Download to read offline





![Do the “work” (e.g. predict labels or w/e): def transform(df: Dataset[_]): DataFrame = { val wordcount = udf { in: String => in.split(" ").size } df.select(col("*"), wordcount(df.col("happy_pandas")).as("happy_panda_counts")) } vic15](https://image.slidesharecdn.com/sparkmlforcustommodels-fosdem20173-170204133552/75/Spark-ML-for-custom-models-FOSDEM-HPC-2017-8-2048.jpg)
 final val outputCol = new Param[String](this, "outputCol", "The output column") def setInputCol(value: String): this.type = set(inputCol, value) def setOutputCol(value: String): this.type = set(outputCol, value) Jason Wesley Upton](https://image.slidesharecdn.com/sparkmlforcustommodels-fosdem20173-170204133552/75/Spark-ML-for-custom-models-FOSDEM-HPC-2017-9-2048.jpg)





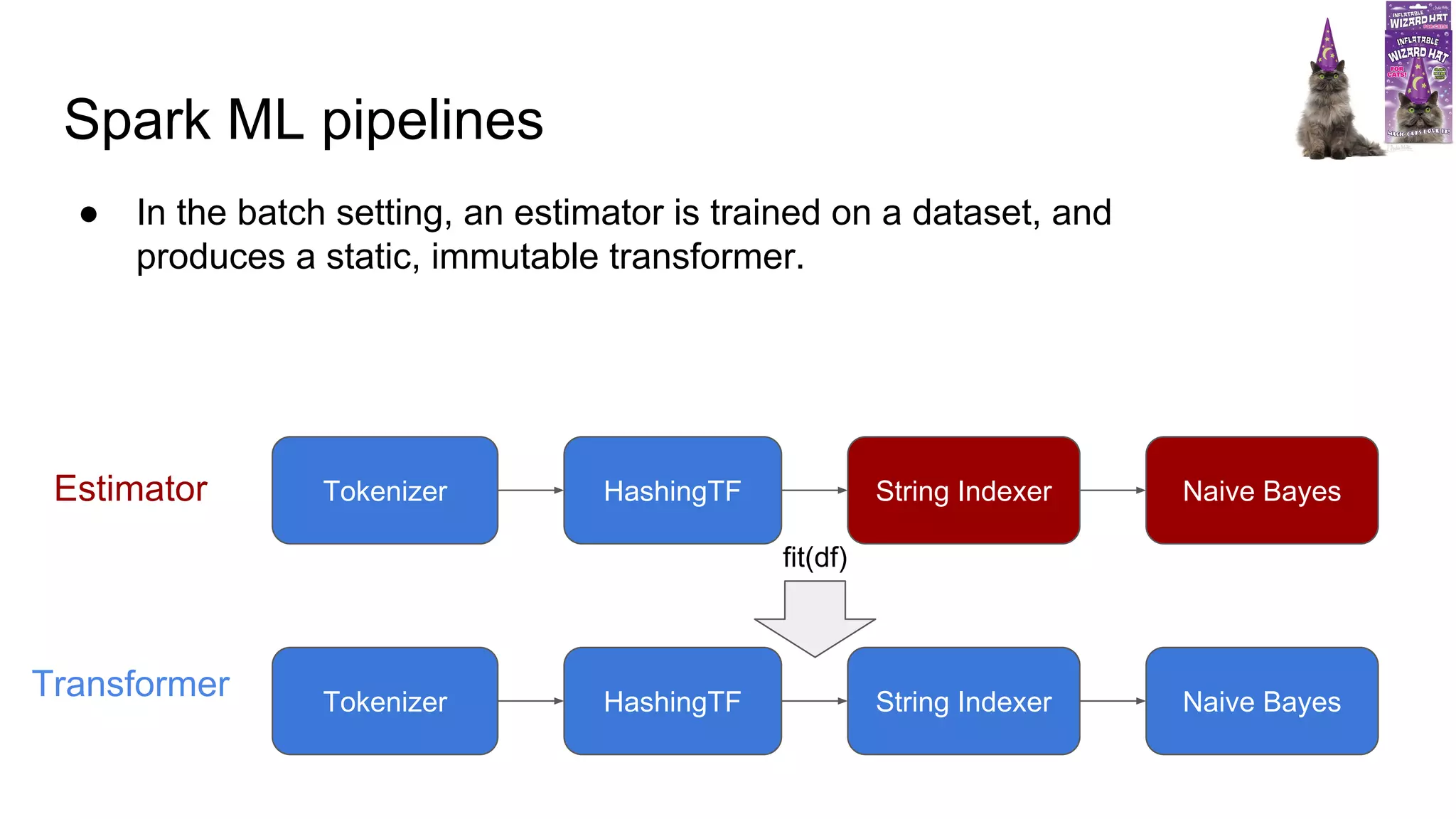
- Spark ML pipelines involve estimators that are trained on datasets to produce immutable transformers. - A transformer must define transformSchema() to validate the input schema, transform() to do the work, and copy() for cloning. - Configurable transformers take parameters like inputCol and outputCol to allow configuration for meta algorithms. - Estimators are similar but fit() returns a model instead of directly transforming.