





















The document covers a webinar led by Chris Lavery, a Senior Site Reliability Engineer at Weaveworks, discussing GitOps and Site Reliability Engineering (SRE). It highlights the importance of data-driven decisions, service level indicators (SLIs), service level objectives (SLOs), and the role of progressive delivery in managing deployment risks. The presentation emphasizes balancing feature availability with deployment velocity to enhance both operational efficiency and service reliability.
Introduction of Chris Lavery, Senior Site Reliability Engineer at Weaveworks. Overview of Weaveworks and GitOps methodology.
Definition and significance of SRE in modern development and operations, the shift towards cloud and digital services.
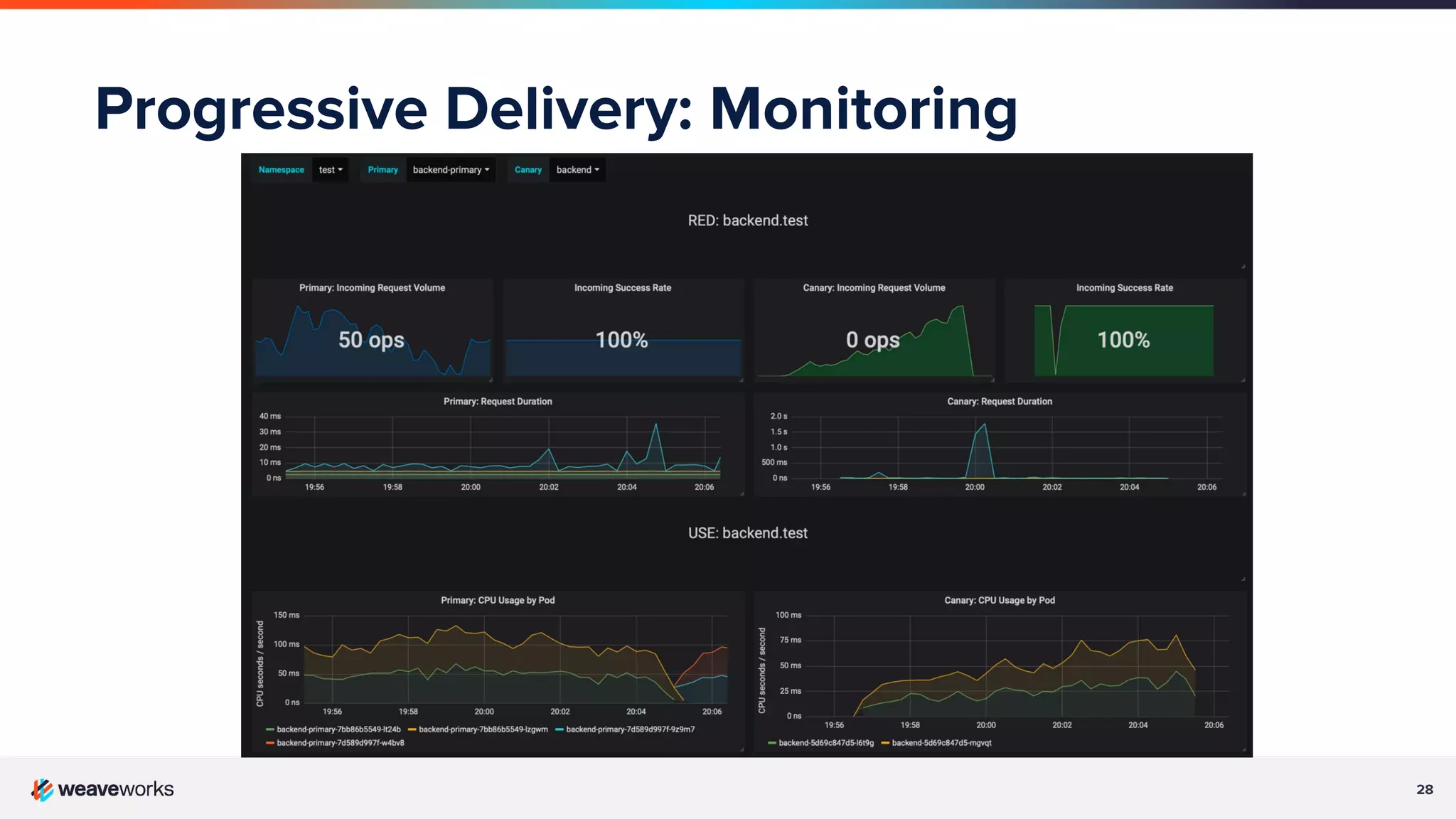
The importance of observability in modern distributed systems through metrics, logging, and APM.
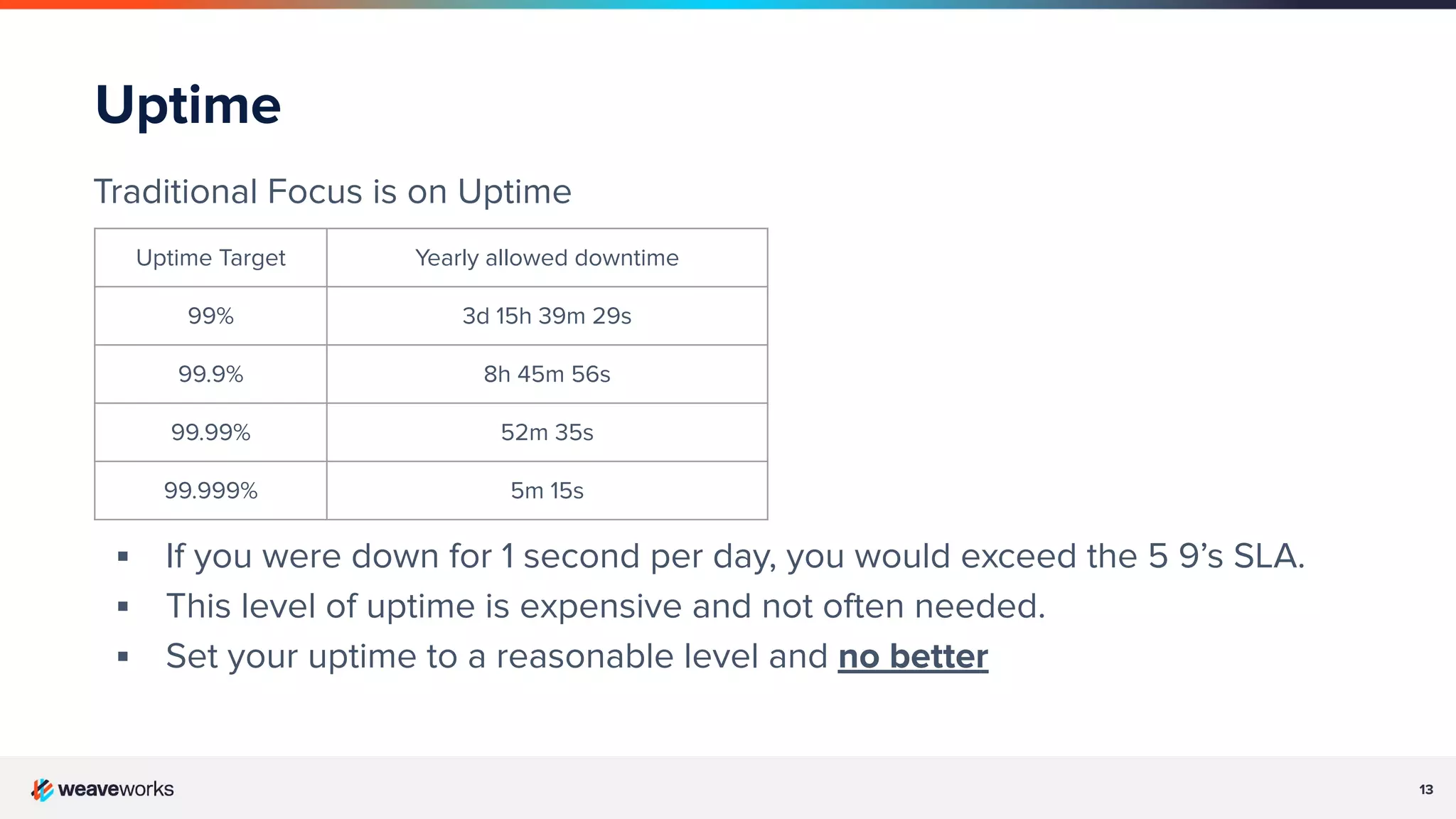
Definitions and differences between SLIs, SLOs, and SLAs. Discussion on setting realistic uptime goals and error budgets.
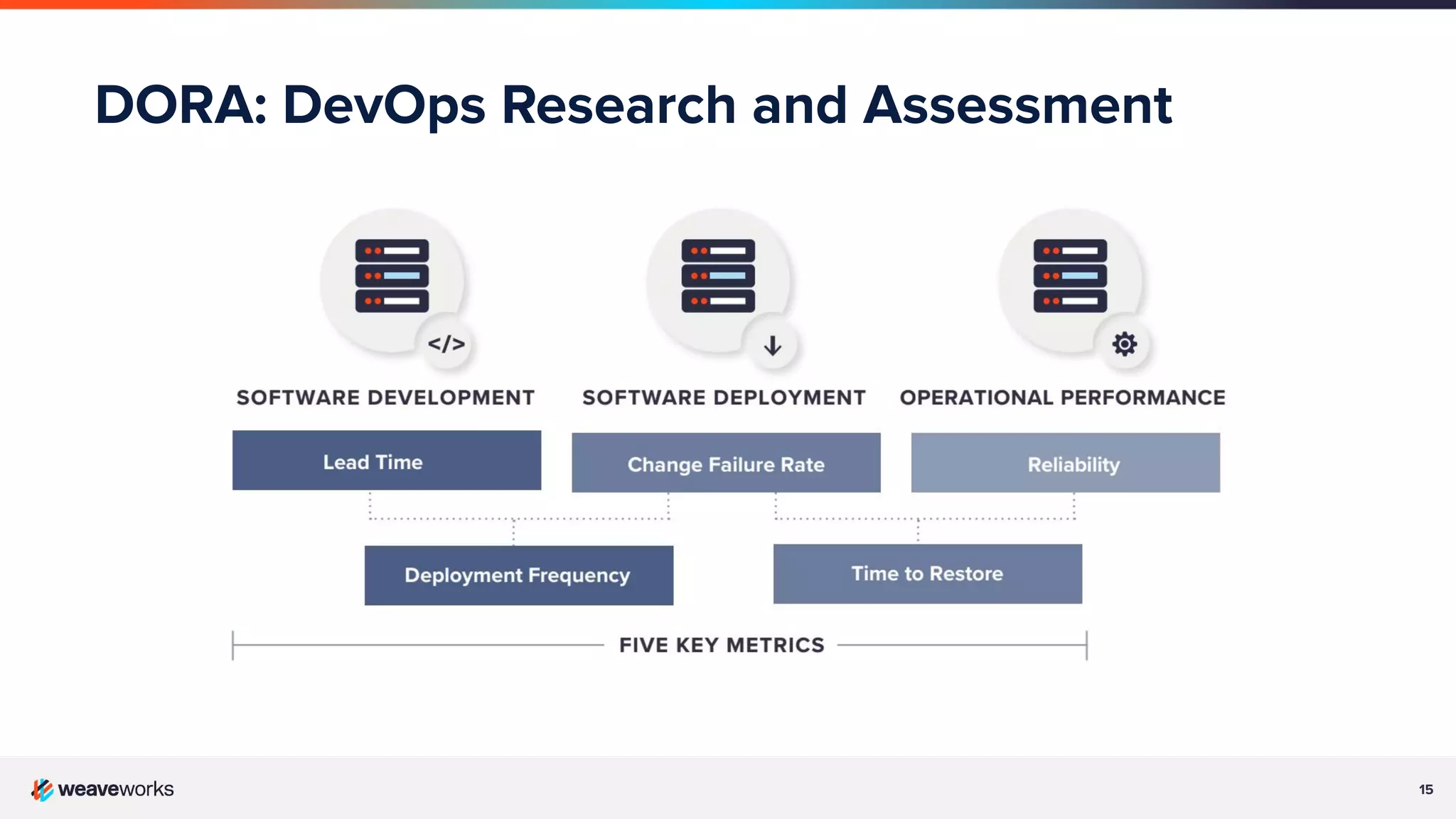
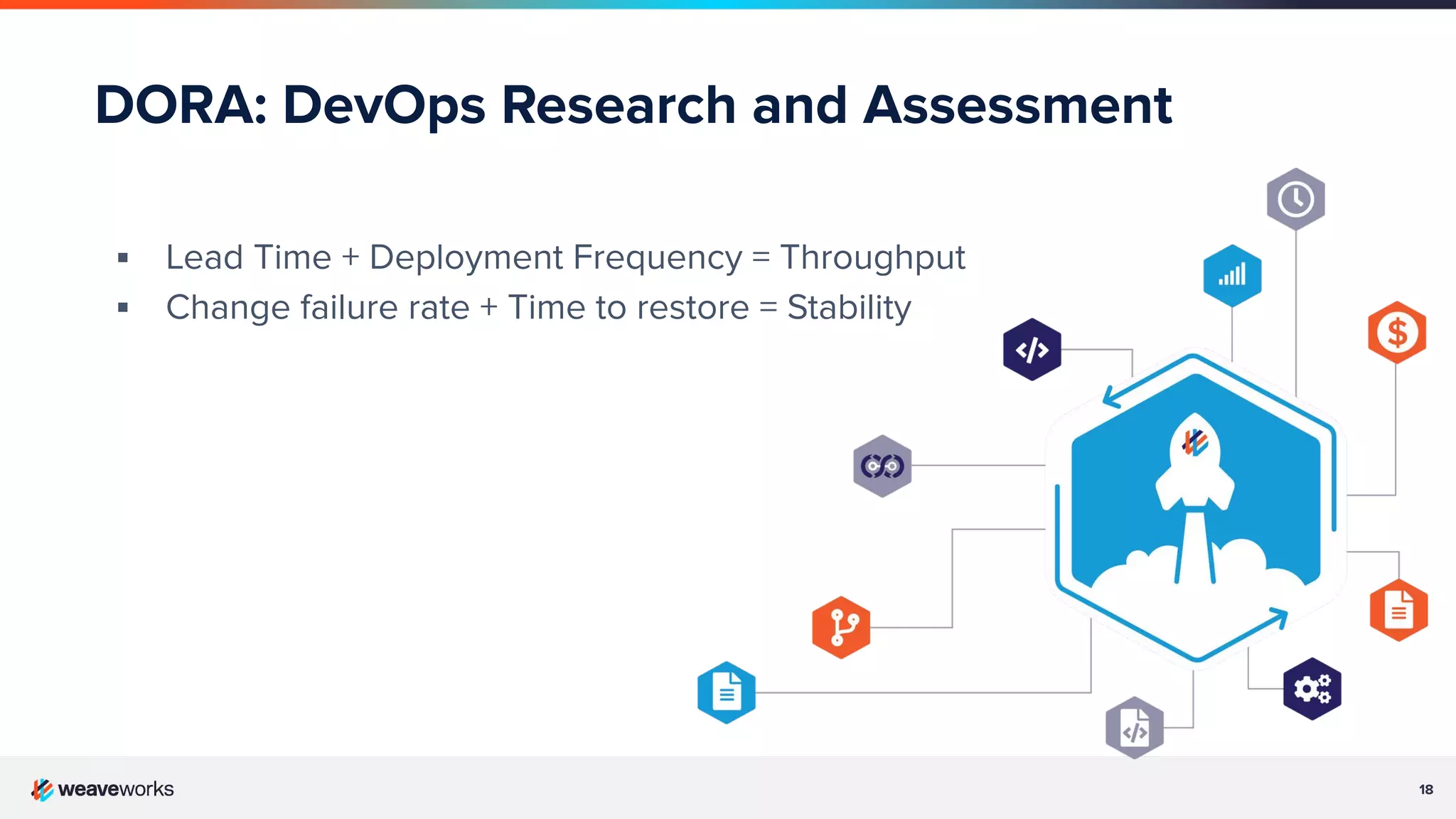
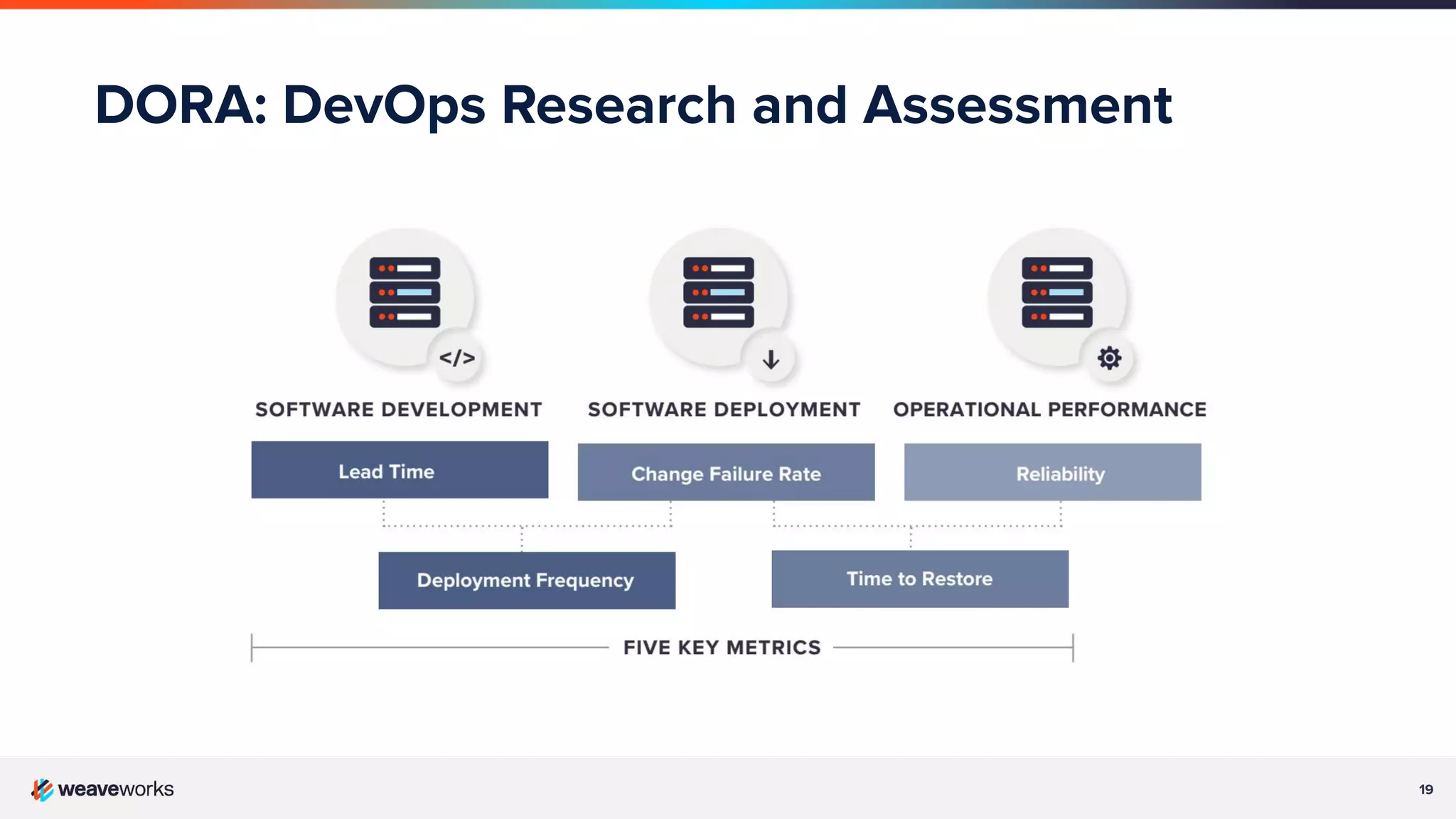
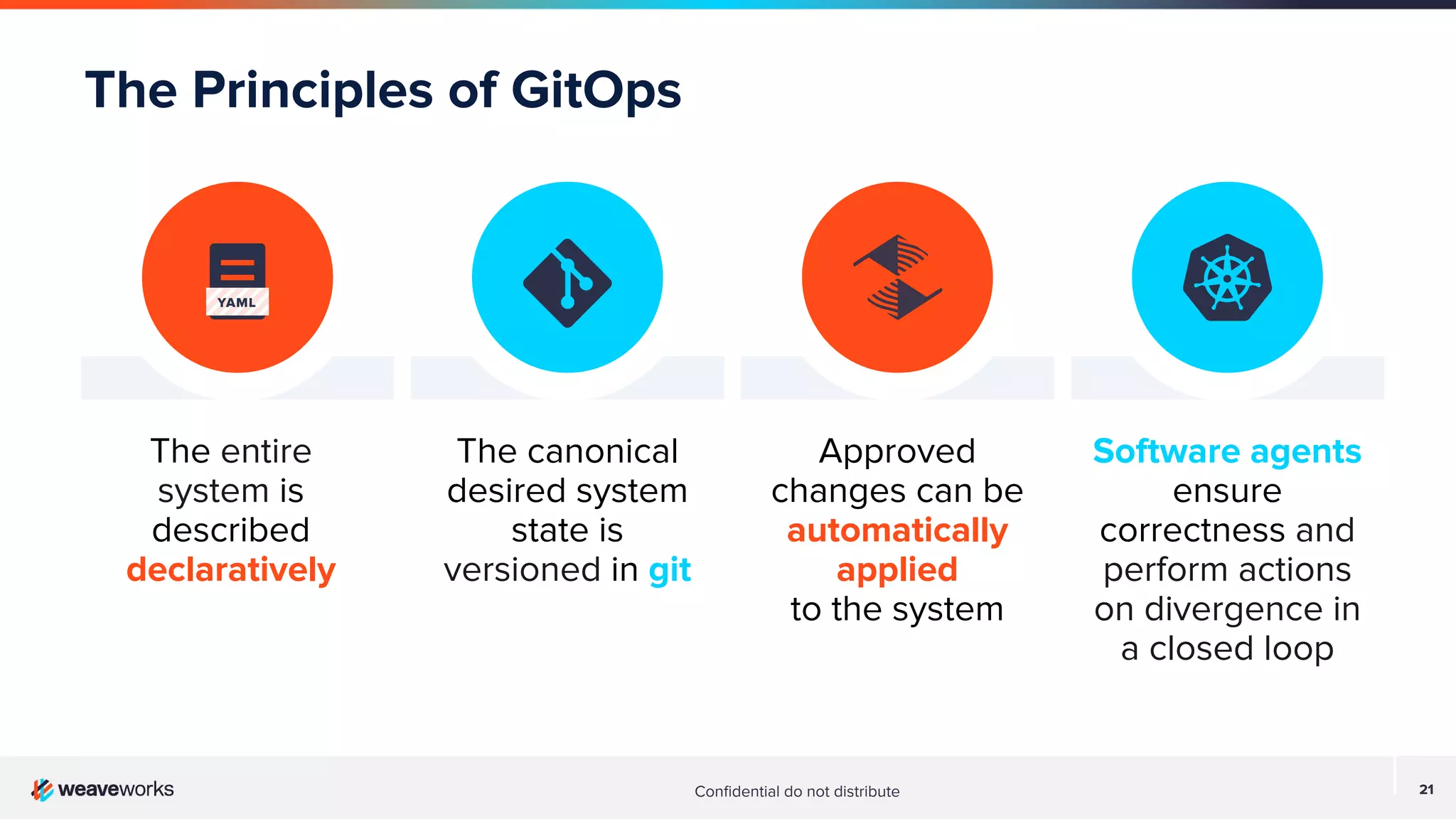
Overview of DevOps Research Assessment metrics focusing on lead time, deployment frequency, and stability metrics.Key principles of GitOps: declarative system states, version control in Git, and automated applications of changes.
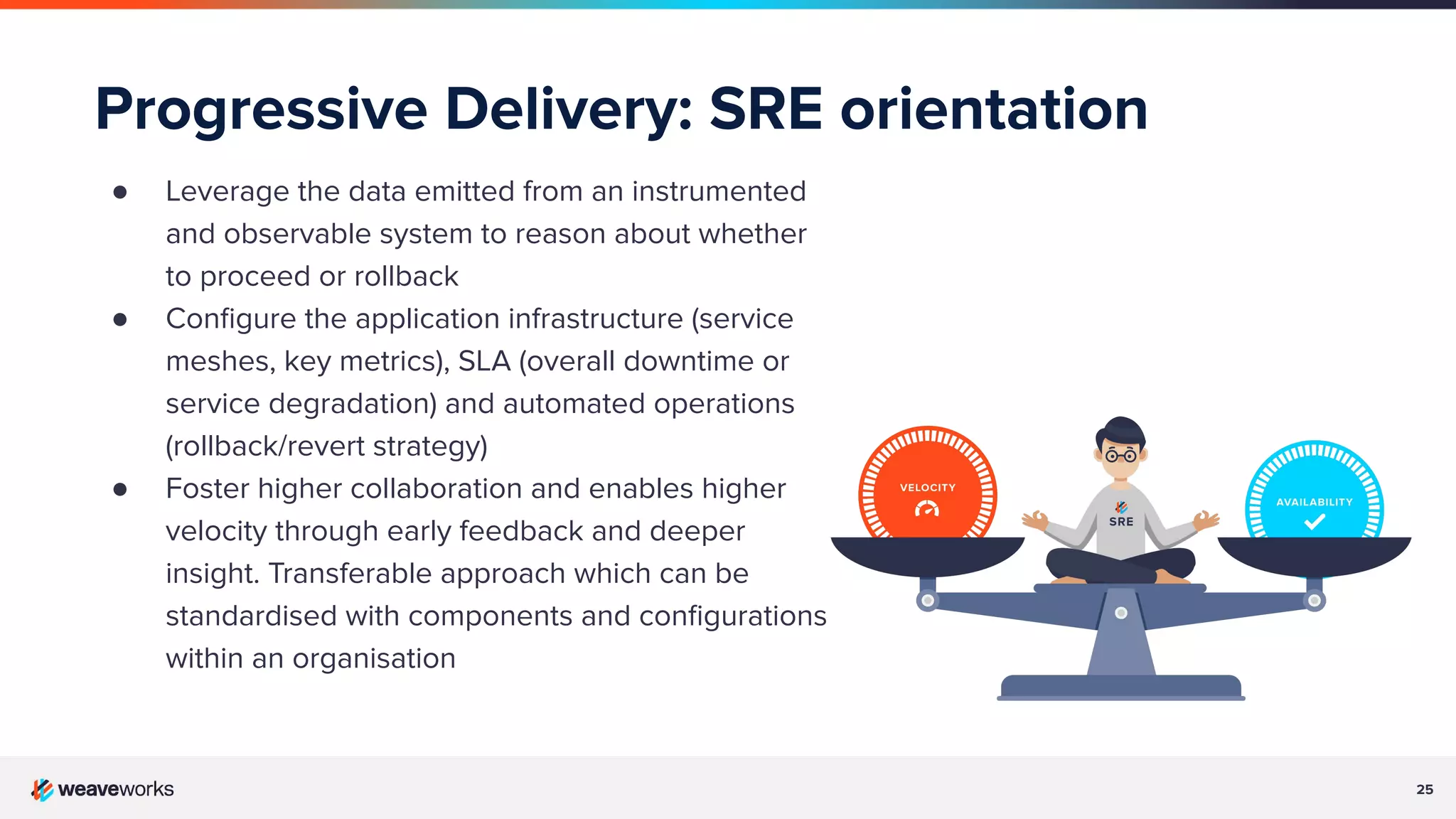
Importance of managing risk in availability and feature velocity, contrasting traditional systems with SRE principles.
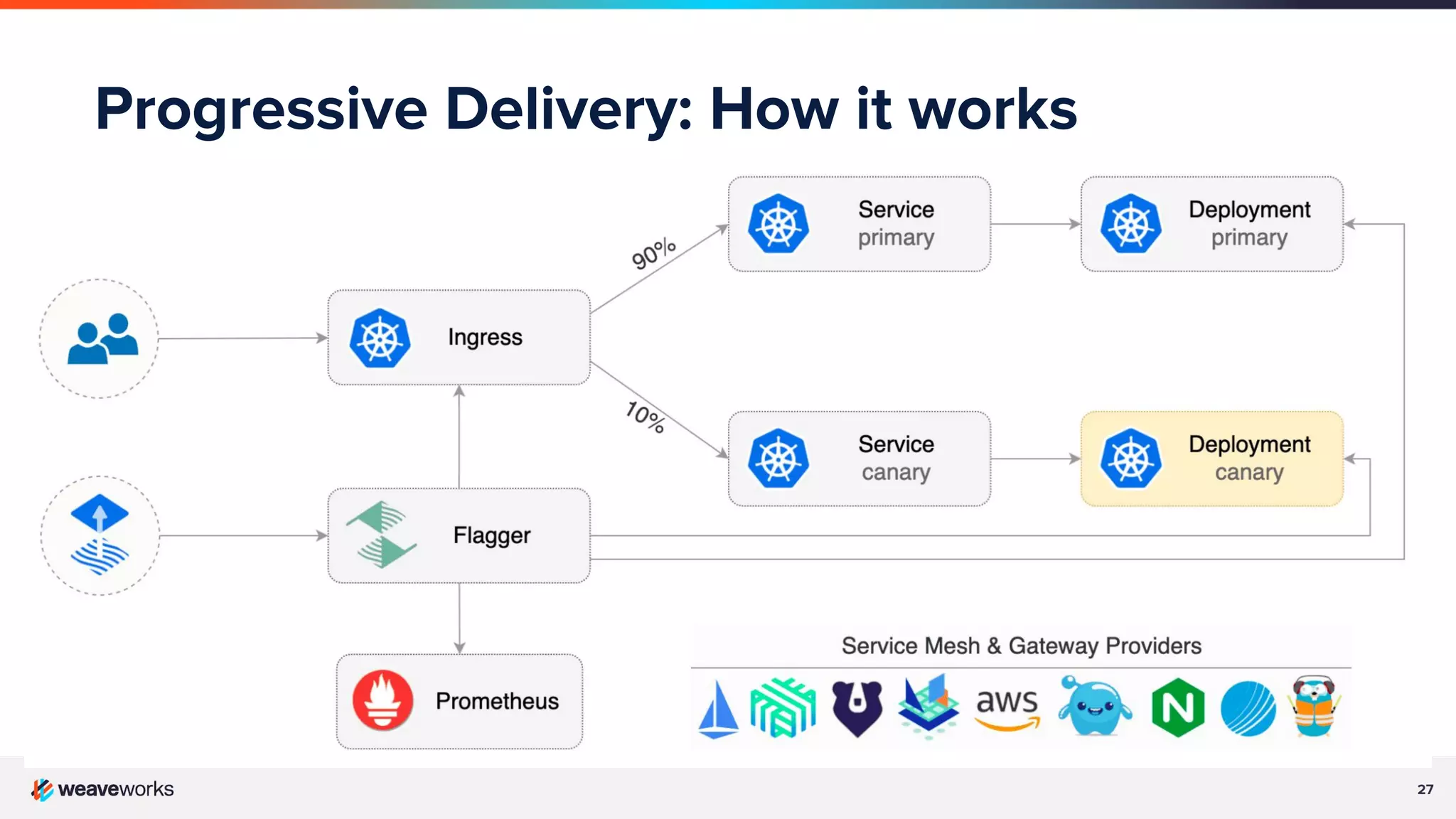
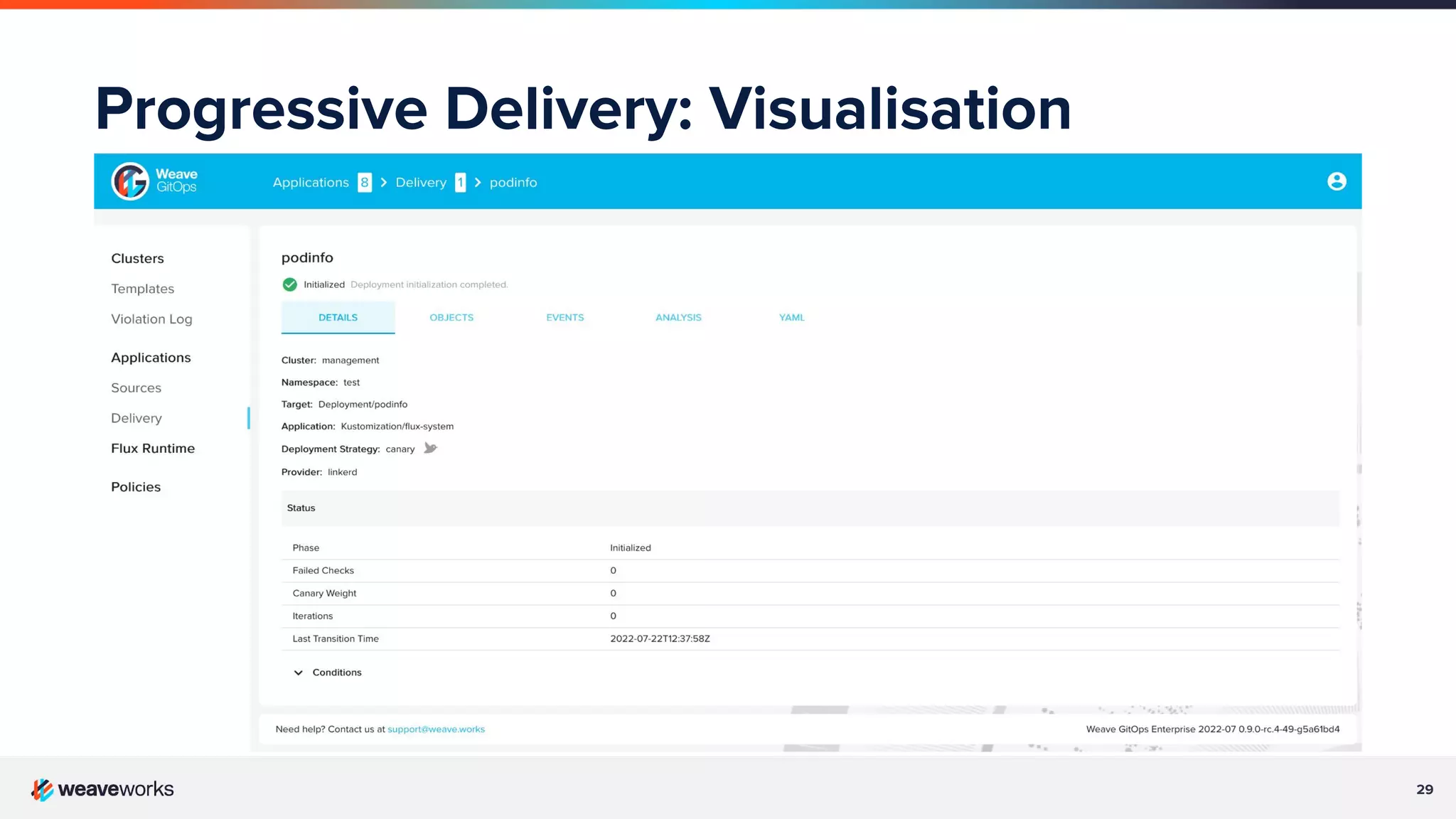
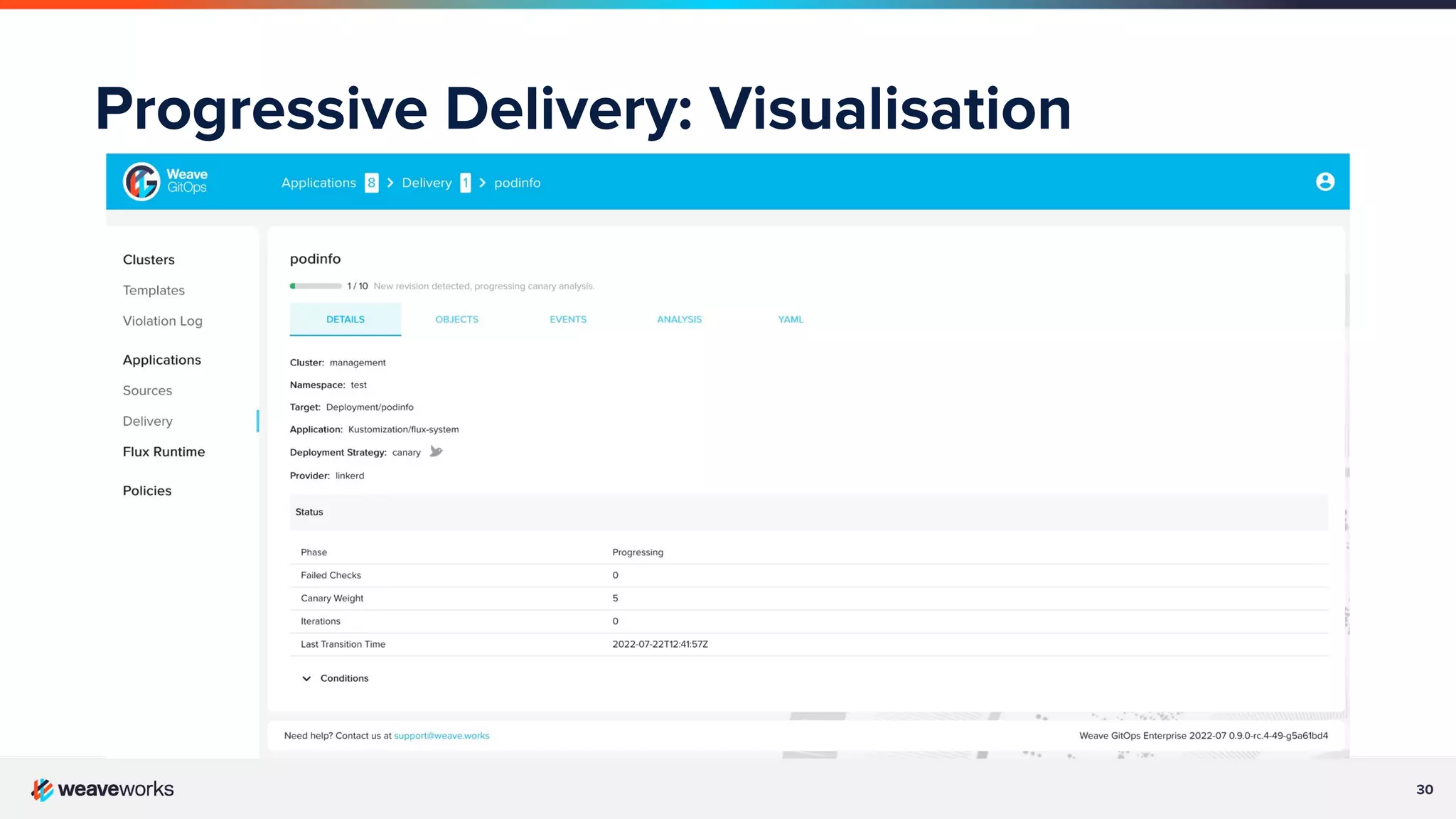
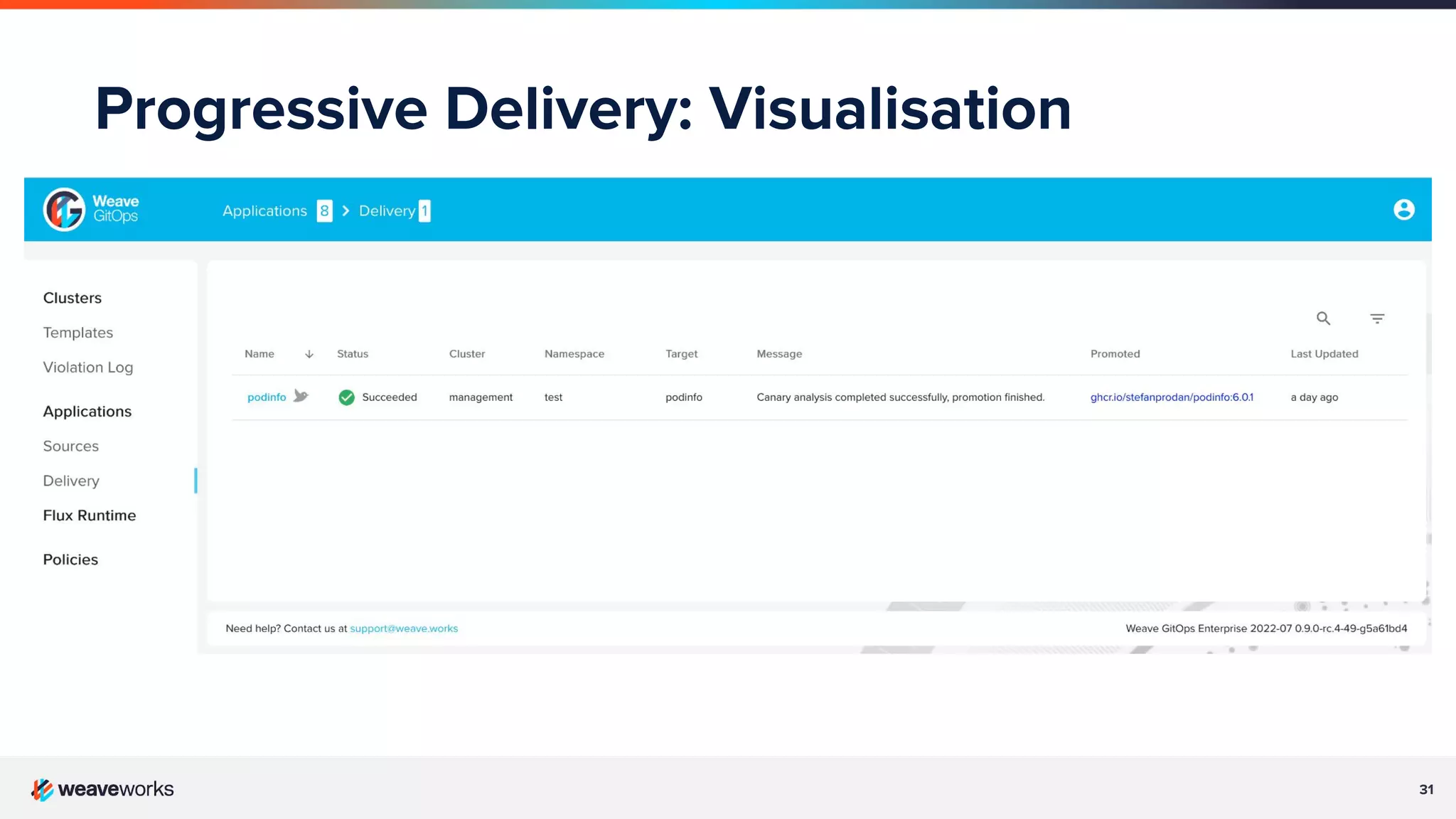
Description of progressive delivery, its implementation strategies (A/B testing, canary), and benefits.
Benefits shown from GitOps & Progressive Delivery: increased deployment frequency, shorter lead times, and recovery.
Advantages and disadvantages of various deployment strategies including Rolling, Canary, Blue/Green, and Feature Flags.