Download to read offline






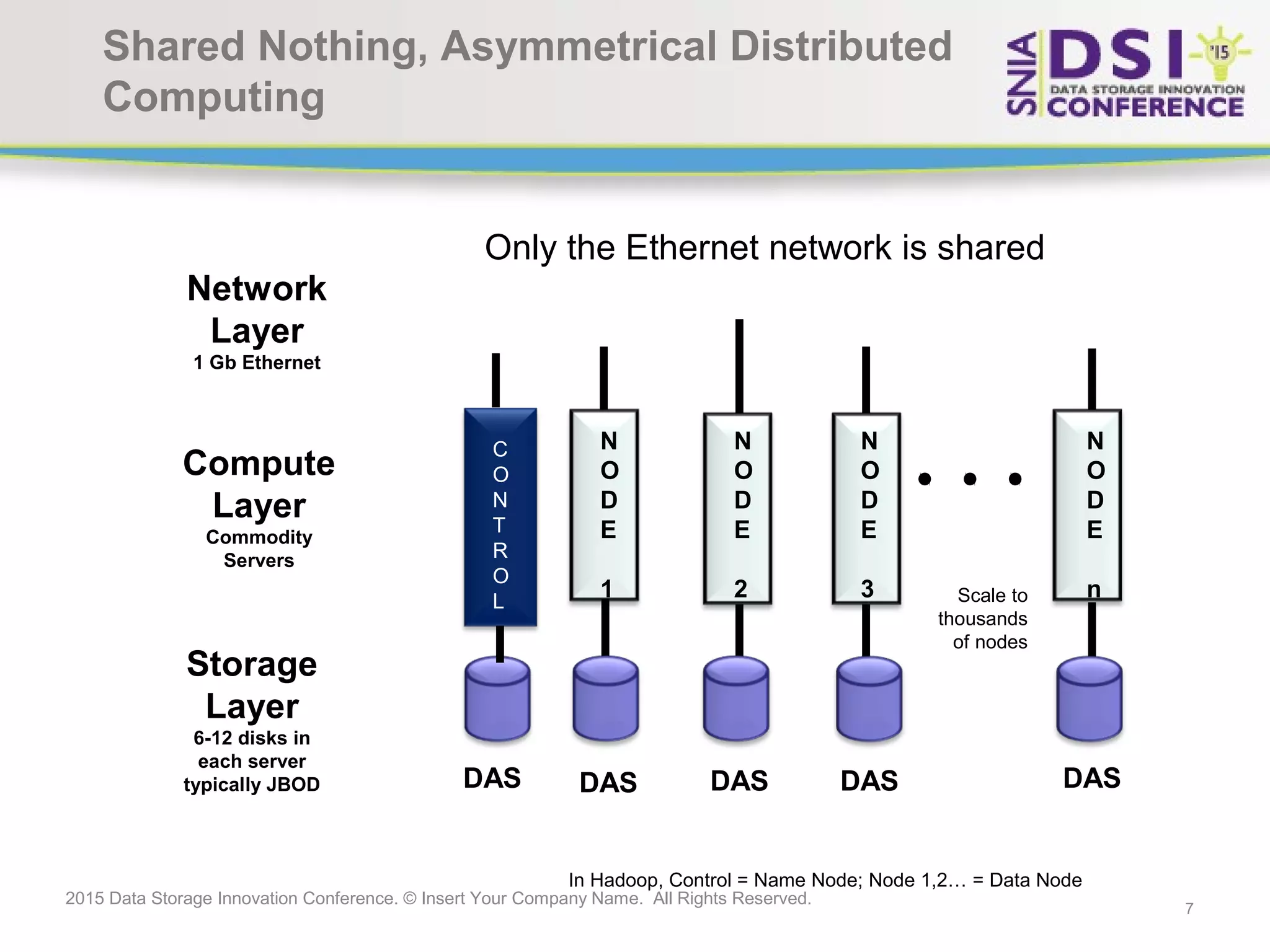
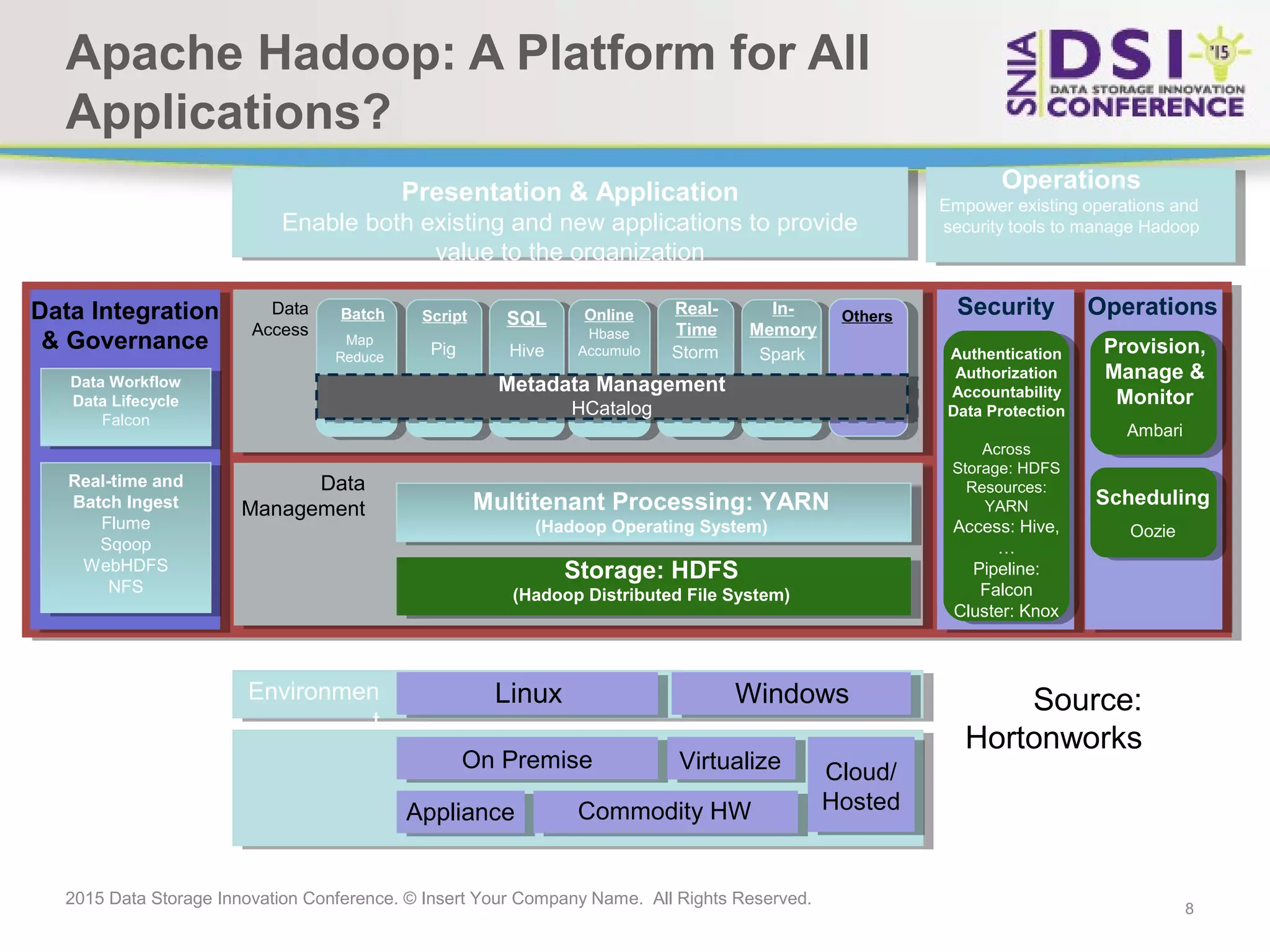

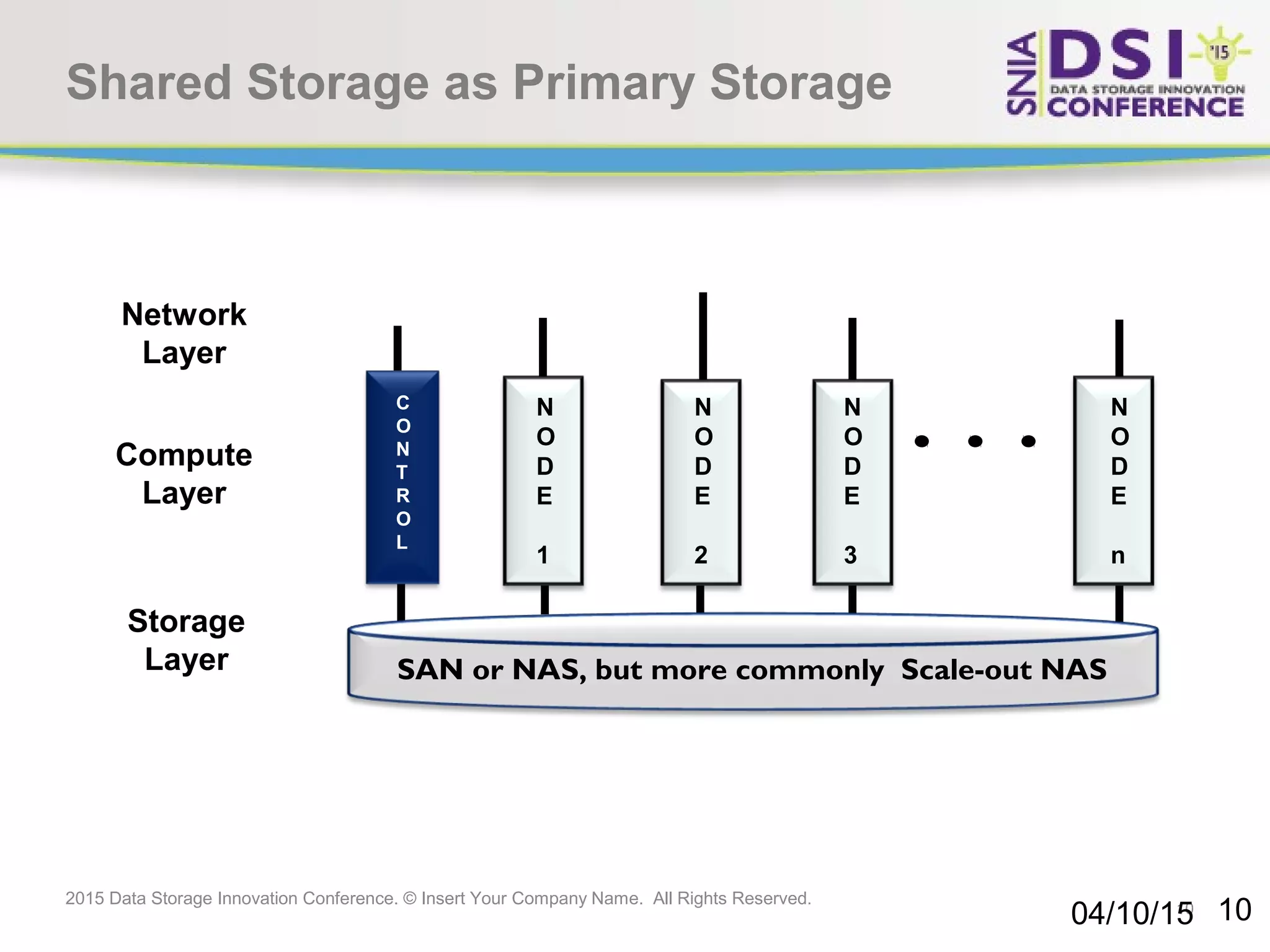
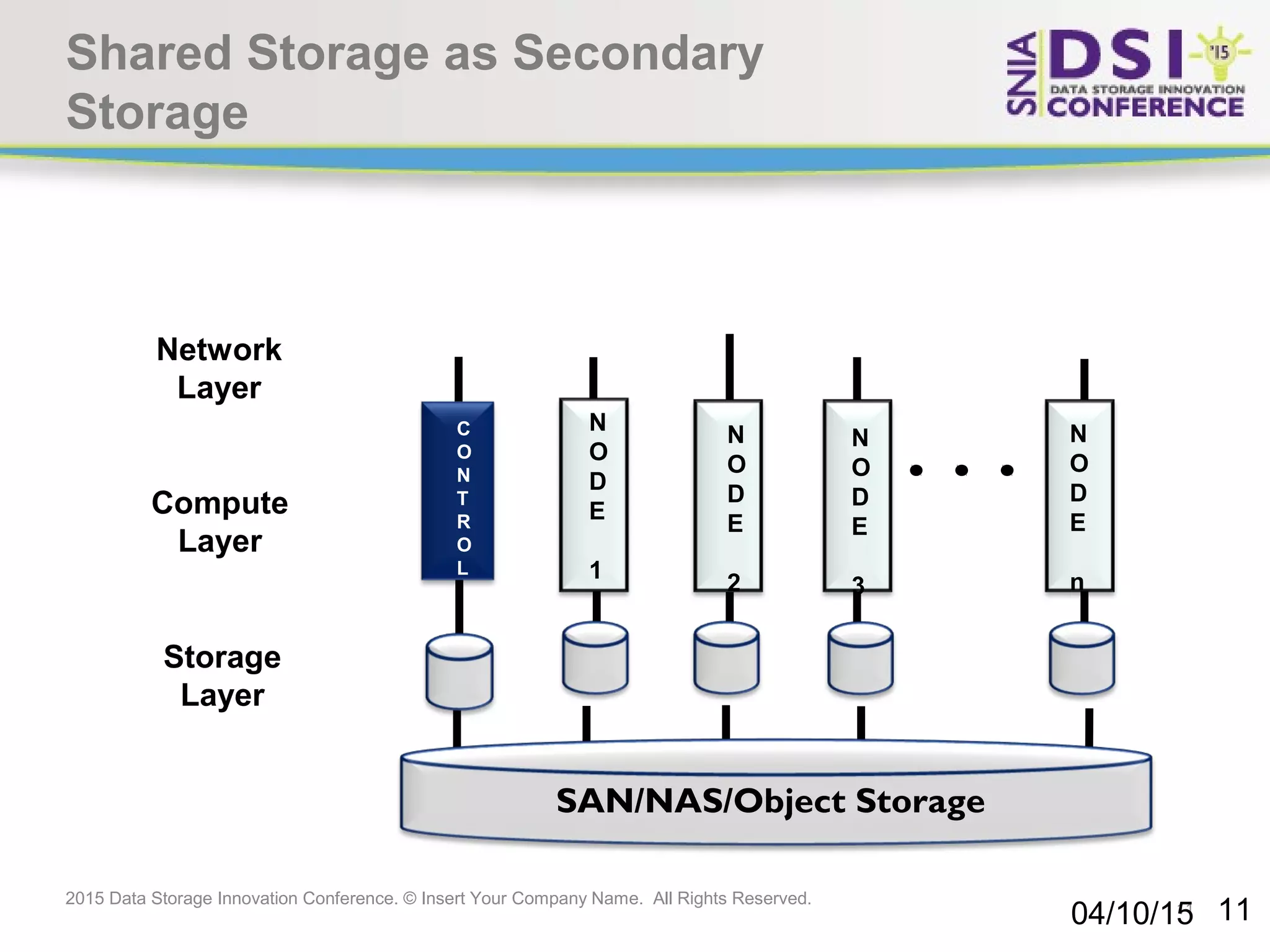
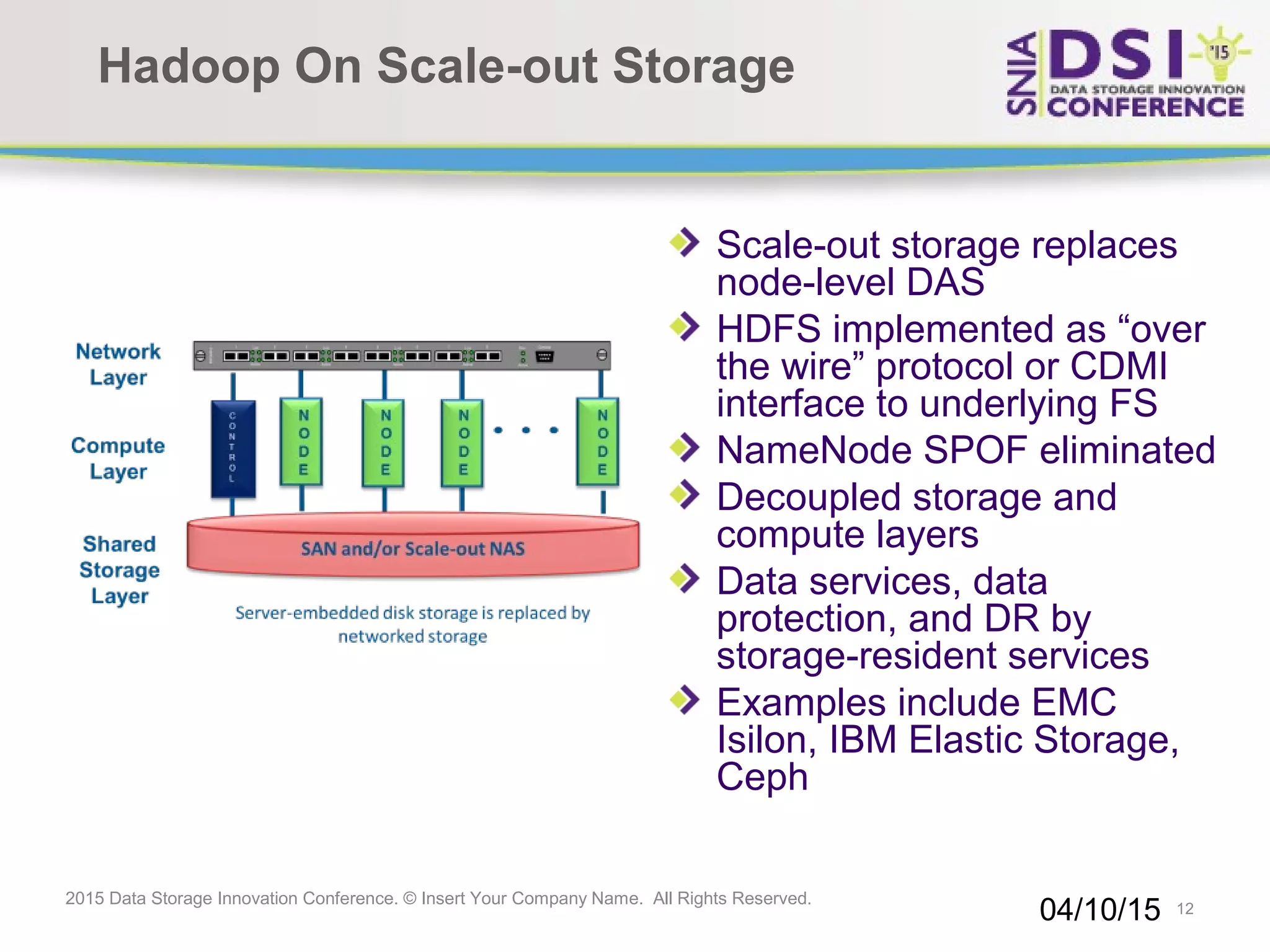

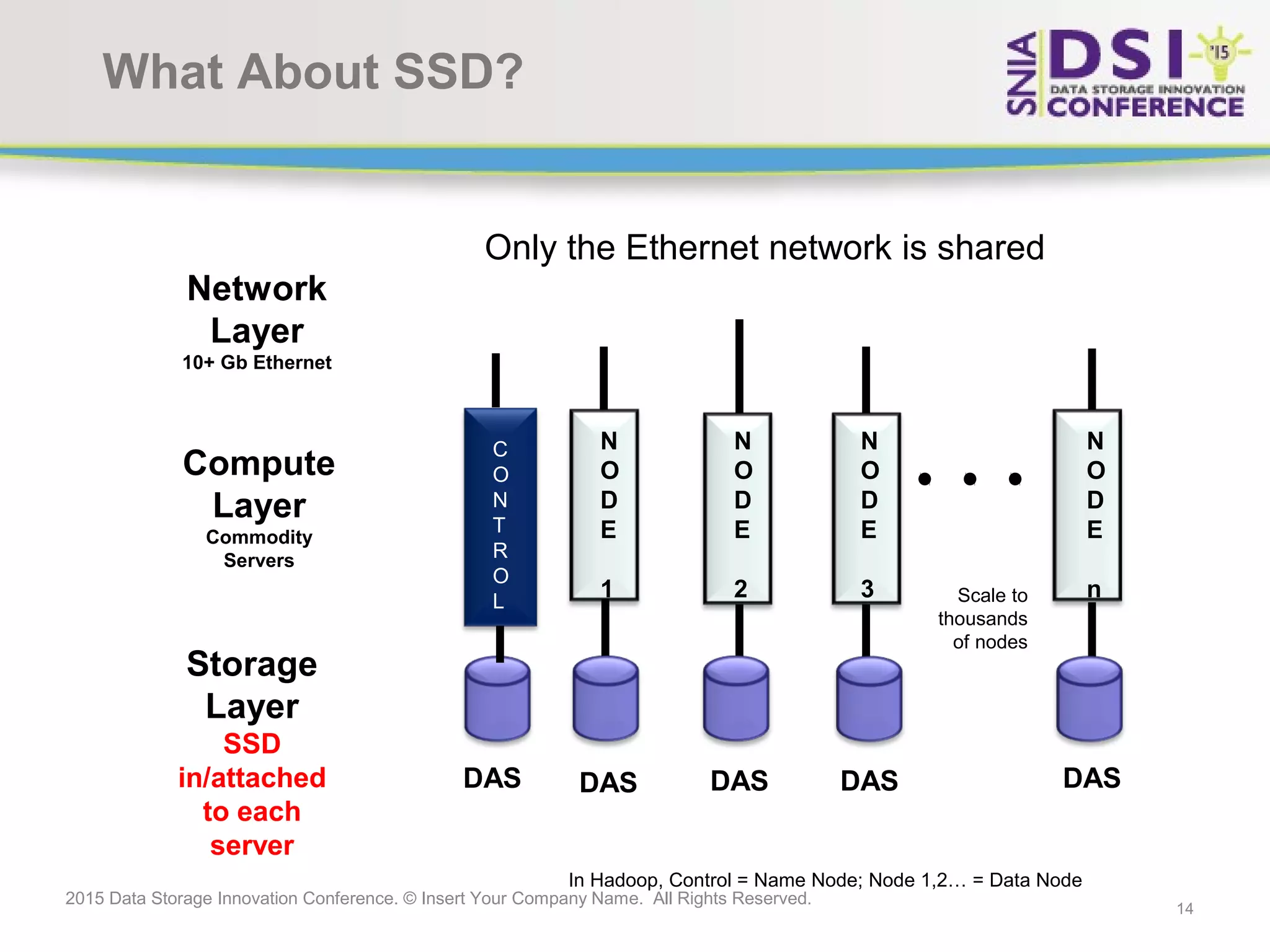
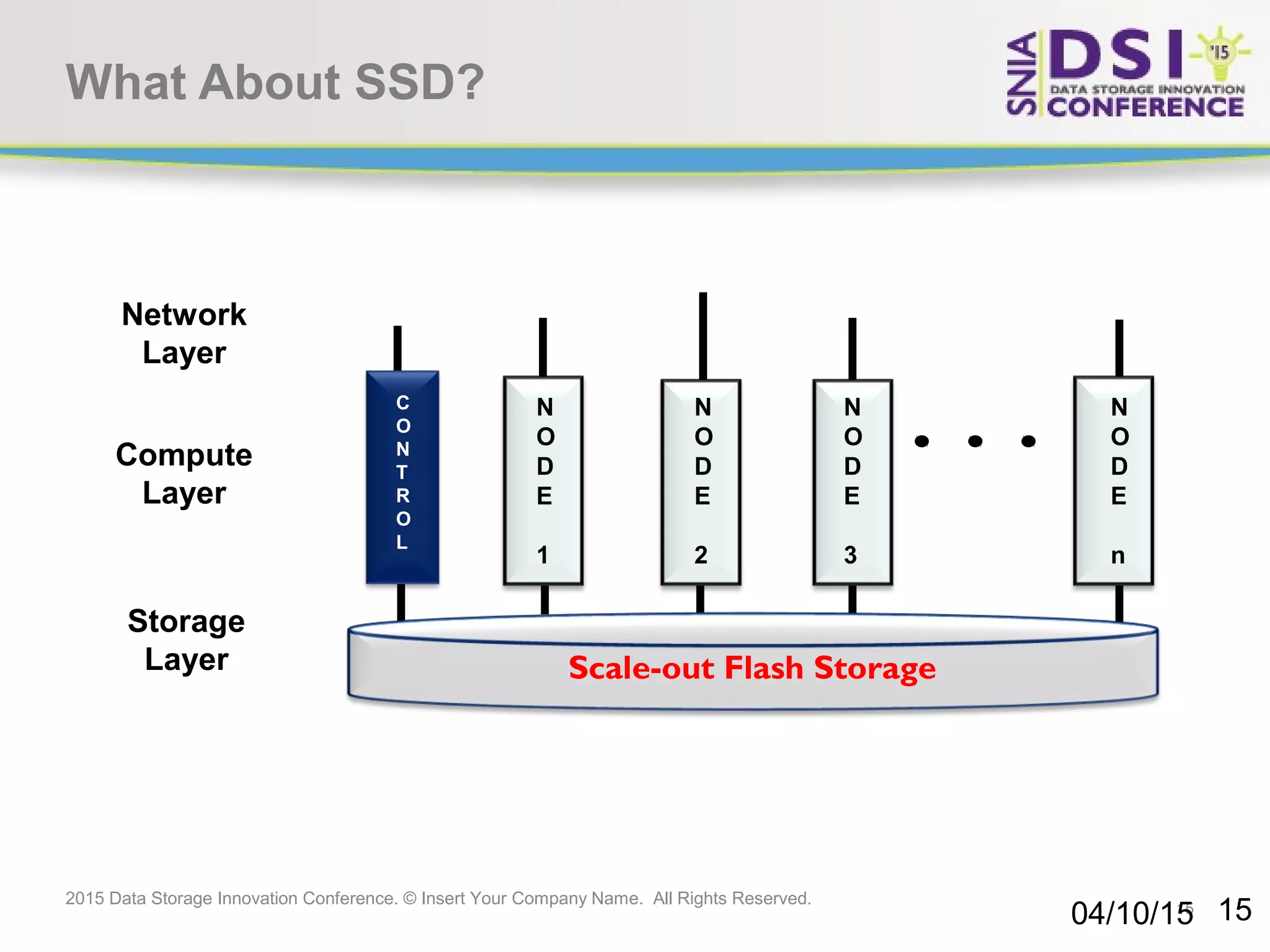




The document discusses the challenges and solutions in big data storage at the 2015 Data Storage Innovation Conference, emphasizing the need for high-performance, scalable storage that minimizes the distance between processing and data. It highlights the advantages and disadvantages of various architectures, including Hadoop, SSD, and in-memory computing. The conclusion stresses the importance of a long-term storage solution, involving enterprise storage architects in managing big data analytics.