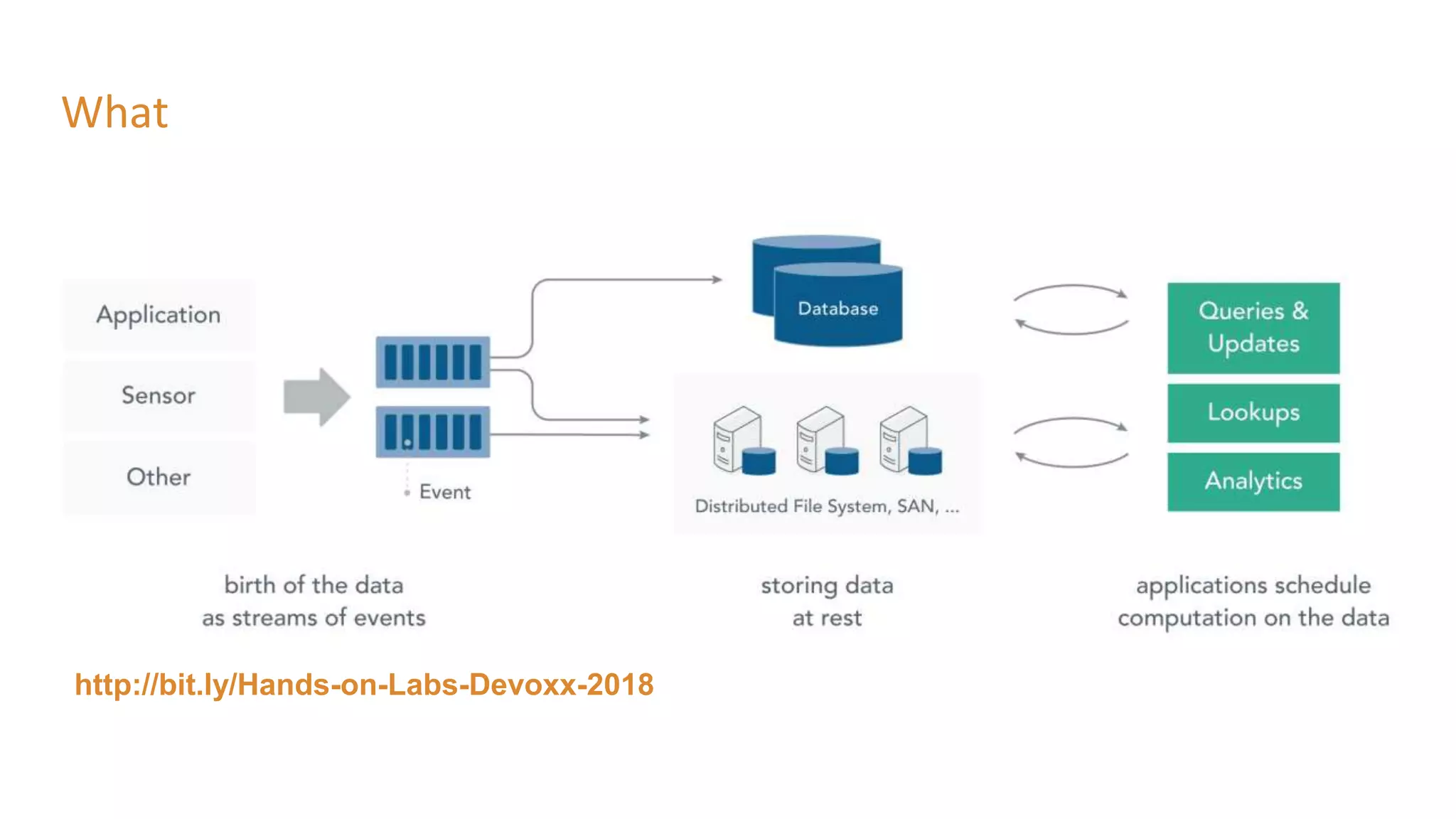
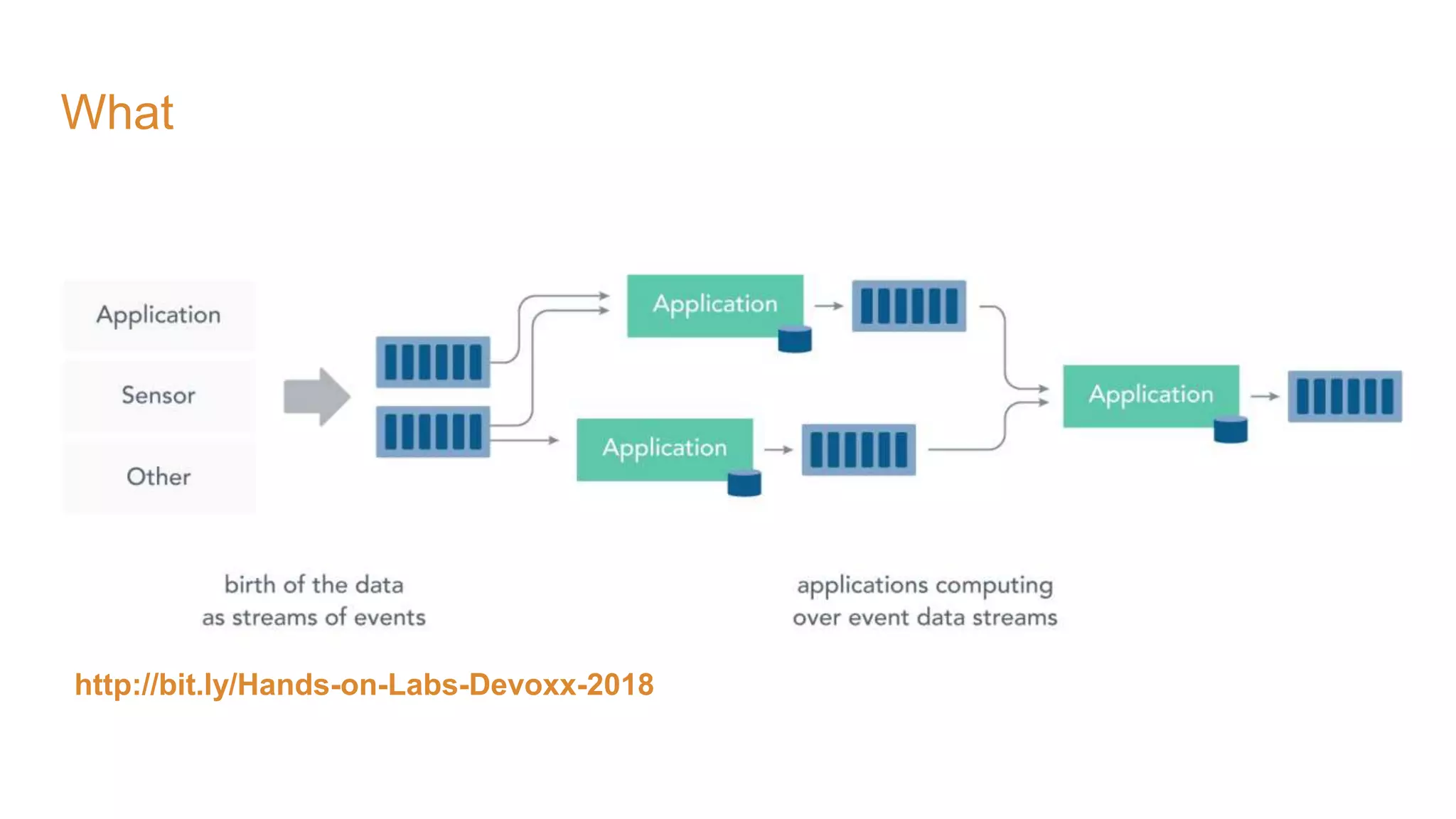
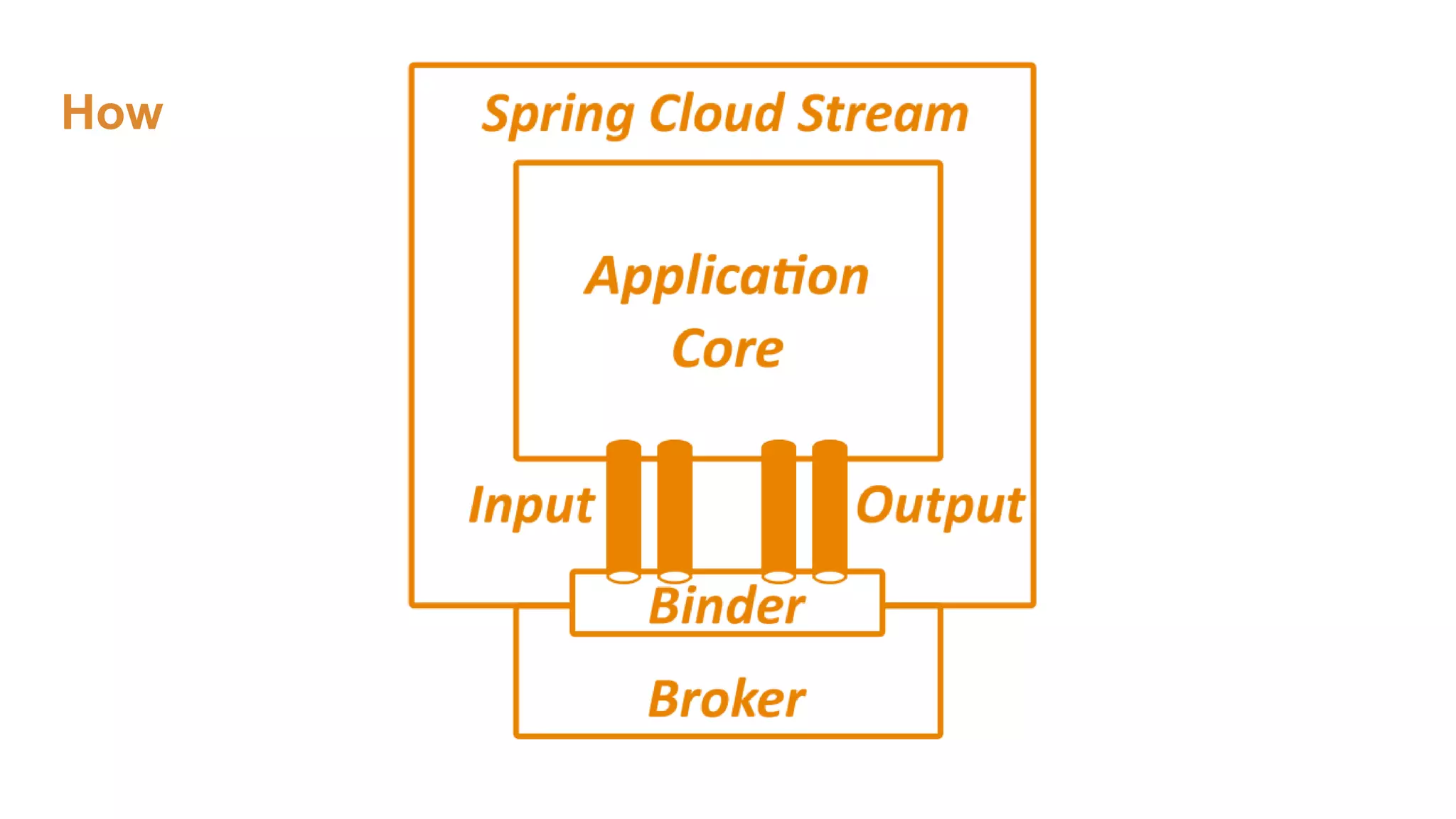
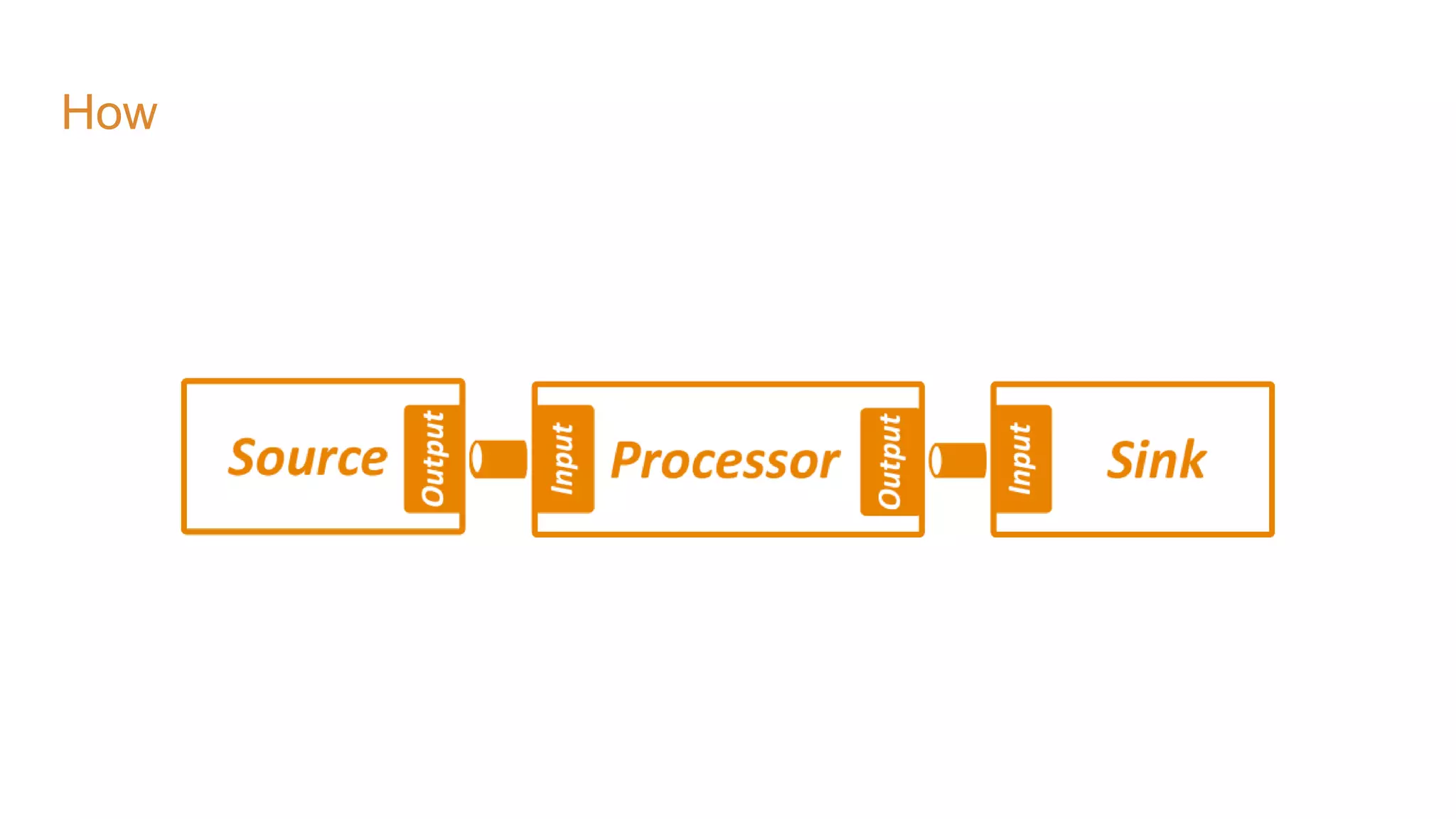
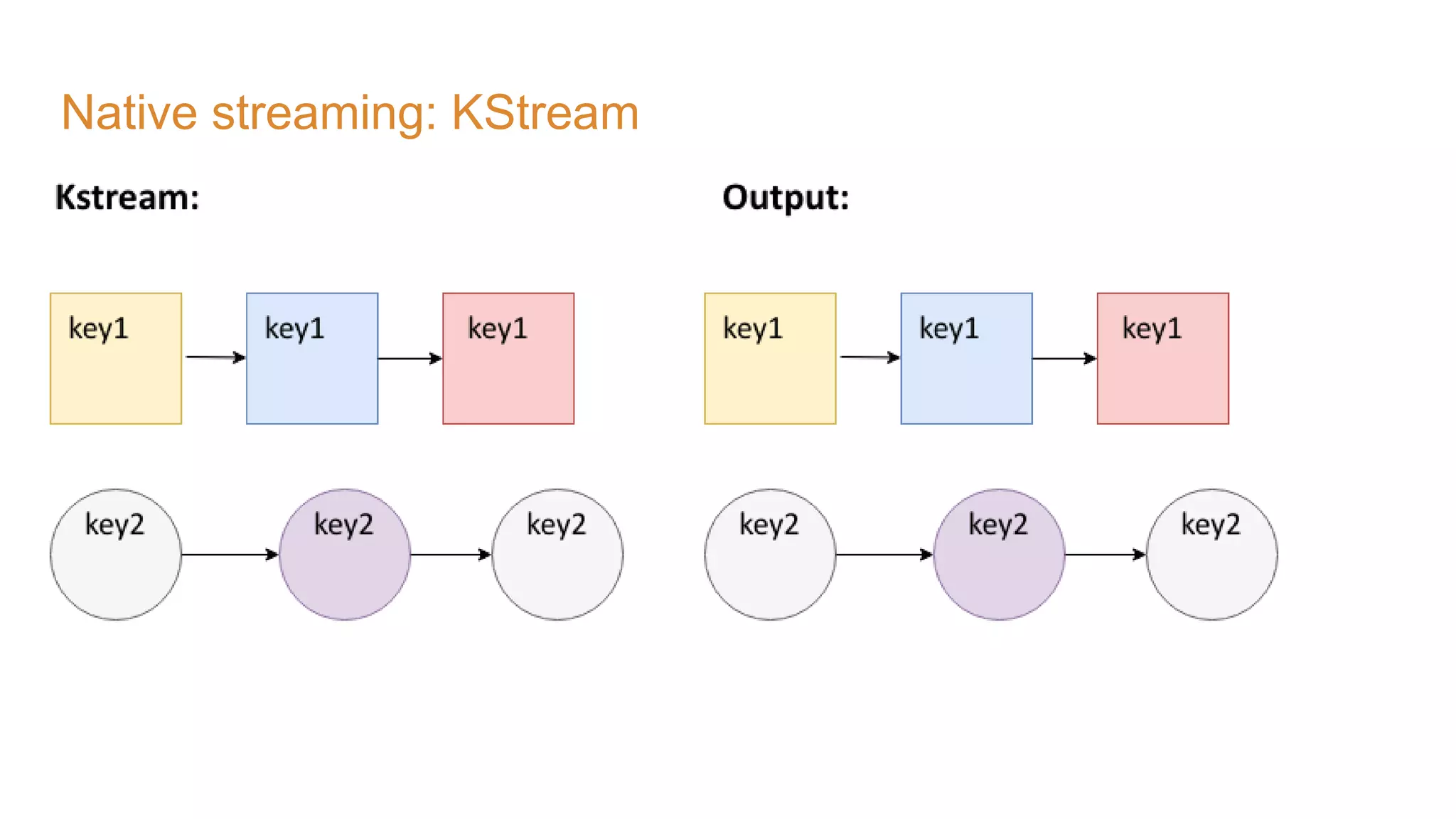
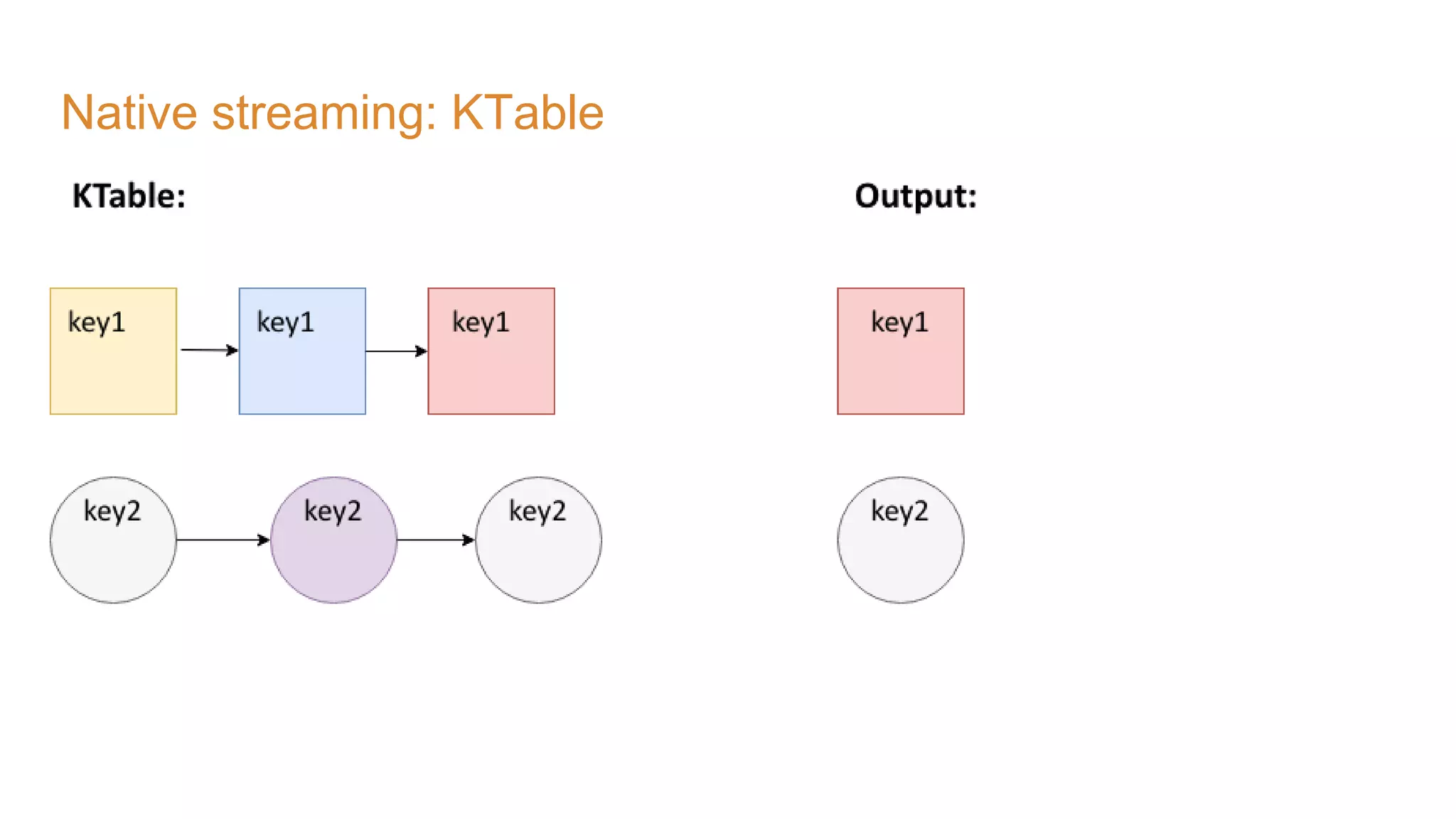
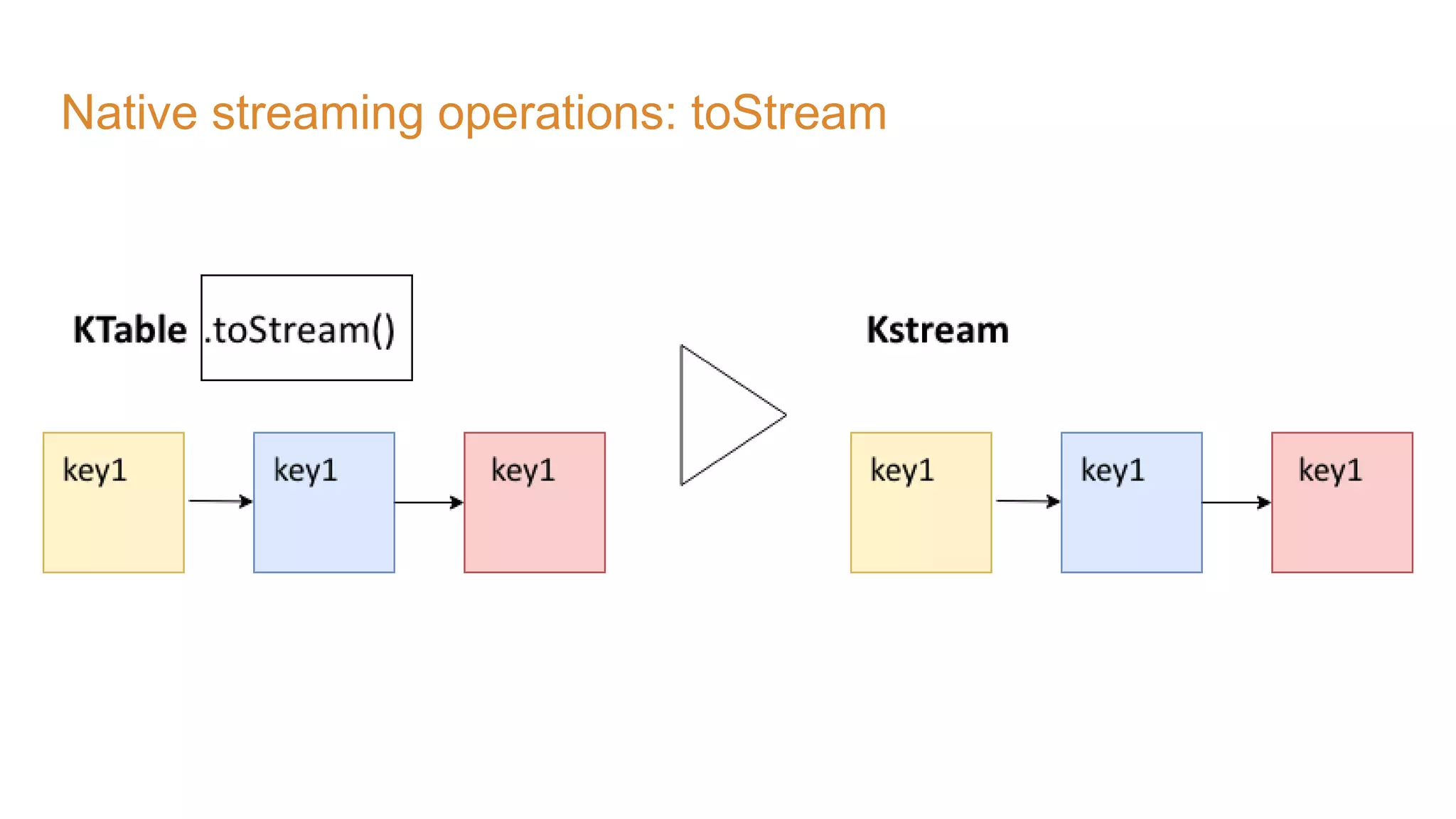
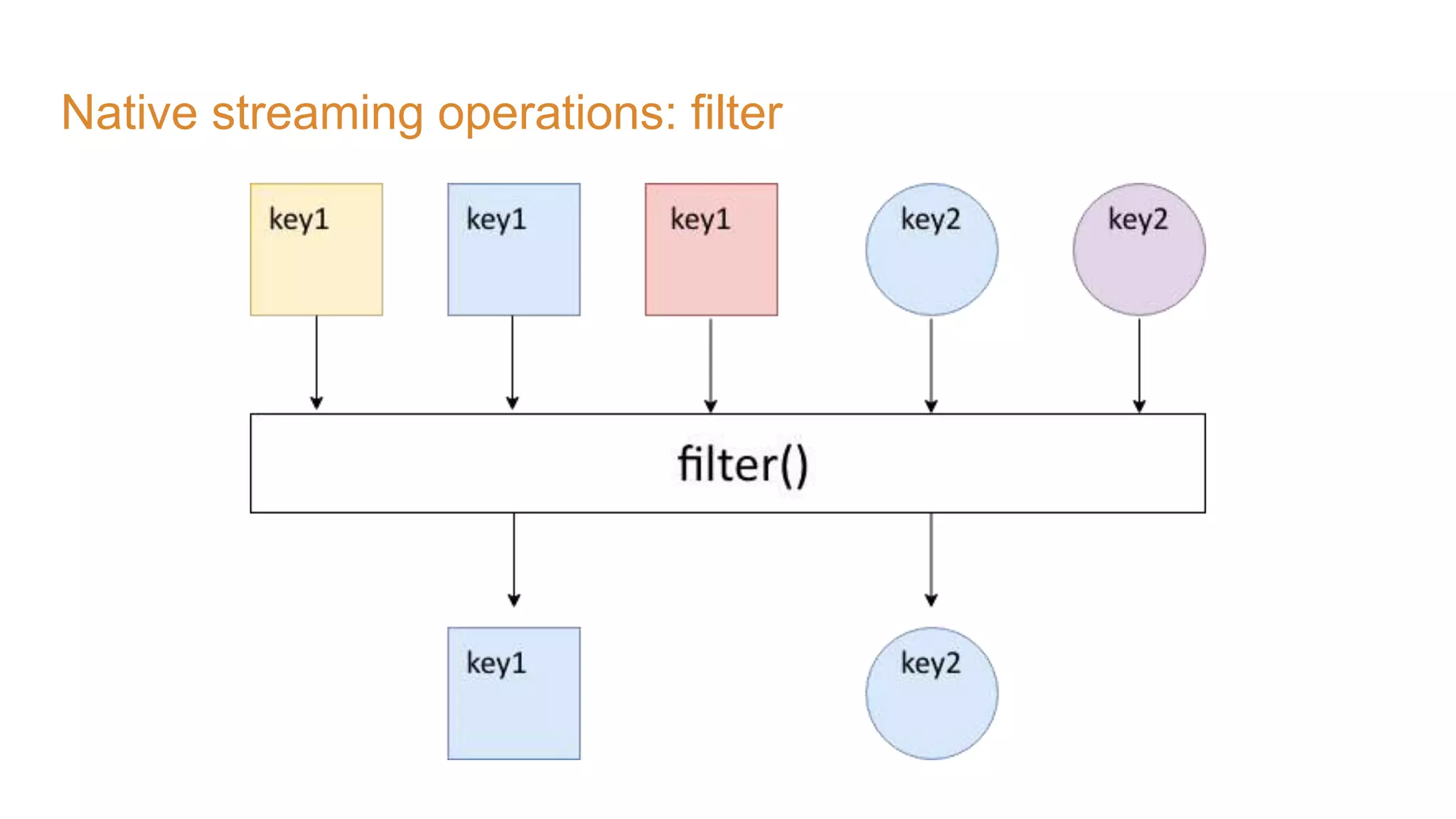
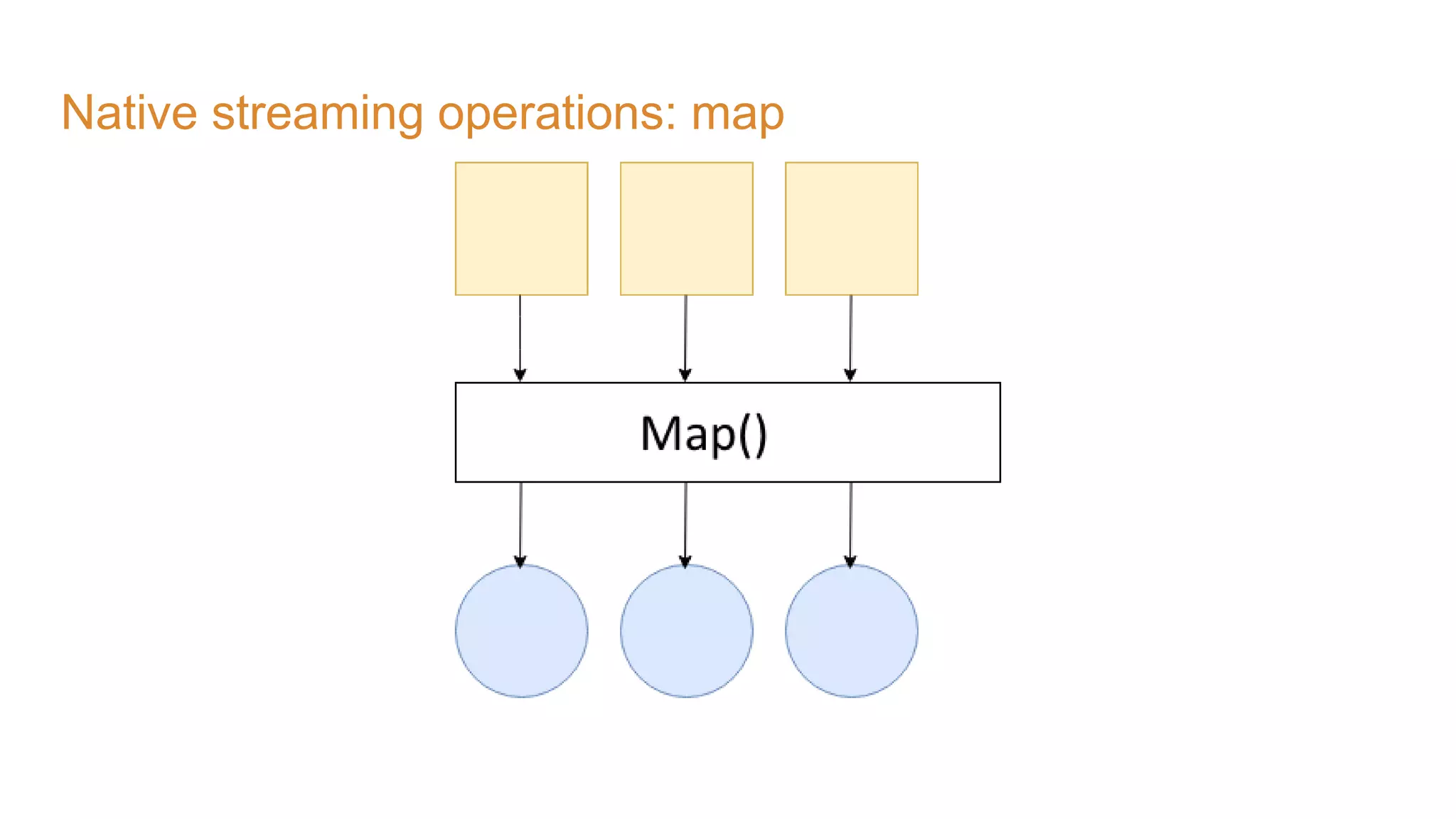
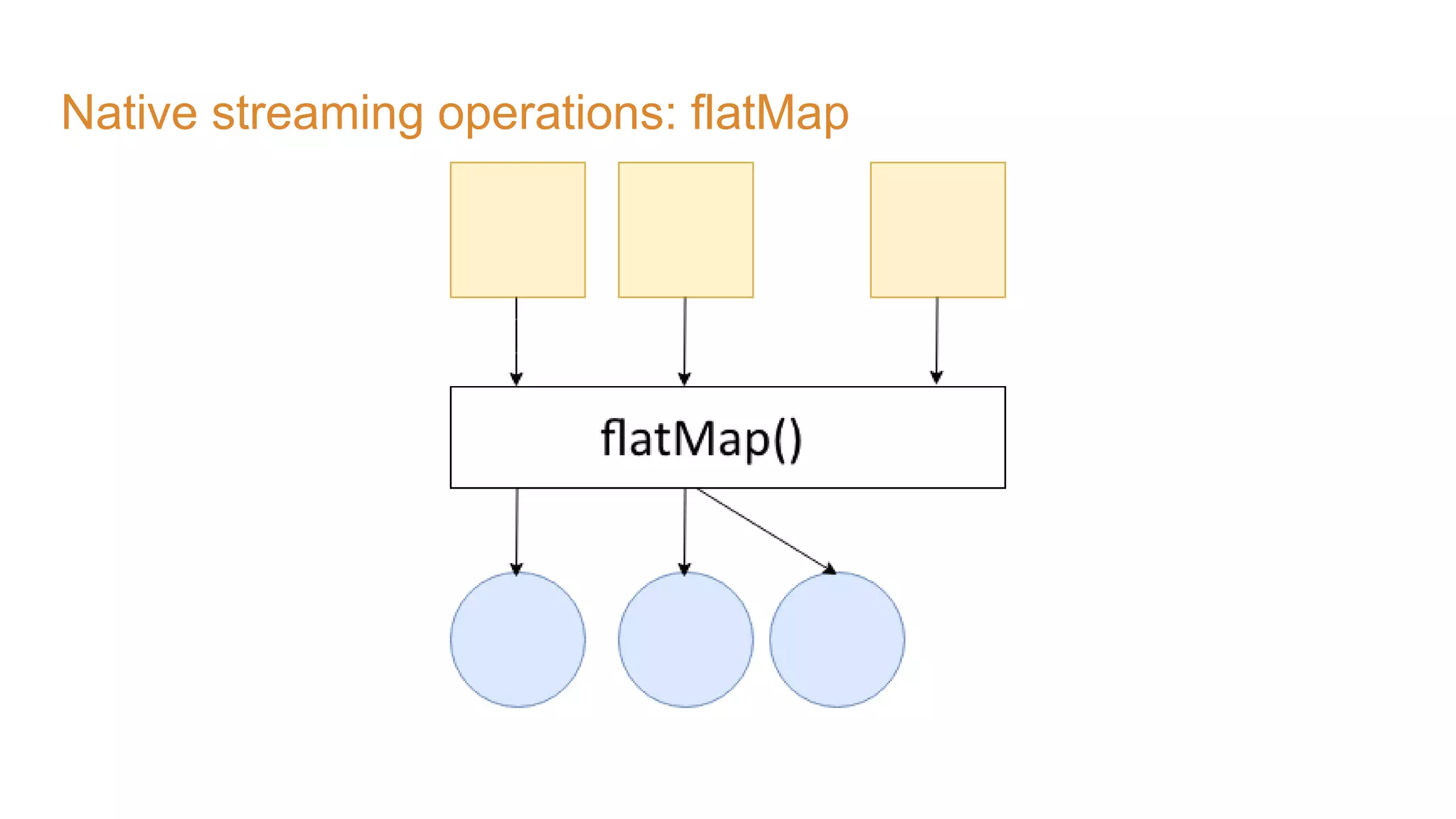
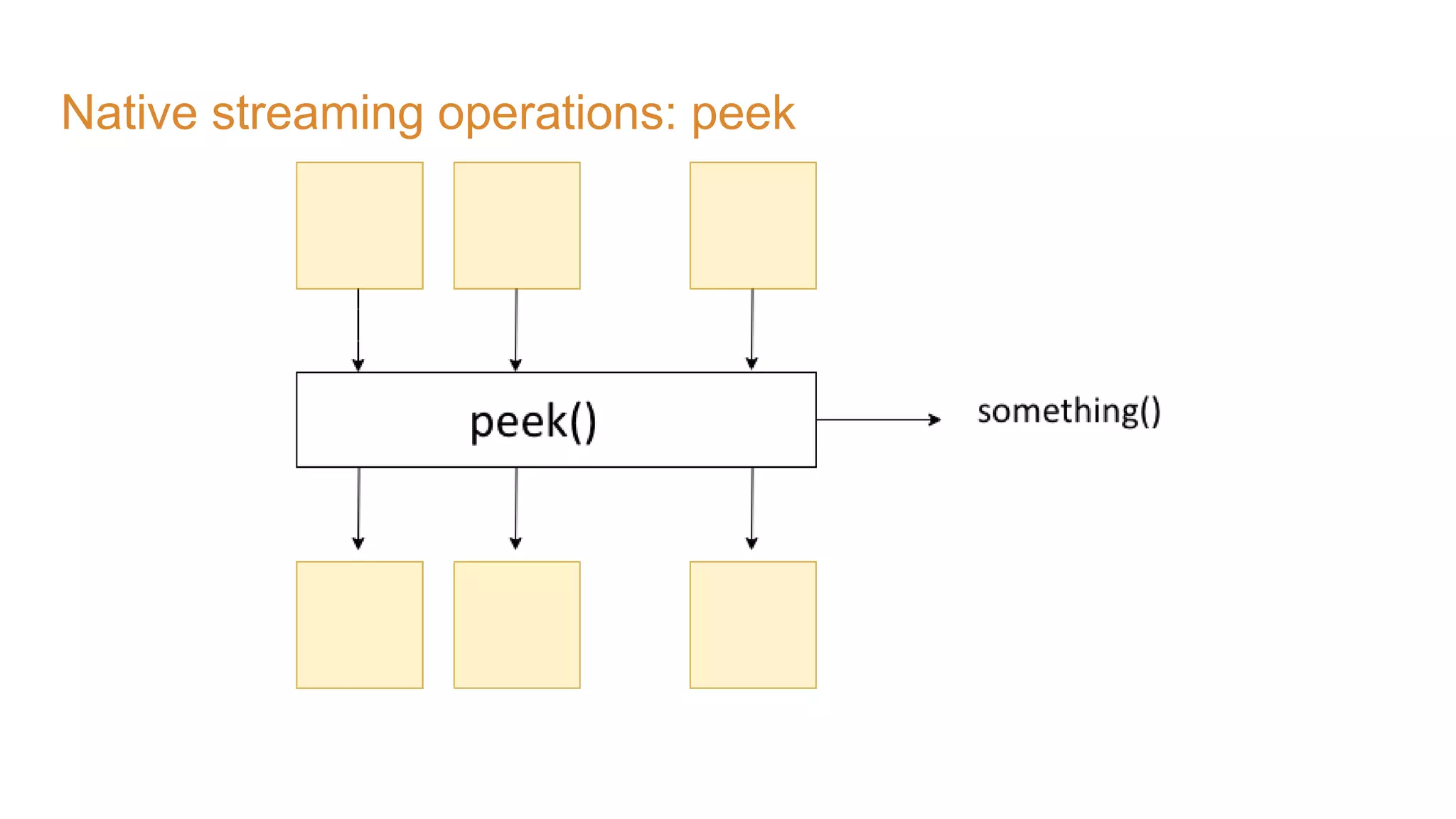
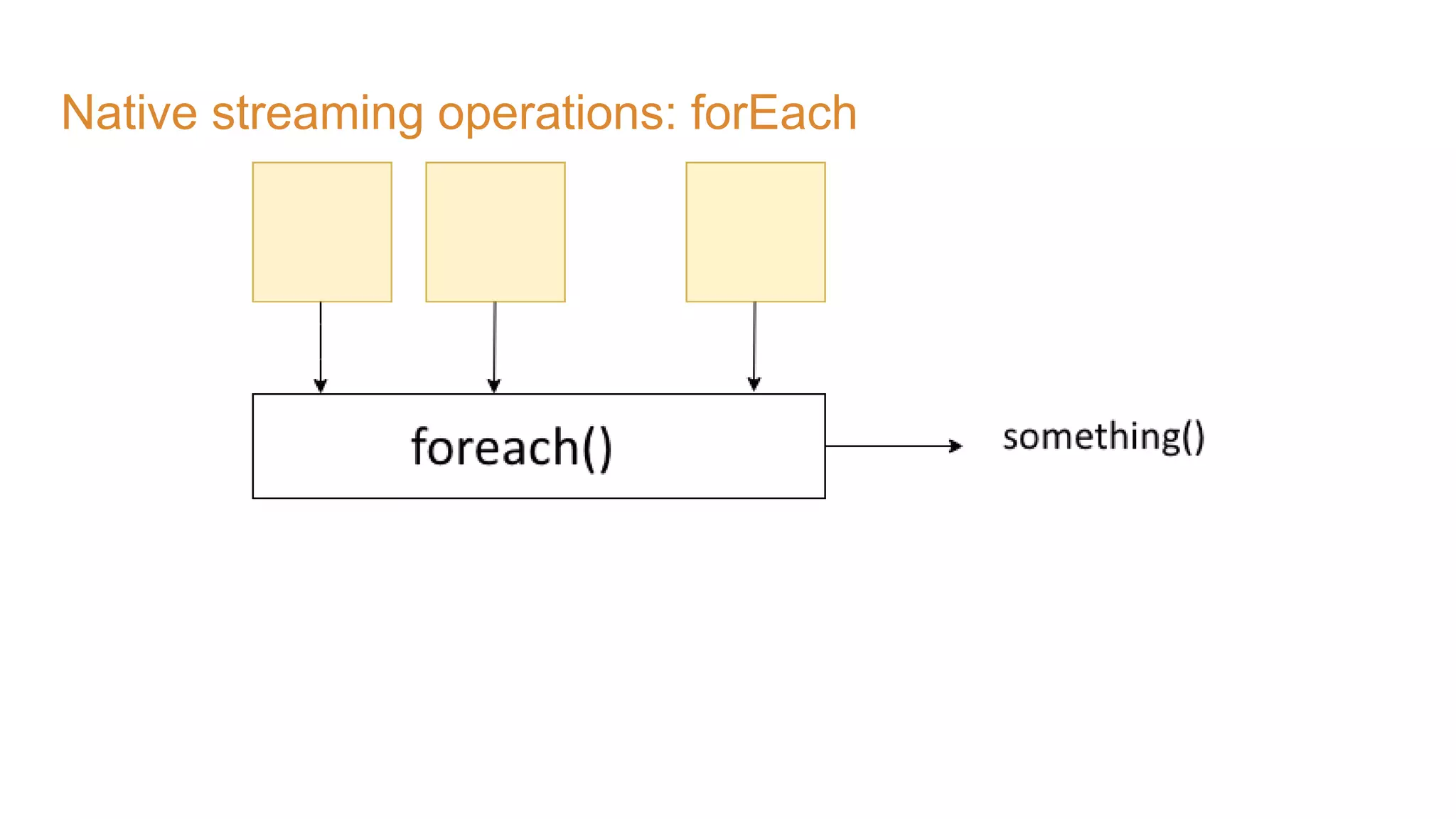
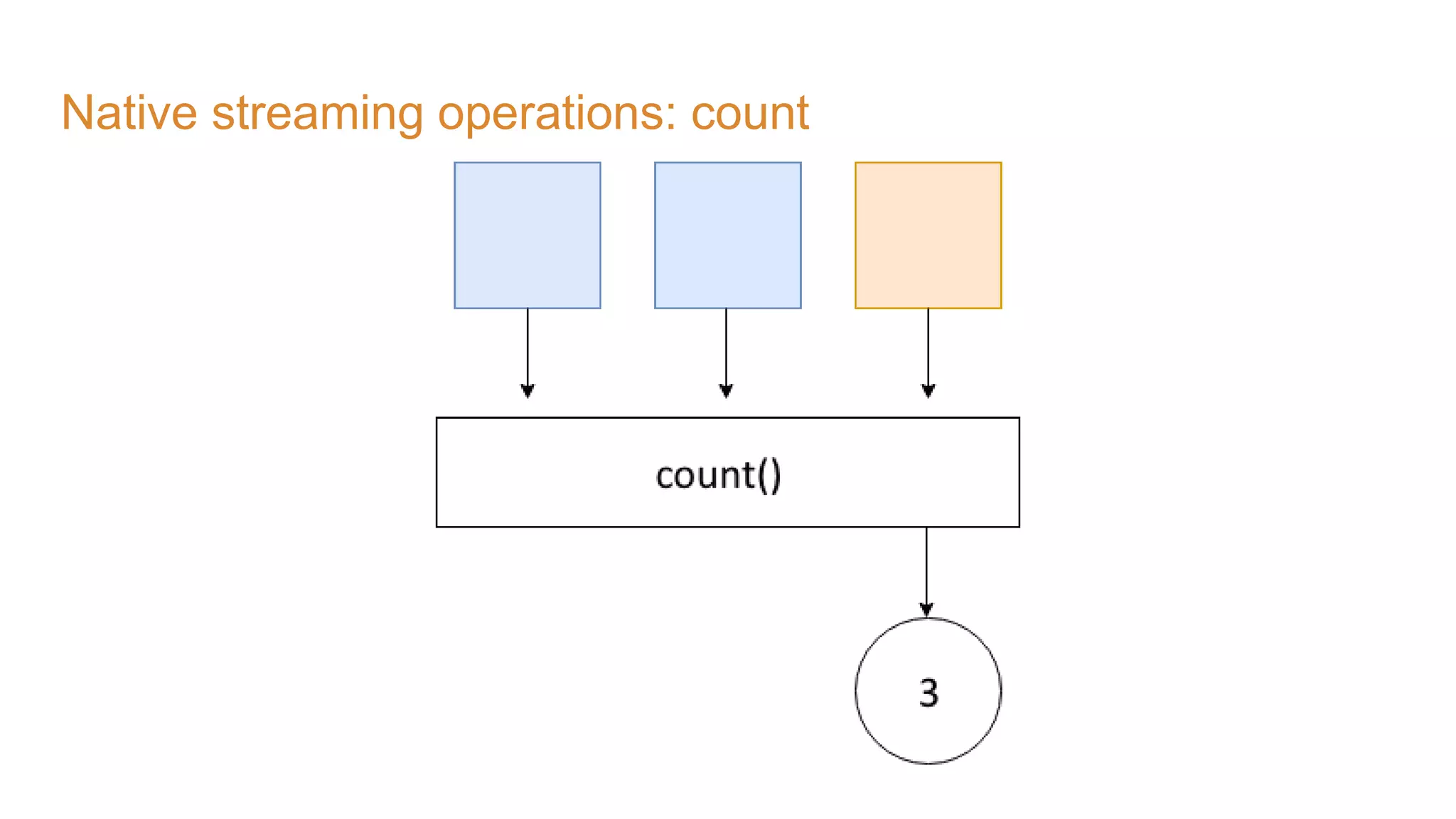
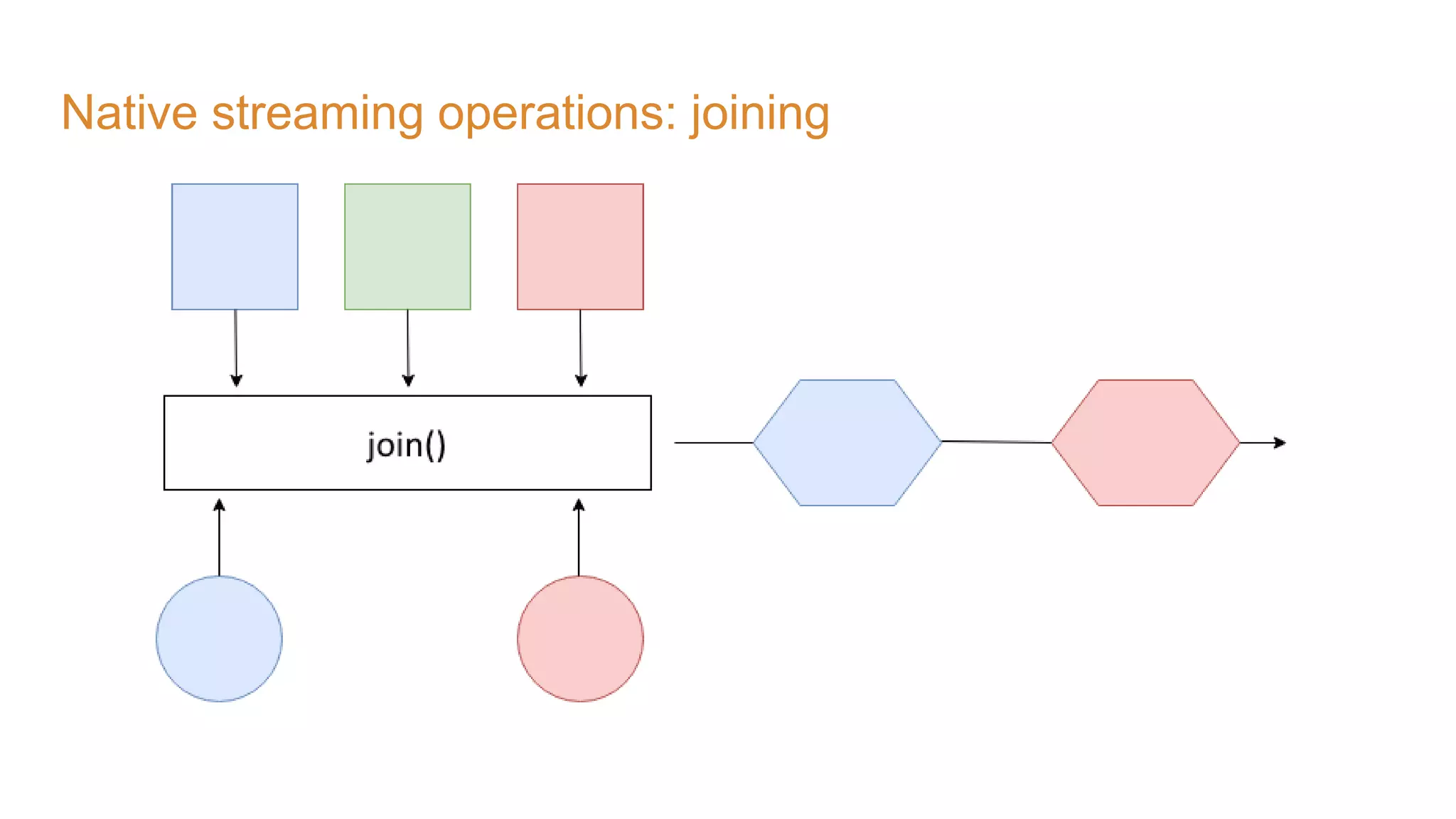
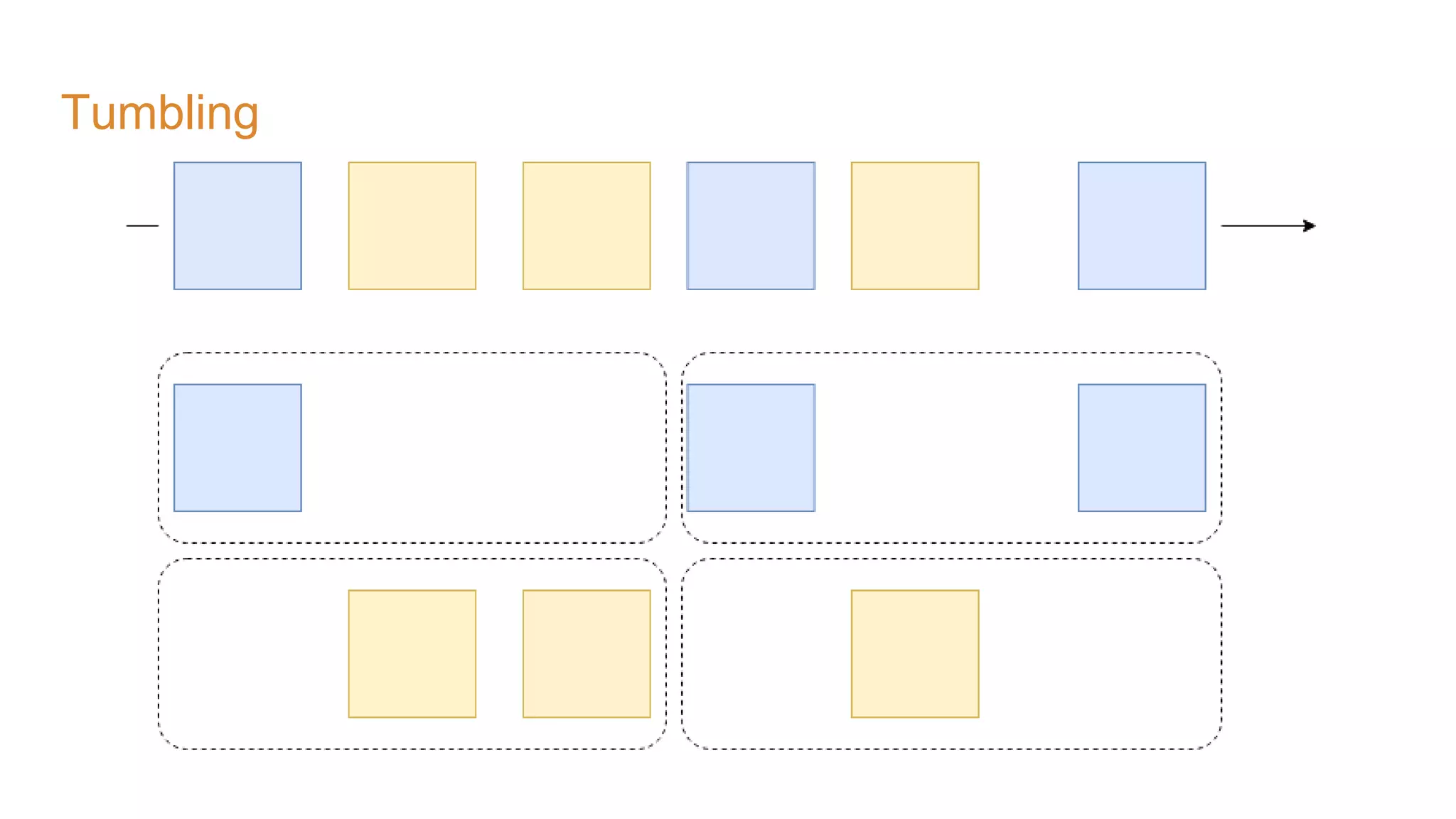
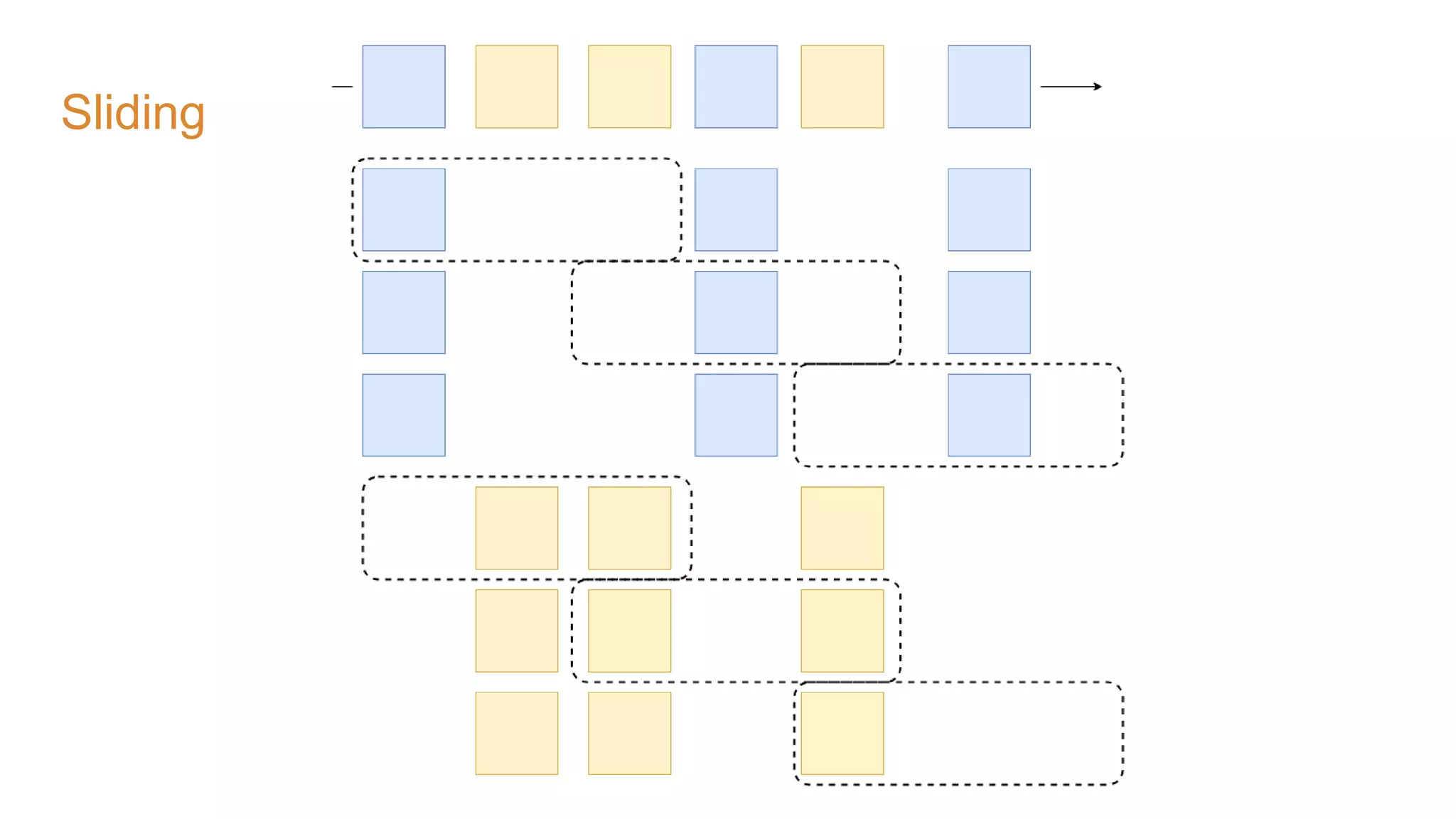
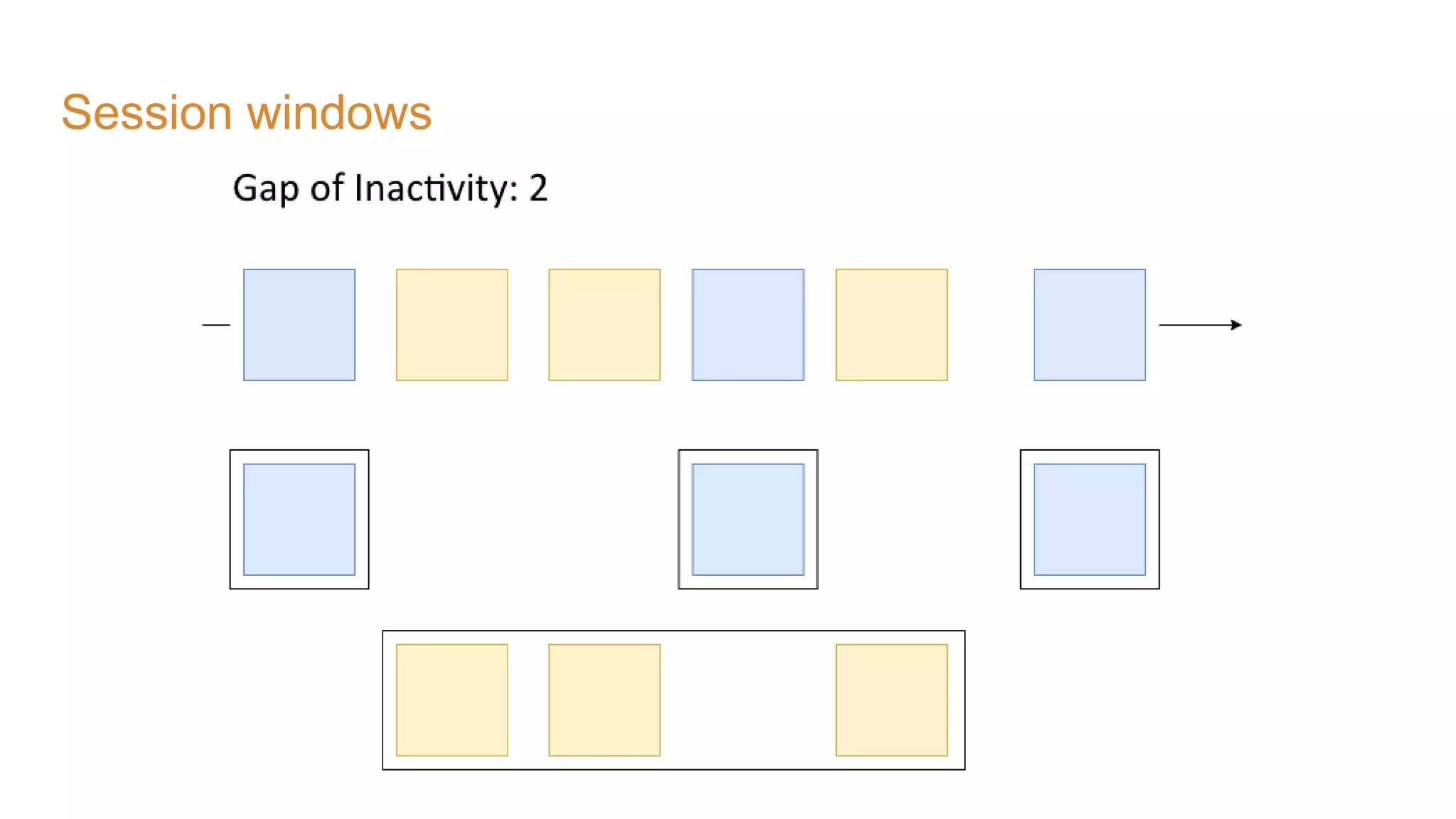
The document covers the setup and processing of live traffic data using Kafka Streams, focusing on event-driven architecture and the benefits of stream processing. It details the structure of traffic data in XML format, along with examples and lessons learned during the implementation process. Additionally, it outlines various labs demonstrating the integration of Kafka with Spring Cloud Stream and highlights different streaming operations, including stateless and stateful methods.