Downloaded 232 times













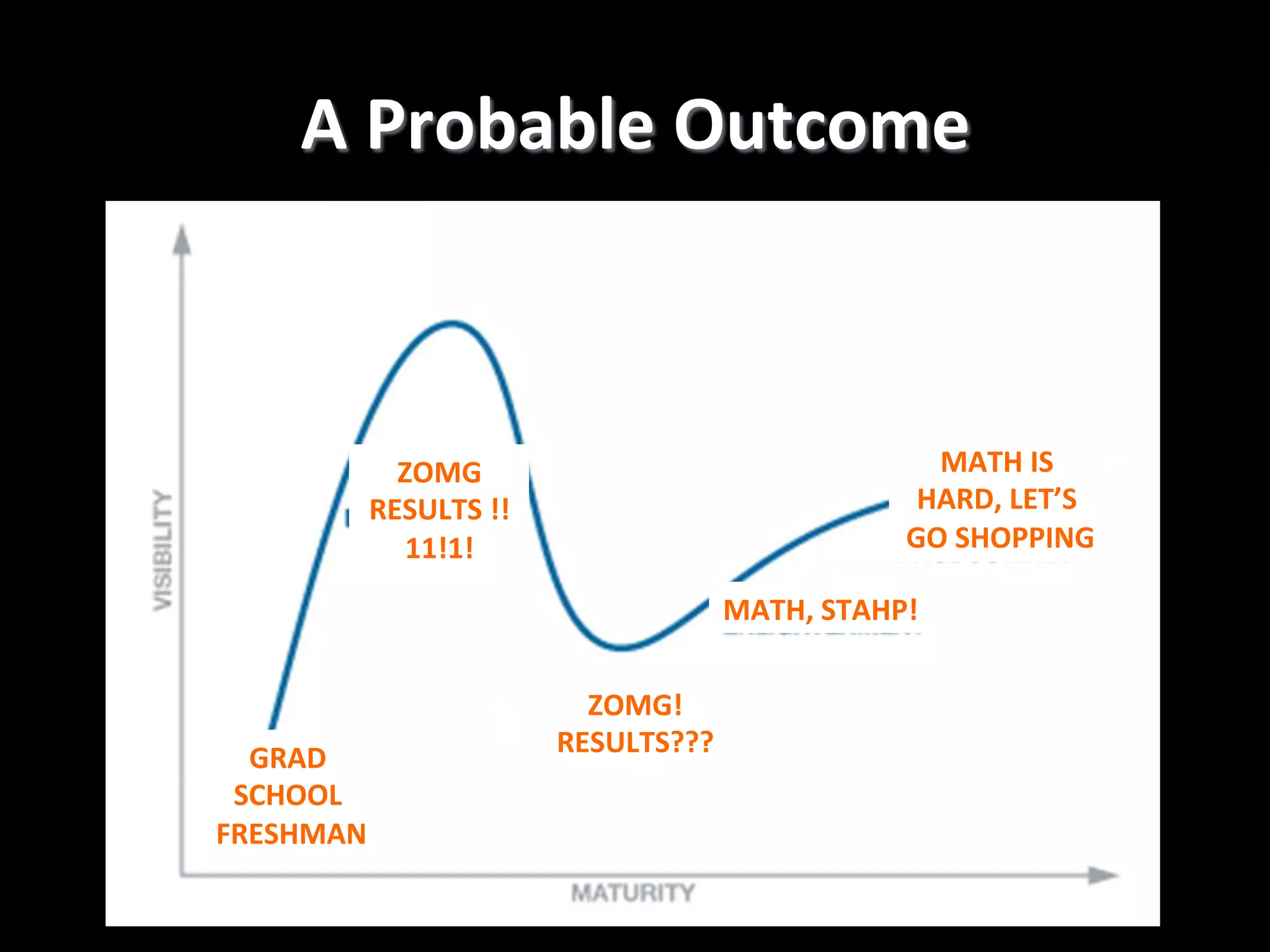


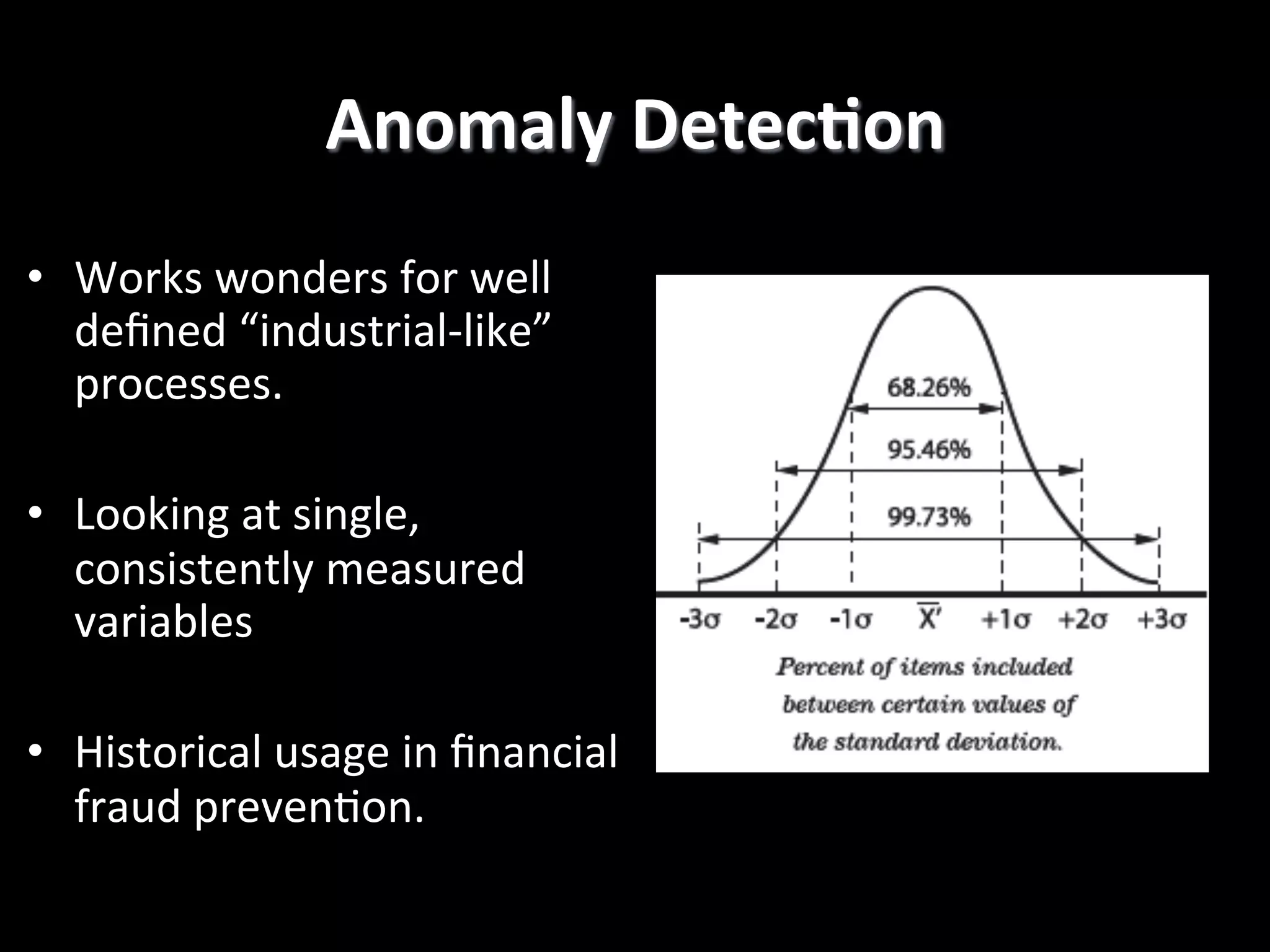
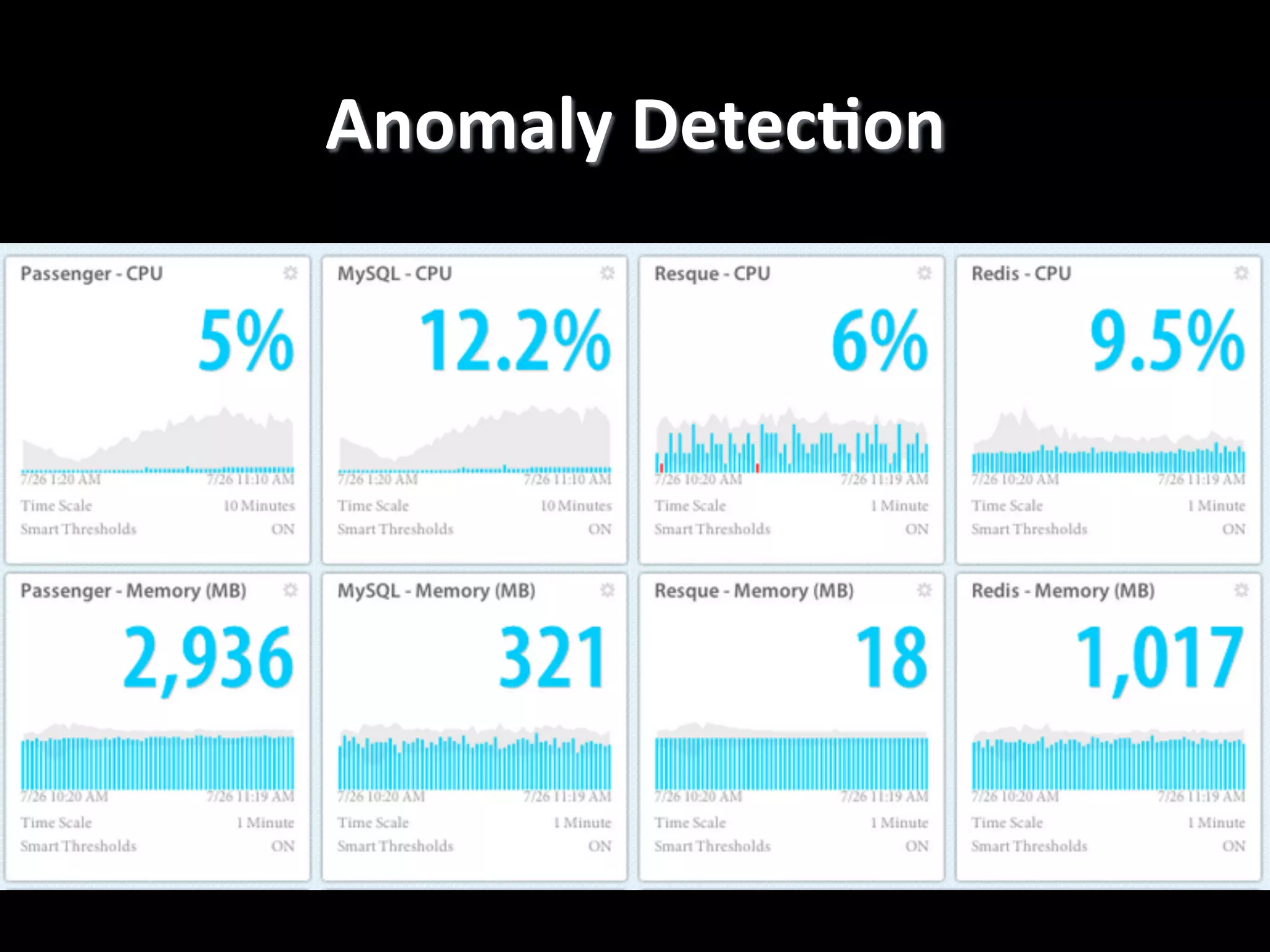


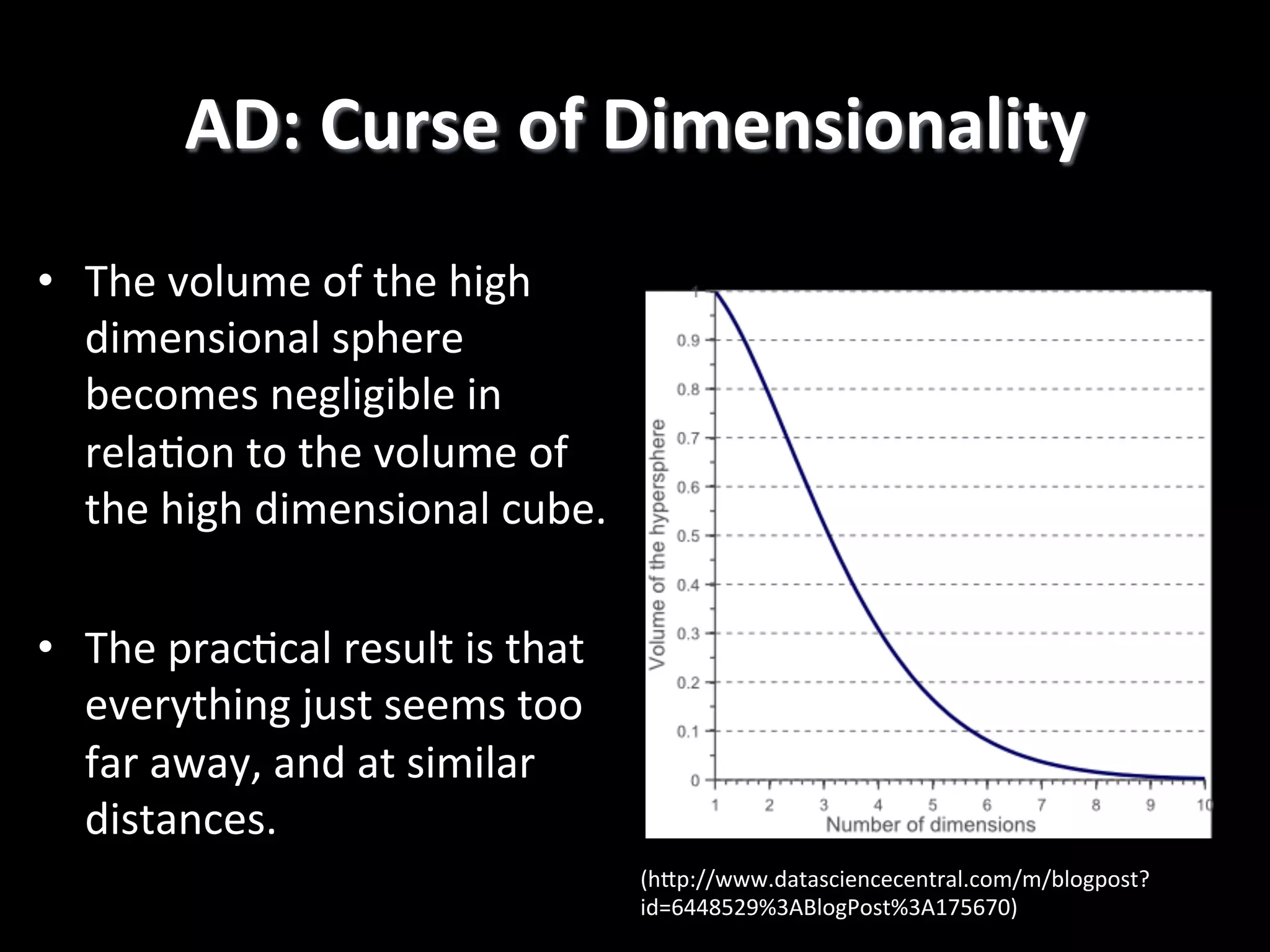

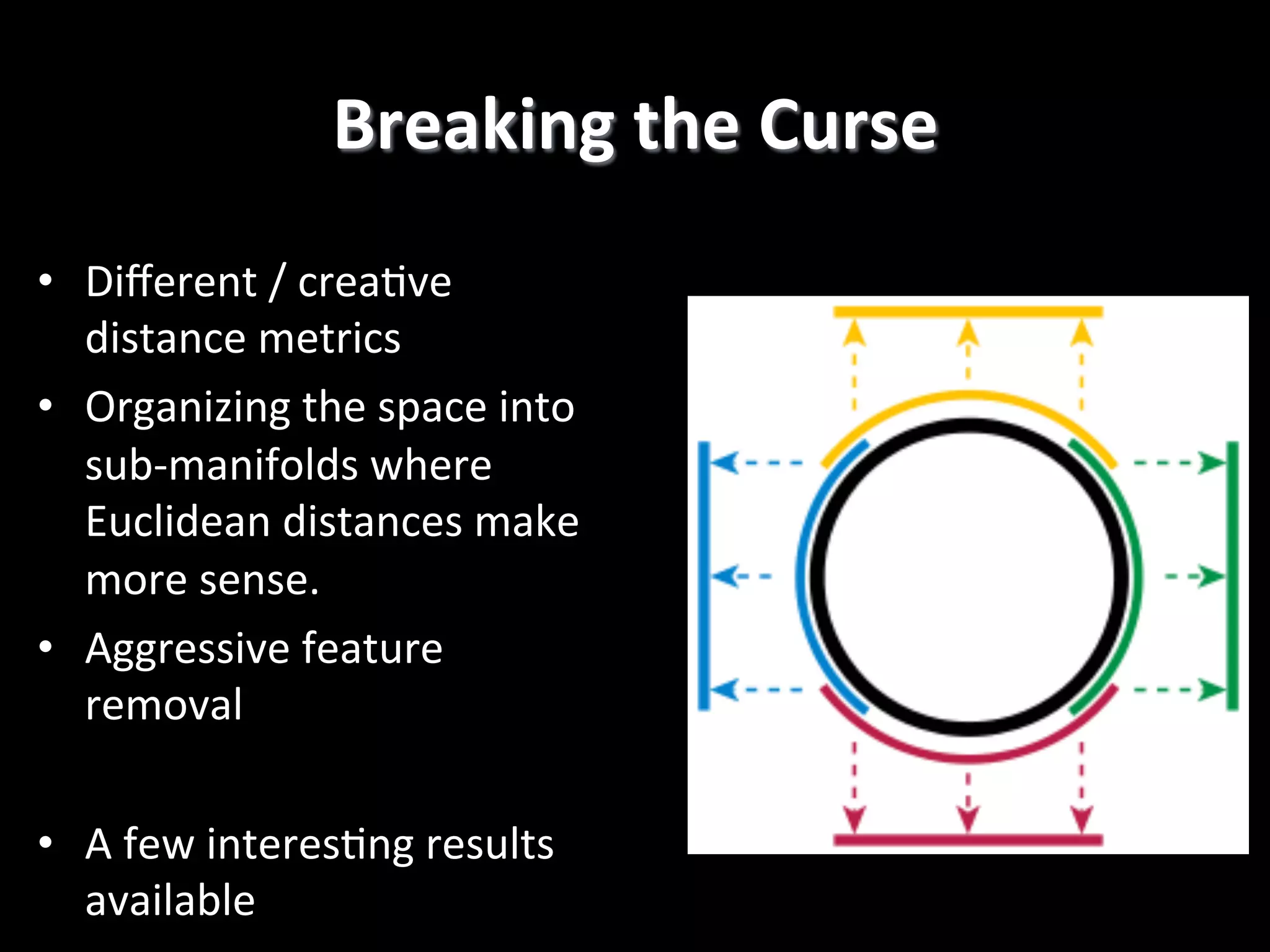




















The document discusses machine learning-based security monitoring. It begins with an introduction of the speaker, Alex Pinto, and an agenda that will include a discussion of anomaly detection versus classification techniques. It then covers some history of anomaly detection research dating back to the 1980s. It also discusses challenges with anomaly detection, such as the curse of dimensionality with high-dimensional data and lack of ground truth labels. The document emphasizes communicating these machine learning concepts clearly.