Download as PDF, PPTX















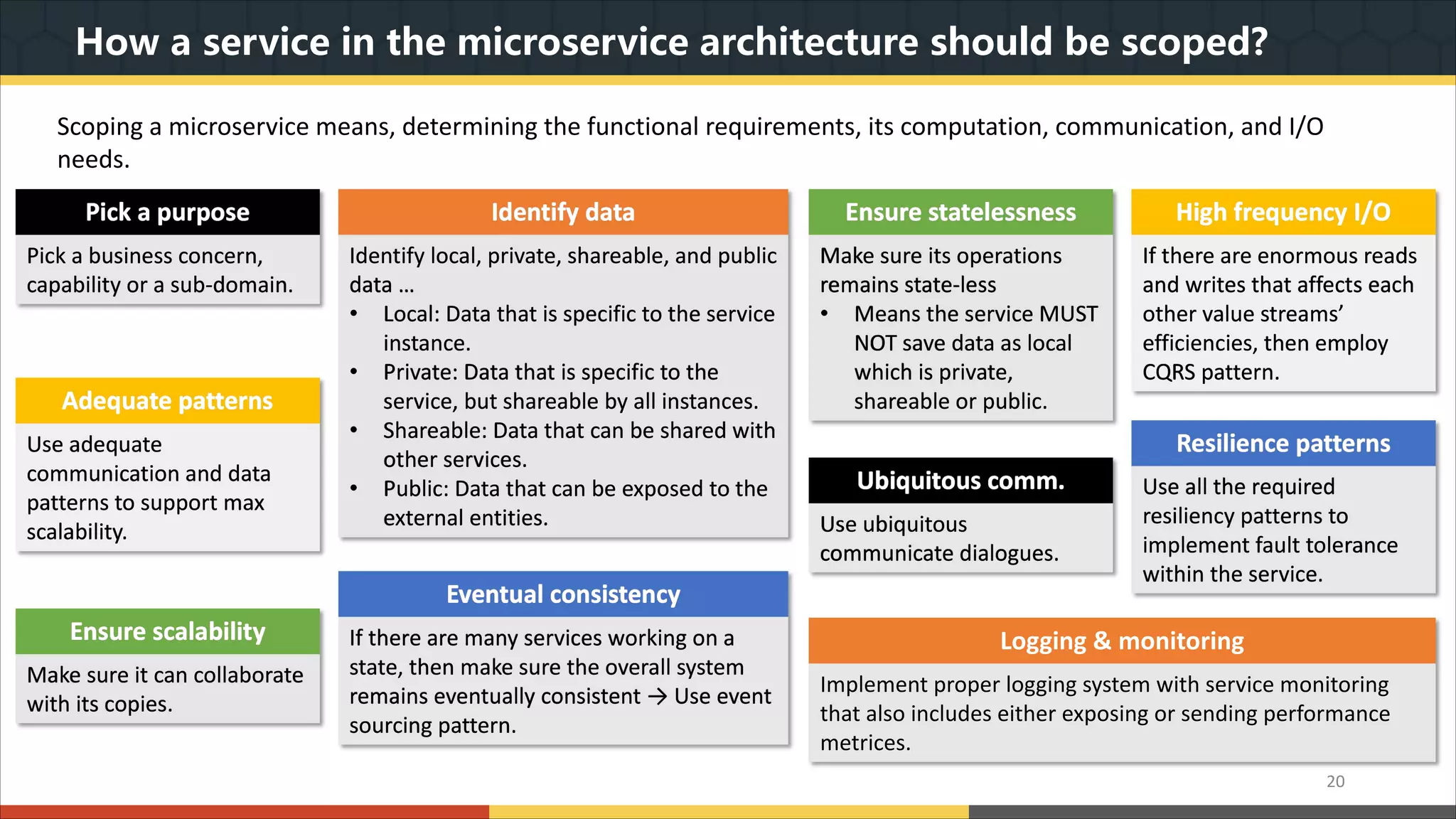

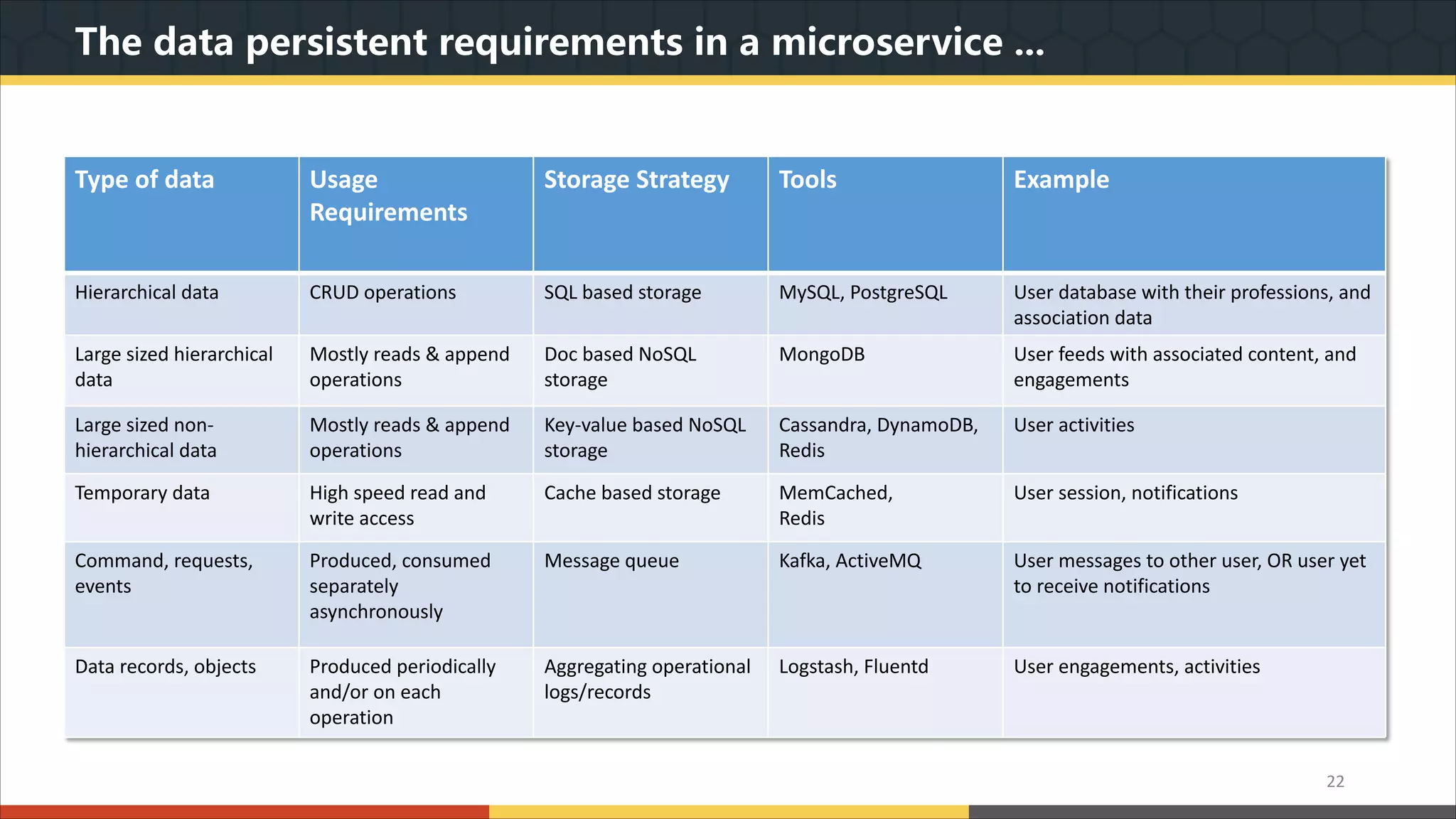

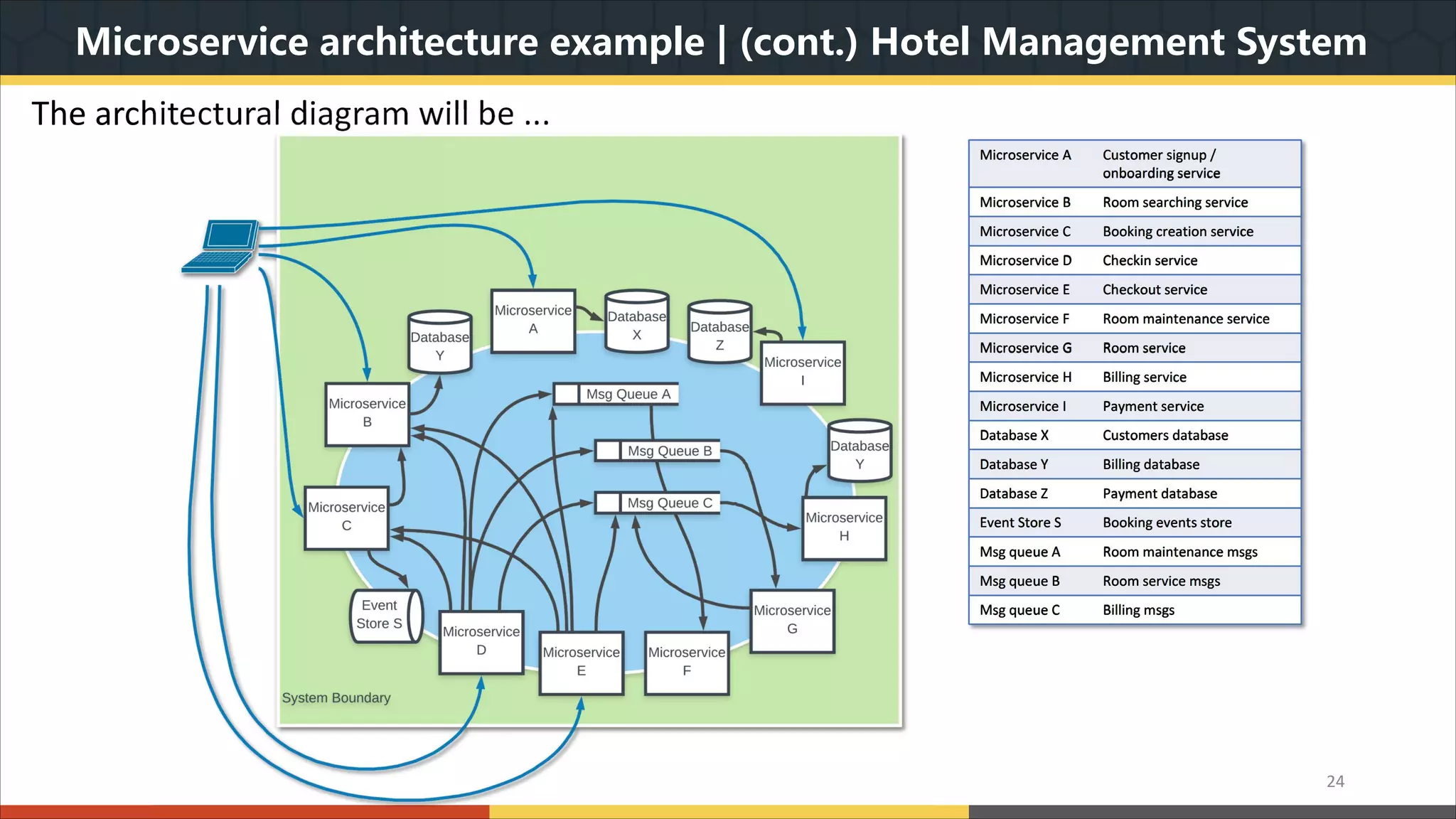
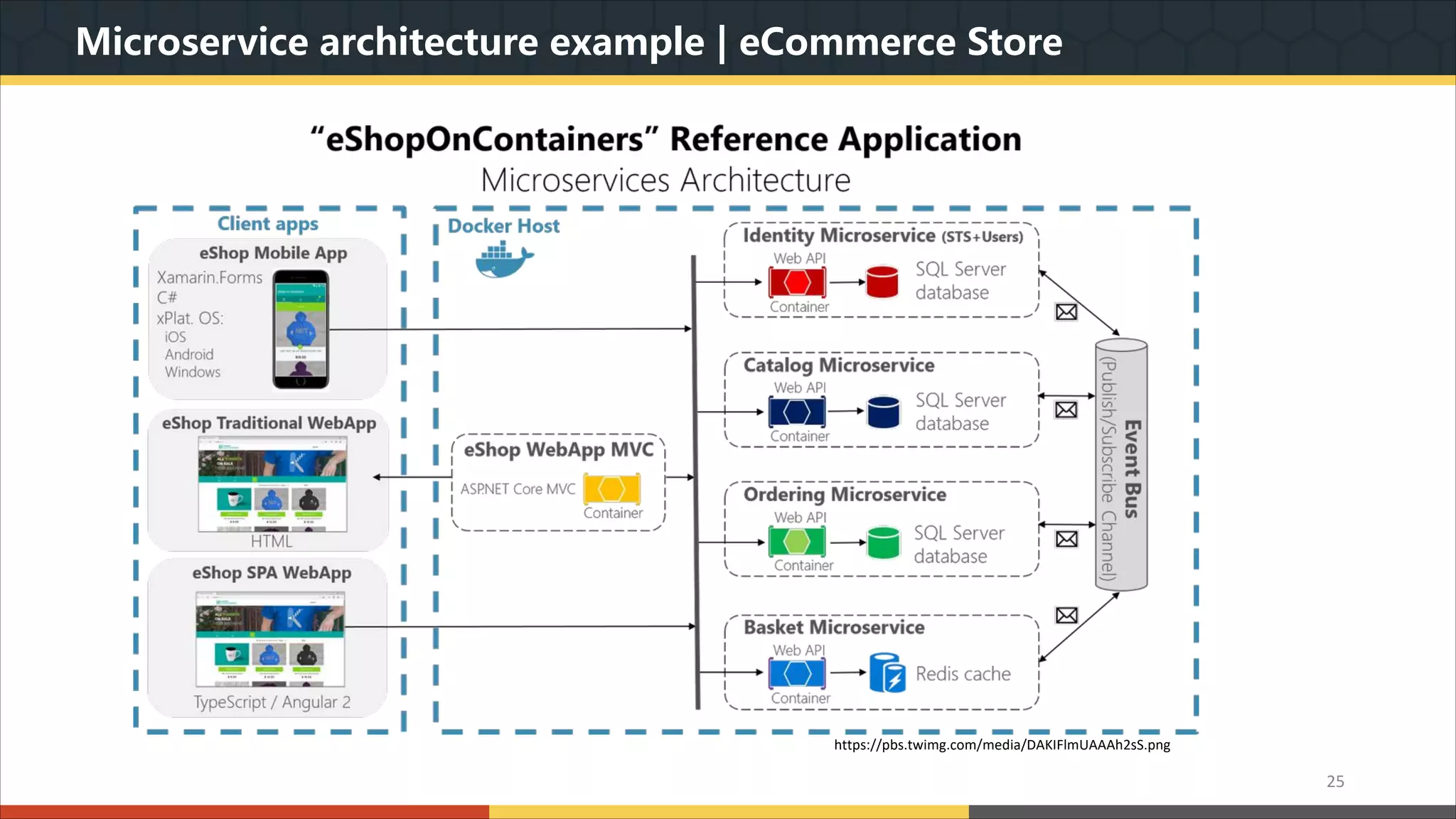

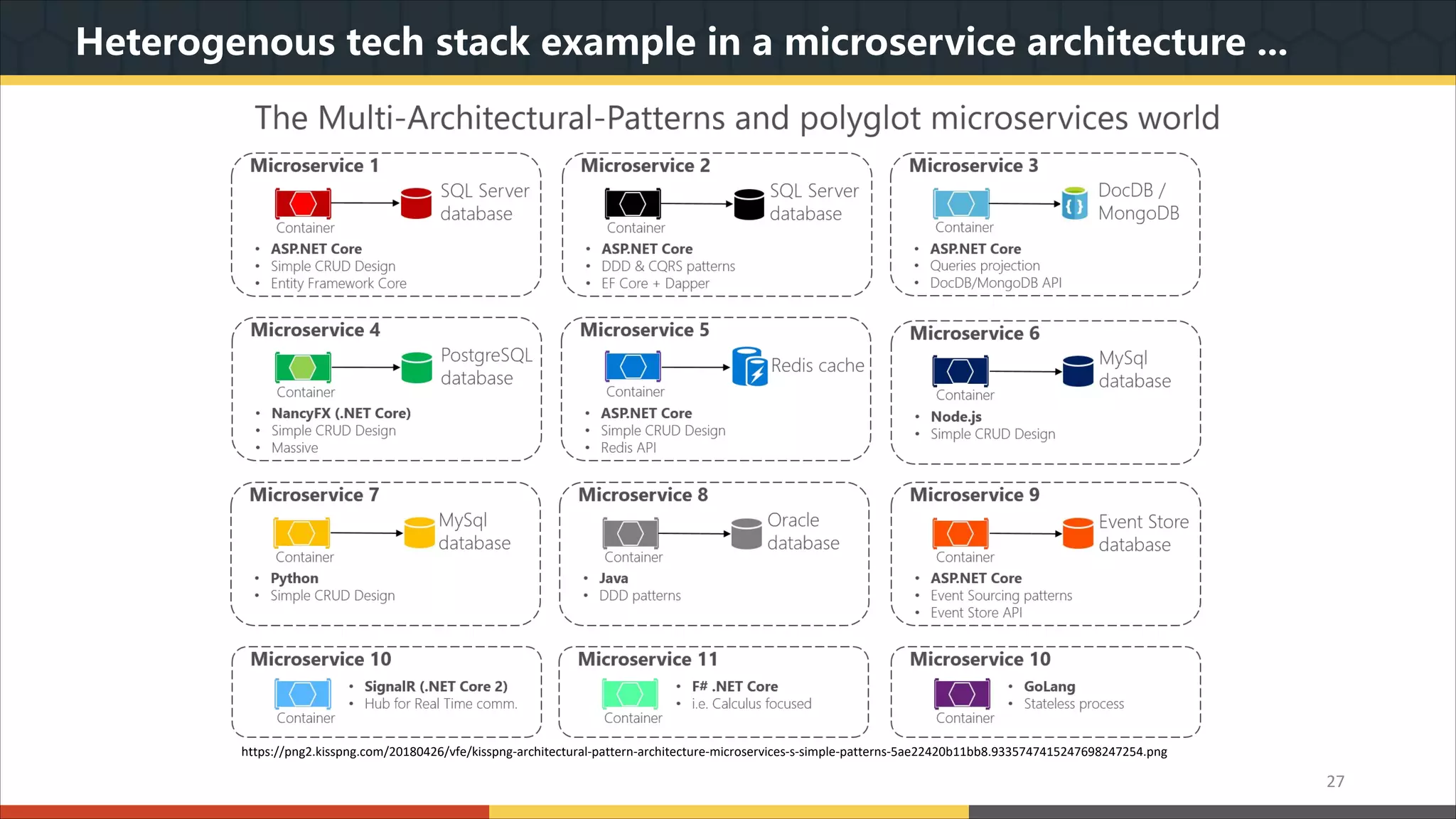








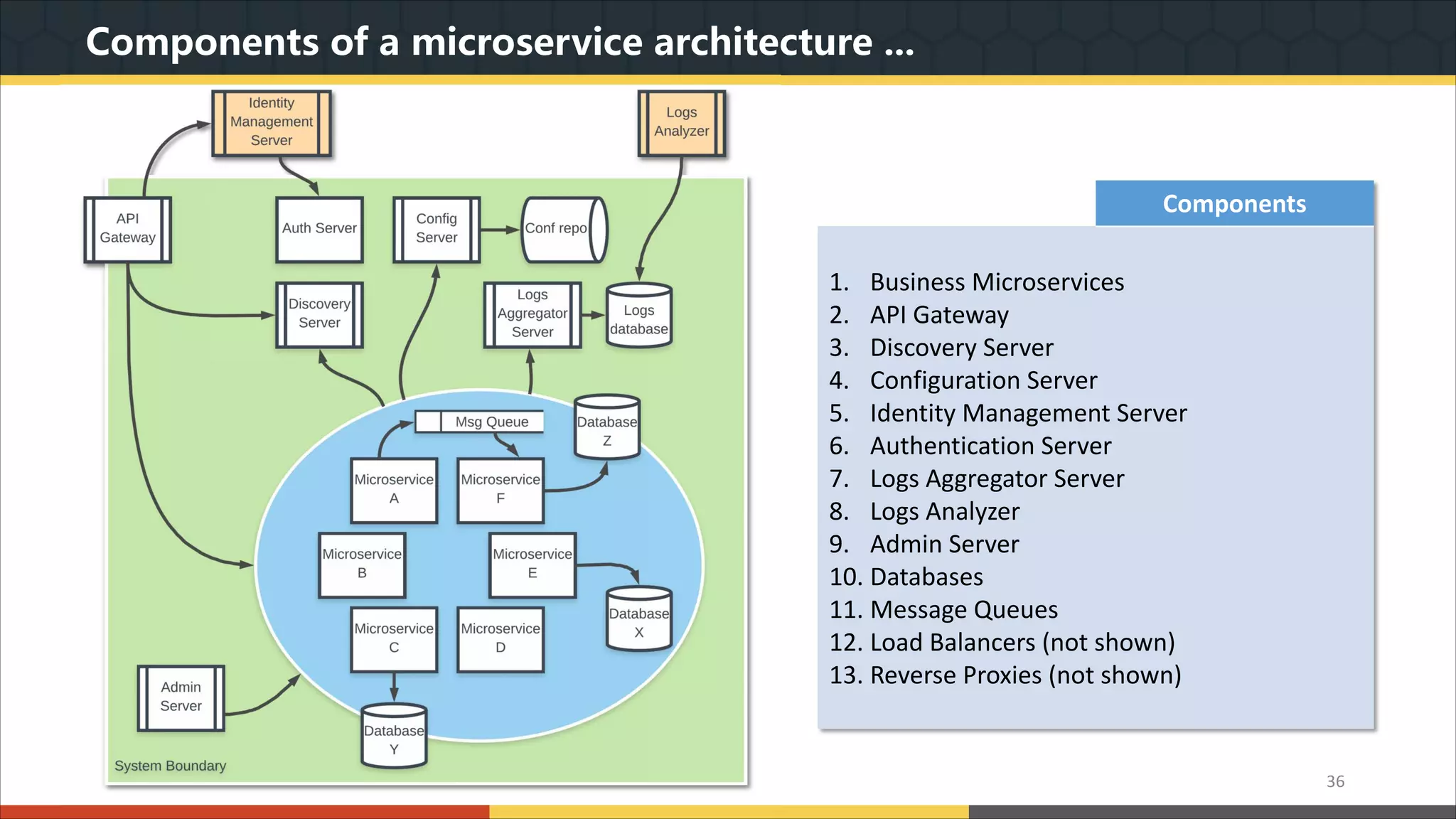

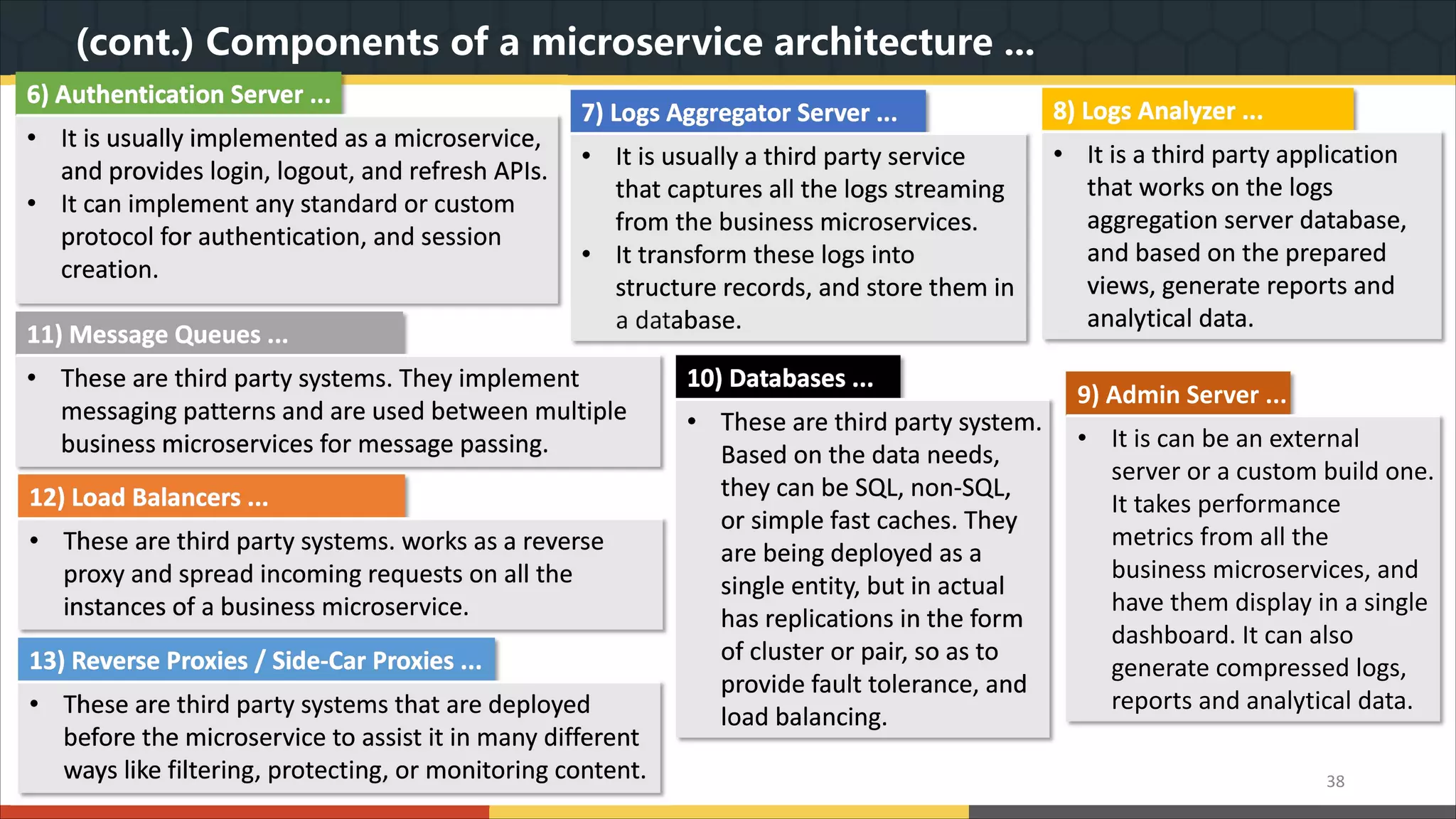
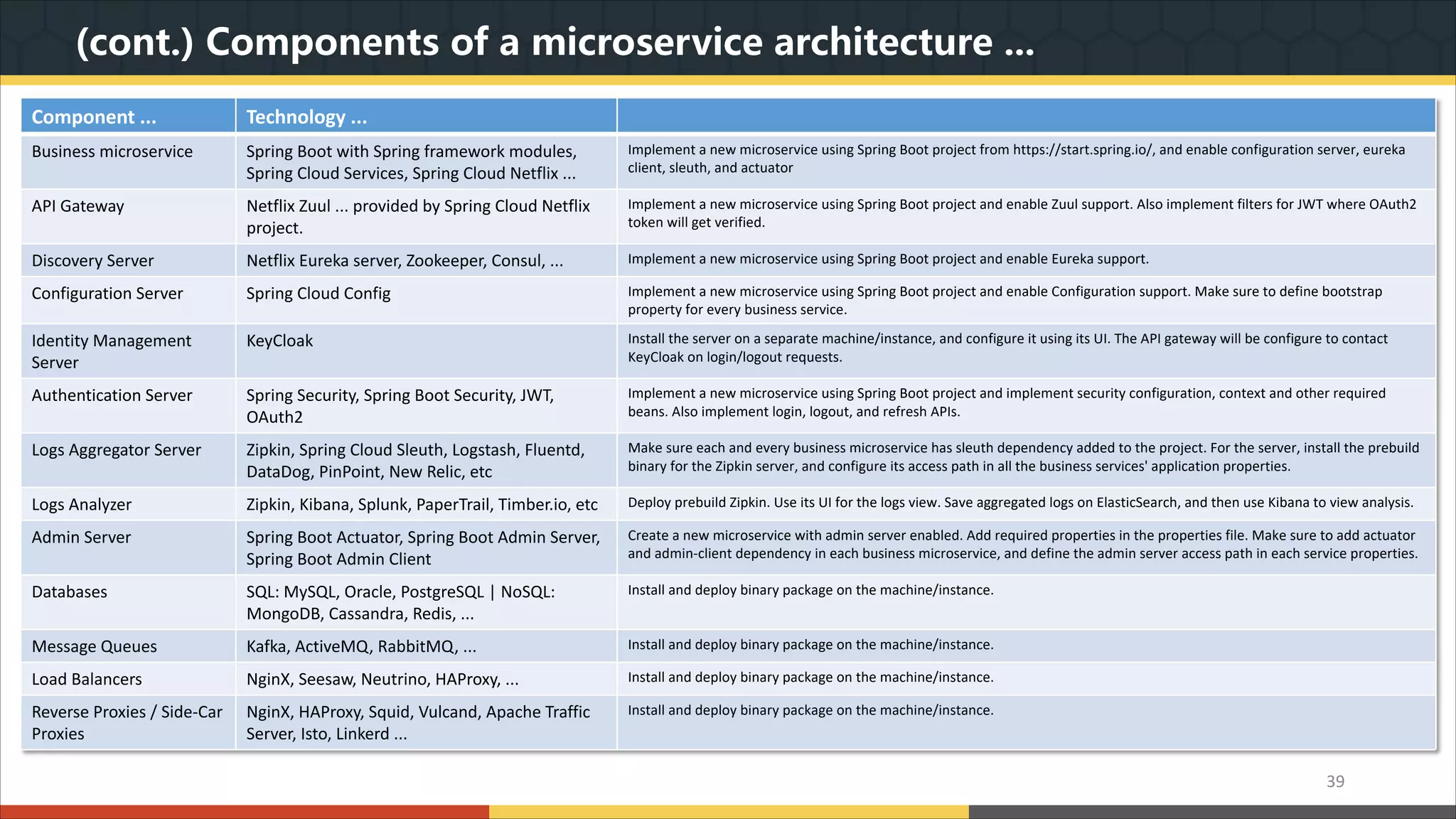

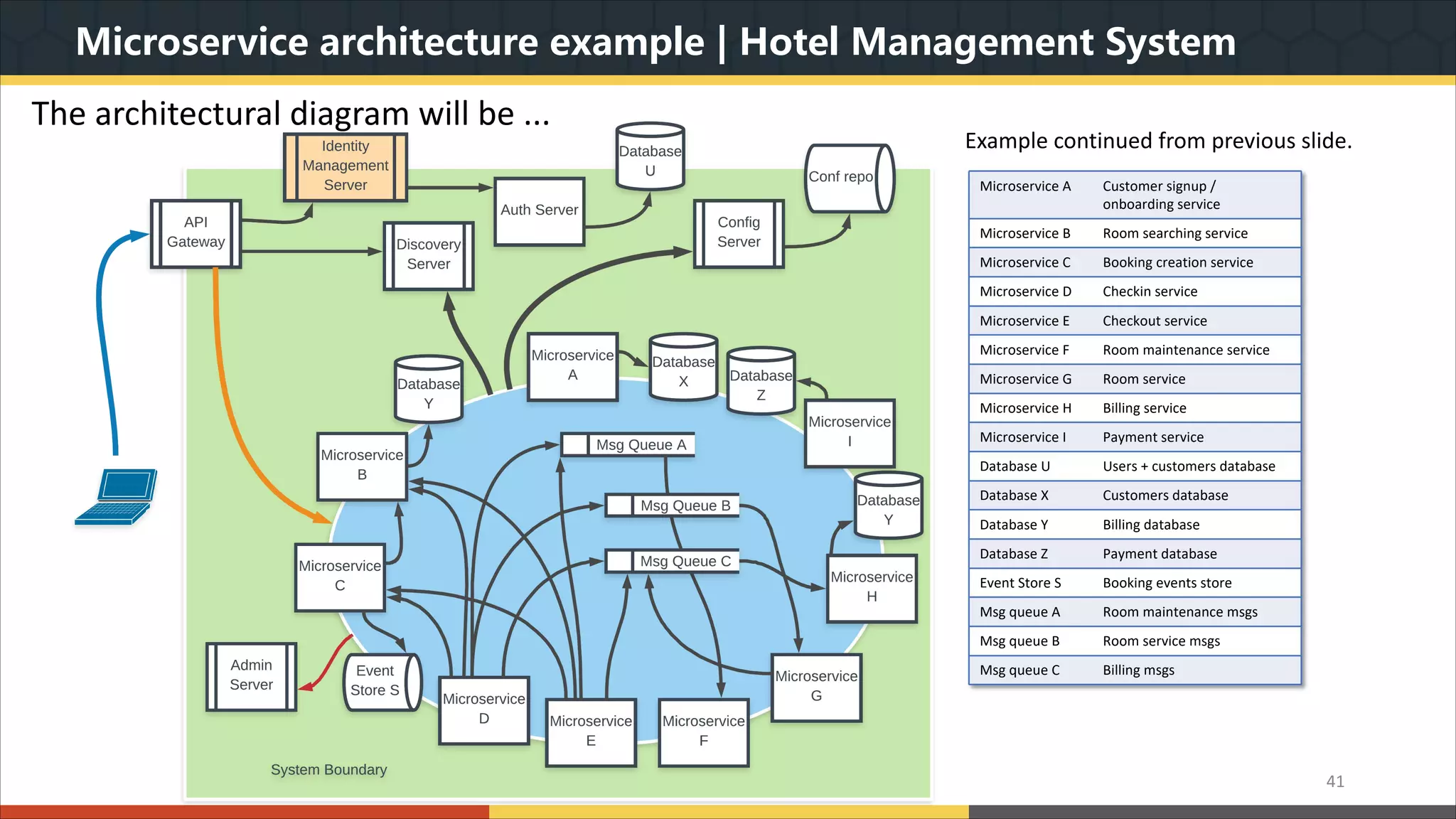

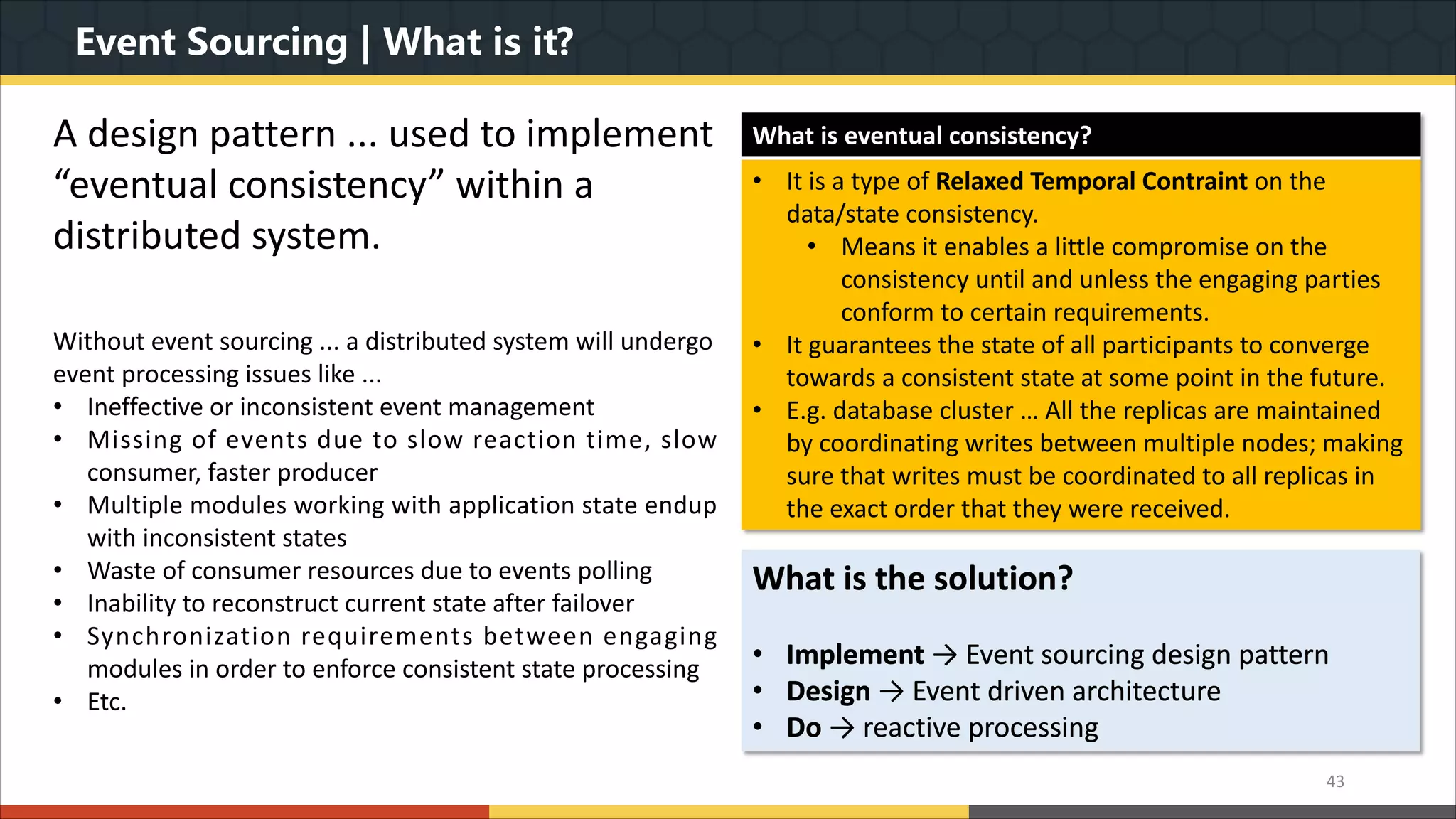
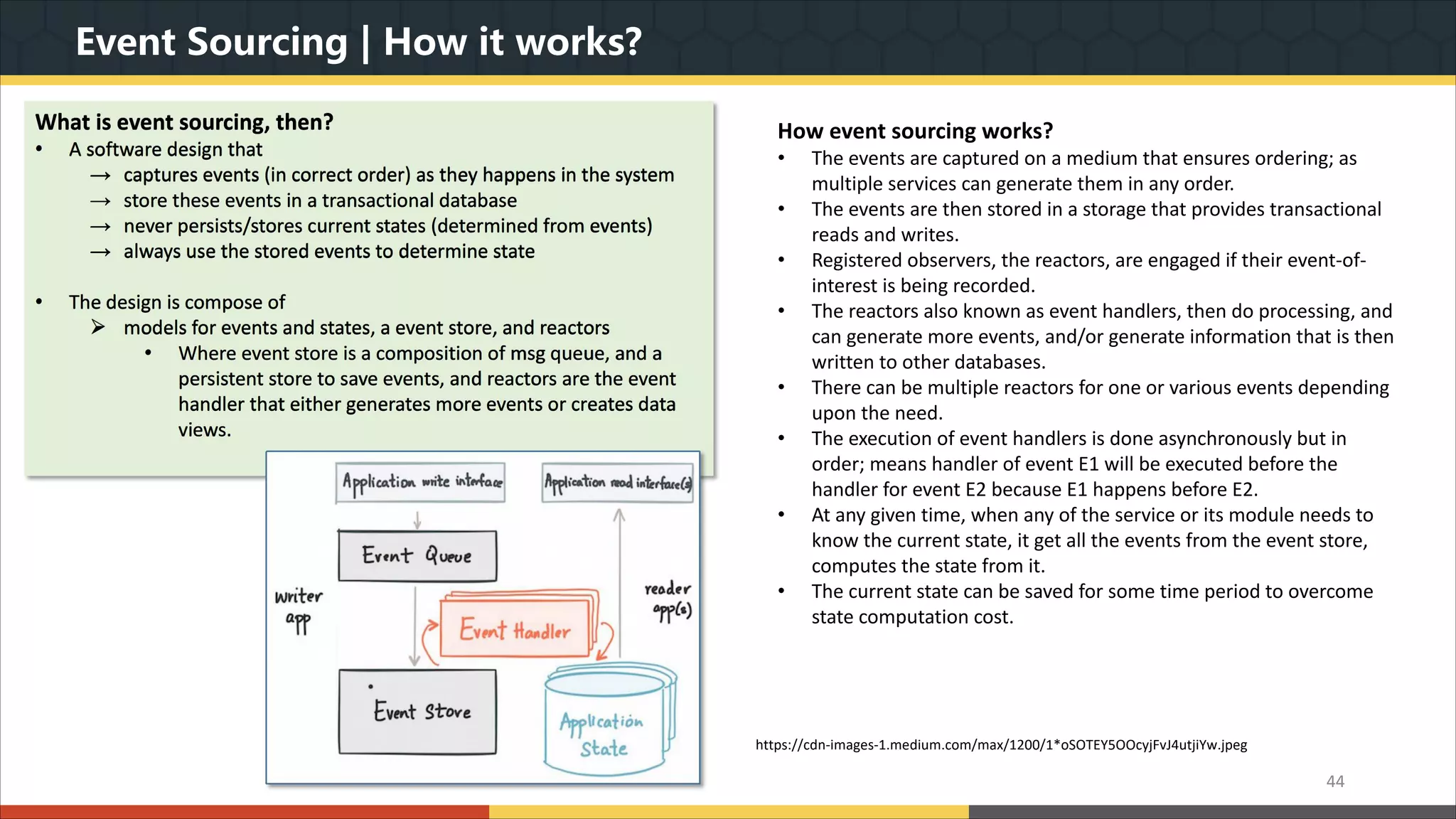
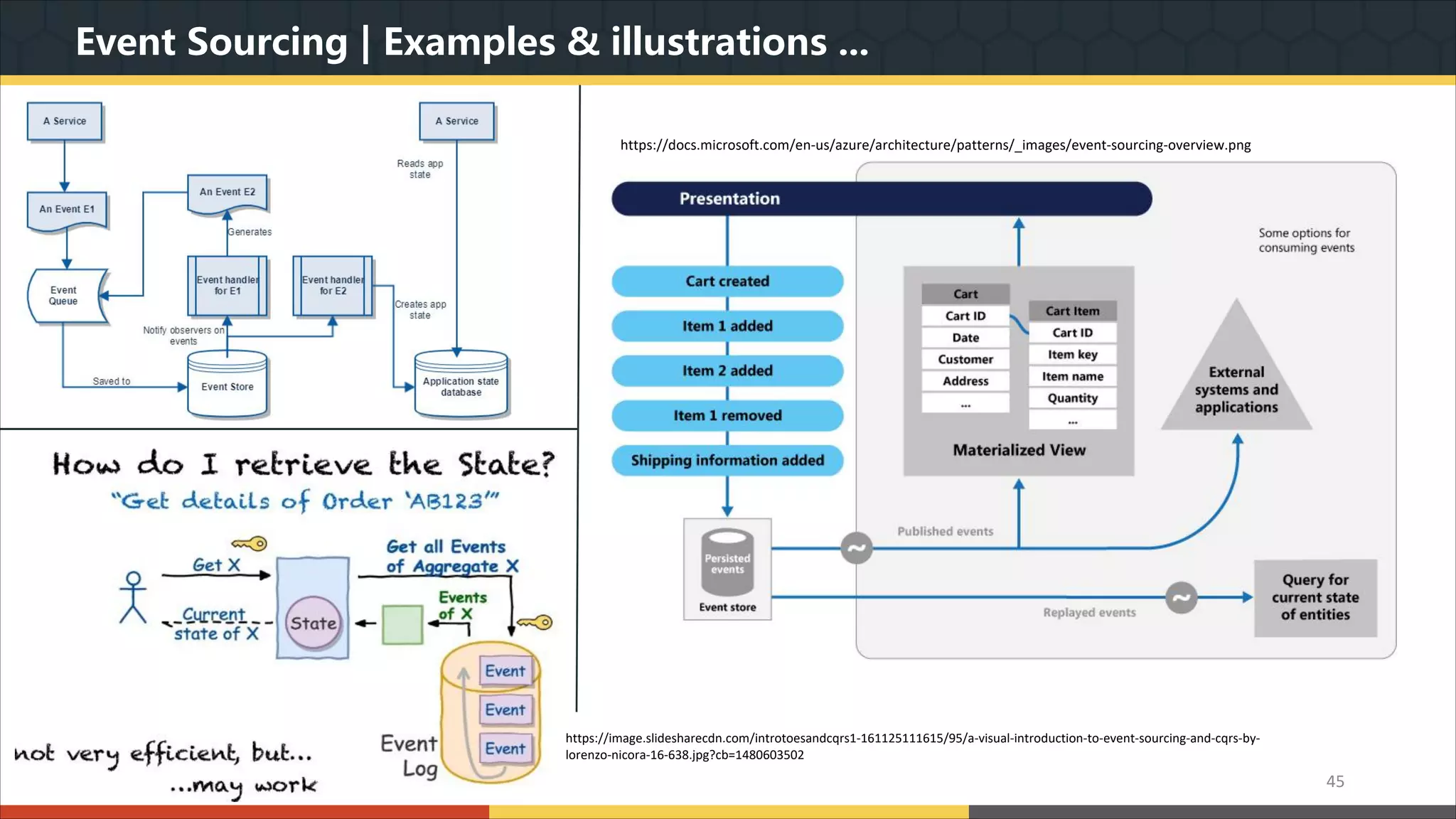









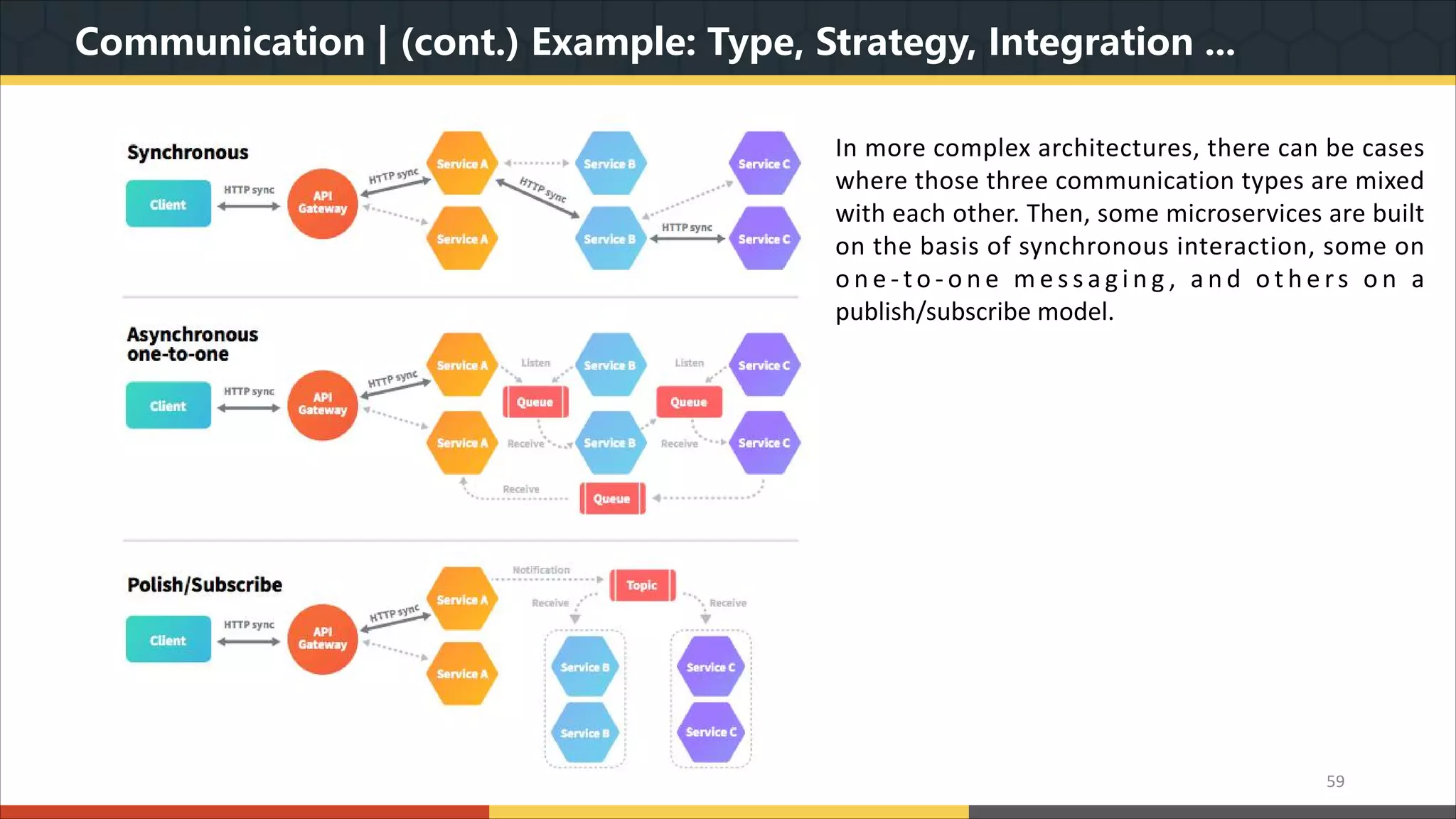

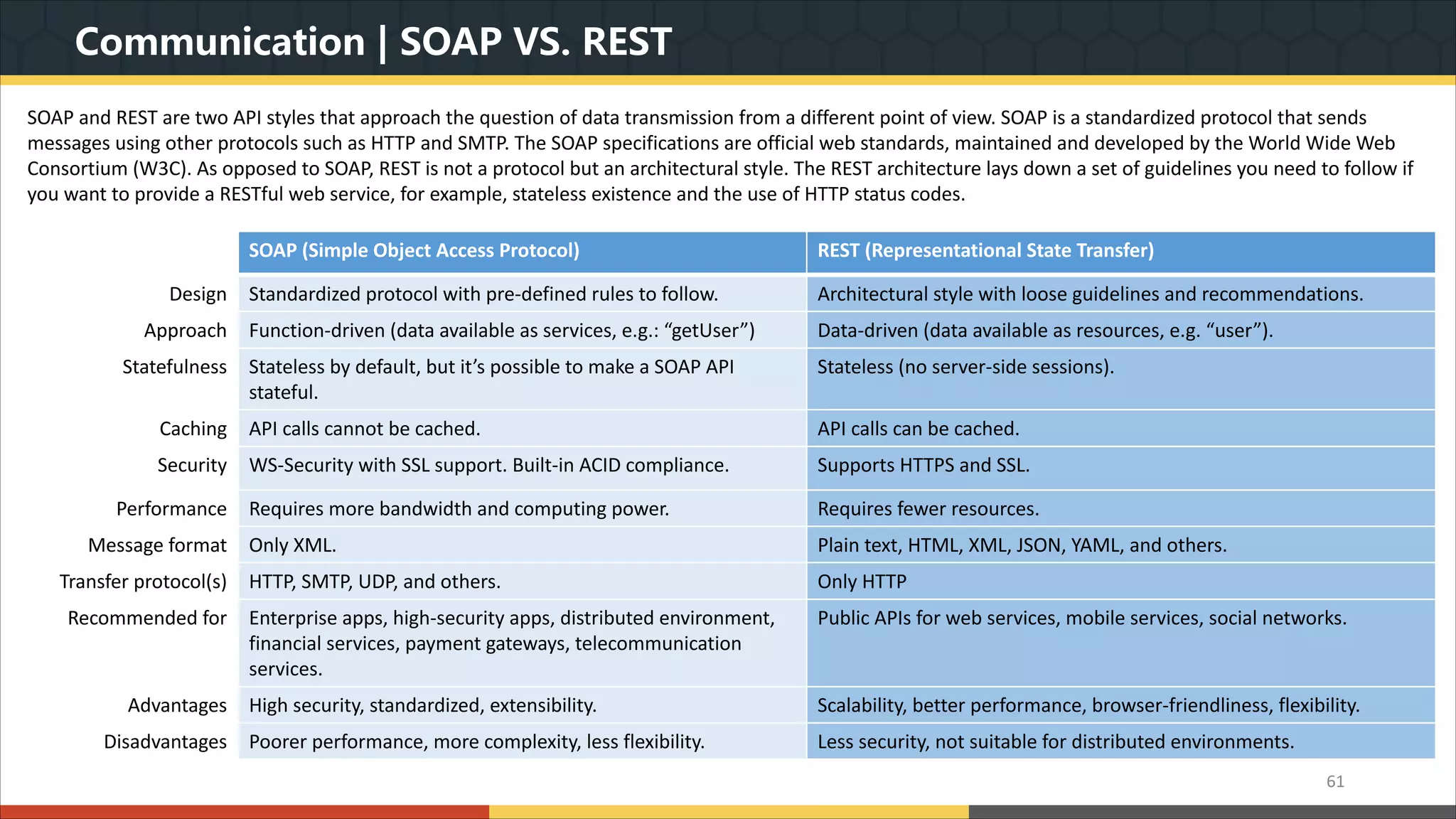









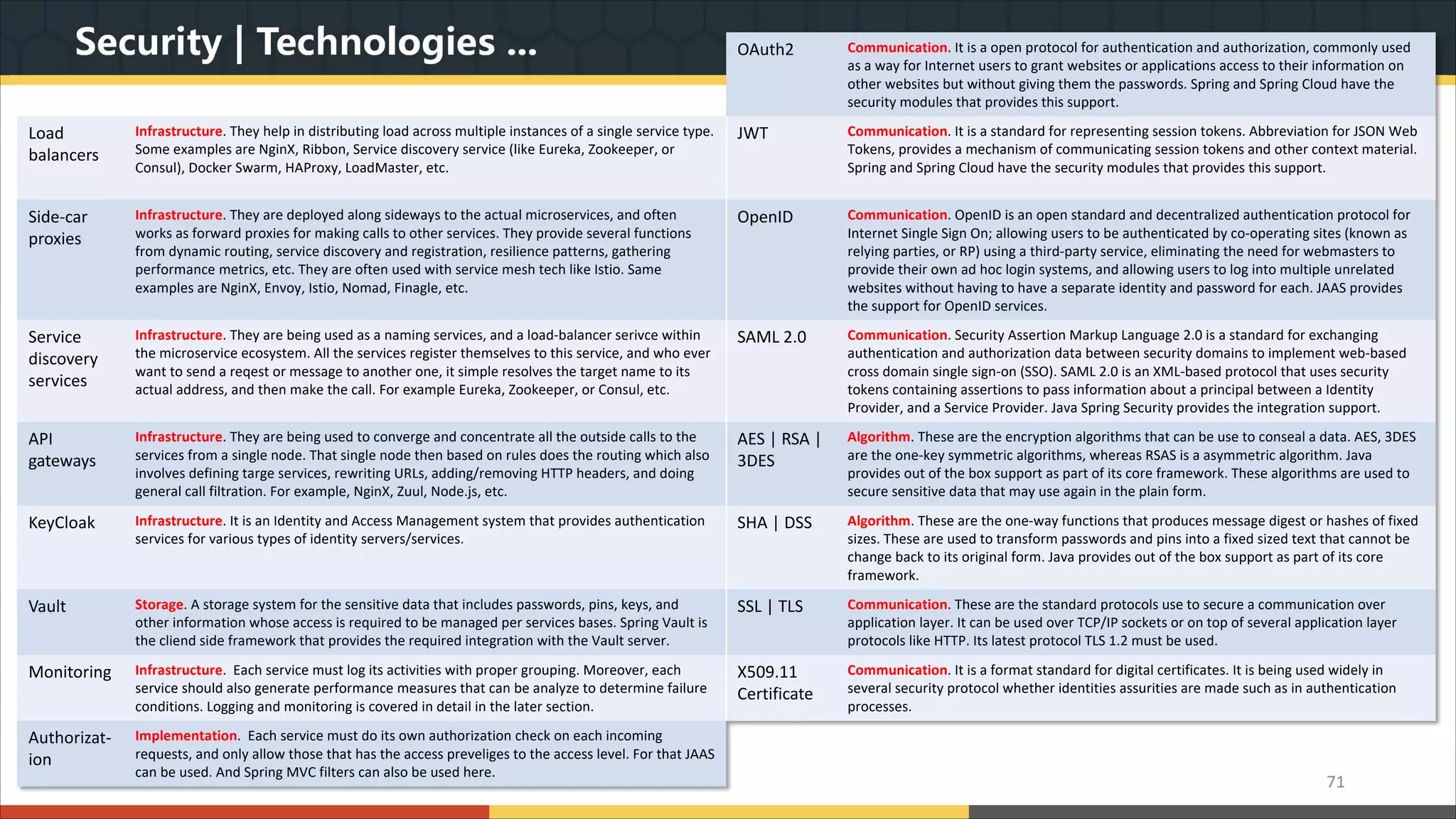
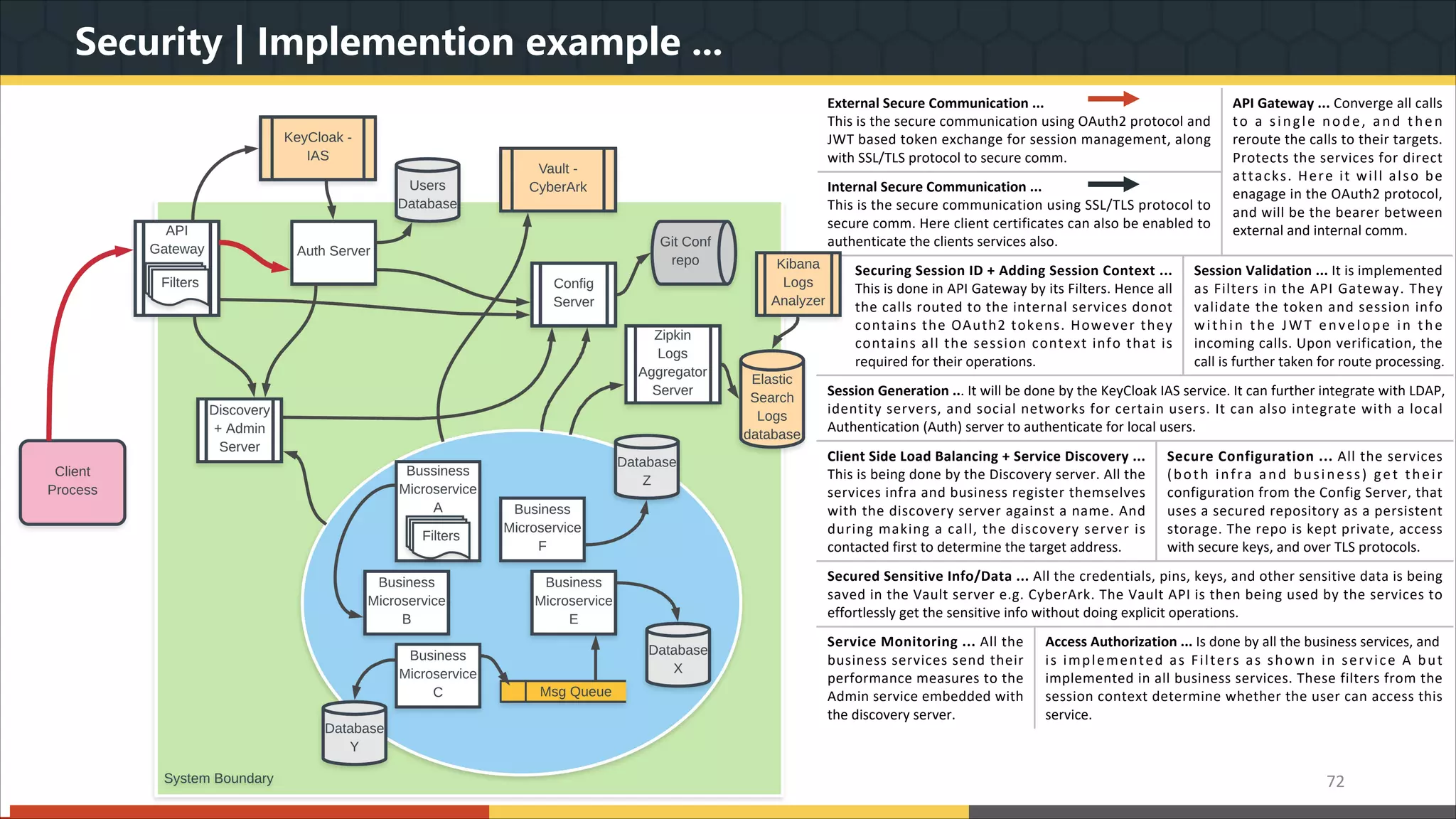





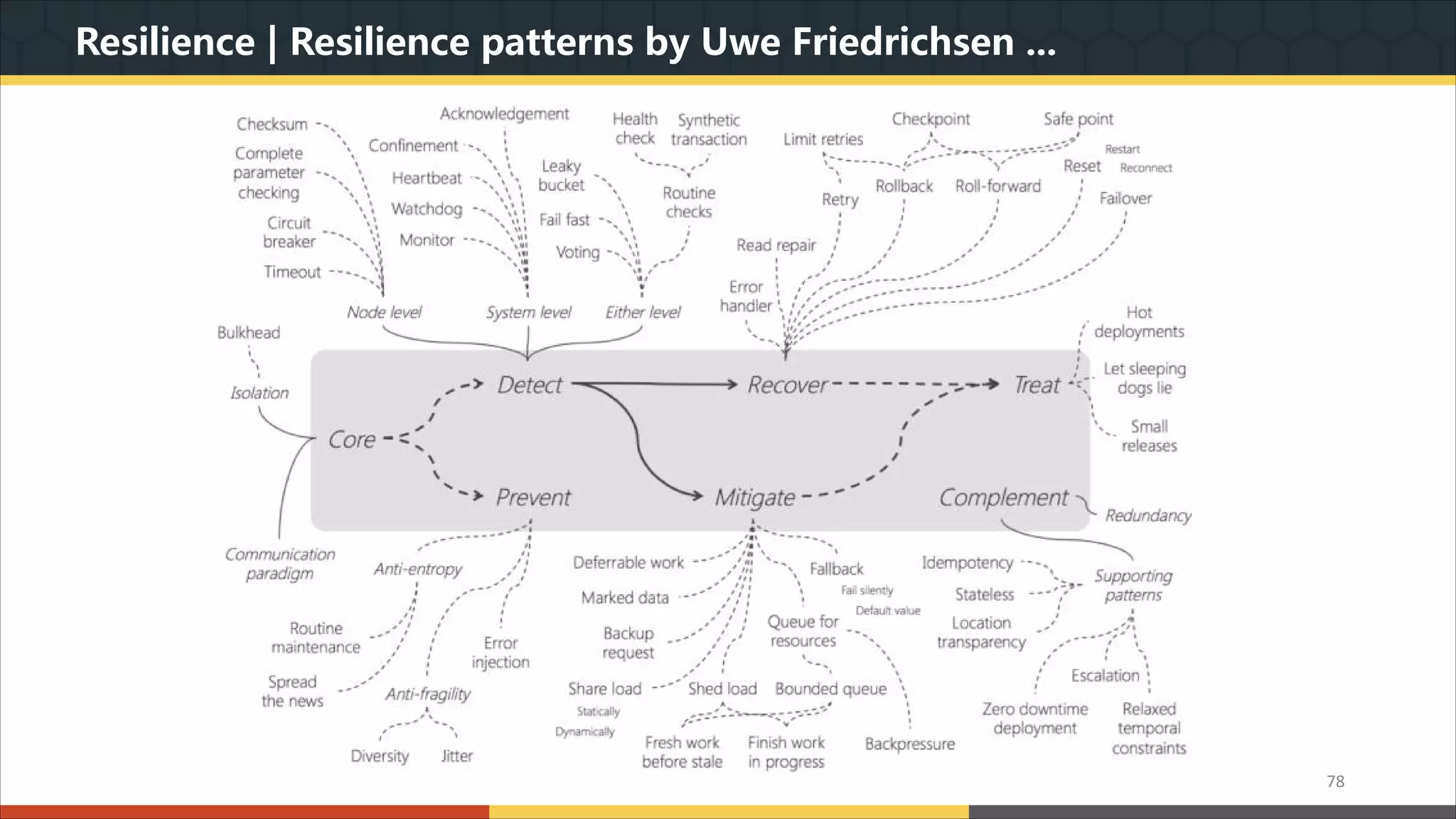
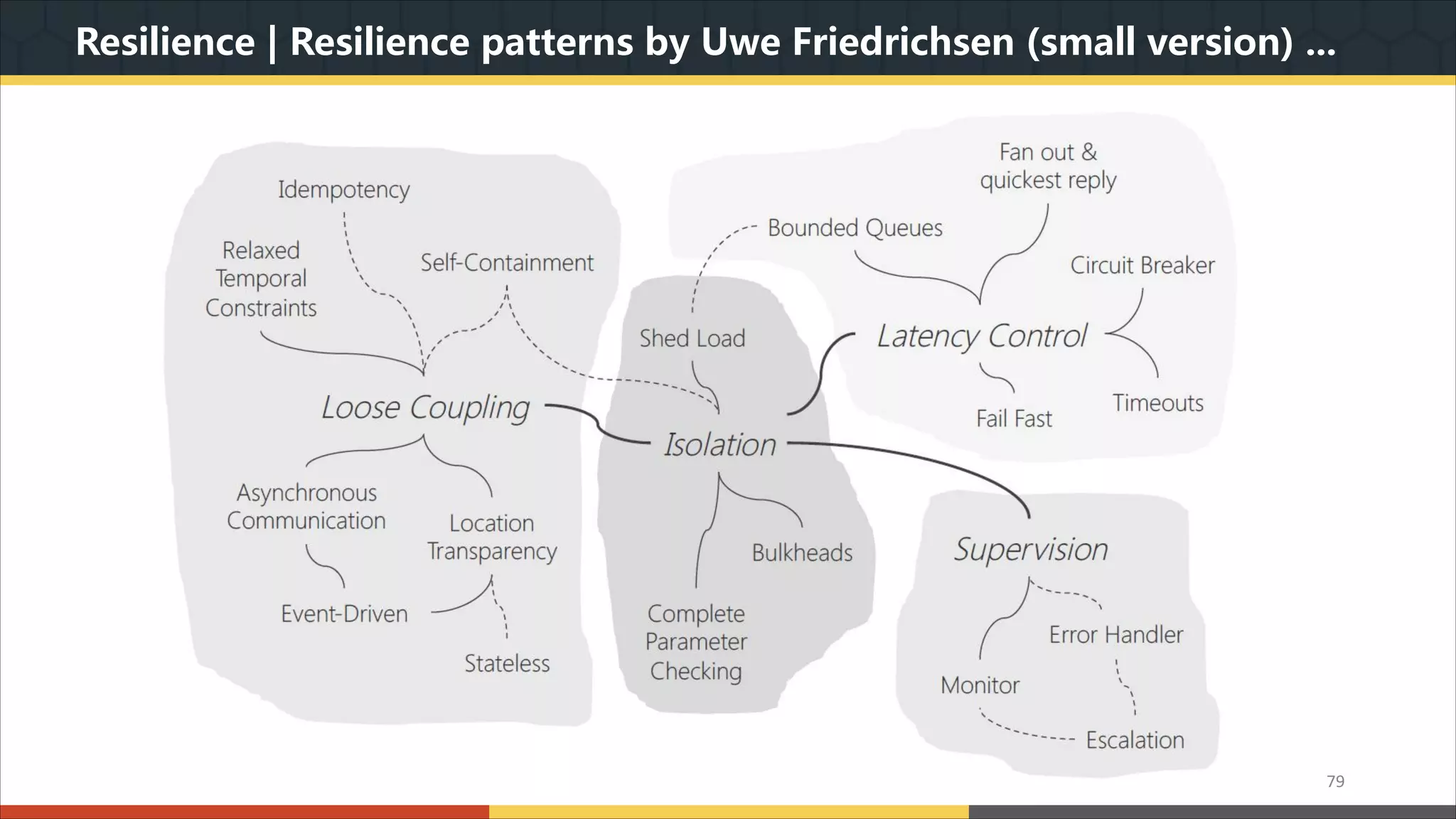
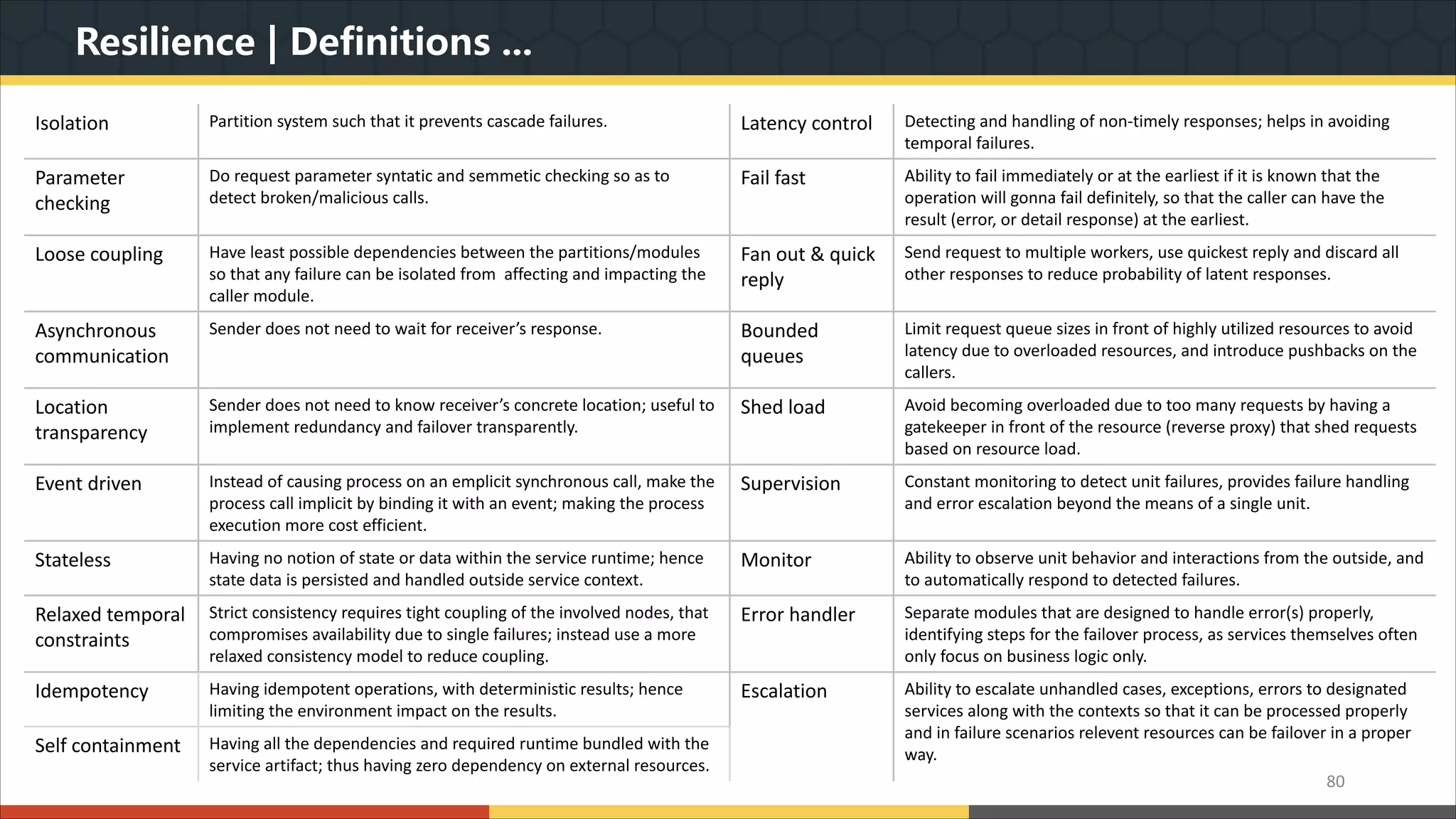


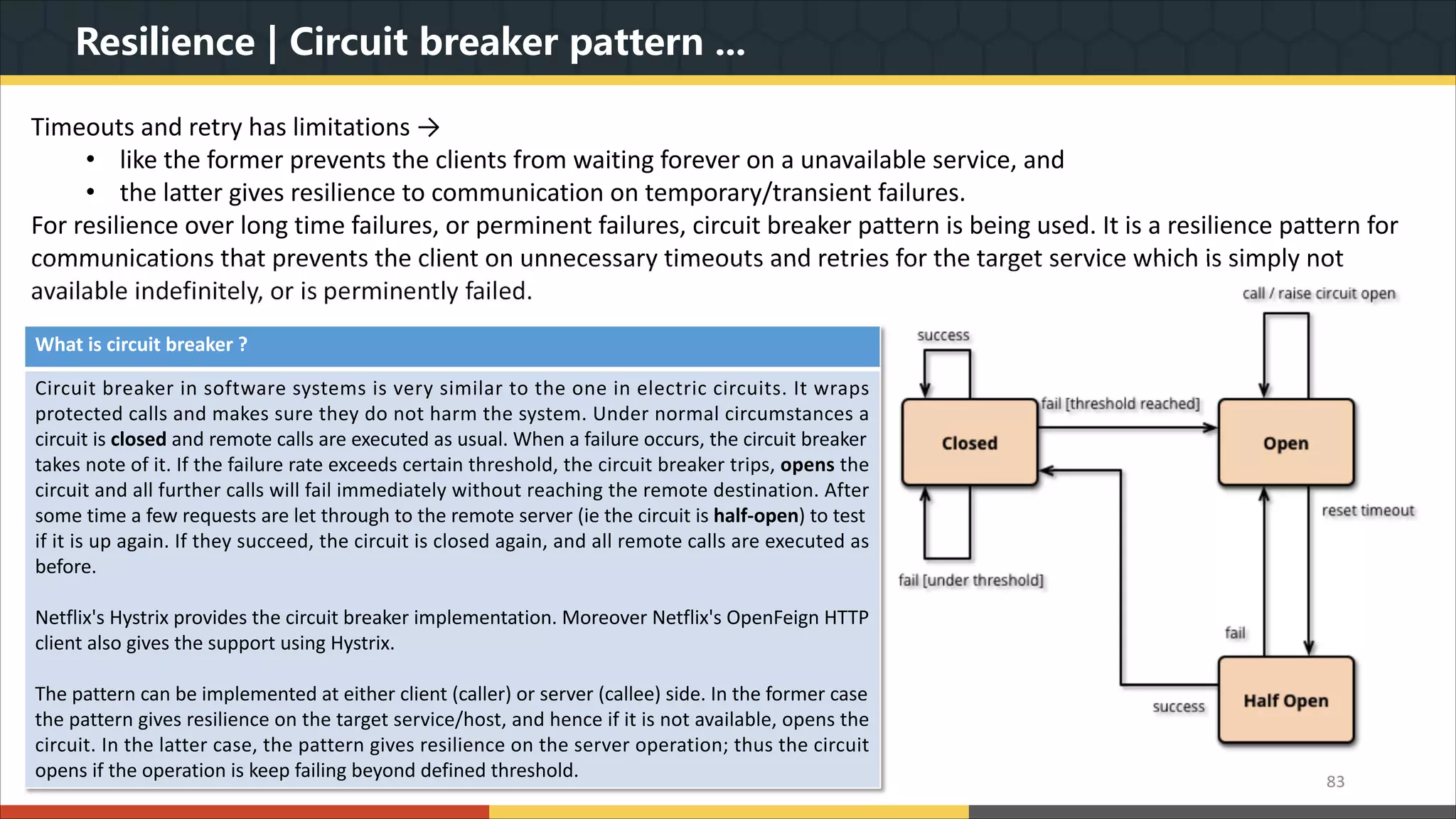


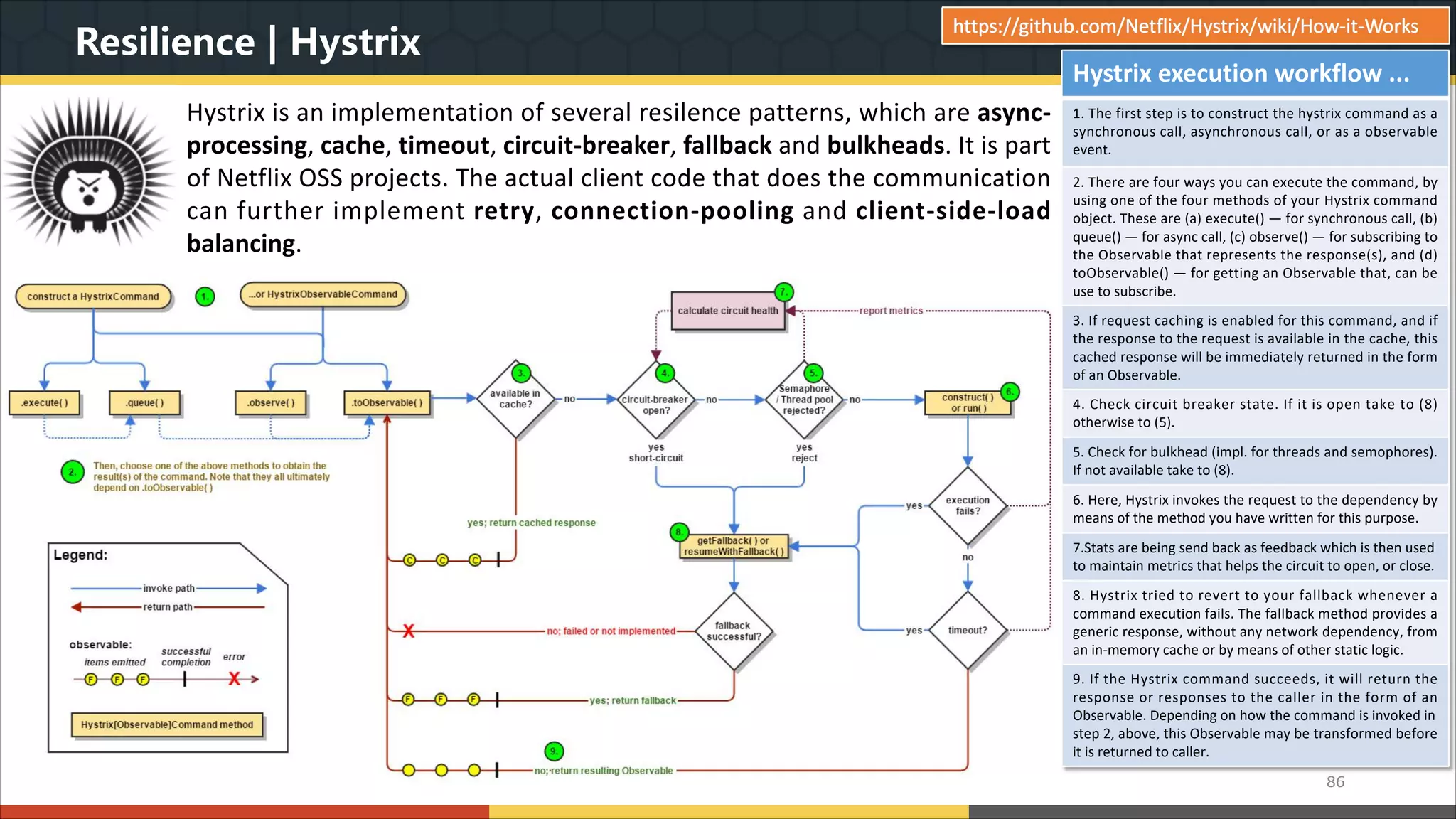








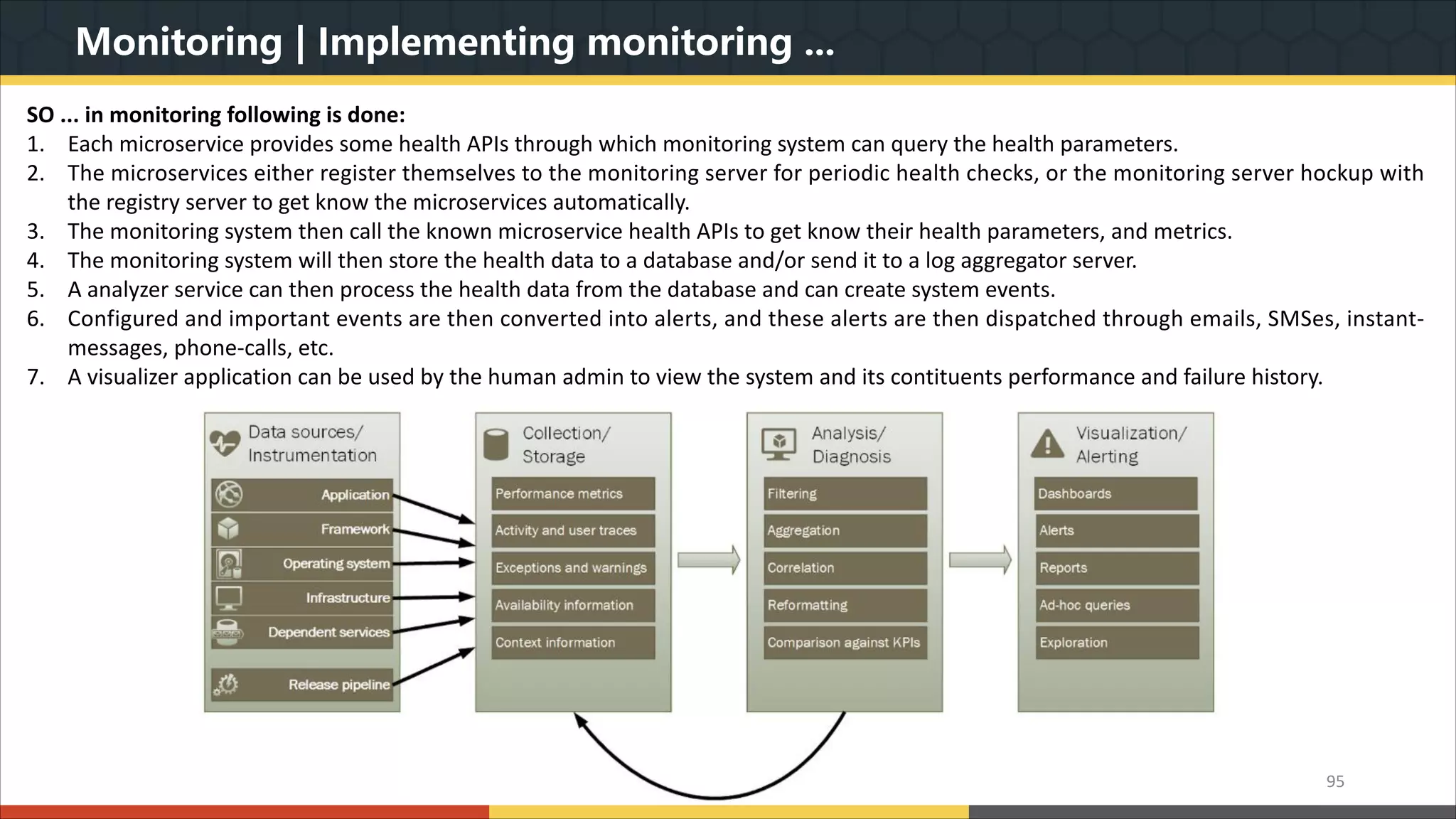



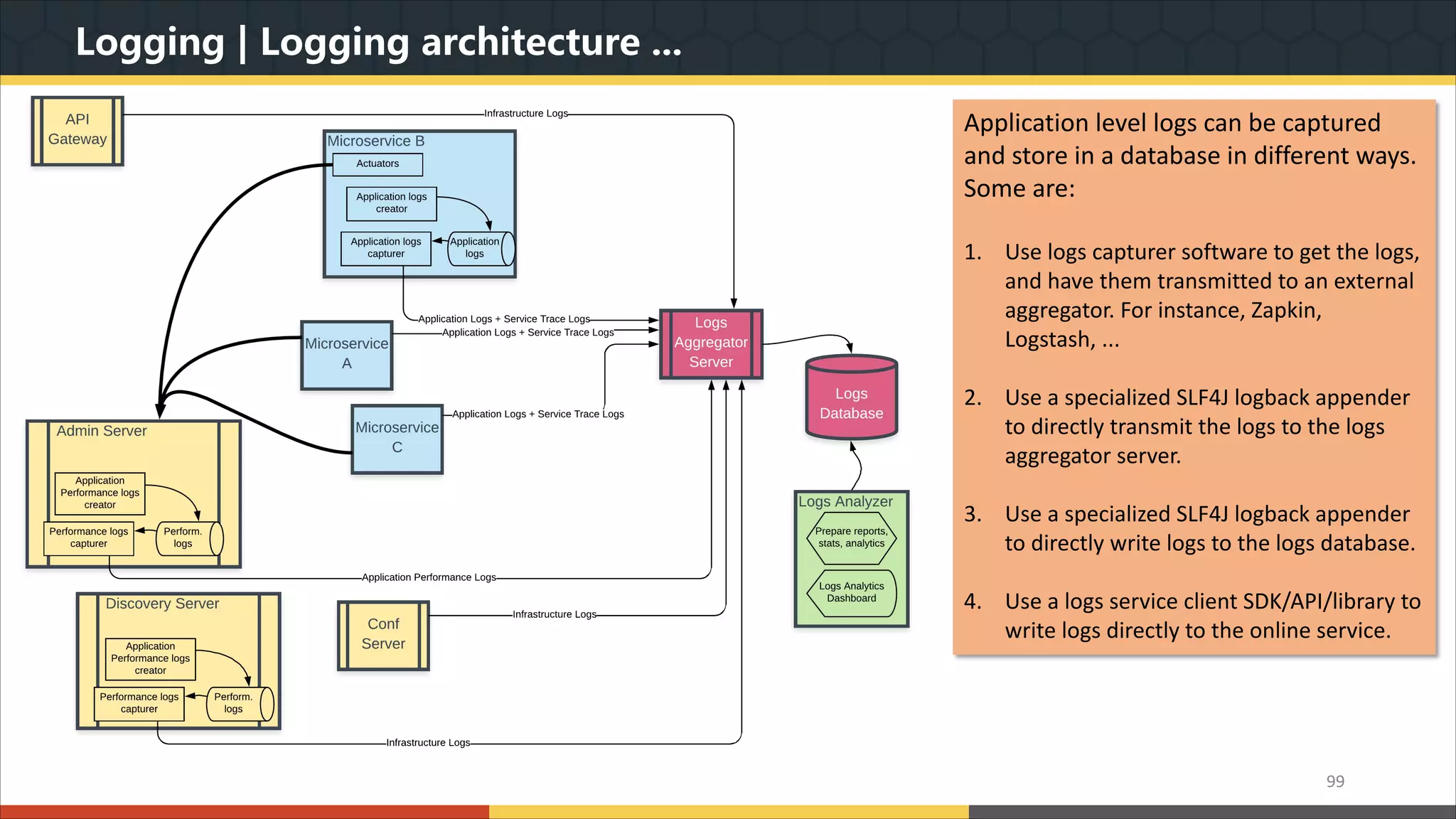
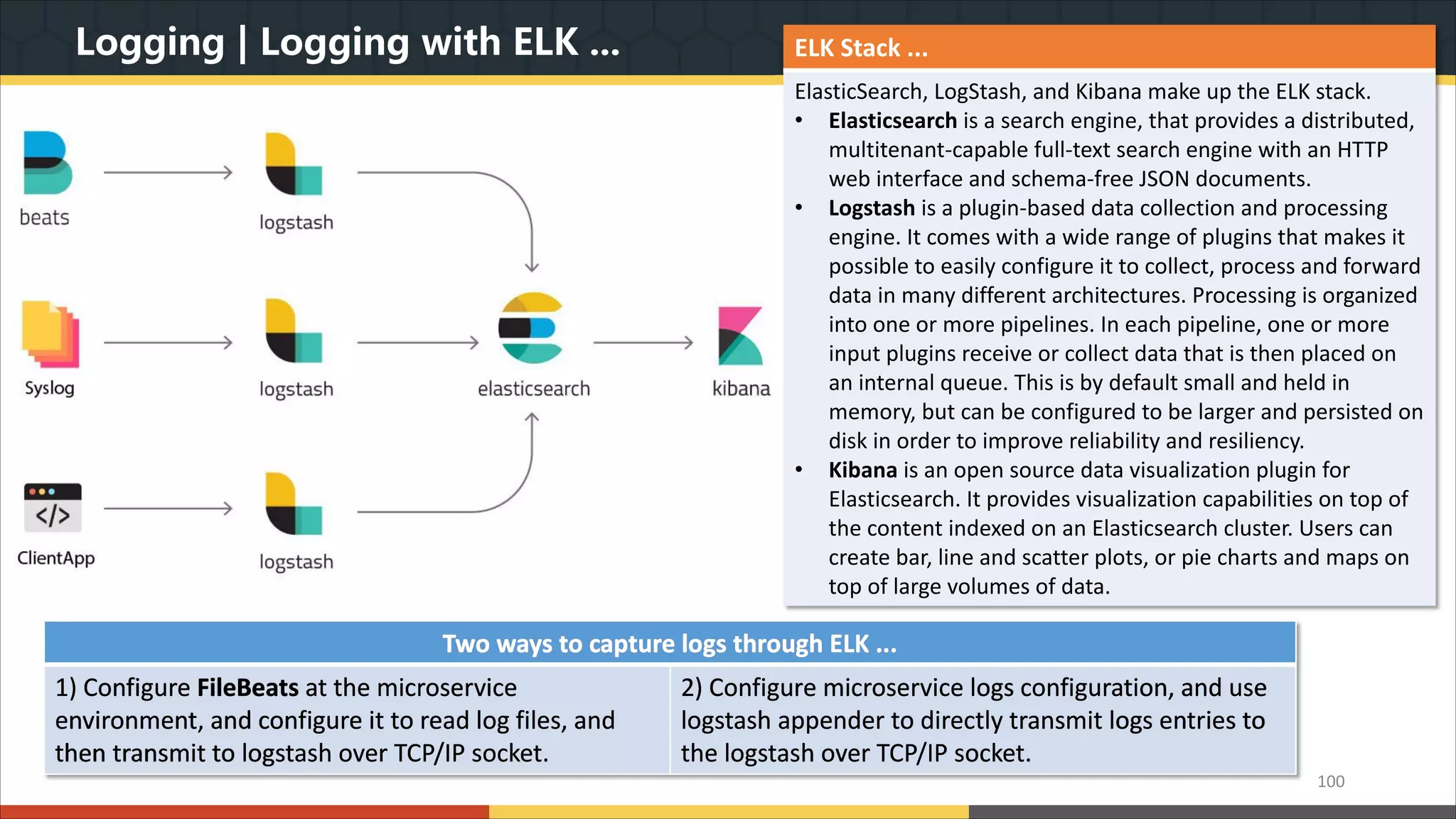

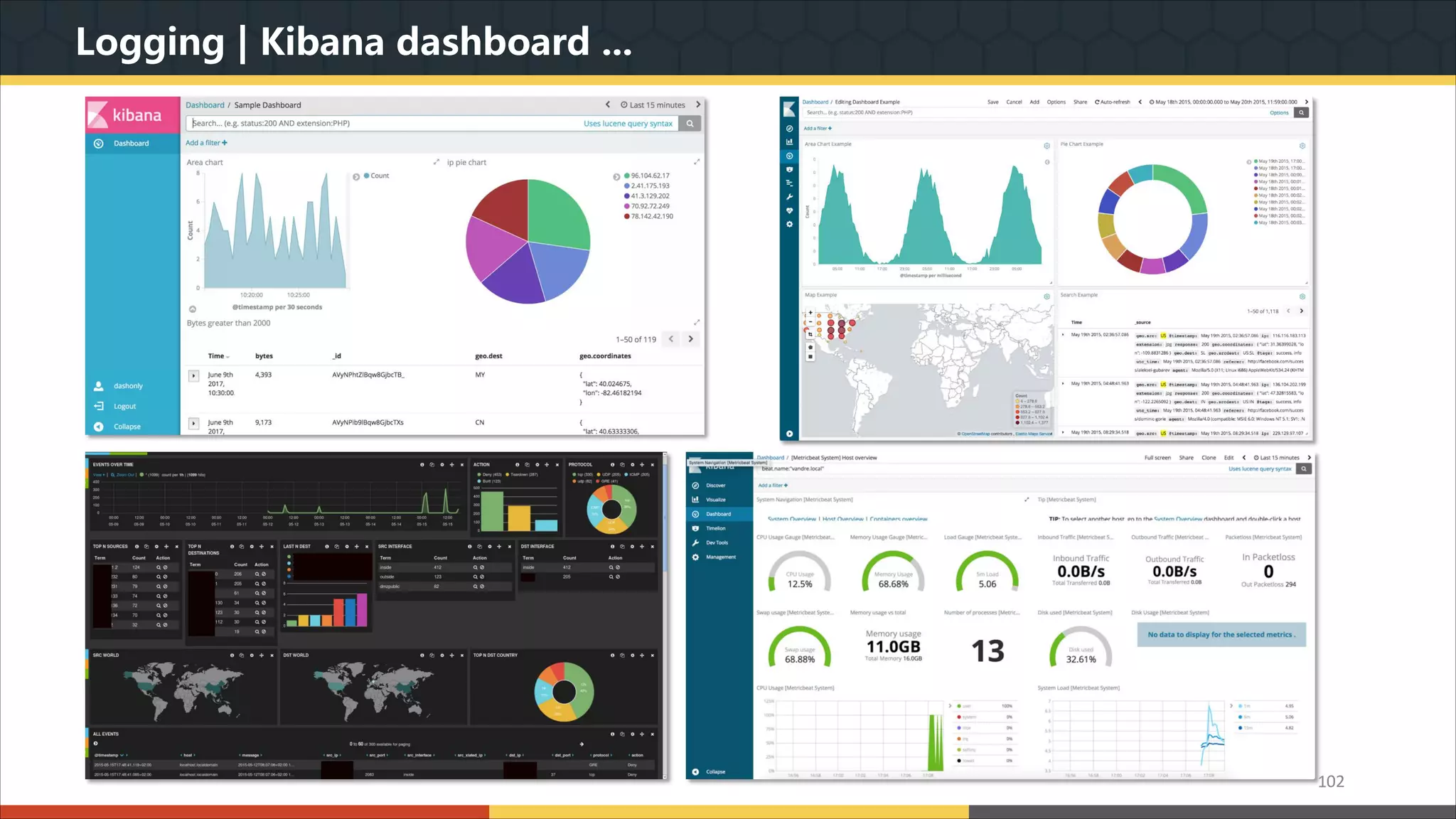
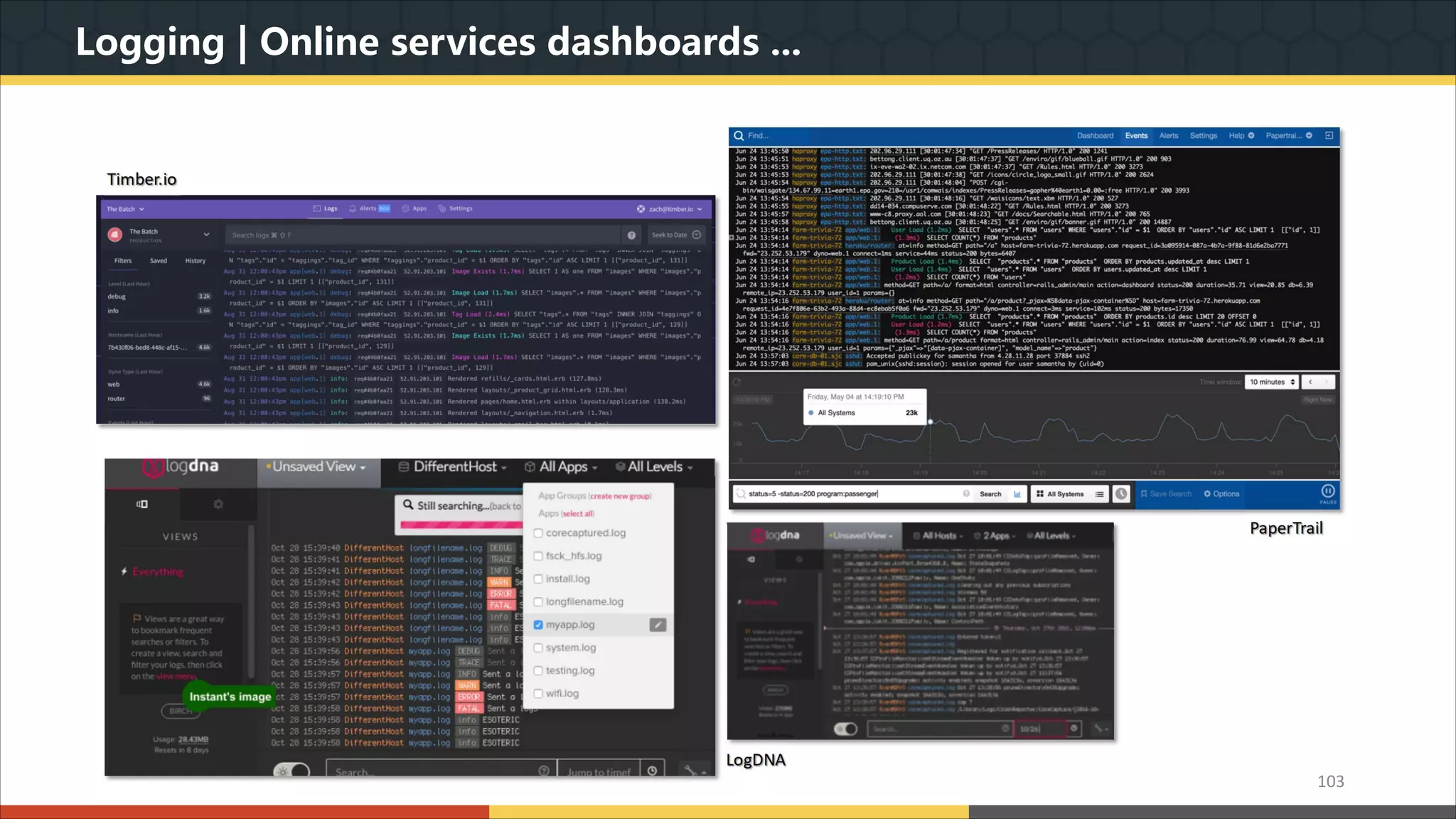






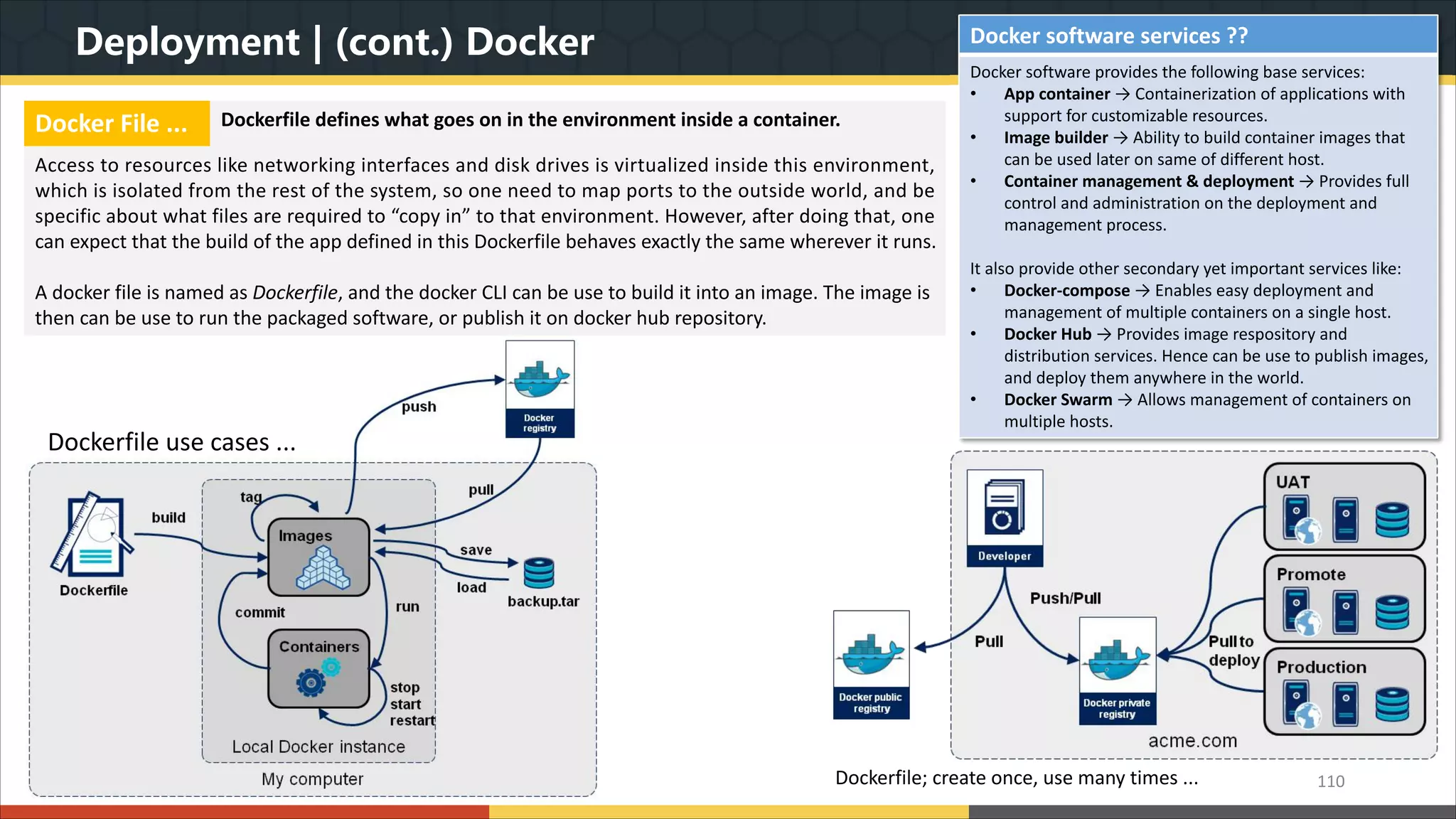

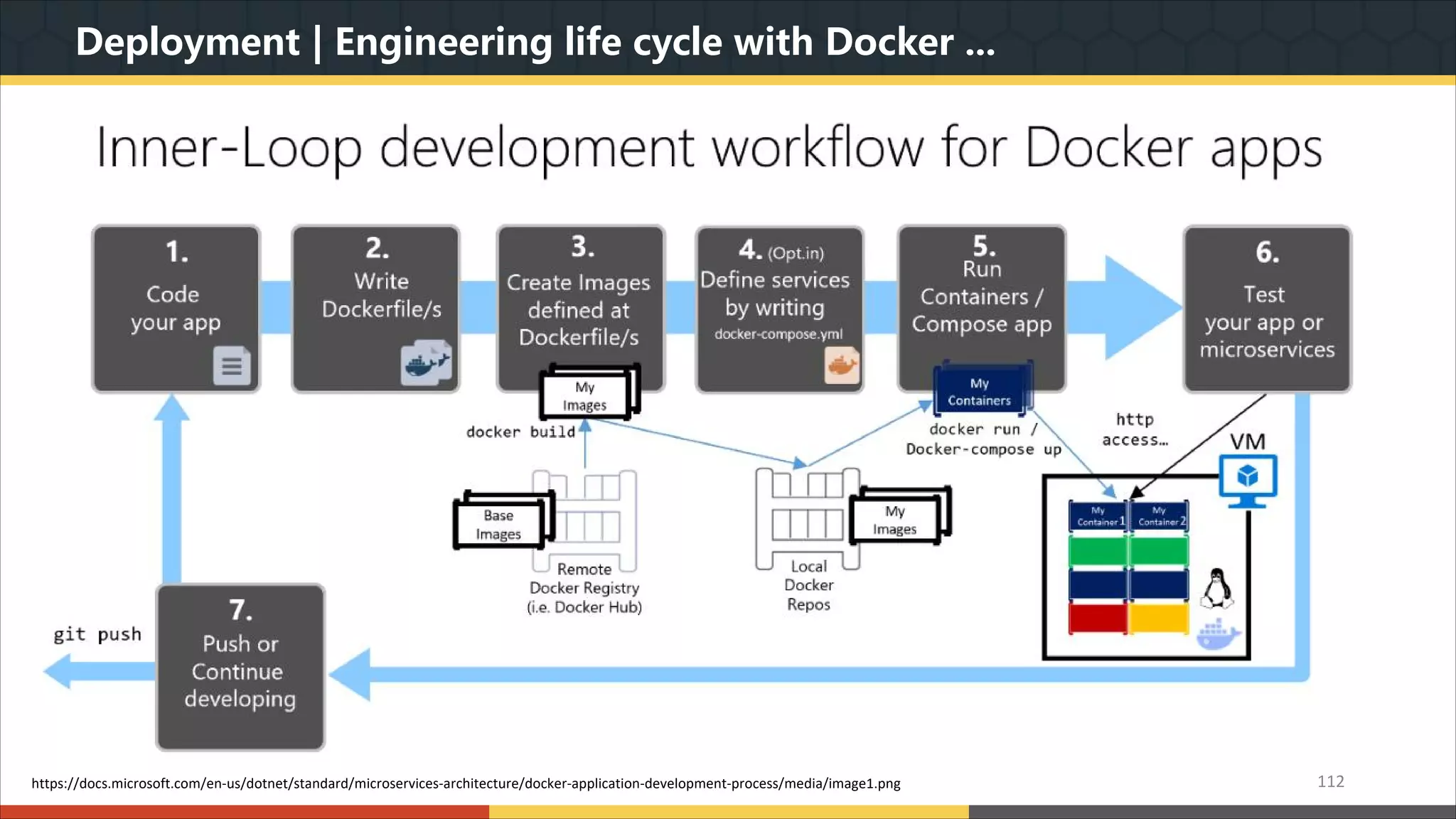
















This document provides a comprehensive overview of microservice architecture, particularly in the context of Java and Spring Boot technologies, outlining its historical evolution, benefits over traditional monolithic architecture, and key characteristics. It emphasizes the importance of independent services that promote easy manageability, scalability, and resilience, while also discussing challenges associated with microservices such as operational complexity and eventual consistency. Additionally, it highlights various companies successfully employing microservice architecture, underscoring its significance in modern software development.