Downloaded 44 times


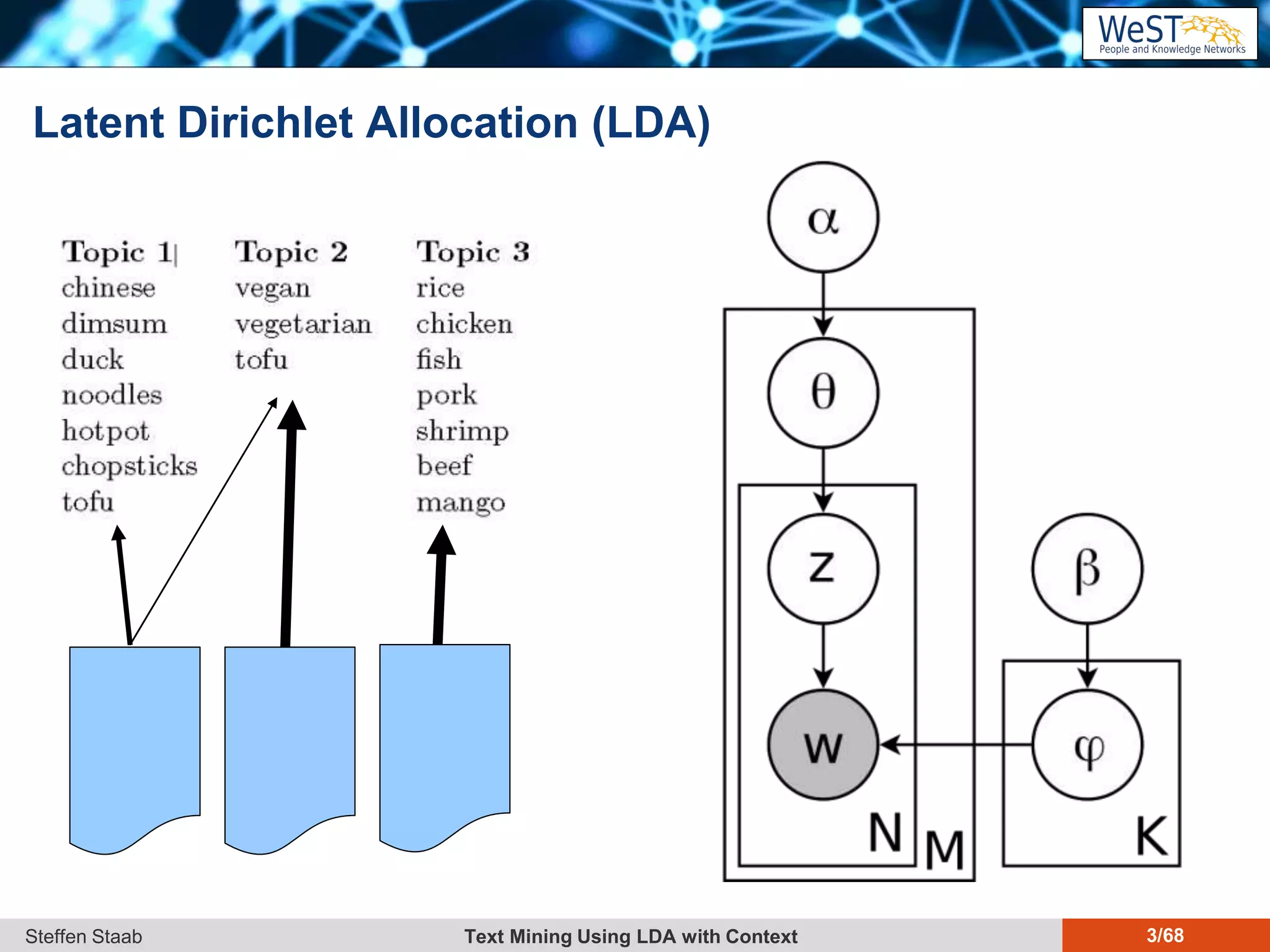
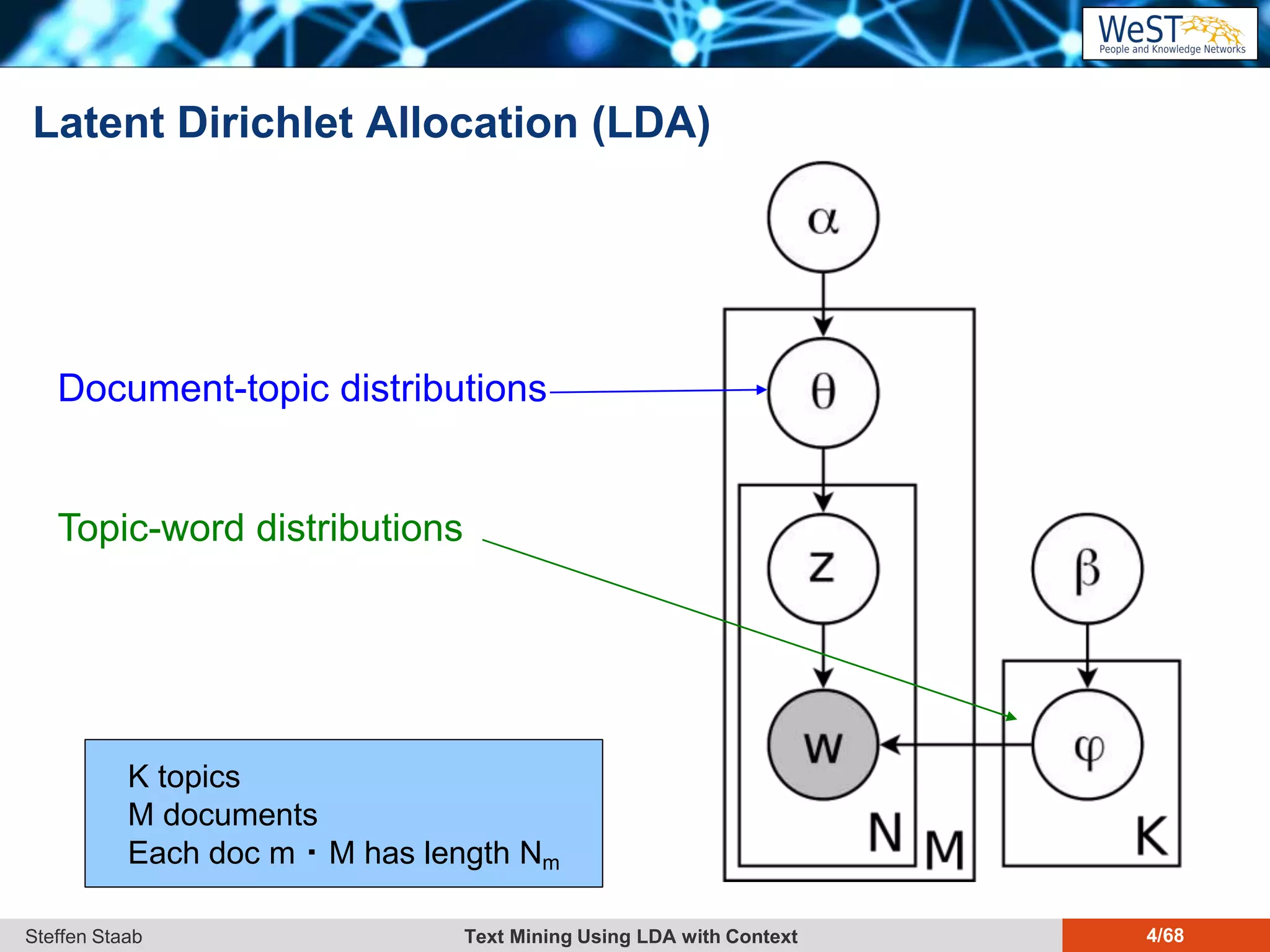
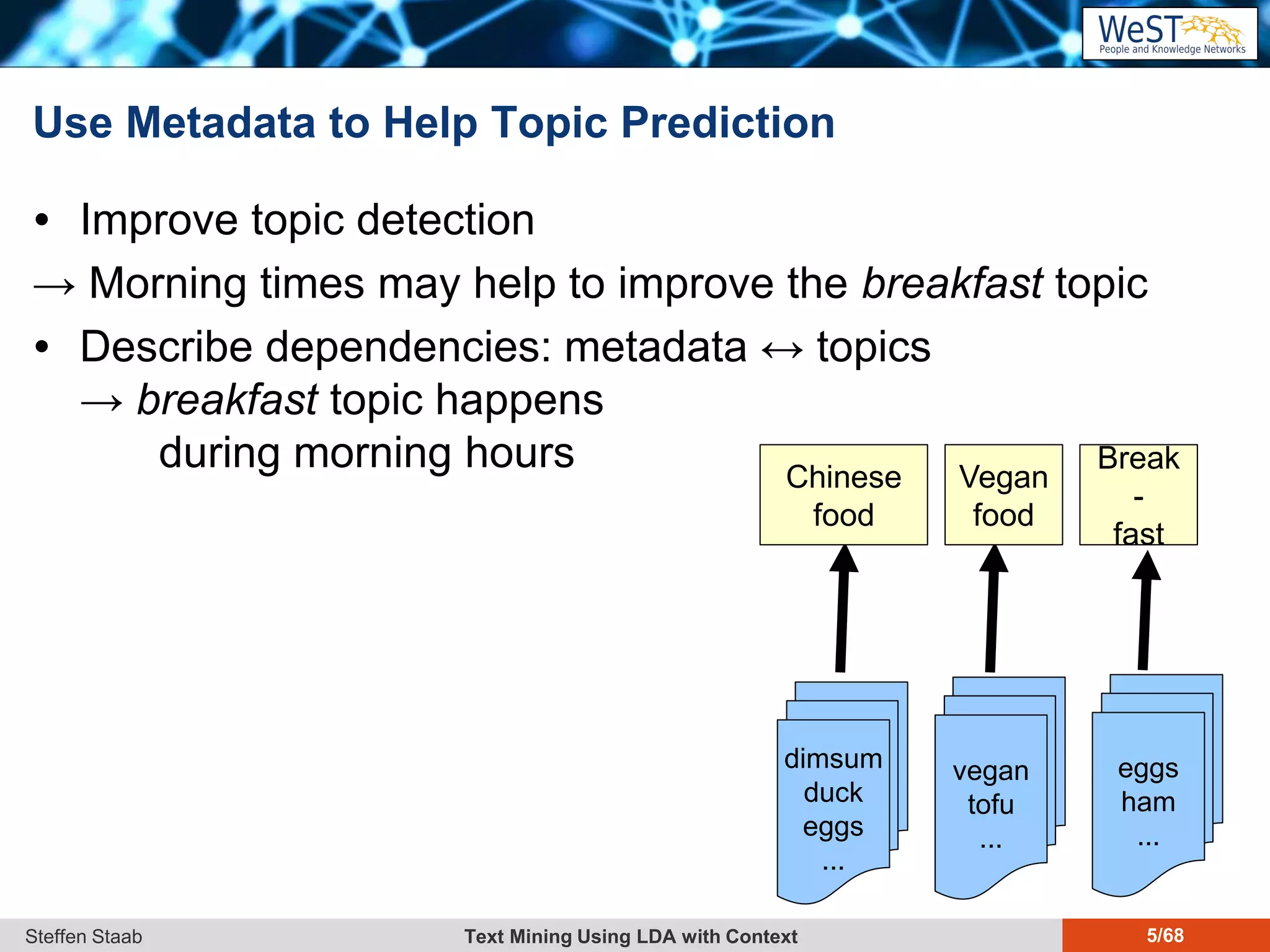
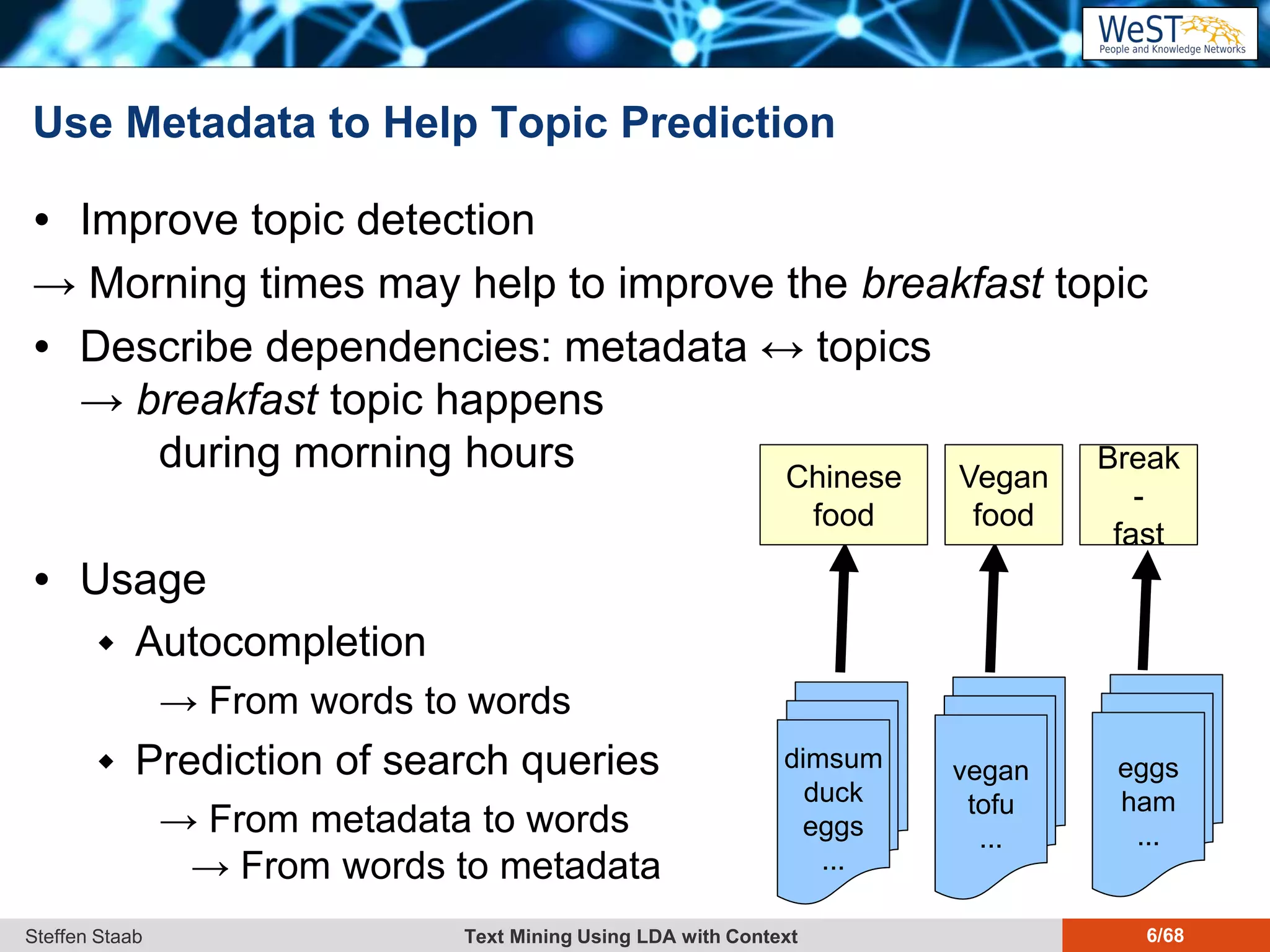
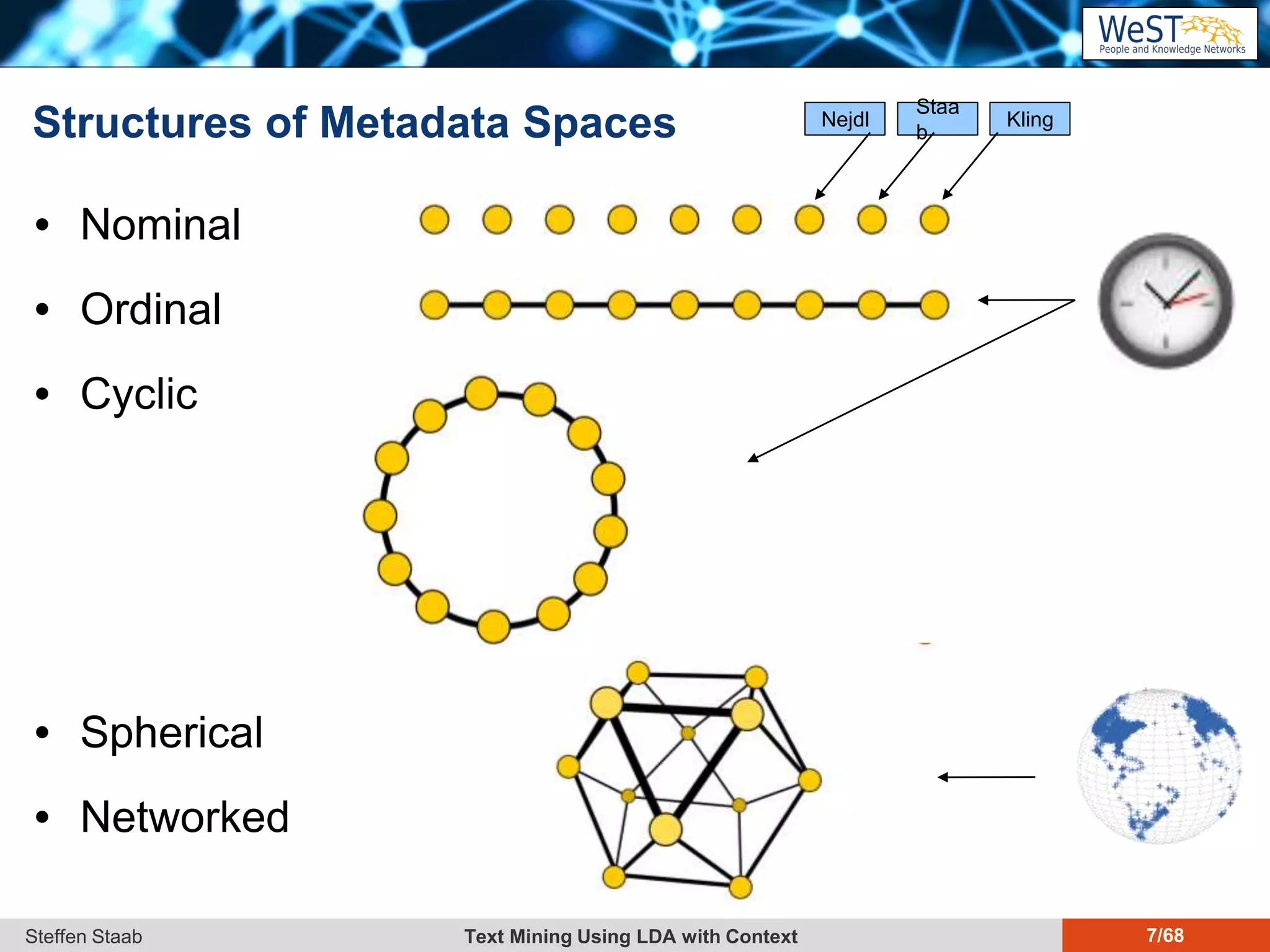






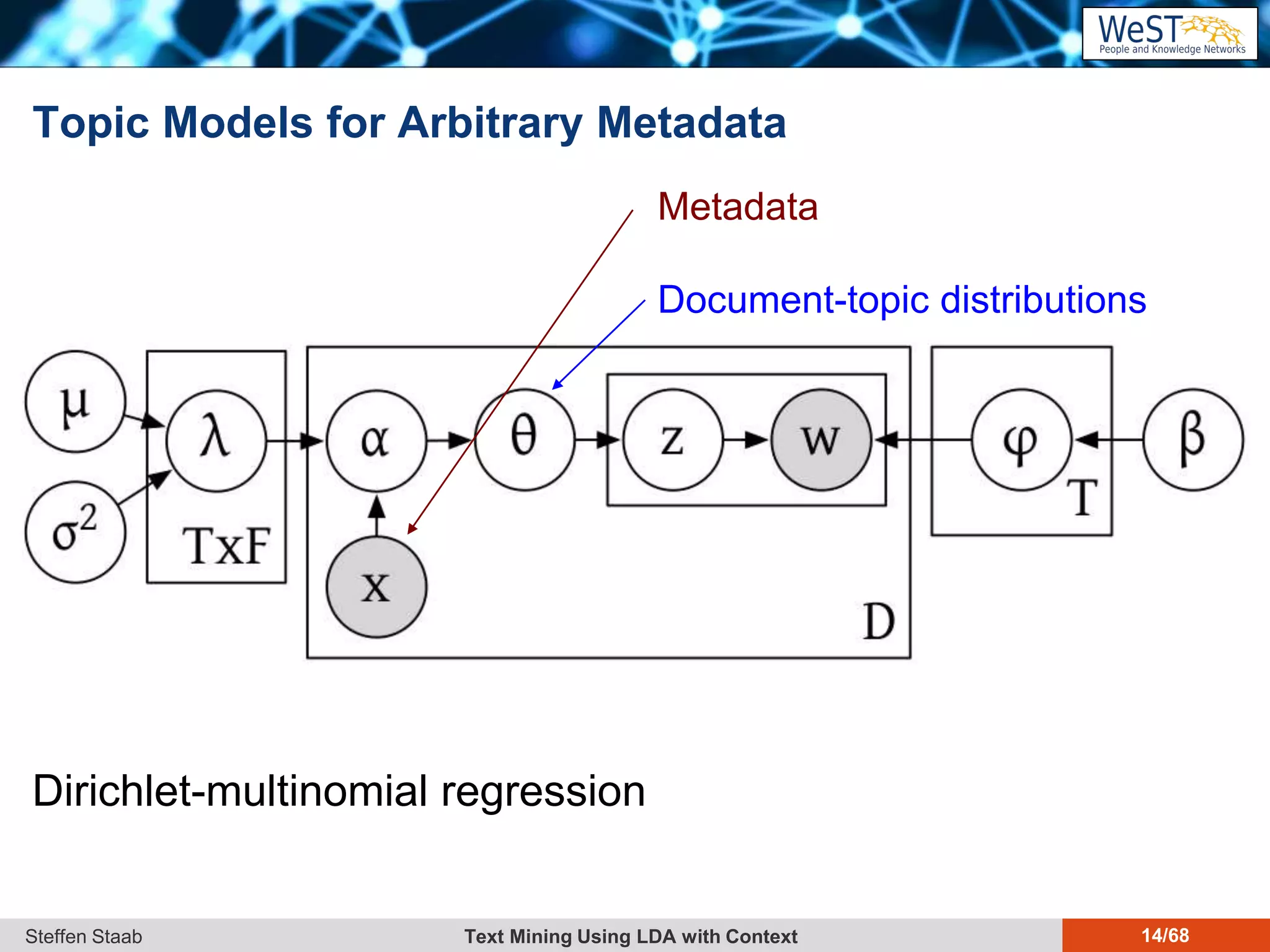
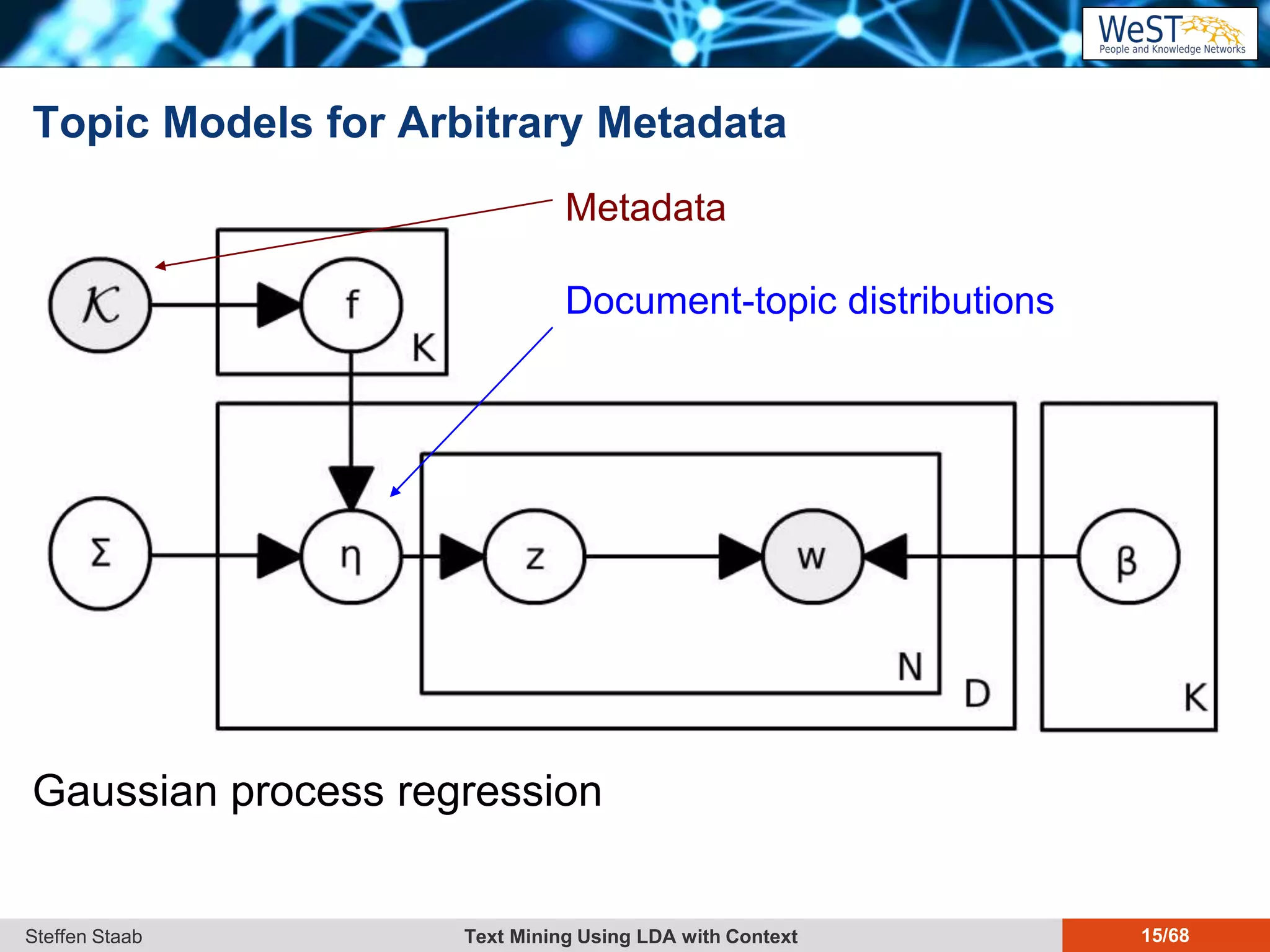
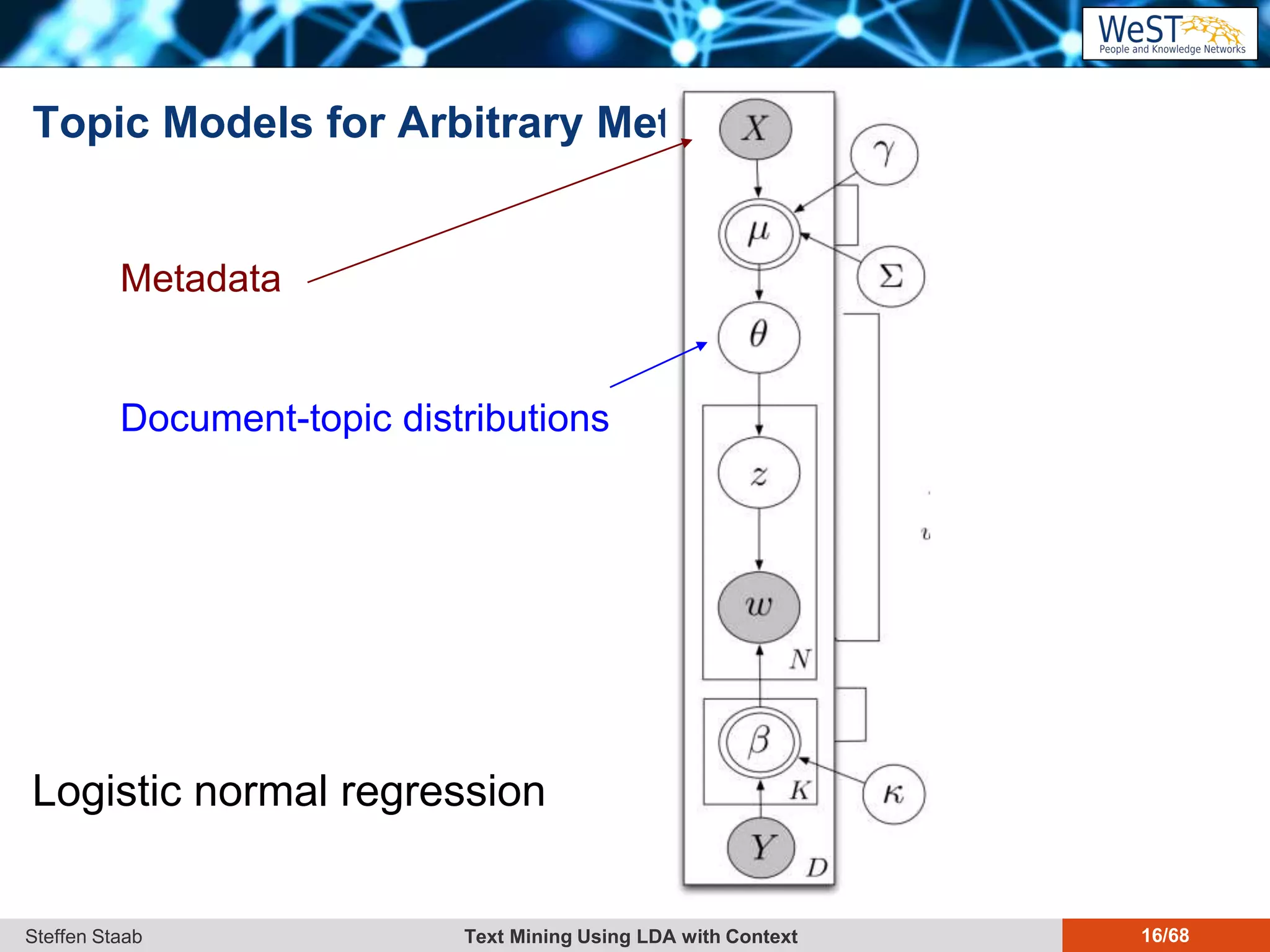





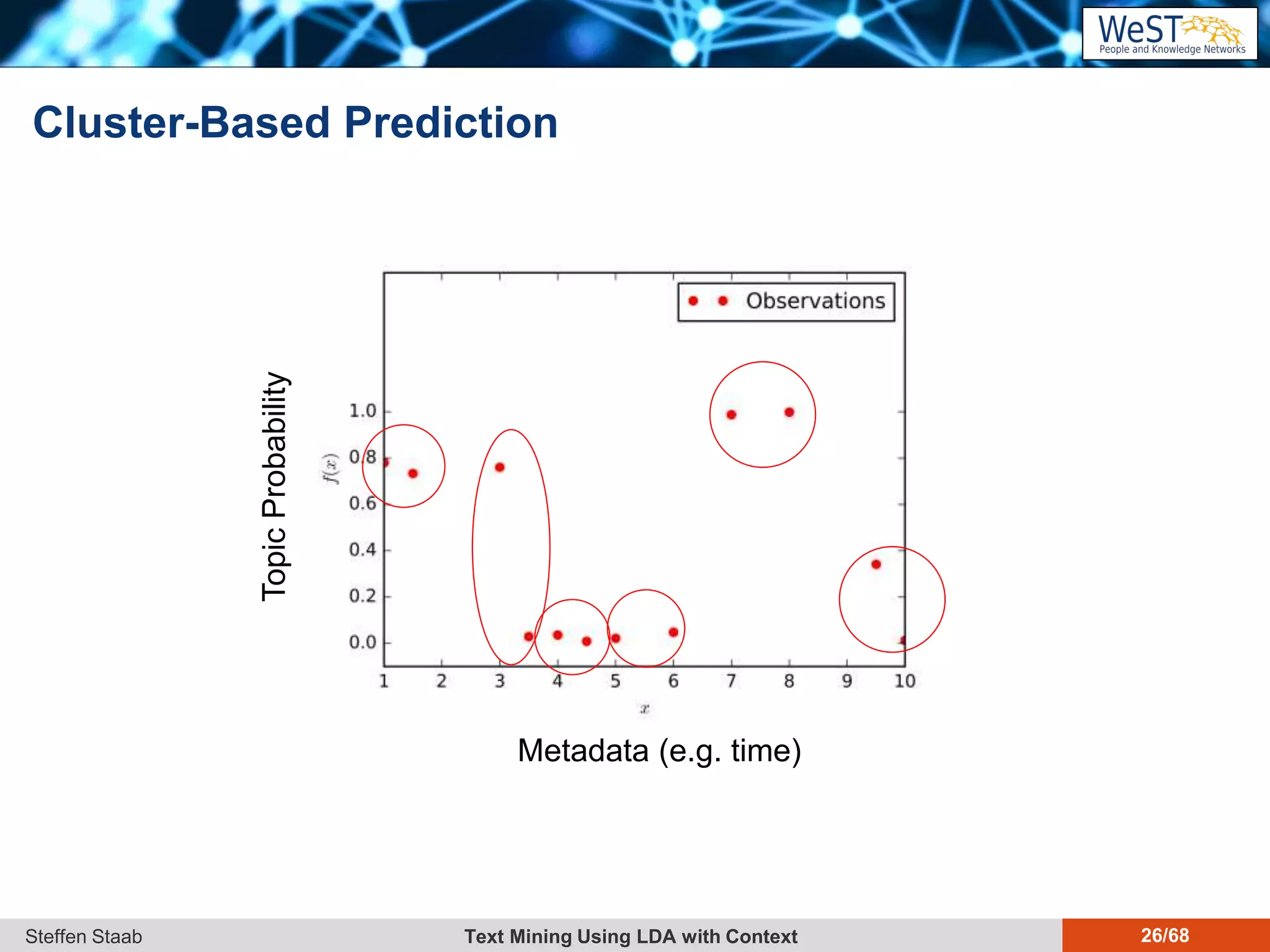
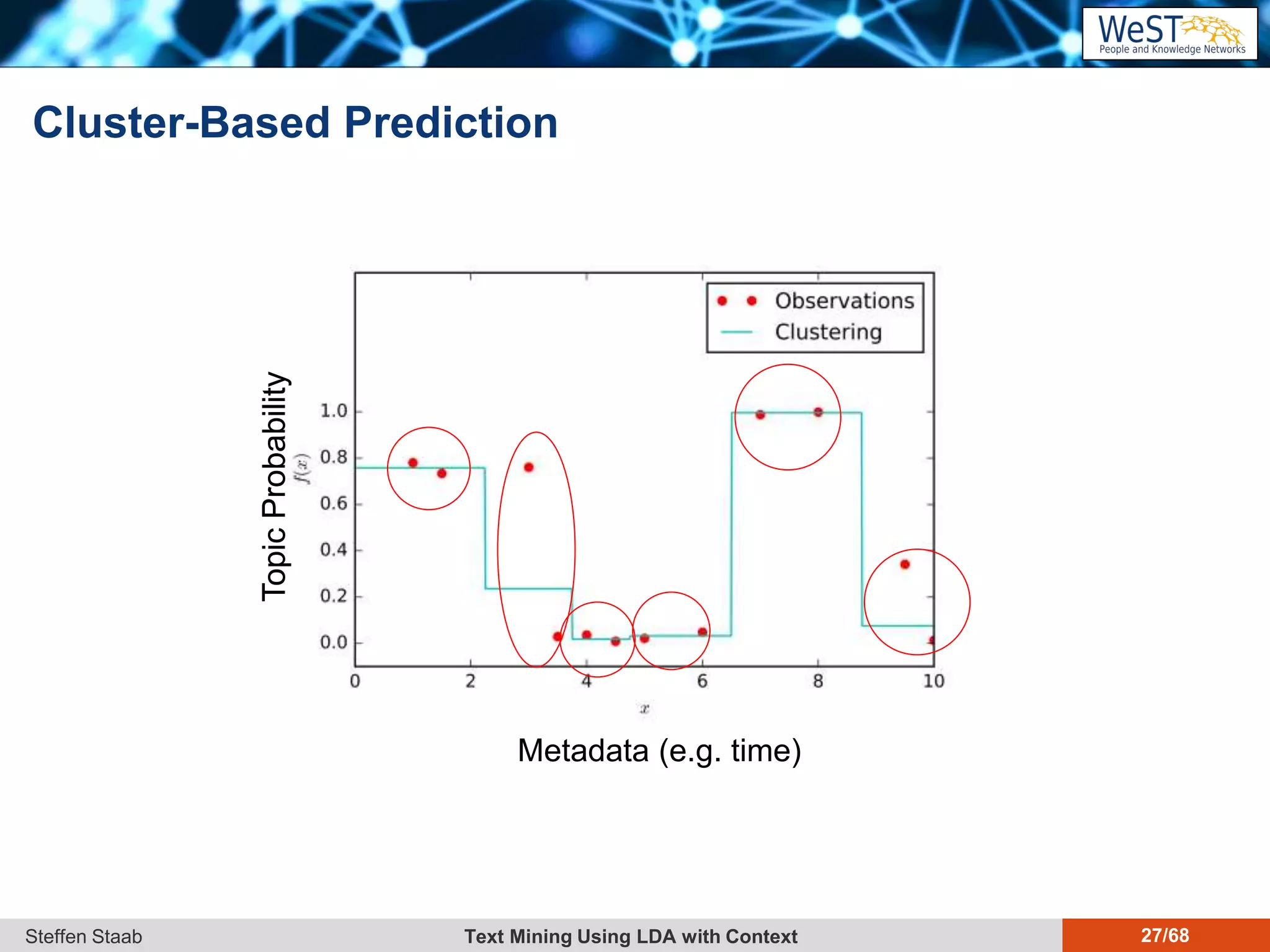
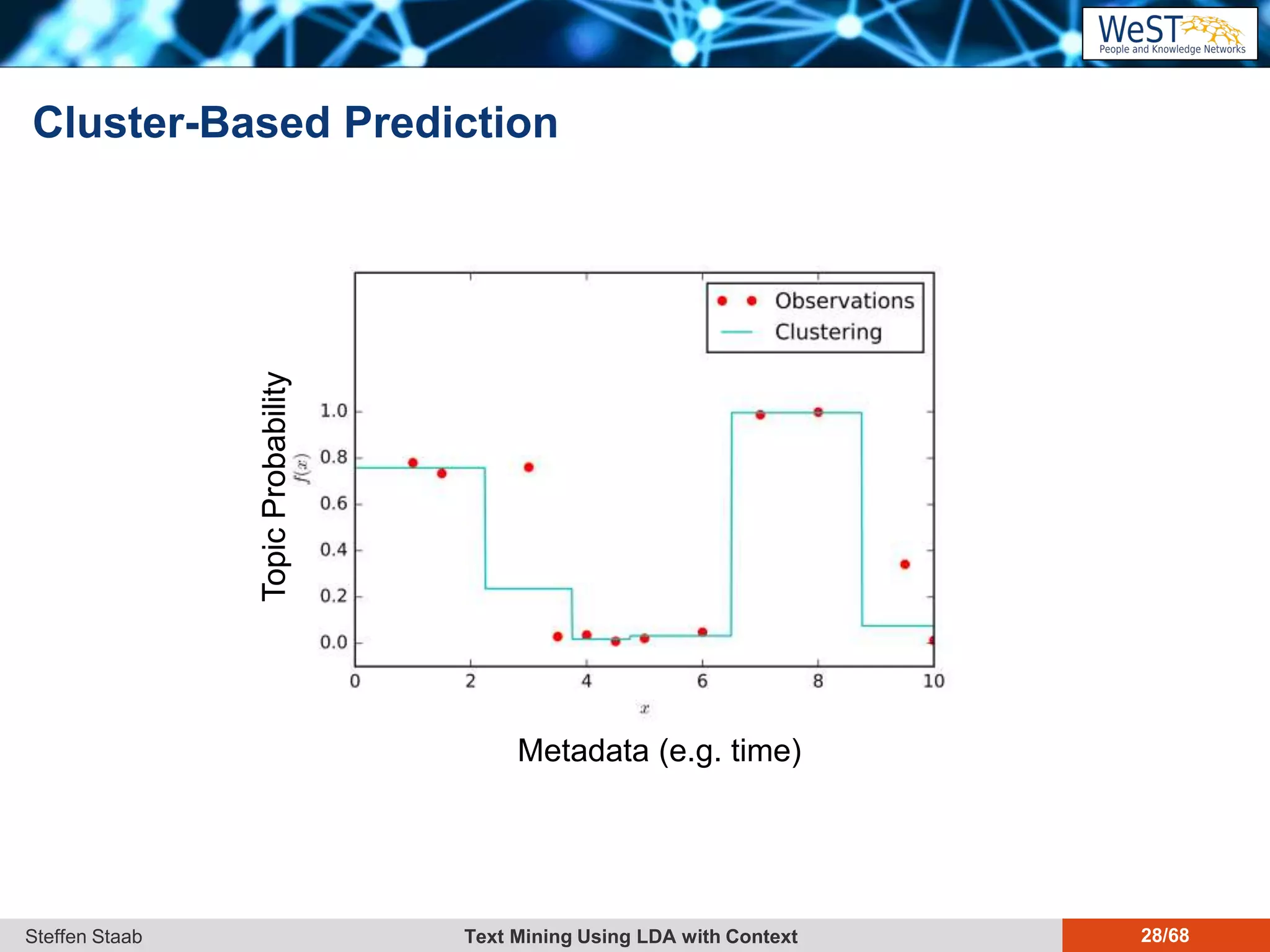





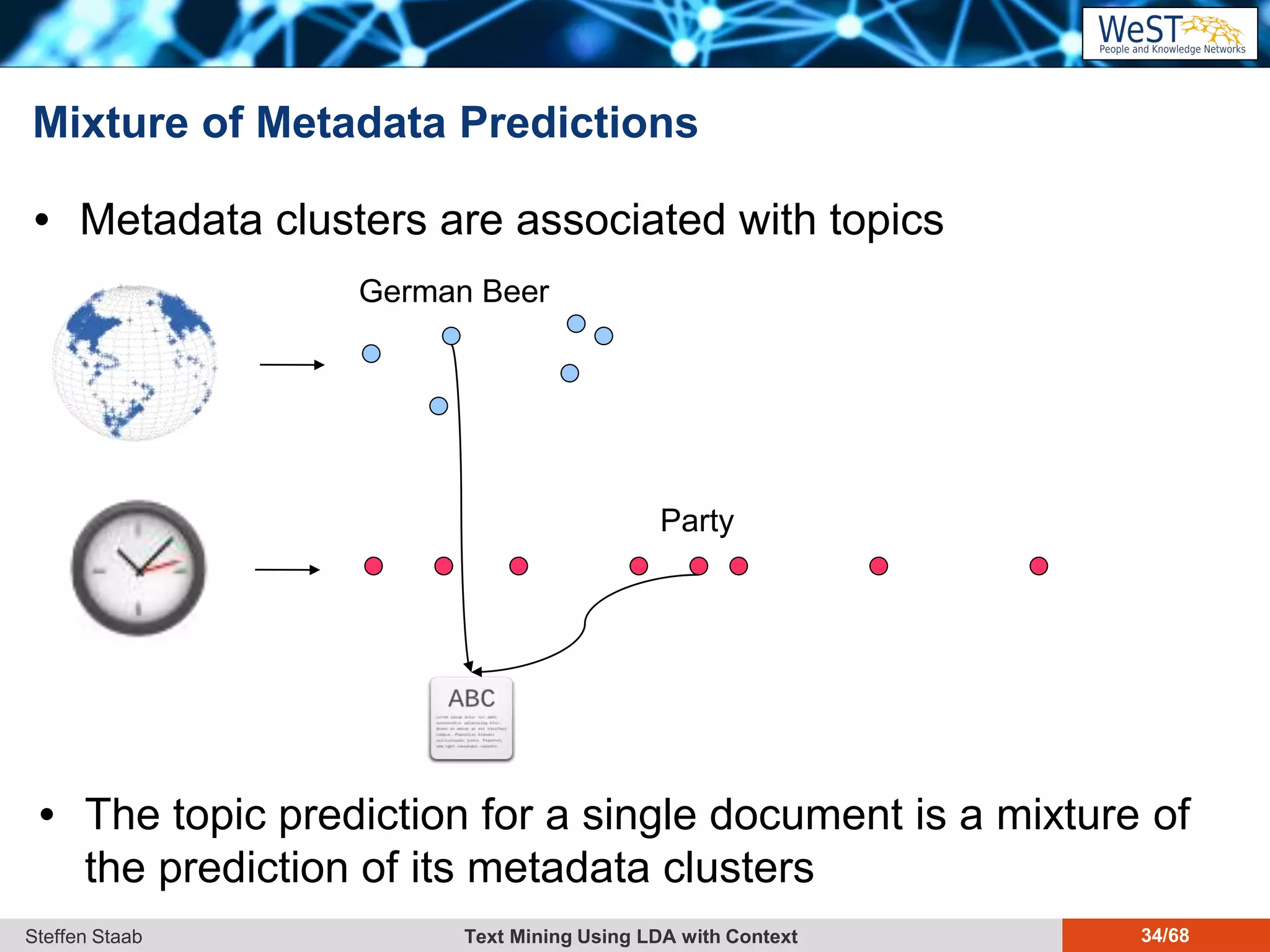

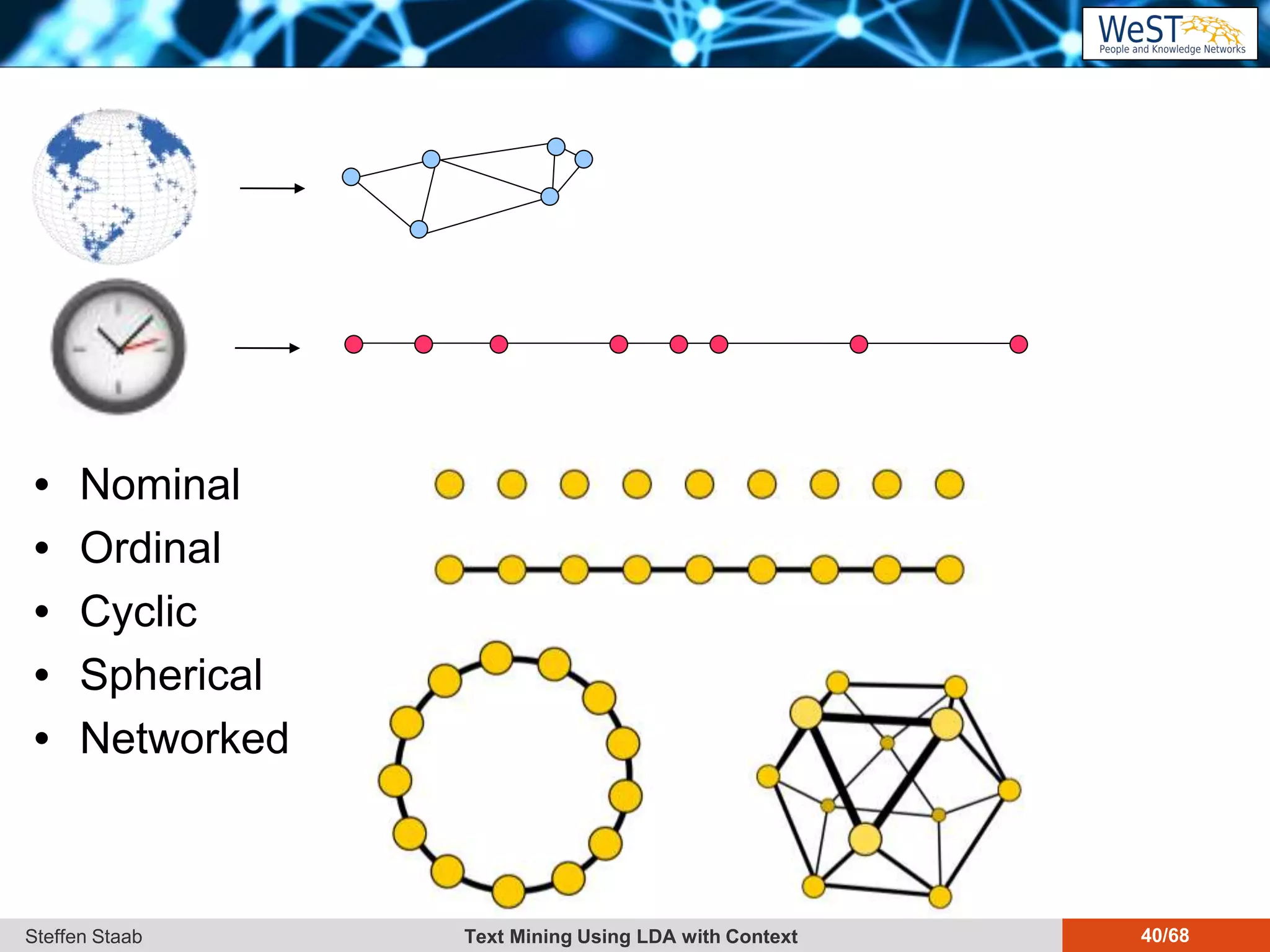


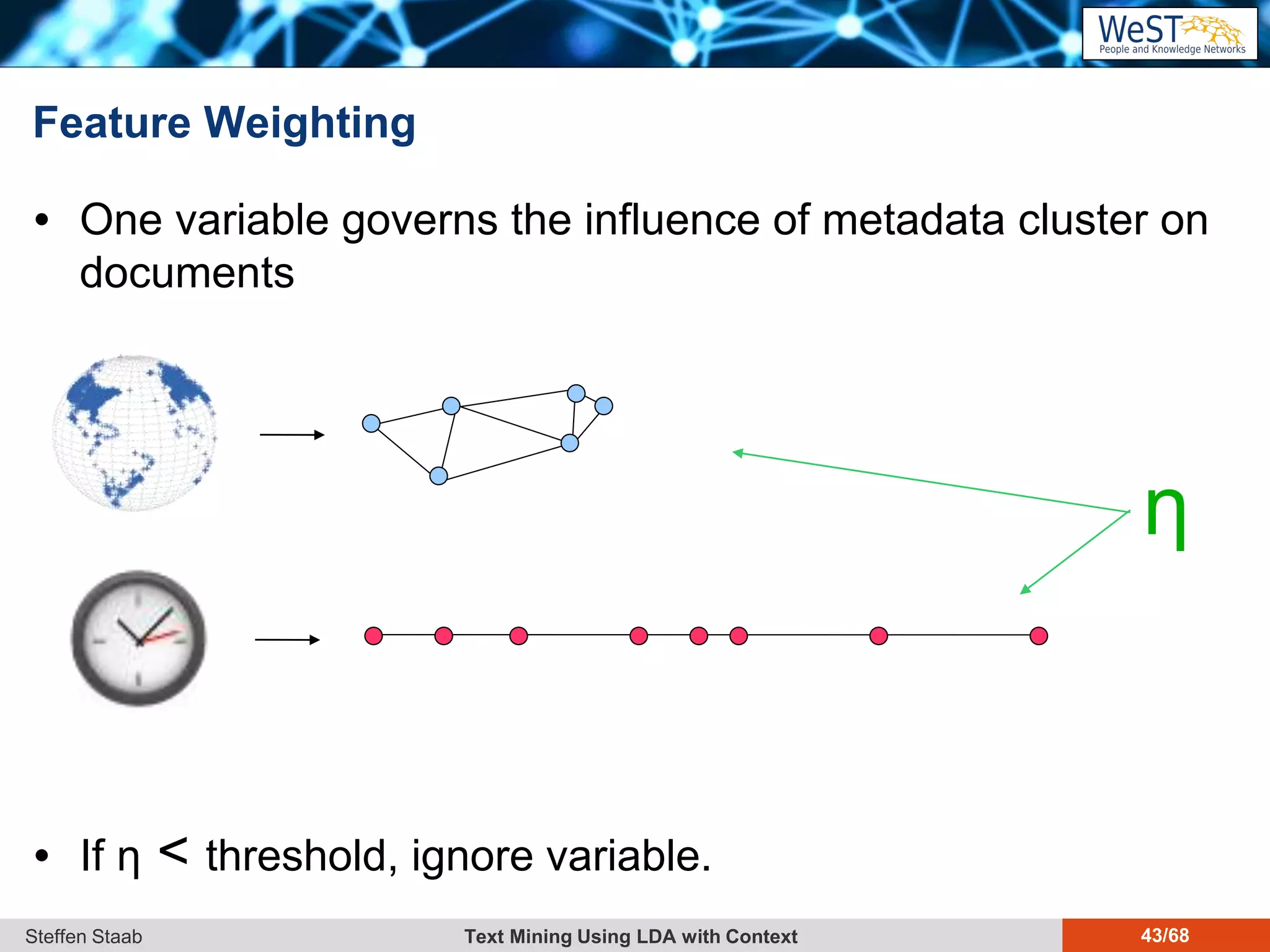


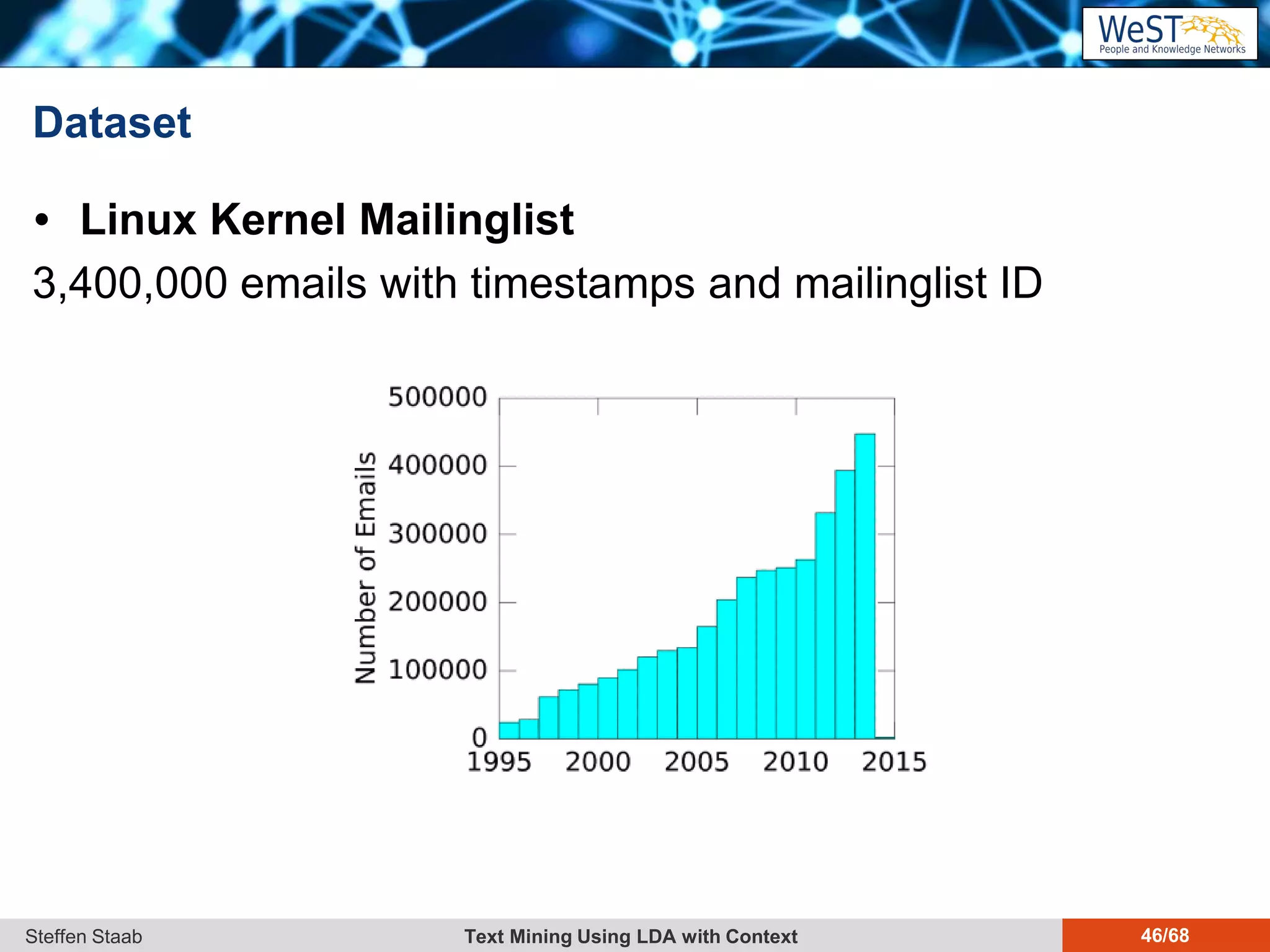


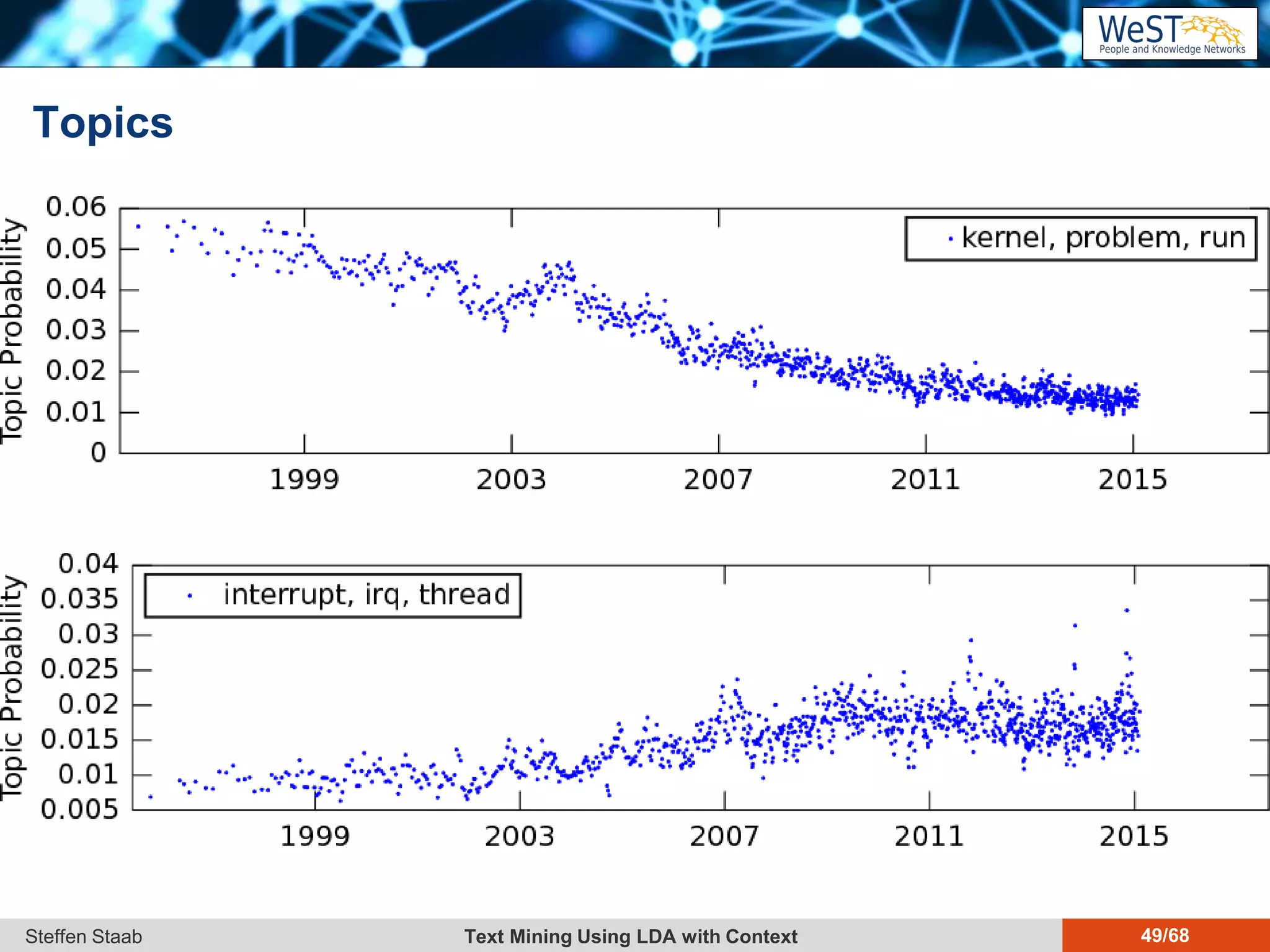
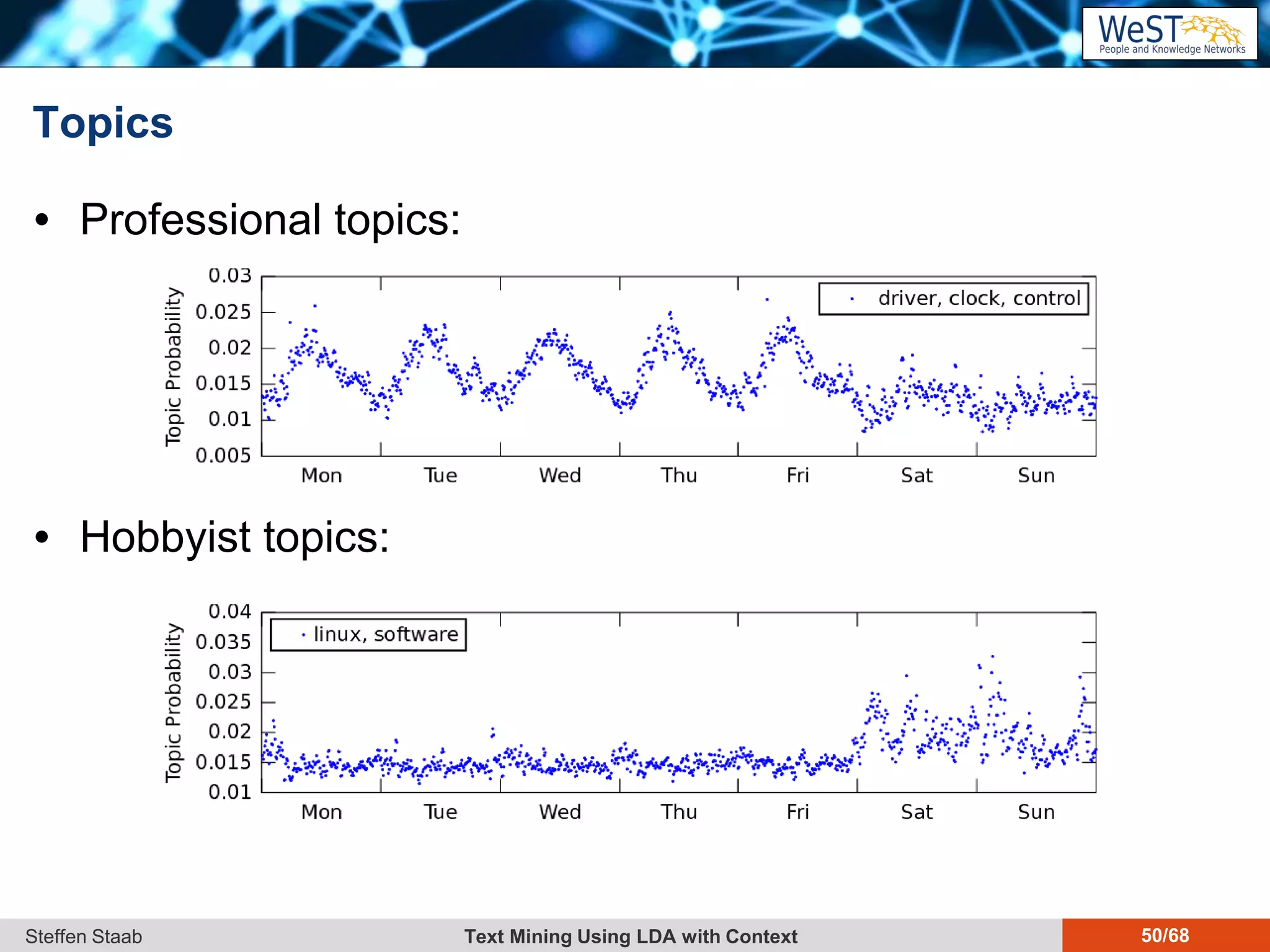
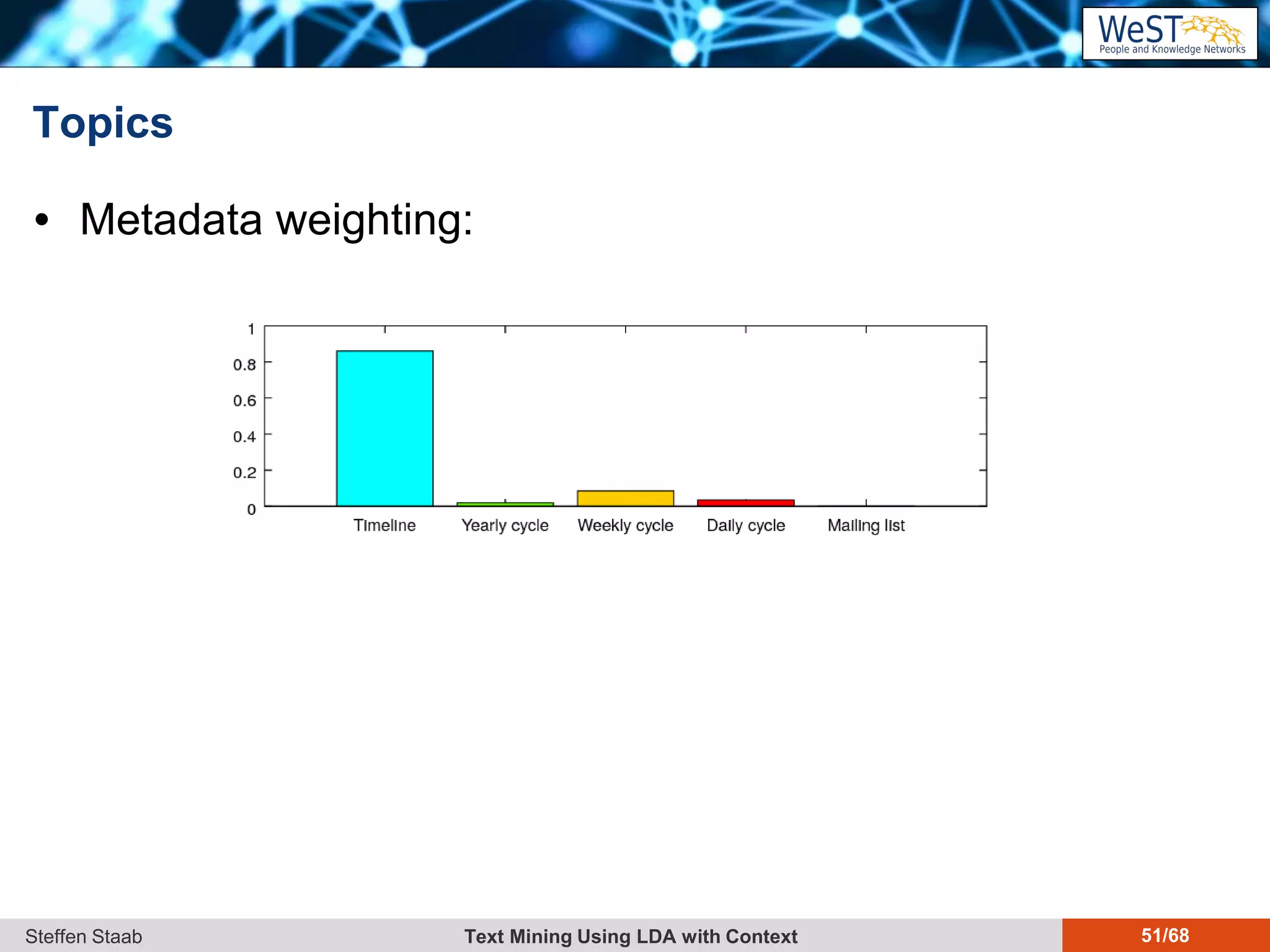
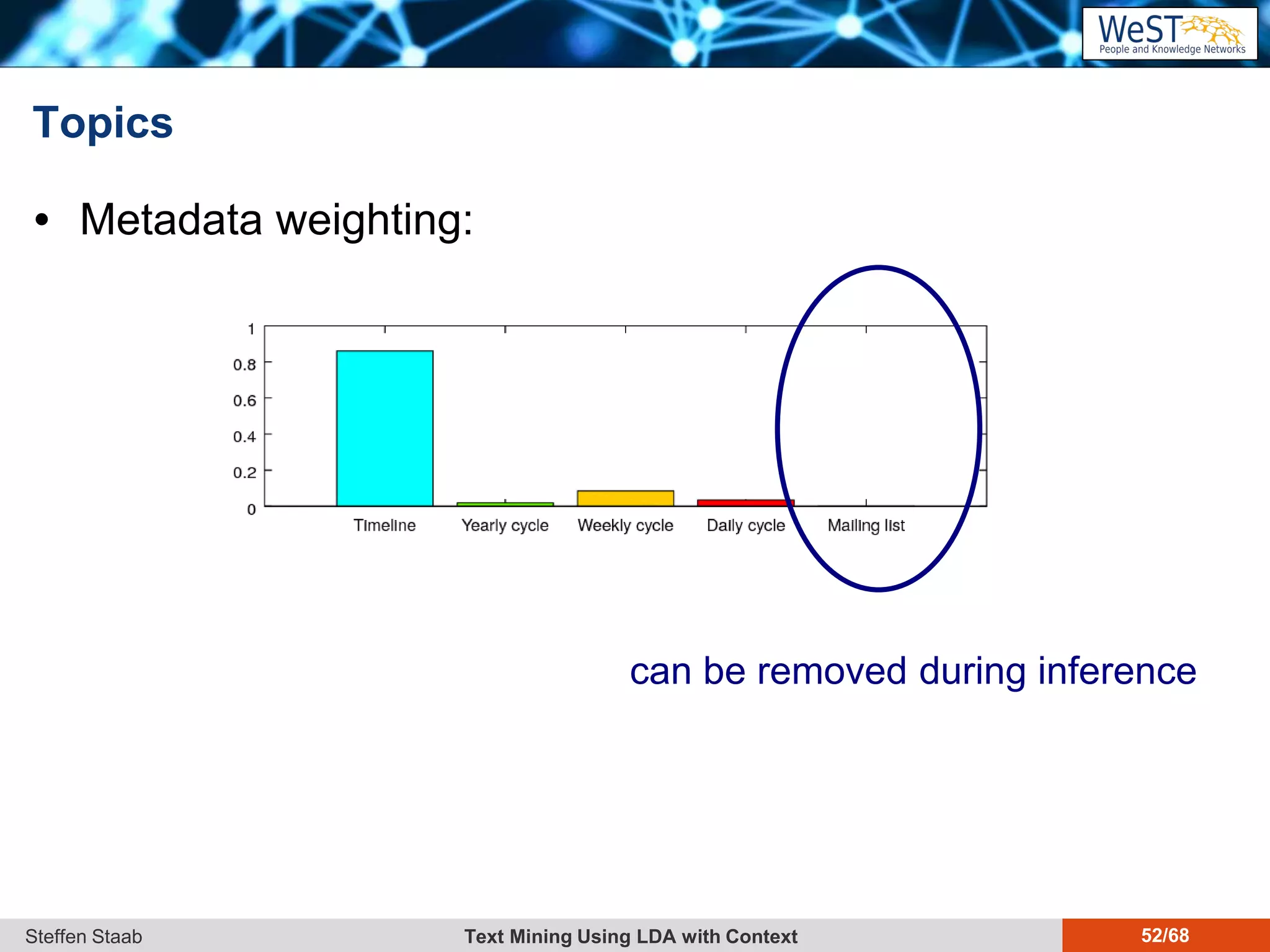

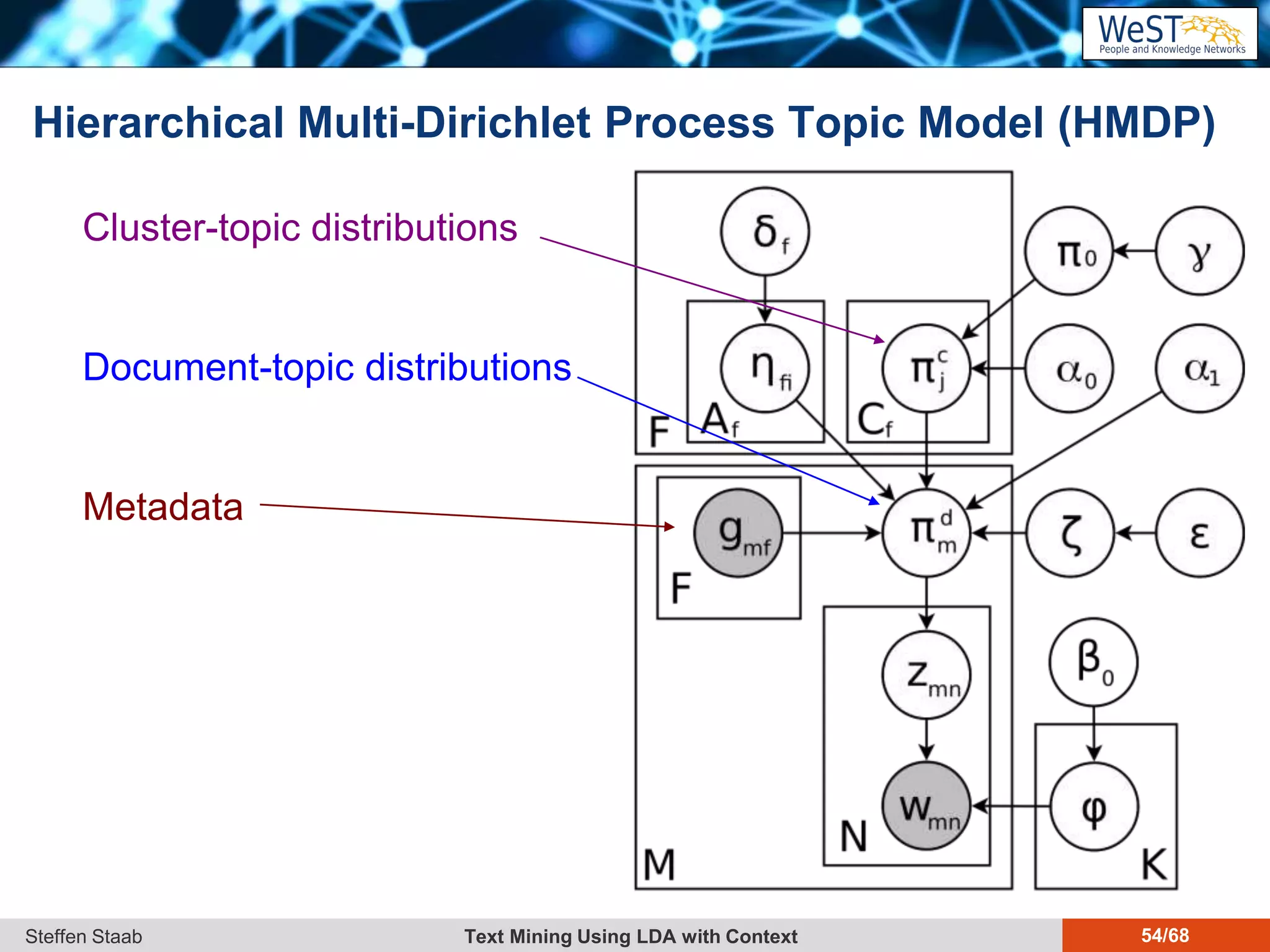
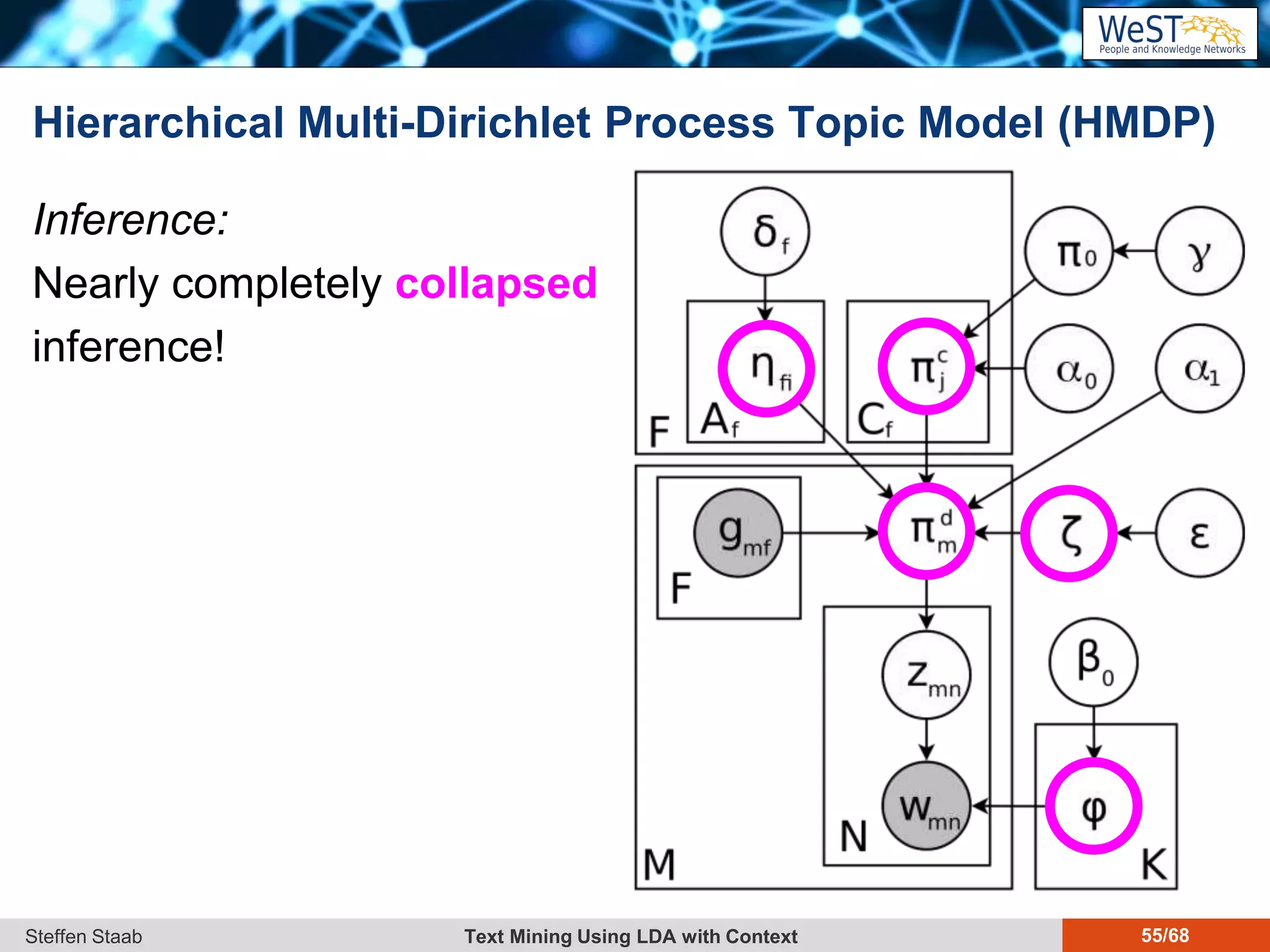
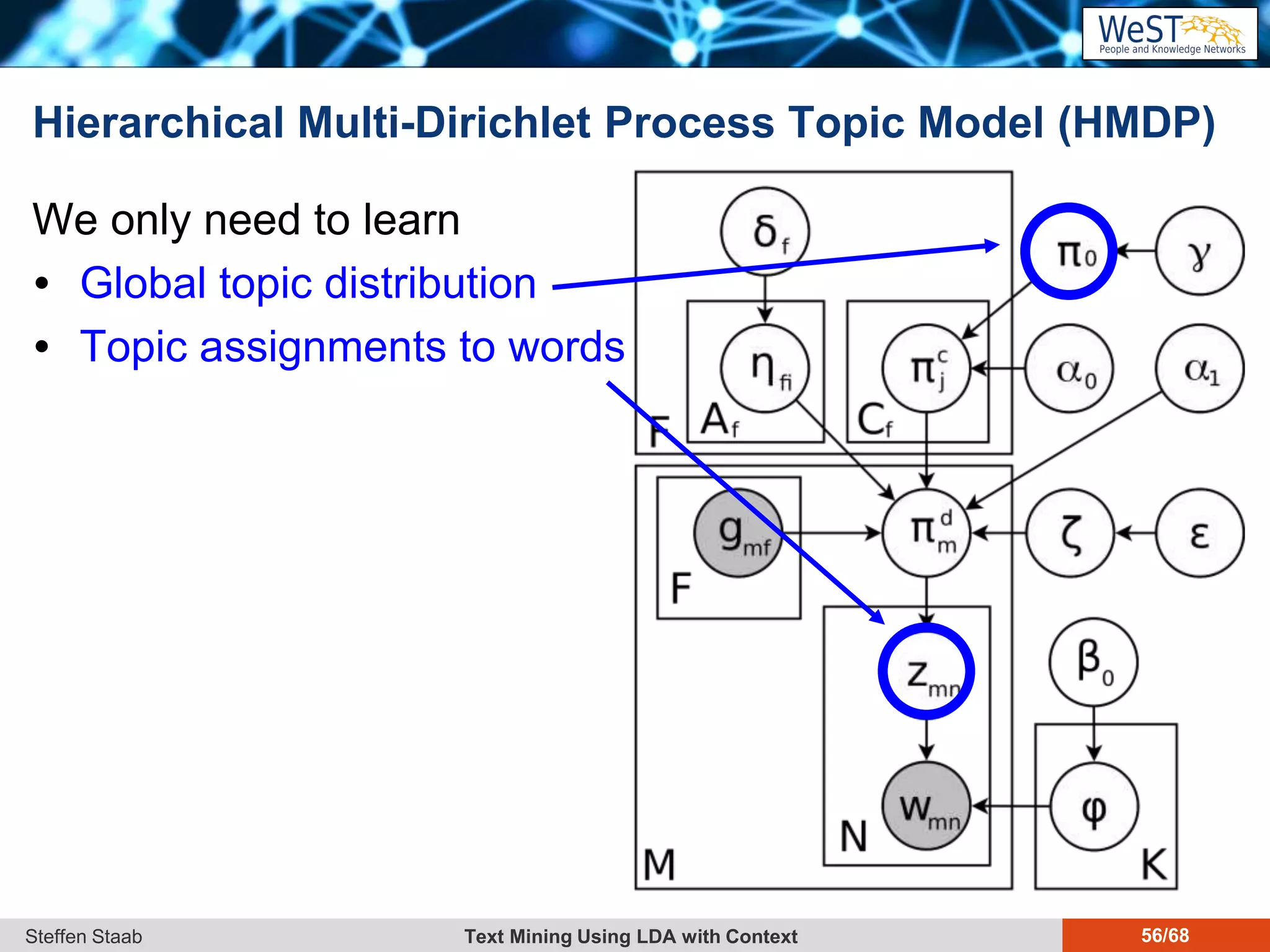
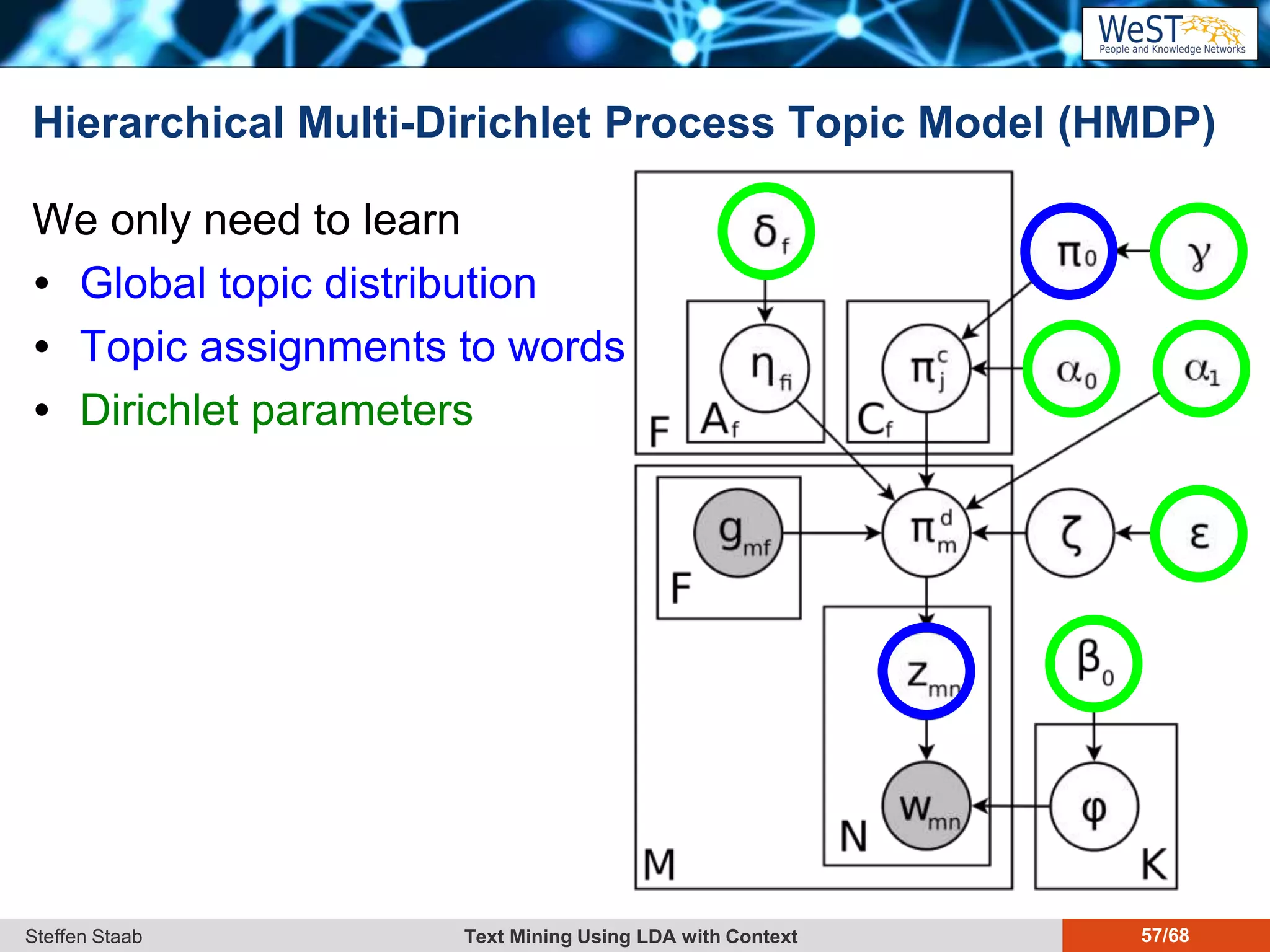











This document discusses text mining using Latent Dirichlet Allocation (LDA) with a focus on leveraging metadata for improved topic detection. It highlights the challenges of using metadata in text mining models, the development of topic models for arbitrary metadata, and efficient inference mechanisms for hierarchical multi-dirichlet process (HMDP) models. The text also compares various topic modeling approaches, emphasizing interpretation and computational efficiency.