Download to read offline
![1 Practice of Streaming Processing of Dynamic Graphs: Concepts, Models, and Systems Maciej Besta1, Marc Fischer2, Vasiliki Kalavri3, Michael Kapralov4, Torsten Hoefler1 1Department of Computer Science, ETH Zurich 2PRODYNA (Schweiz) AG; 3Department of Computer Science, Boston University 4School of Computer and Communication Sciences, EPFL Abstract—Graph processing has become an important part of various areas of computing, including machine learning, medical applications, social network analysis, computational sciences, and others. A growing amount of the associated graph processing workloads are dynamic, with millions of edges added or removed per second. Graph streaming frameworks are specifically crafted to enable the processing of such highly dynamic workloads. Recent years have seen the development of many such frameworks. However, they differ in their general architectures (with key details such as the support for the concurrent execution of graph updates and queries, or the incorporated graph data organization), the types of updates and workloads allowed, and many others. To facilitate the understanding of this growing field, we provide the first analysis and taxonomy of dynamic and streaming graph processing. We focus on identifying the fundamental system designs and on understanding their support for concurrency, and for different graph updates as well as analytics workloads. We also crystallize the meaning of different concepts associated with streaming graph processing, such as dynamic, temporal, online, and time-evolving graphs, edge-centric processing, models for the maintenance of updates, and graph databases. Moreover, we provide a bridge with the very rich landscape of graph streaming theory by giving a broad overview of recent theoretical related advances, and by discussing which graph streaming models and settings could be helpful in developing more powerful streaming frameworks and designs. We also outline graph streaming workloads and research challenges. F 1 INTRODUCTION Analyzing massive graphs has become an important task. Example applications are investigating the Internet struc- ture [46], analyzing social or neural relationships [25], or capturing the behavior of proteins [73]. Efficient processing of such graphs is challenging. First, these graphs are large, reaching even tens of trillions of edges [57], [155]. Second, the graphs in question are dynamic: new friendships appear, novel links are created, or protein interactions change. For example, 500 million new tweets in the Twitter social net- work appear per day, or billions of transactions in retail transaction graphs are generated every year [13]. Graph streaming frameworks such as STINGER [85] or Aspen [71] emerged to enable processing and analyzing dy- namically evolving graphs. Contrarily to static frameworks such as Ligra [108], [209], such systems execute graph an- alytics algorithms (e.g., PageRank) concurrently with graph updates (e.g., edge insertions). Thus, these frameworks must tackle unique challenges, for example effective modeling and storage of dynamic datasets, efficient ingestion of a stream of graph updates concurrently with graph queries, or support for effective programming model. In this work, we present the first taxonomy and analysis of such system aspects of the streaming processing of dynamic graphs. Moreover, we crystallize the meaning of different con- cepts in streaming and dynamic graph processing. We in- vestigate the notions of temporal, time-evolving, online, and dynamic graphs. We also discuss the differences between graph streaming frameworks and the edge-centric engines, as well as a related class of graph database systems. We also analyze relations between the practice and the theory of streaming graph processing to facilitate incorpo- rating recent theoretical advancements into the practical setting, to enable more powerful streaming frameworks. There exist different related theoretical settings, such as streaming graphs [167] or dynamic graphs [43] that come with different goals and techniques. Moreover, each of these set- tings comes with different models, for example the dynamic graph stream model [130] or the semi-streaming model [84]. These models assume different features of the processed streams, and they are used to develop provably efficient streaming algorithms. We analyze which theoretical settings and models are best suited for different practical scenarios, providing guidelines for architects and developers on what concepts could be useful for different classes of systems. Next, we outline models for the maintenance of updates, such as the edge decay model [235]. These models are independent of the above-mentioned models for developing streaming algorithms. Specifically, they aim to define the way in which edge insertions and deletions are considered for updating different maintained structural graph proper- ties such as distances between vertices. For example, the edge decay model captures the fact that edge updates from the past should gradually be made less relevant for the current status of a given structural graph property. Finally, there are general-purpose dataflow systems such as Apache Flink [54] or Differential Dataflow [168]. We discuss the support for graph processing in such designs. In general, we provide the following contributions: arXiv:1912.12740v3 [cs.DC] 11 Mar 2021](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-1-2048.jpg)
![2 n: number of vertices m: number of edges d: maximum graph degree 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 0 1 0 0 0 0 0 0 0 0 1 1 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 0 0 0 1 0 0 0 0 1 0 0 0 0 1 1 1 0 0 0 1 1 0 0 0 0 0 1 1 0 0 1 0 0 1 1 0 0 0 1 0 1 0 0 1 1 0 1 1 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 1 1 1 1 0 1 1 1 1 1 0 1 n ... 1 ... n 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1 n ... 1 ∅ 11 12 11 12 10 9 10 11 12 16 9 10 12 14 16 16 6 7 1116 5 6 7 1112 2 3 6 9 10 16 14 3 4 6 7 1016 16 15 7 1116 16 13 6 7 8 9 11 13 12 15 14 d ... ... Number of tuples: 2 3 4 5 6 7 16 11 11 12 10 9 10 11 12 16 9 10 12 14 16 15 3 12 6 6 6 6 7 7 7 7 ... 2 3 4 5 6 7 16 11 11 12 10 9 10 11 12 16 9 10 12 14 16 15 3 12 6 6 6 6 7 7 7 7 1 ... 2m (undirected), m (directed) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1 n ... Neighborhoods can be sorted or unsorted ... 1 2m or m ... An n x n matrix Unweighted graph: a cell is one bit Pointers from vertices to their neighborhoods Neighbor- hoods contain records with vertex IDs, linked with pointers Weighted graph: a cell is one integer Pointers from vertices to their neighborhoods 2m or m One tuple corresponds to one edge Offset array is optional Adjacency Matrix (AM) Adj. List (AL) & CSR Edge List (sorted, unsorted) INPUT GRAPH: No offset array in unsorted edge list 7 9 Adjacency List CSR Neighbor- hoods are contiguous Remarks on enabling dynamic updates in a given representation: O(1) O(n ) 2 Used approach: compression to limit storage overheads O(d) + O(1) O(log d) + O(d) O(m) + O(n) O(m) + O(m) Used approach: neighborhoods formed by linked lists of contiguous chunks of edges AL CSR Add or delete edge: Size: finding edge edge removal Tradeoffs for edge lists are similar to those for AL or CSR AM Add or delete edge: Size: AL CSR edge data pointers + + ( ) ( ) 1 2 3 11 12 13 14 15 16 1 n ... ∅ 11 12 11 2 3 6 9 10 16 14 3 4 6 7 1016 16 15 7 1116 16 13 6 7 8 9 11 13 12 15 14 A block, size (example) = 3 Blocking (within a neighborhood) Blocked CSR Blocks form a linked list 1 2 3 11 12 13 14 15 16 1 n ... ∅ 11 12 11 2 3 6 9 10 16 14 3 4 6 7 1016 16 15 7 1116 16 13 6 7 8 9 11 13 12 15 14 Empty space preserved at the end of each block, to accelerate edge inserts Gaps (within a neighborhood) Blocked CSR Block size determines the tradeoff between locality and ease of updates Blocking (across neighborhoods) Small neighborhoods are stored in the same block in memory (e.g. a page) to speed up some read queries 1 2 3 11 12 13 14 15 16 1 n ... ∅ 11 12 11 2 3 6 9 10 16 14 3 4 6 7 1016 16 15 7 1116 16 13 6 7 8 9 11 13 12 15 14 Blocked CSR Selected popular optimizations related to CSR (more details: Table 2, Section 4) Used in: STINGER, LLAMA, faimGraph, LiveGraph, ... Used in: LiveGraph, Sha et al. Used in: Concerto, Hornet Fig. 1: Illustration of fundamental graph representations (Adjacency Matrix, Adjacency List, Edge List, CSR) and remarks on their usage in dynamic settings. • We crystallize the meaning of different concepts in dy- namic and streaming graph processing, and we analyze the connections to the areas of graph databases and to the theory of streaming and dynamic graph algorithms. • We provide the first taxonomy of graph streaming frameworks, identifying and analyzing key dimensions in their design, including data models and organiza- tion, concurrent execution, data distribution, targeted architecture, and others. • We use our taxonomy to survey, categorize, and com- pare over graph streaming frameworks. • We discuss in detail the design of selected frameworks. Complementary Surveys and Analyses We provide the first taxonomy and survey on general streaming and dynamic graph processing. We complement related surveys on the theory of graph streaming models and algorithms [6], [167], [183], [240], analyses on static graph processing [23], [39], [75], [110], [166], [207], and on general streaming [129]. Finally, only one prior work summarized types of graph updates, partitioning of dynamic graphs, and some chal- lenges [225]. 2 BACKGROUND AND NOTATION We first present concepts used in all the sections. We sum- marize the key symbols in Table 1. G = (V, E) An unweighted graph; V and E are sets of vertices and edges. w(e) The weight of an edge e = (u, v). n, m Numbers of vertices and edges in G; |V | = n, |E| = m. Nv The set of vertices adjacent to vertex v (v’s neighbors). dv, d The degree of a vertex v, the maximum degree in a graph. TABLE 1: The most important symbols used in the paper. Graph Model We model an undirected graph G as a tuple (V, E); V = {v1, ..., vn} is a set of vertices and E = {e1, ..., em} ⊆ V × V is a set of edges; |V | = n and |E| = m. If G is directed, we use the name arc to refer to an edge with a direction. Nv denotes the set of vertices adjacent to vertex v, dv is v’s degree, and d is the maximum degree in G. If G is weighted, it is modeled by a tuple (V, E, w). Then, w(e) is the weight of an edge e ∈ E. Graph Representations We also summarize fundamen- tal static graph representations; they are used as a basis to develop dynamic graph representations in different frame- works. These are the adjacency matrix (AM), the adjacency](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-2-2048.jpg)
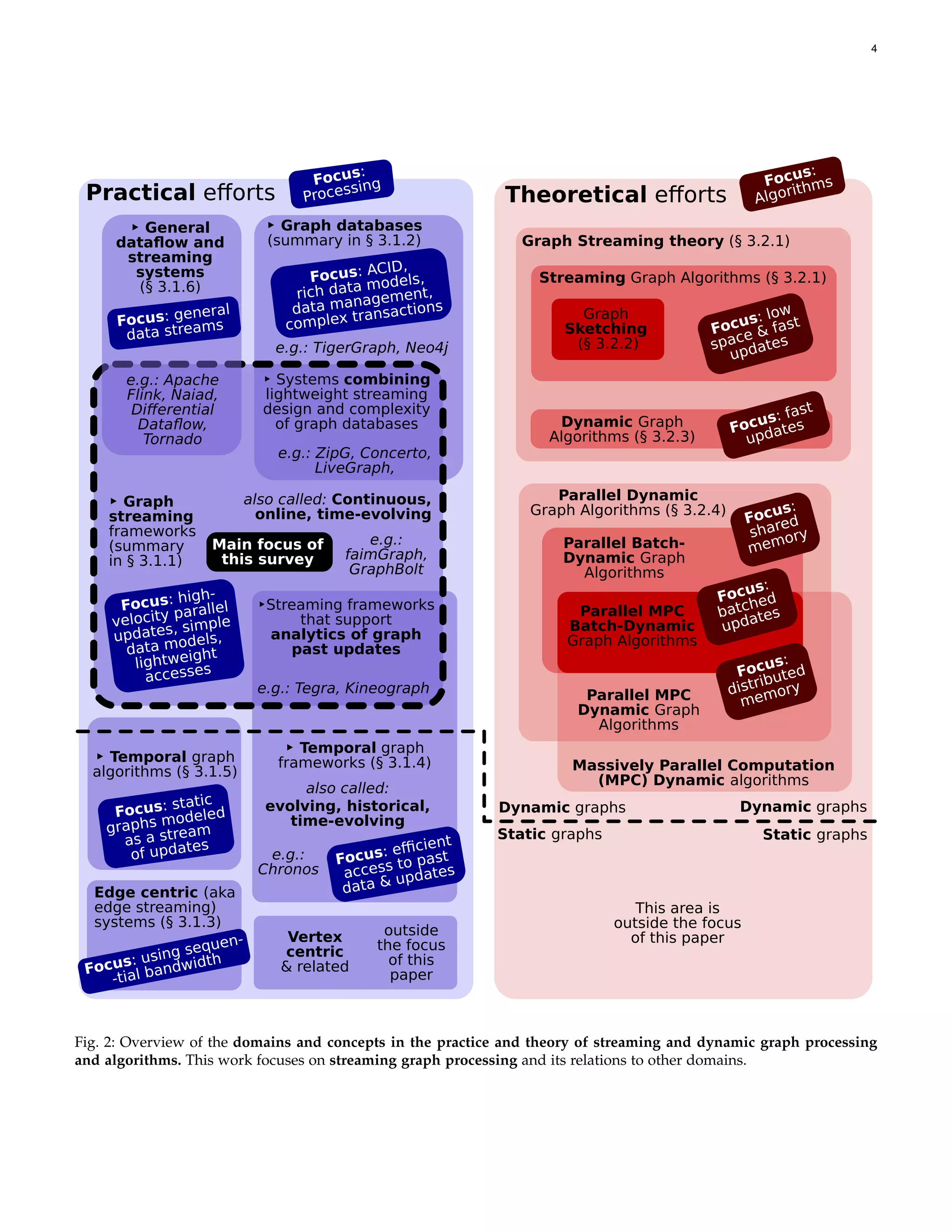
![3 list (AL), the edge list (EL), and the Compressed Sparse Row (CSR, sometimes referred to as Adjacency Array [49])1 . We illustrate these representations and we provide remarks on their dynamic variants in Figure 1. In AM, a matrix M ∈ {0, 1}n,n determines the connectivity of vertices: Mu,v = 1 ⇔ (u, v) ∈ E. In AL, each vertex u has an associ- ated adjacency list Au. This adjacency list maintains the IDs of all vertices adjacent to u. We have v ∈ Au ⇔ (u, v) ∈ E. AM uses O n2 space and can check connectivity of two vertices in O (1) time. AL requires O (n + m) space and it can check connectivity in O (|Au|) ⊆ O (d) time. EL is similar to AL in the asymptotic time and space complexity as well as the general design. The main difference is that each edge is stored explicitly, with both its source and destination vertex. In AL and EL, a potential cause for inefficiency is scanning all edges to find neighbors of a given vertex. To alleviate this, index structures are employed [42]. Finally, CSR resembles AL but it consists of n contiguous arrays with neighborhoods of vertices. Each array is usually sorted by vertex IDs. CSR also contains a structure with offsets (or pointers) to each neighborhood array. Graph Accesses We often distinguish between graph queries and graph updates. A graph query (also called a read) may perform some computation on a graph and it returns information about the graph without modifying its struc- ture. Such query can be local, also referred to as fine (e.g., accessing a single vertex or edge) or global (e.g., a PageRank analytics computation returning ranks of vertices). A graph update, also called a mutation, modifies the graph structure and/or attached labels or values (e.g., edge weights). 3 CLARIFICATION OF CONCEPTS AND AREAS The term “graph streaming” has been used in different ways and has different meanings, depending on the context. We first extensively discuss and clarify these meanings, and we use this discussion to precisely illustrate the scope of our taxonomy and analyses. We illustrate all the considered concepts in Figure 2. To foster developing more powerful and versatile systems for dynamic and streaming graph processing, we also summarize theoretical concepts. 3.1 Applied Dynamic and Streaming Graph Processing We first outline the applied aspects and areas of dynamic and streaming graph processing. 3.1.1 Streaming, Dynamic, and Time-Evolving Graphs Many works [71], [79] use a term “streaming” or “streaming graphs” to refer to a setting in which a graph is dynamic [202] (also referred to as time-evolving [122], continuous [70], or online [87]) and it can be modified with updates such as edge insertions/deletions. This setting is the primary focus of this survey. In the work, we use “dynamic” to refer to the graph dataset being modified, and we reserve “streaming” to refer to the form of incoming graph accesses or updates. 3.1.2 Graph Databases and NoSQL Stores Graph databases [38] are related to streaming and dy- namic graph processing in that they support graph updates. 1 Some works use CSR to describe a graph representation where all neighborhoods form a single contiguous array [147]. In this work, we use CSR to indicate a representation where each neighborhood is contiguous, but not necessarily all of them together. Graph databases (both “native” graph database systems and NoSQL stores used as graph databases (e.g., RDF stores or document stores)) were described in detail in a recent work [38] and are beyond the main focus of this paper. However, there are numerous fundamental differences and similarities between graph databases and graph streaming frameworks, and we discuss these aspects in Section 7. 3.1.3 Streaming Processing of Static Graphs Some works [41], [181], [195], [242] use “streaming” (also referred to as edge-centric) to indicate a setting in which the input graph is static but its edges are processed in a stream- ing fashion (as opposed to an approach based on random accesses into the graph data). Example associated frame- works are X-Stream [195], ShenTu [155], RStream [229], and several FPGA designs [41]. Such designs are outside the main focus of this survey; some of them were described by other works dedicated to static graph processing [41], [75]. 3.1.4 Historical Graph Processing There exist efforts into analyzing historical (also referred to as – somewhat confusingly – temporal or [time]-evolving) graphs [50], [83], [92], [111]–[113], [140], [141], [154], [169], [170], [172], [173], [188], [191], [199], [213], [214], [219], [228], [234], [239]. As noted by Dhulipala et al. [71], these efforts differ from streaming/dynamic/time-evolving graph anal- ysis in that one stores all past (historical) graph data to be able to query the graph as it appeared at any point in the past. Contrar- ily, in streaming/dynamic/time-evolving graph processing, one focuses on keeping a graph in one (present) state. Additional snapshots are mainly dedicated to more efficient ingestion of graph updates, and not to preserving historical data for time-related analytics. Moreover, almost all works that focus solely on temporal graph analysis, for example the Chronos system [112], are not dynamic (i.e., they are offline): there is no notion of new incoming updates, but solely a series of past graph snapshots (instances). These ef- forts are outside the focus of this survey (we exclude these efforts, because they come with numerous challenges and design decisions (e.g., temporal graph models [239], tempo- ral algebra [172], strategies for snapshot retrieval [234]) that require separate extensive treatment, while being unrelated to the streaming and dynamic graph processing). Still, we describe concepts and systems that – while focusing on streaming processing of dynamic graphs, also enable keeping and processing historical data. One such example is Tegra [121]. 3.1.5 Temporal Graph Algorithms Certain works analyze graphs where edges carry timing information, e.g., the order of communication between en- tities [232], [233]. One method to process such graphs is to model them as a stream of incoming edges, with the arrival time based on temporal information attached to edges. Thus, while being static graphs, their representation is dynamic. Thus, we picture these schemes as being partially in the dynamic setting in Figure 2. These works come with no frameworks, and are outside the focus of our work. 3.1.6 General Dataflow and Streaming Systems General streaming and dataflow systems, such as Apache Flink [54], Naiad [177], Tornado [206], or Differential Dataflow [168], can also be used to process dynamic graphs.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-3-2048.jpg)
![5 However, most of the dimensions of our taxonomy are not well-defined for these general purpose systems. Overall, these systems provide a very general programming model and impose no restrictions on the format of streaming updates or graph state that the users construct. Thus, in principle, they could process queries and updates concur- rently, support rich attached data, or even use transactional semantics. However, they do not come with pre-built fea- tures specifically targeting graphs. 3.2 Theory of Streaming and Dynamic Graphs We next proceed to outline concepts in the theory of dy- namic and streaming graph models and algorithms. Despite the fact that detailed descriptions are outside the scope of this paper, we firmly believe that explaining the associated general theoretical concepts and crystallizing their relations to the applied domain may facilitate developing more pow- erful streaming systems by – for example – incorporating efficient algorithms with provable bounds on their perfor- mance. In this section, we outline different theoretical areas and their focus. In general, in all the following theoret- ical settings, one is interested in maintaining (sometimes approximations to) a structural graph property of interest, such as connectivity structure, spectral structure, or shortest path distance metric, for graphs that are being modified by incoming updates (edge insertions and deletions). 3.2.1 Streaming Graph Algorithms In streaming graph algorithms [63], [84], one usually starts with an empty graph with no edges (but with a fixed set of vertices). Then, at each algorithm step, a new edge is inserted into the graph, or an existing edge is deleted. Each such algorithm is parametrized by (1) space complexity (space used by a data structure that maintains a graph being up- dated), (2) update time (time to execute an update), (3) query time (time to compute an estimate of a given structural graph property), (4) accuracy of the computed structural property, and (5) preprocessing time (time to construct the initial graph data structure) [44]. Different streaming models can introduce additional assumptions, for example the Sliding Window Model provides restrictions on the number of previous edges in the stream, considered for estimating the property [63]. The goal is to develop algorithms that minimize different pa- rameter values, with a special focus on minimizing the storage for the graph data structure. While space complexity is the main focus, significant effort is devoted to optimizing the runtime of streaming algorithms, specifically the time to process an edge update, as well as the time to recover the final solution (see, e.g., [150] and [134] for some recent developments). Typically the space requirement of graph streaming algorithms is O(n polylog n) (this is known as the semi-streaming model [84]), i.e., about the space needed to store a few spanning trees of the graph. Some recent works achieve ”truly sublinear” space o(n), which is sublinear in the number of vertices of the graph and is particularly good for sparse graphs [21], [22], [48], [81], [132], [133], [185]. The reader is referred to surveys on graph streaming algorithms [105], [167], [178] for more references. Applicability in Practical Settings Streaming algo- rithms can be used when there are hard limits on the max- imum space allowed for keeping the processed graph, as well as a need for very fast updates per edge. Moreover, one should bear in mind that many of these algorithms provide approximate outcomes. Finally, the majority of these algo- rithms assumes the knowledge of certain structural graph properties in advance, most often the number of vertices n. 3.2.2 Graph Sketching and Dynamic Graph Streams Graph sketching [11] is an influential technique for pro- cessing graph streams with both insertions and deletions. The idea is to apply classical sketching techniques such as COUNTSKETCH [171] or distinct elements sketch (e.g., HYPERLOGLOG [90]) to the edge incidence matrix of the input graph. Existing results show how to approximate the connectivity and cut structure [11], [15], spectral struc- ture [134], [135], shortest path metric [11], [136], or sub- graph counts [128], [130] using small sketches. Extensions to some of these techniques to hypergraphs were also pro- posed [106]. Some streaming graph algorithms use the notion of a bounded stream, i.e., the number of graph updates is bounded. Streaming and applying all such updates once is referred to as a single pass. Now, some streaming graph algorithms allow for multiple passes, i.e., streaming all edge updates more than once. This is often used to improve the approximation quality of the computed solution [84]. There exist numerous other works in the theory of streaming graphs. Variations of the semi-streaming model allow stream manipulations across passes, (also known as the W-Stream model [68]) or stream sorting passes (known as the Stream-Sort model [7]). We omit these efforts are they are outside the scope of this paper. 3.2.3 Dynamic Graph Algorithms In the related area of dynamic graph algorithms one is inter- ested in developing algorithms that approximate a combi- natorial property of the input graph of interest (e.g., connec- tivity, shortest path distance, cuts, spectral properties) under edge insertions and deletions. Contrarily to graph stream- ing, in dynamic graph algorithms one puts less focus on minimizing space needed to store graph data. Instead, the primary goal is to minimize time to conduct graph updates. This has led to several very fast algorithms that provide updates with amortized poly-logarithmic update time complexity. See [24], [43], [55], [76], [78], [91], [223] and references within for some of the most recent developments. Applicability in Practical Settings Dynamic graph al- gorithms can match settings where primary focus is on fast updates, without severe limitations on the available space. 3.2.4 Parallel Dynamic Graph Algorithms Many algorithms were developed under the parallel dy- namic model, in which a graph undergoes a series of incom- ing parallel updates. Next, the parallel batch-dynamic model is a recent development in the area of parallel dynamic graph algorithms [3], [4], [210], [221]. In this model, a graph is modified by updates coming in batches. A batch size is usually a function of n, for example log n or √ n. Updates from each batch can be applied to a graph in parallel. The motivation for using batches is twofold: (1) incorporating parallelism into ingesting updates, and (2) reducing the cost per update. The associated algorithms focus on minimizing](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-5-2048.jpg)
![6 time to ingest updates into the graph while accurately maintaining a given structural graph property. A variant [77] that combines the parallel batch-dynamic model with the Massively Parallel Computation (MPC) model [137] was also recently described. The MPC model is motivated by distributed frameworks such as MapRe- duce [67]. In this model, the maintained graph is stored on a certain number of machines (additionally assuming that the data in one batch fits into one machine). Each machine has a certain amount of space sublinear with respect to n. The main goal of MPC algorithms is to solve a given problem using O(1) communication rounds while minimizing the volume of data communicated between the machines [137]. Finally, another variant of the MPC model that ad- dresses dynamic graph algorithms but without considering batches, was also recently developed [119]. Applicability in Practical Settings Algorithms devel- oped in the above models may be well-suited for enhancing streaming graph frameworks as these algorithms explicitly (1) maximize the amount of parallelism by using the concept of batches, and (2) minimize time to ingest updates. 4 TAXONOMY OF FRAMEWORKS We identify a taxonomy of graph streaming frameworks. We offer a detailed analysis of concrete frameworks using the taxonomy in Section 5 and in Tables 2–3. Overall, the identified taxonomy divides all the associated aspects into six classes: ingesting updates (§ 4.1), historical data mainte- nance (§ 4.2), dynamic graph representation (§ 4.3), incremen- tal changes (§ 4.4), programming API and models (§ 4.5), and general architectural features (§ 4.6). Due to space constraints, we focus on the details of the system architecture and we only sketch the straightforward taxonomy aspects (e.g., whether a system targets CPUs or GPUs) and list2 them in § 4.6. 4.1 Architecture of Ingesting Updates The first core architectural aspect of any graph streaming framework are the details of ingesting incoming updates. 4.1.1 Concurrent Queries and Updates We start with the method of achieving concurrency between queries and updates (mutations). One such popular method is based on snapshots. Here, updates and queries are isolated from each other by making them execute on two different copies (snapshots) of the graph data. At some point, such snapshots are merged together. Depending on a system, the scope of data duplica- tion (i.e., only a part of the graph may be copied into a new snapshot) and the details of merging may differ. Second, one can use logging. The graph representation contains a dedicated data structure (a log) for keeping the incoming updates; queries are being processed in parallel. At some point, depending on system details, the logged updates are integrated into the main graph representation. In fine-grained synchronization, in contrast to snap- shots and logging (where updates are merged with the main graph representation during dedicated phases), updates are incorporated into the main dataset as soon as they arrive, often interleaved with queries, using synchronization proto- cols based on fine-grained locks and/or atomic operations. 2 More details are in the extended paper version (see the link on page 1) A variant of fine-grained synchronization is Differential Dataflow [168], where the ingestion strategy allows for concurrent updates and queries by relying on a combina- tion of logical time, maintaining the knowledge of updates (referred to as deltas), and progress tracking. Specifically, the differential dataflow design operates on collections of key-value pairs enriched with timestamps and delta values. It views dynamic data as additions to or removals from input collections and tracks their evolution using logical time. The Rust implementation of differential dataflow3 contains implementations of incremental operators that can be composed into a possibly cyclic dataflow graph to form complex, incremental computations that automatically up- date their outputs when their inputs change. Finally, as also noted in past work [71], a system may simply do not enable concurrency of queries and updates, and instead alternate between incorporating batches of graph updates and graph queries (i.e., updates are being applied to the graph structure while queries wait, and vice versa). This type of architecture may enable a high ratio of digesting updates as it does not have to resolve the problem of the consistency of graph queries running interleaved, concurrently, with updates being digested. However, it does not enable a concurrent execution of updates and queries. 4.1.2 Batching Updates and Queries A common design choice is to ingest updates, or resolve queries, in batches, i.e., multiple at a time, to amortize over- heads from ensuring consistency of the maintained graph. We distinguish this design choice in the taxonomy because of its widespread use. Moreover, we identify a popular optimization in which a batch of edges to be removed or inserted is first sorted based on the ID of adjacent vertices. This introduces a certain overhead, but it also facilitates par- allel ingestion of updates: updates associated with different vertices can be easier identified. 4.1.3 Transactional Support We distinguish systems that support transactions, under- stood as units of work that enable isolation between concur- rent accesses and correct recovery from potential failures. Moreover, some (but not all) systems ensure the ACID semantics of transactions. 4.2 Architecture of Historical Data Maintenance While we do not focus on systems solely dedicated to the off-line analysis of historical graph data, some streaming systems enable different forms of accessing/analyzing such data. 4.2.1 Storing Past Snapshots In general, a streaming system may enable storing past snapshots, i.e., consistent past views (instances) of the whole dataset. However, one rarely keeps the whole past graph instances in memory due to storage overheads. Two methods for maintaining such instances while minimizing storage requirements can be identified across different sys- tems. First, one can store updates together with timestamps to be able to derive a graph instance at a given moment in time. Second, one can keep differences (“deltas”) between past graph instances (instead of full instances). 3 https://github.com/TimelyDataflow/differential-dataflow](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-6-2048.jpg)
![7 4.2.2 Visibility of Past Graph Updates There are several ways in which the information about past updates can be stored. Most systems only maintain a “live” version of the graph, where information about the past updates is not maintained4 , in which all incoming graph updates are being incorporated into the structure of the maintained graph and they are all used to update or derive maintained structural graph properties. For example, if a user is interested in distances between vertices, then – in the snapshot model – the derived distances use all past graph updates. Formally, if we define the maintained graph at a given time t as Gt = (V, Et), then we have Et = {e | e ∈ E ∧ t(e) ≤ t}, where E are all graph edges and t(e) is the timestamp of e ∈ E [235]. Some streaming systems use the sliding window model, in which edges beyond certain moment in the past are being omitted when computing graph properties. Using the same notation as above, the maintained graph can be modeled as Gt,t0 = (V, Et,t0 ), where Et,t0 = {e | e ∈ E ∧ t ≤ t(e) ≤ t0 }. Here, t and t0 are moments in time that define the width of the sliding window, i.e., a span of time with graph updates that are being used for deriving certain query answers [235]. Both the snapshot model and the sliding window model do not reflect certain important aspects of the changing re- ality. The former takes into account all relationships equally, without distinguishing between the older and more re- cent ones. The latter enables omitting old relationships but does it abruptly, without considering the fact that certain connections may become less relevant in time but still be present. To alleviate these issues, the edge decay model was proposed [235]. In this model, each edge e (with a timestamp t(e) ≤ t) has an independent probability Pf (e) of being included in an analysis. Pf (e) = f(t − t(e)) is a non- decreasing decay function that determines how fast edges age. The authors of the edge decay model set f to be decreasing exponentially, with the resulting model being called the probabilistic edge decay model. 4.3 Architecture of Dynamic Graph Representation Another core aspect of a streaming framework is the used representation of the maintained graph. 4.3.1 Used Fundamental Graph Representations While the details of how each system maintains the graph dataset usually vary, the used representations can be grouped into a small set of fundamental types. Some frame- works use one of the basic graph representations (AL, EL, CSR, or AM) which are described in Section 2. No systems that we analyzed uses an uncompressed AM as it is inefficient with O(n2 ) space, especially for sparse graphs. Systems that use AM, for example GraphIn, focus on compression of the adjacency matrix [35], trying to mitigate storage and query overheads. Other graph representations are based on trees, where there is some additional hierarchical data structure imposed on the otherwise flat connectivity data; this hierarchical information is used to accelerate dynamic queries. Finally, frameworks constructed on top of more 4 This approach is sometimes referred to as the “snapshot” model. Here, the word “snapshot” means “a complete view of the graph, with all its updates”. This naming is somewhat confusing, as “snapshot” can also mean “a specific copy of the graph generated for concurrent processing of updates and queries”, cf. § 4.1. general infrastructure use a representation provided by the underlying system. We also consider whether a framework supports data distribution over multiple serves. Any of the above rep- resentations can be developed for either a single server or for a distributed-memory setting. Details of such distributed designs are system-specific. 4.3.2 Blocking Within and Across Neighborhoods In the taxonomy, we distinguish a common design choice in systems based on CSR or its variants. Specifically, one can combine the key design principles of AL and CSR by dividing each neighborhood into contiguous blocks (also referred to as chunks) that are larger than a single vertex ID (as in a basic AL) but smaller than a whole neighborhood (as in a basic CSR). This offers a tradeoff between flexible mod- ifications in AL and more locality (and thus more efficient neighborhood traversals) in CSR [193]. Now, this blocking scheme is applied within each single neighborhood. We also distinguish a variant where multiple neighborhoods are grouped inside one block. We will refer to this scheme as blocking across neighborhoods. An additional optimization in the blocking scheme is to pre-allocate some reserved space at the end of each such contiguous block, to offer some number of fast edge insertions that do not require block reallocation. All these schemes are pictured in Figure 1. 4.3.3 Supported Types of Vertex and Edge Data Contrarily to graph databases that heavily use rich graph models such as the Labeled Property Graph [16], graph streaming frameworks usually offer simple data models, focusing on the graph structure and not on rich data attached to vertices or edges. Still, different frameworks support basic additional vertex or edge data, most often weights. Next, in certain systems, both an edge and a vertex can have a type or an attached property. Finally, an edge can also have a timestamp that indicates the time of inserting this edge into the graph. A timestamp can also indicate a modification (e.g., an update of a weight of an existing edge). Details of such rich data are specific to each framework. 4.3.4 Indexing Structures One uses indexing structures to accelerate different queries. In our taxonomy, we distinguish indices that speed up queries related to the graph structure, rich data (i.e., vertex or edge properties or labels), and historic (temporal) aspects (e.g., indices for edge timestamps). 4.4 Architecture of Incremental Changes A streaming framework may support an approach called “incremental changes” for faster convergence of graph algo- rithms. Assume that a certain graph algorithm is executed and produces some results, for example page ranks of each vertex. Now, the key observation behind the incremental changes is that the subsequent graph updates may not necessarily result in large changes to the derived page rank values. Thus, instead of recomputing the ranks from scratch, one can attempt to minimize the scope of recomputation, resulting in “incremental” changes to the ranking results. In our taxonomy, we will distinguish between supporting incremental changes in the post-compute mode and in the live mode. In the former, an algorithm first finishes,](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-7-2048.jpg)
![8 then some graph mutations are applied, and afterwards the system may apply incremental changes to update the results of the algorithm. In the latter, both the mutations and the incremental changes may be applied during the execution of the algorithm, to update its outcomes as soon as possible. 4.5 Supported Programming API The final part of our taxonomy is the supported program- ming API. We identify two key classes of such APIs. First, a framework may offer a selection of functions for modifying the maintained graph; such API may consist of simple basic functions (e.g., insert an edge) or complex ones (e.g., merge two graphs). Here, we additionally identify APIs for triggered events taking place upon specific updates, and for accessing and manipulating the logged graph updates (that await being ingested into the graph representation). The second key API that a framework may support consists of functions for running graph computations on top of the maintained graph. Here, we identify specific APIs for controlling graph algorithms (e.g., PageRank) processing the main (i.e., “live”) graph snapshot, or for controlling such computations running on top of past snapshots. Moreover, our taxonomy includes an API for incremental processing of the outcomes of graph algorithms (cf. § 4.4). 4.6 General Architectural Features of Frameworks The general features are the location of the maintained graph data (e.g., main memory or GPU memory), whether it is distributed, what is the targeted hardware architecture (general CPUs or GPUs), and whether a system is general- purpose or is it developed specifically for graph analytics. 5 ANALYSIS OF FRAMEWORKS We now analyze existing frameworks using our taxonomy (cf. Section 4) in Tables 2 – 3, and in the following text. We also describe selected frameworks in more detail. We use symbols “–”, “˜”, and “é” to indicate that a given system offers a given feature, offers a given feature in a limited way, and does not offer a given feature, respectively5 . “?” indicates we were unable to infer this information based on the available documentation. 5.1 Analysis of Designs for Ingesting Updates We start with analyzing the method for achieving concur- rency between updates and queries. Note that, with queries, we mean both local (fine) reads (e.g., fetching a weight of a given edge), but also global analytics (e.g., running PageRank) that also do not modify the graph structure. First, most frameworks use snapshots. We observe that such frameworks have also some other snapshot-related design feature, for example Grace (uses snapshots also to implement transactions), GraphTau and Tegra (both support storing past snapshots), or DeltaGraph (harnesses Haskell’s feature to create snapshots). Second, a large group of frame- works use logging and fine-grained synchronization. In the latter case, the interleaving of updates and read queries is supported only with respect to fine reads (i.e., parallel 5 We encourage participation in this survey. In case the reader possesses additional information relevant for the tables, the authors would welcome the input. We also encourage the reader to send us any other information that they deem important, e.g., details of systems not mentioned in the current survey version. ingestion of updates while running global analytics such as PageRank are not supported in the considered systems). Furthermore, two interesting methods for efficient con- current ingestion of updates and queries have recently been proposed in the RisGraph system [86] and by Sha et al. [202]. The former uses scheduling of updates, i.e., the system uses fine-grained synchronization enhanced with a specialized scheduler that manipulates the ordering and timing of applying incoming updates to maximize through- put and minimize latency (different timings of applying updates may result in different performance penalties). In the latter, one overlaps the ingestion of updates with trans- ferring the information about queries (e.g., over PCIe). We observe that, while almost all systems use batching, only a few sort batches; the sorting overhead often exceeds benefits from faster ingestion. Next, only five frameworks support transactions, and four in total offer the ACID se- mantics of transactions. This illustrates that performance and high ingestion ratios are prioritized in the design of streaming frameworks over overall system robustness. Some frameworks that support ACID transactions rely with this respect on some underlying data store infrastructure: Sinfonia (for Concerto) and CouchDB (for the system by Mondal et al.). Others (Grace and LiveGraph) provide their own implementations of ACID. 5.2 Analysis of Support for Keeping Historical Data Our analysis shows that reasonably many systems (11) support keeping past data in some way. Yet, only a few offer more than simply keeping past updates with timestamps. Specifically, Kineograph, CelliQ, GraphTau, a system by Sha et al., and Tegra, fully support keeping past graph snapshots, as well as the sliding window model and vari- ous optimizations, such as maintaining indexing structures over historical data to accelerate fetching respective past instances. We discover that Tegra has a particularly rich set of features for analyzing historical data efficiently, ap- proaching in its scope offline temporal frameworks such as Chronos [112]. Another system with a rich set of such fea- tures is Kineograph, the only one to support the exponential decay model of the visibility of past updates. 5.3 Analysis of Graph Representations Most frameworks use some form of CSR. In certain cases, CSR is combined with an EL to form a dual representation; EL is often (but not exclusively) used in such cases as a log to store the incoming edges, for example in GraphOne. Certain other frameworks use AL, prioritizing the flexibility of graph updates over locality of accesses. Most frameworks based on CSR use blocking within neighborhoods (i.e., each neighborhood consists of a linked list of contiguous blocks (chunks)). This enables a tradeoff between the locality of accesses and time to perform up- dates. The smaller the chunks are, the easier is to update a graph, but simultaneously traversing vertex neighborhoods requires more random memory accesses. Larger chunks improve locality of traversals, but require more time to update the graph structure. Two frameworks (Concerto and Hornet) use blocking across neighborhoods. This may help in achieving more locality whenever processing many small neighborhoods that fit in a block.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-8-2048.jpg)
![9 Reference D? Data location Arch. Con? B? sB? T? acid? P? L? S? D? Edge updates Vertex updates Remarks STINGER [79] é Main mem. CPU é – – é é ˜ (τ) – é é – (A/R) ˜∗ (A/R) ∗ Removal is unclear UNICORN [216] – Main mem. CPU é – é é é é – é é – (A/R) – (A/R) Extends IBM InfoSphere Streams [45] DISTINGER [85] – Main mem. CPU é – é é é é – é é – (A/R) – (A/R) Extends STINGER [79] cuSTINGER [103] é GPU mem. GPU∗ é – é é é é – é é – (A/R) – (A/R) Extends STINGER [79]. ∗ Single GPU. EvoGraph [200] é Main mem. GPU∗ é – é é é ˜ – é é – (A/R) – (A/R) Supports multi-tenancy to share GPU resources. ∗ Single GPU. Hornet [49] é GPU, main mem. GPU† é∗ – – é é é – é é – (A/R/U) – (A/R/U) ∗ Not mentioned. † Single GPU GraPU [204], [205] – Main mem., disk CPU é – é∗ é é é – é é – (A/R) é ∗ Batches are processed with non-straightforward schemes Grace [189] é Main mem. CPU – (s) – ? – – ˜† – é é – (A/R/U) – (A/R) † To implement transactions Kineograph [56] – Main mem. CPU – (s) – é – é – – – – – (A/U∗ ) – (A/U∗ ) ∗ Custom update functions are possible LLAMA [159] é Main mem., disk CPU – (s) – – é é – (∆) – é é – (A/R) – (A/R) — CellIQ [120] – Disk (HDFS) CPU – (s) ˜∗ é é é – – – é – (A/R) – (A/R) Extends GraphX [101] and Spark [237]. ∗ No details. GraphTau [122] – Main mem., disk CPU – (s)∗ – é é é – (∆) – – é – (A/R) – (A/R) Extends Spark. ∗ Offers more than simple snapshots. DeltaGraph [69] é Main mem. CPU – (s)∗ é é é é é – é é – (A/R) – (A/R) ∗ Relies on Haskell’s features to create snapshots GraphIn [201] é∗ Main mem. CPU ˜ (s) – é é é é† – é é ˜∗ (A/R) ˜∗ (A/R) ∗ Details are unclear. † Only mentioned Aspen [71] é Main mem., disk CPU – (s)∗ ? ? é é é – é é – (A/R) – (A/R) ∗ Focus on lightweight snapshots; enables serializability Tegra [121] – Main mem., disk CPU – (s) ? ? é é – (∆) ˜∗ – ? – (A/R) – (A/R) Extends Spark. ∗ Live updates are considered but outside core focus. GraphInc [51] – Main mem., disk CPU – (l)∗ ? ? é é é – é é – (A/R/U) – (A/R/U) Extends Apache Giraph [1]. ∗ Keeps separate storage for the graph structure and for Pregel computations, but no details are provided. ZipG [139] – Main mem. CPU – (l) ? ? é é ˜ (τ) – é é – (A/R/U) – (A/R/U) Extends Spark Succinct [5] GraphOne [147] é Main mem. CPU – (l) – – é é ˜ – é é – (A/R) – (A/R) Updates of weights are possible LiveGraph [243] é Main mem., disk CPU – (l) é na – – é – é é – (A/R/U) – (A/R/U) — Concerto [151] – Main mem. CPU – (f)∗ – é – – é – é é ˜ (A/U) ˜ (A/U) ∗ A two-phase commit protocol based on fine-grained atomics aimGraph [230] é GPU mem. GPU∗ ˜ (f)† – ? é é é – é é – (A/R) é ∗ Single GPU. † Only fine reads/updates are considered. faimGraph [231] é GPU, main mem. GPU∗ ˜ (f)† – – é é é – é é – (A/R) – (A/R) ∗ Single GPU. † Only fine reads/updates, using locks/atomics. GraphBolt [162] é Main mem. CPU ˜ (f)∗ – – é é é – é é – (A/R) – (A/R) Uses Ligra [209]. ∗ Fine edge updates are supported. RisGraph [86] é Main mem. CPU – (sc)∗ –† ? é é – – é é – (A/R) ˜ (A/R) ∗ Details in § 5.1. GPMA (Sha [202]) ˜∗ GPU mem. GPU∗ ˜ (o)† – ? é é é – – é – (A/R) é ∗ Multiple GPUs within one server. † Details in § 5.1. KickStarter [227]∗ – Main mem. CPU na∗ – na∗ na∗ na∗ na∗ – na∗ na∗ – (A/R) ? Uses ASPIRE [226]. ∗ It is a technique, not a full system. Mondal et al. [174] – Main mem.∗ CPU ˜† ?† ?† – – é – ?† ?† ˜† (A) ˜† (A) ∗ Uses CouchDB as backend [14], † Unclear (relies on CouchDB) iGraph [126] – Main mem. CPU ? – é é é é – é é ˜ (A/U) ˜ (A/U) Extends Spark Sprouter [2] – Main mem., disk CPU ? ? é é é é – é é ˜ (A) ? Extends Spark TABLE 2: Comparison of selected representative works. They are grouped by the method of achieving concurrency between queries and updates (mutations). Within each group, the systems are sorted by publication date. “D?” (distributed): does a design target distributed environments such as clusters, supercomputers, or data centers? “Data location”: the location of storing the processed dataset (“Main mem.”: main memory; a system is primarily in-memory). “Arch.”: targeted architecture. “Con?” (a method of achieving concurrent updates and queries): does a design support updates (e.g., edge insertions and removals) proceeding concurrently with queries that access the graph structure (e.g., edge lookups or PageRank computation). Whenever supported, we detail the method used for maintaining this concurrency: (s): snapshots, (l): logging, (f): fine-grained synchronization, (sc): scheduling, (o): overlap. “B?” (batches): are updates batched? “sB?” (sorted batches): can batches of updates be sorted for more performance? “T?” (transactions): are transactions supported? “acid?”: are ACID transaction properties offered? “P”: Does the system enable storing past graph snapshots? “(∆)”: Snapshots are stored using some “delta scheme”. “(τ)”: snapshots can be inferred from maintained timestamps. “L?” (live): are live updates supported (i.e., does a system maintain a graph snapshot that is “up-to-date”: it continually ingests incoming updates)? “S?” (sliding): does a system support the Sliding Window Model for accessing past updates? “D?” (decay): does a system support the Decay Model for accessing past updates? “Vertex / edge updates”: support for inserting and/or removing edges and/or vertices; “A”: add, “R”: remove, “U”: update. “–”: Support. “˜”: Partial / limited support. “é”: No support. “?”: Unknown. A few systems use graph representations based on trees. For example, Sha et al. [202] use a variant of packed memory array (PMA), which is an array with all neighborhoods (i.e., essentially a CSR) augmented with an implicit binary tree structure that enables edge insertions and deletions in O(log2 n) time. Frameworks constructed on top of a more general in- frastructure use a representation provided by the under- lying system. For example, GraphTau [122], built on top of Apache Spark [238], uses the underlying data structure called Resilient Distributed Datasets (RDDs) [238]. Other frameworks from this category use data representations that are harnessed by general processing systems or databases, for example KV stores, tables, or general collections. All considered frameworks use some form of indexing. However, the indexes mostly keep the locations of vertex neighborhoods. Such an index is usually a simple array of size n, with cell i storing a pointer to the neighborhood Ni; this is a standard design for frameworks based on CSR. Whenever CSR is combined with blocking, a correspond- ing framework also offers the indexing of blocks used for storing neighborhoods contiguously. For example, this is the case for faimGraph and LiveGraph. Frameworks based on more complex underlying infrastructure benefit from indexing structures offered by the underlying system. For example, Concerto uses hash indexing offered by MySQL, and CellIQ and others can use structures offered by Spark. Finally, relatively few frameworks apply indexing of addi- tional rich vertex or edge data, such as properties or labels. This is due to the fact that streaming frameworks, unlike graph databases, place more focus on the graph structure and much less on rich attached data. For example, STINGER indexes edges and vertices with given labels.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-9-2048.jpg)
![10 Reference Rich edge data Rich vertex data Tested analytics workloads Fundamental representation iB? aB? Id? Ic? IL?PrM? PrC? Remarks STINGER [79] – (T, W, TS) – (T) CL, BC, BFS, CC, k-core CSR – é – (a, d)é é – (sm) é Grace [189] ˜ (W) é PR, CC, SSSP, BFS, DFS CSR ˜∗ é – (a) é é – (sm) é ∗ Due to partitioning of neighborhoods. Concerto [151] – (P) – (P) k-hop, k-core CSR ? – – é é – (sm, tr∗ )– (sa, i)∗ ∗ Graph views and event-driven processing LLAMA [159] – (P) – (P) PR, BFS, TC CSR∗ – é – (a, t) é é – (sm) é ∗ multiversioned DISTINGER [85] – (T, W, TS) – (T, W) PR CSR – é – (a, d)é é – (sm) é — cuSTINGER [103] ˜∗ (W, P, TS)˜∗ (W, P)TC CSR é é – (a, d)é é – (sm) é ∗ No details aimGraph [230] ˜∗ (W) ˜∗ (W) — CSR∗ – é – (a) é é – (sm) é ∗ Resembles CSR. Hornet [49] ˜ (W) é BFS, SpMV, k-Truss CSR é – – (a) é é – (sm) é — faimGraph [231] – (W, P) – (W, P) PR, TC CSR∗ – é – (a) é é – (sm) é ∗ Resembles CSR LiveGraph [243] – (T, P) – (P) PR, CC CSR – (g) é – (a) é é – (sm)∗ é ∗ Primarily a data store GraphBolt [162] – (W) é PR, BP, LP, CoEM, CF, TCCSR – é – (a) – (m)– – (sm) – (sa∗ , i) ∗ Relies on BSP and Ligra’s mappings GraphIn [201] é ˜ (P) BFS, CC, CL CSR + EL é é ? – é – (sm) – (sa, i)† † Relies on GAS. EvoGraph [200] é é TC, CC, BFS CSR + EL é é ? – é – (sm) – (sa, i) — GraphOne [147] ˜ (W) é BFS, PR, 1-Hop-query CSR + EL – é – (a, t) é é – (sm, ss) – (sa, p) — GraPU [204], [205] ˜ (W) é BFS, SSSP, SSWP AL∗ é é – (a) – (m)˜ – (sm) – (sa, i, sai)∗ Relies on GoFS RisGraph [86] – (W) é CC, BFS, SSSP, SSWP AL ? ? – (a) – é – (sm) – (sa, p) — Kineograph [56] é é TR, SSSP, k-exposure KV store + AL∗ ? é – (a) – é – (sm) ˜ (sa)† ∗ Details are unclear. † Uses vertex-centric Mondal et al. [174]é é — KV store + documents∗ é é – (a) é é – (sm)∗ ?∗ ∗ Relies on CouchDB CellIQ [120] – (P) – (P) Cellular specific Collections (series)∗ é é – (a, d)– é – (sm) – (sa, i)† ∗ Based on RDDs. † Focus on geopartitioning. iGraph [126] ? é PR RDDs é é – – é – (sm) – (sa, i)∗ ∗ Relies on vertex-centric BSP GraphTau [122] é é PR, CC RDDs (series) é é ? –∗ – – (sm) – (sa, i, p)† ∗ Unclear. † Relies on BSP and vertex-centric. ZipG [139] – (T, P, TS) – (P) TAO LinkBench Compressed flat files é é – (a) é é – (sm) é — Sprouter [2] ? ? PR Tables∗ é é ? é é – (sm) é ∗ Relies on HGraphDB DeltaGraph [69] é é — Inductive graphs∗ é é é é é – (sm, am)– (sa)† ∗ Specific to functional languages [69]. † Mappings of vertices/edges GPMA (Sha [202]) ˜ (TS) é PR, BFS, CC Tree-based (PMA) ˜ (g)∗ é – (a) é é – (sm) é ∗ A single contiguous array with gaps in it Aspen [71] é é∗ BFS, BC, MIS, 2-hop, CL Tree-based (C-Trees) – é – (a) é é – (sm) ˜ (sa)∗ ∗ Relies on Ligra Tegra [121] – (P) – (P) PR, CC Tree-based (PART [65]) –∗ é – (a) – é – (sm) – (sa† , i, p)∗ For properties. † Relies on GAS GraphInc [51] – (P) – (P) SSSP, CC, PR ?∗ é é ˜ (a) – é – (sm) ˜ (sa)∗ ∗ Relies on Giraph’s structures and model UNICORN [216] é é PR, RW ?∗ é é ? – é – (sm) – (sa, i) ∗ Uses InfoSphere KickStarter [227] ˜ (W) é SSWP, CC, SSSP, BFS na∗ na∗ na∗ na∗ – (m)é – (sm) na∗ ∗ Kickstarter is a technique, not a system TABLE 3: Comparison of selected representative works. They are grouped by the used fundamental graph representation (within each group, by publication date). “Rich edge/vertex data”: enabling additional data to be attached to an edge or a vertex (“T”: type, “P”: property, “W”: weight, “TS”: timestamp). “Tested analytics workloads”: evaluated workloads beyond simple queries (PR: PageRank, TR: TunkRank, CL: clustering, BC: Betweenness Centrality, CC: Connected Components, BFS: Breadth-First Search, SSSP: Single Source Shortest Paths, DFS: Depth-First Search, TC: Triangle Counting, SpMV: Sparse matrix-vector multiplication, BP: Belief Propagation, LP: Label Propagation, CoEM: Co-Training Expectation Maximization, CF: Collaborative Filtering, SSWP: Single Source Widest Path, TAO LinkBench: workloads used in Facebook’s TAO and in LinkBench [19], MIS: Maximum Independent Set), RW: Random Walk. “Fundamental Representation”: A key representation used to store the graph structure; all representation are explained in Section 4. “iB”: Is blocking used to increase the locality of edges within the representation of a single neighborhood? “(g)”: one uses empty gaps at the ends of blocks, to provide pre-allocated empty storage for faster edge insertions. “aB”: Is blocking used to increase the locality of edges across different neighborhoods (i.e., can one store different neighborhoods within one block)? “Id”: Is indexing used? “(a)”: Indexing of the graph adjacency data, “(d)”: Indexing of rich edge/vertex data, “(t)”: Indexing of different graph snapshots, in the time dimension? “Ic”: Are incremental changes supported? “(m)”: Explicit support for monotonic algorithms in the context of incremental changes. “IL”: Does the system support live (on-the-fly) incremental changes? “PrM”: Does the system offer a dedicated programming model (or API) related to graph modifications? “(sm)”: API for simple graph modifications. “(am)”: API for advanced graph modifications. “(tr)”: API for triggered reactions to graph modifications. “(ss)”: API for manipulating with the updates awaiting being ingested (e.g., stored in the log). “PrC”: Does the system offer a dedicated programming model (or API) related to graph computations (i.e., analytics running on top of the graph being modified)? “(sa)”: API for graph algorithms / analytics (e.g., PageRank) processing the main (i.e., up- to-date) graph snapshot. “(p)”: API for graph algorithms / analytics (e.g., PageRank) processing the past graph snapshots. “(i)”: API for incremental processing of graph algorithms / analytics. “(sai)” (i.e., (sa) + (i)): API for graph algorithms / analytics processing the incremental changes themselves. “–”, “˜”, “é”: A design offers a given feature, offers it in a limited way, and does not offer it, respectively. “?”: Unknown.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-10-2048.jpg)
![11 5.4 Analysis of Support for Incremental Changes Around half of the considered frameworks support incre- mental changes to accelerate global graph analytics running on top of the maintained graph datasets. Frameworks that do not support them (e.g., faimGraph) usually put less focus on global analytics in the streaming setting. While the details for achieving incremental changes vary across systems, they all first identify which graph parts require re- computation. For example, GraphIn and EvoGraph make the developer responsible for implementing a dedicated func- tion that detects inconsistent vertices, i.e., vertices that became affected by graph updates. This function takes as arguments a batch of incoming updates and the vertex property related to the graph problem being solved (e.g., a parent in the BFS traversal problem). Whenever any update in the batch affects a specified property of some vertex, this vertex is marked as inconsistent, and is scheduled for recomputation. GraphBolt and KickStarter both carefully track dependen- cies between vertex values (that are being computed) and edge modifications. The difference between these two lies in how they minimize the amount of needed recomputation. For this, GraphBolt assumes the Bulk Synchronous Parallel (BSP) [222] computation model while KickStarter uses the fact that in many graph algorithms, the vertex value is simply selected from one single incoming edge. Unlike some other systems (e.g., Kineograph), GraphBolt and KickStarter enable performance gains also in the event of edge dele- tions, not only insertions. Similarly to GraphBolt, GraphInc also targets iterative algorithms; it uses a technique called memoization to reduce the amount of recomputation. Specif- ically, it maintains the state of all computations performed, and uses this state whenever possible to quickly deliver results if a graph changes. RisGraph applies KickStarter’s approach for incremental computation to its design based on concurrent ingestion of fine-grained updates and queries. Finally, Tegra, GraphTau, GraPU, CellIQ, and Kineograph implement incremental computation using the underlying infrastructure and its capability to maintain past graph snapshots. They derive differences between consecutive snapshots, and use these differences to identify parts of a graph that must be recomputed. We discover that GraphTau and GraphBolt employ “live” incremental changes, i.e., they are able to identify opportunities for reusing the results of a graph algorithm even before it finishes running. This is done in the context of iterative analytics such as PageRank, where the potential for incremental changes is identified between iterations. The systems that support incremental changes focus on monotonic graph algorithms, i.e., algorithms, where the computed properties (e.g., vertex distances) are consistently either increasing or decreasing. 5.5 Analysis of Offered Programming APIs We first analyze the supported APIs for graph modifica- tions. All considered frameworks support a simple API for manipulating the graph, which includes operations such as adding or removing an edge. However, some frameworks offer more capabilities. Concerto has special functions for programming triggered events, i.e., events taking place automatically upon certain specific graph modifications. DeltaGraph offers unique graph modification capabilities, for example merging graphs. GraphOne comes with a set of interesting functions for accessing and analyzing the updates waiting in the log structure to be ingested. This can be used to apply some form of preprocessing of the updates, or to run some analytics on the updates. We also discuss supported APIs for running global ana- lytics on the maintained graph. First, we observe that a large fraction of frameworks do not support developing graph an- alytics at all. These systems, for example faimGraph, focus completely on graph mutations and local queries. However, other systems do offer an API for graph analytics (e.g., PageRank) processing the main (live) graph snapshot. These systems usually harness some existing programming model, for example Bulk Synchronous Parallel (BSP) [222]. Further- more, frameworks that enable maintaining past snapshots, for example Tegra, also offer APIs for running analytics on such graphs. Finally, systems offering incremental changes also offer the associated APIs. 5.6 Used Programming Model We also discuss in more detail what programming models are used to develop graph analytics. As of now, there are no established programming models for dynamic graph analysis. Most frameworks, for example GraphInc, fall back to a model used for static graph processing (most often the vertex-centric model [127], [161]), and make the dynamic nature of the graph transparent to the developer. Another re- cent example is GraphBolt that offers the Bulk Synchronous Parallel (BSP) [222] programming model and combines it with incremental updates to be able to solve certain graph problems on dynamic graphs. Some engines, however, extend an existing model for static graph processing. For example, GraphIn extends the gather-apply-scatter (GAS) paradigm [156] to enable react- ing to incremental updates. Specifically, the key part of this Incremental Gather Apply Scatter (I-GAS) is an API that enables the user to specify how to construct the inconsistency graph i.e., a part of the processed graph that must be recom- puted in order to appropriately update the desired results (for a specific graph problem such as BFS or PageRank). For this, the user implements a designated method that takes as input the batch of next graph updates, and uses this information to construct a list of vertices and/or edges, for which a given property (e.g., the rank) must be recomputed. This also includes a user-defined function that acts as a heuristic to check if a static full recomputation is cheaper in expectation than an incremental pass. It is the users responsibility to ensure that correctness is guaranteed in this model, for example by conservatively marking vertices inconsistent. Graph updates can consist of both inserts and removals. They are applied in batches and exposed to the user automatically by a list of inconsistent vertices for which properties (e.g., vertex degree) have been changed by the update. Therefore, queries are always computed on the most recent graph state. 5.7 Supported Types of Graph Updates Different systems support different forms of graph updates. The most widespread update is edge insertion, offered by all the considered systems. Second, edge deletions are supported by most frameworks. Finally, a system can also](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-11-2048.jpg)
![12 explicitly enable adding or removing a specified vertex. In the latter, a given vertex is removed with its adjacent edges. 5.8 Analysis of Relations to Theoretical Models First, despite the similarity of names, the (theoretical) field of streaming graph algorithms is not well connected to graph streaming frameworks: the focus of the former are fast algorithms operating with tight memory constraints that by assumption prevent from keeping the whole graph in mem- ory, which is not often the case for the latter. Similarly, graph sketching focuses on approximate algorithms in a streaming setting, which is of little interest to streaming frameworks. On the other hand, the (theoretical) settings of dynamic graph algorithms and parallel dynamic graph algorithms are similar to that of the streaming frameworks. Their common assumption is that the whole maintained graph is available for queries (in-memory), which is also common for the streaming frameworks. Moreover, the batch dynamic model is even closer, as it explicitly assumes that edge updates arrive in batches, which reflects a common optimization in the streaming frameworks. We conclude that future de- velopments in streaming frameworks could benefit from deepened understanding of the above mentioned theoretical areas. For example, one could use the recent parallel batch dynamic graph connectivity algorithm [3] in the imple- mentation of any streaming framework, for more efficient connected components problem solution. 6 DISCUSSION OF SELECTED FRAMEWORKS We now provide general descriptions about selected frame- works, for readers interested in some specific systems. 6.1 STINGER [79] And Its Variants STINGER [79] is a data structure and a corresponding software package. It adapts and extends the CSR format to support graph updates. Contrarily to the static CSR design, where IDs of the neighbors of a given vertex are stored contiguously, neighbor IDs in STINGER are divided into contiguous blocks of a pre-selected size. These blocks form a linked list, i.e., STINGER uses the blocking design. The block size is identical for all the blocks except for the last blocks in each list. One neighbor vertex ID u in the neighborhood of a vertex v corresponds to one edge (v, u). STINGER supports both vertices and edges with different types. One vertex can have adjacent edges of different types. One block always contains edges of one type only. Besides the associated neighbor vertex ID and type, each edge has its weight and two time stamps. The time stamps can be used in algorithms to filter edges, for example based on the insertion time. In addition to this, each edge block contains certain metadata, for example lowest and highest time stamps in a given block. Moreover, STINGER provides the edge type array (ETA) index data structure. ETA contains pointers to all blocks with edges of a given type to accelerate algorithms that operate on specific edge types. To increase parallelism, STINGER updates a graph in batches. For graphs that are not scale-free, a batch of around 100,000 updates is first sorted so that updates to different vertices are grouped. In the process, deletions may be sepa- rated from insertions (they can also be processed in parallel with insertions). For scale-free graphs, there is no sorting phase since a small number of vertices will face many updates which leads to workload imbalance. Instead, each update is processed in parallel. Fine locking on single edges is used for synchronization of updates to the neighborhood of the same vertex. To insert an edge or to verify if an edge exists, one traverses a selected list of blocks, taking O(d) time. Consequently, inserting an edge into Nv takes O(dv) work and depth. STINGER is optimized for the Cray XMT supercomputing systems that allow for massive thread- level parallelism. Still, it can also be executed on general multi-core commodity servers. Contrarily to other works, STINGER and its variants does not provide a framework but a library to operate on the data structure. Therefore, the user is in full control, for example to determine when updates are applied and what programming model is used. DISTINGER [85] is a distributed version of STINGER that targets “shared-nothing” commodity clusters. DISTINGER inherits the STINGER design, with the following modifica- tions. First, a designated master process is used to interact between the DISTINGER instance and the outside world. The master process maps external (application-level) vertex IDs to the internal IDs used by DISTINGER. The master process maintains a list of slave processes and it assigns incoming queries and updates to slaves that maintain the associated part of the processed graph. Each slave maintains and is responsible for updating a portion of the vertices together with edges attached to each of these vertices. The graph is partitioned with a simple hash-based scheme. The inter-process communication uses MPI [97], [104] with es- tablished optimizations such as message batching or overlap of computation and communication. cuSTINGER [103] extends STINGER for CUDA GPUs. The main design change is to replace lists of edge blocks with contiguous adjacency arrays, i.e. a single adjacency array for each vertex. Moreover, contrarily to STINGER, cuSTINGER always separately processes updates and deletions, to better utilize massive parallelism in GPUs. cuSTINGER offers several “meta-data modes”: based on the user’s needs, the framework can support only unweighted edges, weighted edges without any additional associated data, or edges with weights, types, and additional data such as time stamps. However, the paper focuses on unweighted graphs that do not use time stamps and types, and the exact GPU design of the last two modes is unclear [103]. 6.2 Work by Mondal et al. [174] A system by Mondal et al. [174] focuses on data replica- tion, graph partitioning, and load balancing. As such, the system is distributed: on each compute node, a replication manager decides locally (based on analyzing graph queries) what vertex is replicated and what compute nodes store its copies. The main contribution is the definition of a fairness criterion which denotes that at least a certain configurable fraction of neighboring vertices must be replicated on some compute node. This approach reduces pressure on network bandwidth and improves latency for queries that need to fetch neighborhoods (common in social network analysis). The framework stores the data on Apache CouchDB [17], an in-memory key-value store. No detailed information how the data is represented is given.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-12-2048.jpg)
![13 6.3 LLAMA [159] LLAMA [159] (Linked-node analytics using LArge Multiversioned Arrays) – similarly to STINGER – digests graph updates in batches. It differs from STINGER in that each such batch generates a new snapshot of graph data using a copy-on-write approach. Specifically, the graph in LLAMA is represented using a variant of CSR that relies on large multiversioned arrays. Contrarily to CSR, the array that maps vertices to per-vertex structures is divided into smaller parts, so called data pages. Each part can belong to a different snapshot and contains pointers to the single edge array that stores graph edges. To create a new snapshot, new data pages and a new edge array are allocated that hold the delta that represents the update. This design points to older snapshots and thus shares some data pages and parts of the edge array among all snapshots, enabling lightweight updates. For example, if there is a batch with edge insertions into the neighborhood of vertex v, this batch may become a part of v’s adjacency list within a new snapshot, but only represents the update and relies on the old graph data. Contiguous allocations are used for all data structures to improve allocation and access time. LLAMA also focuses on out-of-memory graph process- ing. For this, snapshots can be persisted on disk and mapped to memory using mmap. The system is implemented as a library, such that users are responsible to ingest graph updates and can use a programming model of their choice. LLAMA does not impose any specific programming model. Instead, if offers a simple API to iterate over the neighbors of a given vertex v (most recent ones, or the ones belonging to a given snapshot). 6.4 GraphIn [201] GraphIn [201] uses a hybrid dynamic data structure. First, it uses an AM (in the CSR format) to store the adjacency data. This part is static and is not modified when updates arrive. Second, incremental graph updates are stored in dedicated edge lists. Every now and then, the AM with graph structure and the edge lists with updates are merged to update the structure of AM. Such a design maximizes performance and the amount of used parallelism when accessing the graph structure that is mostly stored in the CSR format. 6.5 GraphTau [122] GraphTau [122] is a framework based on Apache Spark and its data model called resilient distributed datasets (RDD) [238]. RDDs are read-only, immutable, partitioned collections of data sets that can be modified by different operators (e.g., map, reduce, filter, and join). Similarly to GraphX [101], GraphTau exploits RDDs and stores a graph snapshot (called a GraphStream) using two RDDs: an RDD for storing vertices and edges. Due to the snapshots, the framework offers fault tolerance by replaying the processing of respective data streams. Different operations allow to re- ceive data form multiple sources (including graph databases such as Neo4j and Titan) and to include unstructured and tabular data (e.g., from RDBMS). To maximize parallelism when ingesting updates, it applies the snapshot scheme: graph workloads run concurrently with graph updates us- ing different snapshots. GraphTau only enables using the window sliding model. It provides options to write custom iterative and window algorithms by defining a directed acyclic graph (DAG) of operations. The underlying Apache Spark framework analyzes the DAG and processes the data in parallel on a compute cluster. For example, it is possible to write a function that explicitly handles sub-graphs that are not part of the graph any more due to the shift of the sliding window. The work focuses on iterative algorithms and stops the next iteration when an update arrives even when the algorithm has not converged yet. This is not an issue since the implemented algorithms (PageRank and CC) can reuse the previous result and converge on the updated snapshot. In GraphTau, graph updates can consist of both inserts and removals. They are applied in batches and exposed to the program automatically by the new graph snapshot. Therefore, queries are always computed on the most recent graph for the selected window. 6.6 faimGraph [231] faimGraph [231] (fully-dynamic, autonomous, independent management of graphs) is a library for graph processing on a single GPU with focus on fully-dynamic edge and vertex updates (add, remove) - contrarily, some GPU frame- works [202], [230] focus only on edge updates. It allocates a single block of memory on the GPU to prevent memory fragmentation. A memory manager autonomously handles data management without round-trips to the CPU, enabling fast initialization and efficient updates since no intervention from the host is required. Generally, the GPU memory is partitioned into vertex data, edge data and management data structures such as index queues which keep track of free memory. Also, the algorithms that run on the graph operate on this allocated memory. The vertex data and the edge data grow from opposite sides of the memory region to not restrict the amount of vertices and edges. Vertices are stored in dedicated vertex data blocks that can also contain user-defined properties and meta information. For example, vertices store their according host identifier since the host can dynamically create vertices with arbitrary identifiers and vertices are therefore identified on the GPU using their memory offset. To store edges, the library implements a combination of the linked list and adjacency array resulting in pages that form a linked list. This enables the growth and shrink of edge lists and also optimizes memory locality. Further, properties can be stored together with edges. The design does not return free memory to the device, but keeps it allocated as it might be used during graph processing - so the parallel use of the GPU for other processing is limited. In such cases, faimGraph can be reinitialized to claim memory (or expand memory if needed). Updates can be received from the device or from the host. Further, faimGraph relies on a bulk update scheme, where queries cannot be interleaved with updates. However, the library supports exploiting parallelism of the GPU by running updates in parallel. faimGraph mainly presents a new data structure and therefore does not enforce a certain program- ming model.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-13-2048.jpg)
![14 6.7 Hornet [49] Hornet [49] is a data structure and associated system that focuses on efficient batch updates (inserting, deleting, and updating vertices and edges), and more effective mem- ory utilization by requiring no re-allocation and no re- initialization of used data structures during computation. To achieve this, Hornet implements its own memory manager. The graph is maintained using an AL: vertices are stored in an array, with pointers pointing to the associated adjacency list. The lists are (transparently to the user) stored in blocks that can hold edges in counts that are powers of two. The allocation of specific edge lists to specific blocks is resolved by the system. Finally, B+ trees are used to maintain the blocks efficiently and to keep track of empty space. Hornet implements the bulk update scheme in which bulk updates and graph queries alternate. The bulk update exploits parallelism for efficient usage of the GPU resources. No specific programming model is enforced. 6.8 GraphOne [147] GraphOne [147] focuses on the parallel efficient execution of both global graph algorithms (such as PageRank) and stream analytics while supporting high velocity streaming graph updates. To achieve this goal, the graph updates are first appended to an edge list. If this edge list exceeds a certain archiving threshold, the updates are moved as a batch in parallel from the edge list to the adjacency list. Only a small amount of overlapping data must be kept both in the edge list and the adjacency list to ensure no interruption of already running graph algorithms. Similarly to faimGraph [231], the adjacency list consists of chained, cache-aligned blocks to increase locality. Further, high degree vertices store their edges in page-aligned memory to reduce chaining and their memory footprint. This design provides different advantages: First, it exploits the fast edge list for immediate updates and stream processing, and provides snapshots of the adjacency list for long running graph analytics. Second, two ways to access the graph are offered (stream or batch analysis), allowing to select the most suitable way for a given algorithm. Third, multiple snapshots of the adjacency list can be created in a lightweight way, such that queries are processed immediately when they arrive. Since deletes are applied by marking the according edges or vertices to not affect snapshots, a compaction phase removes stale data. The graph data store allows to implement vertex-centric, edge-centric and Sliding Window algorithms - contrarily to other solutions which mostly support only the vertex-centric model. Also, graph updates are written periodically to disk for persistence. Since the data is not persisted immediately, some recent data might get lost in case of an unexpected shutdown, such that a stream broker might be required. 6.9 Aspen [71] The Aspen framework [71] uses a novel data structure called the C-tree to store graph structures. A C-tree is based on a purely-functional compressed search tree. A functional search tree is a search tree data structure that can be expressed only by mathematical functions, which makes the data structure immutable (since a mathematical function must always re- turn the same result for the same input, independently of any state associated with the data structure). Furthermore, functional search trees offer lightweight snapshots, prov- ably efficient running times, and they facilitate concurrent processing of queries and updates. Now, the C-tree extends purely-functional search trees: it overcomes the poor space usage and low locality. Elements represented by the tree are stored in chunks and each chunk is stored contiguously in an array, leading to improved locality. To improve the space usage, chunks can be compressed by applying difference encoding, since each block stores a sorted set of integers. A graph is represented as a tree-of-trees: A purely- functional tree stores the set of vertices (vertex-tree) and each vertex stores the edges in its own C-tree (edge-tree). Additional information is stored in the vertex-tree such that basic graph structural properties, such as the total number of edges and vertices, can be queried in constant time. Similarly, the trees can be augmented to store properties (such as weights), but it is omitted in the described work. For algorithms that operate on the whole graph (such as BFS), it is possible to precompute a flat snapshot: instead of accessing all vertices by querying the vertex-tree, an array is used to directly store the pointers to the vertices. This approach requires an initial overhead, but reduces access time to edges and ultimately decreases runtimes of various algorithms. Similarly to Aspen, Tegra [121] and the work by Sha et al. [202] also use trees to represent the graph. No specific programming model is enforced. The API allows any number of parallel readers and a single writer. No reader or writer is ever blocked and the framework guarantees strict serializability. The update routines allow to both add and remove edges or vertices. They are applied in batches and not exposed to running algorithms. Instead, algorithms run on an immutable snapshot. 6.10 Tegra [121] Tegra [121] enables graph analysis based on graph updates that are a part of any window of time. This implies that Tegra must store the full history of the graph, in contrast to most systems that often store only one state (and the snapshots, on which graph algorithms are running). There- fore, this system faces different challenges: it must be able to share graph data among different windows and share state between parallel running queries. To achieve these goals, Tegra relies on a novel computation model, the Incremental Computation by entity Expansion (ICE) model: Many graph algorithms run iteratively and converge to a solution, al- lowing to reuse certain parts of the previous solution when the graph is updated. Others [51], [200], [201], [206], [216] have already focused on such algorithms, but are often restricted to graph expansion (i.e. no removals are allowed) to guarantee correctness. ICE extends this approach and recomputes graph algorithms on the subgraphs that are affected by the recomputation. Therefore, also removals of vertices and edges can be taken into account. Since the track- ing of state and the following recomputation might lead to high overhead, a cost model is used and the framework switches to full recomputation if needed. To support the ICE model, the core data structure of Tegra is an adaptive radix tree - a tree data structure that enables efficient updates and range scans. It allows to map a graph efficiently by storing it in two trees (a vertex tree and an edge tree) and create lightweight snapshots by generat-](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-14-2048.jpg)
![15 ing a new root node that holds the differences. For scaling, the graph is partitioned (by the hash of the vertex ID) among compute nodes. Users can interface with Tegra by the given API and can manually create new snapshots of the graph. The system can also automatically create snapshots when a certain limit of changes is reached. Therefore, queries and updates (that can be ingested from main memory or graph databases) run concurrently. The framework also stores the changes that happened in-between snapshots, allowing to restore any state and apply computations on any window. Since the snapshots take a lot of memory, they are written to disk using the last recently used policy. The framework is implemented on top of Apache Spark [238] that handles scheduling and work distribution. 6.11 Apache Flink [54] Apache Flink [54] is a general purpose streaming system for streaming and batch computations. These two concepts are usually considered different, but Flink treats them similarly. Two user APIs are available for implementation: the DataSet API for batch processing and the DataStream API for un- bounded stream processing. A variety of custom operators can be implemented, allowing to maintain computation state, define iterative dataflows, compute over a stream win- dow, and implement algorithms from the Bulk Synchronous Parallel model [222]. Both APIs generate programs that are represented as a directed acyclic graph of operators con- nected by data streams. Since operators can keep state and the system makes no assumption over the input streams, it is suited for graph streaming for rich data (edge and vertex properties), and it enables the user to update the graph and execute a broad range of graph algorithms. 6.12 Others Other streaming frameworks come with similar design tradeoffs and features [18], [82], [113], [123], [125], [144], [162], [196], [227], [229], [241]. We now briefly describe examples, providing a starting point for further reading. GraphInc [51] is a framework built on top of Giraph [163] that enables the developer to develop programs using the vertex-centric abstraction, which is then executed by the runtime over dynamic graphs. UNICORN [216] is a system that relies on InfoSphere, a large-scale, distributed data stream processing middleware developed at IBM Research. DeltaGraph [69] is a Haskell library for graph processing, which performs graph updates lazily. iGraph [126] is a system implemented on top of Apache Spark [238] and GraphX [101] that focuses on hash-based vertex-cut par- titioning strategies for dynamic graphs, and proposes to use the vertex-centric programming model for such graphs. However, it is unclear on the details of developing differ- ent graph algorithms with the proposed approach. Evo- Graph [200] is a simple extension of GraphIn. Whenever a batch of updates arrives, EvoGraph decides whether to use an incremental form of updating its structure, similar to that in GraphIn, or whether to recompute the maintained graph stored as an AM. Sprouter [2] is another system built on top of Spark. PAST [74] is a framework for processing spatio- temporal graphs with up to 100 trillion edges that track people, locations, and their connections. It relies on the underlying Cassandra storage [149]. 7 GRAPH DATABASES Streaming graph frameworks, similarly to graph databases, maintain a dynamically changing graph dataset under a series of updates and queries to the graph data. However, there are certain crucial differences that we now discuss. We refer the reader to a recent survey on the latter class of systems [38], which provides details of native graph databases such as Neo4j [193], RDF stores [62], and other types of NoSQL stores used for managing graphs. In the following, we exclude RDF streaming designs as we identify them to be strongly related to the domain of database systems, and point the reader to respective publications for more details [47], [52], [100], [146]. 7.1 Graph Databases vs. Graph Streaming Systems We compare graph databases and graph streaming frame- works mostly according to our taxonomy, but we also touch on other aspects such as key targeted workloads and their characteristics. Targeted Workloads Graph databases have traditionally focused on simple fine graph queries or updates, related to both the graph structure (e.g., verify if two vertices are connected) and the rich attached data (e.g., fetch the value of a given property) [80]. Another important class are “business intelligence” complex queries (e.g., fetch all vertices modeling cars, sorted by production year) [217]. Only recently, there has been interest in augmenting graph databases with capabilities to run global analytics such as PageRank [53]. In contrast, streaming frameworks focus on fine updates and queries, and on global analytics, but not on complex business intelligence queries. These frameworks put more focus on high velocity updates that can be rapidly ingested into the maintained. Next, of key interest are queries into the structure of the adjacency of vertices. This is often in contrast to graph databases, where many queries focus on the rich data attached to edges and vertices. These differences are reflected in all the following design aspects. Ingesting Updates Graph databases can use many different underlying designs (RDBMS style engines, native graph databases, KV stores, document stores, and oth- ers [38]), which means they may use different schemes for ingesting updates. However, a certain general difference between graph streaming frameworks and graph databases is that graph databases often include transactional support with ACID properties [38], [109], while very few streaming frameworks supports transactions and the ACID seman- tics of transactions. The streaming graph updates, even if sometimes they also referred to as transactions [243], are usually “lightweight”: single edge insertions or deletions, rather than arbitrary pattern matching queries common in graph database workloads. Overall, streaming frameworks focus on lightweight methods for fast and scalable ingestion of incoming updates, which includes optimizations such as batching of updates. Graph Models and Representations Graph databases usually deal with complex and rich graph models (such as the Labeled Property Graph [16] or Resource Description Framework [62]) where both vertices and edges may be of different types and may be associated with arbitrary rich properties such as pictures, strings, arrays of integers, or even data blobs. In contrast, graph data models in stream- NSA?](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-15-2048.jpg)
![16 ing frameworks are usually simple, without support for arbitrary attached properties. This reflects the fact that the main focus in streaming frameworks is to investigate the structure of the maintained graph and its changes, and usually not rich attached data. This is also reflected by the associated indexing structures. While graph database systems maintain complex distributed index structures to accelerate different forms of queries over the rich attached data, streaming frameworks use simple index structures, most often only pointers to each vertex neighborhood, and very rarely additional structures pointing to edges/vertices with, e.g., common labels (an example streaming framework with such indexes is STINGER). Data Distribution Another interesting observation is support for data replication and data sharding. These two concepts refer to, respectively, the ability to replicate the maintained graph to more than one server (to accelerate certain read queries), and to partition the same single graph into several servers (to enable storing large graphs fully in-memory and to accelerate different types of accesses). Interestingly, streaming frameworks that enable distributed computation also support the more powerful but also more complex data sharding. Contrarily, while many dis- tributed data stores used as graph databases (e.g., document stores) enable sharding as well, the class of “native” graph databases do not always support sharding. For example, the well-known Neo4j [193] graph databases only recently added support for sharding for some of its queries. Keeping Historical Data We observe that streaming frameworks often offer dedicated support for maintaining historical data, starting from simple forms such as dedicated edge insertion timestamps (e.g., in STINGER), to rich forms such as full historical data in a form of snapshots and dif- ferent optimizations to minimize storage overheads (e.g., in Tegra). In contrast, graph databases most often do not offer such dedicated schemes. However, the generality of the used graph models facilitates maintaining such information at the user level (e.g., the user can use a timestamp label and/or property attached to each vertex or edge). Incremental Changes We do not know of any graph databases that offer explicit dedicated support for incremen- tal changes. However, as most of such systems do not offer open source implementations, confirming this is hard. How- ever, many streaming frameworks offer strong support for incremental changes, both in the form of its architecture and computational model tuned for this purpose, and its offered programming API. This is because incremental changes specifically target accelerating global graph analytics such as PageRank. These analytics have always been of key focus for streaming frameworks, and only recently became a relevant use case for graph databases [53]. Programming APIs and Models Despite a lack of agree- ment on a single language for querying graph databases, all the languages (e.g., SPARQL [186], Gremlin [194], Cypher [93], [117], and SQL [64]) provide rich support for pattern matching queries [80] or business intelligence queries [217]. On the other hand, streaming frameworks do not offer such support. However, they do come with rich APIs for global graph analytics. Summary In summary, graph databases and stream- ing frameworks, despite different shared characteristics, are mostly complementary designs. Graph databases focus on rich data models and complex business intelligence workloads, while streaming frameworks’ central interest are lightweight models and very fast update ingestion rates and global analytics. This can be seen in, for example, the design of the GraphTau framework, which explicitly offers an in- terface to load data for analytics from a graph database. Thus, using both systems together may often help to combine their advantages. Simultaneously, the gap between these two system classes is slowly shrinking, especially from the side of graph databases, where focus on global analytics and more performance can be seen in recent designs [53]. 7.2 Systems Combining Both Areas We describe example systems that provide features related to both graph streaming frameworks and graph databases. Concerto [151] is a distributed in-memory graph store. The system presents features that can be found both in graph streaming frameworks (real-time graph queries and focus on fast, concurrent ingestion of updates) and in graph databases (triggers, ACID properties). It relies on Sinfonia [8], an infrastructure that provides a flat memory region over a set of distributed servers. Further, it offers ACID guarantees by distributed transactions (similar to the two-phase commit protocol) and writing logs to disk. The transactions are only short living for small operations such as reading and writing memory blocks; no transactions are available that consist of multiple updates. The graph data is stored by Sinfonia directly within in-memory objects that make up a data structure similar to an adjacency list. This data structure can also hold arbitrary properties. ZipG [139] is a framework with focus on memory- efficient storage. It builds on Succint [5], a data store that supports random access to compressed unstructured data. ZipG exploits this feature and stores the graph in two files. The vertex file consists of the vertices that form the graph. Each row in the file contains the data related to one vertex, including the vertex properties. The edge file contains the edges stored in the graph. A single record in the edge file holds all edges of a particular type (e.g., a relationship or a comment in a social network) that are incident to a vertex. Further, this record contains all the properties of these edges. To enable fast access to the properties, metadata (e.g., lengths of different records, and offsets to the positions of different records) are also maintained by ZipG files. Succint compresses these files and creates immutable logs that are kept in main memory for fast access. Updates to the graph are stored in a single log store and compressed after a threshold is exceeded, allowing to run updates and queries concurrently. Pointers to the information on updates are managed such that logs do not have to be scanned during a query. Contrary to traditional graph databases, the system does not offer strict consistency or transactions. Finally, LiveGraph [243] targets both transactional graph data management and graph analytics. Similarly to graph databases, it implements the property graph model and sup- ports transactions, and similarly to analytics frameworks, it handles long running tasks that access the whole graph. For high performance, the system focuses on sequential data accesses. Vertices are stored in an array of vertex blocks on which updates are secured by a lock and applied](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-16-2048.jpg)
![17 using copy-on-write. For edges, a novel graph data structure is presented, called transactional edge log. Similar to an adjacency list there is a list of edges per vertex, but the data structure keeps all insertions, deletions and updates as edge log entries appended to the list. The data is stored in blocks, consisting of a header, edge log entries of fixed size and property entries (stored separately from the edge log entries). Each edge log entry stores the incident vertex, a create time and an update time. During a transaction, the reader receives a time stamp and reads only the data for which the create time is smaller than the given time stamp. Also the update time must be considered to omit stale data. Data is read starting from a tail pointer so a reader sees the updates first (no need to scan the old data). Further optimizations are applied, e.g., a Bloom filter allows to check quickly for existing edges. For an update, a writer must acquire a lock of the vertex. New data is appended on the tail of the edge log entries. Since the transaction edge log grows over time, a compression scheme is applied which is non-blocking for readers. The system guarantees persistence by writing data into a log and keeps changes locally until the commit phase, guaranteeing snapshot isolated transactions. 8 PERFORMANCE ANALYSIS We now summarize key insights about performance of the described frameworks. We focus on (1) identifying the fastest frameworks, and on (2) understanding the performance effects of various design choices. Due to space constraints, we refer the reader to respective publications for the details of the evaluation setup. For concreteness, we report specific performance numbers, but the general performance patterns of the analyzed effects are similar for other input datasets and hardware architectures used in respective works. Summary of performance-oriented goals Two main performance goals of the studied frameworks are (1) max- imizing the throughput of ingested updates, usually ex- pressed in millions of inserted (or deleted) edges per second, and (2) accelerating graph analytics running on top of the maintained graph. We observe that, while almost all the frameworks consider goal (1), the ones that also consider (2) are systematically slower than the ones that solely focus on (1). This is because systems focusing on graph analytics often support incremental updates, which often comes with overheads for the raw rate of update ingestion (e.g., due to analyzing on-the-fly the impact of incoming updates on graph analytics outcomes). For example, GraphBolt, the state-of-the-art framework that supports incremental up- dates, offers “up to 1 million edge updates in just few sec- onds” [162]. In contrast, a framework such as Aspen, which does not support incremental updates, delivers nearly 100 million edge updates per second. Frameworks such as As- pen still attempt at minimizing performance penalties when running graph analytics, compared to the running times of static graph processing frameworks, but without considering the costs of recomputation when a graph changes. What is the highest ingestion rate on a CPU? Based on the analysis of related work, we conclude that the fastest frameworks targeting CPUs are Aspen and Gra- phOne [71], [147]. They outperform other frameworks (STINGER, LLAMA) in ingestion rates, while incurring little overheads for graph analytics, compared to static processing systems such as Ligra. Aspen has somewhat higher inges- tion rates over GraphOne (94.5M vs. 66.4M edge updates / second), but the latter also enables data persistence. What is the highest ingestion rate on a GPU? Based on the available data, the fastest graph streaming frame- work targeting GPUs is faimGraph [231]. It outperforms cuSTINGER, Hornet, and GPMA, achieving processing rates of 200M edge updates / second. Incremental Changes Comparison of EvoGraph to STINGER illustrates that using incremental changes in Tri- angle Counting gives a speedup of more than 6× [200]. Moreover, Kineograph with incremental changes outper- forms its non-incremental variant by 2× for Single Source Shortest Paths (SSSP) and TunkRank analytics. Overall, in- cremental changes consistently enable more performance for recomputing graph analytics. Comparison to graph databases Both Grace and Neo4j offer ACID transactions. Yet, Grace outperforms Neo4j by even two orders of magnitude [189] for numerous graph analytics. One key reason for this is the compact CSR based graph representation used in Grace. Contrarily, Neo4j uses the Labeled Property Graph, which enables many work- loads not available in Grace (e.g., business intelligence) but comes with performance penalties due to large amounts of metadata. Neo4j also uses the AL graph representation, which is not efficient for neighborhood traversals and in- flates the representation size even further because it requires many pointers. Comparing Neo4j to Concerto [151] and to ZipG [139] gives similar outcomes. Scalability In STINGER, scaling the number of par- allel threads T performing graph updates proportionally increases the update rate (from 125k updates/s for T = 1 to 1.5M updates/s for T = 32) [79]. At T = 32, the rate saturates. This is due to congestion from atomics. Batch size In many frameworks, for example cuSTINGER, increasing the batch size B results in, at first, steady proportional increase in the rate of ingested graph updates (from 2·104 for B = 1 to 107 for B = 10, 000) [103]. However, at some point (B ≈ 10, 000), the rate stops to improve. We conjecture this is due to memory bandwidth saturation. These performance patterns are similar for both edge insertions and deletions, and for other frameworks. However, there also exist certain differences. For example, while Aspen’s ingestion rate also increases with B, it has much lower absolute ingestion times for small batch sizes. This is because startup overheads of processing a batch are much higher in cuSTINGER (and also in STINGER). Sorting batches The impact from batch sorting heavily depends on the input graph dataset. For graphs without a large degree distribution skew, batch sorting may bring 10× speedup [79]. However, whenever a graph has many vertices that have very small degrees (e.g., when degree dis- tribution skew is large), such vertices receive few updates, while only a few high-degree vertices receive the majority of updates. In such cases, sorting does not bring speedups, and may even be detrimental for overall performance because its overhead begins to dominate the (small) gains [79]. Transactional support A popular way to implement transactions based on snapshots is to use the copy-on-write mechanism. The impact of this mechanism is evaluated in Grace [189]. The authors execute different graph analytics like Pagerank](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-17-2048.jpg)
![18 (PageRank, Connected Components, SSSP) while running a specified number of transactional graph updates. Depend- ing on the considered algorithm, the overheads are up to 2.5×, compared to the runtime without transactions. The key reason is that copying an updated item immediately to a new location disrupts any caching optimizations. Edge log size Some systems, for example GraphOne, use a combination of CSR and EL, with the latter storing edge updates awaiting ingestion. The size of such a log EL structure has some impact of the rate of ingested updates. For example, in GraphOne, increasing the EL size from 1M to 8M entries increases ingestion rate by 25%. Larger EL sizes have no performance impact [147]. 8.1 Specific Streaming Solutions There are works on streaming and dynamic graphs that focus on solving a specific graph problem in a dynamic setting. Details of such solutions are outside the core fo- cus of this survey. We outline them as a reference point for the reader. First, different designs target effective par- titioning of streaming graph datasets [87]–[89], [116], [118], [165], [182], [184], [187], [208], [236]. Second, different works focus on solving a specific graph problem in a streaming setting. Targeted problems include graph clus- tering [114], mining periodic cliques [190], search for per- sistent communities [152], [192], tracking conductance [94], event pattern [180] and subgraph [176] discovery, solving ego-centric queries [175], pattern detection [59], [60], [95], [96], [143], [153], [203], [215], densest subgraph identifica- tion [124], frequent subgraph mining [20], dense subgraph detection [158], construction and querying of knowledge graphs [58], stream summarization [102], graph sparsifica- tion [10], [28], k-core maintenance [12], shortest paths [212], Betweenness Centrality [115], [211], [220], Triangle Count- ing [160], Katz Centrality [224], mincuts [99], [145] Con- nected Components [164], or PageRank [61], [107]. 9 CHALLENGES Many research challenges related to streaming graph frame- works are similar to those in graph databases [38]. First, one should identify the most beneficial design choices for different use cases in the domain of streaming and dynamic graph processing. As shown in this paper, existing systems support numerous forms of data organi- zation and types of graph representations, and it is unclear how to match these different schemes for different workload scenarios. A strongly related challenge, similarly to that in graph databases, is a high-performance system design for supporting both OLAP and OLTP style workloads. One can also try to accelerate different graph analytics problems in the streaming setting, for example graph coloring [26]. Second, while there is no consensus on a standard lan- guage for querying graph databases, even less is established for streaming frameworks. Different systems provide dif- ferent APIs or programming abstractions [218]. Difficulties are intensified by a similar lack of consensus on most ben- eficial techniques for update ingestion and on computation models. This area is rapidly evolving and one should expect numerous new ideas, before a certain consensus is reached. Moreover, contrarily to static graph processing, little research exists into accelerating streaming graph process- ing using hardware acceleration such as FPGAs [29], [41], [66], high-performance networking hardware and associ- ated abstractions [30], [31], [34], [72], [97], [197], low-cost atomics [179], [198], hardware transactions [33], and oth- ers [9], [30]. One could also investigate topology-aware or routing-aware data distribution for graph streaming, especially together with recent high-performance network topologies [32], [142] and routing [27], [40], [98], [157]. Finally, ensuring speedups due to different data modeling abstractions, such as the algebraic abstraction [36], [37], [138], [148], may be a promising direction. We also observe that, despite the fact that several stream- ing frameworks offer distributed execution and data shard- ing, the highest rate of ingestion is achieved by shared- memory single-node designs (cf. Section 8). An interesting challenge would be to make these designs distributed and to ensure that their ingestion rates increase even further, proportionally to the number of used compute nodes. Finally, an interesting question is whether graph databases are inherently different from streaming frame- works. While merging these two classes of systems is an interesting ongoing effort, reflected by systems such as Graphflow [131] with many potential benefits, the differ- ence in the associated workloads and industry requirements may be fundamentally different for a single unified solution. 10 CONCLUSION Streaming and dynamic graph processing is an important research field. It is used to maintain numerous dynamic graph datasets, simultaneously ensuring high-performance graph updates, queries, and analytics workloads. Many graph streaming frameworks have been developed. They use different data representations, they are based on miscel- laneous design choices for fast parallel ingestion of updates and resolution of queries, and they enable a plethora of queries and workloads. We present the first analysis and taxonomy of the rich landscape of streaming and dynamic graph processing. We crystallize a broad number of related concepts (both theoretical and practical), we list and catego- rize existing systems and discuss key design choices, we ex- plain associated models, and we discuss related fields such as graph databases. Our work can be used by architects, developers, and project managers who want to select the most advantageous processing system or design, or simply understand this broad and fast-growing field. Acknowledgements We thank Khuzaima Daudjee for useful sug- gestions regarding related work. We thank PRODYNA AG (Darko Križić, Jens Nixdorf, and Christoph Körner) for generous support, and anonymous reviewers for comments that helped to significantly enhance the paper quality. This work was funded by Google European Doctoral Fellowship and ETH Zurich. REFERENCES [1] Apache Giraph Project. https://giraph.apache.org/. [2] T. Abughofa and F. Zulkernine. Sprouter: Dynamic graph pro- cessing over data streams at scale. In DEXA, pages 321–328. Springer, 2018. [3] U. A. Acar, D. Anderson, G. E. Blelloch, and L. Dhulipala. Parallel batch-dynamic graph connectivity. In ACM SPAA, pages 381–392, 2019.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-18-2048.jpg)
![19 [4] U. A. Acar, A. Cotter, B. Hudson, and D. Türkoglu. Parallelism in dynamic well-spaced point sets. In ACM SPAA, pages 33–42, 2011. [5] R. Agarwal et al. Succinct: Enabling queries on compressed data. In NSDI, pages 337–350, 2015. [6] C. Aggarwal and K. Subbian. Evolutionary network analysis: A survey. ACM Computing Surveys (CSUR), 47(1):10, 2014. [7] G. Aggarwal, M. Datar, S. Rajagopalan, and M. Ruhl. On the streaming model augmented with a sorting primitive. In IEEE FOCS, pages 540–549, 2004. [8] M. K. Aguilera, A. Merchant, M. Shah, A. Veitch, and C. Kara- manolis. Sinfonia: a new paradigm for building scalable dis- tributed systems. In ACM SIGOPS Op. Sys. Rev., 2007. [9] J. Ahn, S. Hong, S. Yoo, O. Mutlu, and K. Choi. A scalable processing-in-memory accelerator for parallel graph processing. ACM SIGARCH Comp. Arch. News, 2016. [10] K. J. Ahn and S. Guha. Graph sparsification in the semi-streaming model. In ICALP, pages 328–338. Springer, 2009. [11] K. J. Ahn, S. Guha, and A. McGregor. Graph sketches: sparsi- fication, spanners, and subgraphs. In ACM PODS, pages 5–14, 2012. [12] H. Aksu, M. Canim, Y.-C. Chang, I. Korpeoglu, and Ö. Ulusoy. Distributed k-core view materialization and maintenance for large dynamic graphs. IEEE TKDE, 26(10):2439–2452, 2014. [13] K. Ammar. Techniques and systems for large dynamic graphs. In SIGMOD’16 PhD Symposium, pages 7–11. ACM, 2016. [14] J. C. Anderson, J. Lehnardt, and N. Slater. CouchDB: the definitive guide: time to relax. ” O’Reilly Media, Inc.”, 2010. [15] A. Andoni, J. Chen, R. Krauthgamer, B. Qin, D. P. Woodruff, and Q. Zhang. On sketching quadratic forms. In ACM ITCS, pages 311–319, 2016. [16] R. Angles, M. Arenas, P. Barceló, A. Hogan, J. Reutter, and D. Vrgoč. Foundations of Modern Query Languages for Graph Databases. in ACM Comput. Surv., 50(5):68:1–68:40, 2017. [17] Apache Software Foundation. Apache CouchDB. https:// couchdb.apache.org/. [18] S. Aridhi et al. Bladyg: A graph processing framework for large dynamic graphs. Big data research, 9:9–17, 2017. [19] T. G. Armstrong, V. Ponnekanti, D. Borthakur, and M. Callaghan. Linkbench: a database benchmark based on the facebook social graph. In ACM SIGMOD, pages 1185–1196, 2013. [20] C. Aslay, M. A. U. Nasir, G. De Francisci Morales, and A. Gionis. Mining frequent patterns in evolving graphs. In ACM CIKM, pages 923–932, 2018. [21] S. Assadi, S. Khanna, and Y. Li. On estimating maximum matching size in graph streams. SODA, 2017. [22] S. Assadi, S. Khanna, Y. Li, and G. Yaroslavtsev. Maximum matchings in dynamic graph streams and the simultaneous com- munication model. 2016. [23] O. Batarfi, R. El Shawi, A. G. Fayoumi, R. Nouri, A. Barnawi, S. Sakr, et al. Large scale graph processing systems: survey and an experimental evaluation. Cluster Computing, 18(3):1189–1213, 2015. [24] S. Behnezhad, M. Derakhshan, M. Hajiaghayi, C. Stein, and M. Sudan. Fully dynamic maximal independent set with poly- logarithmic update time. FOCS, 2019. [25] T. Ben-Nun, M. Besta, S. Huber, A. N. Ziogas, D. Peter, and T. Hoefler. A modular benchmarking infrastructure for high- performance and reproducible deep learning. arXiv preprint arXiv:1901.10183, 2019. [26] M. Besta, A. Carigiet, K. Janda, Z. Vonarburg-Shmaria, L. Giani- nazzi, and T. Hoefler. High-performance parallel graph coloring with strong guarantees on work, depth, and quality. In Proceed- ings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–17, 2020. [27] M. Besta, J. Domke, M. Schneider, M. Konieczny, S. Di Girolamo, T. Schneider, A. Singla, and T. Hoefler. High-performance rout- ing with multipathing and path diversity in ethernet and hpc networks. IEEE Transactions on Parallel and Distributed Systems, 2020. [28] M. Besta et al. Slim graph: Practical lossy graph compression for approximate graph processing, storage, and analytics. 2019. [29] M. Besta, M. Fischer, T. Ben-Nun, J. De Fine Licht, and T. Hoefler. Substream-centric maximum matchings on fpga. In ACM/SIGDA FPGA, pages 152–161, 2019. [30] M. Besta, S. M. Hassan, S. Yalamanchili, R. Ausavarungnirun, O. Mutlu, and T. Hoefler. Slim noc: A low-diameter on-chip network topology for high energy efficiency and scalability. In ACM SIGPLAN Notices, 2018. [31] M. Besta and T. Hoefler. Fault tolerance for remote memory access programming models. In ACM HPDC, pages 37–48, 2014. [32] M. Besta and T. Hoefler. Slim fly: A cost effective low-diameter network topology. In ACM/IEEE Supercomputing, pages 348–359, 2014. [33] M. Besta and T. Hoefler. Accelerating irregular computations with hardware transactional memory and active messages. In ACM HPDC, 2015. [34] M. Besta and T. Hoefler. Active access: A mechanism for high- performance distributed data-centric computations. In ACM ICS, 2015. [35] M. Besta and T. Hoefler. Survey and taxonomy of lossless graph compression and space-efficient graph representations. arXiv preprint arXiv:1806.01799, 2018. [36] M. Besta, R. Kanakagiri, H. Mustafa, M. Karasikov, G. Rätsch, T. Hoefler, and E. Solomonik. Communication-efficient jaccard similarity for high-performance distributed genome compar- isons. arXiv preprint arXiv:1911.04200, 2019. [37] M. Besta, F. Marending, E. Solomonik, and T. Hoefler. Slimsell: A vectorizable graph representation for breadth-first search. In IEEE IPDPS, pages 32–41, 2017. [38] M. Besta, E. Peter, R. Gerstenberger, M. Fischer, M. Podstawski, C. Barthels, G. Alonso, and T. Hoefler. Demystifying graph databases: Analysis and taxonomy of data organization, system designs, and graph queries. arXiv preprint arXiv:1910.09017, 2019. [39] M. Besta, M. Podstawski, L. Groner, E. Solomonik, and T. Hoefler. To push or to pull: On reducing communication and synchroniza- tion in graph computations. In ACM HPDC, 2017. [40] M. Besta, M. Schneider, K. Cynk, M. Konieczny, E. Henriksson, S. Di Girolamo, A. Singla, and T. Hoefler. Fatpaths: Routing in supercomputers and data centers when shortest paths fall short. In ACM/IEEE Supercomputing, 2019. [41] M. Besta, D. Stanojevic, J. D. F. Licht, T. Ben-Nun, and T. Hoefler. Graph processing on fpgas: Taxonomy, survey, challenges. arXiv preprint arXiv:1903.06697, 2019. [42] M. Besta, D. Stanojevic, T. Zivic, J. Singh, M. Hoerold, and T. Hoefler. Log (graph): a near-optimal high-performance graph representation. In PACT, pages 7–1, 2018. [43] S. Bhattacharya, M. Henzinger, and D. Nanongkai. A new deterministic algorithm for dynamic set cover. FOCS, 2019. [44] S. Bhattacharya, M. Henzinger, D. Nanongkai, and C. Tsourakakis. Space-and time-efficient algorithm for maintaining dense subgraphs on one-pass dynamic streams. In ACM STOC, 2015. [45] A. Biem, E. Bouillet, H. Feng, A. Ranganathan, A. Riabov, O. Ver- scheure, H. Koutsopoulos, and C. Moran. Ibm infosphere streams for scalable, real-time, intelligent transportation services. In ACM SIGMOD, 2010. [46] P. Boldi and S. Vigna. The webgraph framework i: compression techniques. In ACM WWW, pages 595–602, 2004. [47] J. Broekstra et al. Sesame: A generic architecture for storing and querying rdf and rdf schema. In ISWC, pages 54–68. Springer, 2002. [48] M. Bury, E. Grigorescu, A. McGregor, M. Monemizadeh, C. Schwiegelshohn, S. Vorotnikova, and S. Zhou. Structural results on matching estimation with applications to streaming. Algorithmica, 81(1):367–392, 2019. [49] F. Busato, O. Green, N. Bombieri, and D. A. Bader. Hornet: An efficient data structure for dynamic sparse graphs and matrices on gpus. In IEEE HPEC, pages 1–7, 2018. [50] J. Byun, S. Woo, and D. Kim. Chronograph: Enabling tempo- ral graph traversals for efficient information diffusion analysis over time. IEEE Transactions on Knowledge and Data Engineering, 32(3):424–437, 2019. [51] Z. Cai, D. Logothetis, and G. Siganos. Facilitating real-time graph mining. In ACM CloudDB, pages 1–8, 2012. [52] J.-P. Calbimonte, O. Corcho, and A. J. Gray. Enabling ontology- based access to streaming data sources. In Springer ISWC, 2010. [53] M. Capotă, T. Hegeman, A. Iosup, A. Prat-Pérez, O. Erling, and P. Boncz. Graphalytics: A big data benchmark for graph- processing platforms. In Proceedings of the GRADES’15, pages 1–6. 2015. [54] P. Carbone, A. Katsifodimos, S. Ewen, V. Markl, S. Haridi, and K. Tzoumas. Apache flink: Stream and batch processing in a single engine. IEEE-CS Bull. Tech. Com. on Data Eng., 2015.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-19-2048.jpg)
![20 [55] S. Chechik and T. Zhang. Fully dynamic maximal independent set in expected poly-log update time. FOCS, 2019. [56] R. Cheng, J. Hong, A. Kyrola, Y. Miao, X. Weng, M. Wu, F. Yang, L. Zhou, F. Zhao, and E. Chen. Kineograph: taking the pulse of a fast-changing and connected world. In ACM EuroSys, pages 85–98, 2012. [57] A. Ching, S. Edunov, M. Kabiljo, D. Logothetis, and S. Muthukr- ishnan. One trillion edges: Graph processing at facebook-scale. Proceedings of the VLDB Endowment, 8(12):1804–1815, 2015. [58] S. Choudhury, K. Agarwal, S. Purohit, B. Zhang, M. Pirrung, W. Smith, and M. Thomas. Nous: Construction and querying of dynamic knowledge graphs. In IEEE ICDE, pages 1563–1565, 2017. [59] S. Choudhury, L. Holder, G. Chin, K. Agarwal, and J. Feo. A selectivity based approach to continuous pattern detection in streaming graphs. arXiv preprint arXiv:1503.00849, 2015. [60] S. Choudhury, S. Purohit, P. Lin, Y. Wu, L. Holder, and K. Agar- wal. Percolator: Scalable pattern discovery in dynamic graphs. In ACM WSDM, pages 759–762, 2018. [61] M. E. Coimbra, R. Rosa, S. Esteves, A. P. Francisco, and L. Veiga. Graphbolt: Streaming graph approximations on big data. arXiv preprint arXiv:1810.02781, 2018. [62] R. Cyganiak, D. Wood, and M. Lanthaler. RDF 1.1 Concepts and Abstract Syntax. Available at https://www.w3.org/TR/ rdf11-concepts/. [63] M. Datar, A. Gionis, P. Indyk, and R. Motwani. Maintaining stream statistics over sliding windows. SIAM journal on com- puting, 31(6):1794–1813, 2002. [64] C. J. Date and H. Darwen. A Guide to the SQL Standard, volume 3. Addison-Wesley New York, 1987. [65] A. Dave, J. E. Gonzalez, M. J. Franklin, and I. Stoica. Persistent adaptive radix trees: Efficient fine-grained updates to immutable data. [66] J. de Fine Licht et al. Transformations of high-level synthesis codes for high-performance computing. arXiv:1805.08288, 2018. [67] J. Dean and S. Ghemawat. Mapreduce: simplified data processing on large clusters. Communications of the ACM, 51(1):107–113, 2008. [68] C. Demetrescu, I. Finocchi, and A. Ribichini. Trading off space for passes in graph streaming problems. ACM TALG, 6(1):6, 2009. [69] P. Dexter, Y. D. Liu, and K. Chiu. Lazy graph processing in haskell. In ACM SIGPLAN Notices, volume 51, pages 182–192. ACM, 2016. [70] P. Dexter, Y. D. Liu, and K. Chiu. Formal foundations of continu- ous graph processing. arXiv preprint arXiv:1911.10982, 2019. [71] L. Dhulipala et al. Low-latency graph streaming using com- pressed purely-functional trees. arXiv:1904.08380, 2019. [72] S. Di Girolamo, K. Taranov, A. Kurth, M. Schaffner, T. Schneider, J. Beránek, M. Besta, L. Benini, D. Roweth, and T. Hoefler. Network-accelerated non-contiguous memory transfers. arXiv preprint arXiv:1908.08590, 2019. [73] L. Di Paola, M. De Ruvo, P. Paci, D. Santoni, and A. Giuliani. Protein contact networks: an emerging paradigm in chemistry. Chemical reviews, 113(3):1598–1613, 2012. [74] M. Ding et al. Storing and querying large-scale spatio-temporal graphs with high-throughput edge insertions. arXiv:1904.09610, 2019. [75] N. Doekemeijer and A. L. Varbanescu. A survey of parallel graph processing frameworks. Delft University of Technology, page 21, 2014. [76] R. Duan, H. He, and T. Zhang. Dynamic edge coloring with improved approximation. In ACM-SIAM SODA, pages 1937– 1945, 2019. [77] D. Durfee, L. Dhulipala, J. Kulkarni, R. Peng, S. Sawlani, and X. Sun. Parallel batch-dynamic graphs: Algorithms and lower bounds. SODA, 2020. [78] D. Durfee, Y. Gao, G. Goranci, and R. Peng. Fully dynamic spectral vertex sparsifiers and applications. In ACM STOC, pages 914–925, 2019. [79] D. Ediger, R. McColl, J. Riedy, and D. A. Bader. Stinger: High performance data structure for streaming graphs. In IEEE HPEC, pages 1–5, 2012. [80] O. Erling, A. Averbuch, J. Larriba-Pey, H. Chafi, A. Gubichev, A. Prat, M.-D. Pham, and P. Boncz. The LDBC Social Network Benchmark: Interactive Workload. in SIGMOD, pages 619–630, 2015. [81] H. Esfandiari, M. Hajiaghayi, V. Liaghat, M. Monemizadeh, and K. Onak. Streaming algorithms for estimating the matching size in planar graphs and beyond. ACM Trans. Algorithms, 2018. [82] J. Fairbanks, D. Ediger, R. McColl, D. A. Bader, and E. Gilbert. A statistical framework for streaming graph analysis. In IEEE/ACM ASONAM, pages 341–347, 2013. [83] A. Fard, A. Abdolrashidi, L. Ramaswamy, and J. A. Miller. Towards efficient query processing on massive time-evolving graphs. In 8th International Conference on Collaborative Computing: Networking, Applications and Worksharing (CollaborateCom), pages 567–574. IEEE, 2012. [84] J. Feigenbaum, S. Kannan, A. McGregor, S. Suri, and J. Zhang. On graph problems in a semi-streaming model. Theoretical Computer Science, 348(2-3):207–216, 2005. [85] G. Feng et al. Distinger: A distributed graph data structure for massive dynamic graph processing. In IEEE Big Data, pages 1814–1822, 2015. [86] G. Feng, Z. Ma, D. Li, X. Zhu, Y. Cai, W. Han, and W. Chen. Risgraph: A real-time streaming system for evolving graphs. arXiv preprint arXiv:2004.00803, 2020. [87] I. Filippidou and Y. Kotidis. Online and on-demand partitioning of streaming graphs. In IEEE Big Data, pages 4–13. [88] H. Firth and P. Missier. Workload-aware streaming graph parti- tioning. In EDBT/ICDT Workshops. Citeseer, 2016. [89] H. Firth, P. Missier, and J. Aiston. Loom: Query-aware partition- ing of online graphs. arXiv preprint arXiv:1711.06608, 2017. [90] P. Flajolet, É. Fusy, O. Gandouet, and F. Meunier. Hyperloglog: the analysis of a near-optimal cardinality estimation algorithm. In Discrete Mathematics and Theoretical Computer Science, pages 137– 156, 2007. [91] S. Forster and G. Goranci. Dynamic low-stretch trees via dynamic low-diameter decompositions. In ACM STOC, pages 377–388, 2019. [92] F. Fouquet, T. Hartmann, S. Mosser, and M. Cordy. Enabling lock-free concurrent workers over temporal graphs composed of multiple time-series. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, pages 1054–1061. ACM, 2018. [93] N. Francis, A. Green, P. Guagliardo, L. Libkin, T. Lindaaker, V. Marsault, S. Plantikow, M. Rydberg, P. Selmer, and A. Taylor. Cypher: An evolving query language for property graphs. In ACM SIGMOD, pages 1433–1445, 2018. [94] S. Galhotra, A. Bagchi, S. Bedathur, M. Ramanath, and V. Jain. Tracking the conductance of rapidly evolving topic-subgraphs. Proc. VLDB, 8(13):2170–2181, 2015. [95] J. Gao, C. Zhou, and J. X. Yu. Toward continuous pattern detection over evolving large graph with snapshot isolation. The VLDB Journal—The International Journal on Very Large Data Bases, 25(2):269–290, 2016. [96] J. Gao, C. Zhou, J. Zhou, and J. X. Yu. Continuous pattern detection over billion-edge graph using distributed framework. In IEEE ICDE, pages 556–567, 2014. [97] R. Gerstenberger et al. Enabling Highly-scalable Remote Memory Access Programming with MPI-3 One Sided. In ACM/IEEE Supercomputing, 2013. [98] S. Ghorbani, Z. Yang, P. Godfrey, Y. Ganjali, and A. Firoozshahian. Drill: Micro load balancing for low-latency data center networks. In ACM SIGCOMM, pages 225–238, 2017. [99] L. Gianinazzi, P. Kalvoda, A. De Palma, M. Besta, and T. Hoefler. Communication-avoiding parallel minimum cuts and connected components. In ACM SIGPLAN Notices, volume 53, pages 219– 232. ACM, 2018. [100] F. Goasdoué, I. Manolescu, and A. Roatiş. Efficient query an- swering against dynamic rdf databases. In ACM EDBT, pages 299–310, 2013. [101] J. E. Gonzalez, R. S. Xin, A. Dave, D. Crankshaw, M. J. Franklin, and I. Stoica. Graphx: Graph processing in a distributed dataflow framework. In OSDI, 2014. [102] X. Gou, L. Zou, C. Zhao, and T. Yang. Fast and accurate graph stream summarization. In 2019 IEEE 35th International Conference on Data Engineering (ICDE), pages 1118–1129. IEEE, 2019. [103] O. Green and D. A. Bader. custinger: Supporting dynamic graph algorithms for gpus. In IEEE HPEC, 2016. [104] W. Gropp, T. Hoefler, T. Rajeev, and E. Lusk. Using Advanced MPI: Modern Features of the Message-Passing Interface. The MIT Press, 2014. [105] S. Guha and A. McGregor. Graph synopses, sketches, and streams: A survey. PVLDB, 5(12):2030–2031, 2012.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-20-2048.jpg)
![21 [106] S. Guha, A. McGregor, and D. Tench. Vertex and hyperedge connectivity in dynamic graph streams. In ACM PODS, pages 241–247, 2015. [107] W. Guo, Y. Li, M. Sha, and K.-L. Tan. Parallel personalized pager- ank on dynamic graphs. Proceedings of the VLDB Endowment, 11(1):93–106, 2017. [108] M. Han and K. Daudjee. Giraph unchained: barrierless asyn- chronous parallel execution in pregel-like graph processing sys- tems. VLDB, 2015. [109] M. Han and K. Daudjee. Providing serializability for pregel-like graph processing systems. In EDBT, pages 77–88, 2016. [110] M. Han, K. Daudjee, K. Ammar, M. T. Özsu, X. Wang, and T. Jin. An experimental comparison of pregel-like graph processing systems. Proc. VLDB, 7(12):1047–1058, 2014. [111] W. Han, K. Li, S. Chen, and W. Chen. Auxo: a temporal graph management system. Big Data Mining and Analytics, 2(1):58–71, 2018. [112] W. Han, Y. Miao, K. Li, M. Wu, F. Yang, L. Zhou, V. Prabhakaran, W. Chen, and E. Chen. Chronos: a graph engine for temporal graph analysis. In 9th European Conference on Computer Systems, page 1. ACM, 2014. [113] T. Hartmann, F. Fouquet, M. Jimenez, R. Rouvoy, and Y. Le Traon. Analyzing complex data in motion at scale with temporal graphs. 2017. [114] M. Hassani, P. Spaus, A. Cuzzocrea, and T. Seidl. I-hastream: density-based hierarchical clustering of big data streams and its application to big graph analytics tools. In CCGrid, pages 656– 665. IEEE, 2016. [115] T. Hayashi, T. Akiba, and Y. Yoshida. Fully dynamic betweenness centrality maintenance on massive networks. Proceedings of the VLDB Endowment, 9(2):48–59, 2015. [116] L. Hoang, R. Dathathri, G. Gill, and K. Pingali. Cusp: A cus- tomizable streaming edge partitioner for distributed graph ana- lytics. In 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 439–450. IEEE, 2019. [117] F. Holzschuher and R. Peinl. Performance of graph query languages: comparison of cypher, gremlin and native access in neo4j. In ACM EDBT/ICDT, 2013. [118] J. Huang and D. J. Abadi. Leopard: Lightweight edge-oriented partitioning and replication for dynamic graphs. Proceedings of the VLDB Endowment, 9(7):540–551, 2016. [119] G. F. Italiano, S. Lattanzi, V. S. Mirrokni, and N. Parotsidis. Dy- namic algorithms for the massively parallel computation model. In ACM SPAA, 2019. [120] A. Iyer, L. E. Li, and I. Stoica. Celliq: Real-time cellular network analytics at scale. In NSDI, 2015. [121] A. Iyer, Q. Pu, K. Patel, J. Gonzalez, and I. Stoica. Tegra: Efficient ad-hoc analytics on time-evolving graphs. Technical report, 2019. [122] A. P. Iyer, L. E. Li, T. Das, and I. Stoica. Time-evolving graph processing at scale. In ACM GRADES, 2016. [123] S. Ji et al. A low-latency computing framework for time-evolving graphs. The Journal of Supercomputing, 75(7):3673–3692, 2019. [124] H. Jin, C. Lin, H. Chen, and J. Liu. Quickpoint: Efficiently identifying densest sub-graphs in online social networks for event stream dissemination. IEEE Transactions on Knowledge and Data Engineering, 2018. [125] P. Joaquim. Hourglass-incremental graph processing on hetero- geneous infrastructures. [126] W. Ju, J. Li, W. Yu, and R. Zhang. igraph: an incremental data processing system for dynamic graph. Frontiers of Computer Science, 10(3):462–476, 2016. [127] V. Kalavri, V. Vlassov, and S. Haridi. High-level programming abstractions for distributed graph processing. IEEE TKDE, 2017. [128] J. Kallaugher, M. Kapralov, and E. Price. The sketching complex- ity of graph and hypergraph counting. FOCS, 2018. [129] S. Kamburugamuve and G. Fox. Survey of distributed stream processing. Bloomington: Indiana University, 2016. [130] D. M. Kane, K. Mehlhorn, T. Sauerwald, and H. Sun. Counting arbitrary subgraphs in data streams. In International Colloquium on Automata, Languages, and Programming, pages 598–609. Springer, 2012. [131] C. Kankanamge, S. Sahu, A. Mhedbhi, J. Chen, and S. Salihoglu. Graphflow: An active graph database. In ACM SIGMOD, pages 1695–1698, 2017. [132] M. Kapralov, S. Khanna, and M. Sudan. Approximating matching size from random streams. SODA, 2014. [133] M. Kapralov, S. Mitrovic, A. Norouzi-Fard, and J. Tardos. Space efficient approximation to maximum matching size from uniform edge samples. SODA, 2020. [134] M. Kapralov, A. Mousavifar, C. Musco, C. Musco, N. Nouri, A. Sidford, and J. Tardos. Fast and space efficient spectral sparsification in dynamic streams. SODA, abs/1903.12150, 2020. [135] M. Kapralov, N. Nouri, A. Sidford, and J. Tardos. Dynamic streaming spectral sparsification in nearly linear time and space. CoRR, abs/1903.12150, 2019. [136] M. Kapralov and D. P. Woodruff. Spanners and sparsifiers in dynamic streams. PODC, 2014. [137] H. Karloff, S. Suri, and S. Vassilvitskii. A model of computation for mapreduce. In ACM-SIAM SODA, 2010. [138] J. Kepner, P. Aaltonen, D. Bader, A. Buluç, F. Franchetti, J. Gilbert, D. Hutchison, M. Kumar, A. Lumsdaine, H. Meyerhenke, et al. Mathematical foundations of the graphblas. In 2016 IEEE High Performance Extreme Computing Conference (HPEC), pages 1–9. IEEE, 2016. [139] A. Khandelwal, Z. Yang, E. Ye, R. Agarwal, and I. Stoica. Zipg: A memory-efficient graph store for interactive queries. In ACM SIGMOD, 2017. [140] U. Khurana and A. Deshpande. Efficient snapshot retrieval over historical graph data. In 2013 IEEE 29th International Conference on Data Engineering (ICDE), pages 997–1008. IEEE, 2013. [141] U. Khurana and A. Deshpande. Storing and analyzing historical graph data at scale. arXiv preprint arXiv:1509.08960, 2015. [142] J. Kim, W. J. Dally, S. Scott, and D. Abts. Technology-driven, highly-scalable dragonfly topology. In 2008 International Sympo- sium on Computer Architecture, pages 77–88. IEEE, 2008. [143] K. Kim, I. Seo, W.-S. Han, J.-H. Lee, S. Hong, H. Chafi, H. Shin, and G. Jeong. Turboflux: A fast continuous subgraph matching system for streaming graph data. In Proceedings of the 2018 International Conference on Management of Data, pages 411–426. ACM, 2018. [144] J. King, T. Gilray, R. M. Kirby, and M. Might. Dynamic sparse- matrix allocation on gpus. In International Conference on High Performance Computing, pages 61–80. Springer, 2016. [145] D. Kogan and R. Krauthgamer. Sketching cuts in graphs and hypergraphs. In Proceedings of the 2015 Conference on Innovations in Theoretical Computer Science, pages 367–376. ACM, 2015. [146] S. Komazec, D. Cerri, and D. Fensel. Sparkwave: continuous schema-enhanced pattern matching over rdf data streams. In 6th ACM International Conference on Distributed Event-Based Systems, pages 58–68. ACM, 2012. [147] P. Kumar and H. H. Huang. Graphone: A data store for real-time analytics on evolving graphs. In USENIX FAST, 2019. [148] G. Kwasniewski, M. Kabić, M. Besta, J. VandeVondele, R. Solcà, and T. Hoefler. Red-blue pebbling revisited: near optimal par- allel matrix-matrix multiplication. In ACM/IEEE Supercomputing, page 24. ACM, 2019. [149] A. Lakshman and P. Malik. Cassandra: a decentralized structured storage system. ACM SIGOPS Operating Systems Review, 44(2):35– 40, 2010. [150] K. G. Larsen, J. Nelson, H. L. Nguyen, and M. Thorup. Heavy hitters via cluster-preserving clustering. Commun. ACM, 62(8):95– 100, 2019. [151] M. M. Lee, I. Roy, A. AuYoung, V. Talwar, K. Jayaram, and Y. Zhou. Views and transactional storage for large graphs. In ACM/IFIP/USENIX Middleware, 2013. [152] R.-H. Li, J. Su, L. Qin, J. X. Yu, and Q. Dai. Persistent community search in temporal networks. In 2018 IEEE 34th International Conference on Data Engineering (ICDE), pages 797–808. IEEE, 2018. [153] Y. Li, L. Zou, M. T. Özsu, and D. Zhao. Time constrained continuous subgraph search over streaming graphs. In 2019 IEEE 35th International Conference on Data Engineering (ICDE), pages 1082–1093. IEEE, 2019. [154] W. Lightenberg, Y. Pei, G. Fletcher, and M. Pechenizkiy. Tink: A temporal graph analytics library for apache flink. In Companion Proceedings of the The Web Conference 2018, pages 71–72, 2018. [155] H. Lin, X. Zhu, B. Yu, X. Tang, W. Xue, W. Chen, L. Zhang, T. Hoefler, X. Ma, X. Liu, et al. Shentu: processing multi-trillion edge graphs on millions of cores in seconds. In ACM/IEEE Supercomputing, page 56. IEEE Press, 2018. [156] Y. Low, J. E. Gonzalez, A. Kyrola, D. Bickson, C. E. Guestrin, and J. Hellerstein. Graphlab: A new framework for parallel machine learning. arXiv preprint arXiv:1408.2041, 2014.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-21-2048.jpg)
![22 [157] Y. Lu, G. Chen, B. Li, K. Tan, Y. Xiong, P. Cheng, J. Zhang, E. Chen, and T. Moscibroda. Multi-path transport for {RDMA} in datacenters. In NSDI, 2018. [158] S. Ma, R. Hu, L. Wang, X. Lin, and J. Huai. Fast computation of dense temporal subgraphs. In ICDE, pages 361–372. IEEE, 2017. [159] P. Macko, V. J. Marathe, D. W. Margo, and M. I. Seltzer. Llama: Efficient graph analytics using large multiversioned arrays. In 2015 IEEE 31st International Conference on Data Engineering, pages 363–374. IEEE, 2015. [160] D. Makkar, D. A. Bader, and O. Green. Exact and parallel triangle counting in dynamic graphs. In 2017 IEEE 24th International Conference on High Performance Computing (HiPC), pages 2–12. IEEE, 2017. [161] G. Malewicz, M. H. Austern, A. J. Bik, J. C. Dehnert, I. Horn, N. Leiser, and G. Czajkowski. Pregel: a system for large-scale graph processing. In ACM SIGMOD, 2010. [162] M. Mariappan and K. Vora. Graphbolt: Dependency-driven synchronous processing of streaming graphs. In ACM EuroSys, 2019. [163] C. Martella, R. Shaposhnik, D. Logothetis, and S. Harenberg. Practical graph analytics with apache giraph, volume 1. Springer, 2015. [164] R. McColl, O. Green, and D. A. Bader. A new parallel algorithm for connected components in dynamic graphs. In 20th Annual International Conference on High Performance Computing, pages 246–255. IEEE, 2013. [165] A. McCrabb, E. Winsor, and V. Bertacco. Dredge: Dynamic repartitioning during dynamic graph execution. In Proceedings of the 56th Annual Design Automation Conference 2019, page 28. ACM, 2019. [166] R. R. McCune et al. Thinking like a vertex: a survey of vertex- centric frameworks for large-scale distributed graph processing. ACM CSUR, 2015. [167] A. McGregor. Graph stream algorithms: a survey. ACM SIGMOD Record, 2014. [168] F. McSherry, D. G. Murray, R. Isaacs, and M. Isard. Differential dataflow. In CIDR, 2013. [169] Y. Miao, W. Han, K. Li, M. Wu, F. Yang, L. Zhou, V. Prabhakaran, E. Chen, and W. Chen. Immortalgraph: A system for storage and analysis of temporal graphs. ACM Transactions on Storage (TOS), 11(3):14, 2015. [170] O. Michail. An introduction to temporal graphs: An algorithmic perspective. Internet Mathematics, 12(4):239–280, 2016. [171] G. T. Minton and E. Price. Improved concentration bounds for count-sketch. In ACM-SIAM SODA, 2014. [172] V. Z. Moffitt and J. Stoyanovich. Temporal graph algebra. In Proceedings of The 16th International Symposium on Database Pro- gramming Languages, pages 1–12, 2017. [173] V. Z. Moffitt and J. Stoyanovich. Towards sequenced semantics for evolving graphs. In EDBT, pages 446–449, 2017. [174] J. Mondal and A. Deshpande. Managing large dynamic graphs efficiently. In ACM SIGMOD, 2012. [175] J. Mondal and A. Deshpande. Eagr: Supporting continuous ego-centric aggregate queries over large dynamic graphs. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of data, pages 1335–1346. ACM, 2014. [176] J. Mondal and A. Deshpande. Casqd: continuous detection of activity-based subgraph pattern queries on dynamic graphs. In Proceedings of the 10th ACM International Conference on Distributed and Event-based Systems, pages 226–237. ACM, 2016. [177] D. G. Murray, F. McSherry, M. Isard, R. Isaacs, P. Barham, and M. Abadi. Incremental, iterative data processing with timely dataflow. Communications of the ACM, 59(10):75–83, 2016. [178] S. Muthukrishnan et al. Data streams: Algorithms and appli- cations. Foundations and Trends® in Theoretical Computer Science, 2005. [179] L. Nai, R. Hadidi, J. Sim, H. Kim, P. Kumar, and H. Kim. Graphpim: Enabling instruction-level pim offloading in graph computing frameworks. In IEEE HPCA, 2017. [180] M. H. Namaki, P. Lin, and Y. Wu. Event pattern discovery by keywords in graph streams. In 2017 IEEE International Conference on Big Data (Big Data), pages 982–987. IEEE, 2017. [181] S. Neuendorffer and K. Vissers. Streaming systems in FPGAs. In Intl. Workshop on Embedded Computer Systems, pages 147–156. Springer, 2008. [182] D. Nicoara, S. Kamali, K. Daudjee, and L. Chen. Hermes: Dynamic partitioning for distributed social network graph databases. In EDBT, pages 25–36, 2015. [183] T. C. O’connell. A survey of graph algorithms under extended streaming models of computation. In Fundamental Problems in Computing, pages 455–476. Springer, 2009. [184] A. Pacaci and M. T. Özsu. Experimental analysis of streaming algorithms for graph partitioning. In Proceedings of the 2019 International Conference on Management of Data, pages 1375–1392. ACM, 2019. [185] P. Peng and C. Sohler. Estimating graph parameters from random order streams. 2018. [186] J. Pérez, M. Arenas, and C. Gutierrez. Semantics and complexity of sparql. ACM TODS, 34(3):16, 2009. [187] F. Petroni, L. Querzoni, K. Daudjee, S. Kamali, and G. Iacoboni. HDRF: Stream-based partitioning for power-law graphs. In Pro- ceedings of the 24th ACM International on Conference on Information and Knowledge Management, pages 243–252. ACM, 2015. [188] E. Pitoura. Historical graphs: models, storage, processing. In European Business Intelligence and Big Data Summer School, pages 84–111. Springer, 2017. [189] V. Prabhakaran, M. Wu, X. Weng, F. McSherry, L. Zhou, and M. Haradasan. Managing large graphs on multi-cores with graph awareness. In USENIX ATC, 2012. [190] H. Qin, R.-H. Li, G. Wang, L. Qin, Y. Cheng, and Y. Yuan. Mining periodic cliques in temporal networks. In ICDE, pages 1130–1141. IEEE, 2019. [191] C. Ren, E. Lo, B. Kao, X. Zhu, and R. Cheng. On querying historical evolving graph sequences. Proceedings of the VLDB Endowment, 4(11):726–737, 2011. [192] J. Riedy and D. A. Bader. Multithreaded community monitoring for massive streaming graph data. In 2013 IEEE International Symposium on Parallel Distributed Processing, Workshops and Phd Forum, pages 1646–1655. IEEE, 2013. [193] I. Robinson, J. Webber, and E. Eifrem. Graph database internals. In Graph Databases, Second Edition, chapter 7, pages 149–170. O’Relly, 2015. [194] M. A. Rodriguez. The gremlin graph traversal machine and language (invited talk). In ACM DBPL, 2015. [195] A. Roy, I. Mihailovic, and W. Zwaenepoel. X-stream: Edge-centric graph processing using streaming partitions. In ACM SOSP, 2013. [196] S. Sallinen, R. Pearce, and M. Ripeanu. Incremental graph processing for on-line analytics. In 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 1007–1018. IEEE, 2019. [197] P. Schmid, M. Besta, and T. Hoefler. High-performance dis- tributed rma locks. In ACM HPDC, pages 19–30, 2016. [198] H. Schweizer, M. Besta, and T. Hoefler. Evaluating the cost of atomic operations on modern architectures. In IEEE PACT, pages 445–456, 2015. [199] K. Semertzidis and E. Pitoura. Time traveling in graphs using a graph database. In EDBT/ICDT Workshops, 2016. [200] D. Sengupta and S. L. Song. Evograph: On-the-fly efficient min- ing of evolving graphs on gpu. In International Supercomputing Conference, pages 97–119. Springer, 2017. [201] D. Sengupta, N. Sundaram, X. Zhu, T. L. Willke, J. Young, M. Wolf, and K. Schwan. Graphin: An online high performance incremental graph processing framework. In European Conference on Parallel Processing, pages 319–333. Springer, 2016. [202] M. Sha, Y. Li, B. He, and K.-L. Tan. Accelerating dynamic graph analytics on gpus. Proceedings of the VLDB Endowment, 11(1):107– 120, 2017. [203] M. Shao, J. Li, F. Chen, and X. Chen. An efficient framework for detecting evolving anomalous subgraphs in dynamic networks. In IEEE INFOCOM 2018-IEEE Conference on Computer Communi- cations, pages 2258–2266. IEEE, 2018. [204] F. Sheng, Q. Cao, H. Cai, J. Yao, and C. Xie. Grapu: Accel- erate streaming graph analysis through preprocessing buffered updates. In ACM SoCC, 2018. [205] F. Sheng, Q. Cao, and J. Yao. Exploiting buffered updates for fast streaming graph analysis. IEEE Transactions on Computers, 2020. [206] X. Shi, B. Cui, Y. Shao, and Y. Tong. Tornado: A system for real- time iterative analysis over evolving data. In ACM SIGMOD, 2016. [207] X. Shi, Z. Zheng, Y. Zhou, H. Jin, L. He, B. Liu, and Q.-S. Hua. Graph processing on gpus: A survey. ACM Computing Surveys (CSUR), 50(6):81, 2018.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-22-2048.jpg)
![23 [208] Z. Shi, J. Li, P. Guo, S. Li, D. Feng, and Y. Su. Partitioning dynamic graph asynchronously with distributed fennel. Future Generation Computer Systems, 71:32–42, 2017. [209] J. Shun and G. E. Blelloch. Ligra: a lightweight graph processing framework for shared memory. In ACM Sigplan Notices, vol- ume 48, pages 135–146. ACM, 2013. [210] N. Simsiri, K. Tangwongsan, S. Tirthapura, and K. Wu. Work- efficient parallel union-find with applications to incremental graph connectivity. In Euro-Par, pages 561–573, 2016. [211] E. Solomonik, M. Besta, F. Vella, and T. Hoefler. Scaling between- ness centrality using communication-efficient sparse matrix mul- tiplication. In ACM/IEEE Supercomputing, page 47, 2017. [212] S. Srinivasan, S. Riazi, B. Norris, S. K. Das, and S. Bhowmick. A shared-memory parallel algorithm for updating single-source shortest paths in large dynamic networks. In HiPC, pages 245– 254. IEEE, 2018. [213] M. Steinbauer and G. Anderst-Kotsis. Dynamograph: a dis- tributed system for large-scale, temporal graph processing, its implementation and first observations. In Proceedings of the 25th International Conference Companion on World Wide Web, pages 861– 866, 2016. [214] J. Sun, C. Faloutsos, S. Papadimitriou, and P. S. Yu. Graphscope: parameter-free mining of large time-evolving graphs. In Proceed- ings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 687–696, 2007. [215] X. Sun, Y. Tan, Q. Wu, and J. Wang. A join-cache tree based approach for continuous temporal pattern detection in streaming graph. In ICSPCC, pages 1–6. IEEE, 2017. [216] T. Suzumura, S. Nishii, and M. Ganse. Towards large-scale graph stream processing platform. In ACM WWW, pages 1321–1326, 2014. [217] G. Szárnyas, A. Prat-Pérez, A. Averbuch, J. Marton, M. Paradies, M. Kaufmann, O. Erling, P. Boncz, V. Haprian, and J. B. Antal. An Early Look at the LDBC Social Network Benchmark’s Business Intelligence Workload. GRADES-NDA, pages 9:1–9:11, 2018. [218] A. Tate et al. Programming abstractions for data locality. PADAL Workshop 2014. [219] M. Then, T. Kersten, S. Günnemann, A. Kemper, and T. Neu- mann. Automatic algorithm transformation for efficient multi- snapshot analytics on temporal graphs. Proceedings of the VLDB Endowment, 10(8):877–888, 2017. [220] A. Tripathy and O. Green. Scaling betweenness centrality in dy- namic graphs. In 2018 IEEE High Performance extreme Computing Conference (HPEC), pages 1–7. IEEE, 2018. [221] T. Tseng, L. Dhulipala, and G. Blelloch. Batch-parallel euler tour trees. In SIAM ALENEX, 2019. [222] L. G. Valiant. A bridging model for parallel computation. Com- munications of the ACM, 33(8):103–111, 1990. [223] J. van den Brand and D. Nanongkai. Dynamic approximate shortest paths and beyond: Subquadratic and worst-case update time. FOCS, 2019. [224] A. van der Grinten, E. Bergamini, O. Green, D. A. Bader, and H. Meyerhenke. Scalable katz ranking computation in large static and dynamic graphs. arXiv preprint arXiv:1807.03847, 2018. [225] L. M. Vaquero, F. Cuadrado, and M. Ripeanu. Systems for near real-time analysis of large-scale dynamic graphs. arXiv:1410.1903, 2014. [226] K. Vora et al. Aspire: exploiting asynchronous parallelism in iterative algorithms using a relaxed consistency based dsm. ACM SIGPLAN Notices, pages 861–878, 2014. [227] K. Vora et al. Kickstarter: Fast and accurate computations on streaming graphs via trimmed approximations. ACM SIGOPS Operating Systems Review, 2017. [228] K. Vora, R. Gupta, and G. Xu. Synergistic analysis of evolving graphs. ACM TACO, 13(4):32, 2016. [229] K. Wang, Z. Zuo, J. Thorpe, T. Q. Nguyen, and G. H. Xu. Rstream: marrying relational algebra with streaming for efficient graph mining on a single machine. In USENIX OSDI, pages 763–782, 2018. [230] M. Winter et al. Autonomous, independent management of dynamic graphs on gpus. In IEEE HPEC, 2017. [231] M. Winter, D. Mlakar, R. Zayer, H.-P. Seidel, and M. Stein- berger. faimgraph: high performance management of fully- dynamic graphs under tight memory constraints on the gpu. In ACM/IEEE Supercomputing, 2018. [232] H. Wu, J. Cheng, S. Huang, Y. Ke, Y. Lu, and Y. Xu. Path problems in temporal graphs. VLDB, 2014. [233] H. Wu, Y. Huang, J. Cheng, J. Li, and Y. Ke. Reachability and time-based path queries in temporal graphs. In IEEE ICDE, 2016. [234] L. Xiangyu, L. Yingxiao, G. Xiaolin, and Y. Zhenhua. An efficient snapshot strategy for dynamic graph storage systems to support historical queries. IEEE Access, 8:90838–90846, 2020. [235] W. Xie, Y. Tian, Y. Sismanis, A. Balmin, and P. J. Haas. Dynamic interaction graphs with probabilistic edge decay. In IEEE ICDE, pages 1143–1154, 2015. [236] S. Yang, X. Yan, B. Zong, and A. Khan. Towards effective partition management for large graphs. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, pages 517–528. ACM, 2012. [237] M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma, M. McCauly, M. J. Franklin, S. Shenker, and I. Stoica. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster com- puting. In USENIX NSDI, 2012. [238] M. Zaharia, R. S. Xin, P. Wendell, T. Das, M. Armbrust, A. Dave, X. Meng, J. Rosen, S. Venkataraman, M. J. Franklin, et al. Apache spark: a unified engine for big data processing. Communications of the ACM, 59(11):56–65, 2016. [239] A. Zaki, M. Attia, D. Hegazy, and S. Amin. Comprehensive sur- vey on dynamic graph models. International Journal of Advanced Computer Science and Applications, 7(2):573–582, 2016. [240] J. Zhang. A survey on streaming algorithms for massive graphs. Managing and Mining Graph Data, pages 393–420, 2010. [241] Y. Zhang, R. Chen, and H. Chen. Sub-millisecond stateful stream querying over fast-evolving linked data. In Proceedings of the 26th Symposium on Operating Systems Principles, pages 614–630. ACM, 2017. [242] S. Zhou, R. Kannan, H. Zeng, and V. K. Prasanna. An fpga framework for edge-centric graph processing. In Proceedings of the 15th ACM International Conference on Computing Frontiers, pages 69–77. ACM, 2018. [243] X. Zhu, G. Feng, M. Serafini, X. Ma, J. Yu, L. Xie, A. Aboul- naga, and W. Chen. Livegraph: A transactional graph storage system with purely sequential adjacency list scans. arXiv preprint arXiv:1910.05773, 2019.](https://image.slidesharecdn.com/1912-210605084152/75/Practice-of-Streaming-Processing-of-Dynamic-Graphs-Concepts-Models-and-Systems-NOTES-23-2048.jpg)

This document presents the first analysis and taxonomy of dynamic and streaming graph processing systems, highlighting their architectural differences and performance aspects. It addresses various concepts such as dynamic, temporal, online, and time-evolving graphs, and discusses the recent theoretical advancements that could enhance practical frameworks. The work aims to guide architects and developers by categorizing and comparing different graph streaming frameworks and their corresponding workloads and challenges.