Download as PDF, PPTX




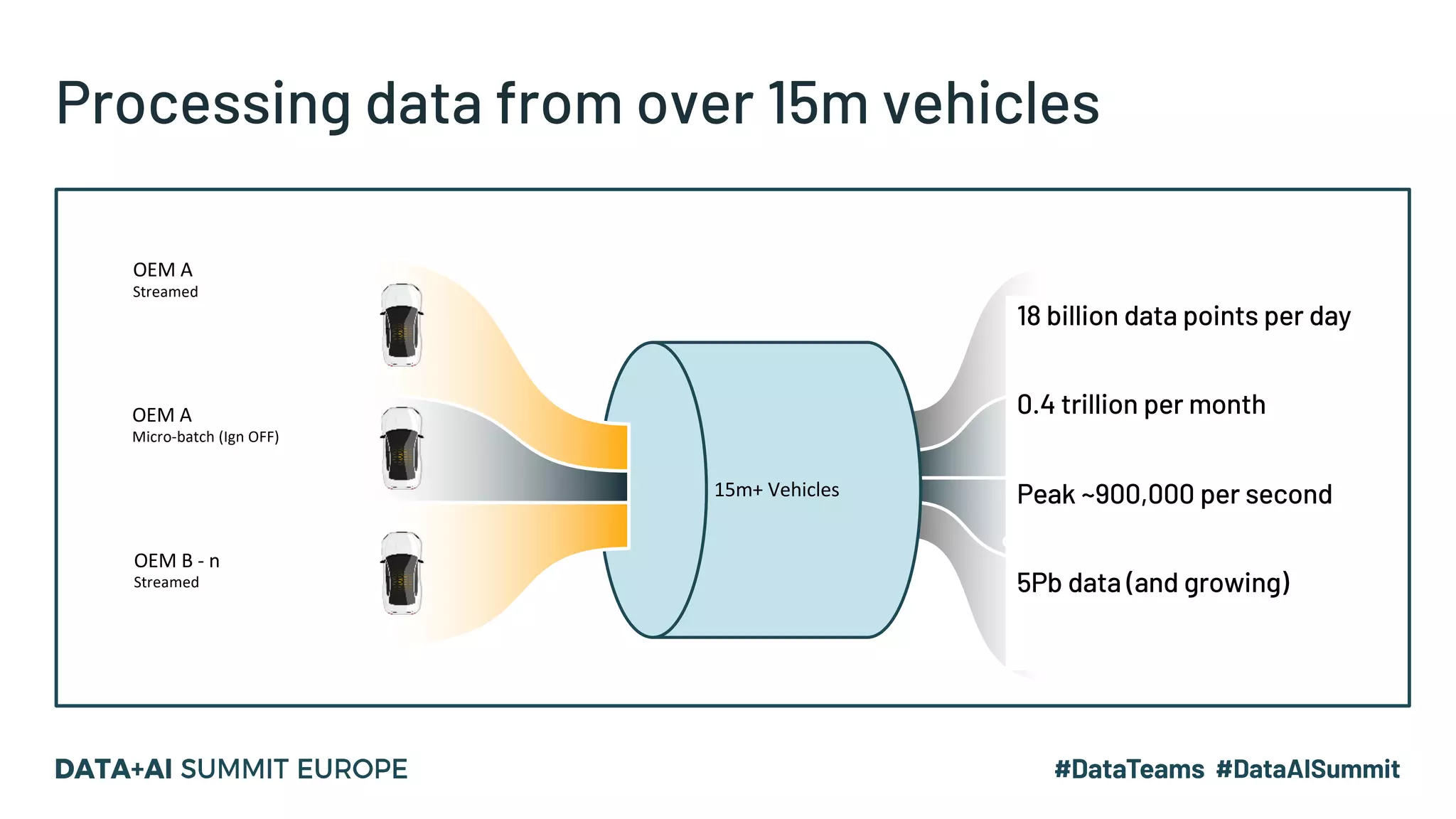
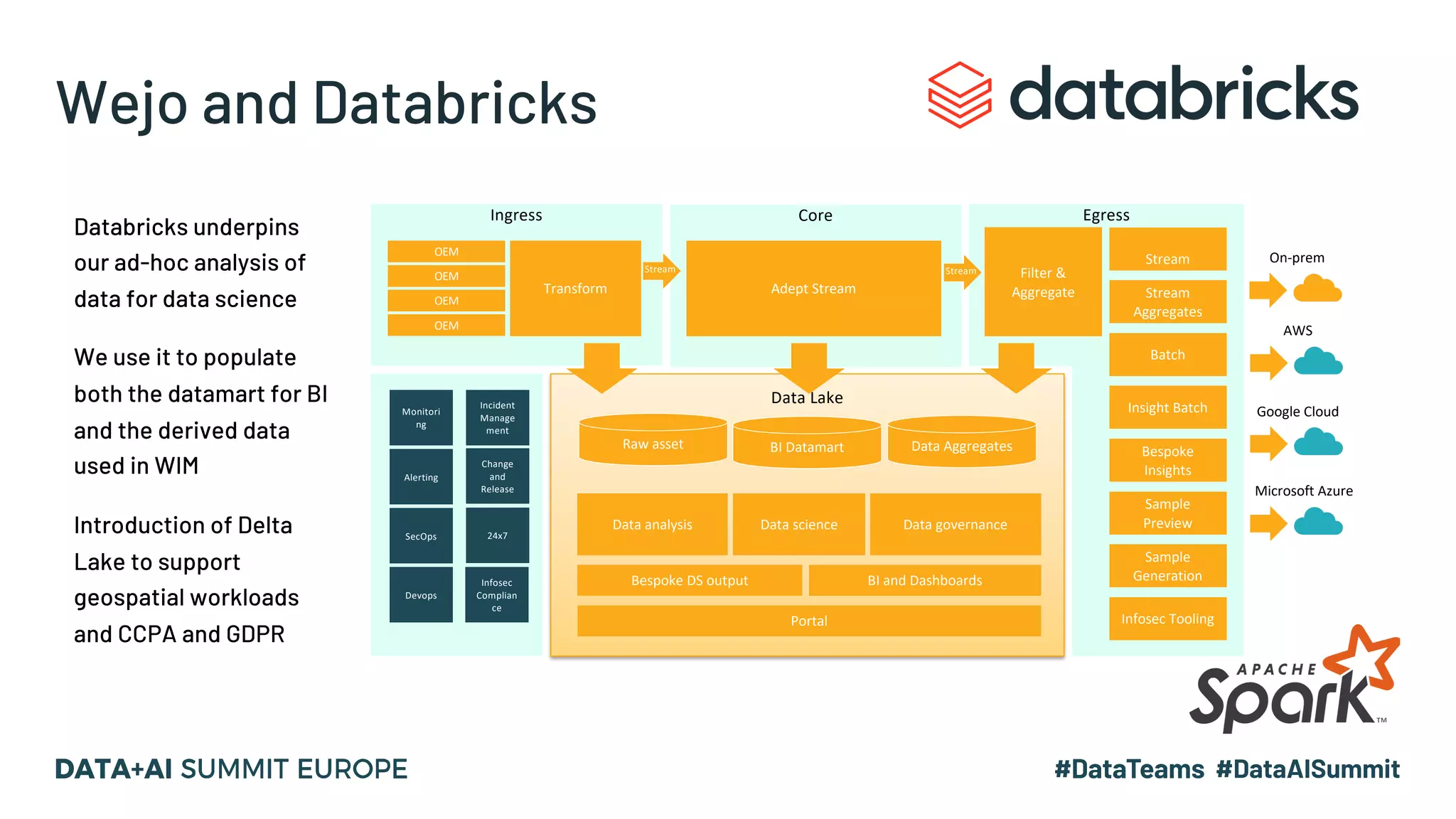
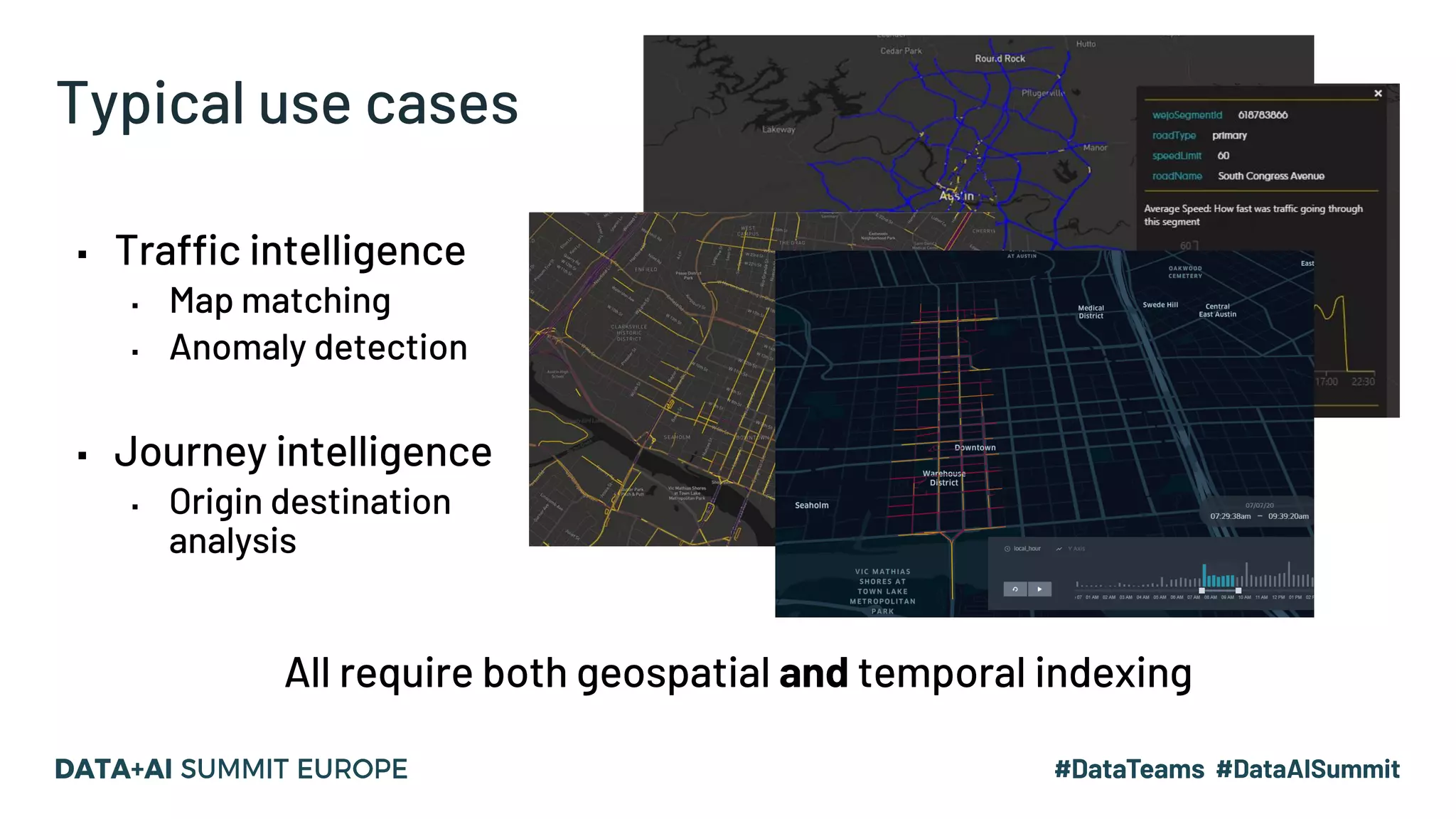








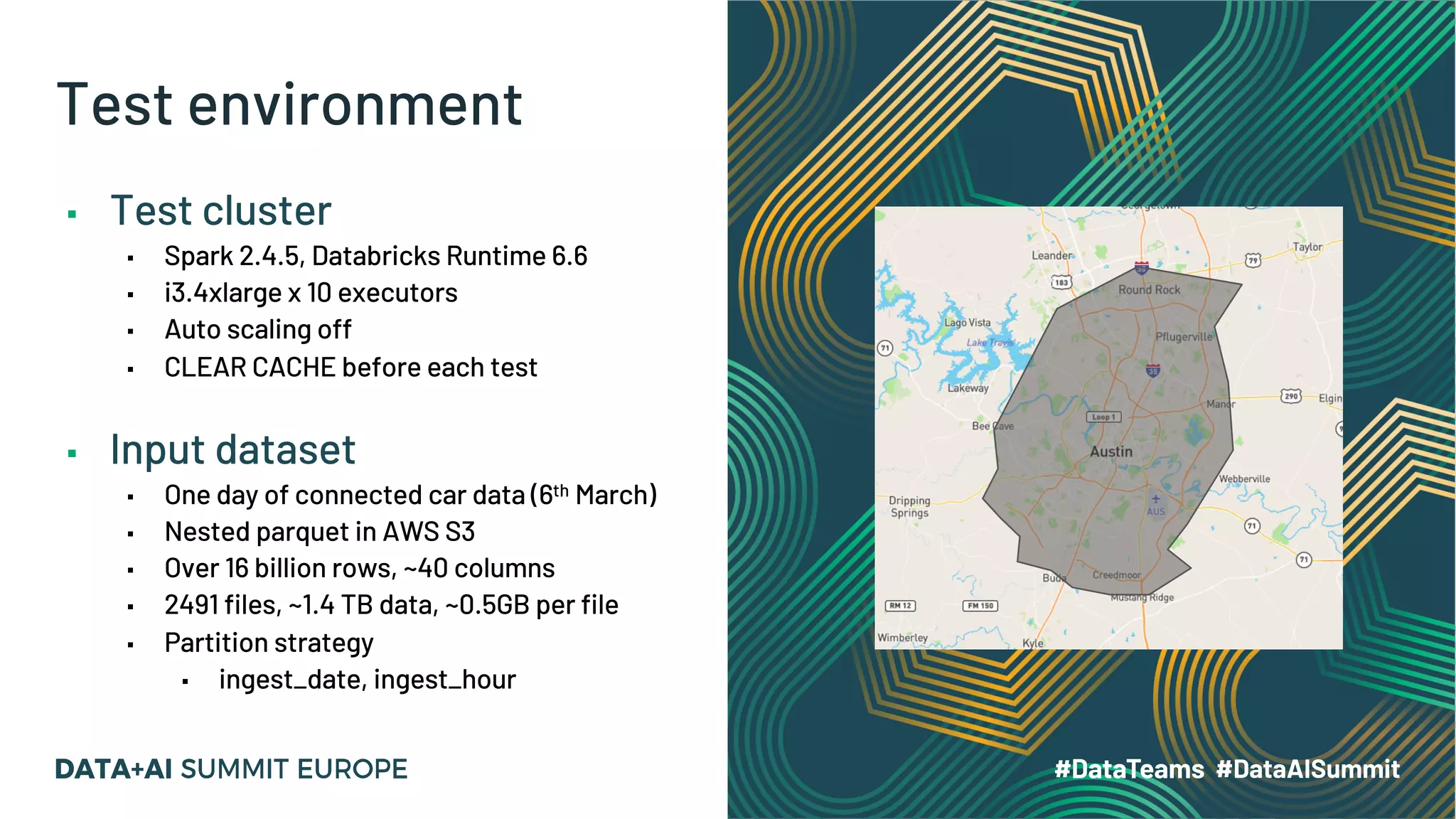
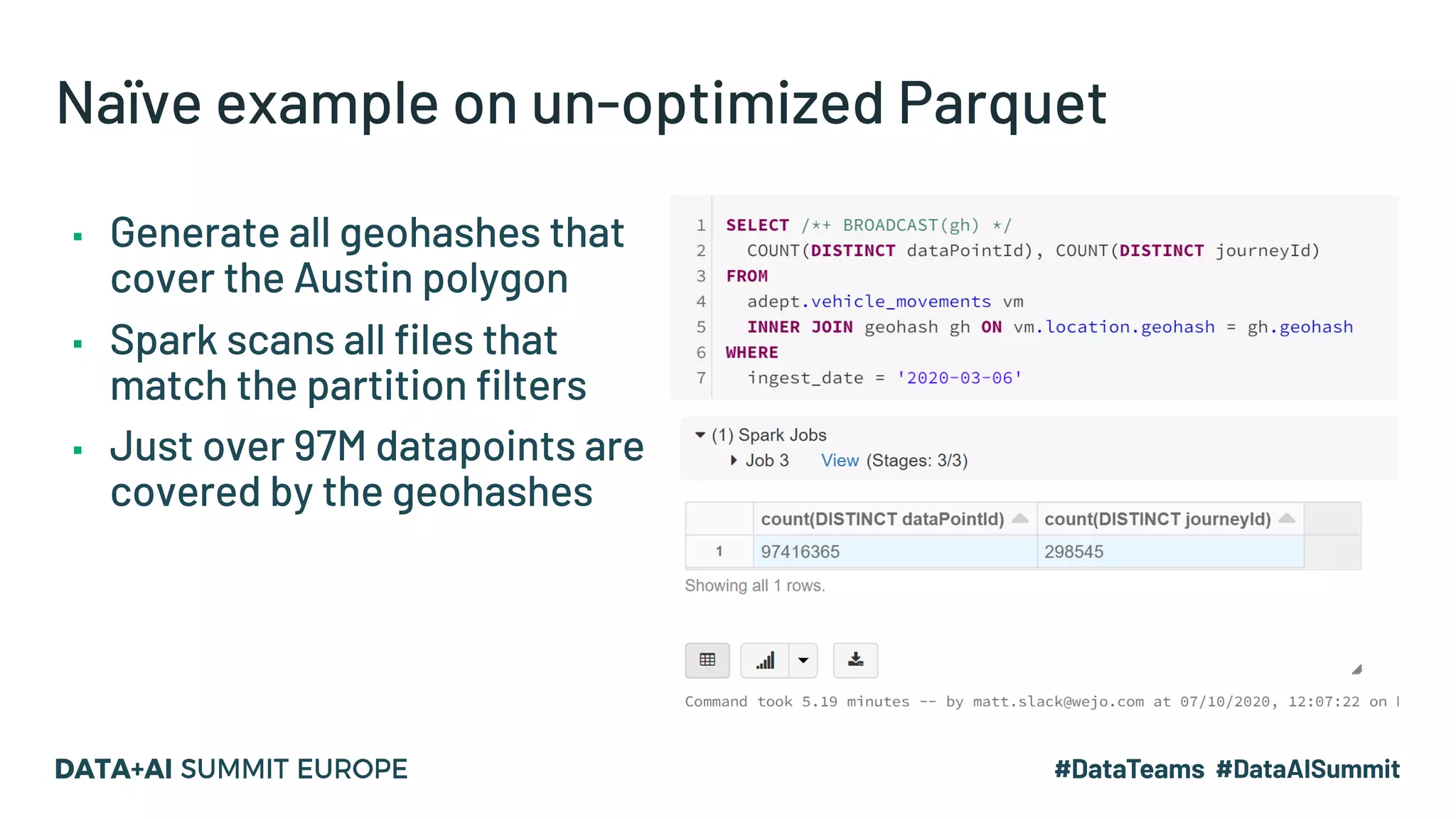




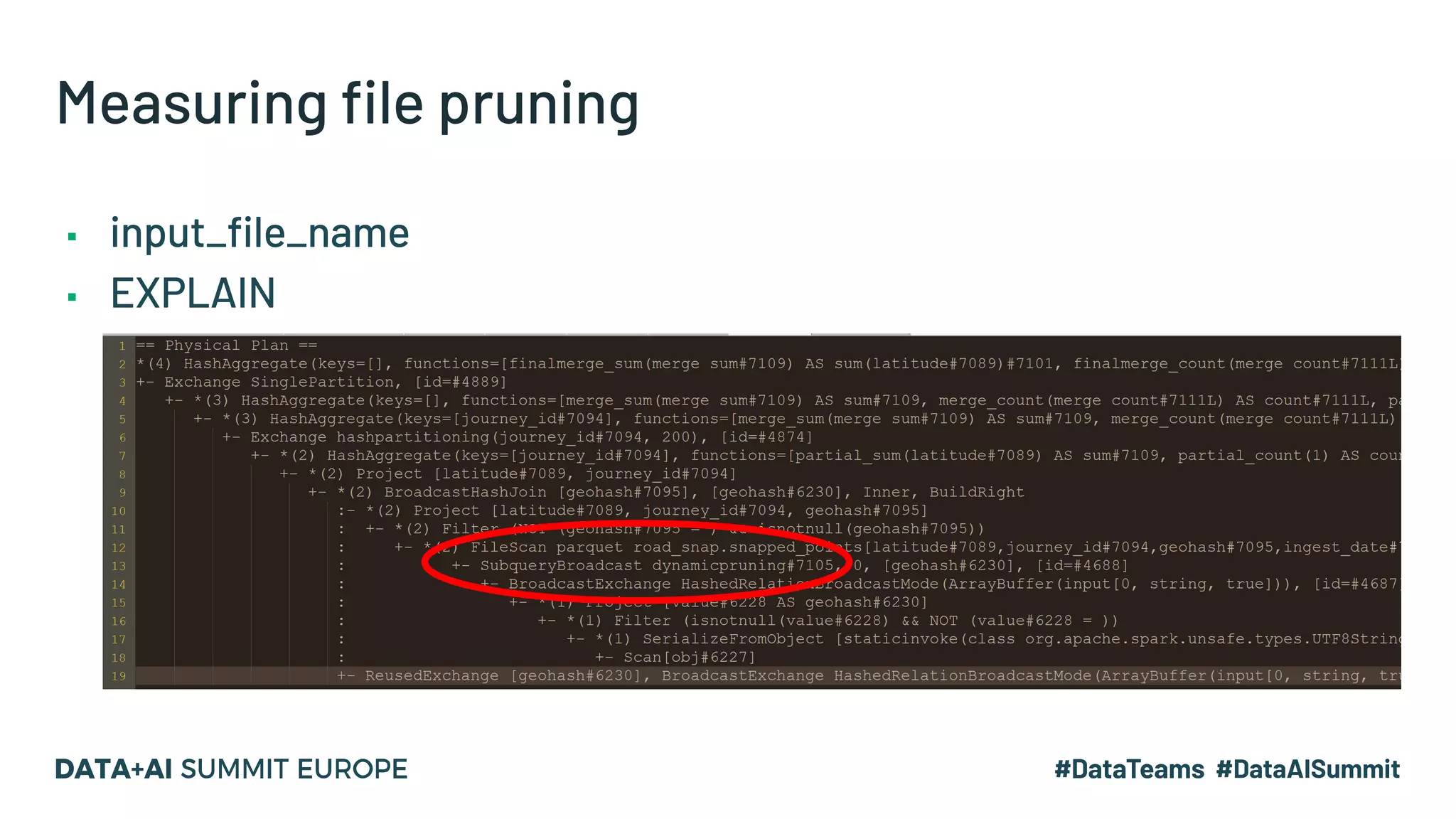
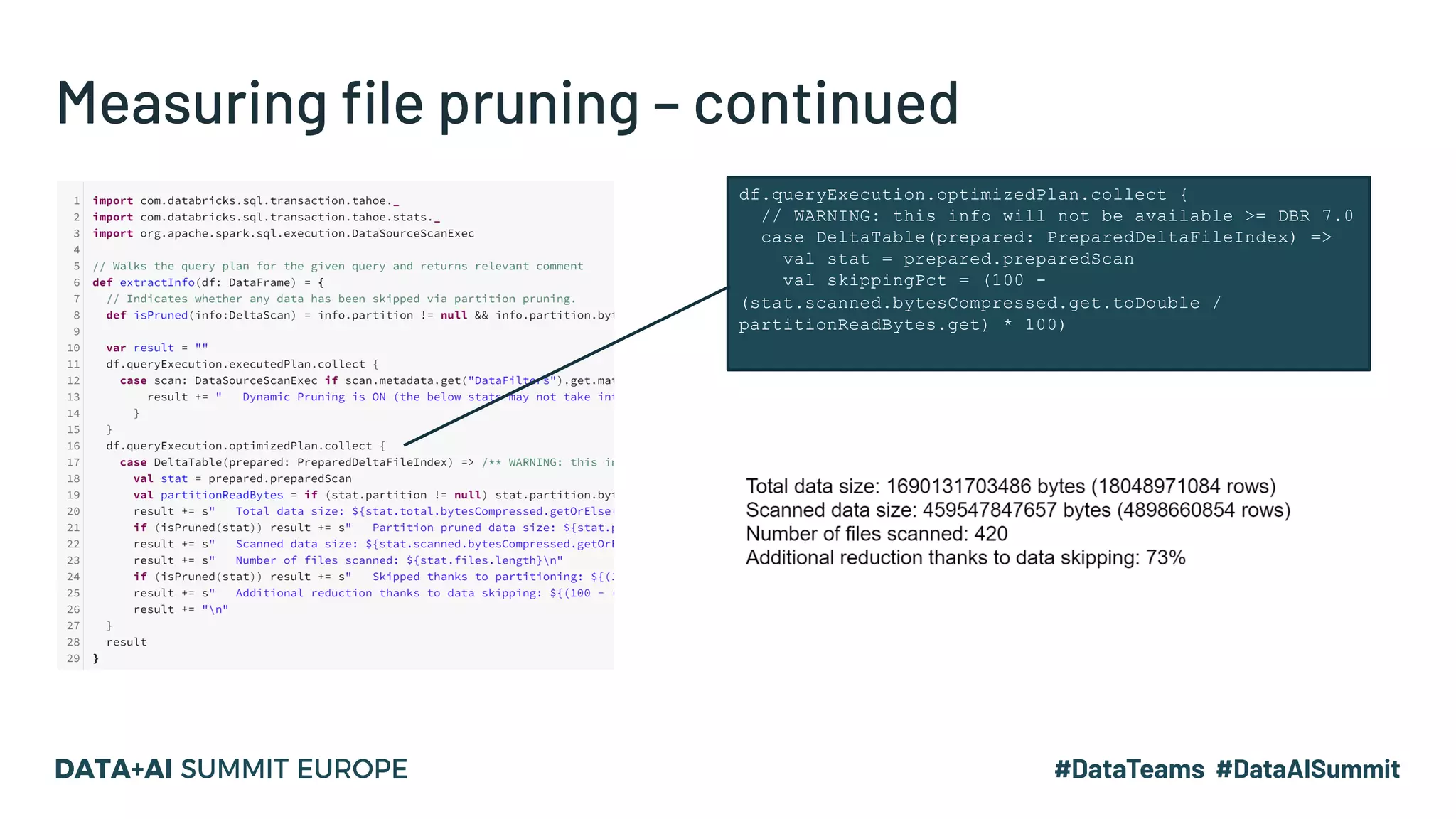

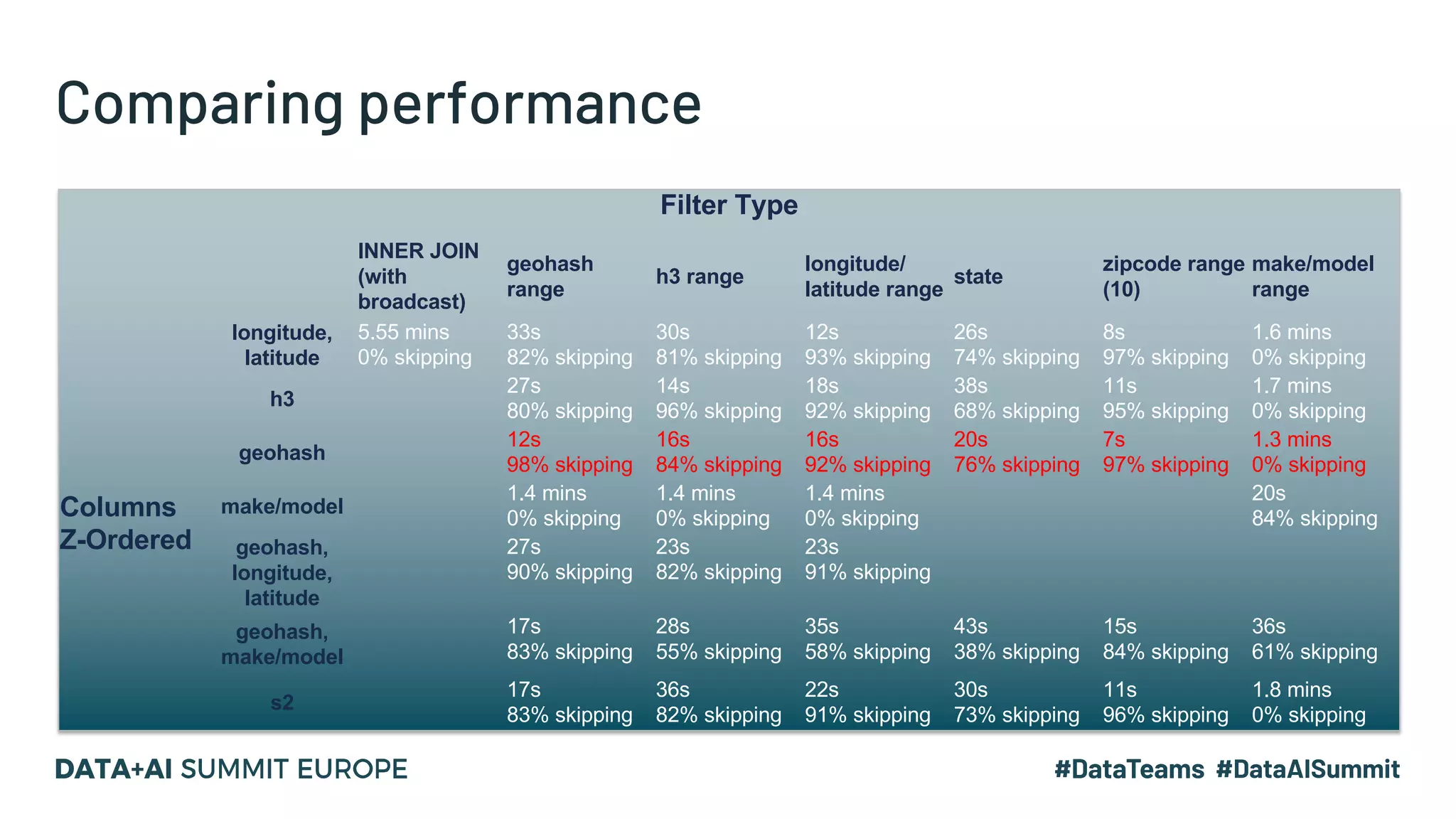
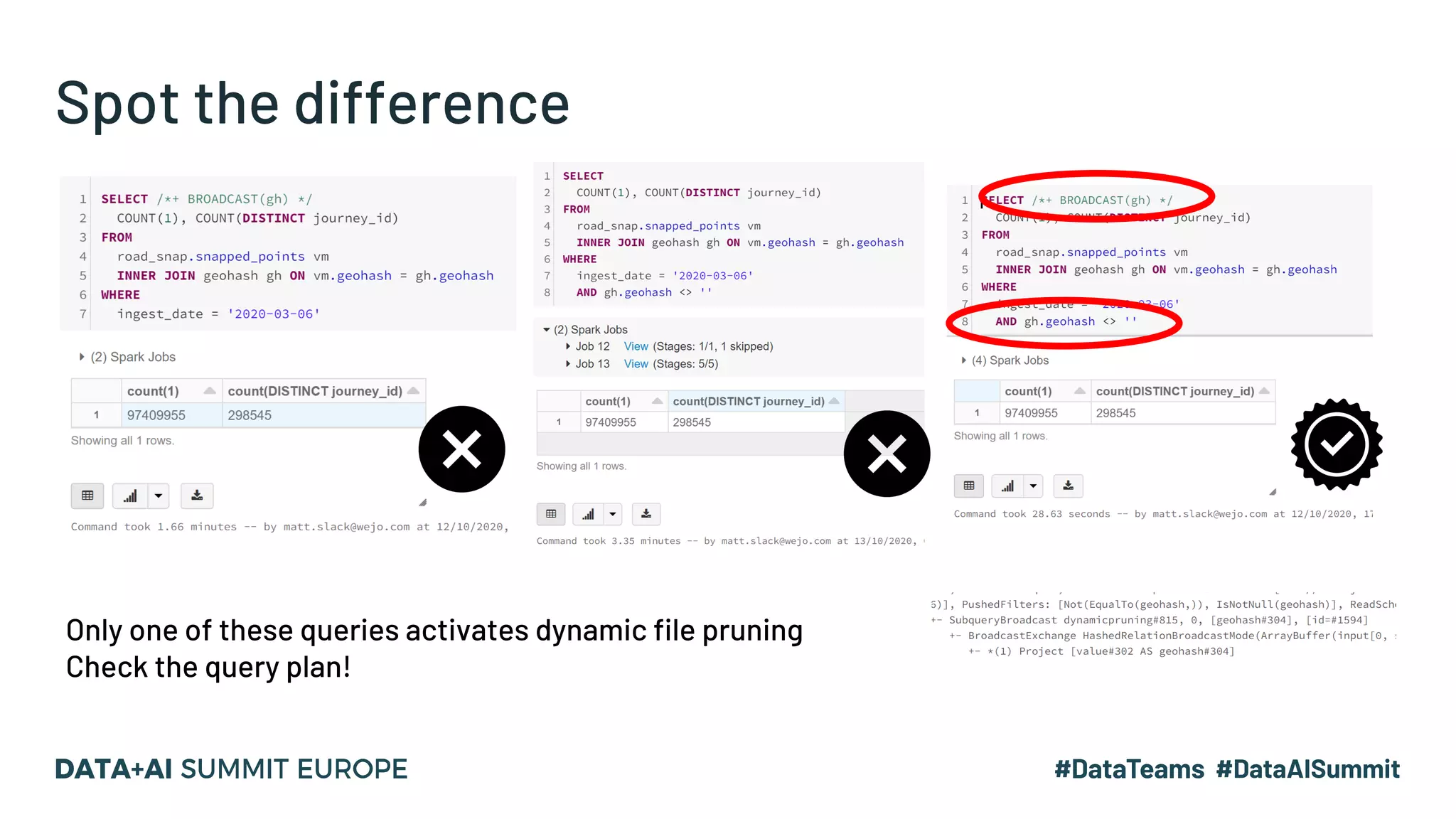


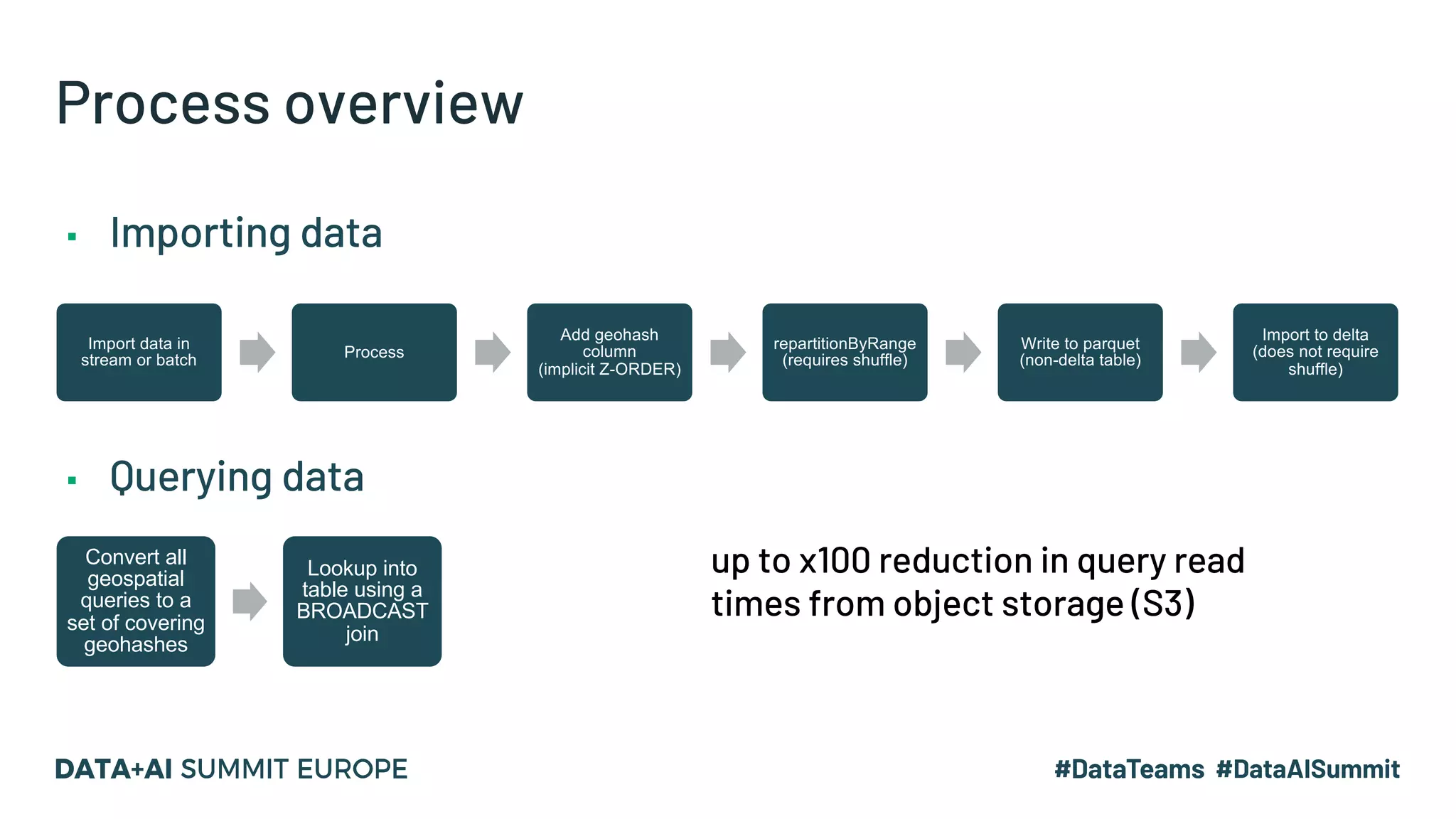



The document discusses optimizing geospatial queries using dynamic file pruning techniques at Wejo, which processes extensive data from over 15 million vehicles. It covers indexing strategies, the introduction of Delta Lake for geospatial workloads, and the advantages of dynamic file and partition pruning to enhance query performance. It highlights the effectiveness of Z-ordering to improve data co-locality and reduce read times from object storage.