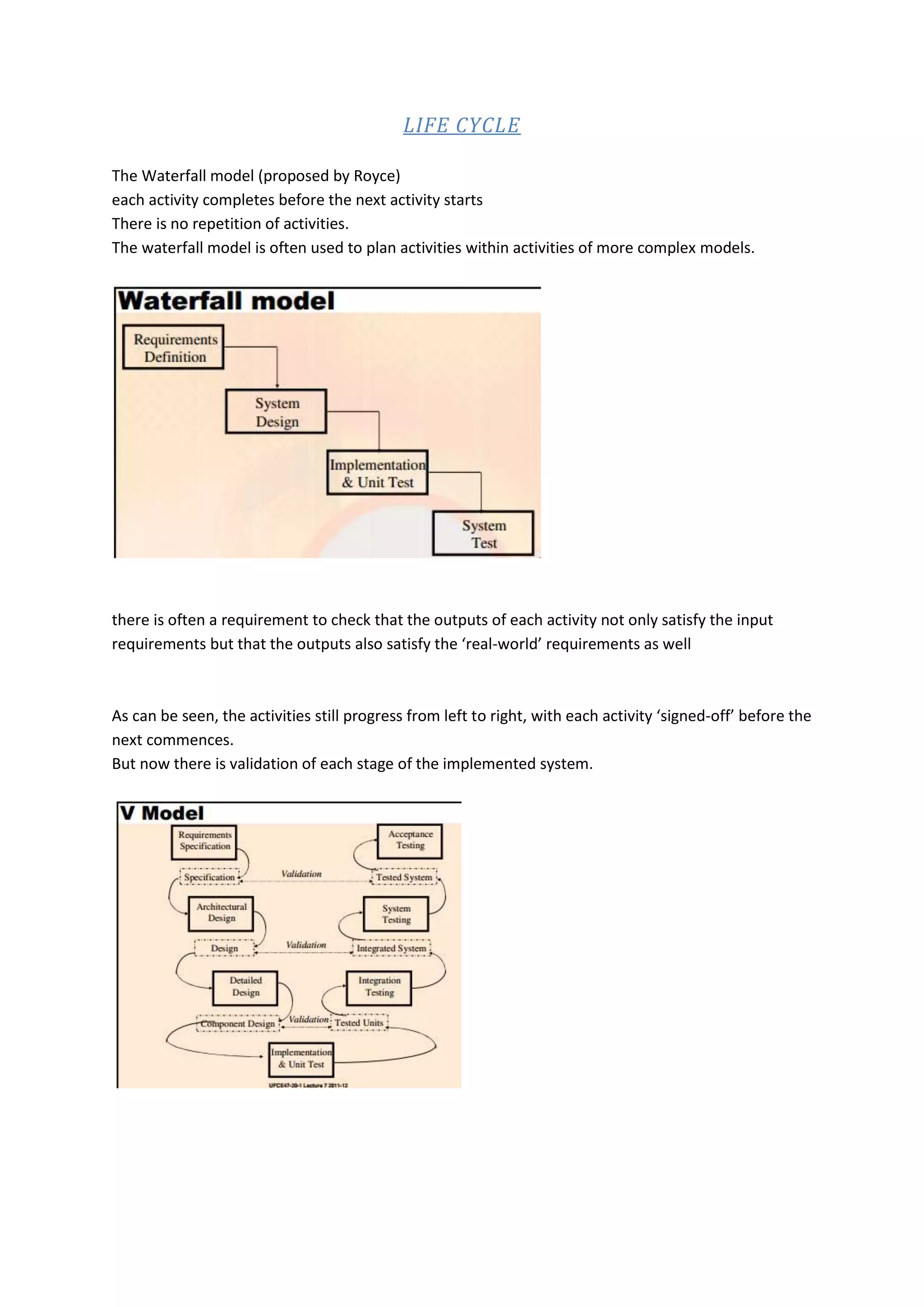
The document provides instructions for several common UNIX commands: 1. The "is -l" command lists files in long format with details like size, owner, and modification date. 2. The "cp" and "rm" commands copy and remove files, with "rm -i" requesting confirmation before deleting. 3. The "chmod" command changes permissions on files for users, groups, and others regarding read, write, and execute access.