Downloaded 19 times









![ Let’s do some Cleansing, for example #exclude trip with time less than 60 seconds data_trip<-data_trip[( data_trip$trip_time_in_secs)>60,] #exclude trip with distance less than 0.1 miles data_trip<-data_trip[( data_trip$trip_distance)>0.1,] data_trip<-data_trip [!(data_trip$pickup_latitude==0 | data_trip$pickup_longitude==0),]](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-10-2048.jpg)
![#work on a selection of the NYC area data_trip<-data_trip[( data_trip$pickup_latitude>(40.62)& data_trip$pickup_latitude<40.9 & data_trip$pickup_longitude>(-74.1)& data_trip$pickup_longitude<(-73.75)& data_trip$dropoff_latitude>(40.62)& data_trip$dropoff_latitude<40.9& data_trip$dropoff_longitude>(-74.1)& data_trip$dropoff_longitude<(73.75)) ,]](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-11-2048.jpg)


![ Plot some Histograms #Distribution of number of passengers per trip hist(data_trip$passenger_count,6, main="Distribution of Number of Passengers per Trip",xlab="Number of Passengers p/Trip") rect(par("usr")[1], par("usr")[3], par("usr")[2], par("usr")[4], col = "grey") hist(data_trip$passenger_count,6, add = TRUE,col=" lightgoldenrod2 ")](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-14-2048.jpg)

![#Distribution of payment_type barplot(sort(table(data_fares$payment_type), decreasing = TRUE), xaxt = 'n') rect(par("usr")[1], par("usr")[3], par("usr")[2], par("usr")[4], col = "grey") barplot(sort(table(data_fares$payment_type), decreasing = TRUE), ylab="Frequency“, col="lightgoldenrod2", add =TRUE, main="Distribution of Payement Type“)](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-16-2048.jpg)

![#Distribution of number of trip time length hist(data_trip$trip_time_in_secs/60,10, xlim=c(0,100),main="Distribution of Trip Time",xlab="Trip Time in minutes") rect(par("usr")[1], par("usr")[3], par("usr")[2], par("usr")[4], col = "grey") hist(data_trip$trip_time_in_secs/60,10, add = TRUE,col="lightgoldenrod2")](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-18-2048.jpg)

![#Distribution of number of trip distance hist(data_trip$trip_distance,100,xlim=c(0,40), main="Distribution of Trip Distance", xlab="Trip Distance") rect(par("usr")[1], par("usr")[3], par("usr")[2], par("usr")[4], col = "grey") hist(data_trip$trip_distance,100, add =TRUE, col="lightgoldenrod2")](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-20-2048.jpg)

![#Distribution of fare amount (full domain) hist(data_fares$fare_amount, main="Distribution of Fare Amount", xlab="Fare Amount") rect(par("usr")[1], par("usr")[3], par("usr")[2], par("usr")[4], col = "grey") hist(data_fares$fare_amount,add = TRUE,col="lightgoldenrod2")](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-22-2048.jpg)
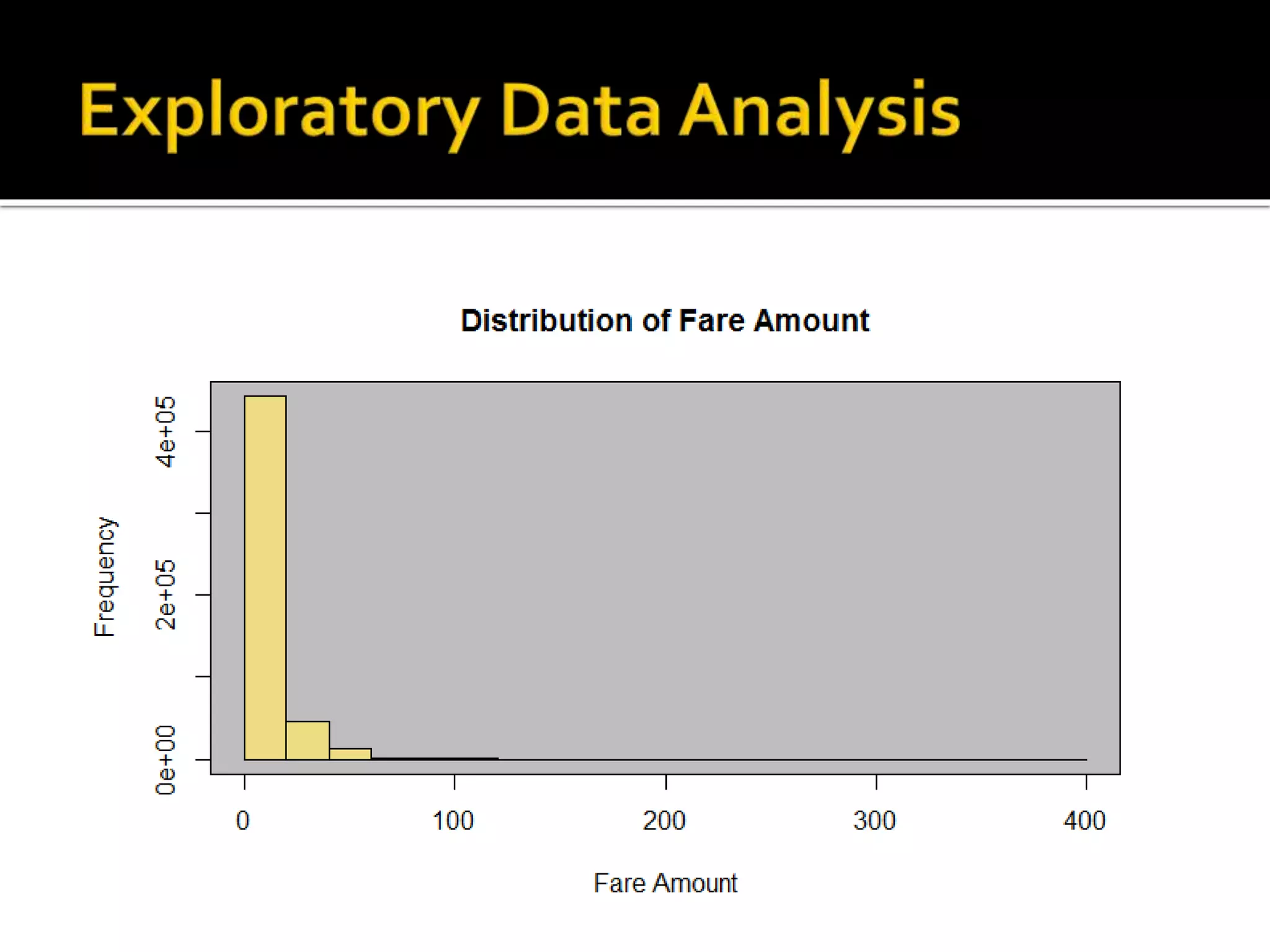
![#Distribution of fare amount (restricted domain) hist(data_fares$fare_amount,xlim=c(0,80),200, main="Distribution of Fare Amount", xlab="Fare Amount") rect(par("usr")[1], par("usr")[3], par("usr")[2], par("usr")[4], col = "grey“) hist(data_fares$fare_amount,200, xlim=c(0,80),add = TRUE,col="lightgoldenrod2")](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-24-2048.jpg)
![#Distribution of tip amount hist(data_fares$tip_amount,500,xlim=c(0,20), main="Distribution of Tip Amount", xlab="Tip Amount") rect(par("usr")[1], par("usr")[3], par("usr")[2], par("usr")[4], col = "grey") hist(data_fares$tip_amount,500,xlim=c(0,20),add = TRUE,col="lightgoldenrod2")](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-26-2048.jpg)

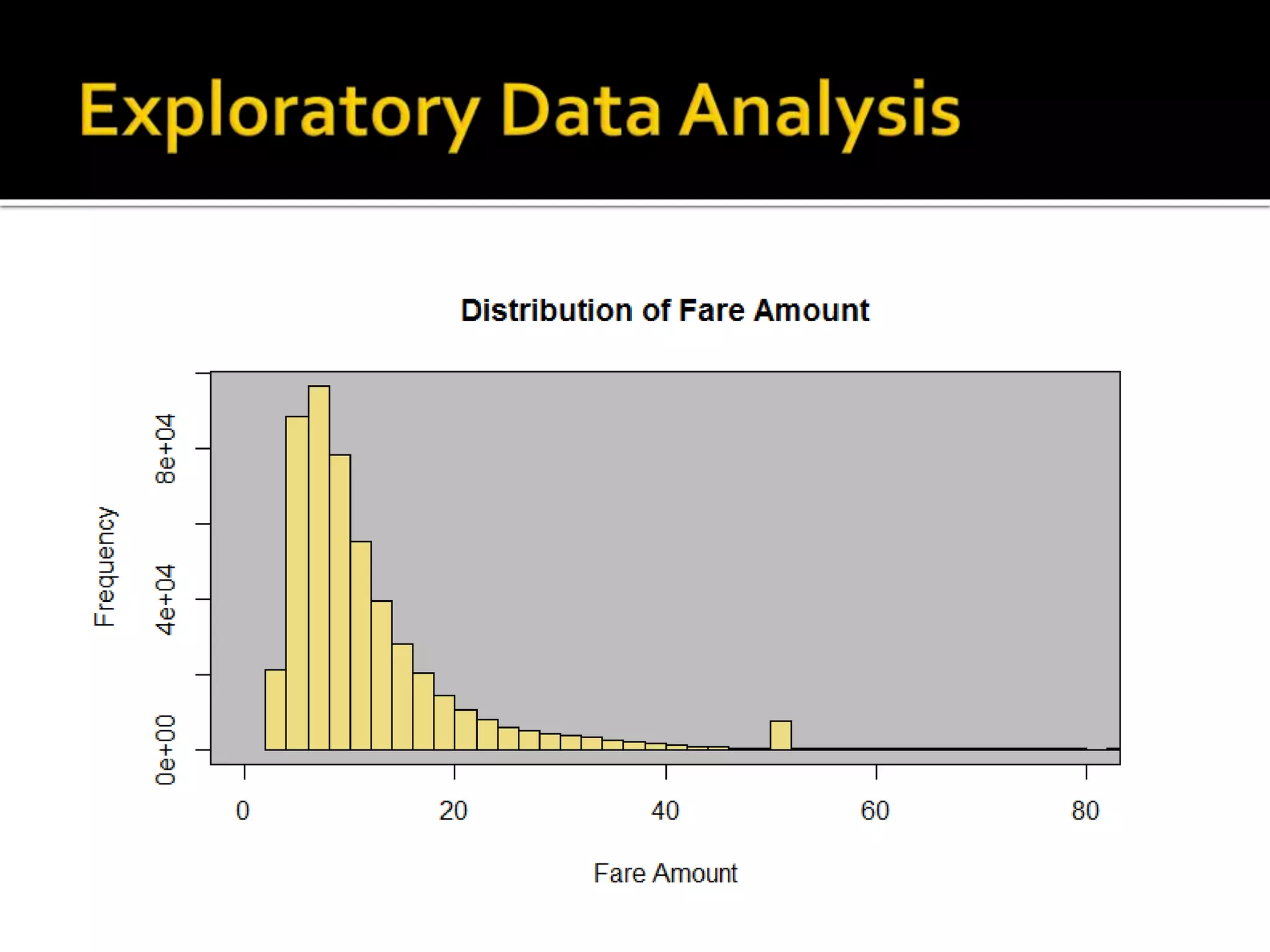
![#Distribution of Total Amount hist(data_fares$total_amount,1000,xlim=c(0,100), main="Distribution of Total Amount", xlab="Total Amount") rect(par("usr")[1], par("usr")[3], par("usr")[2], par("usr")[4], col = "grey") hist(data_fares$total_amount,add = TRUE, col="lightgoldenrod2",1000,xlim=c(0,100))](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-28-2048.jpg)
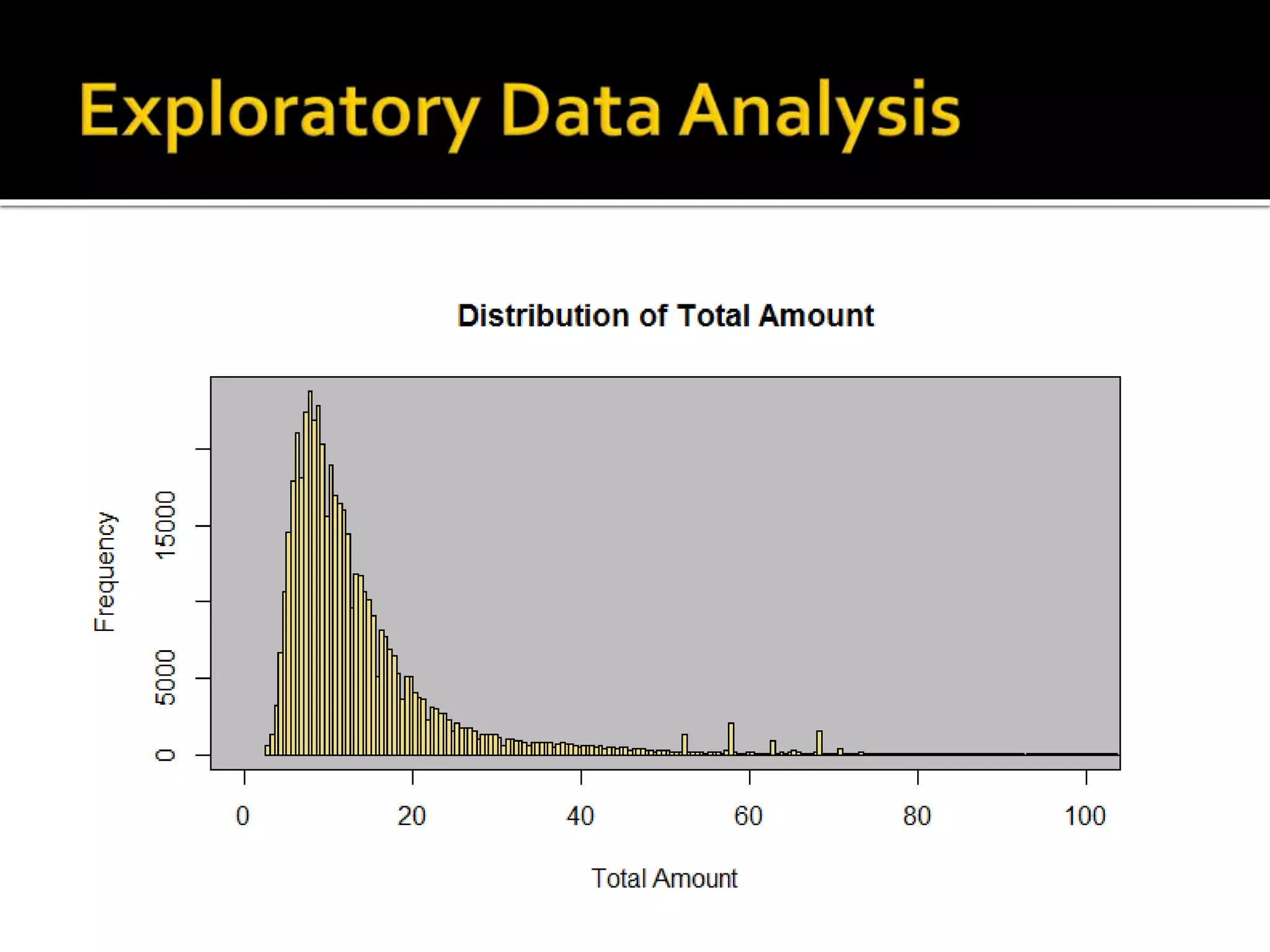
![#Distribution of pickups during the day barplot(table(data_trip$pickup_hour)) rect(par("usr")[1], par("usr")[3], par("usr")[2], par("usr")[4], col = "grey") barplot(table(data_trip$pickup_hour), add = TRUE, col="lightgoldenrod2", main="Distribution of Pickups in 24H", ylab="Frequency")](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-30-2048.jpg)
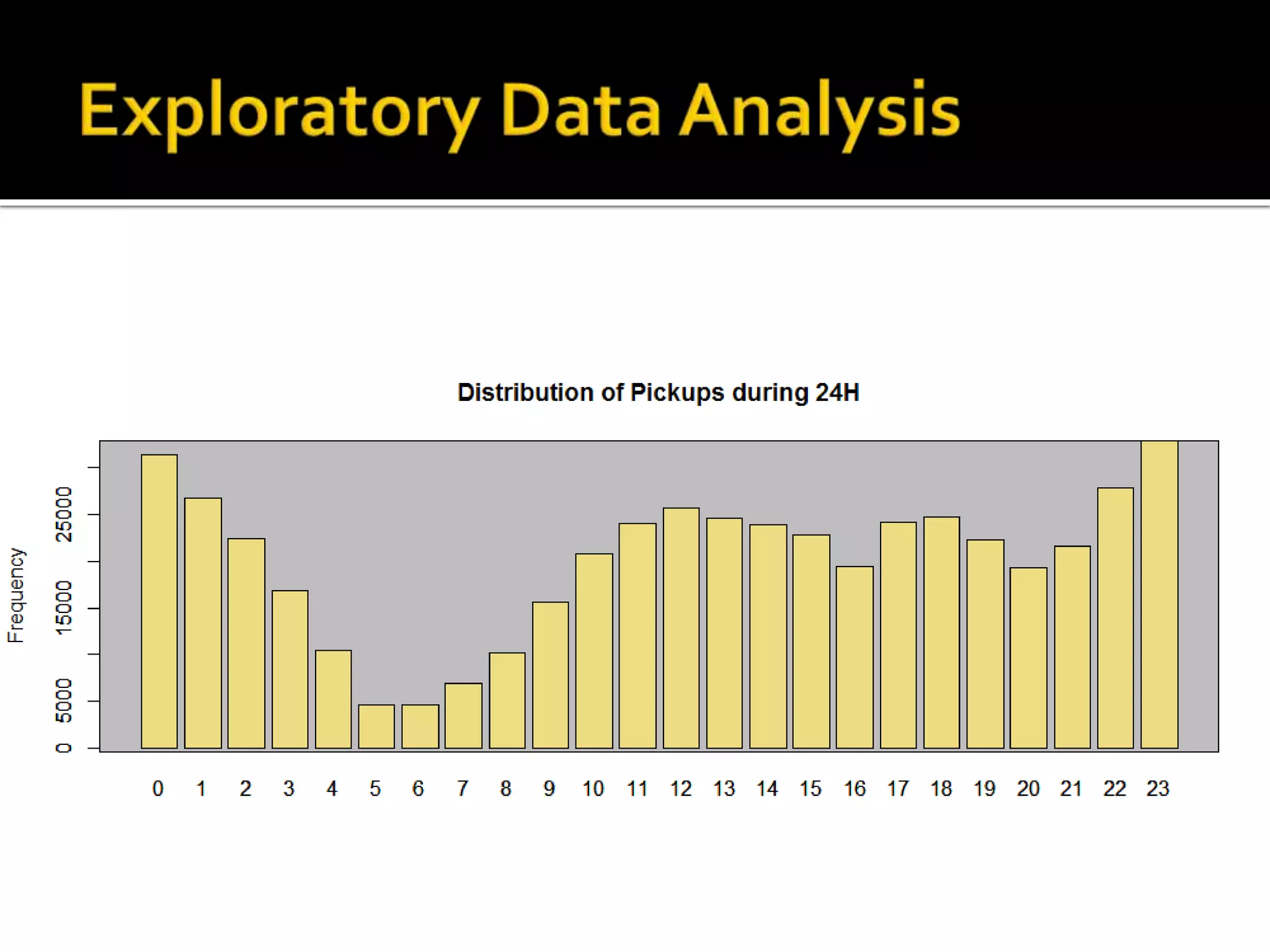
![#Distribution of pickups during the day (ordered) barplot(sort(table(data_trip$pickup_hour), decreasing = TRUE)) rect(par("usr")[1], par("usr")[3], par("usr")[2], par("usr")[4], col = "grey") barplot(sort(table(data_trip$pickup_hour), decreasing = TRUE)),add = TRUE, col="lightgoldenrod2", main="Distribution of Pickups in 24H", ylab="Frequency")](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-32-2048.jpg)
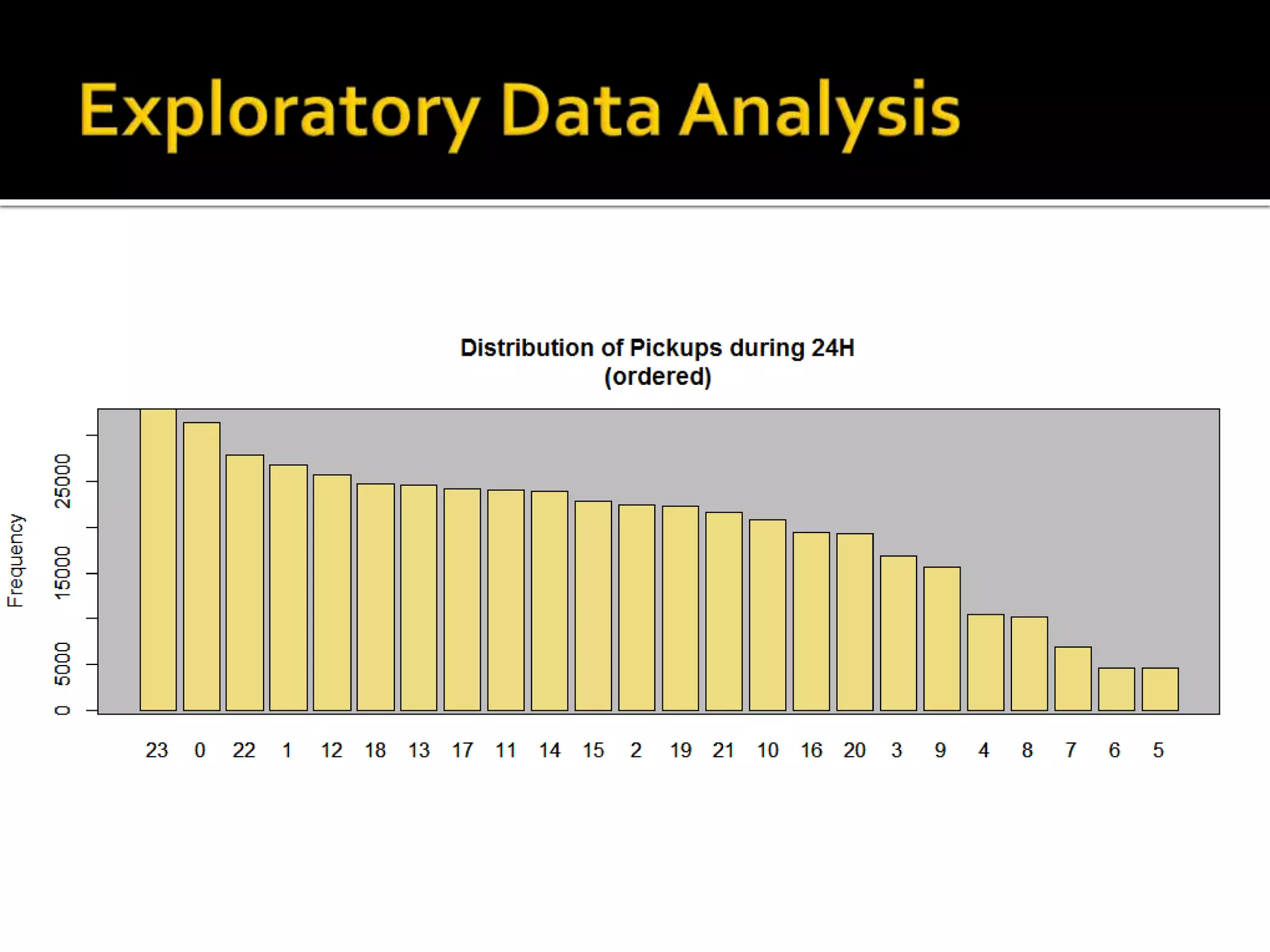
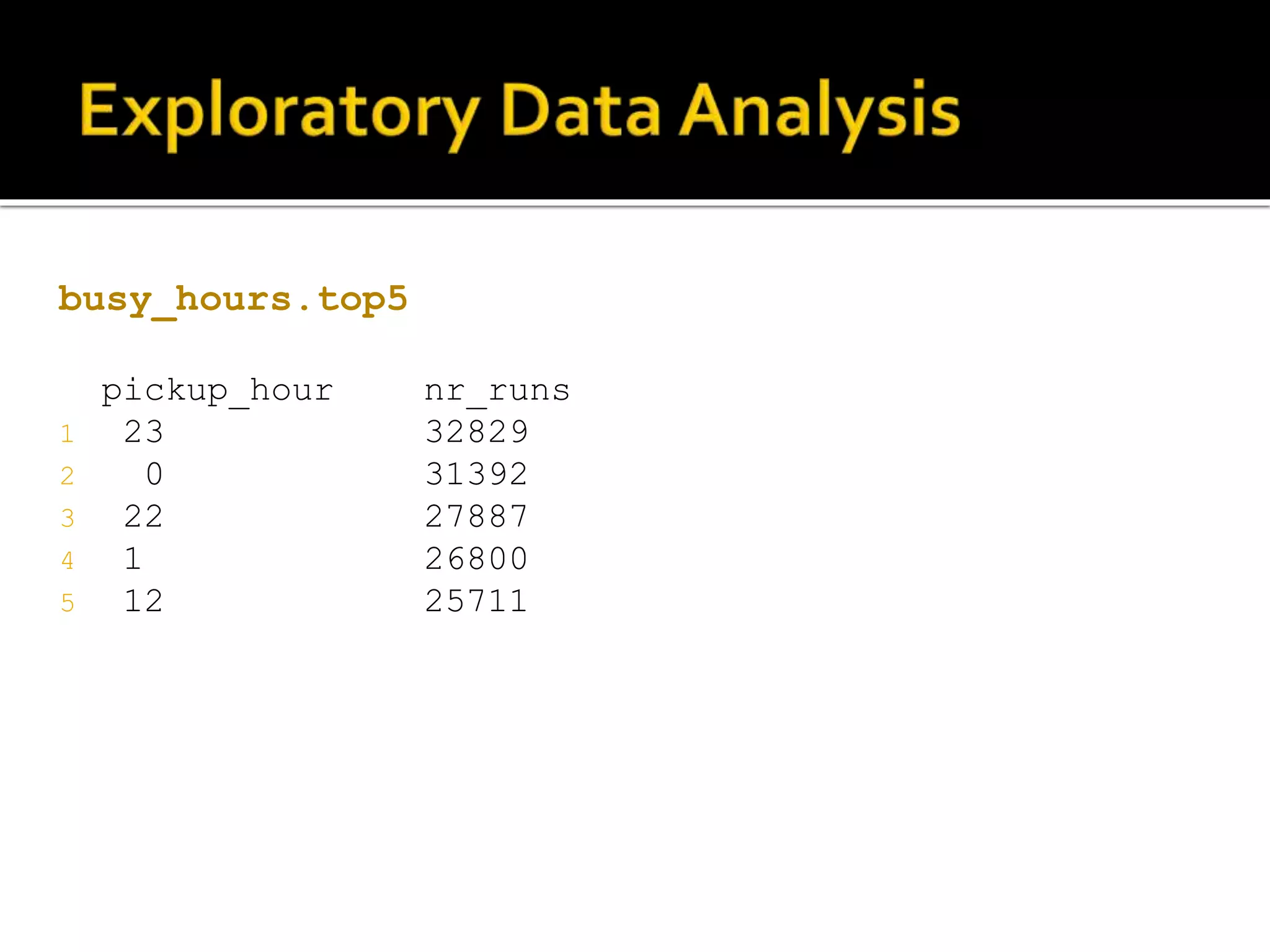
![#Top 5 busiest hours of the day busy_hours<-aggregate(data_trip$ones ~ data_trip$pickup_hour, data_trip, sum) #select top 5 pickup_hours busy_hours.top5<- busy_hours %>% arrange(desc(busy_hours[,2])) %>% top_n(5) names(busy_hours.top5)[names(busy_hours.top5)== "data_trip$pickup_hour"]<-"pickup_hour" names(busy_hours.top5)[names(busy_hours.top5)== "data_trip$ones"] <- "nr_runs"](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-34-2048.jpg)
![#Distribution of pickups during the day in % names(busy_hours)[names(busy_hours)== "data_trip$pickup_hour"]<-"pickup_hour“ names(busy_hours)[names(busy_hours)== "data_trip$ones"] <- "counter“ hoursum<-sum(busy_hours$counter) busy_hours$perc<-busy_hours$counter/hoursum](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-36-2048.jpg)




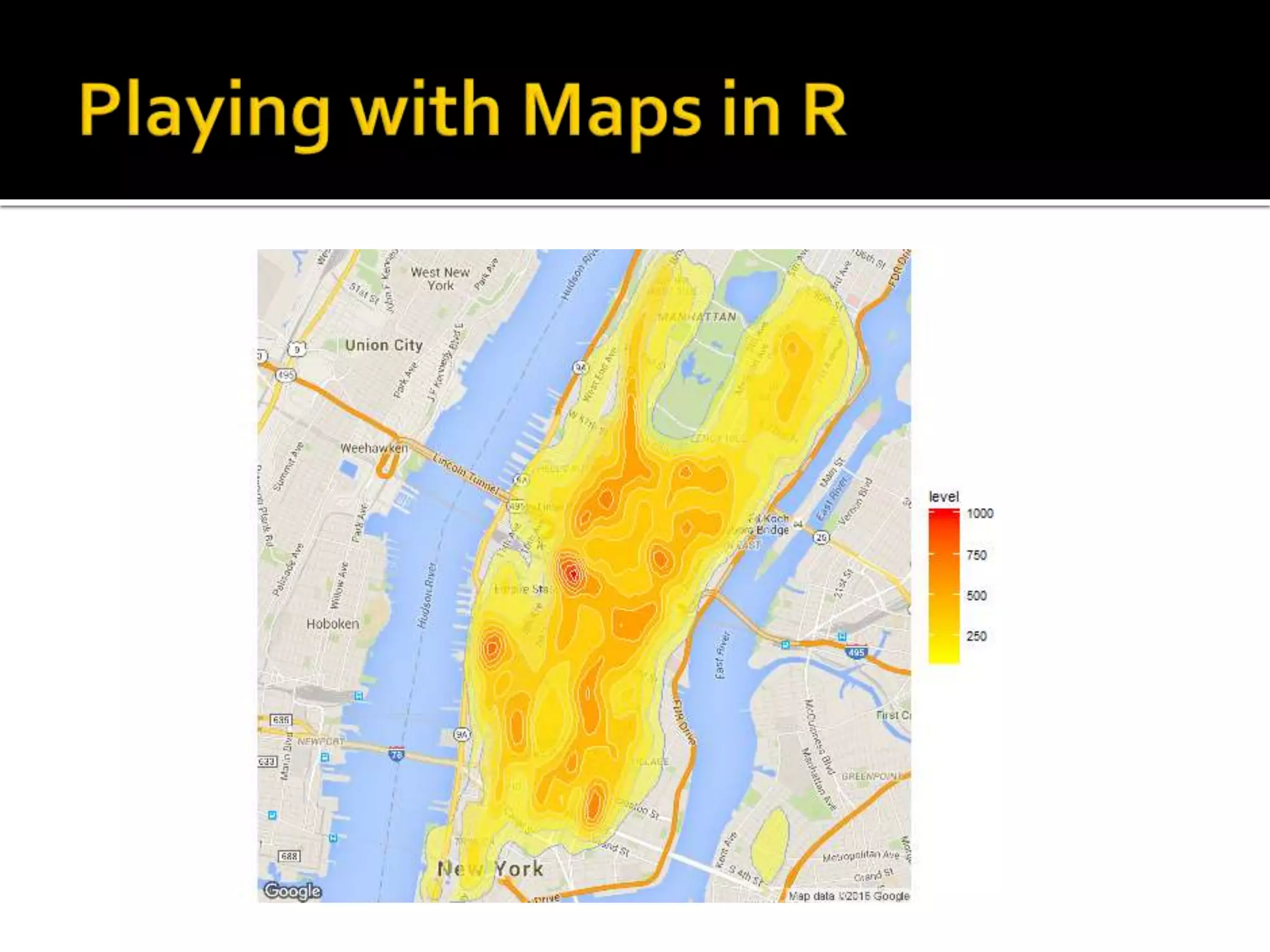
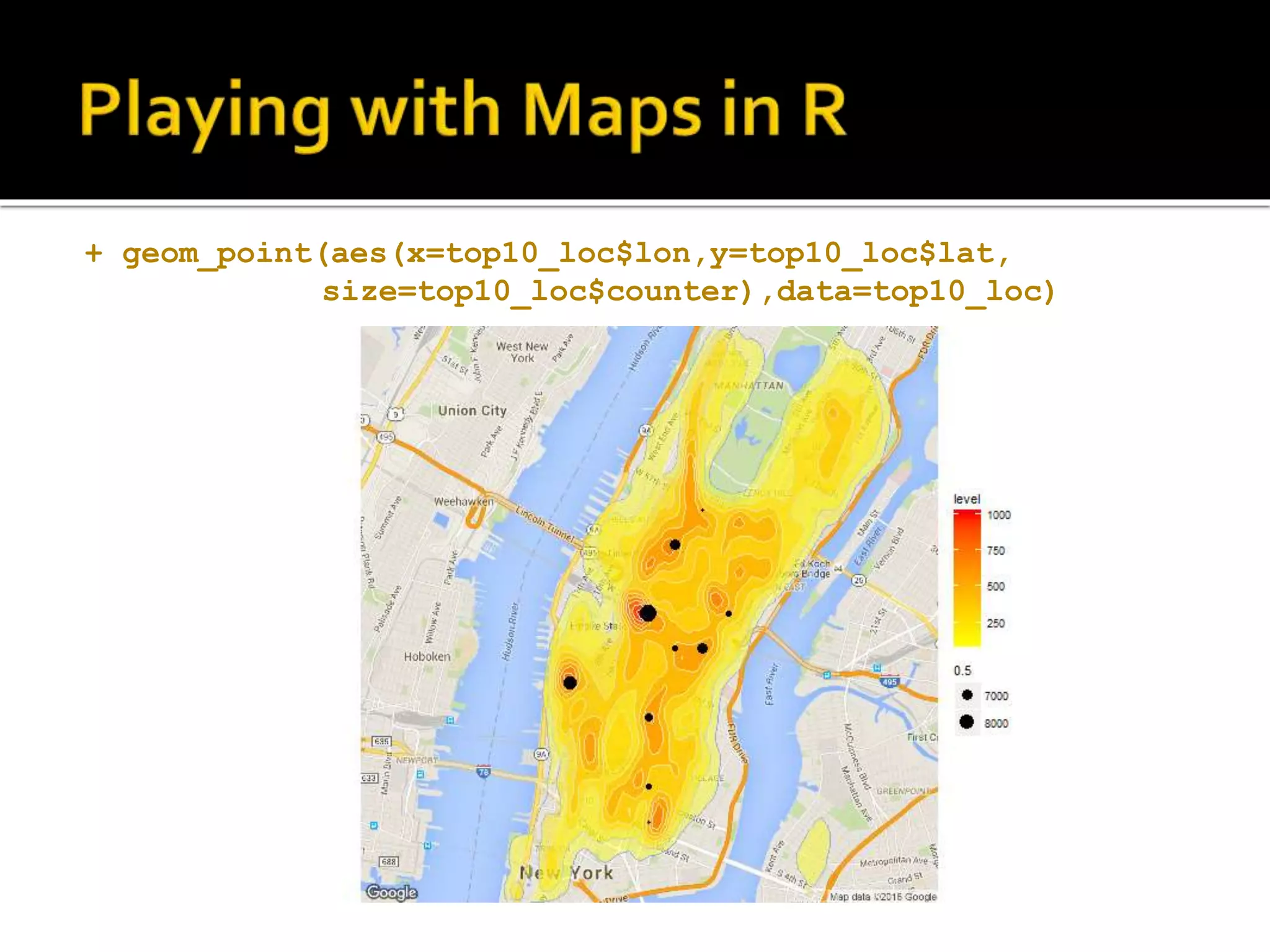
![#groupby trip identifier and count busy_locations <- aggregate(data_trip$ones ~ data_trip$trip_start, data_trip, sum) names(busy_locations)[names(busy_locations)== "data_trip$trip_start"] <- "location“ names(busy_locations)[names(busy_locations)== "data_trip$ones"] <- "counter"](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-41-2048.jpg)
![#total number of trip tripsum <- sum(busy_locations$counter) #total number of trip busy_locations$perc <- busy_locations$counter /tripsum top10_loc <- busy_locations %>% arrange( desc(busy_locations[,2])) %>% top_n(10)](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-42-2048.jpg)
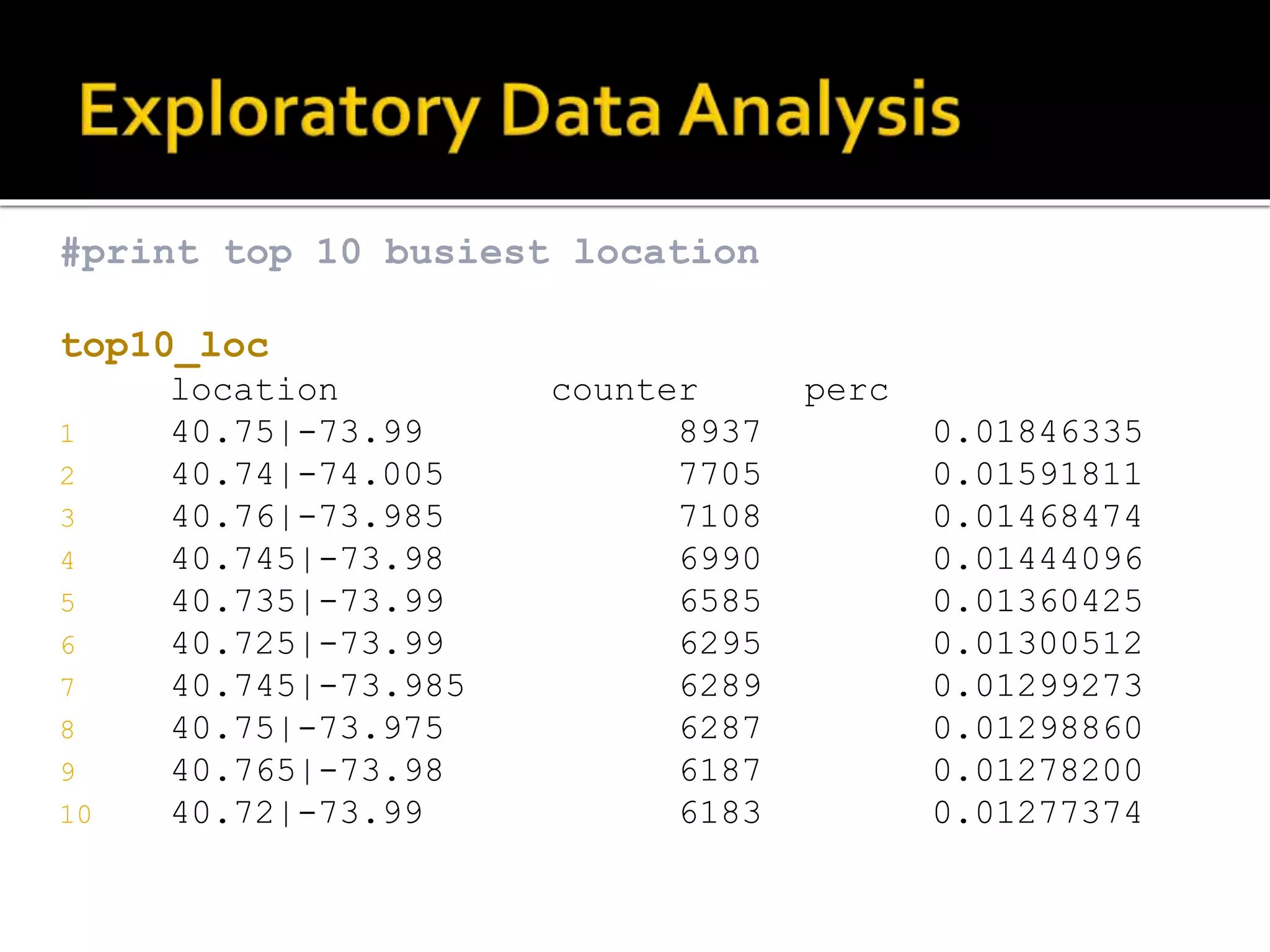
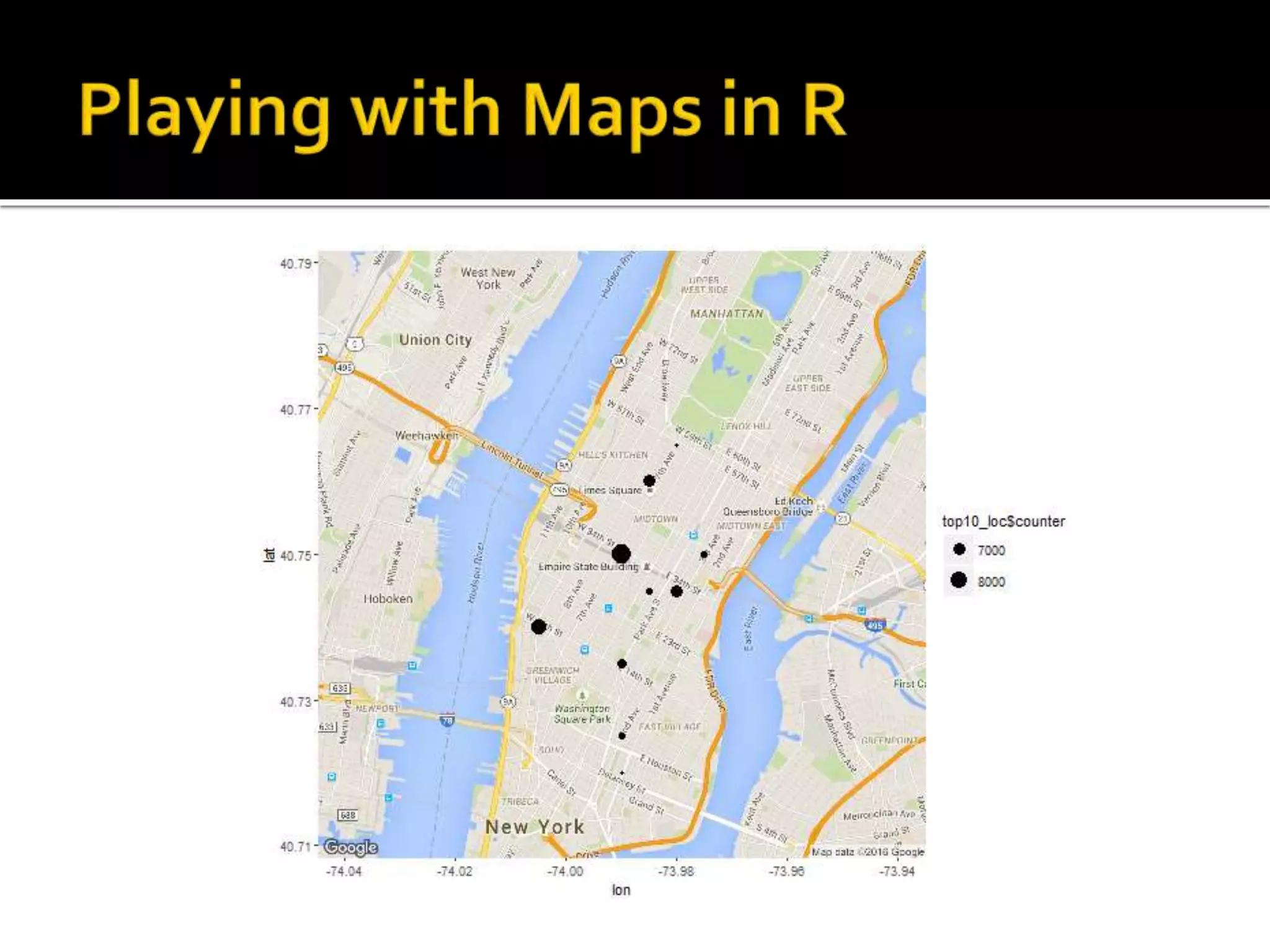
![#get address of busy locations C <- unlist(strsplit(top10_loc$location, "[|]")) coordinates = matrix(as.double(c), nrow=10, ncol=2,byrow=TRUE) top10_loc$lat<-coordinates[,1] top10_loc$lon<-coordinates[,2] top10_loc$address<-mapply(FUN = function(lon, lat) revgeocode(c(lon, lat)), top10_loc$lon, top10_loc$lat)](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-44-2048.jpg)
![top10_loc$address [1] "137 W 33rd St, New York, NY 10120, USA" [2] "345 W 13th St, New York, NY 10014, USA" [3] "1585-1589 Broadway, New York, NY 10036, USA" [4] "145 E 32nd St, New York, NY 10016, USA" [5] "10 Union Square E, New York, NY 10003, USA" [6] "42 2nd Ave, New York, NY 10003, USA" [7] "110-112 Madison Ave, New York, NY 10016, USA" [8] "633-637 3rd Ave, New York, NY 10017, USA" [9] "Carnegie Hall, 152 W 57th St, New York, NY 10019, USA" [10] "129-131 Allen St, New York, NY 10002, USA"](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-45-2048.jpg)



![#build map for a sample of pickups data_sample<-data_trip[sample(nrow(data_trip), 400000), ] ggmap(ny_map, extent = "device") + geom_point(aes(x = data_sample$pickup_longitude, y = data_sample$pickup_latitude), colour = "yellow", alpha = 0.1, size = 1, data = data_sample)](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-50-2048.jpg)






![#compute standard deviation for every trip trips<-aggregate(data_trip$trip_time_in_secs ~ data_trip$trip_id, data_trip, sd) #get the trip with highest standard deviation #and find pickup and dropoff locations trips.topsd<-trips %>% arrange(desc(trips[,2])) %>% top_n(10) names(trips.topsd)[names(trips.topsd)== "data_trip$trip_id"] <- "trip_id" names(trips.topsd)[names(trips.topsd)== "data_trip$trip_time_in_secs"] <- "trip_sd"](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-59-2048.jpg)
![#recover from google maps and print top 10 trip by sd trip_text=list() for(i in 1:10) { coords=matrix(as.double(unlist(strsplit( trips.topsd$trip_id[i], "[|]"))), nrow=2,ncol=2,byrow=TRUE) from=coords[1,] to=coords[2,] origin<-mapply(FUN = function(lon, lat) revgeocode(c(lon, lat)), from[2], from[1]) destination<-mapply(FUN = function(lon, lat) revgeocode(c(lon, lat)), to[2], to[1]) trip_text[i]=paste("Trip",i,"from",origin,"to", destination,"has",round(trips.topsd$trip_sd[i],2), " SD.")}](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-60-2048.jpg)
![print(trip_text) [[1]] [1] "Trip 1 from JFK Expressway, Jamaica, NY 11430, USA to JFK Expressway, Jamaica, NY 11430, USA has 3660.94 SD." [[2]] [1] "Trip 2 from Perimeter Rd, Jamaica, NY 11430, USA to 826 Greene Ave, Brooklyn, NY 11221, USA has 3436.54 SD." [[3]] [1] "Trip 3 from 46-36 54th Rd, Flushing, NY 11378, USA to 107-11 Van Wyck Expy, Jamaica, NY 11435, USA has 3181.98 SD.” … … [[10]] [1] "Trip 10 from Central Terminal Area, Jamaica, NY 11430, USA to 34-40 E Houston St, New York, NY 10012, USA has 2206.17 SD."](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-61-2048.jpg)


![#Keep track of tot number of runs for each trip fares_c<-aggregate(df_merge$ones ~ df_merge$trip_id, df_merge, sum) fares_merge=merge(x=fares,y=fares_c, by.x="df_merge$trip_id", by.y="df_merge$trip_id", all.x=TRUE) names(fares_merge)[names(fares_merge)== "df_merge$trip_id"] <- "trip_id" names(fares_merge)[names(fares_merge)== "df_merge$fare_amount"] <- "fare_sd" names(fares_merge)[names(fares_merge)== "df_merge$ones"] <- "trip_count" #exclude trip with less then 30 runs and order fares_merge<-fares_merge[(fares_merge$trip_count>30),] fares_merge<- fares_merge %>% arrange((fares_merge$fare_sd))](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-64-2048.jpg)
![#get some extra information beyond numbers trip_text=list() for(i in 1:10) { coords=matrix(as.double(unlist(strsplit( fares_merge$trip_id[i], "[|]"))), nrow=2, ncol=2,byrow=TRUE) from=coords[1,] to=coords[2,] origin<-mapply(FUN = function(lon, lat) revgeocode(c(lon, lat)), from[2], from[1]) destination<-mapply(FUN = function(lon, lat) revgeocode(c(lon, lat)), to[2], to[1]) trip_text[i]=paste("Trip",i,"starts from",origin,"and end to to",destination) }](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-65-2048.jpg)
![print(trip_text) [[1]] [1] "Trip 1 starts from 1585-1589 Broadway, New York, NY 10036, USA and end to 107-11 Van Wyck Expy, Jamaica, NY 11435, USA" [[2]] [1] "Trip 2 starts from 1700 3rd Ave, New York, NY 10128, USA and end to 53 E 124th St, New York, NY 10035, USA" [[3]] [1] "Trip 3 starts from 330 W 95th St, New York, NY 10025, USA and end to 534 W 112th St, New York, NY 10025, USA" … … [[10]][1] "Trip 10 starts from 762 Amsterdam Ave, New York, NY 10025, USA and end to 192 Claremont Ave, New York, NY 10027, USA"](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-66-2048.jpg)
![#prepare points to visualize nr_points=100 ffrom=matrix(nr_points*2,nrow=nr_points,ncol=2) tto=matrix(nr_points*2,nrow=nr_points,ncol=2) for(i in 1:nr_points) {coords= matrix(as.double(unlist(strsplit( fares_merge$trip_id[i], "[|]"))), nrow=2, ncol=2,byrow=TRUE) from=coords[1,] to=coords[2,] ffrom[i,1]=coords[1,1] ffrom[i,2]=coords[1,2] tto[i,1]=coords[2,1] tto[i,2]=coords[2,2] }](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-67-2048.jpg)
![#transform points in a matrix to points in a dataframe start_end<-as_data_frame(list(from.lat= ffrom[,1],from.lon=ffrom[,2],to.lat=tto[,1], to.lon=tto[,2])) #plot the trip with the lowest fare’s SD ggmap(ny_map, extent = "device") + geom_point(aes(x = start_end$to.lon[1], y = start_end$to.lat[1]), colour = "red", alpha = 0.6, size = 10, data=start_end) + geom_point(aes(x = start_end$from.lon[1], y = start_end$from.lat[1]), colour = "yellow", alpha = 0.6, size = 10, data=start_end)](https://image.slidesharecdn.com/datascienceforbusiness-160117192940/75/Using-R-for-Building-a-Simple-and-Effective-Dashboard-68-2048.jpg)









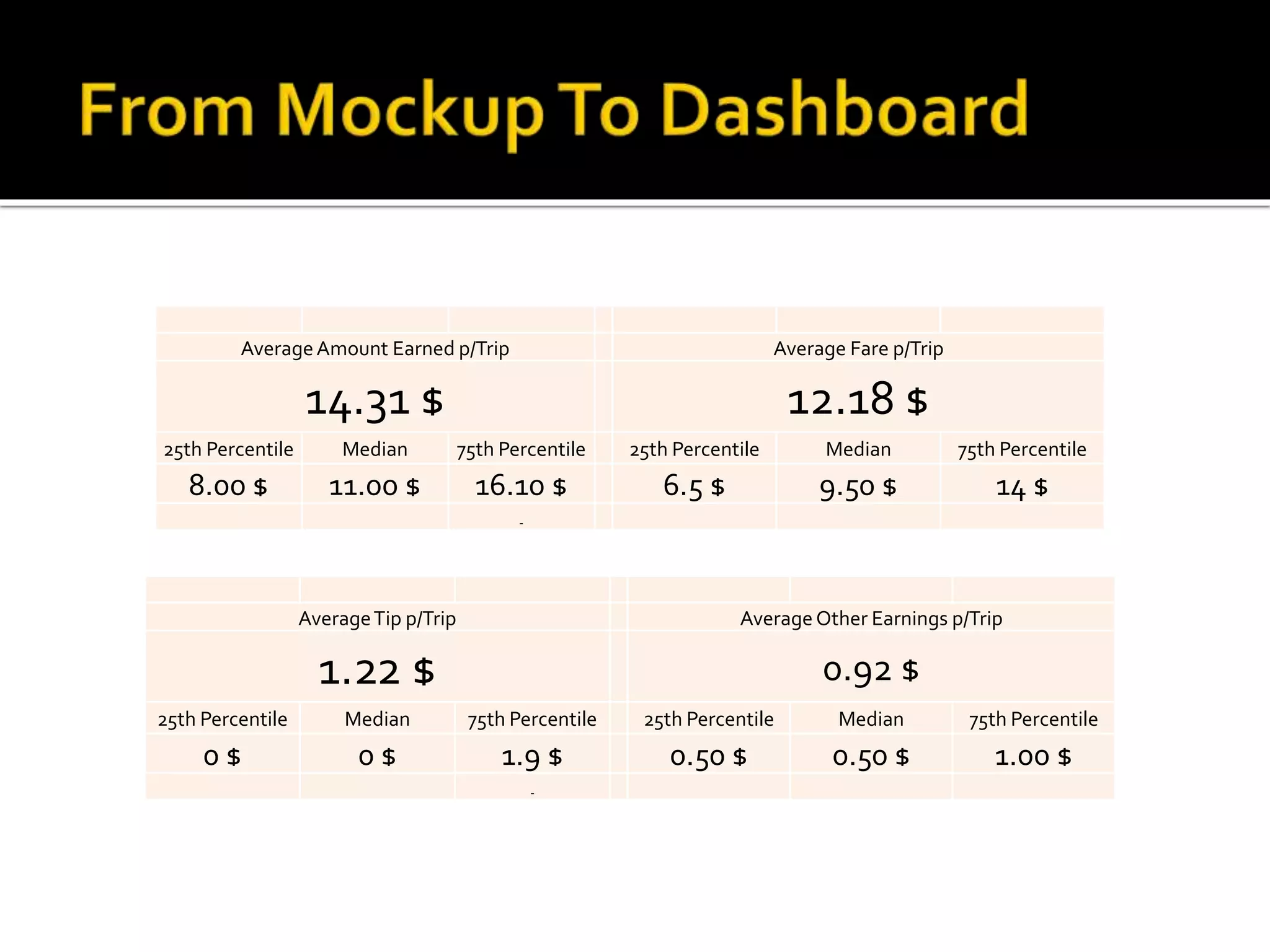







This document outlines the process of using open source data analysis tools like R and Python to gain insights into business and customer behavior, specifically in the context of starting a taxi company in New York City. It provides comprehensive steps for data acquisition, cleansing, analysis, and visualization, including creating dashboards for key performance indicators. The practical guidance is complemented by code snippets for executing data manipulation and generating various visualizations.