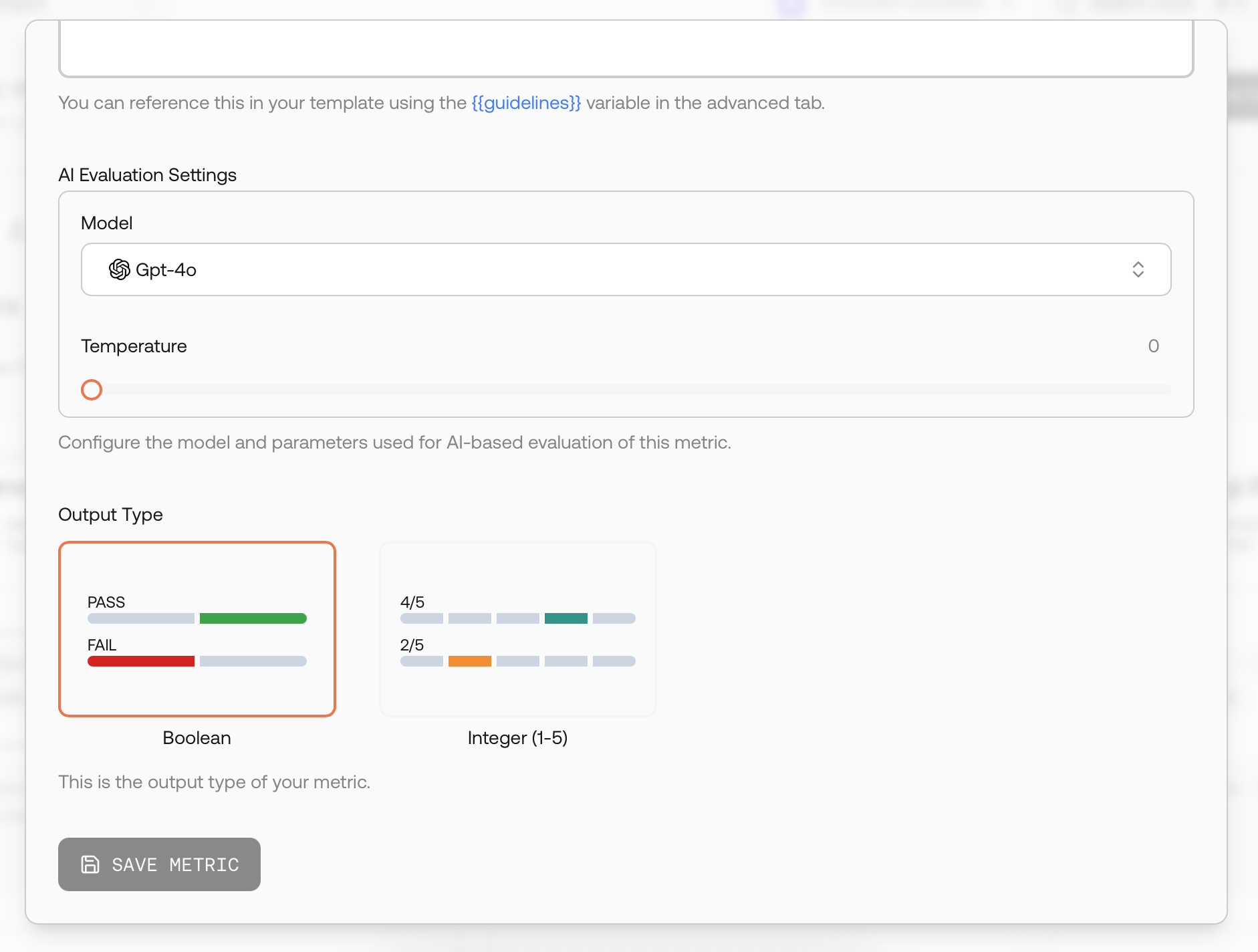


New Metric modal – name, description, evaluation type, and guidelines.
AI evaluator settings and output type.
Choose Boolean (pass/fail) or Integer (1–5).
Guidelines matter. Describe what to reward and what to penalize, and include 1–2 concise examples if helpful. These instructions become the core of the evaluator prompt.
3
Optional: Human‑scored metric
Some criteria are best judged by humans. Select Human as the evaluation type and write clear instructions for reviewers.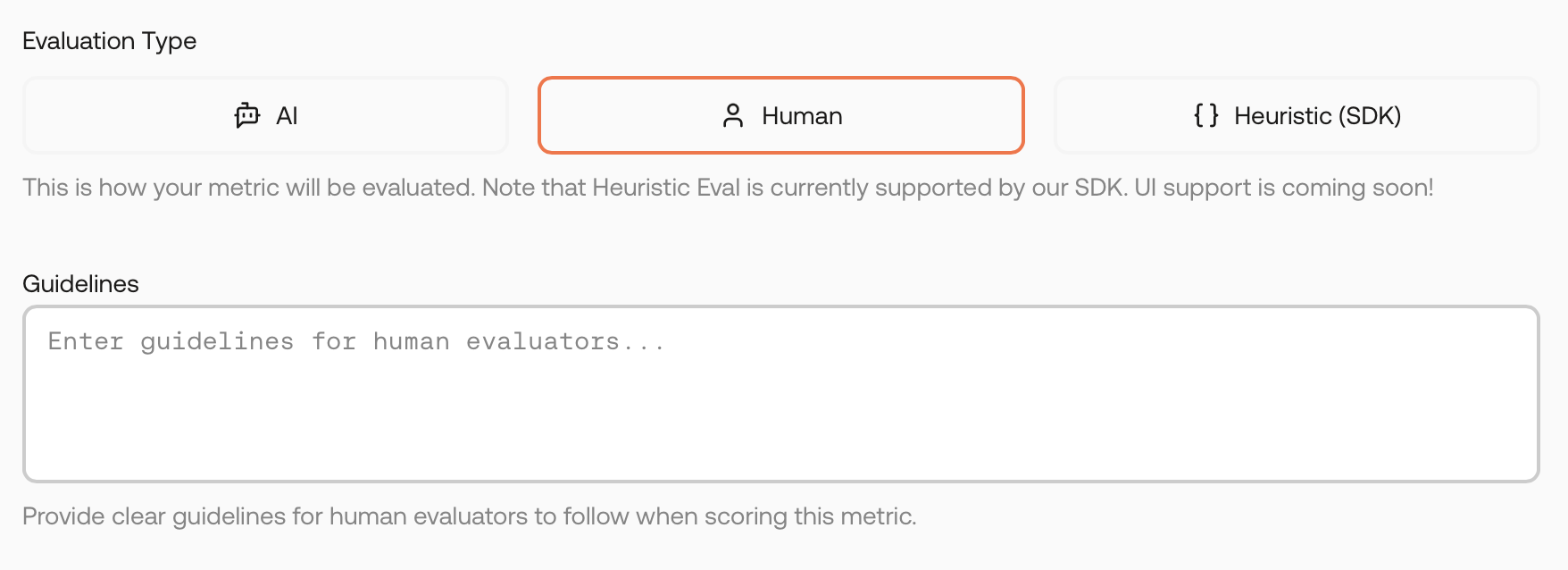
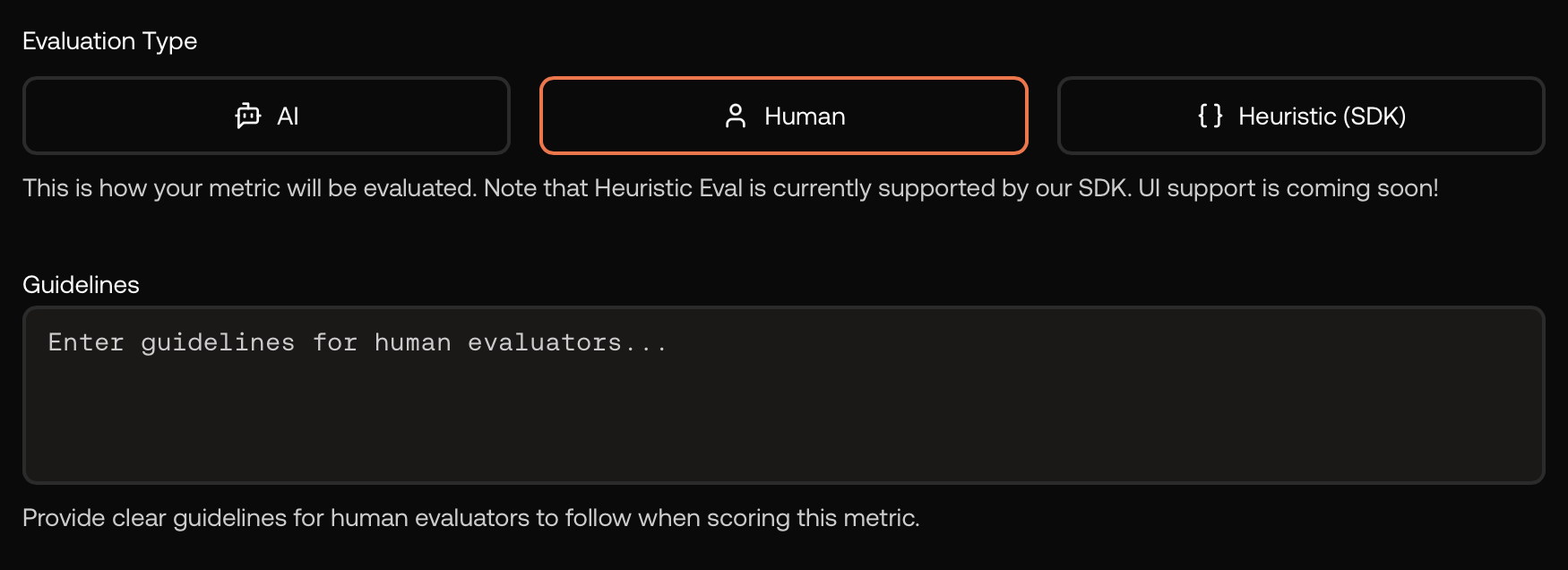
Human evaluation – provide instructions for reviewers.
4
Create a Metric Group
Group related metrics (e.g., Groundedness + Relevance + Safety) so you can select them together during a run.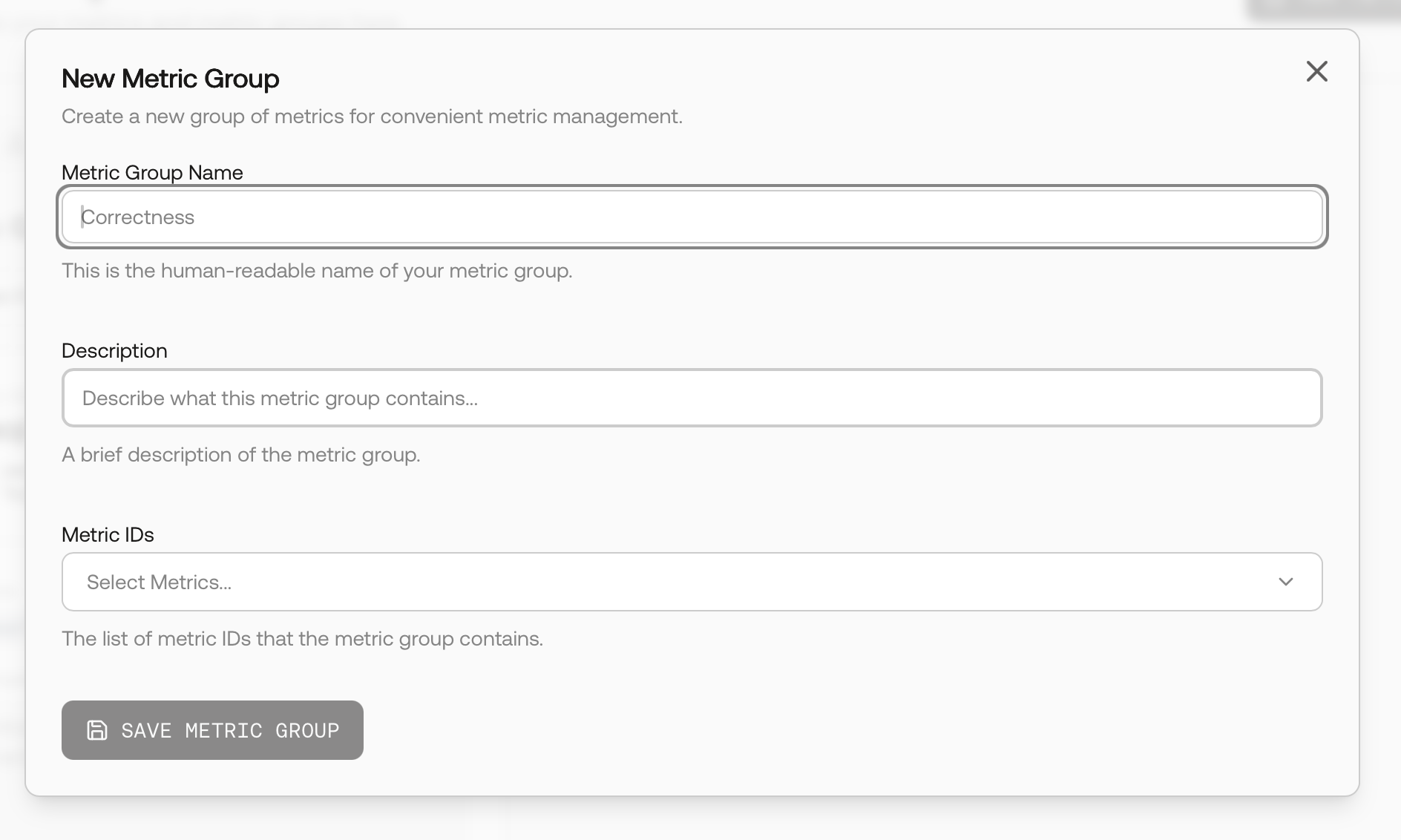
 After saving, you’ll see your groups alongside individual metrics.
After saving, you’ll see your groups alongside individual metrics.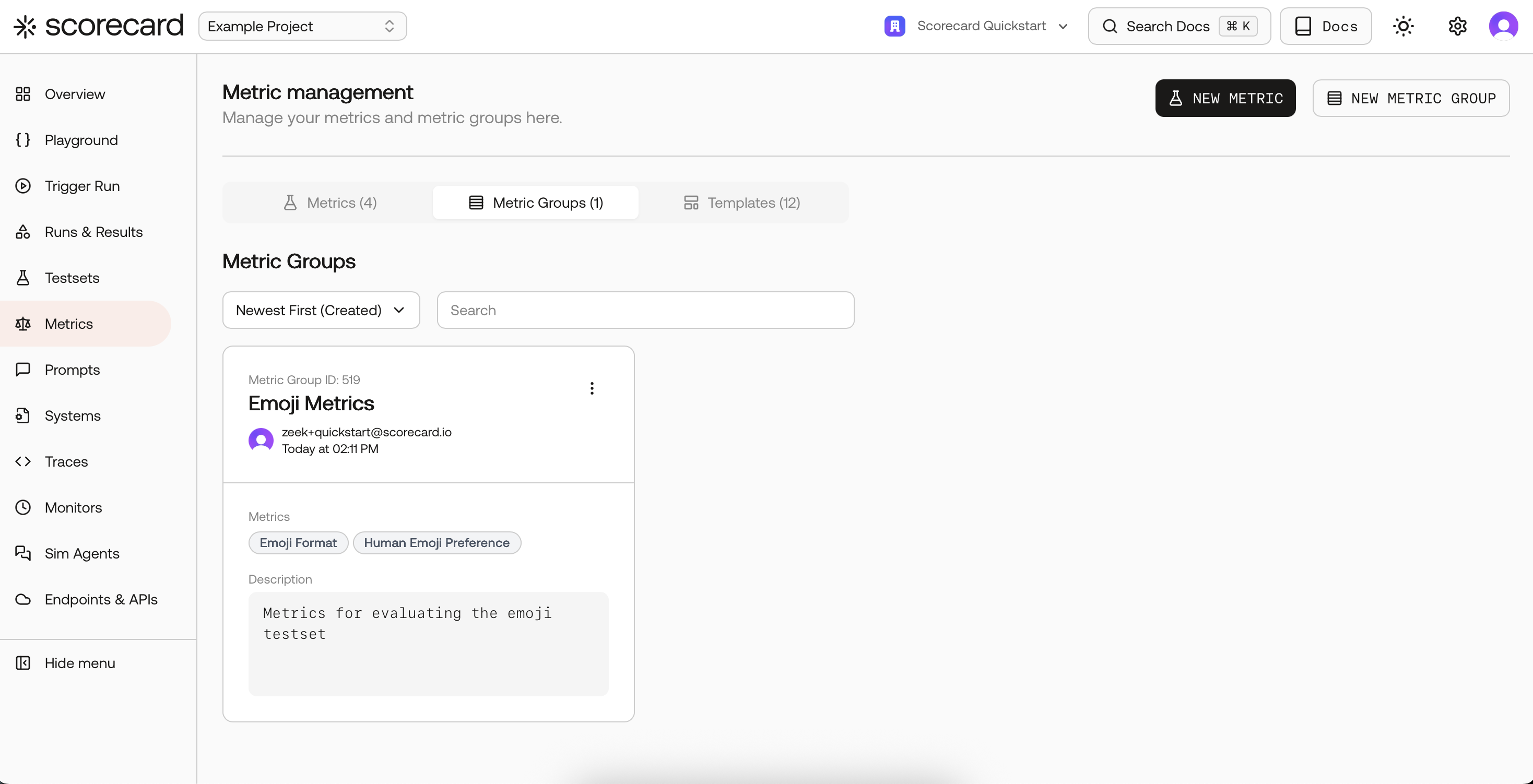
Create a Metric Group and select metrics to include.
Metric Groups overview.
5
Kick off a Run and pick metrics
Start a run from your project dashboard, Playground, or Runs list. In the Kickoff Run modal, choose a Testset, select your System or Endpoint, and add one or more Metrics or a Metric Group.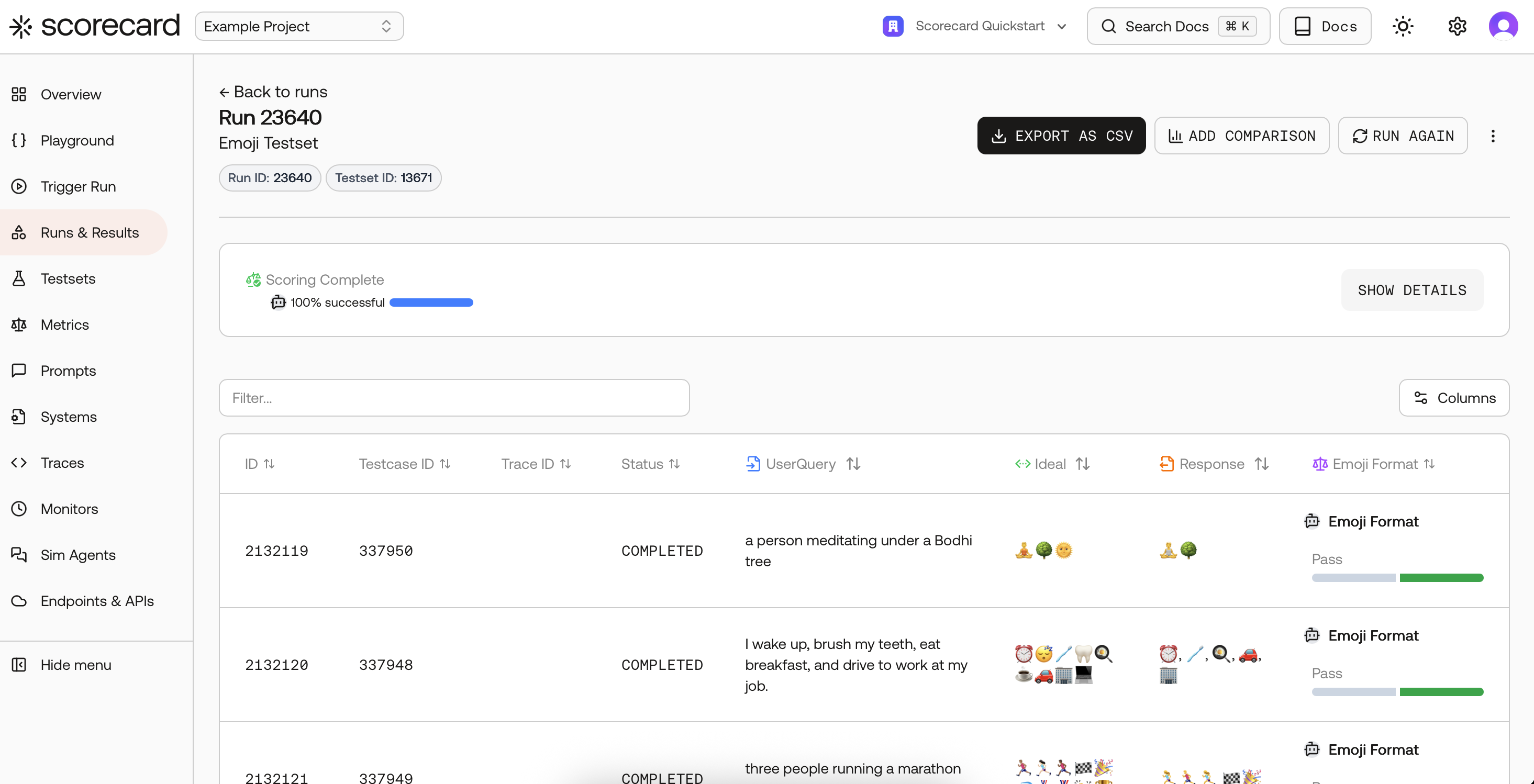
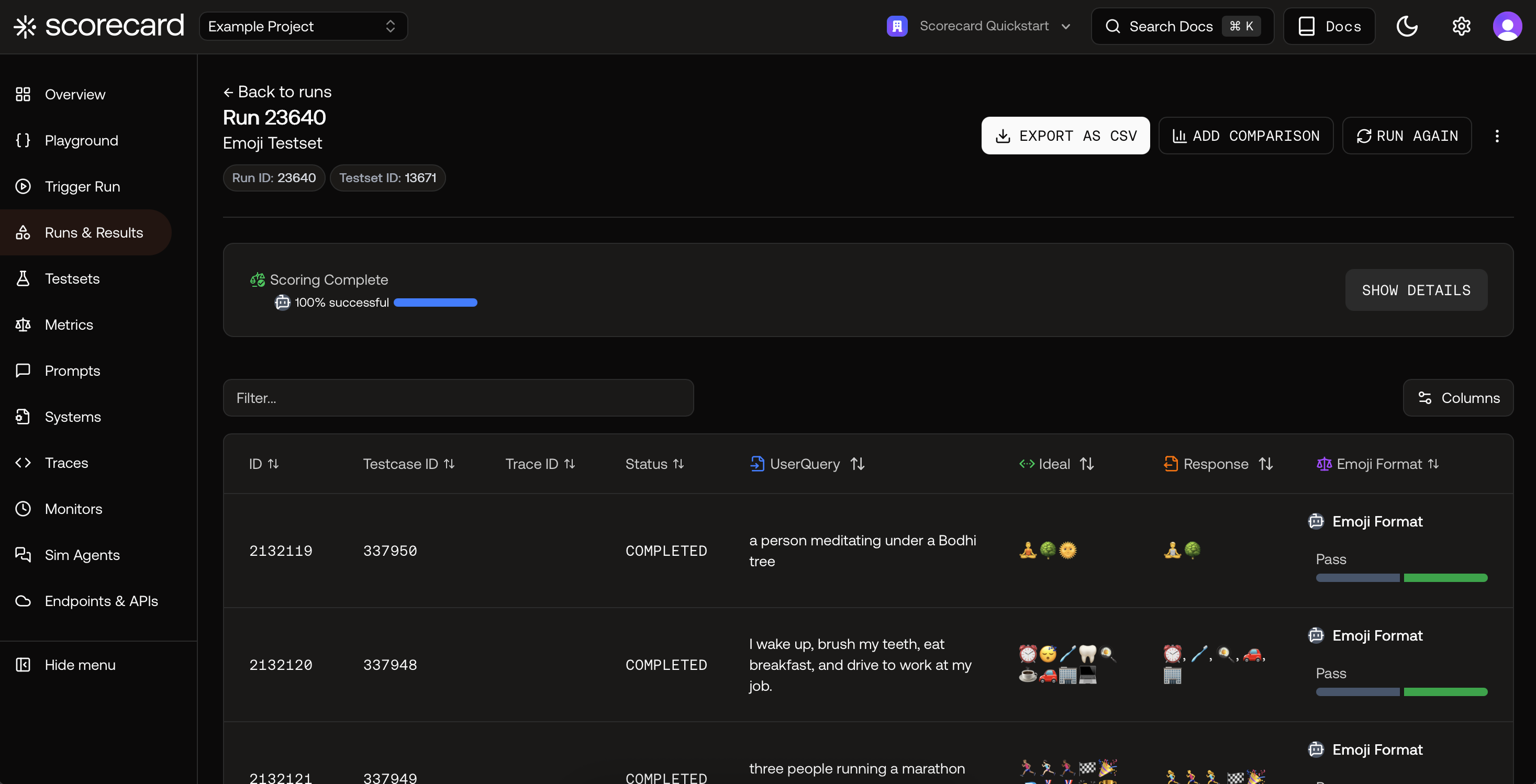
- Pick individual metrics by name, or select a Metric Group for consistency.
- Integer metrics show an average on the run; Boolean metrics show pass‑rate.
- Runs with human‑scored metrics will show status Scoring until reviewers submit results.
Run results with per‑record scores.
6
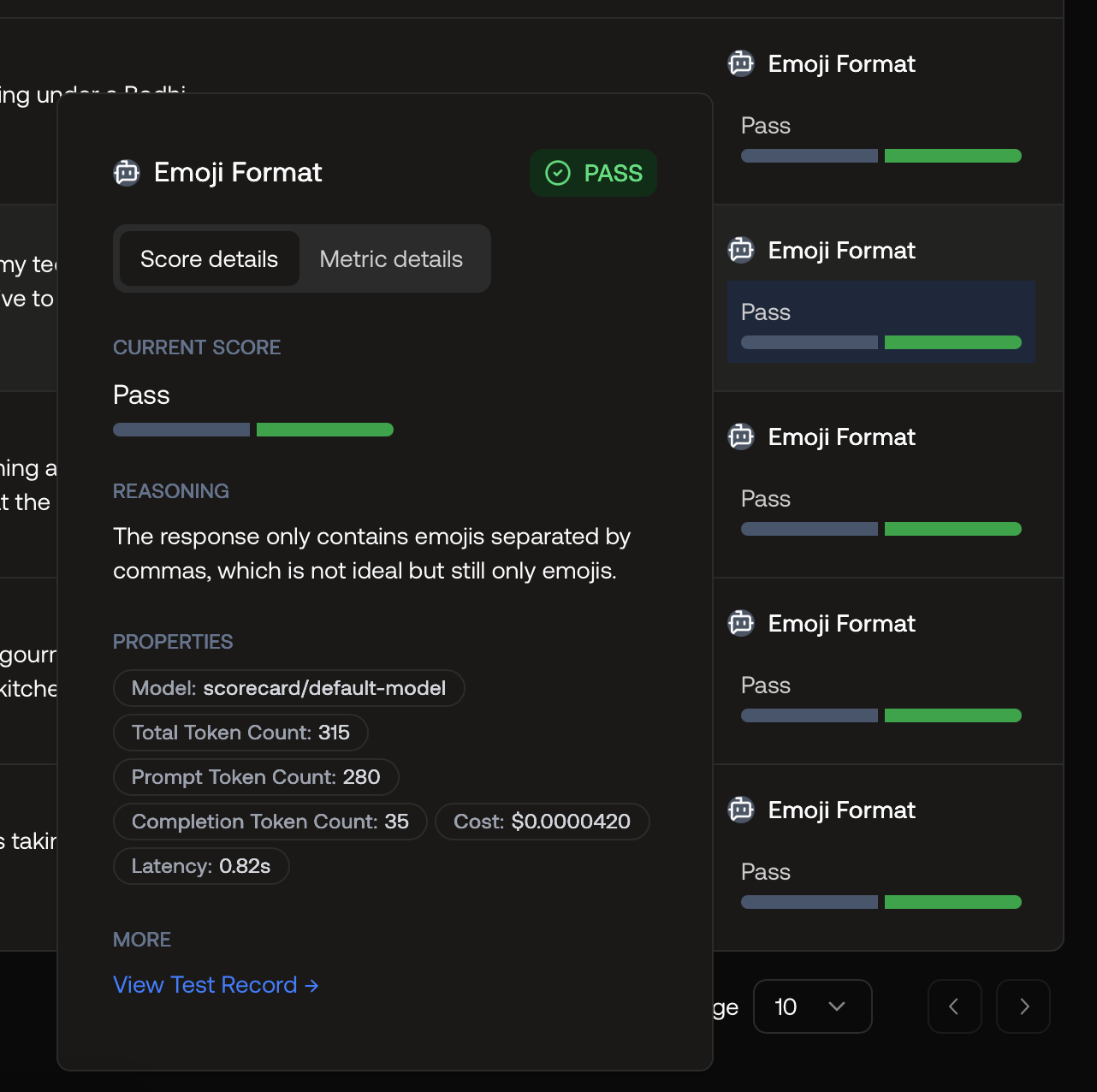
Inspect scores and explanations
Hover over or click a score to view the evaluator’s reasoning and properties. This helps validate and tune your guidelines.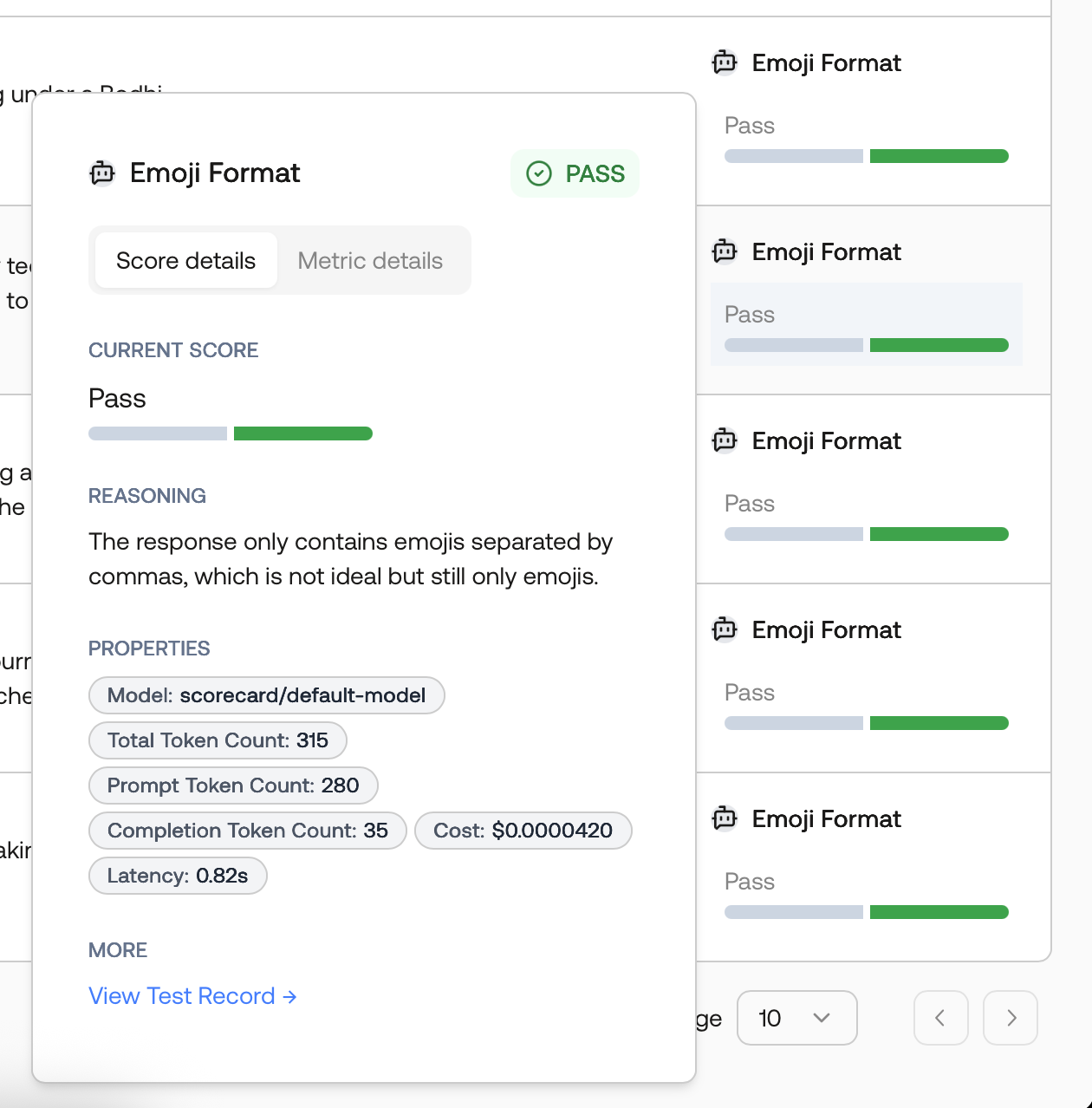
 Drill into any record to see inputs, outputs, expected outputs, and all scores together.
Drill into any record to see inputs, outputs, expected outputs, and all scores together.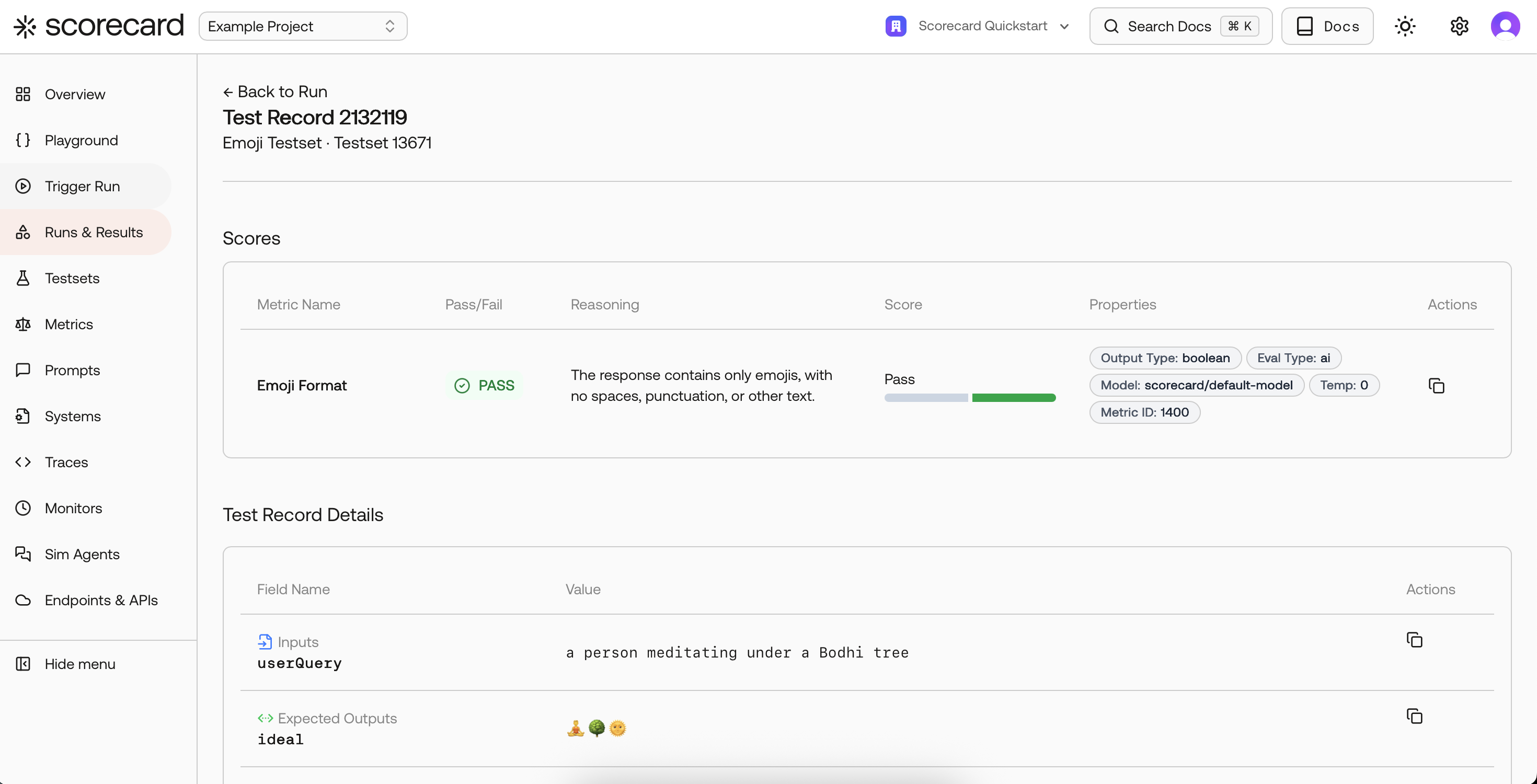
Score explanation with reasoning and model details.
Record view showing inputs/outputs and metric results.
Metric types
- AI‑scored: Uses a model to apply your guidelines consistently and at scale.
- Human‑scored: Great for nuanced judgments or gold‑standard baselines.
- Heuristic (SDK): Deterministic, code‑based checks via the SDK (e.g., latency, regex, policy flags).
- Output types: Choose Boolean (pass/fail) or Integer (1–5).
Second‑party metrics (optional)
If you already use established evaluation libraries, you can mirror those metrics in Scorecard:- MLflow genai: Relevance, Answer Relevance, Faithfulness, Answer Correctness, Answer Similarity
- RAGAS: Faithfulness, Answer Relevancy, Context Recall, Context Precision, Context Relevancy, Answer Semantic Similarity
Best practices for strong metrics
- Be specific. Minimize ambiguity in guidelines; include “what not to do.”
- Pick the right output type. Use Boolean for hard requirements; 1–5 for nuance.
- Keep temperature low. Use ≈0 for repeatable AI scoring.
- Pilot and tighten. Run on 10–20 cases, then refine wording to reduce false positives.
- Bundle into groups. Combine complementary checks (e.g., Relevance + Faithfulness + Safety) to keep evaluations consistent.
Looking for vetted, ready‑to‑use metrics? Explore Best‑in‑Class Metrics and copy templates (including MLflow and RAGAS). You can also create deterministic checks via the SDK using Heuristic metrics.
Related resources
Runs
Create and analyze evaluations
A/B Comparison
Compare two runs side‑by‑side
Monitoring
Continuously score production traffic
Best‑in‑Class Metrics
Explore curated, proven metrics
API Reference
Create metrics via API