This document presents a novel method for query-sensitive comparative summarization of web search results by utilizing the DOM tree structure of web pages. The system generates concise summaries from a set of user-selected URLs, aiding users in quick decision-making by extracting relevant content based on specific feature keywords. This automatic summarization technique enhances efficiency by providing essential information without requiring users to browse multiple web pages.

![Computer Science & Engineering: An International Journal (CSEIJ), Vol.1, No.5, December 2011 32 Automatic summary produced by current search engines contains first few sentences of the web page or the set of sentences containing the query key words. Using this information, users have to decide which of the listed documents in the search result will be most likely to satisfy their information need. This paper is an extension of our work mentioned in [1], proposes a summarization technique, which extracts query relevant important sentences from a set of selected web pages to generate a comparative summary which would be beneficial for the users to make informed decisions. The remainder of this paper is organized as follows: Section 2 provides the motivating examples for this work, Section 3 discusses about the related research works that have been done in this field and Section 4 describes concept based segmentation process guided by the webpage’s DOM tree structure. In section 5, we present the framework for the selection based comparative summarization system. Section 6 compares this system with few other systems, Section 7 discusses about experimentation results and performance measures and in section 8, the paper is concluded with a view on further improvement to this system. 2. MOTIVATING EXAMPLE People normally collect all related material and information before they make a decision about some product or service before they go for it. For example, parents might be interested in collecting details like placement, infrastructure, faculty details, etc related to various Engineering Colleges, before they go for admission. To accomplish this, the user collects placement and other required details of various Engineering Colleges using search engines like Google, prepares a comparative statement manually to find out the best option for admission. The proposed system generates the comparative summary from the set of URLs selected by user from the search result based on the specified feature set. The comparative summary contains the text relevant to placement and training, infrastructure details, result details and fee structures from the selected URLs. This would definitely be helpful to get instant comparative statement. Another example could be the comparison between the services offered by various Banks. Set of Banks can be selected from the list of Bank web sites and comparative summary based on feature keywords like home loan, term deposit, etc would be helpful for users to make quick decisions about their investment. 3. RELATED WORKS Summarization in general can be categorized into two types as extraction based and abstraction based methods. Extractive summary is created by extracting important sentences from the actual content, based on some statistical measures like TFxIDF, SimWithFirst[2],etc. Abstractive summary is created by rewriting sentences on understanding the entire content of the original article by applying NLP techniques. The later technique is more computationally intensive for large data-sets. Concept based automatic summarization directly extracts the sentences, which are related to the main concept of the original document while the query sensitive summarization extracts sentences according to user queries, so as to fit the interests of users. In multi-document summarization the sentences are selected across different documents by considering the concept and diversity of contents in all documents.](https://image.slidesharecdn.com/1211cseij03-190830130135/75/QUERY-SENSITIVE-COMPARATIVE-SUMMARIZATION-OF-SEARCH-RESULTS-USING-CONCEPT-BASED-SEGMENTATION-2-2048.jpg)
![Computer Science & Engineering: An International Journal (CSEIJ), Vol.1, No.5, December 2011 33 Query based summarization system to create a new composed page containing all the query key words was proposed in[3]. Composed page was created by extracting and stitching together the relevant pieces from a particular URL in search result and all its linked documents but not other relevant documents of user’s interest. Segmented topic blocks from HTML DOM tree were utilized to generate summary in [4] by applying a statistical method similar to TFxIDF to measure the importance of sentences and MMR to reduce redundancy. This system focused on the summary of only single document. SimWithFirst (Similarity With First Sentence) and MEAD (Combination of Centroid, Position, and Length Features) called CPSL features were used for both single and multi document text summarization in[5]. Both these techniques show better performance for short document summarization but not suitable for large ones. Document Graph structure of sentences was used in[6] for text summarization. Similarity scores between the query and each sentence in the graph are computed. Document graph construction is an overhead for the summarization process. Balanced hierarchical structure[6] was utilized to organize the news documents based on event topics to generate event based summarization. This method focused on news and event summarization. This research work focuses on the novel idea of generating the aggregation of document summaries. This document summarization makes use of concept based segmentation of DOM tree structure of web pages. This comparative summary is composed of the query sensitive important sentences extracted from concept blocks of different web pages which would be helpful for decision making. 4. CONCEPT BASED SEGMENTATION In general, web page summarization derives from text summarization techniques, while it is a great challenge to summarize Web pages automatically and effectively. Because Web pages differ from traditional text documents in both structure and content. Web pages often have diverse contents such as bullets, images and links. Web documents may contain diversified subjects and information content. Normally, the contents of same subjects will be grouped under the same tag. This system utilizes the Document Object Model (DOM) to analyze the content of the web page. The leaf nodes of DOM tree contain the actual content and the parent nodes generally contain higher level topics or section headings. 4.1 Concept Based Segmentation Process Fig. 1 depicts the concept based segmentation using DOM tree structure. The rectangular nodes represent the HTML tags or the higher level topics and the circular nodes represent the information content within the tag. These circular nodes from left to right constitute a coherent semantic string of the content[4]. The DOM trees of the user selected URLs are processed to generate the summary. Leaf nodes are considered as micro blocks which are the basic building blocks of the summary. Adjacent micro blocks of the same parent tag are merged to form the topic blocks. Each sentence in the topic block is labeled automatically based on the PropBank notations [7][8]. The information about who is doing what to whom clarifies the contribution of each term in a](https://image.slidesharecdn.com/1211cseij03-190830130135/75/QUERY-SENSITIVE-COMPARATIVE-SUMMARIZATION-OF-SEARCH-RESULTS-USING-CONCEPT-BASED-SEGMENTATION-3-2048.jpg)
![Computer Science & Engineering: An International Journal (CSEIJ), Vol.1, No.5, December 2011 34 sentence to the meaning of the main topic of that sentence[9].This concept-based mining model captures the semantic structure of each term within a sentence rather than the frequency of the term alone. This similarity measure outperforms other similarity measures that are based on term analysis models[10]. These sentences are labeled by a semantic role labeler that determines the words which contribute more to the sentence semantics associated with their semantic roles in the sentence. The semantic role labeler identifies the verb argument structures of each sentence in the topic block. The number of generated labeled verb argument structures is entirely dependent on the amount of information in the sentence. The sentence that has many labeled verb argument structures includes many verbs associated with their arguments. The words contributing more to the meaning of the sentence will occur more number of times in the verb argument structure of the sentence. Hence these words will have comparatively higher frequency. ASSERT software which is a publicly distributed semantic labeling tool, is used for this purpose. Each word that has a semantic role in the sentence, is called a concept[4][9]. Concepts can be either words or phrases and are totally dependent on the semantic structure of the sentence. List of concept words and their respective frequency of occurrences for these topic blocks are identified. Concept based similarity between the topic blocks are measured using the concept lists to identify the similar topic blocks. Topic blocks having similarity above the threshold value α(0.6), are combined to form the concept block. Topic blocks having content about the same concept (for example placement and training in a college web site) will be similar to each other. Topic blocks containing information about similar concept word (placement) are merged to form a concept block (placement block having placement details of all departments in the college). The concept block formation could be done offline for all web documents in the repository. The concept block id, conceptual terms, frequency and list of sequence numbers of sentences of each of these concept blocks are stored in the offline database which would be required for processing at run time. These concept blocks contain related information content scattered throughout the Home Dept Admission html head body CSEIT ECE placementresult placementresult placementresult Fig 1. Concept based segmentation](https://image.slidesharecdn.com/1211cseij03-190830130135/75/QUERY-SENSITIVE-COMPARATIVE-SUMMARIZATION-OF-SEARCH-RESULTS-USING-CONCEPT-BASED-SEGMENTATION-4-2048.jpg)
![Computer Science & Engineering: An International Journal (CSEIJ), Vol.1, No.5, December 2011 35 document. The set of sentences in each of these concept blocks are actually present is different parts of the document. Since DOM nodes are processed, the time taken for processing is less when compared to other vector based and document graph[10] based models. The processing time required to build the document graph is avoided in this approach. 4.2 Concept Based Segmentation Algorithm The conceptual term frequency is an important factor in calculating the concept-based similarity measure between topic blocks. The more frequent the concept appears in the verb argument structures[4][9] of a sentence, the more conceptually similar the topic blocks are. Concept based segmentation algorithm is described below: Input : Web document di. Output : Set of concept blocks{Cb1,..Cbn} of di, Concept list of di, L={C1,..Cm} Concept list of topic block tbi, Ctbi ={ck1,..ckm}, k=1..n Step1: Mark all leaf nodes as individual micro blocks in the DOM tree. Step2: Extend the border of the micro block to include all leaf nodes of the same tag to form a topic block so as to have a set of topic blocks TB={tb1, tb2, …tbn}, TB⊂di. Step3: Build concept list for all topic blocks TB ={tb1, tb2, …tbn}. Topic block tbi is a set of sentences, tbi={si1, si2, ..sin1}, si⊂ tbi. Sentence si is a string of concepts, si={ci1,ci2 . . . cim}, ci ⊂ si, if ci is a substring of si Concept ci is a string of words, ci = {wi1,wi2, . . .wik }, where k : number of words in concept ci. m: number of concepts generated from the verb argument structures in sentences n1: total number of sentences in tbi 3.1: Ctbi, L are empty lists. 3.2: Build concept list of each sentence in tbi 3.2.1: si is a new sentence in tbi 3.2.2: Build concepts list Ci from si, Ci ={c1,c2,..cm} 3.2.3: Update concept list Ctbi of topic block tbi and L of document di 3.2.3.1: for each concept ci ⊂ Ci do 3.2.3.2: for each cj⊂ L, do 3.2.3.3: if (ci == cj) then 3.2.3.4: add freq(ci, si) to ctfi of ci // freq(ci, si) returns the frequency of ci in the verb argument // structures of si, added to conceptual term frequency of ci 3.2.3.5: else add new concept to Ctbi, L // added to both L and Ctbi 3.2.3.6: end if 3.2.3.7: end for 3.2.3.8: end for 3.3: Output the concepts list Ctbi 3.4: Output the concepts list L of document di. Step4: The concept based similarity between topic blocks are measured by (1) . 2 2 21 1 121 2121 1),( i CCi ii CCi i ctfweightctfctfweightctftbtbSim tbtbtbtb ×−×−= ∑∑ ∩⊂∩⊂ (1) Where,](https://image.slidesharecdn.com/1211cseij03-190830130135/75/QUERY-SENSITIVE-COMPARATIVE-SUMMARIZATION-OF-SEARCH-RESULTS-USING-CONCEPT-BASED-SEGMENTATION-5-2048.jpg)
![Computer Science & Engineering: An International Journal (CSEIJ), Vol.1, No.5, December 2011 36 ctfi1, ctfi2 : Frequency of concept ci in tb1, tb2 i1,i2 : set of common conceptual terms between tb1, tb2 ctfweighti1,ctfweighti2 : Weight of concept ci with respect to topic blocks tb1, tb2 normalized by the frequency vectors of tb1, tb2,calculated as in (2) ( )∑ = = m k k i i ctf ctf ctfweight 1 2 (2) ctfweighti represents the importance of the concept ci with respect to the concept vector of tbi. The concepts contributing more to the meaning of the sentences in the topic block occurs more times in the verb argument structure of the sentence and in turn gets more weightage. Step5: Merge the topic blocks having concept based similarity measure above the predefined threshold α. Concept block Cbk={set of topic blocks tbi}| ∀tbi, tbj∈Cbk, sim(tbi, tbj)> α, tbi⊂TB, tbj⊂TB, k=1..n Step6: Output Concept blocks Cb1,Cb2,..Cbn Similarity between topic blocks is measured by considering the commonly occurring concepts in both topic blocks, tb1 and tb2. Frequency of these common terms and their topic block based weightage are used to measure the similarity score and is normalized to the range 0 to 1. The concept blocks of each URLs selected by the user are identified. Concept blocks of all URLs in the repository can be identified during preprocessing stage itself. This will reduce the computation complexity at run time. The next section describes about generating the comparative summary on the fly at run time using these concept blocks of the web document. 5. COMPARATIVE SUMMARY GENERATION The architecture of the comparative summarization system is given in Fig.2. User enters the generic query string (eg. Engineering College) through the search engine query interface. Search engine identifies the relevant pages and present the search result in rank order. Then the specific feature keywords based on which comparative summary is to be generated and the set of URLs are obtained from the user. The selected HTML files of the URLs are cleaned by removing unwanted HTML tags (like META tag, ALIGN tag, etc.) which do not contribute much for further processing. Concept blocks of these URLs which were already formed during preprocessing are utilized to generate the summary. The relevance of the concept blocks Cbi to the feature keywords f is measured by means of similarity between the feature keyword string[4][9] and the concept list of each of the concept blocks Cbi.. ∑ ∑ ∈ ∩∈ = Cbit ti Cbift ti if Ctf Ctf Cbfsim 2 ),( (3) Where, f: set of feature keywords,f={f1,f2,..fn}](https://image.slidesharecdn.com/1211cseij03-190830130135/75/QUERY-SENSITIVE-COMPARATIVE-SUMMARIZATION-OF-SEARCH-RESULTS-USING-CONCEPT-BASED-SEGMENTATION-6-2048.jpg)
![Computer Science & Engineering: An International Journal (CSEIJ), Vol.1, No.5, December 2011 37 Cbi: Concept block i, for which the list of concept terms and their frequency were already identified. Simf (f, Cbi) : Similarity between feature keyword string f and Concept block Cbi t : set of common terms between f and Concept list of Cbi Ctfit : frequency of term t in Cbi Simf(f,Cbi) is measured using the conceptual term frequency of the matching concepts of these concept blocks and is normalized by the concept frequency vector of the concept block. The concept block having maximum number of matching concept terms will get high score. The range of Simf(f,Cbi) value lies between 0 and 1, and the similarity increases as this value increases. Synonyms of the feature words and concept terms were taken into consideration for processing. The concept block with maximum similarity is considered as the superset of the summary to be generated. The significance of each sentence in this concept block with respect to the query string is measured. The sentences are considered in the descending order of their score. According to the ratio of summarization required or the number of sentences required, the sentences are extracted from these concept blocks to compose the HTML page for comparative summary. 5.1 Sentence Weight Calculation Content of these concept blocks are ranked with respect to the query string and the feature keywords, using (4). Sentence weight calculation considers[12] the number of occurrences of query string, feature keywords and their distance and frequency, location of the sentence, tag in which the text appears in the document, uppercase words,etc. Fig. 2. Framework of comparative summarization system Web DB Preprocessing Use DOM tree & find micro blocks Clean the documents Form topic blocks by merging micro blocks Find the concept lists of topic blocks Merge similar topic blocks to form concept blocks At Run time Compose & Display Comparative summary Display Search result Search String Search Engine Enter feature keywords Select set of URLs Select top scoring sentences from the concept blocks based on keywords Select relevant concept blocks](https://image.slidesharecdn.com/1211cseij03-190830130135/75/QUERY-SENSITIVE-COMPARATIVE-SUMMARIZATION-OF-SEARCH-RESULTS-USING-CONCEPT-BASED-SEGMENTATION-7-2048.jpg)
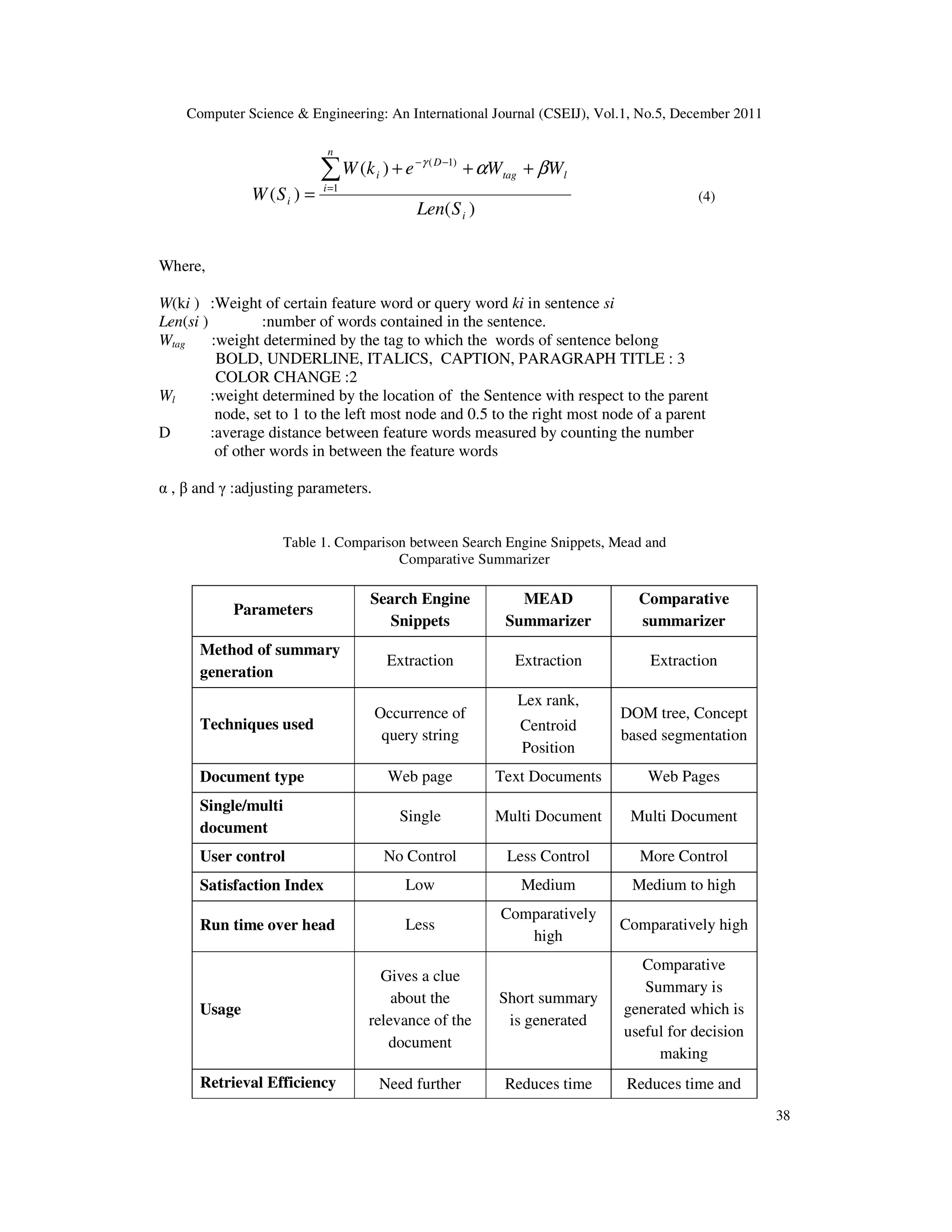
![Computer Science & Engineering: An International Journal (CSEIJ), Vol.1, No.5, December 2011 39 browsing and scanning taken for scanning entire set of documents to understand the core concept effort taken for browsing and scanning various web pages to extract the gist of it The sentences having frequent occurrences of the feature keywords and enclosed in special tags are given preference. Location based weight is assigned according to the location of the sentence within its immediate parent node. The top scoring sentences are extracted and arranged based on the hierarchical structure of the individual documents. The title or first sentence of the immediate parent of the extracted sentence, is chosen as subtitles for a set of leaf node contents. (for example, IT, CSE, ECE in our example). Hence the resulting summary will contain the SECTION-wise summary sentences of a set of URLs chosen by the user for immediate comparison. This is applicable to various decision making situations which require analysis of various parameters from various sources. 6. COMPARISON WITH EXISTING SYSTEMS Various feature of the proposed system and the search snippets and a bench mark text summarization system are compare and is presented in Table 1. As there is no bench mark web document summarizer is available the techniques used in MEAD[14] is compared with the current system. The snippets are the set of sentences displayed by search engines as part of search results along with URLs that are extracted from the web page. These are the line in which the search string occurs in the web page. As given in Table1, the snippets provide vague information which are not sufficient to guess the usefulness of the target page and requires a complete scan of the content to capture the required information. MEAD provides a summary of set of text documents based on Lexrank and Centroid position score. This prepares the summary of the core concept of the documents which might be modified as per the query string. This system makes use of concept based segmentation approach which give more importance to conceptual terms contributing more to the meaning of the sentences. Hence this systems performance is comparatively promising than the other summarization systems. 7. EXPERIMENTAL RESULTS AND DISCUSSION The experimentation of this work was carried out with the real time dataset containing randomly collected 200 web documents from internet related to the educational institutions, algorithms, banking and household items. Normally, the summarization systems are evaluated using intrinsic approach or extrinsic approach [6][11]. Intrinsic approach directly analyzes the quality of the automatic summary through comparing it with the abstract extracted by hand or generated from other different automatic system. Extrinsic approach is a task-oriented approach, which measures the abstract quality according to its contribution. Intrinsic approach was utilized to conduct the experiment of this system. Users including one engineering student, three naïve users and one expert level user were involved in the experimentation process.](https://image.slidesharecdn.com/1211cseij03-190830130135/75/QUERY-SENSITIVE-COMPARATIVE-SUMMARIZATION-OF-SEARCH-RESULTS-USING-CONCEPT-BASED-SEGMENTATION-9-2048.jpg)
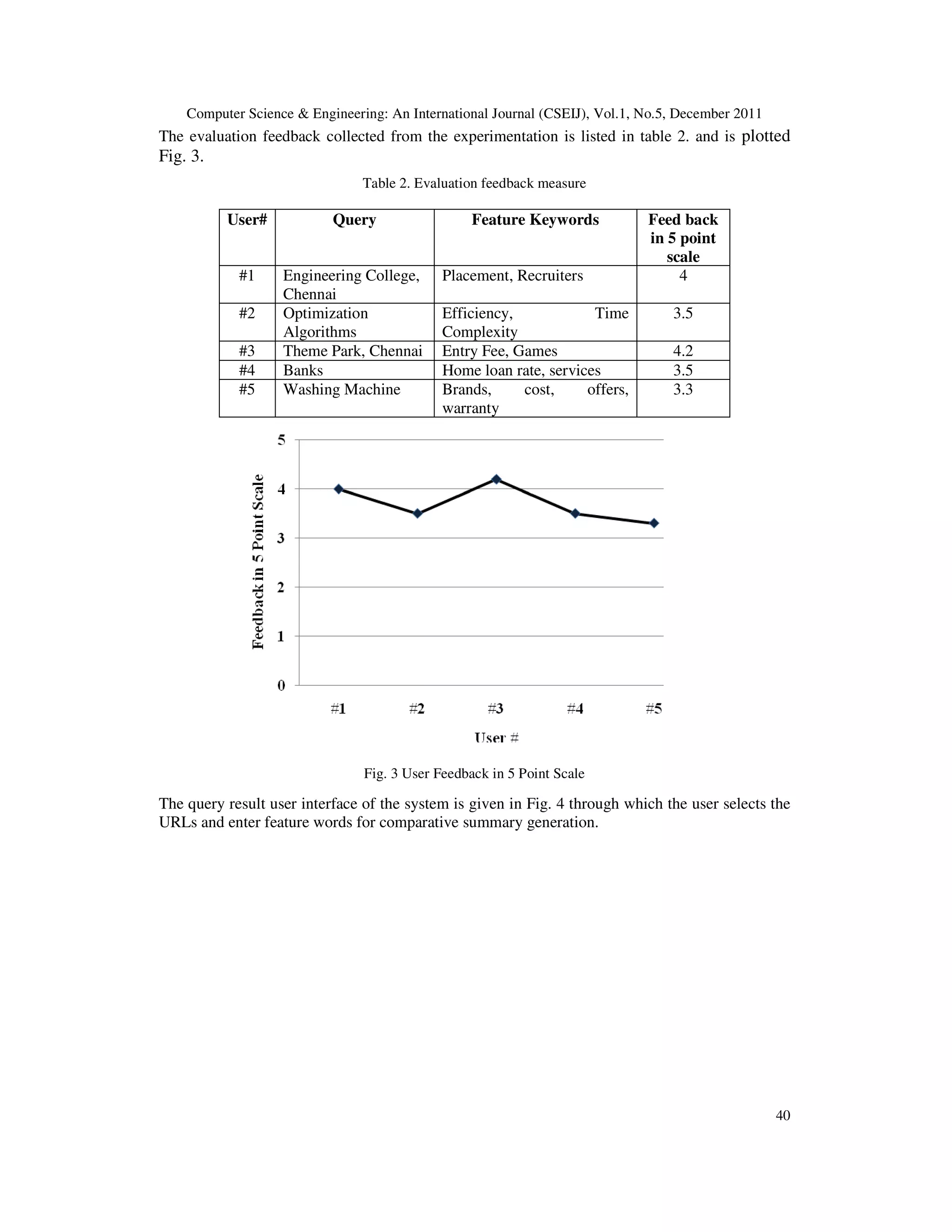

![Computer Science & Engineering: An International Journal (CSEIJ), Vol.1, No.5, December 2011 42 The impact of usage of key words association, document graph model of documents on this system and advanced text clustering techniques for summary generation can be done as a future expansion to this system. REFERENCES [1] Chitra Pasupathi, Baskaran Ramachandran, Sarukesi, “Selection Based Comparative Summarization Using Concept Based Segmentation”, CCIS 197, pp 655-664, Springer-Verlag Berlin Heidelberg, 2011. [2] Md. Mohsin Ali , Monotosh Kumar Ghosh And Abdullah-Al-Mamun, “Multi-Document Text Summarization: Simwithfirst Based Features And Sentence Co-Selection Based Evaluation”, Proceedings Of IEEE International Conference On Future Computer And Communication, PP93-96, 2009. [3] Ramakrishna Varadarajan, Vagelis Hristidis, And Tao Li, “Beyond Single-Page Web Search Results”, IEEE Transactions On Knowledge And Data Engineering, Vol. 20, No. 3, PP411-424, 2008. [4] Zhimin Chen, Jie Shen, “Research On Query-Based Automatic Summarization Of Webpage”, ISECS International Colloquium On Computing, Communication, Control, And Management, pp173-176, 2009. [5] Ahmed A. Mohamed, Sanguthevar Rajasekaran, “Improving Query-Based Summarization Using Document Graphs”, Proceedings of IEEE International Symposium On Signal Processing And Information Technology, PP408-410,2006 [6] Fu Lee Wa, Tak-Lam Wong, Aston Nai Hong Mak, “Organization Of Documents For Multiple Document Summarization”, Proceedings Of The Seventh International Conference On Web-Based Learning, IEEE, PP98-104,2008 [7] Elias Iosif and Alexandros Potamianos, “Unsupervised Semantic Similarity Computation between Terms Using Web Documents”, IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 22, NO. 11, 2010, pp1637-1647. [8] P. Kingsbury and M. Palmer, “Propbank: The Next Level of Treebank,” Proc. Workshop Treebanks and Lexical Theories, 2003 [9] Shady Shehata, Fakhri Karray, Mohamed S. Kamel, “An Efficient Concept-Based Mining Model for Enhancing Text Clustering”, IEEE Transactions On Knowledge And Data Engineering, VOL. 22, NO. 10, pp1360-1371, 2010. [10] Ohm Sornil, Kornnika Gree-Ut, “An Automatic Text Summarization Approach Using Content-Based And Graph-Based Characteristics”, IEEE, 2006. [11] Mani.I, “Summarization Evaluation: An Overview”, Proceedings Of The NTCIR Workshop Meeting On Evaluation Of Chinese And Japanese Text Retrieval And Text Summarization, 2001 [12] Cem Aksoy, Ahmet Bugdayci, Tunay Gur, Ibrahim Uysal and Fazli Can, “Semantic Argument Frequency-Based Multi-Document Summarization”, IEEE, 978-1-4244-5023-7/09, 2009, pp460-464. [13] www.summarization.com/mead/](https://image.slidesharecdn.com/1211cseij03-190830130135/75/QUERY-SENSITIVE-COMPARATIVE-SUMMARIZATION-OF-SEARCH-RESULTS-USING-CONCEPT-BASED-SEGMENTATION-12-2048.jpg)
