Why Big Dataand Where did it come from? Characteristics of Big Challenges and applications of Big Data Enabling Technologies for Big Data Big Data Stack Big Data distribution packages. Contents
3.
What is Bigdata: What is Data? The quantities, characters, or symbols on which operations are performed by a computer, which may be stored and transmitted in the form of electrical signals and recorded on magnetic, optical, or mechanical recording media.
4.
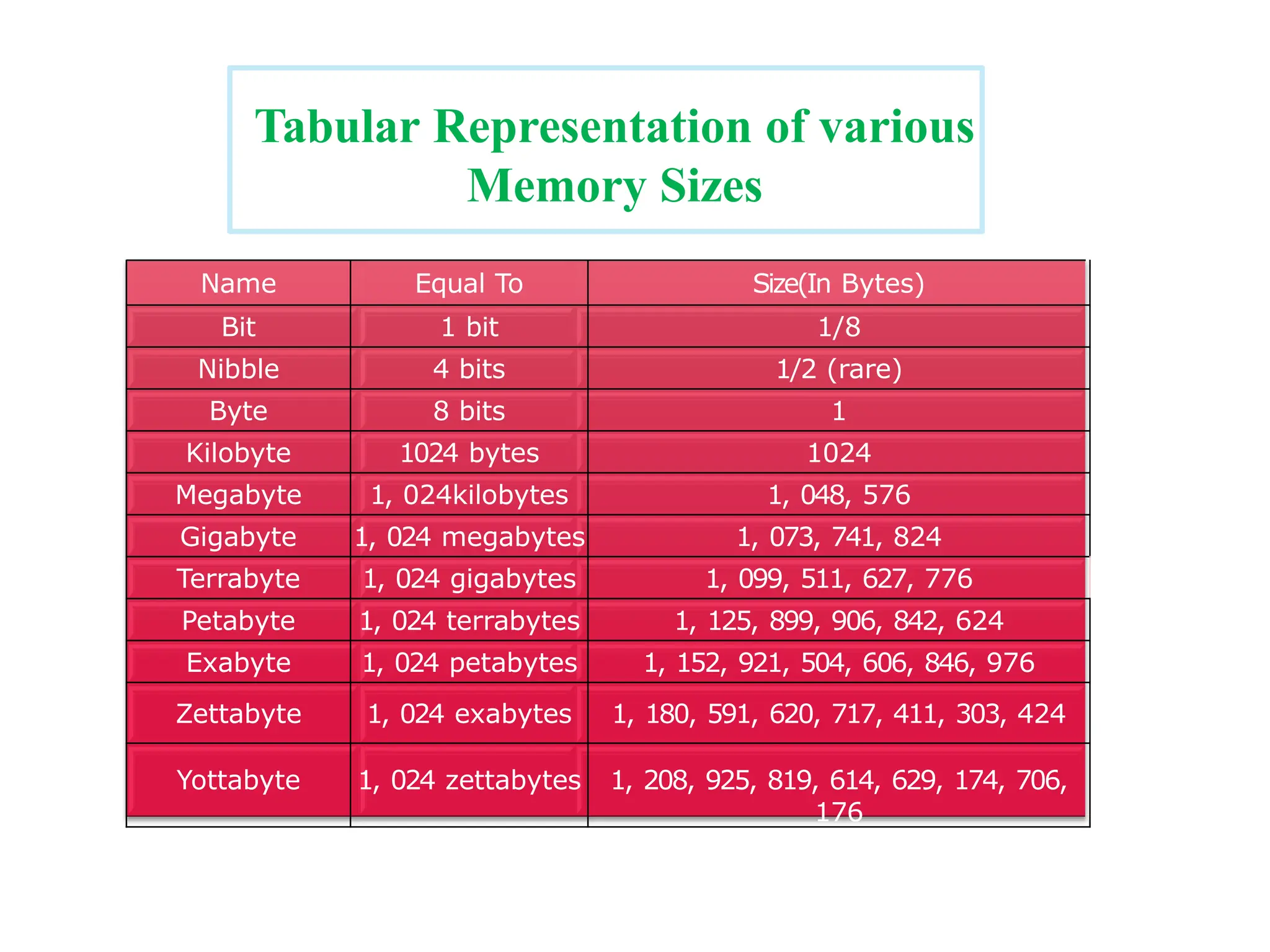
Big data: “Big data”is similar to “small data” but bigger in size (Terabytes (1012 bytes) to Zetabytes (1021 bytes) Big data is a term for a collection of data sets, so large and complex that it becomes often difficult to process using traditional data processing applications. Large data set collected through multiple computers and the analyzed in such a way that association, trends and patterns of human behaviour are revealed. simple way of explaining a big data using, this particular picture which represents only one aspect that is called volume or a size, which is very big, we will see more such challenges in terms of big data in this particular lecture. So, such a huge volume of particular data, poses various challenges, which includes how to capture such a big amount of data how do you cure it? How do you store such big amount of data? How can you search? And how do you share this information? And how to perform the transfer of this huge volume of data?
5.
Examples OfBig Data Following are some the examples of Big Data- The New York Stock Exchange generates about one terabyte of new trade data per day.
6.
Social Media Thestatistic shows that 500+terabytes of new data get ingested into the databases of social media site Facebook, every day. This data is mainly generated in terms of photo and video uploads, message exchanges, putting comments etc. A single Jet engine can generate 10+terabytes of data in 30 minutes of flight time. With many thousand flights per day, generation of data reaches up to many Petabytes. TWITTER
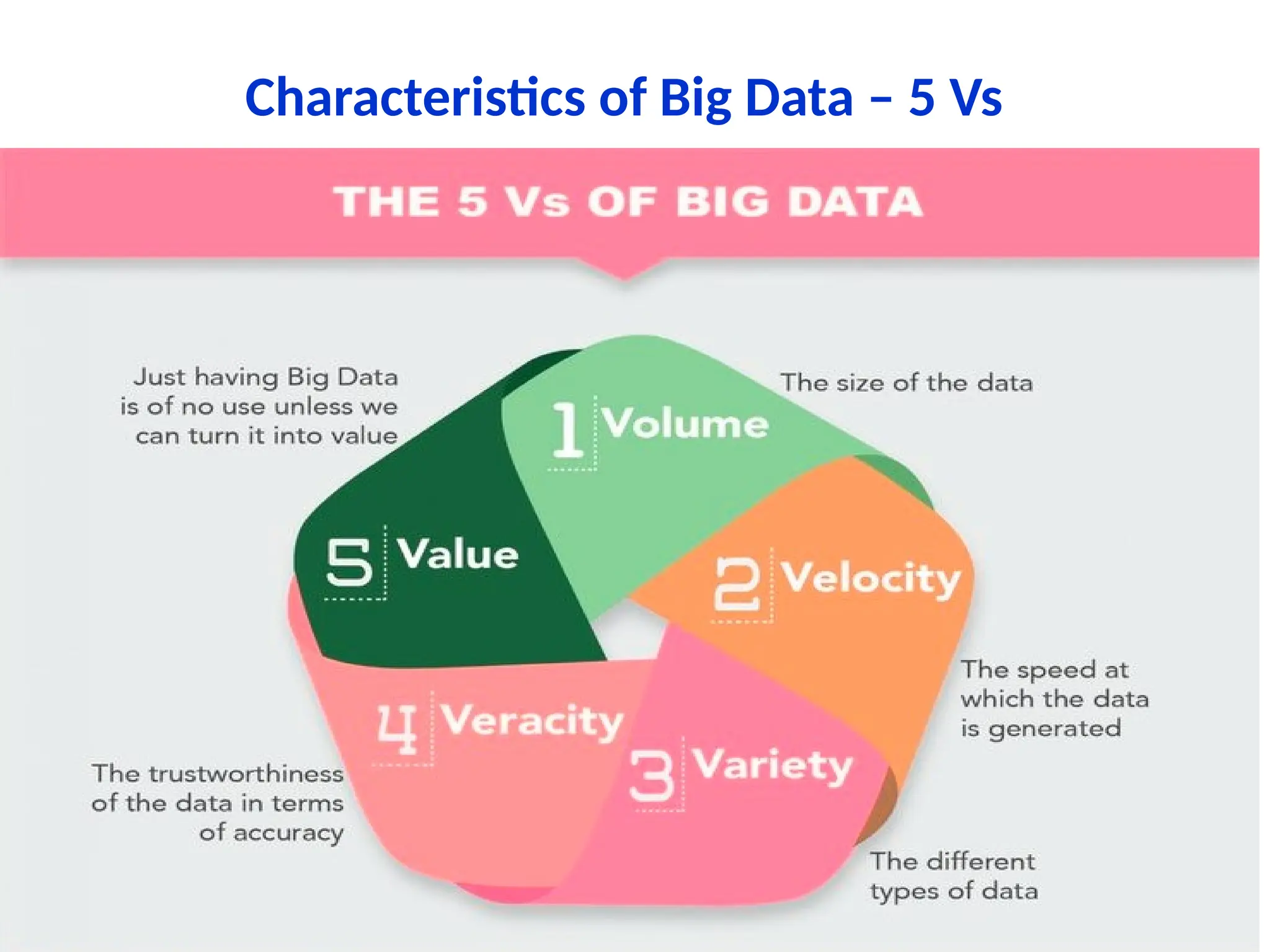
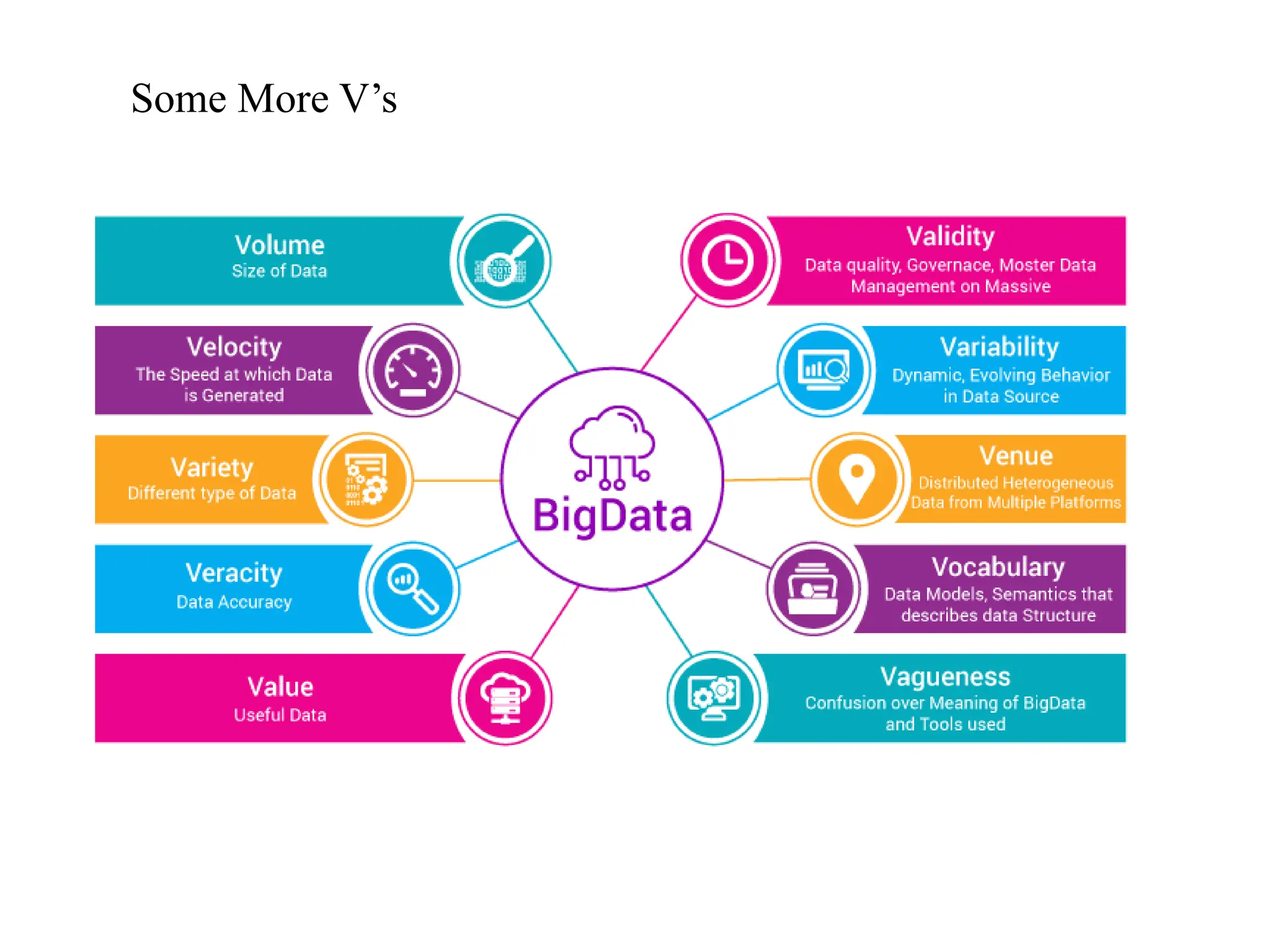
1. Volume: Volume means“How much Data is generated”. Now-a-days, Organizations or Human Beings or Systems are generating or getting very vast amount of Data say TB(Tera Bytes) to PB(Peta Bytes) to Exa Byte(EB) and more.
Example 2. The Earthscopeis the world’s largest science project. Designed to track north America ‘s geological evolution , this observatory records data over 3.8 million square miles , amassing 67 terabytes of data.
13.
2. Velocity: Velocity means“How fast produce Data”. Now-a- days, Organizations or Human Beings or Systems are generating huge amounts of Data at very fast rate. 3. Variety: Variety means “Different forms of Data”. Now-a-days, Organizations or Human Beings or Systems are generating very huge amount of data at very fast rate in different formats. We will discuss in details about different formats of Data soon.
14.
4. Veracity Veracity means“The Quality or Correctness or Accuracy of Captured Data”. Out of 4Vs, it is most important V for any Big Data Solutions. Because without Correct Information or Data, there is no use of storing large amount of data at fast rate and different formats. That data should give correct business value.
Challenges Of BigData: Capturing Storing Searching Sharing Analyzing Visualization
17.
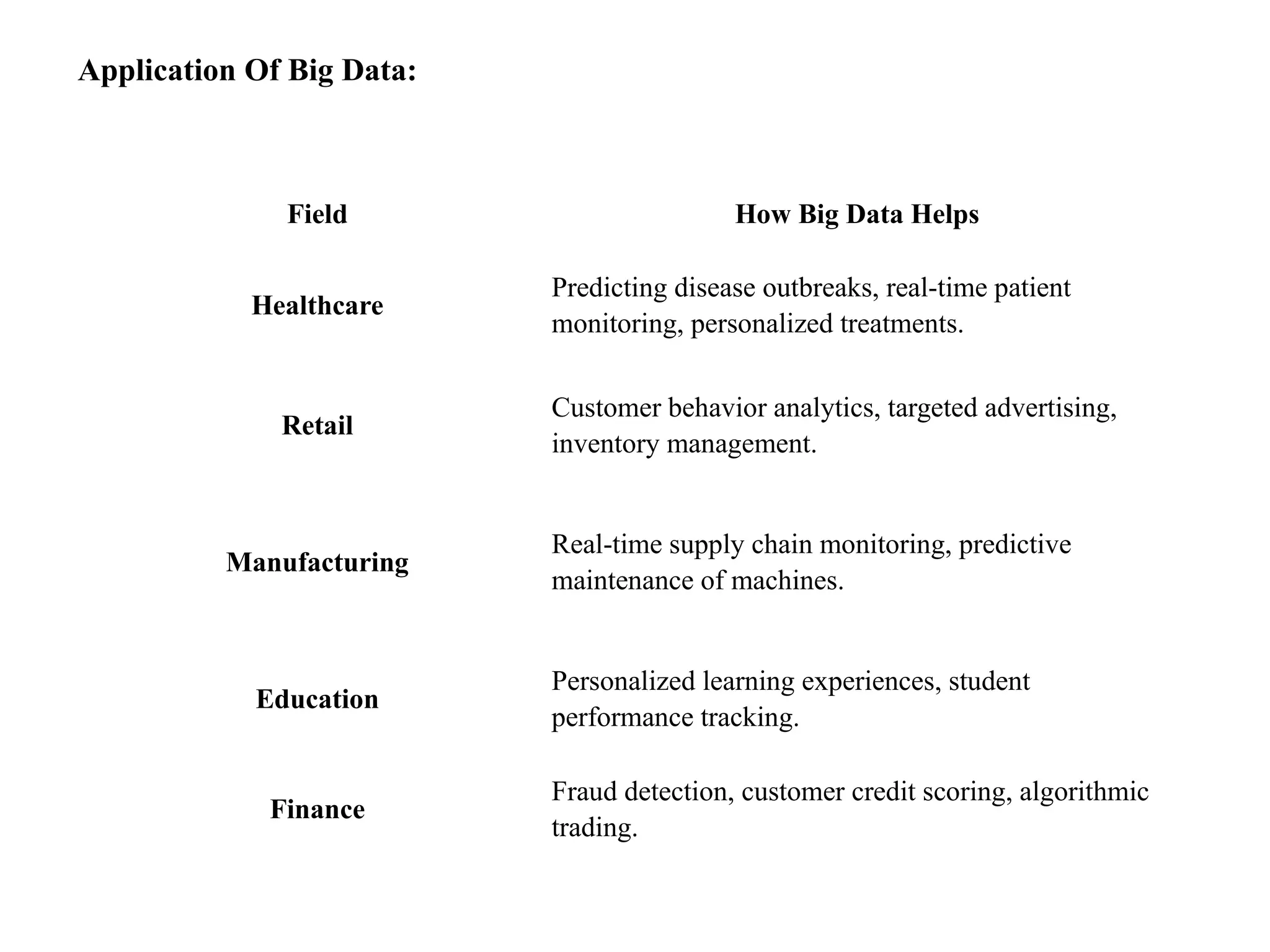
Field How BigData Helps Healthcare Predicting disease outbreaks, real-time patient monitoring, personalized treatments. Retail Customer behavior analytics, targeted advertising, inventory management. Manufacturing Real-time supply chain monitoring, predictive maintenance of machines. Education Personalized learning experiences, student performance tracking. Finance Fraud detection, customer credit scoring, algorithmic trading. Application Of Big Data:
18.
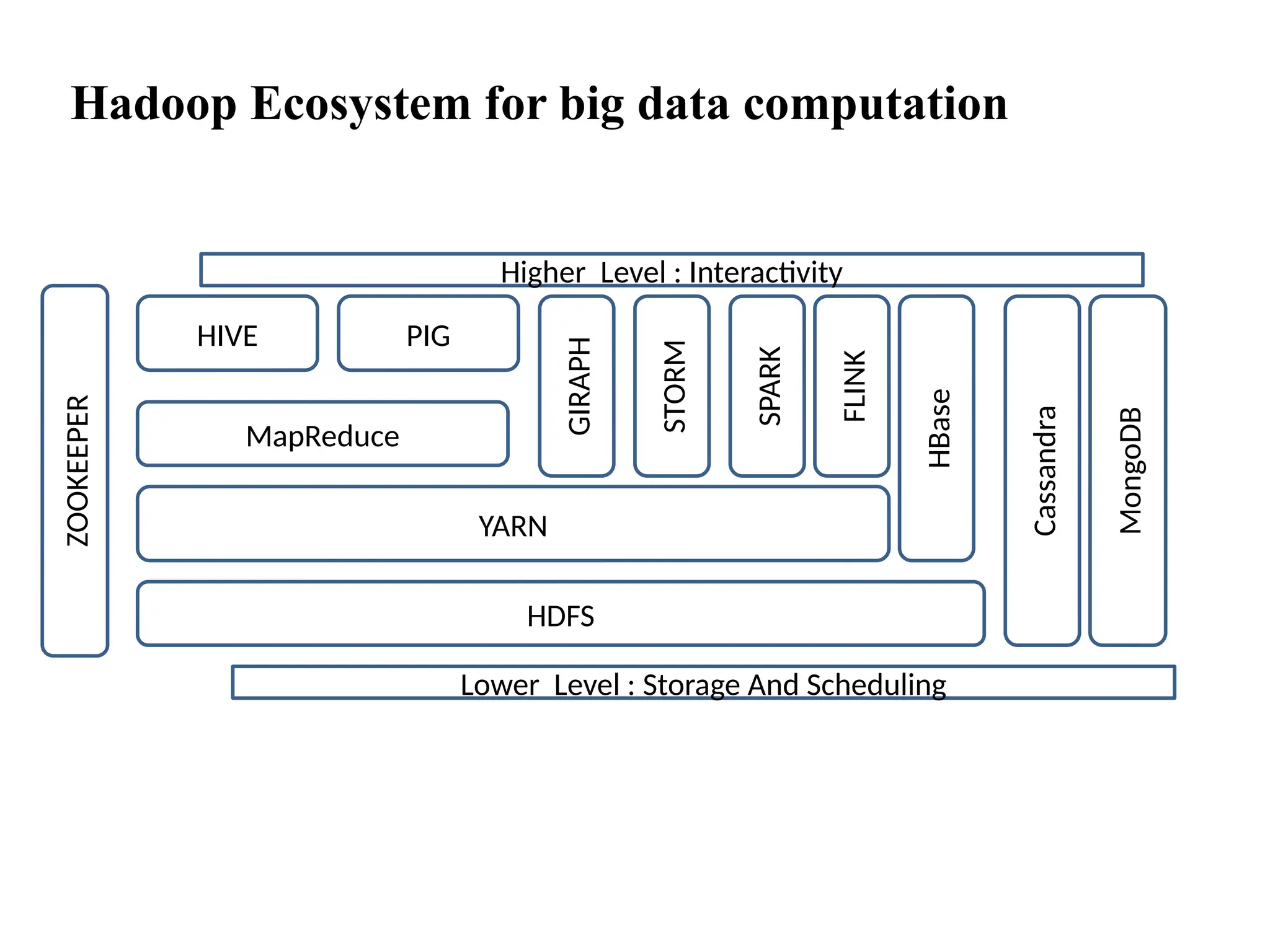
Big Data EnablingTechnologies Big data is used, for a collection of data sets. So large and complex, that it is difficult to process using traditional tools. A recent survey, says that 80% of the data created, in the world are, unstructured. Hence traditional tools, will not be able to handle, such a big data motion. One challenge is, how can we stored and process this big data? In this lecture, we will discuss the technologies and the enabling framework to process the big data
19.
Apache Hadoop isthe tool which is going to be used for, the big data computation. Apache Hadoop is an open source, software framework, for a big data. And, it has two parts, two basic parts. The first one is called, HDFS, Hadoop Distributed File System, the other is called, ‘Programming Model’, which is called a, ‘Map Reduce’. Apache Hadoop HDFS: Is the storage system of hadoop Which Splits big data and distribute across many nodes in a cluster. a. Scaling out of h/w resources b. Fault tolerant MapReduce: Programming model that simplifies parallel programming. a.Map – apply b. Reduce- summarize
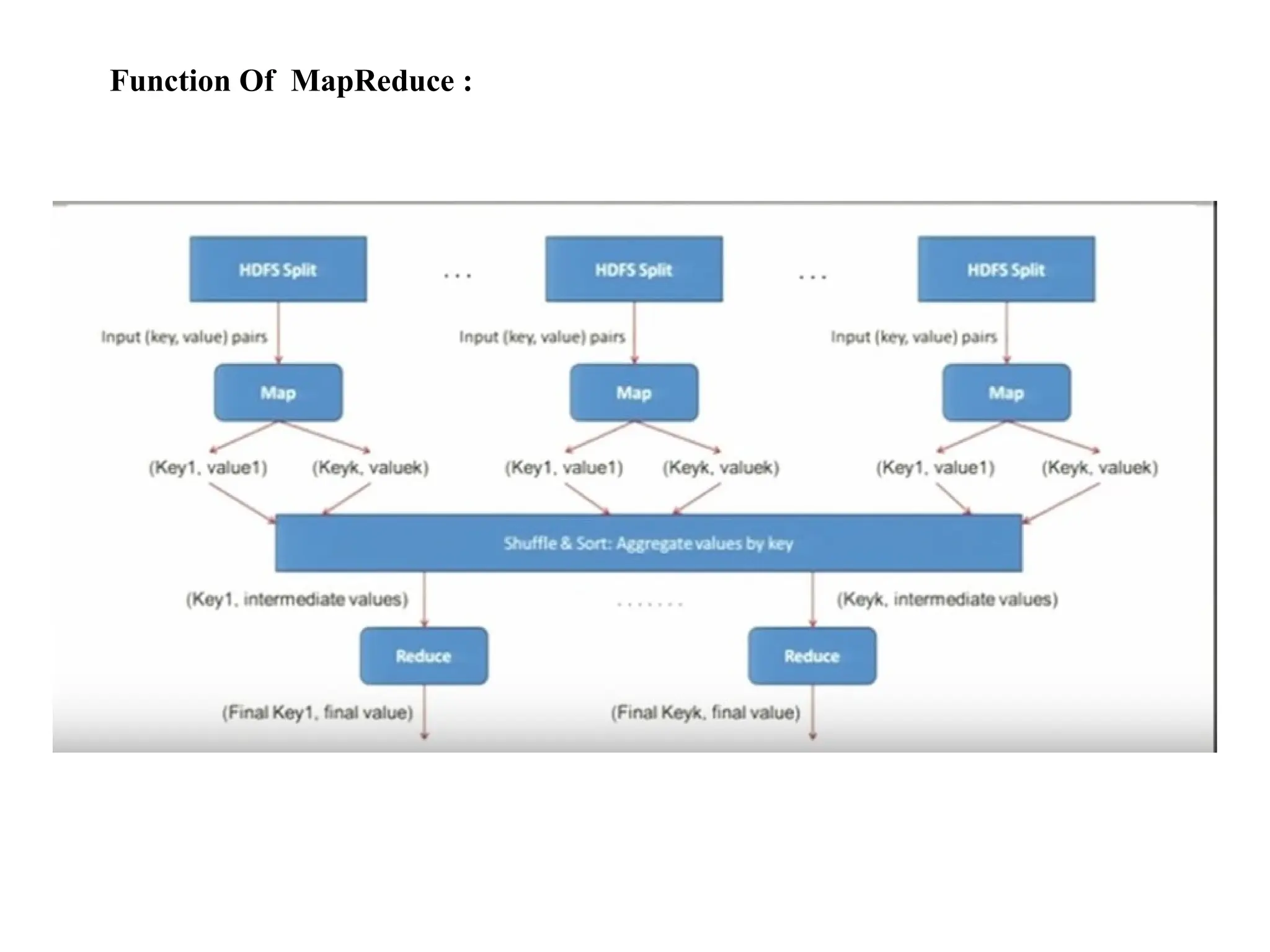
MapReduce : It isa programming model and associated implementation for processing and generating large data set. Users specify a Map function that processes a key/value pair to generate a set of intermediate key/value pairs. Reduce function merges all intermediate values associated with the same intermediate key.
22.
MapReduce programming model—showinghow data flows through its key phases: Map (Apply): Each data chunk is independently processed in parallel, producing intermediate key–value pairs. Shuffle & Sort: These intermediate results are grouped by key and sorted, prepping them for aggregation. Reduce (Summarize): The grouped data is then summarized—typically summed, counted, or otherwise aggregated into the final output
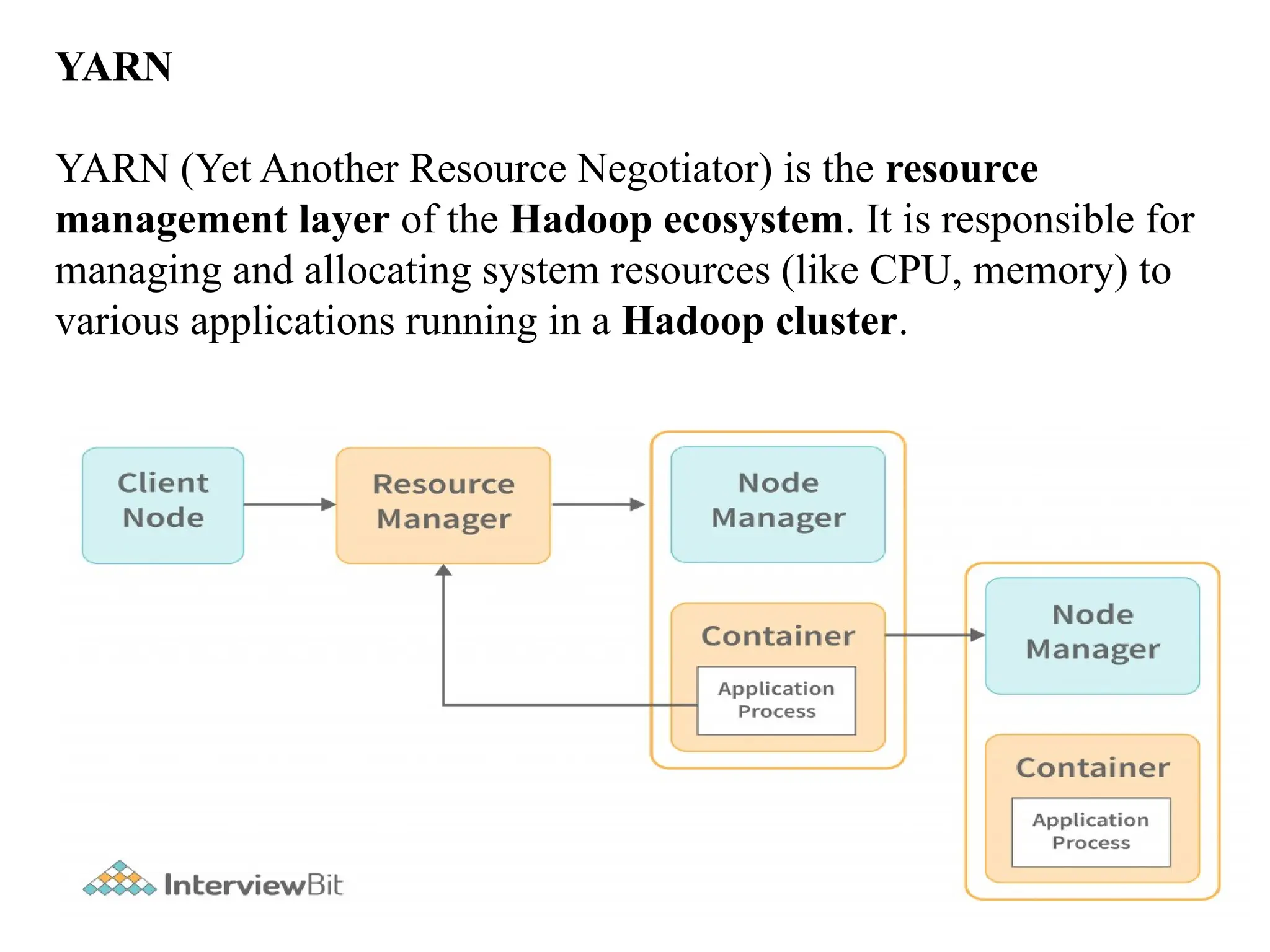
YARN YARN (Yet AnotherResource Negotiator) is the resource management layer of the Hadoop ecosystem. It is responsible for managing and allocating system resources (like CPU, memory) to various applications running in a Hadoop cluster.
25.
Key Components: Resource Manager(RM): It is the central authority in YARN. It decides how to allocate resources (like memory, CPU) to applications. It contains a scheduler that decides which task runs where and when. Applications request resources from the Resource Manager. Node Manager (NM): Runs on each machine (node) in the cluster. Manages resources on that specific node. Launches and monitors tasks in units called containers. Containers: The smallest unit of resource allocation in YARN. When an application needs to run, it is given a container with defined resources (like memory, CPU). These containers are created and managed by the Node Manager under the direction of the Resource Manager.
26.
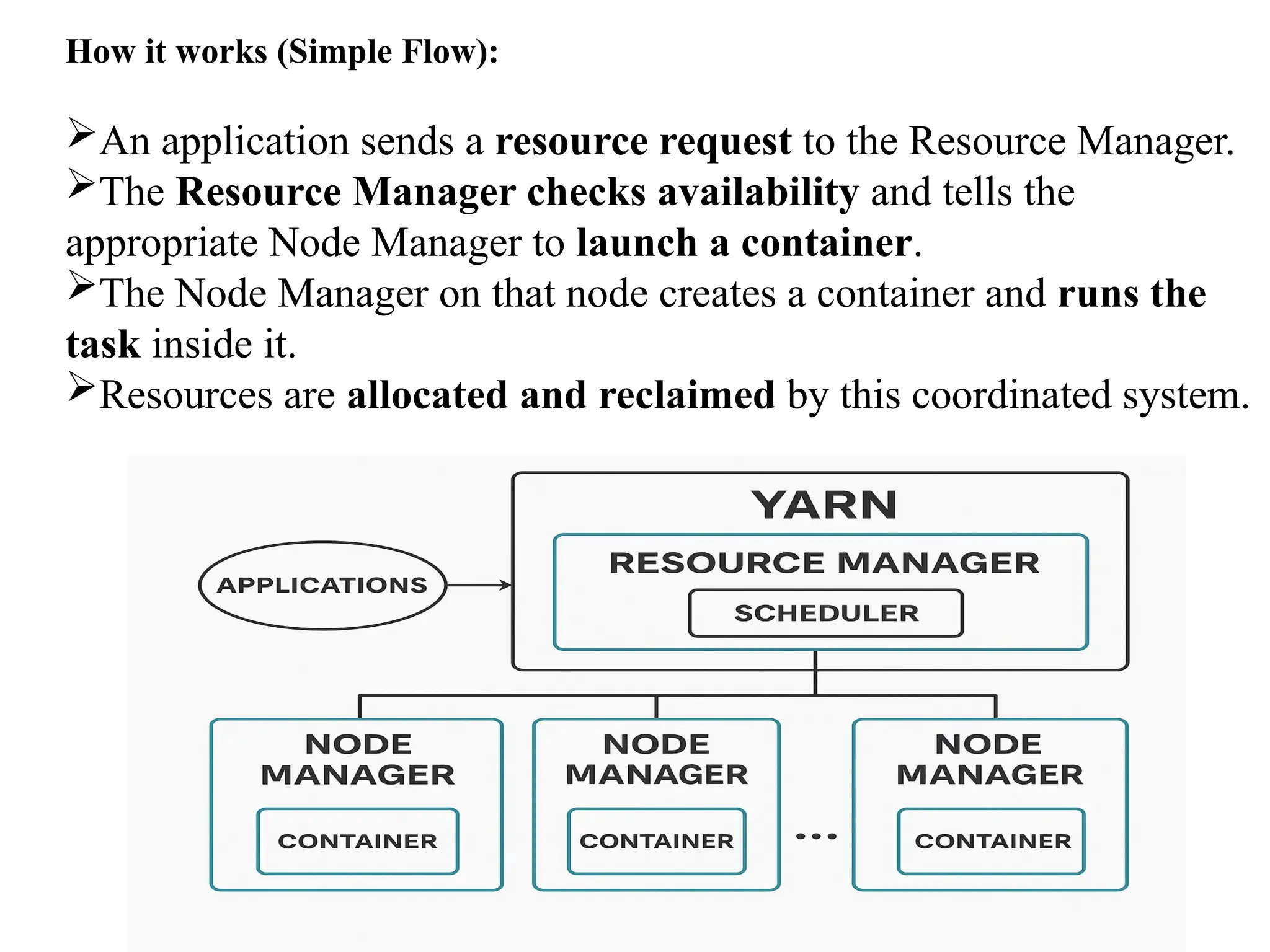
How it works(Simple Flow): An application sends a resource request to the Resource Manager. The Resource Manager checks availability and tells the appropriate Node Manager to launch a container. The Node Manager on that node creates a container and runs the task inside it. Resources are allocated and reclaimed by this coordinated system.
27.
Hive : Itis a distributed data management for hadoop It supports SQL – like query option HiveSQL (HSQL) to access big data It can be used for data mining purpose It runs on top of Hadoop. Apache Hive is a data warehouse infrastructure built on top of Hadoop. It allows you to query and analyze large datasets stored in HDFS (Hadoop Distributed File System) using a SQL-like language called HiveQL.
28.
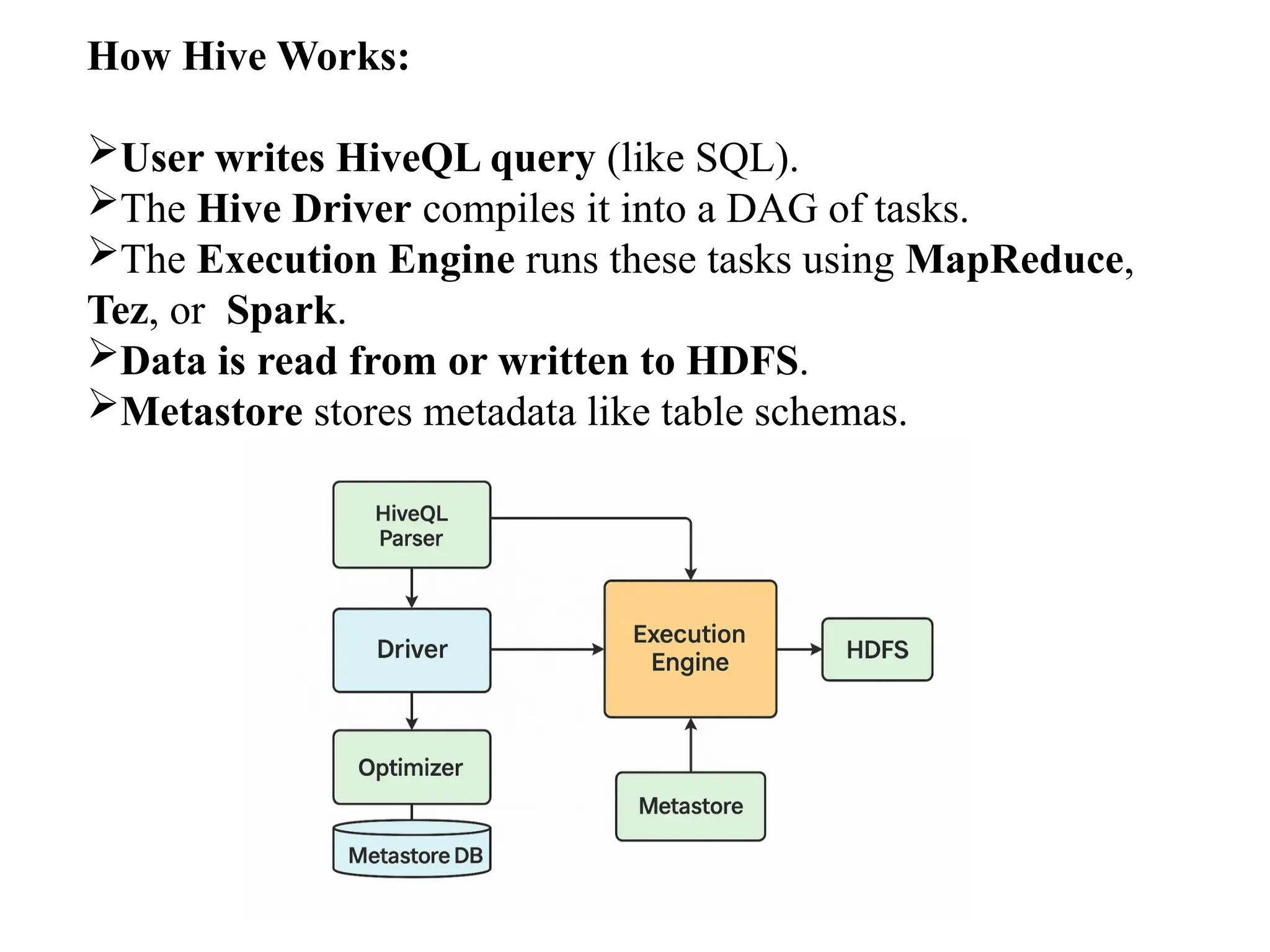
How Hive Works: Userwrites HiveQL query (like SQL). The Hive Driver compiles it into a DAG of tasks. The Execution Engine runs these tasks using MapReduce, Tez, or Spark. Data is read from or written to HDFS. Metastore stores metadata like table schemas.
29.
Apache Spark Apache Sparkis an open-source distributed computing system designed for fast processing of large-scale data. It is known for its speed, ease of use, and rich APIs for data processing — much faster than traditional Hadoop MapReduce. Apache Spark project, runs over, HDFS and this is a big data analytics frame work, which in memory computation. So that the, lightning fast cluster computation, is being performed. So several applications like, Stream processing, Machine learning and Large Scale Graph Processing, are implemented, over this Spark
30.
Why is ZooKeeperNeeded? In a distributed system (like Hadoop, HBase, Kafka), many components run on different servers. They need to coordinate and share information . But this is difficult because: Servers may crash or restart There might be network issues There’s a need for leader election (to decide who is the master) ZooKeeper solves these problems by acting like a central manager that all nodes can talk to.
31.
Apache ZooKeeper isa distributed coordination service . It helps manage large distributed systems by offering centralized services like: Configuration management Naming Distributed synchronization Group services (leader election) ZooKeeper
32.
Feature Explanation Centralized ServiceActs as a shared system for configuration and coordination. Consistency All nodes see the same view of the system. High Availability Even if one ZooKeeper server fails, others keep the system working. Sequential Access Keeps order using timestamps and sequence numbers.
33.
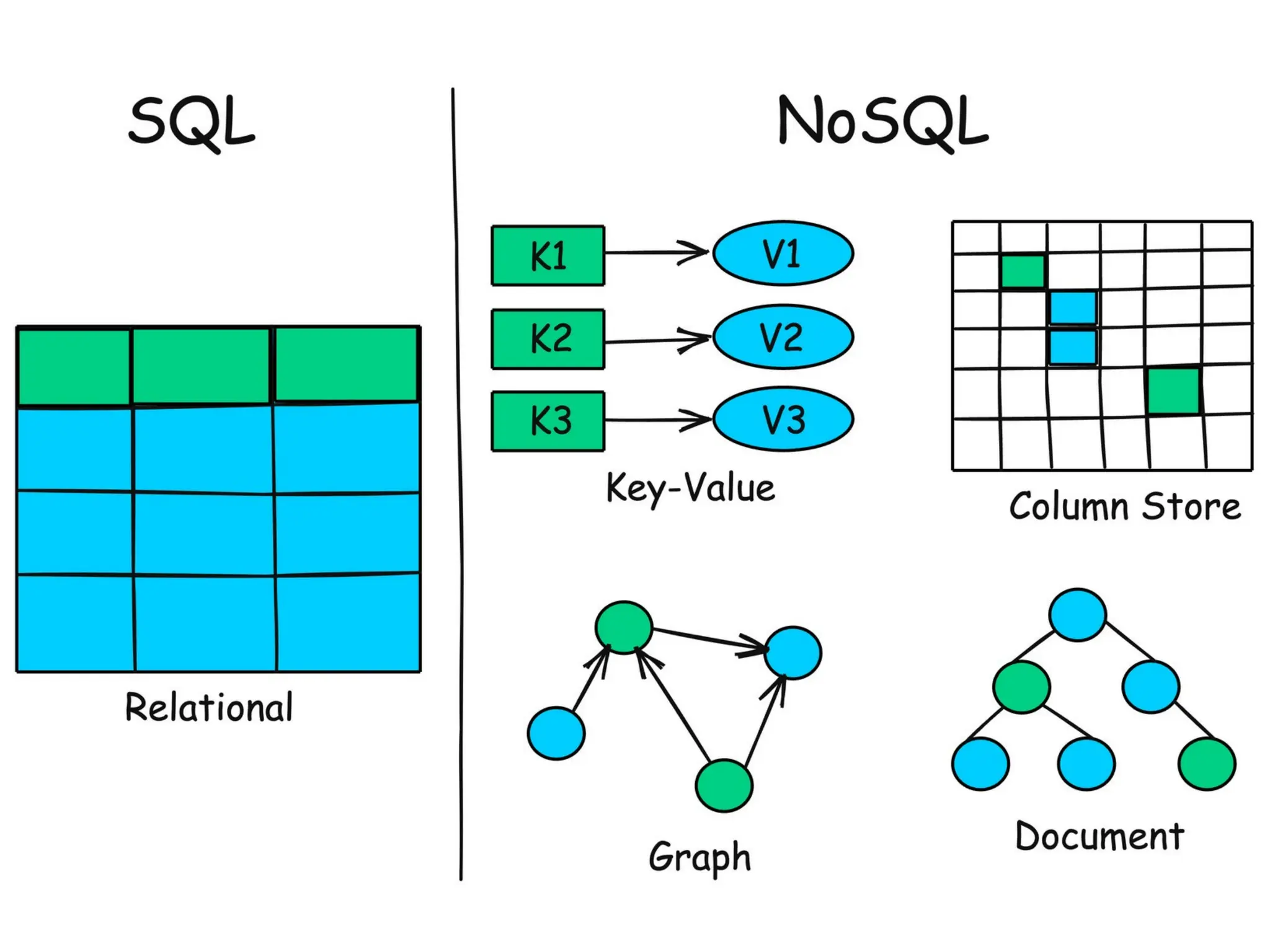
NoSQL Traditional SQL, canbe effectively used to handle the large amount of, structured data. But here in the big data, most of the information is, unstructured form of the data, so basically, NoSQL that is, is required to handle that information, because, traditional SQL required, by the, the data to be, in the structured, data format. So NoSQL data base is, stored unstructured data also, however, it is not, enforced to follow a particular, fixed schema structure and schema keeps on, changing, dynamically. So, each row can have its own set of column values. NoSQL gives a better performance, in storing the massive amount of data compared to the SQL,structure.
35.
Cassandra Cassandra is adistributed database management system which is open source with wide column store, NoSQL database to handle large amount of data across many commodity servers which provides high availability with no single point of failure. It is written in Java and developed by Apache Software Foundation.
36.
Features of Cassandra: Cassandrahas become popular because of its technical features. There are some of the features of Cassandra: 1. Easy data distribution - It provides the flexibility to distribute data where you need by replicating data across multiple data centers. for example: If there are 5 node let say N1, N2, N3, N4, N5 and by using partitioning algorithm we will decide the token range and distribute data accordingly. Each node have specific token range in which data will be distribute. let's have a look on diagram for better understanding. Ring structure with token range.
37.
2. Flexible datastorage - Cassandra accommodates all possible data formats including: structured, semi-structured, and unstructured. It can dynamically accommodate changes to your data structures accordingly to your need. 3. Elastic scalability - Cassandra is highly scalable and allows to add more hardware to accommodate more customers and more data as per requirement. 4. Fast writes - Cassandra was designed to run on cheap commodity hardware. Cassandra performs blazingly fast writes and can store hundreds of terabytes of data, without sacrificing the read efficiency.
38.
5. Always onArchitecture - Cassandra has no single point of failure and it is continuously available for business-critical applications that can't afford a failure. 6. Fast linear-scale performance - Cassandra is linearly scalable therefore it increases your throughput as you increase the number of nodes in the cluster. It maintains a quick response time.
39.
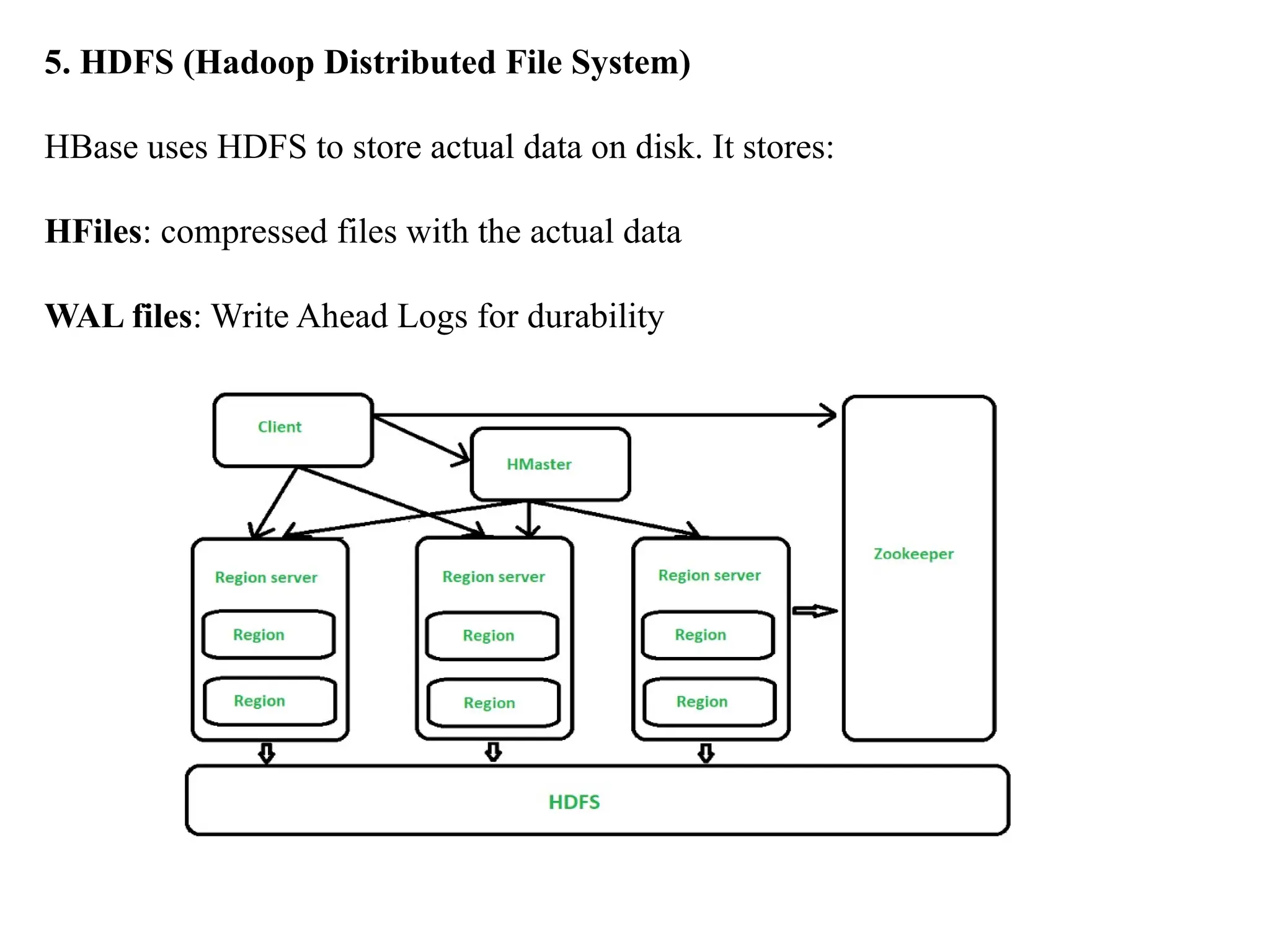
HBase Apache HBase isa distributed, scalable, NoSQL database built on top of the Hadoop Distributed File System (HDFS). It is modeled after Google's Bigtable and is designed for storing large volumes of sparse, unstructured, or semi-structured data across clusters. HBase is column-oriented, supports horizontal scaling, and allows for real-time read/write access, making it an essential component of the Hadoop ecosystem.
40.
Architeture of ApacheHBase Apache HBase follows a master-slave architecture and is built on top of Hadoop HDFS. Here's how its major components work together: Here’s how each part of the Apache HBase architecture works in detail: 1. HMaster Acts as the master node of the HBase cluster. Its main responsibilities include: Coordinating RegionServers Assigning regions to RegionServers Monitoring RegionServer health Handling schema changes, like creating or deleting tables Performing load balancing so no RegionServer is overloaded If the HMaster fails, a backup HMaster can take over to ensure high availability.
41.
2. RegionServer A workernode in HBase, serving client requests. Each RegionServer manages multiple regions, meaning chunks of tables. Internally, RegionServers have: MemStore: stores data in memory for fast writes before persisting to disk HFile: permanent storage format in HDFS BlockCache: caches frequently read data to improve read performance RegionServers also manage WAL (Write Ahead Log) for crash recovery. If a RegionServer fails, the HMaster reassigns its regions to other RegionServers.
42.
3. Region A regionis a horizontal partition of an HBase table (like a subset of rows). Each region contains data for a continuous range of row keys. When a region grows too large (default around 10GB), it automatically splits into smaller regions. Only one RegionServer handles a given region at a time to avoid conflicts. 4. ZooKeeper It's an external, reliable coordination service. HBase uses ZooKeeper to: Track available RegionServers Help clients locate regions quickly Manage master election in case of failure Provide distributed configuration and synchronization Without ZooKeeper, the cluster cannot coordinate properly.
43.
5. HDFS (HadoopDistributed File System) HBase uses HDFS to store actual data on disk. It stores: HFiles: compressed files with the actual data WAL files: Write Ahead Logs for durability
44.
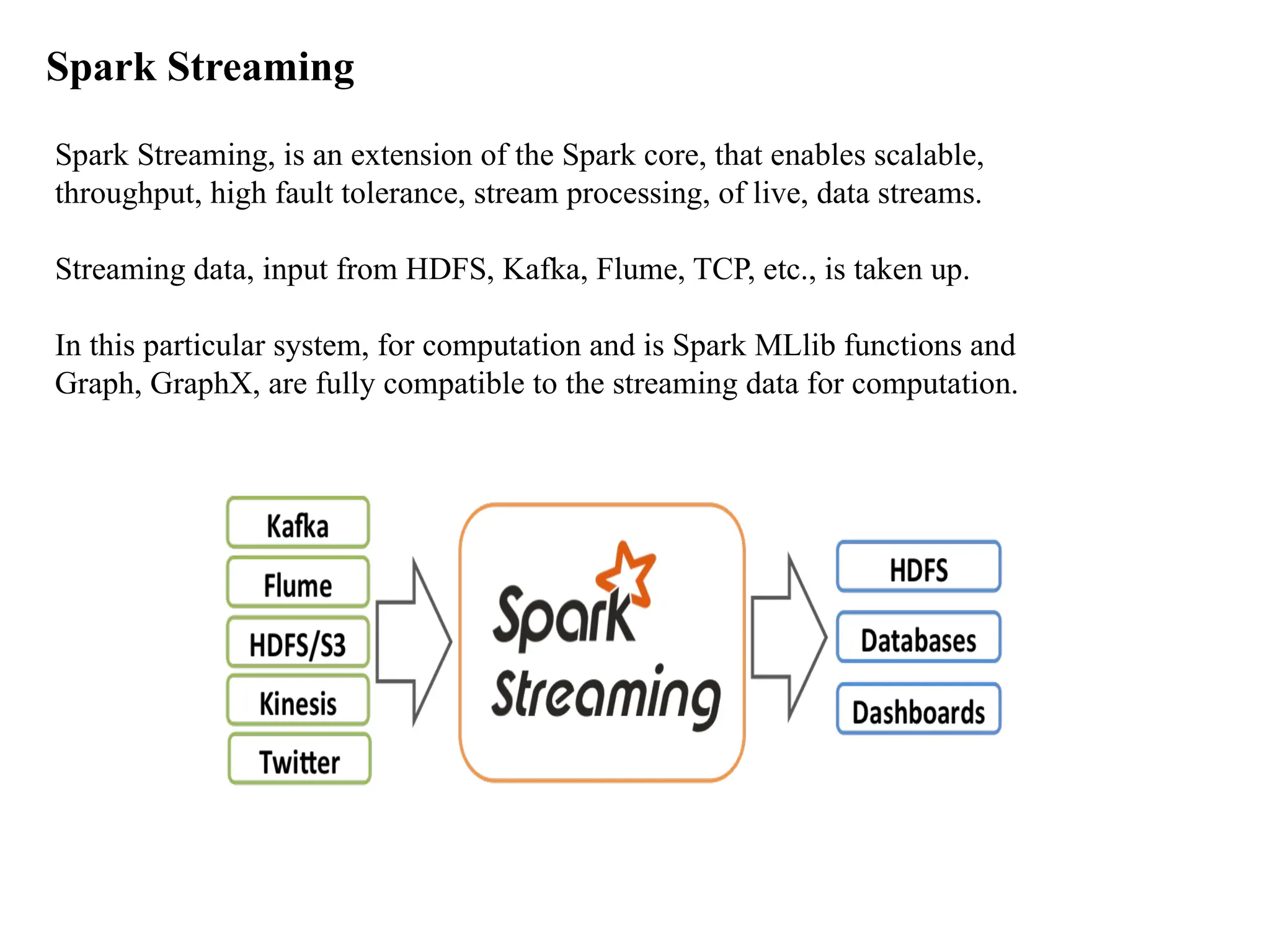
Spark Streaming Spark Streaming,is an extension of the Spark core, that enables scalable, throughput, high fault tolerance, stream processing, of live, data streams. Streaming data, input from HDFS, Kafka, Flume, TCP, etc., is taken up. In this particular system, for computation and is Spark MLlib functions and Graph, GraphX, are fully compatible to the streaming data for computation.
45.
Kafka Apache Kafka isa distributed streaming platform used for building real-time data pipelines and streaming applications. It acts as a fault-tolerant, high-throughput, and low-latency system for handling large volumes of data in motion.
46.
Spark MLib Spark MLlibis a distributed machine learning framework, on top of Spark core. So, MLlib is the Spark’s scalable, machine learning library, which consists of common, machine learning algorithm and utilities. Such as, the Classification algorithm, Regression algorithm, Clustering, Collaborative, filtering, and Dimensionality reduction and all the algorithms, which are there in machine learning, they are a implemented in this particular frame work.
47.
GraphX Spark GraphX isanother Hadoop open source, Apache project and this is the component, which is build over the, core Spark, for computation of a large scale graphs. That is parallel computation of a graph is done using GraphX. So, GraphX extends the Spark RDD’s, by introducing the new graph abstraction. And GraphX reuses by Spark RDD concepts simplifies than on top of it, using the different graph analytics, which basically are graph algorithms.
48.
Big data Stack: TheBig Data Stack is a layered architecture that defines how Big Data systems are built and operated. It includes the technologies required to collect, store, process, analyze, and visualize data at scale. Each layer in the stack plays a specific role — starting from raw data collection to delivering meaningful insights.
49.
•1. Data Sources: Thislayer encompasses all the origins of data, which can be structured, semi-structured, or unstructured. Examples include databases, social media feeds, log files, and sensors. •2. Data Ingestion: This layer focuses on collecting and transporting data from various sources into the big data system. Technologies like Apache Kafka, Flume, and Sqoop are often used for this. •3. Data Storage: This layer is responsible for storing the ingested data, often in distributed file systems like Hadoop Distributed File System (HDFS) or cloud-based storage solutions.
50.
•4. Data Processing: Thislayer handles the processing and transformation of stored data. Frameworks like Apache Spark and Hadoop MapReduce are commonly used for batch processing, while stream processing engines like Apache Kafka and Apache Flink are used for real-time data processing. •5. Data Visualization/Application: This final layer focuses on presenting insights derived from the processed data. This can involve creating dashboards, reports, or applications that utilize the data for decision-making or other purposes.
51.
Big Data distributionpackages Big Data distribution packages—that is, the platforms and frameworks that help organizations store, process, and analyze massive datasets across distributed systems: Core Open-Source Frameworks Apache Hadoop A foundational big data framework providing: HDFS: Distributed storage across clusters of commodity hardware. MapReduce: Batch processing model for handling large-scale computations. Built-in fault tolerance and designed to handle hardware failures gracefully. Apache Spark An in-memory, unified analytics engine favored for: Lightning-fast performance—often much faster than Hadoop's MapReduce. Support for batch processing, streaming, machine learning (via MLlib), SQL (Spark SQL), and graph processing (GraphX). Multi-language support including Python, Java
52.
•Cloudera Distribution IncludingApache Hadoop (CDH): •A comprehensive enterprise-grade distribution of Hadoop and related projects, offering tools for data warehousing, machine learning, and analytics. •Hortonworks Data Platform (HDP): •An open-source framework that provides a stable and secure platform for developing big data solutions. HDP includes components for data management, processing, and governance. •Amazon Elastic MapReduce (EMR): •A cloud-native big data platform that simplifies running big data frameworks like Hadoop and Spark on AWS to process and analyze vast amounts of data.
53.
•IBM InfoSphere BigInsights: •Abig data platform that combines open-source Hadoop with enterprise-grade features like advanced analytics, visualization, and security. •MapR Distribution: •A big data platform that offers high-performance data processing capabilities and supports various data formats and processing engines. •Microsoft Azure HDInsight: • A cloud-based service from Microsoft that makes it easy to process big data using popular open-source frameworks such as Hadoop, Spark, and Hive.
54.
•Google Cloud Dataproc: •Afast, easy-to-use, fully managed cloud service for running Apache Spark and Apache Hadoop clusters. •Dask: A flexible parallel computing library for analytics that enables performance at scale for the tools you love. Dask integrates seamlessly with Python libraries like NumPy, pandas, and scikit-learn.