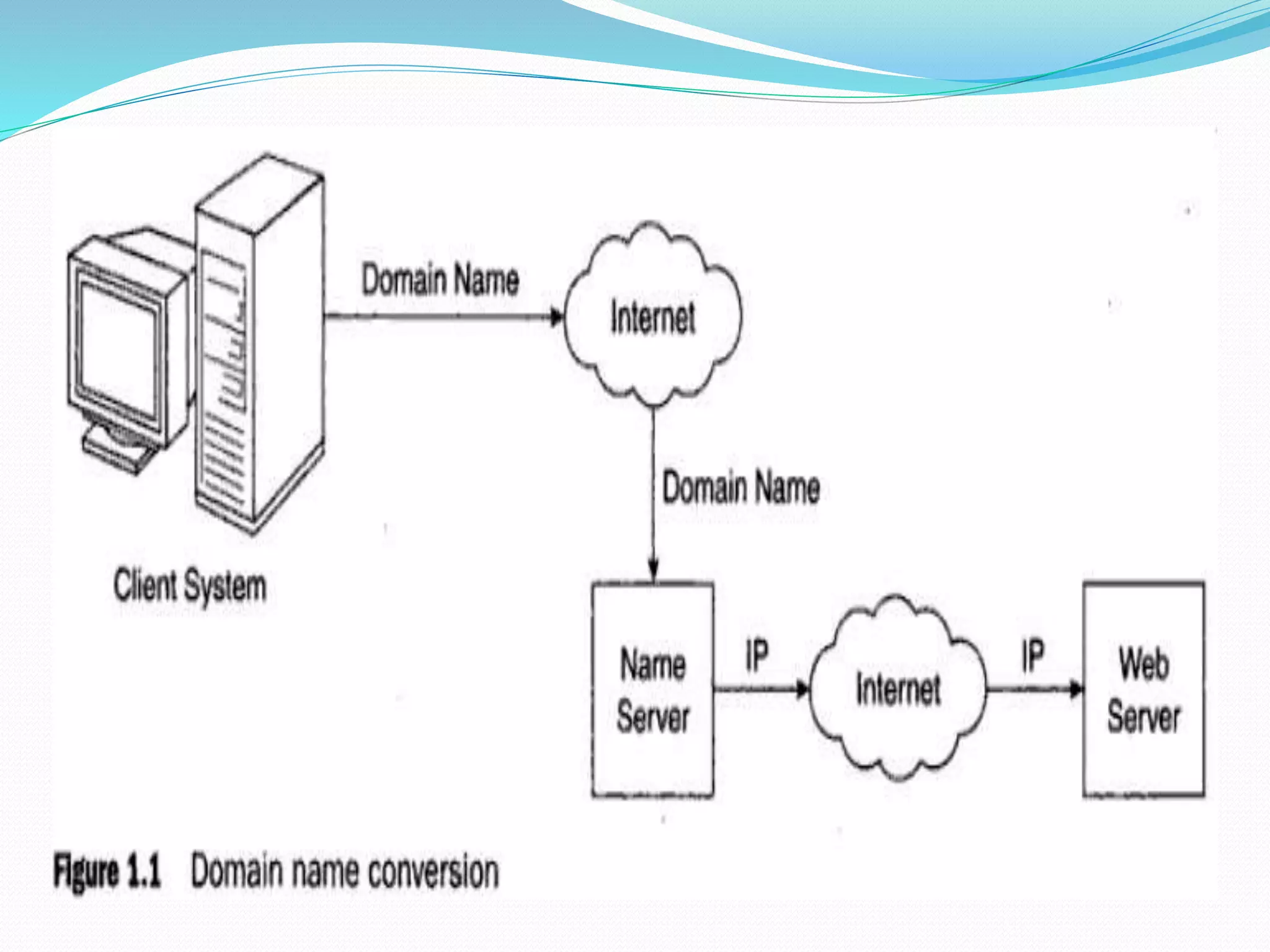
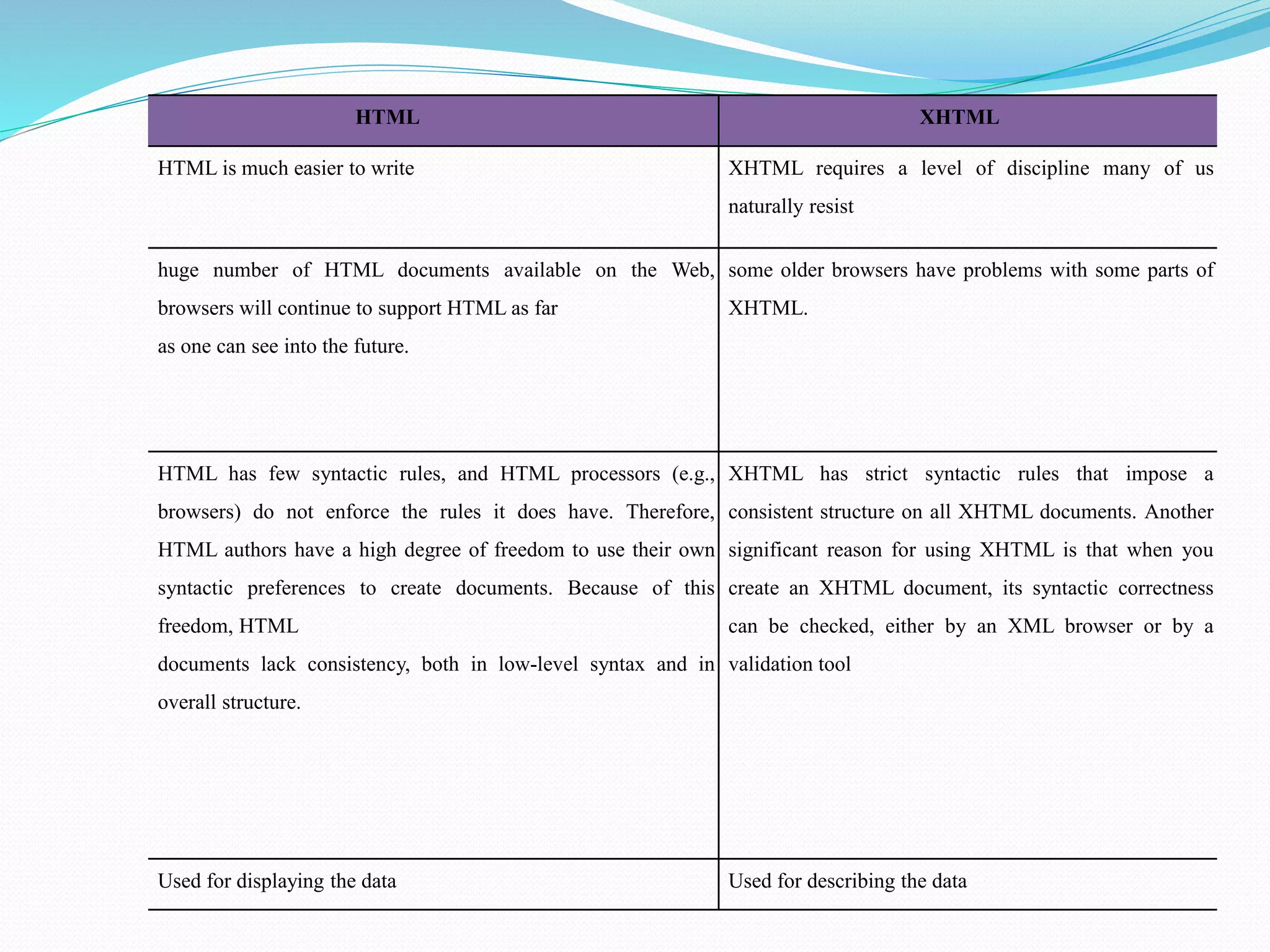
The document provides a history of the origins and development of the Internet from the 1960s to the 1990s. It describes how ARPANET was developed in the 1960s by the US Department of Defense and its Advanced Research Projects Agency (ARPA) to enable resource sharing between researchers. It evolved into a "network of networks" known as the Internet in the 1990s through networks like NSFNET that connected universities. The document also gives brief overviews of web browsers, web servers, URLs, and the Hypertext Transfer Protocol.