Downloaded 11 times



















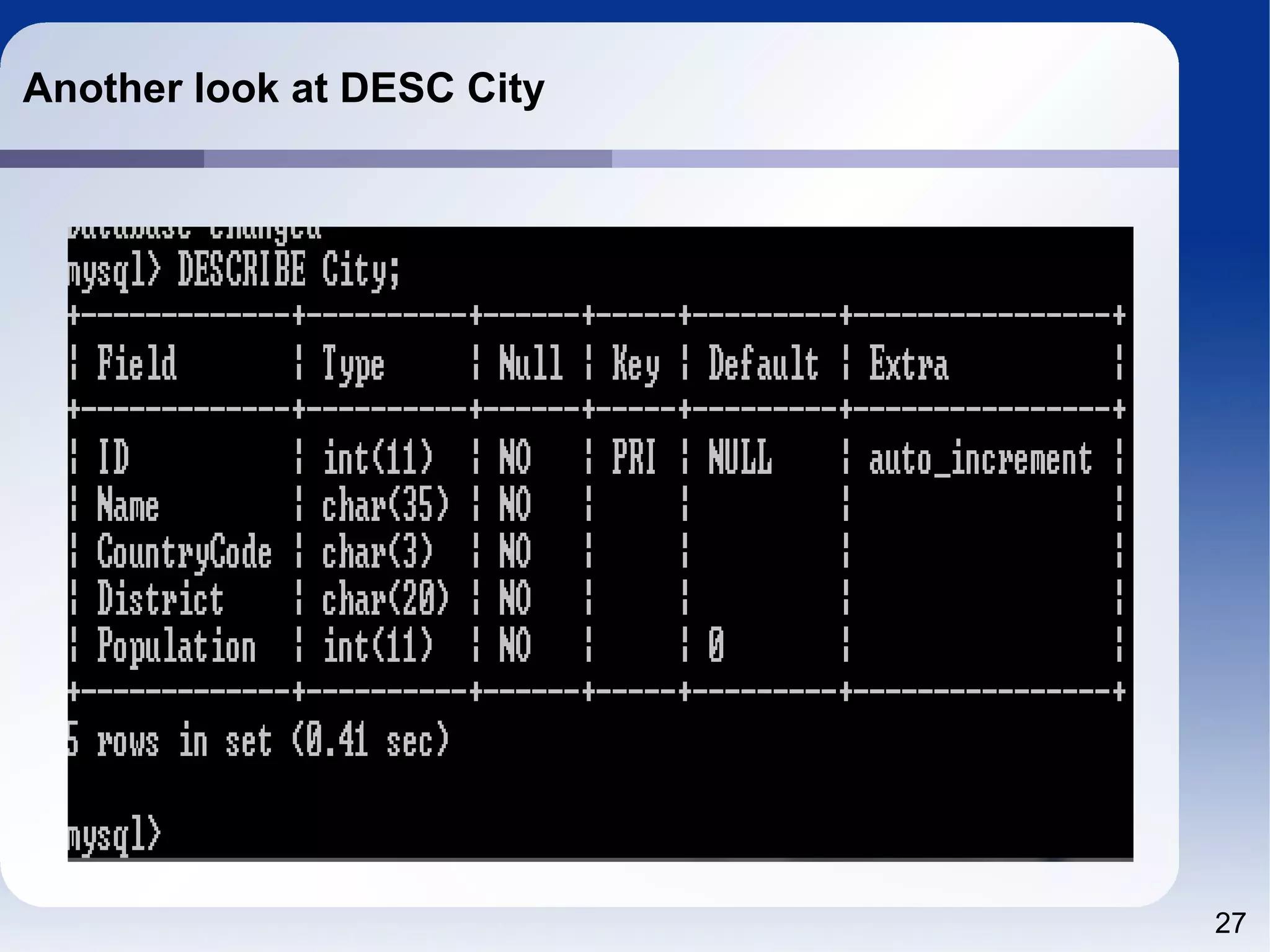
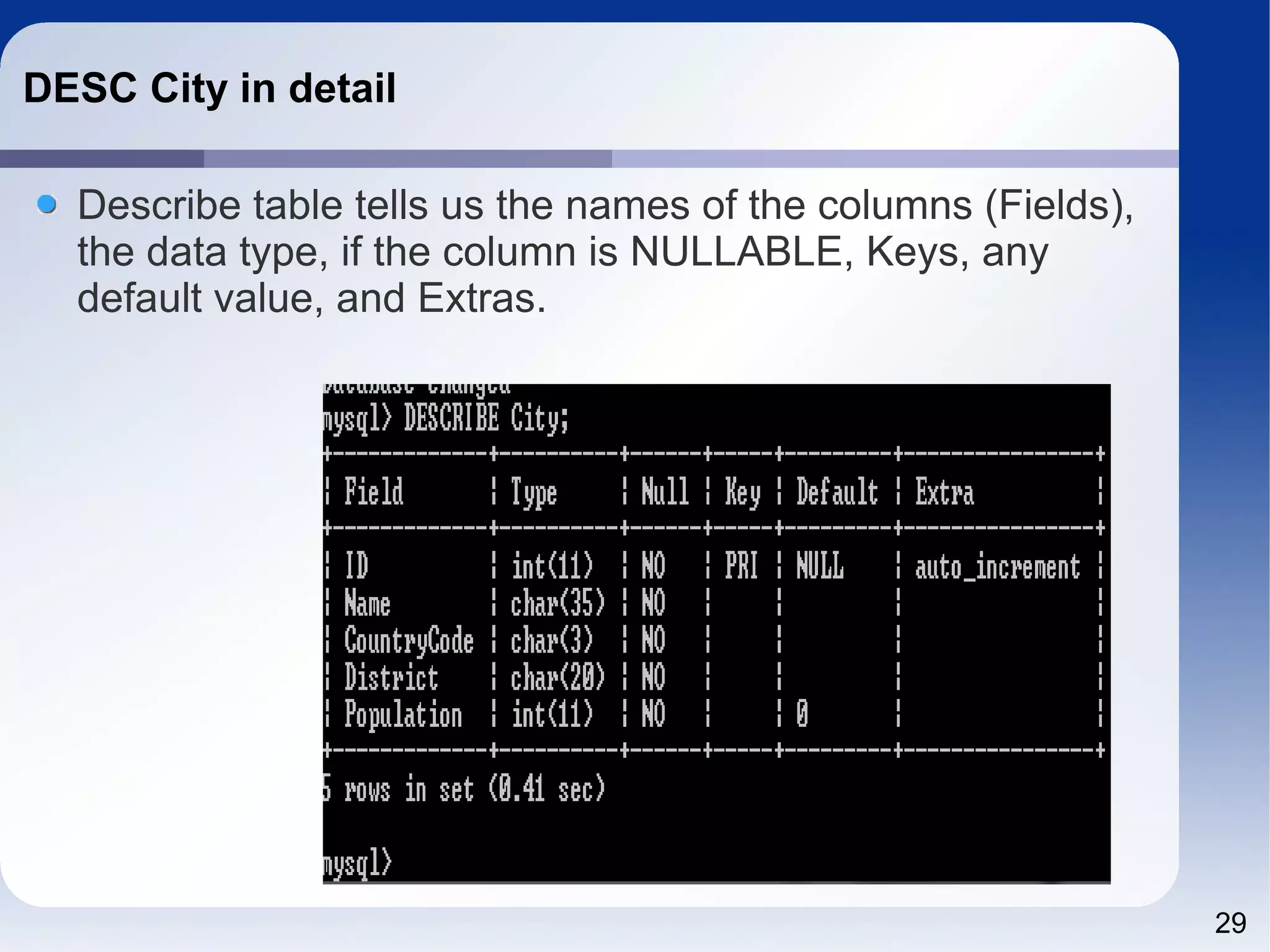
![25 DDL Useful commands – DESC[ribe] table – SHOW CREATE TABLE table –](https://image.slidesharecdn.com/sql4php-141202131544-conversion-gate02/75/SQL-For-PHP-Programmers-25-2048.jpg)


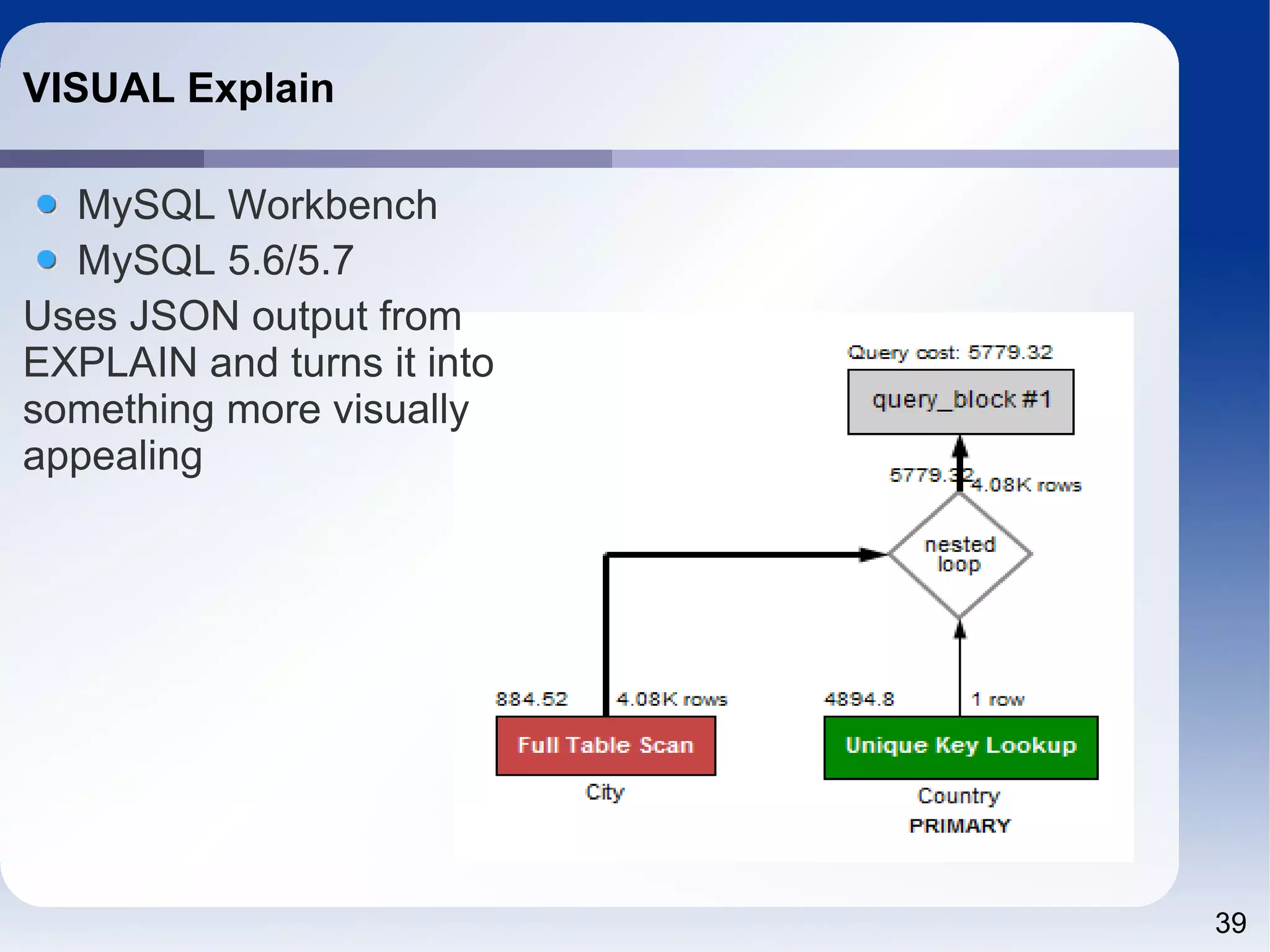
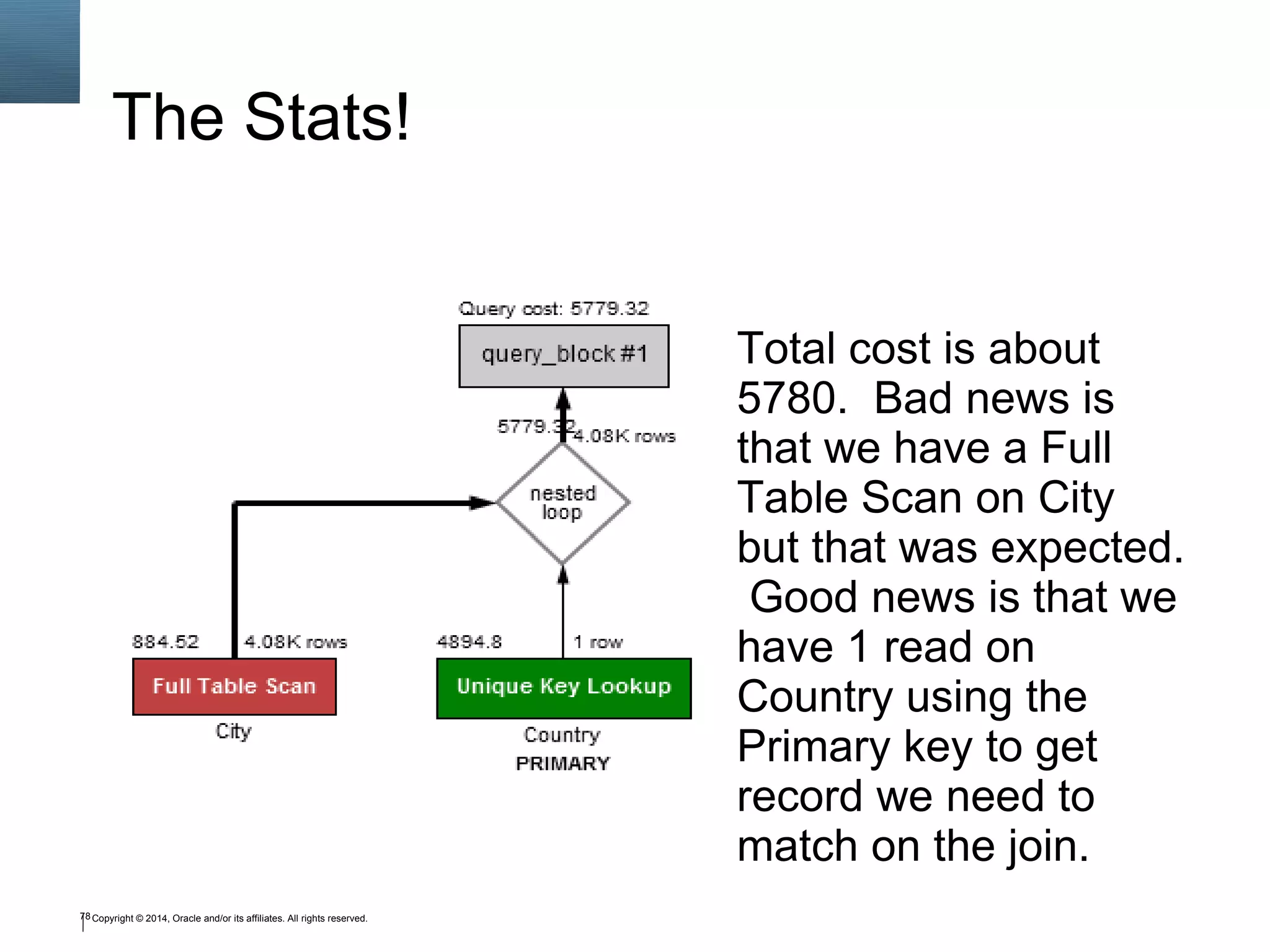
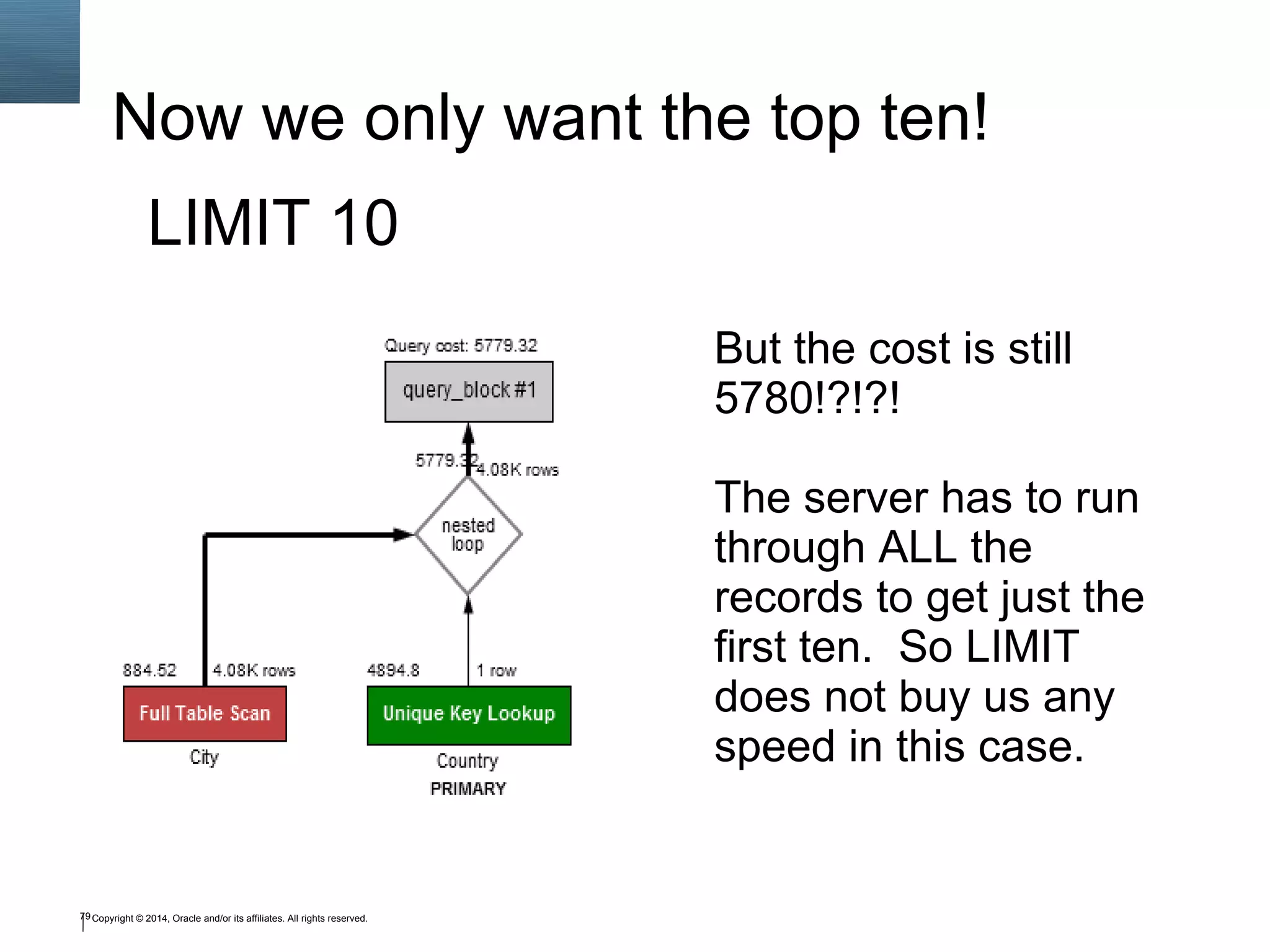
![40 Optimizer Trace { "query_block": { "select_id": 1, "cost_info": { "query_cost": "5779.32" }, "nested_loop": [ { "table": { "table_name": "City", "access_type": "ALL", "rows_examined_per_scan": 4079, "rows_produced_per_join": 4079, "filtered": 100, "cost_info": { "read_cost": "68.72", "eval_cost": "815.80", "prefix_cost": "884.52", "data_read_per_join": "286K" }, "used_columns": [ "Name", "CountryCode", "Population" ] } }, { "table": { "table_name": "Country", "access_type": "eq_ref", "possible_keys": [ "PRIMARY" ], "key": "PRIMARY", "used_key_parts": [ "Code" ], "key_length": "3", "ref": [ "world.City.CountryCode" ], "rows_examined_per_scan": 1, "rows_produced_per_join": 4079, "filtered": 100, "cost_info": { "read_cost": "4079.00", "eval_cost": "815.80", "prefix_cost": "5779.32", "data_read_per_join": "1M" }, "used_columns": [ "Code", "Name"](https://image.slidesharecdn.com/sql4php-141202131544-conversion-gate02/75/SQL-For-PHP-Programmers-40-2048.jpg)



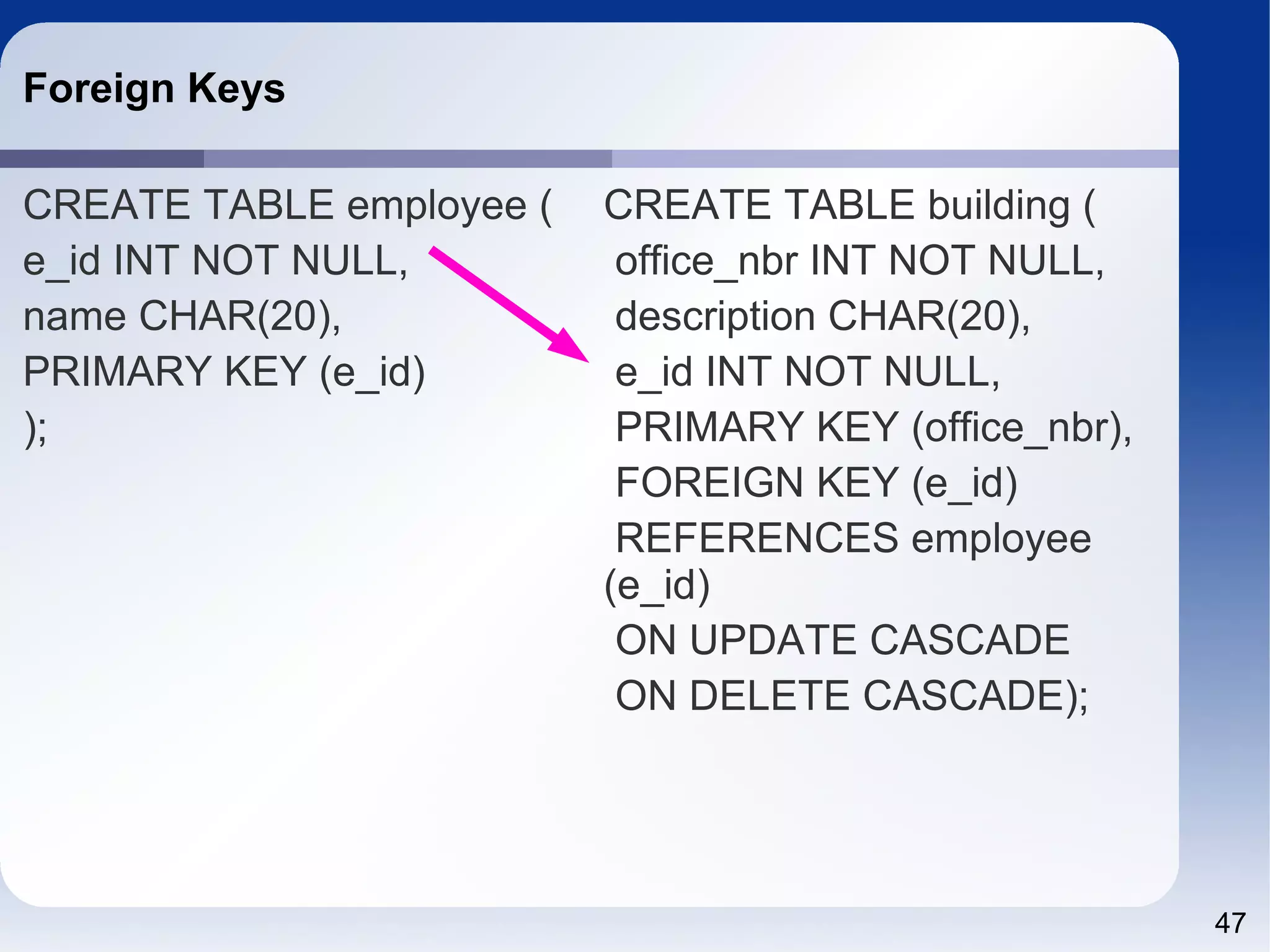

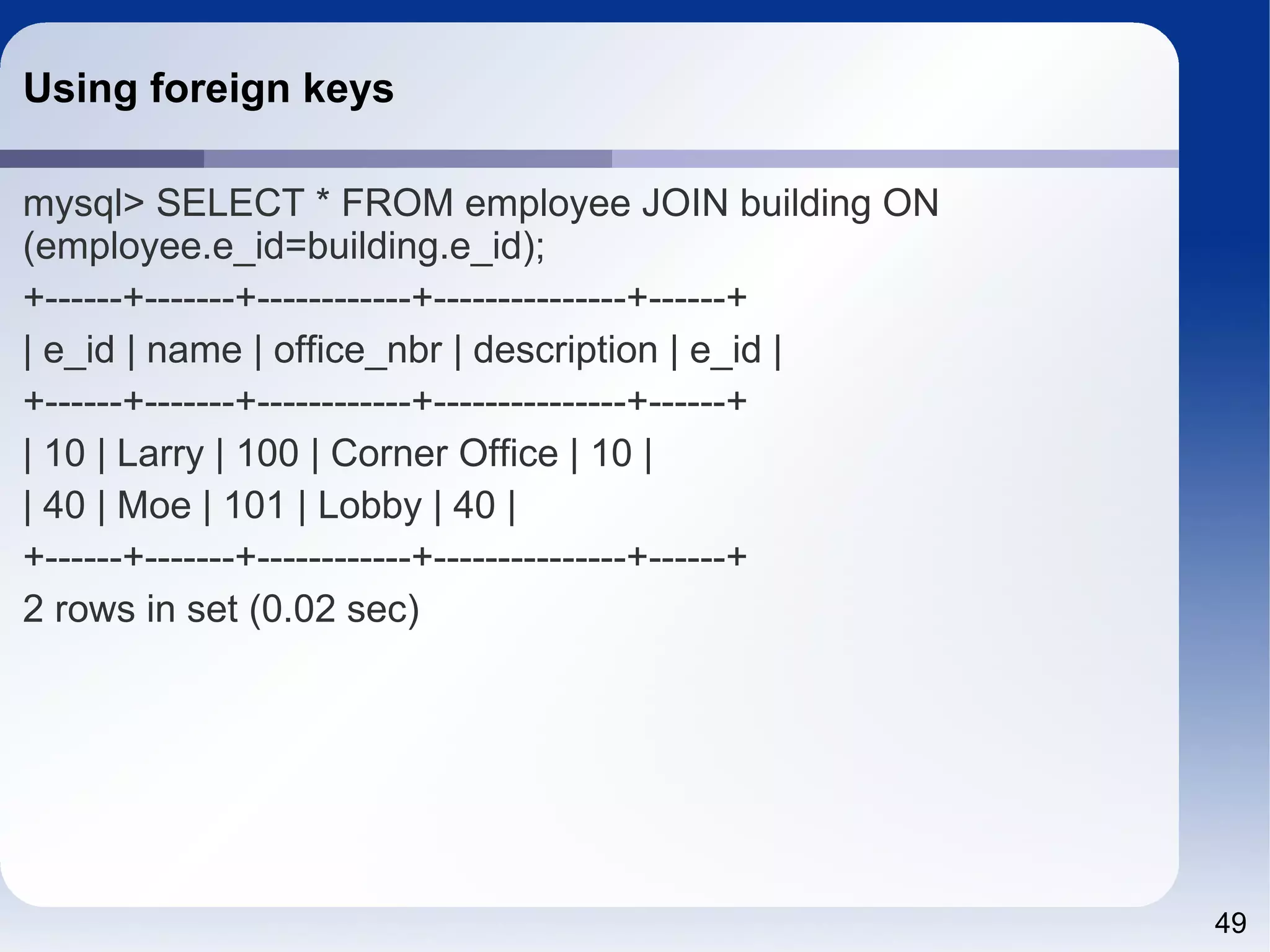
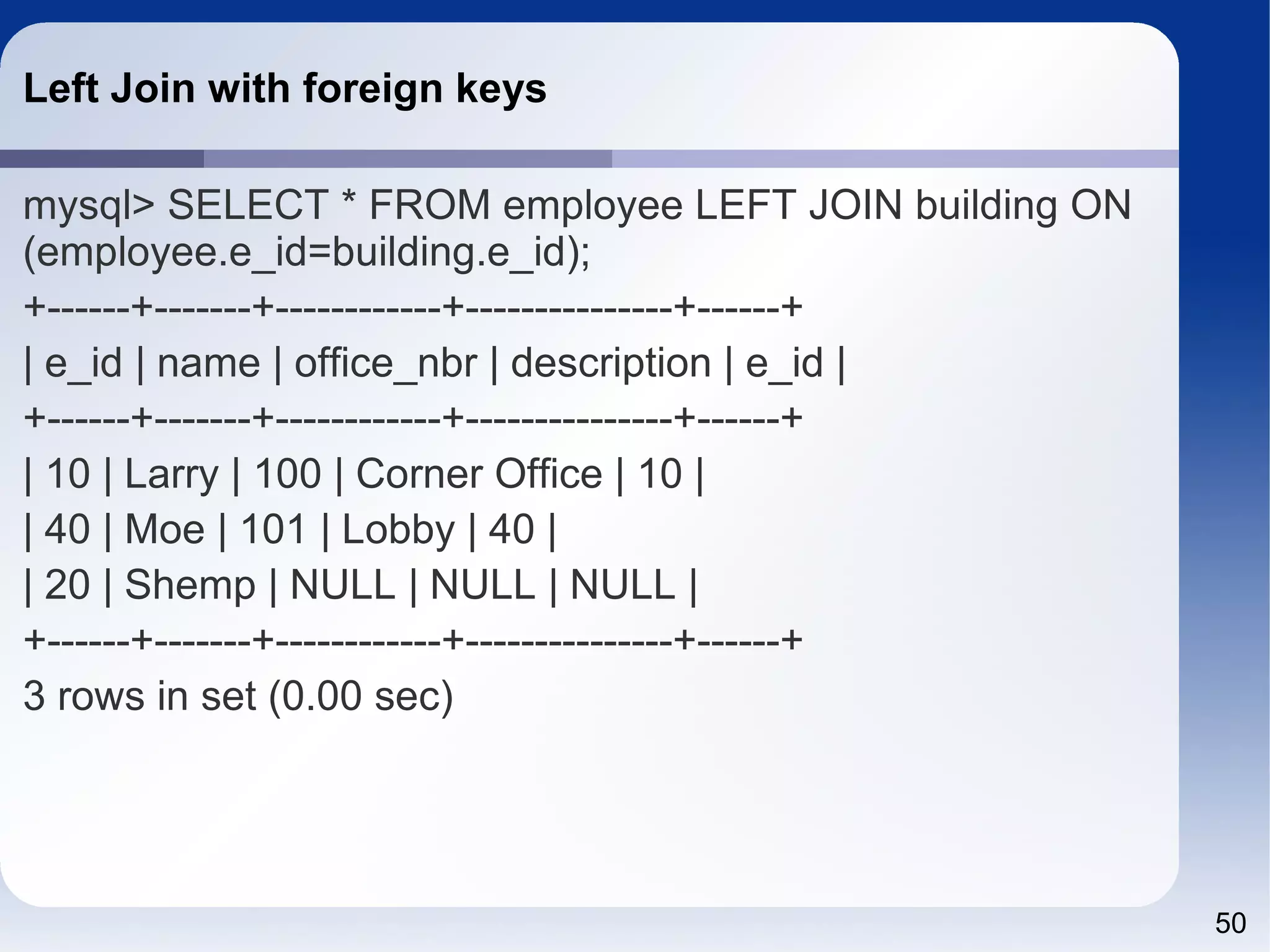


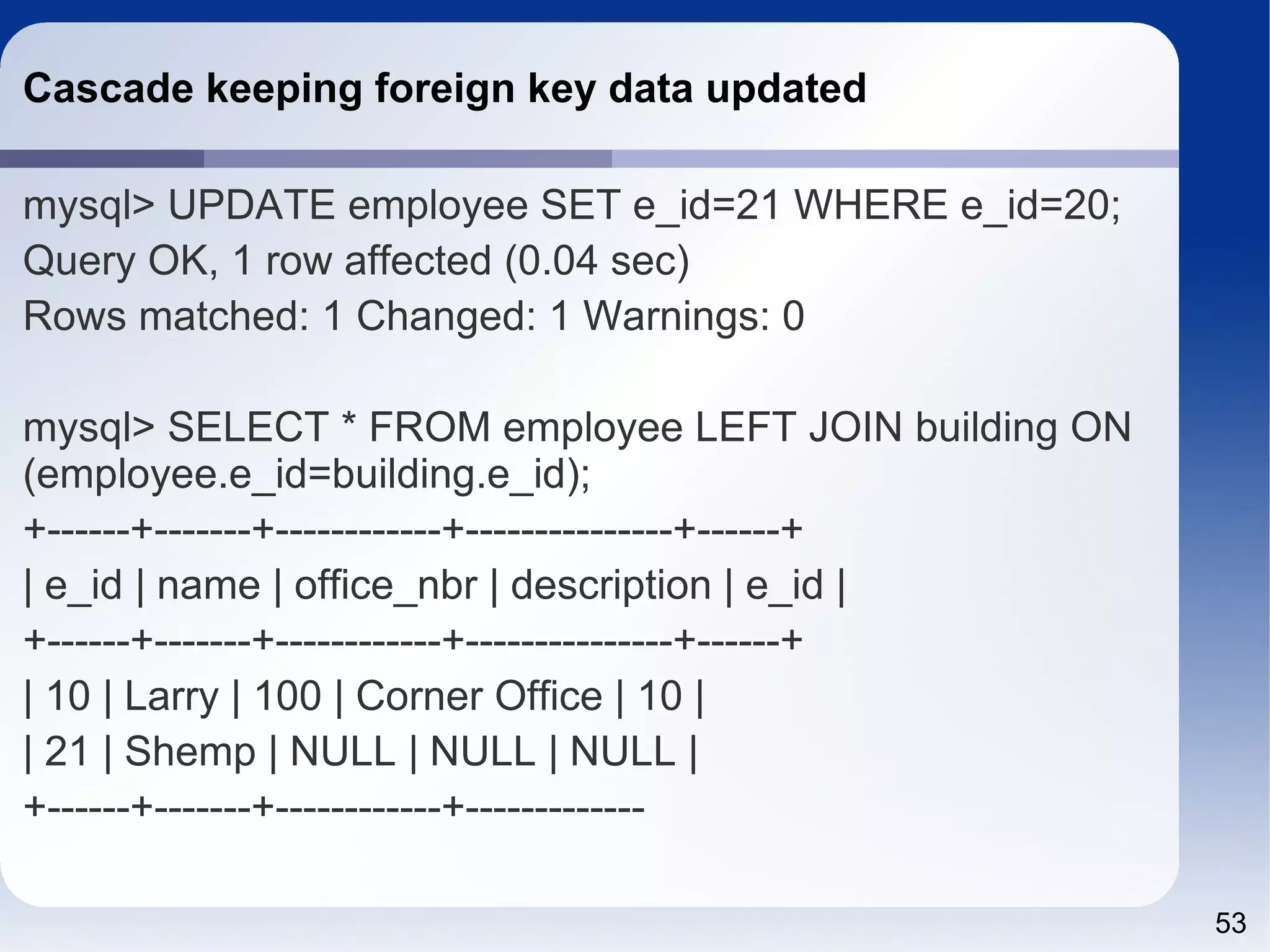

![55 13.1.8 CREATE INDEX Syntax CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [index_type] ON tbl_name (index_col_name,...) [index_option] [algorithm_option | lock_option] ... index_col_name: col_name [(length)] [ASC | DESC] index_type: USING {BTREE | HASH} index_option: KEY_BLOCK_SIZE [=] value | index_type | WITH PARSER parser_name | COMMENT 'string' algorithm_option: ALGORITHM [=] {DEFAULT|INPLACE|COPY} lock_option: LOCK [=] {DEFAULT|NONE|SHARED|EXCLUSIVE}](https://image.slidesharecdn.com/sql4php-141202131544-conversion-gate02/75/SQL-For-PHP-Programmers-55-2048.jpg)


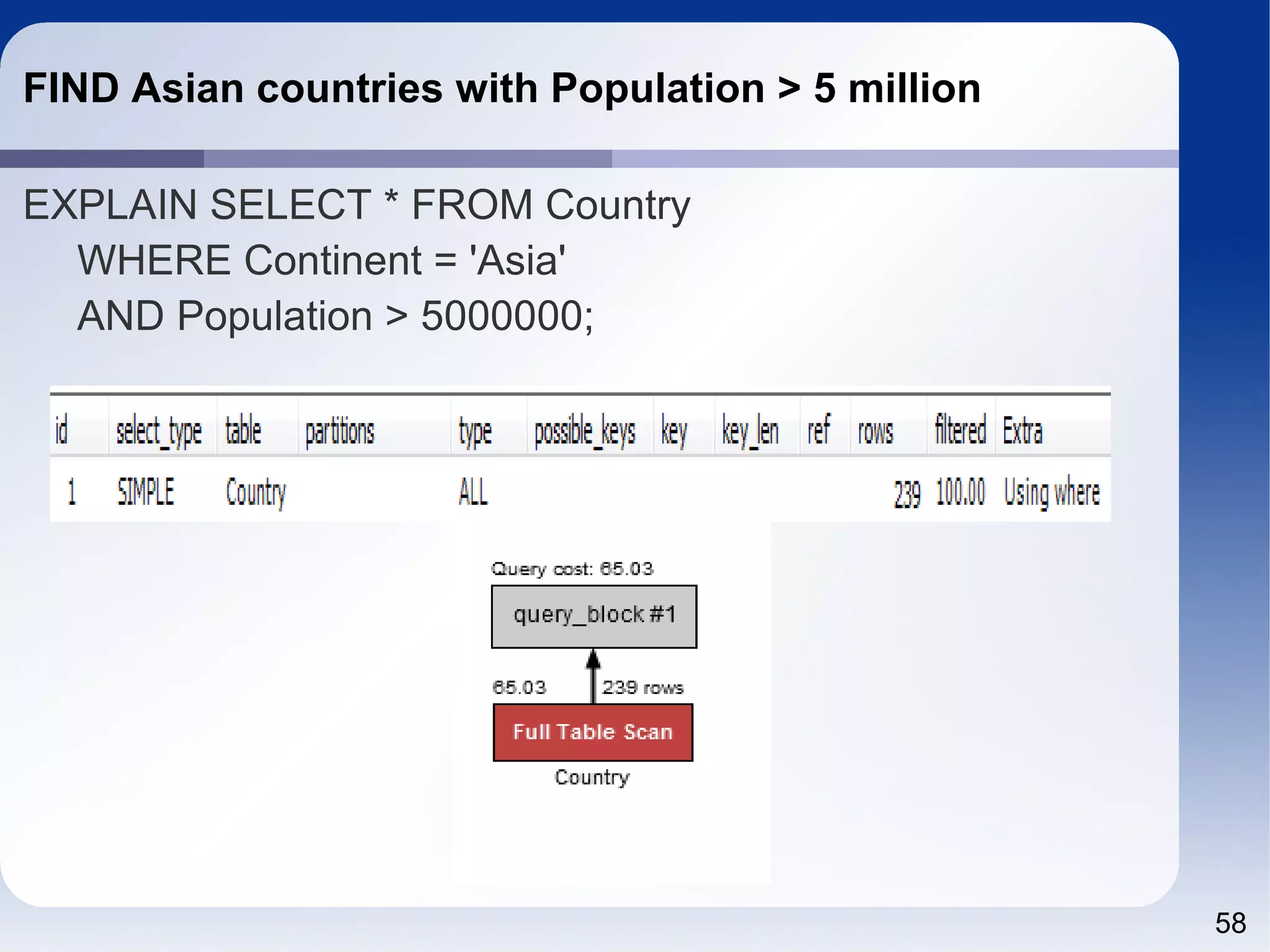

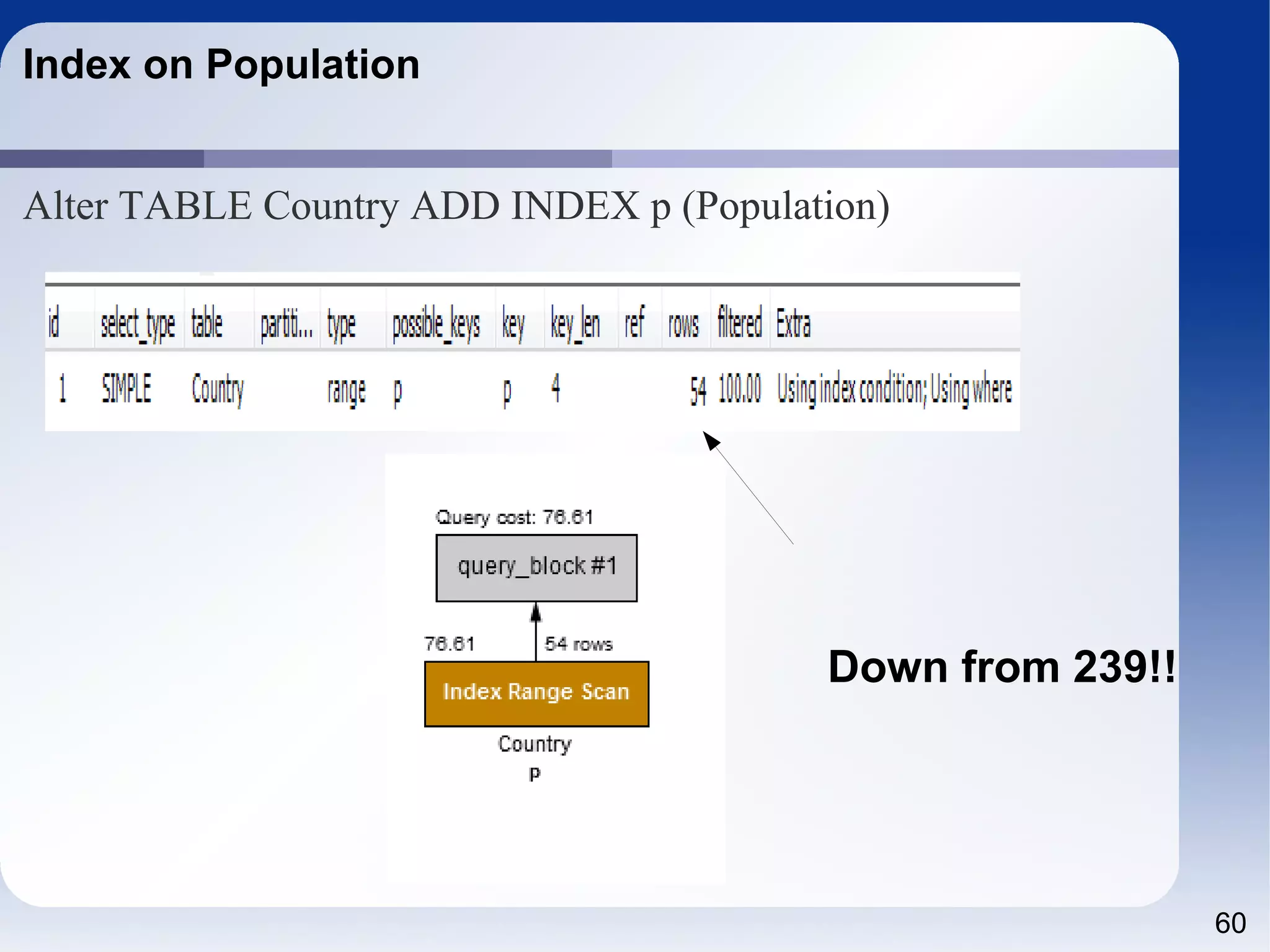

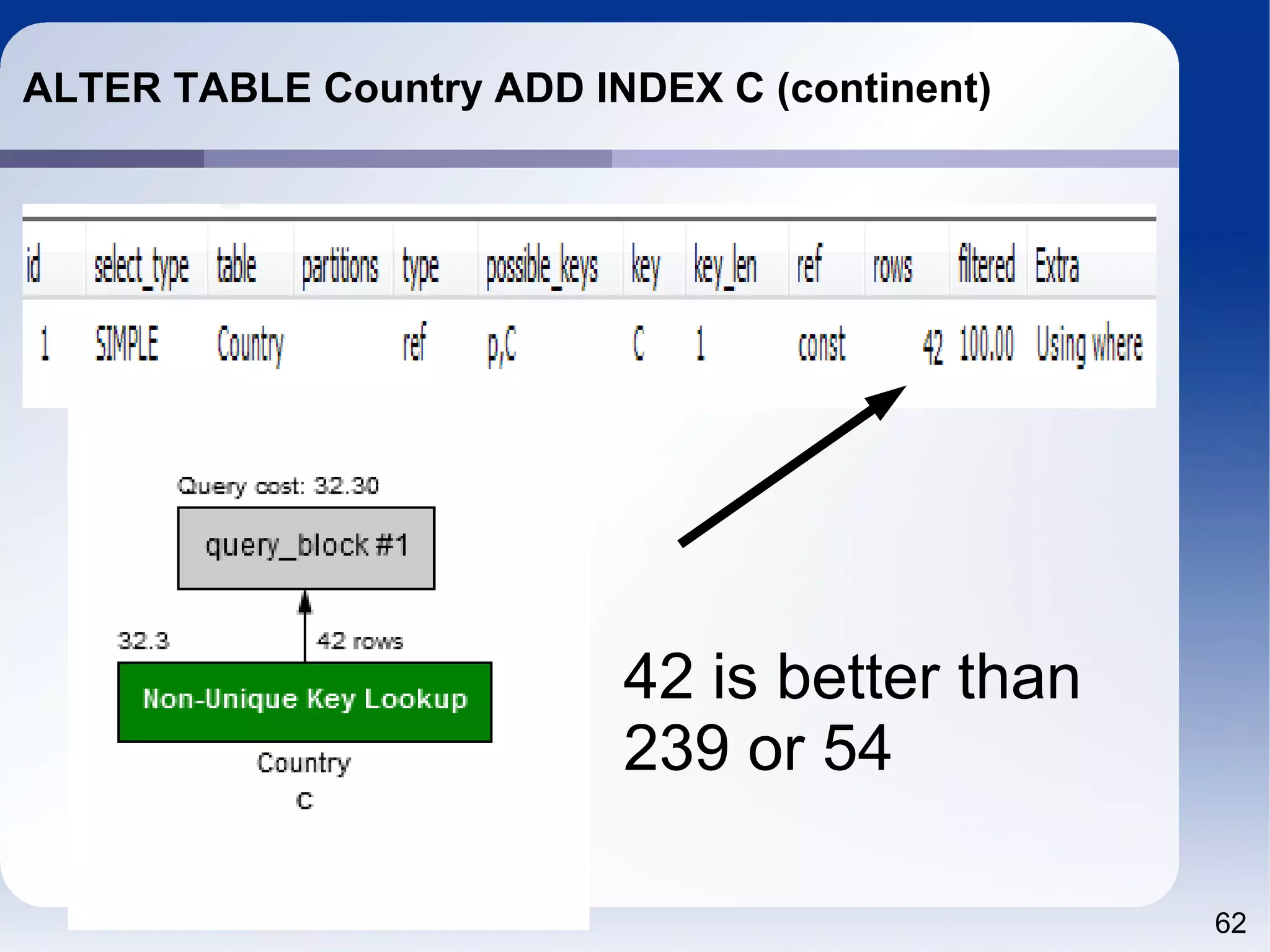
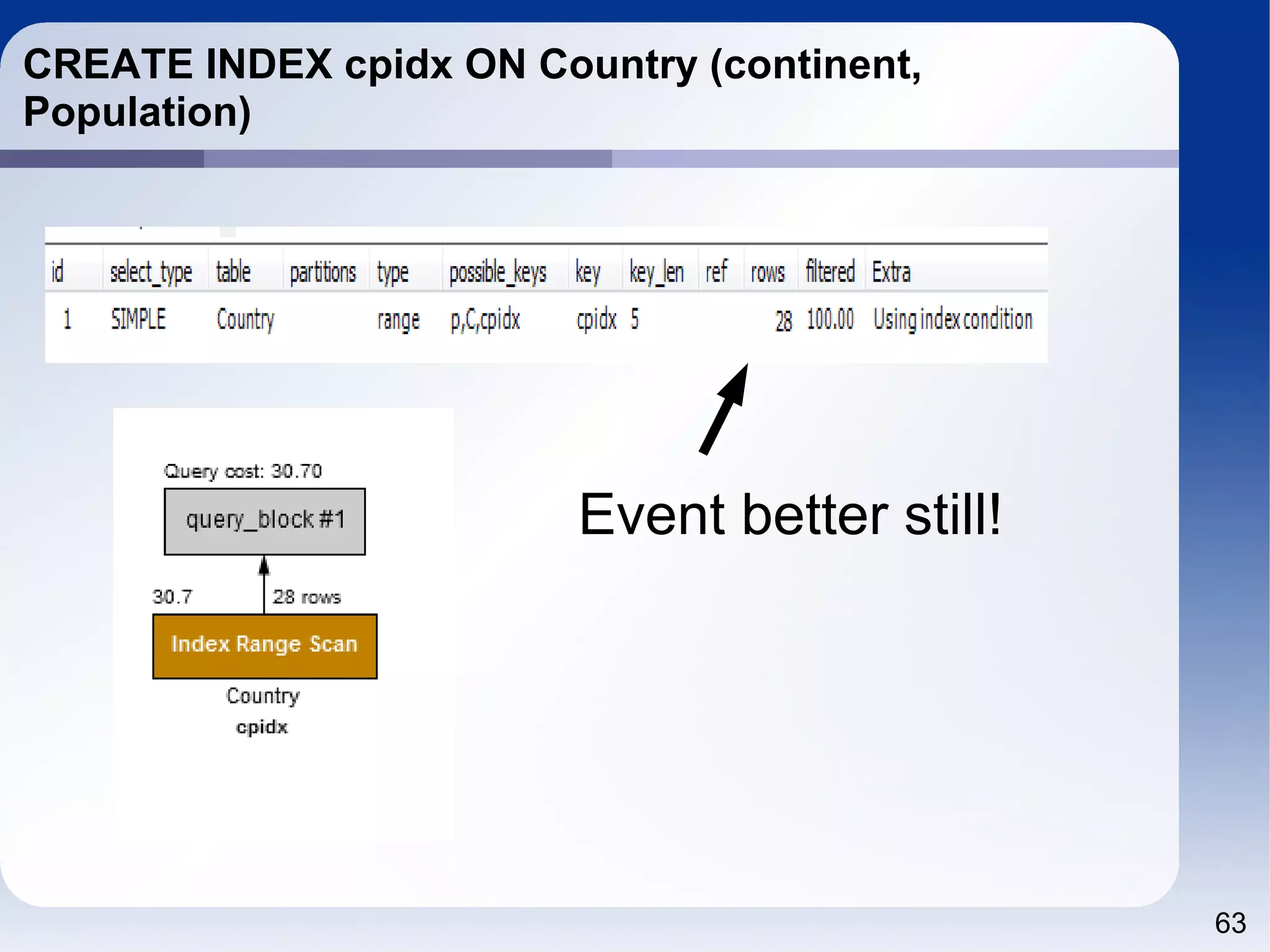






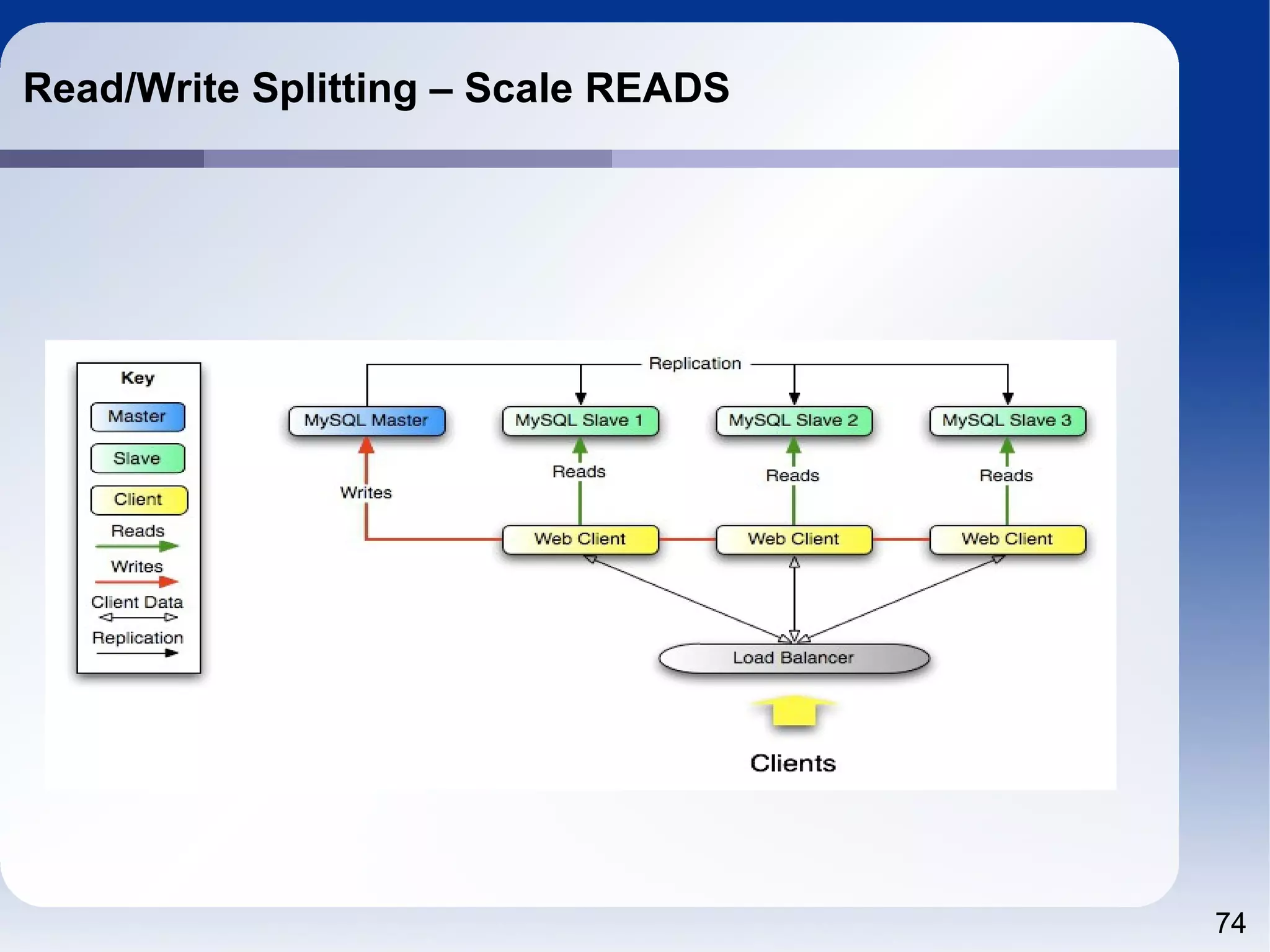
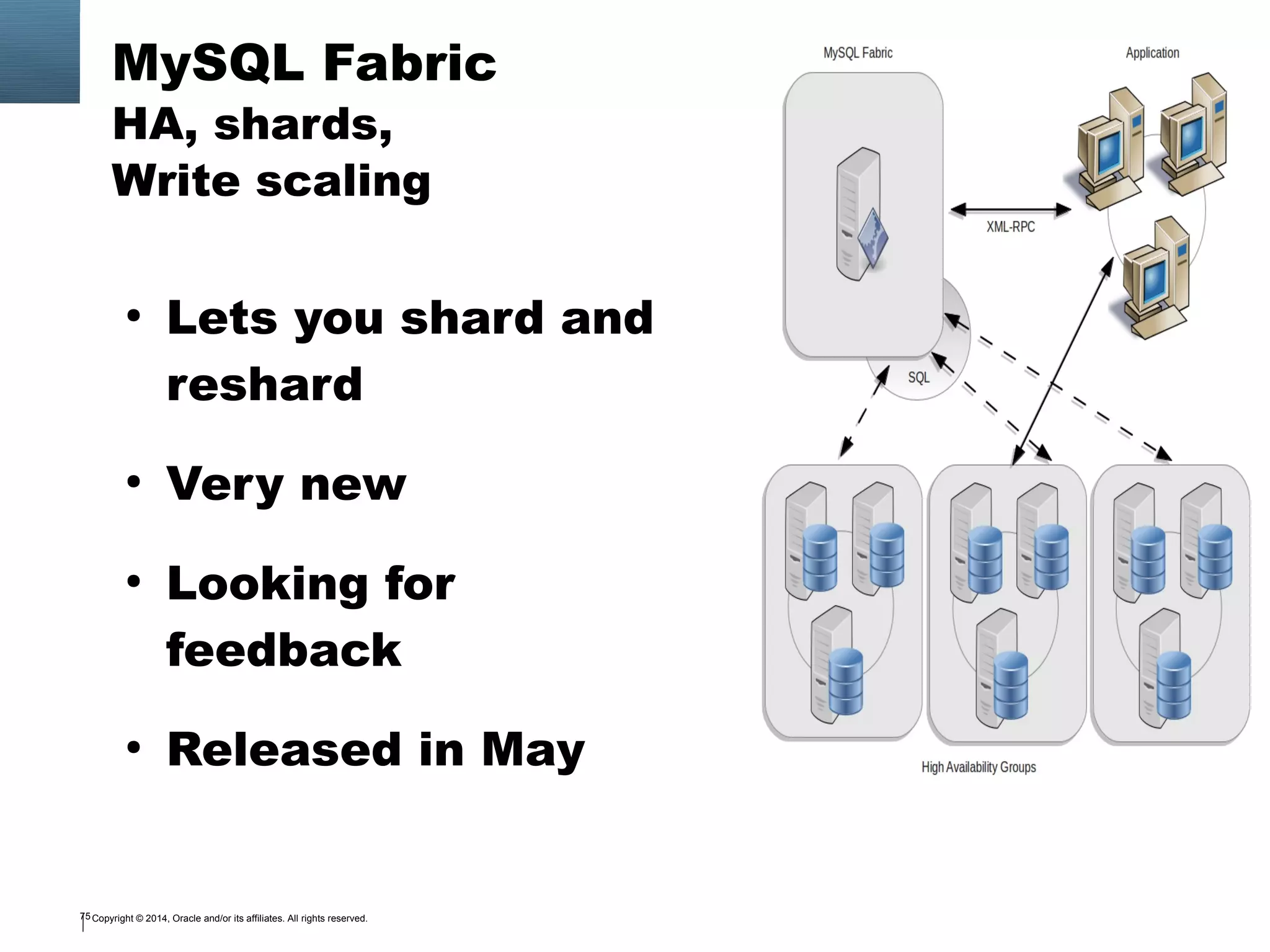













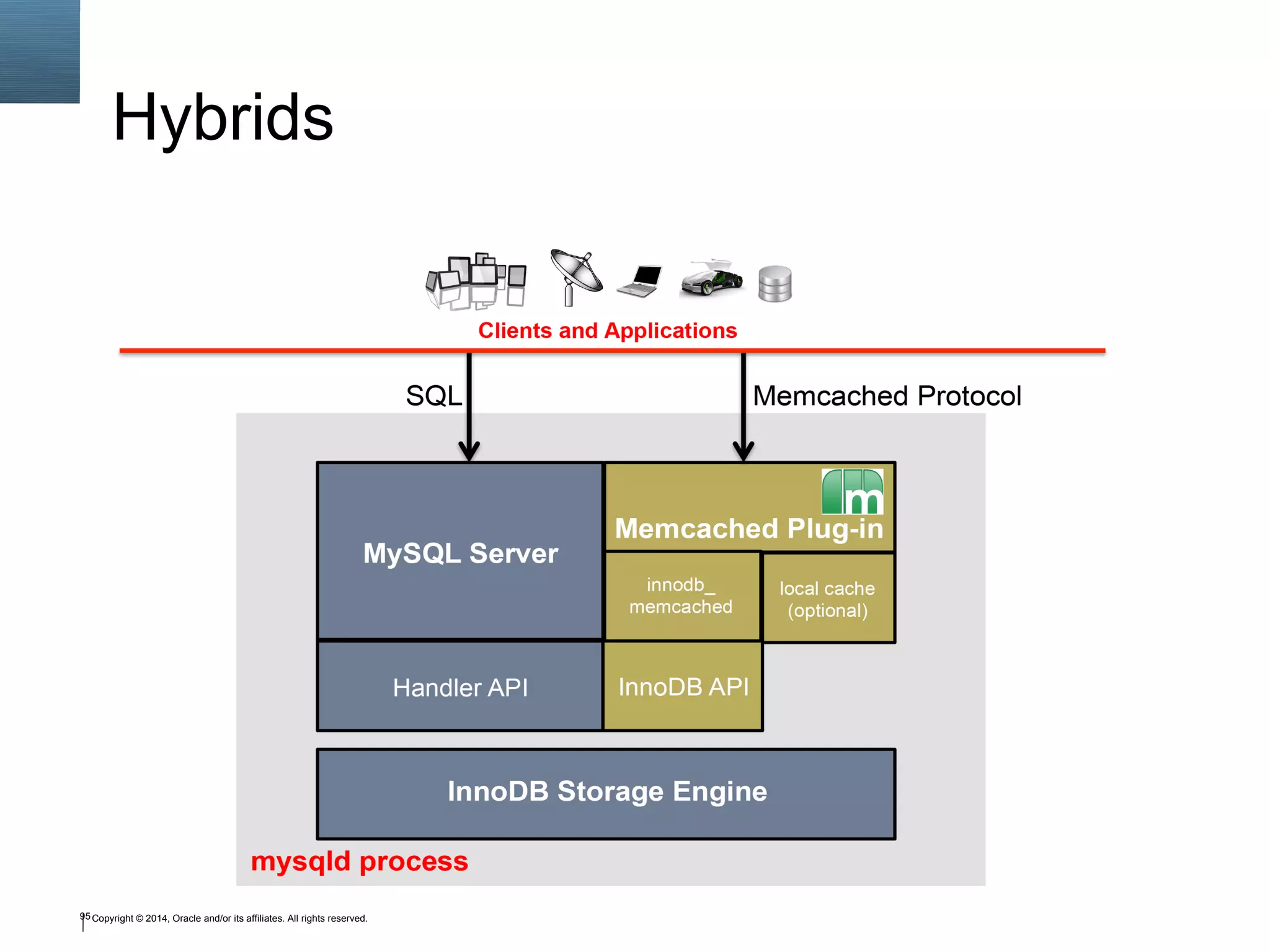
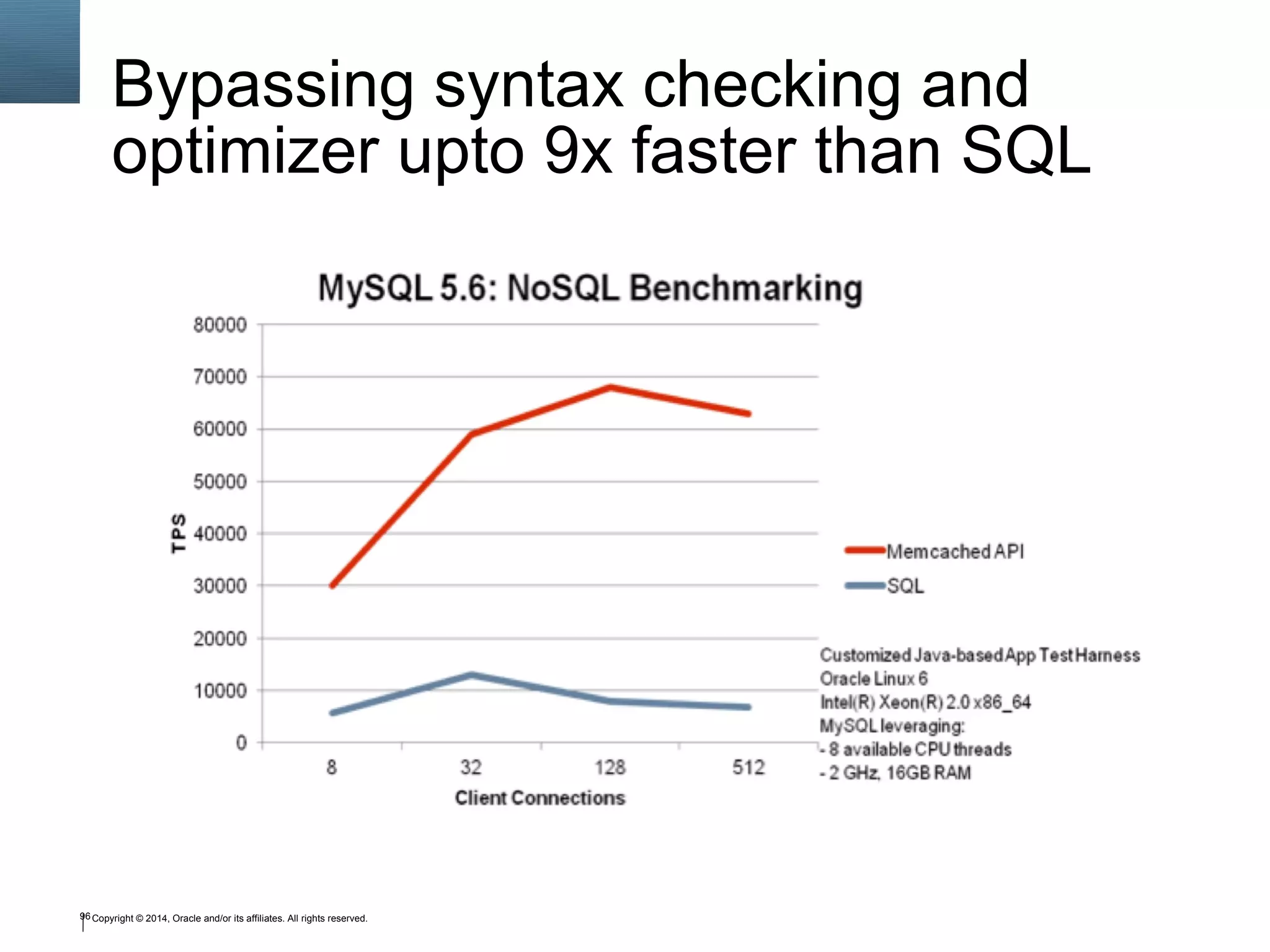








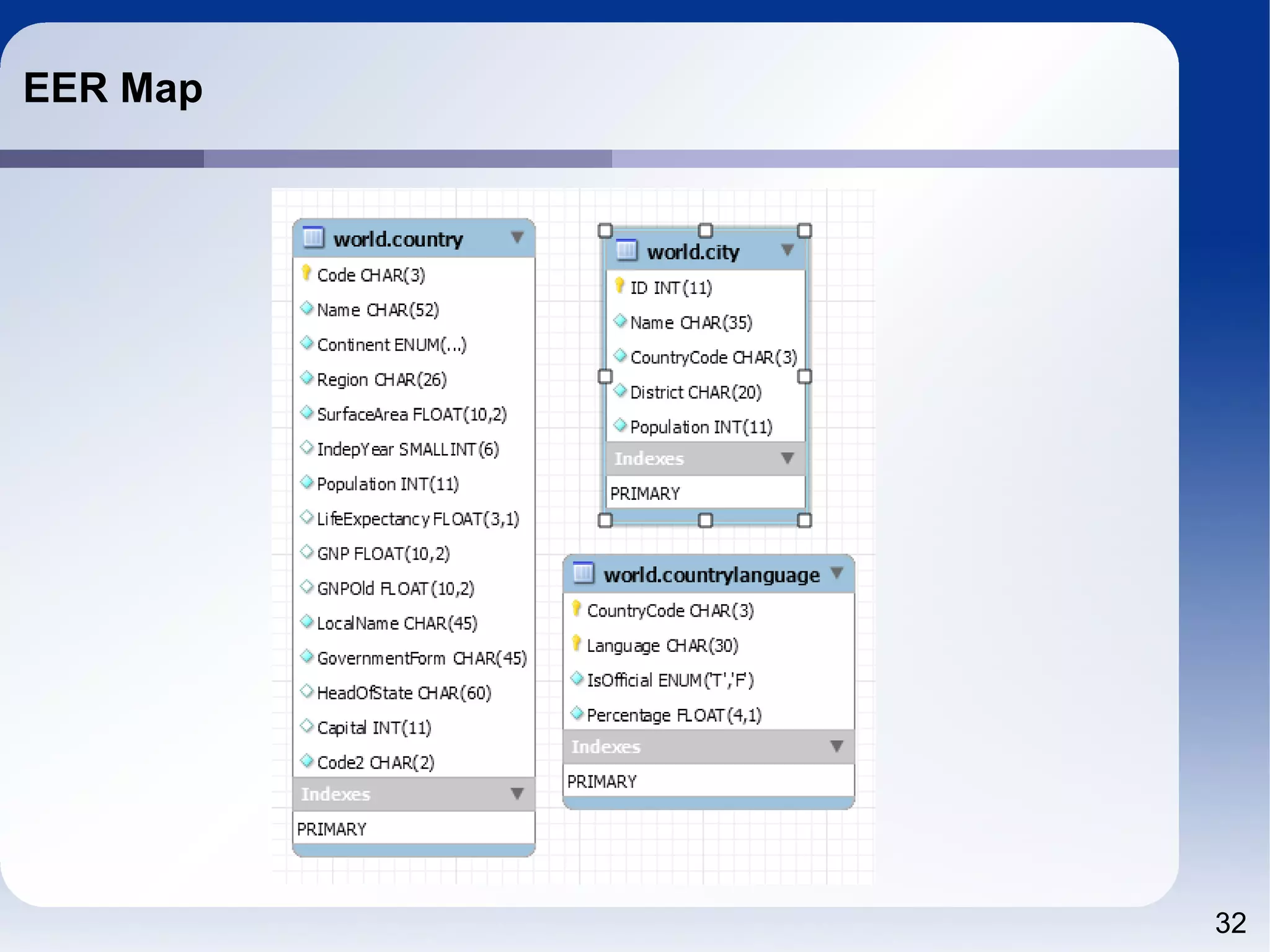
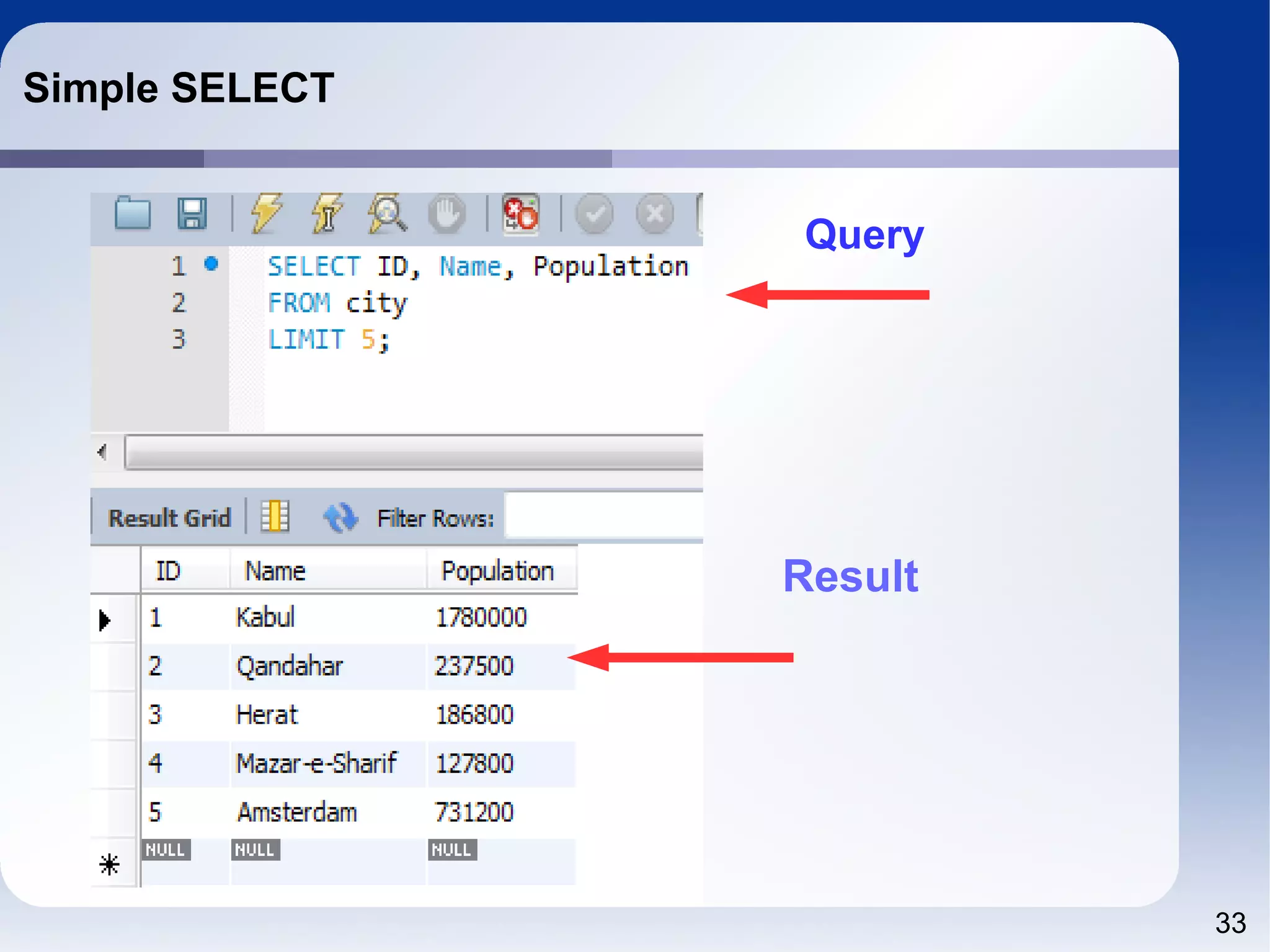
The document outlines a tutorial on SQL and database management, including topics like structured query language, relational algebra, and database normalization. It also emphasizes the importance of eliminating data redundancy and provides practical examples of table creation and manipulation in MySQL. Various SQL commands and their usage, such as Data Definition Language (DDL) and Data Manipulation Language (DML), are also discussed alongside optimization techniques for querying databases.