Download as PDF, PPTX



![Hichem Felouat - hichemfel@nii.ac.jp - 2024 7 Texts to Sequence/Matrix • In natural language processing (NLP), texts can be represented as a sequence or a matrix, depending on the task and the model type. texts = ["I love Algeria", "machine learning", "Artificial intelligence", "AI"] • The total number of documents: 4 • The number of distinct words (Tokenization ): 8 • word_index : {'i': 1, 'love': 2, 'algeria': 3, 'machine': 4, 'learning': 5, 'artificial': 6, 'intelligence': 7, 'ai': 8} • texts_to_sequences : input [Algeria love AI] [3, 2, 8] • sequences_to_texts : input [3, 4, 7, 2, 8, 1, 3] ['algeria machine intelligence love ai i algeria']](https://image.slidesharecdn.com/transformer-240228123303-68fd90f5/75/Natural-Language-Processing-NLP-Transformers-7-2048.jpg)
![Hichem Felouat - hichemfel@nii.ac.jp - 2024 8 Texts to Sequence/Matrix • binary: Whether or not each word is present in the document. This is the default. • count : The count of each word in the document. • freq : The frequency of each word as a ratio of words within each document. • tfidf : The Text Frequency-Inverse Document Frequency (TF-IDF) scoring for each word in the document. texts = [ "blue car and blue window", "black crow in the window","i see my reflection in the window" ]](https://image.slidesharecdn.com/transformer-240228123303-68fd90f5/75/Natural-Language-Processing-NLP-Transformers-8-2048.jpg)

![Hichem Felouat - hichemfel@nii.ac.jp - 2024 10 Sequence Padding • Sequence padding is the process of adding zeroes or other filler tokens to sequences of variable length so that all sequences have the same length. • Many machine learning models require fixed-length inputs, and variable-length sequences can't be fed directly into these models. sequences = [ [1, 2, 3, 4], [1, 2, 3], [1] ] maxlen= 4 result: [[1 2 3 4] [0 1 2 3] [0 0 0 1]]](https://image.slidesharecdn.com/transformer-240228123303-68fd90f5/75/Natural-Language-Processing-NLP-Transformers-10-2048.jpg)











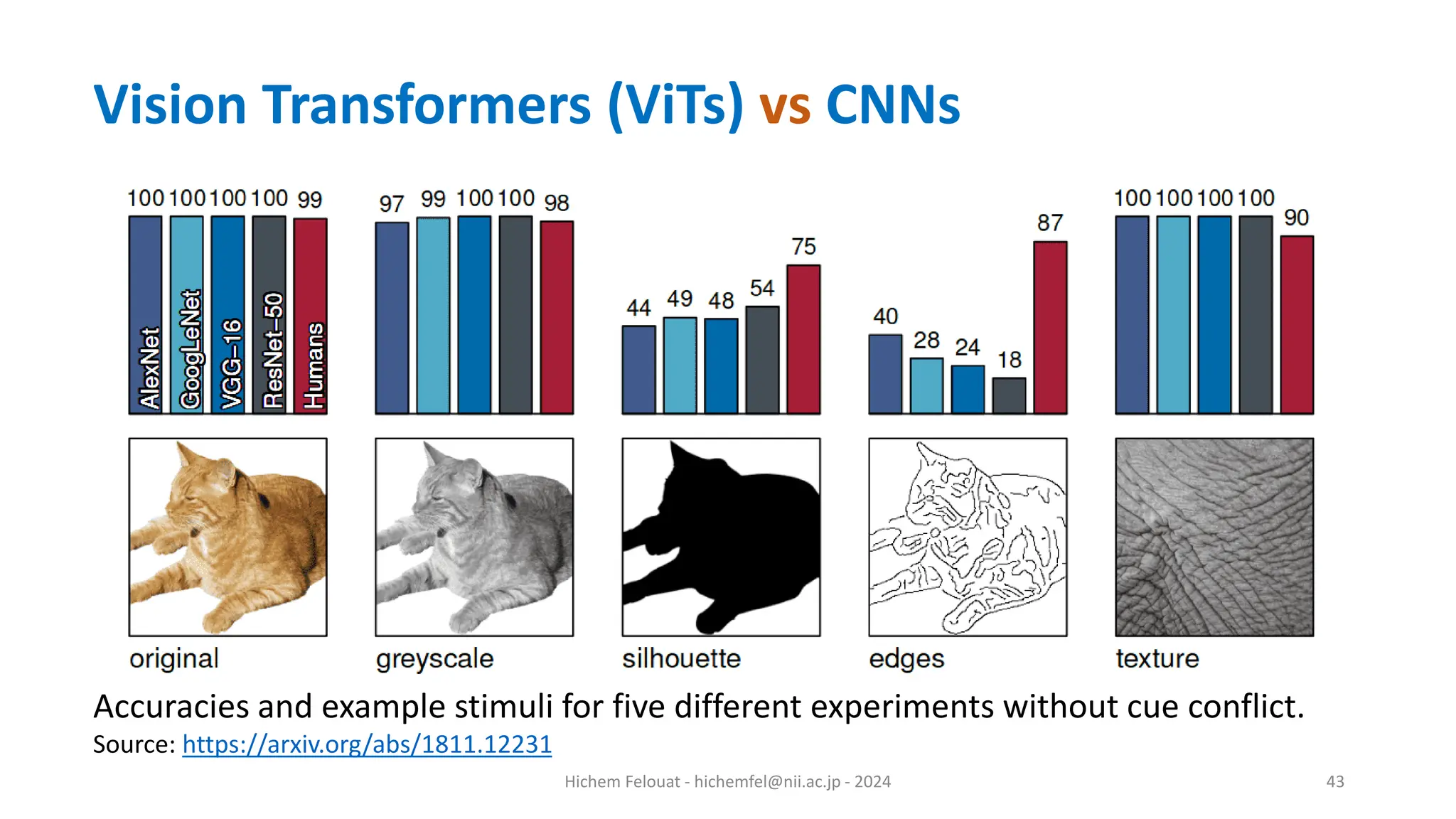
![Hichem Felouat - hichemfel@nii.ac.jp - 2024 41 The authors in [1] demonstrated that CNNs trained on ImageNet are strongly biased towards recognizing textures rather than shapes. Below is an excellent example of such a case: [1]: ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. https://arxiv.org/abs/1811.12231 Vision Transformers (ViTs) vs CNNs](https://image.slidesharecdn.com/transformer-240228123303-68fd90f5/75/Natural-Language-Processing-NLP-Transformers-41-2048.jpg)
![Hichem Felouat - hichemfel@nii.ac.jp - 2024 42 • Neuroscience studies (The importance of shape in early lexical learning [1]) showed that object shape is the single most important cue for human object recognition. • By studying the visual pathway of humans regarding image recognition, researchers identified that the perception of object shape is invariant to most perturbations. So as far as we know, the shape is the most reliable cue. • Intuitively, the object shape remains relatively stable, while other cues can be easily distorted by all sorts of noise [2]. 1: https://psycnet.apa.org/doi/10.1016/0885-2014(88)90014-7 2: https://arxiv.org/abs/1811.12231 Vision Transformers (ViTs) vs CNNs](https://image.slidesharecdn.com/transformer-240228123303-68fd90f5/75/Natural-Language-Processing-NLP-Transformers-42-2048.jpg)


![Hichem Felouat - hichemfel@nii.ac.jp - 2024 46 The authors in [1] looked at the self-attention of the CLS token on the heads of the last layer. Crucially, no labels are used during the self-supervised training. These maps demonstrate that the learned class-specific features lead to remarkable unsupervised segmentation masks and visibly correlate with the shape of semantic objects in the images. 1: Self-Supervised Vision Transformers with DINO https://arxiv.org/abs/2104.14294 Vision Transformers (ViTs) vs CNNs](https://image.slidesharecdn.com/transformer-240228123303-68fd90f5/75/Natural-Language-Processing-NLP-Transformers-46-2048.jpg)

![Hichem Felouat - hichemfel@nii.ac.jp - 2024 48 • The transformer can attend to all the tokens (image patches) at each block by design. The originally proposed ViT model in [1] already demonstrated that heads from early layers tend to attend to far-away pixels, while heads from later layers do not. How heads of different layers attend to their surrounding pixels [1]. [1]: https://arxiv.org/abs/2010.11929 Vision Transformers (ViTs) vs CNNs](https://image.slidesharecdn.com/transformer-240228123303-68fd90f5/75/Natural-Language-Processing-NLP-Transformers-48-2048.jpg)



The document discusses various aspects of natural language processing (NLP) and its applications, including self-attention mechanisms and transformer models. It covers key concepts such as word embeddings, recurrent neural networks (RNNs), and the comparison between vision transformers and traditional convolutional neural networks (CNNs). Additionally, it highlights the performance of large language models and the architecture of vision language models.