Download as PDF, PPTX








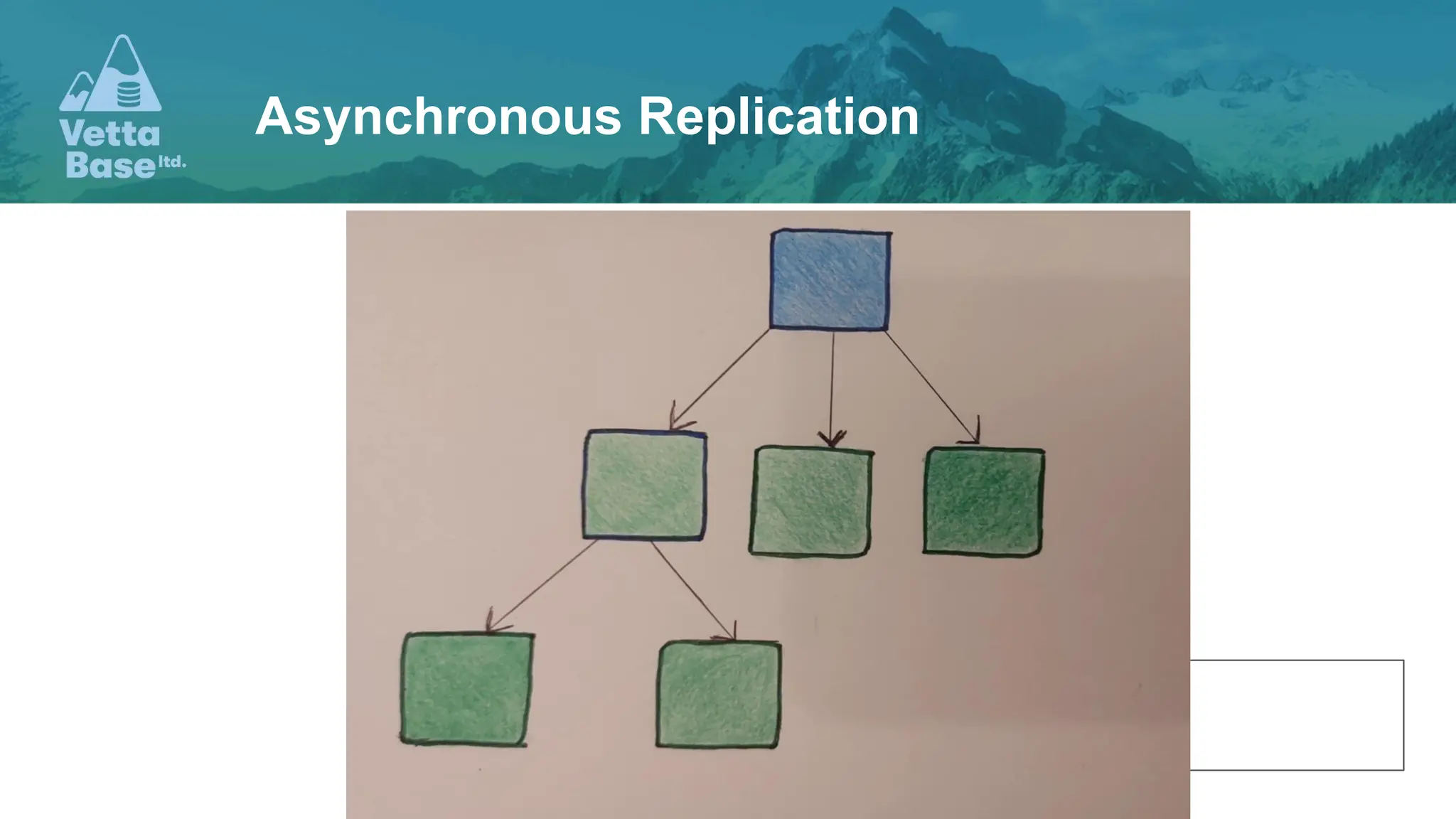
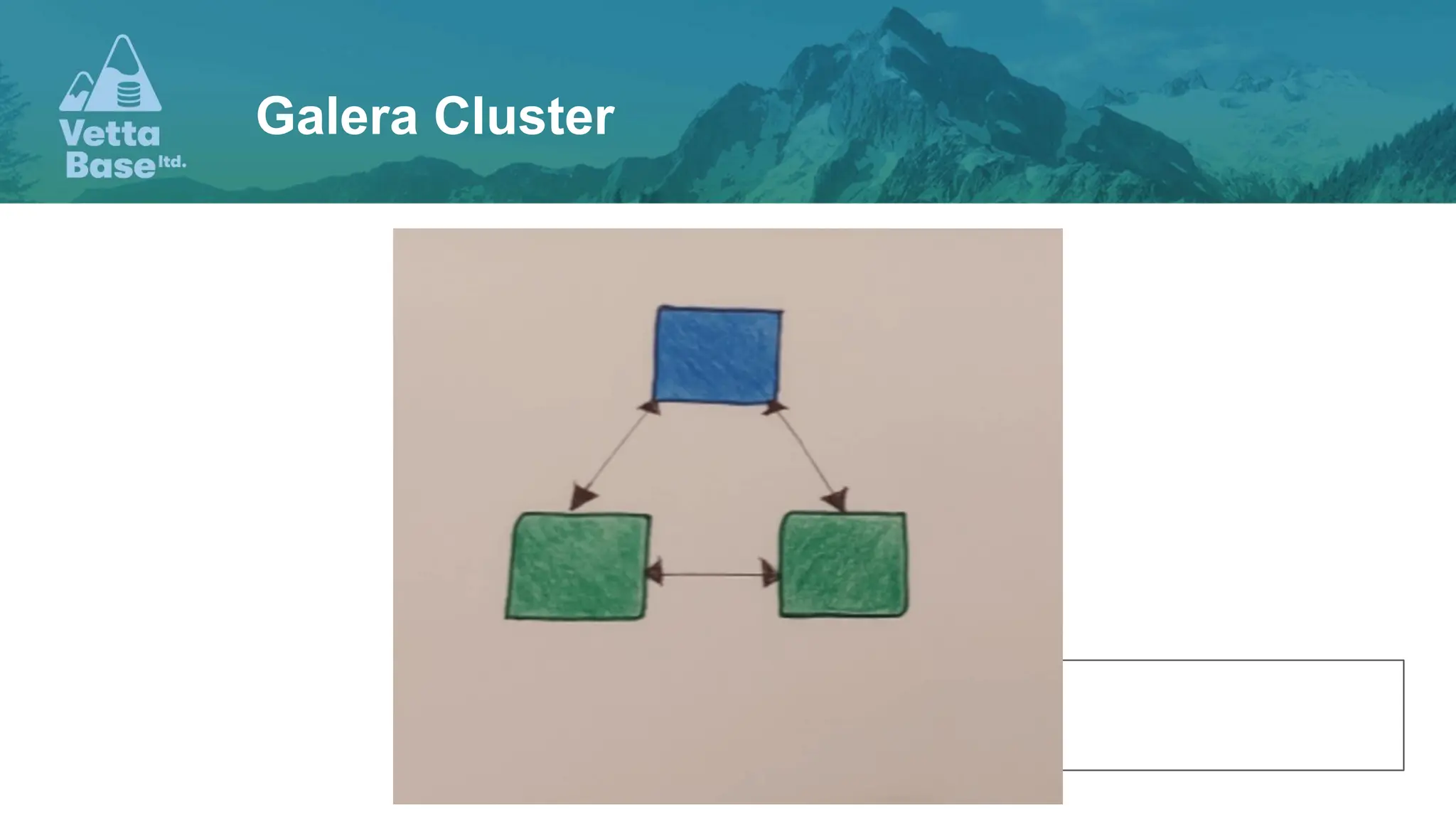



























The document presents a discussion on high availability for databases, emphasizing the importance of having multiple servers to handle SQL queries and ensure seamless operations during server crashes. It covers various topics such as read-write splitting, transactions, deadlocks, and primary keys, offering insights and examples from the perspective of backend development. The document is intended for developers to understand database scalability and improve application performance through effective design choices.