Download to read offline




![5 Avoid the Unnecessary Use Object arrays instead of Maps when you primarily read values and can index via numbers: In DisjointTree Original Map<Vertex, Vertex> vertexMapping = new HashMap<Vertex, Vertex>(); findSet(Vertex v) { Vertex mapped = vertexMapping.get(v); …} New Vertex[] vertexMapping = new Vertex[numDocuments]; findSet (int v) { vertexMapping[v.index] = v; …} Brought runtime down to 42 seconds (if I remember correctly) between using arrays and avoiding object creation. Use Object Arrays instead of Maps](https://image.slidesharecdn.com/javaperformancetweaks29june2016-160629214254/75/Java-Performance-Tweaks-6-2048.jpg)

![7 Avoid the Unnecessary • Use method parameter values when looping heavily • Method parameters live on the processor stack, not the heap • As a result, accessing them is much faster • Shaved off a second or two Original: private int[] getLeastDissimilarPair(DoubleMatrix2D correlationMatrix, boolean force) { for (int i = 0; i < this.numDocuments; i++) for (int j = 0; j < this.numDocuments; j++) New: private int[] getLeastDissimilarPair(DoubleMatrix2D correlationMatrix, int numDocuments, boolean force) { for (int i = 0; i < numDocuments; i++) for (int j = 0; j < numDocuments; j++) Use Method Parameter Values](https://image.slidesharecdn.com/javaperformancetweaks29june2016-160629214254/75/Java-Performance-Tweaks-8-2048.jpg)



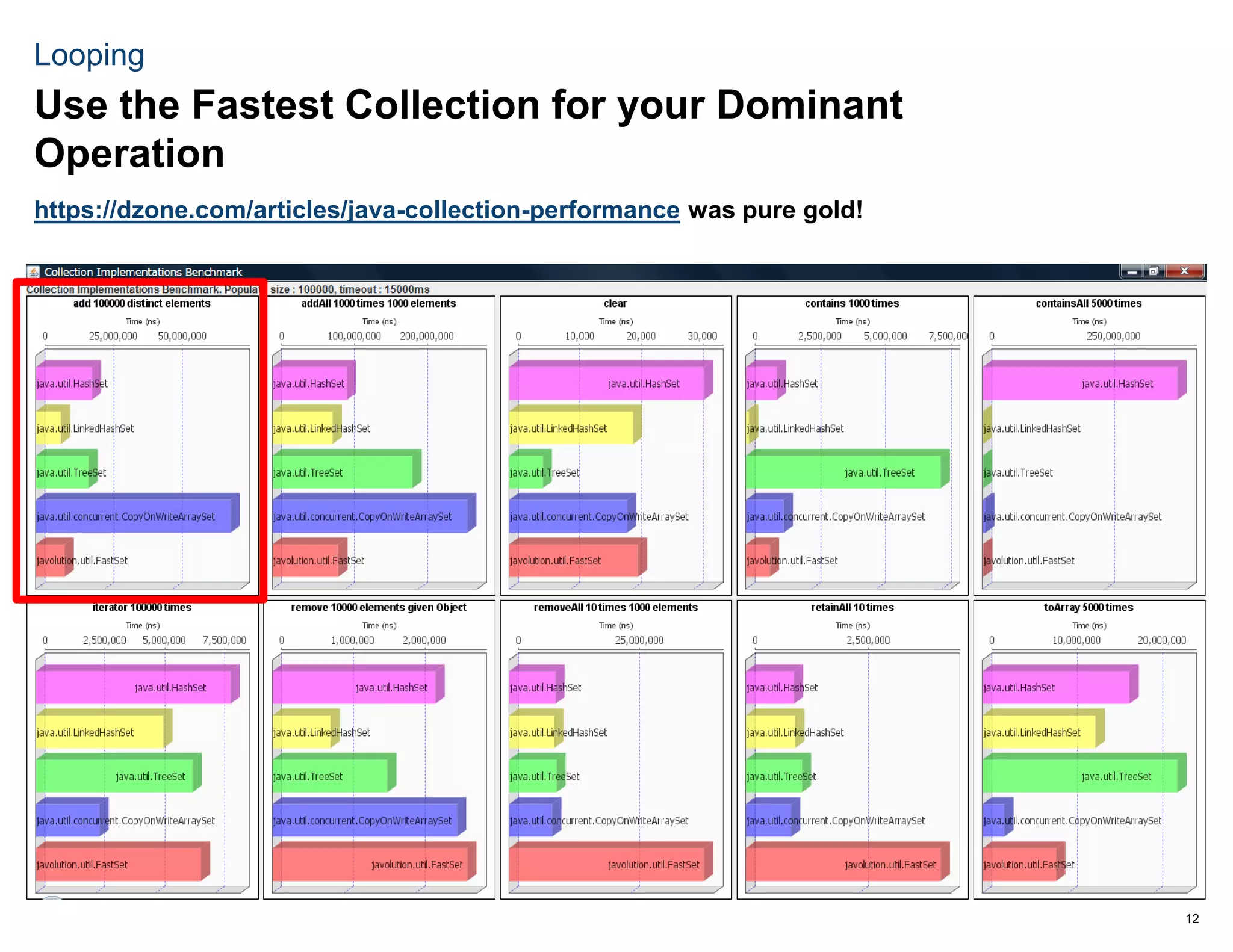










The document discusses various techniques used to optimize the runtime of a Java application called TopicViewer from over 2 minutes to 18 seconds. Some of the key optimizations included replacing the Colt library with the faster ParallelColt library, avoiding unnecessary object creation, using object arrays instead of maps for better performance, parallelizing loops, using non-blocking data structures for heavy I/O, and profiling the application to identify additional opportunities for improvement. The optimizations reduced the runtime by over 8 times from the original 2 minutes 10 seconds.