Downloaded 955 times

































This document discusses ensemble machine learning methods. It introduces classifiers ensembles and describes three common ensemble methods: bagging, boosting, and random forests. For each method, it explains the basic idea, how the method works, advantages and disadvantages. Bagging constructs multiple classifiers from bootstrap samples of the training data and aggregates their predictions through voting. Boosting builds classifiers sequentially by focusing on misclassified examples. Random forests create decision trees with random subsets of features and samples. Ensembles can improve performance over single classifiers by reducing variance.
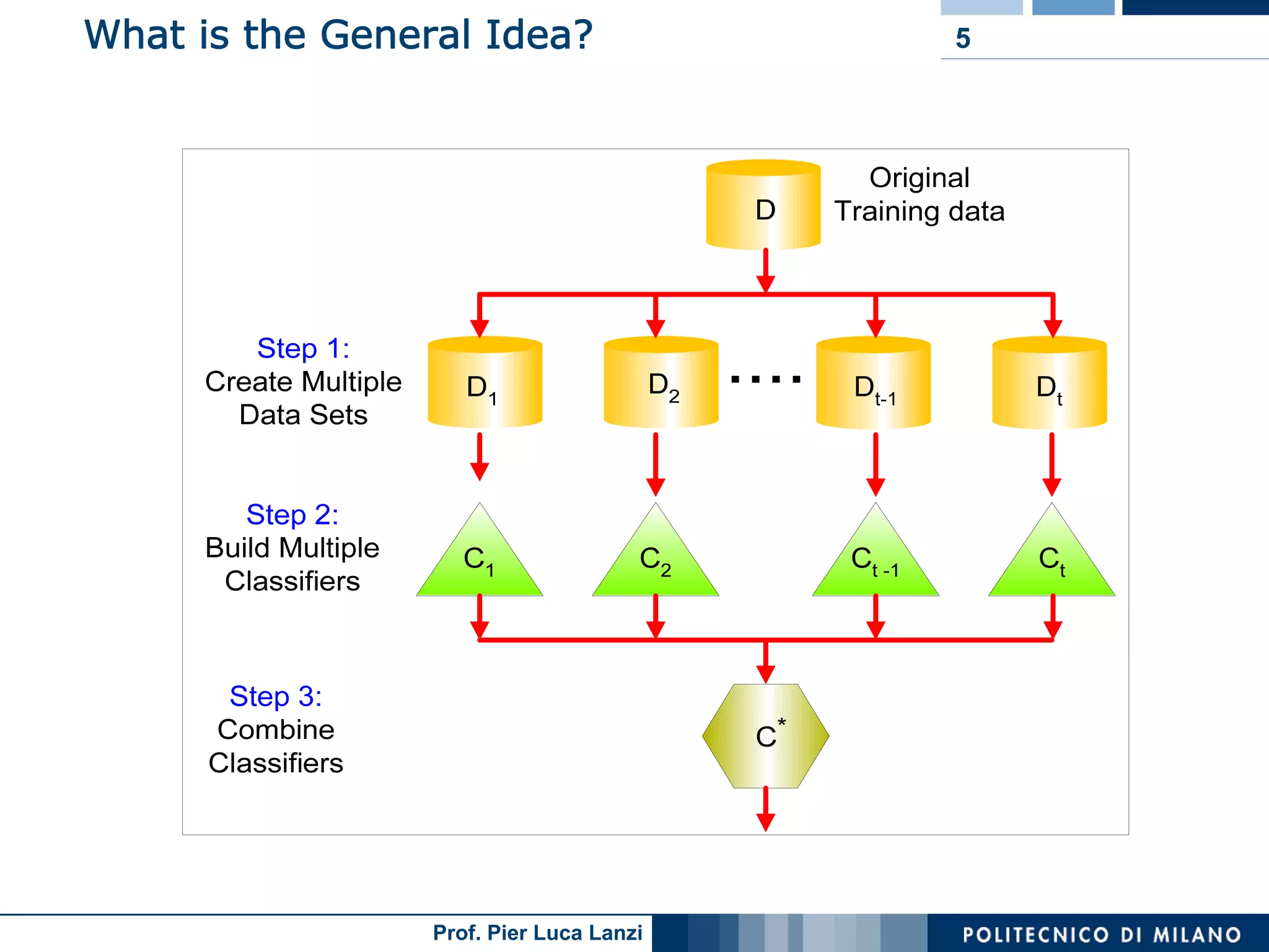
Overview of classifiers ensembles in machine learning, references, and the outline of ensemble methods like bagging, boosting, and random forests.
Ensemble methods involve combining multiple classifiers to enhance prediction accuracy, using various expert models to vote on outputs.
The effectiveness of ensemble classifiers using probability calculations to demonstrate improvement in predictions over single classifiers.
Bagging, a majority voting system among classifiers, reduces variance, enhances prediction stability, and enables handling noisy data.
Bias-variance decomposition helps understand performance fluctuations based on different training sets; bagging is most effective with unstable algorithms.
Bagging enhances decision trees and coefficients but lacks interpretability, often combined with randomized learning strategies.
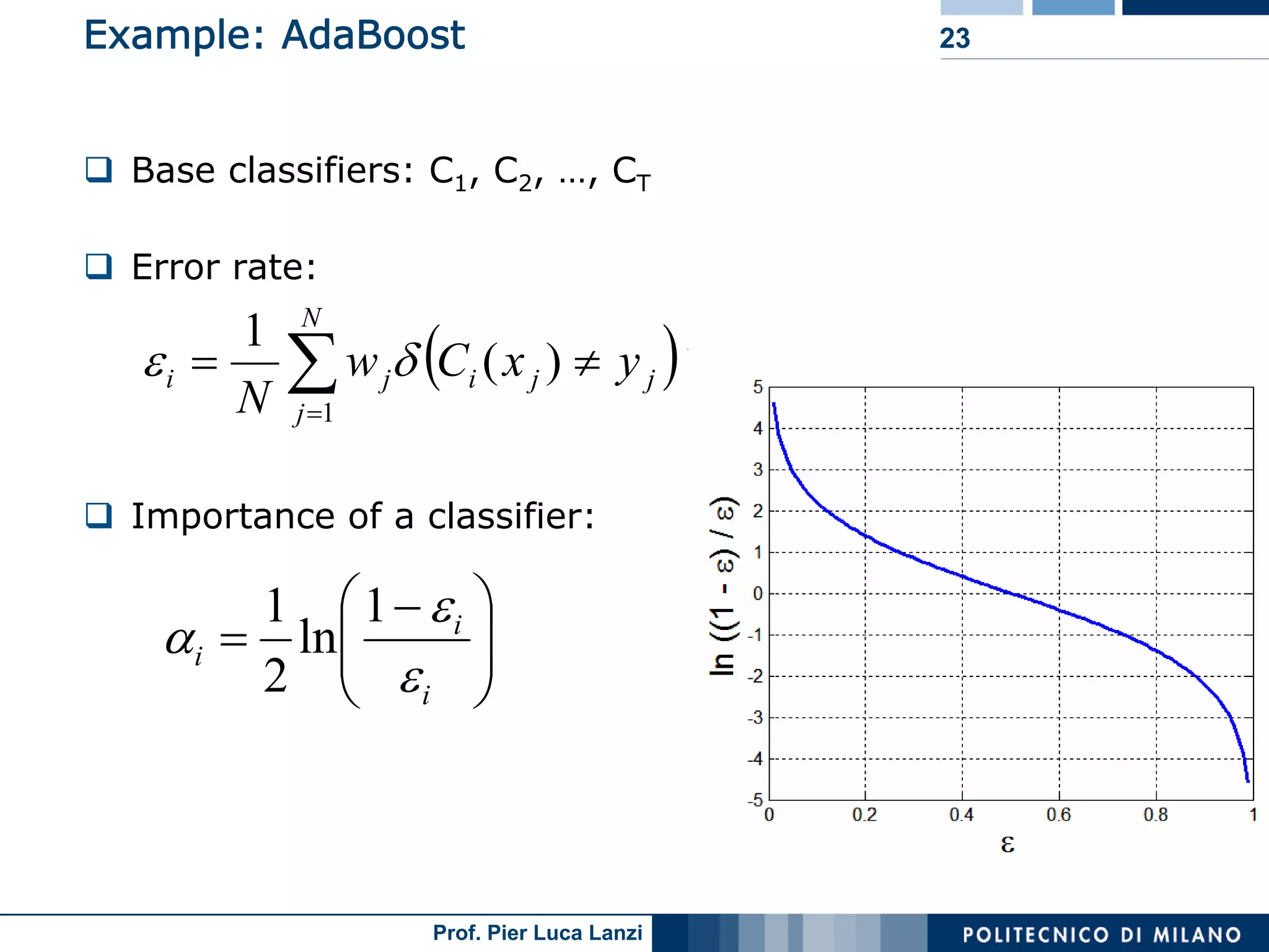
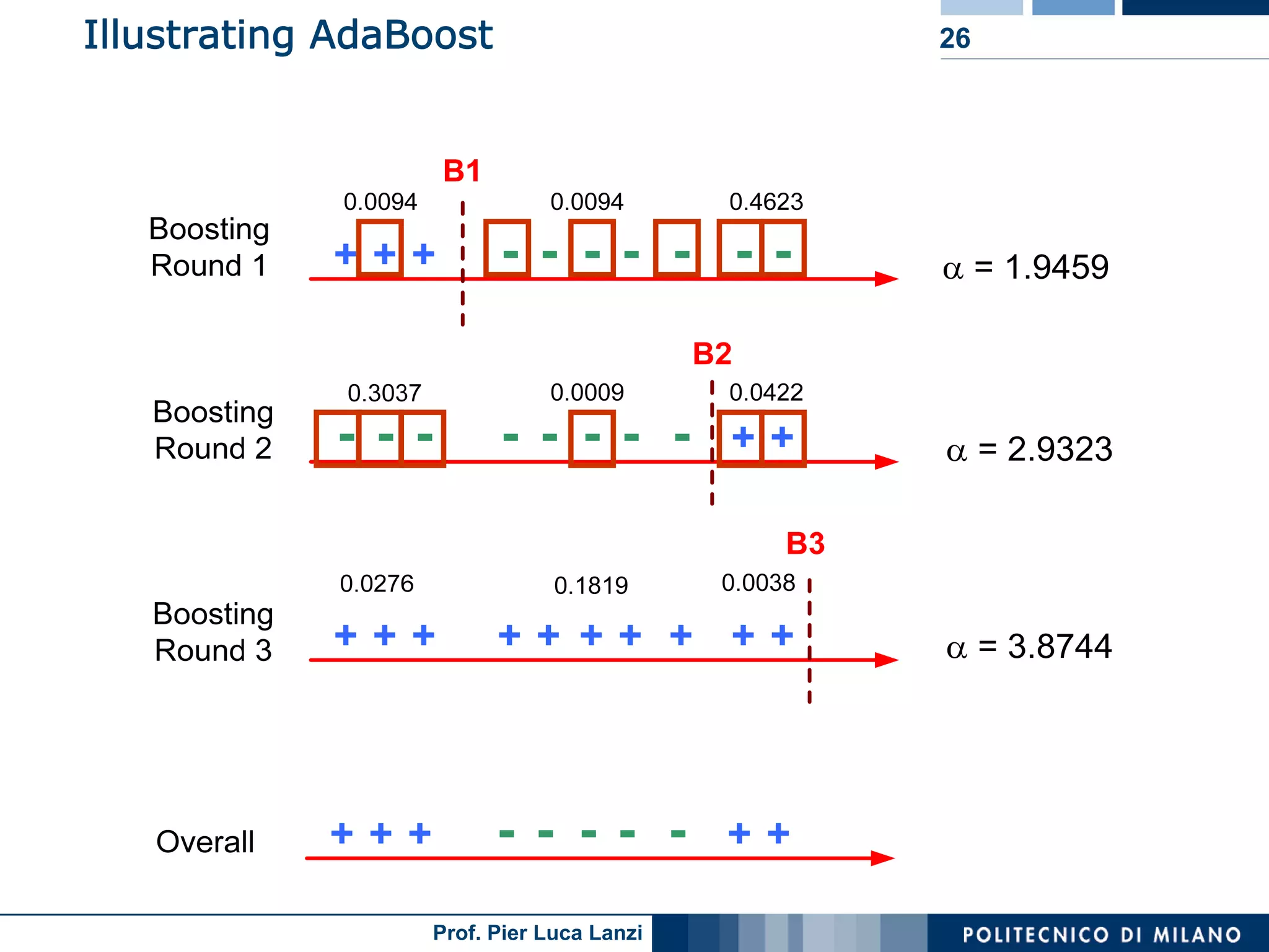
Boosting improves model accuracy through iterative adjustments, emphasizing misclassified instances to refine predictions dynamically.
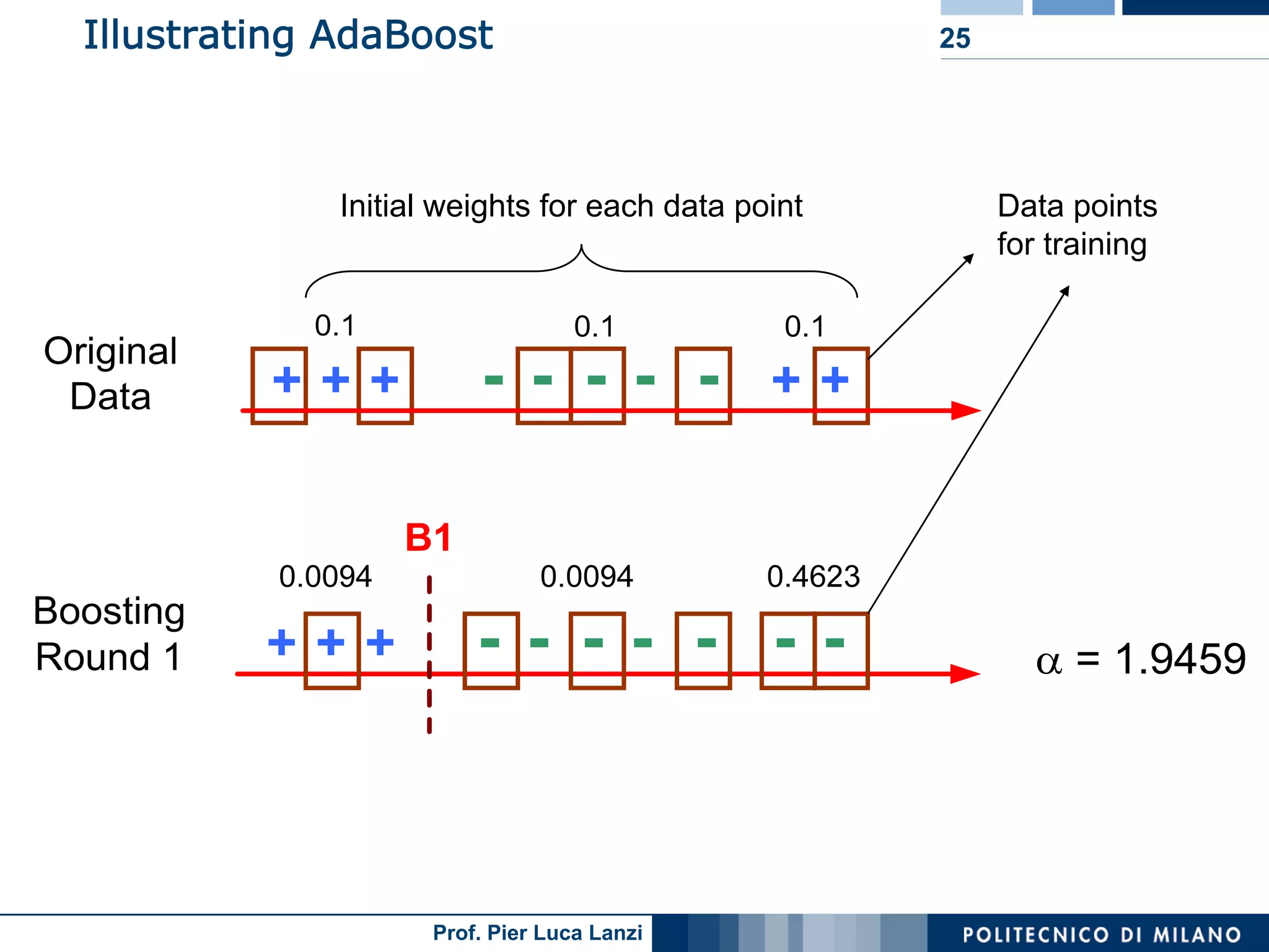
The process of AdaBoost, including initial weight assignments, iteration, and reevaluation of weights based on misclassification performance.
Random forests utilize multiple decision trees, with tree correlation, random sampling, and feature selection enhancing overall robustness and accuracy.
Utilization of out-of-bag estimates for testing, measuring variable importance, and summarizing random forests as a powerful classification tool.
Ensemble models enhance predictive accuracy across various domains, though they compromise interpretability; diversity among classifiers is crucial.