Download as PDF, PPTX






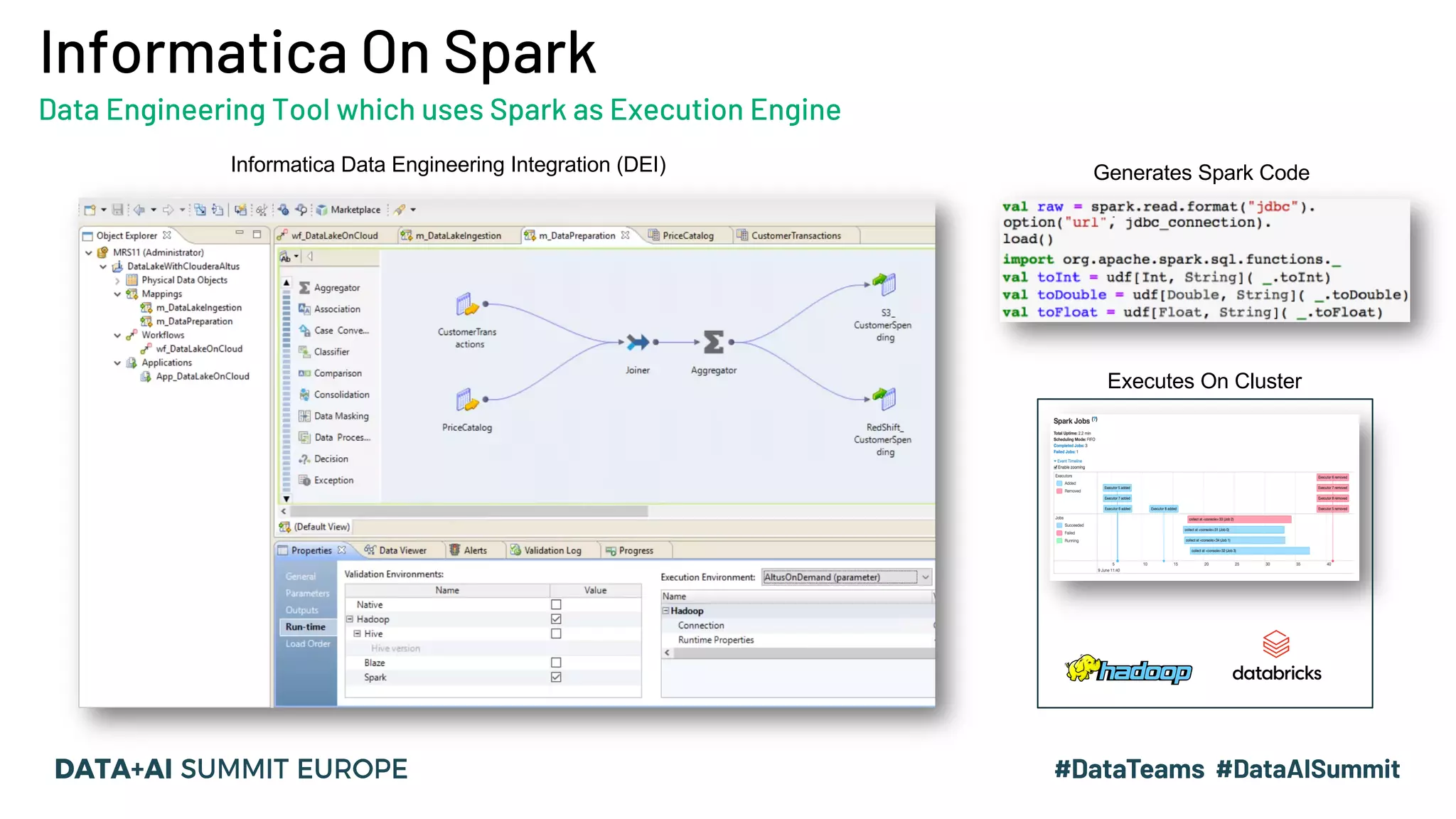
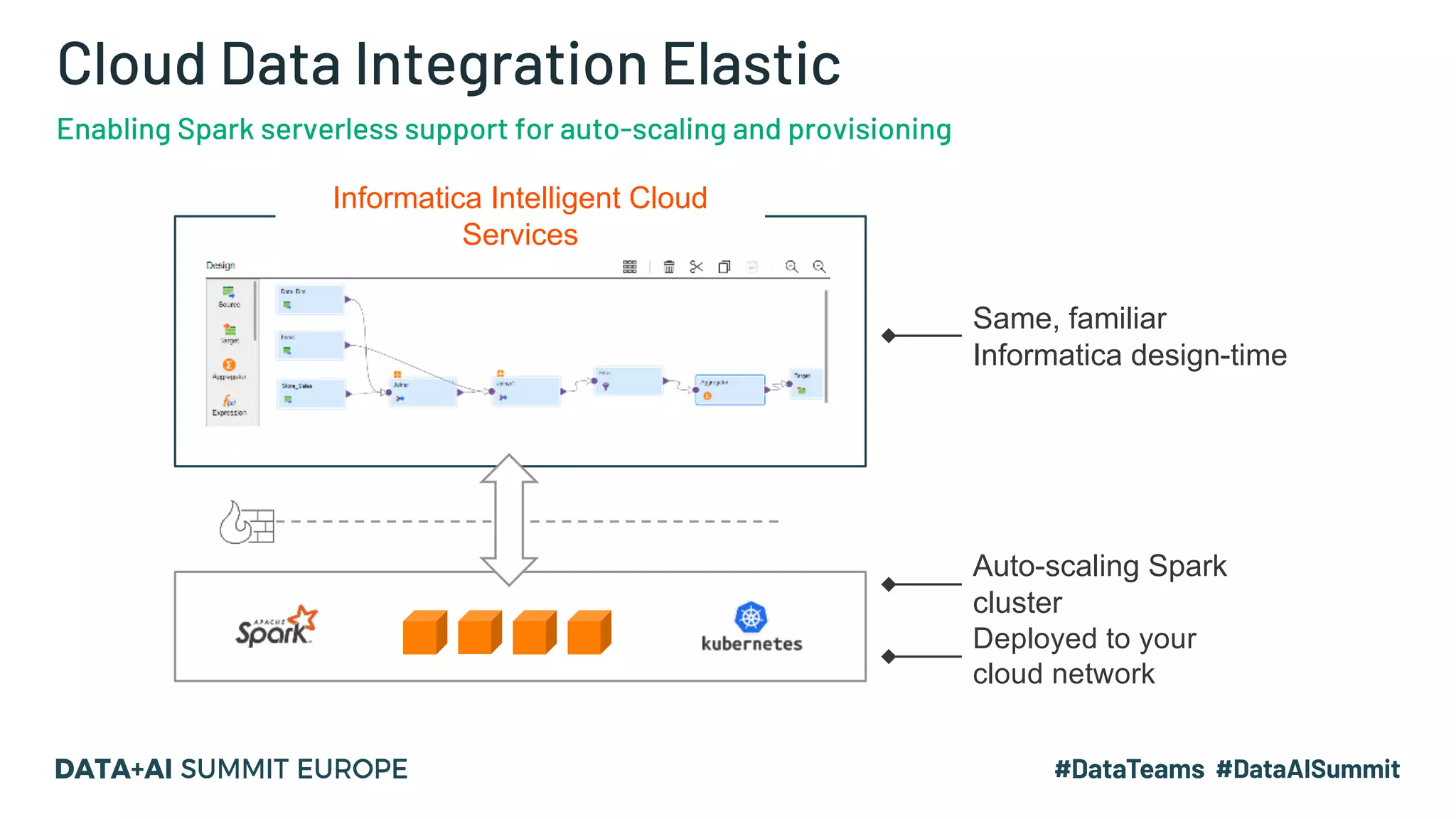

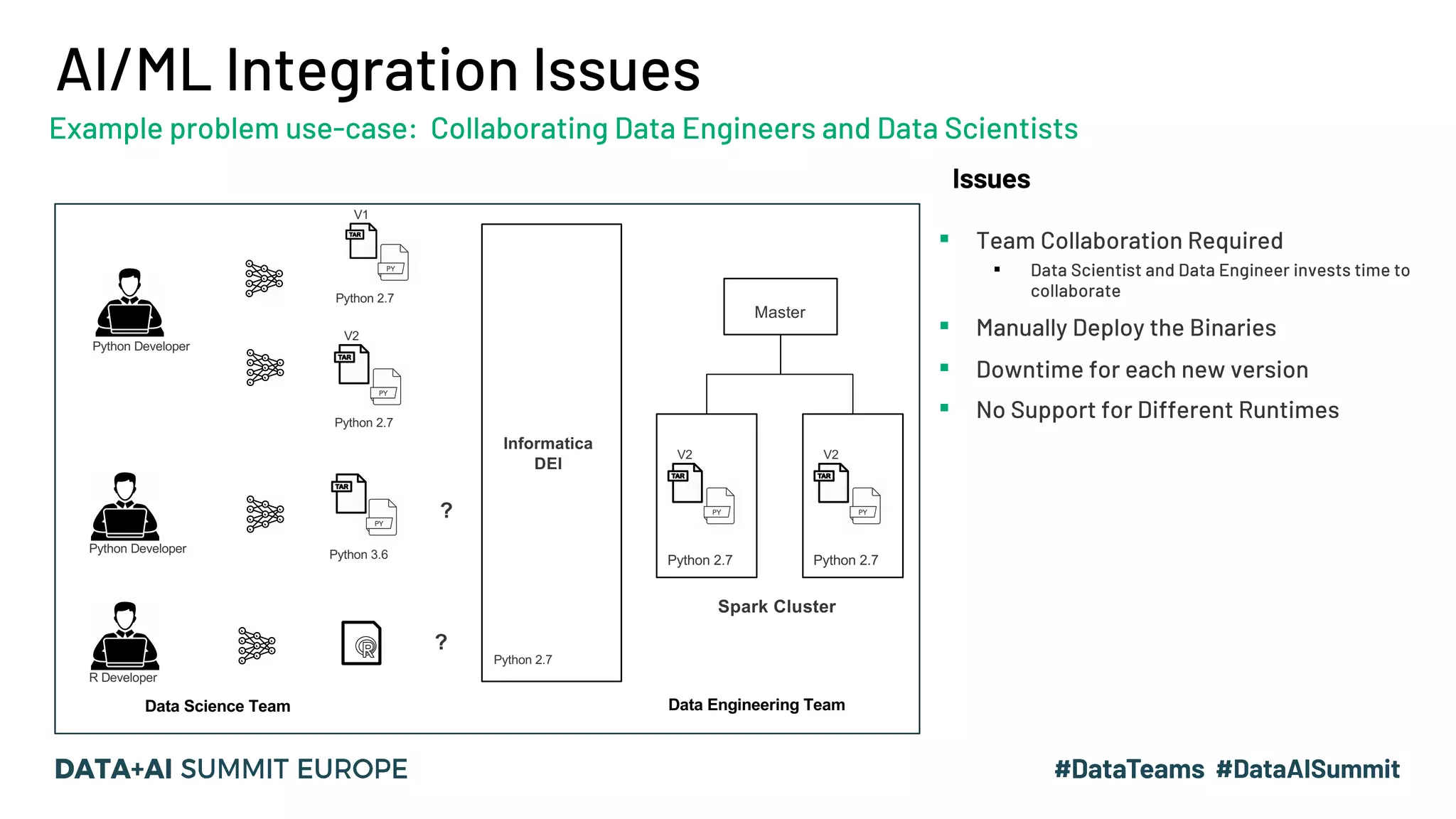

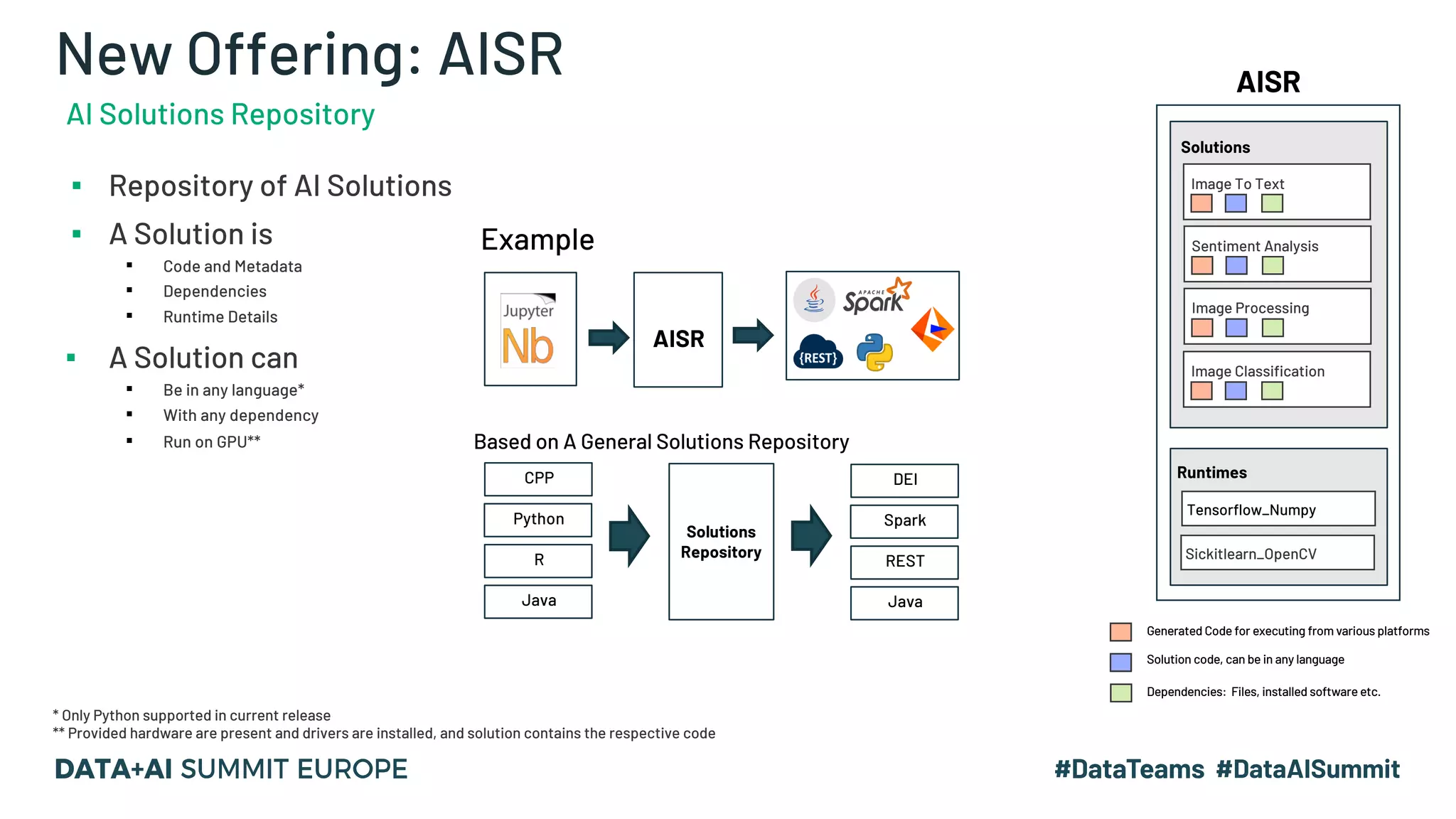
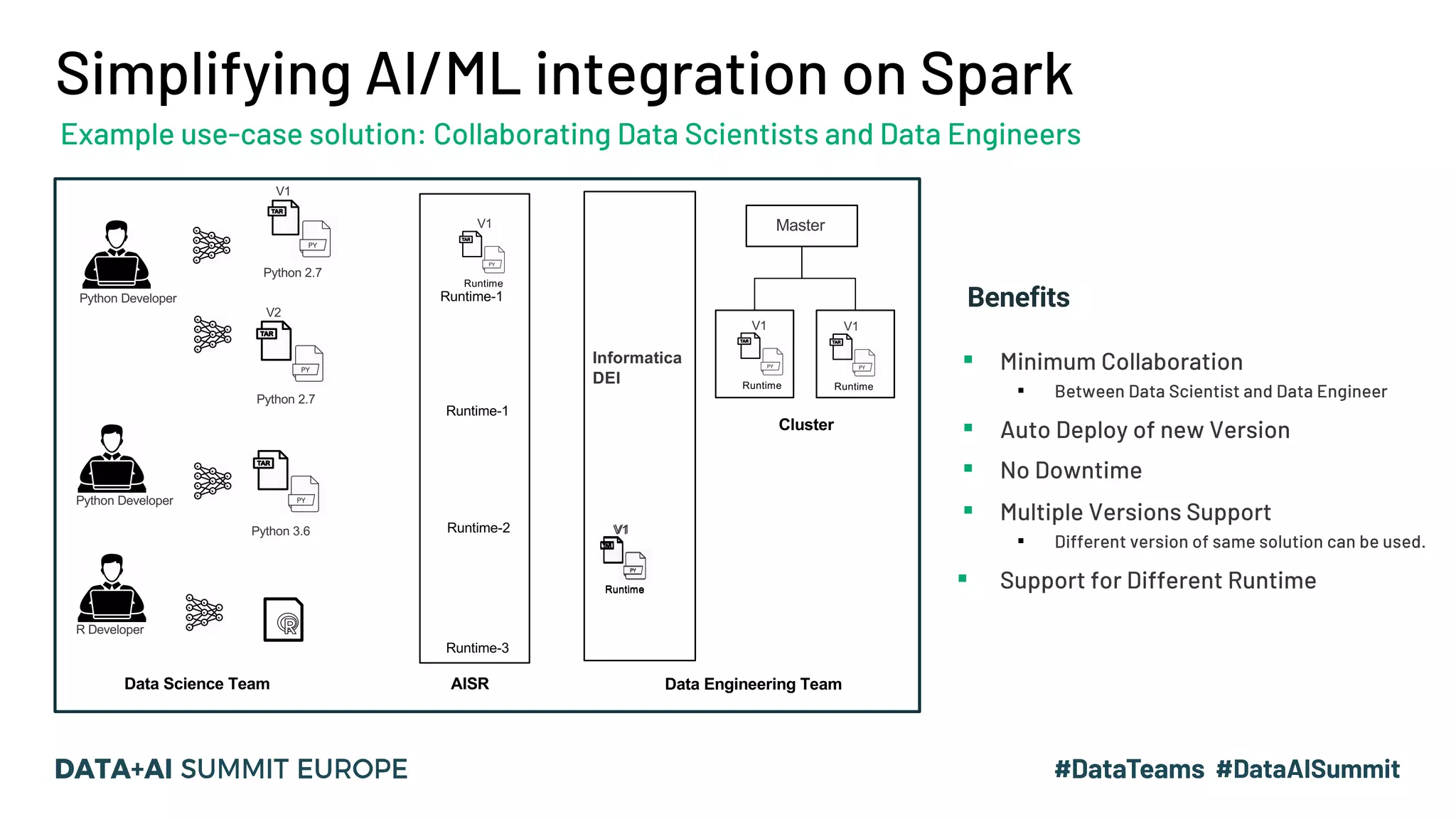

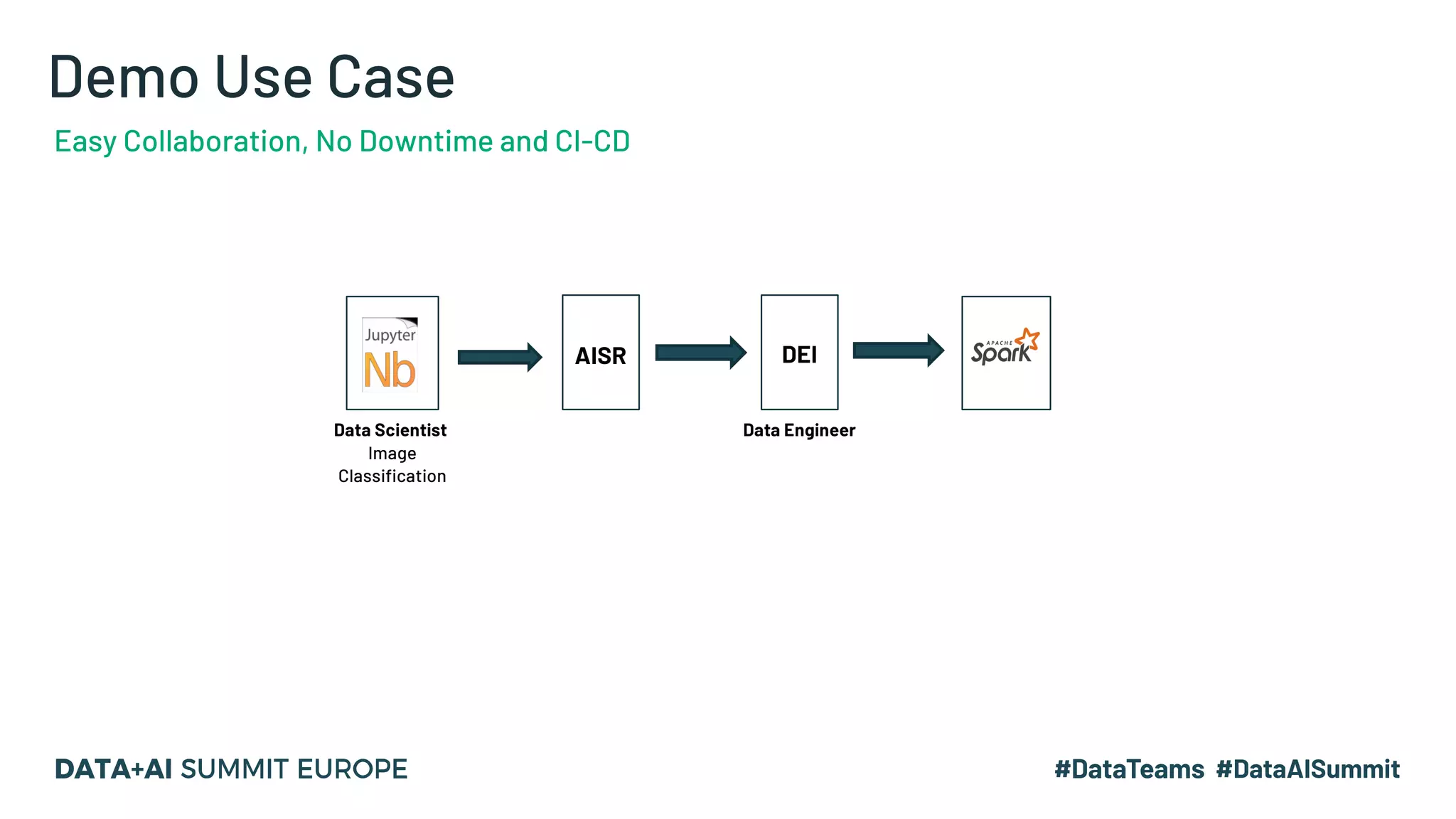
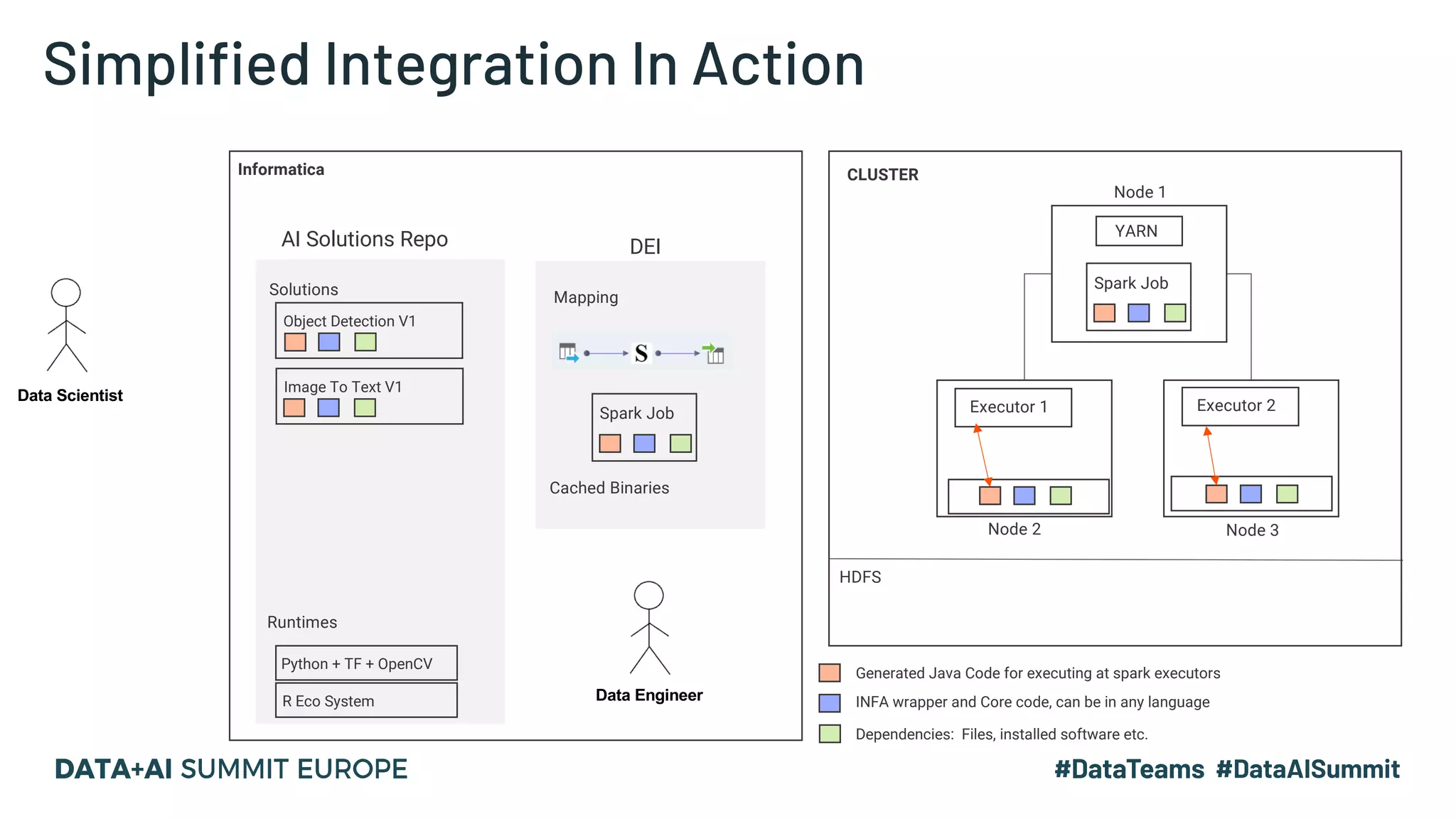
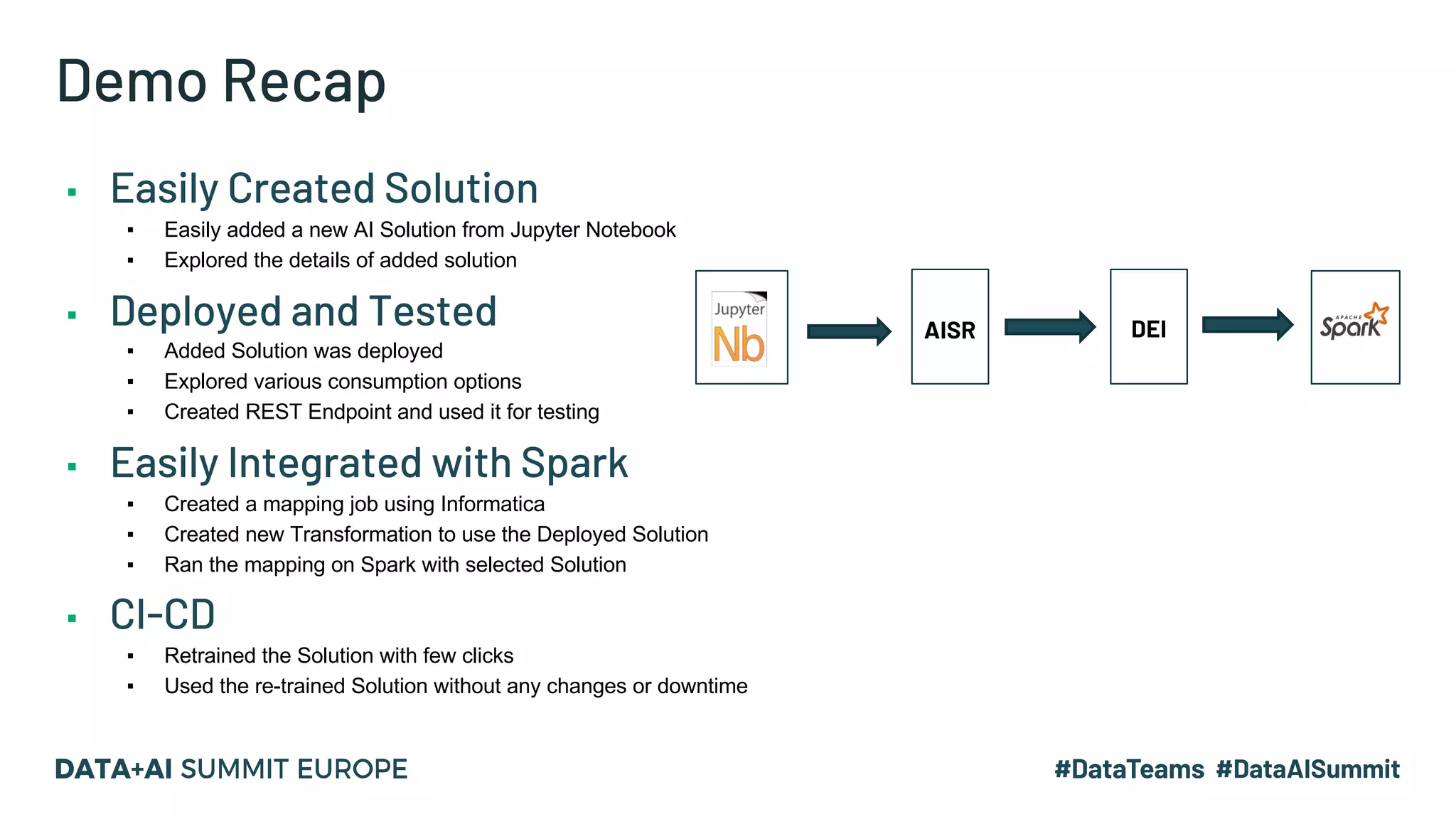




The document outlines a presentation by Hemshankar Sahu, a principal software engineer at Informatica, focusing on simplifying AI integration in Spark through new offerings like AISR. It addresses the challenges faced by data scientists and engineers in operationalizing machine learning algorithms and introduces solutions that minimize collaboration efforts, support faster deployments, and enhance processing efficiency within Spark clusters. Key features of the AISR include a repository for AI solutions, automatic deployment, multi-version support, and a built-in CI/CD process that reduces production costs.