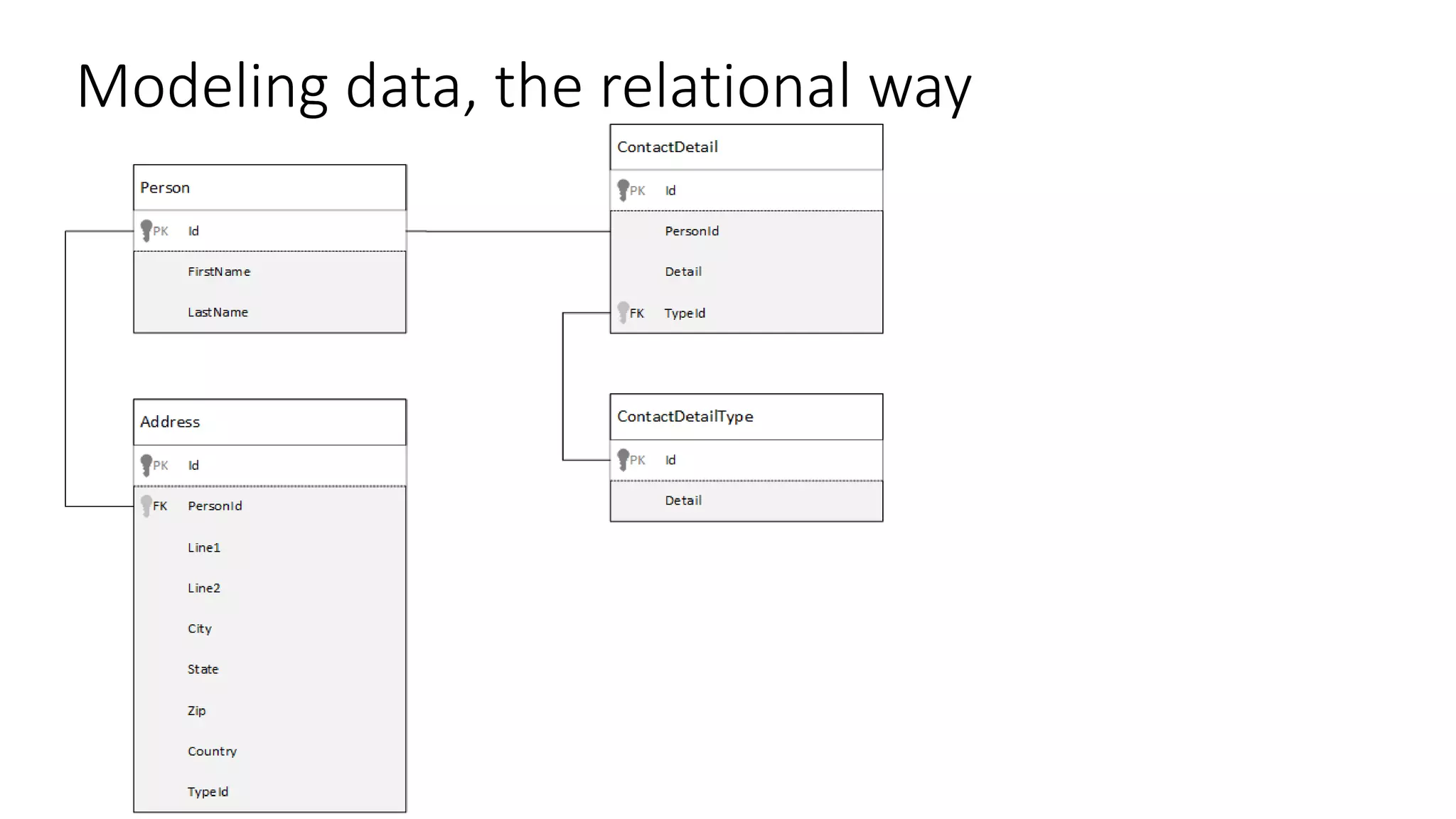
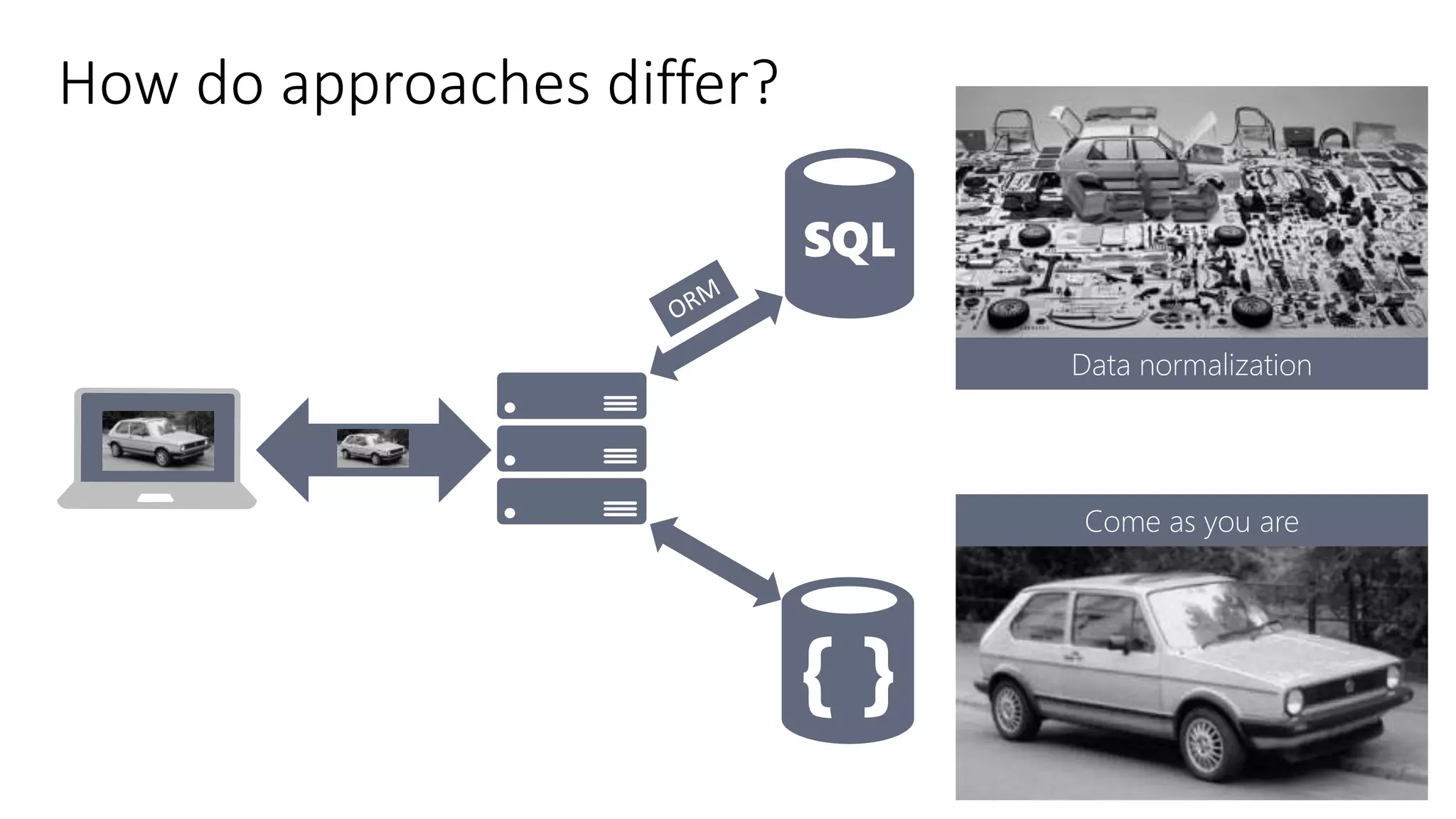
The document discusses document databases, focusing on Azure DocumentDB and how to model data for such databases. It highlights the characteristics of document databases, including their NoSQL nature, simplicity, lack of enforced schemas, and performance scalability. The presentation also emphasizes different modeling strategies like embedding versus referencing data, with guidelines for when to use each approach.




![Document Databases • Part of NoSQL family • Built for simplicity • Built for scale and performance • Non-relational • No enforced schema { "name": "SmugMug", "permalink": "smugmug", "homepage_url": "http://www.smugmug.com", "blog_url": "http://blogs.smugmug.com/", "category_code": "photo_video", "products": [ { "name": "SmugMug", "permalink": "smugmug" } ], "offices": [ { "description": "", "address1": "67 E. Even Ave, Suite 200", "address2": "", "zip_code": "94041", "city": "Mountain View", "state_code": "CA", "country_code": "USA", "latitude": 37.390056, "longitude": -122.067692 } ] }](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-5-2048.jpg)


![Azure DocumentDB: Lightning Round Edition { name:"Azure DocumentDB", deployedAs: "Service", dbType: "Document", connectVia: [ "rest", "sdk" ], deployVia: [ "portal", "rest", "cli", "sdk" ], scaleVia: [ "portal", "rest", "cli", "sdk" ], differsVia: [ "js", "indexing", "consistency" ] }](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-8-2048.jpg)

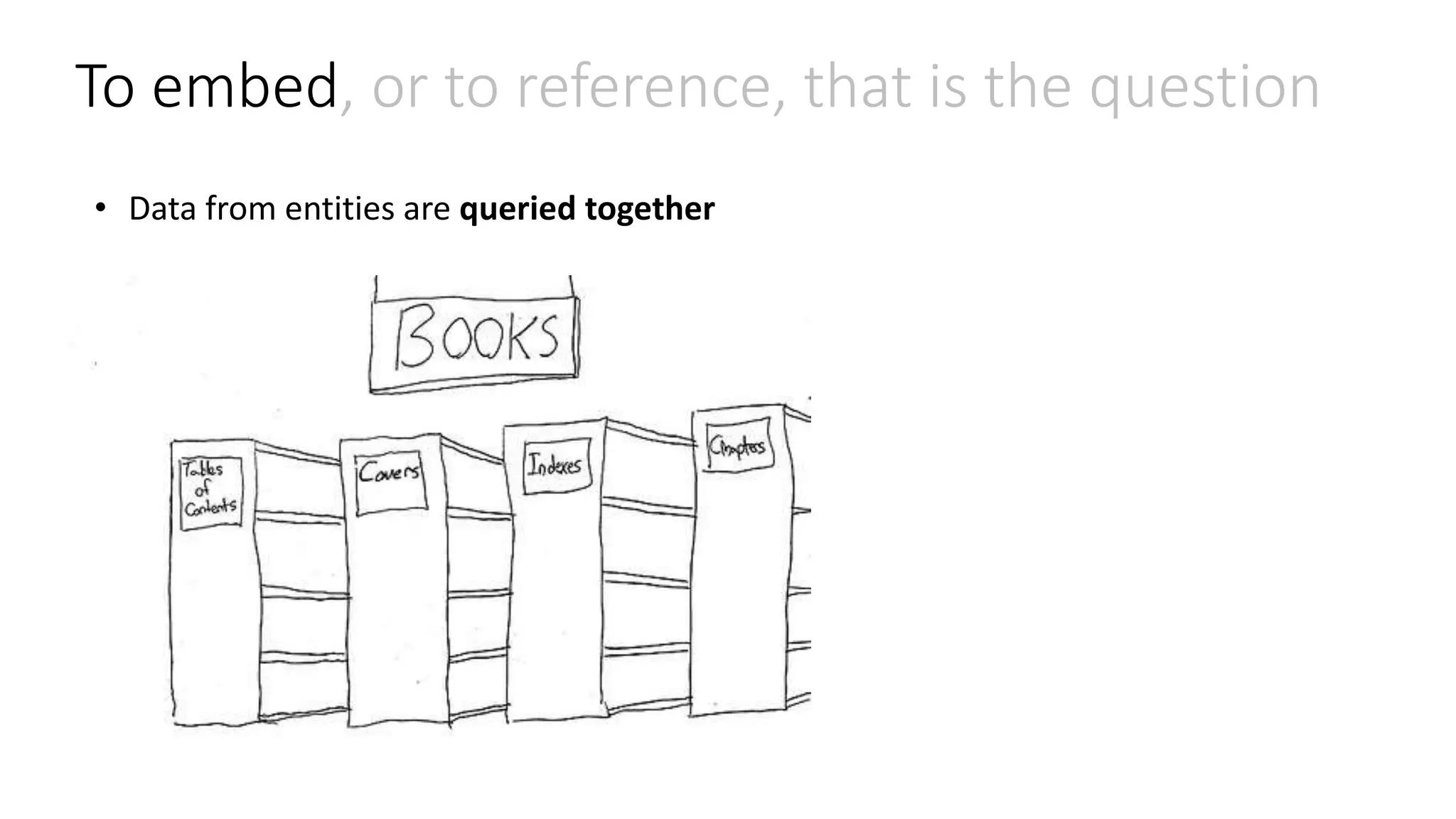
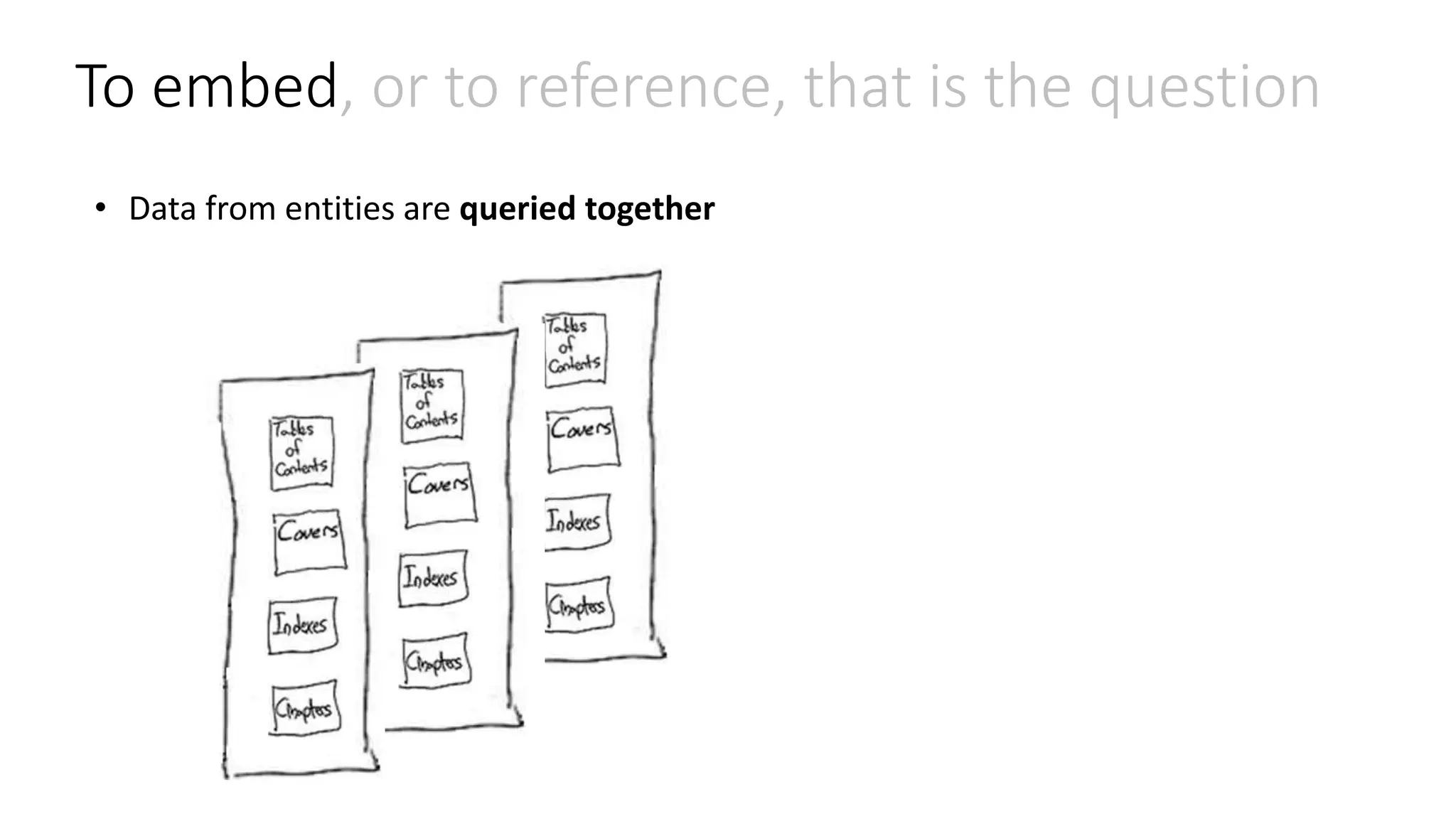
![To embed, or to reference, that is the question • Data from entities are queried together { id: "book1", covers: [ {type: "front", artworkUrl: "http://..."}, {type: "back", artworkUrl: "http://..."} ] index: "", chapters: [ {id: 1, synopsis: "", quote: "", pageCount:24, wordCount:456}, {id: 1, synopsis: "", quote: "", pageCount:24, wordCount:456}, ] }](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-15-2048.jpg)
![To embed, or to reference, that is the question • Data from entities are queried together • The child is a dependent e.g. Order Line depends on Order { id: "order1", customer: "customer1", orderDate: "2014-09-15T23:14:25.7251173Z" lines: [ {product: "13inch screen" , price: 200.00, qty: 50 }, {product: "Keyboard", price:23.67, qty:4} {product: "CPU", price:87.89, qty:1 ] }](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-16-2048.jpg)

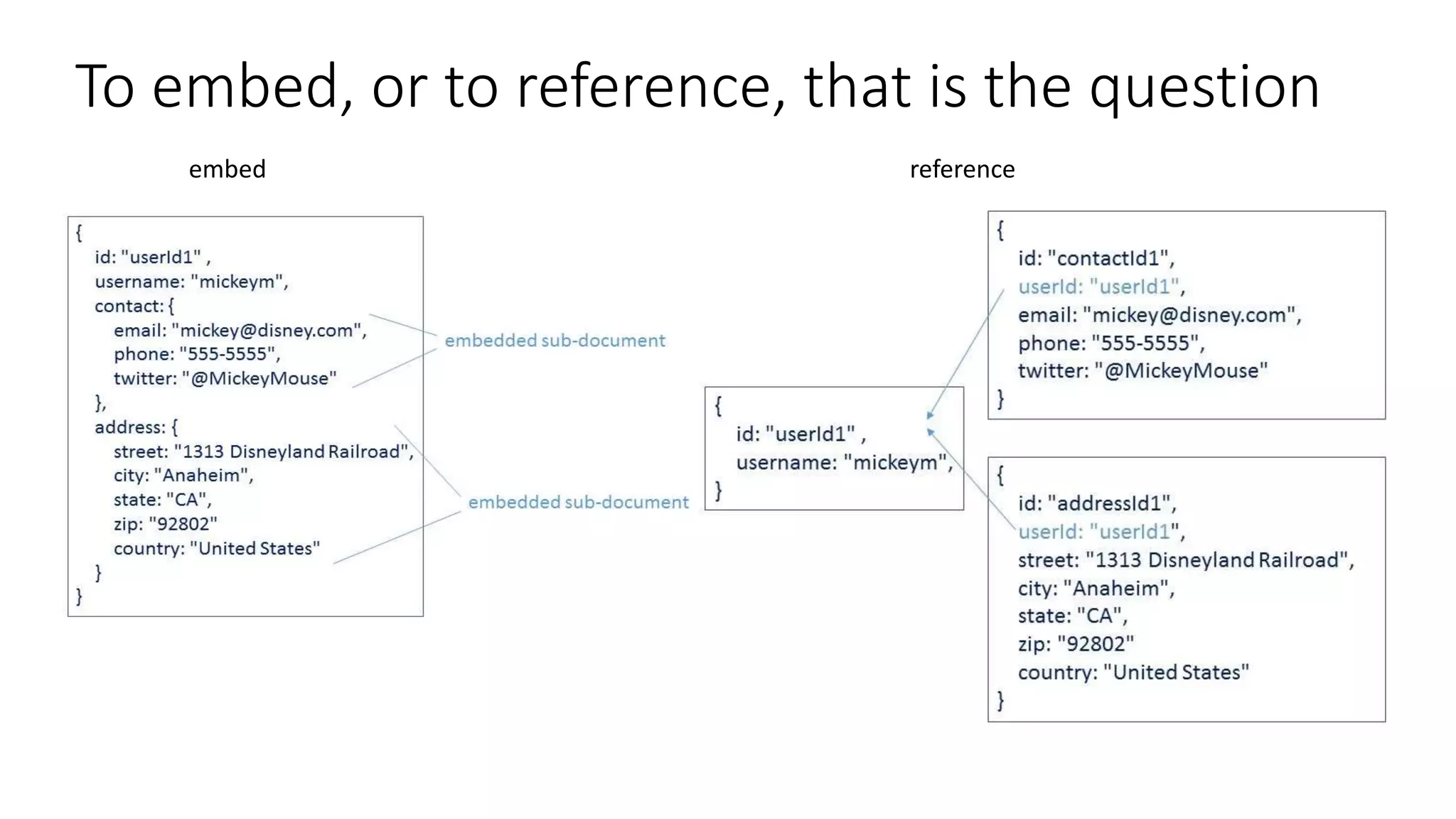
![To embed, or to reference, that is the question • Data from entities are queried together • The child is a dependent e.g. Order Line depends on Order • 1:1 relationship • Similar volatility { id: "person1", name: "Mickey", contactInfo: [ {email: "mickey@disney.com"}, {mobile: "+1 555-5555"}, {twitter: "@MickeyMouse"} ] }](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-18-2048.jpg)
![To embed, or to reference, that is the question • Data from entities are queried together • The child is a dependent e.g. Order Line depends on Order • 1:1 relationship • Similar volatility • The set of values or sub-documents is bounded (1:few) { id: "task1", desc: "deliver an awesome presentation @ #CloudDevelop", categories: ["conference", "talk", "workshop", "business"] }](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-19-2048.jpg)

![To embed, or to reference, that is the question • one-to-many relationships (unbounded) { id: "post1", author: "Mickey Mouse", tags: [ "fun", "cloud", "develop"] } {id: "c1", postId: "post1", comment: "Coolest blog post"} {id: "c2", postId: "post1", comment: "Loved this post, awesome"} {id: "c3", postId: "post1", comment: "This is rad!"} … {id: "c10000", postId: "post1", comment: "You are the coolest cartoon character"} … {id: "c2000000", postId: "post1", comment: "Are we still commeting on this blog?"}](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-21-2048.jpg)
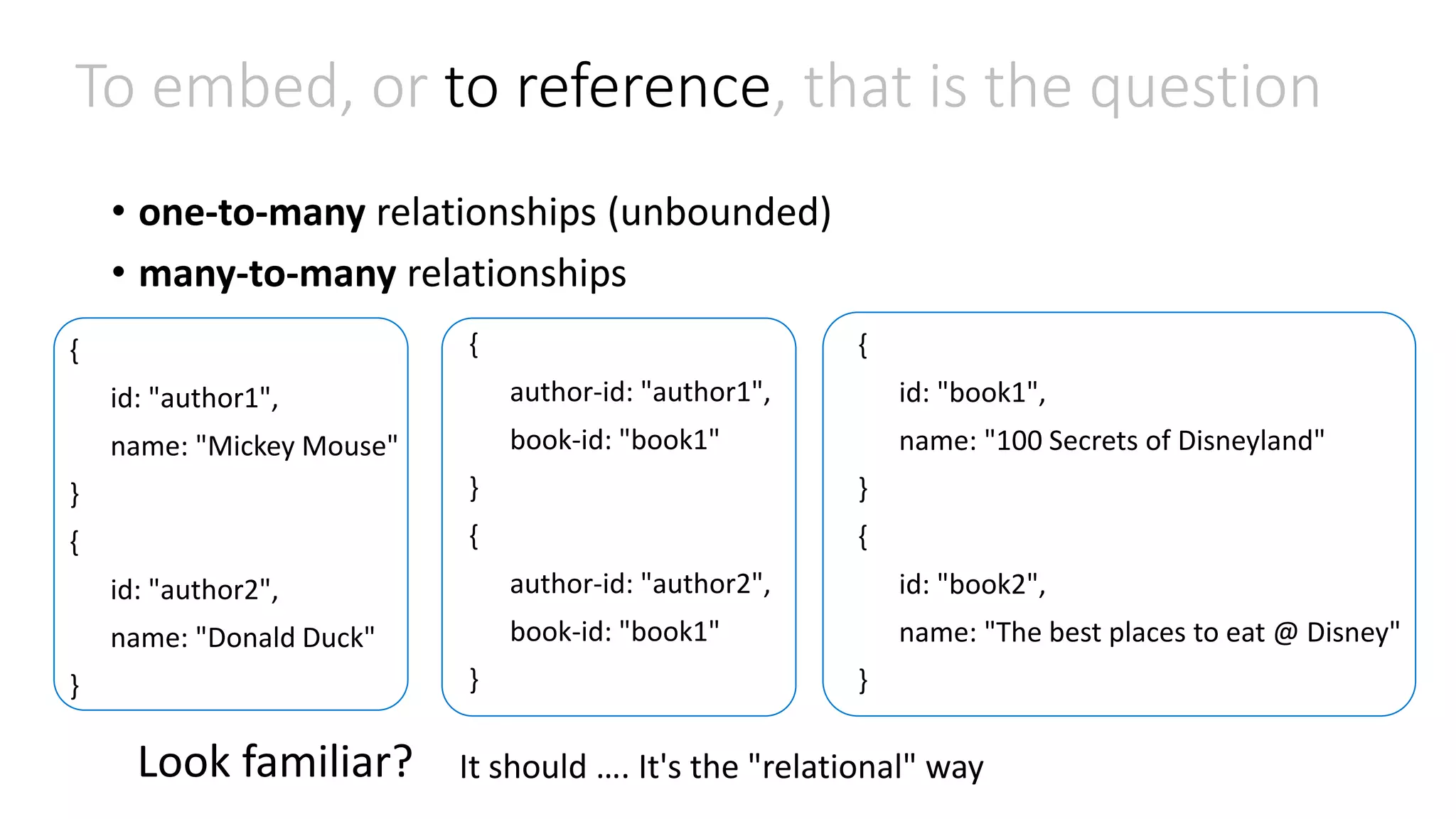
![To embed, or to reference, that is the question • one-to-many relationships (unbounded) • many-to-many relationships { id: "book1", name: "100 Secrets of Disneyland", authors: ["author1", "author2"] } { id: "book2", name: "The best places to eat @ Disney”, authors: ["author1"] } { id: "author1", name: "Mickey Mouse", books: ["book1", "book2"] } { id: "author2", name: "Donald Duck" books: ["book1"] }](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-23-2048.jpg)
![To embed, or to reference, that is the question • one-to-many relationships (unbounded) • many-to-many relationships • Related data changes frequently • The referenced entity is a key entity used by many others { id: "person1", author: "Mickey Mouse", stocks: [ "dis", "msft", "nflx"] } { id: "dis", opening: "52.09", numerOfTrades: 10000, trades: [{time: 083745, qty:57, price: 53.97}, {time: 083746, qty:5, price: 54.01}] }](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-24-2048.jpg)

![Where do you put the reference? Publisher & Book … does publisher refer to book? Publisher document: { id: "mspress", name: "Microsoft Press", books: [ 1, 2, 3, ..., 100, ..., 1000] } Book documents: {id: 1, name: "DocumentDB 101" } {id: 2, name: "DocumentDB for RDBMS Users" } {id: 3, name: "Taking over the world one JSON doc at a time" }](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-26-2048.jpg)
![Where do you put the reference? Publisher & Book … does or book refer to publisher? Publisher document: { id: "mspress", name: "Microsoft Press", books: [ 1, 2, 3, ..., 100, ..., 1000] } Book documents: {id: 1, name: "DocumentDB 101", pub-id: "mspress"} {id: 2, name: "DocumentDB for RDBMS Users", pub-id: "mspress"} {id: 3, name: "Taking over the world one JSON doc at a time", pub-id: "mspress"}](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-27-2048.jpg)
![Is it always black or white? { id: 1, firstName: "Mickey", lastName: "Mouse", books: [1, 2, 3], images: [ {"thumbnail": "http://....png"}, {"profile": "http://....png"}, ], bio: "Mickey Mouse is a funny animal cartoon character and the official mascot of The Walt Disney Company. An anthropomorphic mouse who typically wears red shorts, large yellow shoes, and white gloves, Mickey has become one of the most recognizable cartoon characters." } { id: 1, name: "DocumentDB 101", authors": [ { id: 1, name: "Mickey Mouse", bio: "Mickey Mouse is a funny animal cartoon character and the official mascot of The Walt Disney Company…", thumbnailUrl: "http://....png" } ] }](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-30-2048.jpg)


![How to model hierarchical trees? Jill Ben Susan SvenAndrew Thomas { { id: "Jill", directs: ["Ben", "Susan"] }, { id: "Ben", directs: ["Andrew"] }, { id: "Susan", directs: ["Sven"] }, { id: "Andrew" }, { id: "Sven", directs: ["Thomas"] }, { id: "Thomas" } } SELECT * FROM org WHERE id = "Jill" To get all direct reports for Jill is easy -](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-33-2048.jpg)
![How to model hierarchical trees? Jill Ben Susan SvenAndrew Thomas { { id: "Jill", directs: ["Ben", "Susan"] }, { id: "Ben", directs: ["Andrew"] }, { id: "Susan", directs: ["Sven"] }, { id: "Andrew" }, { id: "Sven", directs: ["Thomas"] }, { id: "Thomas" } } SELECT * FROM emp WHERE ARRAY_CONTAINS(emp.directs, "Ben") To find the manager for an employee is possible -](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-34-2048.jpg)

![How to support keyword search? { id: "CDC101", title: “The Fundamentals of Database Design", titleWords: [ "fundamentals", "database", "design", "database design" ], credits: 10 } Consider using a RegEx to transform words to lowercase and remove any punctuation. Strip out stop words like “to”, “the”, “of” etc. Denormalize keywords in to key phrases](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-36-2048.jpg)
![{ options: ["Embed", "Reference"], rules: "There are no rules, merely guidelines", embed: [ "1:1", "Child is a dependent", "Similar volatility", "favor read speed" ] reference: [ "related data changes frequently", "many:many", "favor writes" ] remember: [ "Don't be scared to experiment and mix & match", "Models change & evolve", "Hybrid models" ] } Summary](https://image.slidesharecdn.com/clouddevelop2015-151023162713-lva1-app6891/75/Modeling-JSON-data-for-NoSQL-document-databases-38-2048.jpg)



