Downloaded 16 times


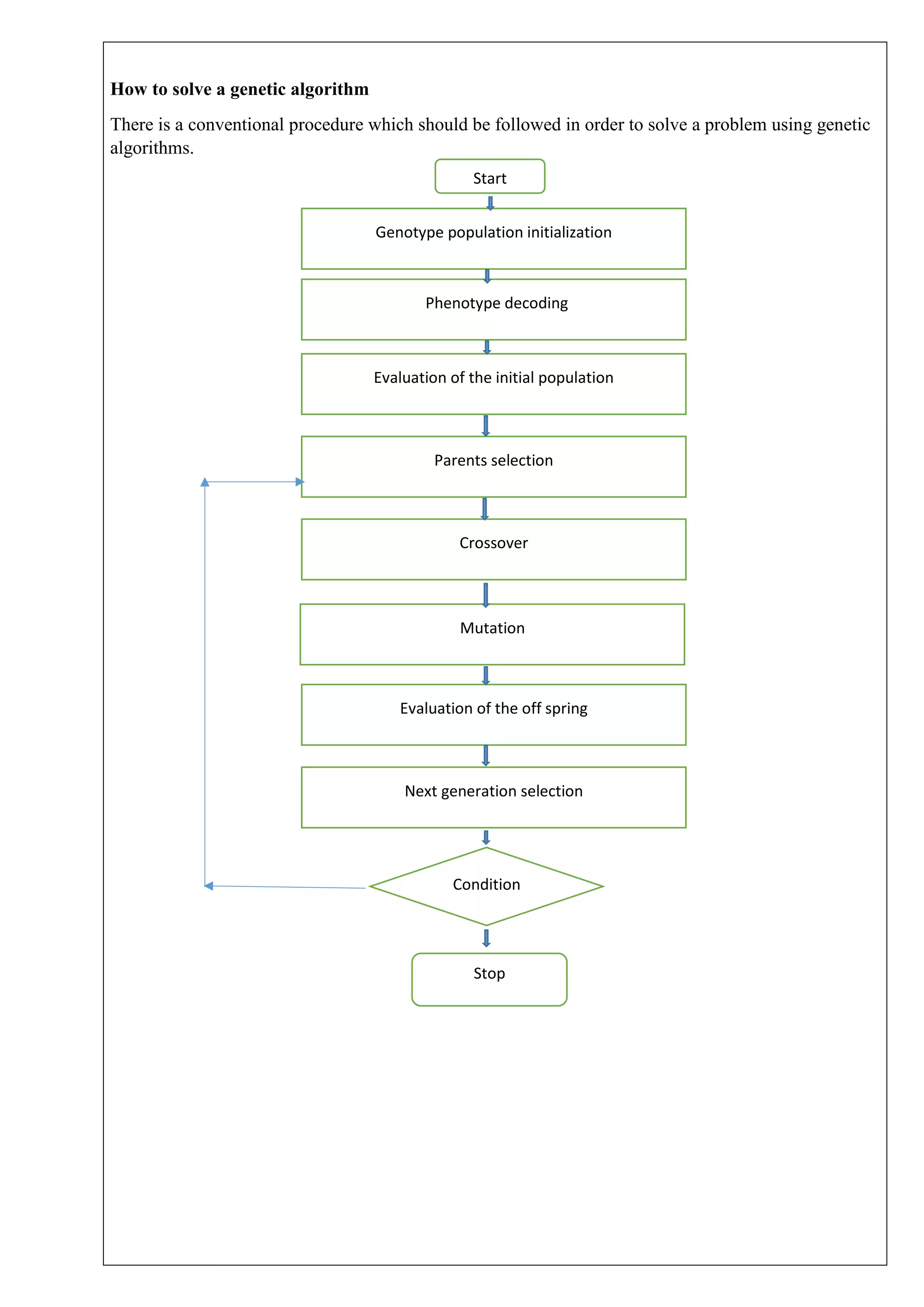











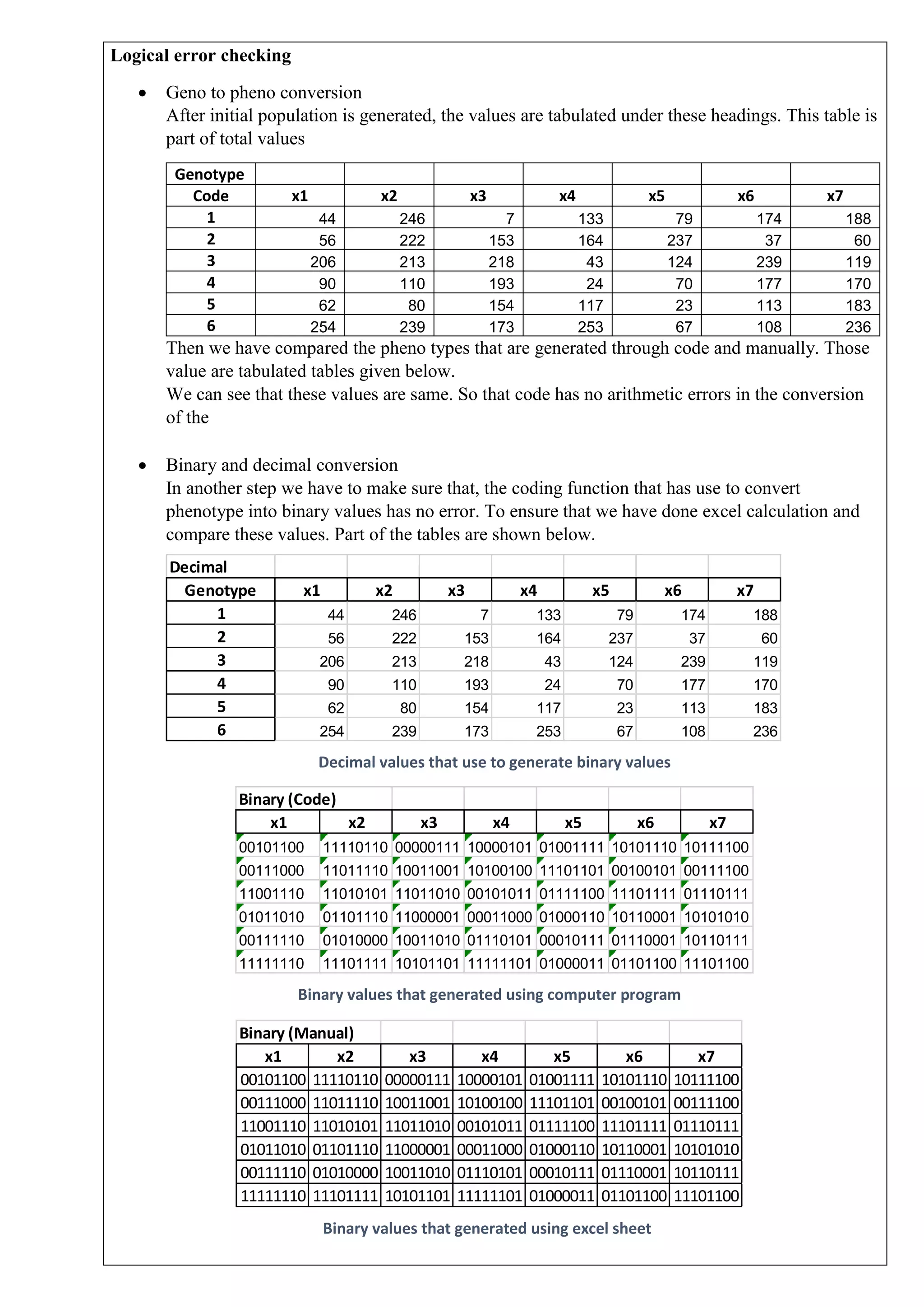
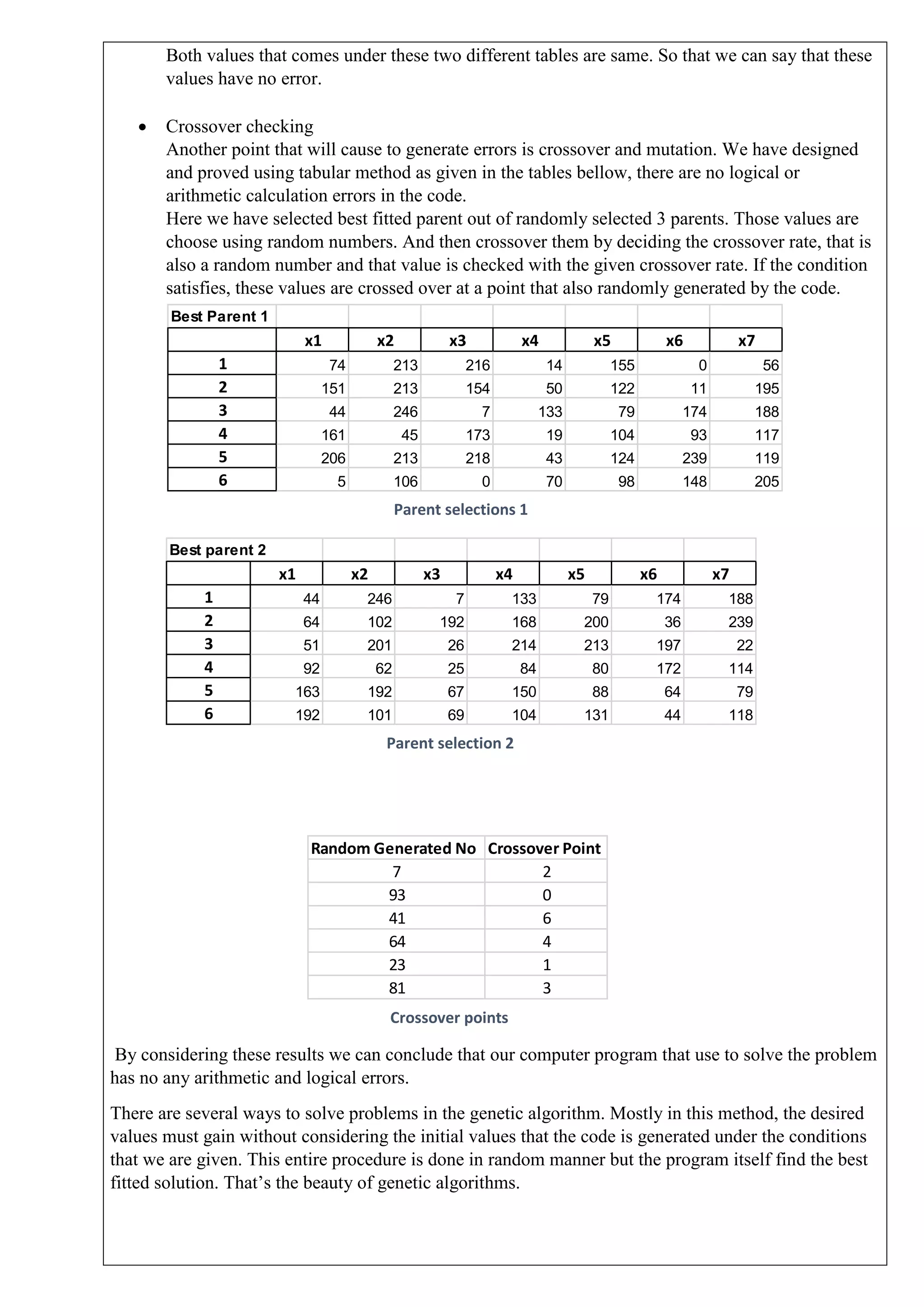
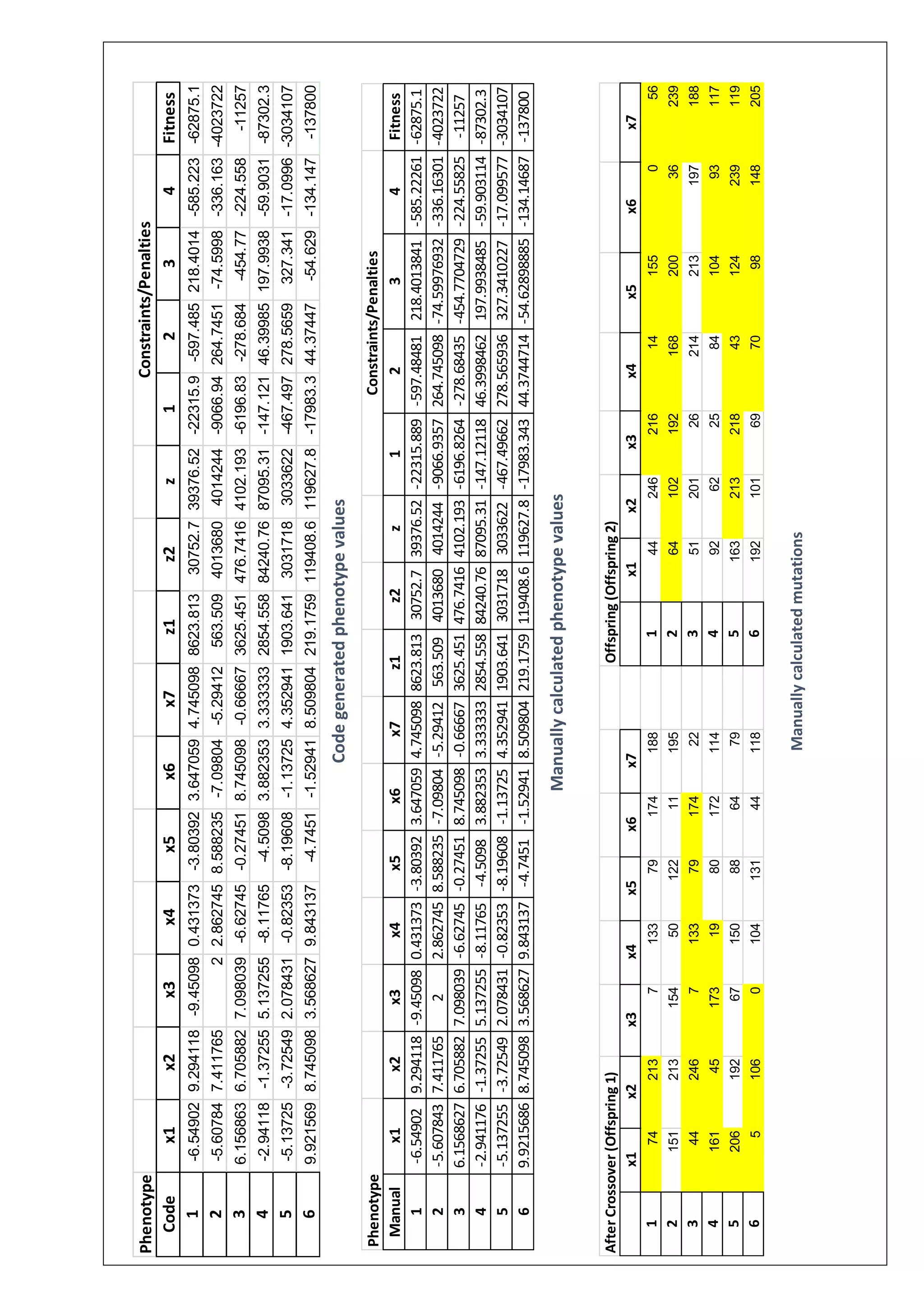


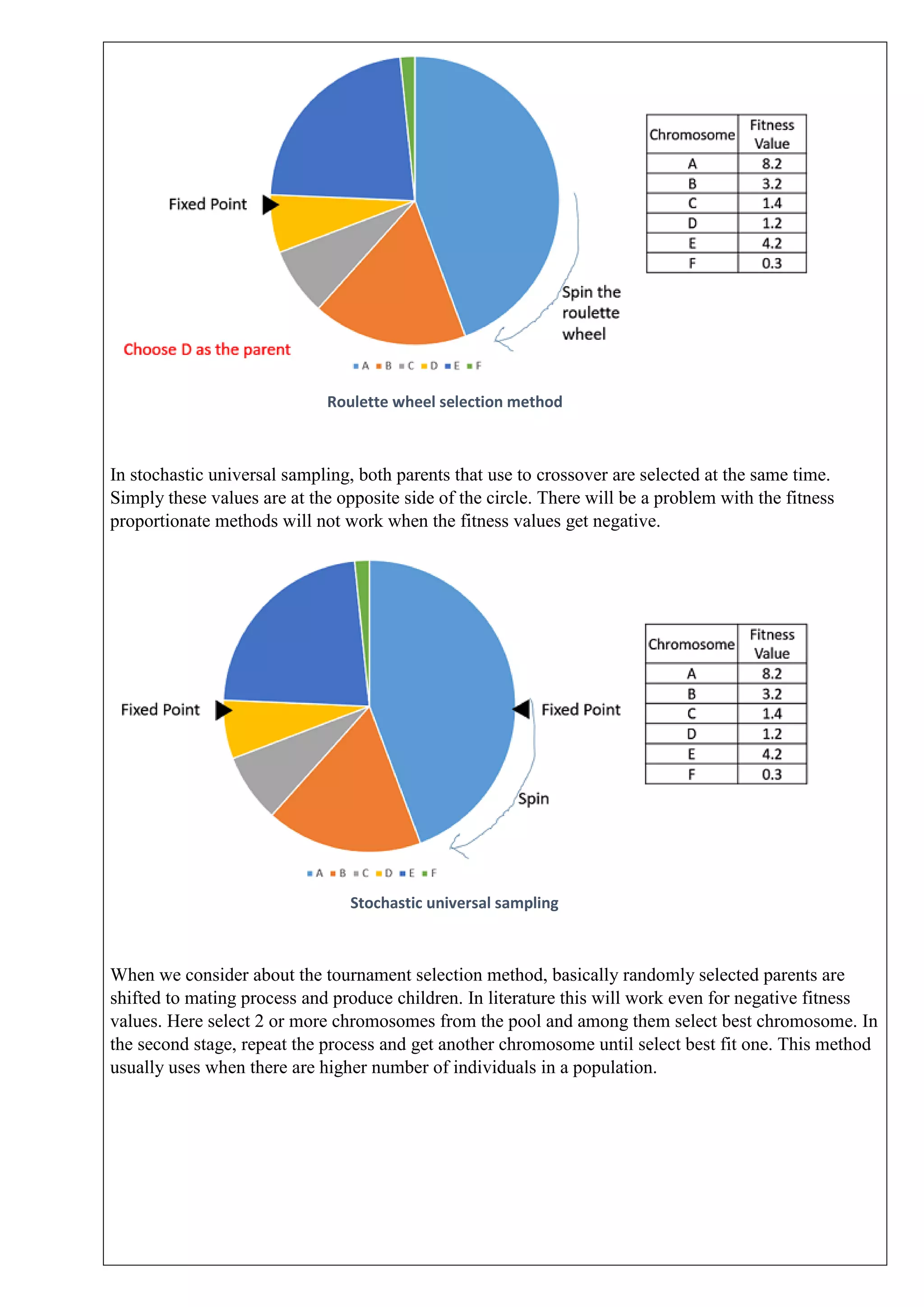




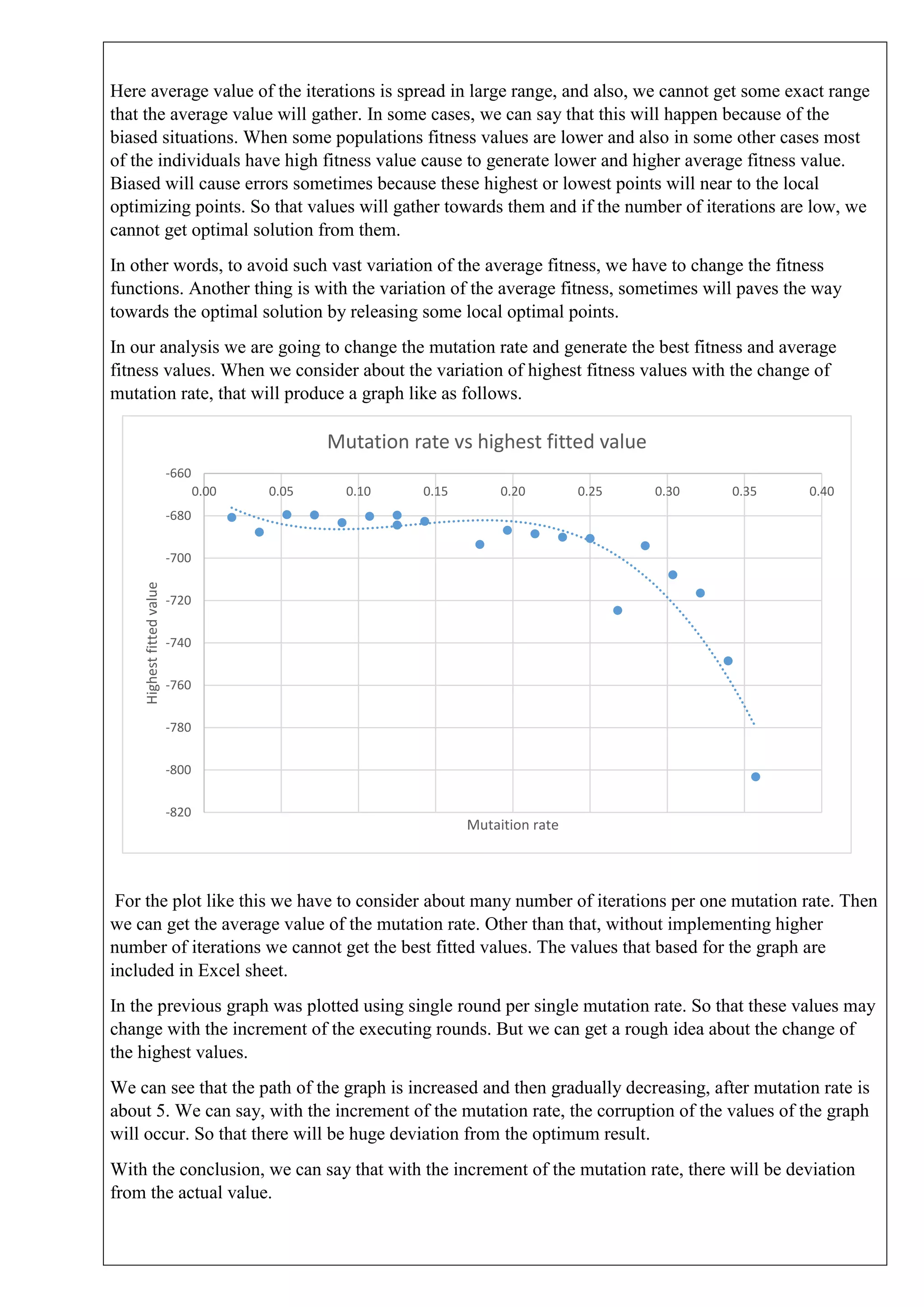
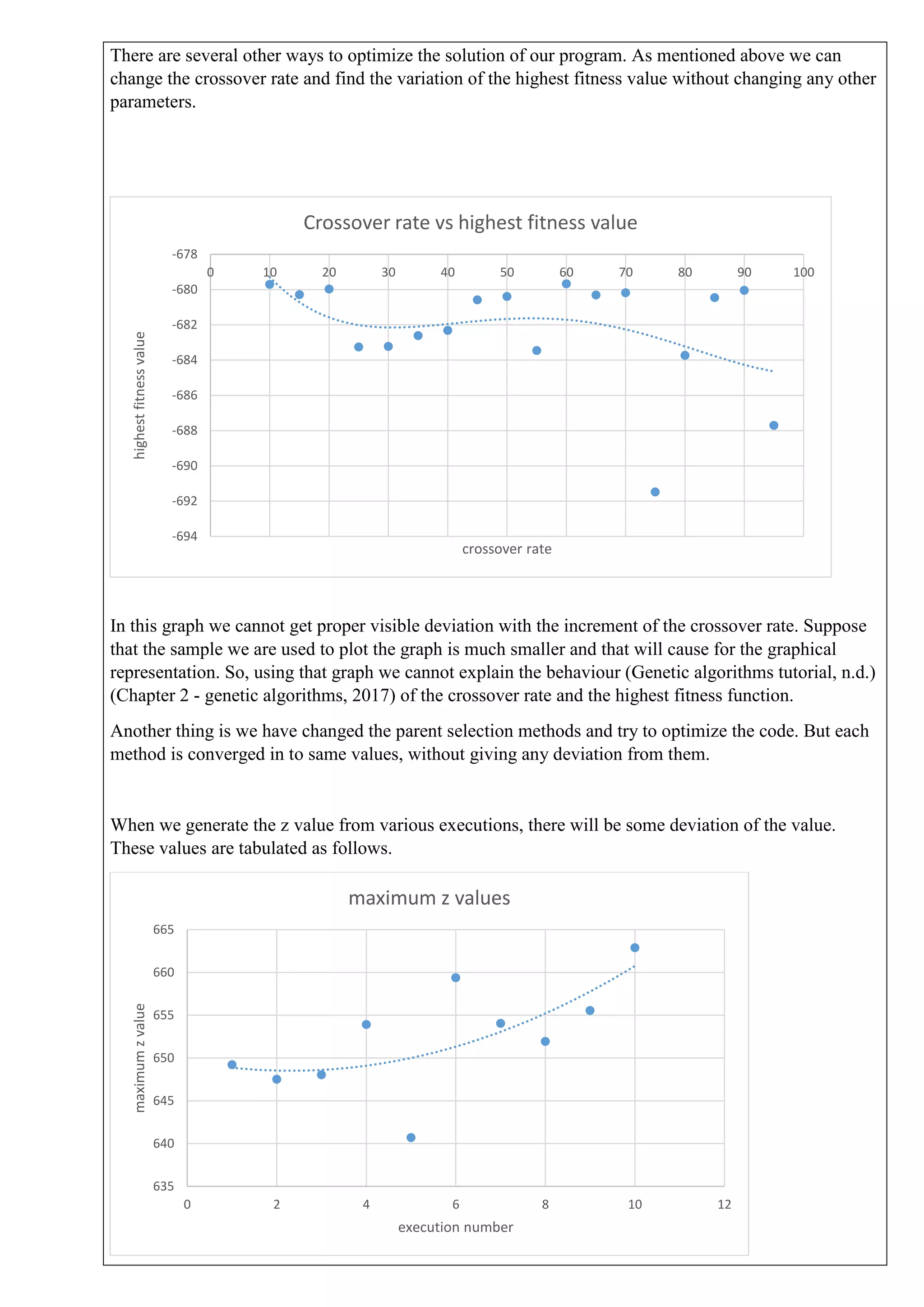

This document describes solving a non-linear programming minimization problem using a genetic algorithm. It discusses: 1) How genetic algorithms work and how they are applied to solve optimization problems. 2) The steps of the genetic algorithm used: initializing the population randomly, decoding genotypes to phenotypes, evaluating fitness, selecting parents, performing crossover and mutation to generate offspring, and selecting the next generation. 3) The specific non-linear problem to be solved, including defining the objective function and constraints. The genetic algorithm parameters and programming concepts used to find the minimum are also described.