Downloaded 264 times














![Expanding on the previous example To add properties to the “Creator”, point through an intermediate resource (the ellipses are resources and the rectangles are literals or text strings): http://www.w3.org/Home/Lassila s:Creator Person://fi/654645635 Name Ora Lassila [email_address] Email](https://image.slidesharecdn.com/20060526aedinburghwww2006-1209475188024136-8/75/Semantic-Web-2-0-Creating-Social-Semantic-Information-Spaces-20-2048.jpg)
![Expanded RDF example shown in RDF/XML <rdf:Description about=“ http://www.w3.org/Home/Lassila ”> <Creator rdf:resource=“ Person://fi/654645635 ”/> </rdf:Description> <rdf:Description about=“ Person://fi/654645635 ”> <Name> Ora Lassila </Name> <Email> [email_address] </Email> </rdf:Description>](https://image.slidesharecdn.com/20060526aedinburghwww2006-1209475188024136-8/75/Semantic-Web-2-0-Creating-Social-Semantic-Information-Spaces-21-2048.jpg)



































































































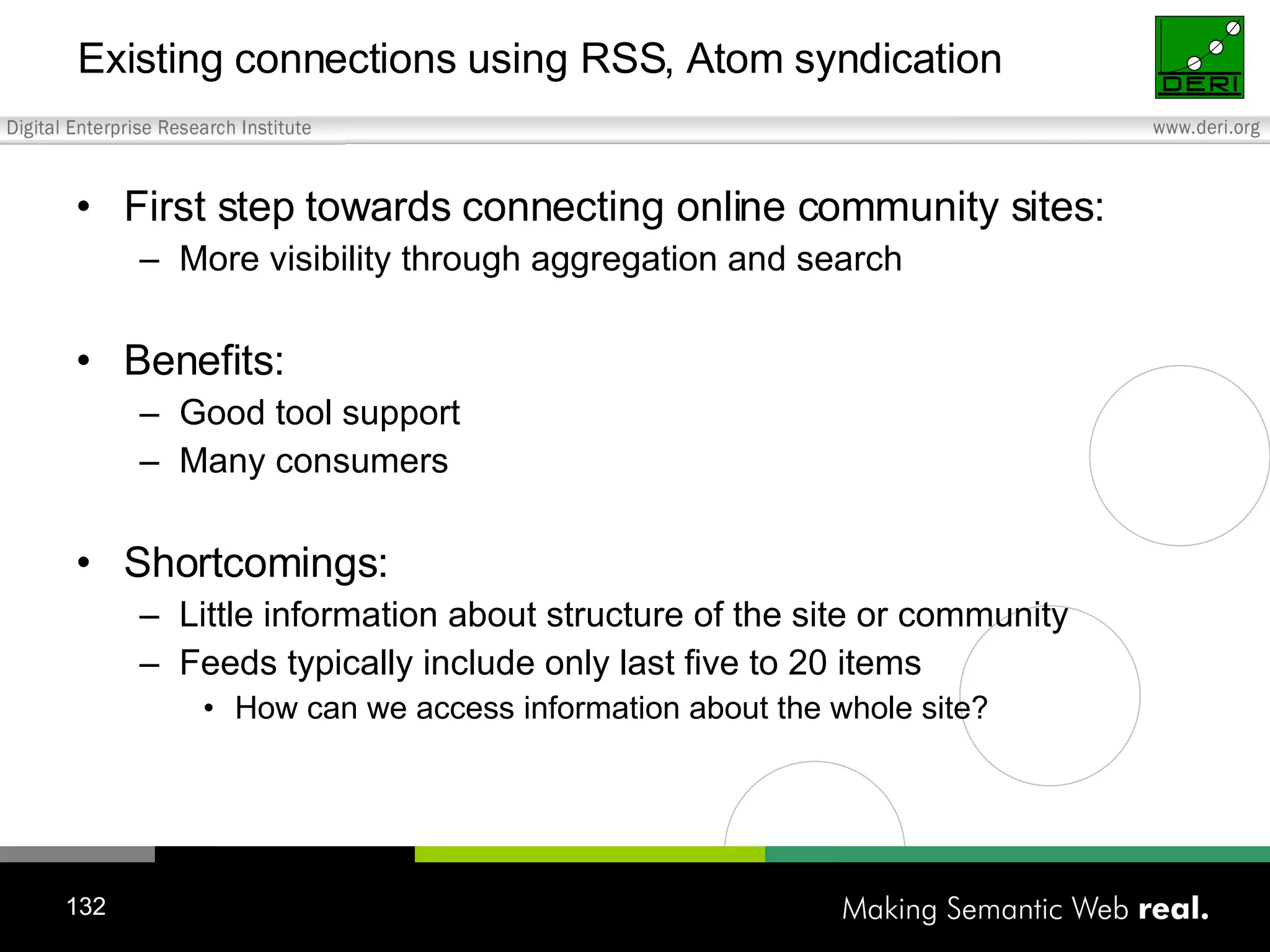

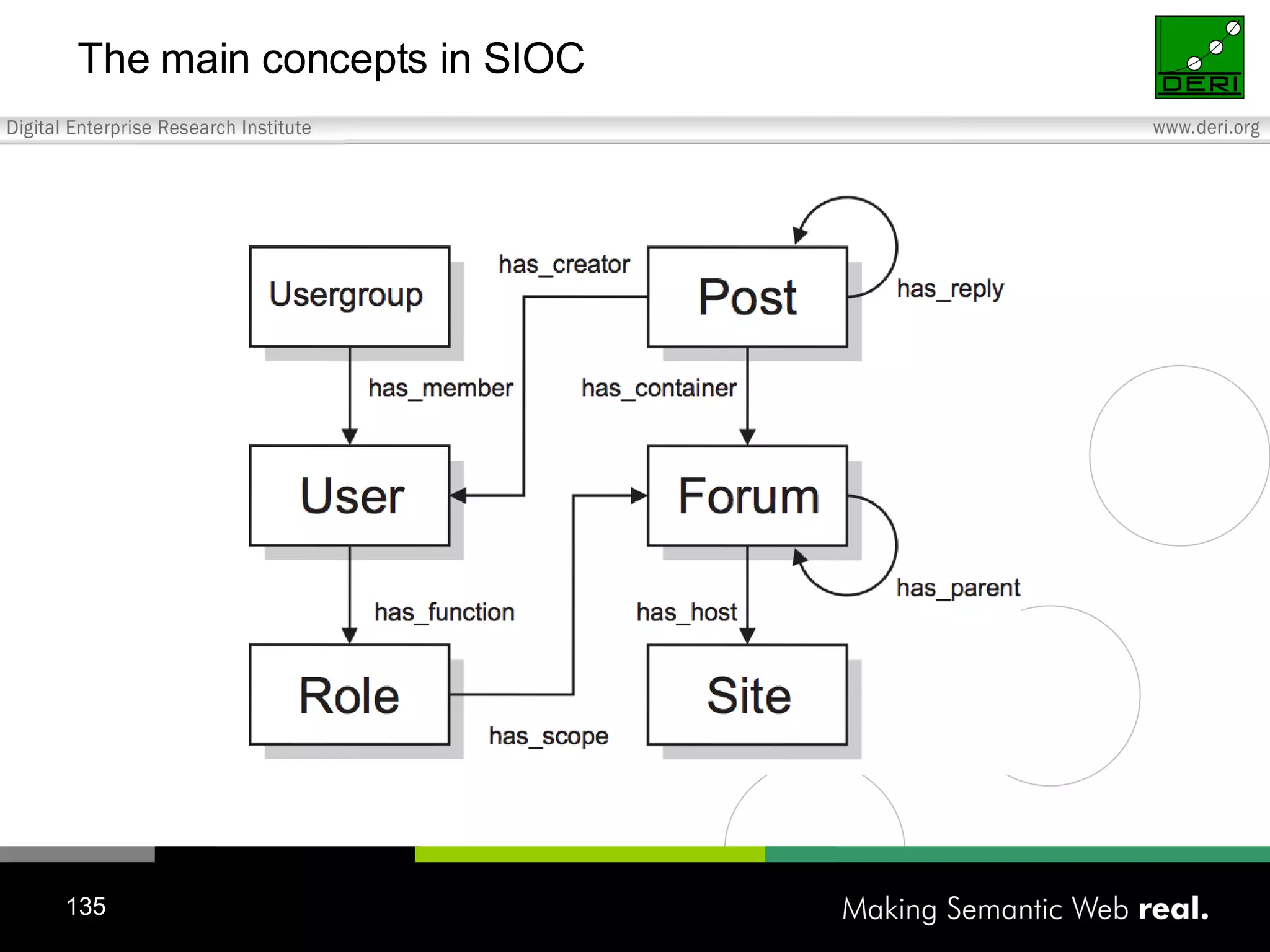
![What is SIOC? (2) Semantically-Interlinked Online Communities (SIOC) Connecting forums, posts from many types of online communities (blogs, forums, mailing lists, etc.) Interesting possibilities: Distributed linked conversations Decentralised discussion channels and communities “ I […] think the concept is HOT” – Robert Douglass, Drupal Developer http://rdfs.org/sioc/](https://image.slidesharecdn.com/20060526aedinburghwww2006-1209475188024136-8/75/Semantic-Web-2-0-Creating-Social-Semantic-Information-Spaces-134-2048.jpg)


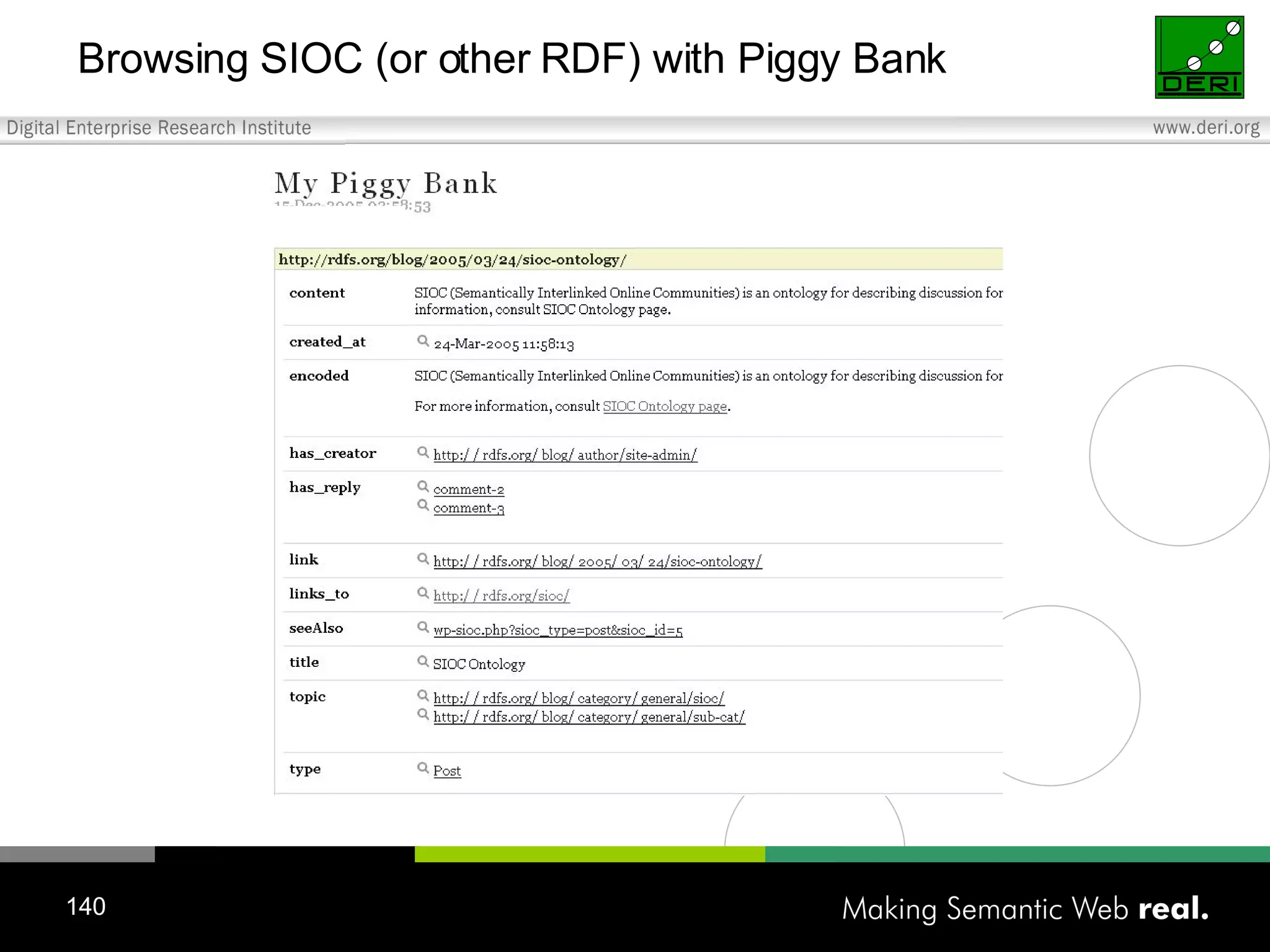
![Create SIOC export modules for popular open-source discussion systems Initial versions of SIOC metadata exporters created for: Content management system (Drupal) http://rdfs.org/sioc/drupal Bulletin board system (phpBB) [in progress] Blogging system (WordPress) http://rdfs.org/sioc/wordpress French blogging system (DotClear) http://apassant.net/blog/2006/03/12/75-plugin-sioc-pour-dotclear Infecting the Web Infrastructure: During next upgrade cycle gigabytes of community data become available How can SIOC data be created?](https://image.slidesharecdn.com/20060526aedinburghwww2006-1209475188024136-8/75/Semantic-Web-2-0-Creating-Social-Semantic-Information-Spaces-138-2048.jpg)








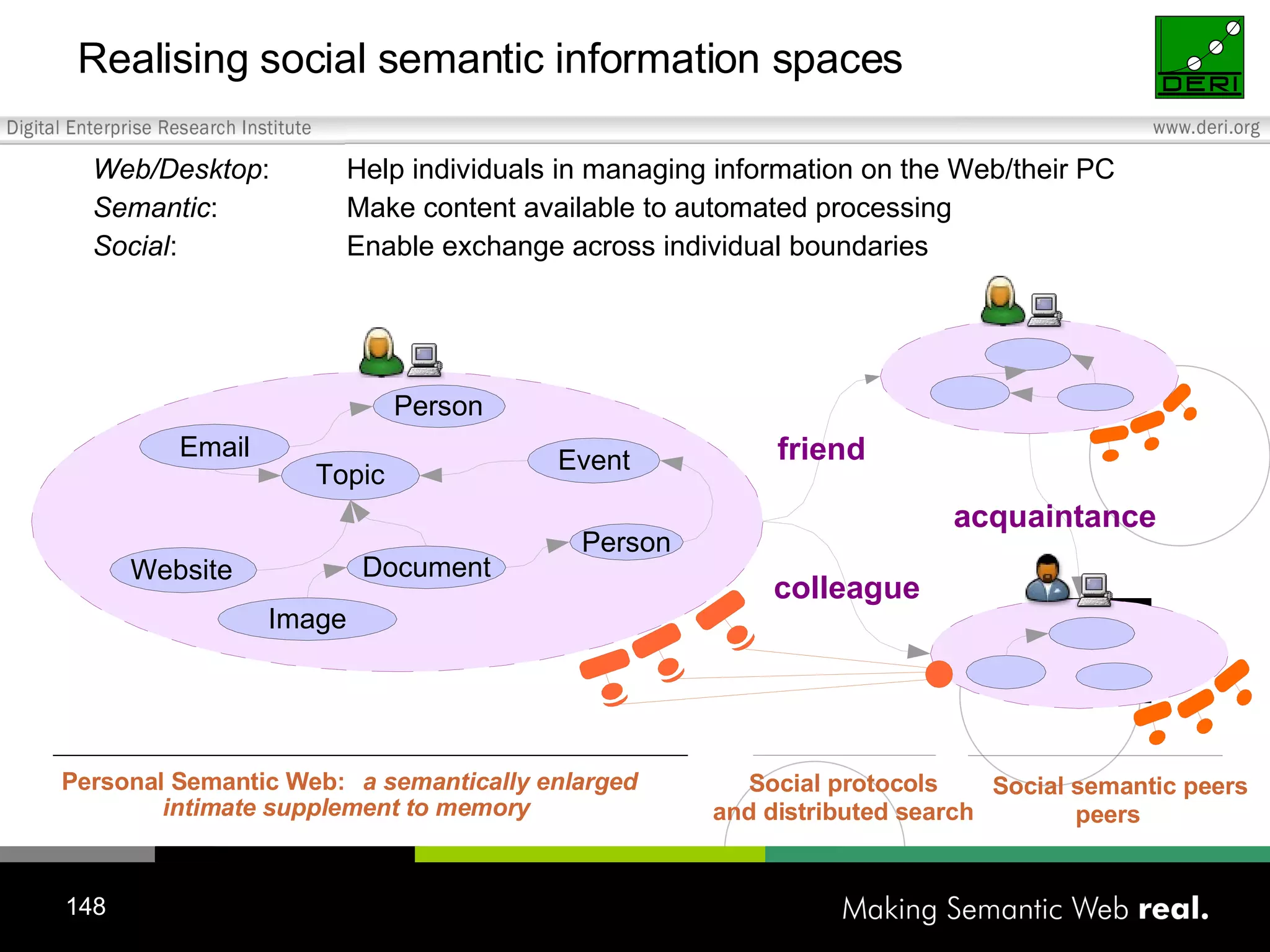

![Reali sing social semantic information spaces: The f irst s ociety- s cale s emantic w eb a pplication Ontology-Driven Distributed Social Networking Ontology-Driven Social Networking Semantic Desktop Social Semantic Information Spaces P2P Networks Semantic Web Semantic P2P Social Networking Phase 1 Phase 2 Phase 3 Memex (Vannevar Bush) A memex is “a device in which an individual stores all his books, records, and communications.” Open Hypertext System (Doug Engelbart) “The open hyperdocument system (OHS) is a standards-based, open source framework for developing collaborative, knowledge management applications.” WWW (Tim Berners-Lee) “There was a second part of the dream […] we could then use computers to help us analyse it, make sense of what we re doing, where we individually fit in, and how we can better work together.” Today necessary technologies & communities exist: Standardised metadata: Semantic Web Scalable distributed infrastructure: P2P Computing Knowledge articulation and interaction: Desktop Technology Processing of unstructured and legacy information: NLP Human centric information exchange: Online Social Networks Driven by today's needs, in the spirit of seminal visions Challenge: Extension & merging of research streams NLP Desktop / Web Inspired by sociological perspectives: On group forming: Viral c ommunication (Reed) On innovative IT-based interaction and feedback: Social translucent systems (Erickson and Kellogg) Smart Mobs (Rheingold) On network modeling and algorithms: Social network research Small world properties Power law distribution (Barabasi and Huberman) Link-based authority algorithms, recommender algorithms (Perugini)](https://image.slidesharecdn.com/20060526aedinburghwww2006-1209475188024136-8/75/Semantic-Web-2-0-Creating-Social-Semantic-Information-Spaces-150-2048.jpg)




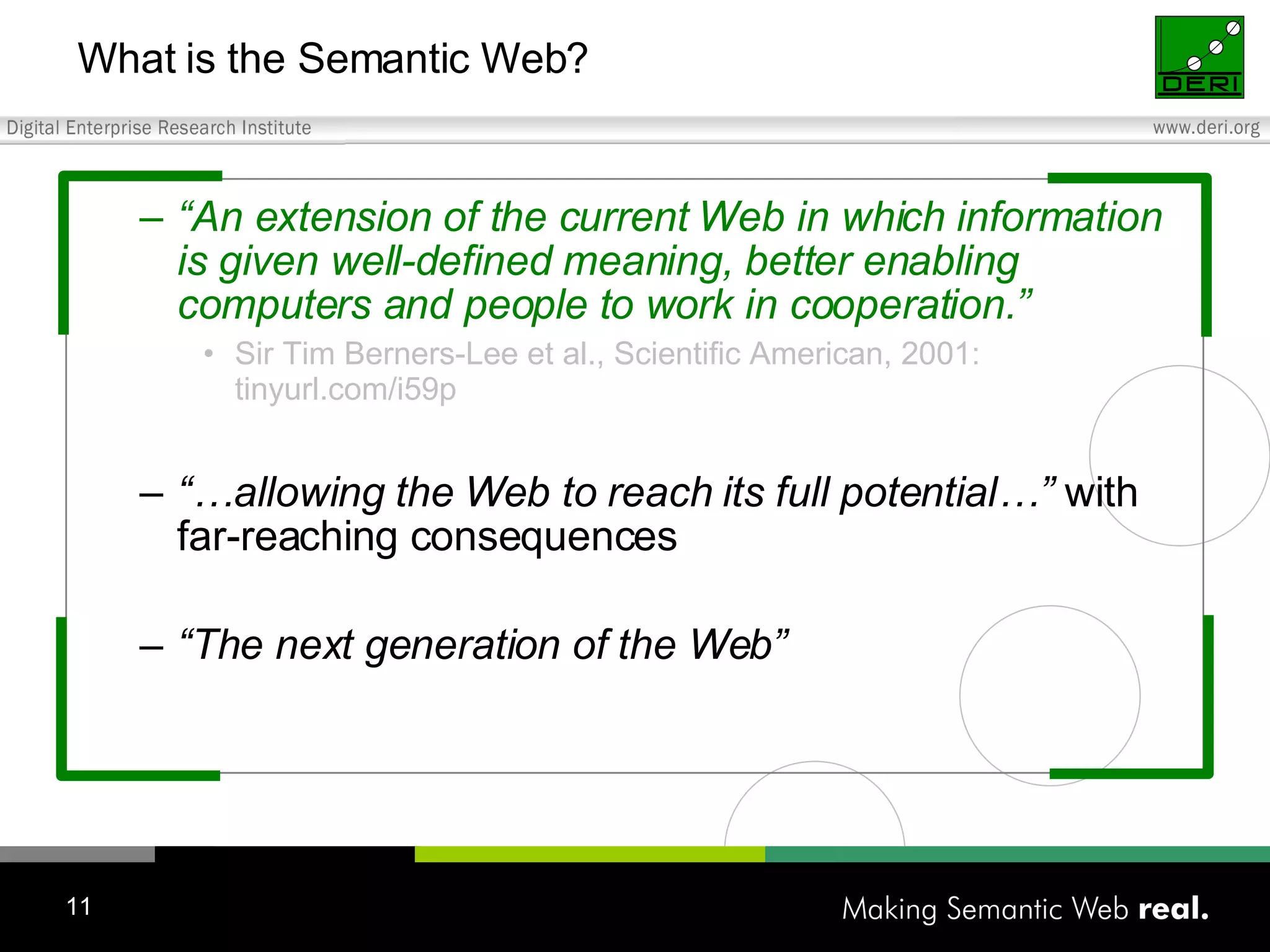
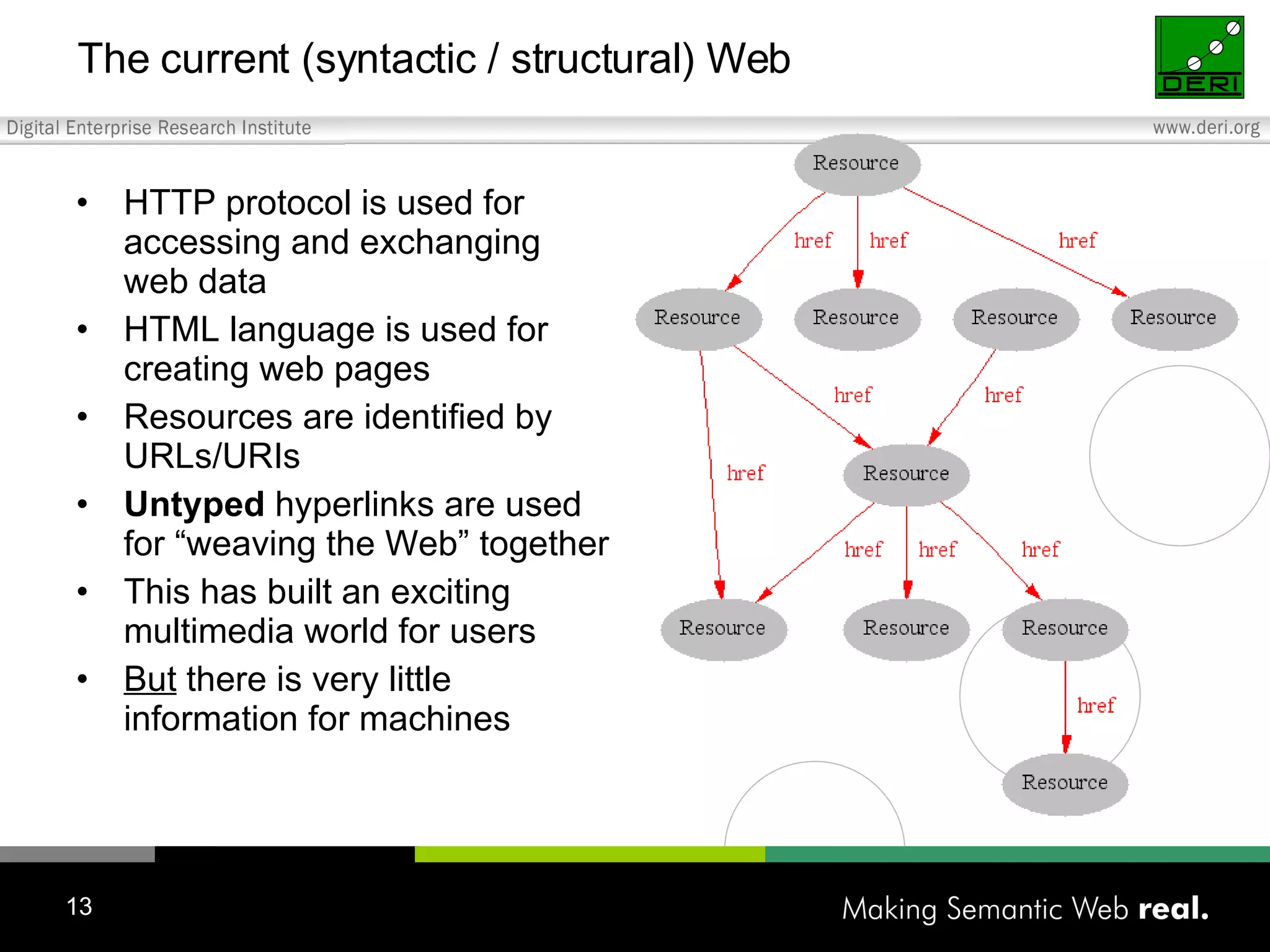
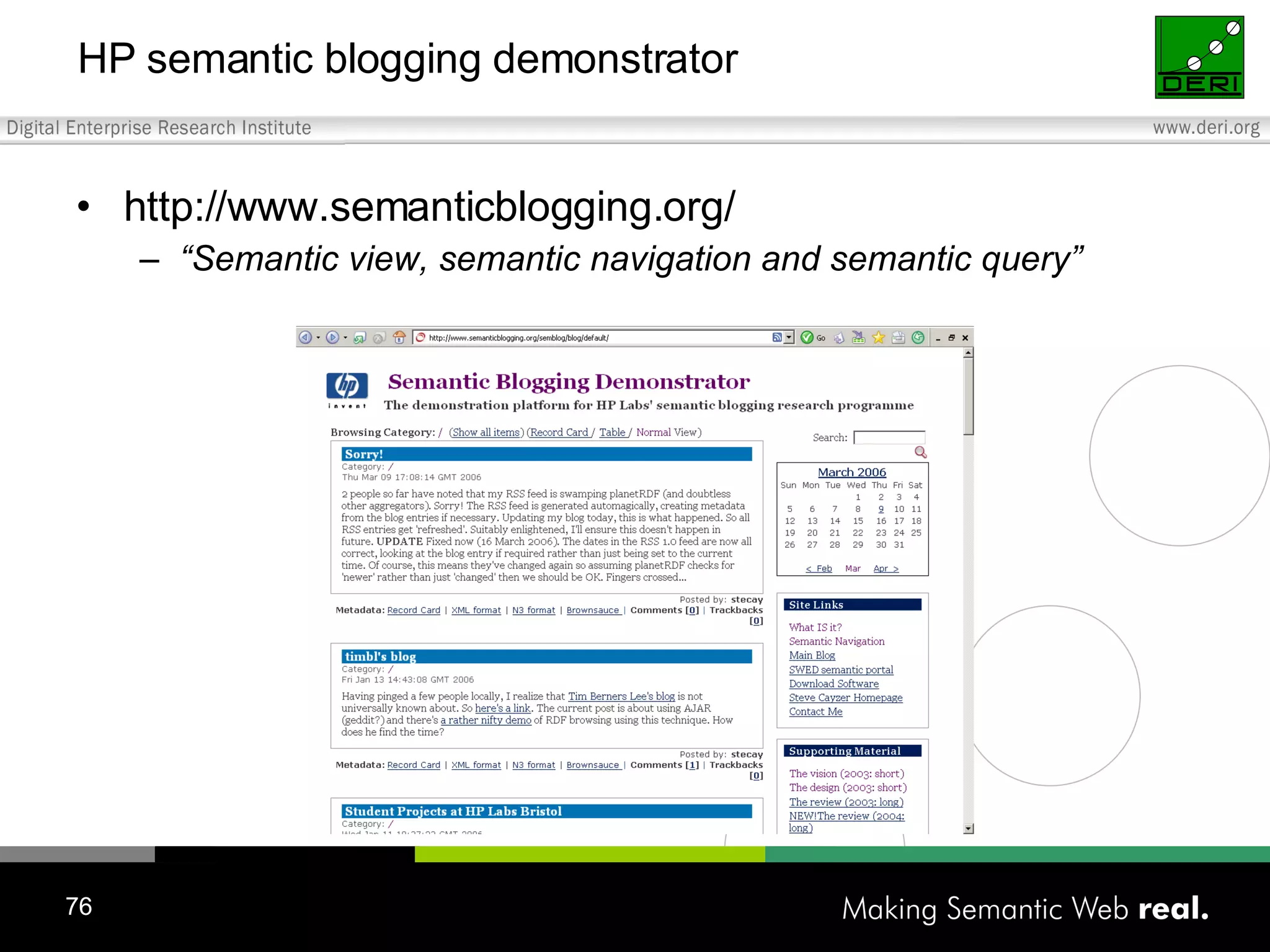
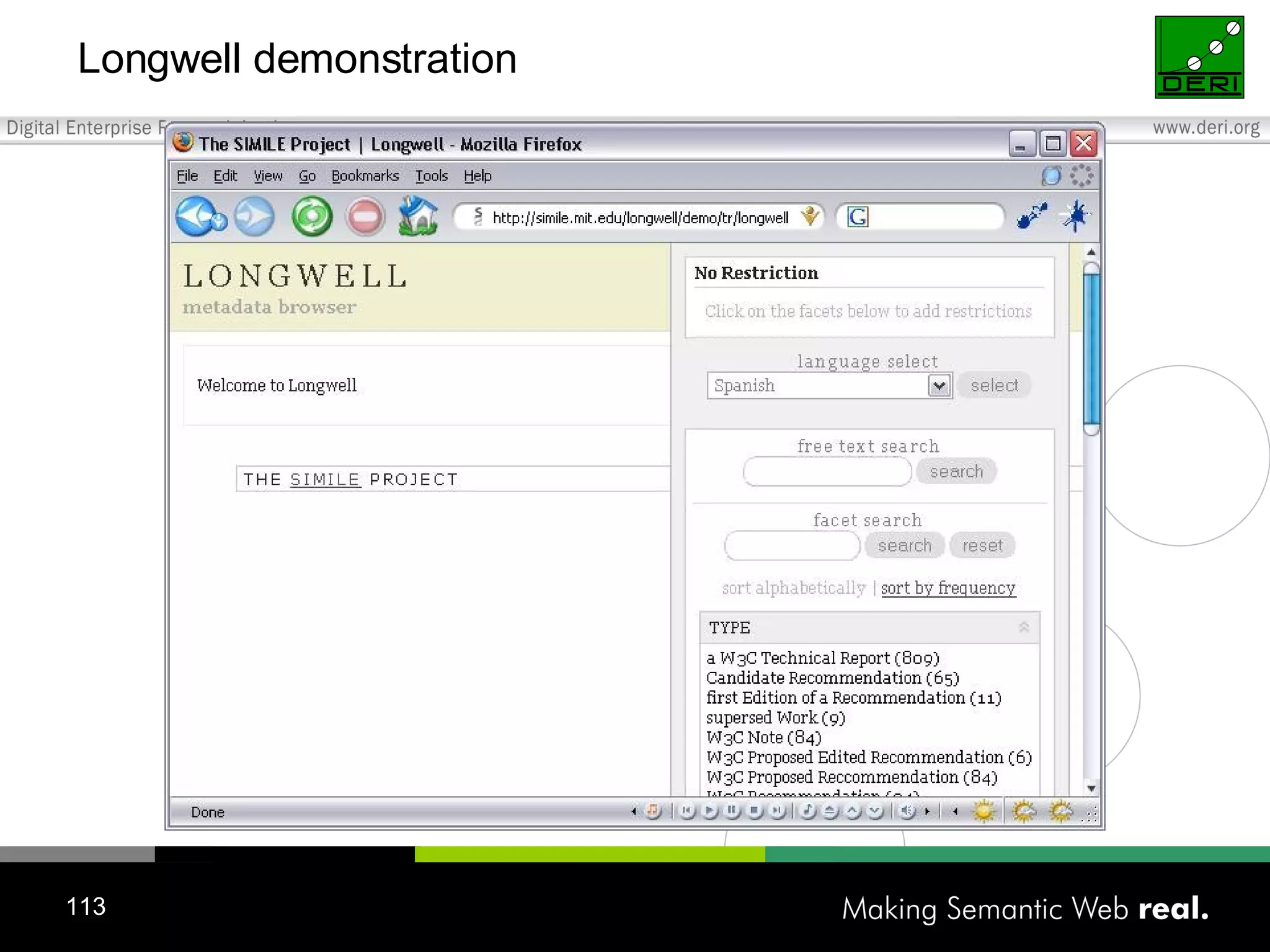
This tutorial provides an overview of applying Semantic Web technologies to emerging Web 2.0 applications and social media to create "Social Semantic Information Spaces." It discusses adding semantics to blogs, wikis, forums, and social networks through standards like RDF and ontologies. The goal is to overcome limitations of these applications and enable more automated information sharing and discovery across interconnected sites and communities.