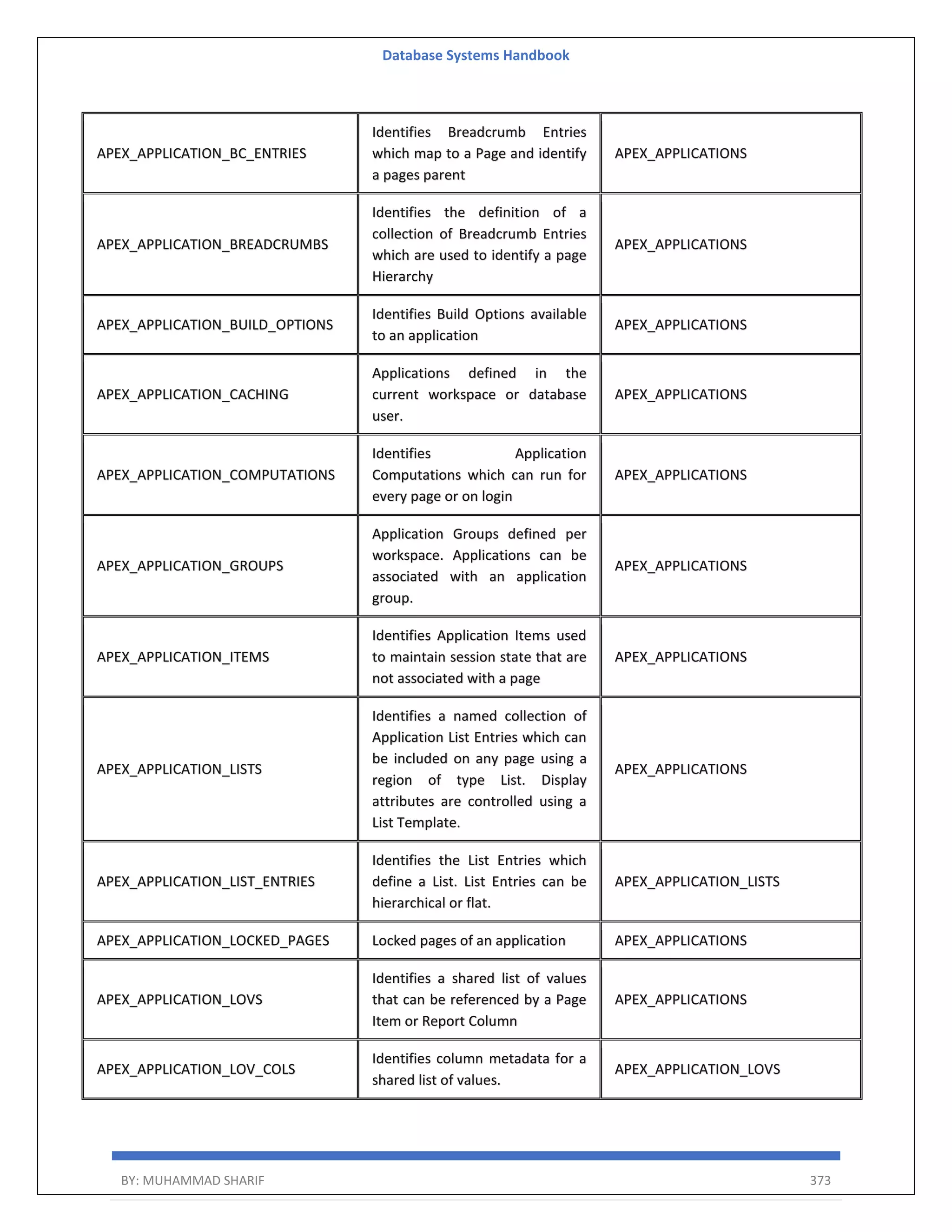
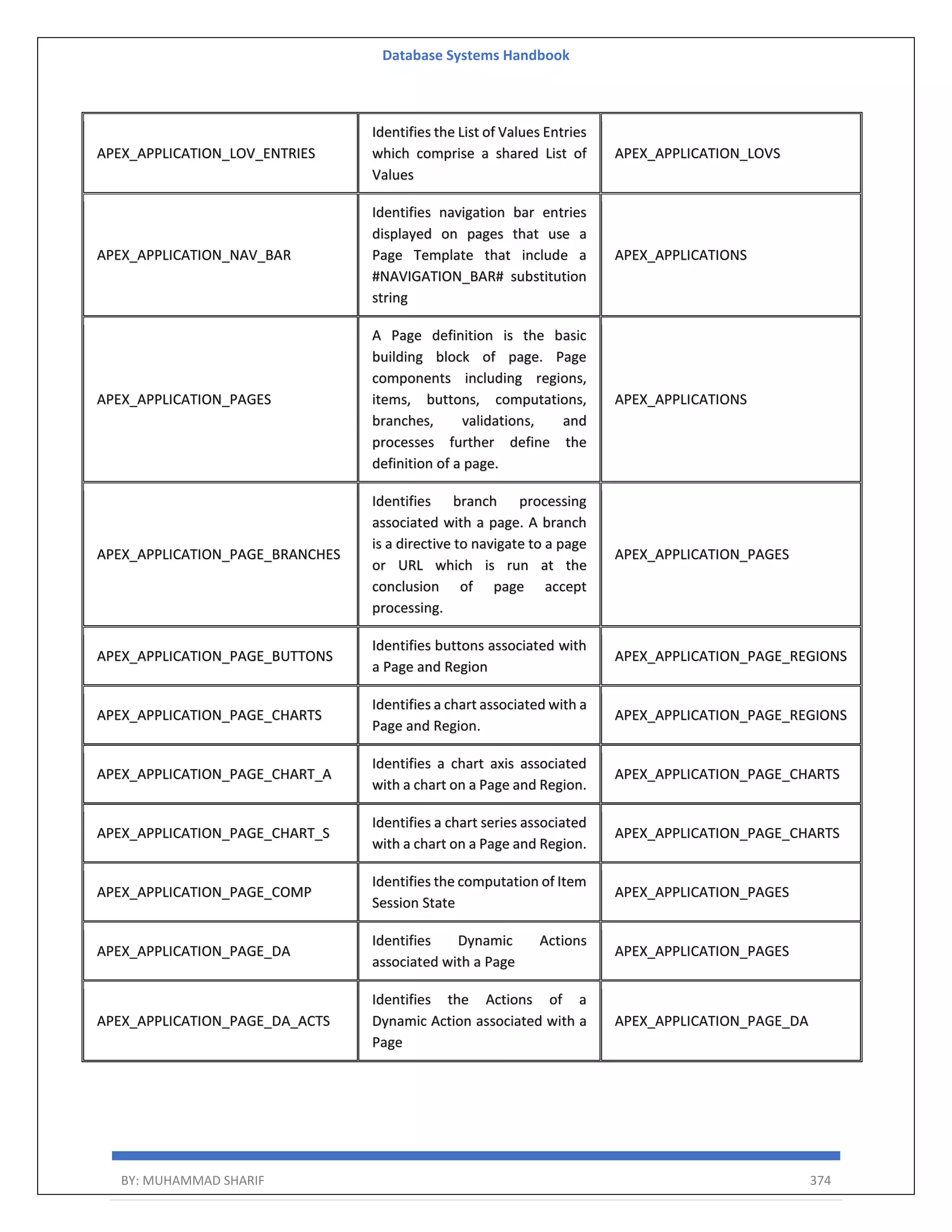
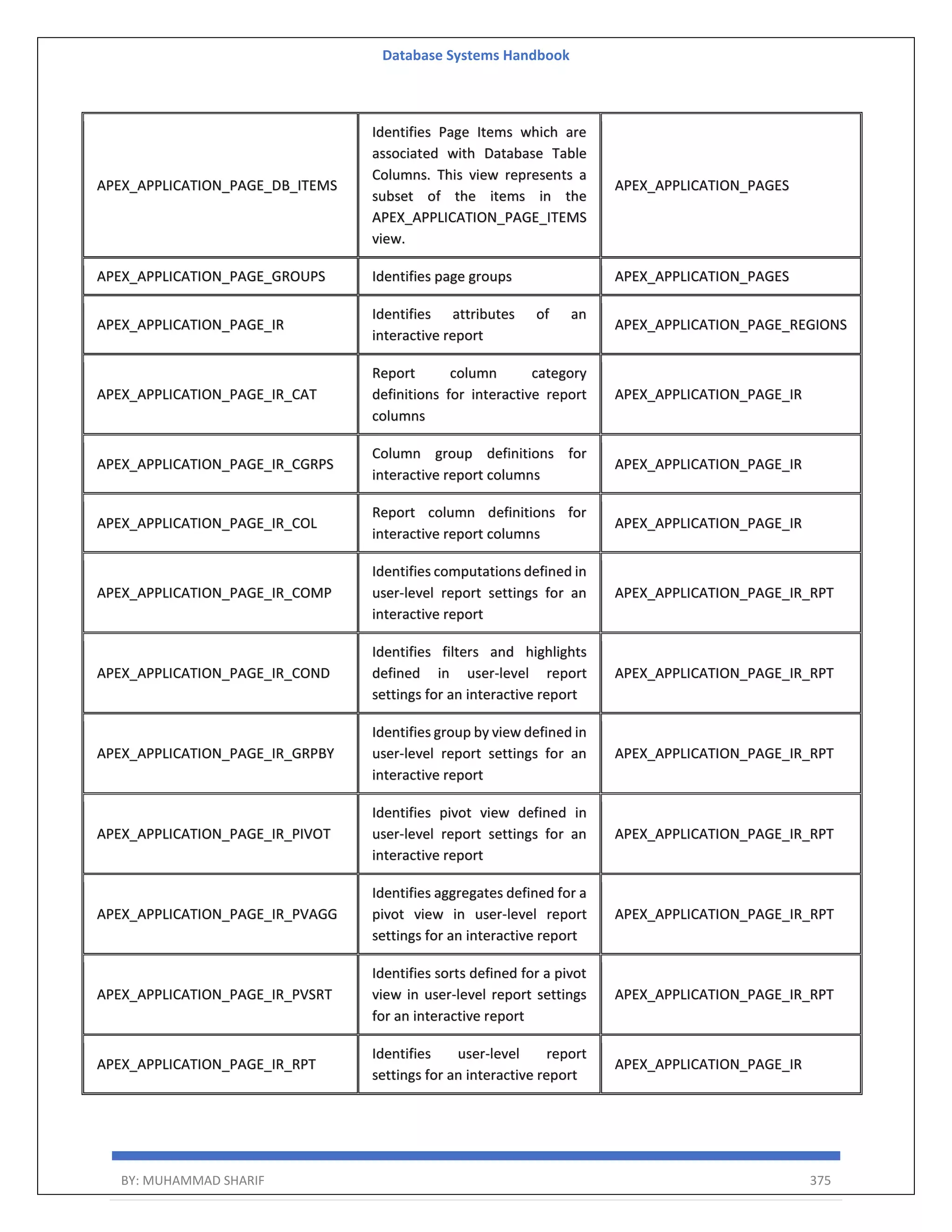
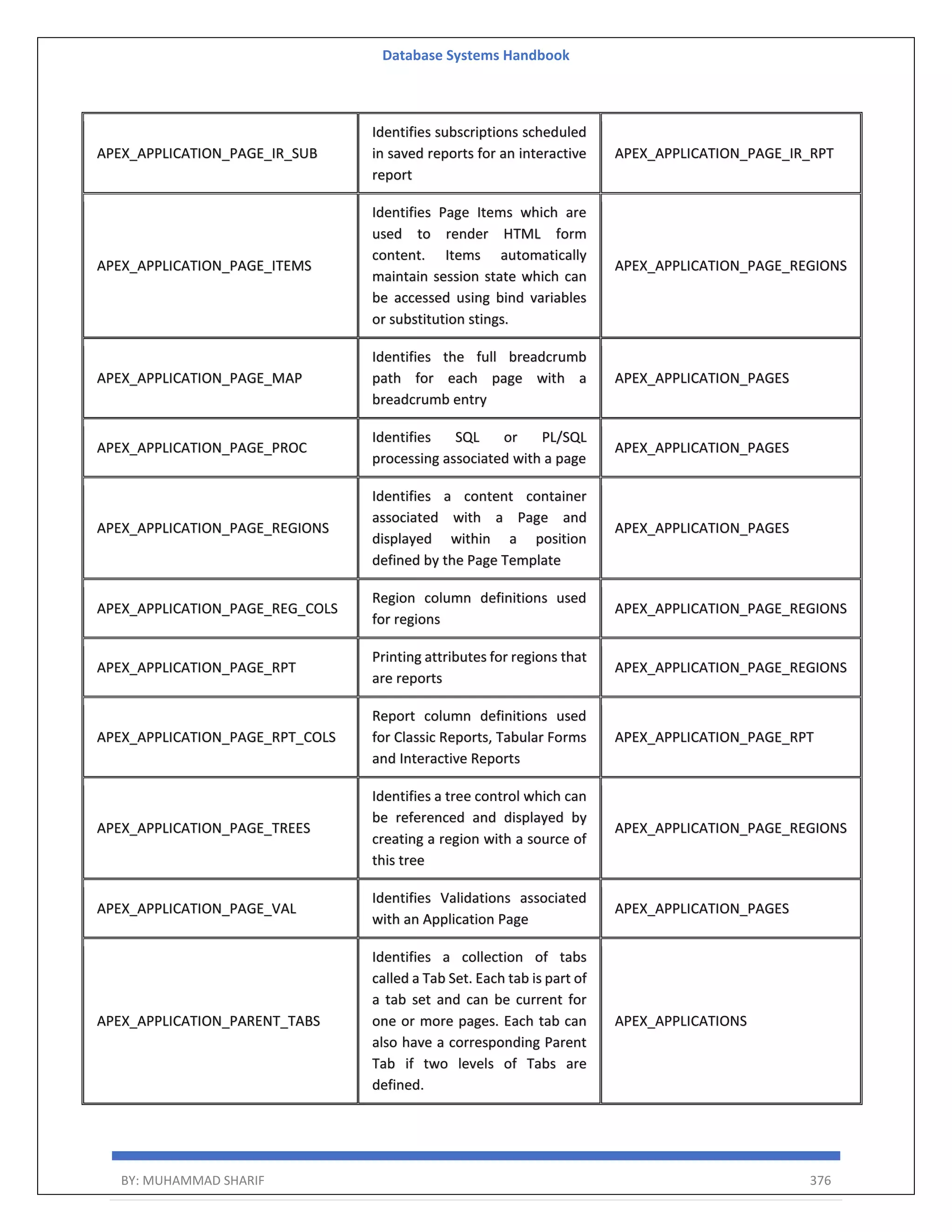
Download to read offline




































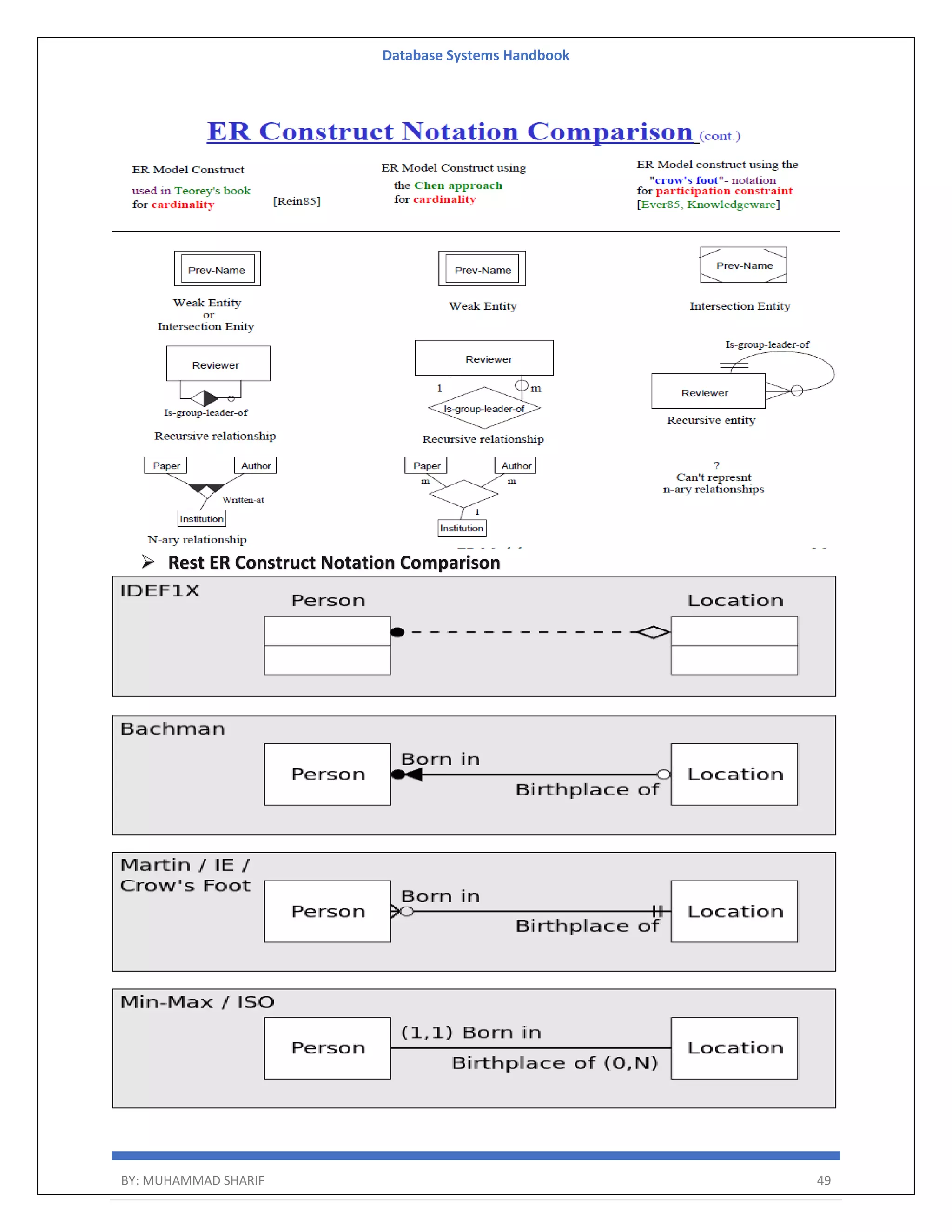



















































































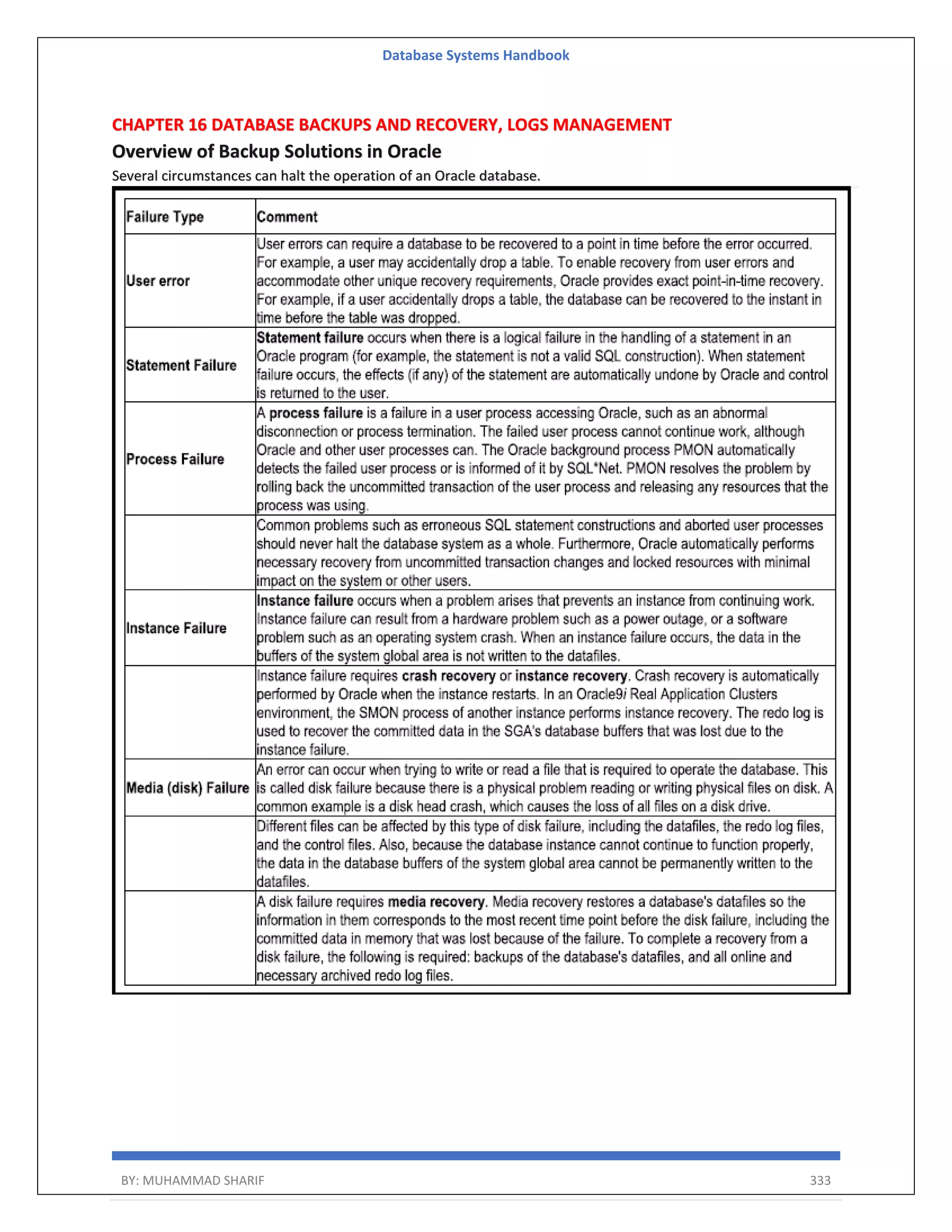
![Database Systems Handbook BY: MUHAMMAD SHARIF 164 Phantom deadlock detection is the condition where the deadlock does not exist but due to a delay in propagating local information, deadlock detection algorithms identify the locks that have been already acquired. There are three alternatives for deadlock detection in a distributed system, namely. Centralized Deadlock Detector − One site is designated as the central deadlock detector. Hierarchical Deadlock Detector − Some deadlock detectors are arranged in a hierarchy. Distributed Deadlock Detector − All the sites participate in detecting deadlocks and removing them. The deadlock detection algorithm uses 3 data structures – Available Vector of length m Indicates the number of available resources of each type. Allocation Matrix of size n*m A[i,j] indicates the number of j the resource type allocated to I the process. Request Matrix of size n*m Indicates the request of each process. Request[i,j] tells the number of instances Pi process is the request of jth resource type. Deadlock Avoidance Deadlock avoidance Acquire locks in a pre-defined order Acquire all locks at once before starting transactions Aborting a transaction is not always a practical approach. Instead, deadlock avoidance mechanisms can be used to detect any deadlock situation in advance. The deadlock prevention technique avoids the conditions that lead to deadlocking. It requires that every transaction lock all data items it needs in advance. If any of the items cannot be obtained, none of the items are locked. The transaction is then rescheduled for execution. The deadlock prevention technique is used in two-phase locking. To prevent any deadlock situation in the system, the DBMS aggressively inspects all the operations, where transactions are about to execute. If it finds that a deadlock situation might occur, then that transaction is never allowed to be executed. Deadlock Prevention Algo 1. Wait-Die scheme 2. Wound wait scheme](https://image.slidesharecdn.com/muhammadsharifdbafulldbmshandbookdatabasesystems-220805041410-d996e5cc/75/Muhammad-Sharif-DBA-full-dbms-Handbook-Database-systems-pdf-164-2048.jpg)











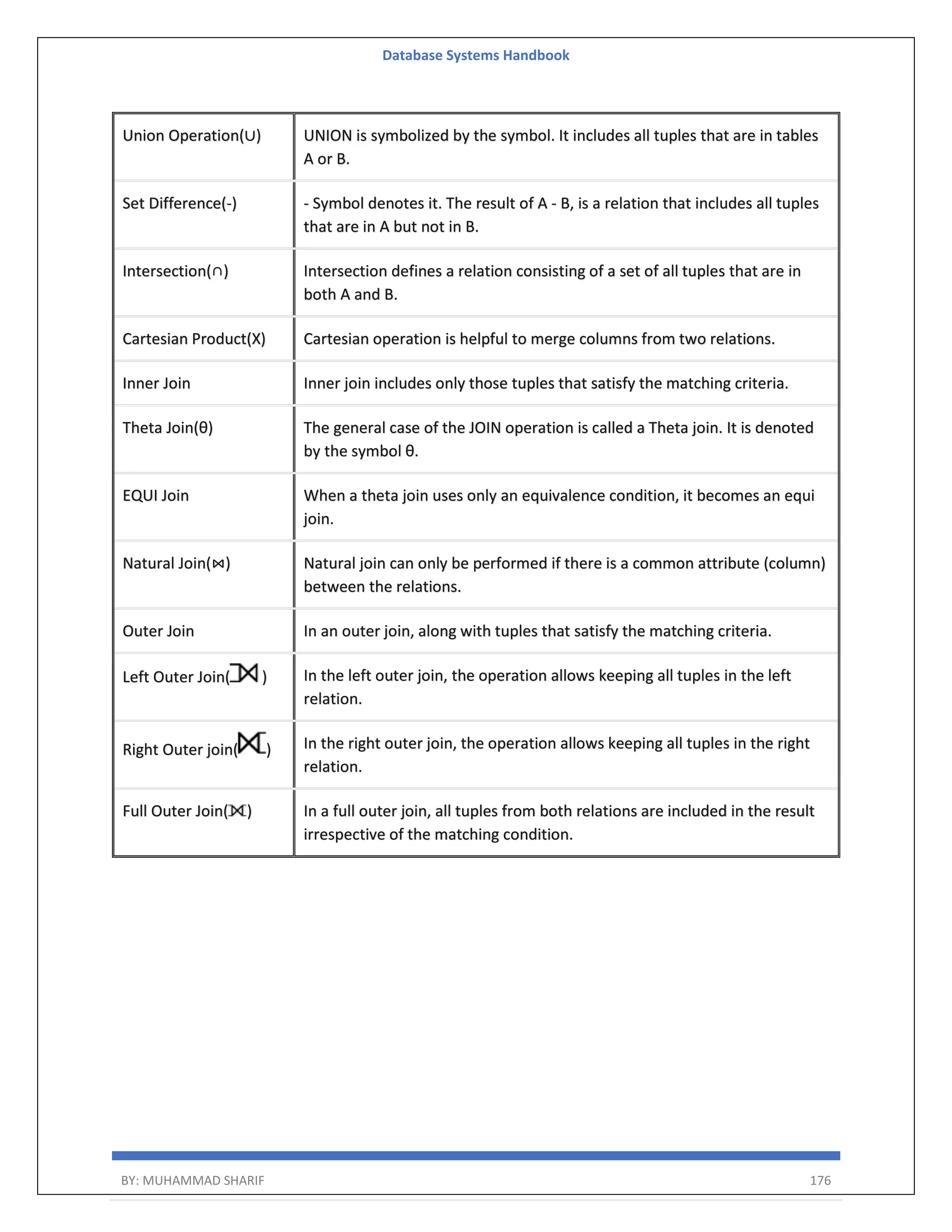












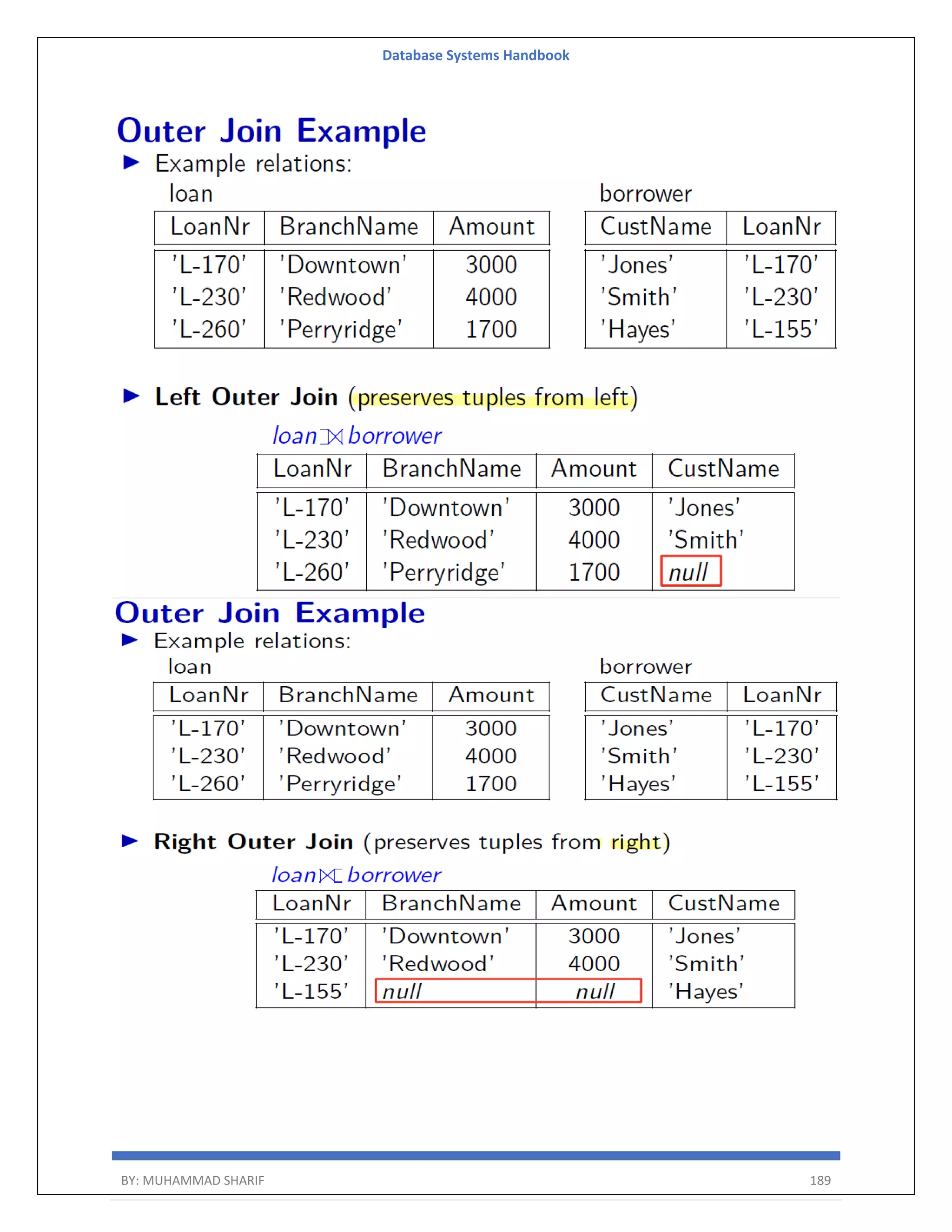







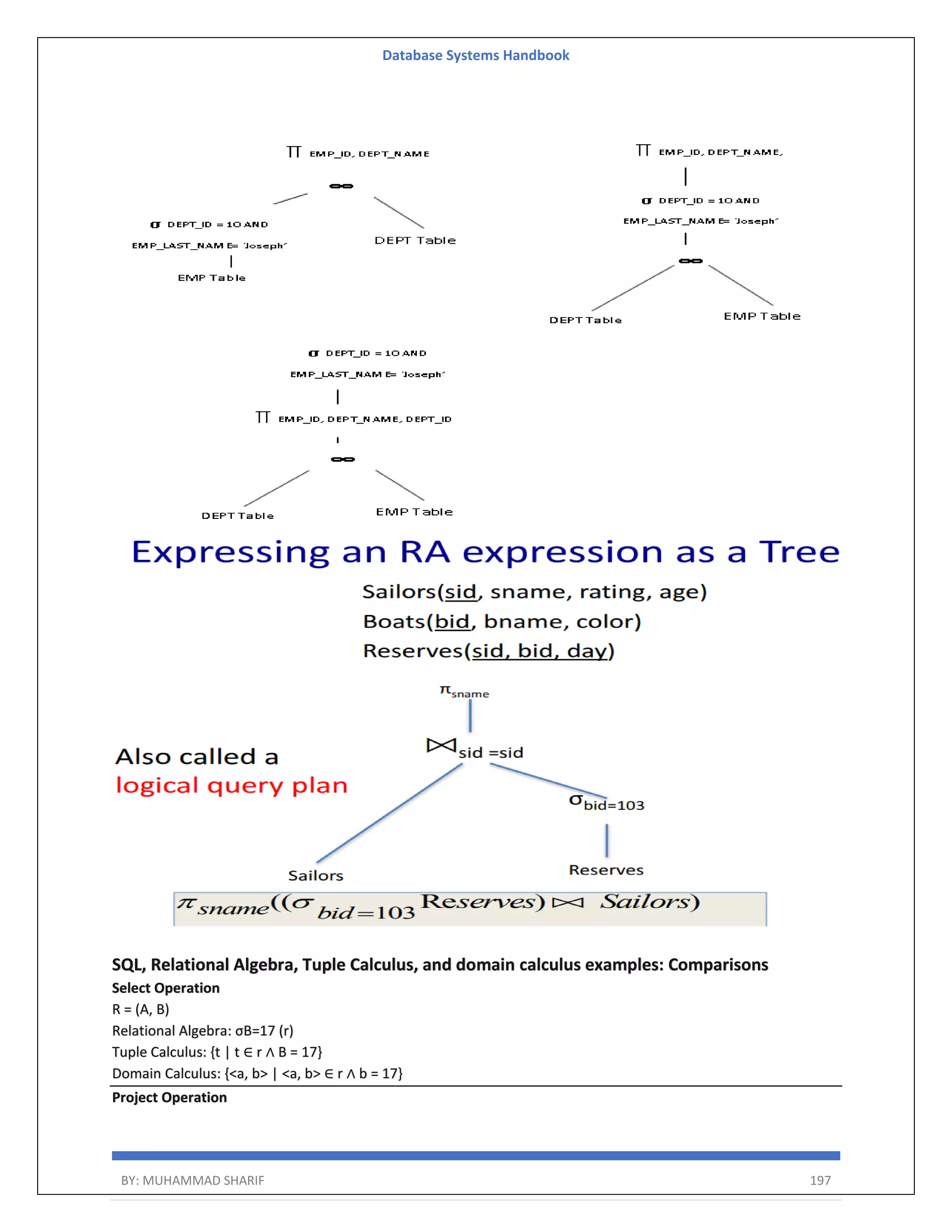
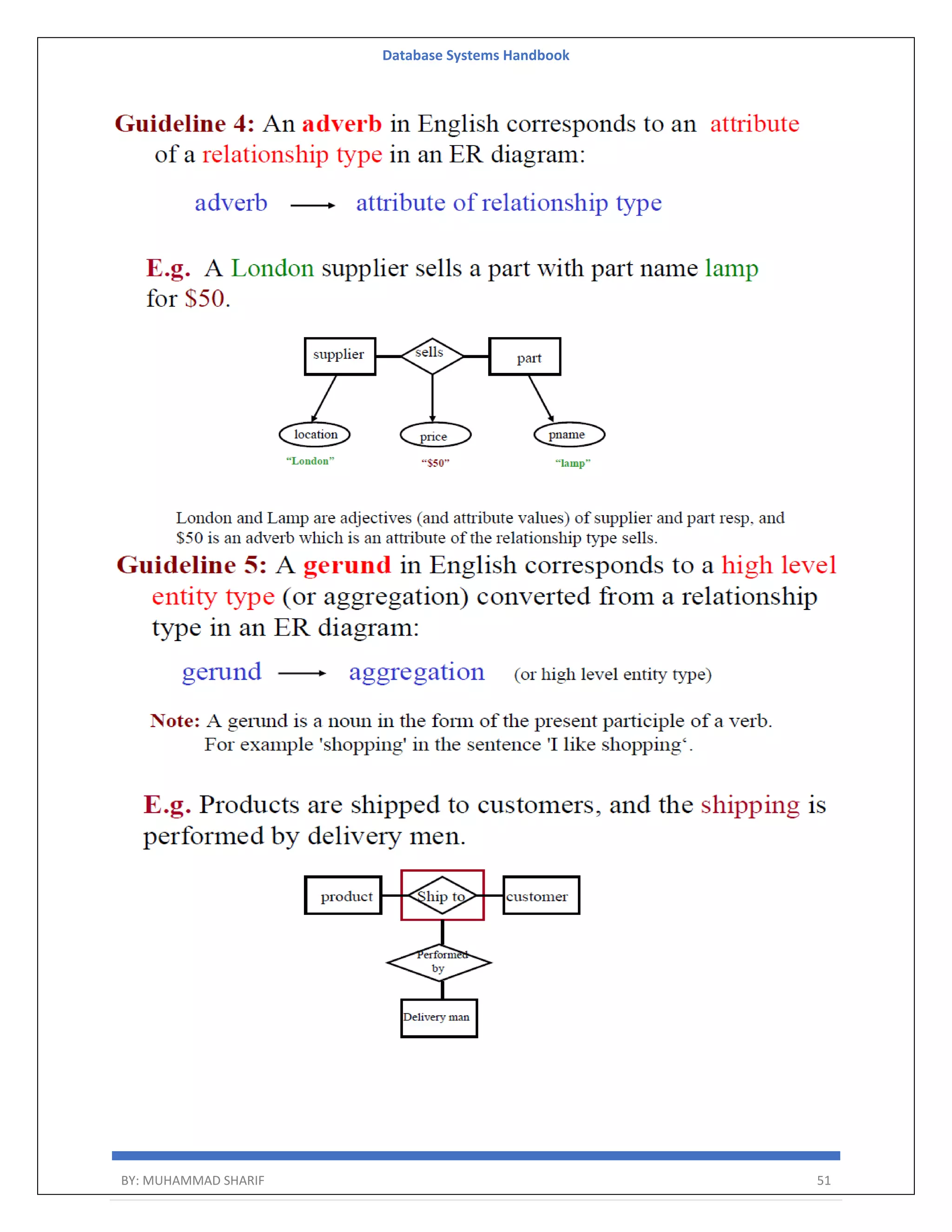
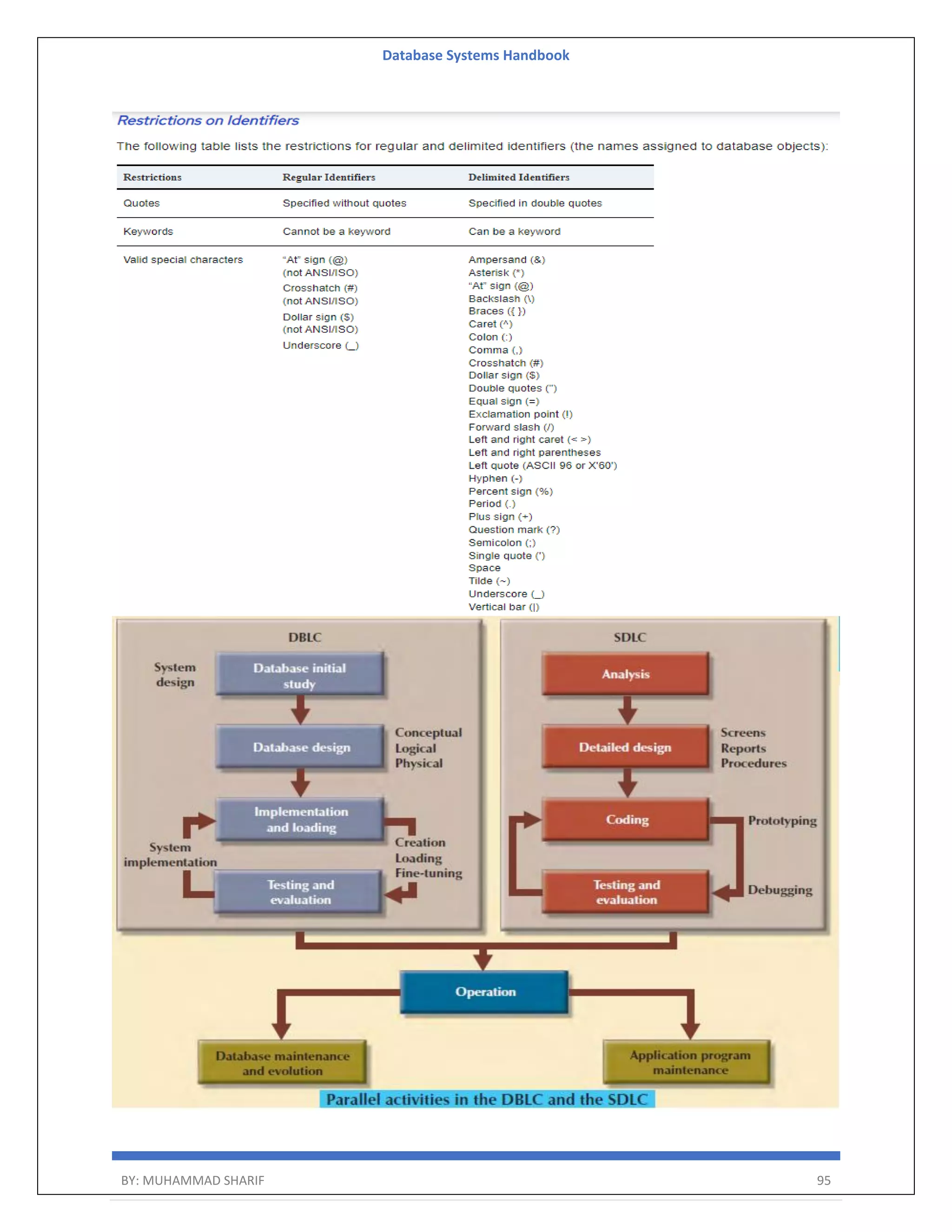
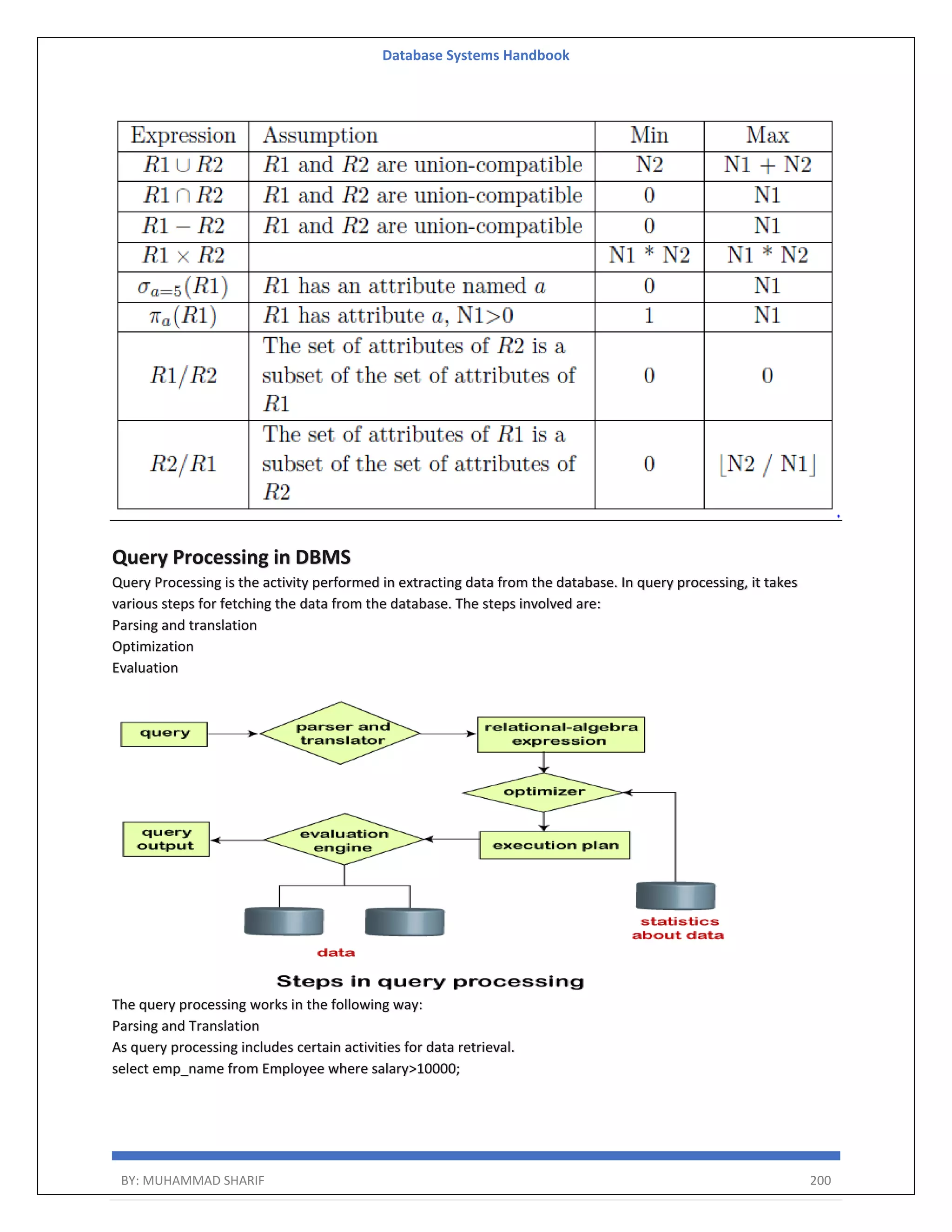
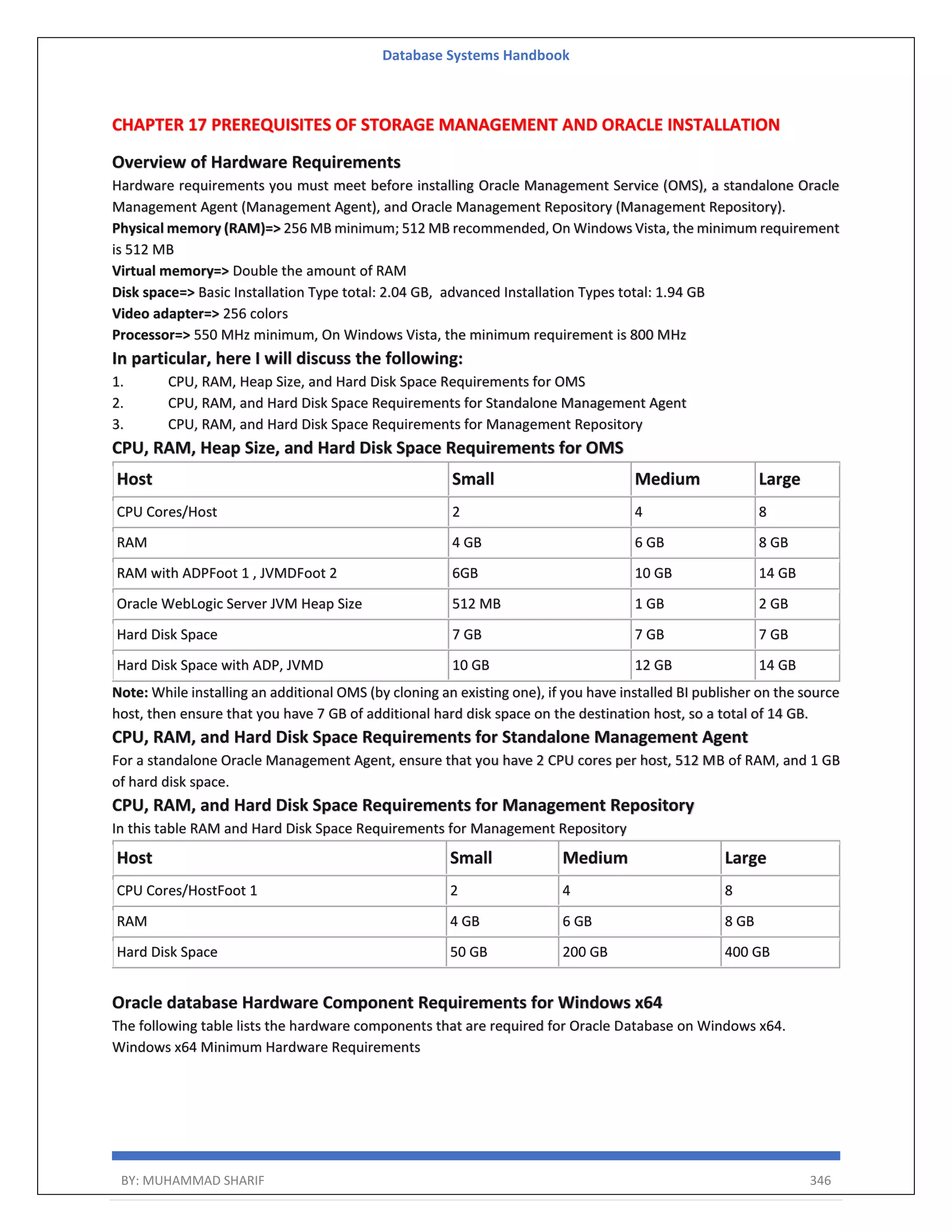
![Database Systems Handbook BY: MUHAMMAD SHARIF 198 R = (A, B) Relational Algebra: ΠA(r) Tuple Calculus: {t | ∃ p ∈ r (t[A] = p[A])} Domain Calculus: {<a> | ∃ b ( <a, b> ∈ r )} Combining Operations R = (A, B) Relational Algebra: ΠA(σB=17 (r)) Tuple Calculus: {t | ∃ p ∈ r (t[A] = p[A] ∧ p[B] = 17)} Domain Calculus: {<a> | ∃ b ( <a, b> ∈ r ∧ b = 17)} Natural Join R = (A, B, C, D) S = (B, D, E) Relational Algebra: r ⋈ s Πr.A,r.B,r.C,r.D,s.E(σr.B=s.B ∧ r.D=s.D (r × s)) Tuple Calculus: {t | ∃ p ∈ r ∃ q ∈ s (t[A] = p[A] ∧ t[B] = p[B] ∧ t[C] = p[C] ∧ t[D] = p[D] ∧ t[E] = q[E] ∧ p[B] = q[B] ∧ p[D] = q[D])} Domain Calculus: {<a, b, c, d, e> | <a, b, c, d> ∈ r ∧ <b, d, e> ∈ s}](https://image.slidesharecdn.com/muhammadsharifdbafulldbmshandbookdatabasesystems-220805041410-d996e5cc/75/Muhammad-Sharif-DBA-full-dbms-Handbook-Database-systems-pdf-198-2048.jpg)






























































































































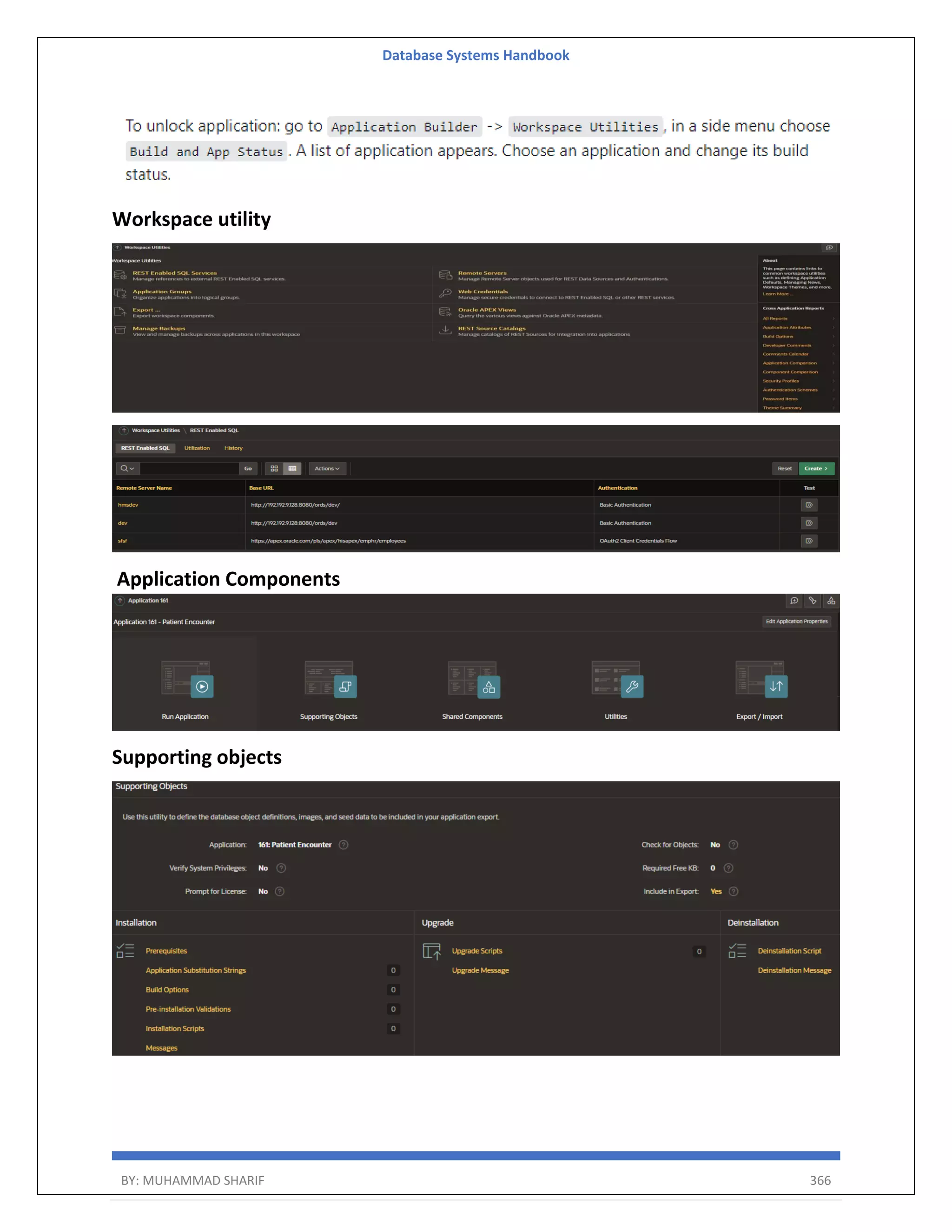
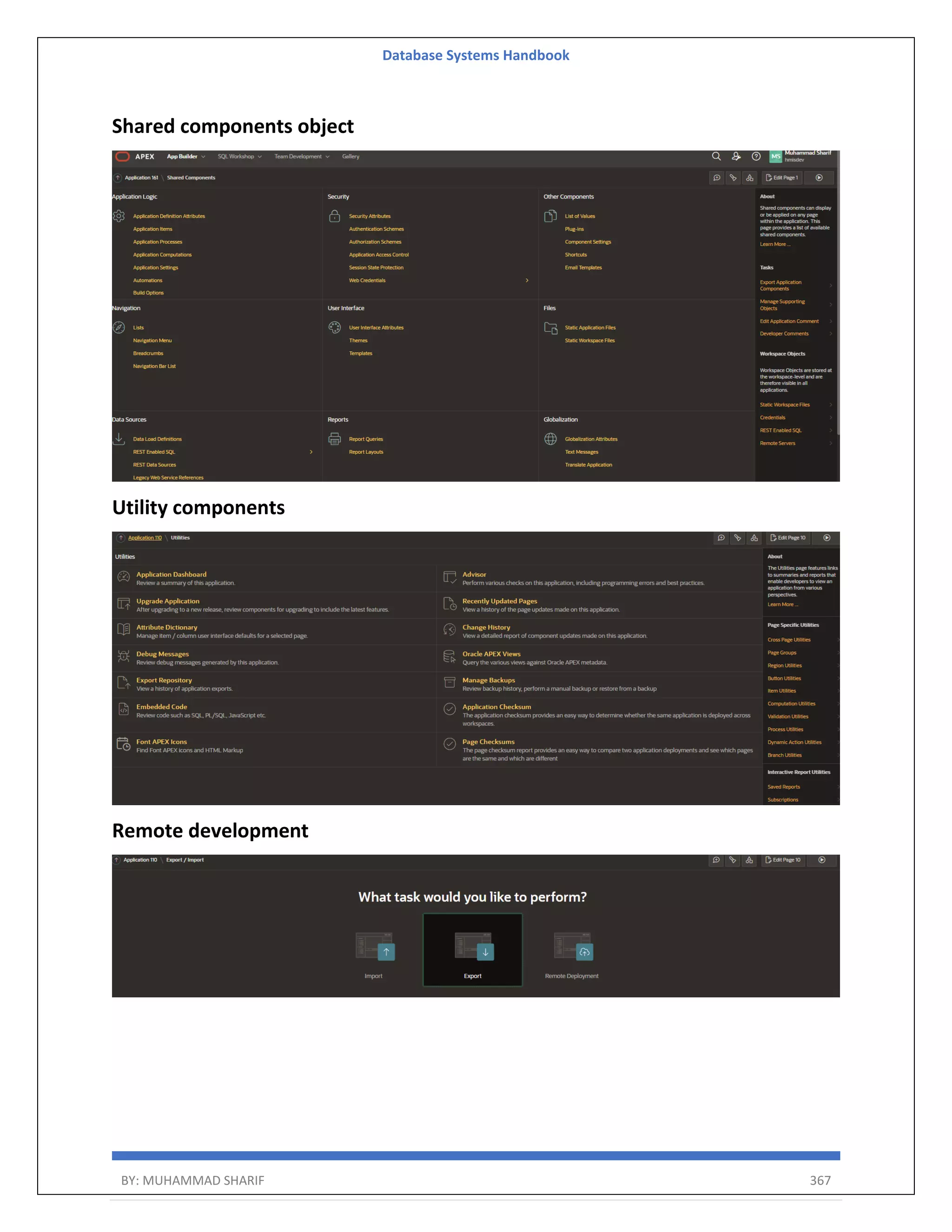
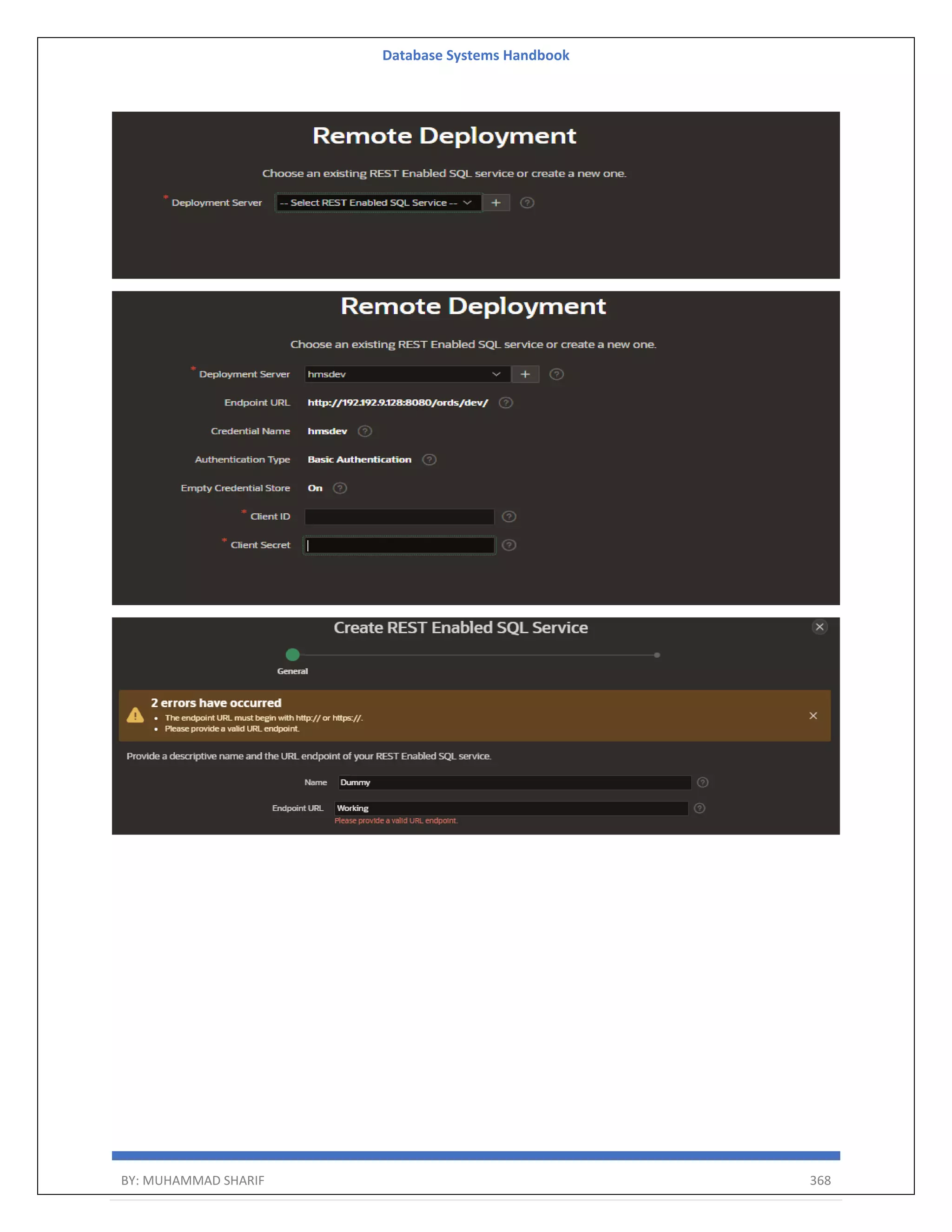










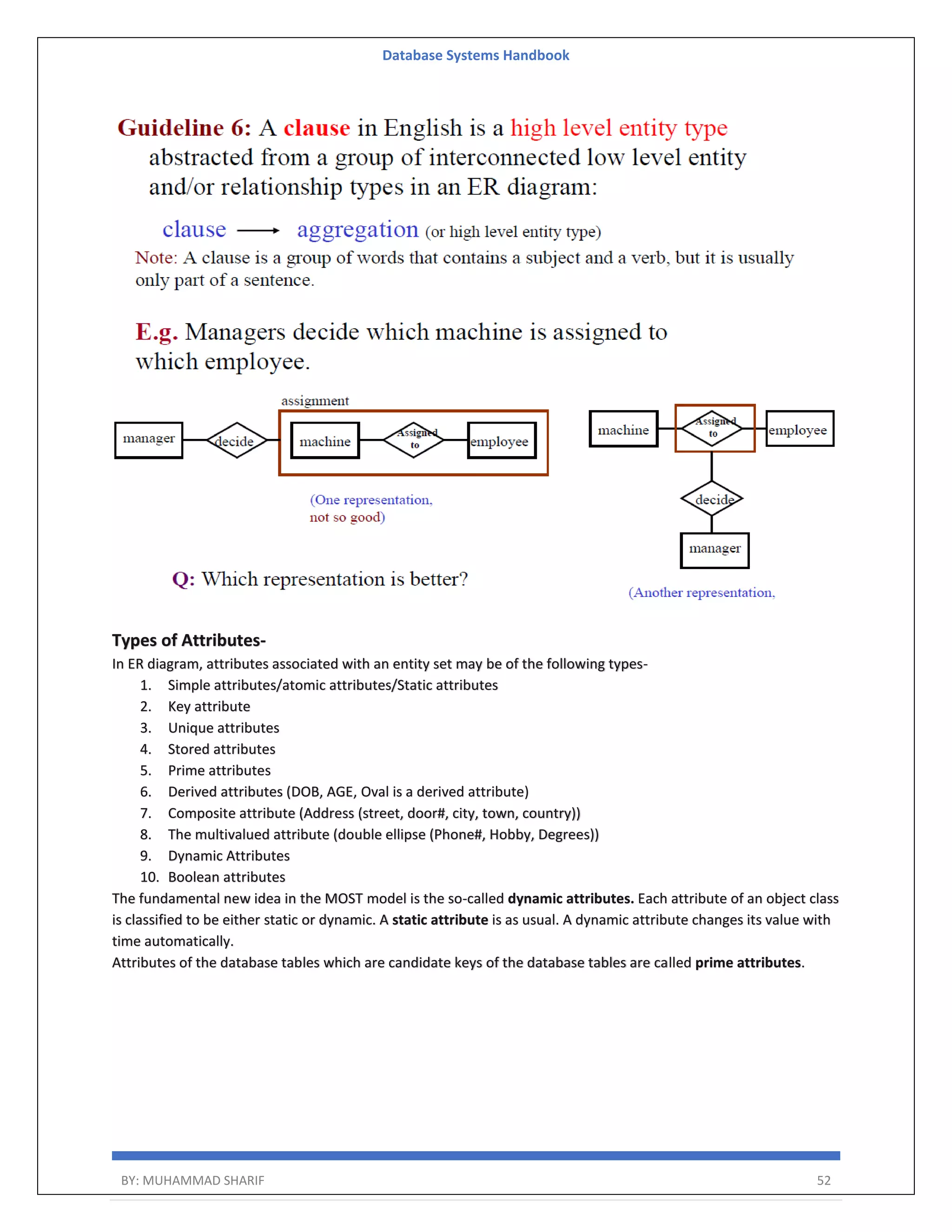
![Database Systems Handbook BY: MUHAMMAD SHARIF 387 instance administrator. If the user does not yet exist, a user record will be created. Enter the administrator's username [ADMIN] User "ADMIN" does not yet exist and will be created. Enter ADMIN's email [ADMIN] Enter ADMIN's password [] Created instance administrator ADMIN. Step Five Create the APEX_LISTENER and APEX_REST_PUBLIC_USER users by running the "apex_rest_config.sql" script. SQL> CONN sys@pdb1 AS SYSDBA SQL> @apex_rest_config.sql Configure RESTful Services. When prompted enter a password for the APEX_LISTENER, APEX_REST_PUBLIC_USER account. sqlplus / as sysdba alter session set container=orclpdb1; @apex_rest_config.sql output SQL> @apex_rest_config.sql Enter a password for the APEX_LISTENER user [] Enter a password for the APEX_REST_PUBLIC_USER user [] ...set_appun.sql ...setting session environment ...create APEX_LISTENER and APEX_REST_PUBLIC_USER users ...grants for APEX_LISTENER and ORDS_METADATA user as last step you can modify again passwords for 3 users: ALTER USER apex_public_user IDENTIFIED BY Dbaora$ ACCOUNT UNLOCK; ALTER USER apex_listener IDENTIFIED BY Dbaora$ ACCOUNT UNLOCK; ALTER USER apex_rest_public_user IDENTIFIED BY Dbaora$ ACCOUNT UNLOCK; Install and configure You can install and configure APEX and ORDS by using the following methods:](https://image.slidesharecdn.com/muhammadsharifdbafulldbmshandbookdatabasesystems-220805041410-d996e5cc/75/Muhammad-Sharif-DBA-full-dbms-Handbook-Database-systems-pdf-387-2048.jpg)

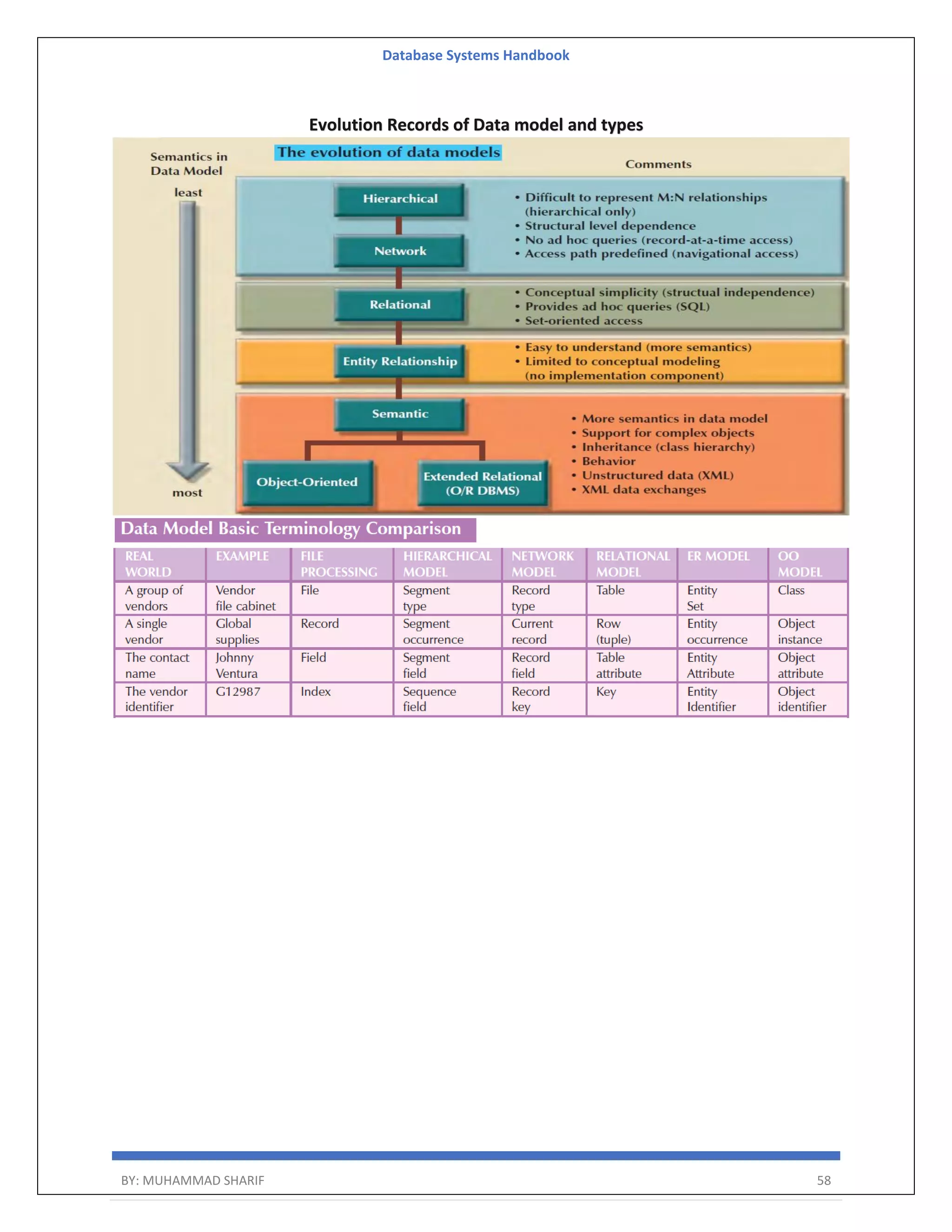
![Database Systems Handbook BY: MUHAMMAD SHARIF 389 [oracle@oel8 ords]$ java -jar ords.war This Oracle REST Data Services instance has not yet been configured. Please complete the following prompts Enter the location to store configuration data: /home/oracle/ords/conf Enter the database password for ORDS_PUBLIC_USER: Confirm password: Requires to login with administrator privileges to verify Oracle REST Data Services schema. Enter the administrator username:sys Enter the database password for SYS AS SYSDBA: Confirm password: Connecting to database user: SYS AS SYSDBA url: jdbc:oracle:thin:@//oel8.dbaora.com:1521/orclpdb1 Retrieving information. Enter 1 if you want to use PL/SQL Gateway or 2 to skip this step. If using Oracle Application Express or migrating from mod_plsql then you must enter 1 [1]: Enter the database password for APEX_PUBLIC_USER: Confirm password: Enter the database password for APEX_LISTENER: Confirm password: Enter the database password for APEX_REST_PUBLIC_USER: Confirm password: Enter a number to select a feature to enable: [1] SQL Developer Web (Enables all features) [2] REST Enabled SQL [3] Database API [4] REST Enabled SQL and Database API [5] None Choose [1]:1 2022-03-19T18:40:34.543Z INFO reloaded pools: [] Installing Oracle REST Data Services version 21.4.2.r0621806 ... Log file written to /home/oracle/ords_install_core_2022-03-19_194034_00664.log ... Verified database prerequisites](https://image.slidesharecdn.com/muhammadsharifdbafulldbmshandbookdatabasesystems-220805041410-d996e5cc/75/Muhammad-Sharif-DBA-full-dbms-Handbook-Database-systems-pdf-389-2048.jpg)
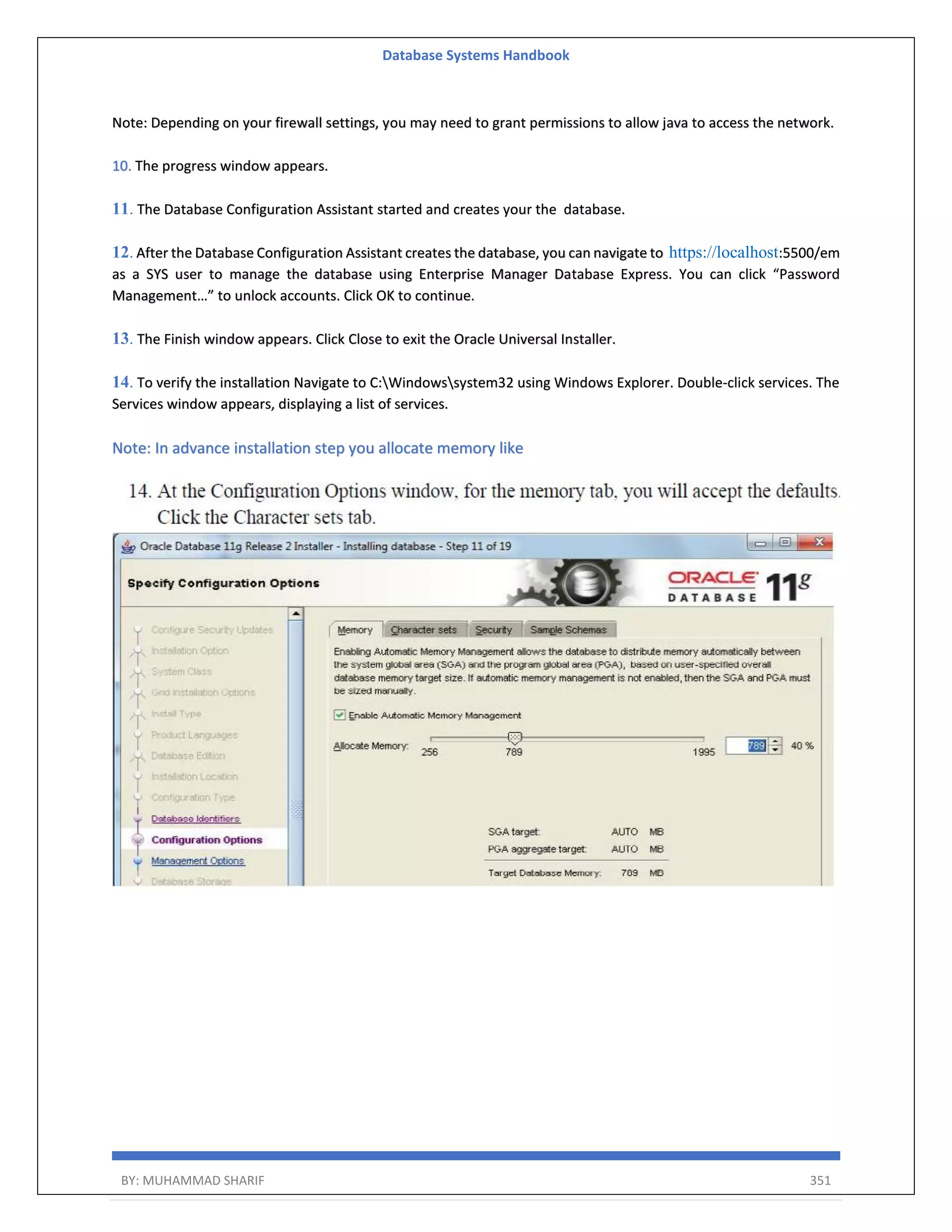
![Database Systems Handbook BY: MUHAMMAD SHARIF 390 ... Created Oracle REST Data Services proxy user ... Created Oracle REST Data Services schema ... Granted privileges to Oracle REST Data Services ... Created Oracle REST Data Services database objects ... Log file written to /home/oracle/ords_install_datamodel_2022-03-19_194044_00387.log ... Log file written to /home/oracle/ords_install_scheduler_2022-03-19_194045_00075.log ... Log file written to /home/oracle/ords_install_apex_2022-03-19_194046_00484.log Completed installation for Oracle REST Data Services version 21.4.2.r0621806. Elapsed time: 00:00:12.611 Enter 1 if you wish to start in standalone mode or 2 to exit [1]:1 Enter 1 if using HTTP or 2 if using HTTPS [1]: Choose [1]:1 As a result ORDS will be running in standalone mode and configured so you can try to logon to apex. After reboot of machine start ORDS in standalone mode in background as following: cd /home/oracle/ords java -jar ords.war standalone & Verify APEX is working Administration page http://hostname:port/ords In this case http://oel8.dbaora.com:8080/ords OR Embedded PL/SQL Gateway (EPG) Configuration If you want to use the Embedded PL/SQL Gateway (EPG) to front APEX, you can follow the instructions here. This is used for both the first installation and upgrades. Run the "apex_epg_config.sql" script, passing in the base directory of the installation software as a parameter. SQL> CONN sys@pdb1 AS SYSDBA SQL> @apex_epg_config.sql /home/oracle OR Oracle HTTP Server (OHS) Configuration If you want to use Oracle HTTP Server (OHS) to front APEX, you can follow the instructions here.](https://image.slidesharecdn.com/muhammadsharifdbafulldbmshandbookdatabasesystems-220805041410-d996e5cc/75/Muhammad-Sharif-DBA-full-dbms-Handbook-Database-systems-pdf-390-2048.jpg)

![Database Systems Handbook BY: MUHAMMAD SHARIF 392 ORDS is started or stopped by starting or stopping the Tomcat instance it is deployed to. Assuming you have the CATALINA_HOME environment variable set correctly, the following commands should be used. Oracle now supports Oracle REST Data Services (ORDS) running in standalone mode using the built-in Jetty web server, so you no longer need to worry about installing WebLogic, Glassfish or Tomcat unless you have a compelling reason to do so. Removing this extra layer means one less layer to learn and one less layer to patch. ORDS can run as a standalone app with a built in webserver. This is perfect for local development purposes but in the real world you will want a decent java application server (Tomcat, Glassfish or Weblogic) with a webserver in front of it (Apache or Nginx). export CATALINA_OPTS="$CATALINA_OPTS -Duser.timezone=UTC" $ $CATALINA_HOME/bin/startup.sh $ $CATALINA_HOME/bin/shutdown.sh ORDS Validate You can validate/fix the current ORDS installation using the validate option. $ $JAVA_HOME/bin/java -jar ords.war validate Enter the name of the database server [ol7-122.localdomain]: Enter the database listen port [1521]: Enter the database service name [pdb1]: Requires SYS AS SYSDBA to verify Oracle REST Data Services schema. Enter the database password for SYS AS SYSDBA: Confirm password: Retrieving information. Oracle REST Data Services will be validated. Validating Oracle REST Data Services schema version 18.2.0.r1831332 ... Log file written to /u01/asi_test/ords/logs/ords_validate_core_2018-08-07_160549_00215.log Completed validating Oracle REST Data Services version 18.2.0.r1831332. Elapsed time: 00:00:06.898 $ Manual ORDS Uninstall In recent versions you can use the following command to uninstall ORDS and provide the information when prompted. # su - tomcat $ cd /u01/ords](https://image.slidesharecdn.com/muhammadsharifdbafulldbmshandbookdatabasesystems-220805041410-d996e5cc/75/Muhammad-Sharif-DBA-full-dbms-Handbook-Database-systems-pdf-392-2048.jpg)
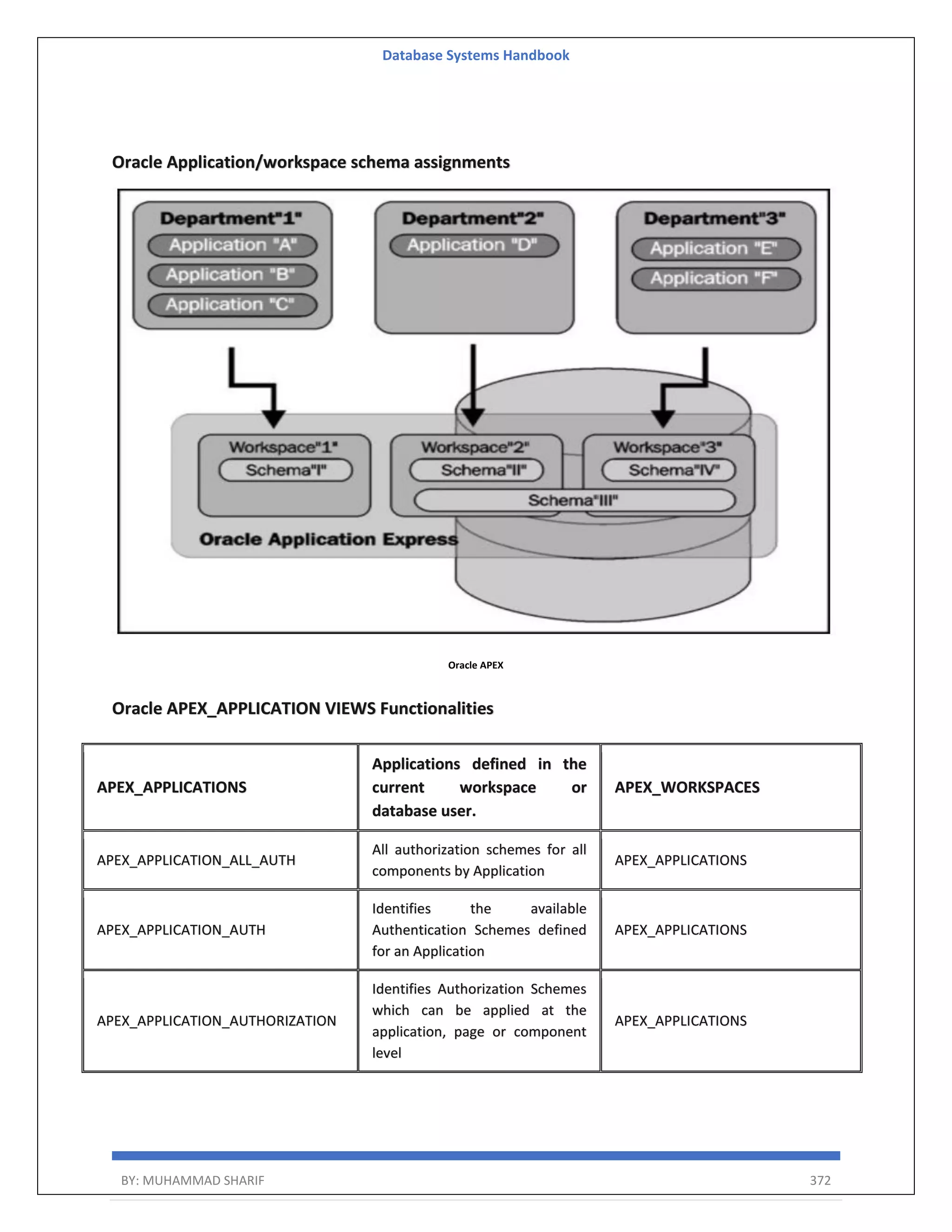
![Database Systems Handbook BY: MUHAMMAD SHARIF 393 $ $JAVA_HOME/bin/java -jar ords.war uninstall Enter the name of the database server [ol7-122.localdomain]: Enter the database listen port [1521]: Enter 1 to specify the database service name, or 2 to specify the database SID [1]: Enter the database service name [pdb1]: Requires SYS AS SYSDBA to verify Oracle REST Data Services schema. Enter the database password for SYS AS SYSDBA: Confirm password: Retrieving information Uninstalling Oracle REST Data Services ... Log file written to /u01/ords/logs/ords_uninstall_core_2018-06-14_155123_00142.log Completed uninstall for Oracle REST Data Services. Elapsed time: 00:00:10.876 $ In older versions of ORDS you had to extract scripts to perform the uninstall in the following way. su - tomcat cd /u01/ords $JAVA_HOME/bin/java -jar ords.war ords-scripts --scriptdir /tmp Perform the uninstall from the "oracle" user using the following commands. su -oracle cd /tmp/scripts/uninstall/core/ sqlplus sys@pdb1 as sysdba @ords_manual_uninstall /tmp/scripts/logs What is an APEX Workspace? An APEX Workspace is a logical domain where you define APEX applications. Each workspace is associated with one or more database schemas (database users) which are used to store the database objects, such as tables, views, packages, and more. APEX applications are built on top of these database objects.](https://image.slidesharecdn.com/muhammadsharifdbafulldbmshandbookdatabasesystems-220805041410-d996e5cc/75/Muhammad-Sharif-DBA-full-dbms-Handbook-Database-systems-pdf-393-2048.jpg)






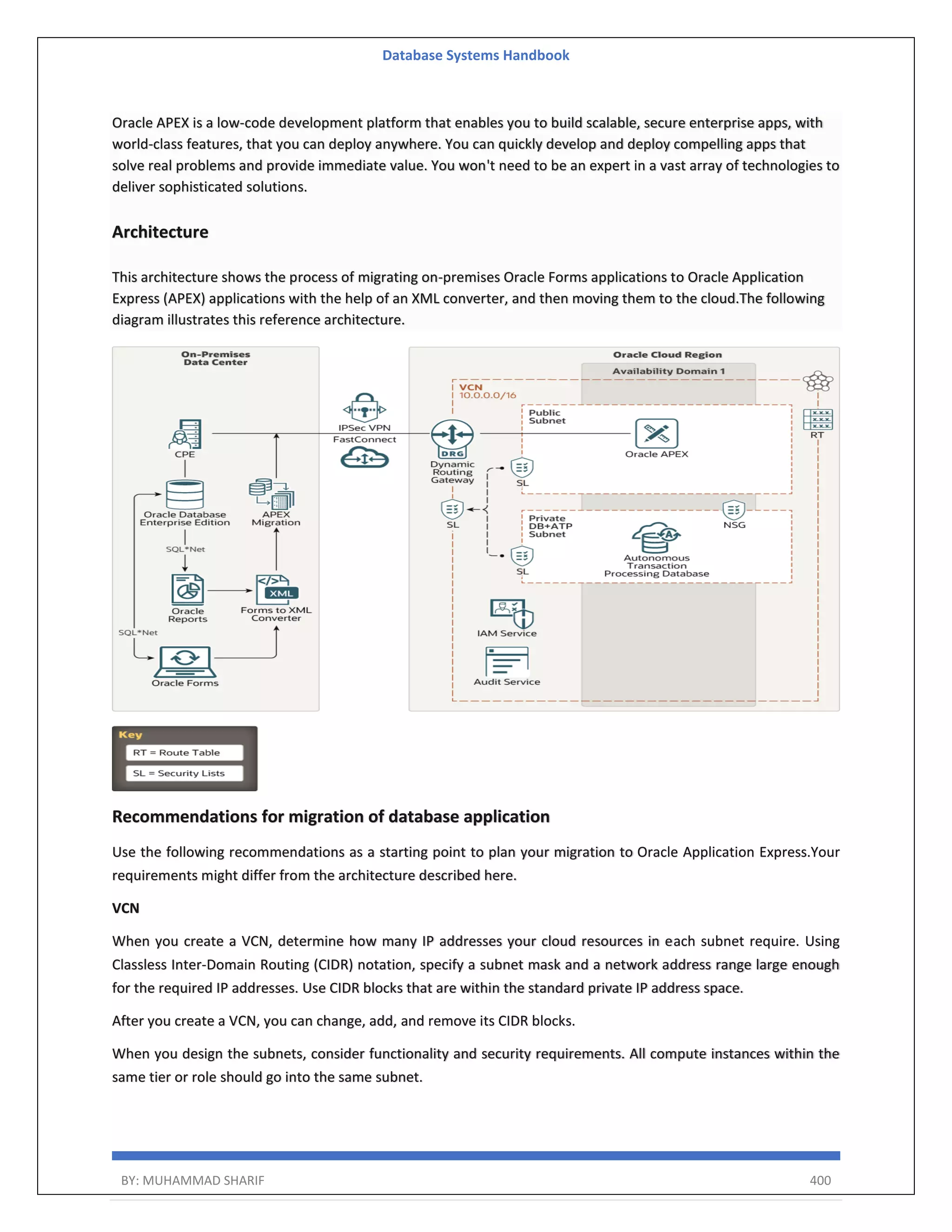























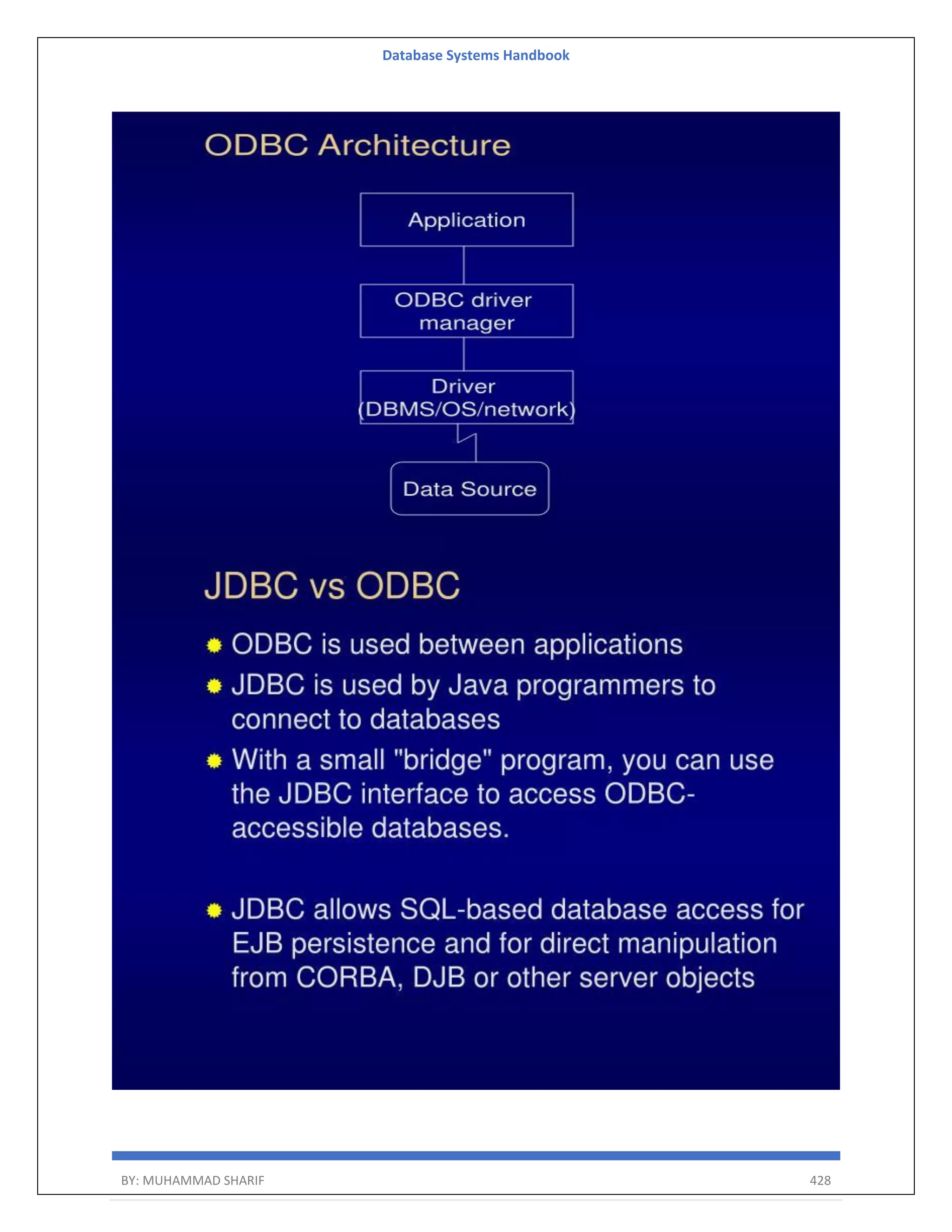

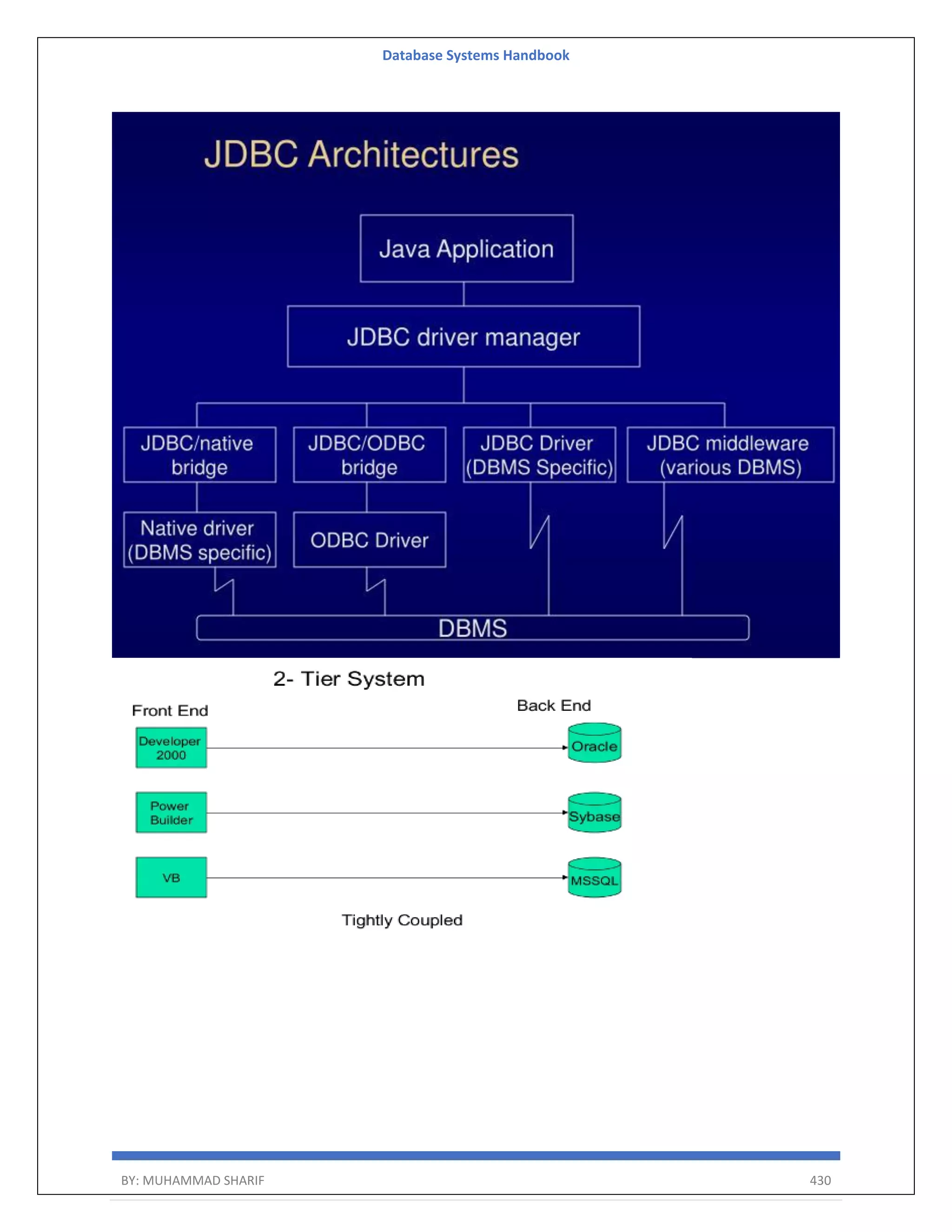
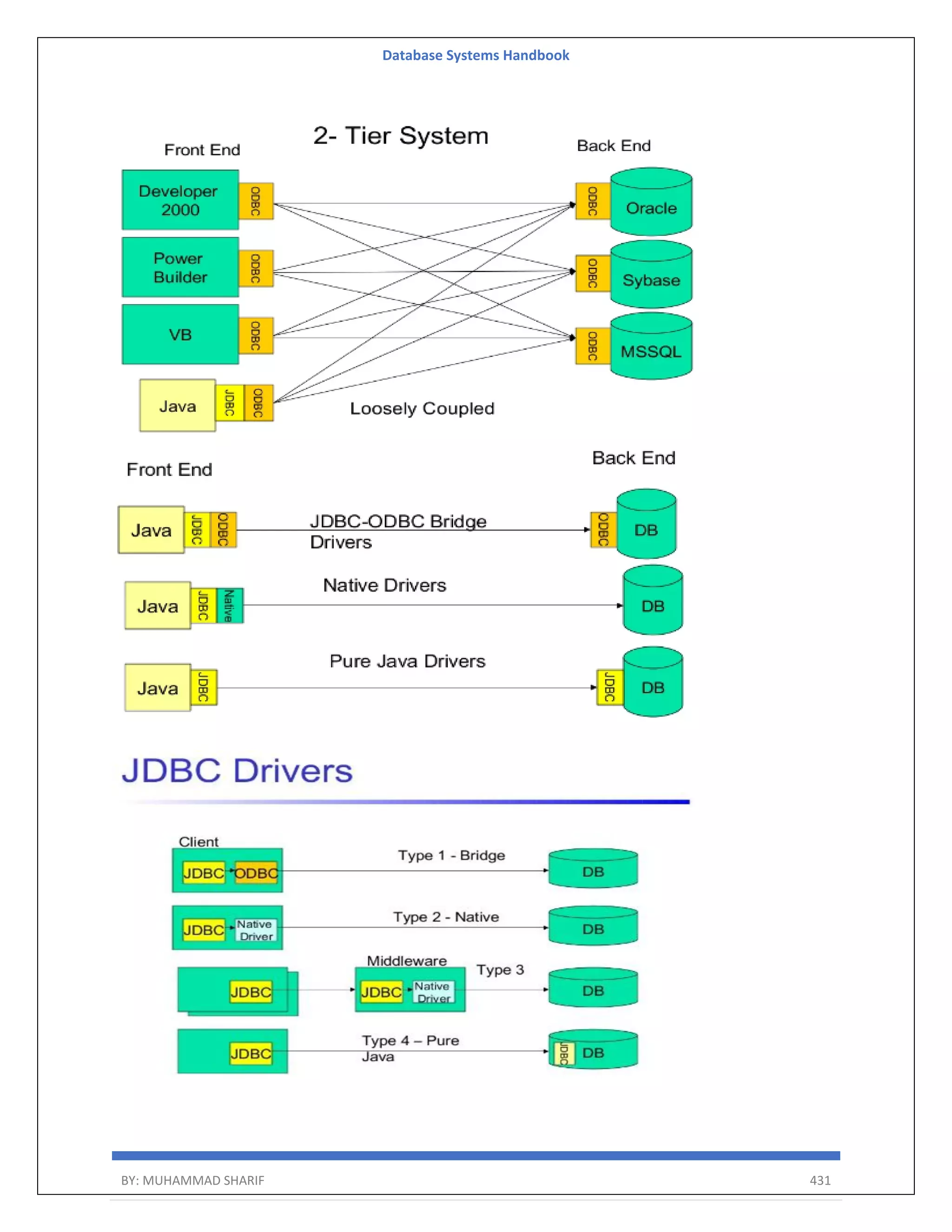


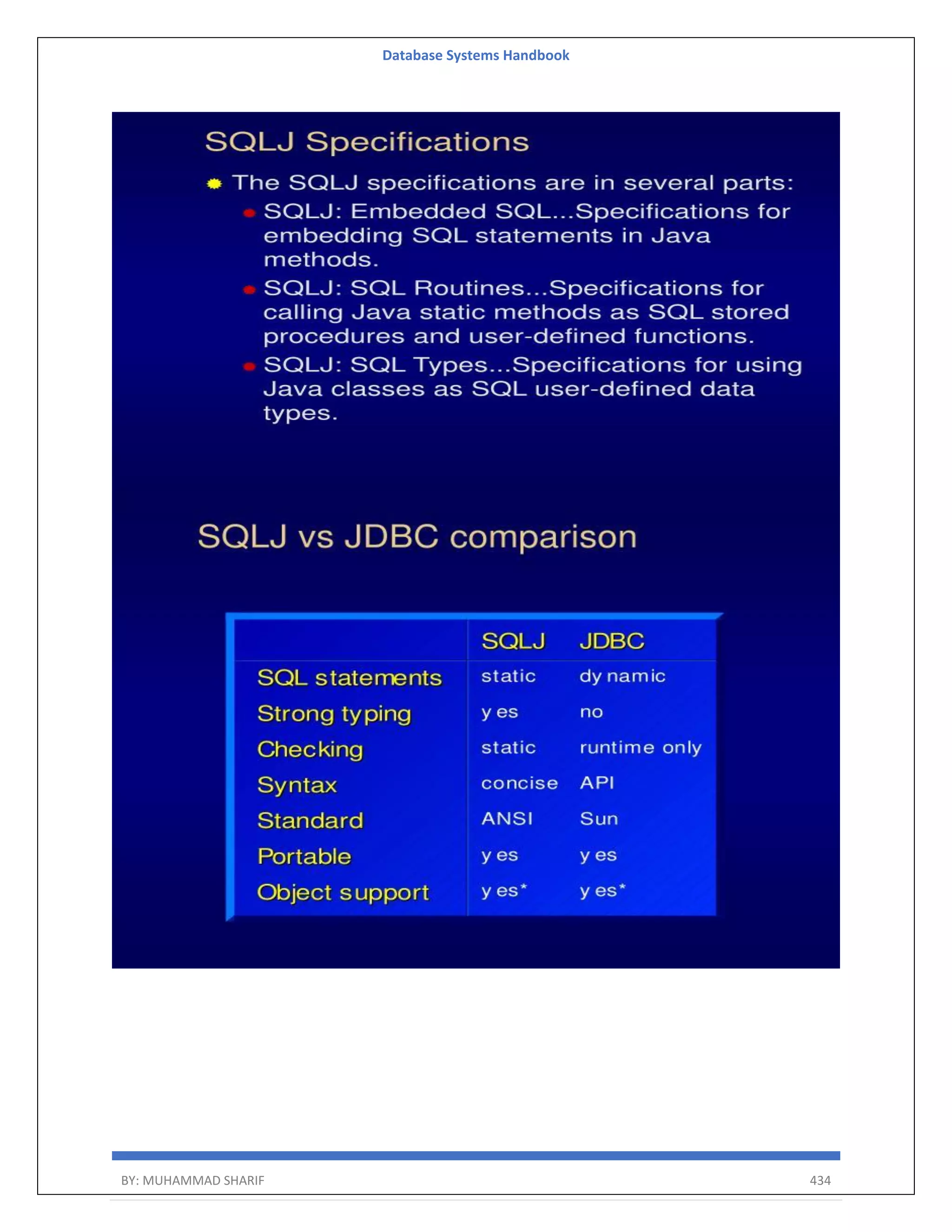




The document is a comprehensive handbook on database systems authored by Muhammad Sharif, detailing various aspects of database management including types of data, database architecture, and systems evolution. It covers concepts such as data types, database management systems, relational models, and architectures, as well as distributed database systems and trends in modern databases. Each chapter addresses specific topics related to databases, illustrating their importance in managing information and ensuring data integrity.