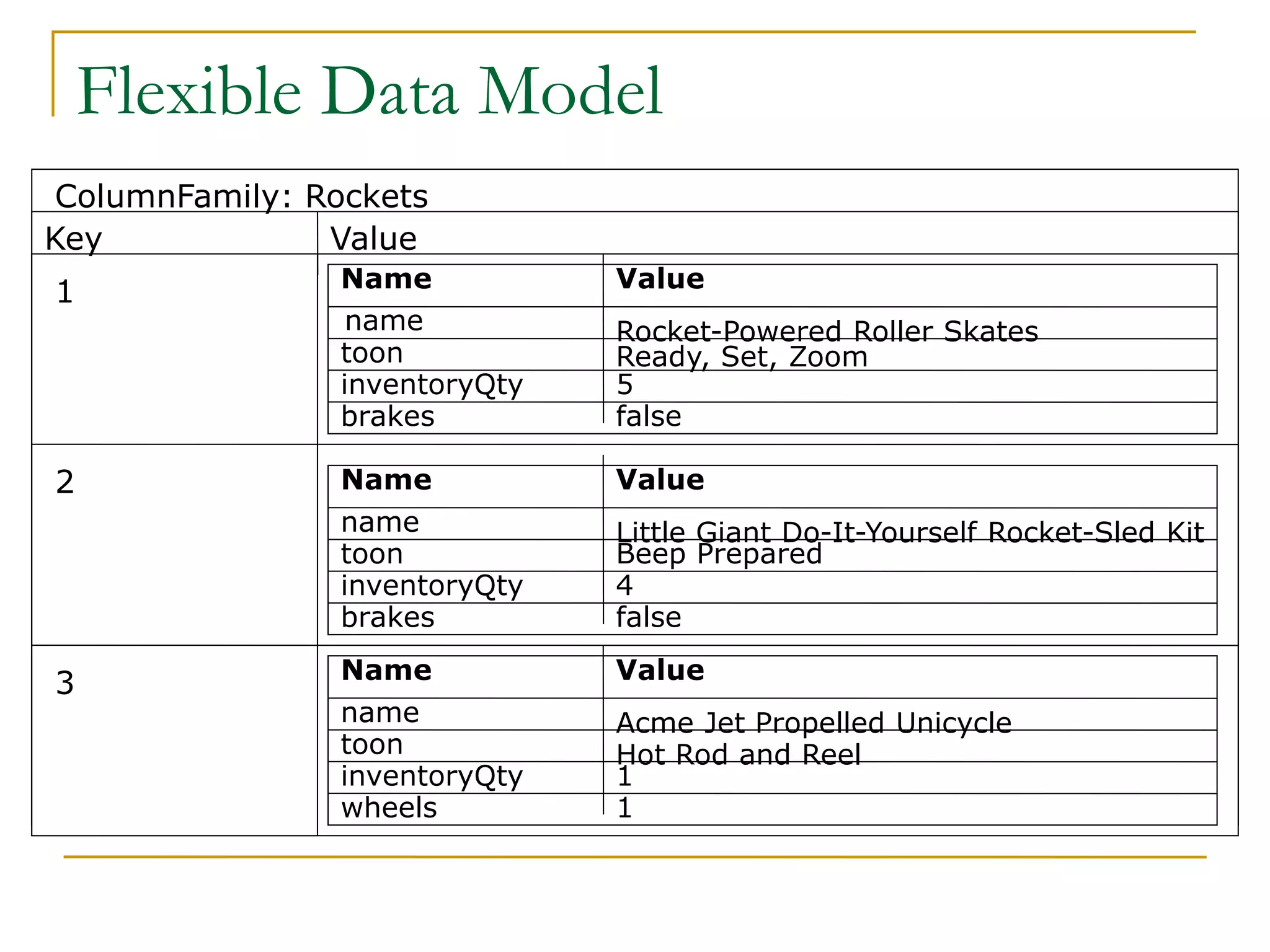
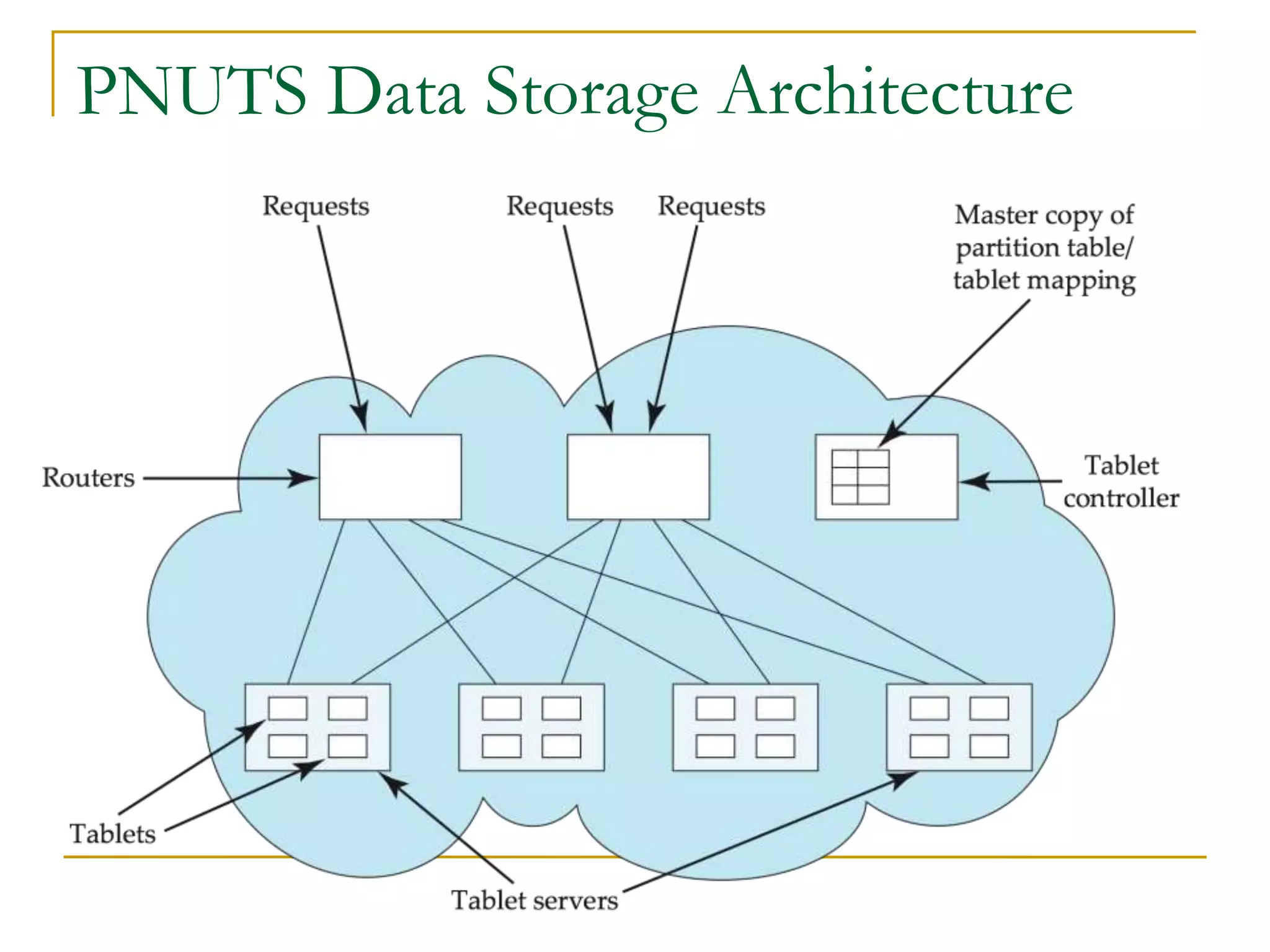
This document discusses distributed data stores and NoSQL databases. It begins by explaining how relational databases do not scale well for large web applications. Distributed key-value data stores like BigTable address this issue by allowing massively parallel data storage and retrieval. NoSQL databases relax ACID properties and do not require fixed schemas. The CAP theorem states that distributed systems can only achieve two of three properties: consistency, availability, and partition tolerance. Most NoSQL databases favor availability over strong consistency. Eventual consistency means copies will become consistent over time without updates. NoSQL is suitable for very large datasets but regular databases remain best for typical organizational use cases.