




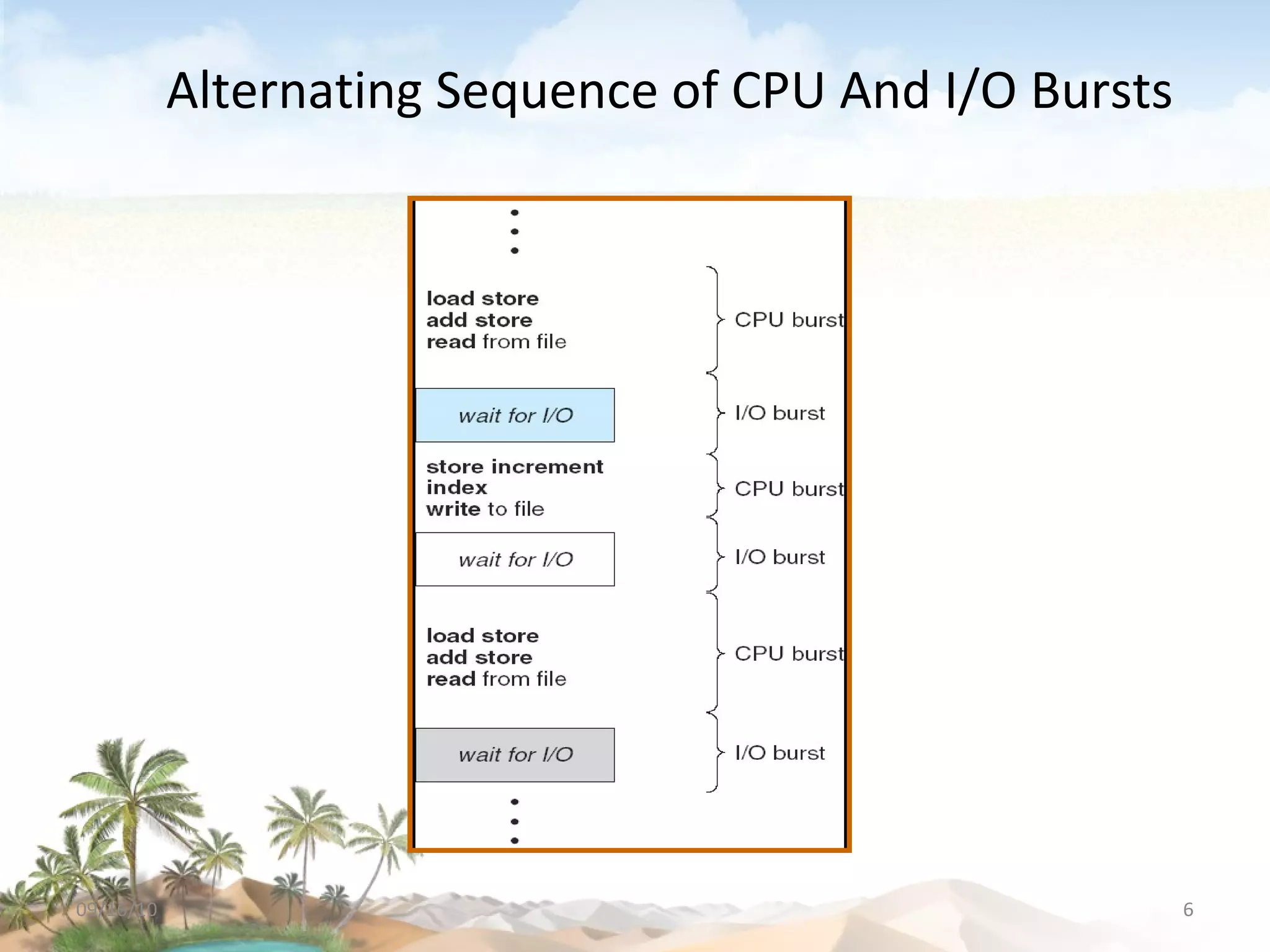











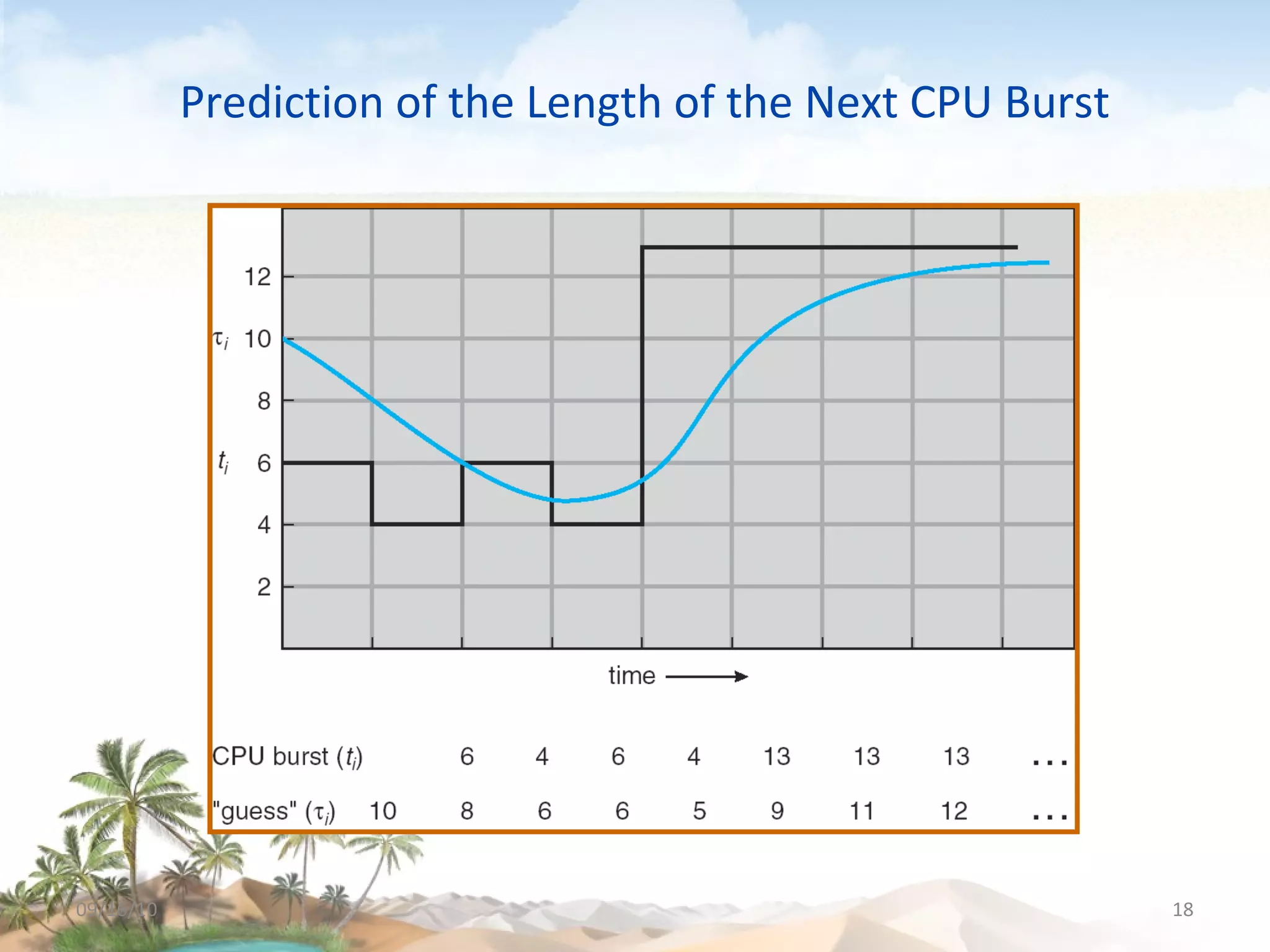




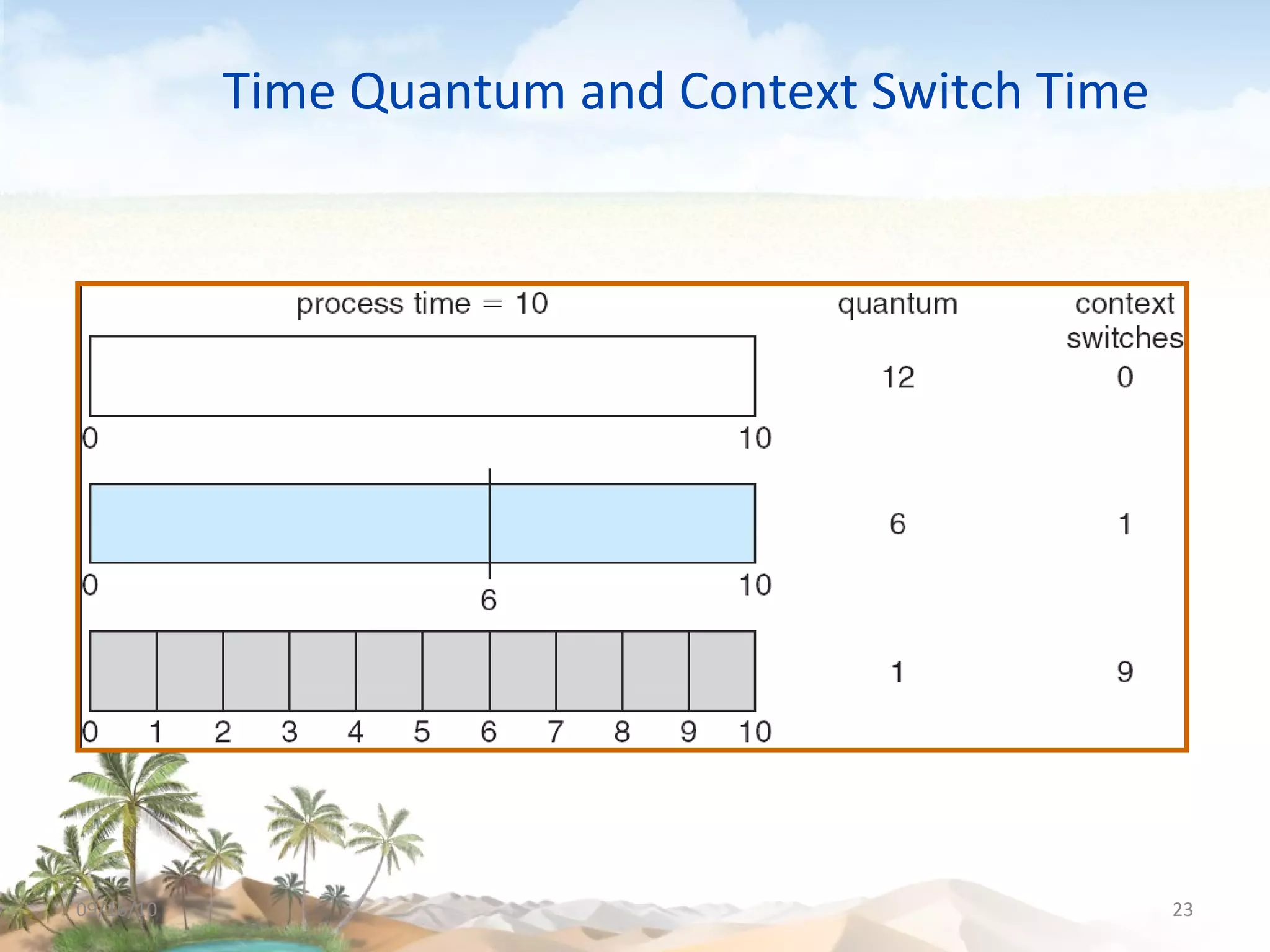
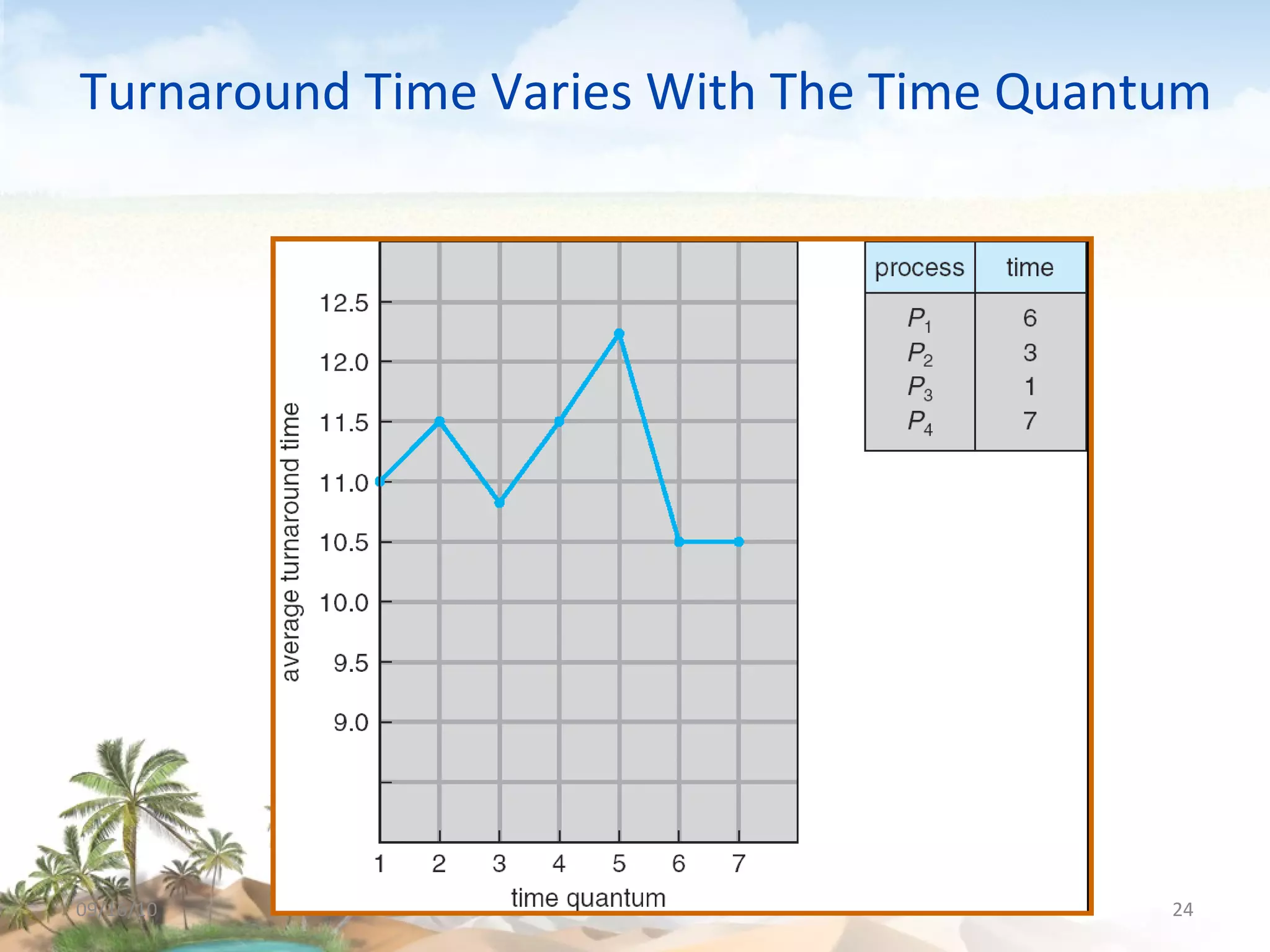

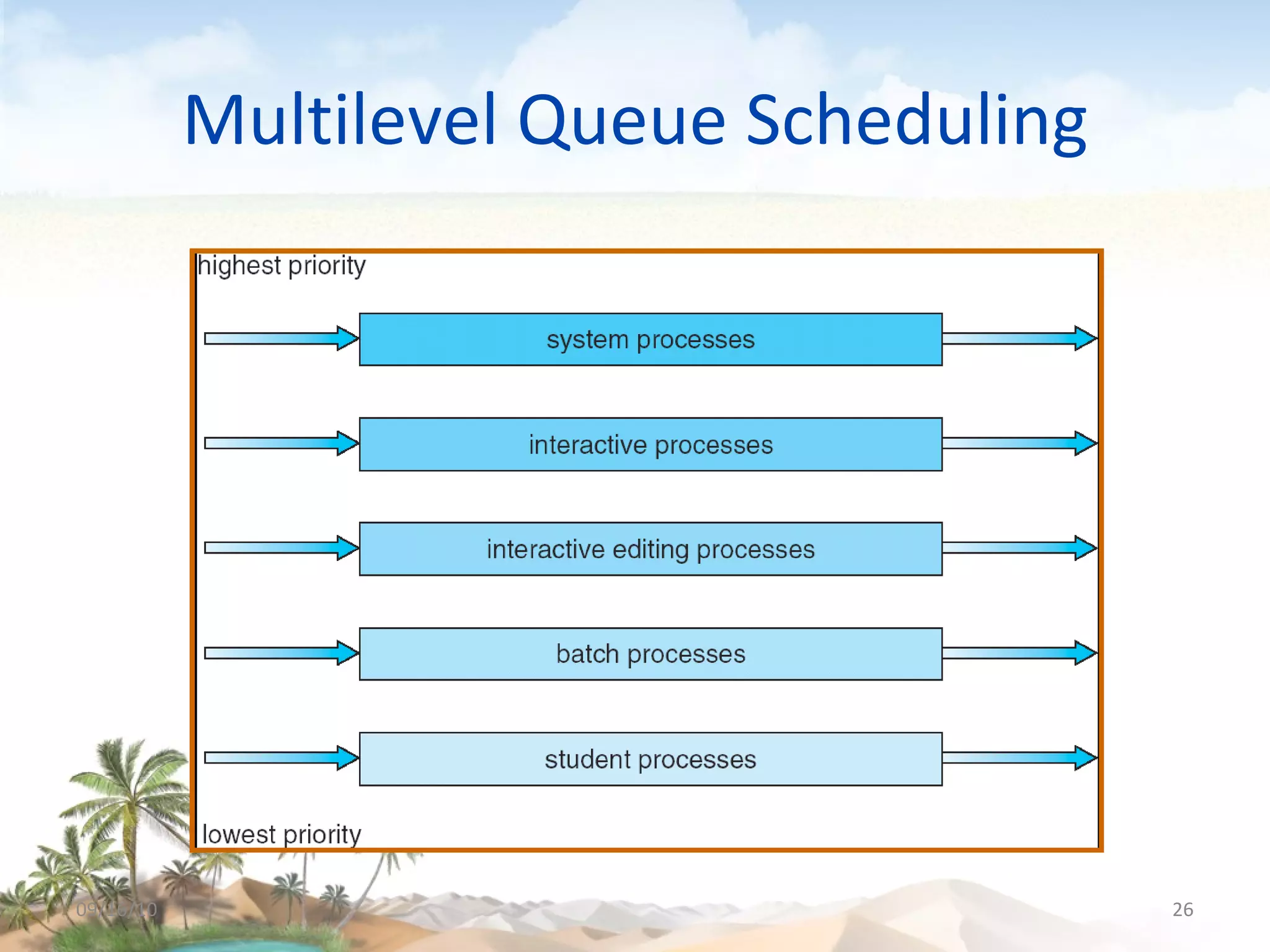


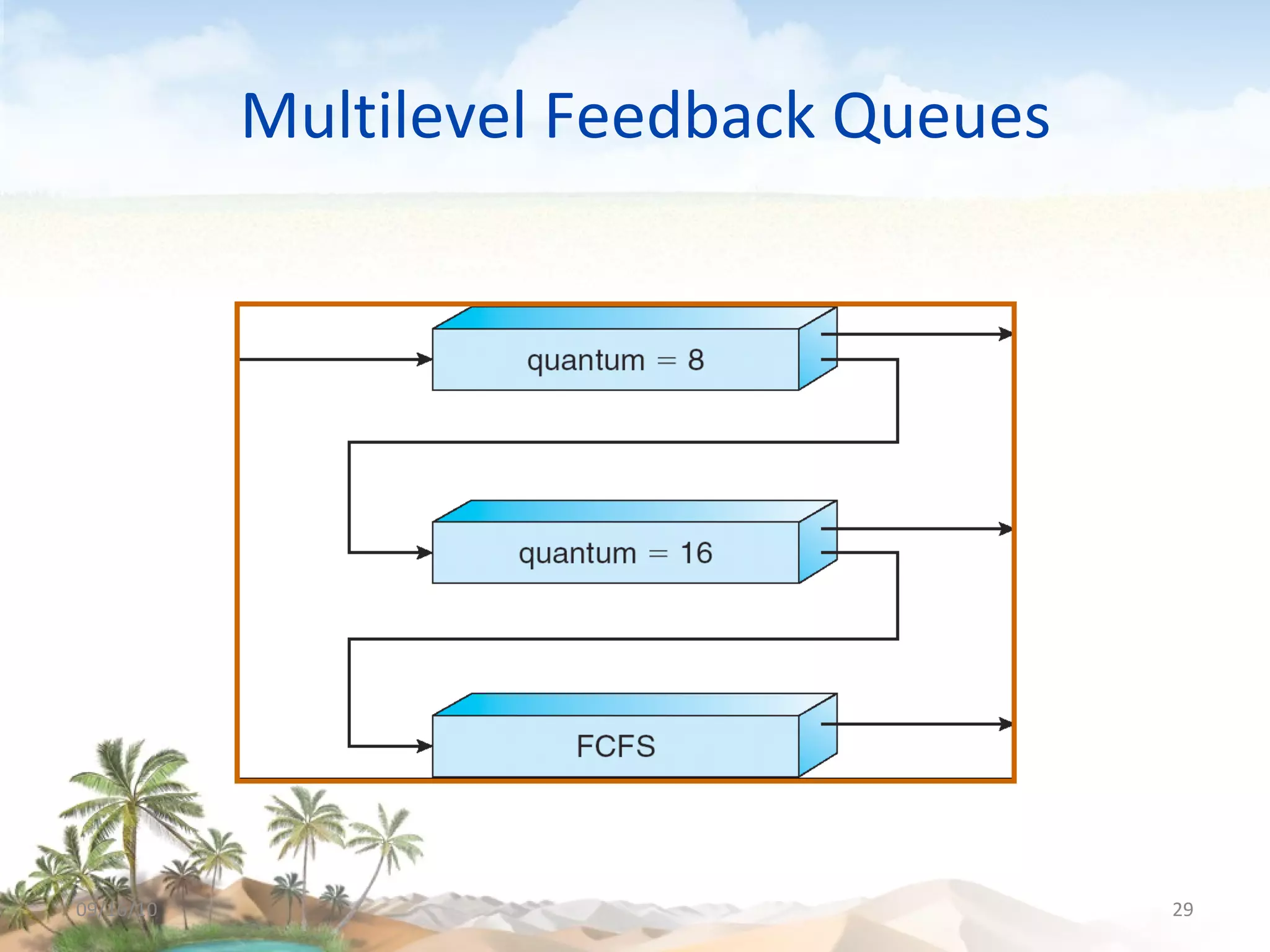











The document discusses several topics related to CPU scheduling, including basic concepts, scheduling criteria, algorithms like first-come first-served (FCFS) and shortest-job-first (SJF), determining CPU burst lengths, priority scheduling, and approaches to scheduling on multiple processors. Key concepts are that the CPU scheduler selects ready processes to run and aims to maximize CPU utilization while minimizing waiting times using algorithms like FCFS, SJF, priority, and round robin scheduling. Load sharing and affinity are considerations for multiprocessor scheduling.