





















![from nltk.stem import PorterStemmer porter = PorterStemmer() words = ['generous','fairly','sings','generation'] for word in words: print(word,"--->",porter.stem(word)) Step 3: Stemming code in Python using NLTK library](https://image.slidesharecdn.com/nlpunit1newkirti-241010085913-d60524df/75/NLP-Introduction-applications-NLP-Pipeline-Steps-in-NLP-31-2048.jpg)

![### import necessary libraries from nltk.stem import WordNetLemmatizer from nltk.tokenize import word_tokenize text = "Very orderly and methodical he looked, with a hand on each knee, and a loud watch ticking a sonorous sermon under his flapped newly bought waist-coat, as though it pitted its gravity and longevity against the levity and evanescence of the brisk fire." # tokenise text tokens = word_tokenize(text) wordnet_lemmatizer = WordNetLemmatizer() lemmatized = [wordnet_lemmatizer.lemmatize(token) for token in tokens] print(lemmatized) Step 4: Lemmatization using nltk](https://image.slidesharecdn.com/nlpunit1newkirti-241010085913-d60524df/75/NLP-Introduction-applications-NLP-Pipeline-Steps-in-NLP-33-2048.jpg)
![program to eliminate stopwords using nltk import nltk from nltk.corpus import stopwords from nltk.tokenize import word_tokenize def remove_stopwords(text): # Tokenize the text into words words = word_tokenize(text) # Get English stopwords english_stopwords = set(stopwords.words('english')) # Remove stopwords from the tokenized words filtered_words = [word for word in words if word.lower() not in english_stopwords] # Join the filtered words back into a single string filtered_text = ' '.join(filtered_words) return filtered_text # Example text text = "NLTK is a leading platform for building Python programs to work with human language data." # Remove stopwords filtered_text = remove_stopwords(text) # Print filtered text print(filtered_text)](https://image.slidesharecdn.com/nlpunit1newkirti-241010085913-d60524df/75/NLP-Introduction-applications-NLP-Pipeline-Steps-in-NLP-35-2048.jpg)



![[('NLTK', 'NNP'), ('is', 'VBZ'), ('a', 'DT'), ('leading', 'VBG'), ('platform', 'NN'), ('for', 'IN'), ('building', 'VBG'), ('Python', 'NNP'), ('programs', 'NNS'), ('to', 'TO'), ('work', 'VB'), ('with', 'IN'), ('human', 'JJ'), ('language', 'NN'), ('data', 'NNS'), ('.', '.')] Output: # CODE to print all the POS TAGS import nltk nltk.download('tagsets') nltk.help.upenn_tagset()](https://image.slidesharecdn.com/nlpunit1newkirti-241010085913-d60524df/75/NLP-Introduction-applications-NLP-Pipeline-Steps-in-NLP-42-2048.jpg)












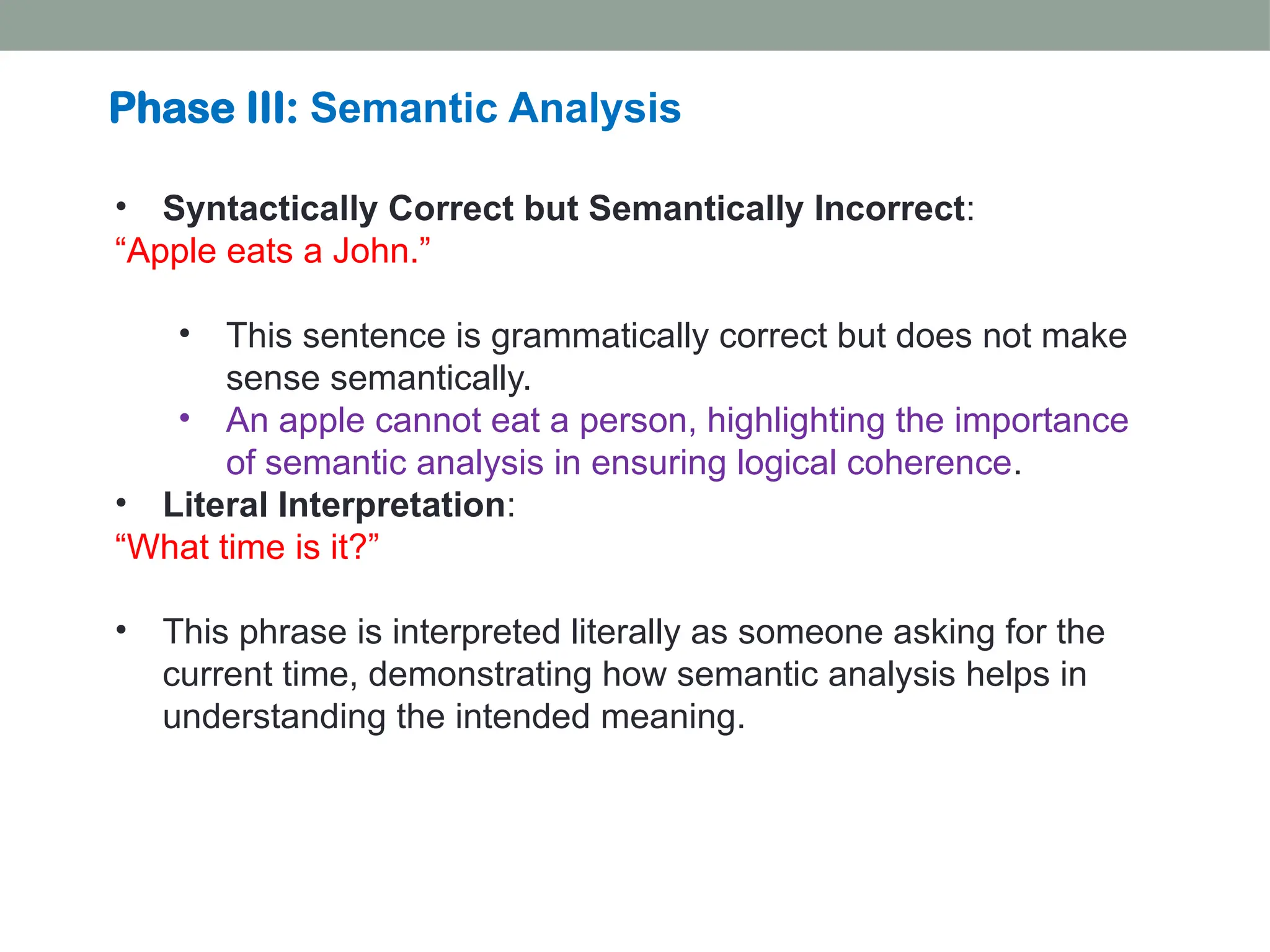













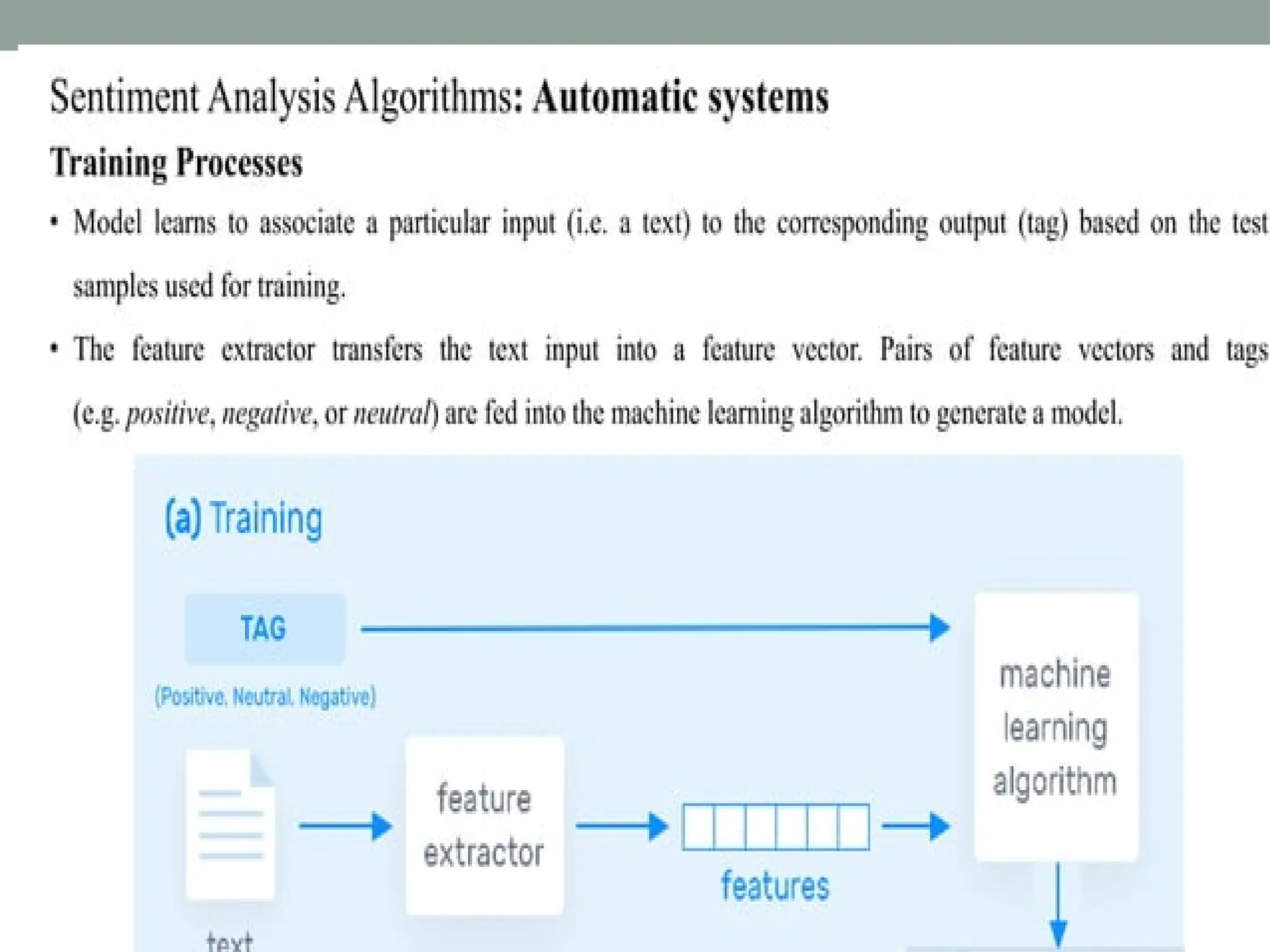
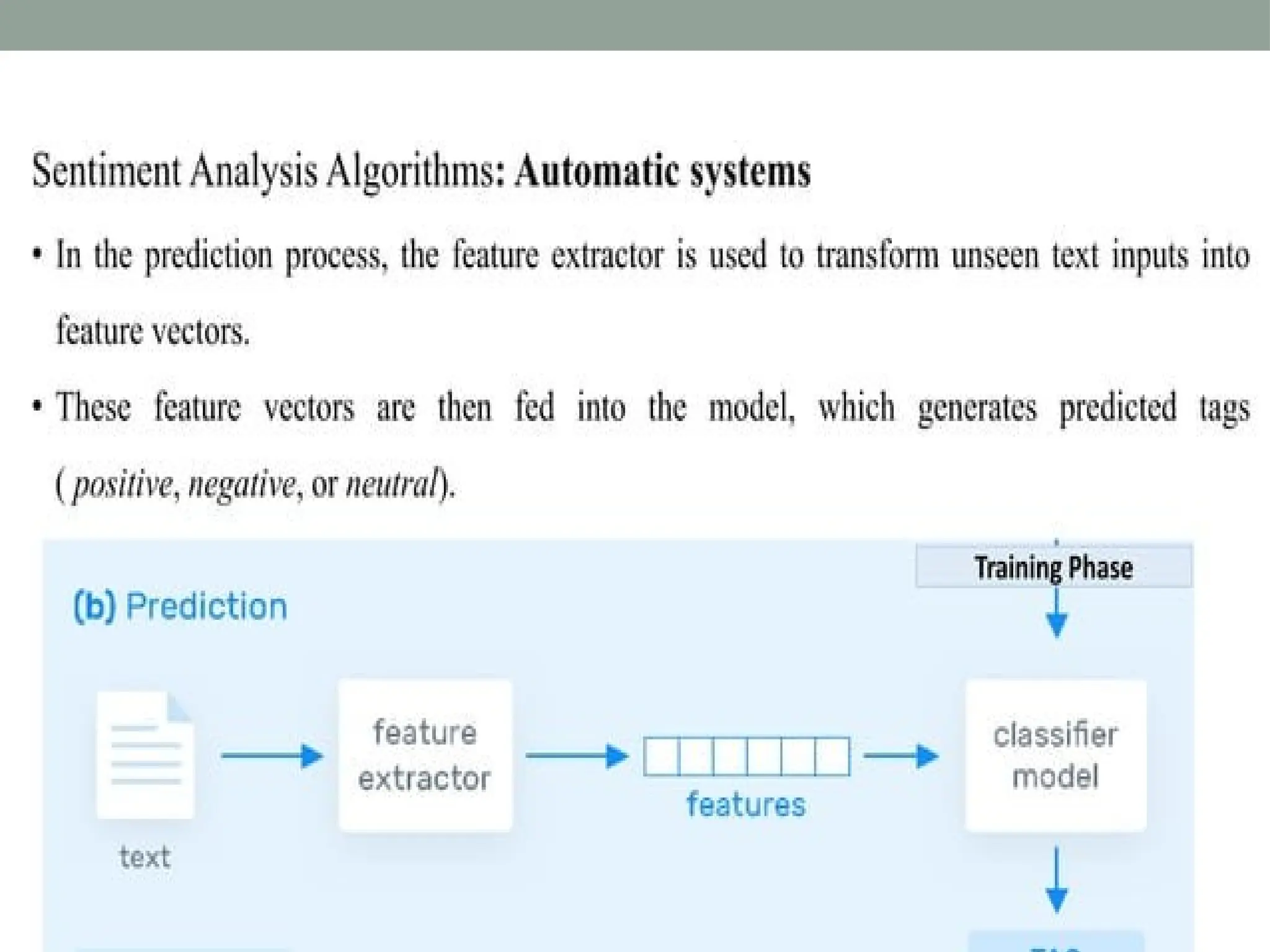
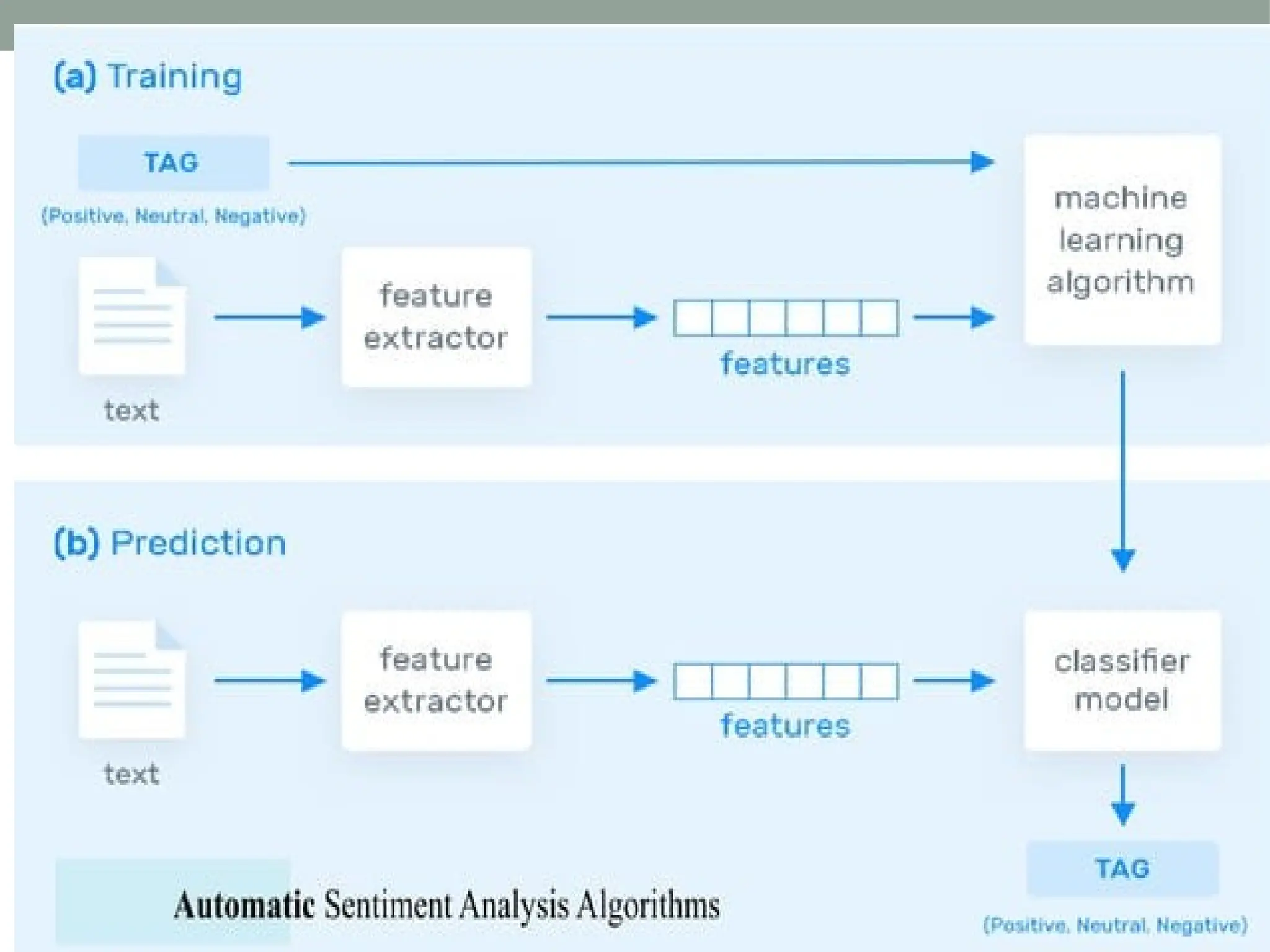
























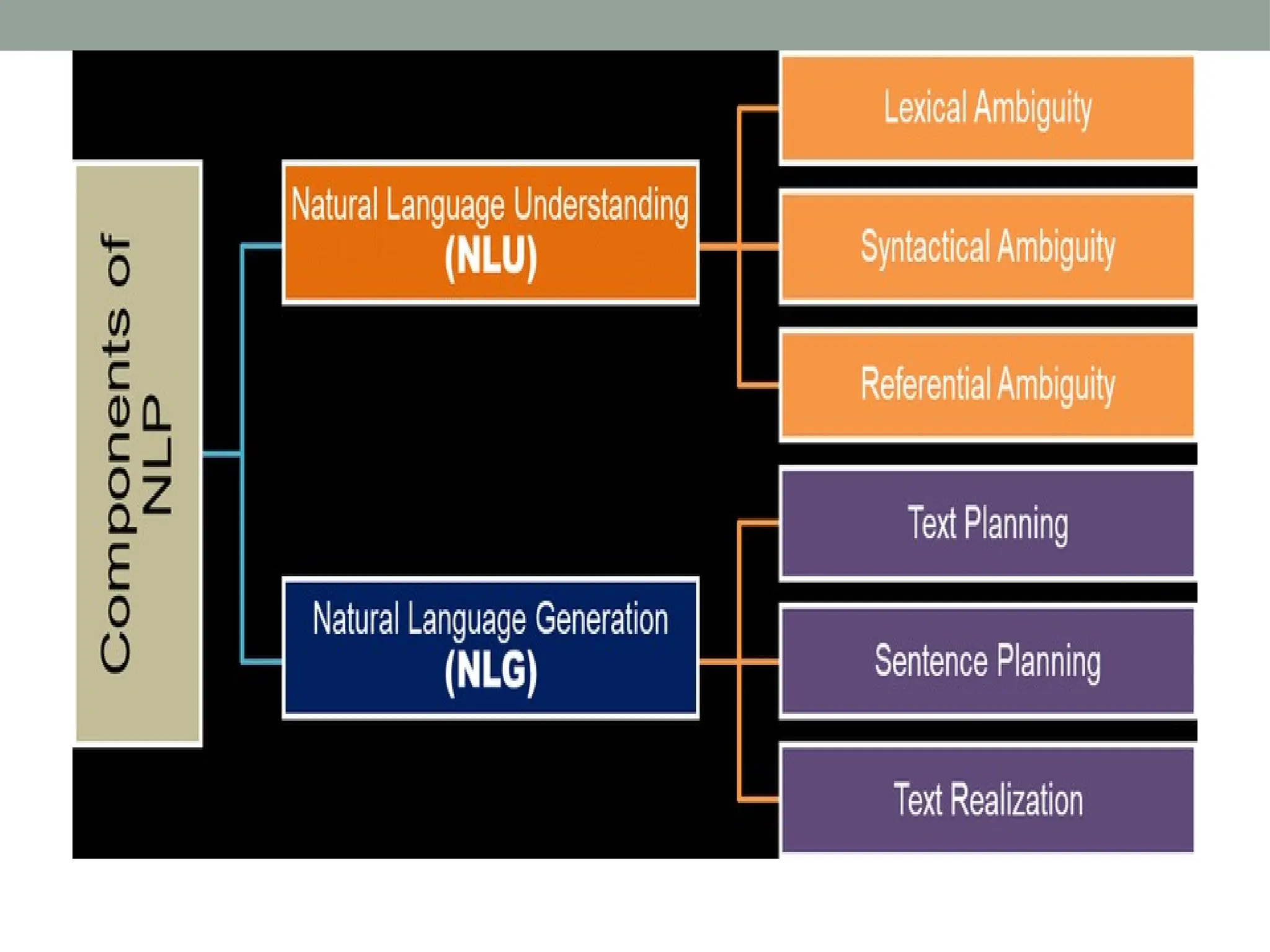
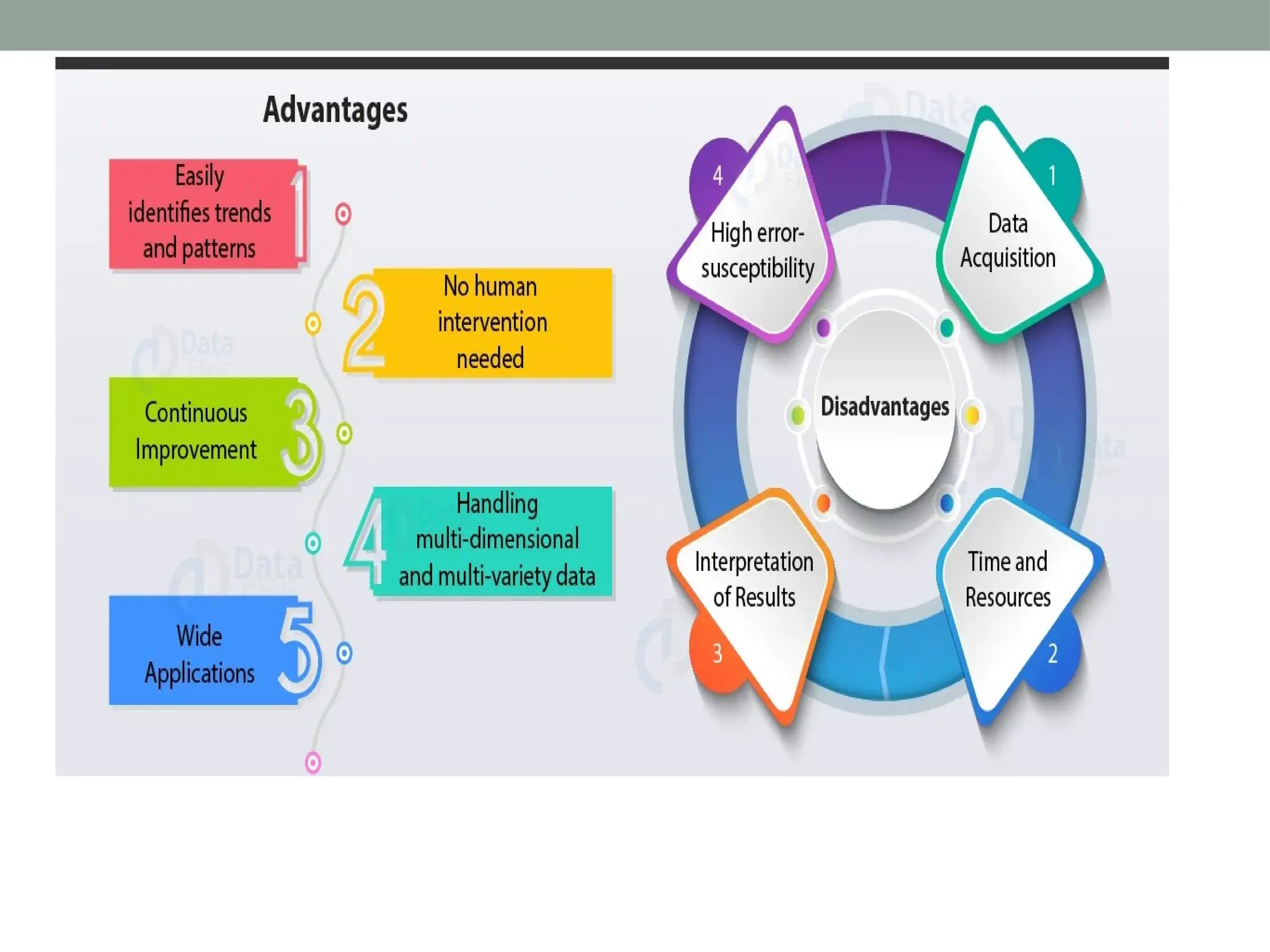
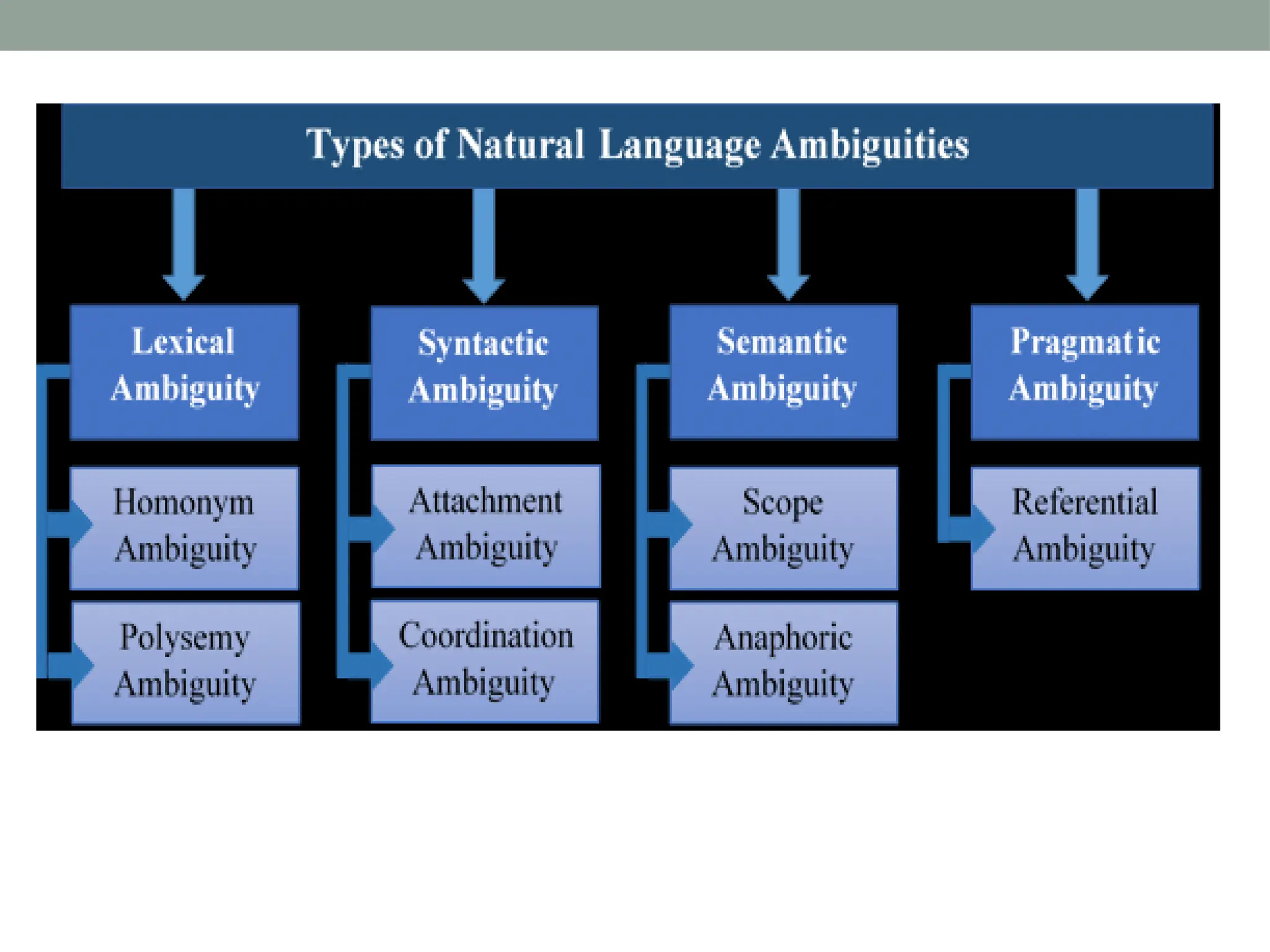
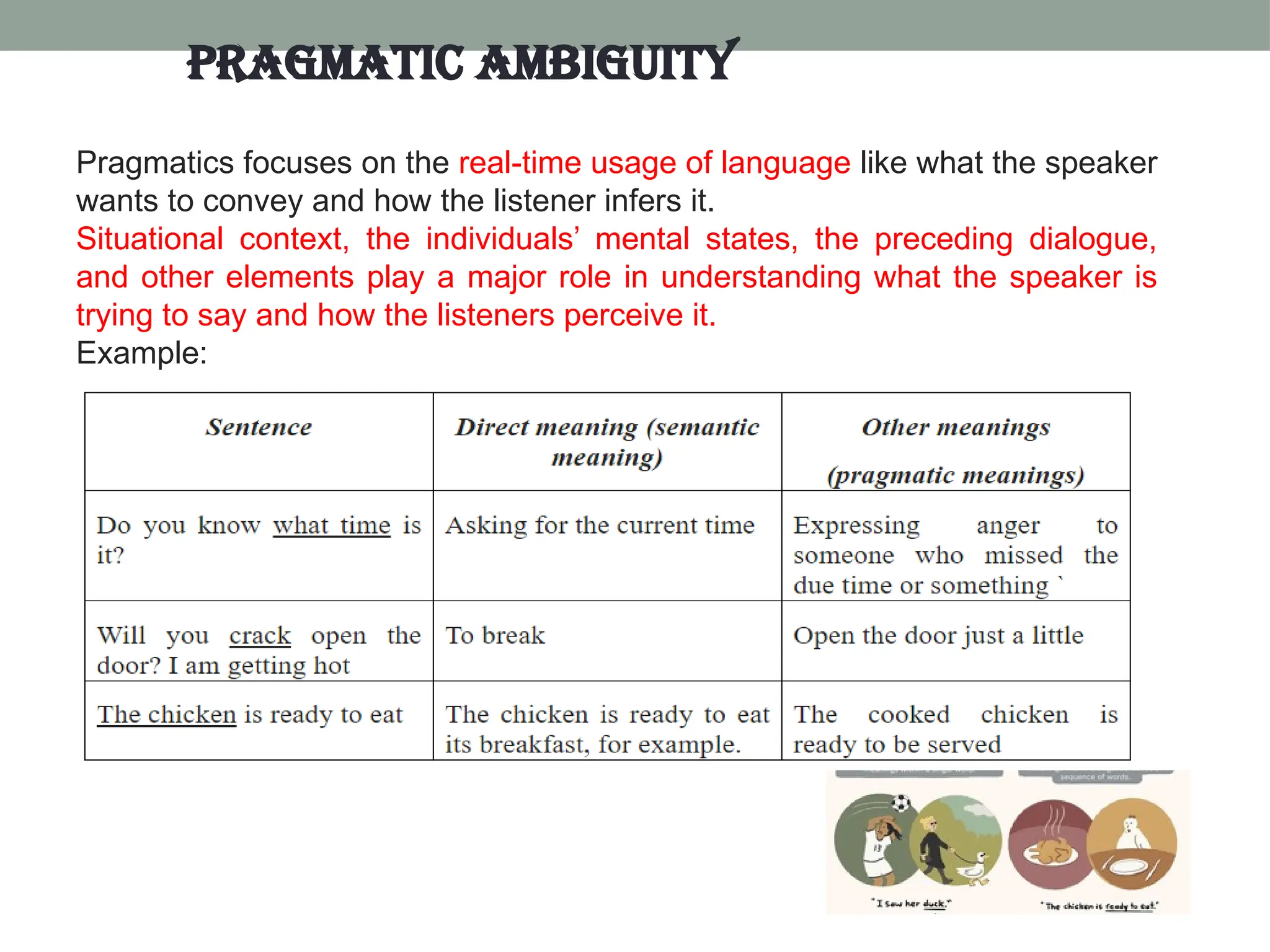
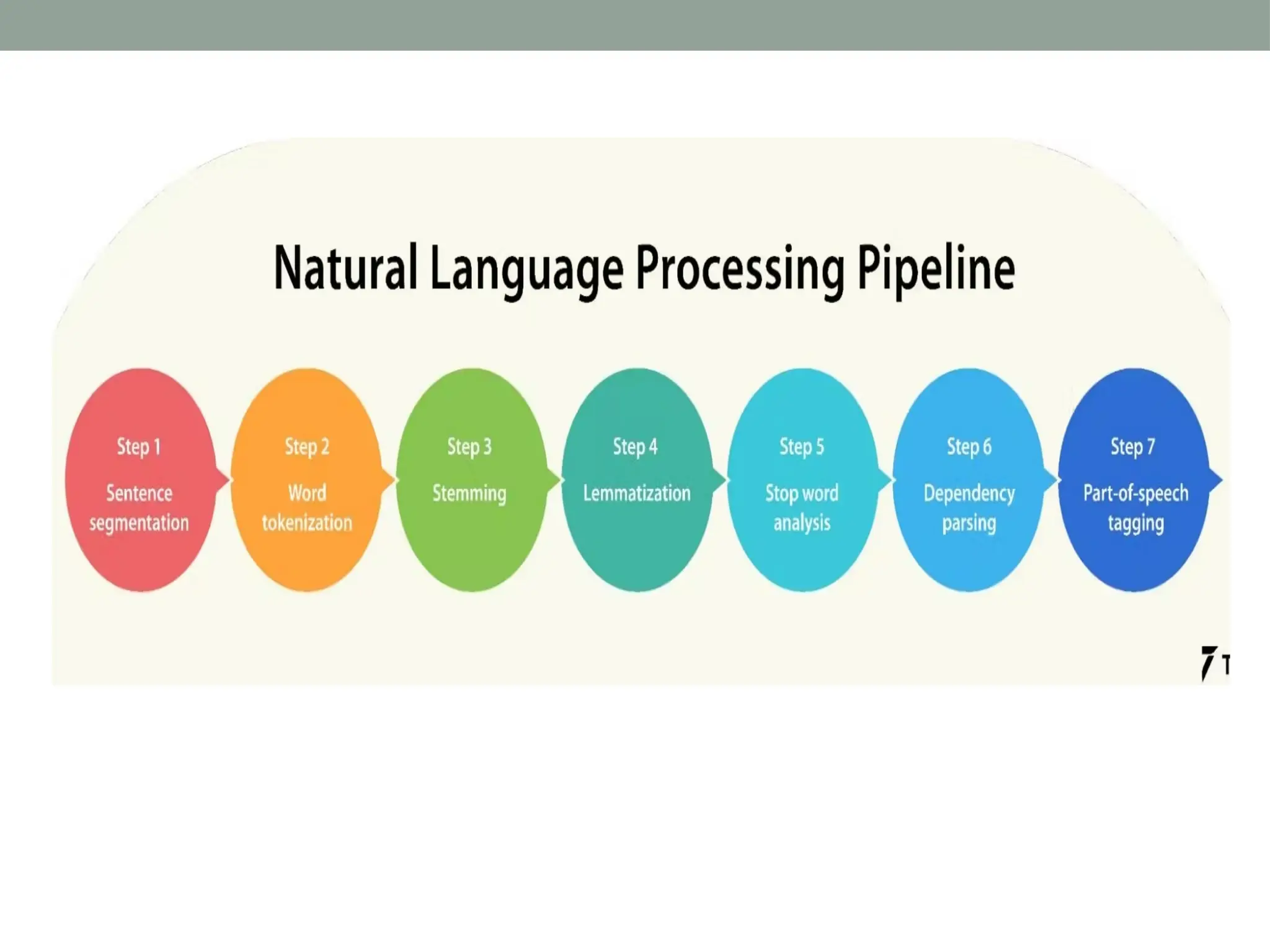
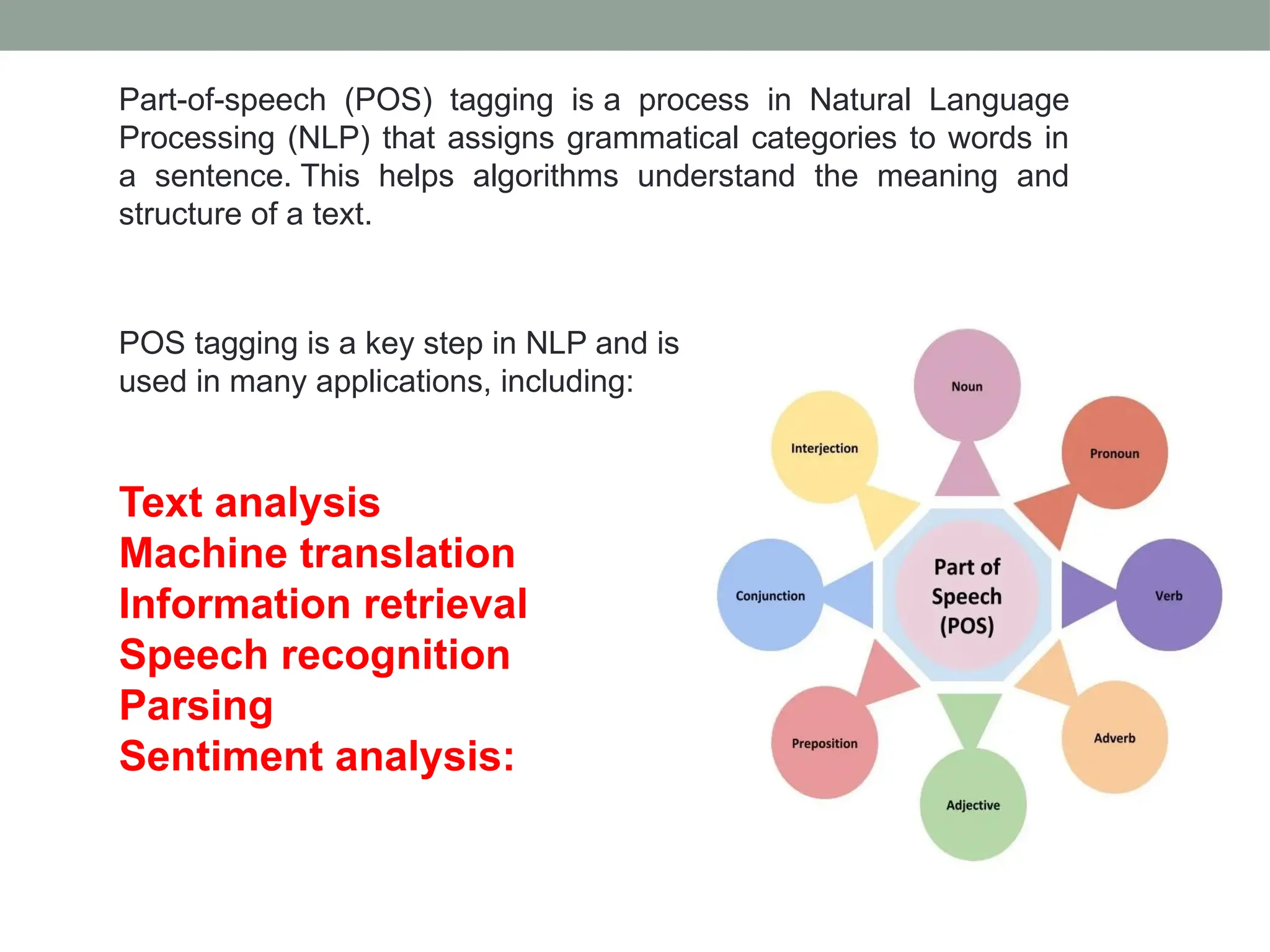
The document discusses natural language processing (NLP), outlining its advantages such as efficiency in answering user queries and assisting in documentation, while also noting disadvantages like context lack and unpredictability. It explains concepts like lexical, syntactic, and semantic ambiguities, providing examples for each, and details various NLP steps including tokenization, stemming, lemmatization, and part-of-speech tagging. Additionally, it touches on advanced topics like named entity recognition and chunking in the NLP pipeline.