Download to read offline
![Generating Co-speech Gestures for the Humanoid Robot NAO through BML Quoc Anh Le and Catherine Pelachaud CNRS, LTCI Telecom ParisTech, France {quoc-anh.le,catherine.pelachaud}@telecom-paristech.fr Abstract. We extend and develop an existing virtual agent system to generate communicative gestures for different embodiments (i.e. virtual or physical agents). This paper presents our ongoing work on an imple- mentation of this system for the NAO humanoid robot. From a spec- ification of multi-modal behaviors encoded with the behavior markup language, BML, the system synchronizes and realizes the verbal and nonverbal behaviors on the robot. Keywords: Conversational humanoid robot, expressive gestures, gesture- speech production and synchronization, Human-Robot Interaction, NAO, GRETA, FML, BML, SAIBA. 1 Introduction We aim at building a model generating expressive communicative gestures for embodied agents such as the NAO humanoid robot [2] and the GRETA virtual agent [11]. To reach this goal, we extend and develop our GRETA system [11], which follows the SAIBA (i.e. Situation, Agent, Intention, Behavior, Anima- tion) framework (cf. Figure 1). The GRETA system consists of three separated modules: the first module, Intent Planning, defines communicative intents to be conveyed. The second, Behavior Planning, plans the corresponding multi-modal behaviors to be realized. And the third module, Behavior Realizer, synchronizes and realizes the planned behaviors. Fig. 1. The SAIBA framework for generating multimodal behavior The results of the first module is the input for the second module presented through an interface described with a representation markup language, named E. Efthimiou, G. Kouroupetroglou, S.-E. Fotinea (Eds.): GW 2011, LNAI 7206, pp. 228–237, 2012. c Springer-Verlag Berlin Heidelberg 2012](https://image.slidesharecdn.com/lncs-120922062406-phpapp02/75/Lecture-Notes-in-Computer-Science-LNCS-1-2048.jpg)
![Generating Co-speech Gestures for the Humanoid Robot NAO through BML 229 FML (i.e Function Markup Language). The output of the second module is en- coded with another representation language, named BML (i.e. Behavior Markup Language) [6] and then sent to the third module. Both FML and BML are XML- based languages and they do not refer to any particular specification agent (e.g. its wrist joint). From given communicative intentions, the system selects and plans gestures taken from a repository of gestures , called Gestural Lexicon or Gestuary (cf. Figure 1). In the repository, gestures are described symbolically with an exten- sion of the BML representation language. Then the system calculates the timing of the selected gestures to be synchronized with speech. After that, the gestures are instantiated as robot joint values and sent to the robot in order to execute the hand-arm movements. Our aim is to be able to use the same system to control both agents (i.e. the virtual one and the physique one). However, the robot and the agent do not have the same movement capacities (e.g. the robot can move its legs and torso but does not have facial expression and has very limited hand-arm movements compared to the agent). Therefore, the nonverbal behaviors to be displayed by the robot may be different from those of the virtual agent. For instance, the robot has only two hand configurations, open and closed; it cannot extend just one finger. Thus, to do a deictic gesture it can make use of its whole right arm to point at a target rather than using an extended index finger as done by the virtual agent. To control communicative behaviors of the robot and the virtual agent, while taking into account their physical constraint, we consider two repertoires of ges- tures, one for the robot and another for the agent. To ensure that both the robot and the virtual agent convey similar information, their gesture repertoires should have entries for the same list of communicative intentions. The elaboration of repertoires encompasses the notion of gesture family with variants proposed by Calbris [1]. Gestures from the same family convey similar meanings but may differ in their shape (i.e. the element deictic exists in both repertoires; it corre- sponds to an extended finger or to an arm extension). In the proposed model, therefore, the Behavior Planning module remains the same for both agents and unchanged from the GRETA system. From the BML scripts outputted by the Behavior Planner, we instantiate BML tags from either gesture repertoires. That is, given a set of intentions and emotions to convey, the GRETA system, through the Behavior Planning, the corresponding sequence of behaviors specified with BML. The Behavior Realizer module has been developed to create the anima- tion for both agents with different behavior capabilities. Figure 2 presents an overview of our system. In this paper, we presents our current implementation of the proposed ex- pressive gesture model for the NAO humanoid robot. This work is conducted within the framework of the French Nation Agency for Research project, named GVLEX (Gesture and Voice for an Expressive Lecture), whose objective is to build an expressive robot able to display communicative gestures with different behavior qualities while telling a story. Whistle other partners of the project deal](https://image.slidesharecdn.com/lncs-120922062406-phpapp02/75/Lecture-Notes-in-Computer-Science-LNCS-2-2048.jpg)
![230 Q.A. Le and C. Pelachaud Fig. 2. An overview of the proposed system with expressive voice, our work focuses on expressive nonverbal behaviors, espe- cially on gestures. In this project, we have elaborated a repository of gestures specific to the robot based on gesture annotations extracted from a storytelling video corpus [8]. The model takes into account the physical characteristics of the robot. Each gesture is guaranteed to be executable by the robot. When gestures are realized, their expressivity is increased by considering a set of quality dimen- sions such as the amplitude (SPC), fluidity (FLD), power (PWR), or speed of gestures (TMP) that has been previously developed for the GRETA agent [3]. The paper is structured as follows. The next section, state of the art describes some recent initiatives in controlling humanoid robot hand-arm gestures. Then, Section 3 presents in detail the design and implementation of a gesture database and a behavior realizer for the robot. Section 4 concludes and proposes some future works. 2 State of the Art Several initiatives have been proposed recently to control multi-modal behaviors of a humanoid robot. Salem et al. [14] use the gesture engine of the MAX virtual agent to drive the ASIMO humanoid robot. Rich et al. [13] implement a system following an event-driven architecture to solve the problem of unpredictability in performance of their MELVIN humanoid robot. Meanwhile, Ng-Thow-Hing et al. [10] develop a system that takes any text as input to select and produce the corresponding gestures for the ASIMO robot. In this system Ng-Thow-Hing added some parameters for expressivity to make gestures more expressive such as tension, smooth and timing of gesture trajectories. These parameters correspond to the power, fluidity and temporal extend in our system. In [7] Kushida et al. equip their robot with a capacity of producing deictic gestures when the robot](https://image.slidesharecdn.com/lncs-120922062406-phpapp02/75/Lecture-Notes-in-Computer-Science-LNCS-3-2048.jpg)
![Generating Co-speech Gestures for the Humanoid Robot NAO through BML 231 gives a presentation on the screen. These systems have several common char- acteristics. They calculate animation parameters of the robot from a symbolic description encoded with a script language such as MURML [14], BML [13], MPML-HR [7], etc. The synchronization of gestures with speech is guaranteed by adapting the gesture movements to the timing of the speech [14,10]. This is also the method used in our system. Some systems have a feedback mechanism to receive and process feedback information from the robot in real time, which is then used to improve the smoothness of gesture movements [14], or to improve the synchronization of gestures with speech [13]. Our system has some differences from these works. It focuses not only on the coordination of gestures and speech but also on the signification and the ex- pressivity of gestures performed by the robot. In fact, the gesture signification is studied carefully when elaborating a repertoire of robot gestures. In terms of ges- ture expressivity, it is enhanced by adding a set of gesture dimension parameters such as spatial extension (SPC), temporal extension (TMP). 3 System Design and Implementation The proposed model is developed based on the GRETA system. It uses its exist- ing Behavior Planner module to select and plan multi-modal behaviors. A new Behavior Realizer module has been developed to adapt to the behavior capabili- ties of the robot. The main objective of this module is to generate the animations, which will be displayed by the robot from received BML messages. This process is divided into two tasks: the first one is to create a gesture database specific to the robot and the second one is to realize selected and planned gestures on the robot. Figure 3 shows different steps of the system. 3.1 Gesture Database Gestures are described symbolically using a BML-based extension language and are stored in a lexicon. All entries of the lexicon are tested to guarantee their realizability on the robot (e.g. avoid collision or conflict between robot joints when doing a gesture, or avoid singular positions where the robot hands cannot reach). The gestures are instantiated dynamically into joint values of the robot when creating the animation in real-time. The instantiation values according to the values of their expressivity parameters. Gesture Annotations. The elaboration of symbolic gestures in the robot lexi- con is based on gesture annotations extracted from a Storytelling Video Corpus, which was recorded and annotated by Jean-Claude Martin et al. [8], a partner of the GVLEX project. To create this corpus, six actors were videotaped while telling a French story ”Three Little Pieces of Night” twice. Two cameras were used (front and side view) to get postural expressions in the three dimensions space. Then, the Anvil video annotation tool [5] is used to annotate gesture information such as its category (i.e. iconic, beat, metaphoric and deictic), its](https://image.slidesharecdn.com/lncs-120922062406-phpapp02/75/Lecture-Notes-in-Computer-Science-LNCS-4-2048.jpg)
![232 Q.A. Le and C. Pelachaud Fig. 3. Steps in the system duration and which hand is being used, etc (cf. Figure 4). Based on the shape of gestures captured from the video and their annotated information, we have elaborated a corresponding symbolic gesture repository. Fig. 4. Gestural annotations from a video corpus with the Anvil tool Gesture Specification. We have proposed a new XML schema as an exten- sion of the BML language to describe symbolically gestures in the repository (i.e. lexicon). The specification of a gesture relies on the gestural description of McNeill [9], the gesture hierarchy of Kendon [4] and some notions from the HamNoSys system [12]. As a result, a hand gesture action may be divided into several phases of wrist movements. The stroke phase carries the meaning of the gesture. It may be preceded by a preparatory phase, which takes the articulatory joints (i.e. hands and wrists) to the position ready for the stroke phase. After that, it may be followed by a retraction phase that returns the hands and arms](https://image.slidesharecdn.com/lncs-120922062406-phpapp02/75/Lecture-Notes-in-Computer-Science-LNCS-5-2048.jpg)
![Generating Co-speech Gestures for the Humanoid Robot NAO through BML 233 to the relax positions or positions initialized for the next gesture (cf. Figure 7). In the lexicon, only the description of the stroke phase is specified for each ges- ture. Other phases are generated automatically by the system. A stroke phase is represented through a sequence of key poses, each of which is described with the information of hand shape, wrist position, palm orientation, etc. The wrist position is always defined by three tags namely vertical location that corresponds to the Y axis, horizontal location that corresponds to the X axis, and location distance corresponding to the Z axis in a limited movement space. Fig. 5. An example of the gesture specification Following the gesture space proposed by McNeill [9], we have five horizon- tal values (XEP, XP, XC, XCC, XOppC ), seven vertical values (YUpperEP, YUpperP, YUpperC, YCC, YLowerC, YLowerP, YLowerEP ), and three dis- tance values (Znear, Zmiddle, Zfar). By combining these values, we have 105 possible wrist positions. An example of the description for the greeting gesture is presented in Figure 5. In this gesture, the stroke phase consists of two key poses. These key poses represent the position of the right hand (here, above the head), the hand shape (open) and the palm orientation (forward). The two key poses are different from only one symbolic value on the horizontal position. This is to display a wave hand movement when greeting someone. The NAO robot cannot rotate its wrist (i.e. it has only the WristYaw joint). Consequently, there is no description of wrist orientation in the gesture specification for the robot. However, this attribute can be added for other agents (e.g. the GRETA agent). Movement Space Specification. Each symbolic position is translated into con- crete joint values of the robot joints when the gestures are realized. In our case, these include four NAO joints: ElbowRoll, ElbowYaw, ShoulderPitch and Shoul- derRoll. In addition to the set of 105 possible wrist positions (i.e. following the gesture space of McNeill, see Table 1), two wrist positions are added to specify re- lax positions. These positions are used in the retraction phase of a gesture. The first](https://image.slidesharecdn.com/lncs-120922062406-phpapp02/75/Lecture-Notes-in-Computer-Science-LNCS-6-2048.jpg)
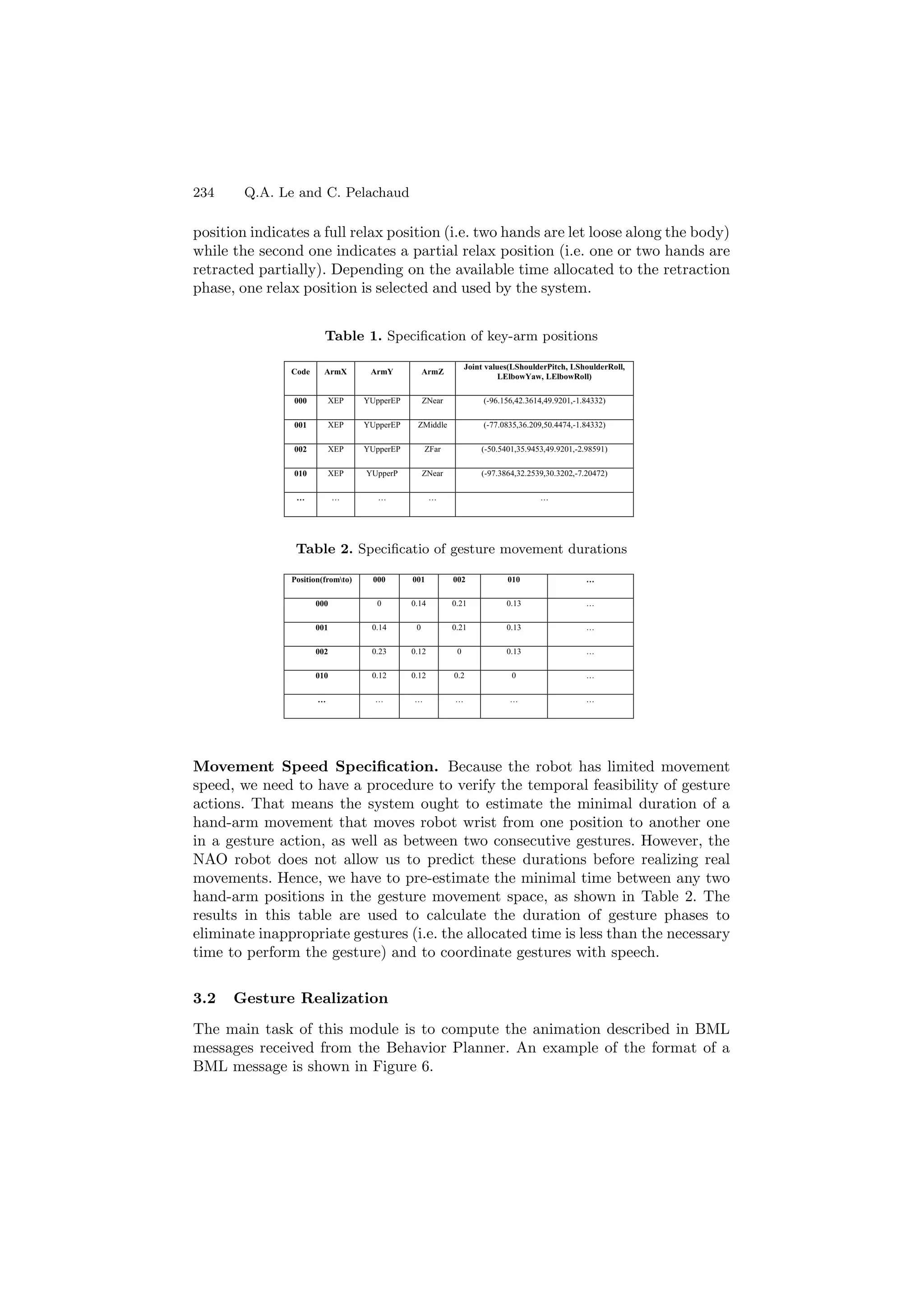
![Generating Co-speech Gestures for the Humanoid Robot NAO through BML 235 Fig. 6. An example of the BML description In our system, we focus on the synchronization of gestures with speech. This synchronization is realized by adapting the timing of the gestures to the speech timing. It means the temporal information of gestures within BML tags are rel- ative to the speech (cf. Figure 6). They are specified through time markers. As shown in Figure 7, they are encoded by seven sync points: start, ready, stroke- start, stroke, stroke-end, relax and end [6]. These sync points divide a gesture action into certain phases such as preparation, stroke, retraction phases as de- fined by Kendon [4]. The most meaningful part occurs between the stroke-start and the stroke-end (i.e. the stroke phase). According to McNeill’s observations [9], a gesture always coincides or lightly precedes speech. In our system, the synchronization between gesture and speech is ensured by forcing the starting time of the stroke phase to coincide with the stressed syllables. The system has to pre-estimate the time required for realizing the preparation phase, in order to make sure that the stroke happens on the stressed syllables of the speech. This pre-estimation is done by calculating the distance between current hand-arm position and the next desired positions. This is also calculated by computing the time it takes to perform the trajectory. The results of this step are obtained by using values in the Tables 1 and 2. The last Execution module (cf. Figure 3) translates gesture descriptions into joint values of the robot. The symbolic positions of the robot hand-arm (i.e. the combination of three values within BML tags respectively: horizontal-location, vertical-location and location-distance) are translated into concrete values of four robot joints: ElbowRoll, ElbowYaw, ShoulderPitch, ShoulderRoll using Table 1. The shape of the robot hands (i.e. the value indicated within hand-shape tag) is translated into the value of the robot joints, RHand and LHand respectively. The palm orientation (i.e. the value specified within palm-orientation tag) and the direction of extended wrist concerns the wrist joints. As Nao has only the WristYaw joint, there is no symbolic description for the direction of the extended wrist in the gesture description. For the palm orientation, this value is translated](https://image.slidesharecdn.com/lncs-120922062406-phpapp02/75/Lecture-Notes-in-Computer-Science-LNCS-8-2048.jpg)
![236 Q.A. Le and C. Pelachaud Fig. 7. Gesture phases and synchronization points into a robot joint, namely WristYaw by calculating the current orientation and the desired orientation of the palm. Finally, the joint values and the timing of movements are sent to the robot. The animation is obtained by interpolating between joint values with the robot built-in proprietary procedures [2]. Data to be sent to the robot (i.e. timed joint values) are sent to a waiting list. This mechanism allows the system to receive and process a series of BML messages continuously. Certain BML messages can be executed with a higher priority order by using an attribute specifying its priority level. This can be used when the robot wants to suspend its current actions to do an exceptional gesture (e.g. make a greeting gesture to a new listener while telling story). 4 Conclusion and Future Work In this paper, we have presented an expressive gesture model for the humanoid robot NAO. The realization of the gestures are synchronized with speech. In- trinsic constraints (e.g. joint and speed limits) are also taken into account. Gesture expressivity is calculated in real-time by setting values to a set of parameters that modulate gestural animation. In the near future, we aim at improving the movement speed specification with the Fitt’s Law (i.e. simulating human movement). So far, the model has been developed for arm-hand gestures only. In the next stage, we will extend the system for head and torso gestures. Then, the system needs to be equipped with a feedback mechanism, which is important to re-adapt the actual state of the robot while scheduling gestures. Last but not least, we aim to validate our model through perceptive evaluations. We will test how expressive the robot is perceived when reading a story. Acknowledgment. This work has been partially funded by the French ANR GVLEX project. References 1. Calbris, G.: Contribution ` une analyse s´miologique de la mimique faciale et a e gestuelle fran¸aise dans ses rapports avec la communication verbale. Ph.D. thesis c (1983) 2. Gouaillier, D., Hugel, V., Blazevic, P., Kilner, C., Monceaux, J., Lafourcade, P., Marnier, B., Serre, J., Maisonnier, B.: Mechatronic design of NAO humanoid. In: Robotics and Automation, ICRA 2009, pp. 769–774. IEEE Press (2009)](https://image.slidesharecdn.com/lncs-120922062406-phpapp02/75/Lecture-Notes-in-Computer-Science-LNCS-9-2048.jpg)


The document describes a system for generating co-speech gestures for the humanoid robot NAO through the Behavior Markup Language (BML). The system extends an existing virtual agent system to generate communicative gestures for both virtual and physical agents like NAO. It takes as input a specification of multi-modal behaviors encoded in BML and synchronizes and realizes the verbal and nonverbal behaviors on the robot. The system includes a behavior planner that selects gestures from a repository and a behavior realizer that generates the animations displayed by the robot based on the BML output from the planner.