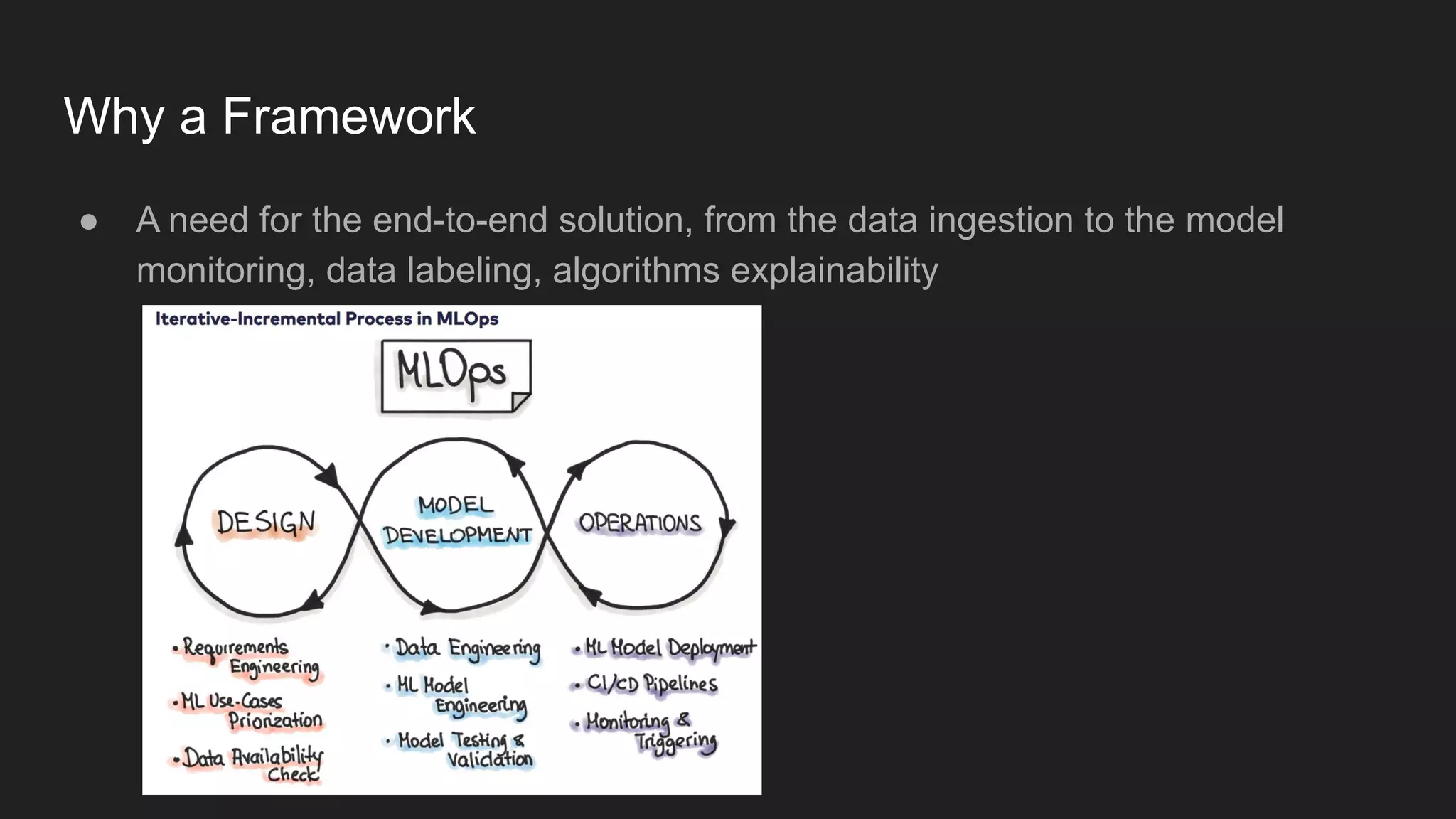
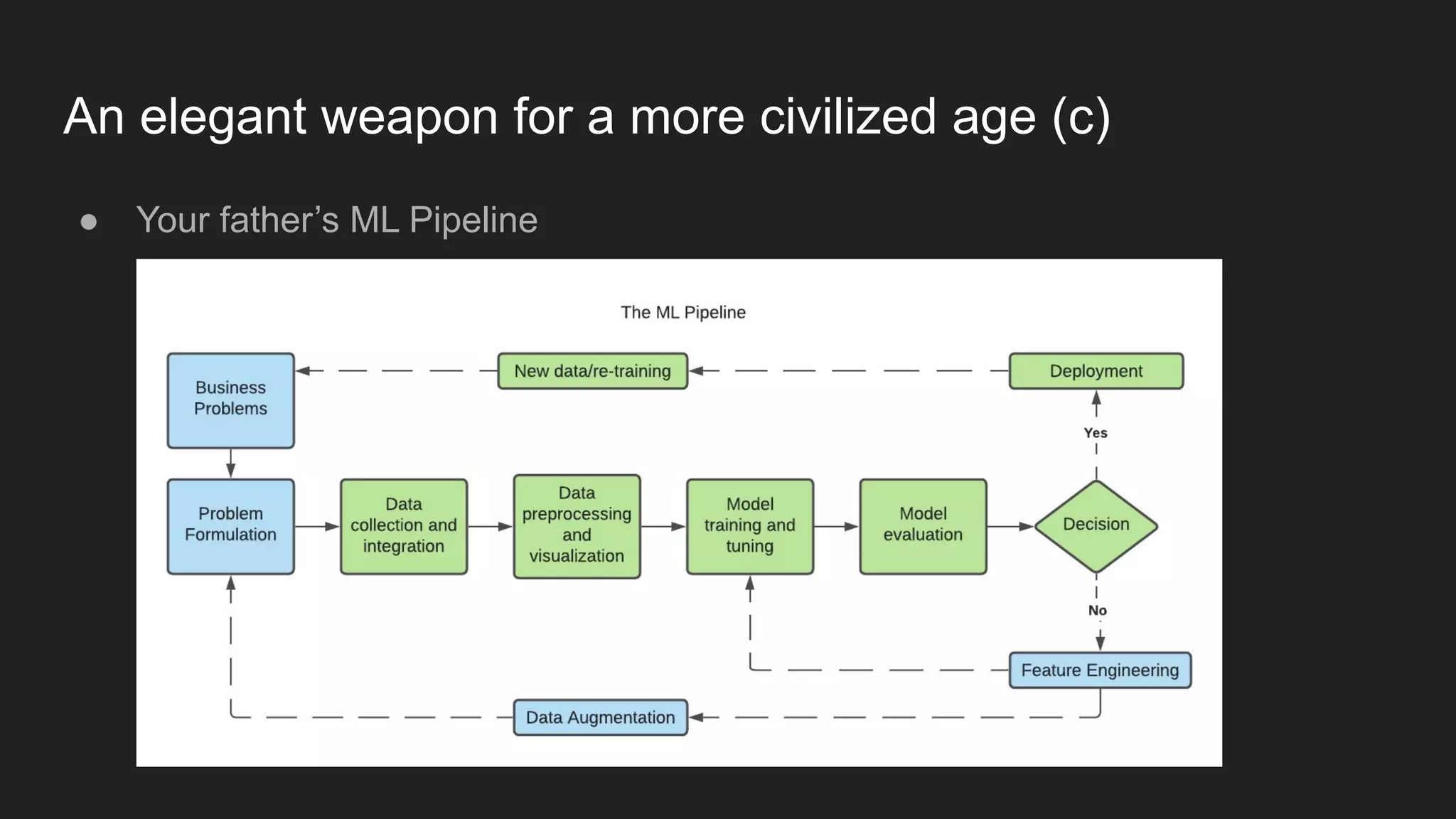
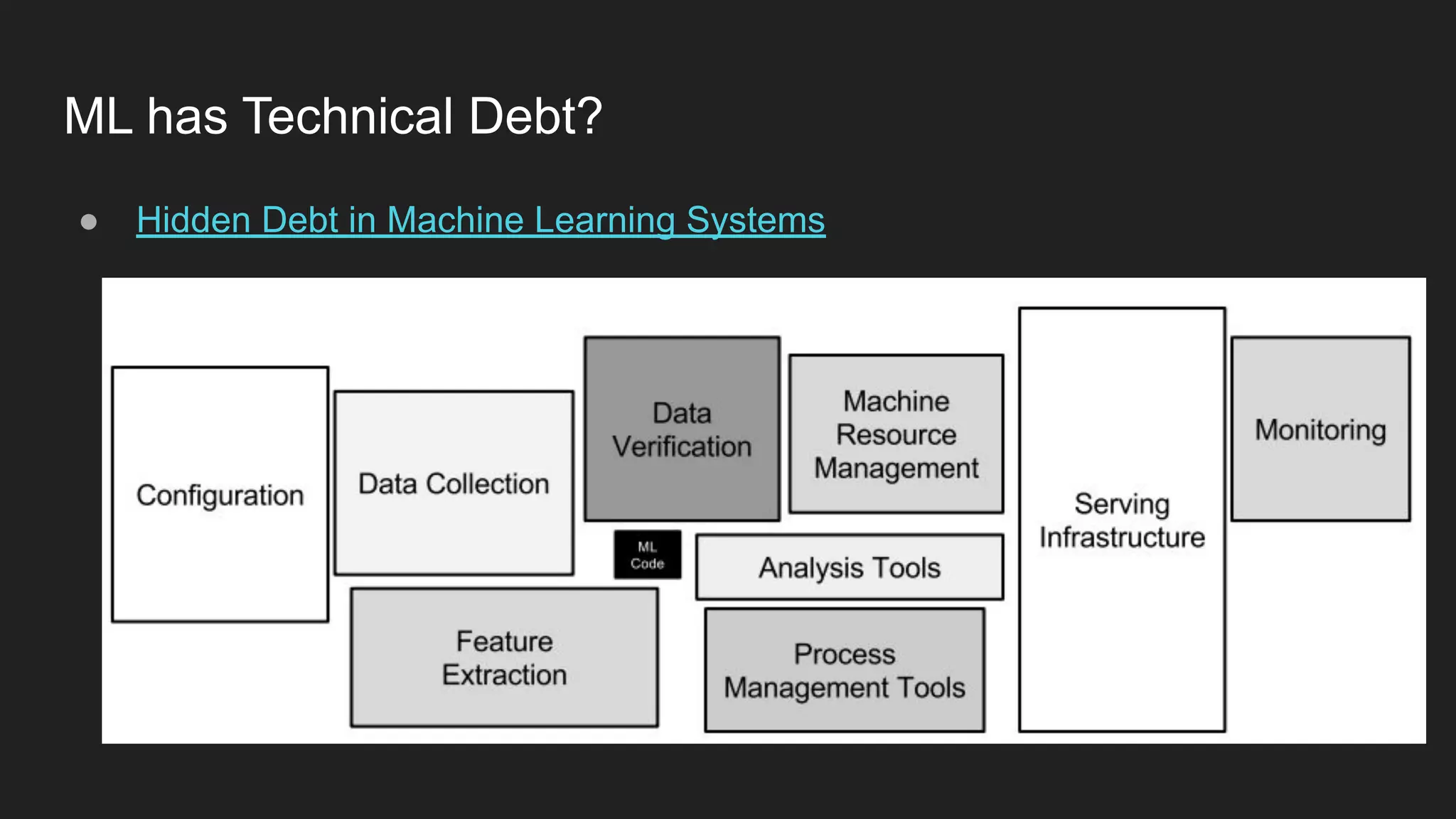
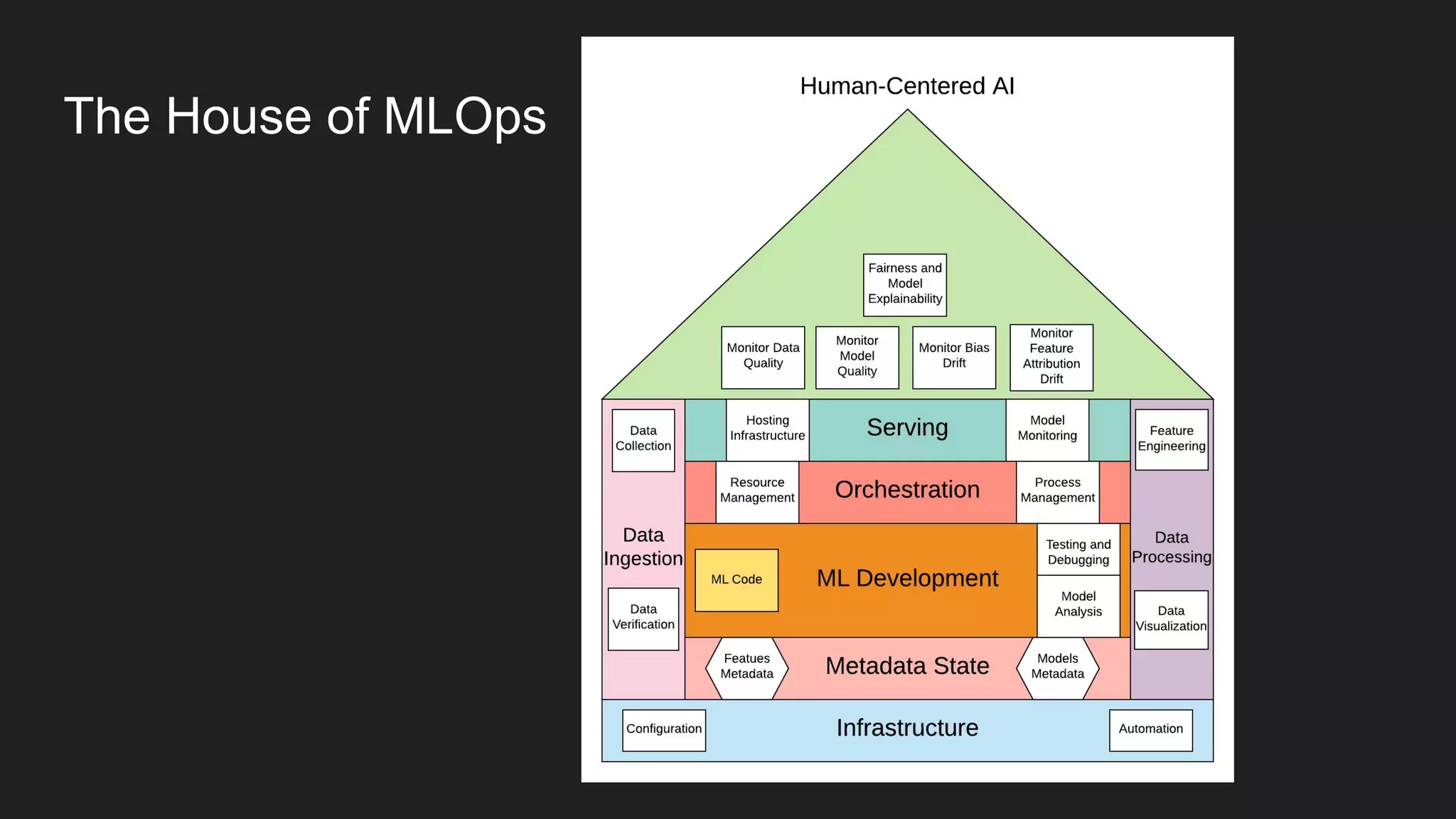
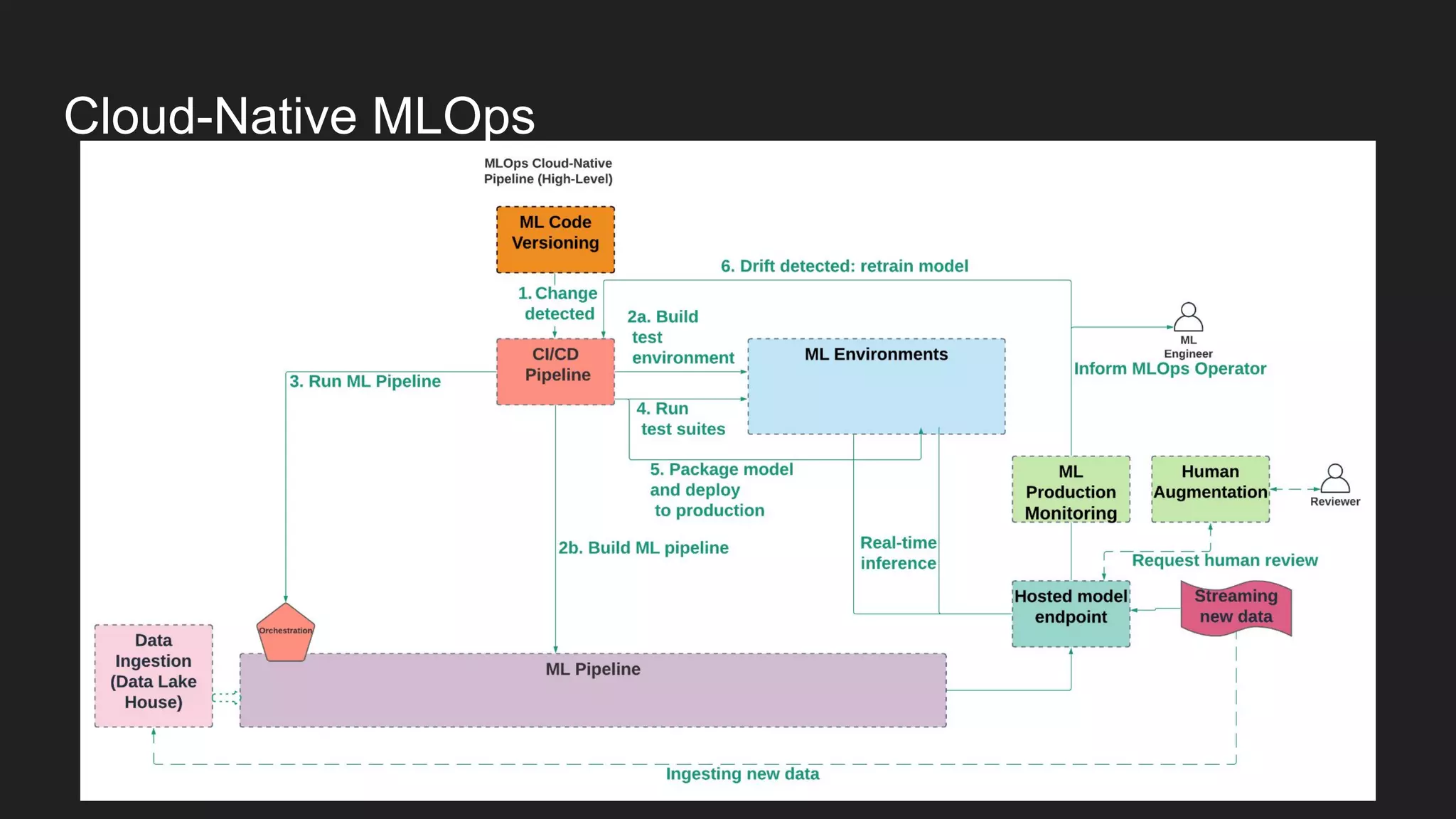
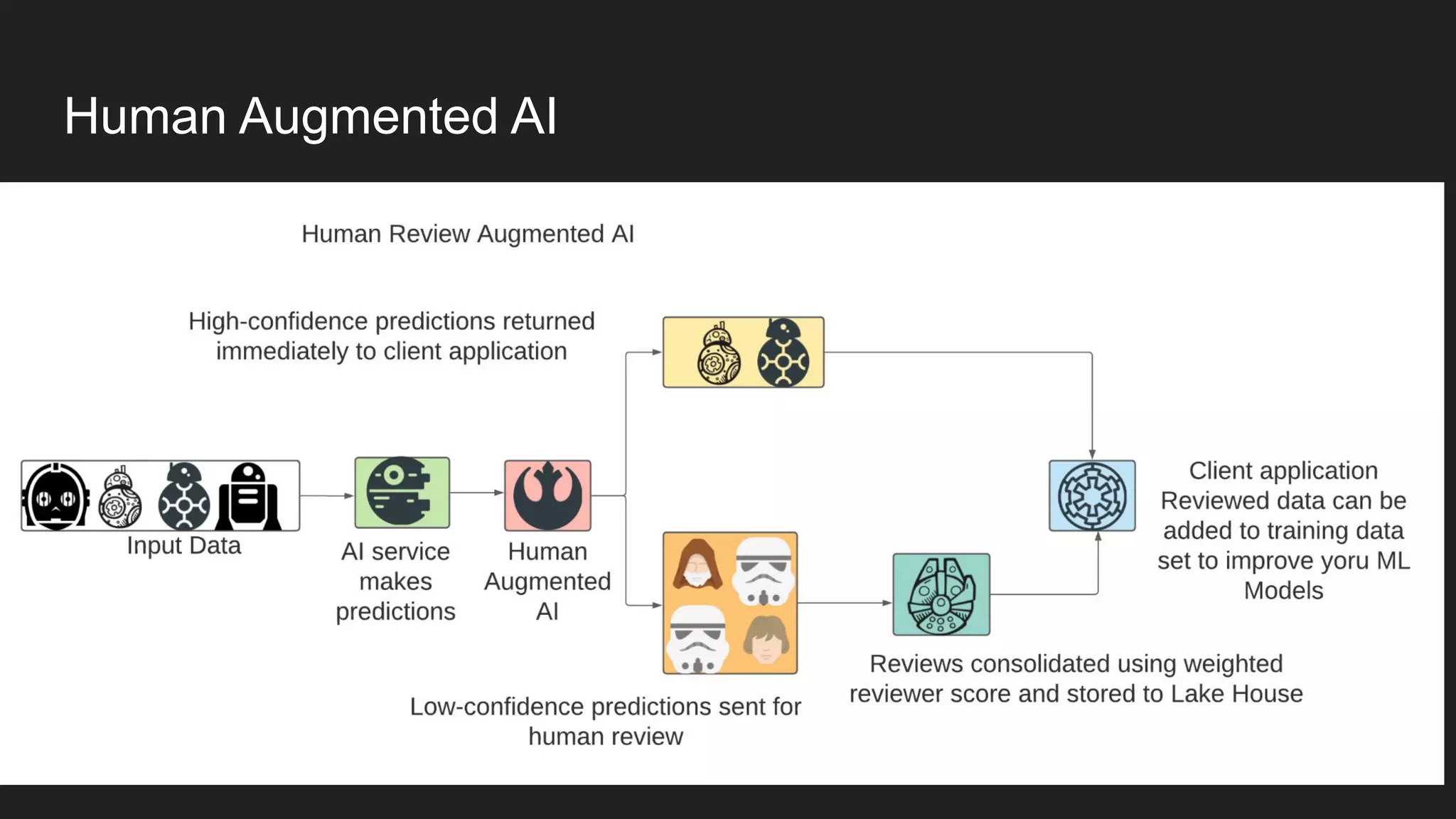
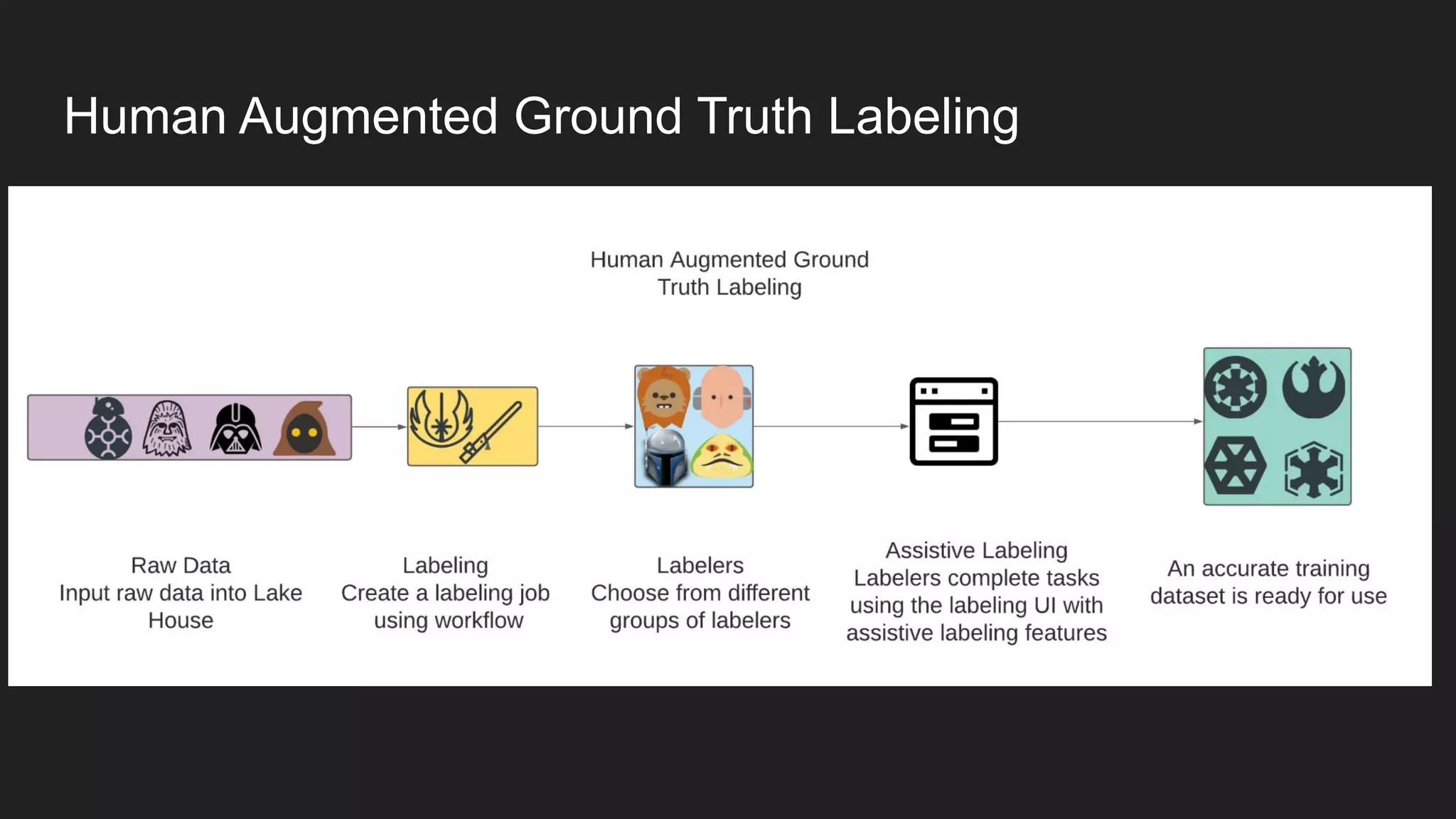
Artem Koval presented on cloud-native MLOps frameworks. MLOps is a process for deploying and monitoring machine learning models through continuous integration and delivery. It addresses fairness, explainability, model monitoring, and human intervention. Modern MLOps frameworks focus on these areas as well as data labeling, testing, and observability. Different levels of MLOps are needed depending on an organization's size, from lightweight for small teams to enterprise-level for large companies with many models. Human-centered AI should be incorporated at all levels by involving humans throughout the entire machine learning process.