Download to read offline






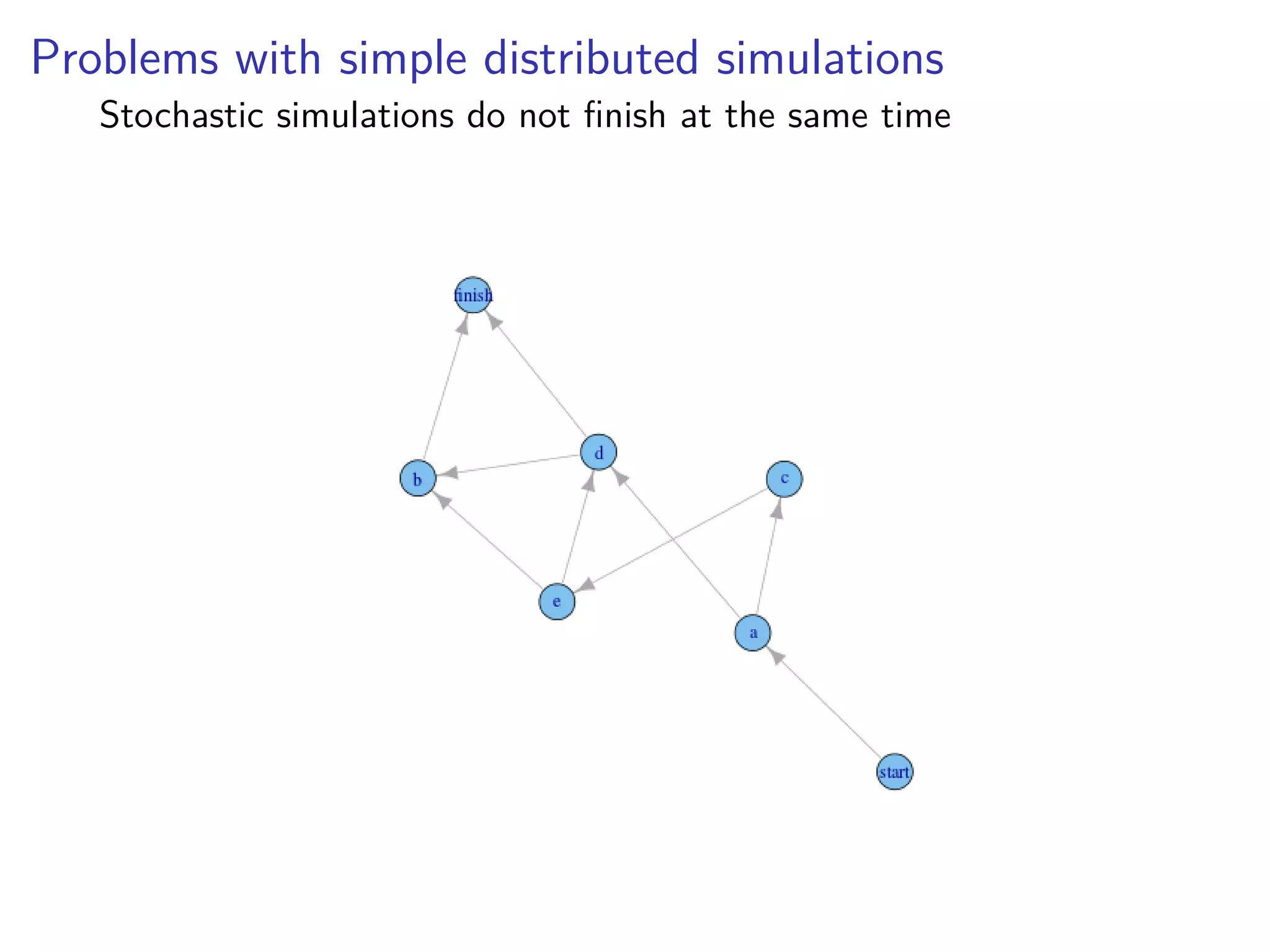











1. The document discusses different approaches to parallelizing 10 million stochastic simulations across 10 scenarios, including distributing simulations across instances, using Redis, and using Dask. 2. Dask was ultimately found to be the fastest and easiest approach, allowing simulations to be run in Python using Kubernetes for elastic scaling. 3. However, the document notes that modeling the simulations directly in R may have been preferable to recreating the model in Python.