Download to read offline




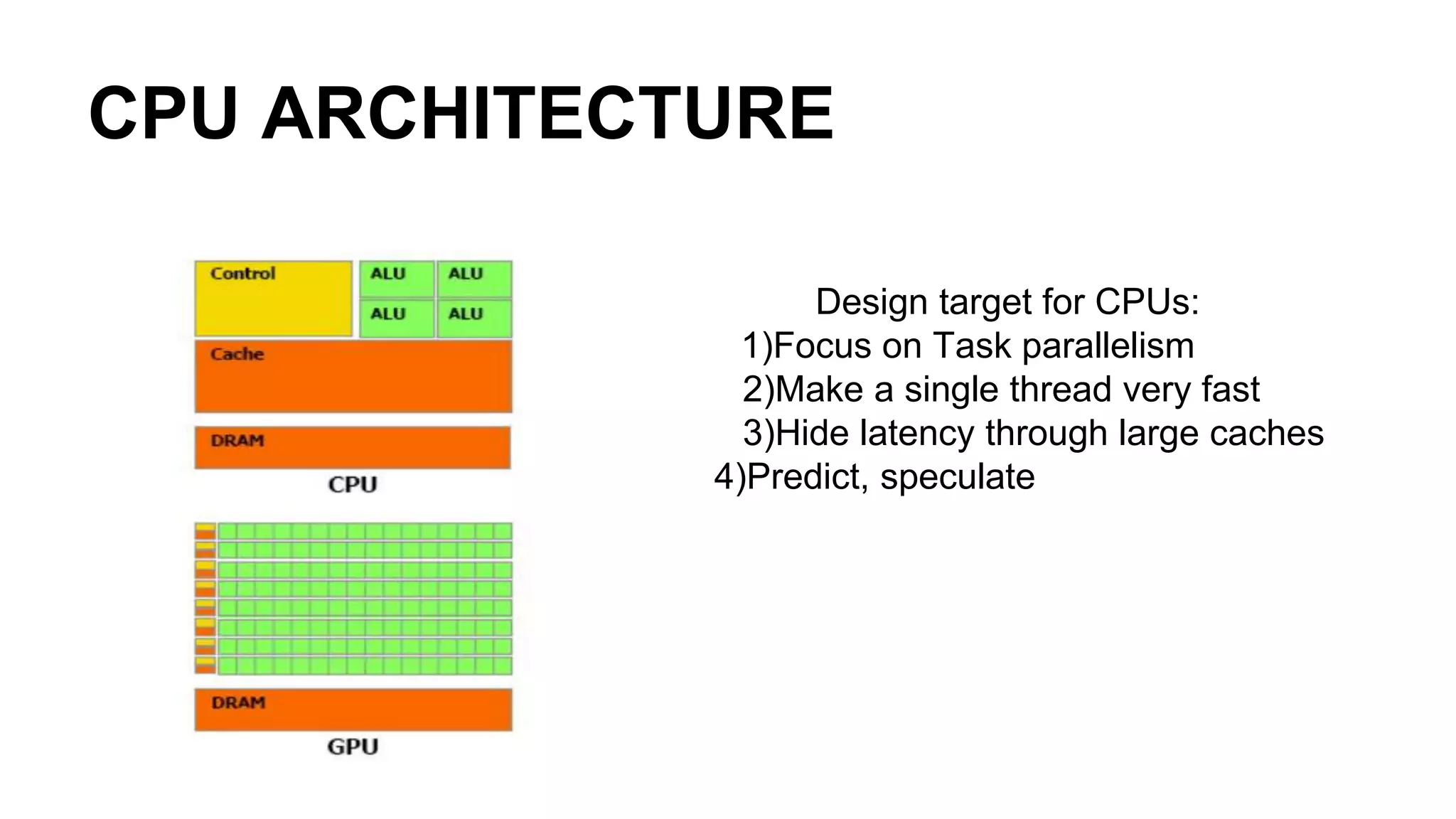
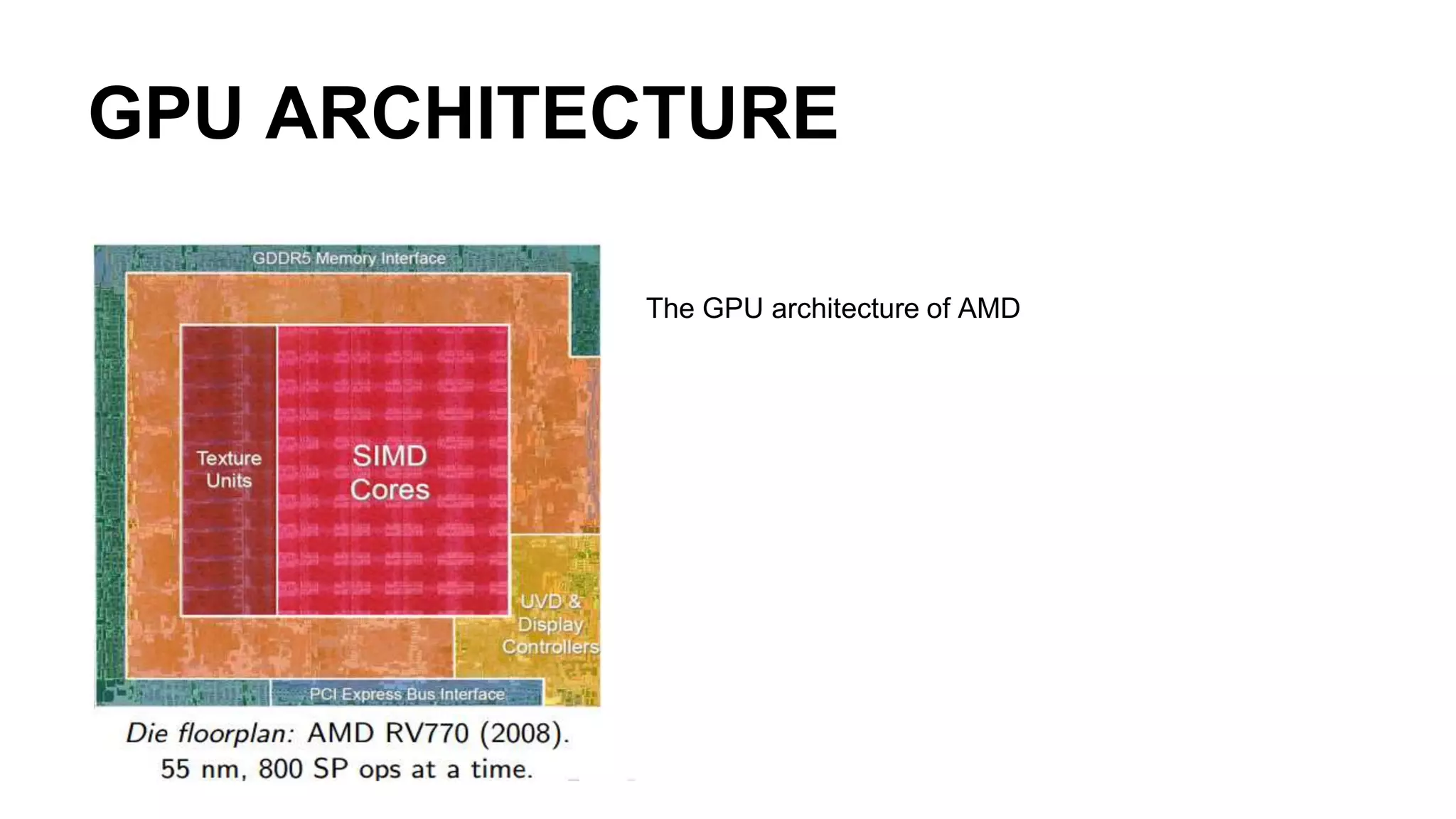
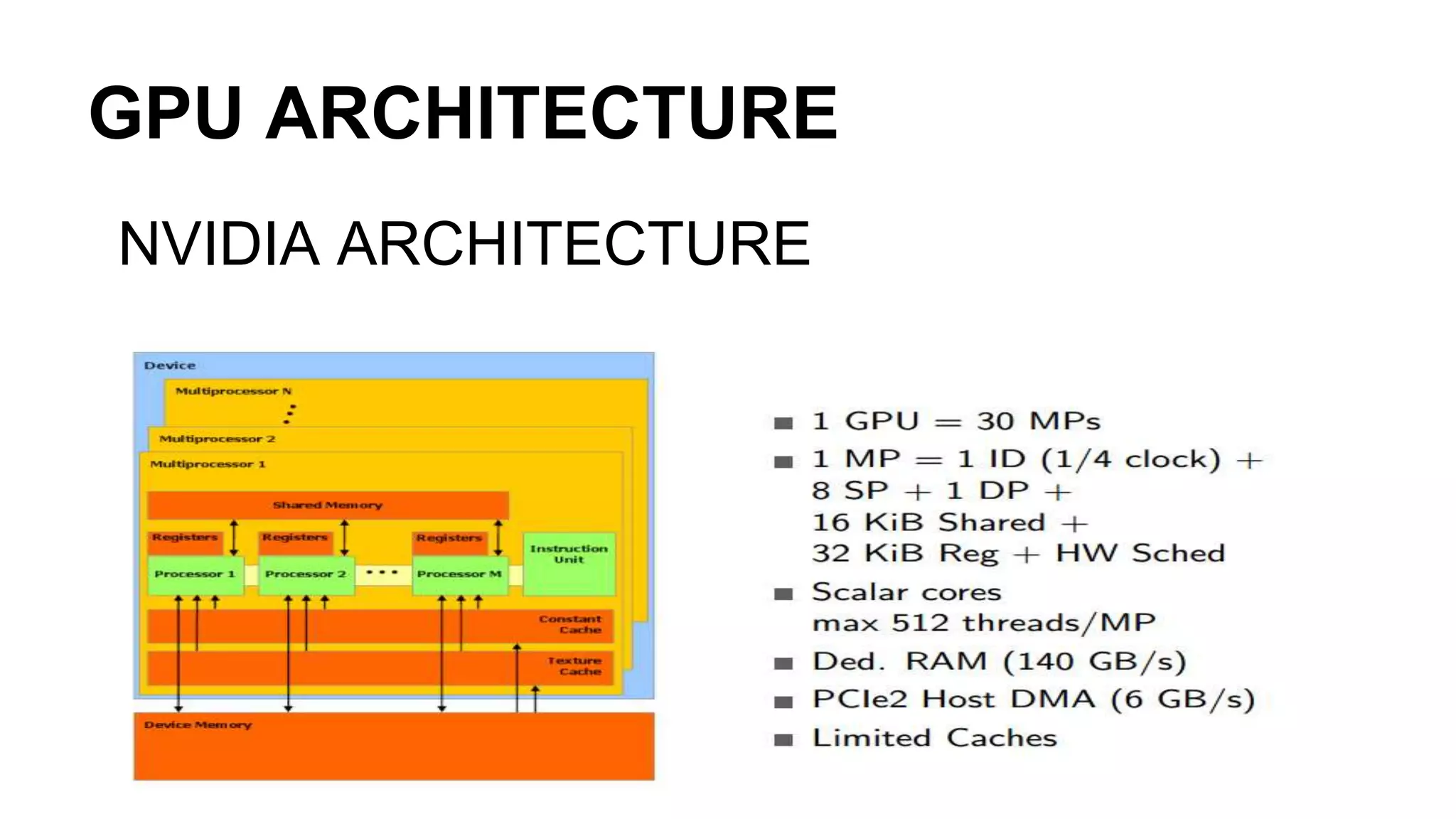
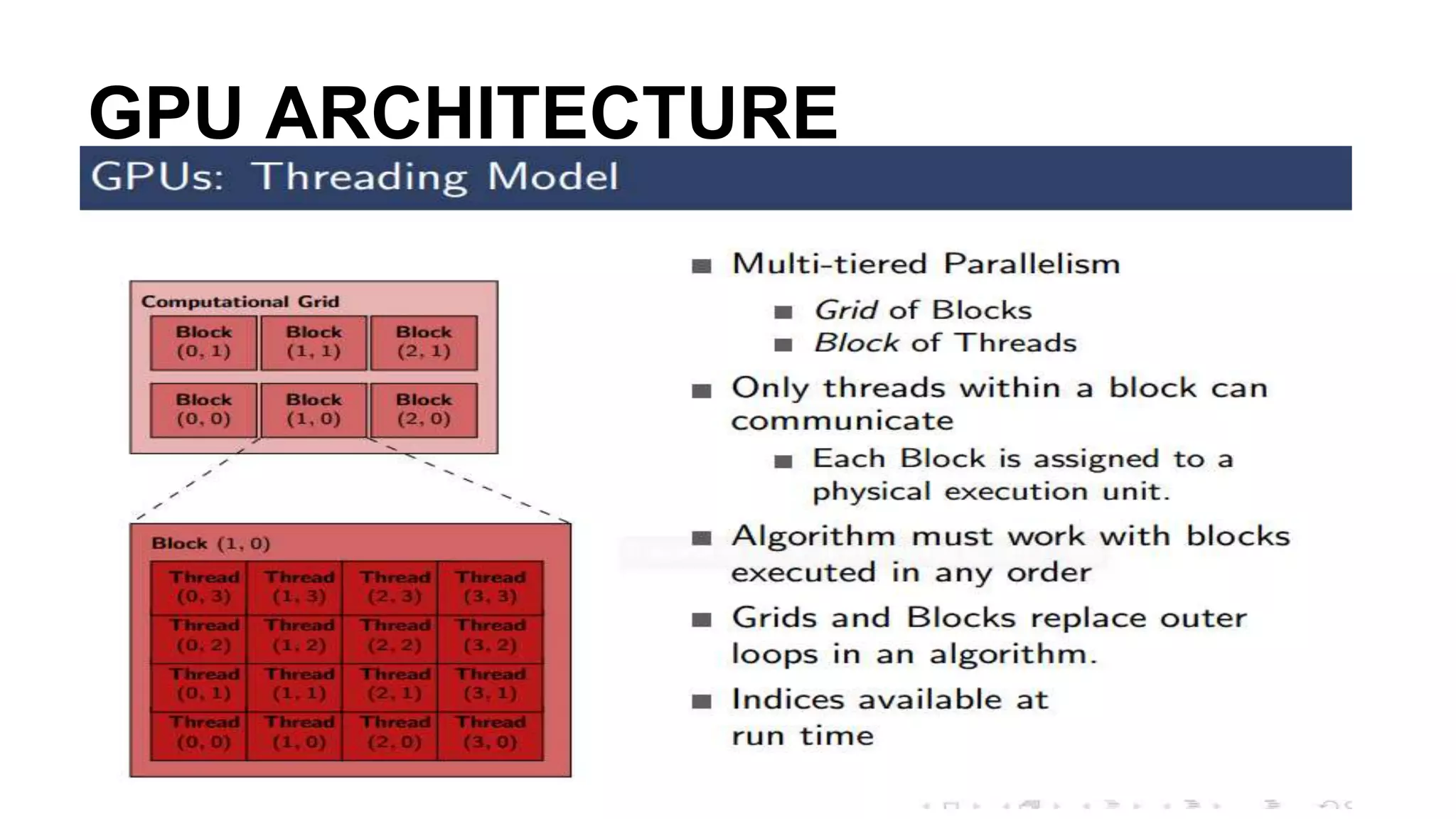


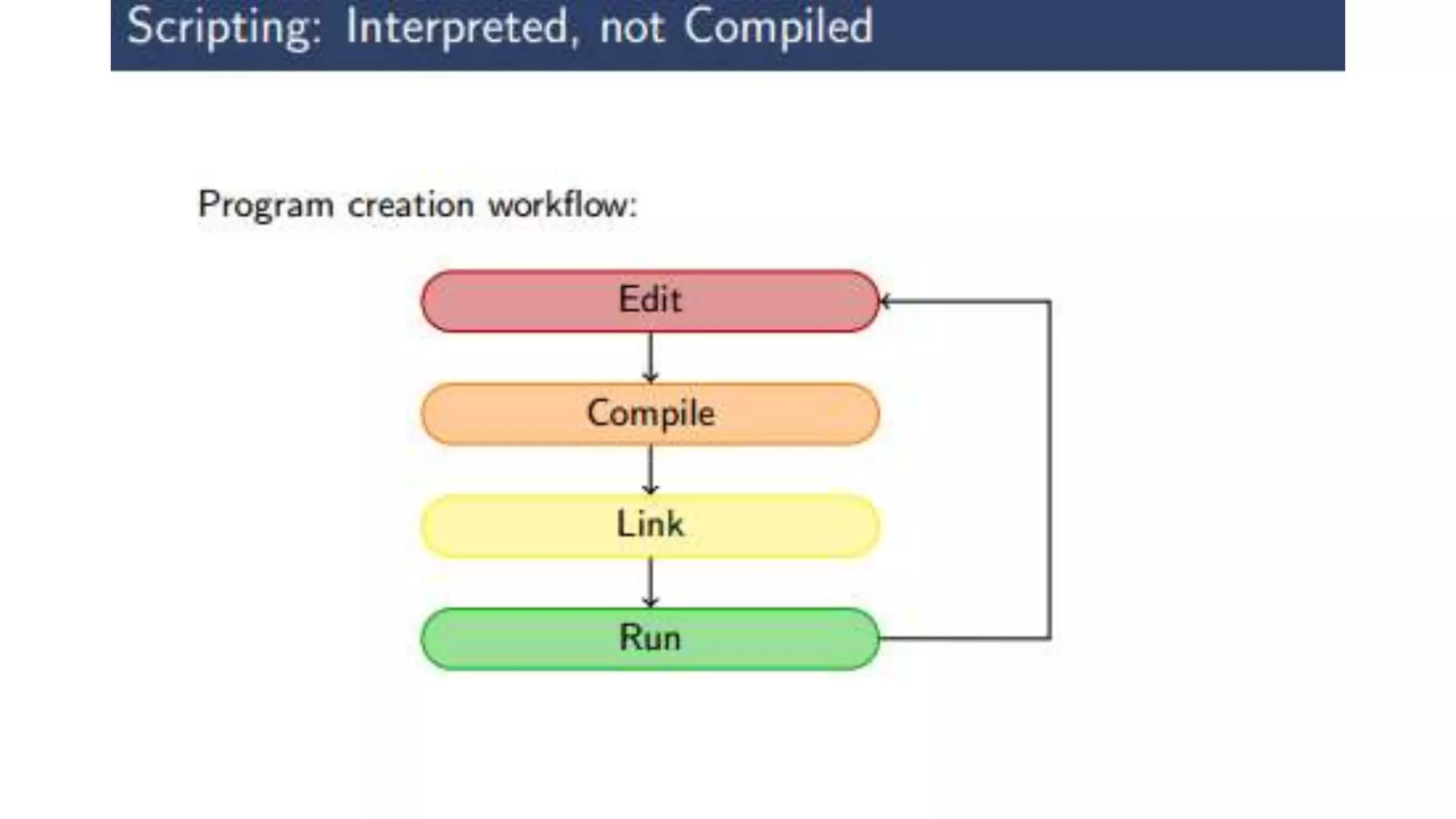
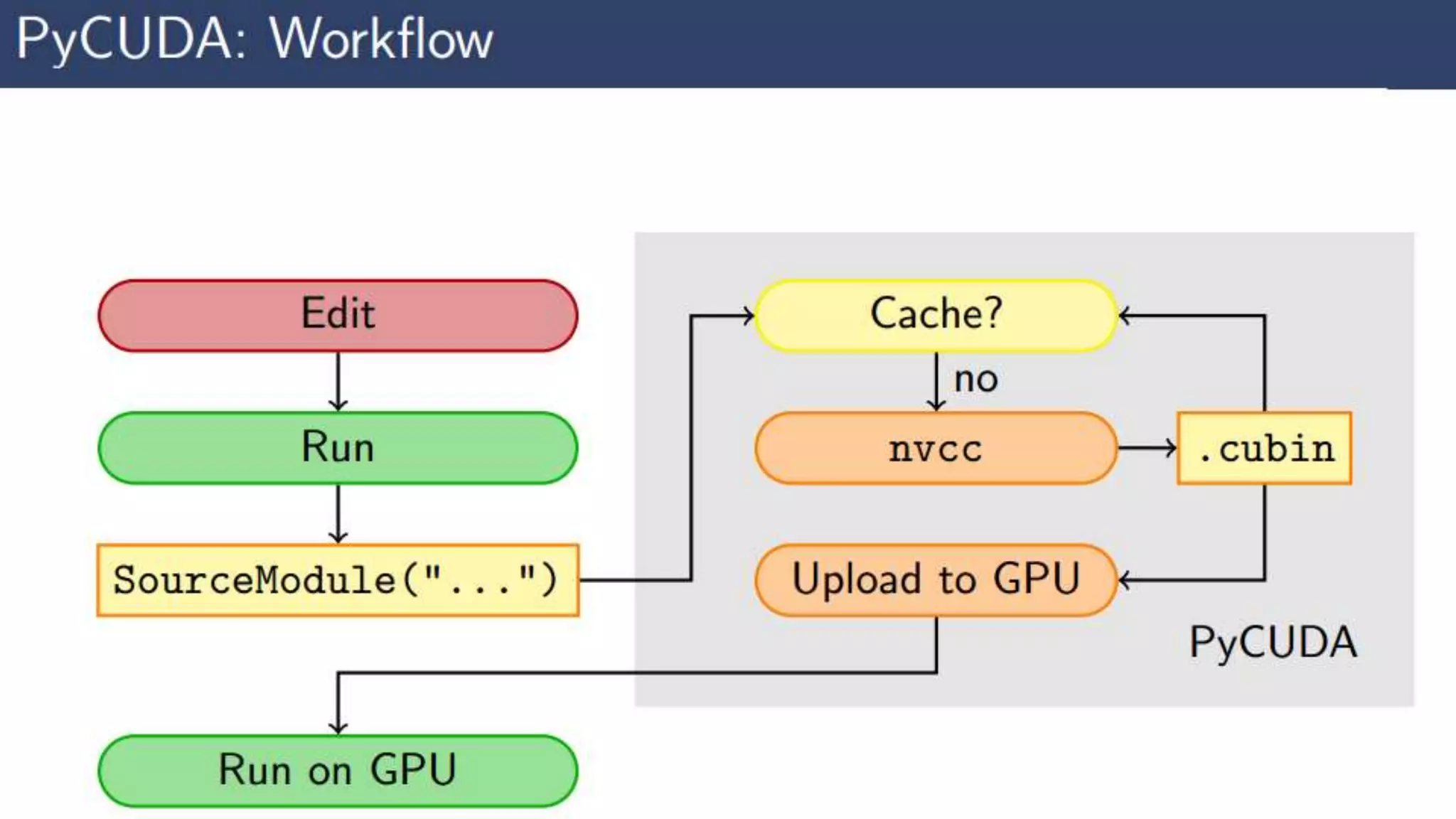
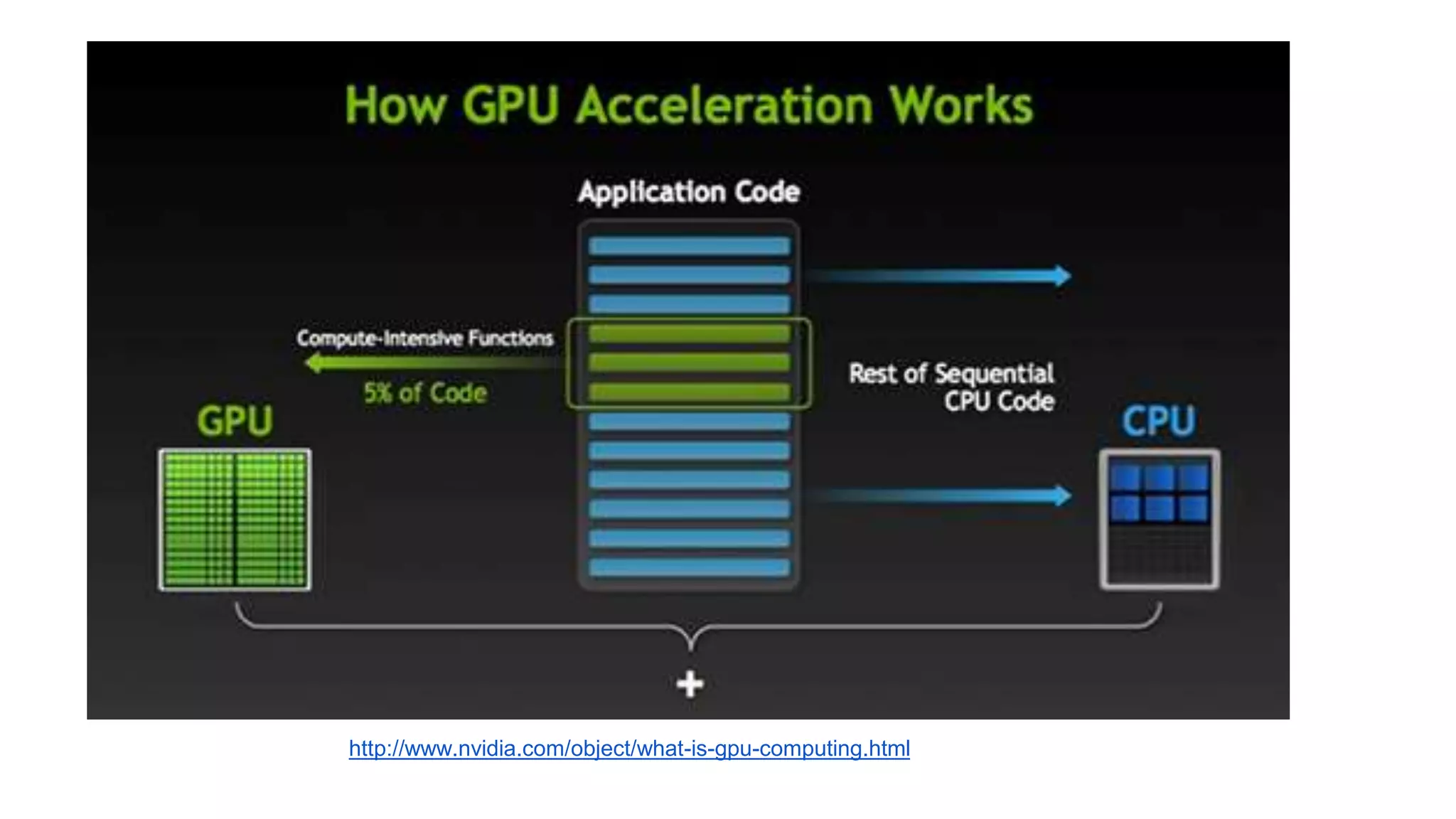







This document provides an introduction to GPU accelerated computing using Python. It discusses why GPUs are useful for accelerating compute intensive applications due to their highly parallel architecture. It also summarizes the CPU and GPU architectures, and why Python is suitable for GPU programming despite differences from GPUs. Finally, it outlines technologies like CUDA, OpenCL, PyCUDA, CUDAMat and Gnumpy that enable GPU programming from Python.