Download as PDF, PPTX







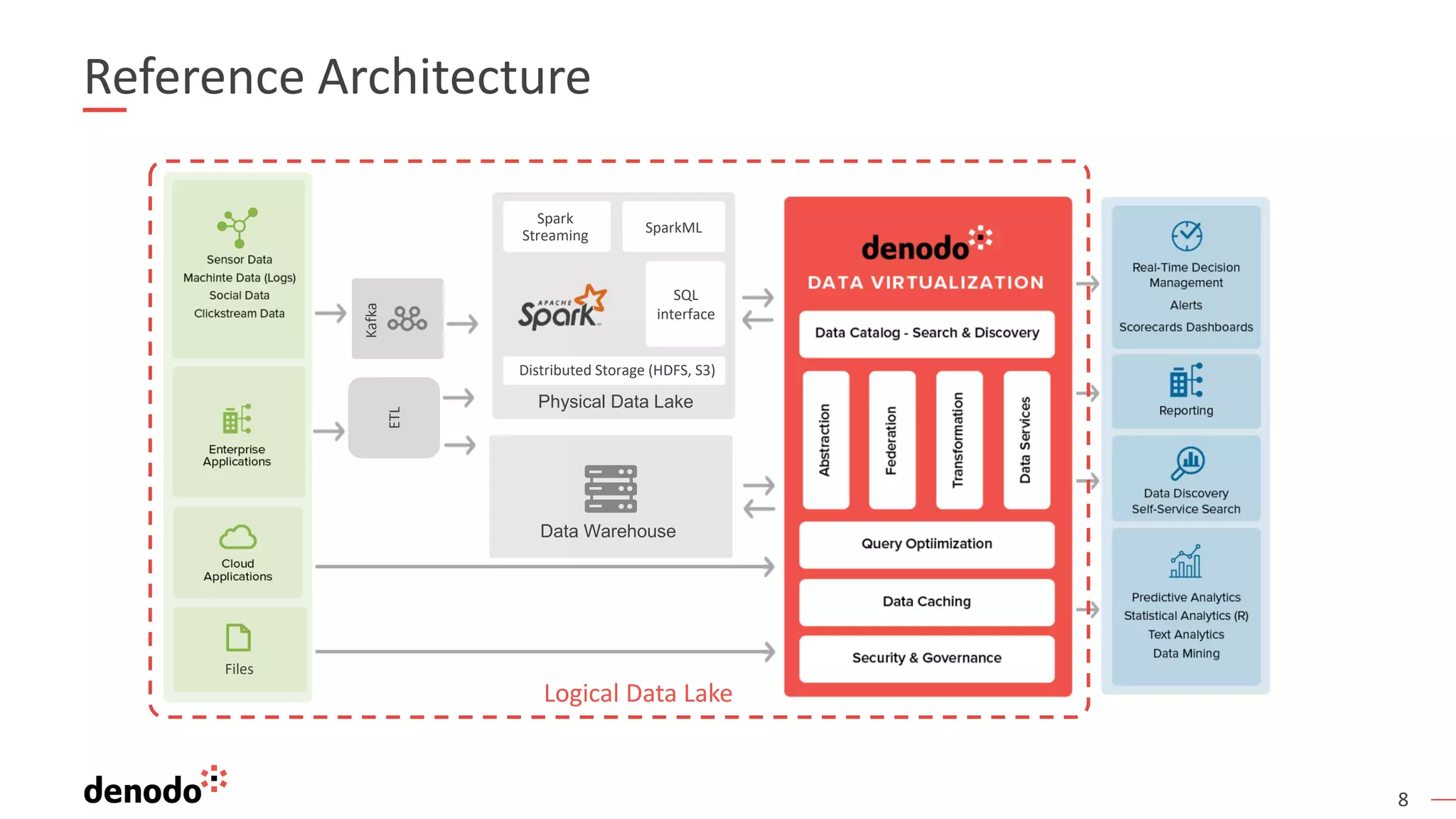

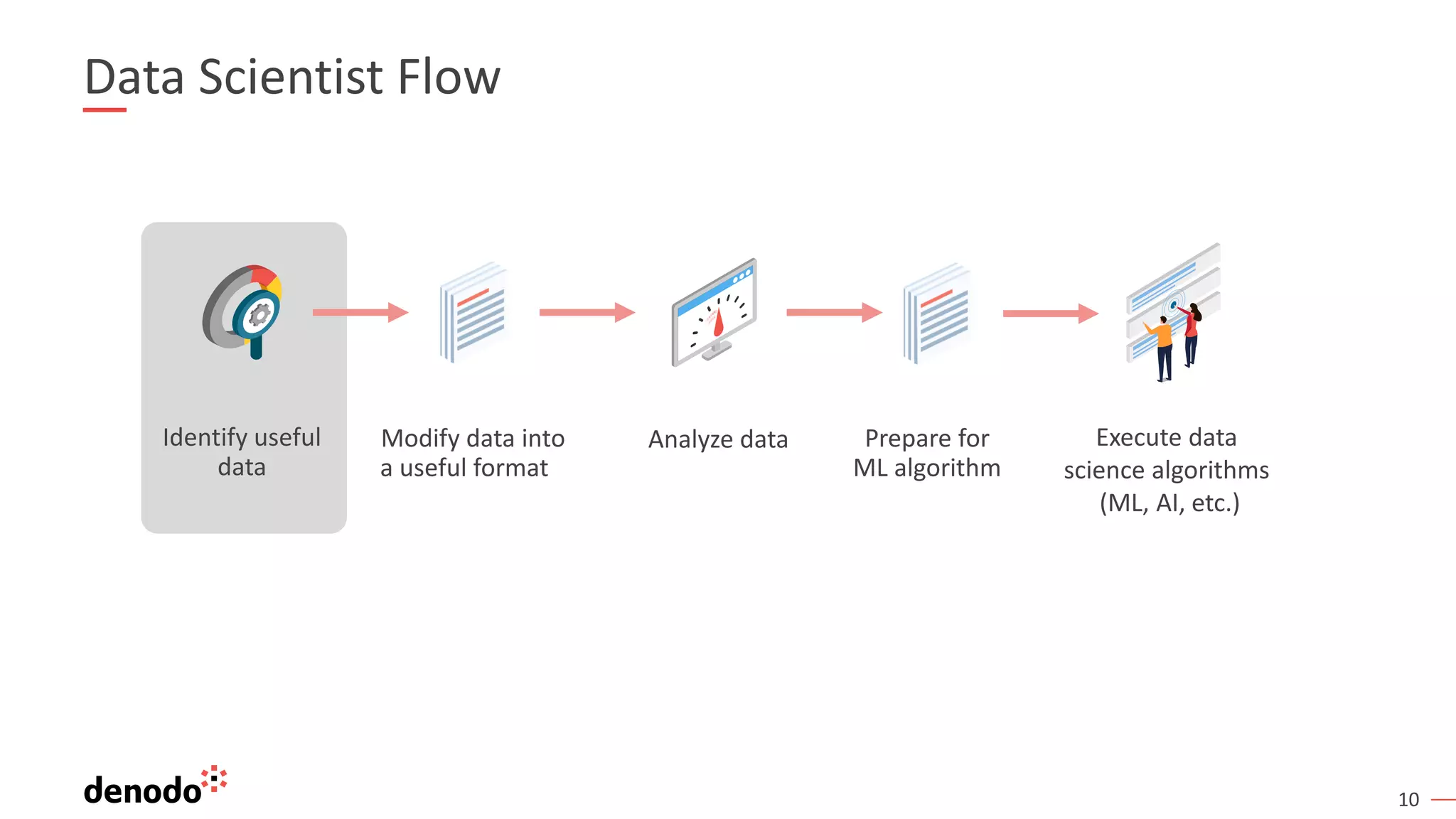

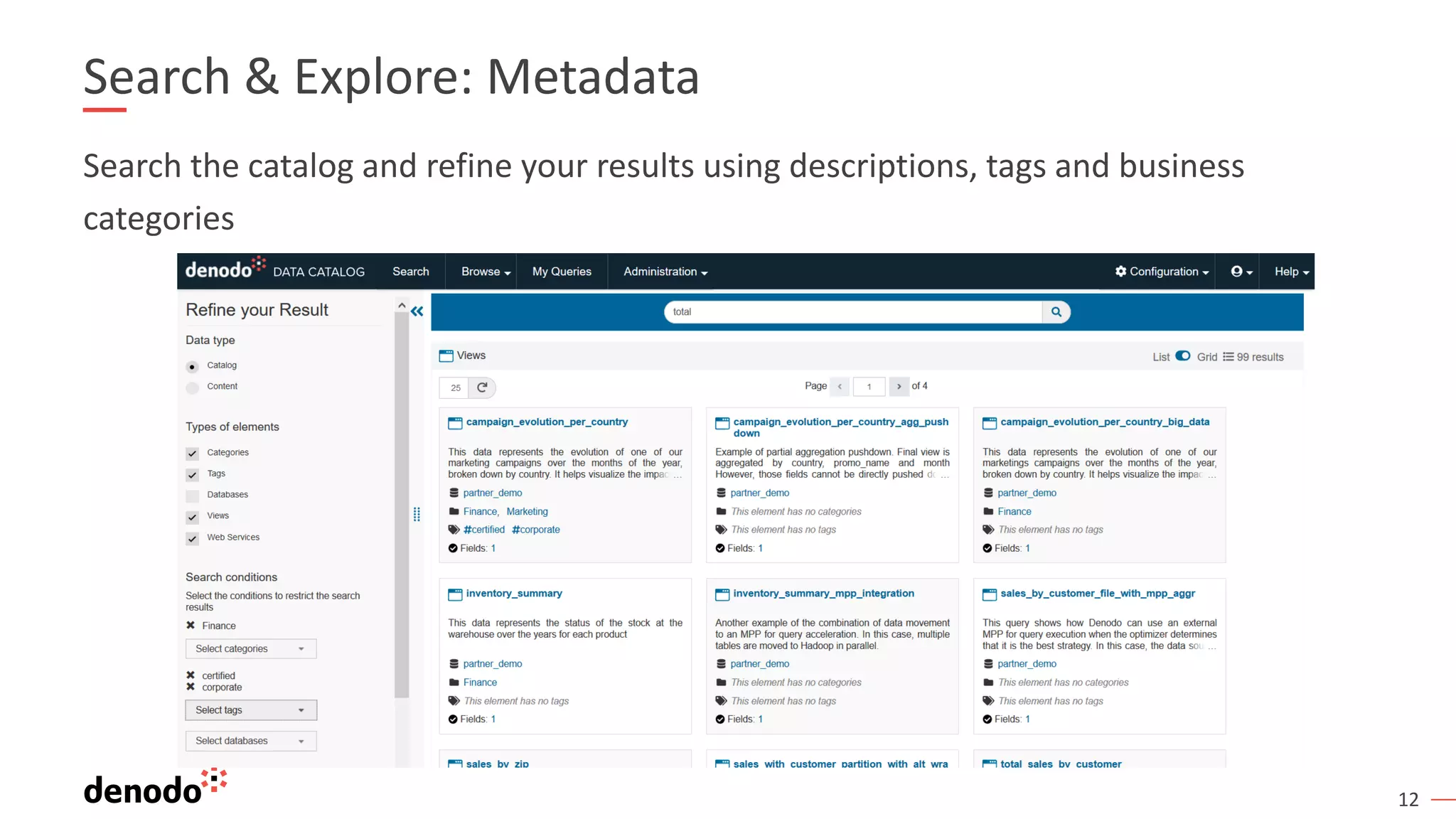
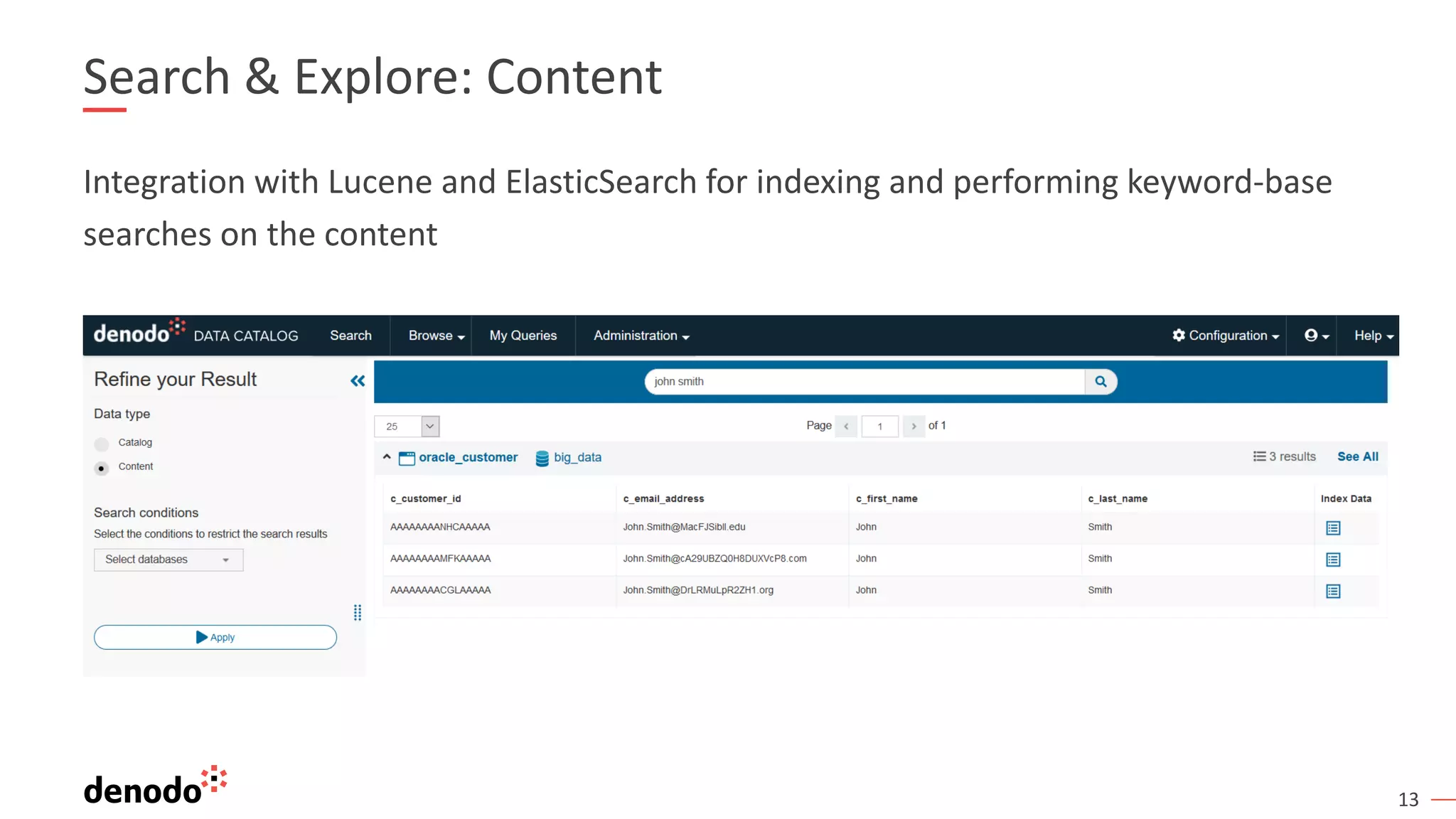
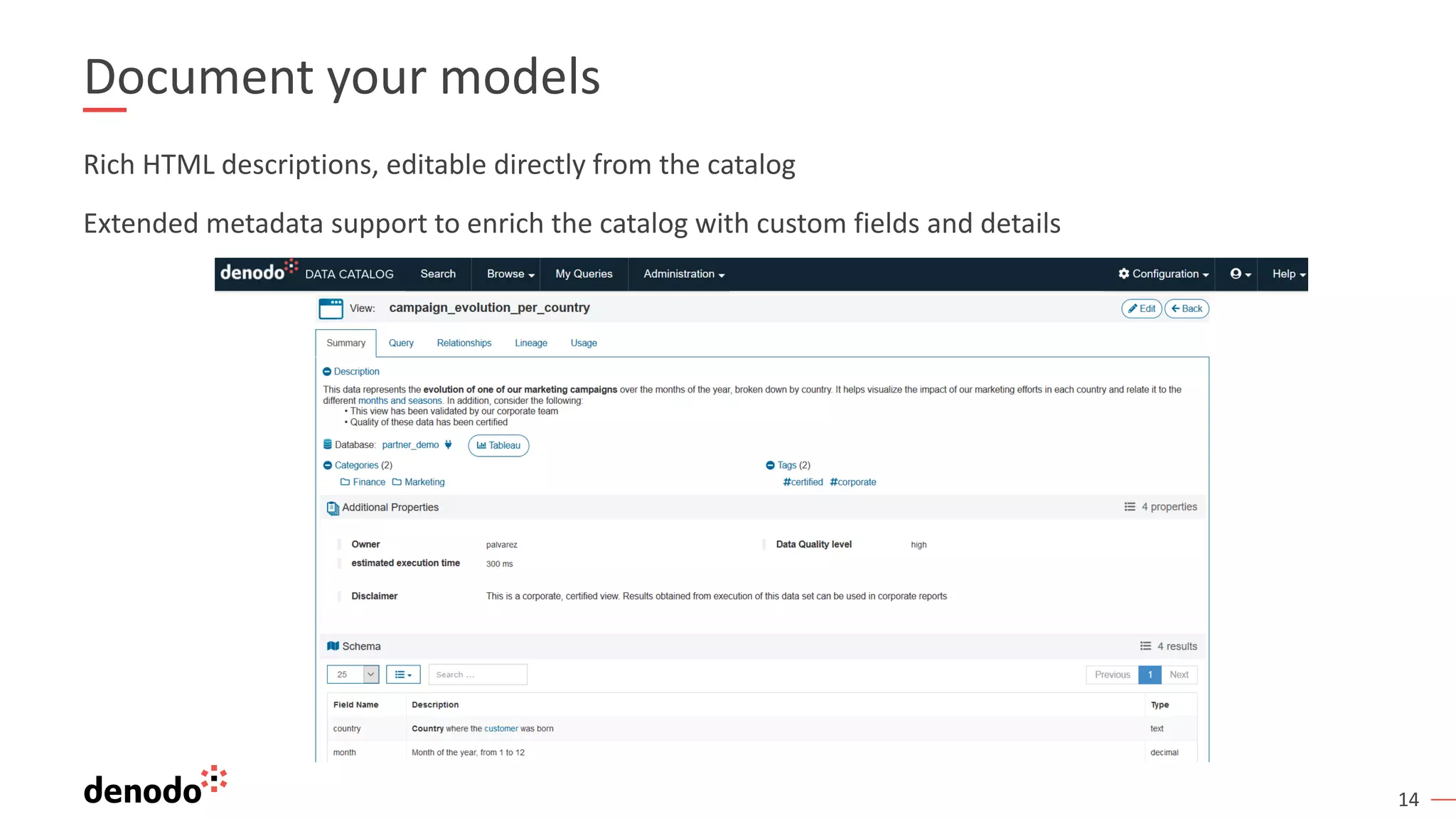
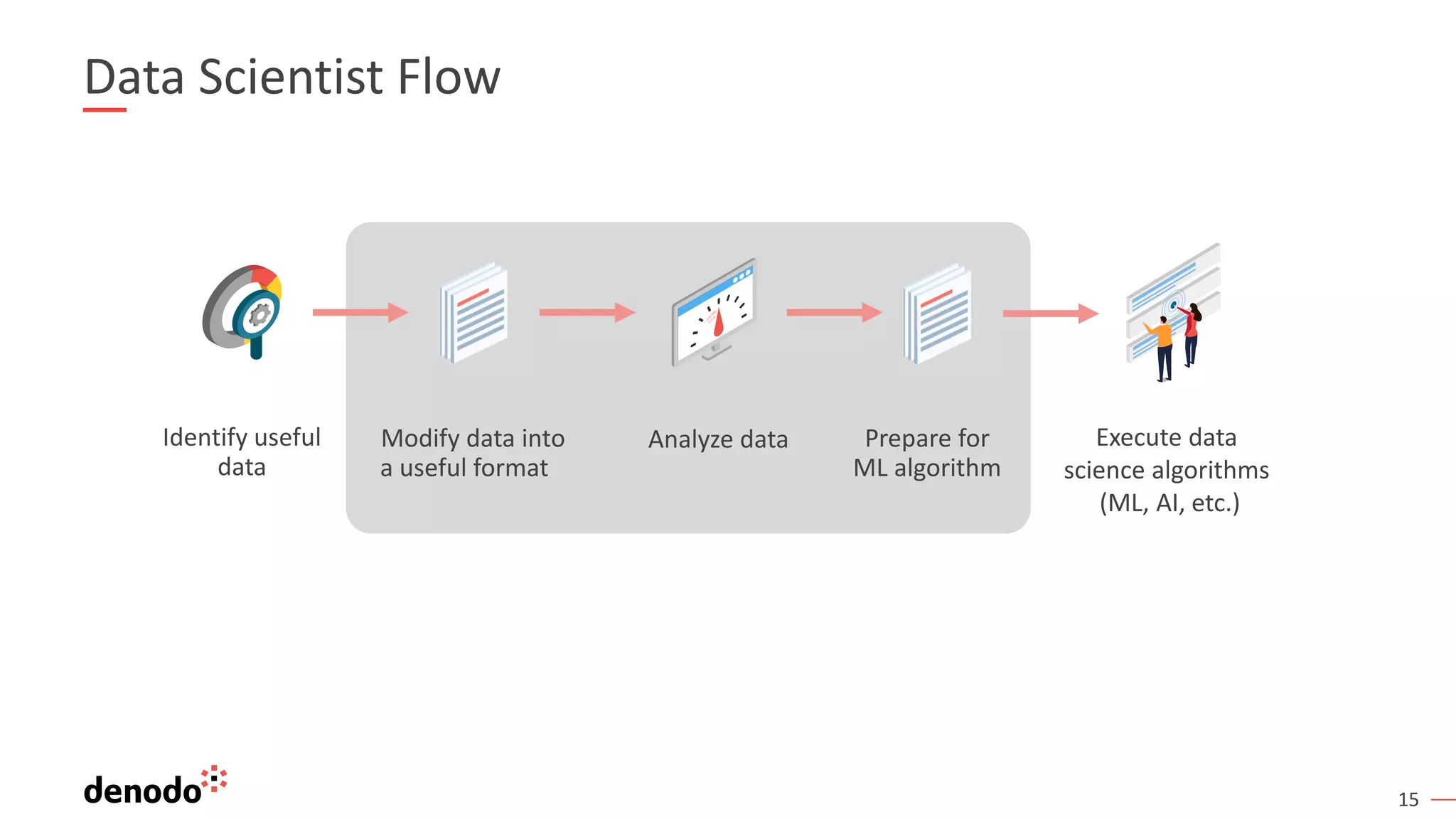

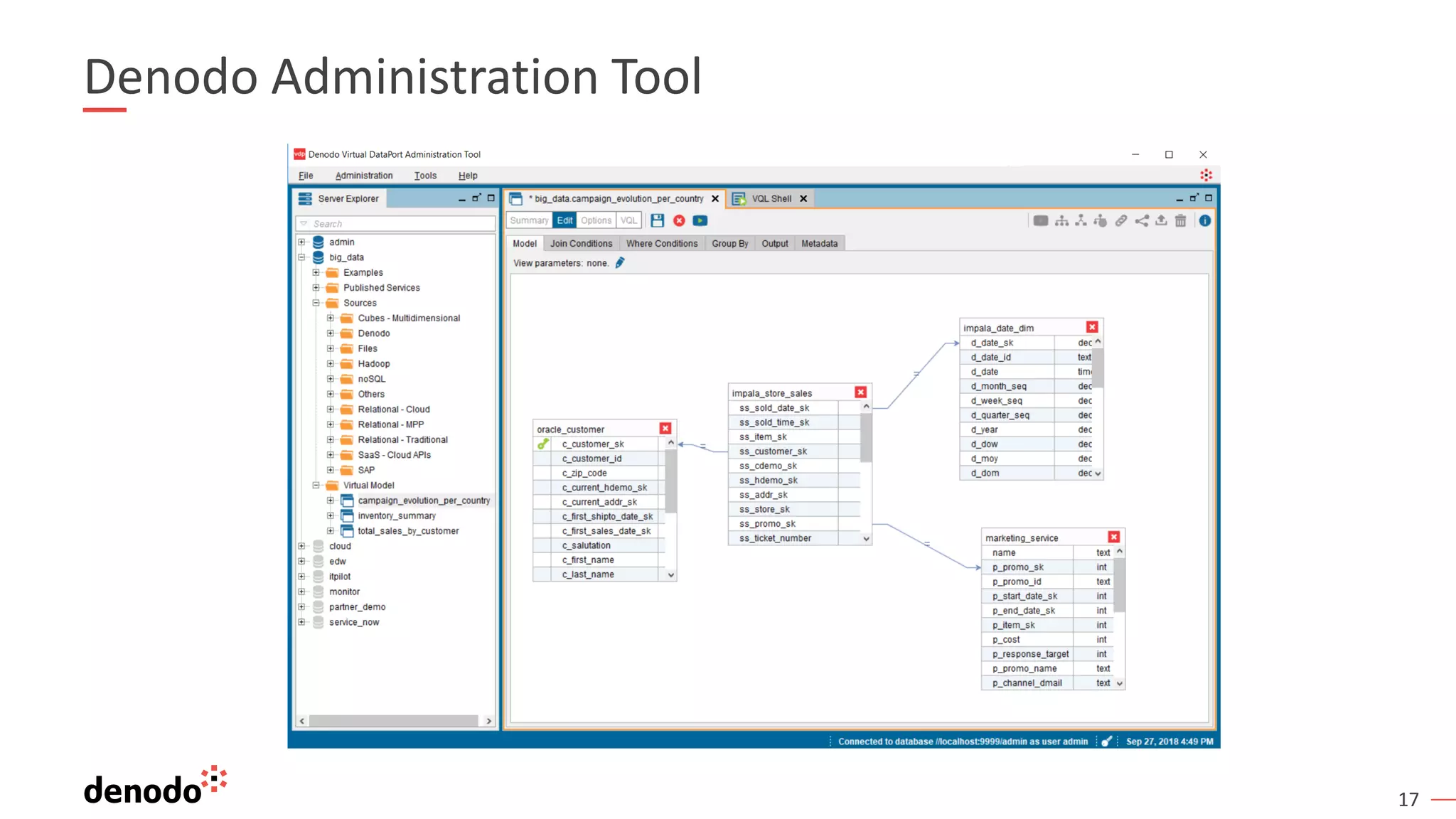
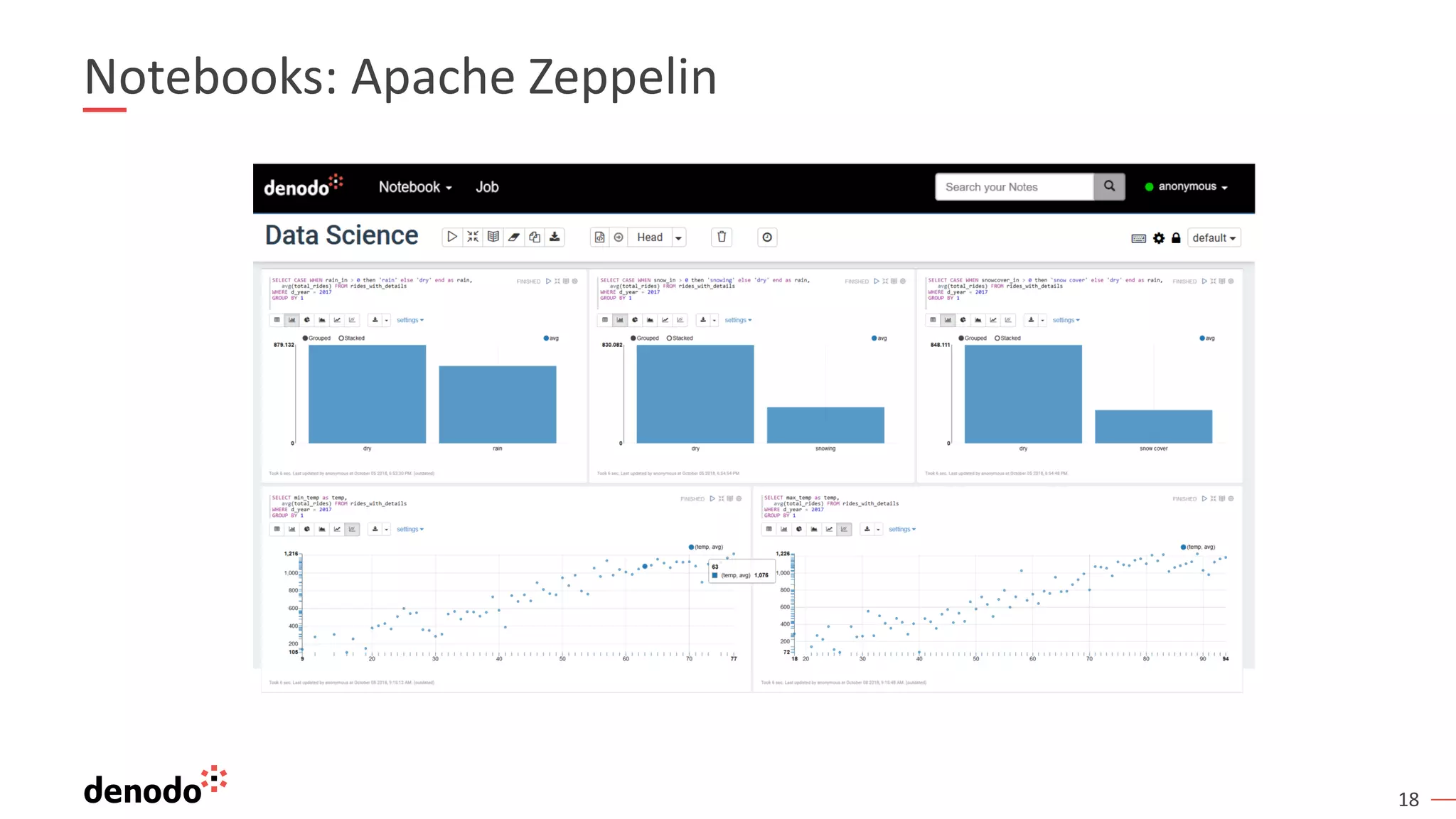

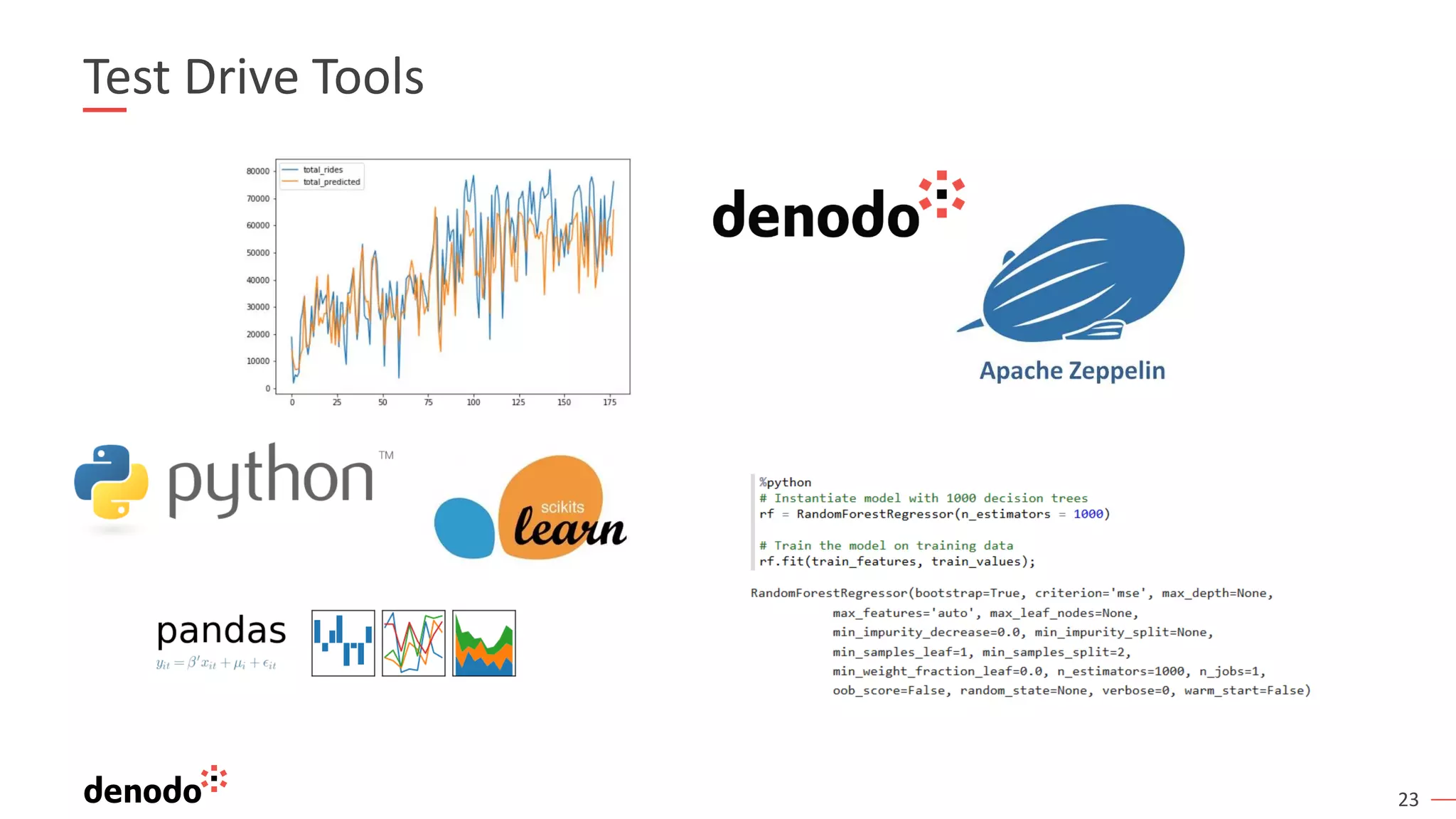







The document discusses a webinar series on data virtualization addressing data integration challenges and enhancing machine learning processes. It outlines the evolution of data science, the workflow of data scientists, and how data virtualization tools like Denodo can simplify data access and manipulation. Key takeaways highlight Denodo's role in improving data exploration and analysis while integrating with big data technologies.