Download as PDF, PPTX








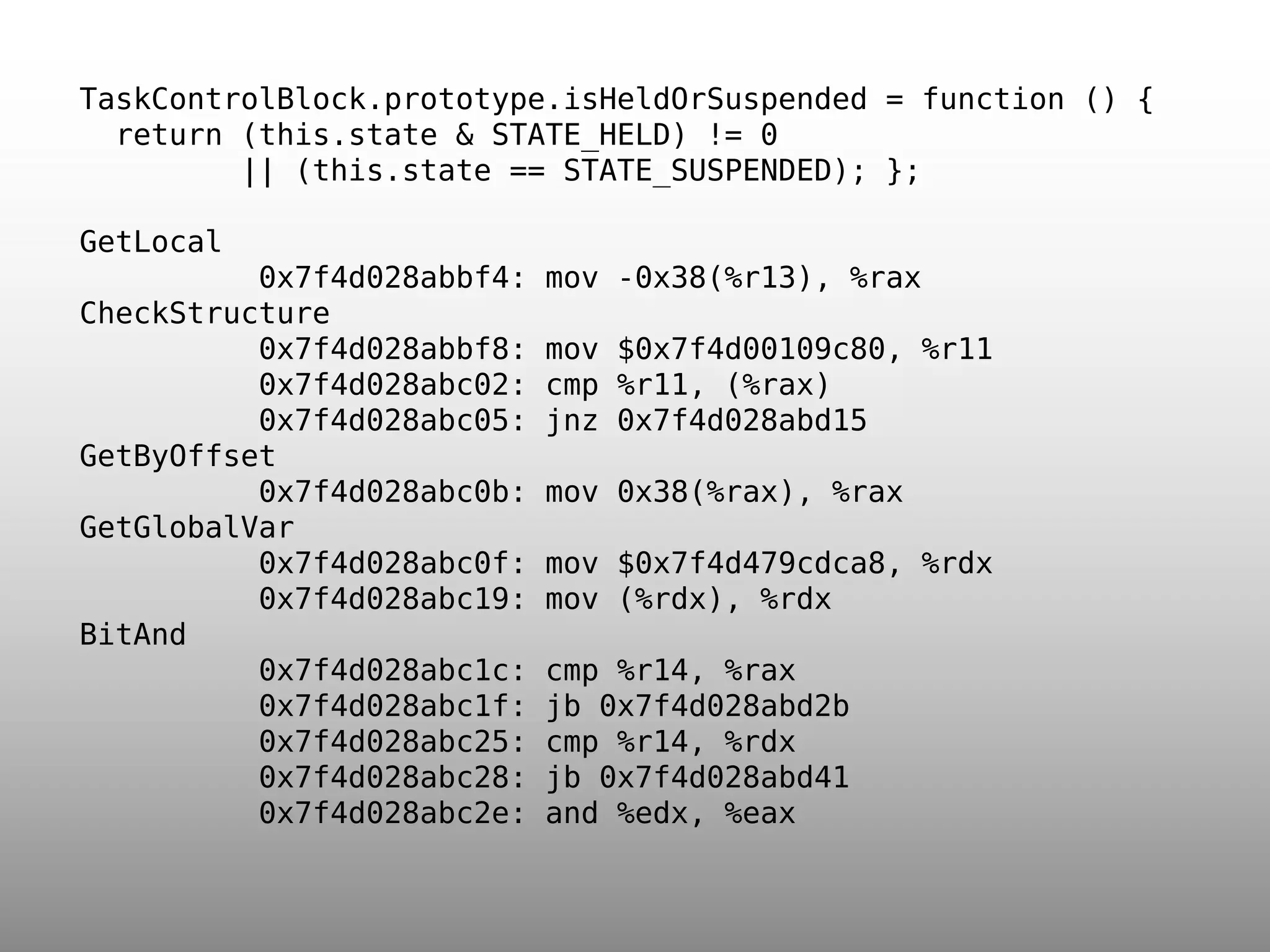
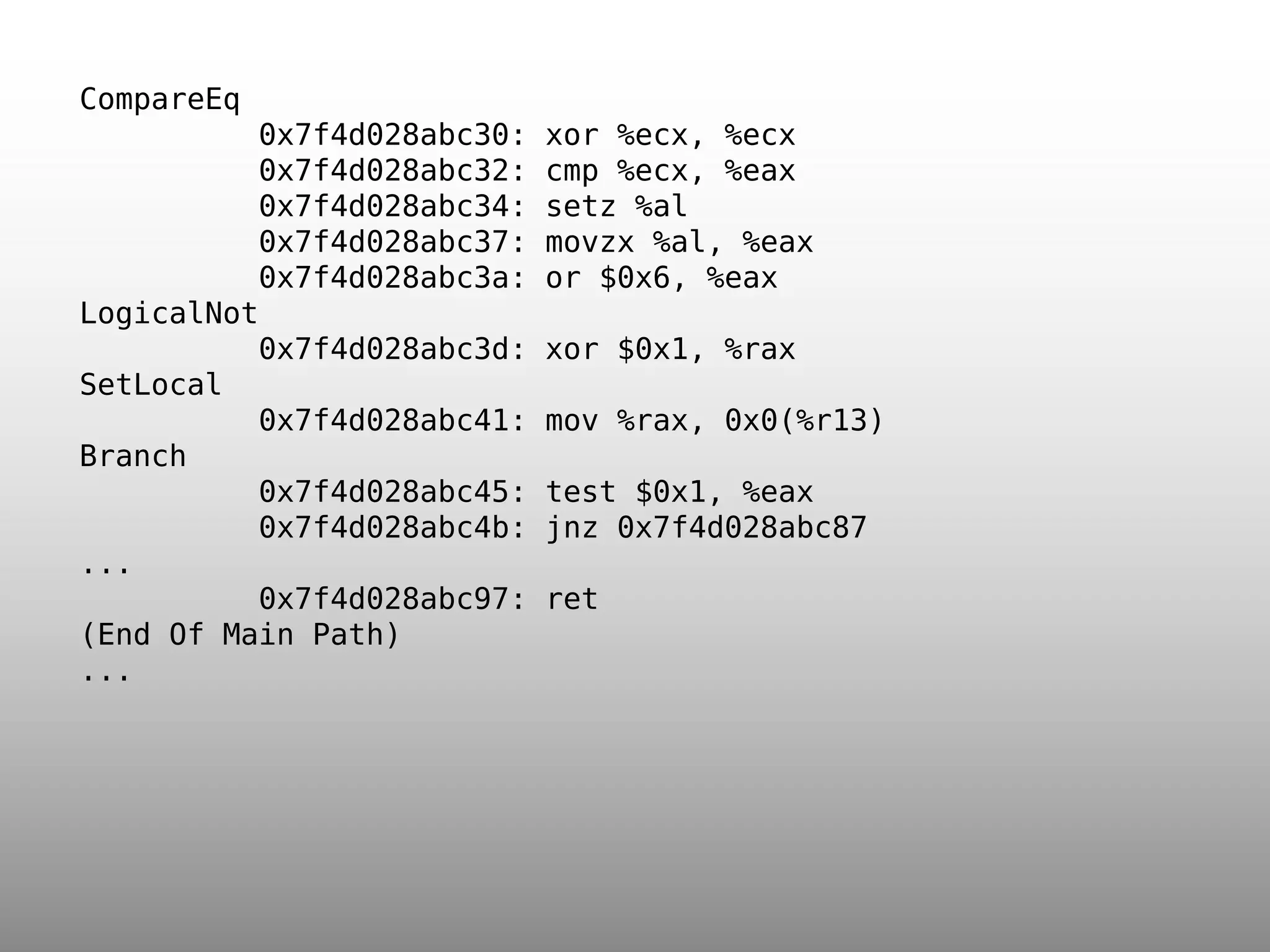


![function am3(i,x,w,j,c,n) { var this_array = this.array; var w_array = w.array; var xl = x&0x3fff, xh = x>>14; while(--n >= 0) { var l = this_array[i]&0x3fff; var h = this_array[i++]>>14; var m = xh*l+h*xl; l = xl*l+((m&0x3fff)<<14)+w_array[j]+c; c = (l>>28)+(m>>14)+xh*h; w_array[j++] = l&0xfffffff; } return c; }](https://image.slidesharecdn.com/jsconf-eu-2012-slides-140206084518-phpapp01/75/JavaScriptCore-s-DFG-JIT-JSConf-EU-2012-17-2048.jpg)
![var l = this_array[i]&0x3fff GetLocal: this_array 0x7f4d02909bf6: mov 0x0(%r13), %r10 GetLocal: i (int32; type check hoisted) 0x7f4d02909bfa: mov -0x40(%r13), %eax GetButterfly: this_array 0x7f4d02909bfe: mov 0x8(%r10), %rdx GetByVal: this_array[i] (array check hoisted) 0x7f4d02909c02: cmp -0x4(%rdx), %eax 0x7f4d02909c05: jae 0x7f4d02909ed2 0x7f4d02909c0b: mov 0x10(%rdx,%rax,8), %rcx 0x7f4d02909c10: test %rcx, %rcx 0x7f4d02909c13: jz 0x7f4d02909ee8 BitAnd: 0x7f4d02909c19: cmp %r14, %rcx 0x7f4d02909c1c: jb 0x7f4d02909efe 0x7f4d02909c22: mov %rcx, %rbx 0x7f4d02909c25: and $0x3fff, %ebx](https://image.slidesharecdn.com/jsconf-eu-2012-slides-140206084518-phpapp01/75/JavaScriptCore-s-DFG-JIT-JSConf-EU-2012-18-2048.jpg)
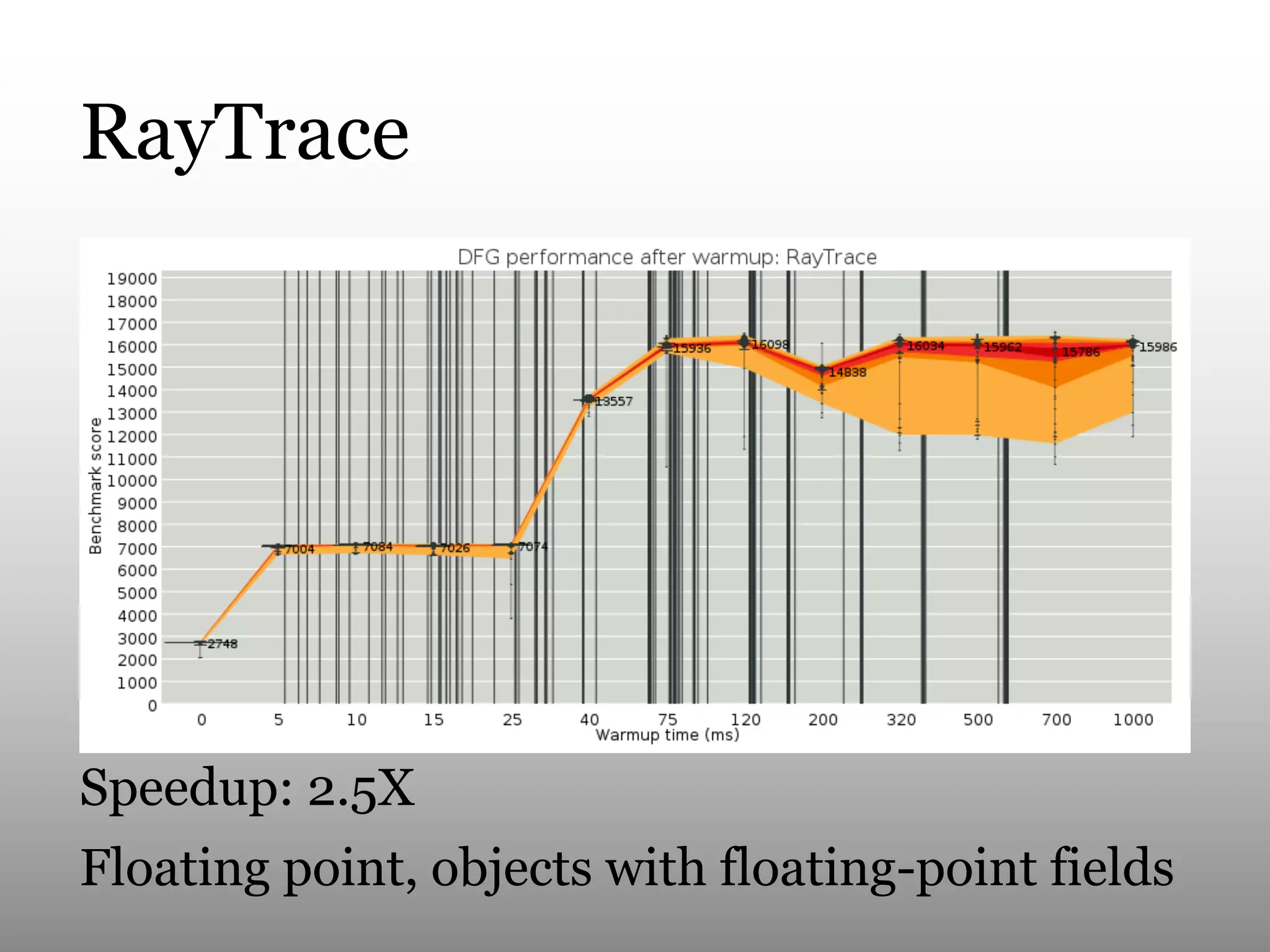

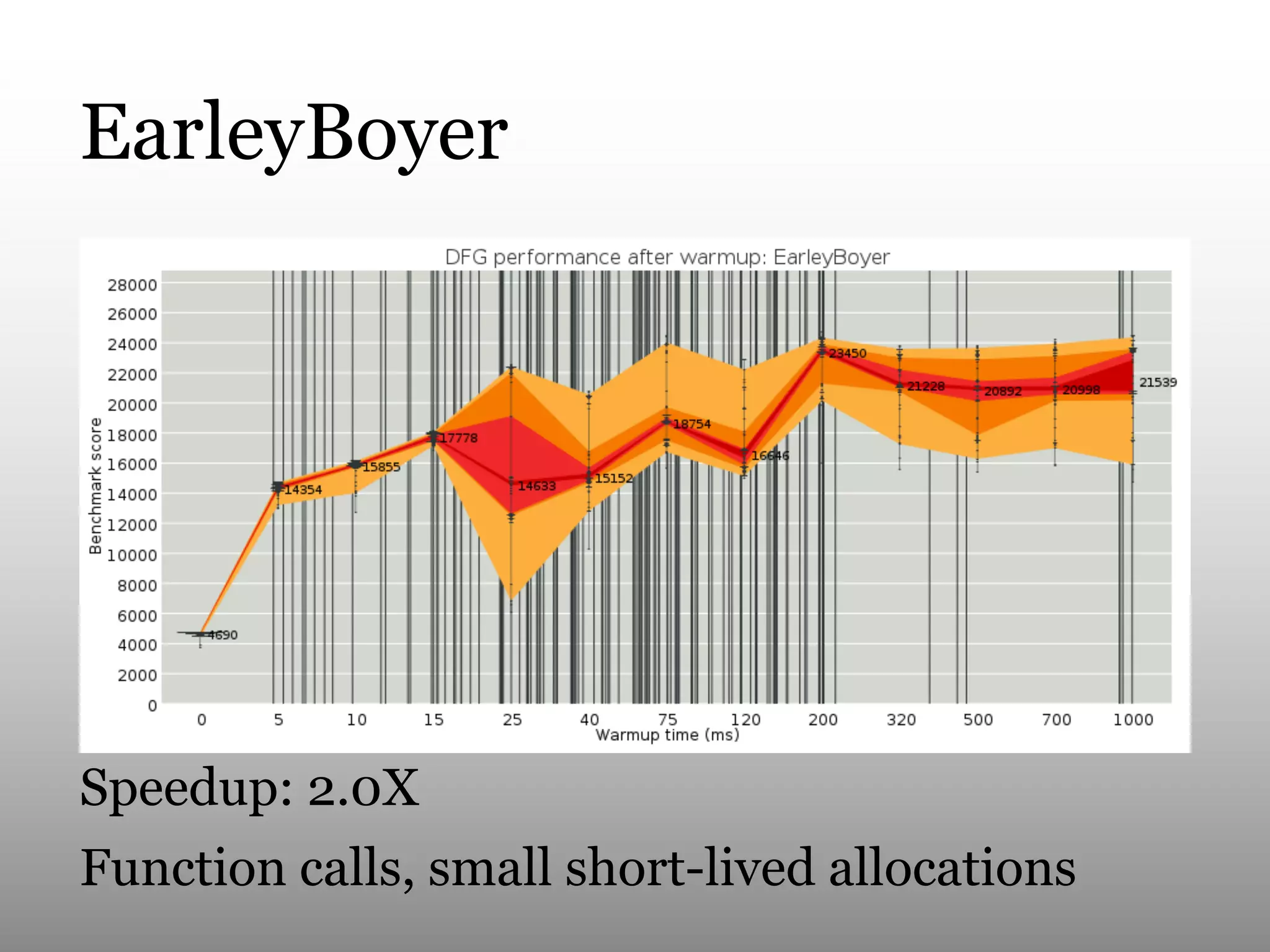

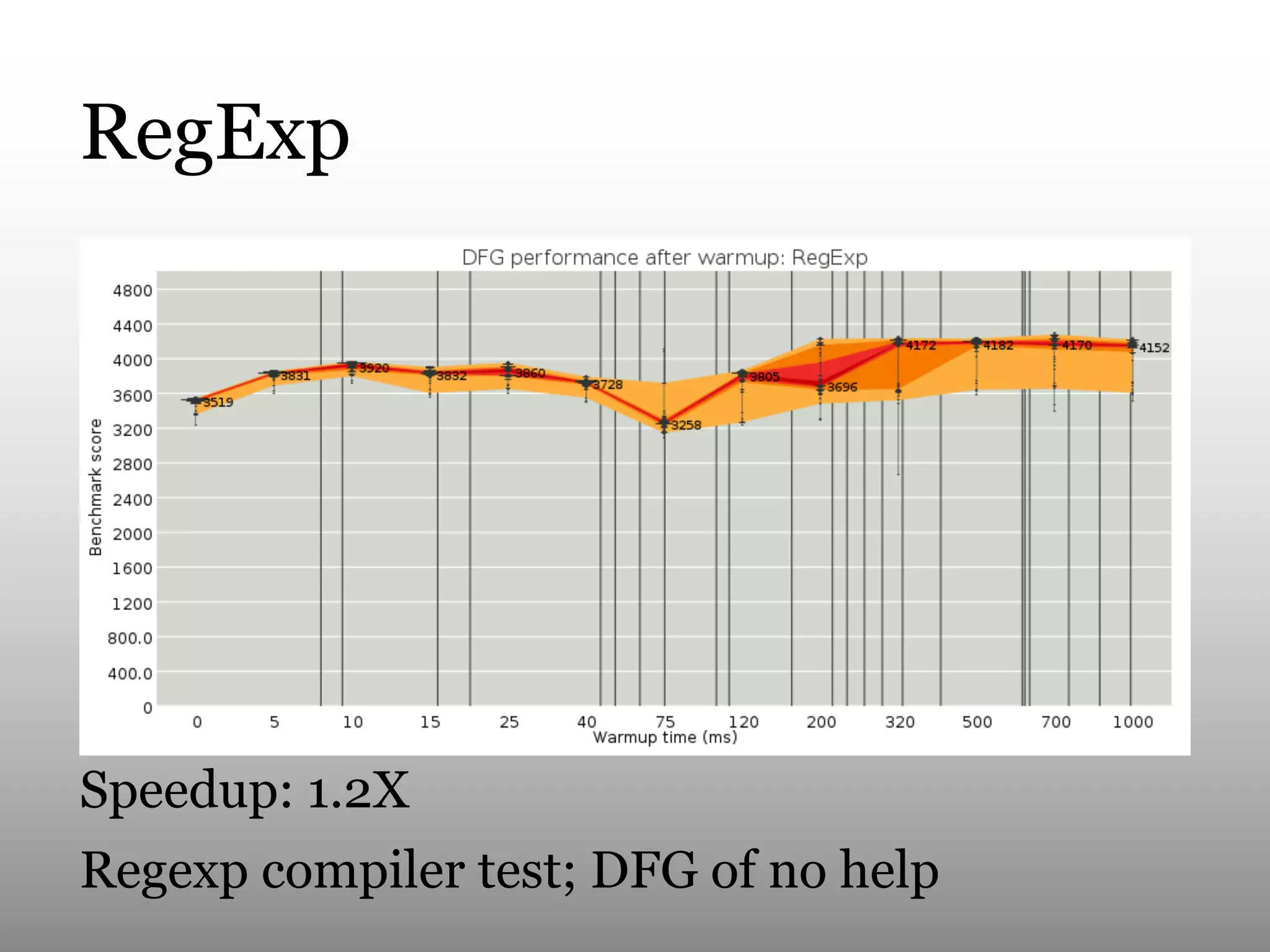
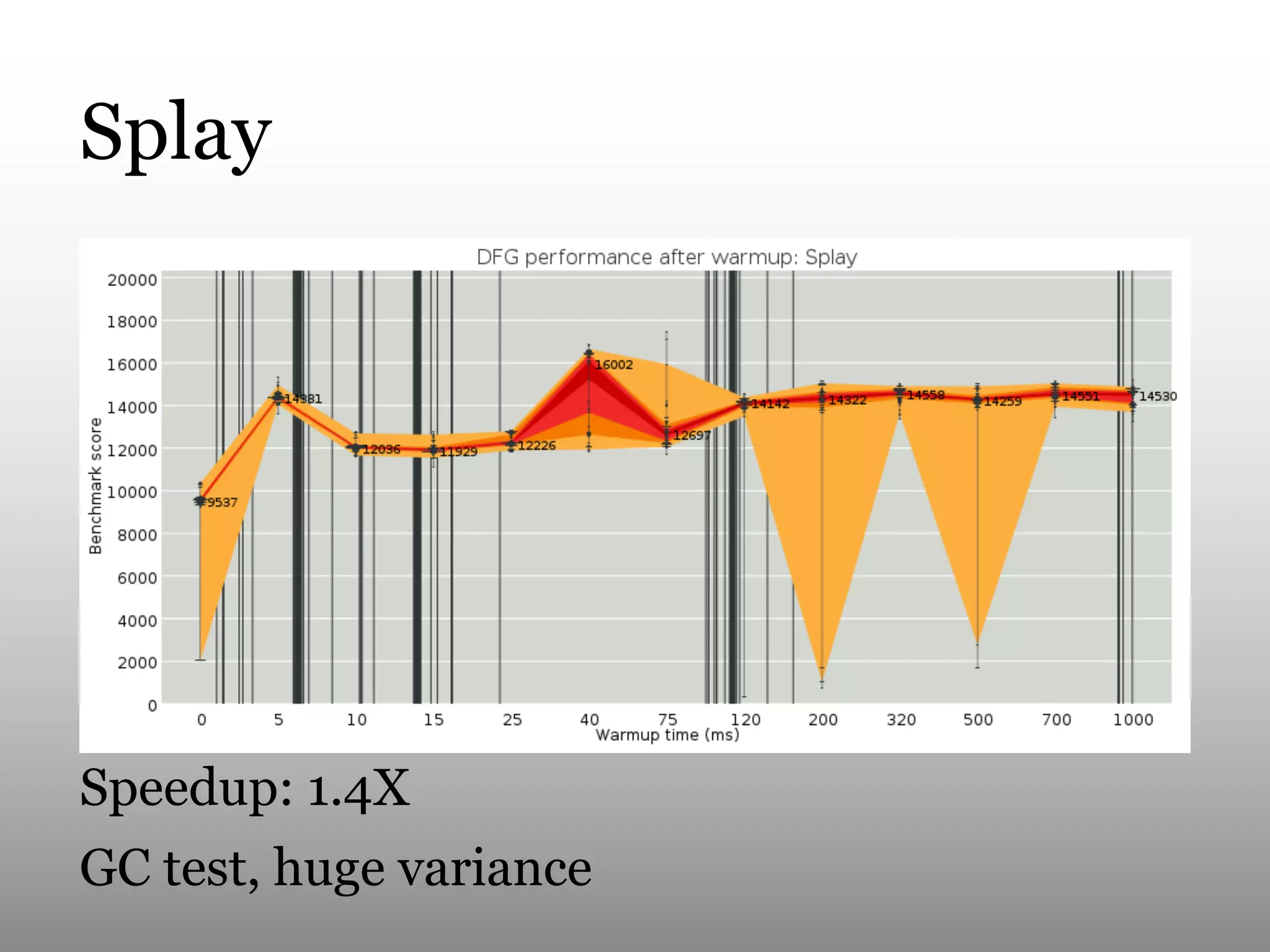
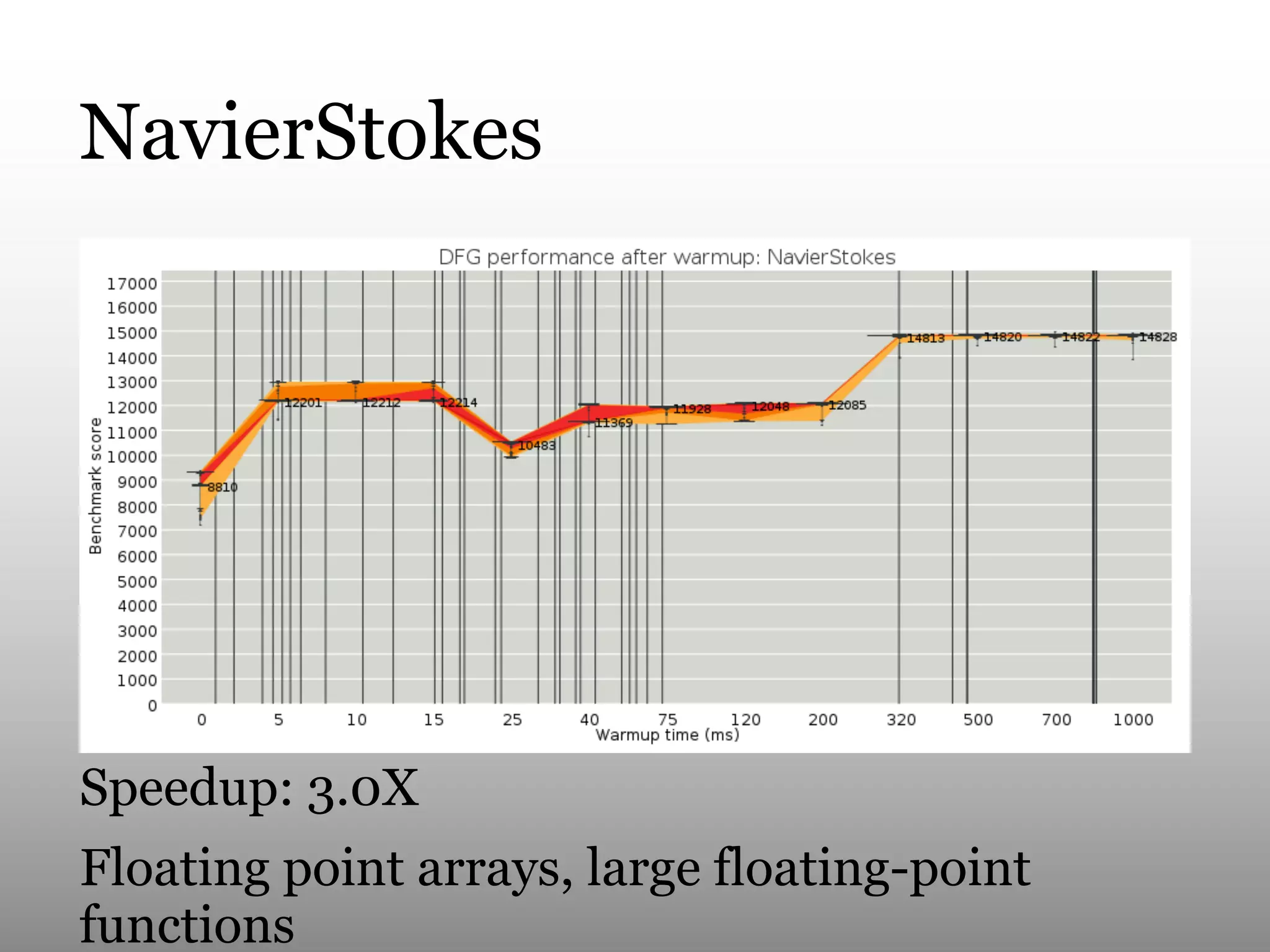



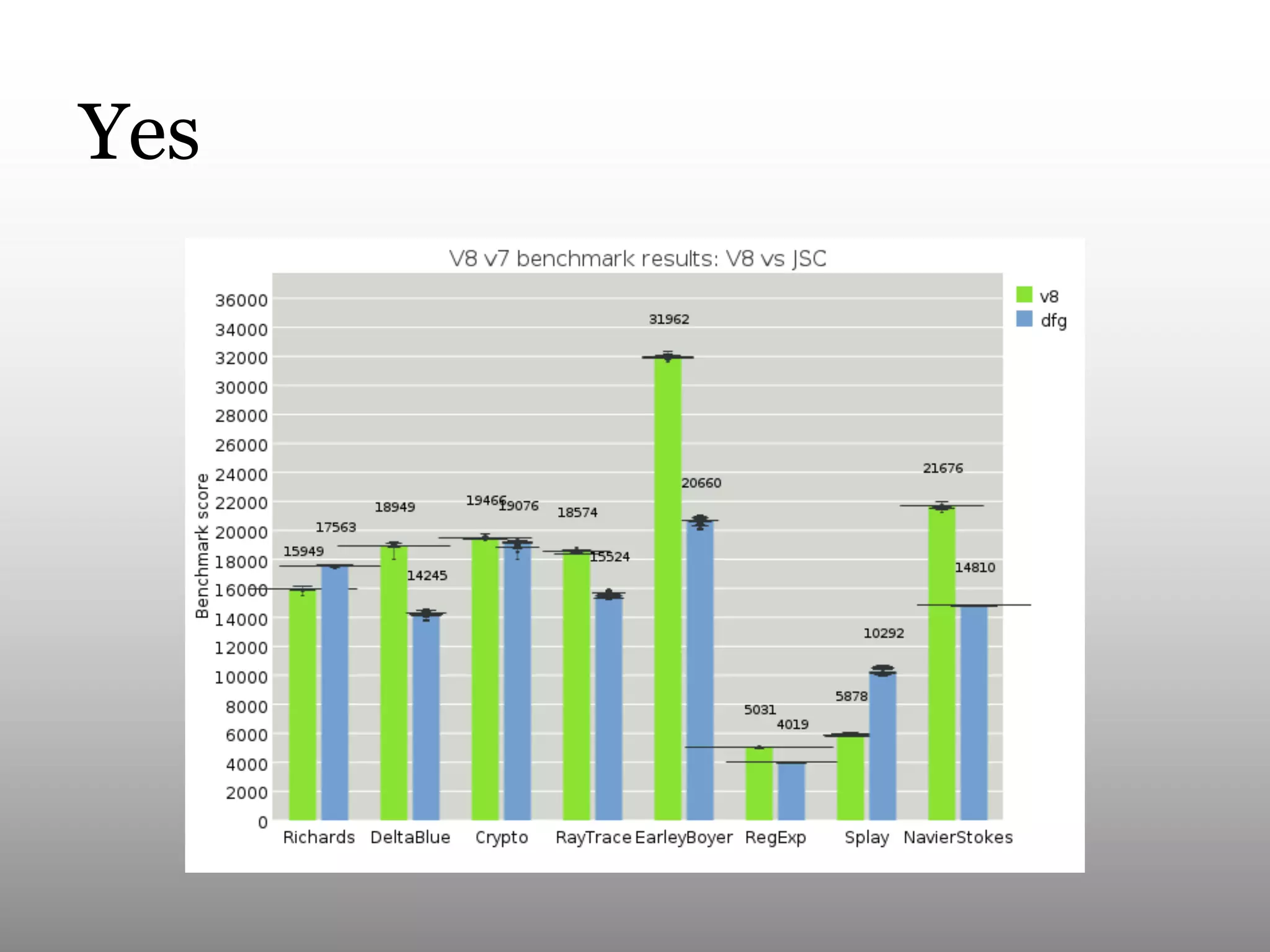

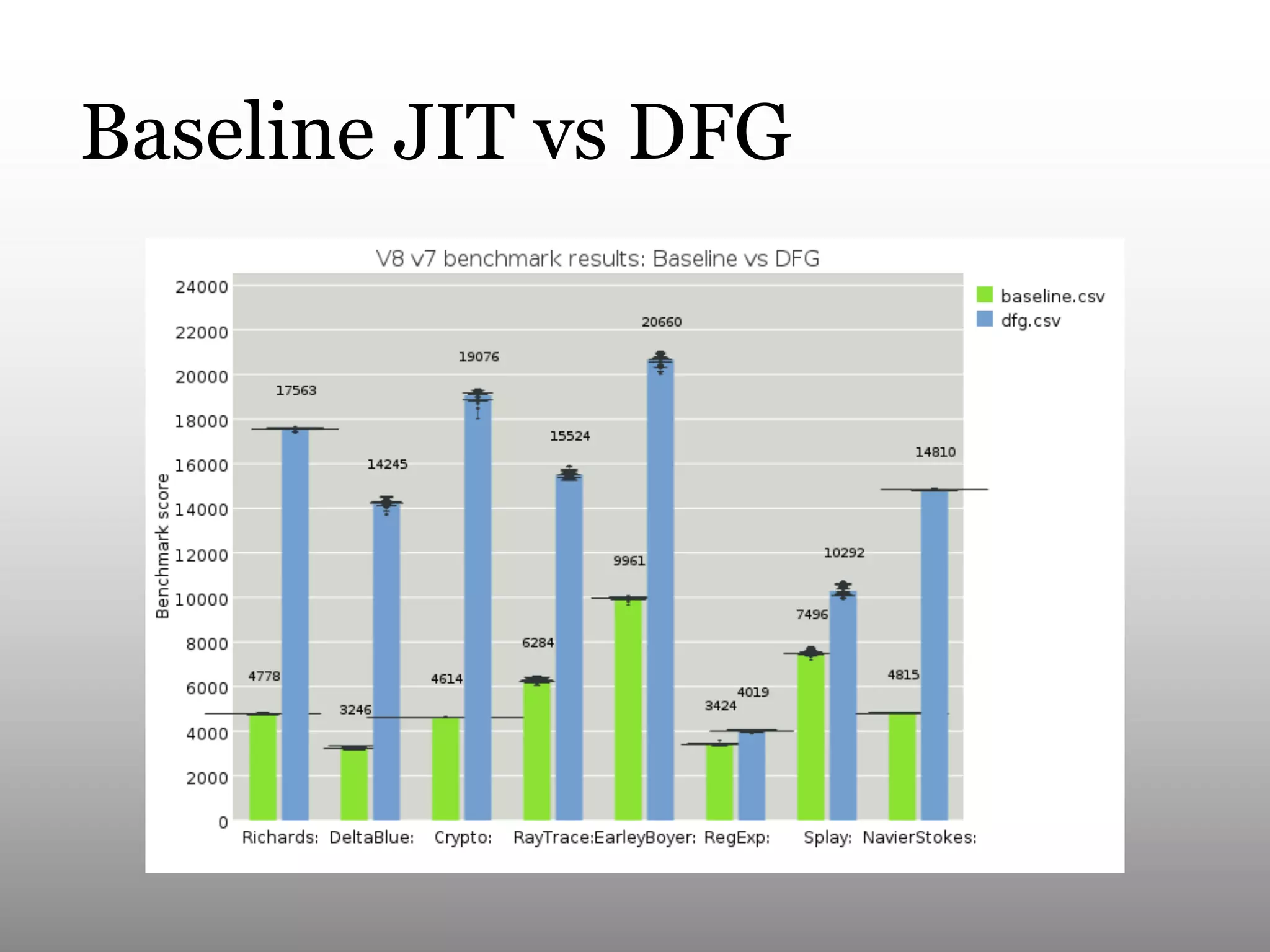
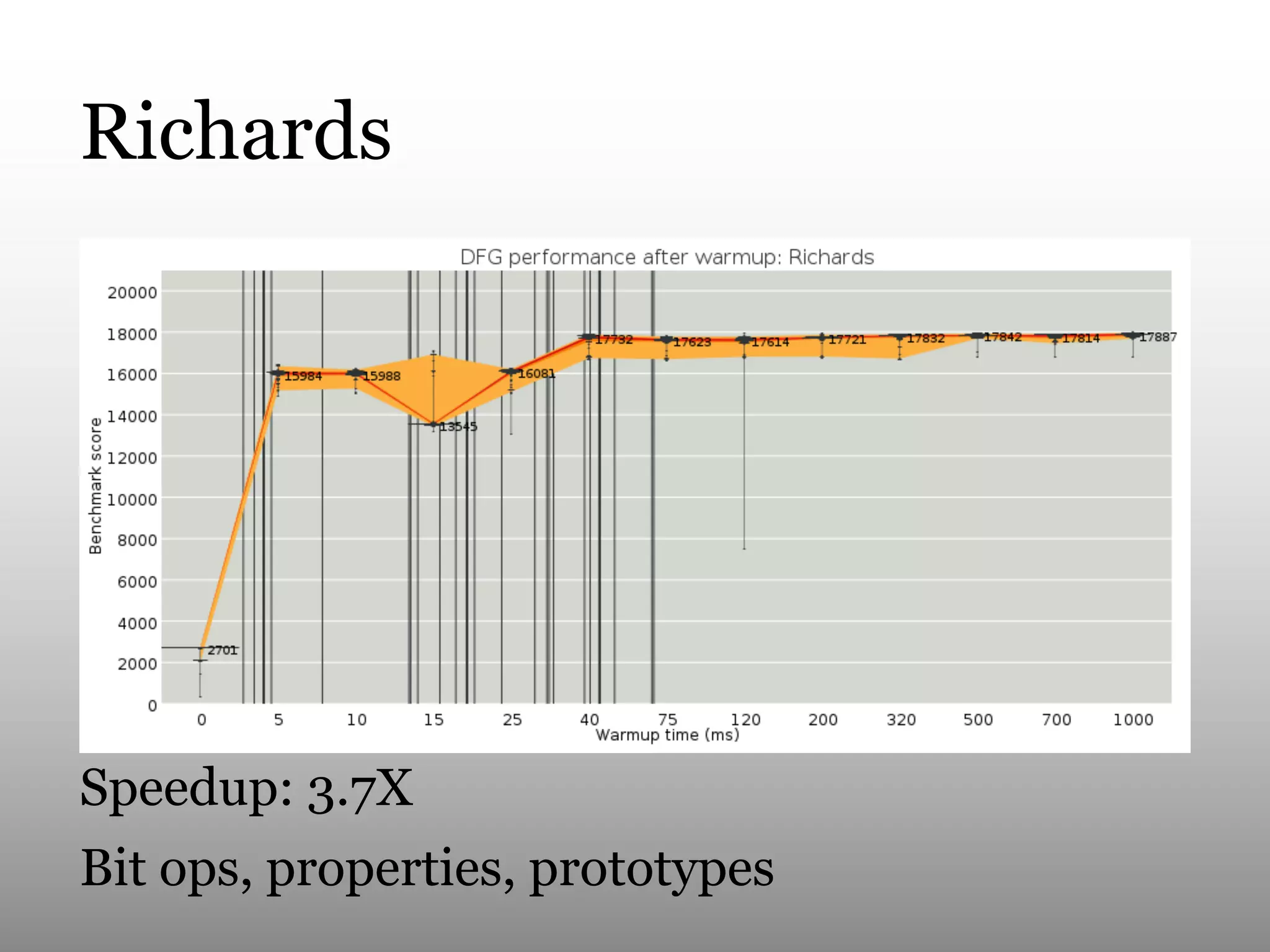
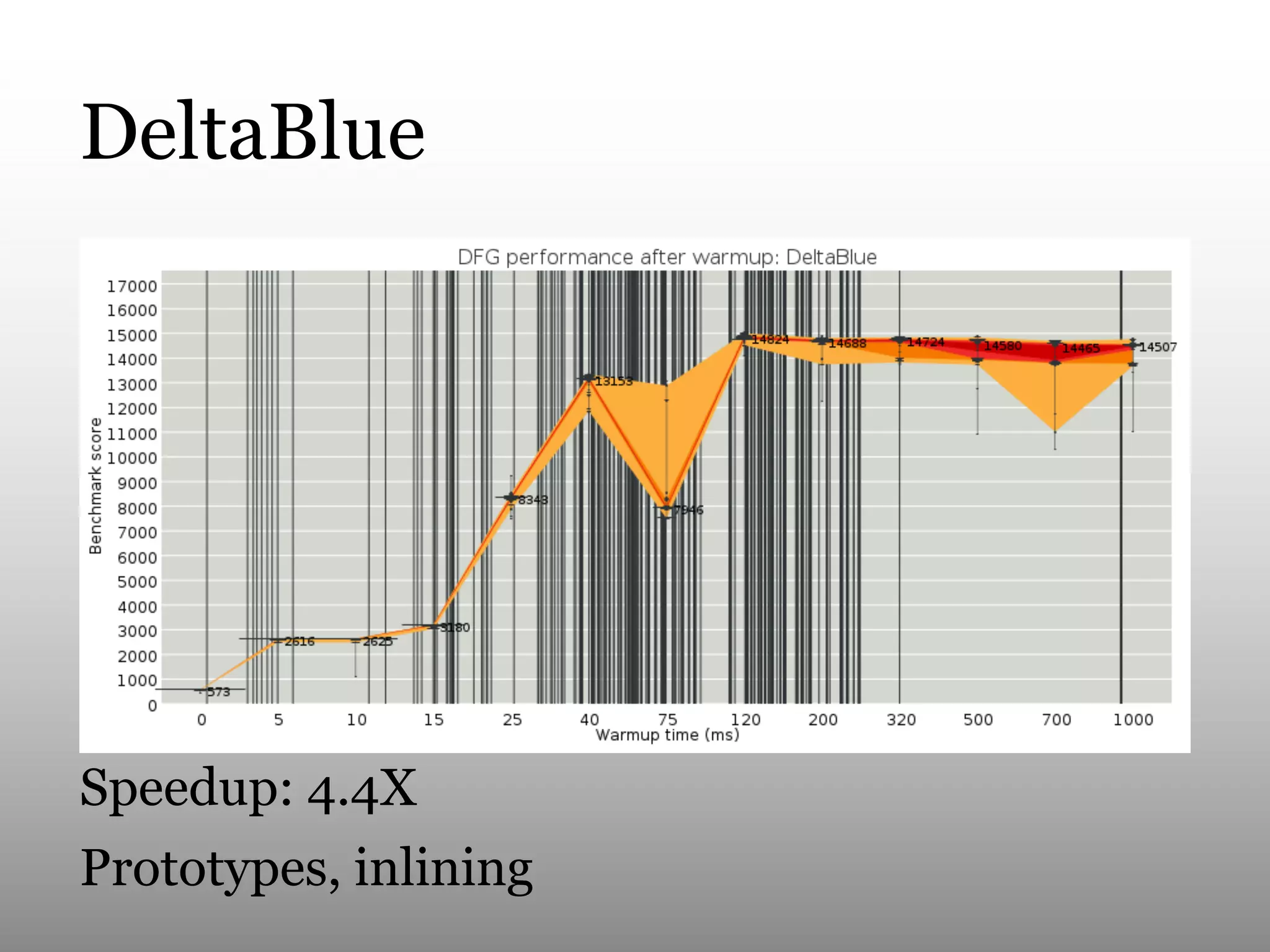
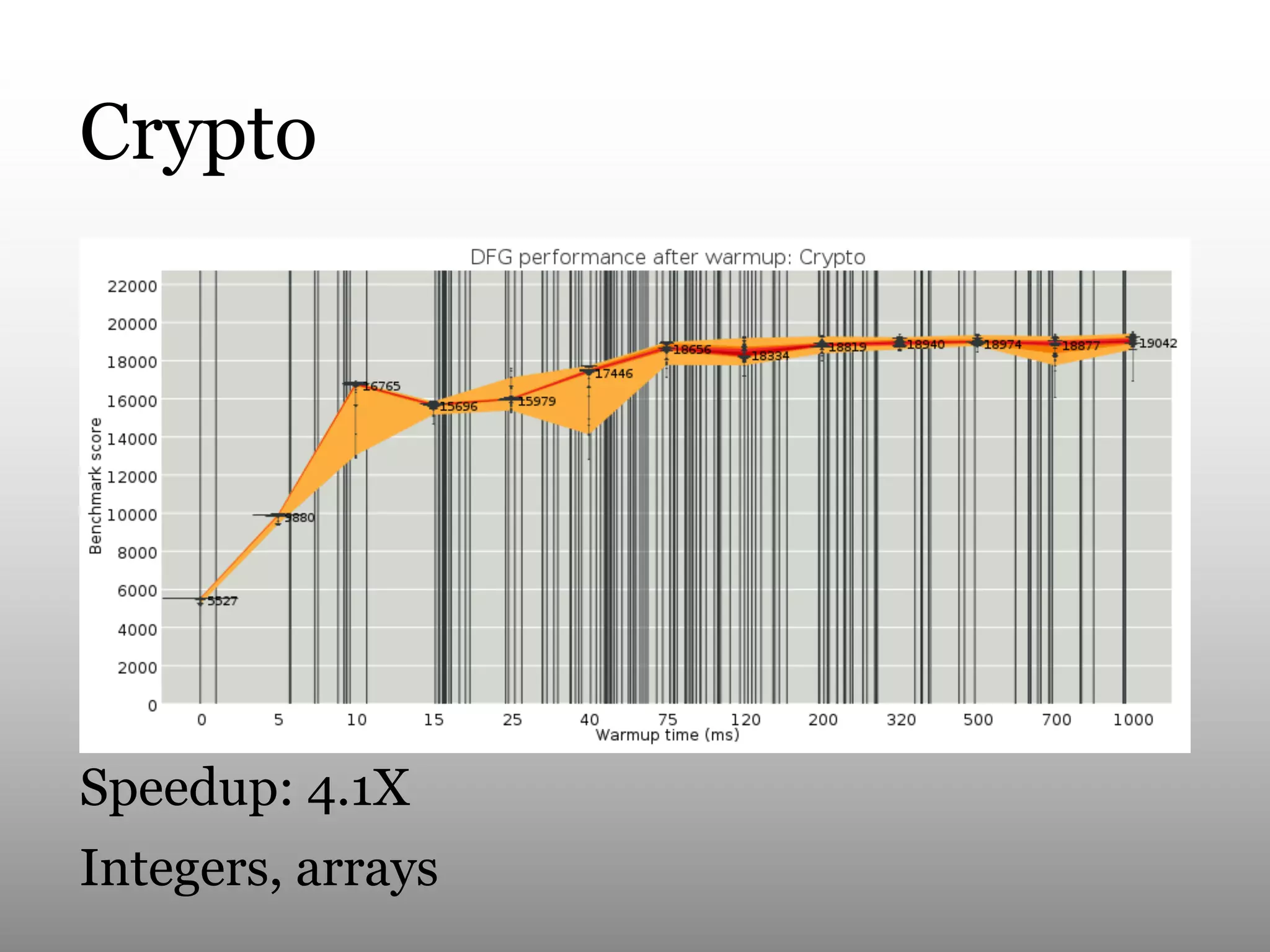
This document summarizes Andy Wingo's talk on JavaScriptCore's optimizing compiler called the DFG JIT. It begins by providing context on Wingo and an overview of JavaScriptCore's compilation pipeline. It then analyzes the performance of DFG JIT on various V8 benchmarks through experimentation with variable warmup times. Key optimizations identified include inlining, integer operations, and floating point arithmetic. The document ends by discussing ways to extract more data from JavaScriptCore like debug options and comparing performance to V8.