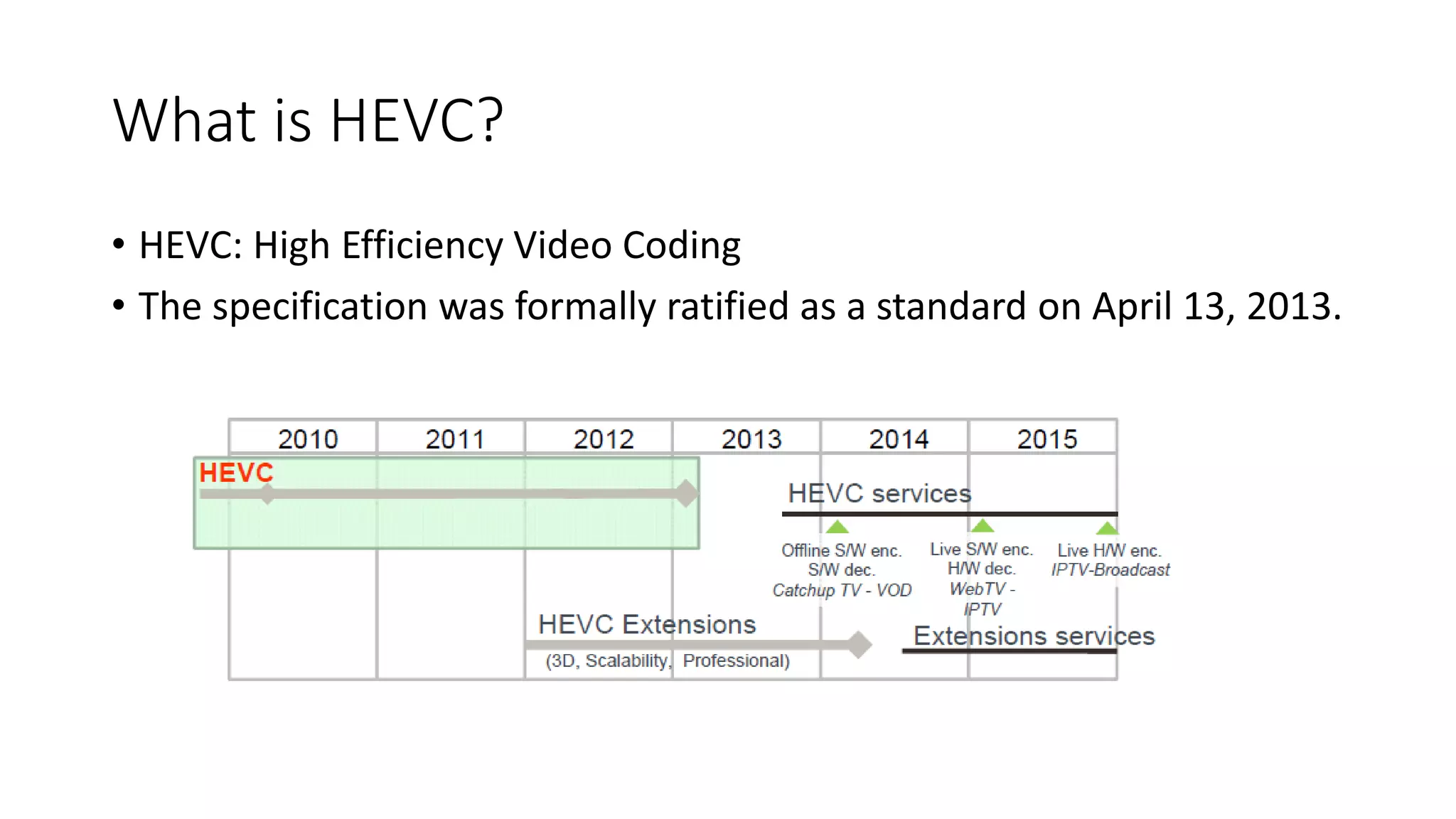
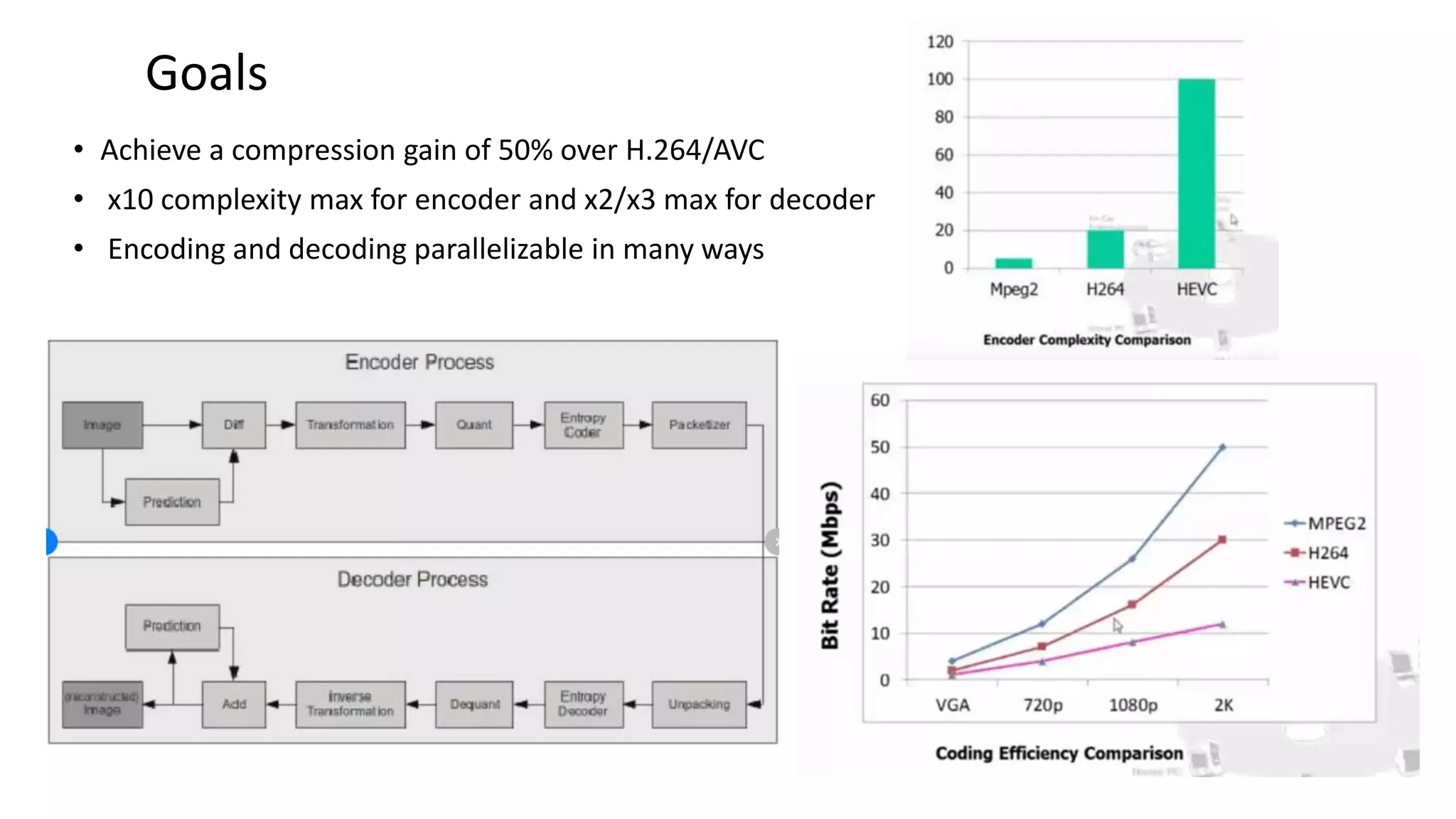
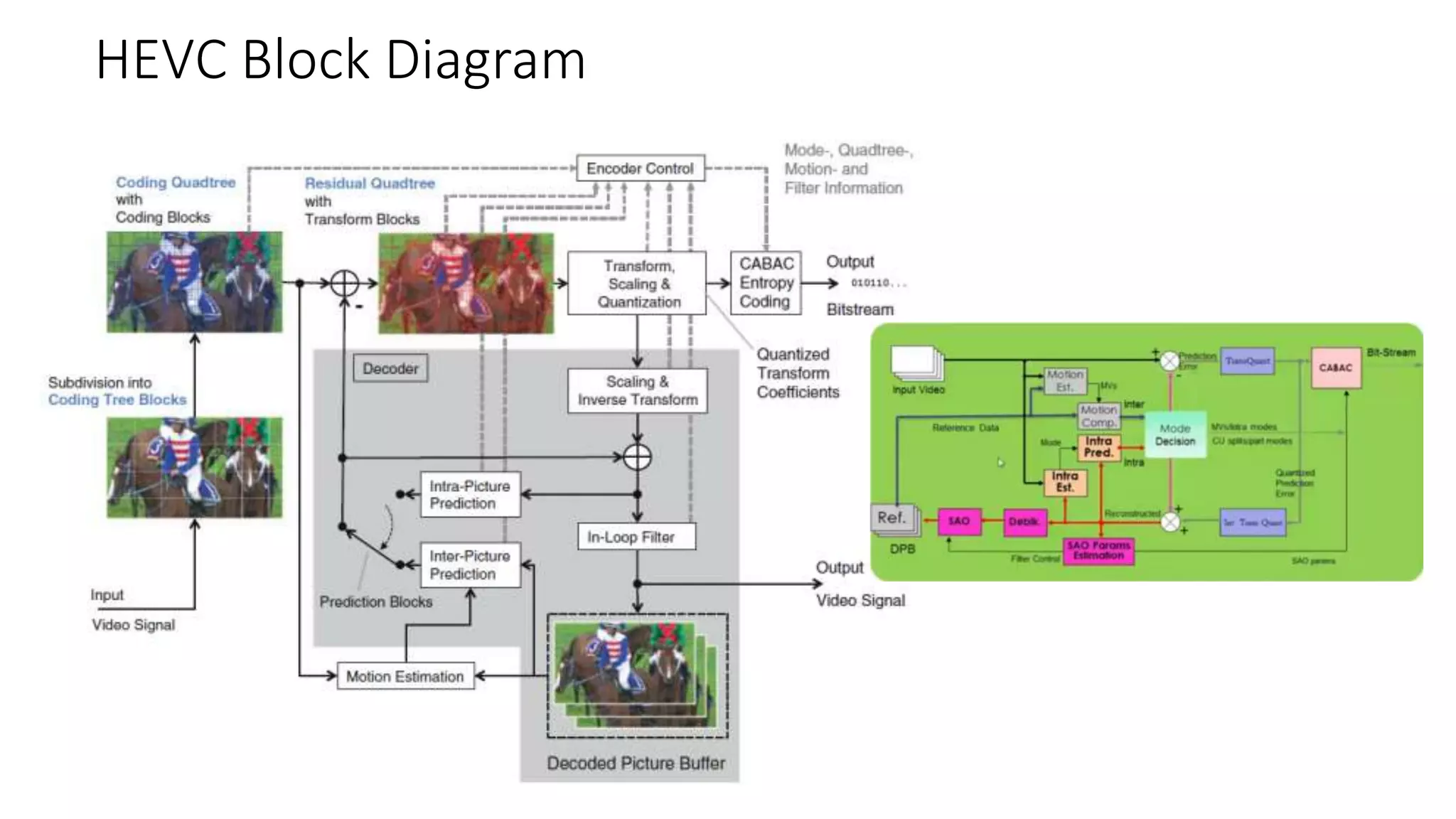
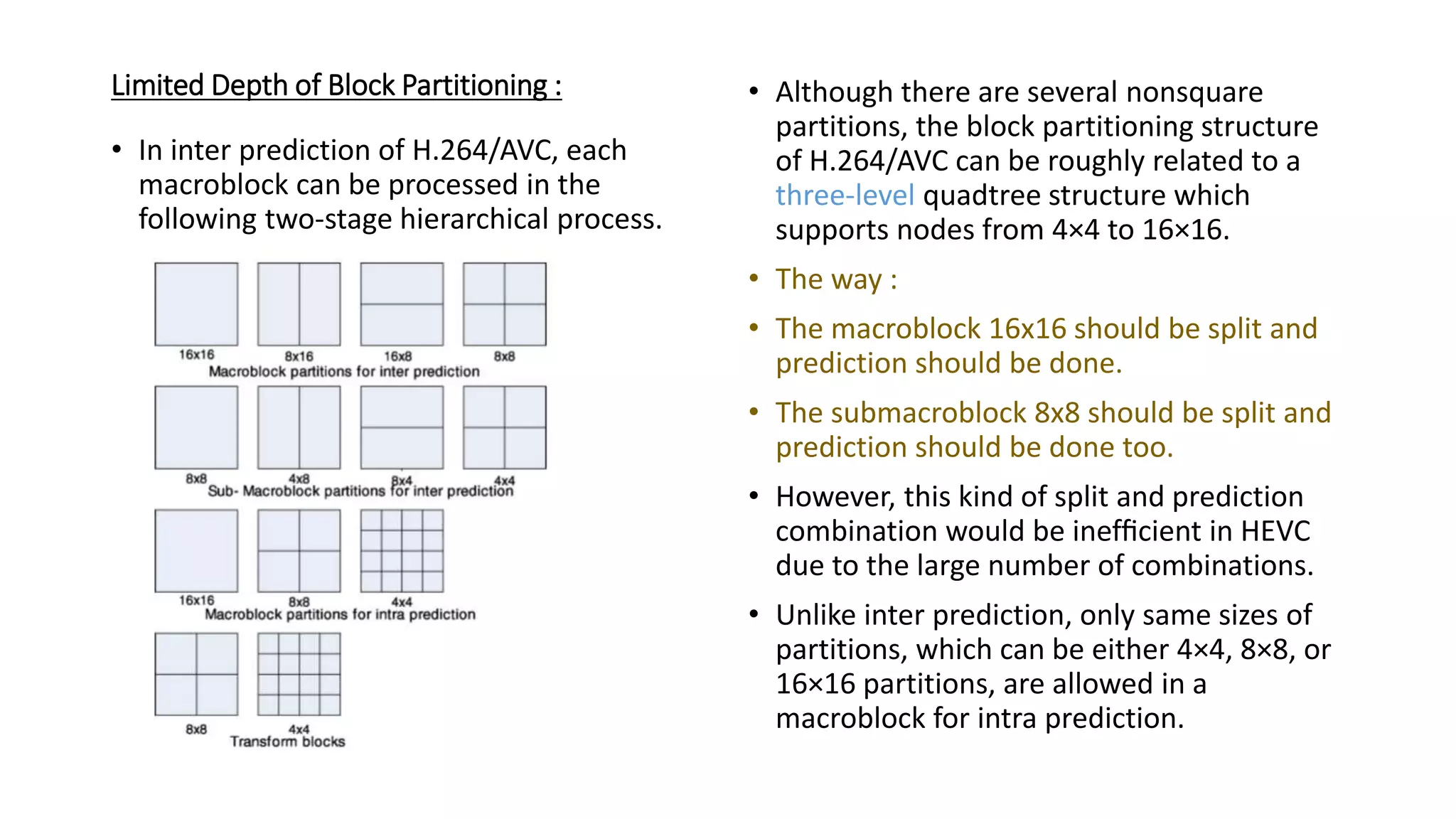
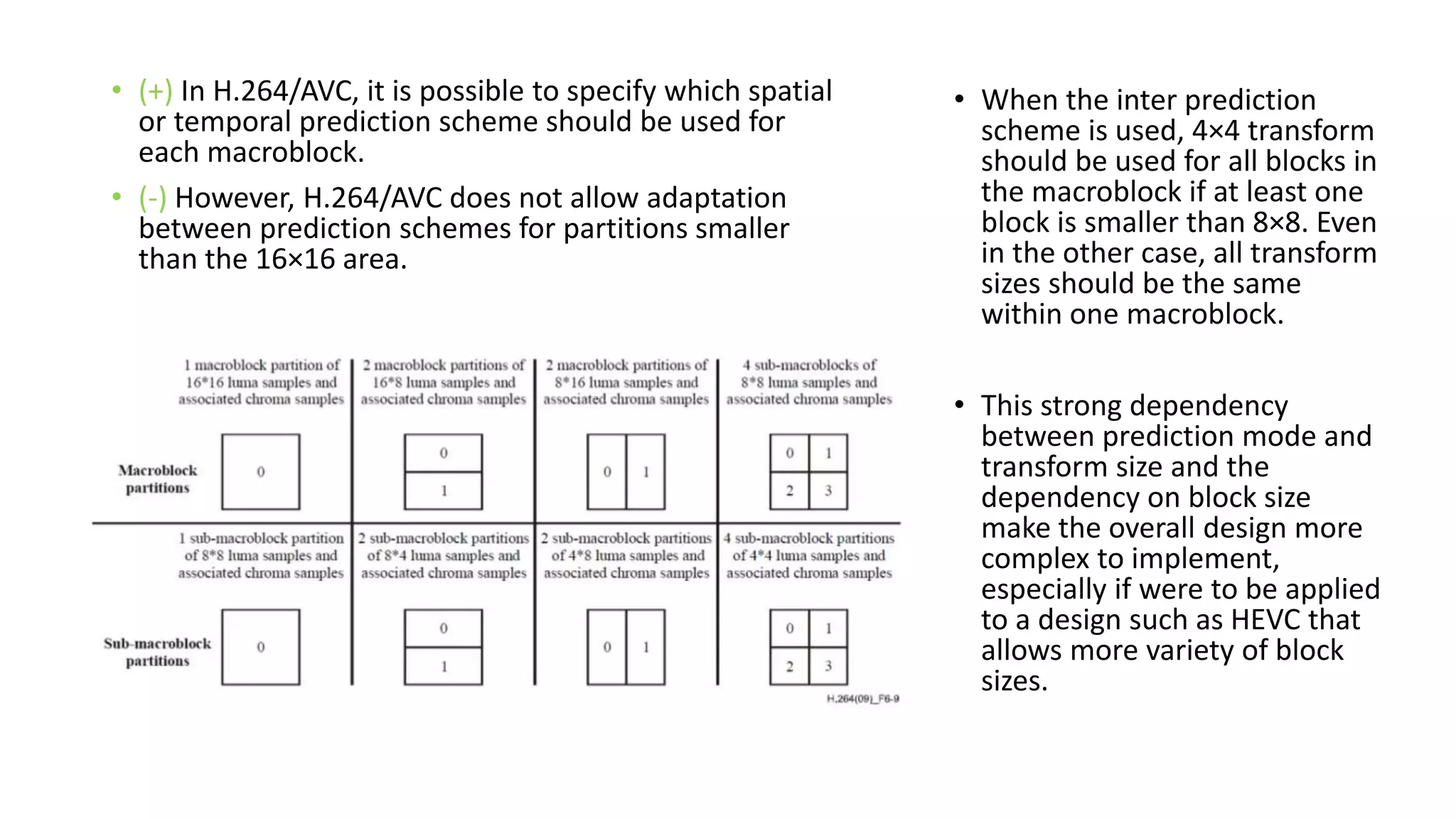
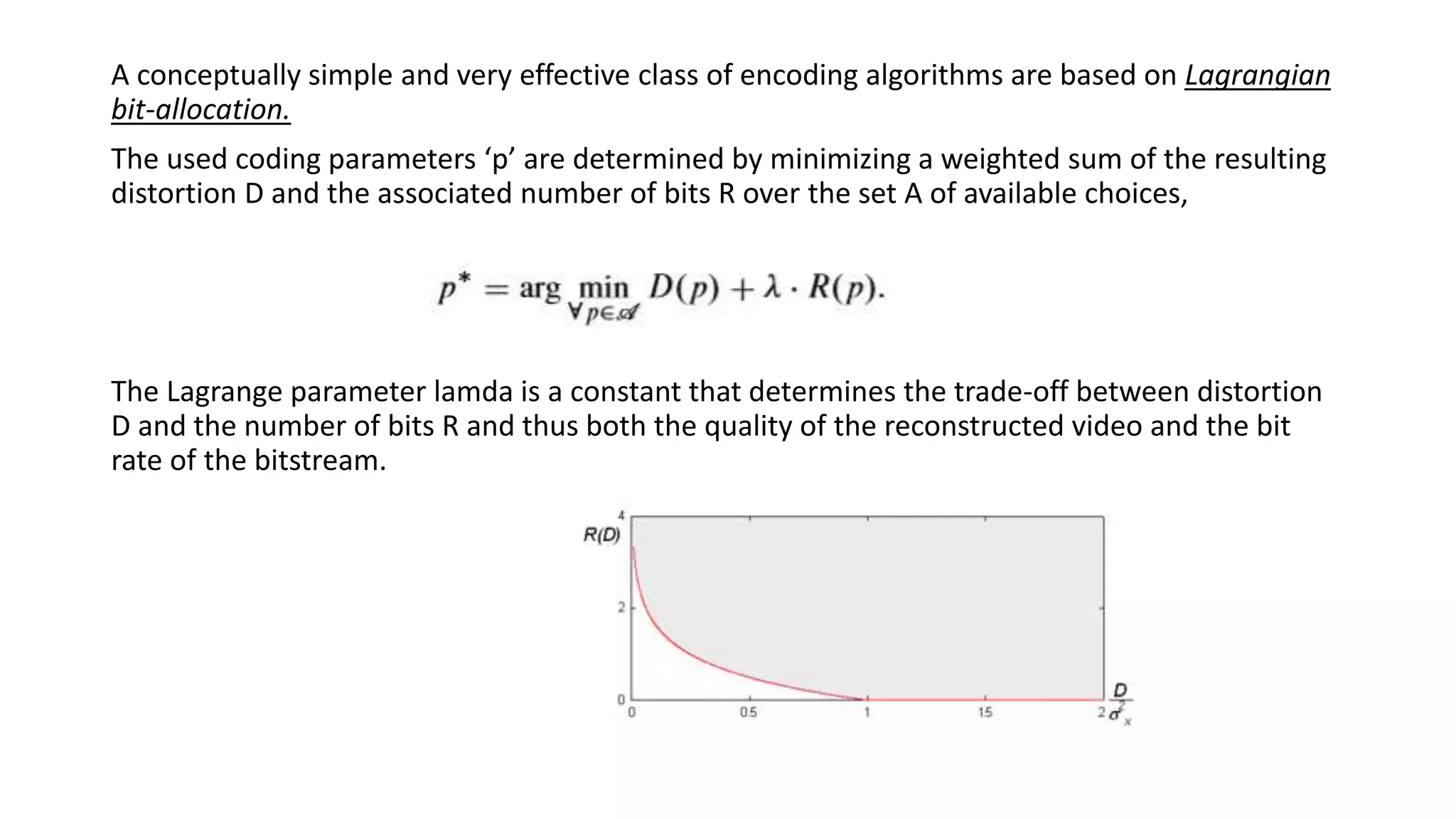
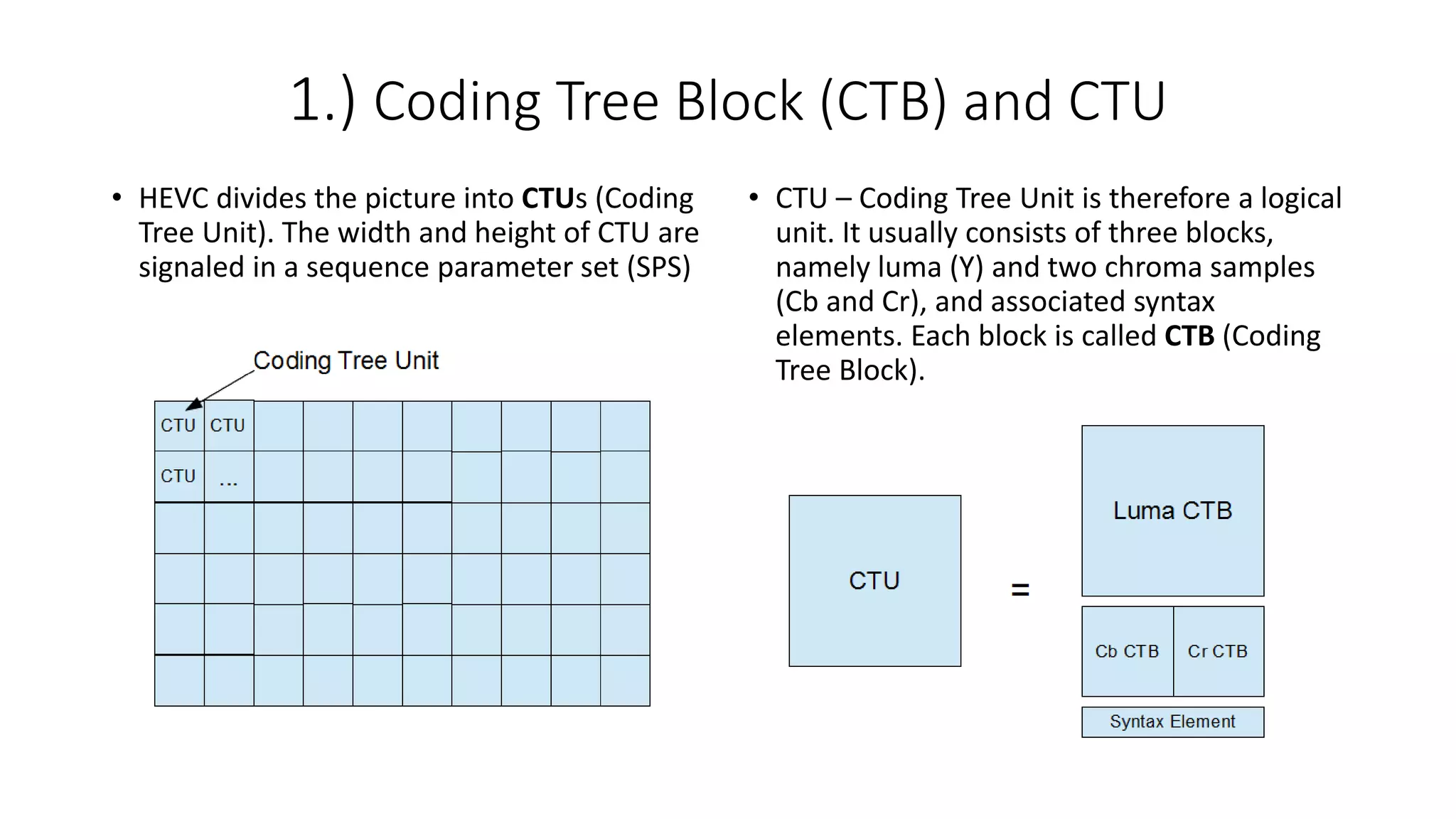
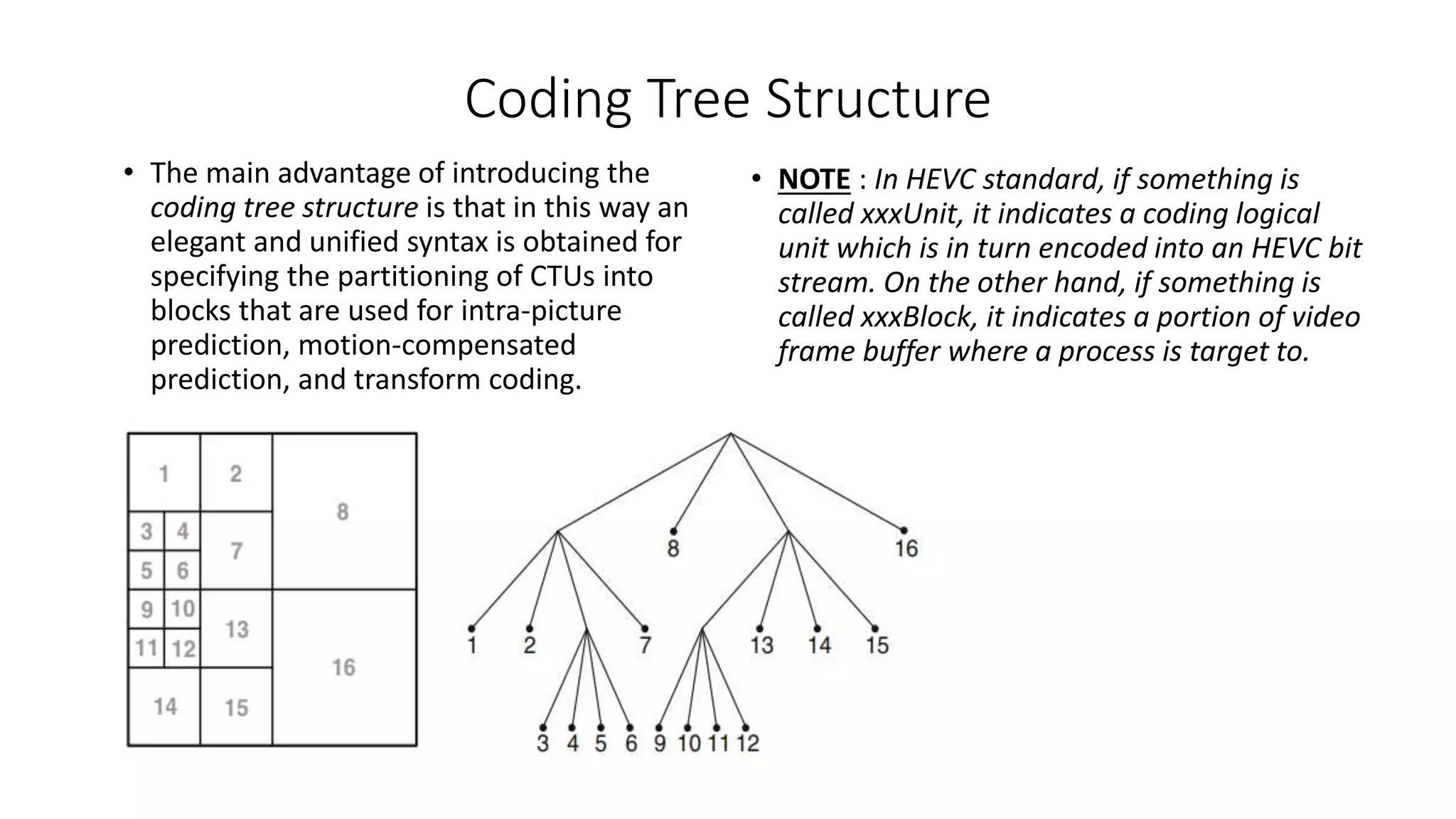
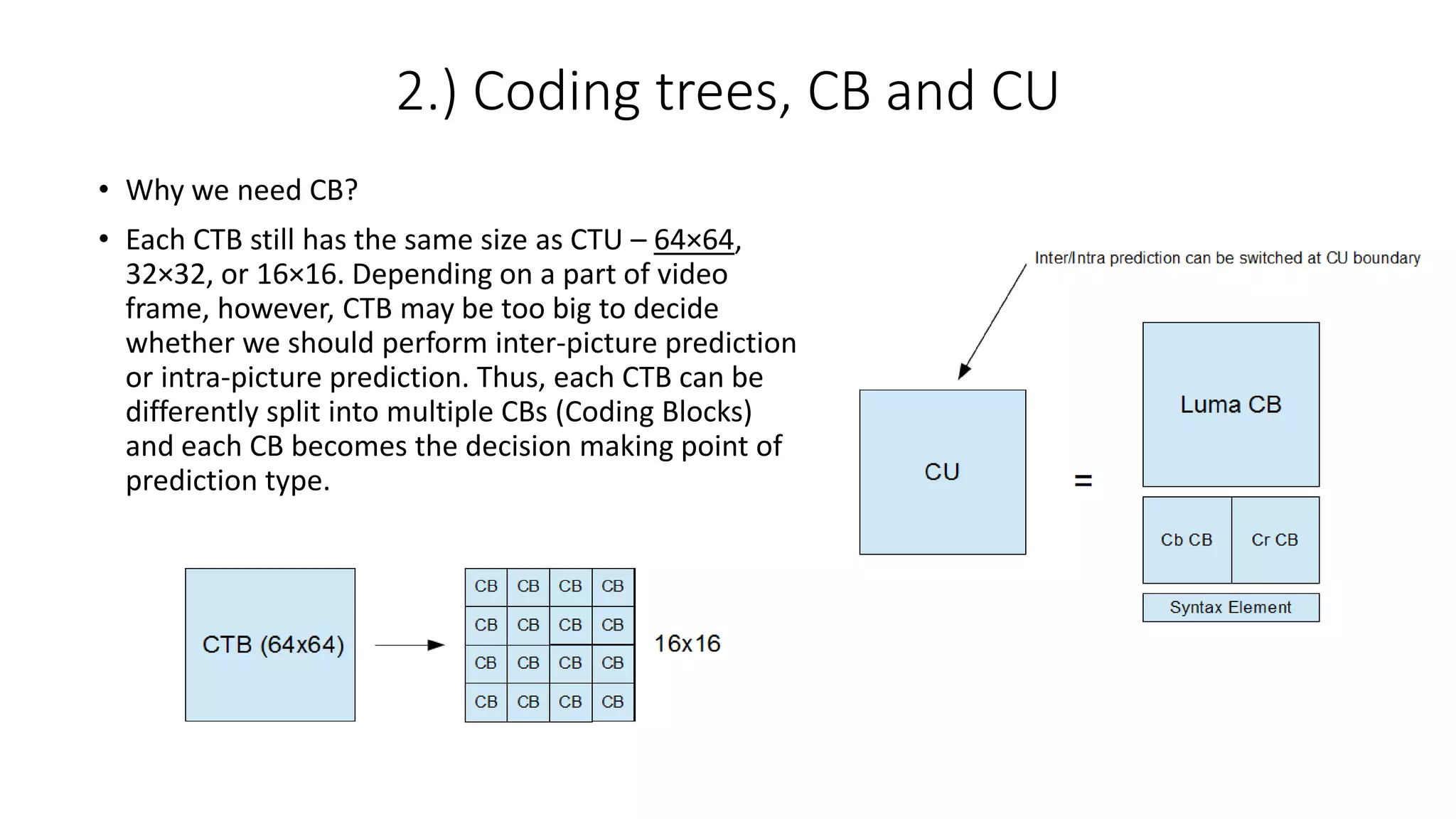
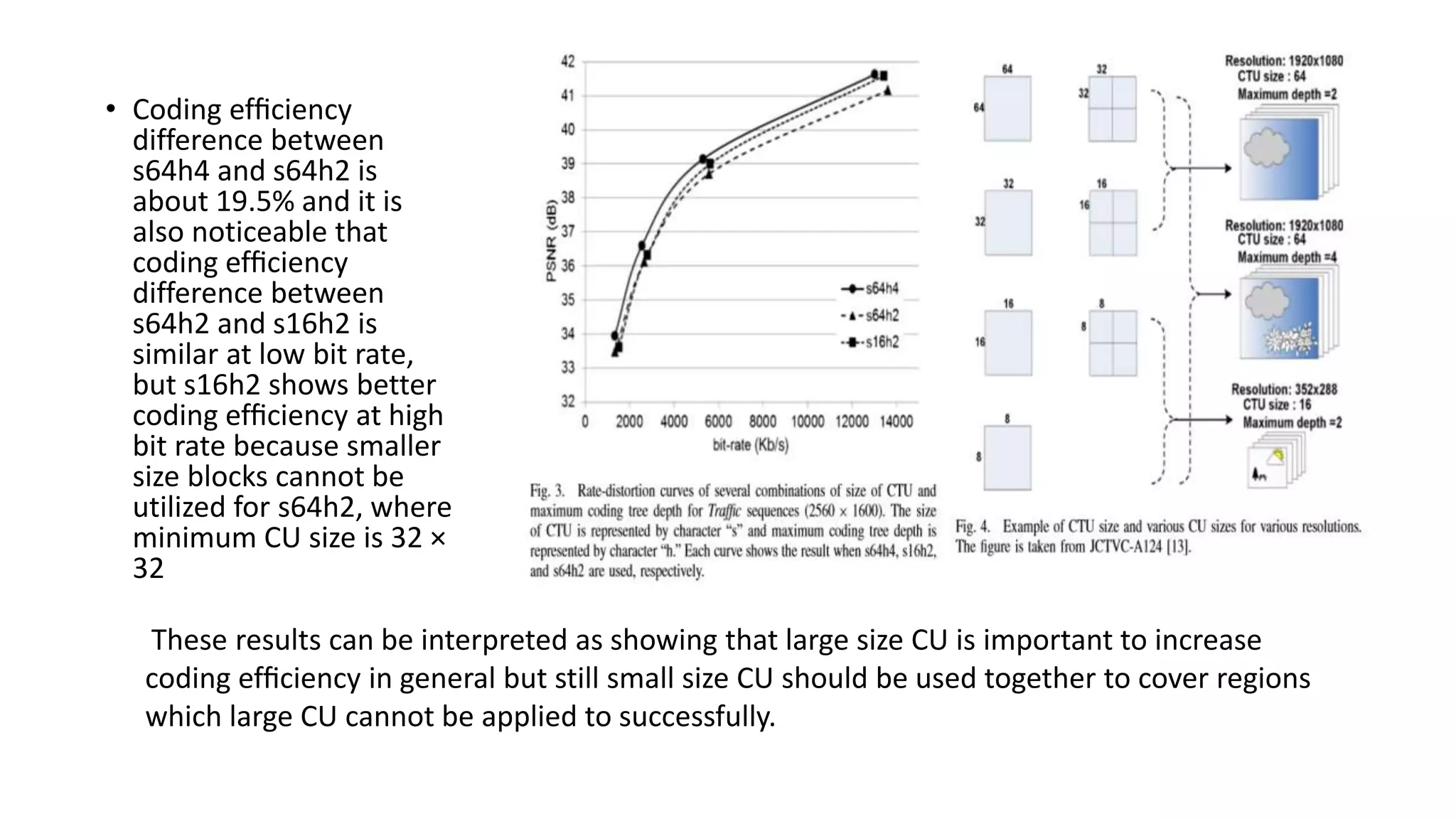
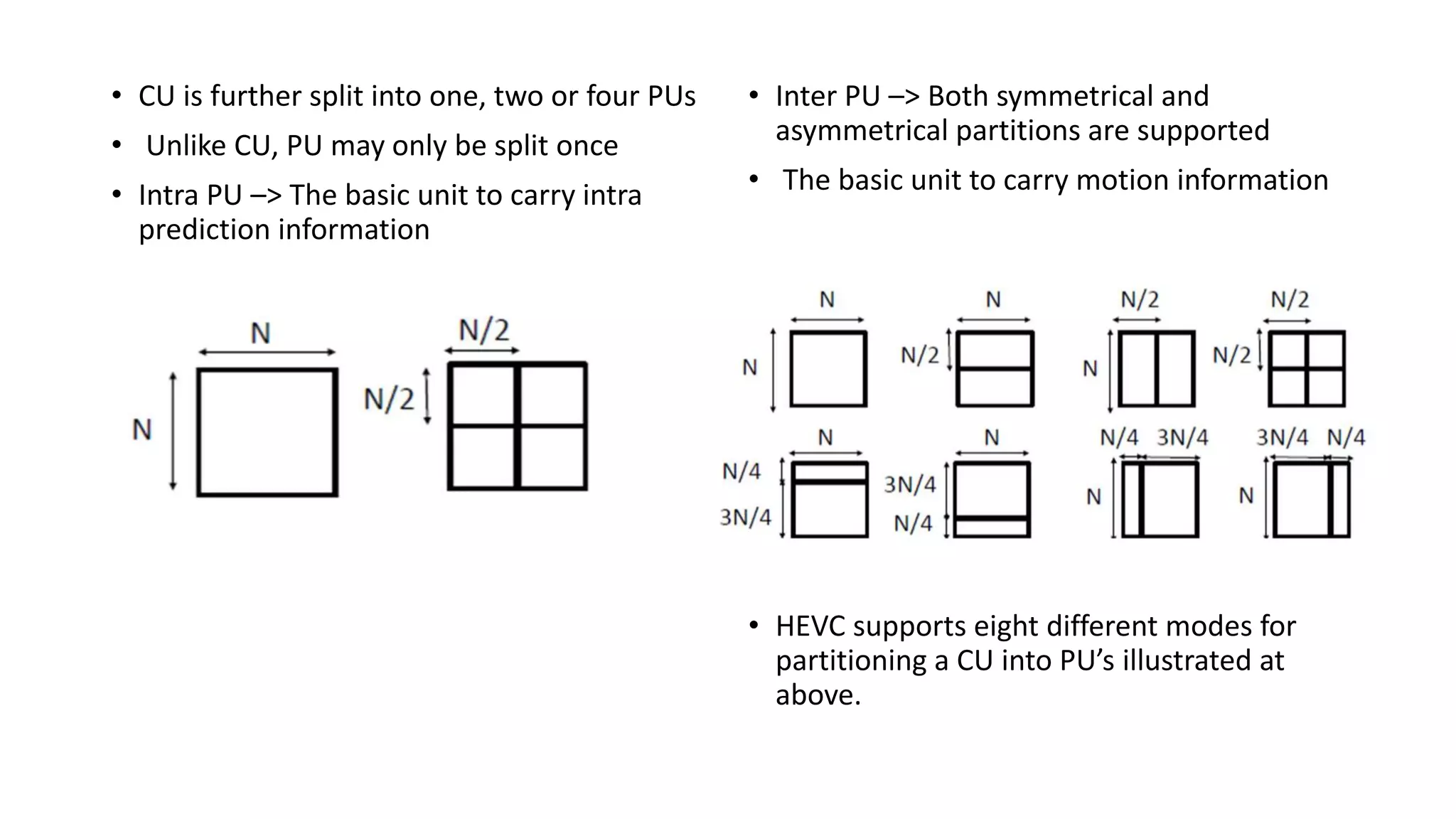
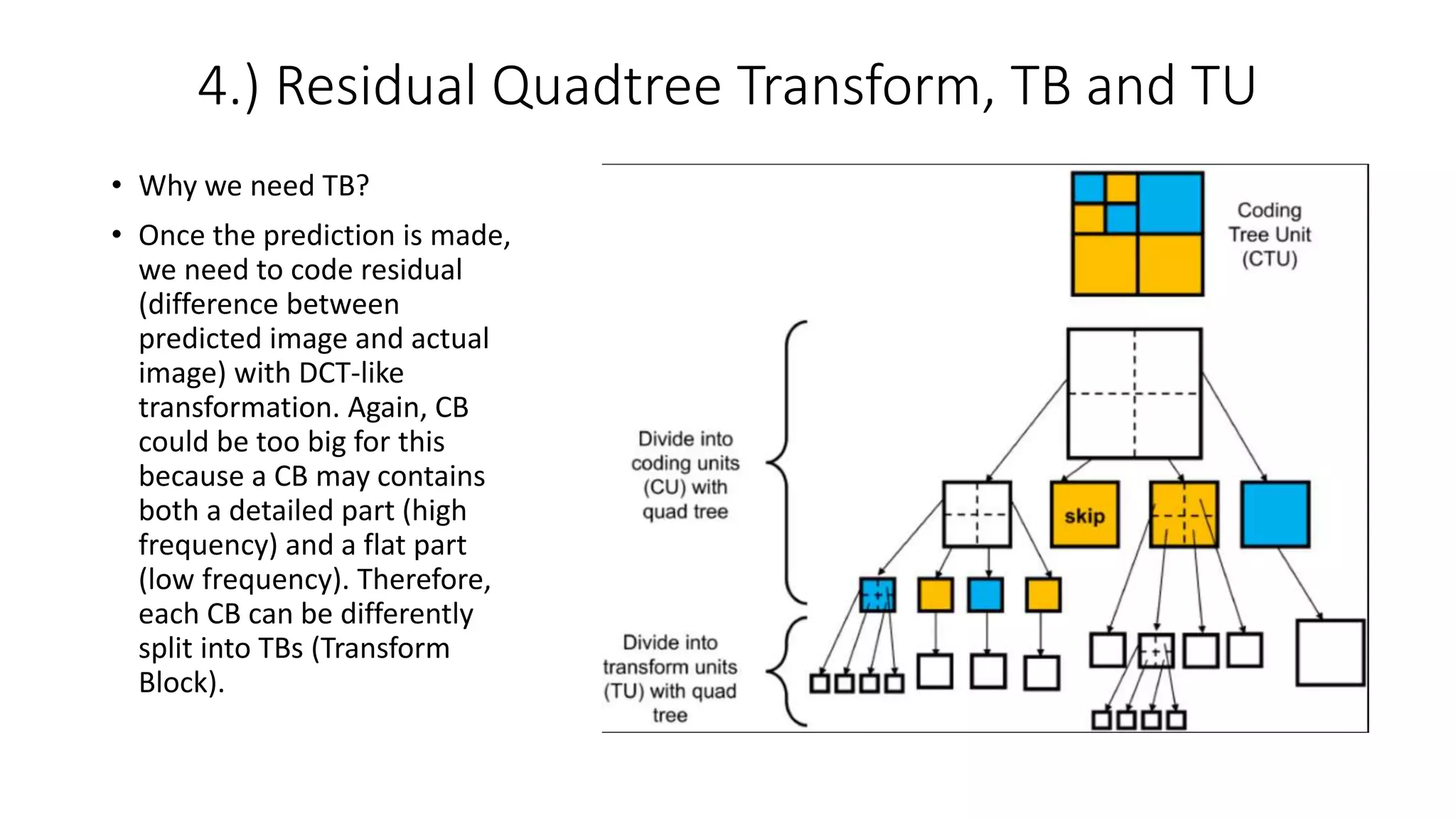
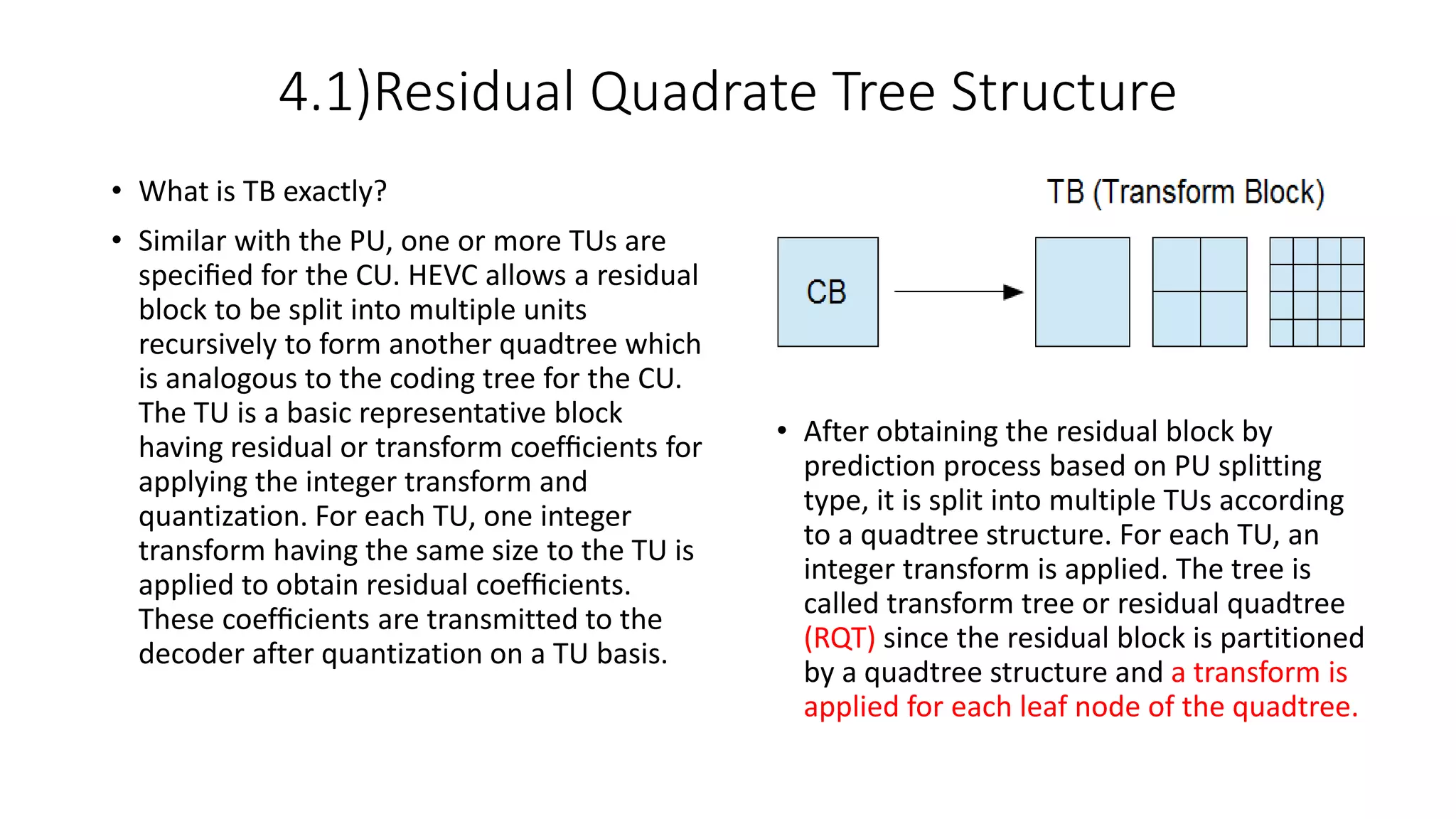
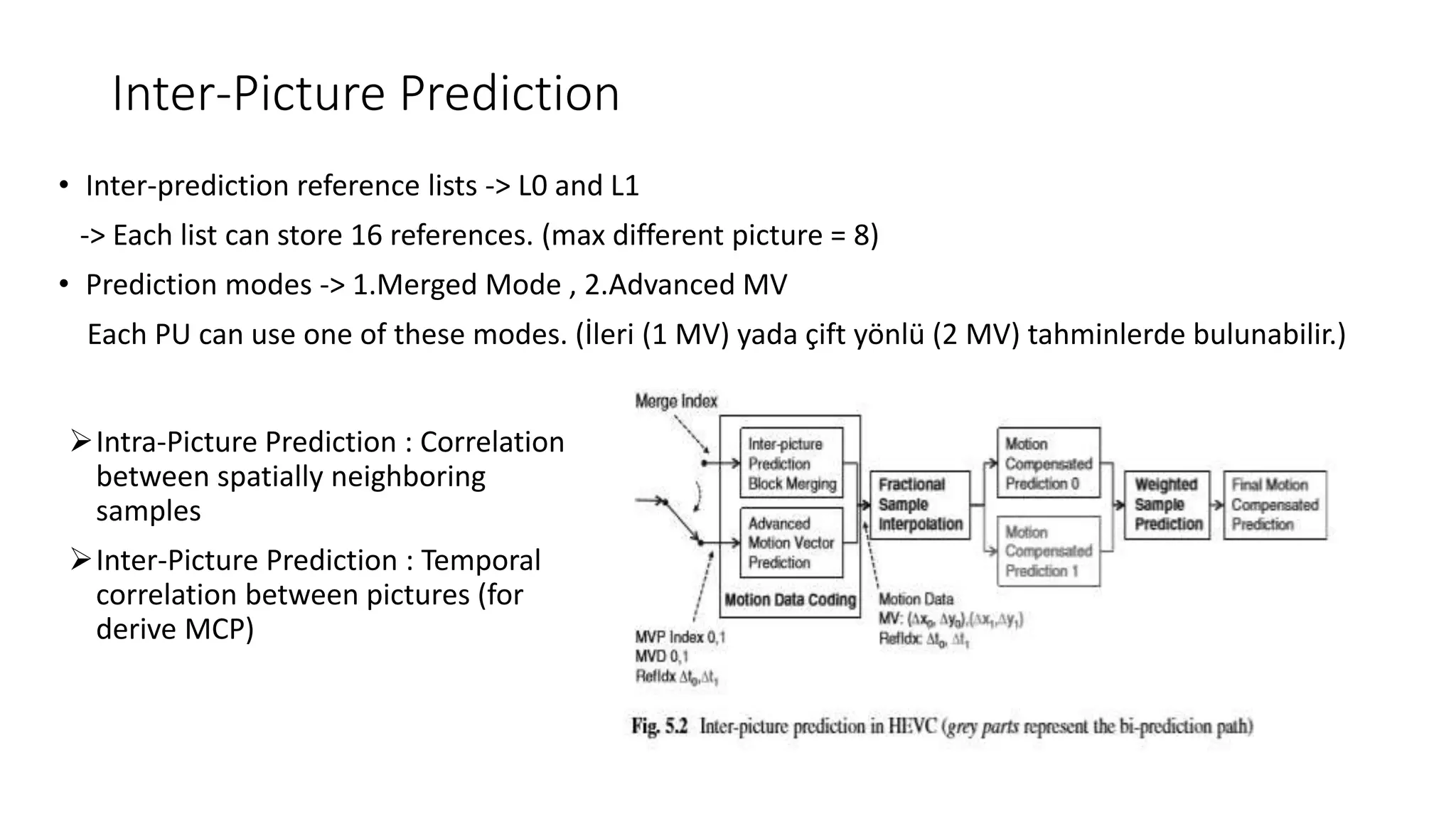
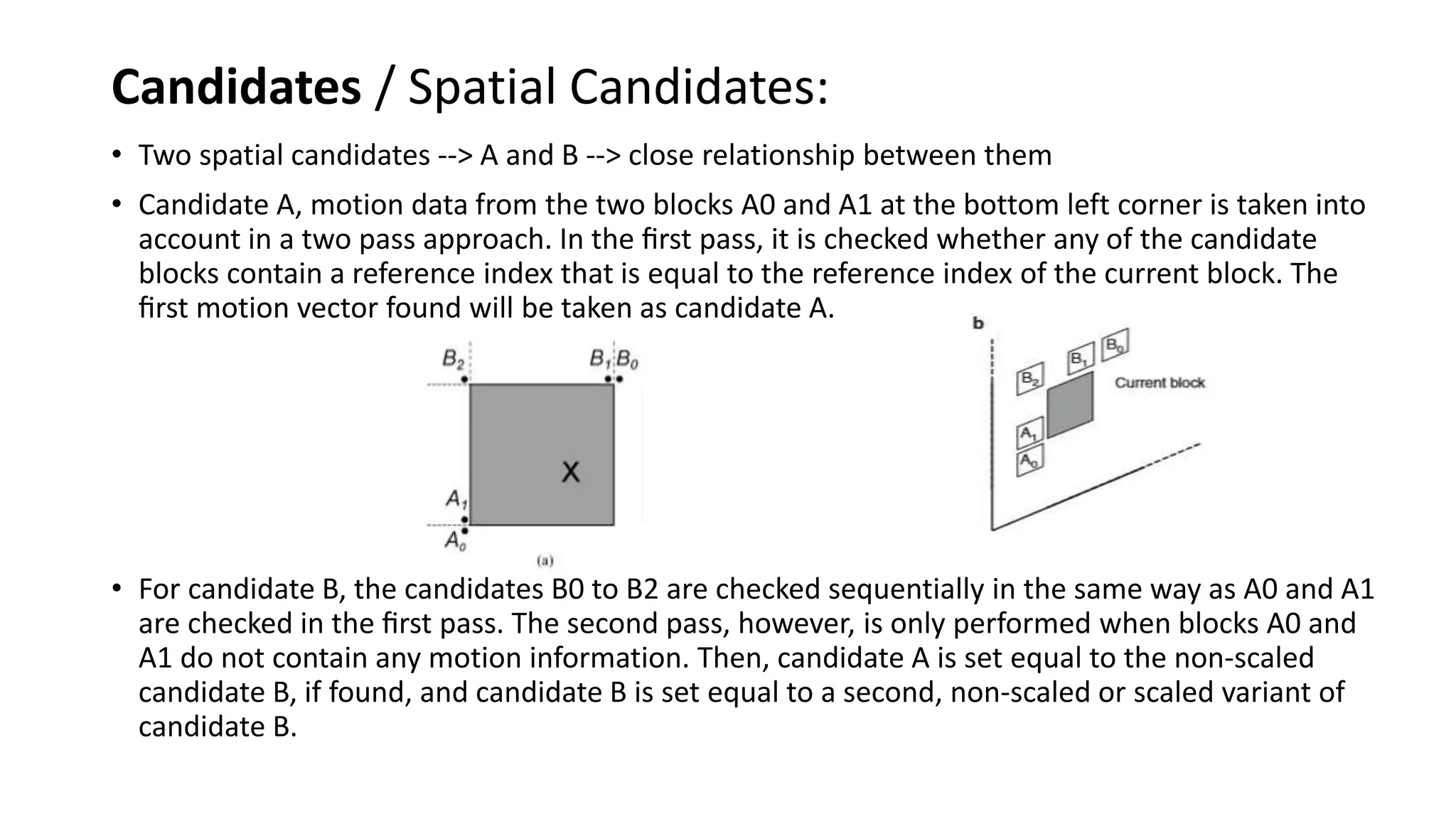
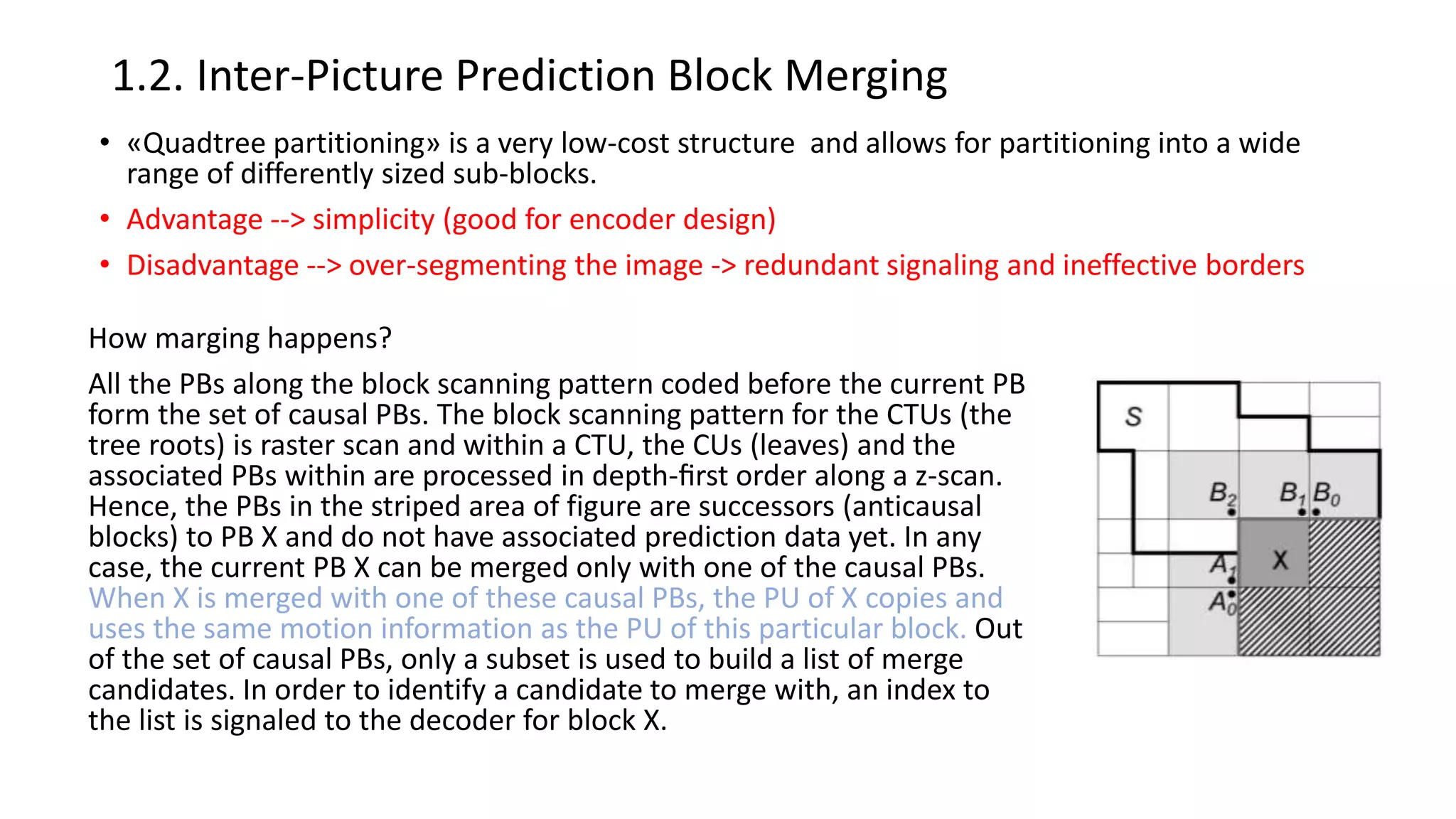
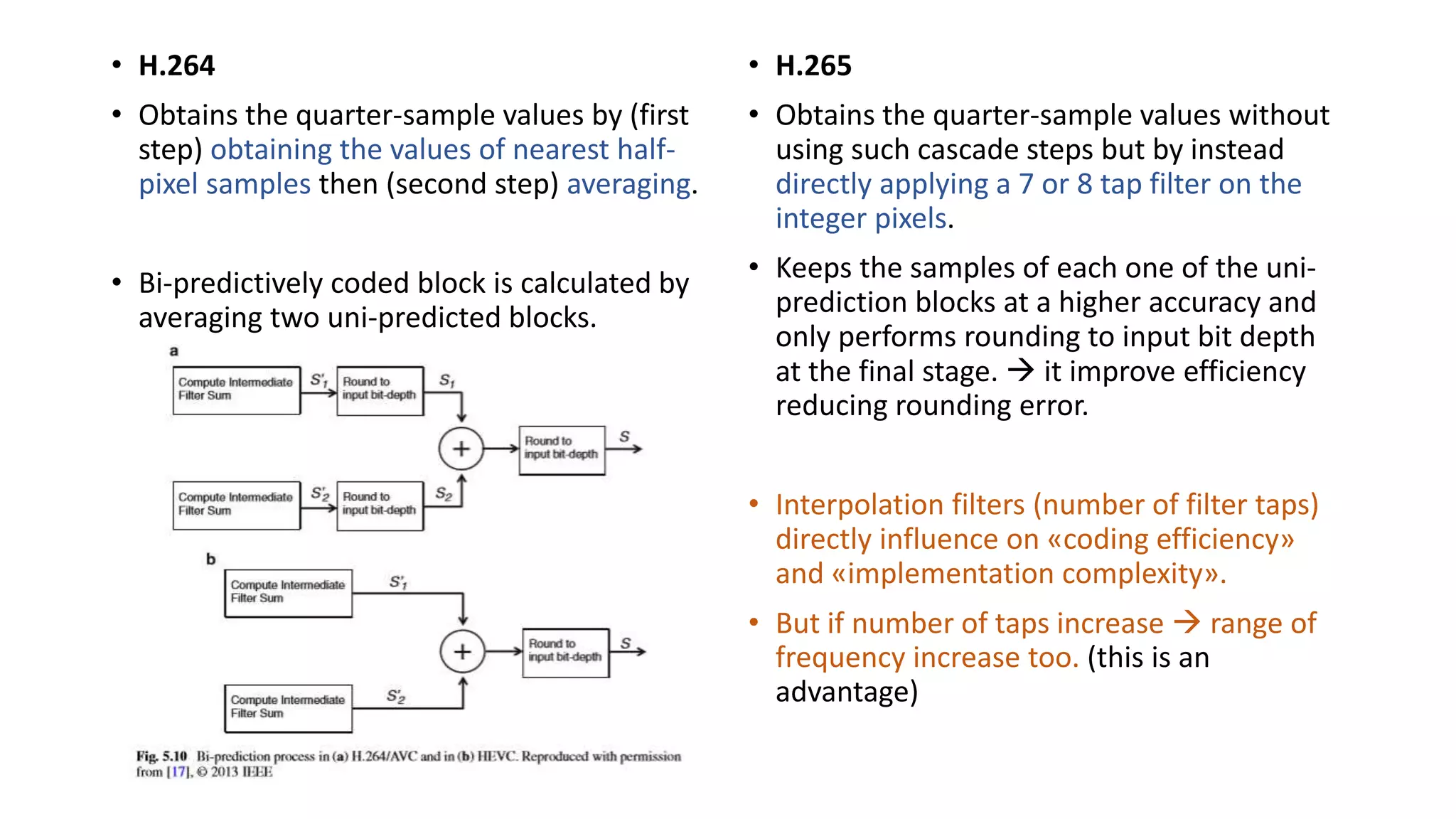
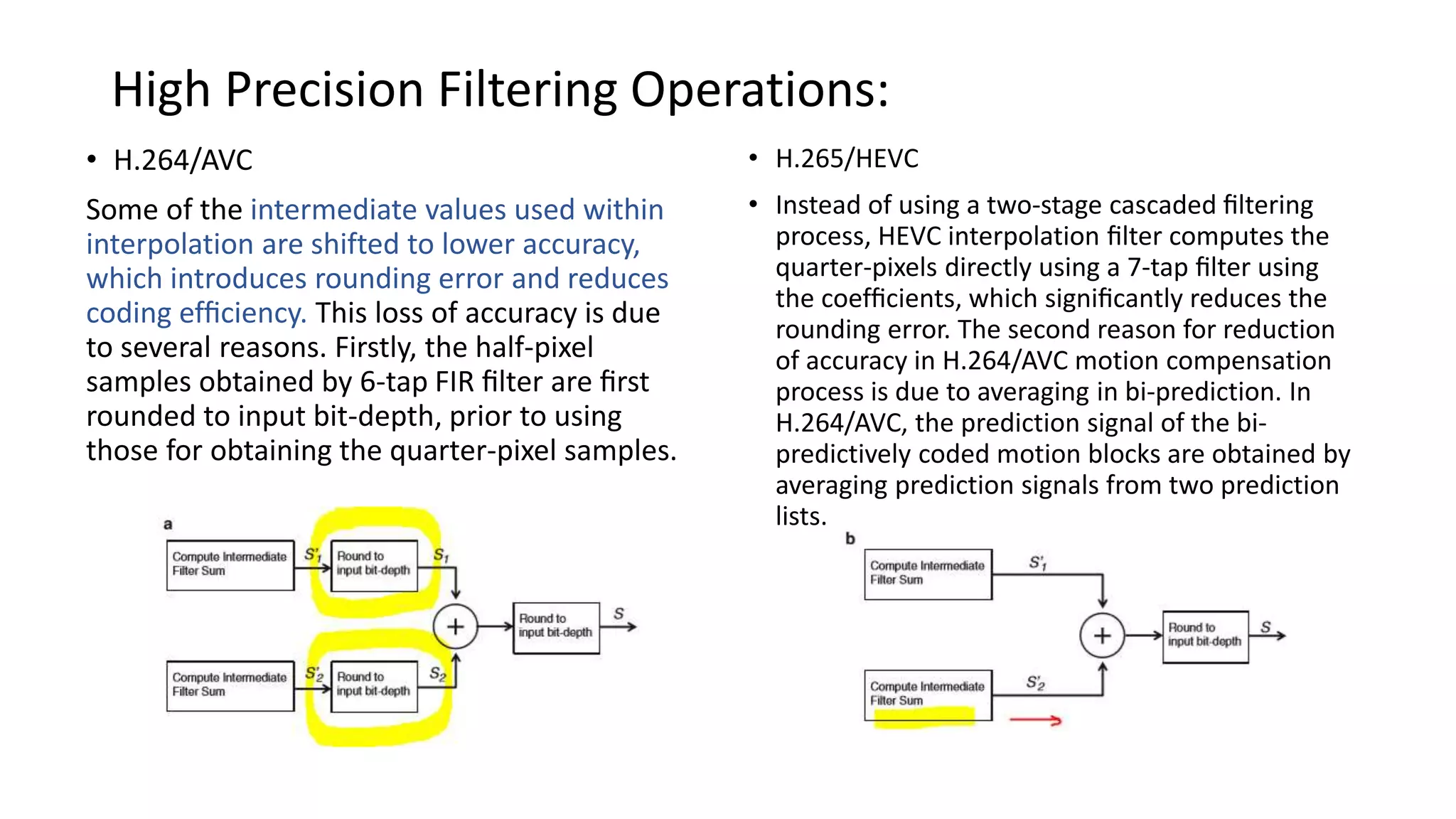
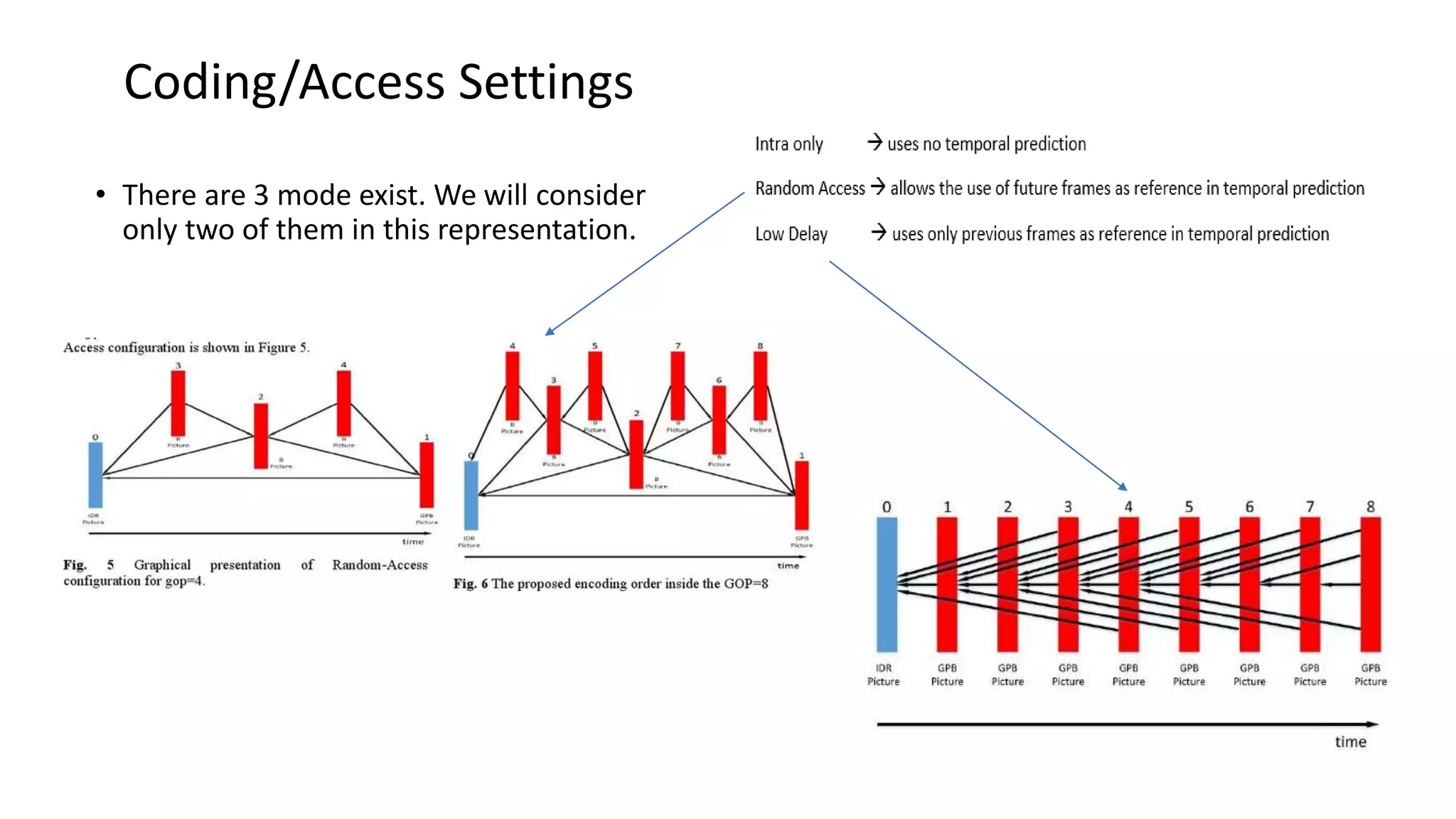
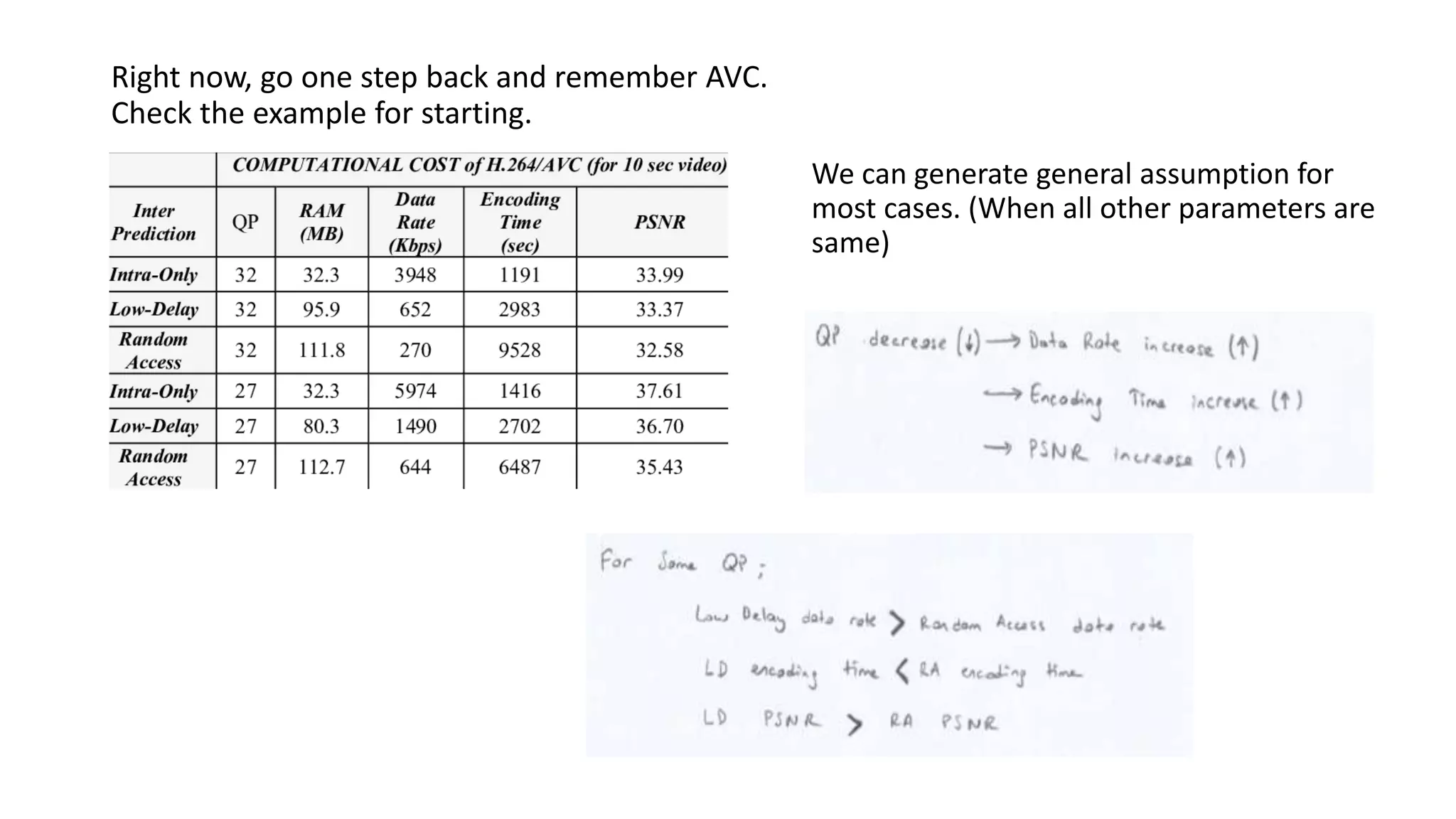
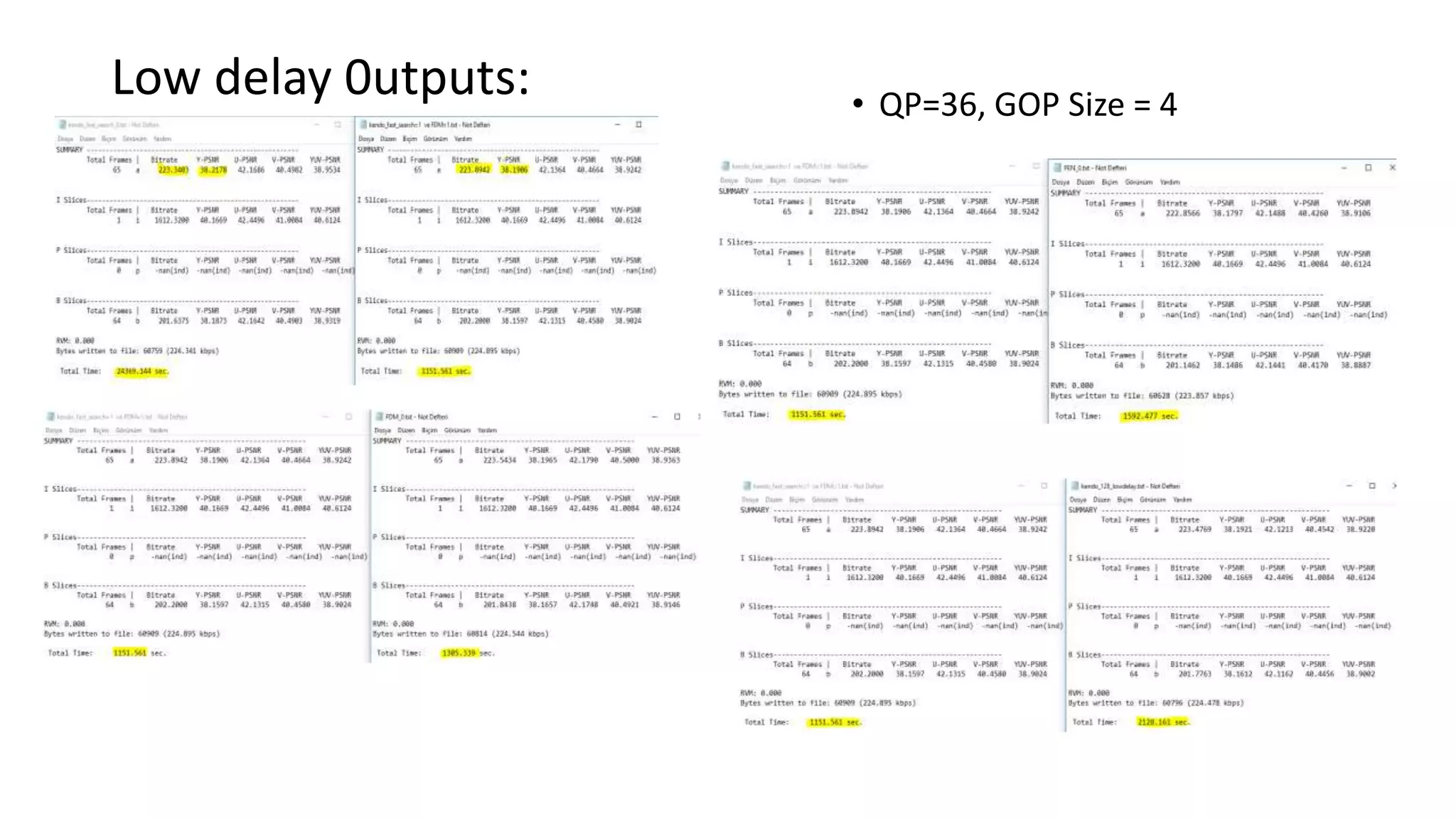
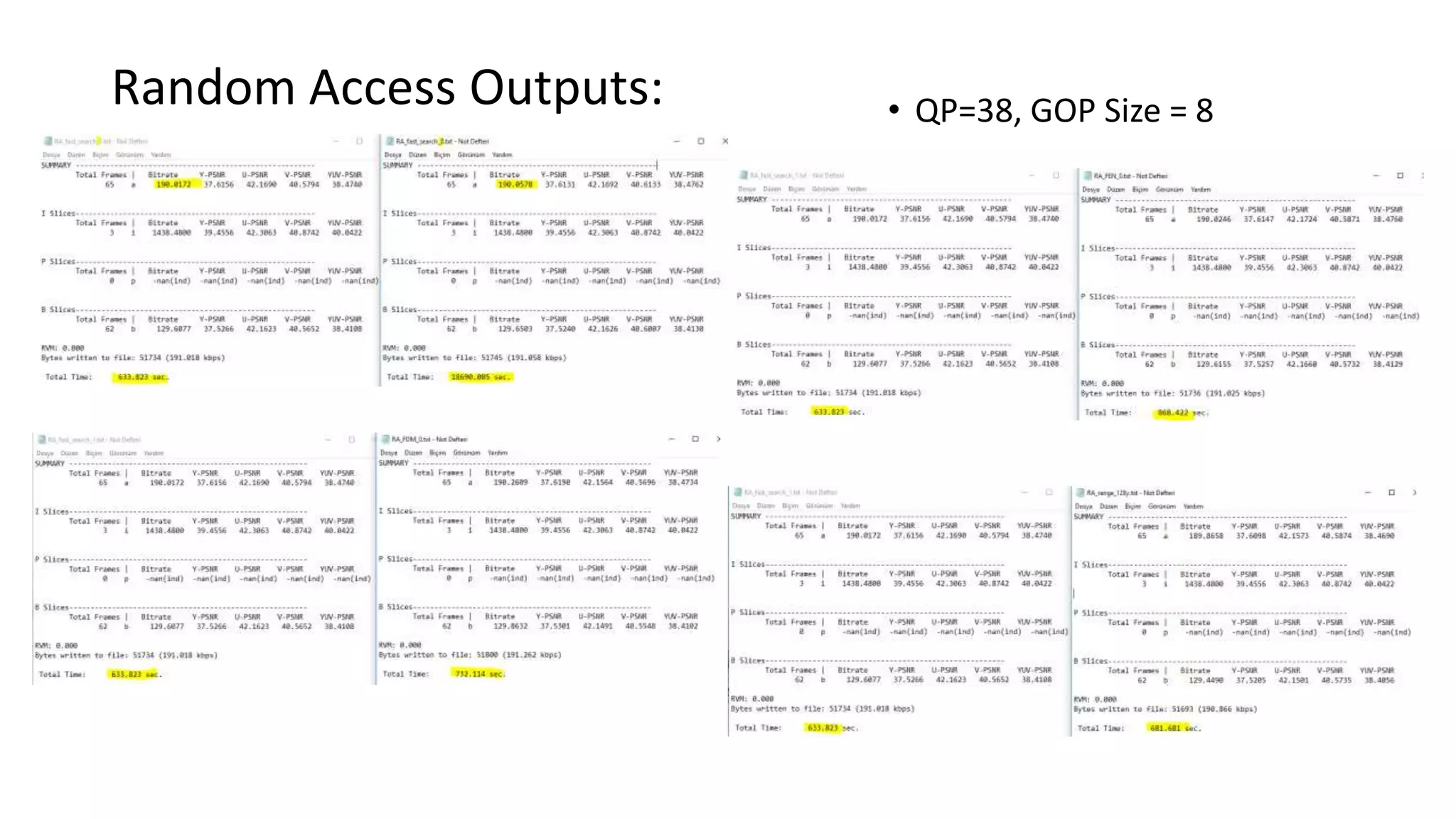
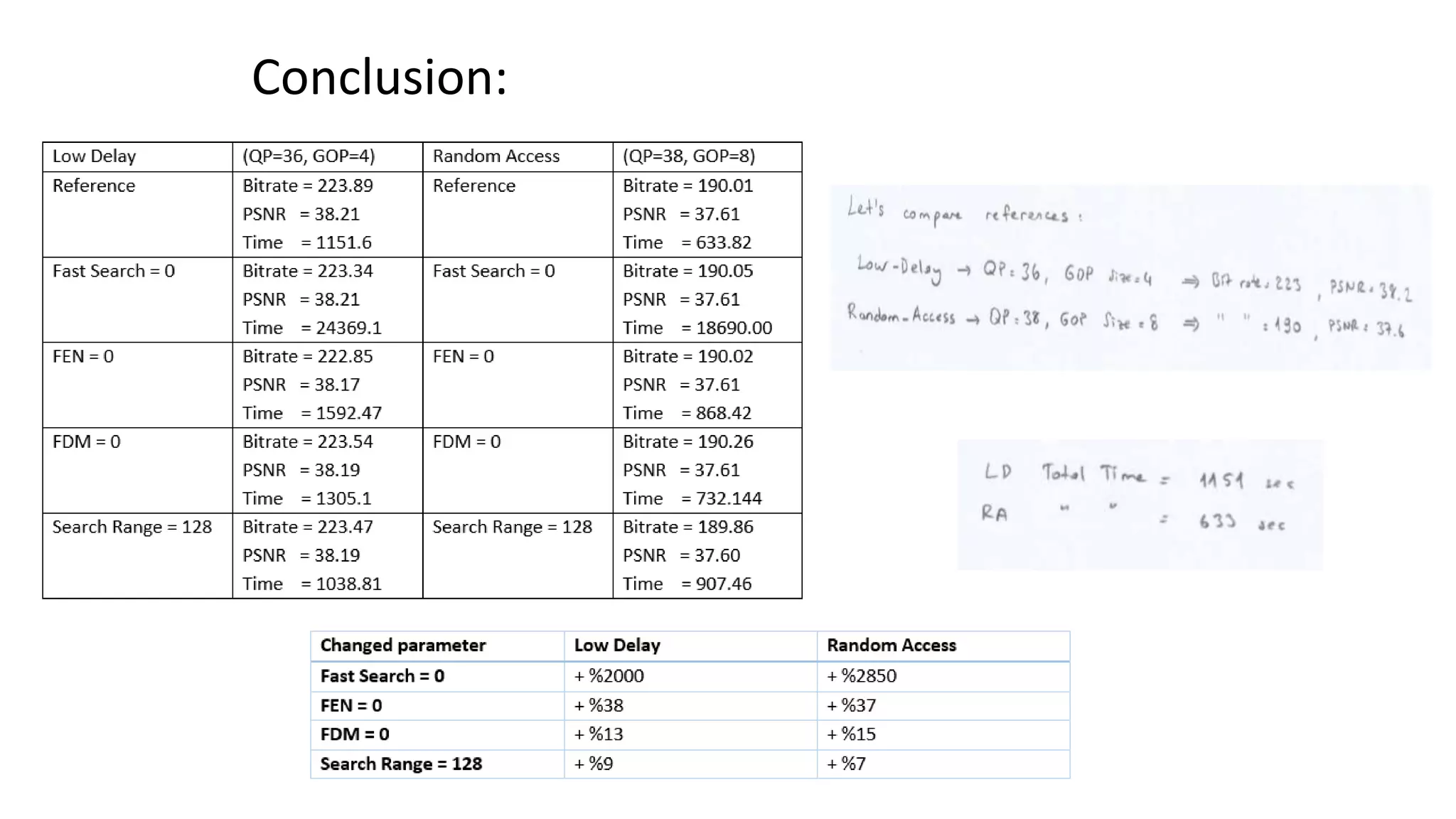
This document discusses key aspects of block partitioning and prediction in the HEVC video compression standard. It begins with an introduction to HEVC and its goals of 50% compression gain over H.264 and increased parallelizability of encoding and decoding. The document then covers tree-structured partitioning of blocks for prediction and transform coding in HEVC, including coding tree blocks, coding units, prediction blocks, and transform units. It also compares block partitioning between H.264 and HEVC and analyzes the impact of varying block sizes on coding efficiency.