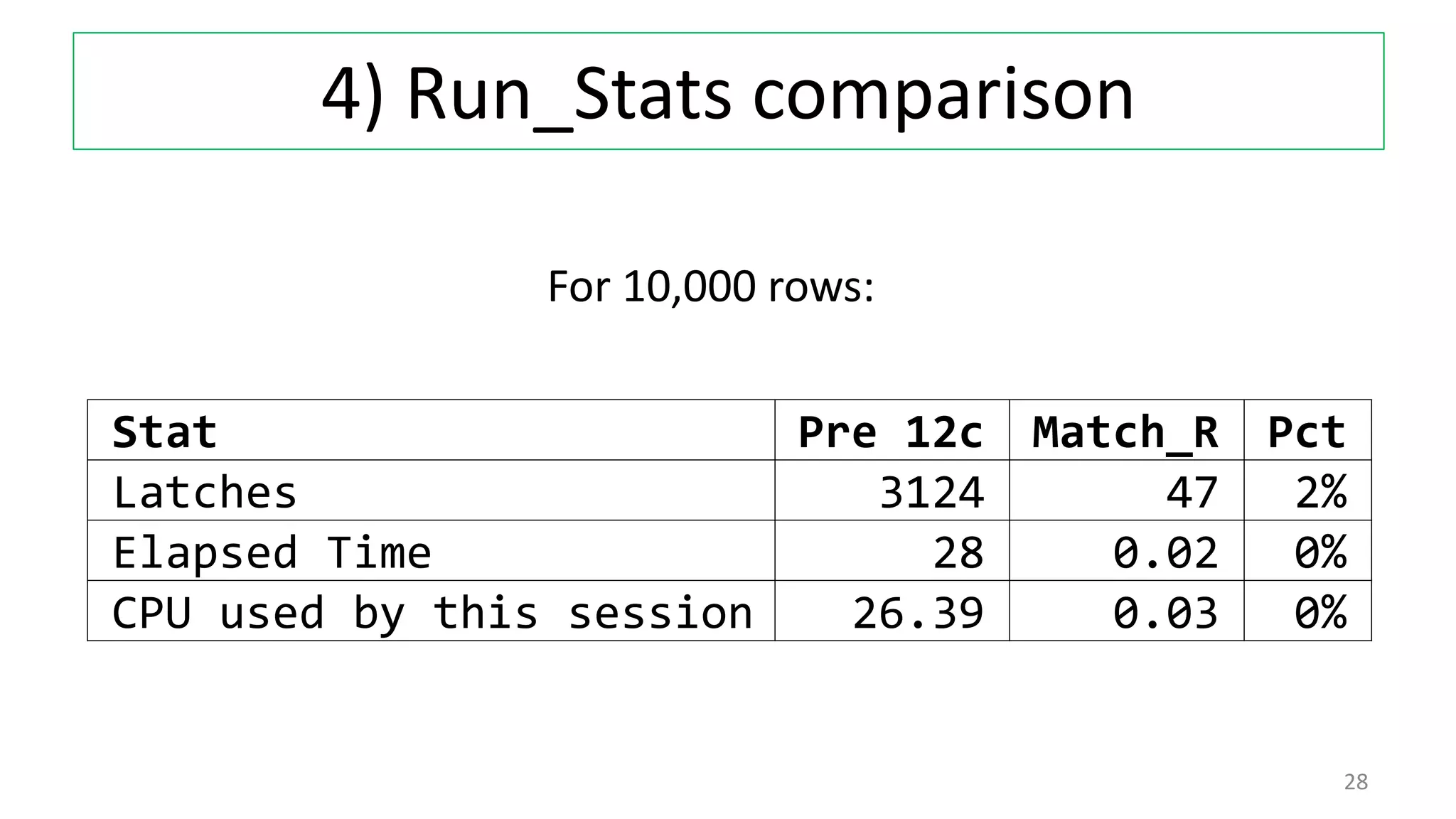
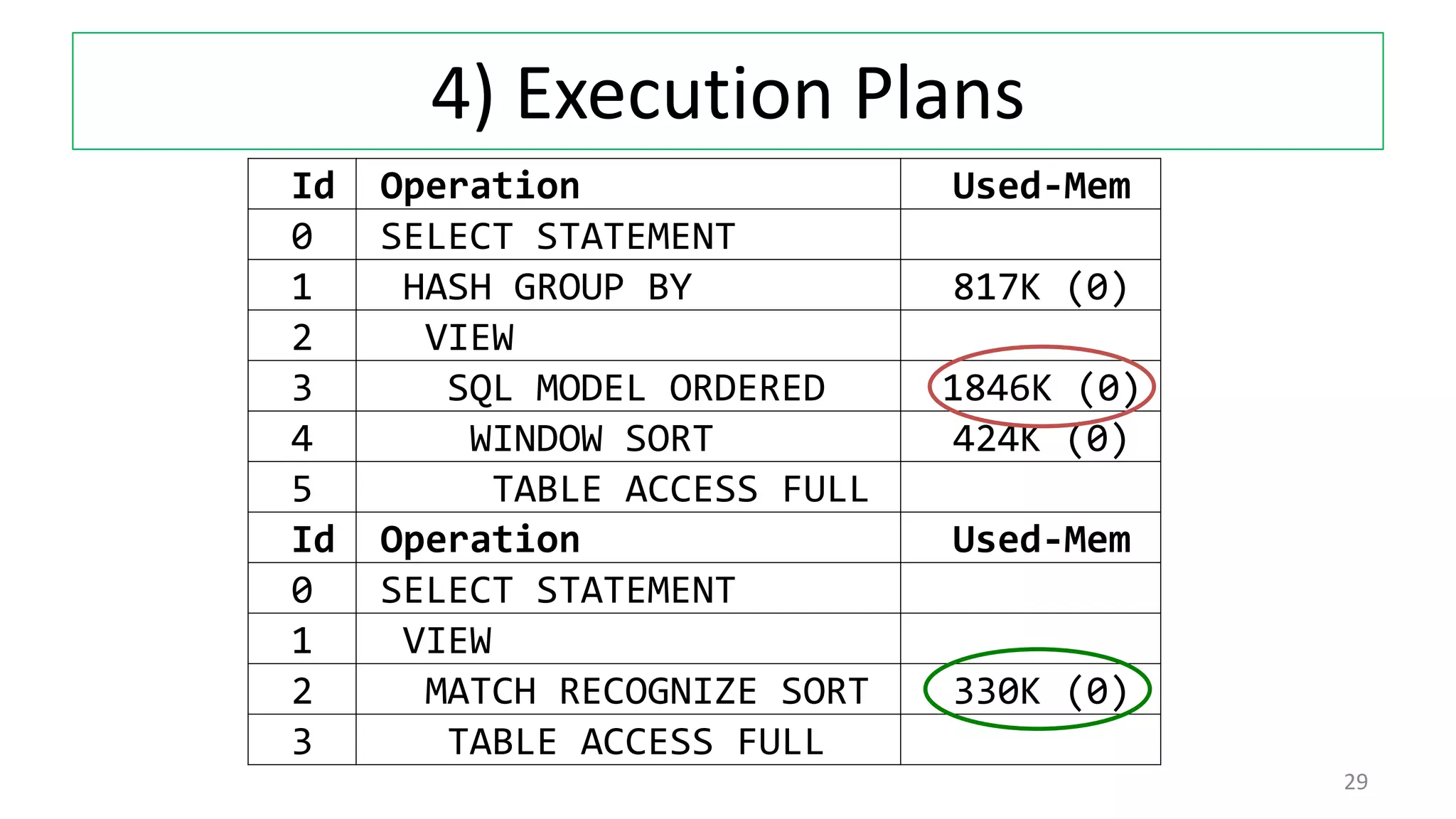
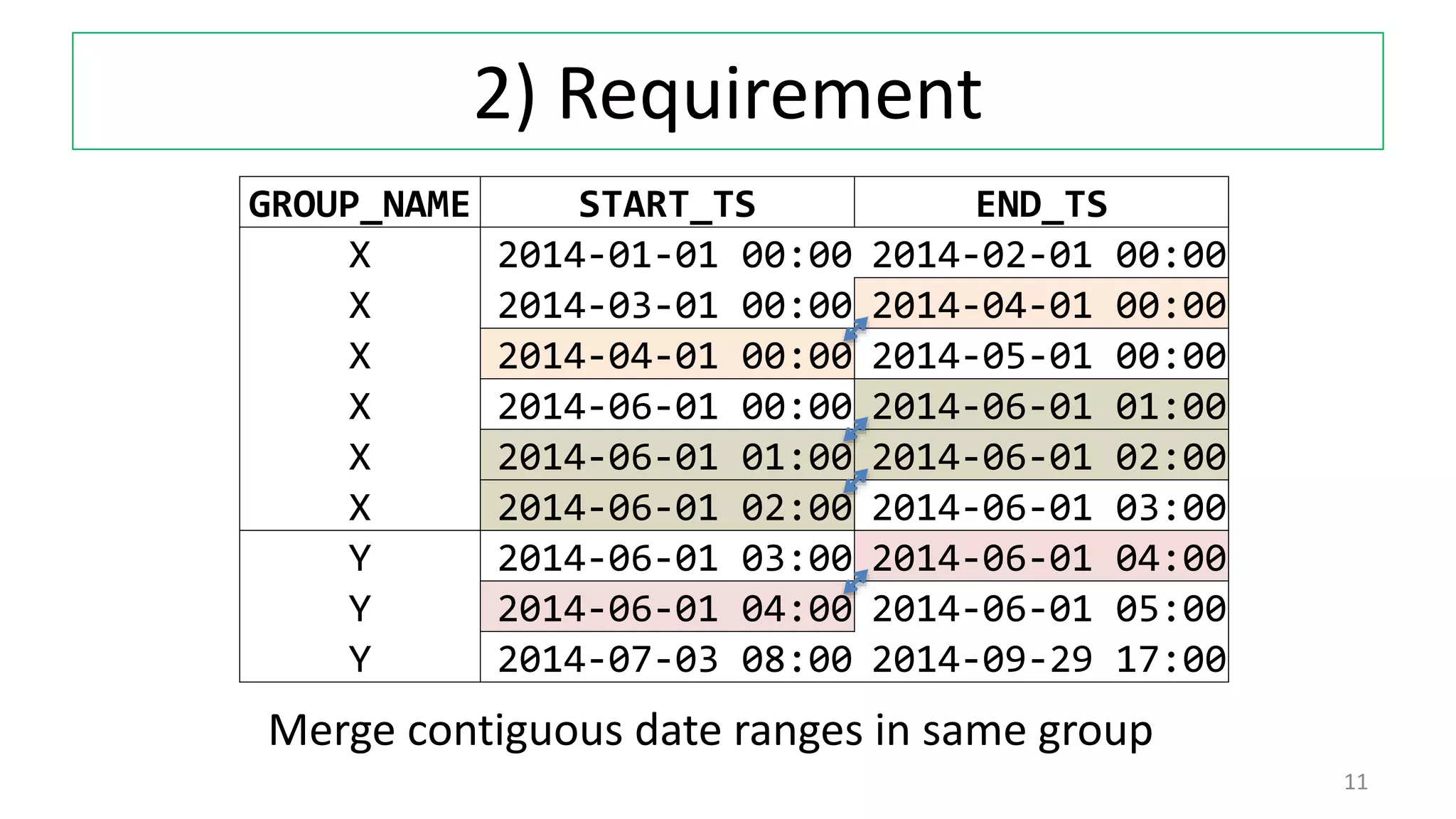
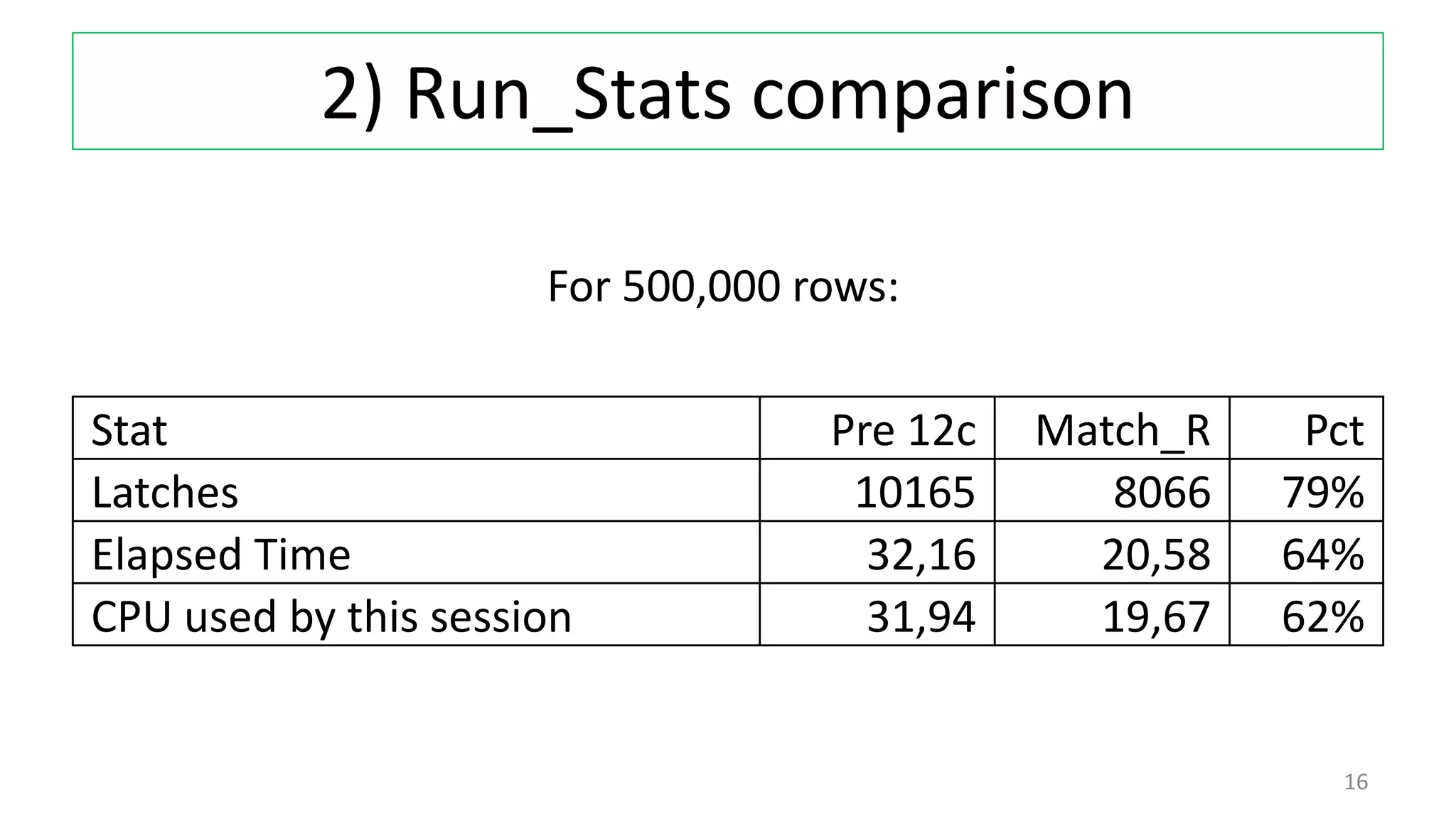
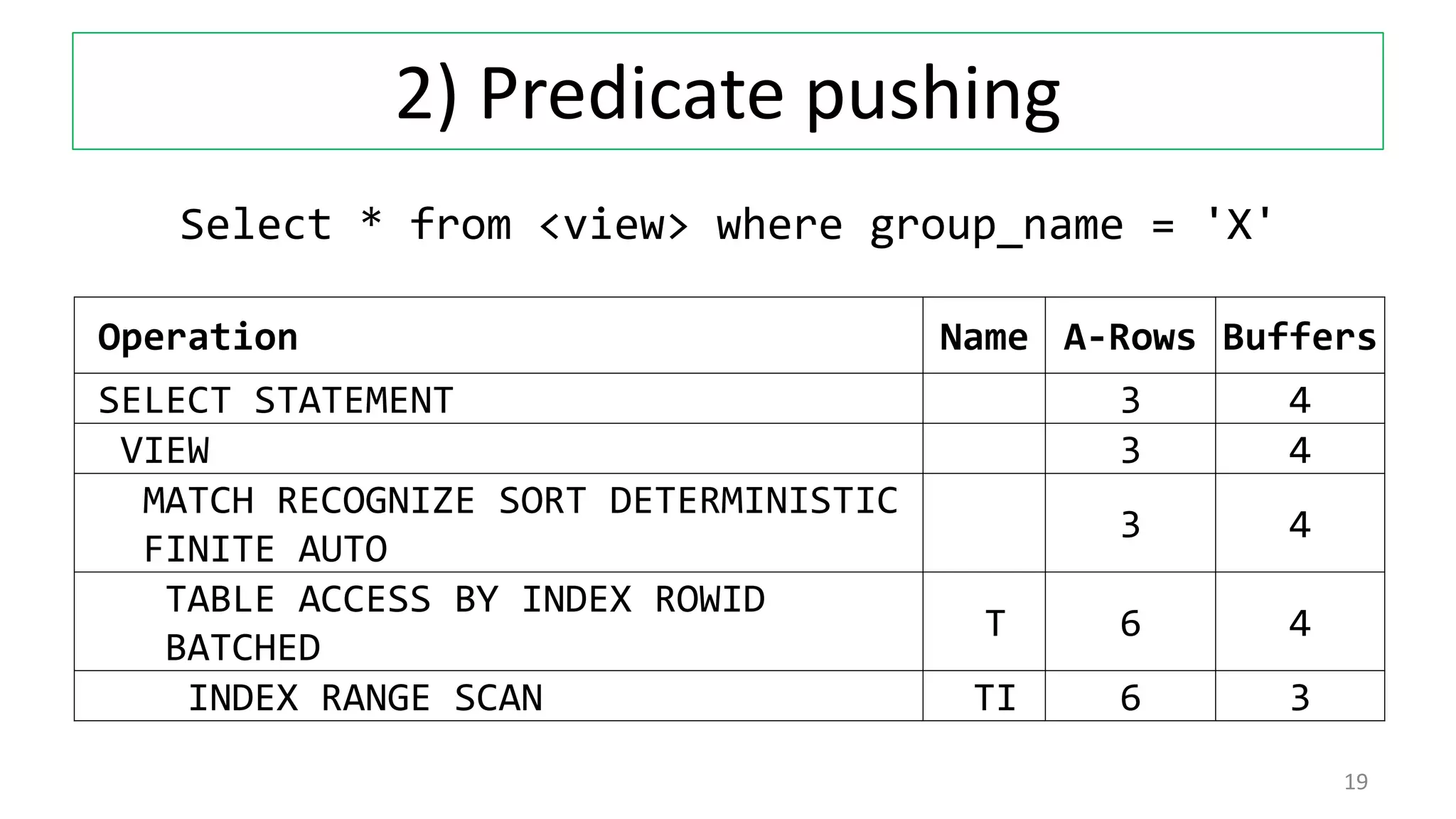
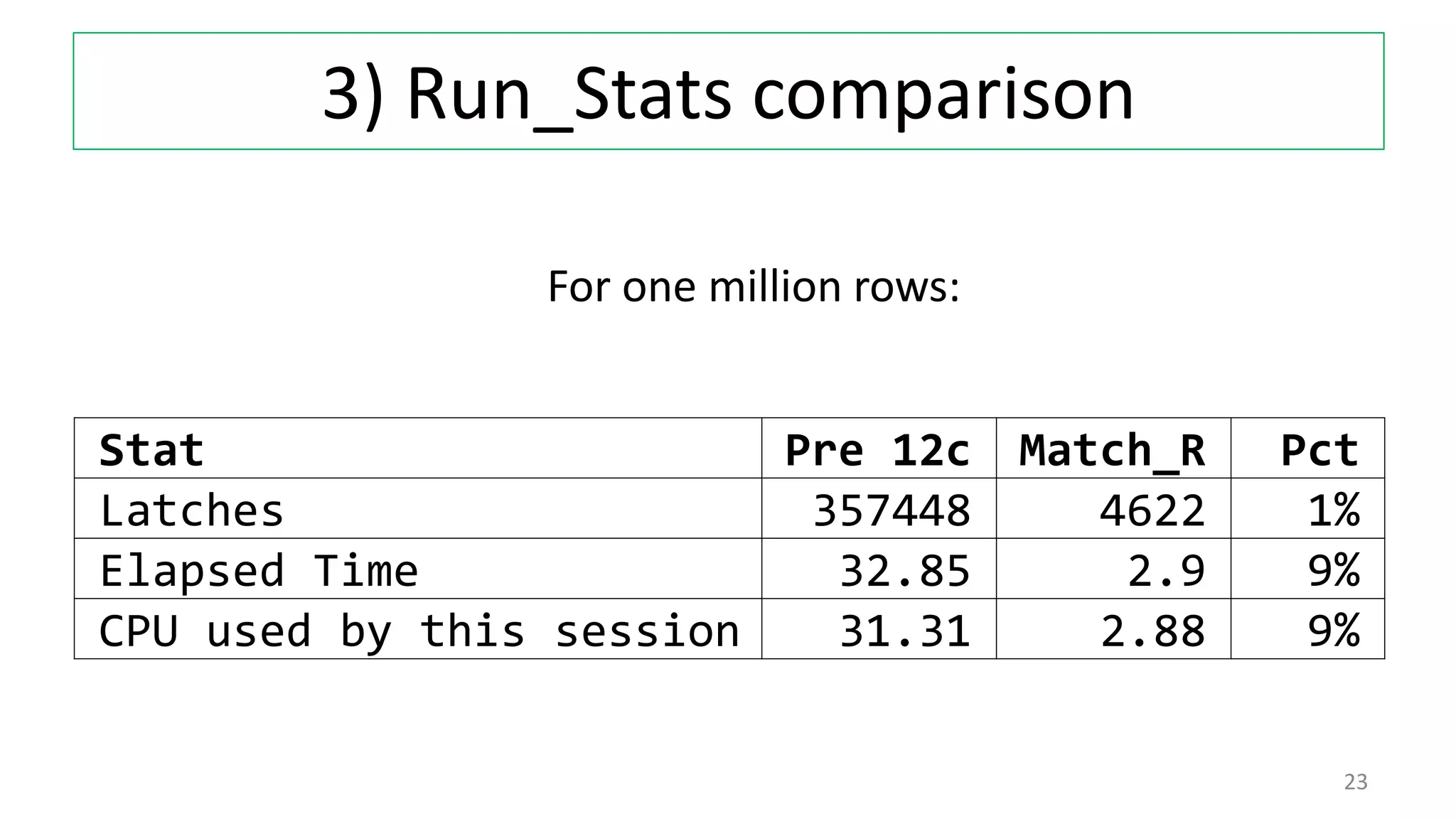
The document discusses various techniques for pattern matching and grouping rows in databases before and after the introduction of MATCH_RECOGNIZE in Oracle 12c. It compares 4 techniques used in pre-12c databases to group and analyze row patterns against using MATCH_RECOGNIZE. For each technique, it provides an example, shows the pre-12c implementation, and demonstrates how MATCH_RECOGNIZE provides a simpler single solution that is more efficient and scalable.





![1) Pre-12c select min(page) firstpage, max(page) lastpage, count(*) cnt FROM ( SELECT page, page – Row_Number() over(order by page) as grp_id FROM t ) GROUP BY grp_id; PAGE [RN] GRP_ID 1 - 1 0 2 - 2 0 3 - 3 0 5 - 4 1 6 - 5 1 7 - 6 1 10 - 7 3 11 - 8 3 12 - 9 3 42 -10 32 6 FIRSTPAGE LASTPAGE CNT 1 3 3 5 7 3 10 12 3 42 42 1 PAGE GRP_ID 1 0 2 0 3 0 5 1 6 1 7 1 10 3 11 3 12 3 42 32](https://image.slidesharecdn.com/rowpatternmatching12ctech14-160929214935/75/Row-Pattern-Matching-in-Oracle-Database-12c-6-2048.jpg)
![Pattern and Matching Rows • PATTERN – Uninterrupted series of input rows – Described as list of conditions (≅ “regular expressions”) PATTERN (A B*) "A" : 1 row, "B*" : 0 or more rows, as many as possible • DEFINE (at least one) row condition [A undefined = TRUE] B AS page = PREV(page)+1 • Each series that matches the pattern is a “match” – "A" and "B" identify the rows that meet each condition – There can be unmatched rows between series 7](https://image.slidesharecdn.com/rowpatternmatching12ctech14-160929214935/75/Row-Pattern-Matching-in-Oracle-Database-12c-7-2048.jpg)









![SELECT s first_site, MAX(e) last_site, MAX(sm) sum_cnt FROM ( SELECT s, e, cnt, sm FROM t MODEL MEASURES (study_site s, study_site e, cnt, cnt sm) RULES ( sm[ > 1] = CASE WHEN sm[cv() - 1] + cnt[cv()] > 65000 OR cnt[cv()] > 65000 THEN cnt[cv()] ELSE sm[cv() - 1] + cnt[cv()] END, s[ > 1] = CASE WHEN sm[cv() - 1] + cnt[cv()] > 65000 OR cnt[cv()] > 65000 THEN s[cv()] ELSE s[cv() - 1] END ) ) GROUP BY s; • DIMENSION with row_number orders data and processing • rn can be used like a subscript • cv() means current row • cv()-1 means previous row DIMENSION BY (row_number() over(order by study_site) rn) rn [cv() – 1] [cv()] [cv()] [cv()] [cv() – 1] [cv()] rn [cv() - 1] [cv()] [cv()] [cv()] [cv() – 1] 20](https://image.slidesharecdn.com/rowpatternmatching12ctech14-160929214935/75/Row-Pattern-Matching-in-Oracle-Database-12c-20-2048.jpg)



![4) Brilliant pre 12c solution SELECT bin, Max (bin_value) bin_value FROM ( SELECT * FROM items MODEL DIMENSION BY (Row_Number() OVER (ORDER BY item_value DESC) rn) MEASURES ( item_name, item_value, Row_Number() OVER (ORDER BY item_value DESC) bin, item_value bin_value, Row_Number() OVER (ORDER BY item_value DESC) rn_m, 0 min_bin, Count(*) OVER () - 3 - 1 n_iters ) RULES ITERATE(100000) UNTIL (ITERATION_NUMBER >= n_iters[1]) ( min_bin[1] = Min(rn_m) KEEP (DENSE_RANK FIRST ORDER BY bin_value)[rn<= 3], bin[ITERATION_NUMBER + 3 + 1] = min_bin[1], bin_value[min_bin[1]] = bin_value[CV()] + Nvl(item_value[ITERATION_NUMBER+4], 0)) ) WHERE item_name IS NOT NULL group by bin; 25](https://image.slidesharecdn.com/rowpatternmatching12ctech14-160929214935/75/Row-Pattern-Matching-in-Oracle-Database-12c-25-2048.jpg)