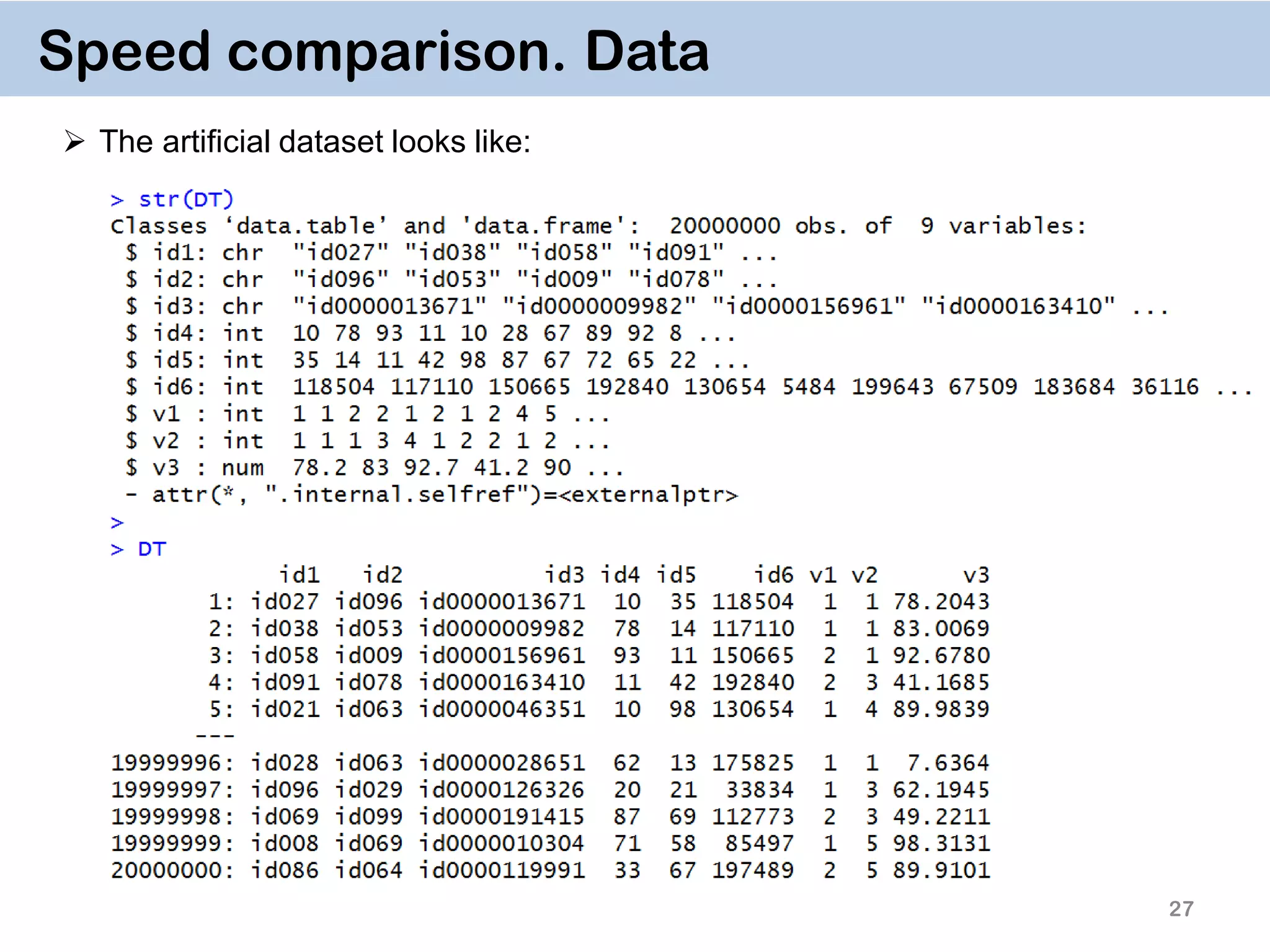
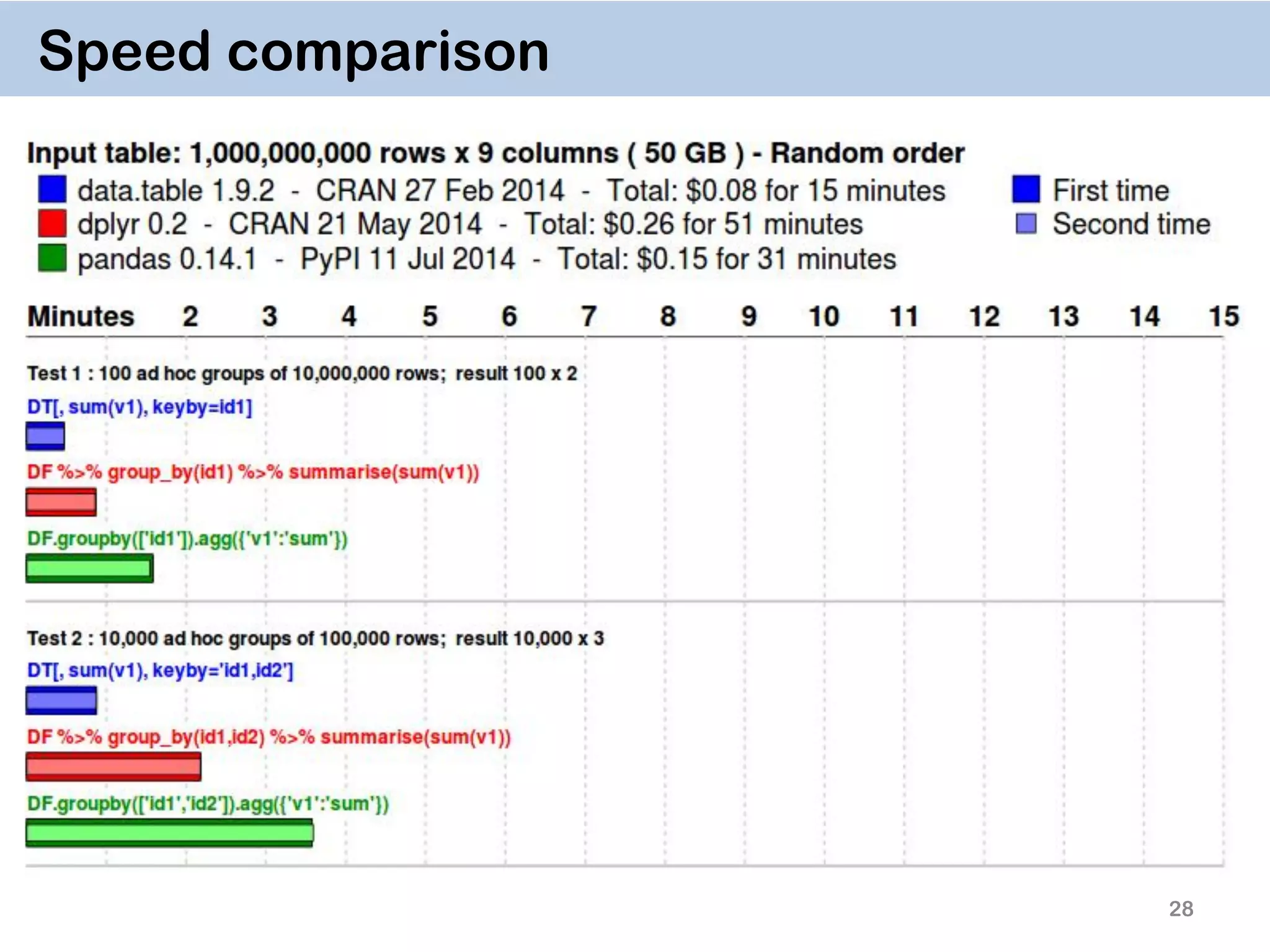
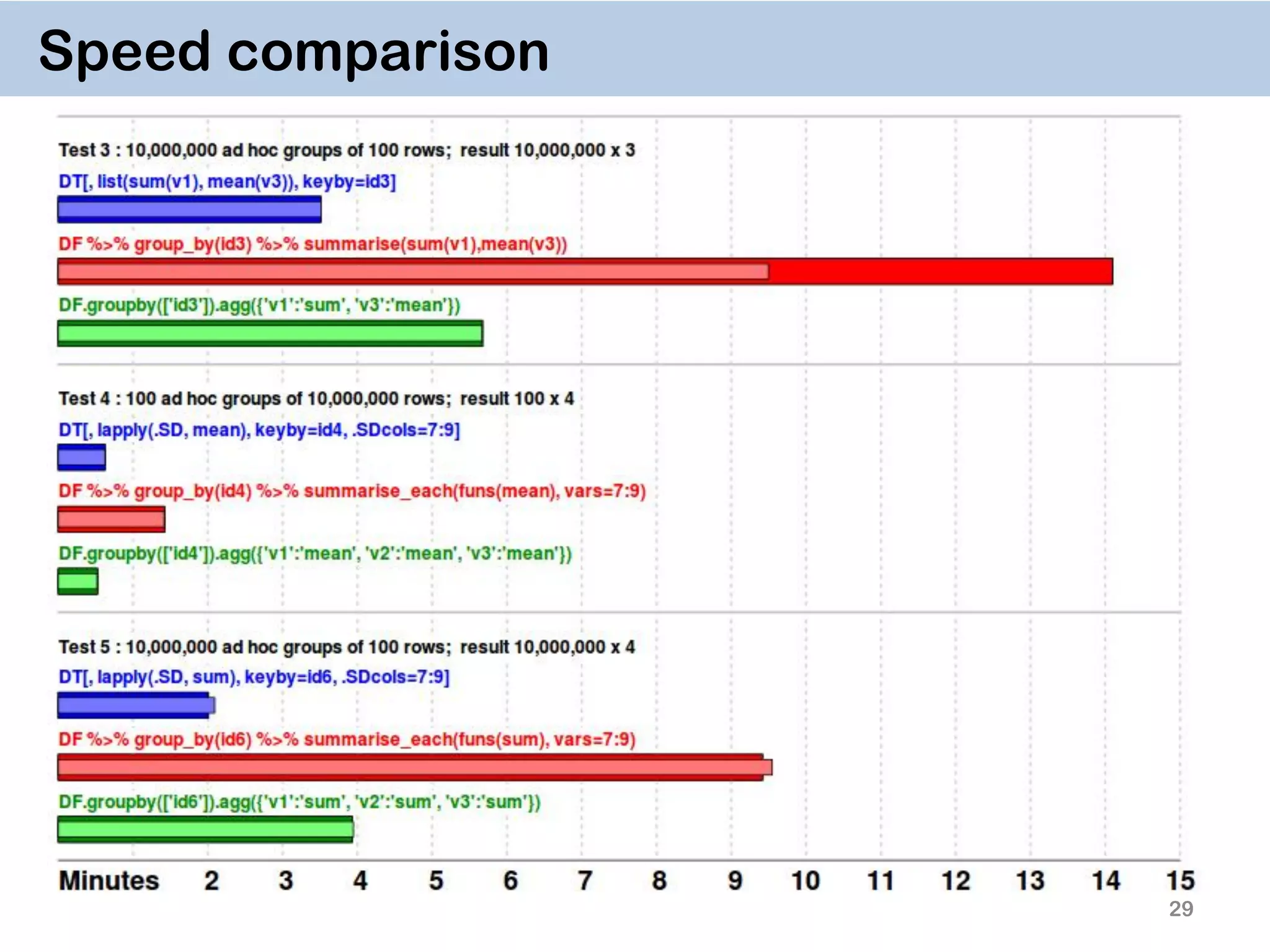
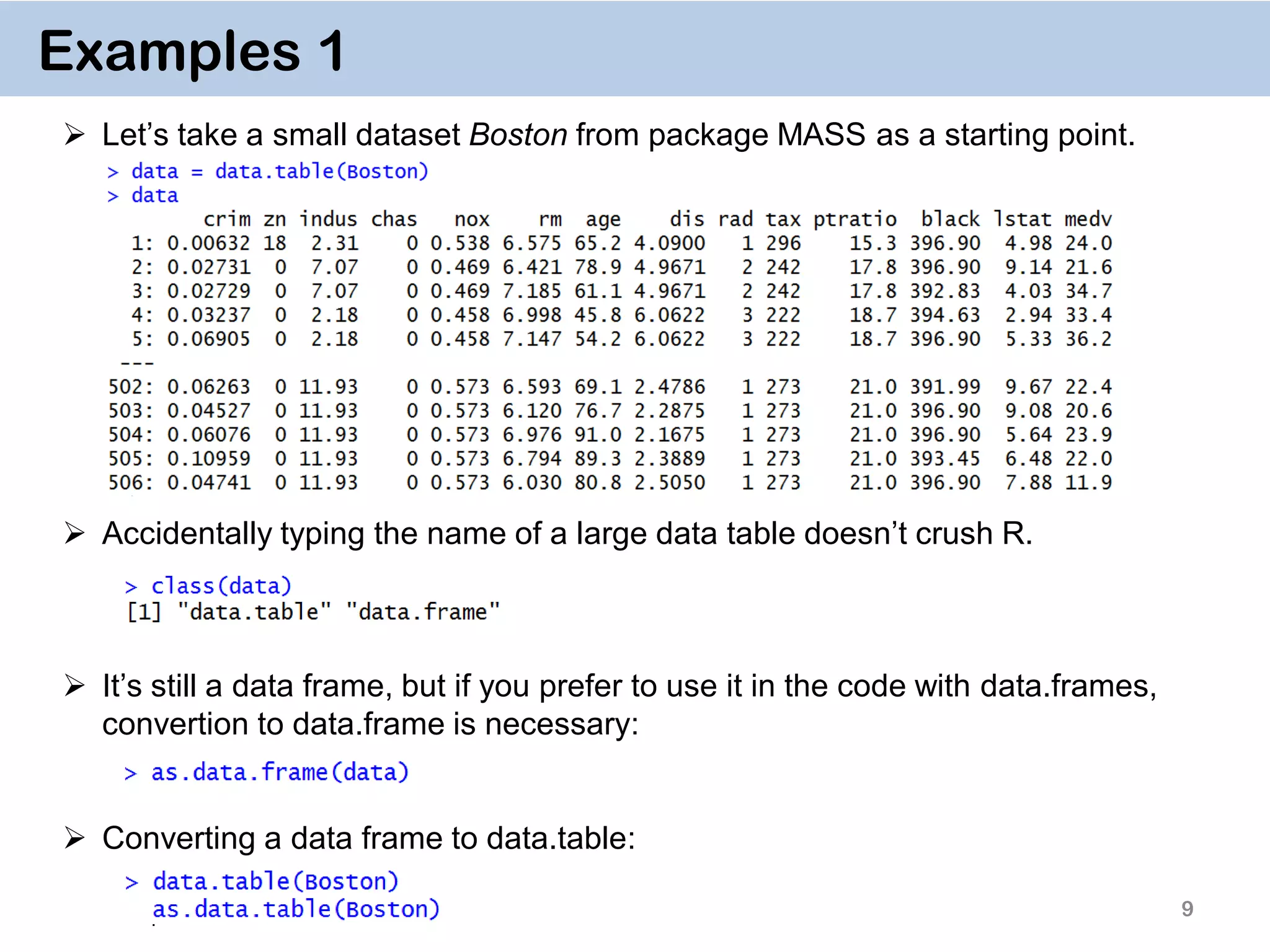
The document discusses the data.table package in R, emphasizing its efficiency and speed for data manipulation tasks, particularly with large datasets. Key features include faster code writing, improved readability, and the ability to efficiently handle operations on extensive data. Limitations and best practices, such as avoiding certain functions and setting keys for optimal performance, are also highlighted.



![dt = data.table(nuc, key="gene_id") dt[,list(A = min(start), B = max(end), C = mean(pctAT), D = mean(pctGC), E = sum(length)), by = key(dt)] # gene_id A B C D E # 1: NM_032291 67000042 67108547 0.5582567 0.4417433 283 # 2: ZZZ 67000042 67108547 0.5582567 0.4417433 283 4 data.table solution takes ~ 3 seconds to run ! easy to program easy to understand](https://image.slidesharecdn.com/presentationdatatablermeetup2-160123140115/75/January-2016-Meetup-Speeding-up-big-data-manipulation-with-data-table-package-4-2048.jpg)



![8 General Syntax DT[i, j, by] rows or logical rule to subset obs. some function of the data To which groups apply the function Take DT, subset rows using i, then calculate j grouped by by](https://image.slidesharecdn.com/presentationdatatablermeetup2-160123140115/75/January-2016-Meetup-Speeding-up-big-data-manipulation-with-data-table-package-8-2048.jpg)





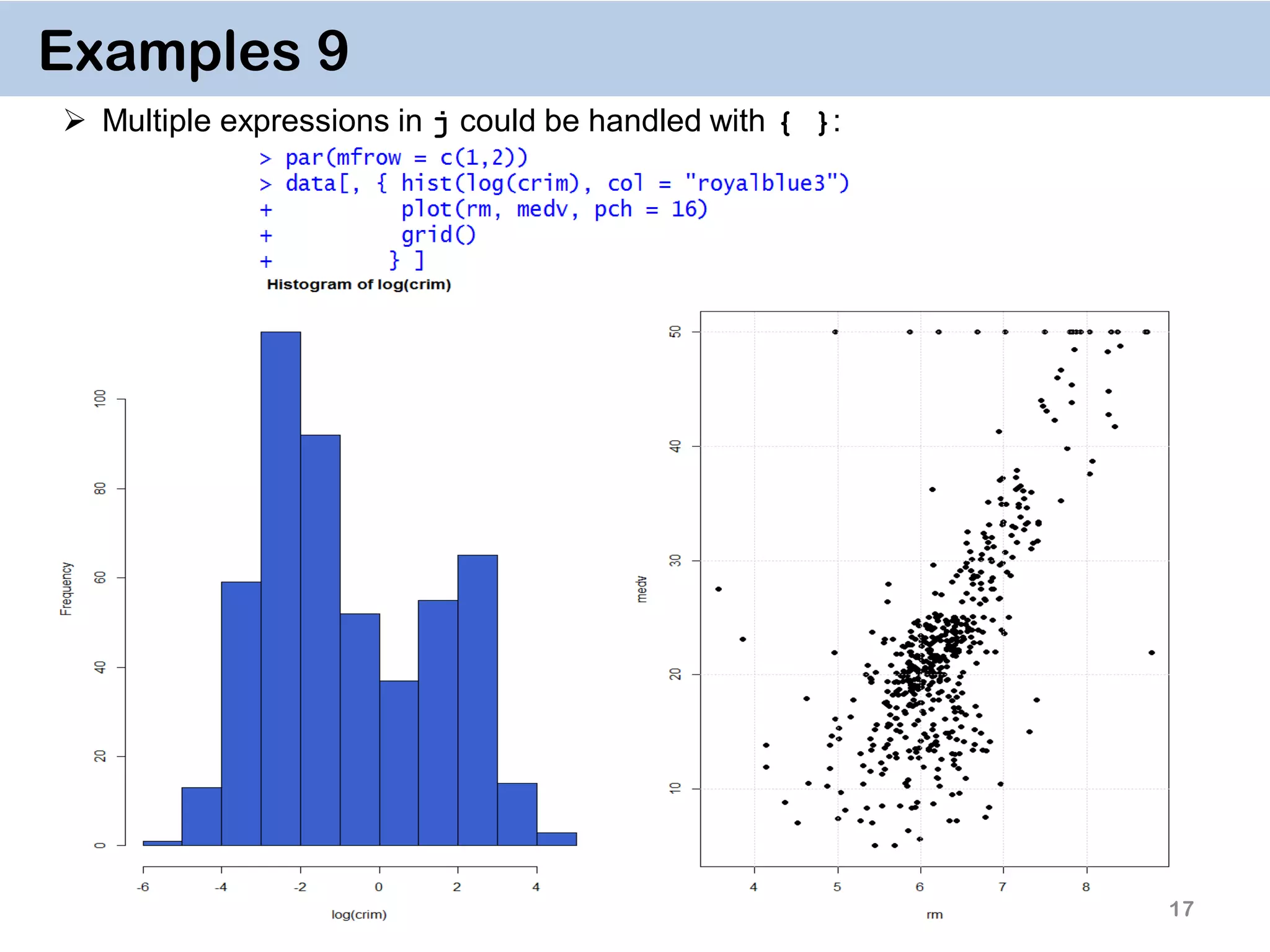

![19 Examples 11. Chaining DT[i, j, by][i, j, by] It’s a very powerful way of doing multiple operations in one command The command for crim.f on the previous slide can thus be done by Or in one go: data[…, …][…, …][…, …][…, …]](https://image.slidesharecdn.com/presentationdatatablermeetup2-160123140115/75/January-2016-Meetup-Speeding-up-big-data-manipulation-with-data-table-package-19-2048.jpg)

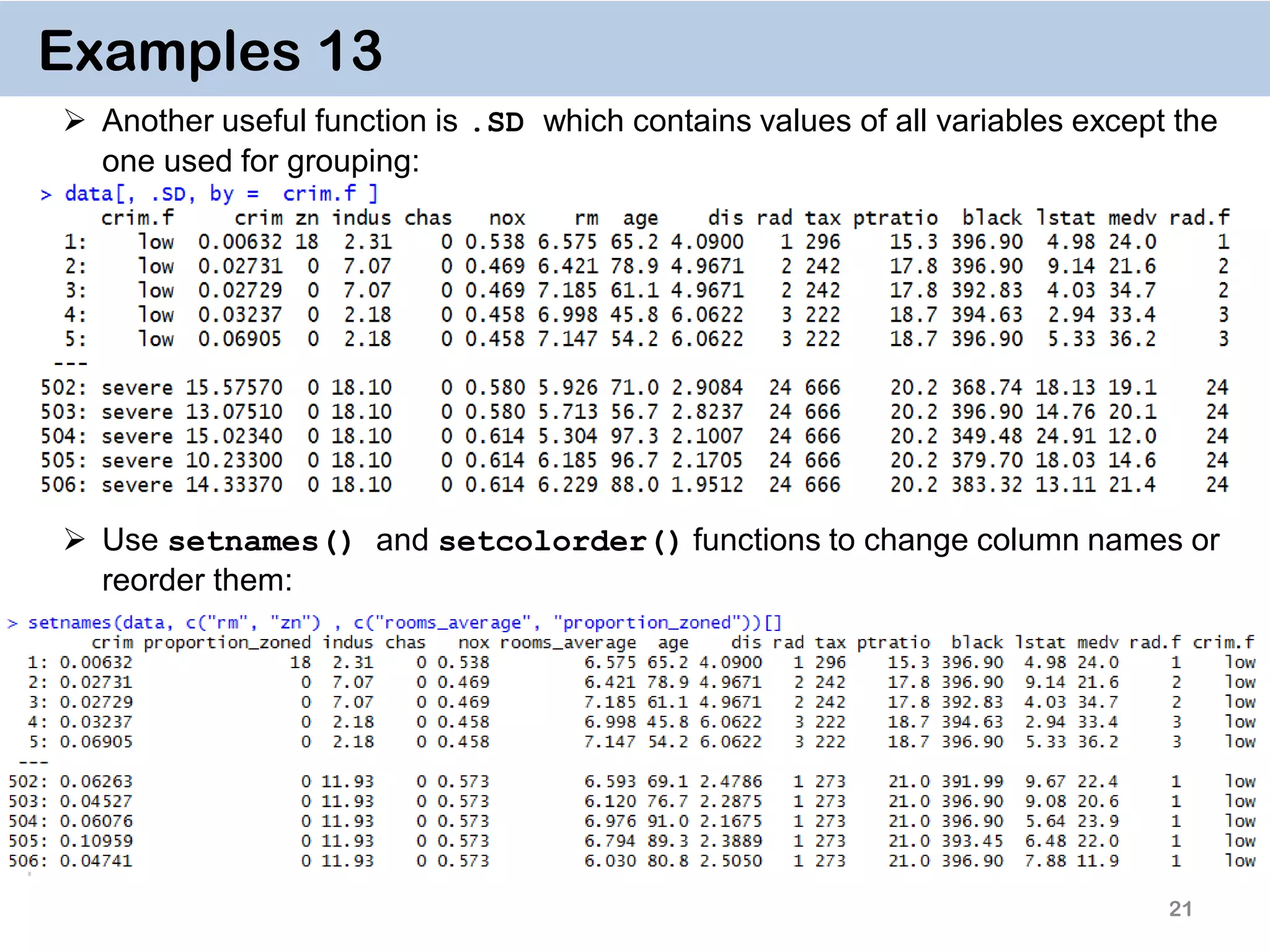
![22 Examples 14. Key on one variable The reason why data.table works so fast is the use of keys. All observations are internally indexed by the way they are stored in RAM and sorted using Radix sort. Any column can be set as a key (list & complex number classes not supported), and duplicate entries are allowed. setkey(DT, colA)introduces an index for column A and sorts the data.table by it increasingly. In contrast to data.frame style, this is done without extra copies and with a very efficient memory use. After that it’s possible to use binary search by providing index values directly data[“1”], which is 100- 1000… times faster than vector scan data[rad.f == “1”] Setting keys is necessary for joins and significantly speeds up things for big data. However, it’s not necessary for by = aggregation.](https://image.slidesharecdn.com/presentationdatatablermeetup2-160123140115/75/January-2016-Meetup-Speeding-up-big-data-manipulation-with-data-table-package-22-2048.jpg)

![24 Vector Scan vs. Binary Search The reason vector scan is so inefficient is that is searches first for entries “7” in rad.f variable row-by-row, then does the same for crim.f, then takes element- wise intersection of logical vectors. Binary search, on the other hand, searches already on sorted variables, and hence cuts the number of observations by half at each step. Since rows of each column of data.tables have corresponding locations in RAM memory, the operations are performed in a very cache efficient manner. In addition, since the matching row indices are obtained directly without having to create huge logical vectors (equal to the number of rows in a data.table), it is quite memory efficient as well. Vector Scan Binary search data[rad.f ==“7” & crim.f == “low”] setkey(data, rad.f, crim.f) data[ .(“7”, “low")] 𝑂(𝑛) 𝑂(log( 𝑛))](https://image.slidesharecdn.com/presentationdatatablermeetup2-160123140115/75/January-2016-Meetup-Speeding-up-big-data-manipulation-with-data-table-package-24-2048.jpg)
![25 What to avoid Avoid read.csv function which takes hours to read in files > 1 Gb. Use fread instead. It’s a lot smarter and more efficient, e.g. it can guess the separator. Avoid rbind which is again notoriously slow. Use rbindlist instead. Avoid using data.frame’s vector scan inside data.table: data[ data$rad.f == "7" & data$crim.f == "low", ] (even though data.table’s vector scan is faster than data.frame’s vector scan, this slows it down.) In general, avoid using $ inside the data.table, whether it’s for subsetting, or updating some subset of the observations: data[ data$rad.f == "7", ] = data[ data$rad.f == "7", ] + 1 For speed use := by group, don't transform() by group or cbind() afterwards data.table used to work with dplyr well, but now it is usually slow: data %>% filter(rad == 1)](https://image.slidesharecdn.com/presentationdatatablermeetup2-160123140115/75/January-2016-Meetup-Speeding-up-big-data-manipulation-with-data-table-package-25-2048.jpg)