Download as PDF, PPTX











![Edge creation match_cols = [”ssn", ”email"] mirrorColNames = [f"_{col}" for col in records.columns] mirror = records.toDF(*mirrorColNames) mcond = [col(c) == col(f'_{c}') for c in match_cols] cond = [(col("id") != col("_id")) & reduce(lambda x,y: x | y, mcond)] edges = records.join(mirror, cond) cond: [Column<b'((NOT (id = _id)) AND (((ssn = _ssn) OR (email = _email))](https://image.slidesharecdn.com/hendrikfrentrup-191031204838/75/Maps-and-Meaning-Graph-based-Entity-Resolution-in-Apache-Spark-GraphX-21-2048.jpg)



, 1)).rdd](https://image.slidesharecdn.com/hendrikfrentrup-191031204838/75/Maps-and-Meaning-Graph-based-Entity-Resolution-in-Apache-Spark-GraphX-25-2048.jpg)
![Edge creation val mirrorColNames = for (col <- records.columns) yield "_"+col.toString val mirror = records.toDF(mirrorColNames: _*) def conditions(matchCols: Seq[String]): Column = { col("id")=!=col("_id") && matchCols.map(c => col(c)===col("_"+c)).reduce(_ || _) } val edges = records.join(mirror, conditions(Seq(”ssn", ”email”))) val edgesRDD = edges .select("id","_id") .map(r => Edge(r.getAs[VertexId](0),r.getAs[VertexId](1),null)) .rdd](https://image.slidesharecdn.com/hendrikfrentrup-191031204838/75/Maps-and-Meaning-Graph-based-Entity-Resolution-in-Apache-Spark-GraphX-26-2048.jpg)

![Resolve operation Columns to match: [“ssn”,”email”] Input: DataFrame Output: DataFrame](https://image.slidesharecdn.com/hendrikfrentrup-191031204838/75/Maps-and-Meaning-Graph-based-Entity-Resolution-in-Apache-Spark-GraphX-28-2048.jpg)
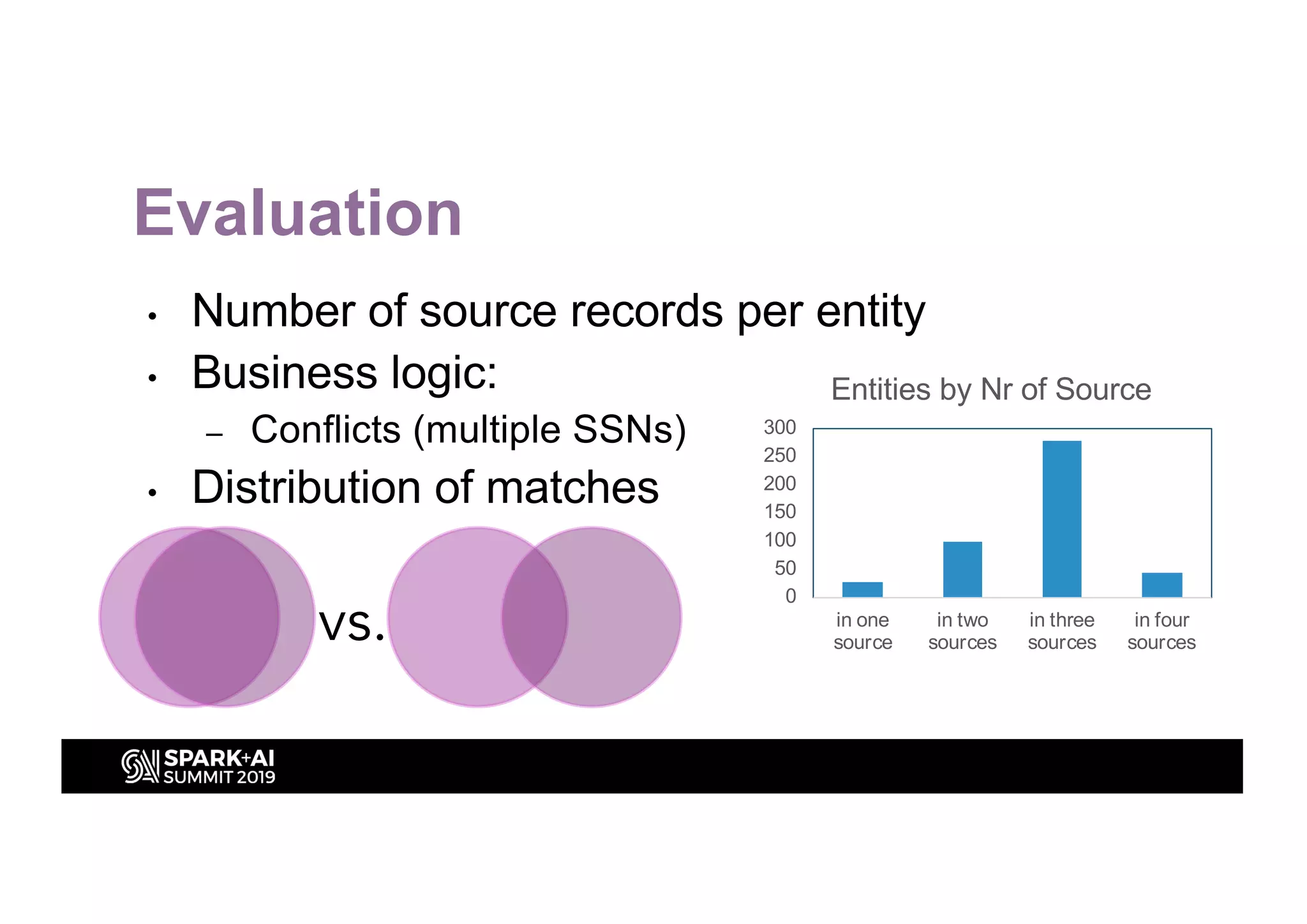


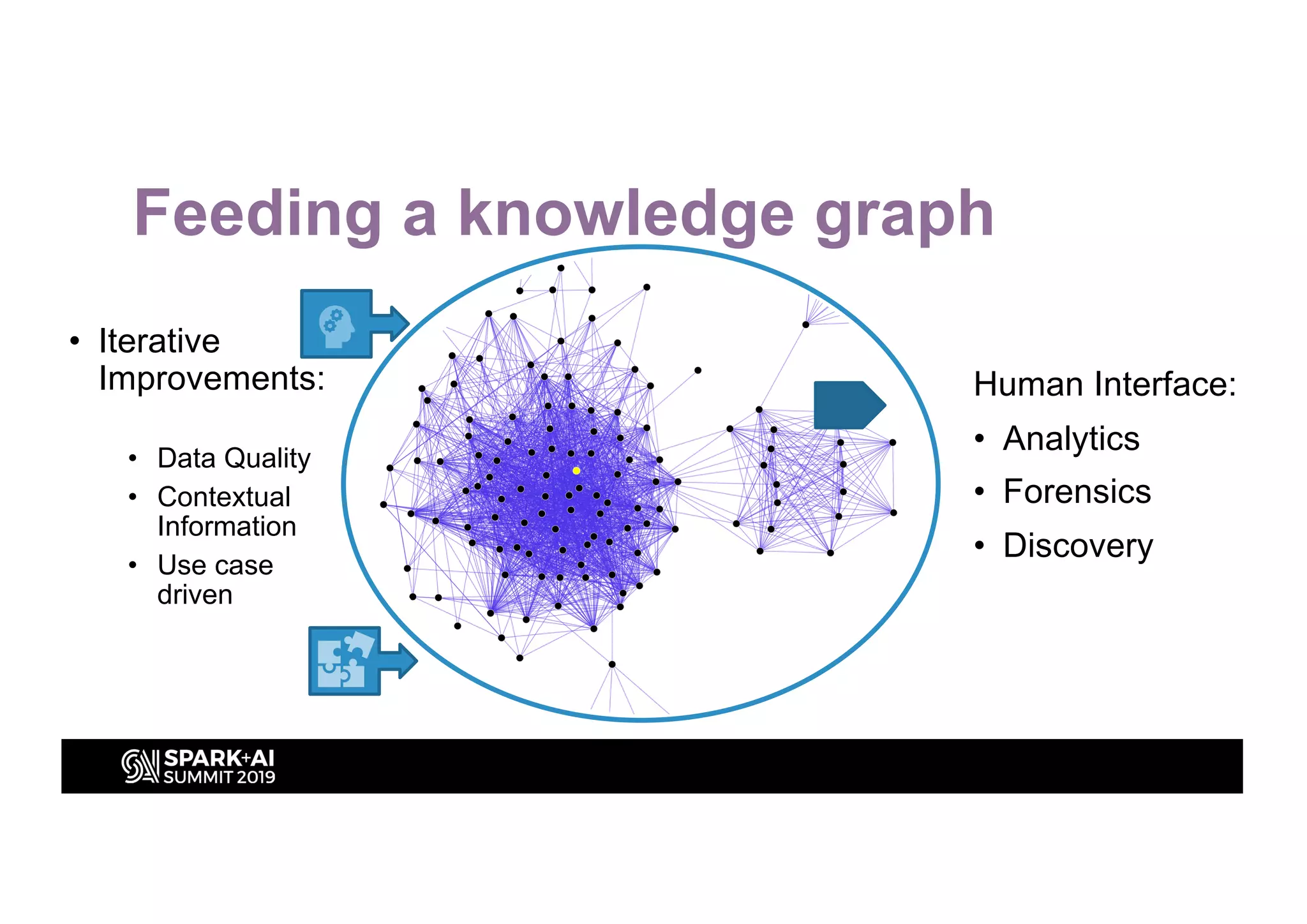





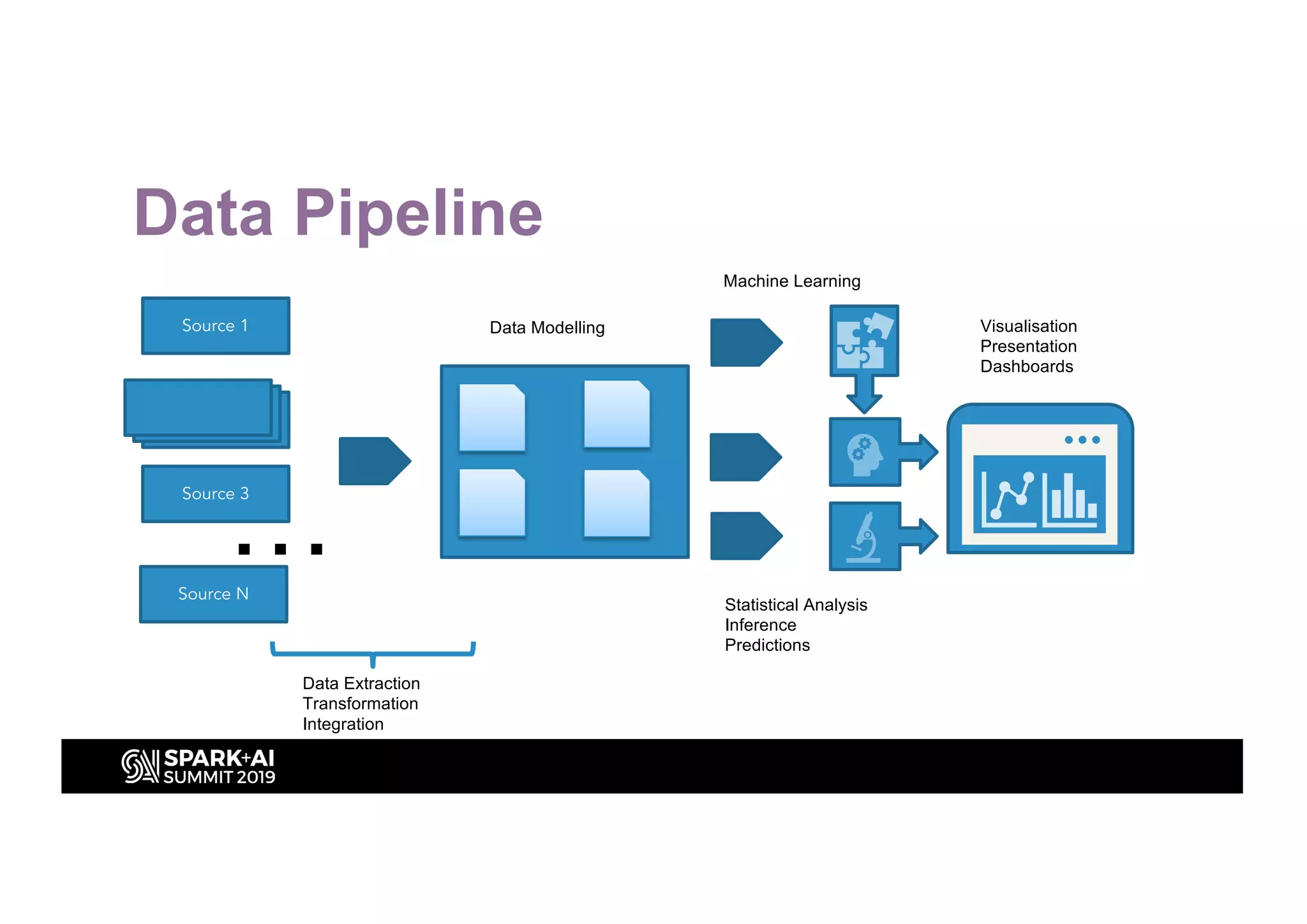
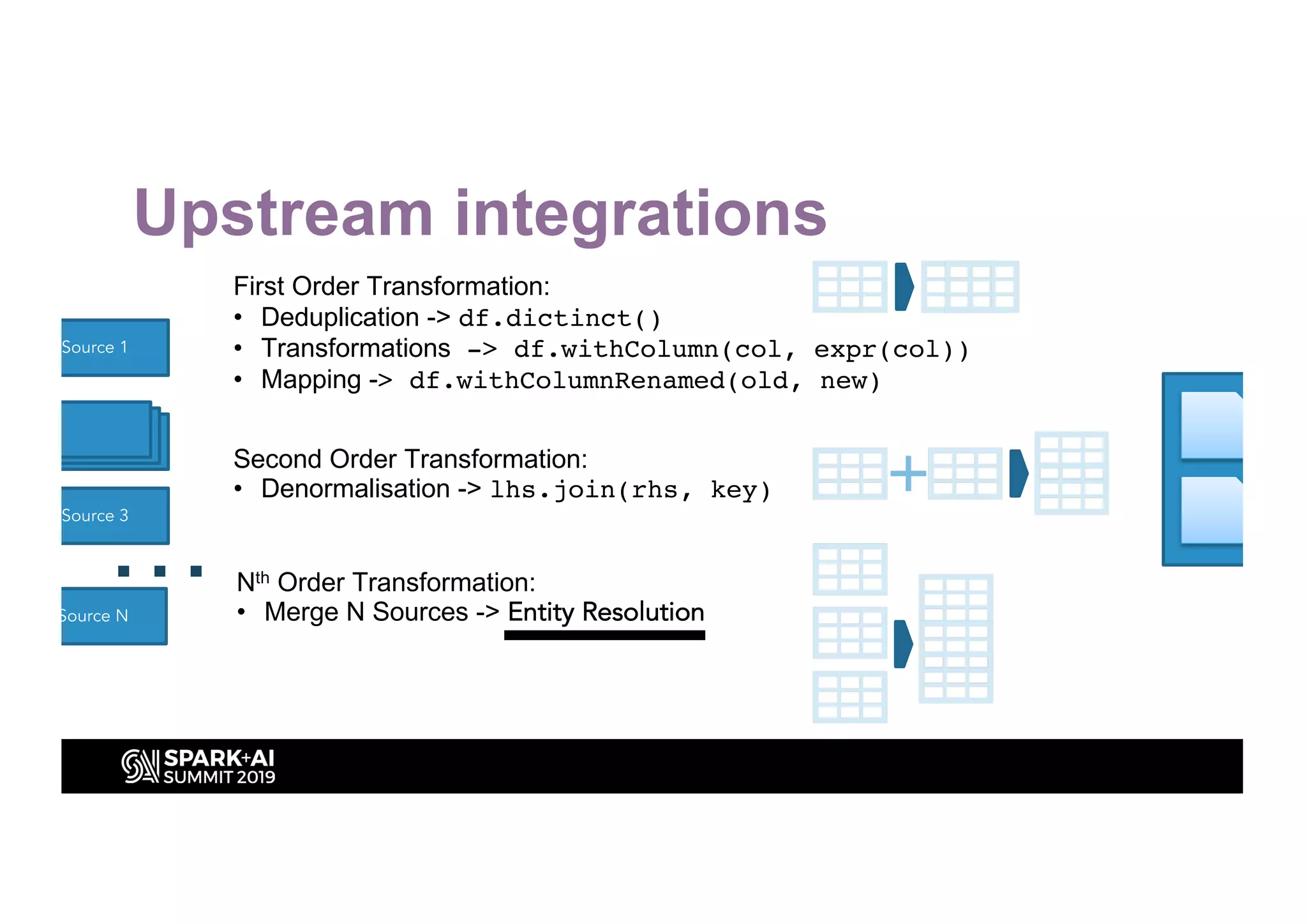
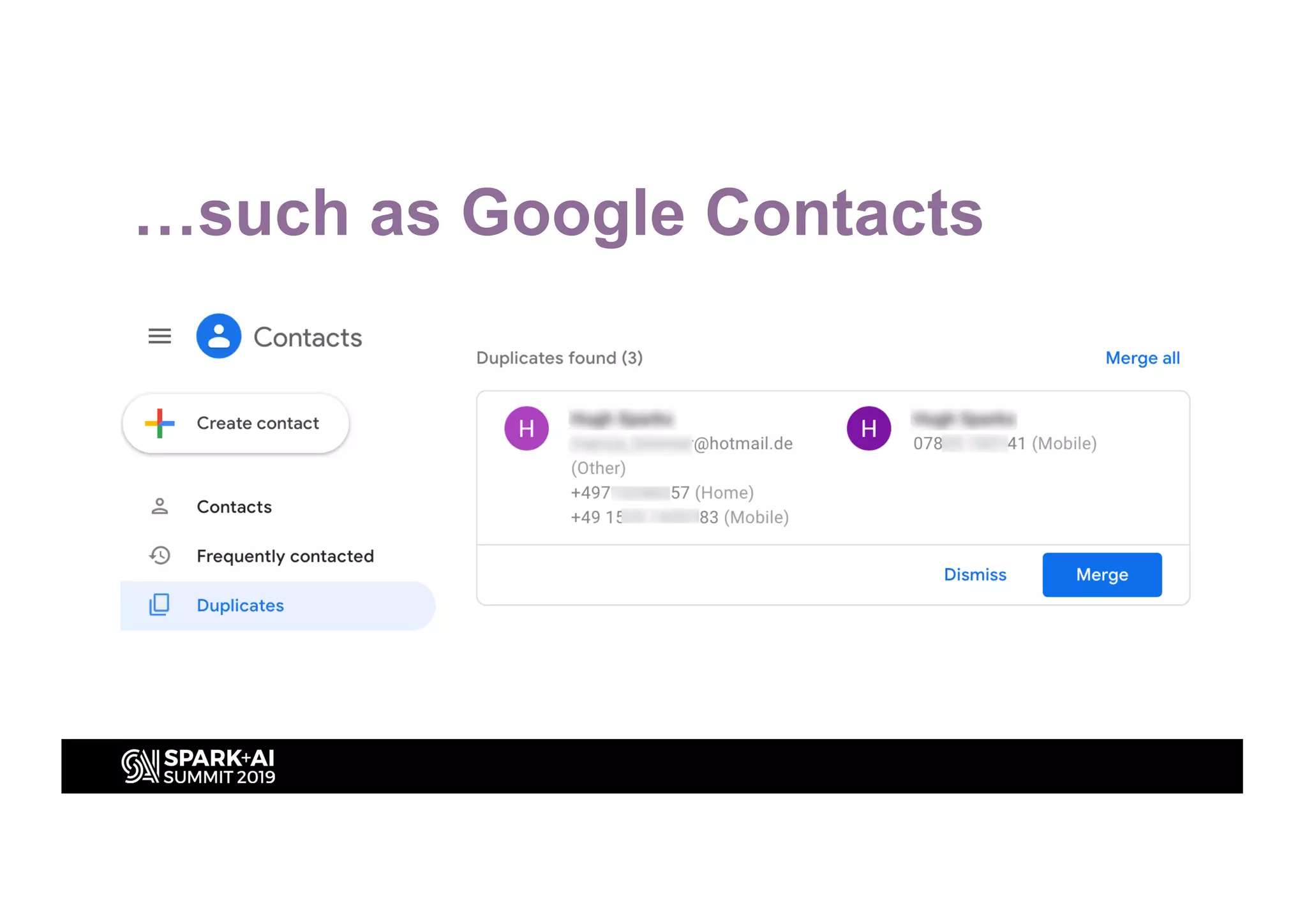
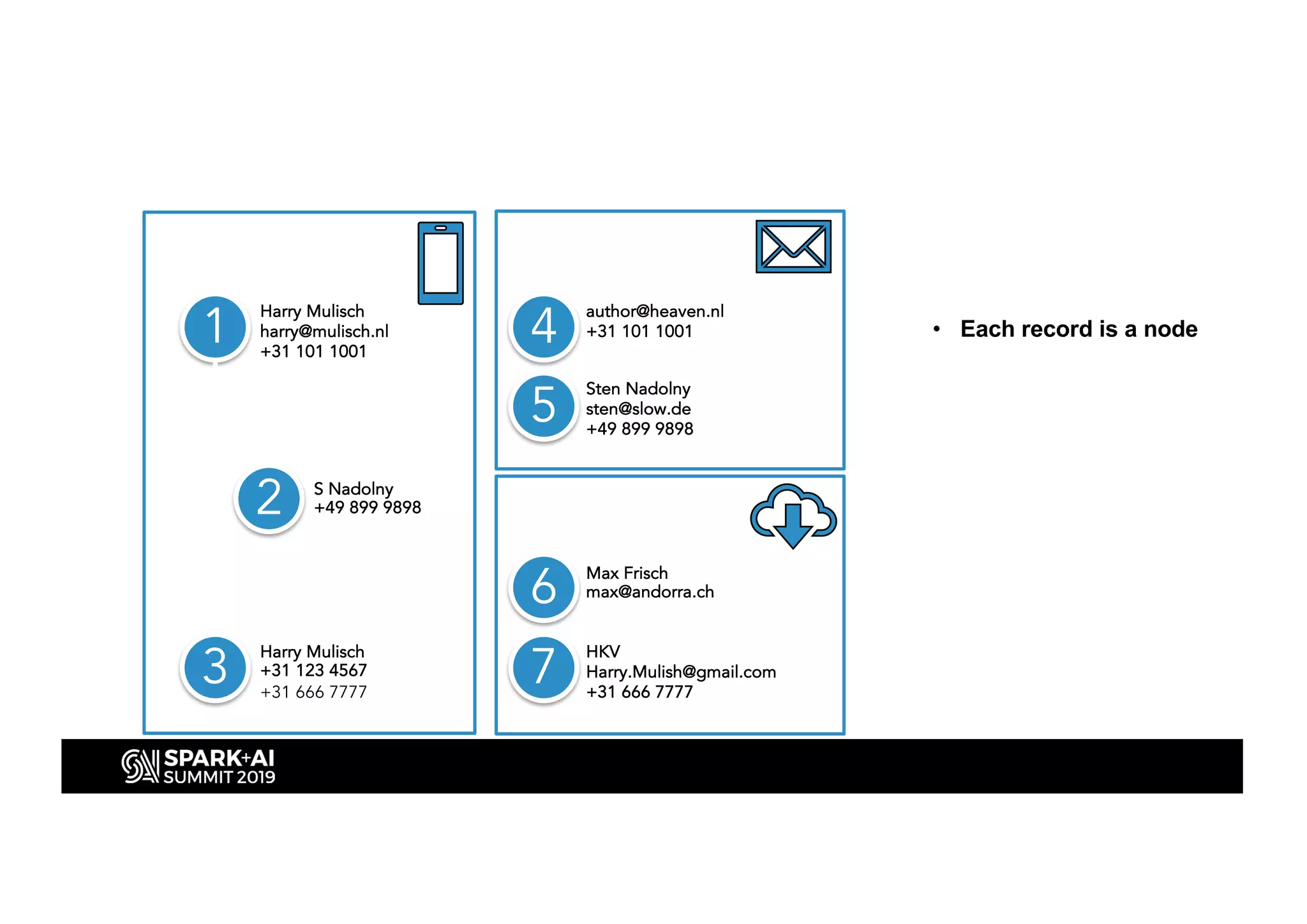
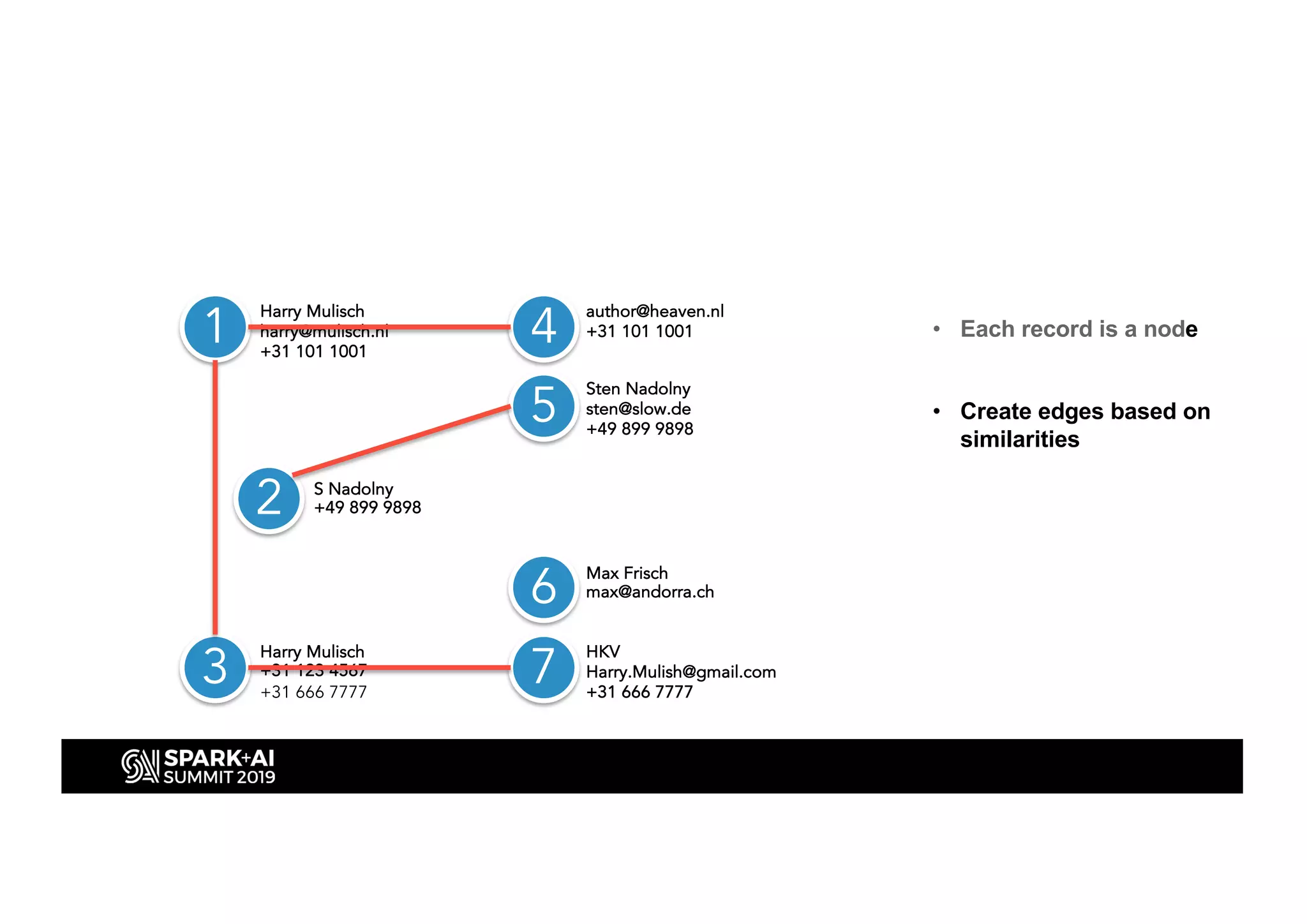
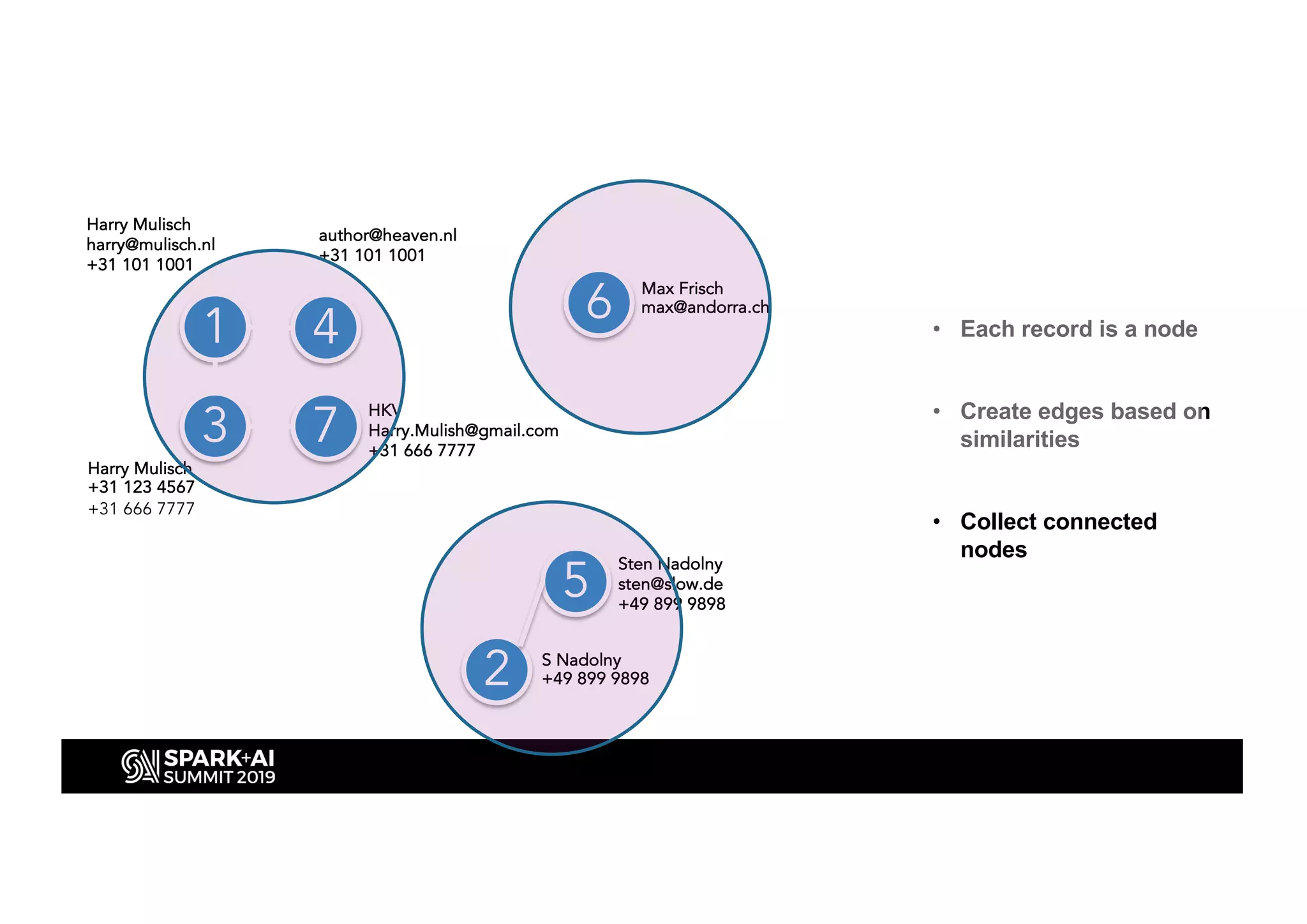
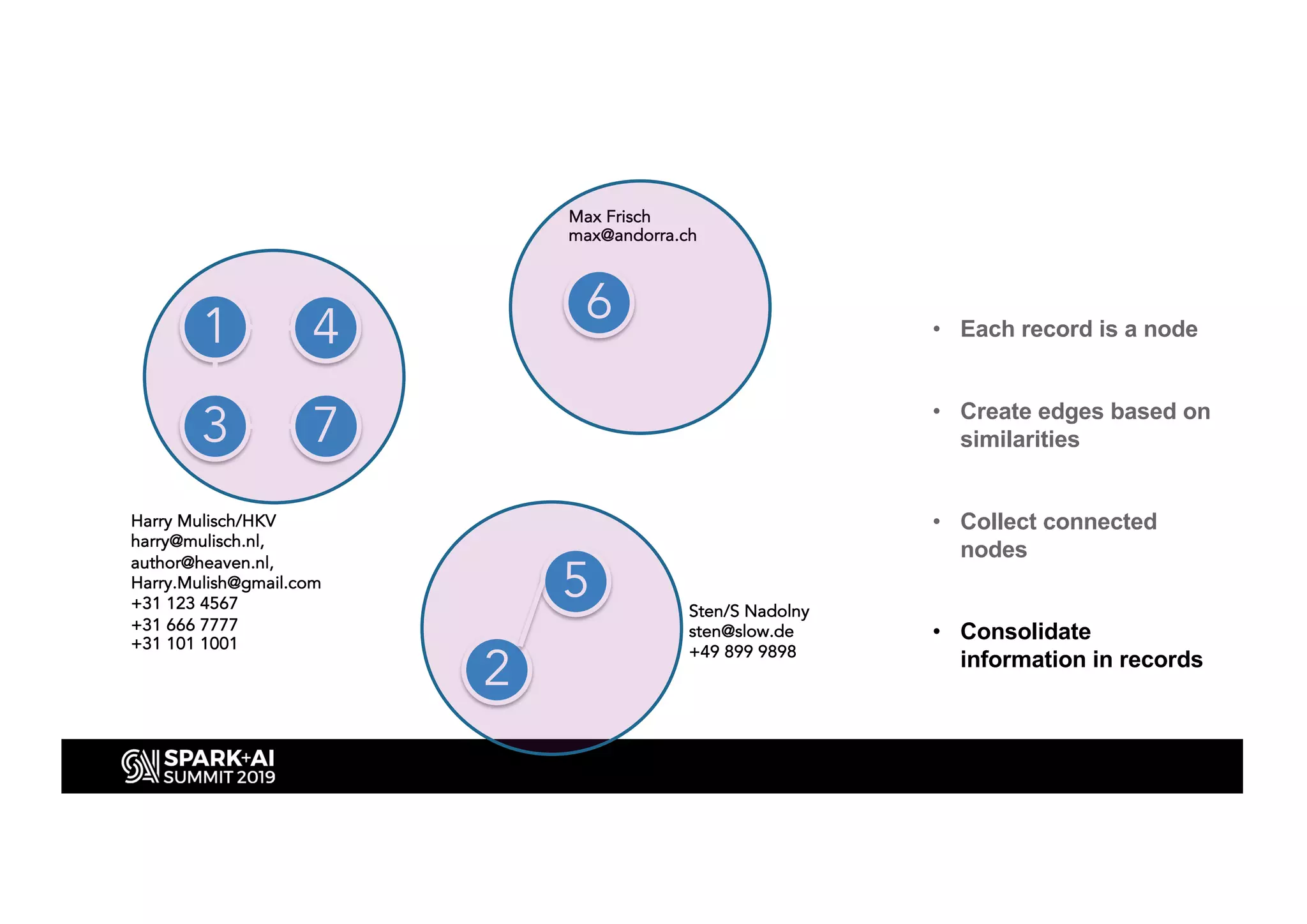
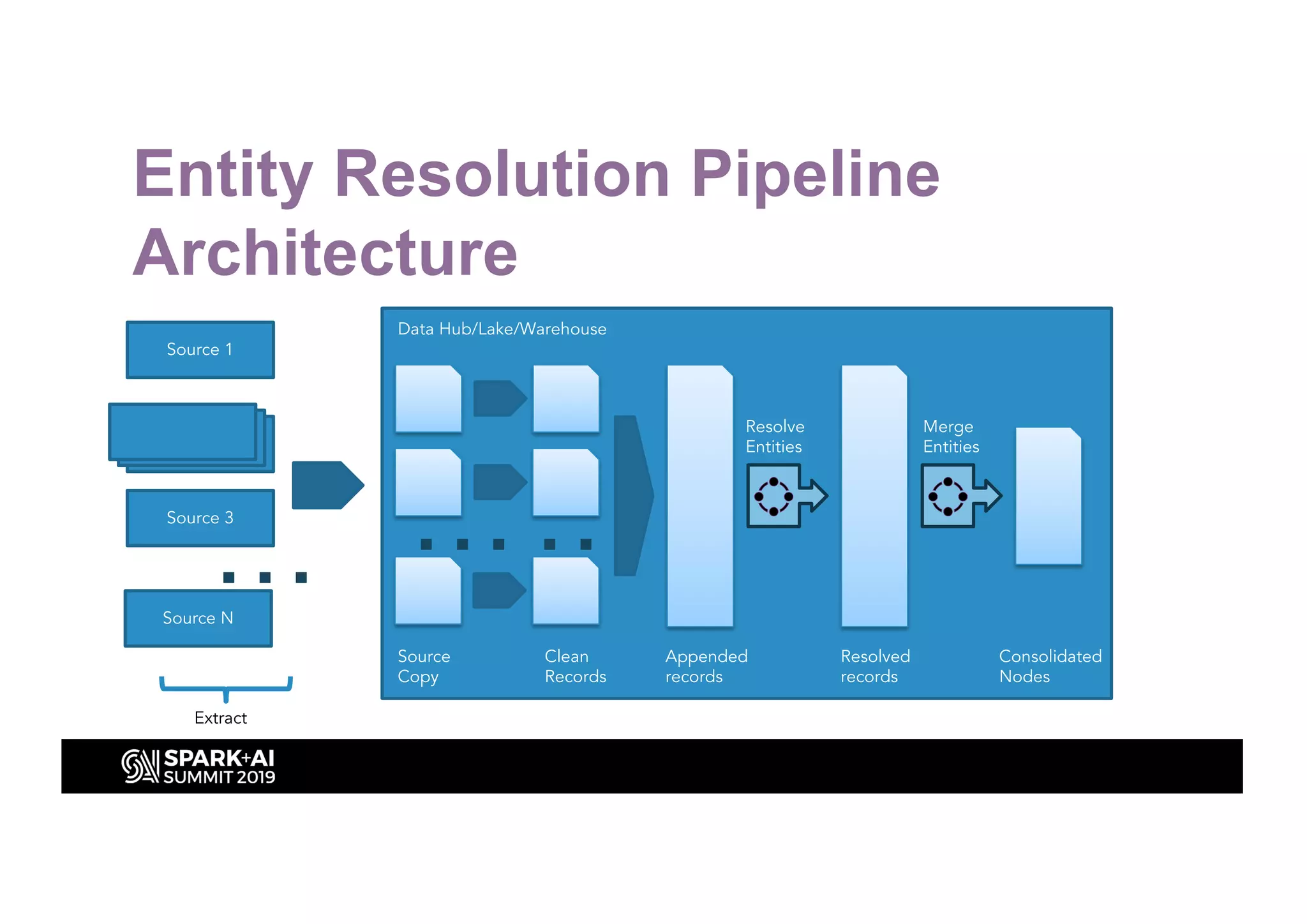
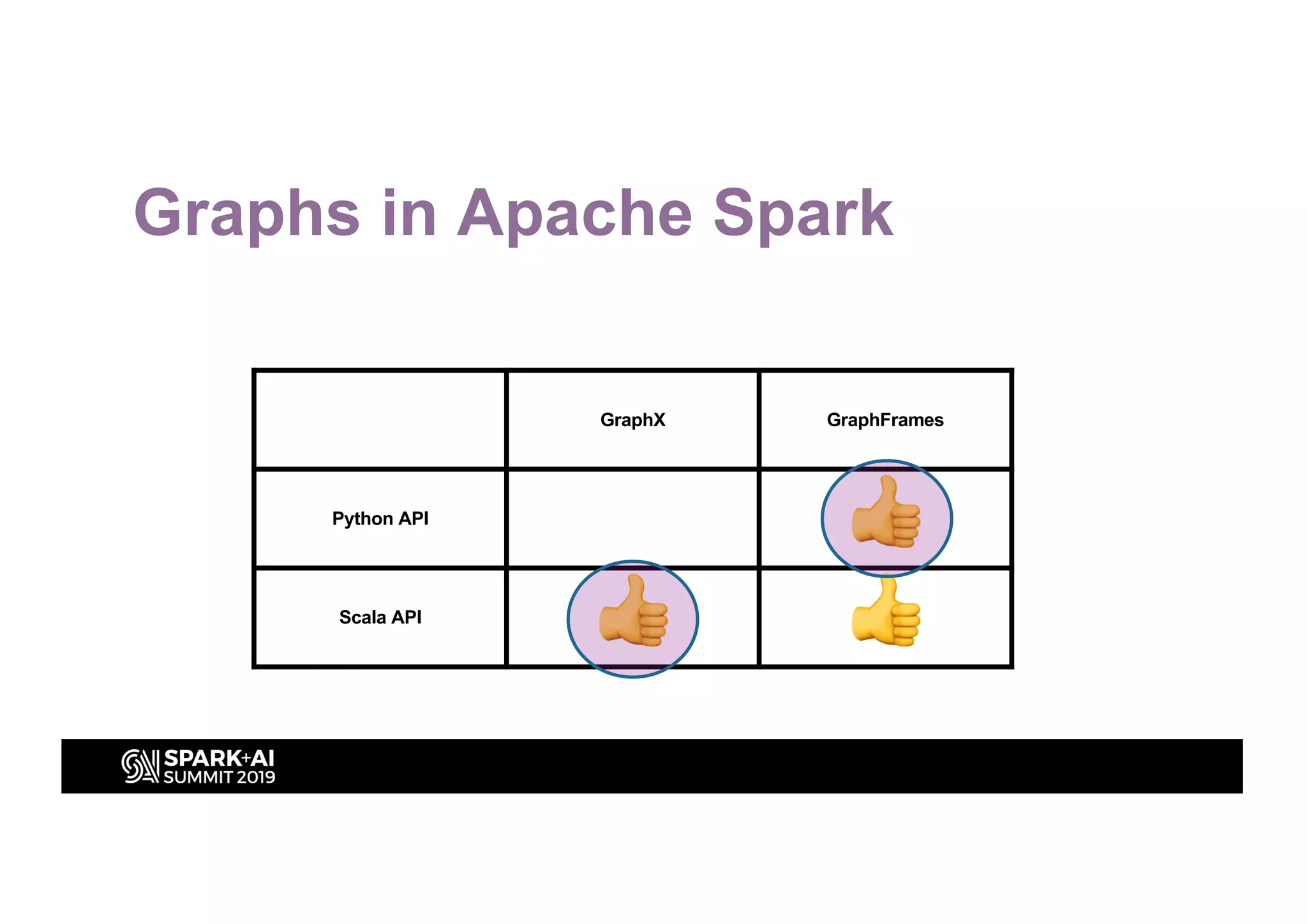
This document discusses entity resolution using graph-based techniques. It begins with an example of resolving duplicate records in an address book. It then provides a high-level overview of the graph algorithm, where each record is a node, edges are created based on similarities, connected nodes are collected, and information is consolidated. The document also summarizes the technical implementation of entity resolution in GraphFrames (Python API) and GraphX (Scala API), and discusses how machine learning can be incorporated, such as for edge creation and partitioning the graph during clustering.