This document describes a study that used a logic-based machine learning approach called APARELL to learn user preferences from pairwise comparisons in a recommender system. APARELL learns description logic rules from examples of users' pairwise item preferences and background knowledge about item properties. It was implemented in a used car recommender system. A user study evaluated the pairwise preference elicitation method compared to a standard list interface. Results showed the pairwise interface was significantly better in recommending items that matched users' preferences.

![2638 r ISSN: 2302-9285 strategy is known as inductive learning, or also known as supervised learning. While the statistical inductive learning is expressed by using numerical method, the generalised principle of logic-based inductive learning is expressed by using some logic language, e.g. Propositional Logic, first order logic (FOL), or description logics (DL). APARELL [1] is one of the inductive algorithm specialised in learning relation in DL language. It is a further implementation of inductive logic programming (ILP) [2] which was developed to learn classification problem in FOL language and DL-Learner [3] which was developed to learn classes in DL language. Some of ILP advantages are simplicity, readability and efficiency to handle numerous data. In this paper, we aim to show the benefit of using logical representation to learn relation between two classes of a set of datapoint with specific characteristics. Learning user preference itself has been studied by many researchers and it has grown to become a specific research field, which called preference learning (PL), introduced by Fürnkranz and Hüllermeier in 2010 [4]. The main purpose of this field is to generate a valid predictive hypothesis model from a set of known value of user preferences. The most common form of this learning output is in a full order ranking. For example, a user may give a preference that he/she likes item A better than item B, item B better than item C. Then the aim of the learning is to produce global ranking, such as, according to that particular user, the following hypothesis is valid: item A item B item C. It uses “” symbol to express the higher order in the ranking position. The most well-known algorithm in this field called label ranking which was also introduced by the same group of the researcher in 2008 [5]. The latest work in this field has been proposed by Pandey, et. al. in [6] which introduced Pref2V ec algorithm using a vector to learn pairwise item preferences and Simpson and Gurevych in 2020 [7] which proposed Bayesian preference learning, which is an improvement from other related work [8–11]. We use pairwise comparisons problem as a case study to learn relations by using a logic-based ap- proach. In this paper, we implemented the learning algorithm in recommender system area to make it easier for the reader to understand the problem. Recommender system (RS) is a subfield of Information Filtering where the main goal is to predict the customer preferences and then recommend the best suited items. The most com- mon method for preference elicitation in recommender system is using ratings, reviews and feedback. There is also an alternative method for elicit user’s taste, called pairwise preference elicitation, where the users can express their favour in the form of choices. In pairwise preference, the user is asked to rank the items based on their liking and it is shown in pair of items. Some researchers like Balakrishnan and Chopra [12] has shown that by using pairwise comparisons, the majority of users (74%) find that the recommendation produced by this preference elicitation method is better than using numeric rating system although only 45% of the participants like to answer the question in pairwise choices. The use of pairwise comparisons can also reduce the user incon- sistency of giving numeric ratings. Pairwise recommender systems have been an interest in these recent years. This is because the use of pairwise comparisons as preference elicitation itself is still uncommon. Research in this area includes using collaborative filtering in pairwise item [13], Orthogonal Pairwise Queries [14], music recommender system based on Gaussian Process [15] and pairwise recommender system using Lazy Decision Tree [16]. On the other hand, most of the work in recommender systems use statistical machine learning to pre- dict the most favourite items of the customers. While this approach has been proven to be statistically accurate, but there are still some disadvantages as they can only work well with a large number of data. In the case when there is not enough data or information given to the system, this approach has to make some approximate calculations to create the recommendation. In this paper, we introduce the use of logic based approach in rec- ommender system which works well with limited data as well. Using a logic-based machine learning approach, the system can also produce a nice explanation of why the recommender system can show such a valid recom- mendation. Studies on the explanatory aspect of recommender systems which shows process transparency to users have been growing [17–19]. People tend to express more, as well as increasing trust and loyalty, if they are able to get the explanation on how the system can give them a recommendation. Some of the studies on explanation interfaces for collaborative filtering method are discussed in a number of other publications [20]. A logic based approach, which use more representative language to express data and model, has a capability to build white box machine learning which can easily be understood by the human. The advantage of this logic based approach has not been widely used in recommender systems. There is an opportunity which can be explored more in this area. In this paper, we describe the implementation of a recommender system for used car sales domain by using our previous work on a logic based approach, called APARELL. From a set of pairwise comparisons, Bulletin of Electr Eng Inf, Vol. 9, No. 6, December 2020 : 2637 – 2649](https://image.slidesharecdn.com/53-2384latex-210807000658/75/On-the-benefit-of-logic-based-machine-learning-to-learn-pairwise-comparisons-2-2048.jpg)
![Bulletin of Electr Eng Inf ISSN: 2302-9285 r 2639 the system can learn the user’s preferences to produce a set of recommendations and provide an explanation of why the system chooses the recommended items. This algorithm has been evaluated and outperformed the other baseline algorithms, which also shows higher accuracy against statistic-based learning algorithm [21]. This method can also be used in other domain such one concept we have proposed for e-learning pairwise recommender system in [22]. The contribution of this paper includes: (1) implementing our novel logic based machine learning approach for a real-life recommender system, (2) introducing the use of pairwise preference in recommender system and (3) evaluating the combination of logic based machine learning with pairwise interface performance against the standard most common list interface. The rest of the paper is organised as follows: in Section 2, we explain the proposed main modules, which consist of the learning algorithm for generating the rules and the recommendation algorithm. We then discuss the research method in Section 3 which discuss about the usability technique and questionnaire, followed by the result analysis in Section 4. Finally, we conclude our work and provide our plan for further work in Section 5. 2. THE PROPOSED METHOD We built the personalised recommender system based on pairwise choices. The system learned from a set of answers given by the users when the choices shown to them. The users could also use filtering system where they could narrow down the options closest to their needs. The system consisted of two main mod- ules: (1) learner and (2) recommender. The learner module was implemented by using a logic-based machine learning algorithm, APARELL and the recommender system was built based on the rules produced by the first module. 2.1. Learning algorithm We have built a general purpose learning algorithm called APARELL (Active Pairwise Relations Learner). The complete description about this algorithm and the technical aspect can be found in our other article in [1]. It is a machine learning algorithm which uses description logics (DL) representation to describe the problem. By using the terms from inductive logic programming (ILP) [23], we explain the representation of APARELL in three parts: (1) hypothesis language, (2) set of examples and (3) background knowledge. 2.1.1. Hypothesis language Hypothesis language is the representation language used to describe the outputs of the machine learn- ing. In APARELL, the hypotheses are described in the forms of specific relation between two individuals or group of individuals which has a set of particular properties (defined as a class or subclass). For example, a car that belongs to Manual and SUV class always better than a car that belong to Automatic class. APARELL will search the best hypothesis from the hypothesis space described as in the previous examples. The hypothesis language used in here is the role itself which is the relation betterthan. The representation of hypothesis lan- guage by using RDF format is written as: carsontology:betterthan rdf:type owl:ObjectProperty. 2.1.2. Set of examples We consider the transitivity in the betterthan relation as its natural behaviour. The transitivity in this context means that whenever a user prefer item A than item B, and prefer item B than item C, we can conclude that this particular user will prefer item A over item C. So we can add this new fact to the examples. Since APARELL uses DL as the representation language, inferring a new fact as transitivity closure can easily be performed by using the ontology reasoners, such as Pellet, FaCT++, HerMiT, ELK, etc. These reasoners have the capability to automatically detect the inferred facts or relations from the given knowledge bases. In addition to that, the betterthan relation satisfies the anti-symmetric property, which means that there is no counter-example exists in the dataset. For instance, if a user likes item A better than item B, there is no single evidence that says this particular user likes item B better than item A (the other way around). Observing this behaviour, APARELL put the additional reverse order of the betterthan relation as negative examples (incorrect data). From here, the algorithm will have a set of positive (correct order) and a set of negative (reverse order) examples to be learned. The representation of examples in RDF format is shown below: On the benefit of logic-based approach to learn pairwise comparisons (Nunung Nurul Qomariyah)](https://image.slidesharecdn.com/53-2384latex-210807000658/75/On-the-benefit-of-logic-based-machine-learning-to-learn-pairwise-comparisons-3-2048.jpg)
![2640 r ISSN: 2302-9285 carsontology:car1 carsontology:betterthan carsontology:car3, carsontology:car4, carsontology:car5, carsontology:car10. 2.1.3. Background knowledge In ILP, background knowledge is important information that the learning algorithm can use to build a set of hypotheses [23]. This important information can be a description of the properties that each individual holds. In DL, the background knowledge is expressed through the classes and their membership. For example, “car 1 belongs to a class: Manual and SUV”. In RDF format, it representation is shown below: carsontology:Hatchback rdf:type owl:Class ; rdfs:subClassOf carsontology:Car; owl:disjointWith carsontology:Suv. carsontology:car1 rdf:type owl:NamedIndividual, carsontology:Car, carsontology:Automatic, carsontology:Petrol, carsontology:Hatchback. 2.1.4. Learning step APARELL as an inductive learner learns from a set of given facts and background knowledge to find the best general hypothesis which correctly explain the information provided. The learning step is shown in Figure 1. In order to find the valid hypotheses, APARELL uses these basic steps as follows: − Start from one positive example from the given input. − Generate the botom clause for the chosen positive example in the previous step. − Start building a possible hypothesis space. In this step, APARELL builds a simple combination of each class available as the bottom clause in the previous step. The top hypothesis will be: Thing is-better-than Thing. − Start searching from the top, capped by the bottom clause. In this step, APARELL is finding the gener- alisations of the bottom clause. It aims to find the most general hypothesis. − Calculate the score. In this step, APARELL only considers the hypothesis which covered none of the negative examples. The scoring function is using the number of positive examples covered. It adds one point for each positive examples covered by the hypothesis. The best hypothesis is the one which has the highest score which means covered more positive examples. − Build the set of possible best hypothesis based on the best score. This process is shown as the greyed box in Figure 1. A set of the valid hypothesis will be the output of the algorithm. − Eliminate the positive examples which have already been covered in the previous hypothesis search. 2.2. Recommendation algorithm The output of APARELL is a set of hypothesis which consistent with the preferences given by the users. Some of the possible APARELL outputs are shown below: (Manual) betterthan (MediumCar) (Hatchback) betterthan (MediumCar) (MediumCar) betterthan (Automatic) (Hatchback) betterthan (Automatic) (Hatchback) betterthan (Estate) (Petrol) betterthan (Diesel) In this implementation, we use a rule-based algorithm which implies that every item that dominated the preferences will always better than the other ones. A directed graph is build to better illustrate the process. Once we have a list of cars family preferred by the users, the system can build the list of recommendation system based on the characteristics found in the APARELL’s rules. For example, in the above output we can draw a directed graph as shown in Figure 2a. From the given output, we can conclude that the users’ most Bulletin of Electr Eng Inf, Vol. 9, No. 6, December 2020 : 2637 – 2649](https://image.slidesharecdn.com/53-2384latex-210807000658/75/On-the-benefit-of-logic-based-machine-learning-to-learn-pairwise-comparisons-4-2048.jpg)

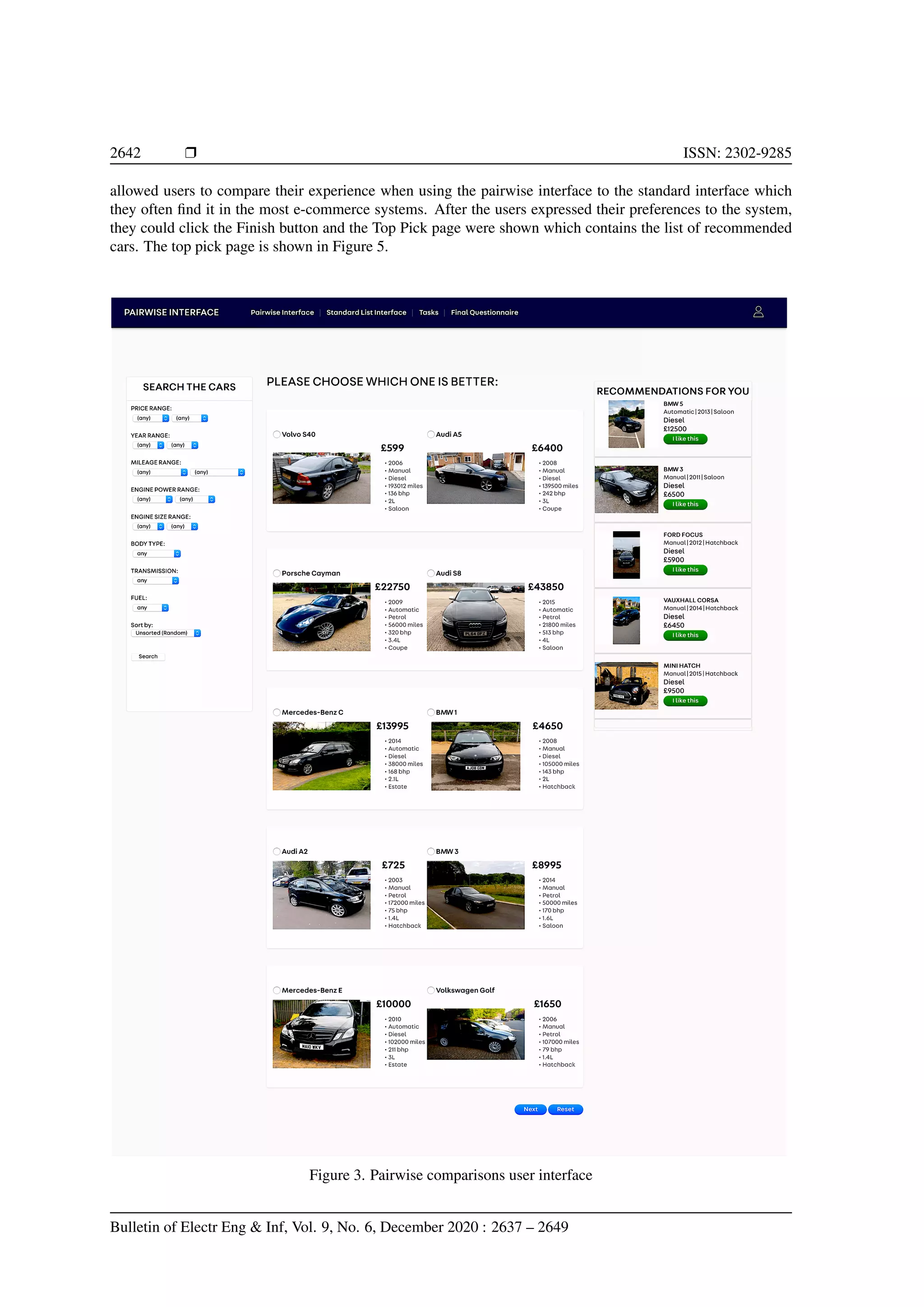
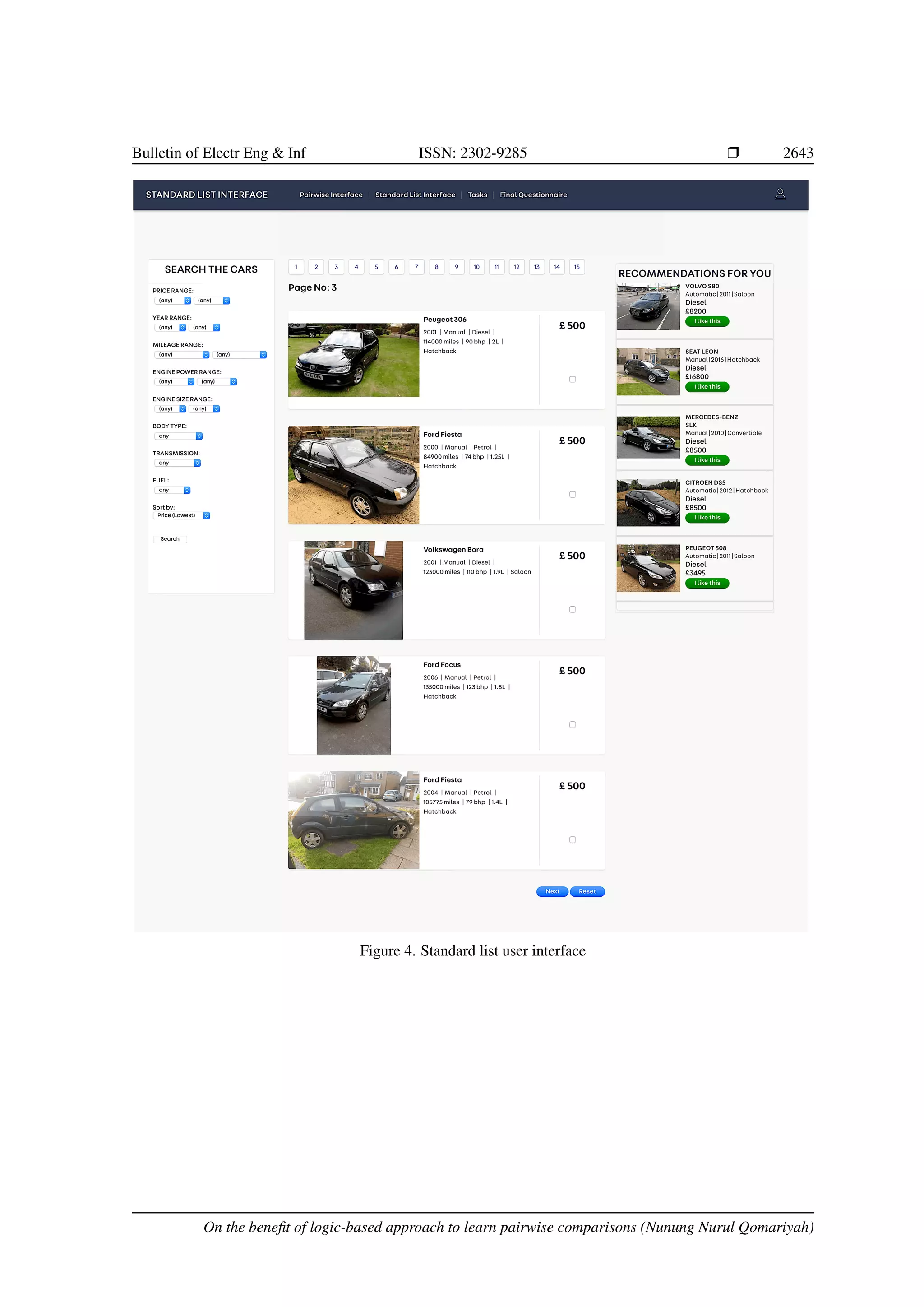
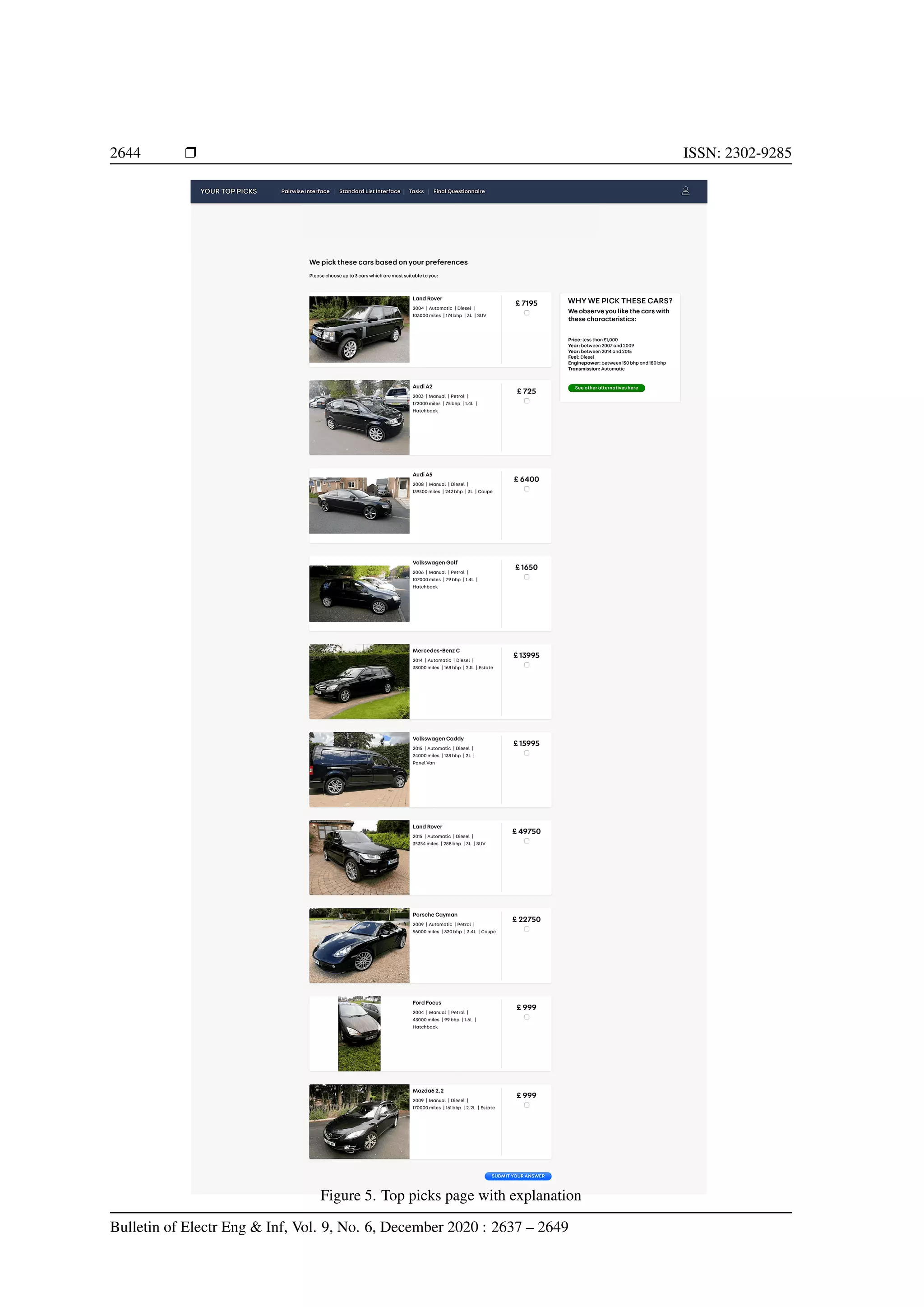
![Bulletin of Electr Eng Inf ISSN: 2302-9285 r 2645 3.1. User study The user study was taken place in York, United Kingdom. We asked the participants to complete two given tasks by using both interfaces, so they could have different experience and were able to evaluate them afterwards. The post-questionnaires used in this experiment were following ResQue, an evaluation framework of recommender systems proposed in [24]. This framework has been used in a similar study in [25]. We invited 24 participants in this study. We used a repeated-measures user study design in which the same individuals tested both user interfaces. We also designed a counter-balanced study in which we randomly divide the participants into two different groups, the first group were asked to evaluate the pairwise interface first, while the other group were asked to evaluate the standard list first. The user manual was provided to guide the users before they started the experiments. A series of demographic information was also collected beforehand. This experiment was conducted anonymously so that the users were not asked for giving their personal identity to comply with ethical practices designed to protect the privacy of the subjects. The dataset consists of 7,360 available used cars used in this experiment were crawled from Autotrader website. The cars have seven attributes, i.e. price, year, mileage, engine power, engine size, body type, transmission, fuel type. The use of the pairwise preference interface consisted of the following steps: − Initially, the interface displayed the top five most popular car models to all users in the right-hand-side (RHS) margin of the page. − The users could choose to apply a search filter to narrow down the types of cars being displayed. (This was optional.) The filter used had the same appearance and functionality as the one provided in the list interface. − Consecutive pages, each containing 5 pairs of cars consistent with the filter options, were displayed and the user was given the option of selecting their preference for each pair. They could also skip any pair. − The APARELL learner was used to update the user model. − If at least 10 pairs had been annotated, the top 10 final recommendations were displayed and the user was invited to select up to three cars that matched their needs. Otherwise, the provisional recommendations were updated on the basis of the revised user model, and the top five displayed in the RHS margin. The use of the list interface consisted of the following steps: − Initially, the interface displayed the top five most popular car models to all users in the right-hand-side (RHS) margin of the page. − The users had to apply a search filter to narrow down the types of cars being displayed. (This was mandatory.) The filter used had the same appearance and functionality as the one provided in the pairwise preference interface. − Consecutive pages, each containing 5 cars consistent with the filter options, were displayed and the user was given the option of flagging up cars of interest. − If at least 10 cars had been flagged up, the first 10 such cars were displayed and the user was invited to select up to three cars that matched their needs. Otherwise, the previous step was repeated, while another 5 cars for each of the top five most popular car models were displayed in the RHS margin. 3.2. User study tasks The participants were given two different tasks to be completed using both interfaces. The tasks were designed to be as close as possible with their daily routines. The tasks were formulated as follows: (1) the participants were asked to find suitable cars for daily commute purposes between their home and office and (2) the participants were asked to find suitable cars for weekend shopping only. Each task needed to be done by using one of the interfaces. In pairwise interface, for each page, the users were shown up to 5 pairs of cars at a time and they could give preference (pick the best one in each pair), they could choose to skip some pairs if they thought they did not like both. 3.3. Post-stage questionnaire Following the evaluation procedure, the participants need to fill in a post-questionnaire after com- pleting each task to measure how good is the recommender system. This questionnaire was using a five-point Likert scale to measure how much the participants agree or disagree on each question. This questionnaire can also be called usability and user satisfaction testing. The evaluation criteria and the questions of the post-stage questionnaire are shown below: On the benefit of logic-based approach to learn pairwise comparisons (Nunung Nurul Qomariyah)](https://image.slidesharecdn.com/53-2384latex-210807000658/75/On-the-benefit-of-logic-based-machine-learning-to-learn-pairwise-comparisons-9-2048.jpg)
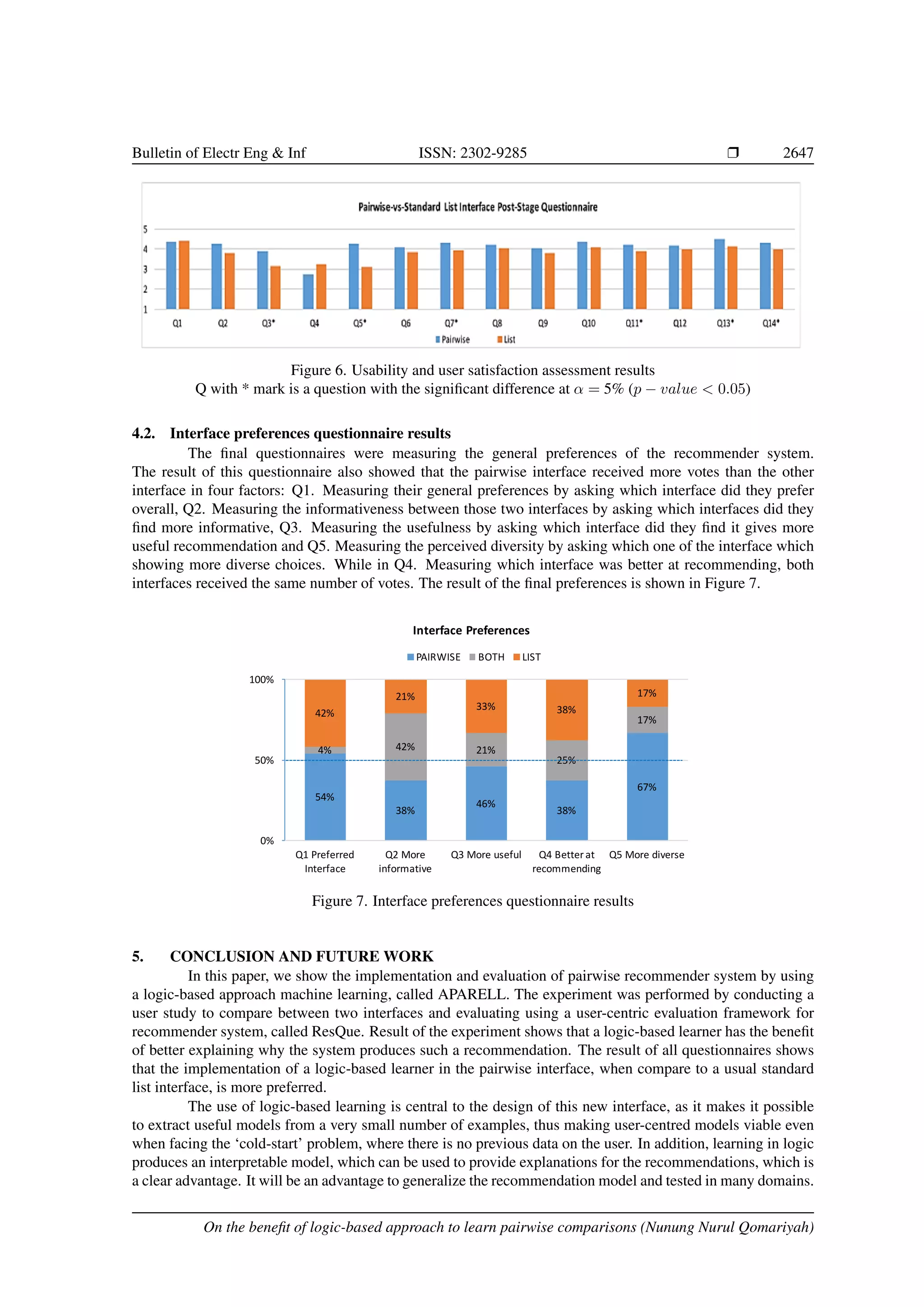
![2646 r ISSN: 2302-9285 − The first group of questions measured the quality of recommended items − Q1. Whether the items recommended by the system matched the users interests − Q2. Whether the list of recommended items were novel and interesting − Q3. Whether the recommended items were diverse − Q4. Whether the items recommended by the system were similar to each other (reverse scale) − The second group of questions measured the quality of the interactivity of the recommender system − Q5. The system explanation on why the recommended items were given − Q6. The attractiveness of the recommender interface layout − Q7. The easiness of finding an item to buy with the help of the recommender − Q8. Whether the users feel supported to find suitable items with the help of the recommender − Q9. Whether the users feel in control of expressing their preferences to the recommender − The third group of questions measured the attitude of the participants after evaluating the system − Q10. The overall satisfaction with the recommender − Q11. How convinced were they with the products recommended − Q12. How confident were they to like the items recommended − The last group of questions were measuring the behavioural intentions − Q13. Whether they would come back and use the system again − Q14. Whether they would purchase the items shown in the recommendation. 3.4. Interface preferences questionnaire After evaluating both interfaces, the participants were given a final questionnaire from [25] to measure their preferences regarding the interfaces as below: − Q1. Measuring their general preferences by asking which interface did they prefer overall. − Q2. Measuring the informativeness between those two interfaces by asking which interfaces did they find more informative. − Q3. Measuring the usefulness by asking which interface did they find it gives more useful recommenda- tion. − Q4. Measuring which interface was better at recommending. − Q5. Measuring the perceived diversity by asking which one of the interfaces showing more diverse choices. This questionnaire allowed the participants to vote either pairwise interface, standard list interface or both if they do not have any preference. 4. RESULTS AND DISCUSSION The 24 participants were recruited from The University of York, UK. Their age were ranged from 20 to 45 years old and the population had a good balance on the gender distribution with 54% male, 42% female and 4% of another gender. 4.1. Post-stage questionnaire results All the ordinal values received from the participants on each question we averaged. In order to under- stand the difference between what the participants feel after reviewing the pairwise interface and after evaluat- ing the standard list interface, we used a paired sample t-test. We display the comparisons on their answer on both interfaces are shown in side-by-side in Figure 6. The significant differences were found for six questions mentioned below with p − value from paired sample t-test is 0.05, they are: [Q3] p-value=0.0208, [Q5:] p- value=0.0019, [Q7] p-value=0.0359, [Q11] p-value=0.0499, [Q13] p-value=0.0359 and [Q14] p-value=0.0256. Even though there were only six questions showed significant differences, the overall average of pairwise in- terface was higher than the standard list interface. Bulletin of Electr Eng Inf, Vol. 9, No. 6, December 2020 : 2637 – 2649](https://image.slidesharecdn.com/53-2384latex-210807000658/75/On-the-benefit-of-logic-based-machine-learning-to-learn-pairwise-comparisons-10-2048.jpg)
![2648 r ISSN: 2302-9285 ACKNOWLEDGEMENT Some parts of this work are supported by Research and Technology Transfer Office, Bina Nusantara University as a part of Bina Nusantara University’s International Research Grant entitled “Modelling Customer Preferences with AI” with contract number: No.026/VR.RTT/IV/2020 and contract date: 6 April 2020. REFERENCES [1] Nunung Nurul Qomariyah and Dimitar Kazakov, ”Learning from Ordinal Data with Inductive Logic Programming in Description Logic,” Proceedings of the Late Breaking Papers of the 27th International Conference on Inductive Logic Programming, 2018. [2] Stephen Muggleton, ”Inductive Logic Programming,” New Generation Computing, vol. 8, no. 4, pp. 295–318, 1991. [3] Jens Lehmann, ”DL-Learner: Learning Concepts in Description Logics,” The Journal of Machine Learn- ing Research, vo. 10, pp. 2639–2642, 2009. [4] Johannes Fürnkranz and Eyke Hüllermeier,” Preference Learning: An Introduction,” Preference Learning, pp. 1–17, 2010. [5] Eyke Hüllermeier, Johannes Fürnkranz, Weiwei Cheng, and Klaus Brinker, ”Label Ranking by Learning Pairwise Preferences,” Artificial Intelligence, vol. 172, no. 16, pp. 1897–1916, 2008. [6] G. Pandey, S. Wang, Z. Ren, and Y. Chang, ”Vectors of Pairwise Item Preferences,” Proceedings of European Conference on Information Retrieval, pp. 323-336, 2019. [7] E. Simpson and I. Gurevych, ”Scalable Bayesian Preference Learning for Crowds,” Machine Learning, vol. 109, pp. 689-718, 2020. [8] G. Chen, F. Zhu, and P. A. Heng, ”Large-Scale Bayesian Probabilistic Matrix Factorization with Memo- Free Distributed Variational Inference,” ACM Transactions on Knowledge Discovery from Data, vol. 12, no. 3, pp. 31:1–31:24, 2018. [9] B. Han, Y. Pan, and I. W. Tsang, ”Robust Plackett-Luce Model for k-ary Crowdsourced Preferences,” Machine Learning, vol. 107, no. 4, pp. 675–702, 2018. [10] Y. Pan, B. Han, and I. W. Tsang, ”Stagewise Learning for Noisy k-ary Preferences,” Machine Learning, vol. 107, no. 8–10, pp. 1333 – 1361, 2018. [11] X. Wang, et al., ”Blind Men and the Elephant: Thurstonian Pairwise Preference for Ranking in Crowd- sourcing” Proceedings of the 16th international conference on data mining (ICDM), pp. 509–518, 2016. [12] S. Balakrishnan and S. Chopra, ”Two of A Kind or the Ratings Game? Adaptive Pairwise Preferences and Latent Factor Models,” Proceedings of the 10th IEEE International Conference on Data Mining (ICDM), pp. 725–730, 2010. [13] W. Pan, L. Chen and Z. Ming, ”Personalized Recommendation with Implicit Feedback via Learning Pairwise Preferences over Item-sets,” Knowledge and Information Systems, 2018. [14] Li Qian, Jinyang Gao and H. V. Jagadish, ”Learning User Preferences by Adaptive Pairwise Comparison,” Proceedings of the VLDB Endowment, vol. 8, no. 11, pp. 1322–1333, 2015. [15] B. S. Jensen, J. S. Gallego and J. Larsen, ”A Predictive Model of Music Preference Using Pairwise Com- parisons,” Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp 1977–1980, 2012. [16] Lior Rokach and Slava Kisilevich, ”Initial Profile Generation in Recommender Systems Using Pairwise Comparison,” IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 42, no. 6, pp. 1854–1859, 2012. [17] Behnoush Abdollahi and Olfa Nasraoui, ”Using Explainability for Constrained Matrix Factorization,” Proceedings of the 11th ACM Conference on Recommender Systems, pp. 79–83, 2017. [18] Jonathan L. Herlocker, Joseph A. Konstan, and John Riedl, ”Explaining Collaborative Filtering Rec- ommendations,” Proceedings of the ACM Conference on Computer Supported Cooperative Work, pp. 241–250, 2000. [19] Mustafa Bilgic and Raymond J. Mooney, ”Explaining Recommendations: Satisfaction vs. Promo- tion,”Proceedings of Beyond Personalization Workshop, International Conference on Intelligent User Interfaces (IUI), vol. 5, 2005. [20] Nava Tintarev and Judith Masthoff. Designing and Evaluating Explanations for Recommender Systems. Recommender Systems Handbook, pp. 479–510. Springer, 2011. Bulletin of Electr Eng Inf, Vol. 9, No. 6, December 2020 : 2637 – 2649](https://image.slidesharecdn.com/53-2384latex-210807000658/75/On-the-benefit-of-logic-based-machine-learning-to-learn-pairwise-comparisons-12-2048.jpg)
![Bulletin of Electr Eng Inf ISSN: 2302-9285 r 2649 [21] N. N. Qomariyah, and D. Kazakov, ”Learning Binary Preference Relations,” Proceedings of the 4th Joint Workshop on Interfaces and Human Decision Making for Recommender Systems (IntRS), 2017. [22] Nunung Nurul Qomariyah and Ahmad Nurul Fajar, ”Recommender System for e-Learning based on Per- sonal Learning Style,” Proceedings of the 2nd International Seminar on Research of Information Tech- nology and Intelligent Systems (ISRITI), 2020. [23] Stephen Muggleton and Luc De Raedt, ”Inductive Logic Programming: Theory and Methods,” The Jour- nal of Logic Programming, vol. 19, pp. 629–679, 1994. [24] Pearl Pu, Li Chen, and Rong Hu, ”A User-Centric Evaluation Framework for Recommender Systems,” Proceedings of the fifth ACM Conference on Recommender Systems, pp. 157–164, 2011. [25] Rong Hu and Pearl Pu, ”Helping Users Perceive Recommendation Diversity,” Proceedings of Workshop on Novelty and Diversity in Recommender Systems (DiveRS), pp. 43–50, 2011. BIOGRAPHIES OF AUTHORS Nunung N. Qomariyah is a faculty member in Computer Science Department, Bina Nusantara Uni- versity, Jakarta, Indonesia. Formerly, she was a member of Artificial Intelligence Research Group, Computer Science Department, University of York, UK. She was working under Dr. Dimitar Kaza- kov supervision during her PhD study. Her research interest is in the area of Recommender System, particularly in Preference Learning by using pairwise comparisons. She is currently affiliated with Indonesia Section IEEE computer society as professional member. Further info on his homepage: http://international.binus.ac.id/computer-science/faculty/nunung-nurul-qomariyah/ Dimitar Kazakov is an associate professor (senior lecturer) at Computer Science Department, Uni- versity of York, UK. He is currently appointed as the Head of Artificial Intelligence Research Group. He is also the chair of Departmental Teaching Committee. His research interest includes Machine Learning, Natural Language Processing; Machine Learning of Language. Further info on his homepage: https://www-users.cs.york.ac.uk/ kazakov/ Ahmad Nurul Fajar is an associate professor in Computer Science, Graduate Program, Bina Nu- santara University. In 2001, he was graduated from Gunadarma University majoring in Informatics. Master of Science Informatics was completed in 2004 at Bandung Institute of Technology (ITB). He hold PhD degree from Faculty of Computer Science University of Indonesia (UI) in 2014. His research interest is in the area of Software Engineering, Software Development, Information System Analysis and Design, Business Processes, and Service Oriented Architecture. On the benefit of logic-based approach to learn pairwise comparisons (Nunung Nurul Qomariyah)](https://image.slidesharecdn.com/53-2384latex-210807000658/75/On-the-benefit-of-logic-based-machine-learning-to-learn-pairwise-comparisons-13-2048.jpg)