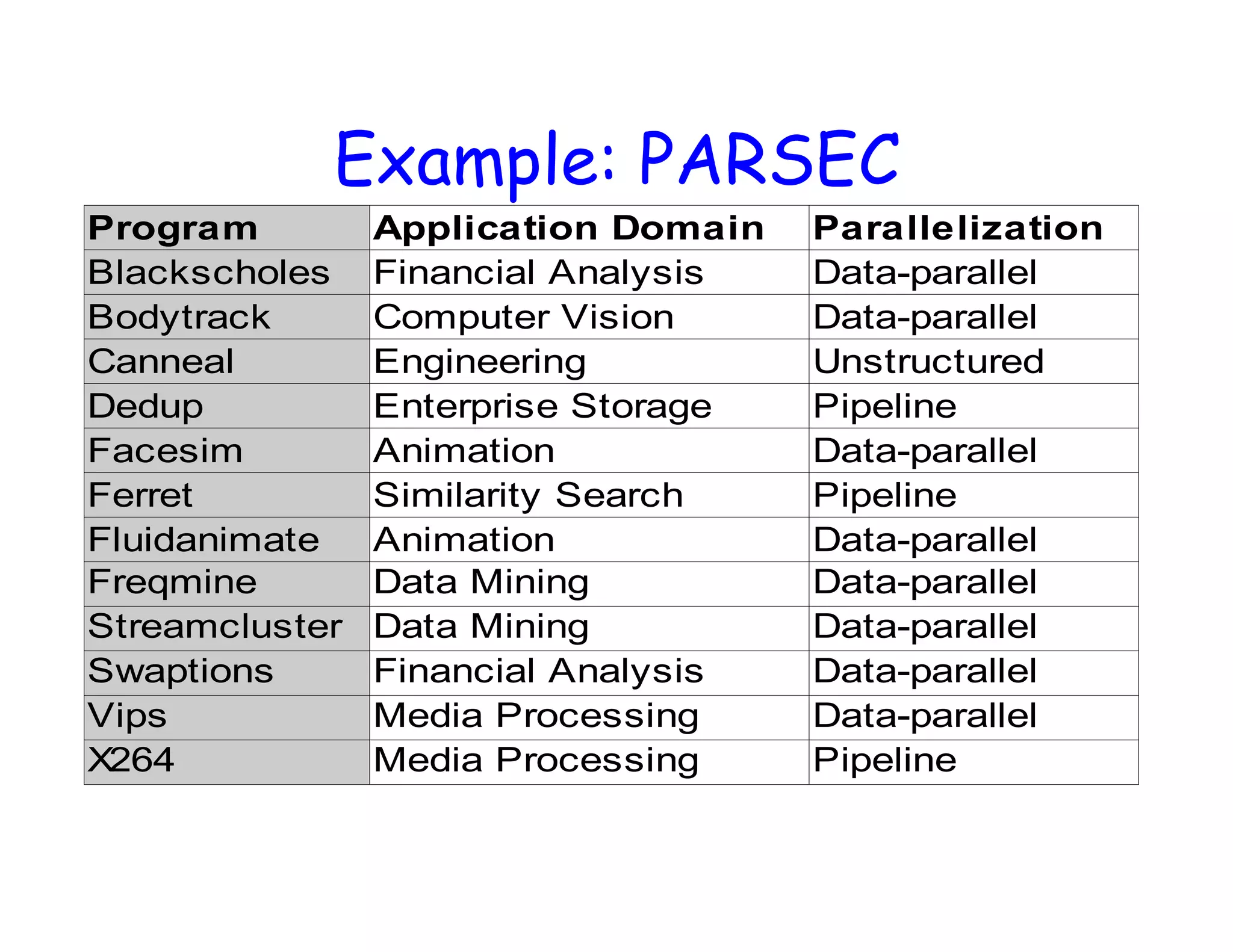
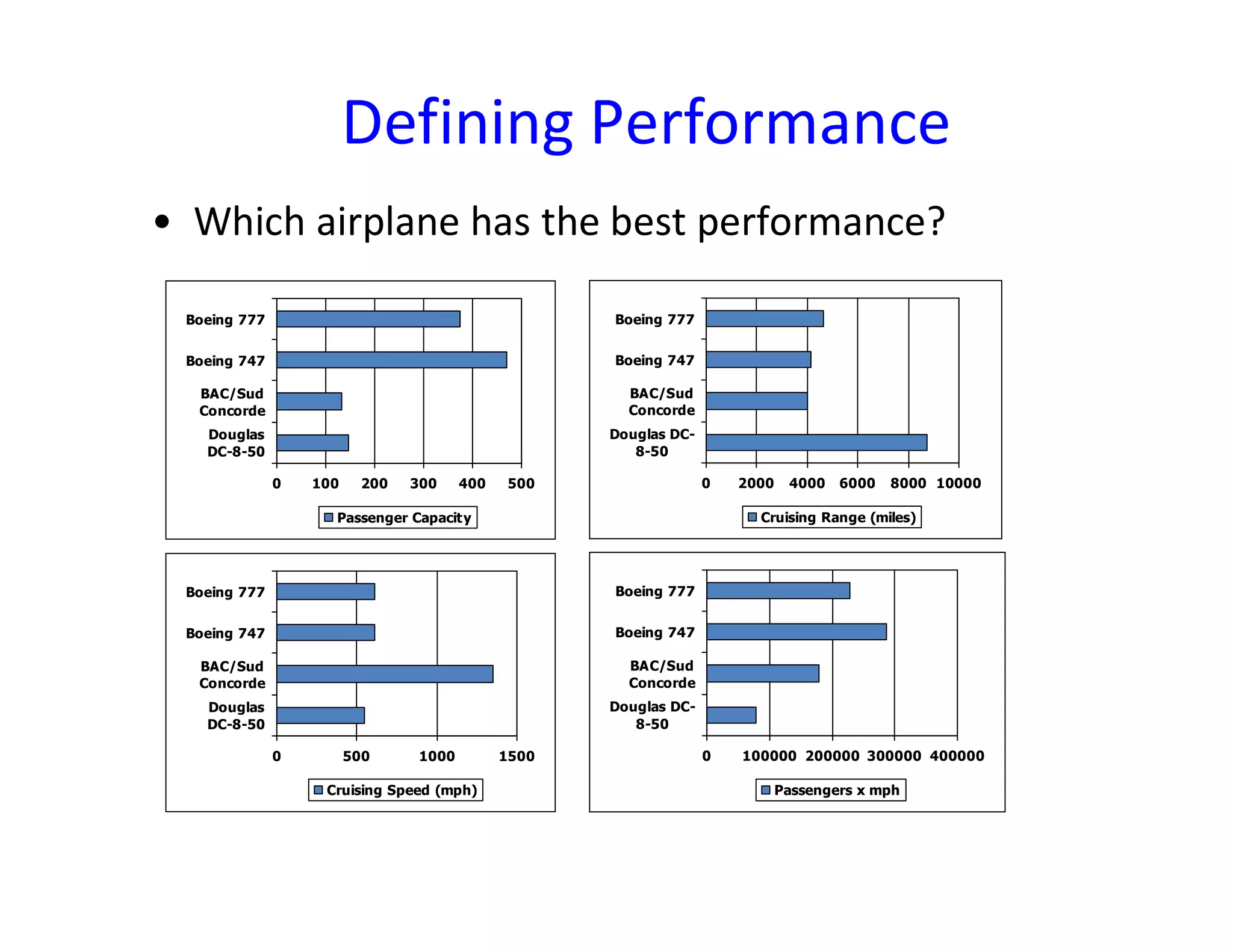
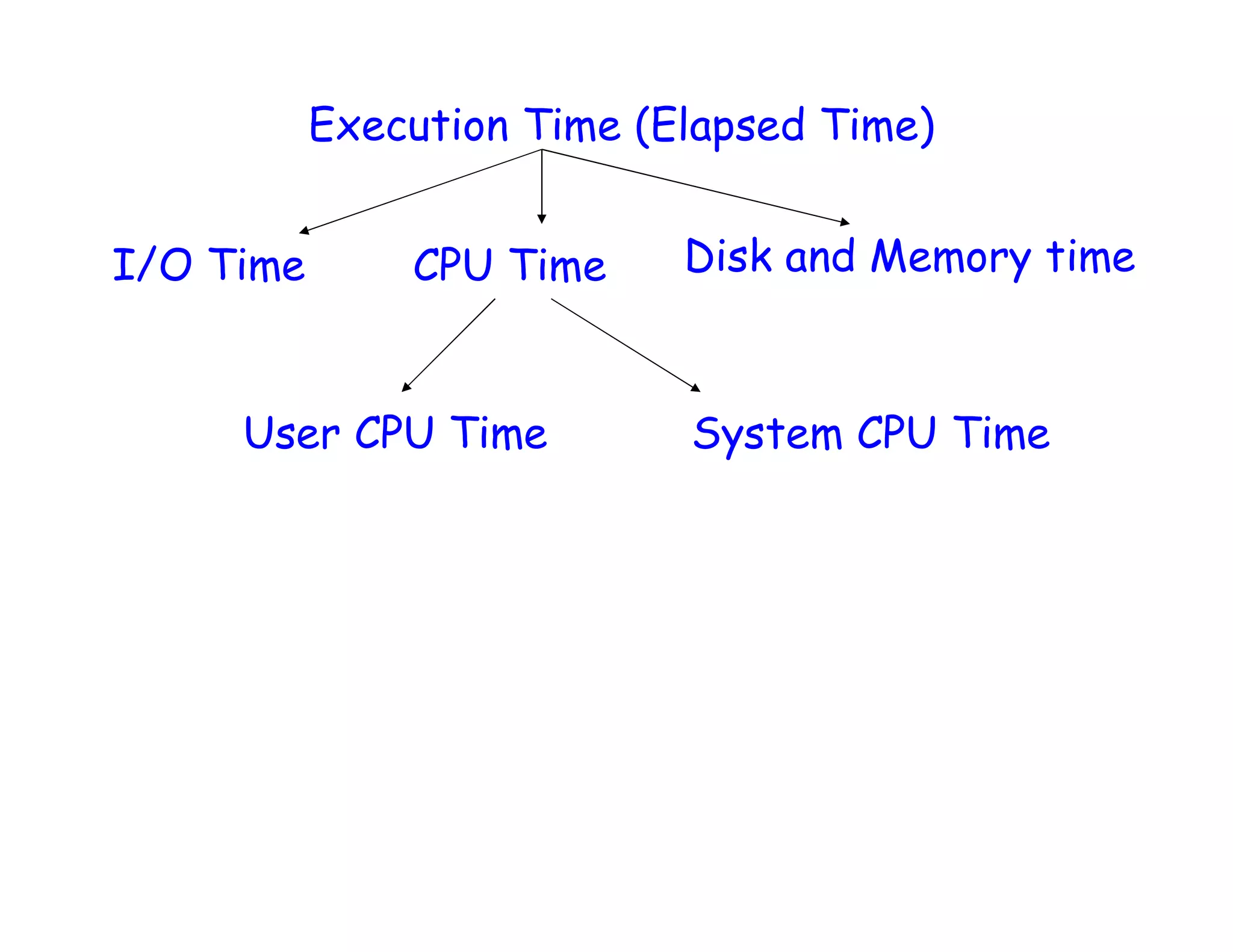
This document discusses performance analysis and parallel computing. It defines performance metrics like speedup, efficiency, and scalability that are used to evaluate parallel programs. Sources of parallel overhead like synchronization, load imbalance, and communication are described. The document also discusses benchmarks used to evaluate parallel systems like PARSEC and Rodinia. It emphasizes that overall execution time captures a system's real performance and depends on factors like CPU time, I/O, memory access, and interactions between programs.



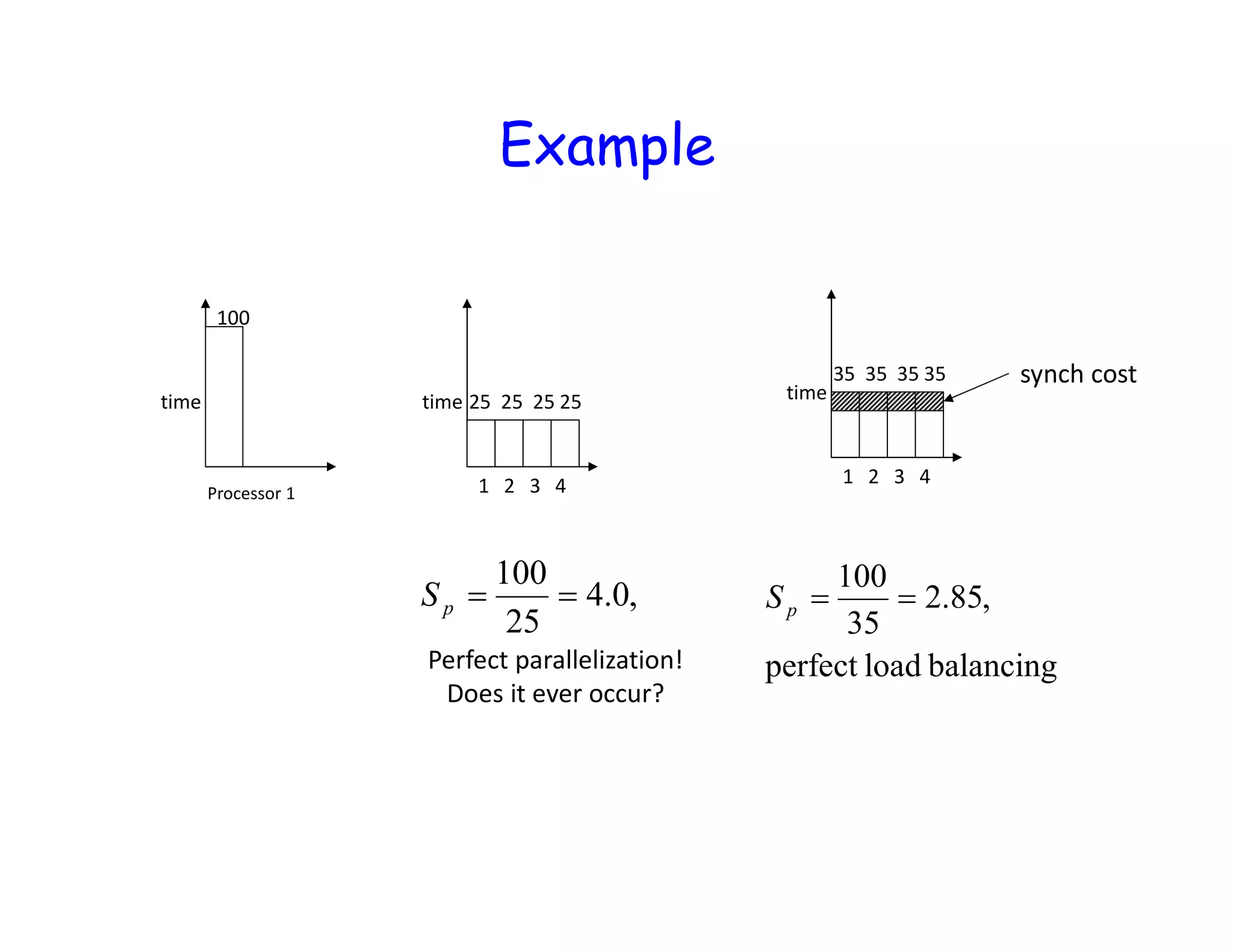
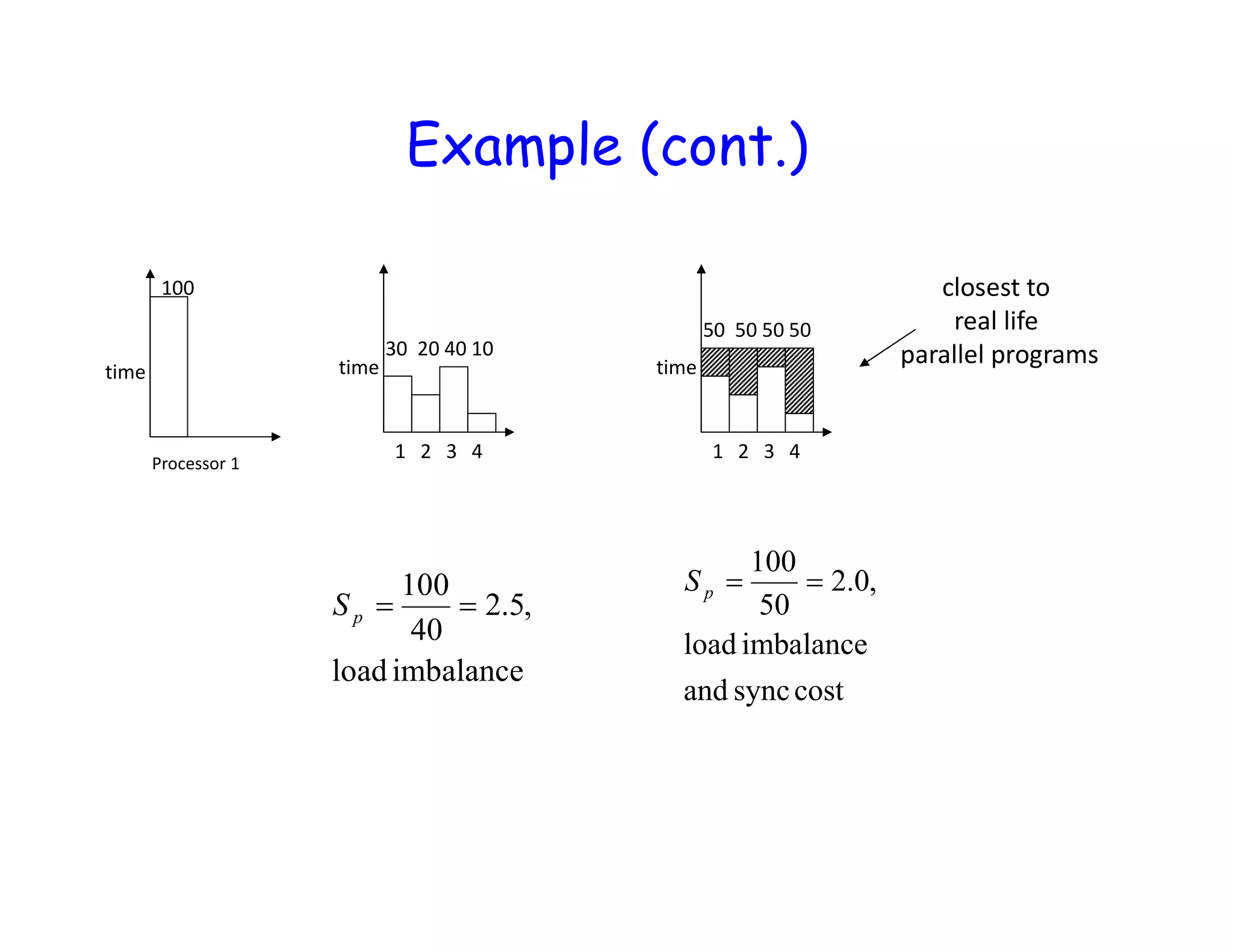









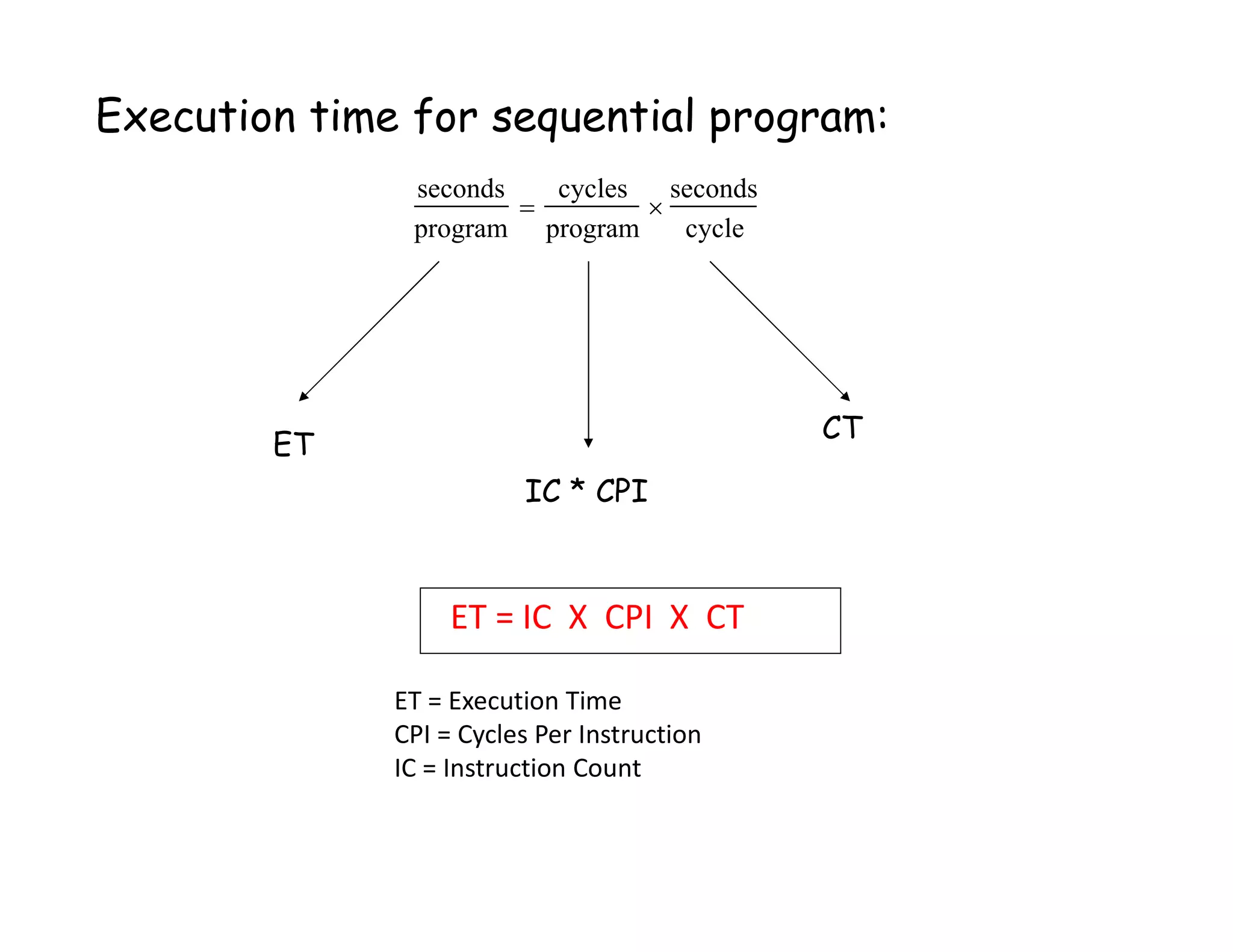

![CPI Example • Suppose we have two implementations of the same instruction set architecture (ISA). For some program, Machine A has a clock cycle time of 250 ps and a CPI of 2.0 Machine B has a clock cycle time of 500 ps and a CPI of 1.2 What machine is faster for this program, and by how much? [ 10-3 = milli, 10-6 = micro, 10-9 = nano, 10-12 = pico, 10-15 = femto ]](https://image.slidesharecdn.com/lecture61-200417022301/75/Parallel-Computing-Lec-6-23-2048.jpg)