Download as PDF, PPTX

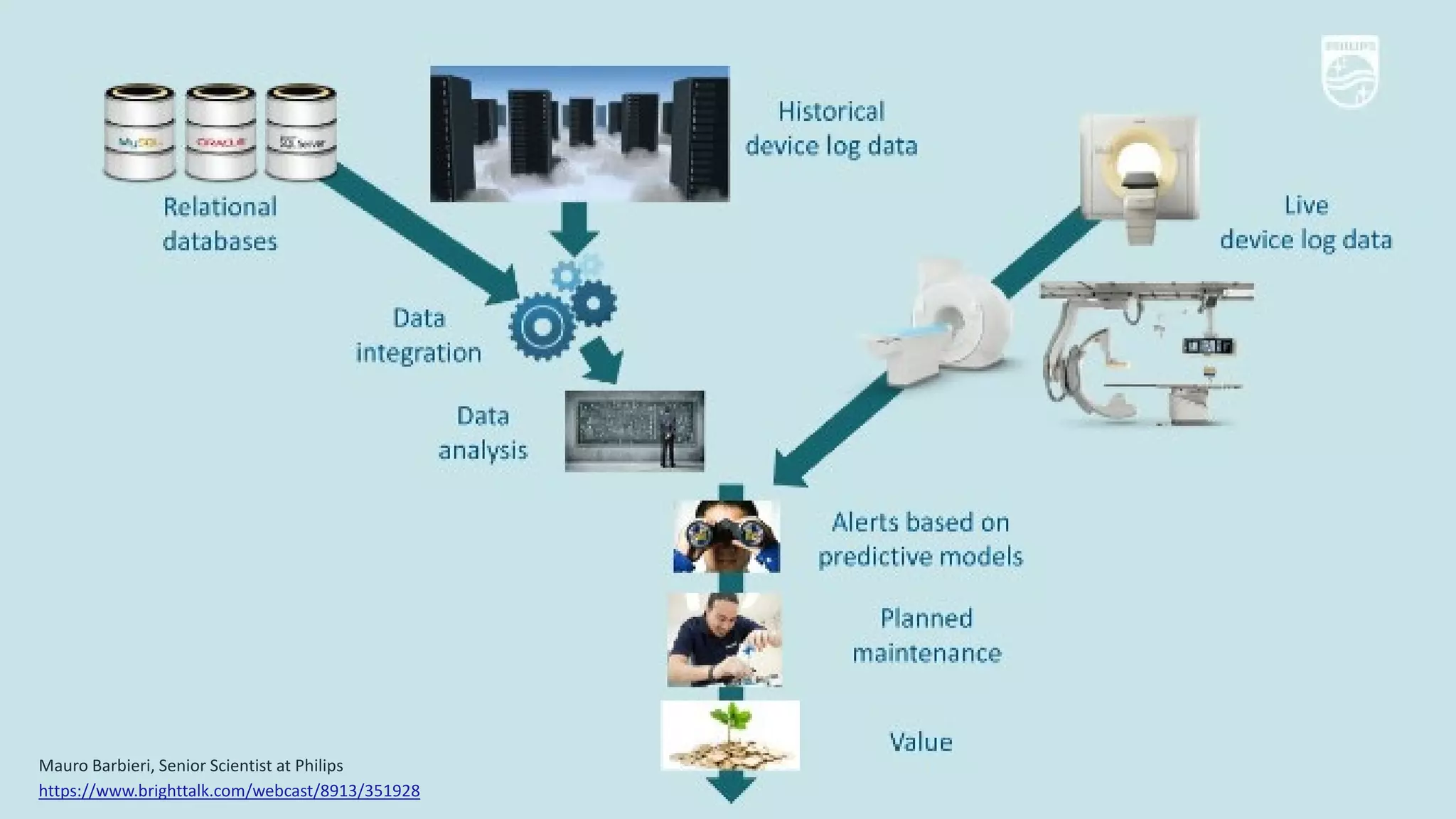
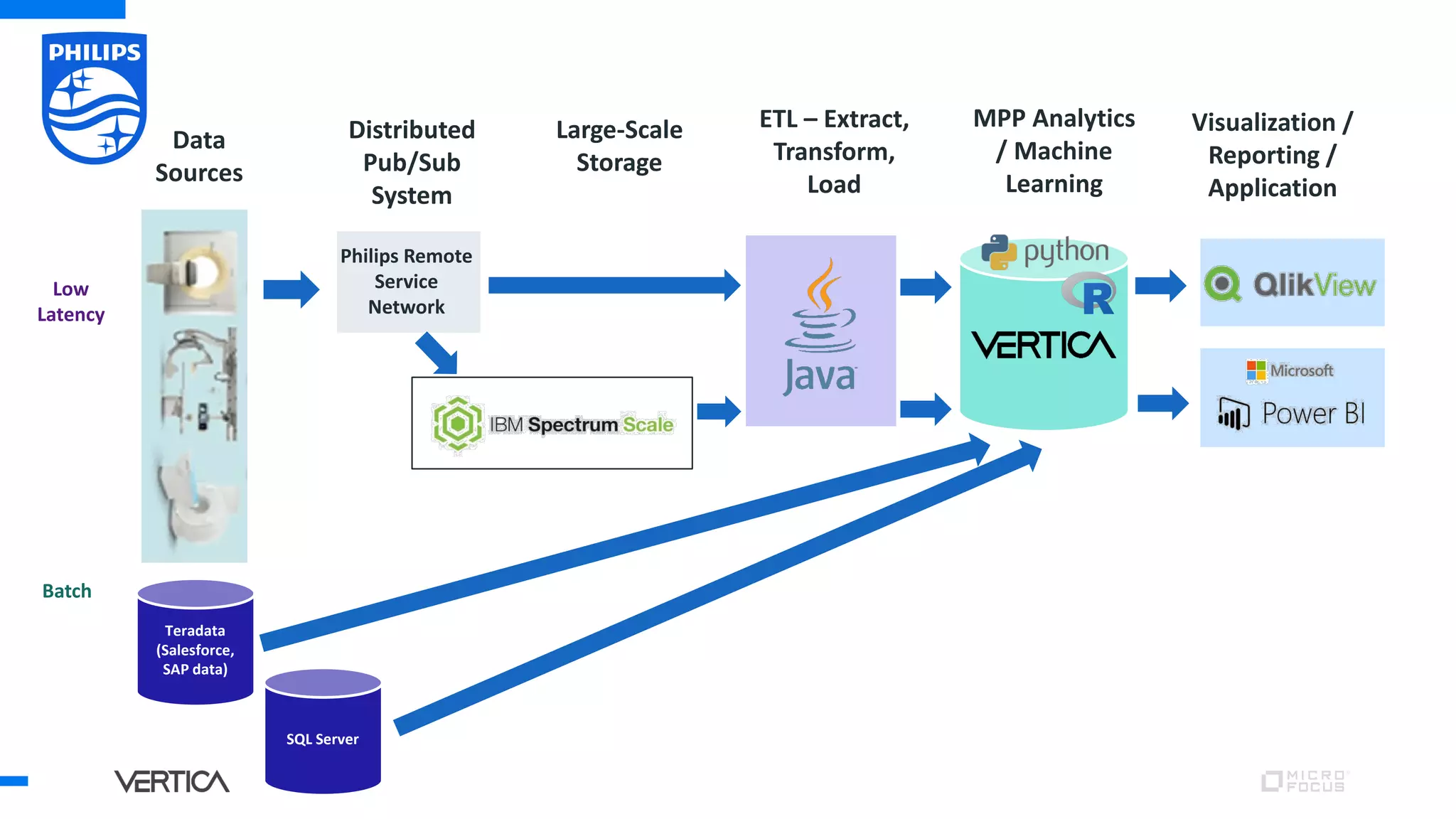
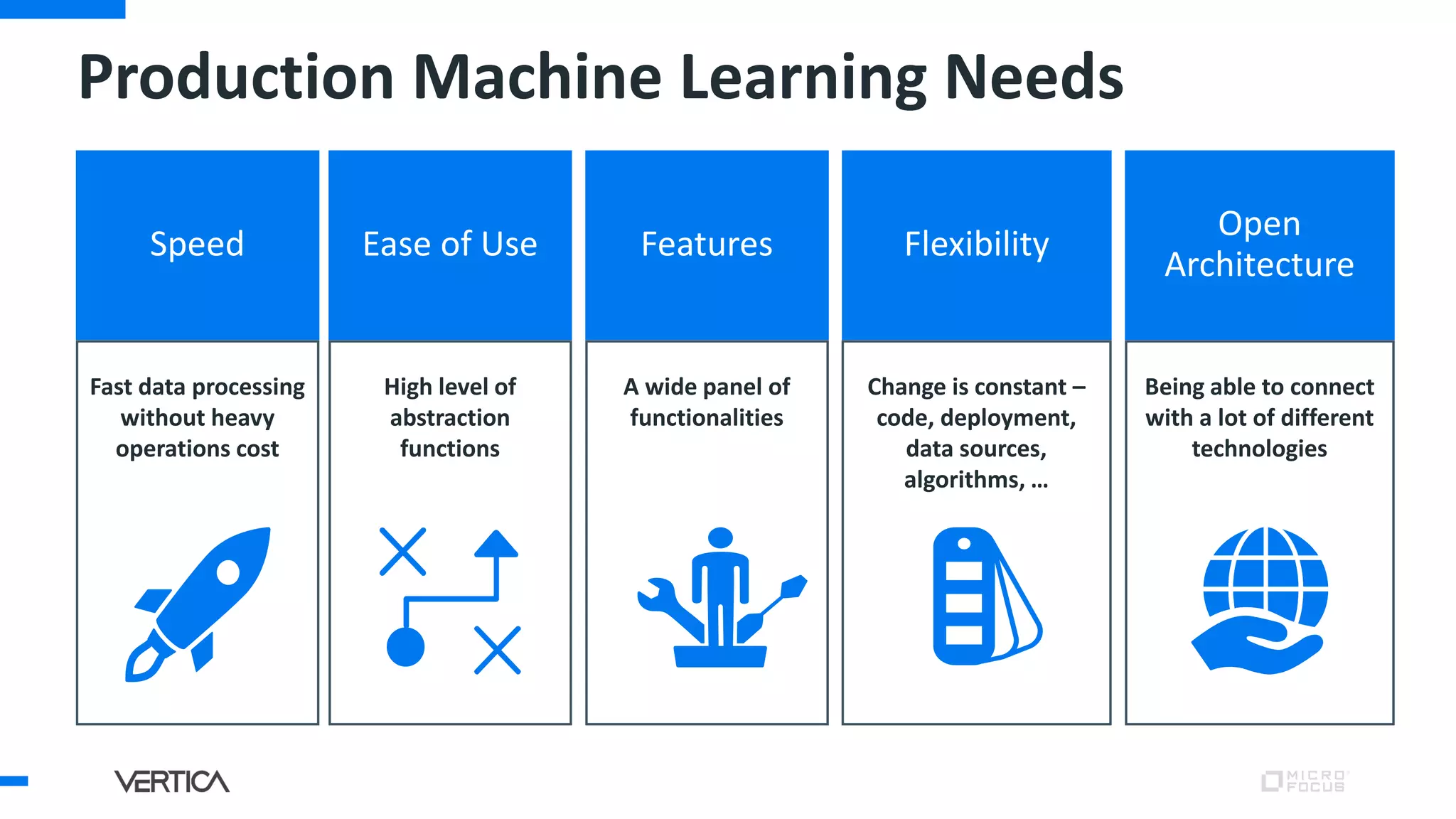
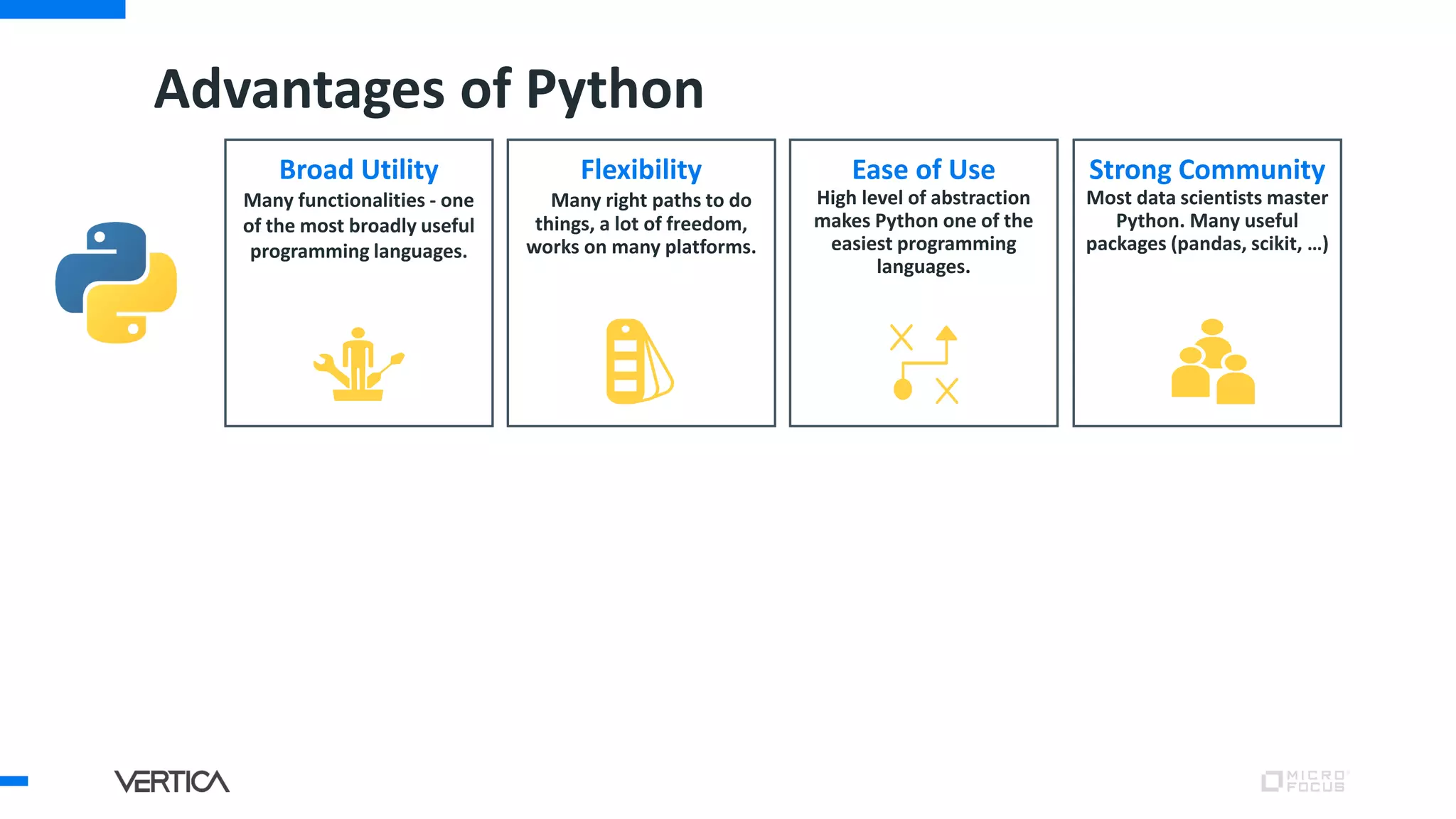

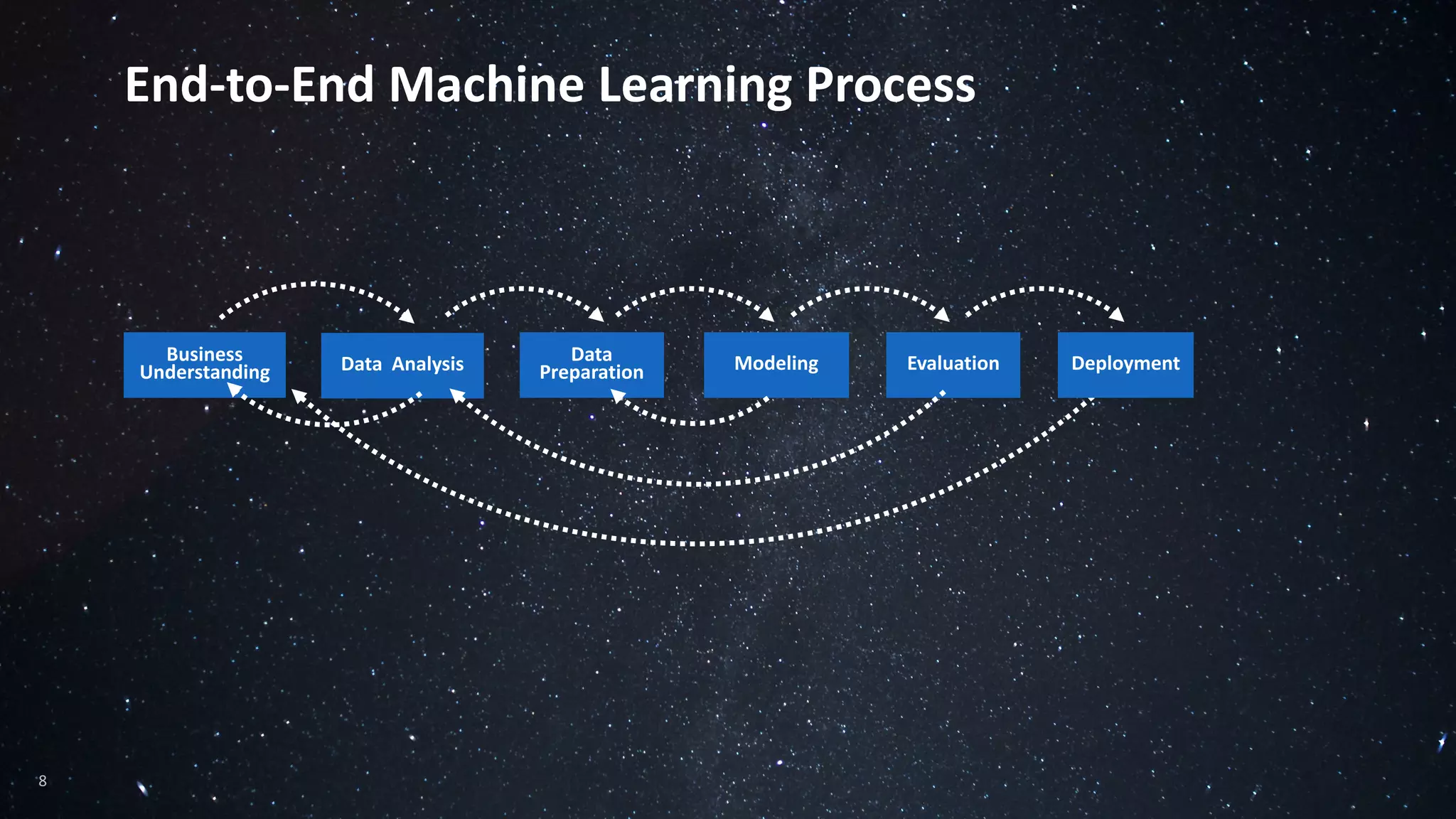
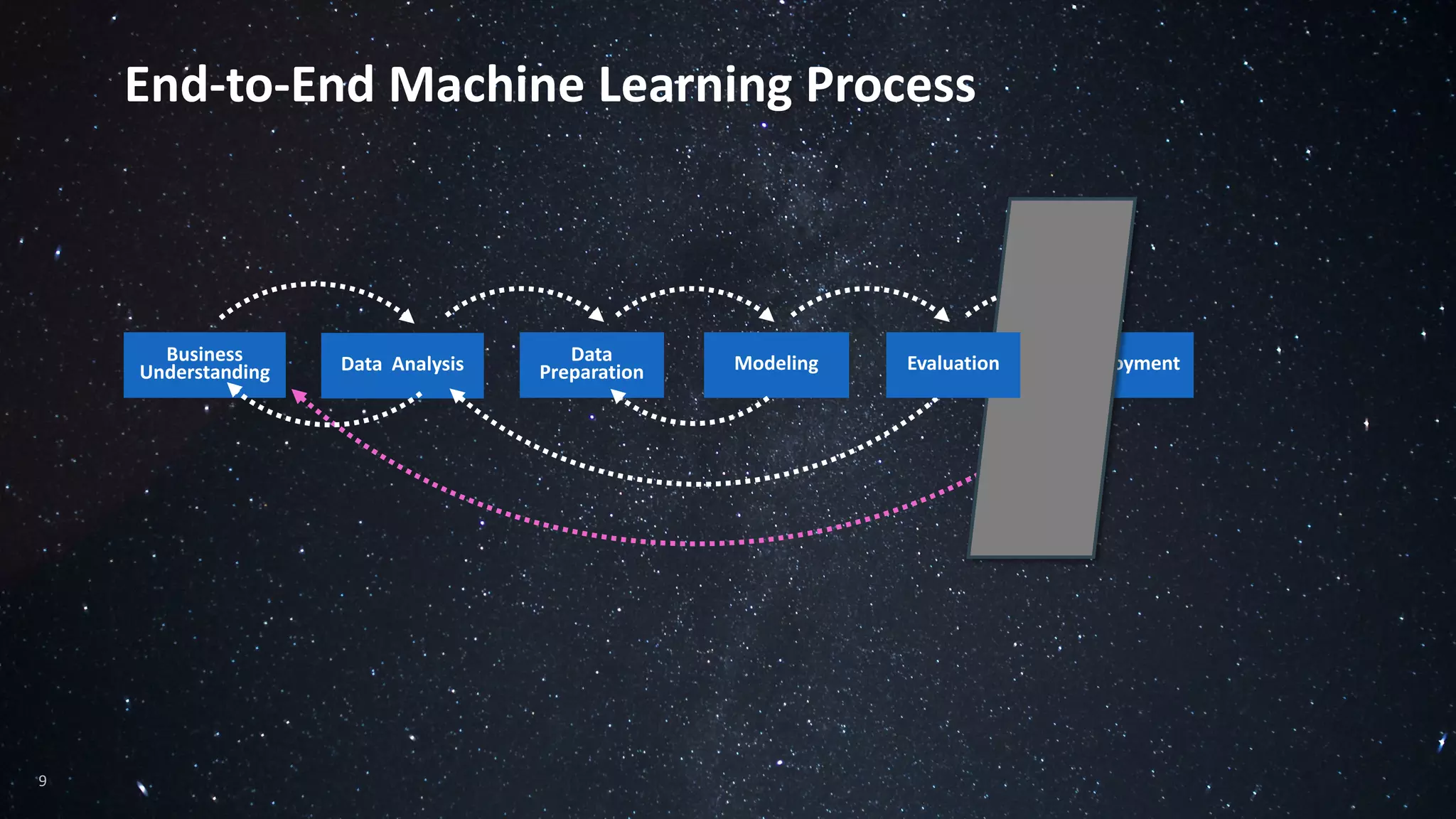


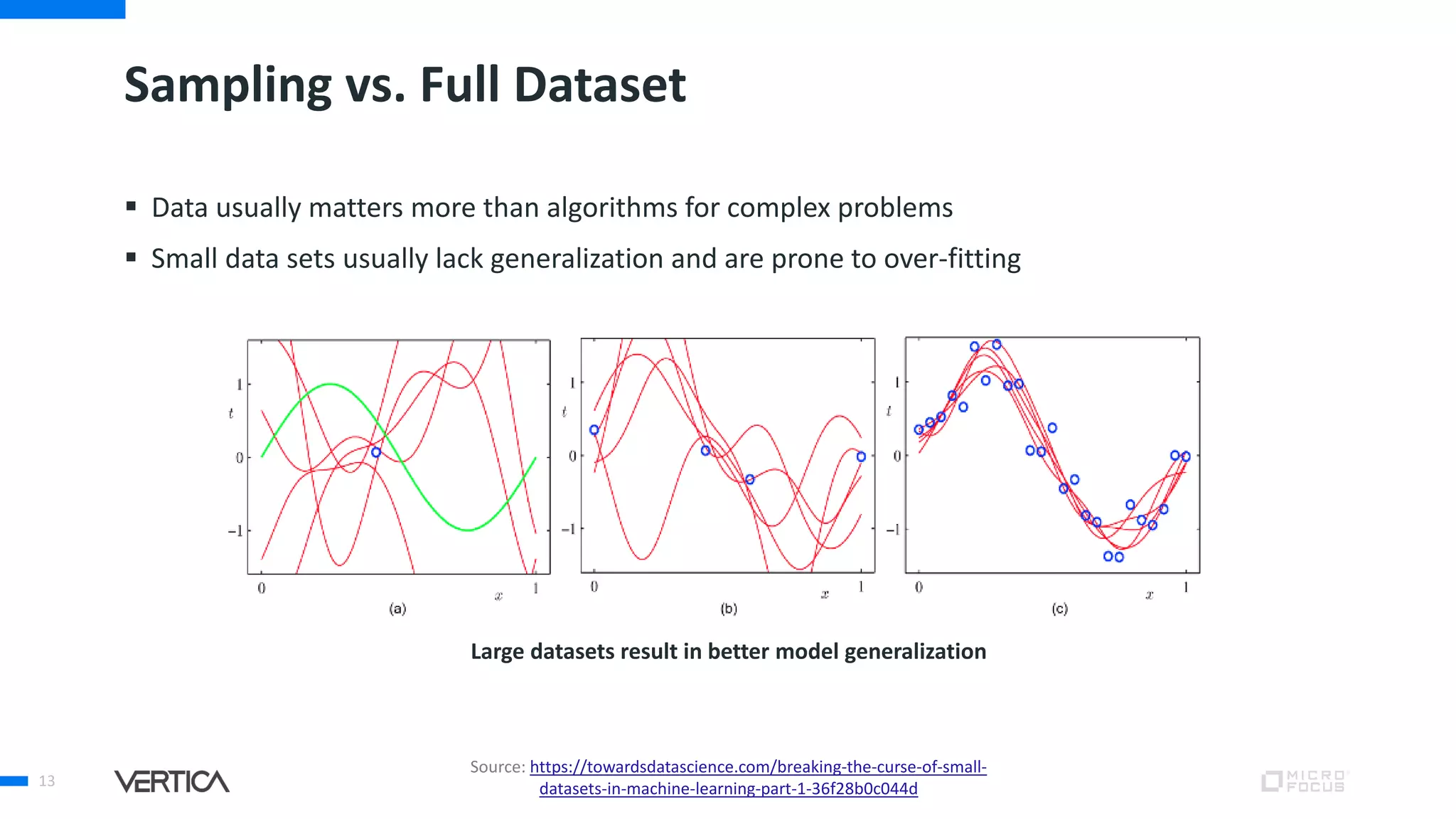




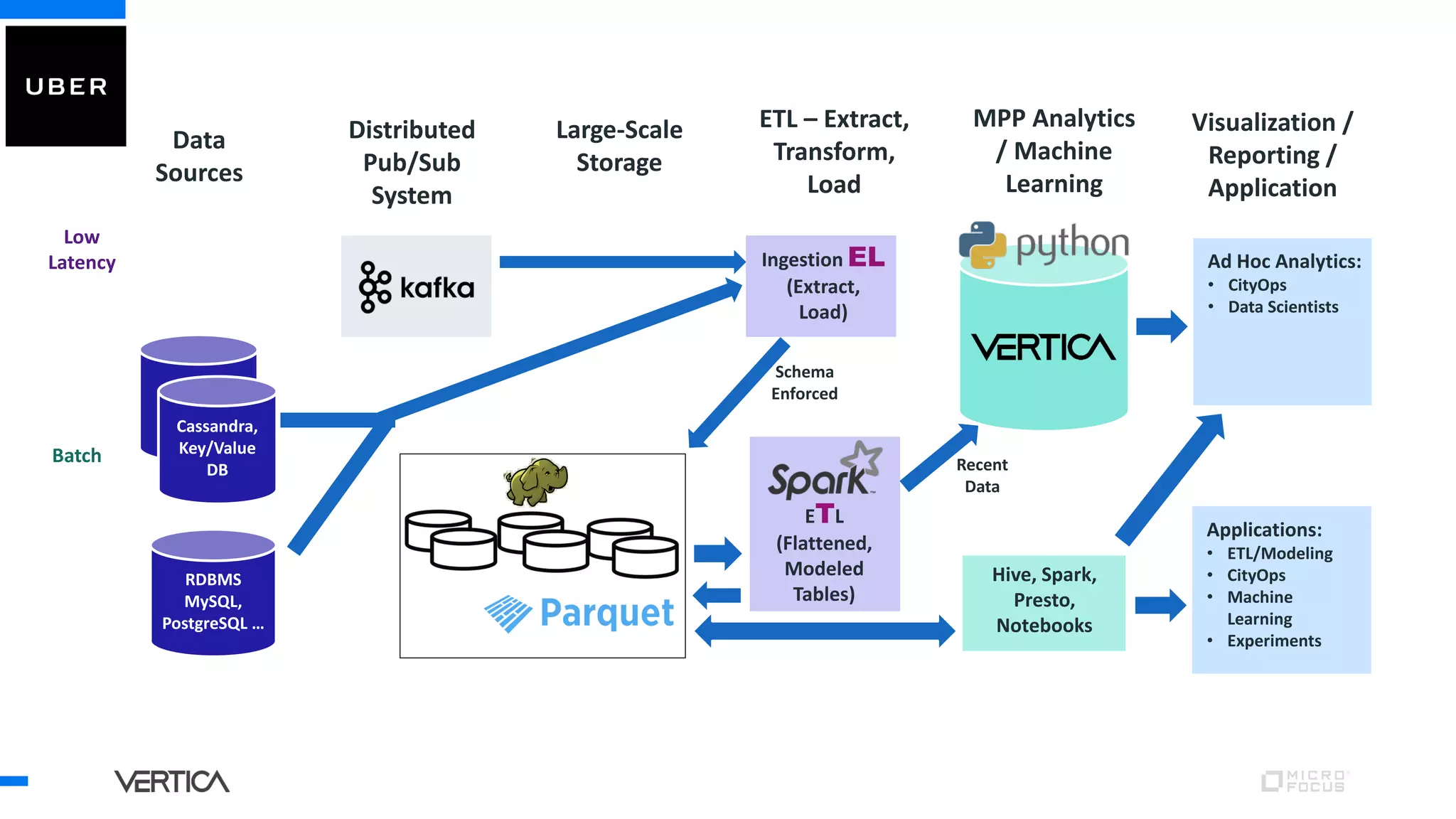
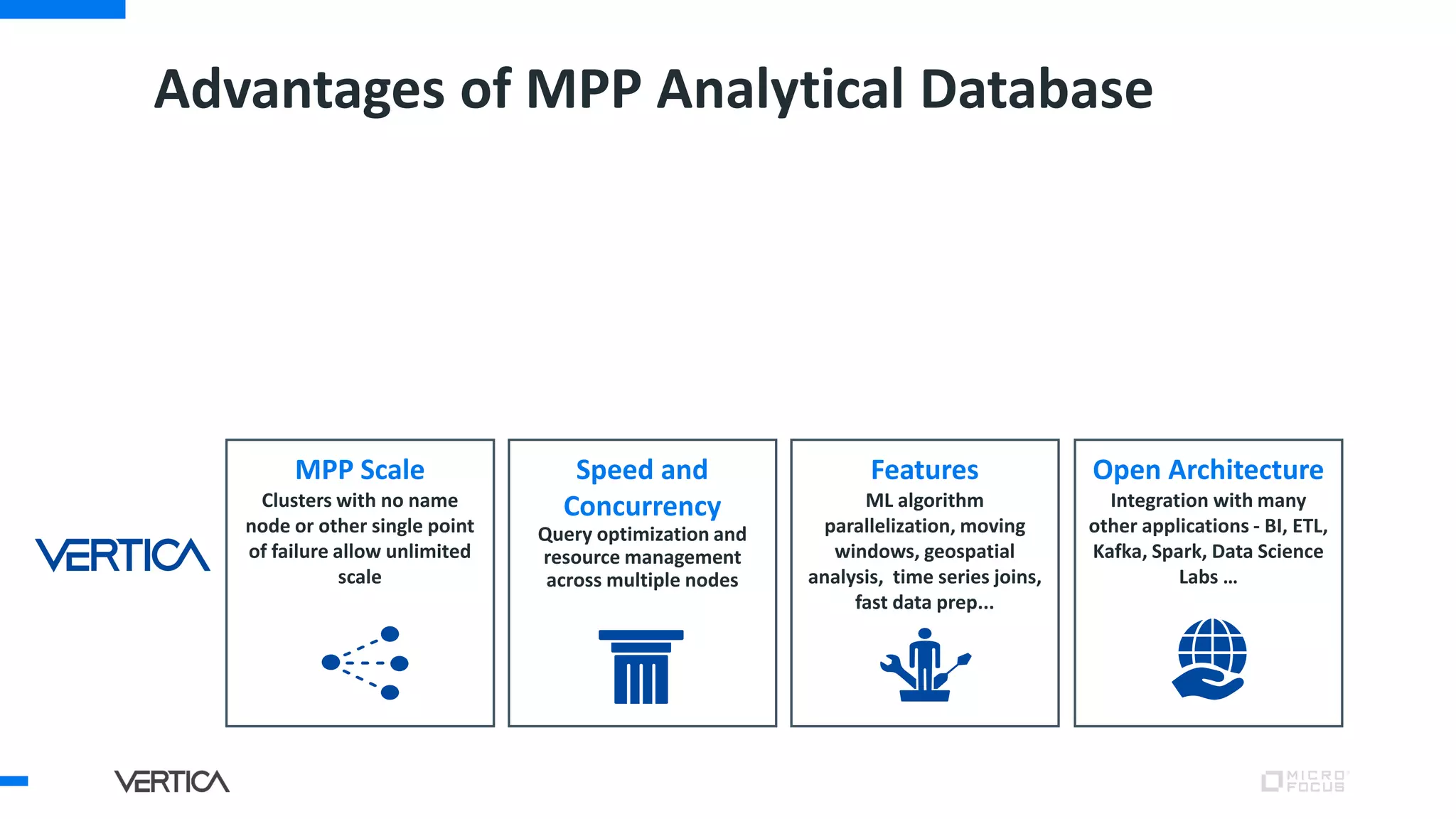
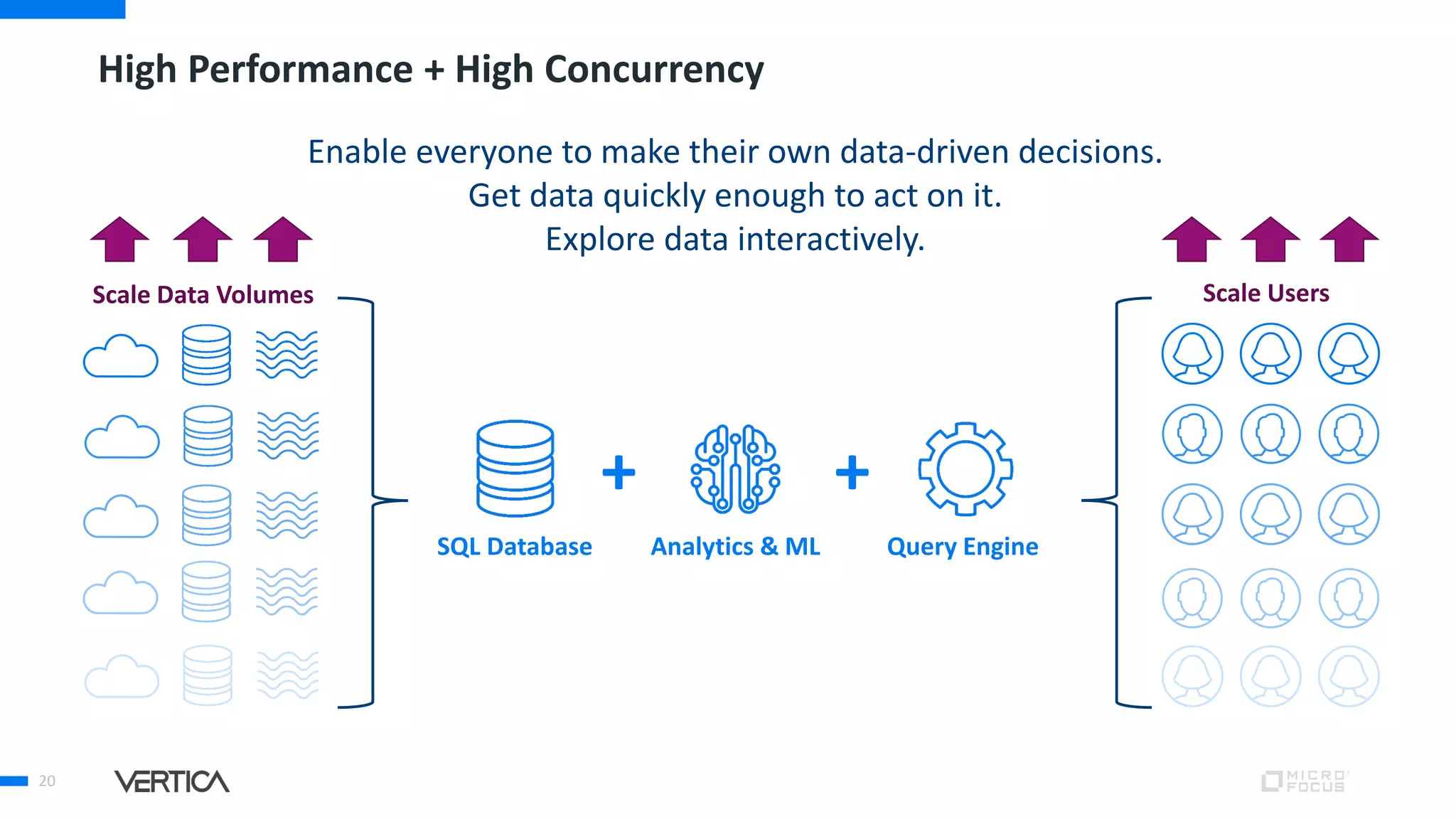
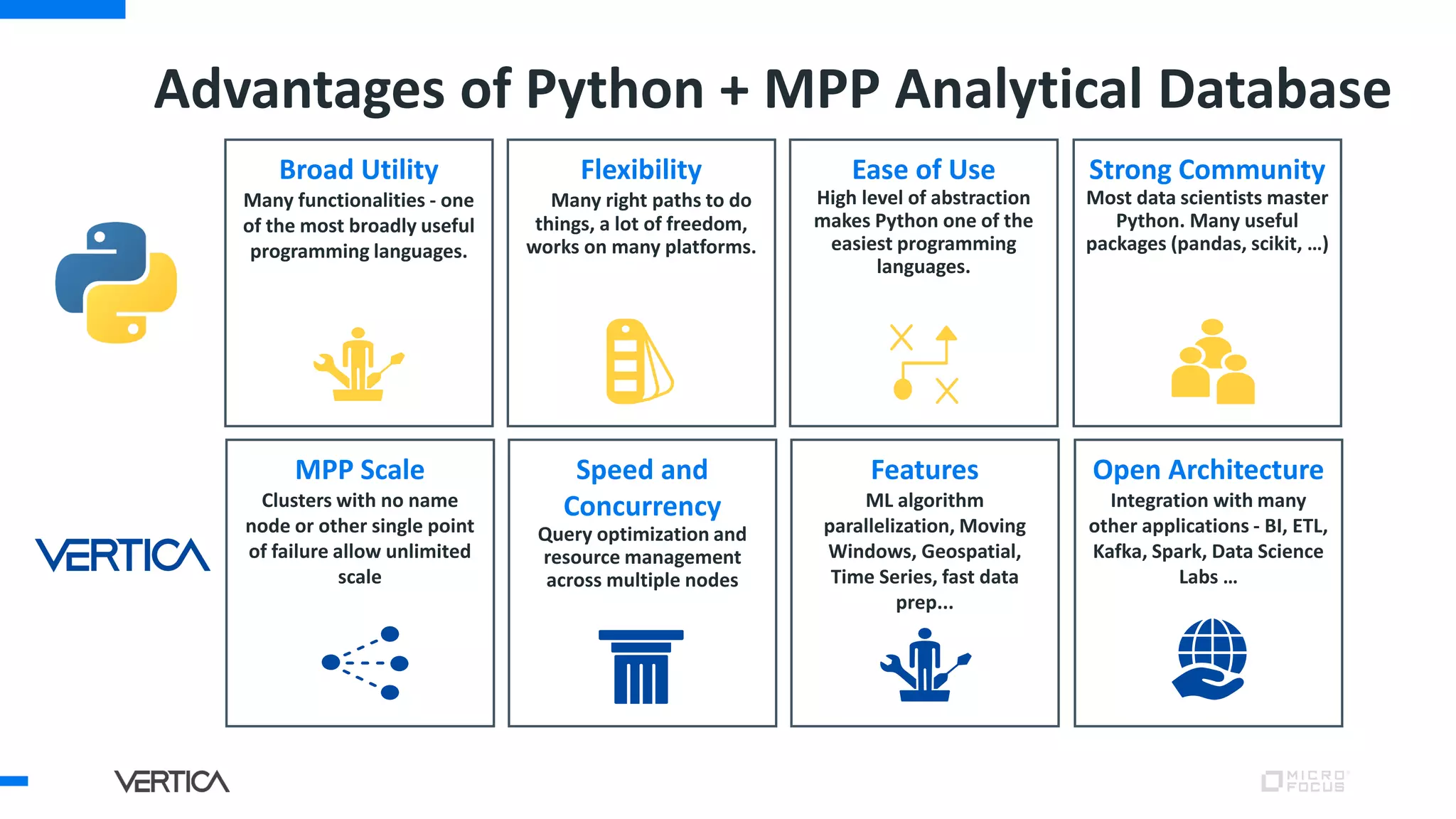
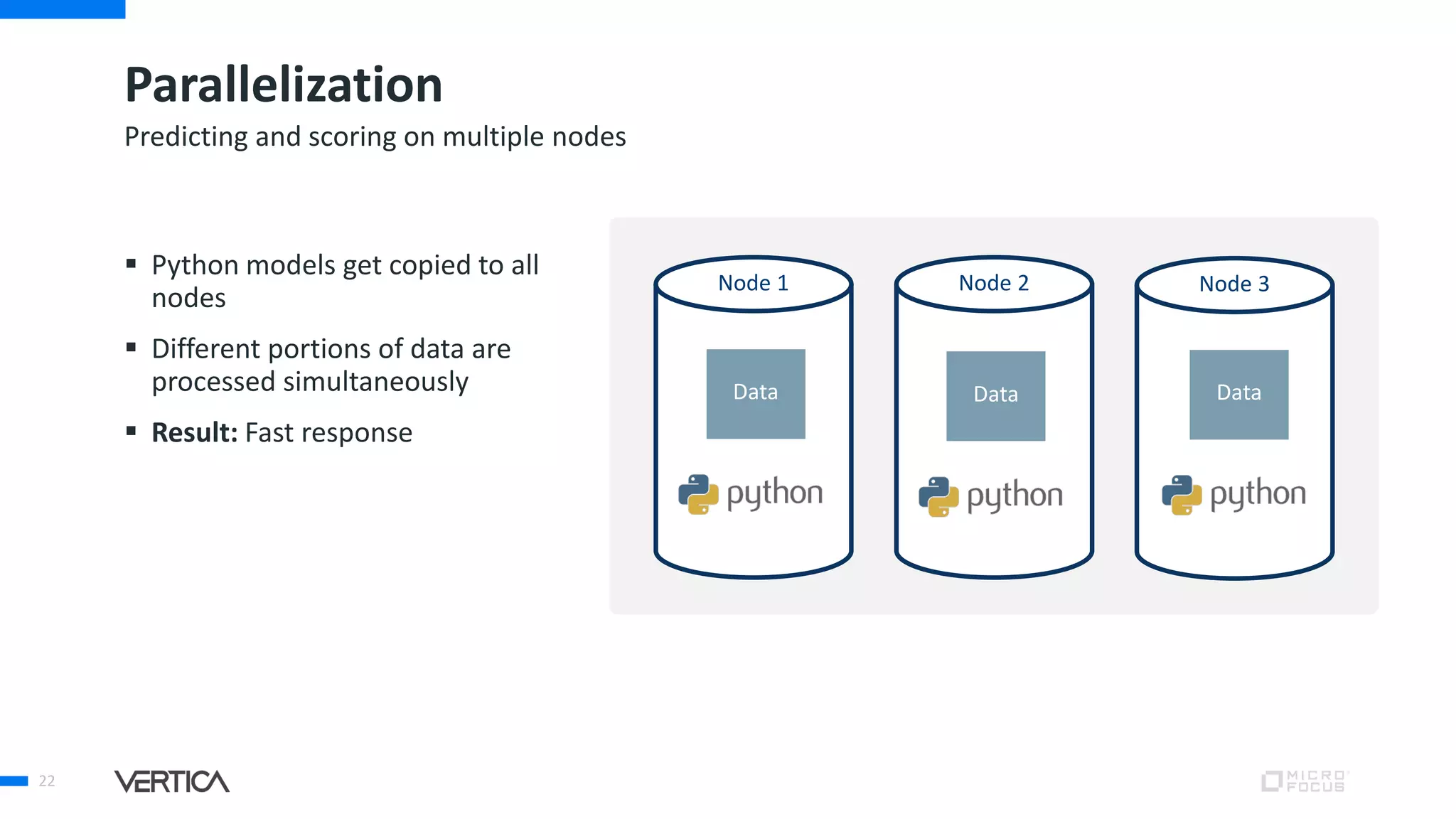
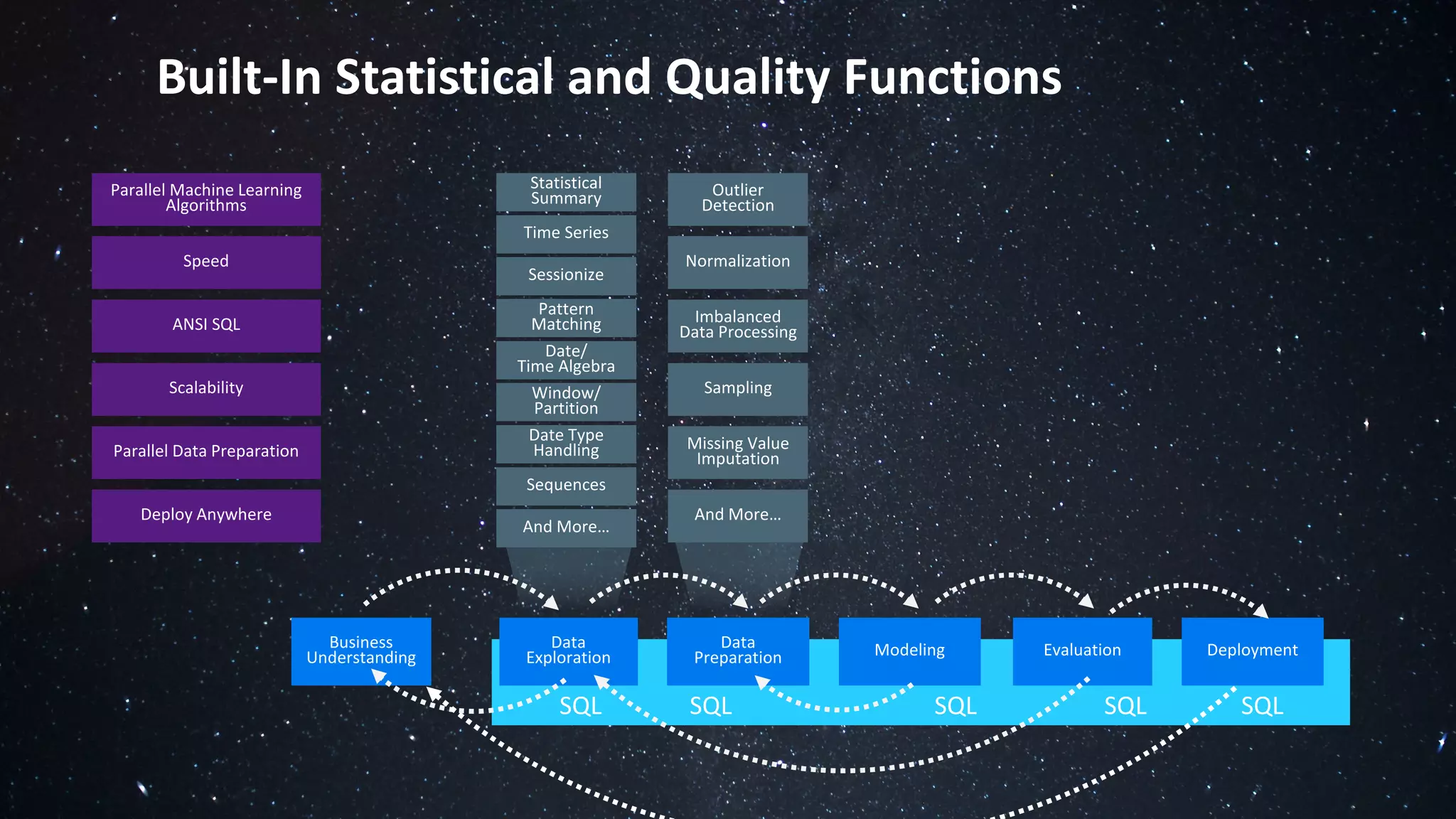
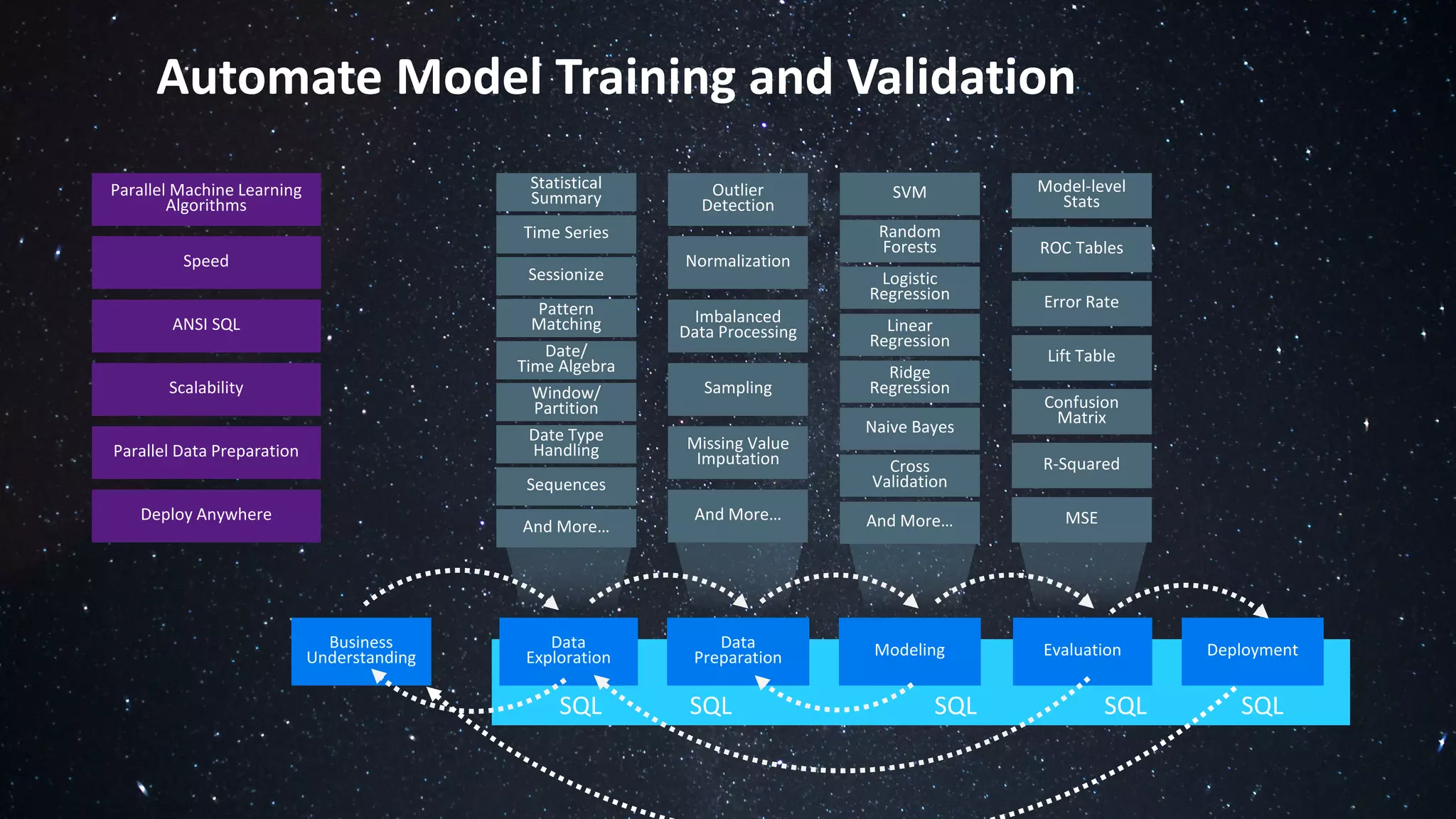
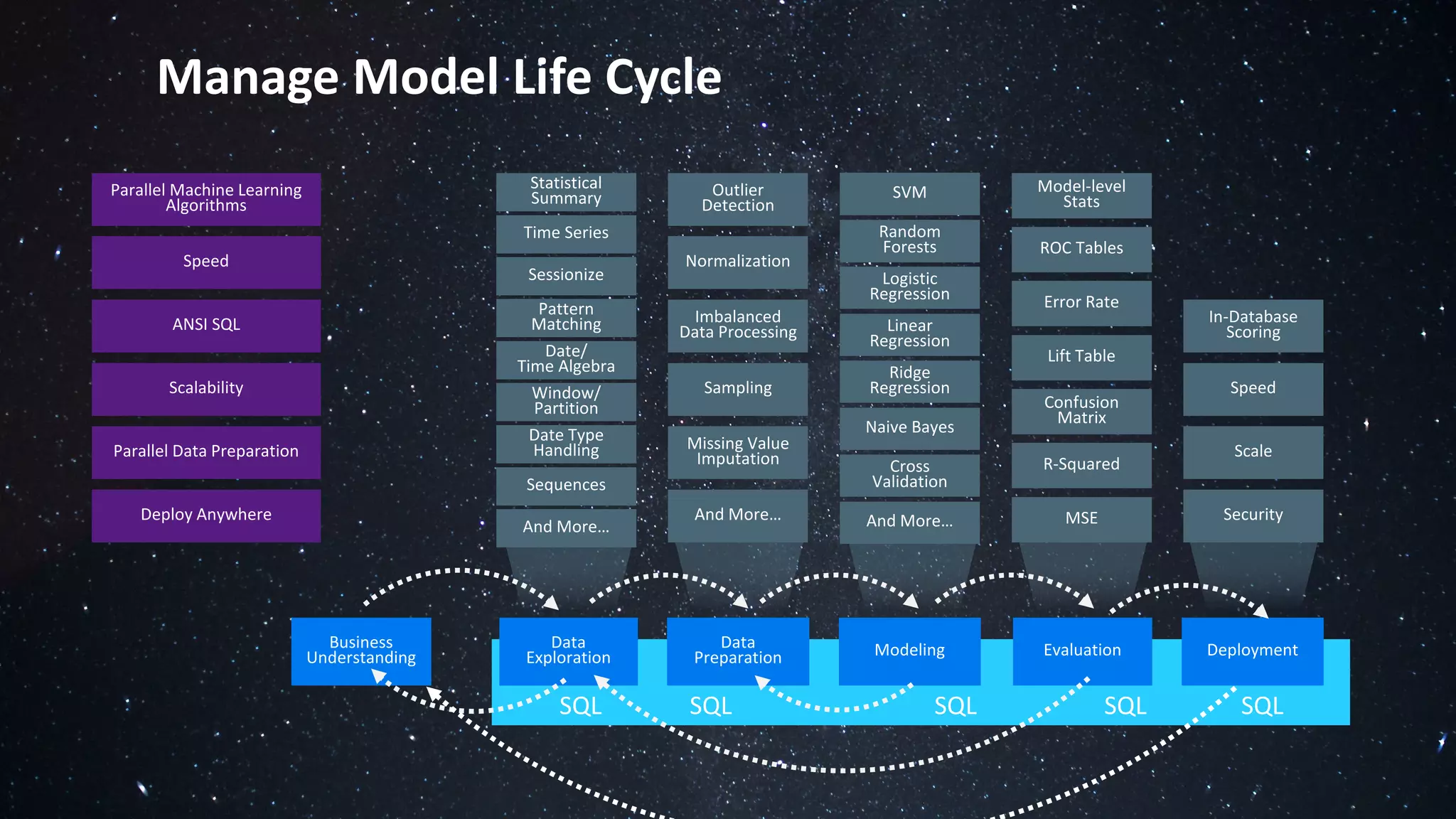




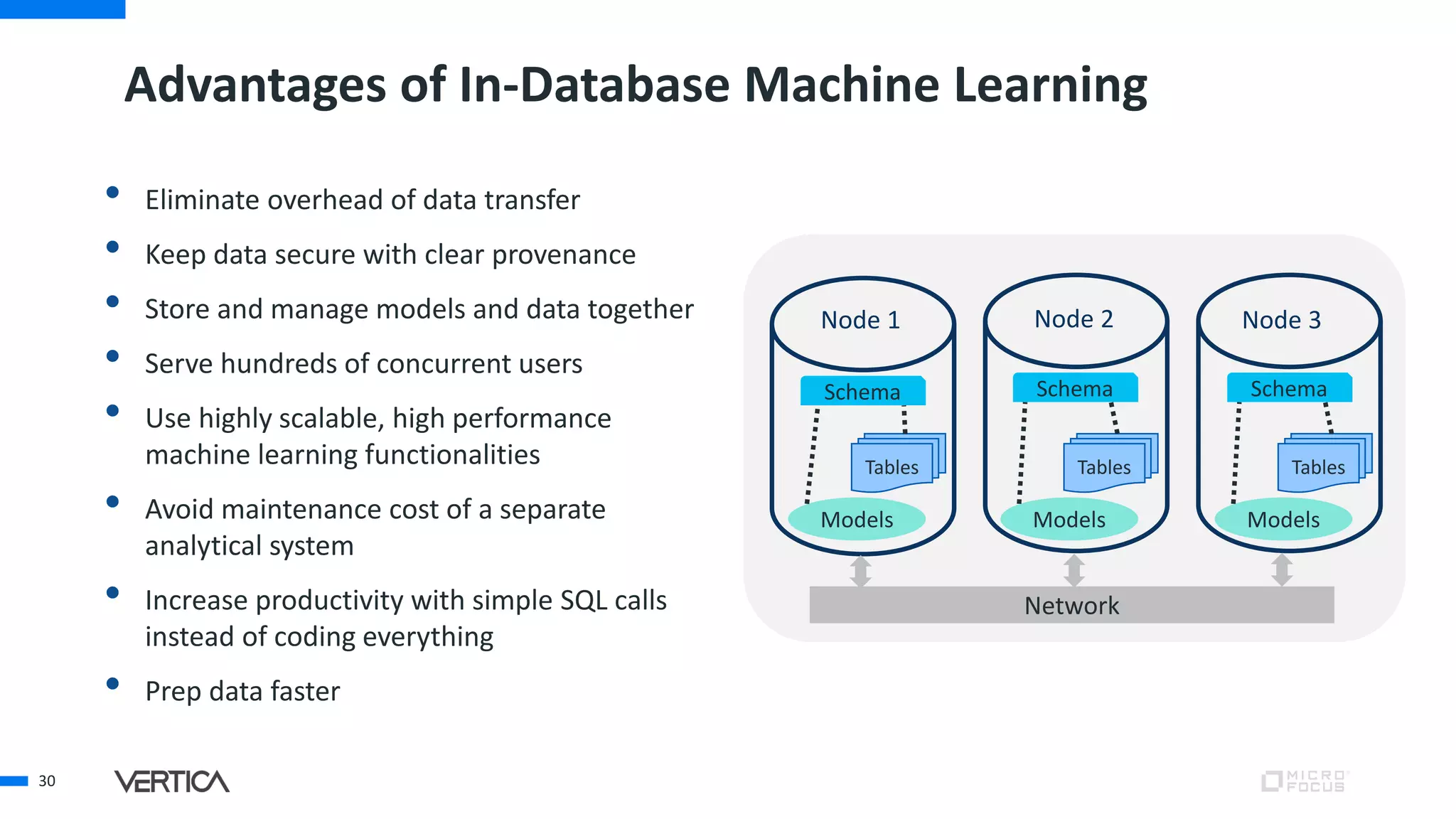

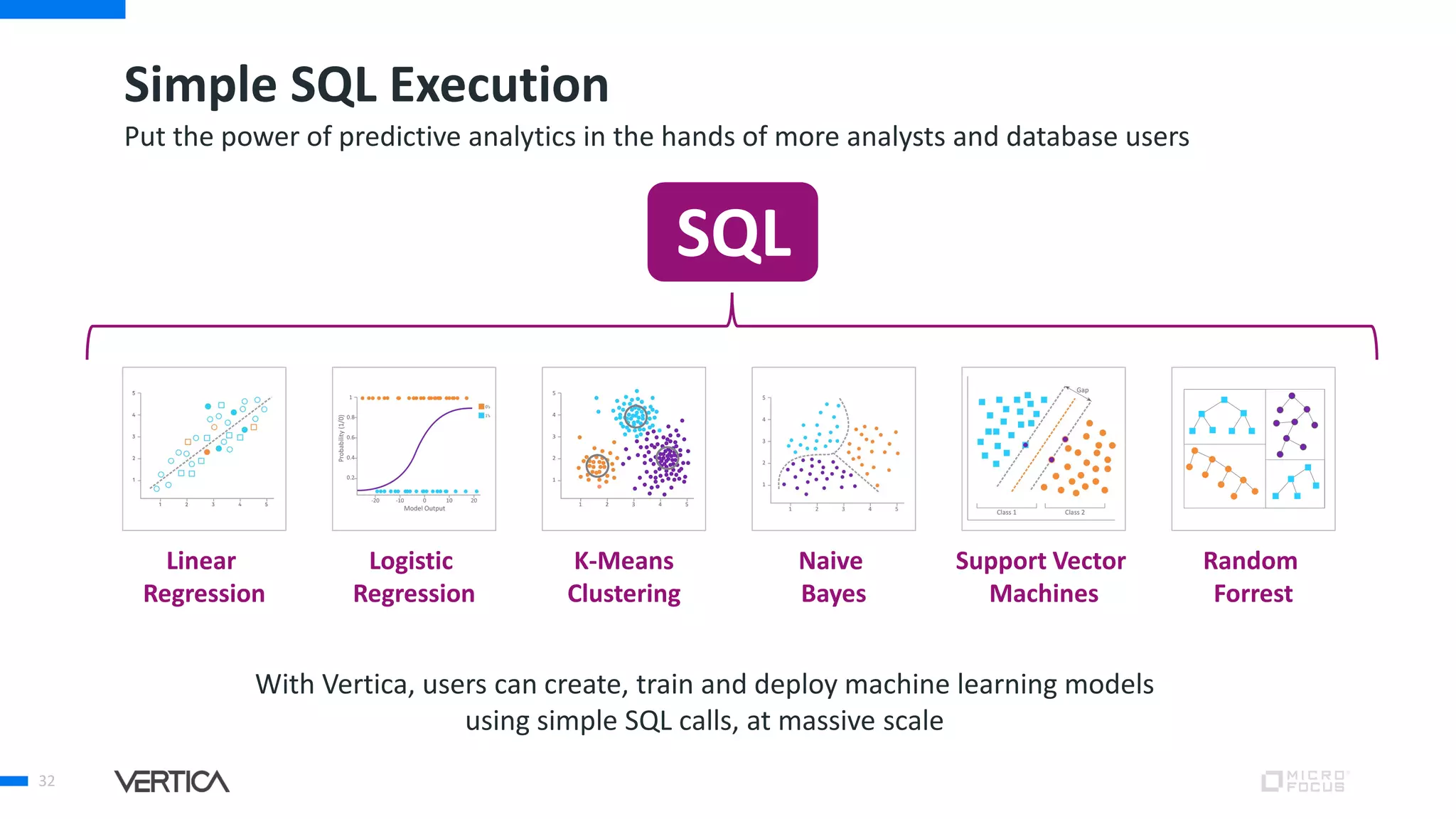
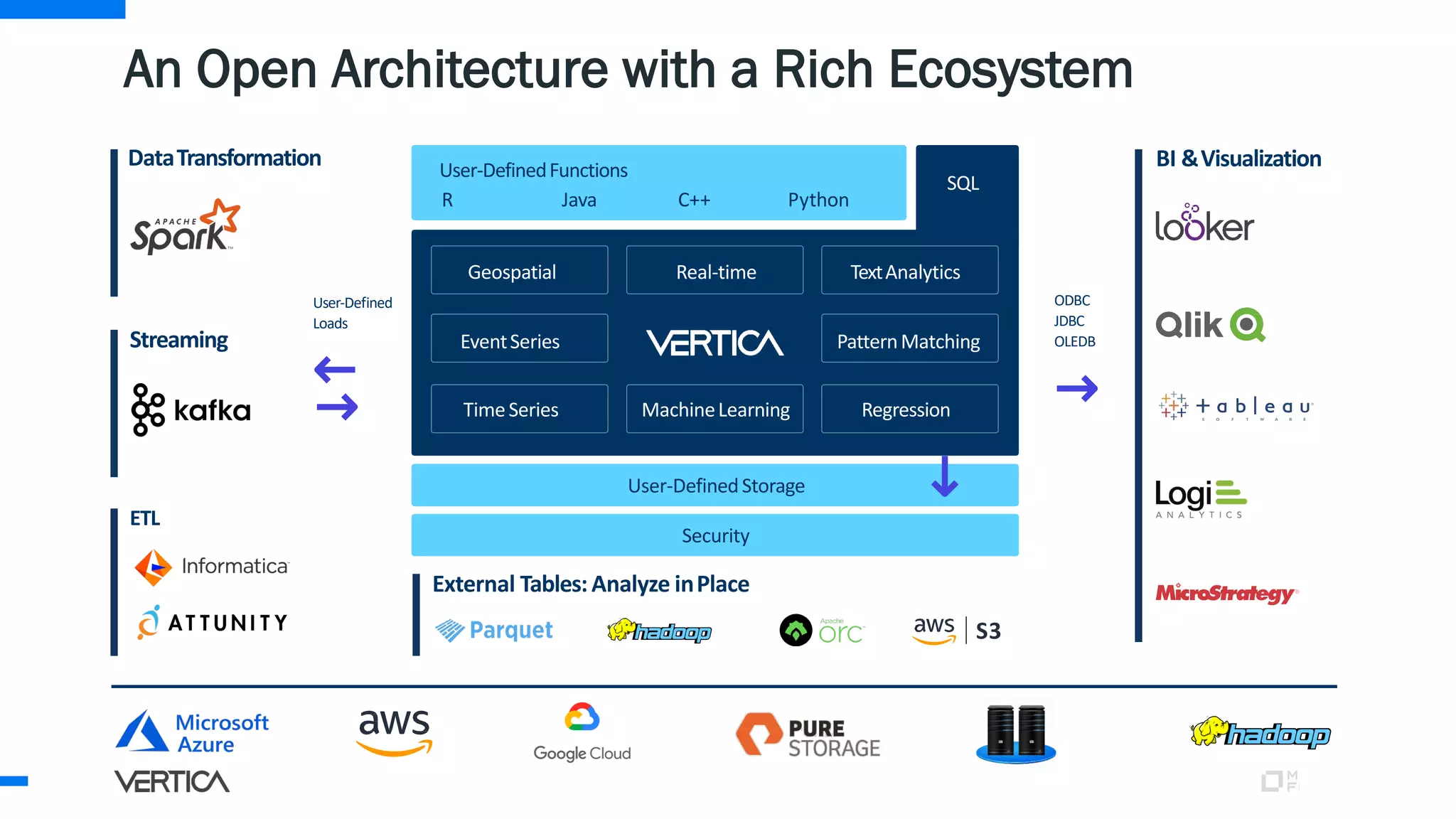
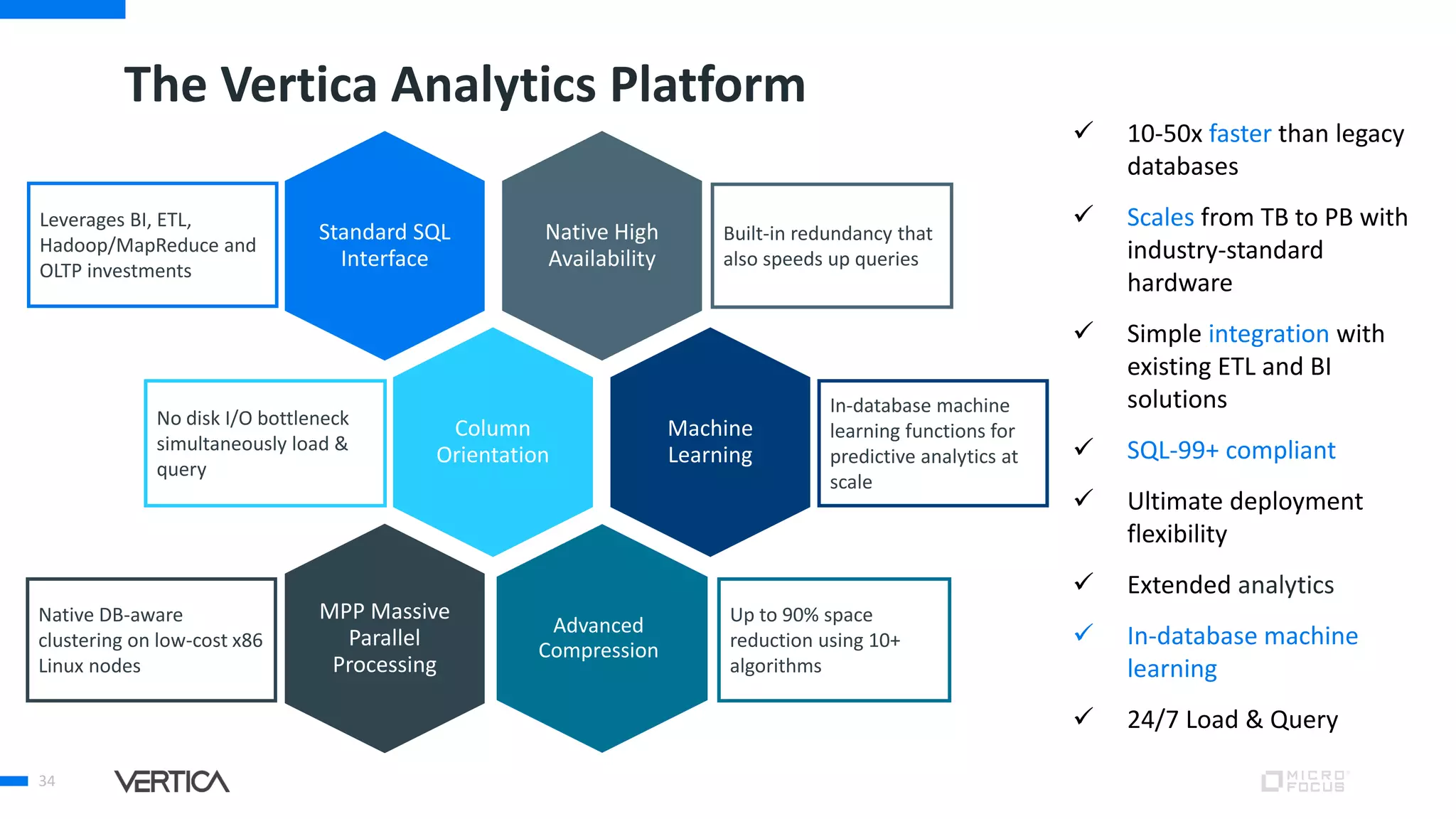

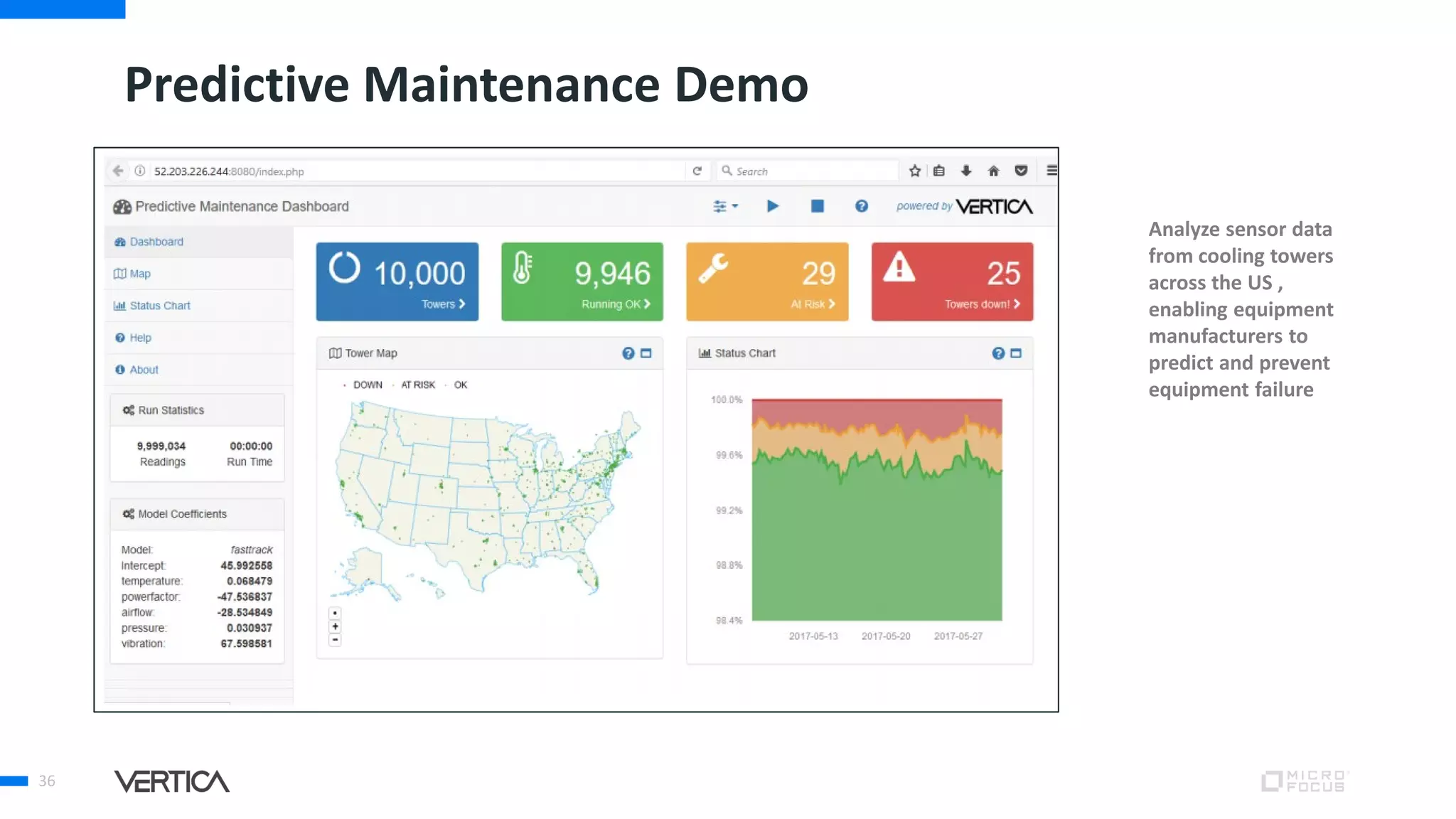
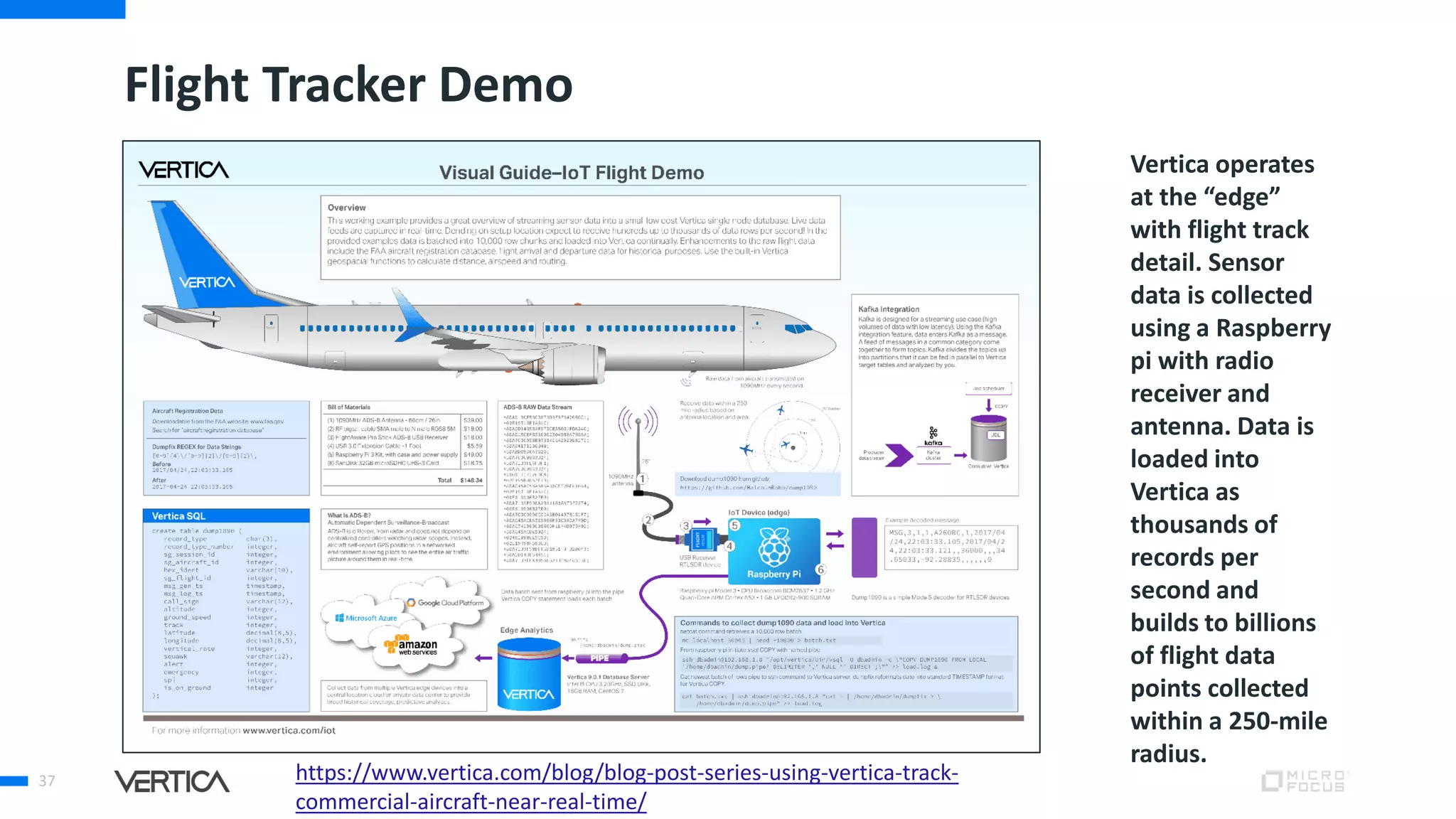






The document discusses the advantages of using Python with the Vertica MPP database for machine learning and analytics, emphasizing speed, flexibility, and the ability to manage large datasets efficiently. It highlights the importance of in-database machine learning to eliminate data transfer overhead, improve security, and enhance productivity for data scientists. The content also touches on challenges related to scaling, data accuracy, and the overall effectiveness of parallel processing in machine learning applications.