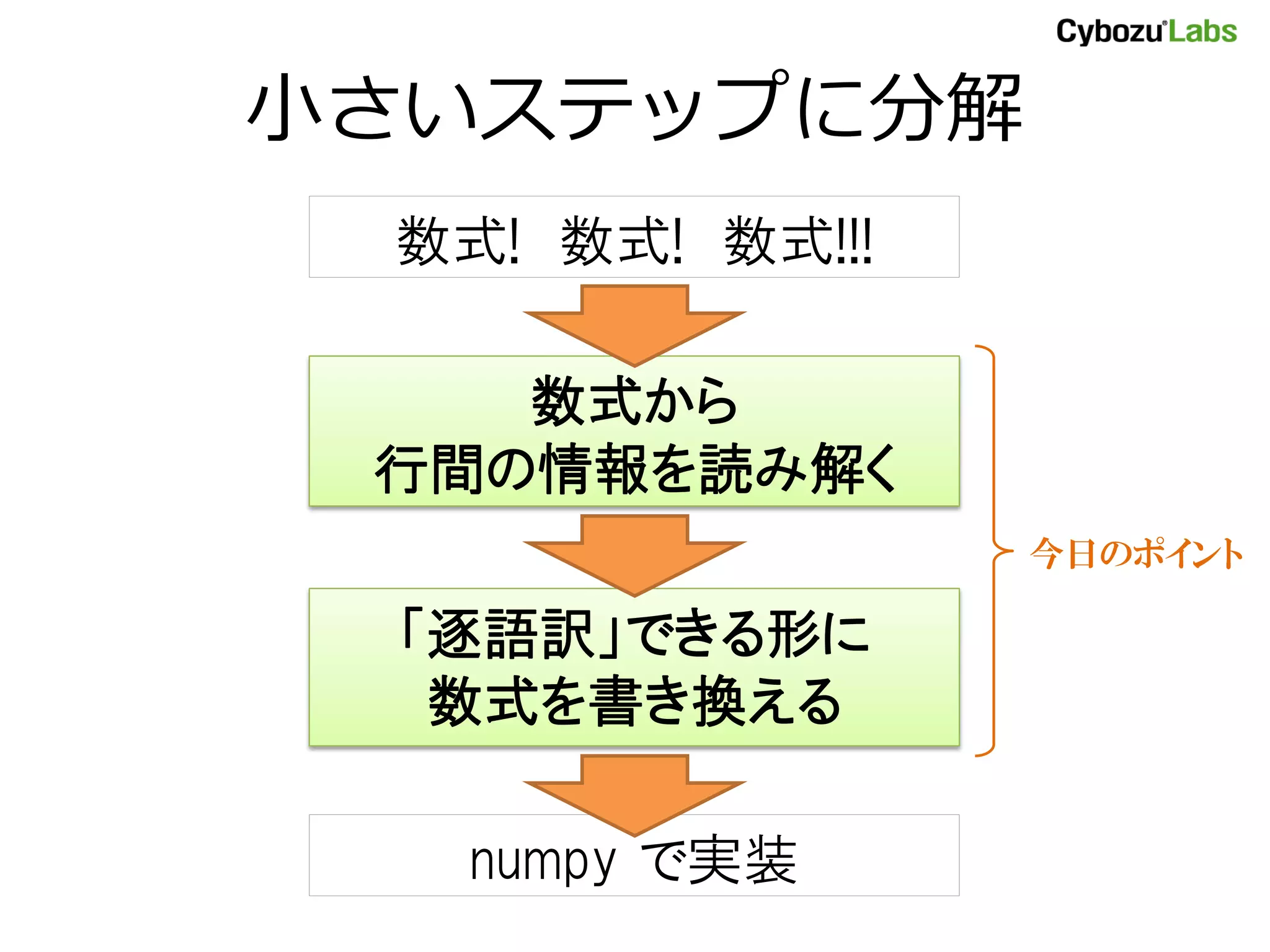
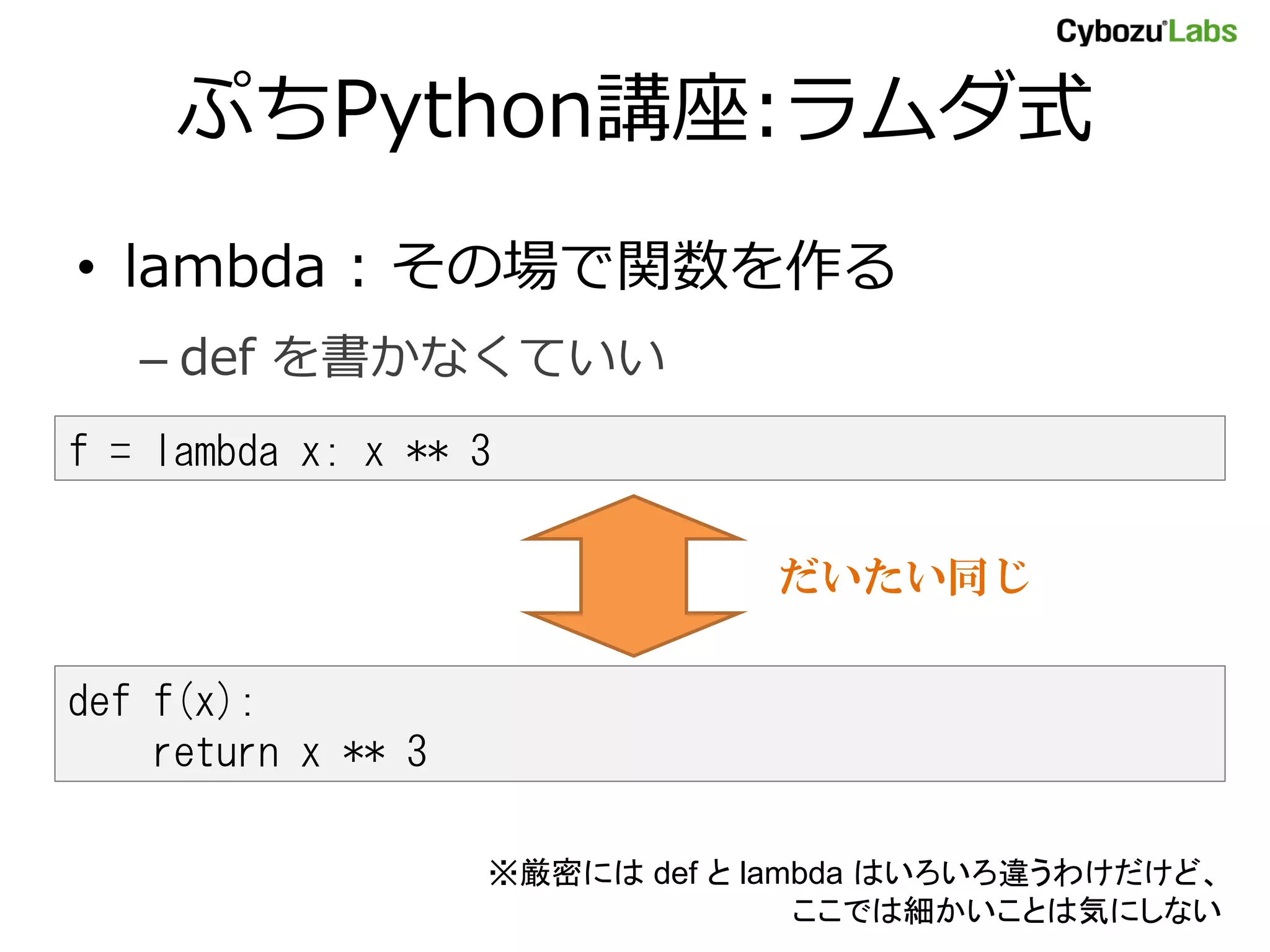
ぷちPython講座:リスト内包 • リスト内包 :ルールから配列を作る – for ループを書かなくていい – R の apply() 系の関数に相当 a = [] for x in xrange(10): a.append(x * x) リスト内包なら簡潔! a = [x * x for x in xrange(10)] ※厳密にはいろいろ(ry
41.
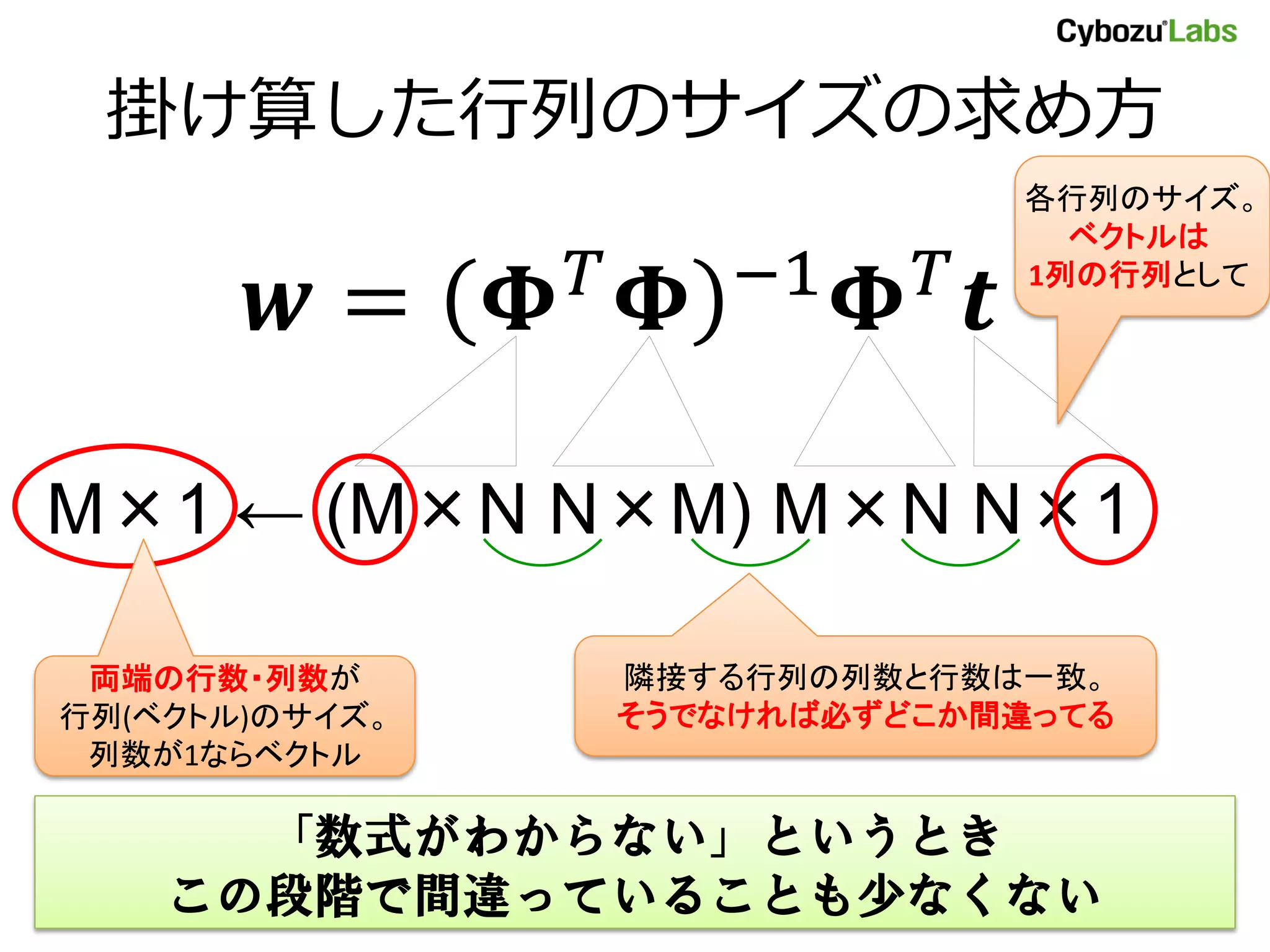
「リスト内包」を使えば…… phi = [ lambda x: 1, lambda x: x, = ( = 0, ⋯ , − 1) lambda x: x ** 2, lambda x: x ** 3 ] こう書ける気がする phi = [lambda x: x ** m for m in xrange(M)] • かんたんになったね!
42.
だめでした…… • 0 2, 1 2 , 2 2 , 3 2 を表示してみる – “1 2 4 8” と出力されることを期待 M = 4 phi = [lambda x: x ** m for m in xrange(M)] print phi[0](2), phi[1](2), phi[2](2), phi[3](2) • ところがこれの実行結果は “8 8 8 8” – って、全部同じ!? なんで???
43.
うまくいかない理由は…… • 「レキシカルスコープ」がどうとか – ちょっとややこしい • 回避する裏技もあるけど…… – もっとややこしい M = 4 phi = [lambda x, c=m: x ** c for m in xrange(M)] print phi[0](2), phi[1](2), phi[2](2), phi[3](2) # => “1 2 4 8” と表示される(ドヤ























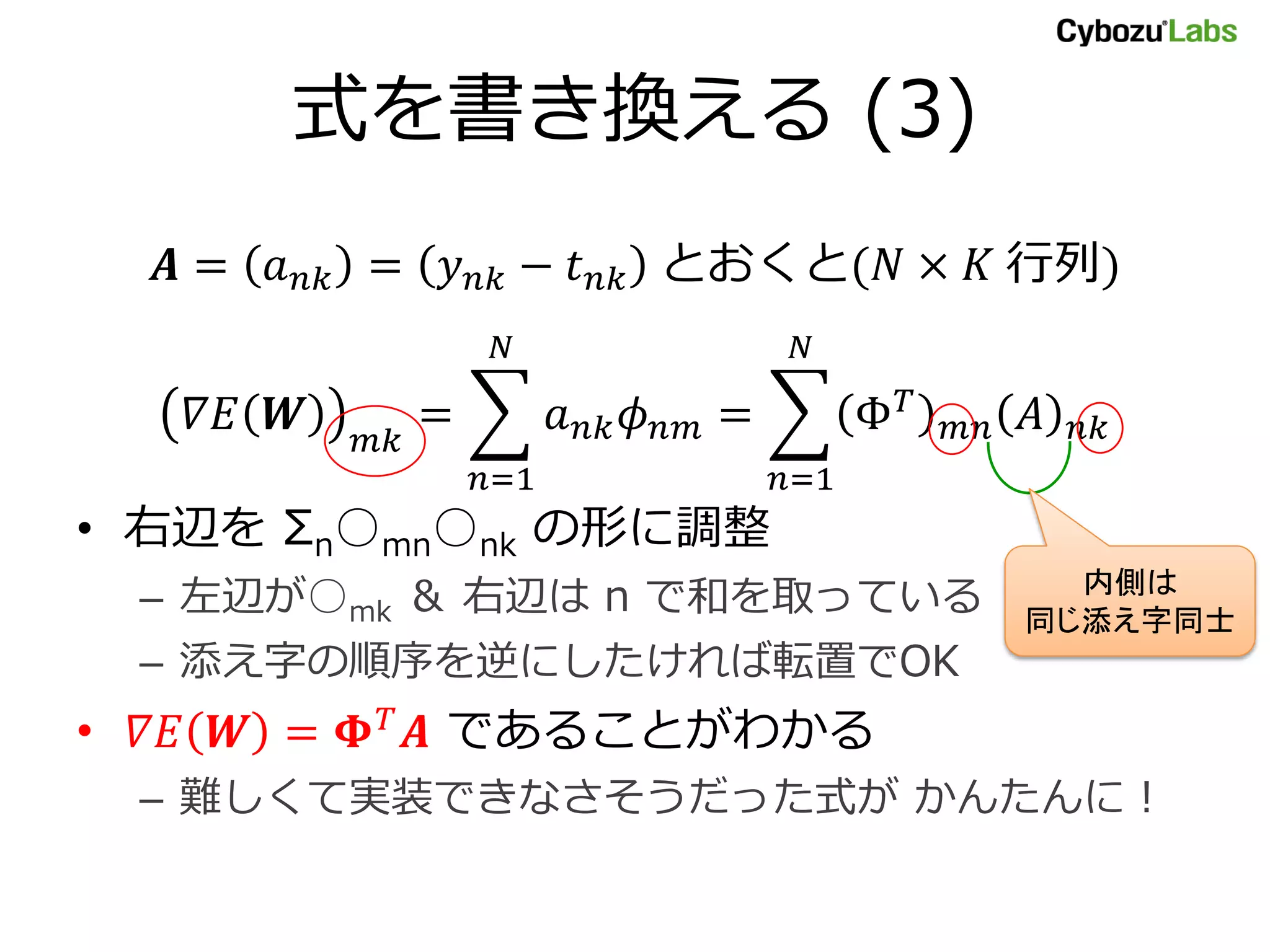




![特徴行列の作り方 (1) # X = N×D 次元の行列(今回は D=1) phi = [ lambda x: 1, lambda x: x, # φ:特徴関数の列 lambda x: x ** 2, # lambda ってなに? lambda x: x ** 3 ] N = len(X) M = len(phi) PHI = numpy.zeros((N, M)) # Φ:N×M行列の入れ物を用意 for n in xrange(N): for m in xrange(M): PHI[n, m] = phi[m](X[n]) # φ_m(x_n)](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-36-2048.jpg)

![つまりラムダ式のところは phi = [ lambda x: 1, # φ_0(x) = 1 lambda x: x, # φ_1(x) = x lambda x: x ** 2, # φ_2(x) = x^2 lambda x: x ** 3 # φ_3(x) = x^3 ] • 実はこの数式の実装でした = ( = 0, ⋯ , − 1) • 繰り返しなんだから、もっとかんたんに できそう](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-39-2048.jpg)
![ぷちPython講座:リスト内包 • リスト内包 : ルールから配列を作る – for ループを書かなくていい – R の apply() 系の関数に相当 a = [] for x in xrange(10): a.append(x * x) リスト内包なら簡潔! a = [x * x for x in xrange(10)] ※厳密にはいろいろ(ry](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-40-2048.jpg)
![「リスト内包」を使えば…… phi = [ lambda x: 1, lambda x: x, = ( = 0, ⋯ , − 1) lambda x: x ** 2, lambda x: x ** 3 ] こう書ける気がする phi = [lambda x: x ** m for m in xrange(M)] • かんたんになったね!](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-41-2048.jpg)
![だめでした…… • 0 2 , 1 2 , 2 2 , 3 2 を表示してみる – “1 2 4 8” と出力されることを期待 M = 4 phi = [lambda x: x ** m for m in xrange(M)] print phi[0](2), phi[1](2), phi[2](2), phi[3](2) • ところがこれの実行結果は “8 8 8 8” – って、全部同じ!? なんで???](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-42-2048.jpg)
![うまくいかない理由は…… • 「レキシカルスコープ」がどうとか – ちょっとややこしい • 回避する裏技もあるけど…… – もっとややこしい M = 4 phi = [lambda x, c=m: x ** c for m in xrange(M)] print phi[0](2), phi[1](2), phi[2](2), phi[3](2) # => “1 2 4 8” と表示される(ドヤ](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-43-2048.jpg)

![特徴行列の作り方 (2) • phi を「ベクトルを返す関数」として定義 – のリストではなく, = ( )を扱う – lambda を書かなくていい – 関数の呼び出し回数も減って高速化 • 行列の生成にもリスト内包を使う numpy の機能の 一部と言っても – numpy.array(リスト内包) は頻出! いいくらい def phi(x): return [x ** m for m in xrange(4)] PHI = numpy.array([phi(x) for x in X])](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-45-2048.jpg)

