Downloaded 224 times


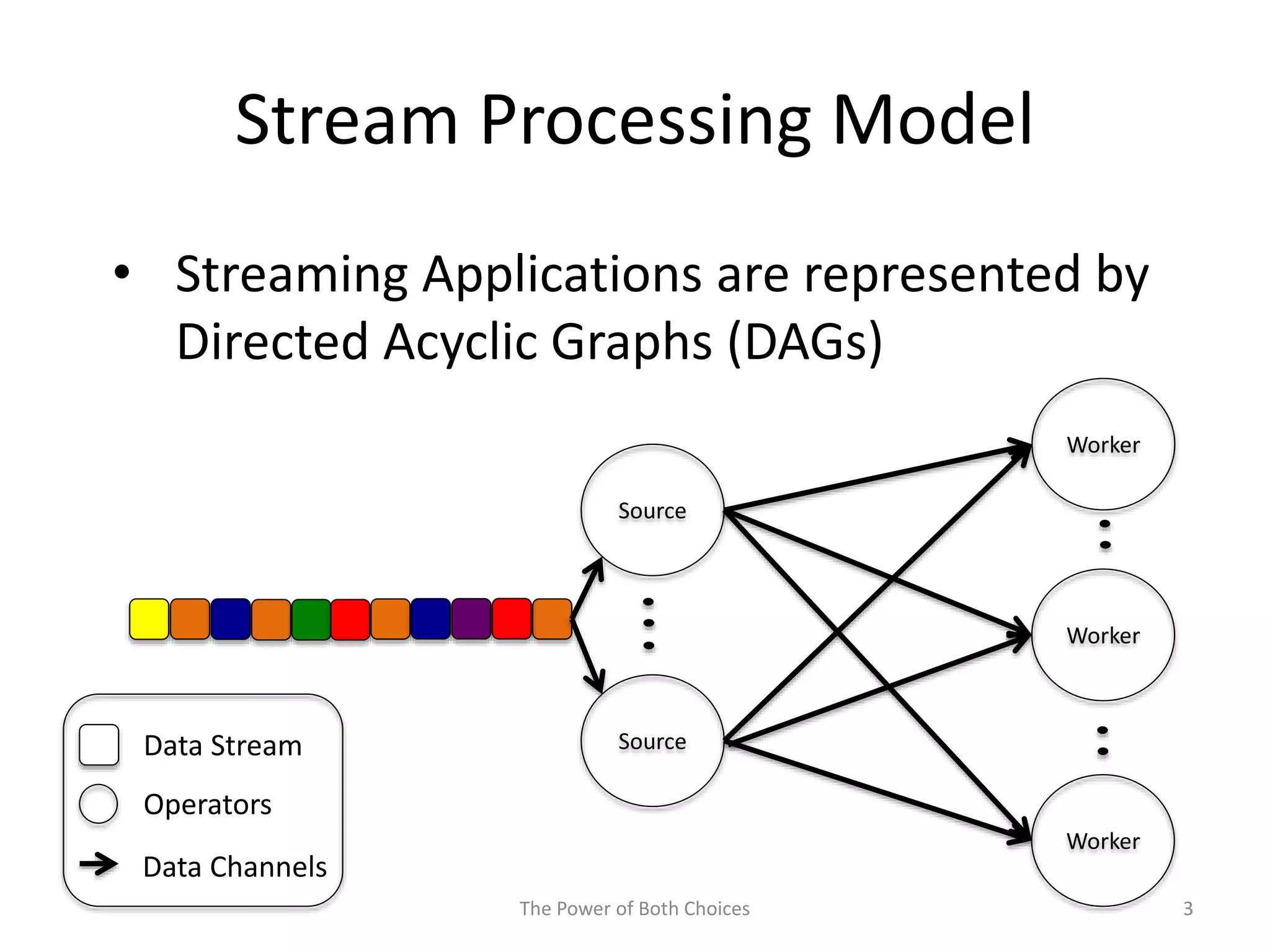

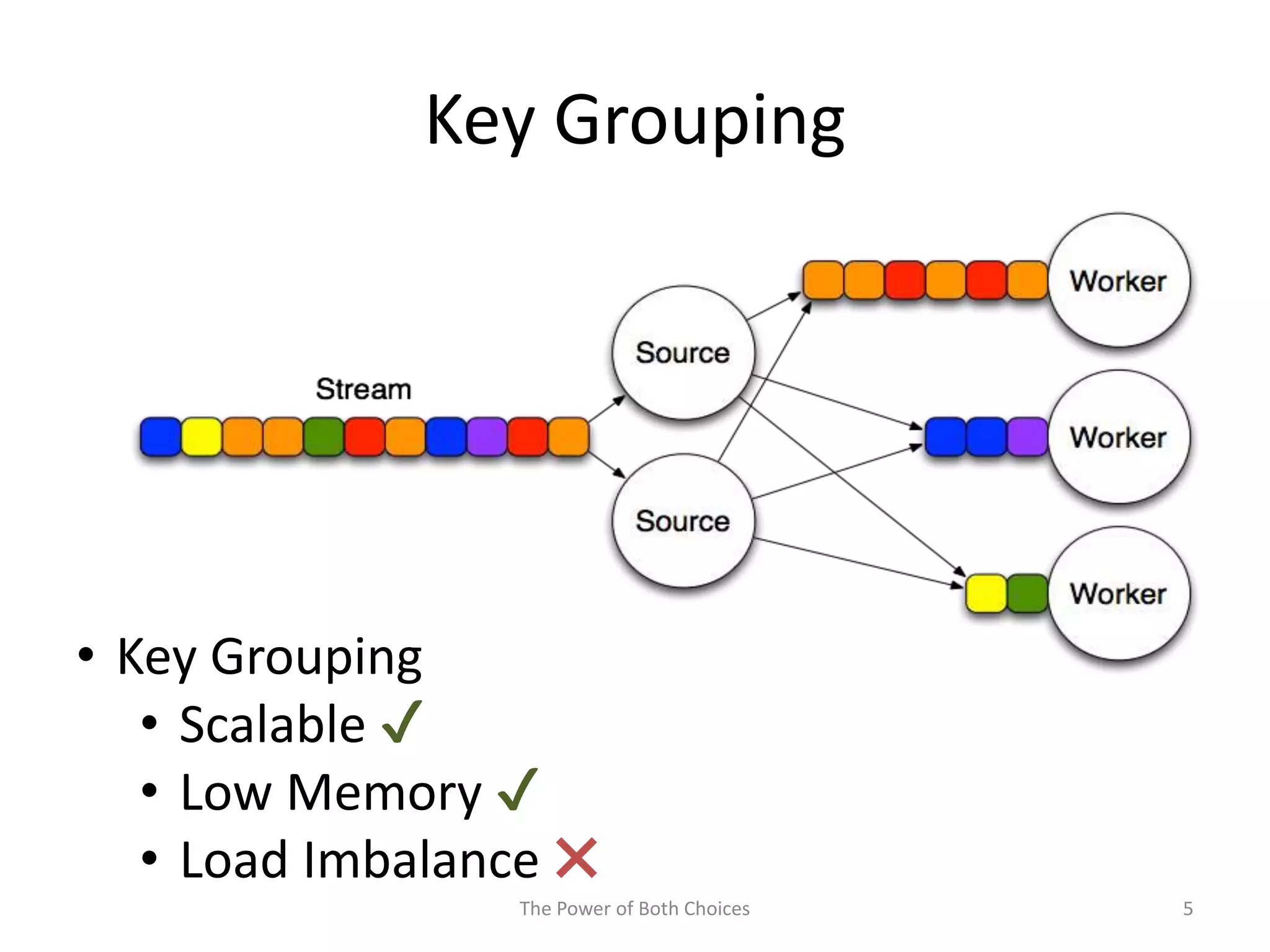
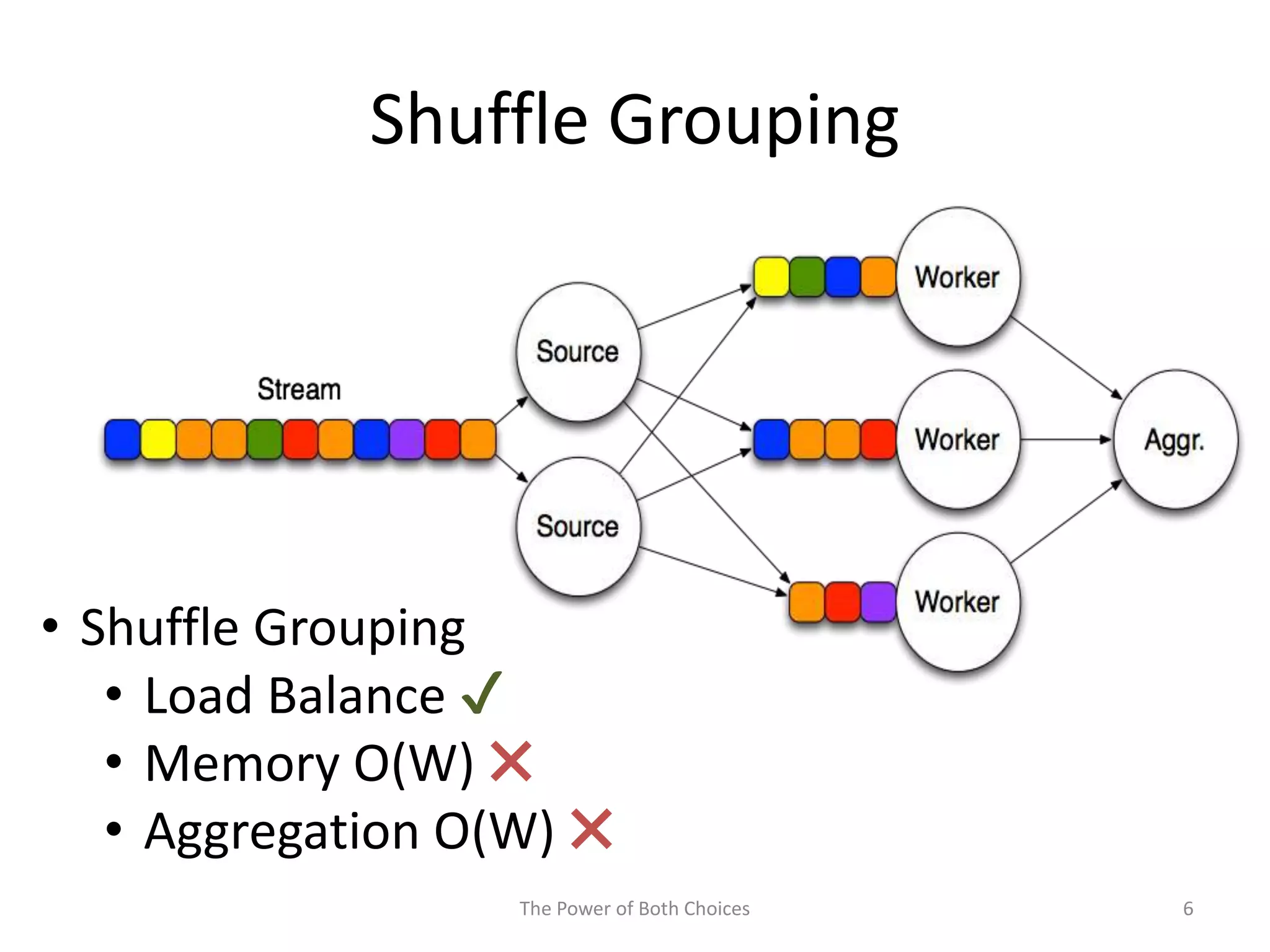



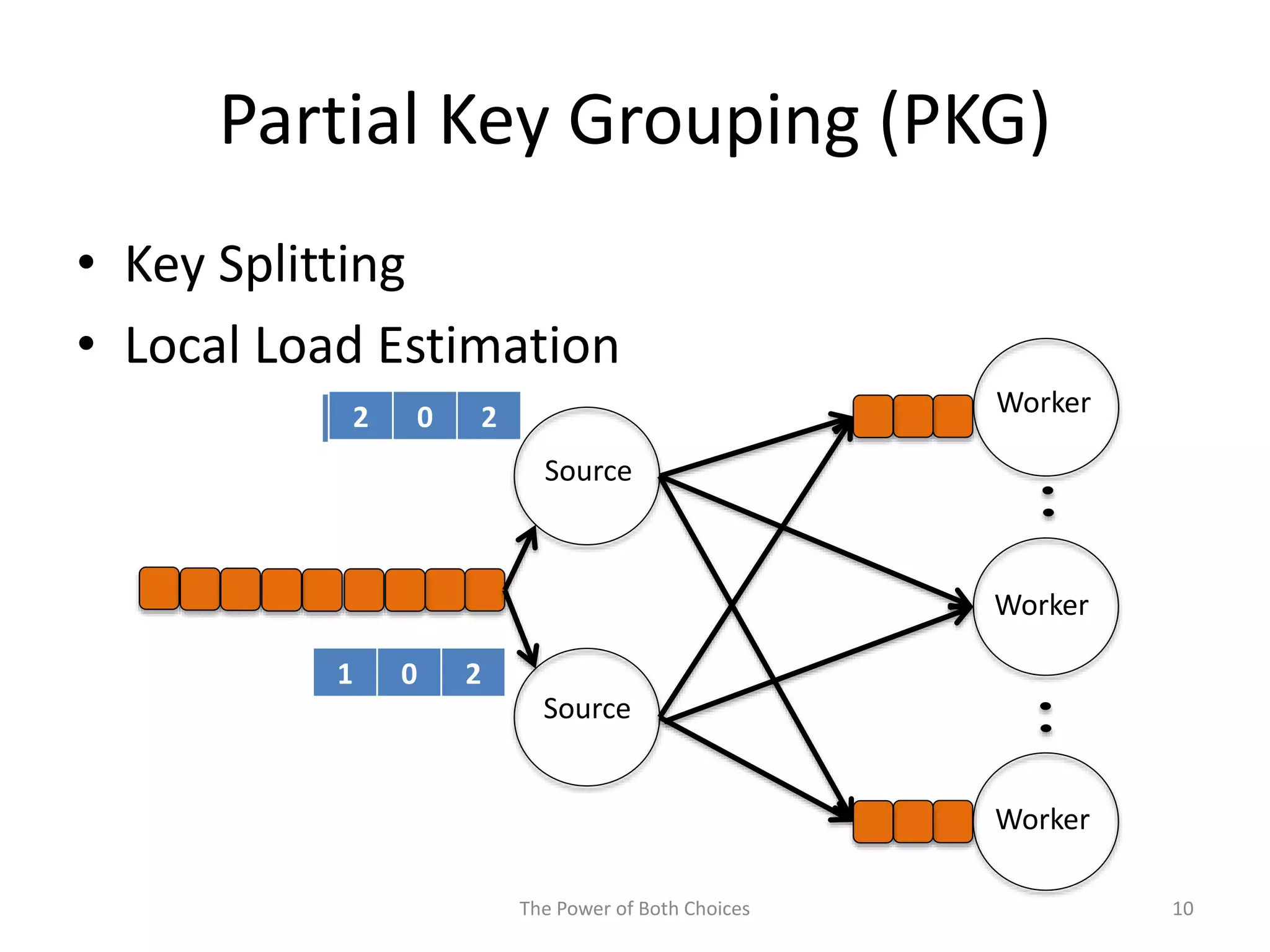
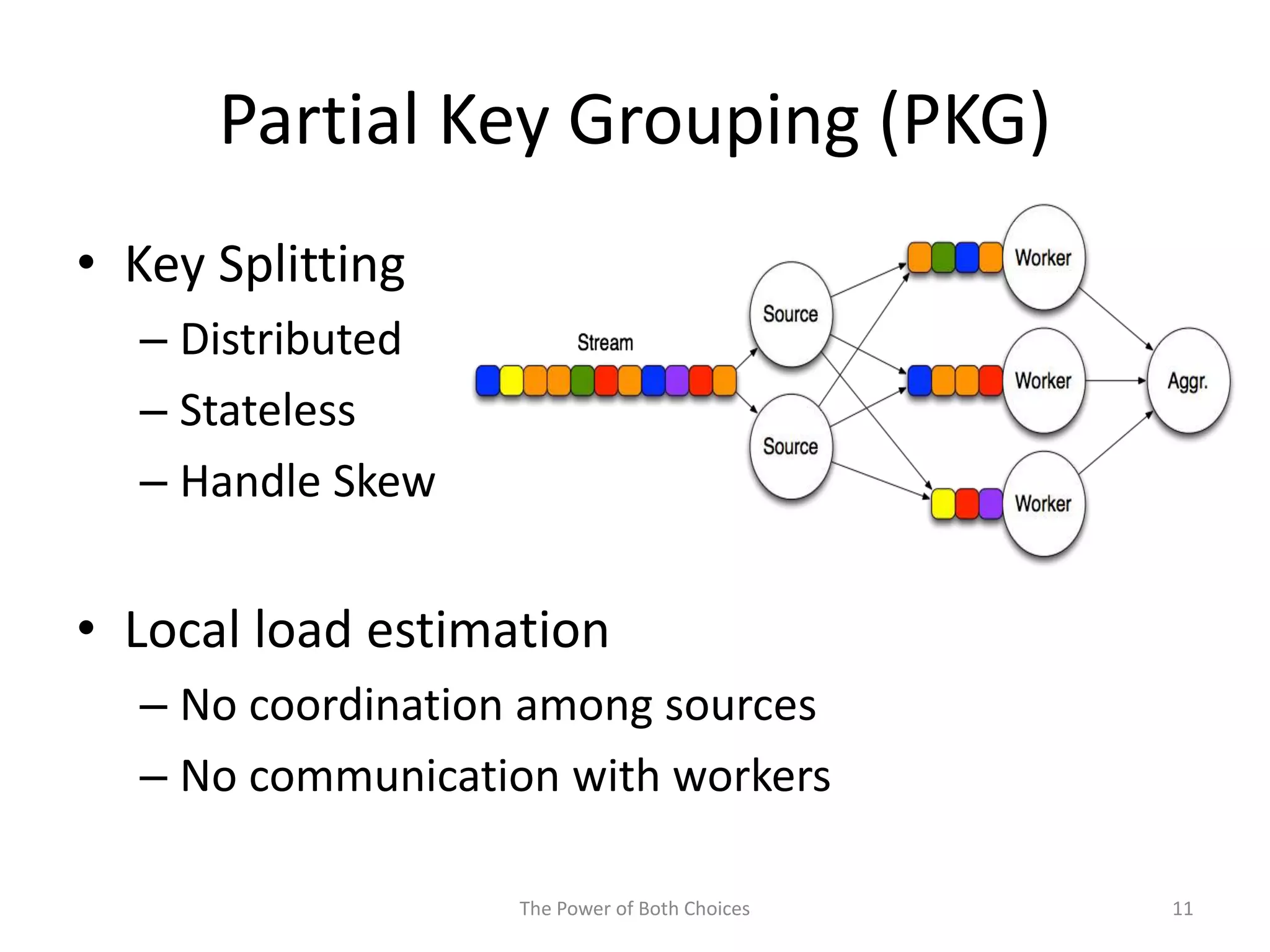
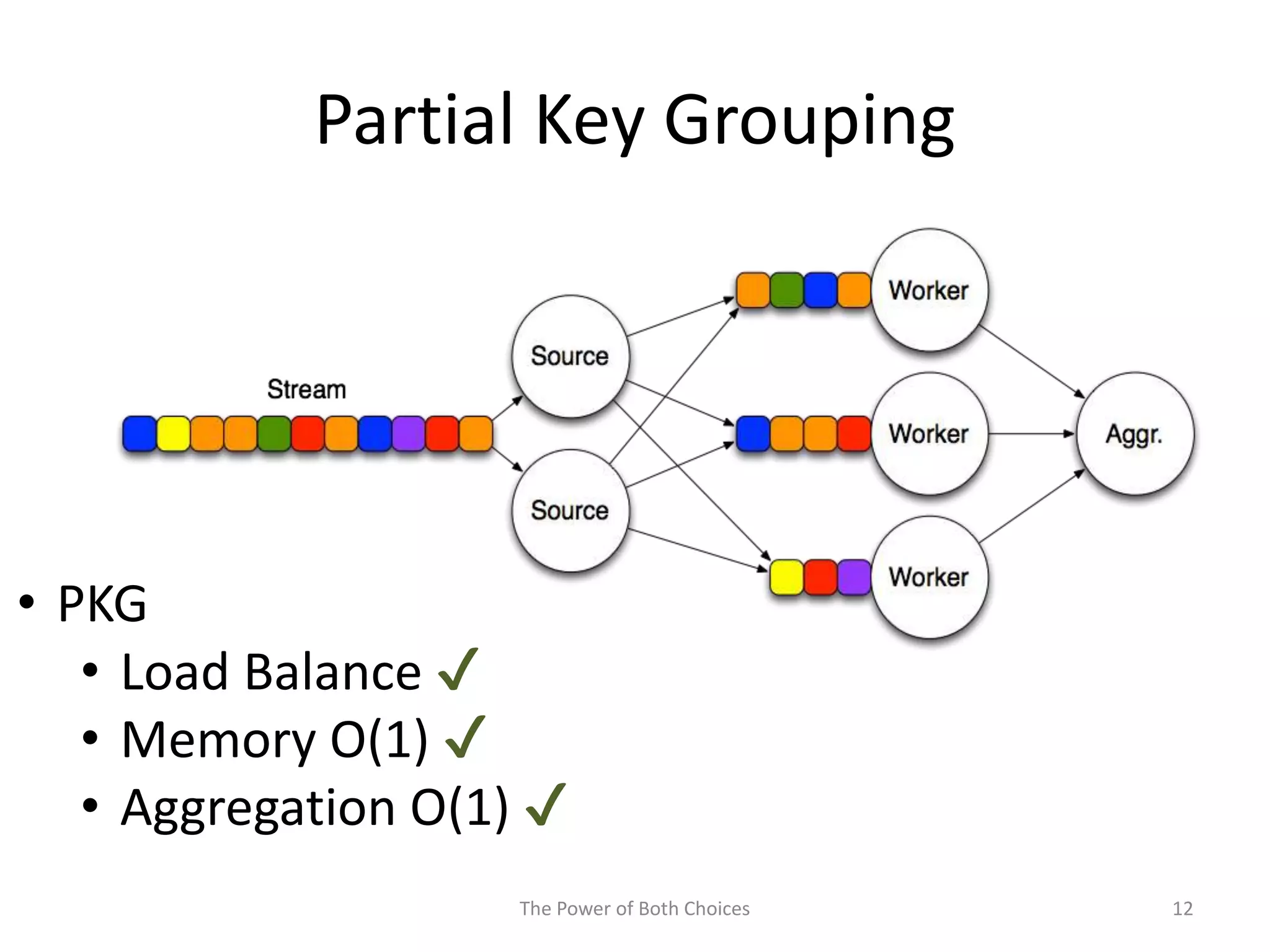







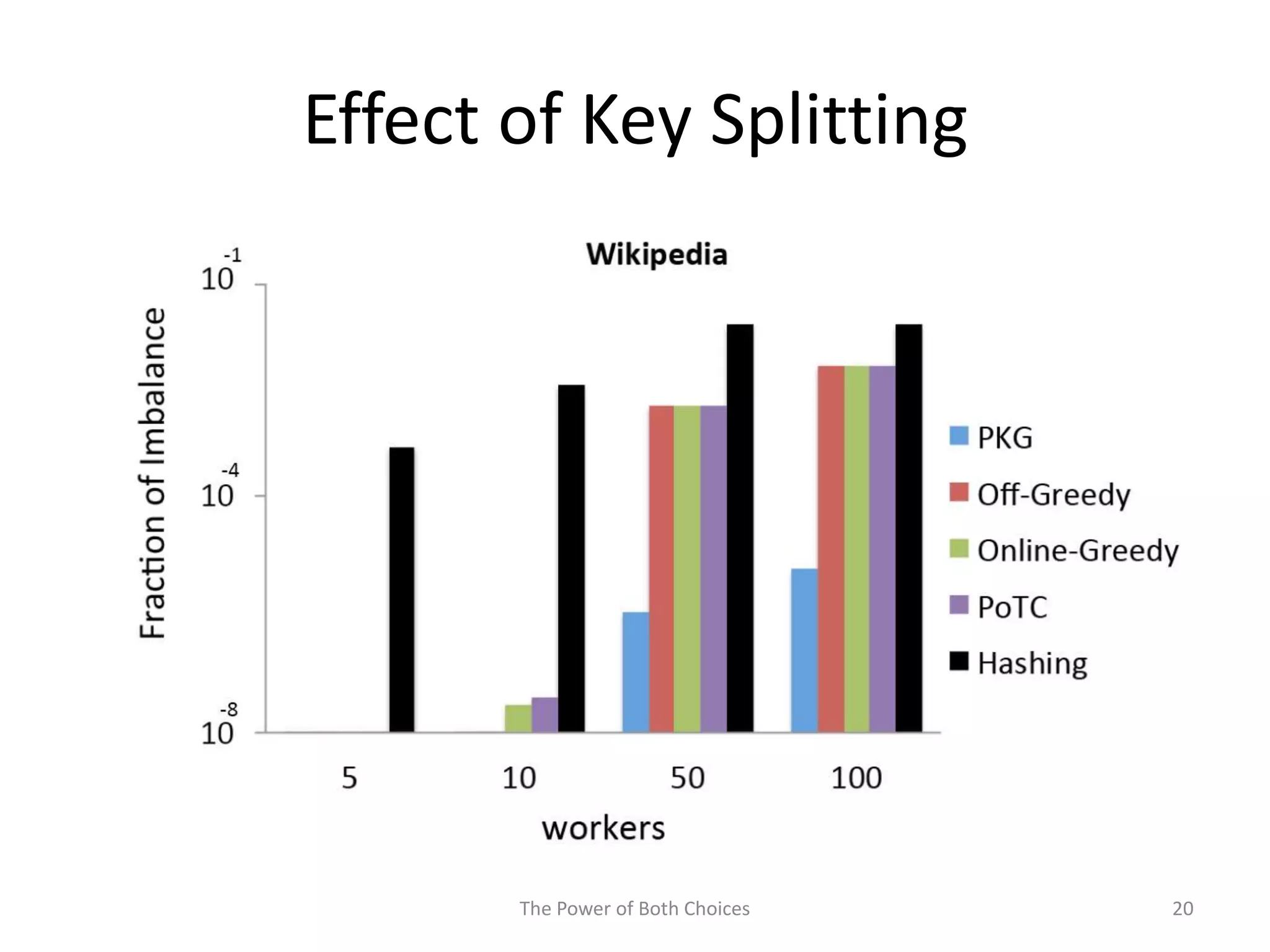
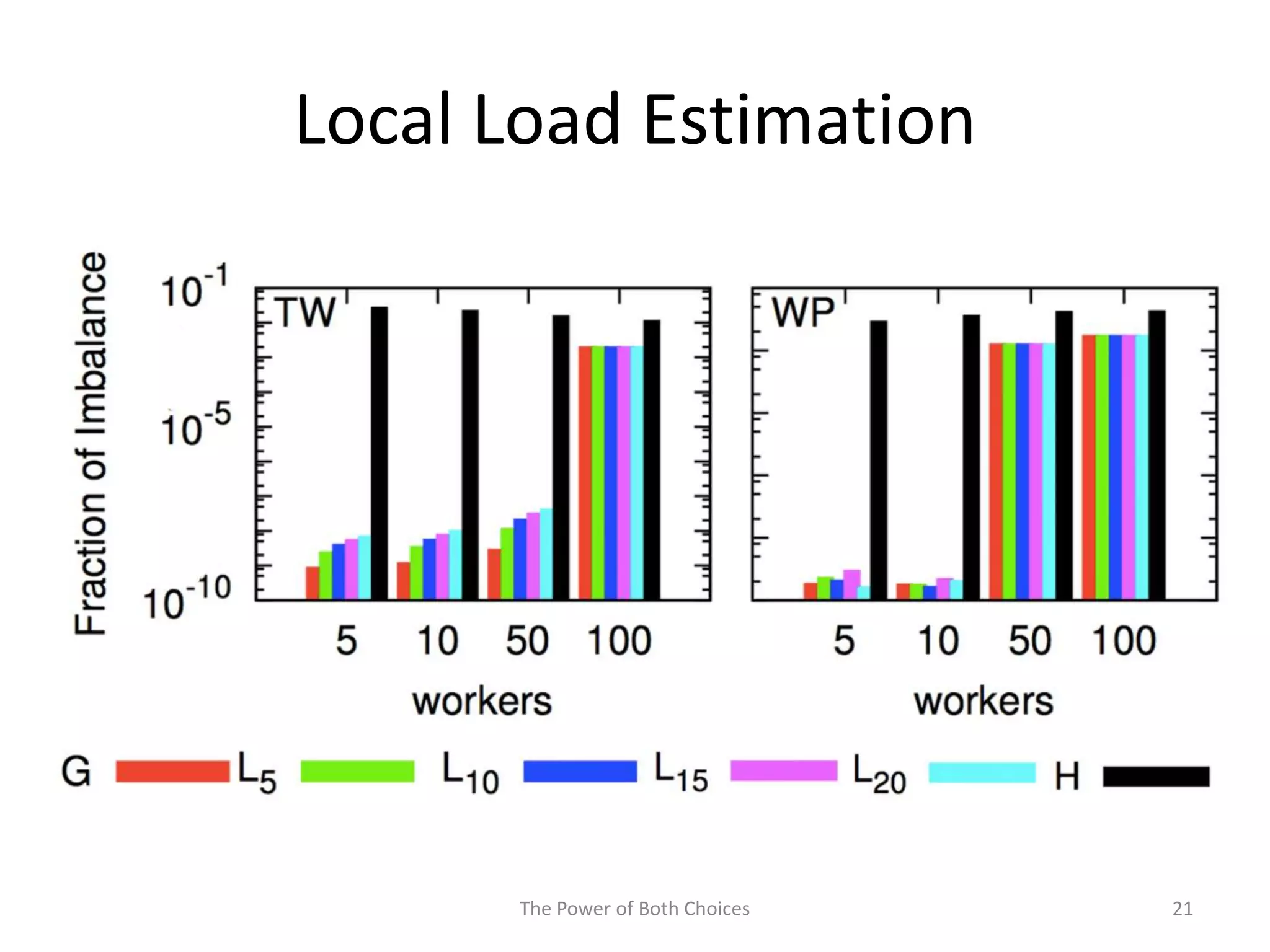
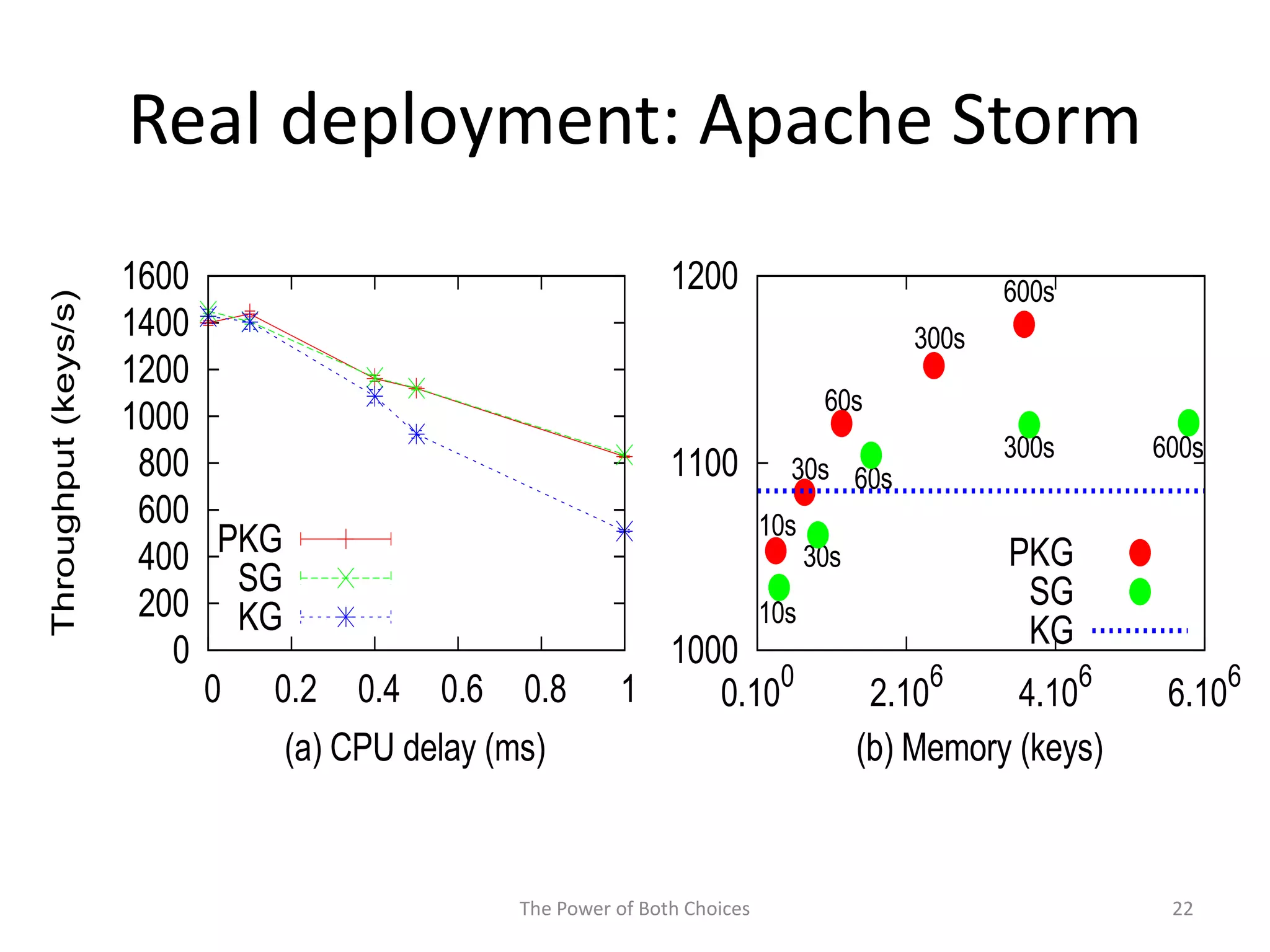




This paper proposes a technique called Partial Key Grouping (PKG) to balance load in distributed stream processing engines. PKG splits keys between workers and assigns instances using the "power of two choices" algorithm. This achieves load balancing while maintaining low memory and aggregation overhead of O(1), unlike shuffle grouping which has O(W) overhead. Experiments on real datasets with Apache Storm show PKG improves throughput by 60% and reduces latency by 45% compared to key grouping and shuffle grouping.