Downloaded 1,000 times

![Definition Apache Cassandra is an open source, distributed, decentralized, elastically scalable, highly available, fault-tolerant, tuneably consistent, column-oriented database that bases its distribution design on Amazon’s Dynamo and its data model on Google’s Bigtable. Created at Facebook, it is now used at some of the most popular sites on the Web [The Definitive Guide, Eben Hewitt, 2010] 13/01/2014 Cassandra Introduction & Key Features by Philipp Potisk 2](https://image.slidesharecdn.com/cassandraintrofeatures-140115130458-phpapp01-140116140029-phpapp01/75/Cassandra-Introduction-Features-2-2048.jpg)










Apache Cassandra is an open-source, distributed, decentralized, and highly available database characterized by elastic scalability and tunable consistency, originally developed at Facebook. Key features include a column-oriented key-value store, a SQL-like query interface (CQL), and optimized high performance suitable for large-scale applications. Notable users like eBay employ Cassandra for various applications, including fraud detection and real-time insights.
Introduction to Apache Cassandra, its purpose, and context for the meetup.
Definition of Apache Cassandra as a highly available, fault-tolerant, decentralized database.
Historical context of Cassandra's development referencing Dynamo, Bigtable, and OpenSource.
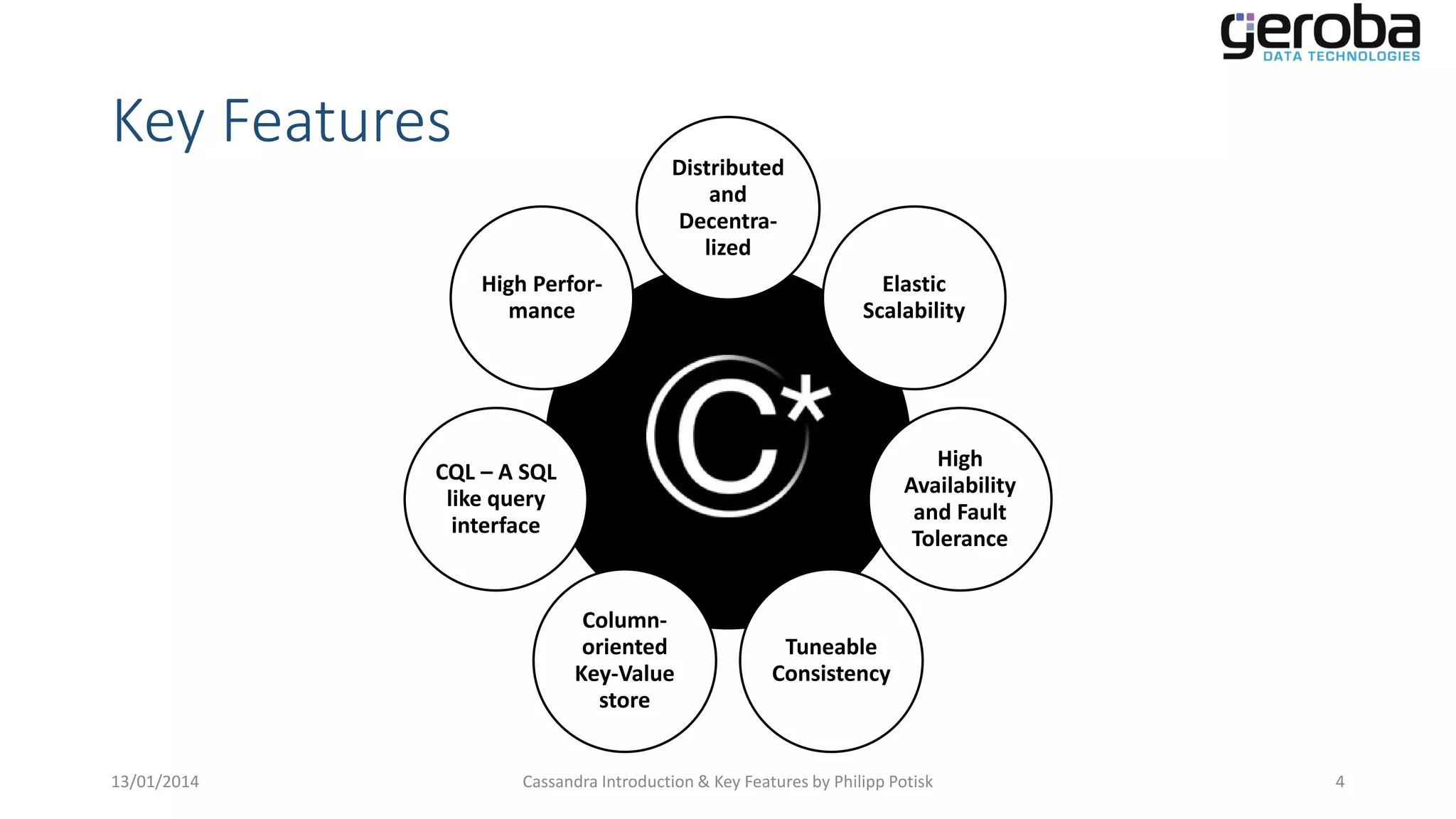
Highlights the essential features of Cassandra including distribution, scalability, and consistency.
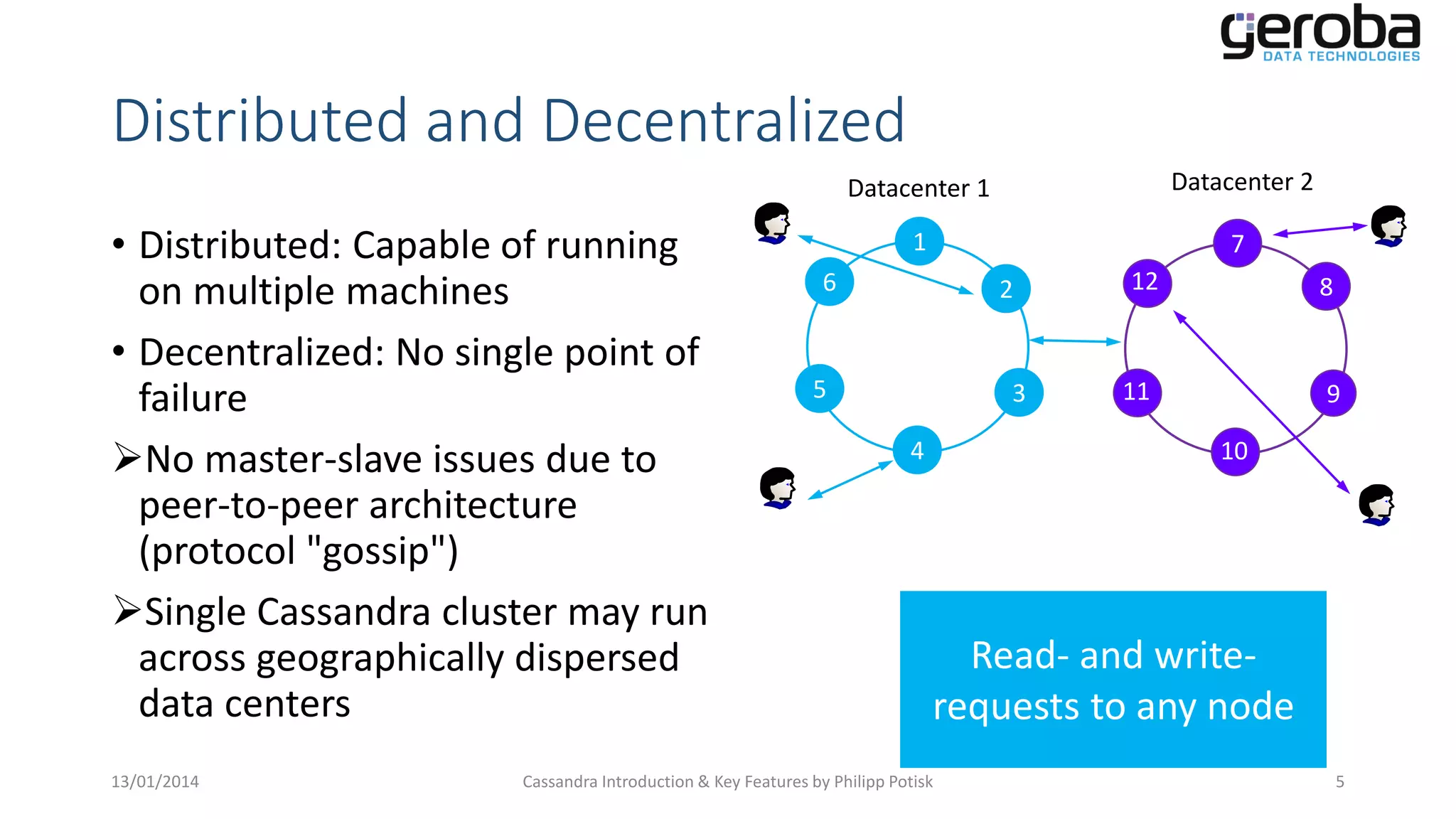
Explains the distributed architecture of Cassandra with peer-to-peer mechanics and geographical capabilities.
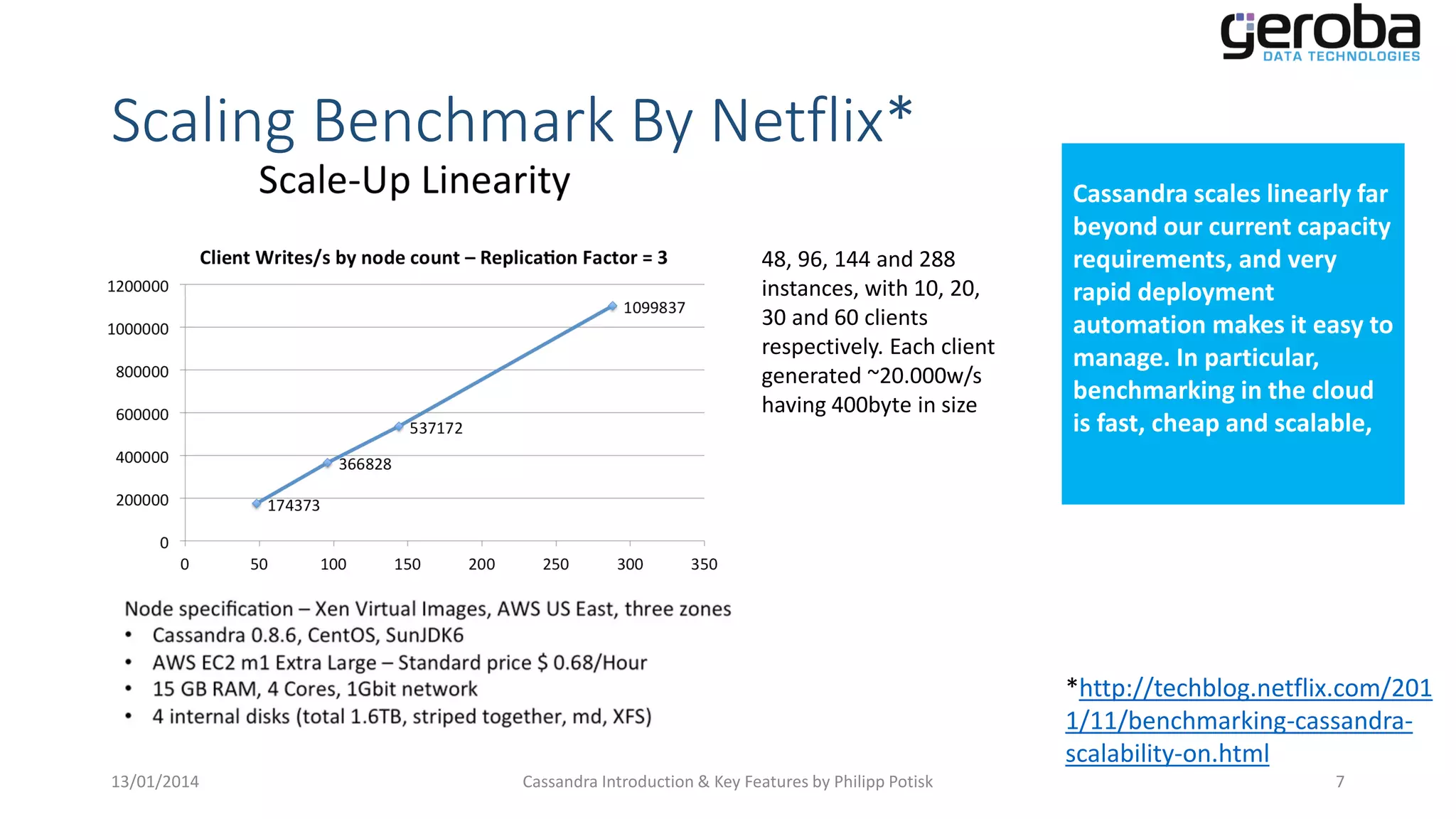
Details on Cassandra's ability to horizontally scale and maintain performance as nodes are added.
Netflix benchmark data showing Cassandra's linear scalability across various instances.
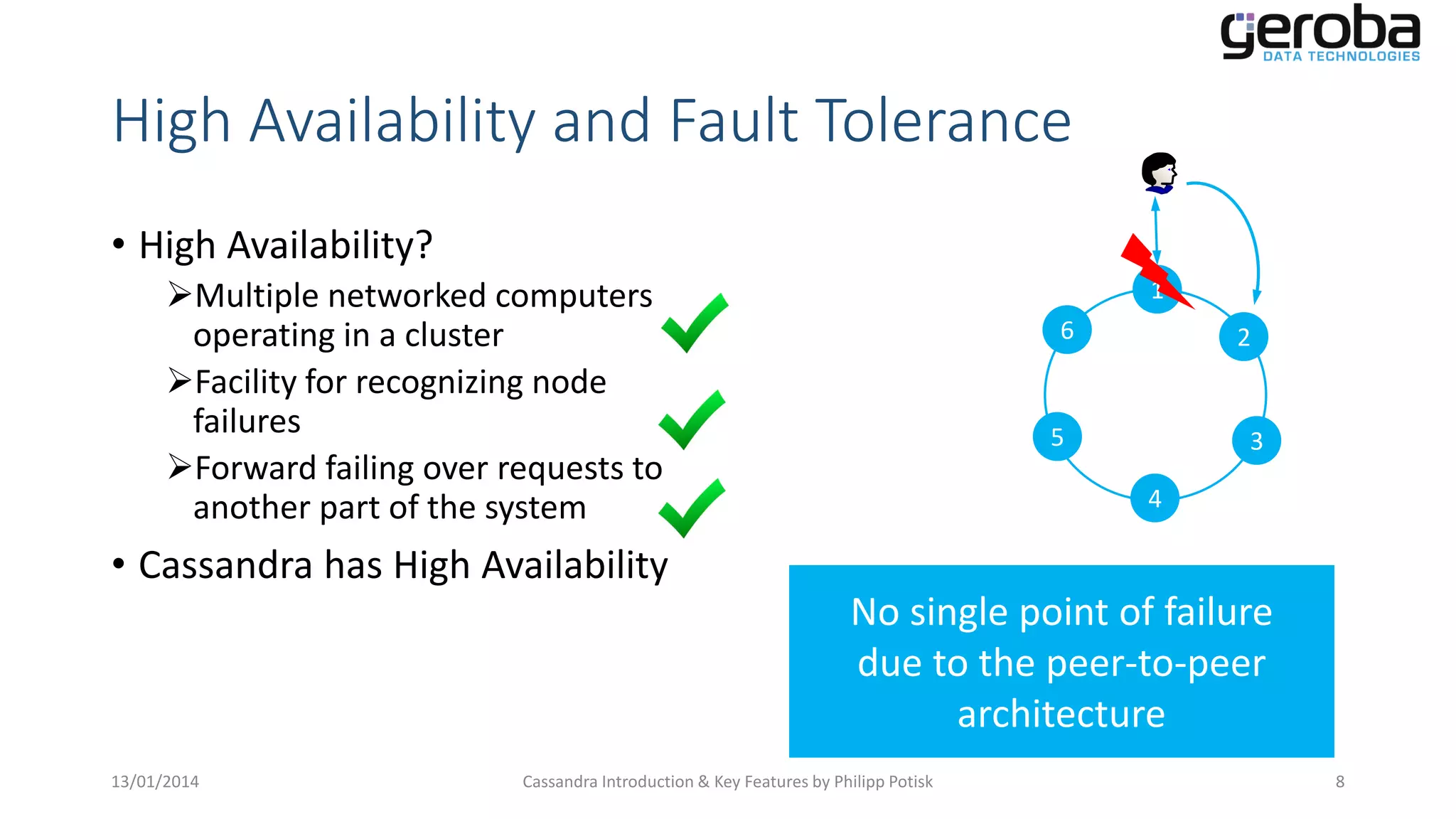
Describes the importance of high availability in Cassandra and its mechanism for handling node failures.
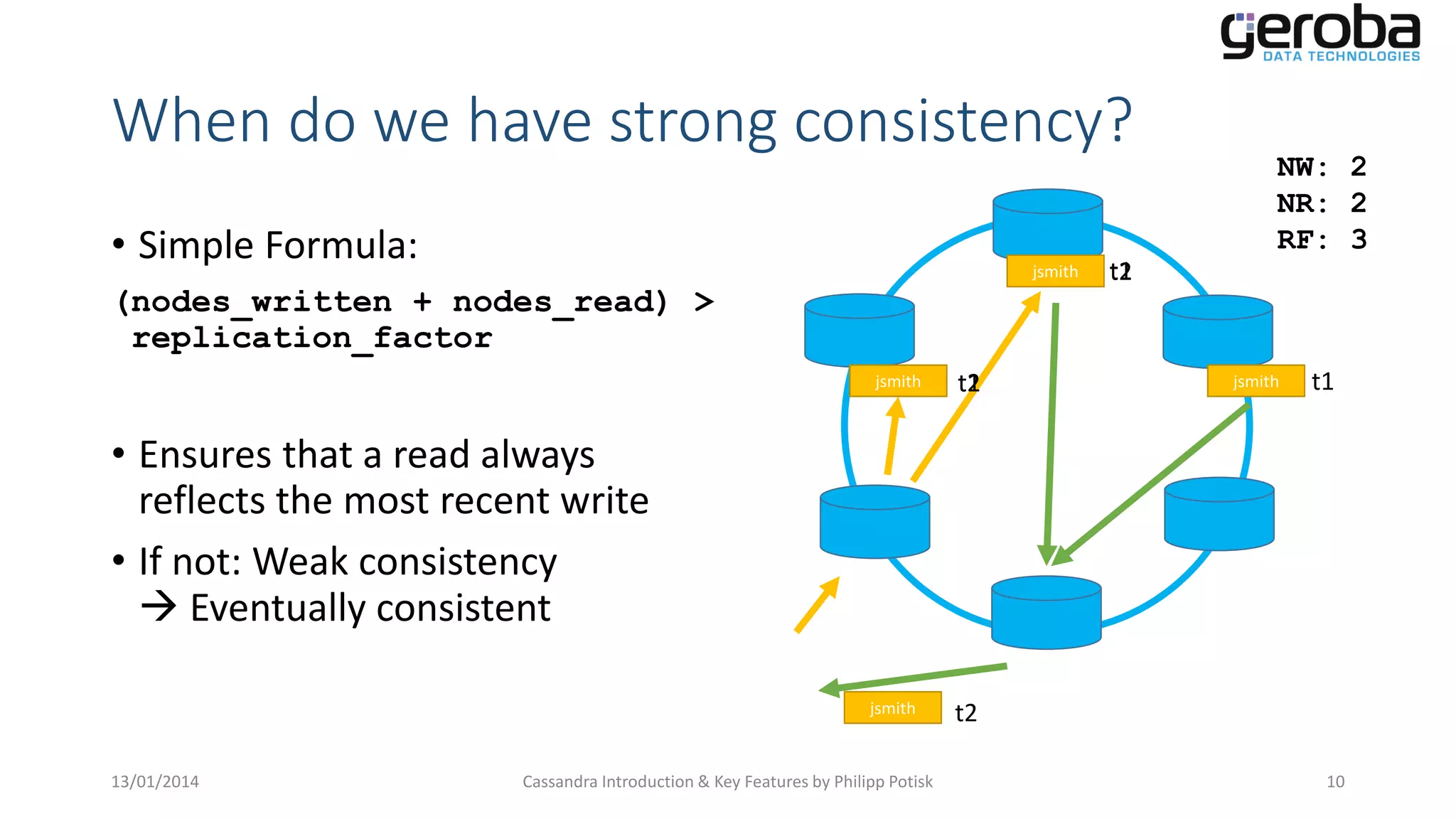
Explains how Cassandra allows tuning of consistency levels for read and write operations based on use cases.
Illustrates conditions for achieving strong consistency versus eventual consistency in operations.
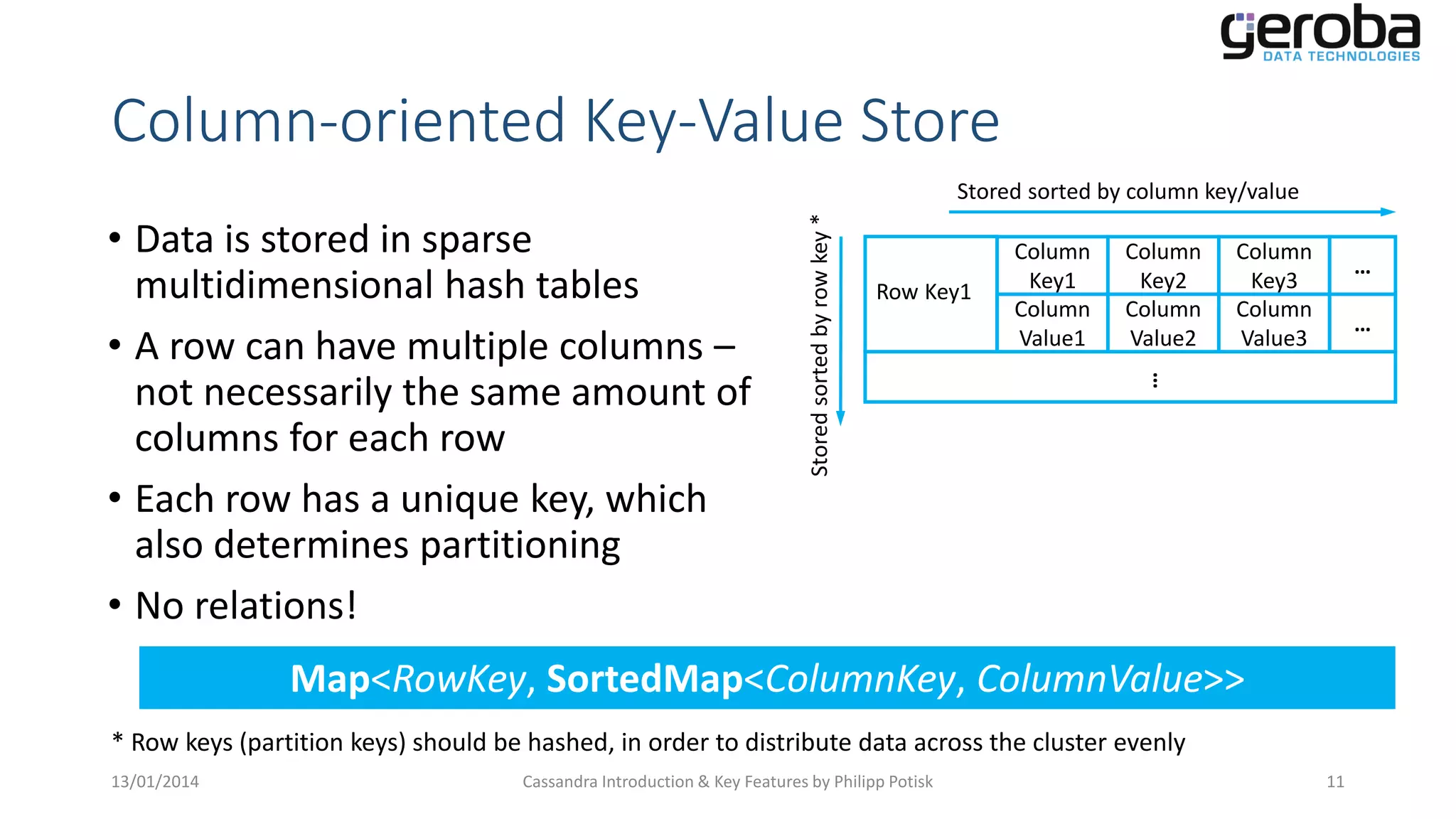
Describes how Cassandra stores data in a column-oriented key-value format without fixed schemas.
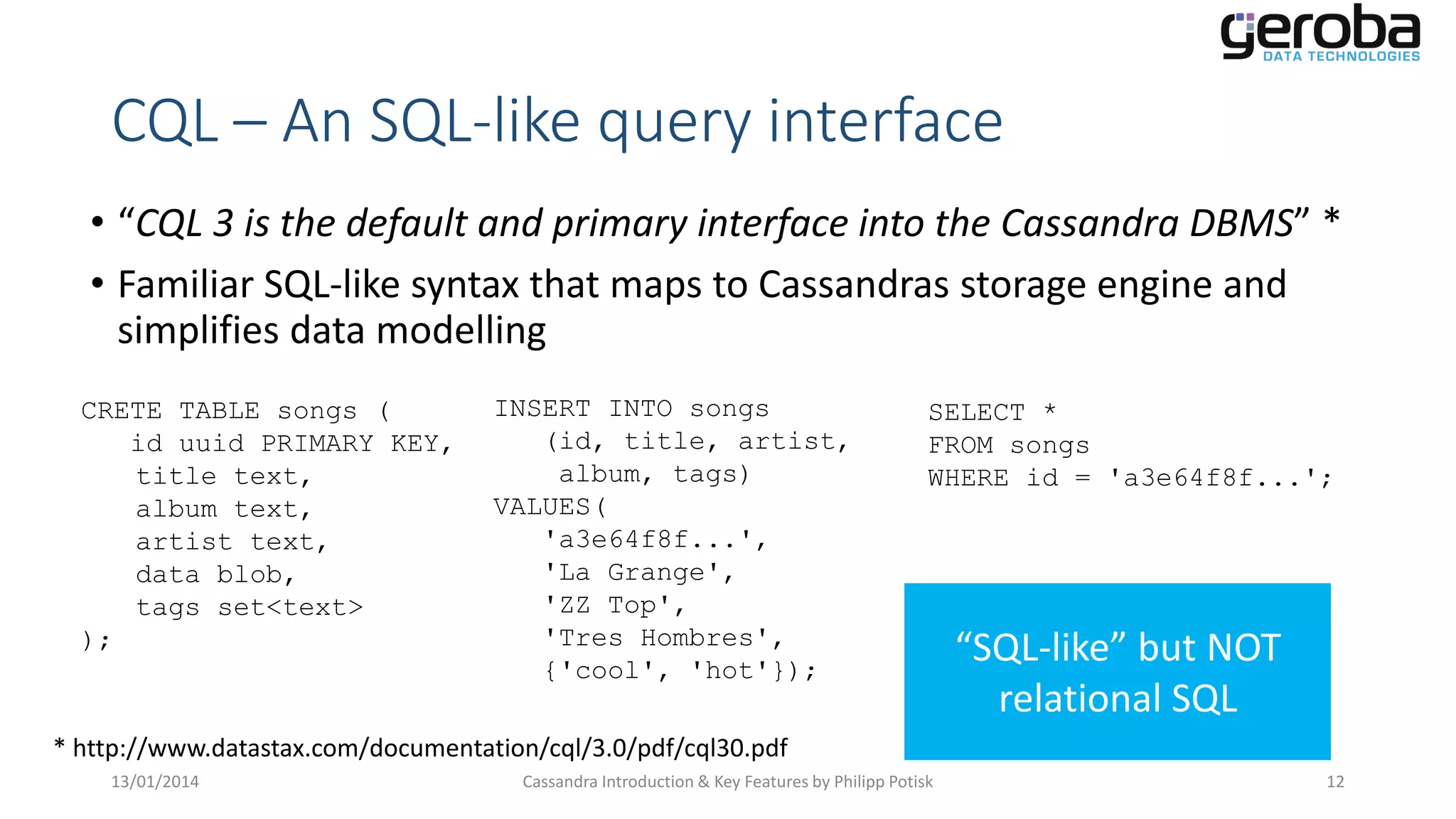
Overview of Cassandra Query Language (CQL) designed to simplify data interaction.
Details on Cassandra's design optimizations to ensure high write-throughput and performance.
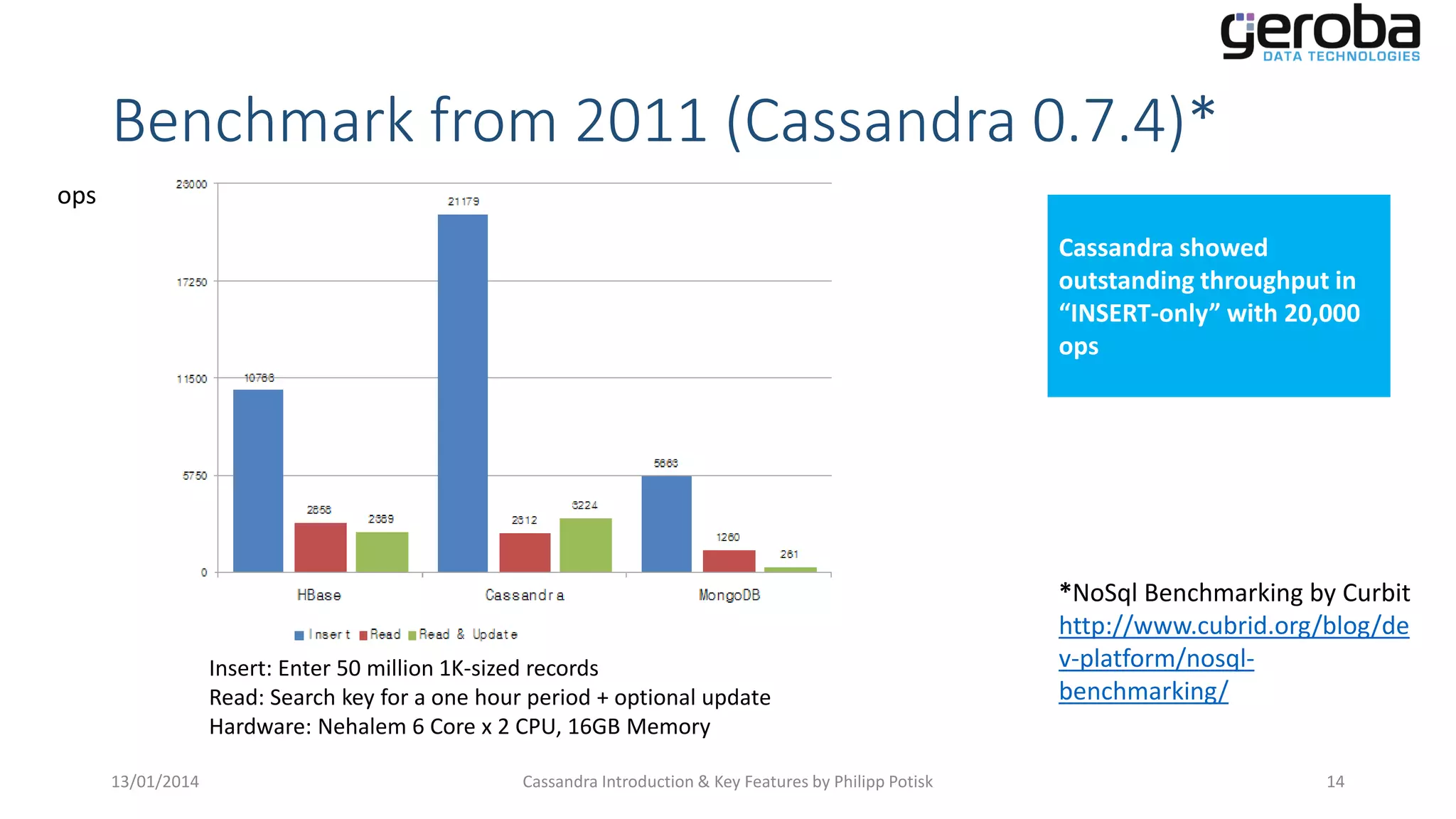
2011 performance benchmarks demonstrating Cassandra's impressive insert capabilities.
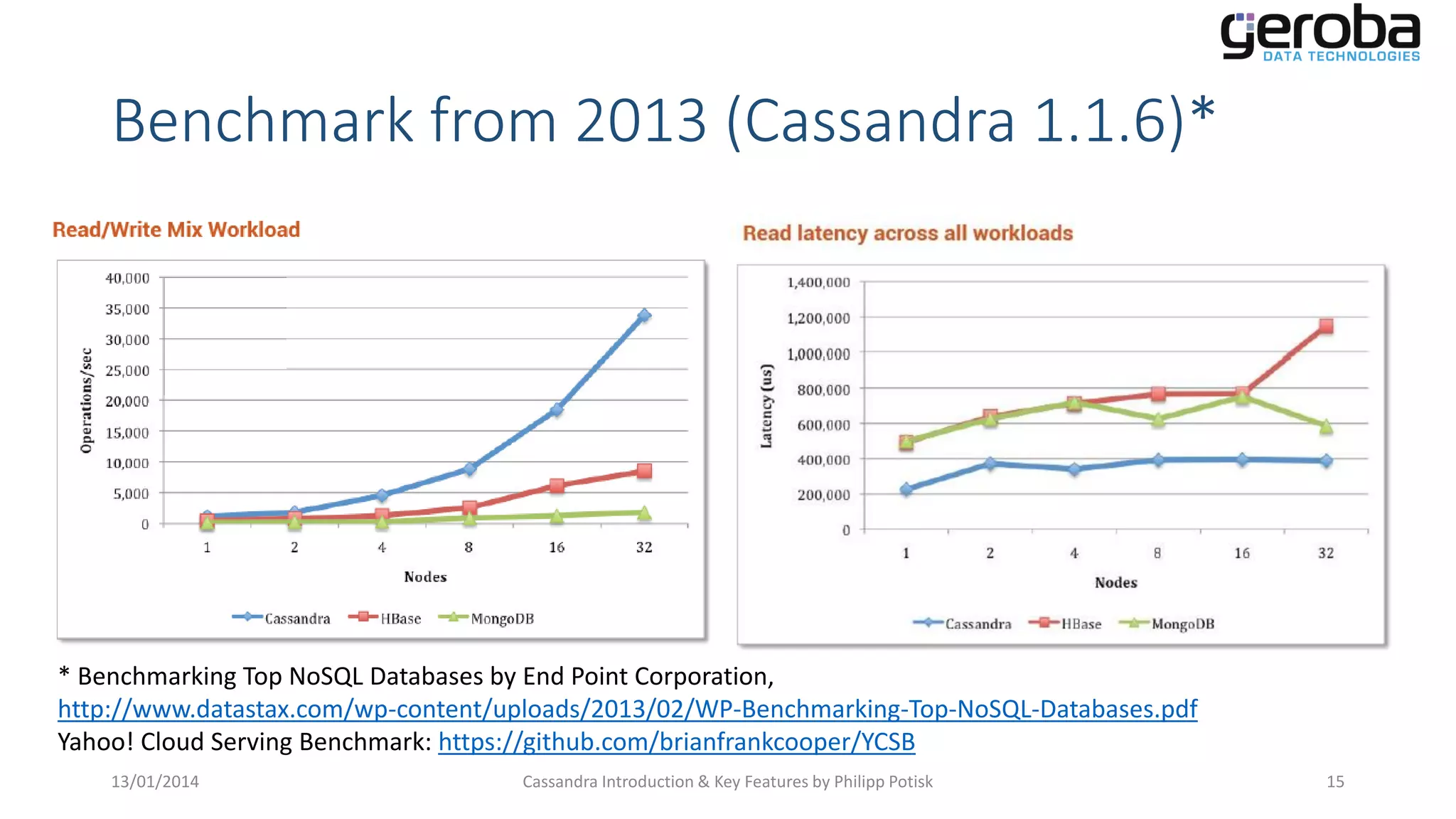
References benchmark studies from 2013, comparing the capabilities of NoSQL databases including Cassandra.
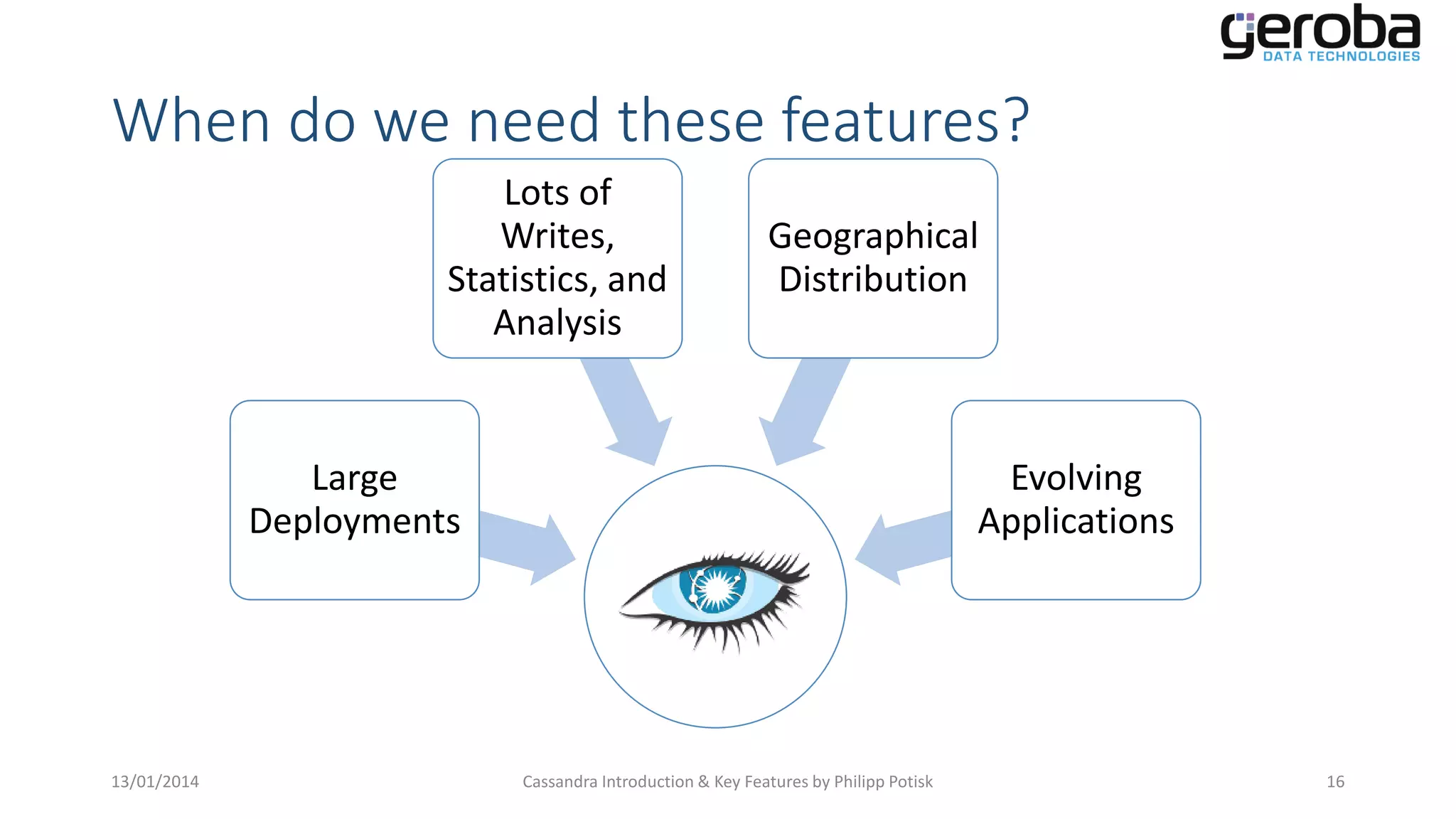
Identifies scenarios where Cassandra's features are advantageous including large deployments and geographic distribution.
Discusses who utilizes Cassandra, specifically highlighting eBay's substantial data infrastructure.
Detailed use cases from eBay showcasing why Cassandra was chosen for various applications.
Brief mention of how Cassandra integrates with Hadoop for data processing.
Summary of Cassandra including history, key features, and specific use case highlights.