Download as PDF, PPTX








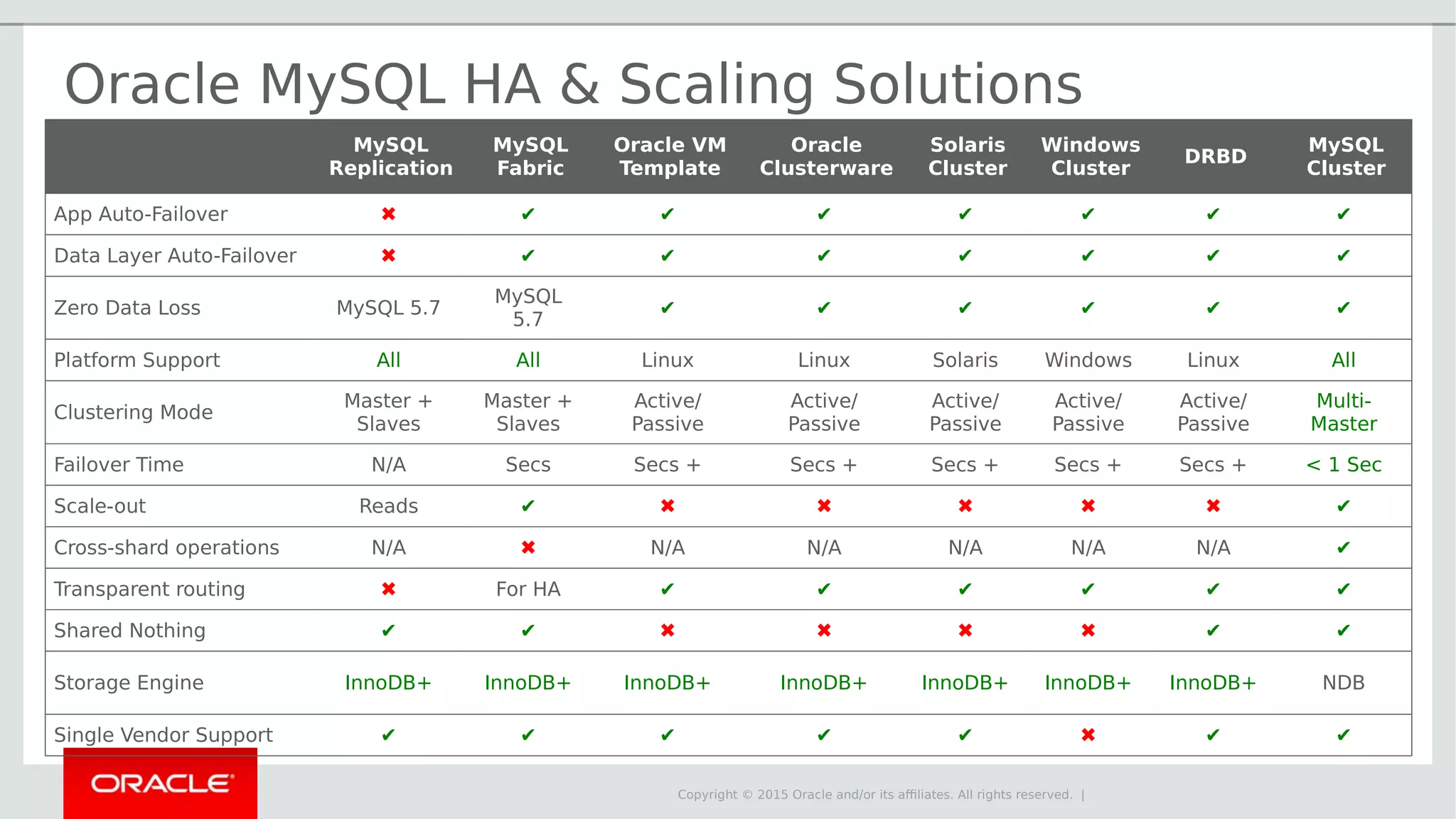






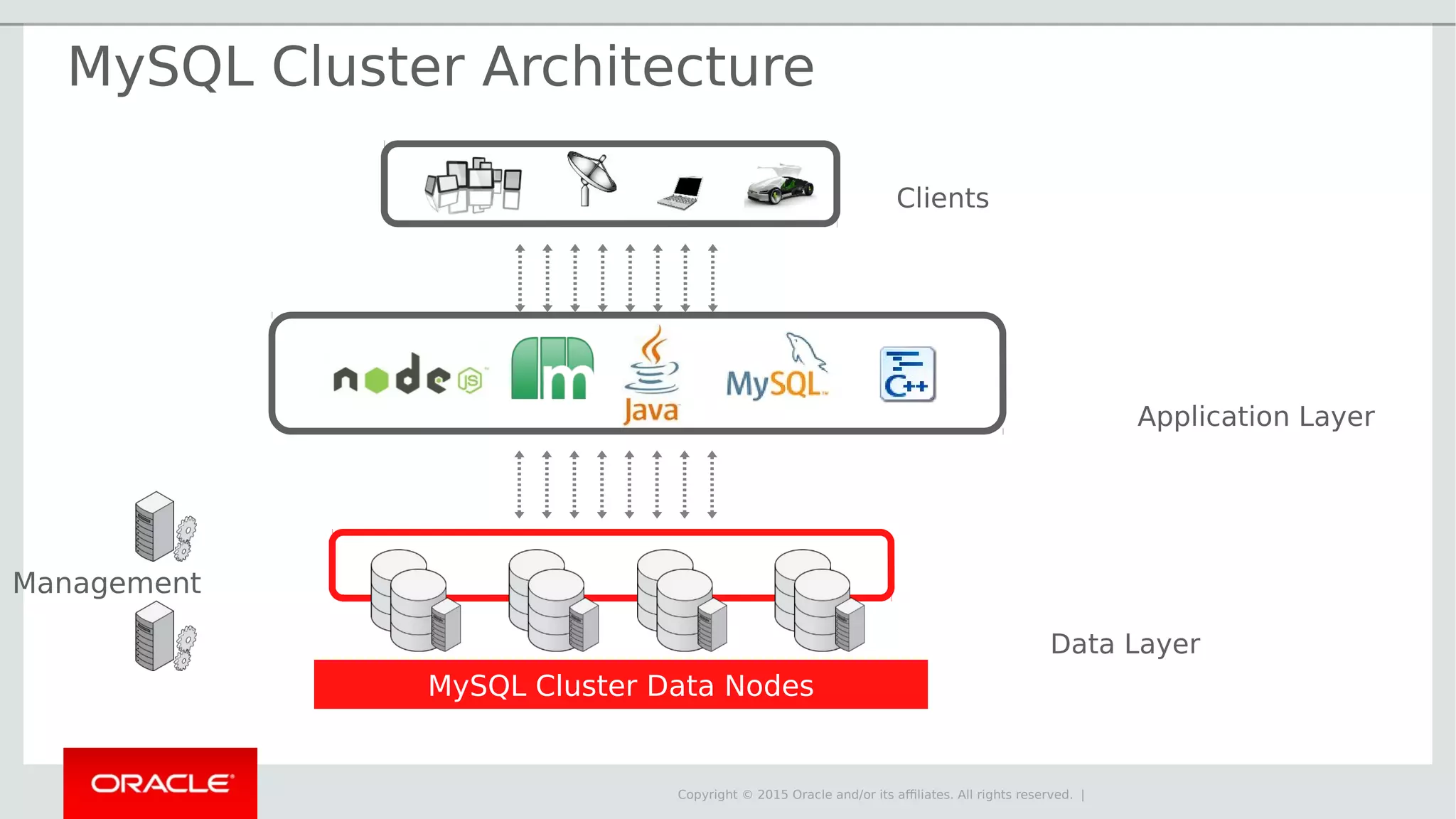
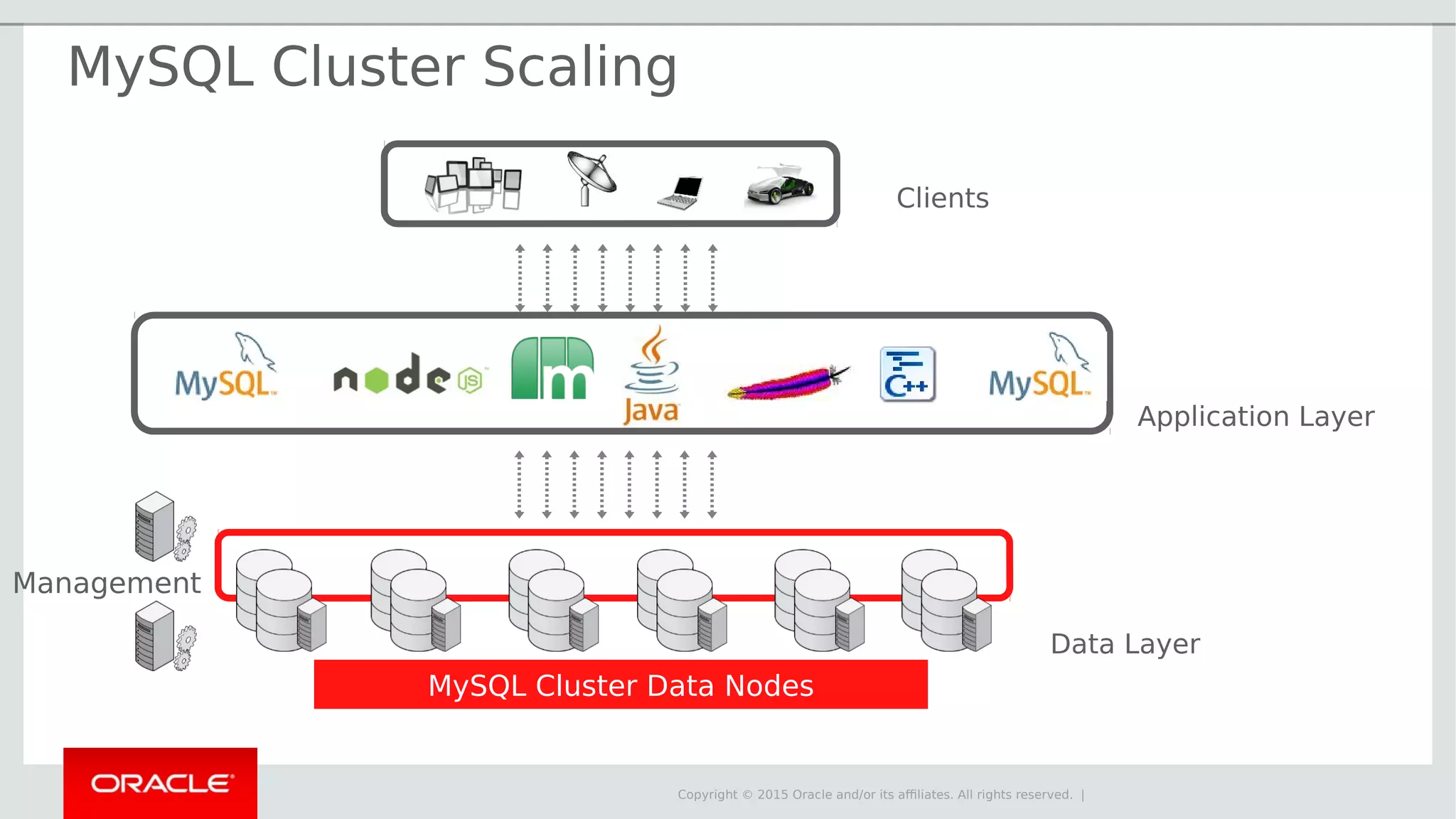
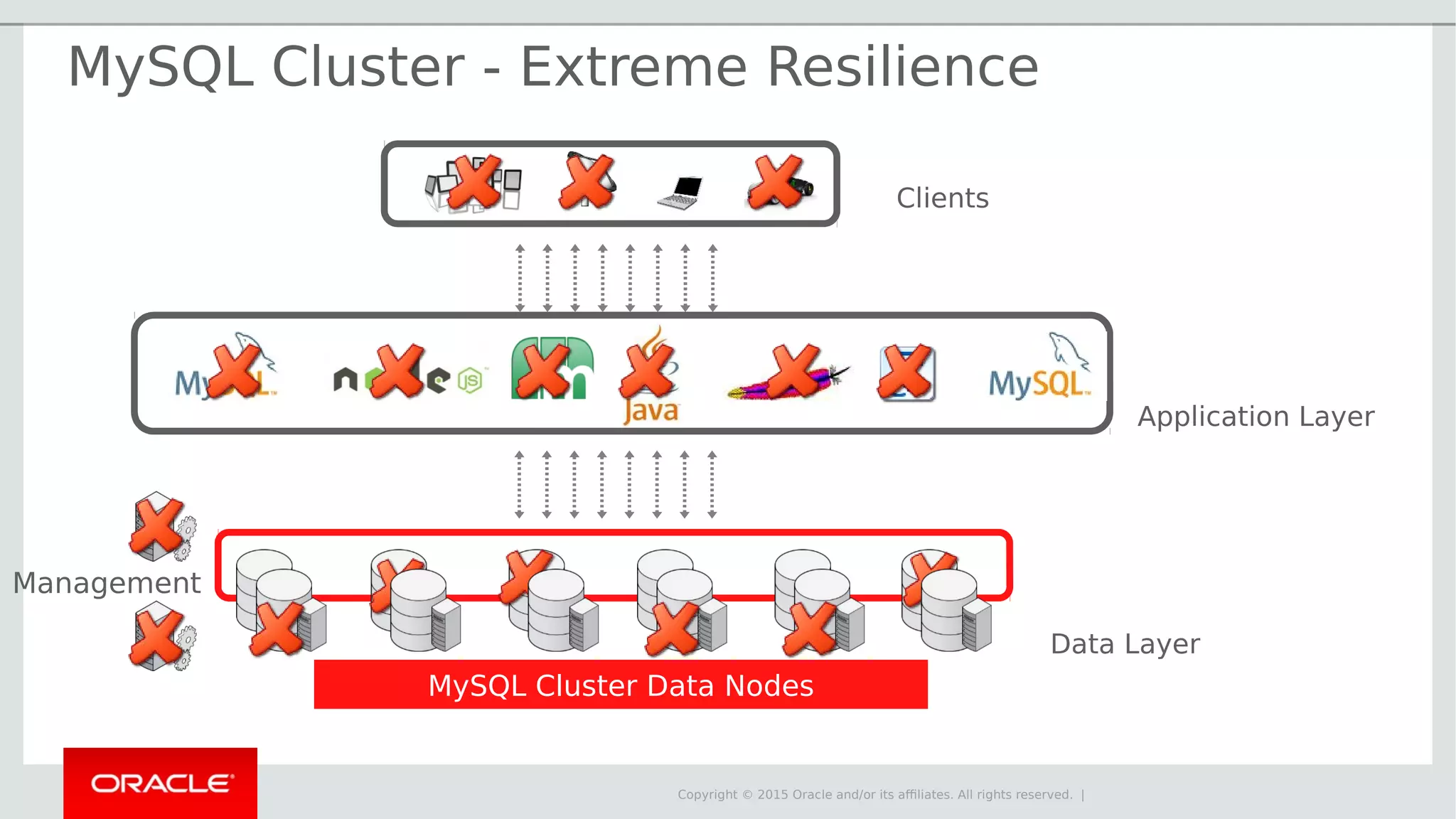
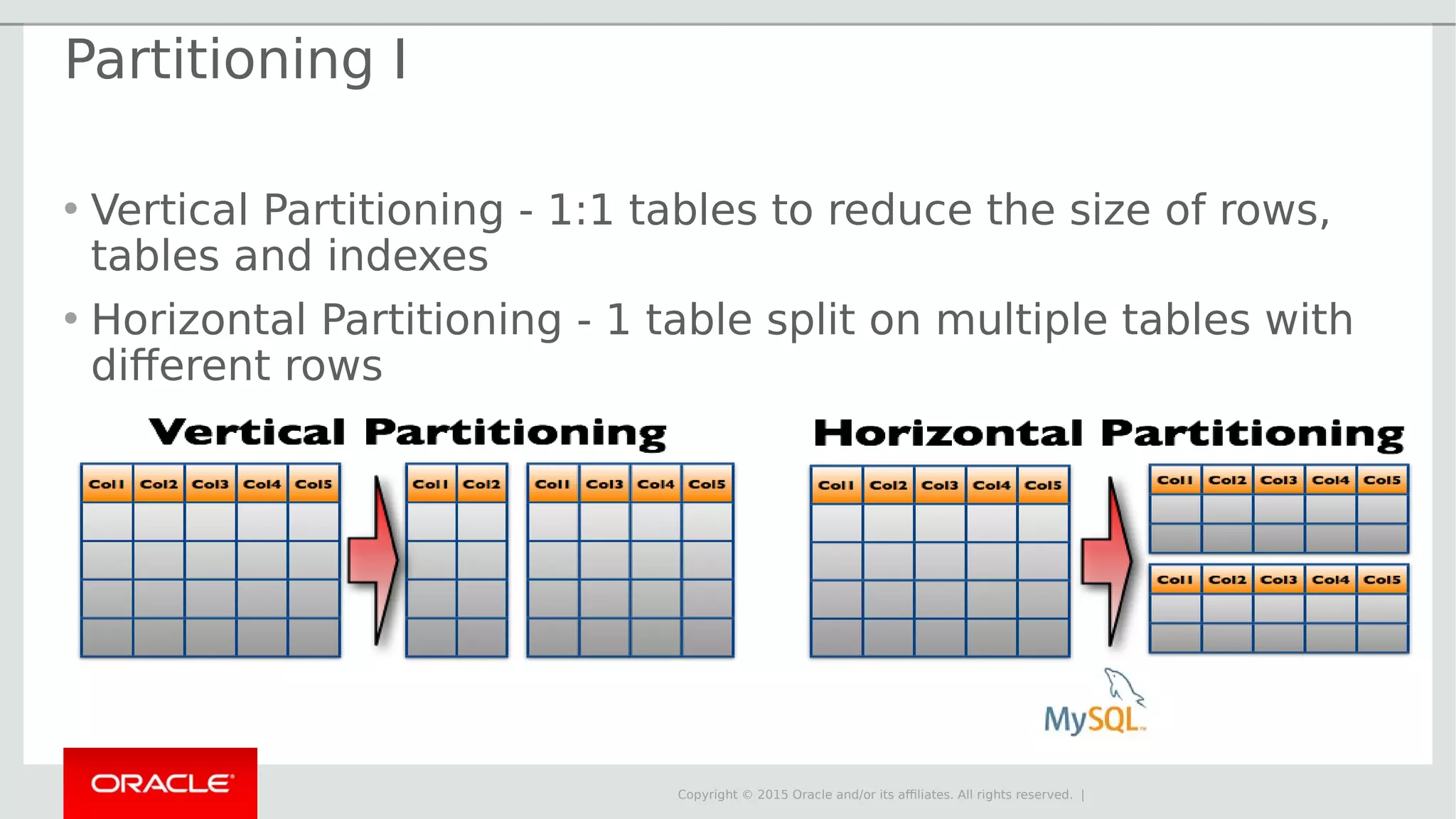




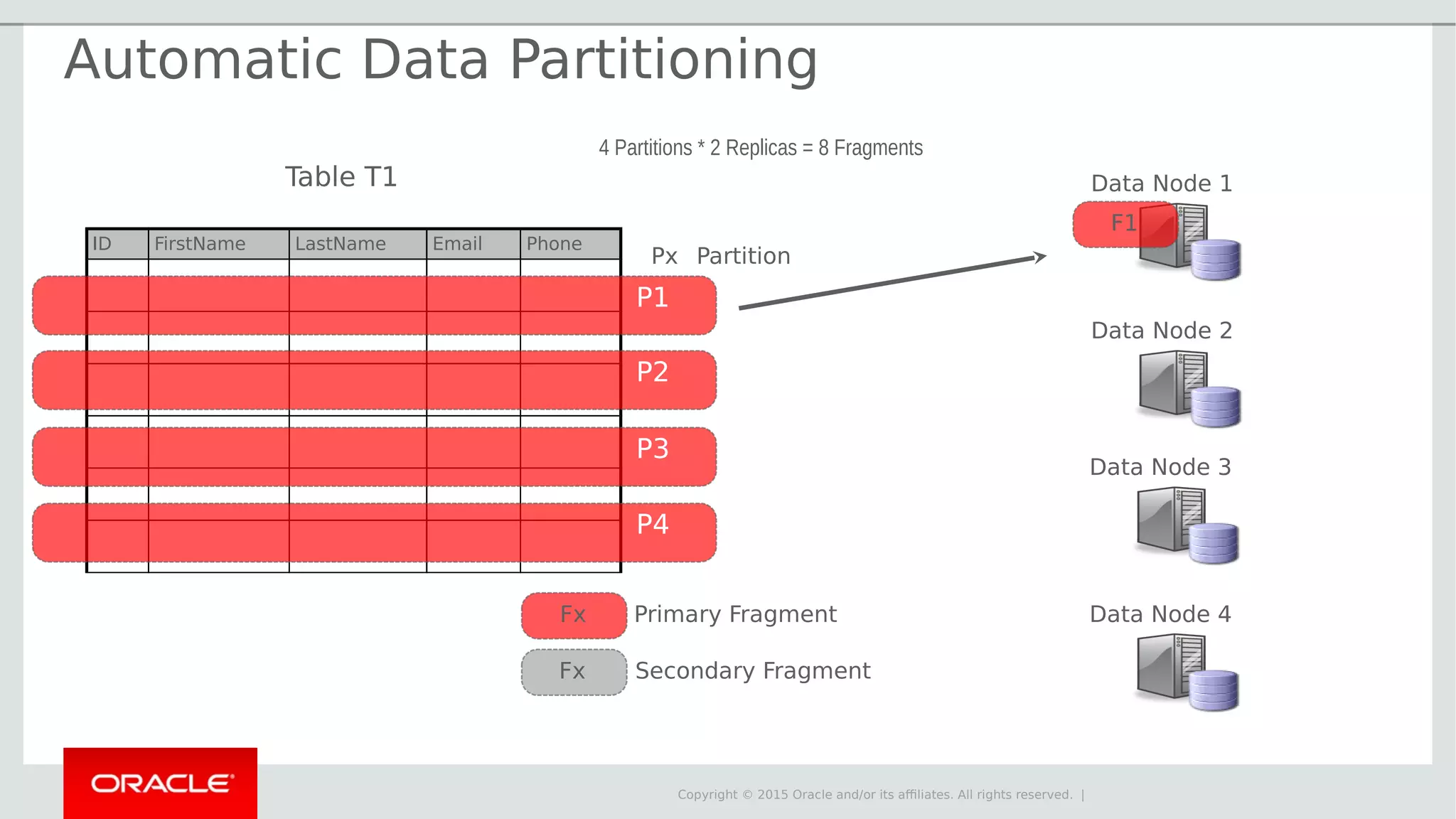
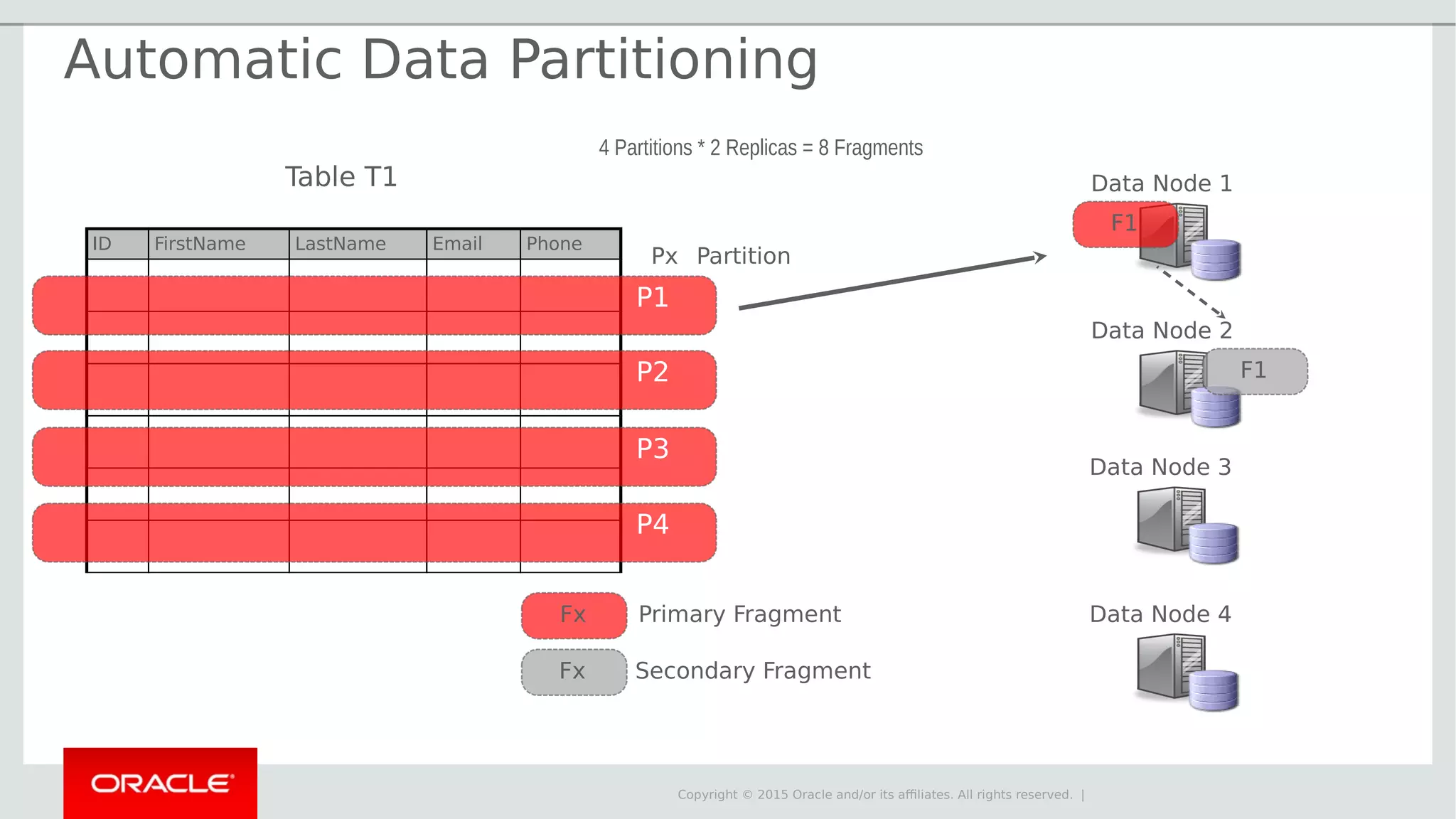
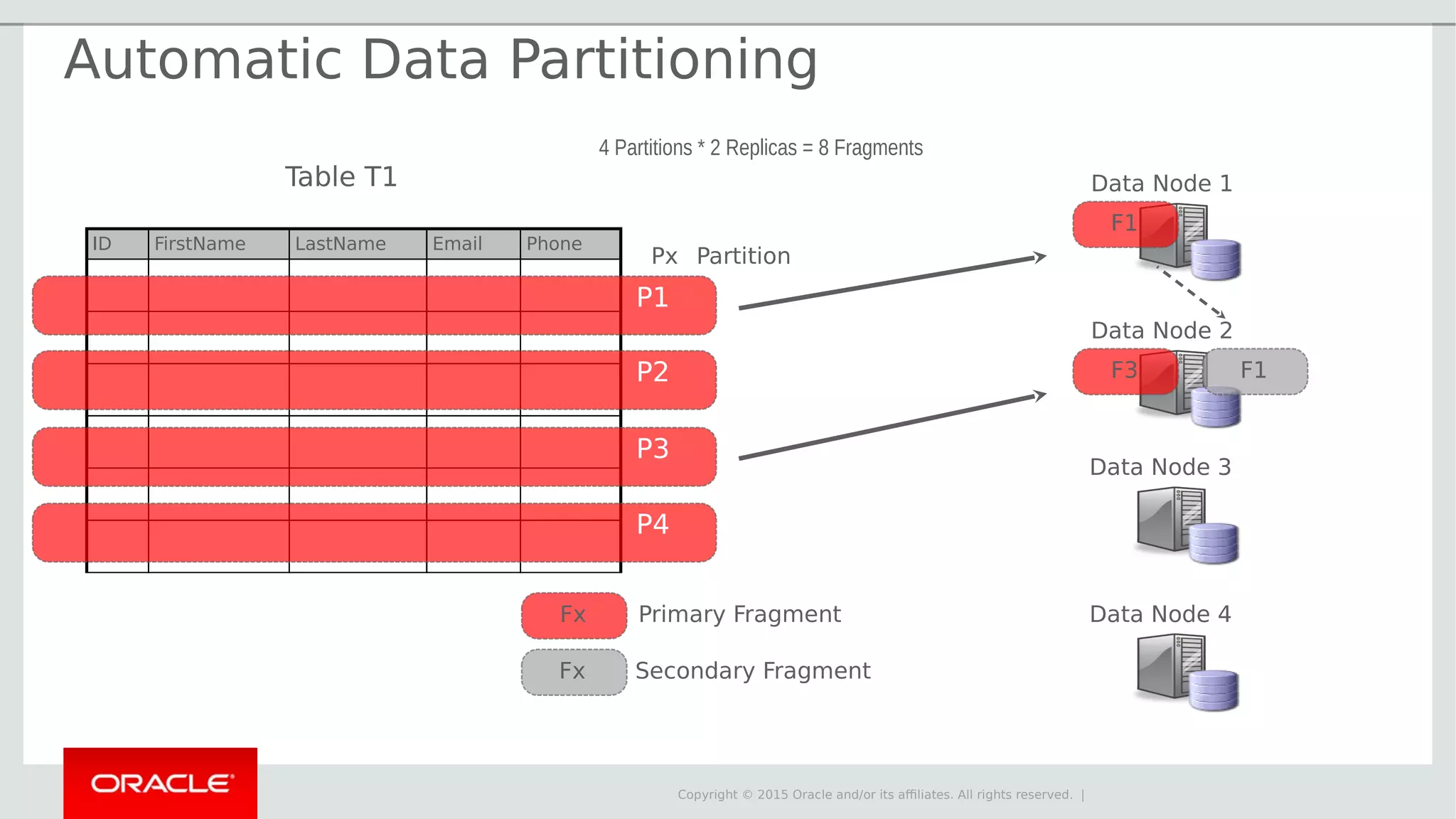
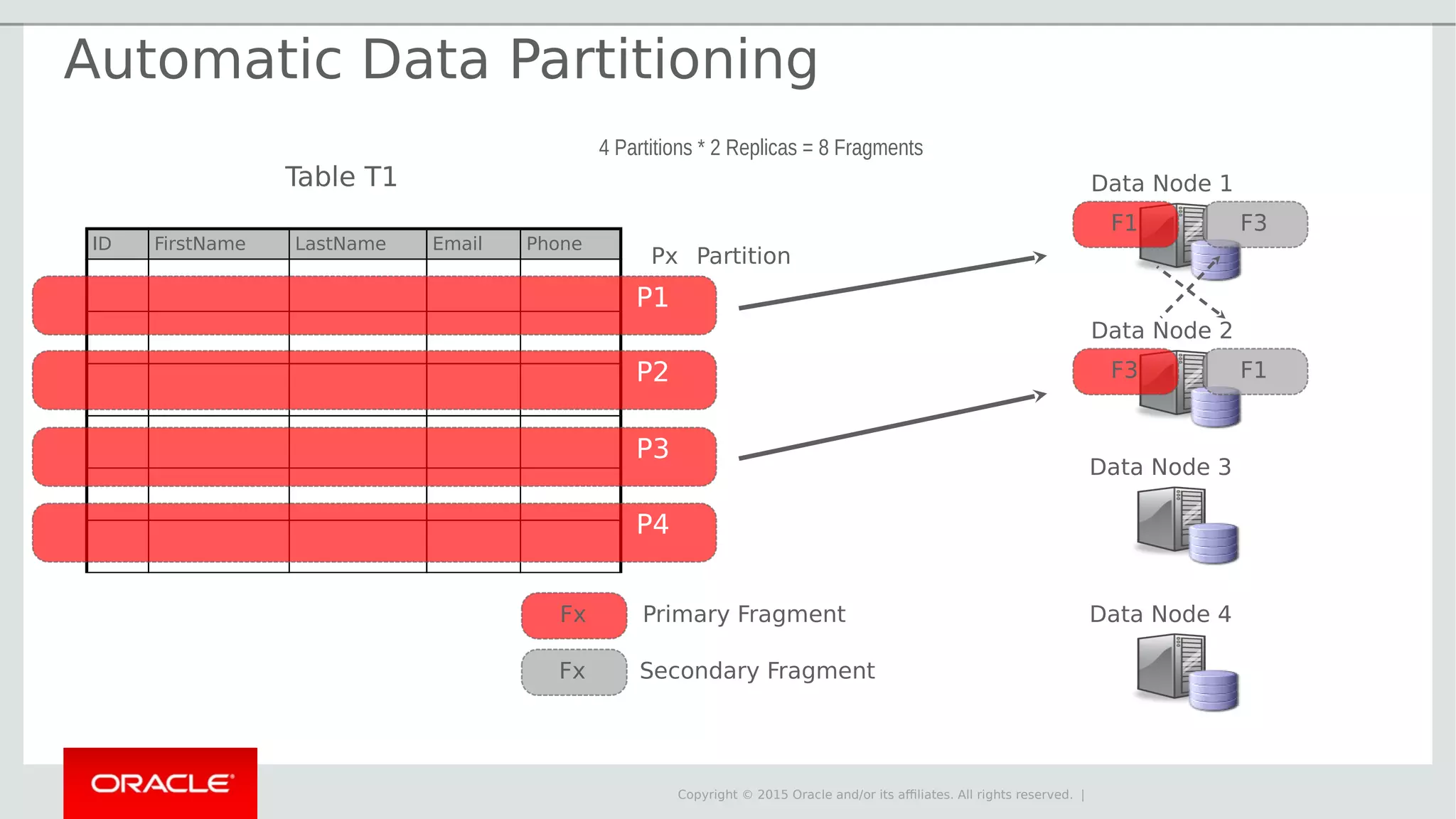
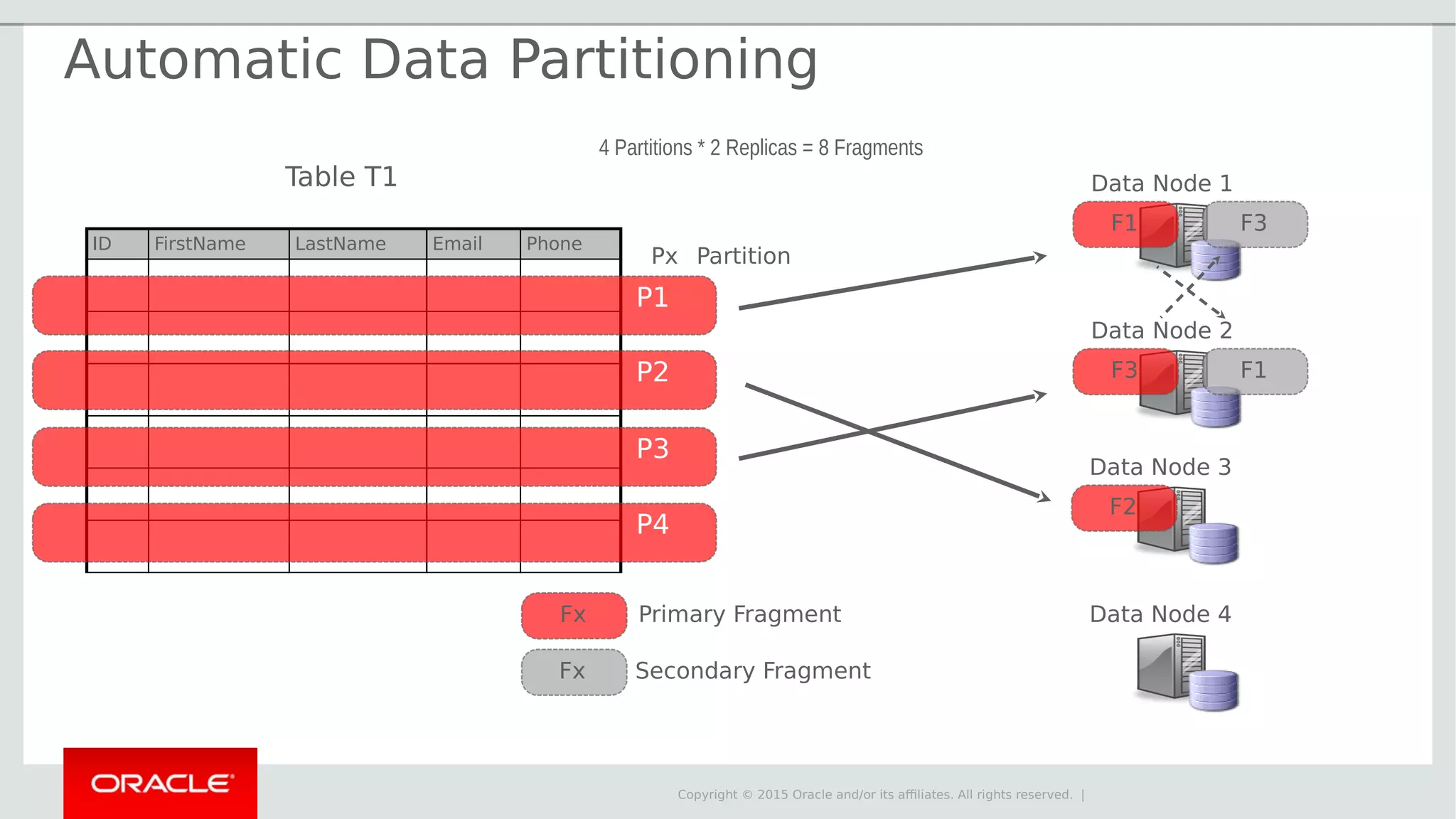
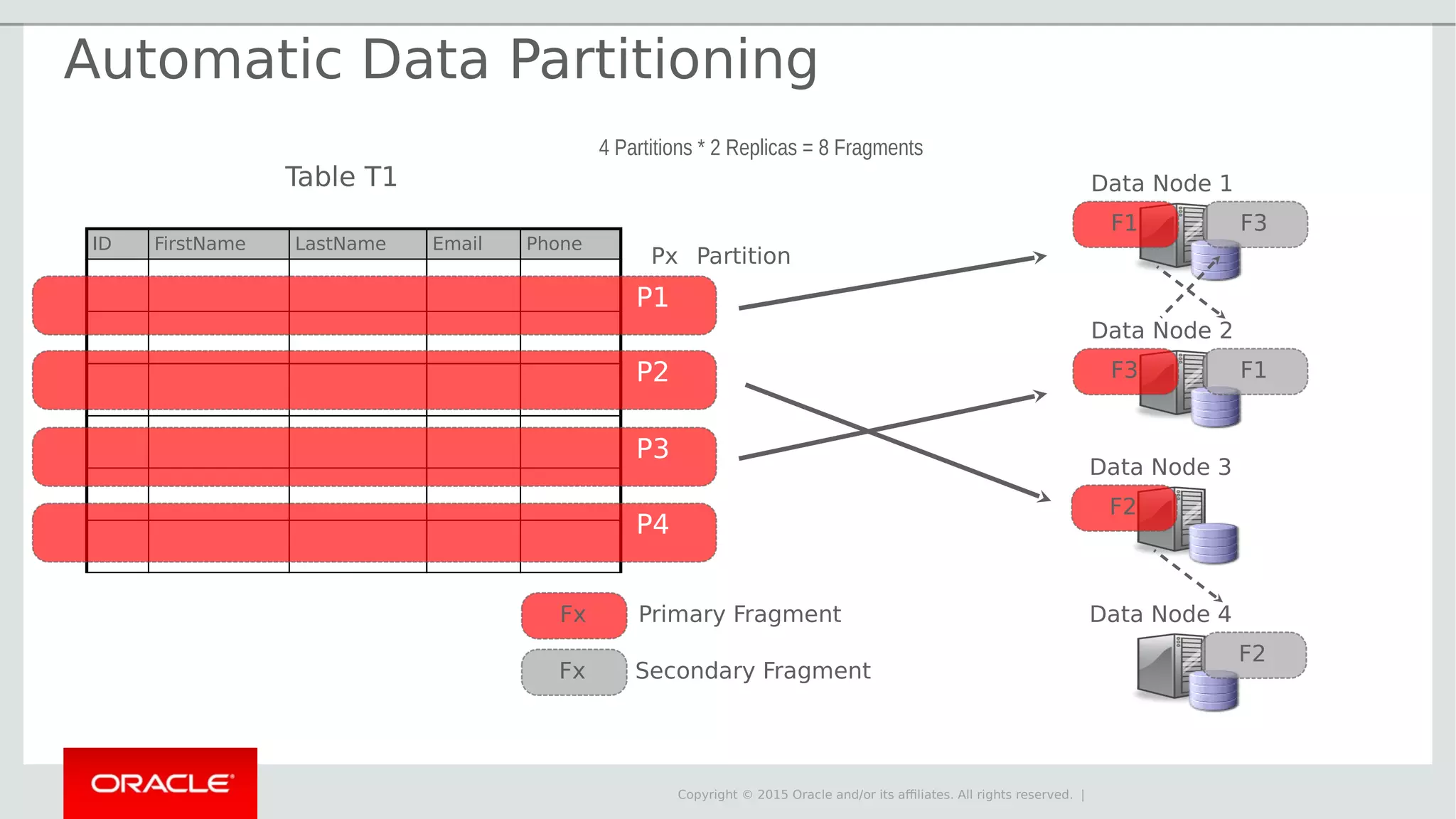
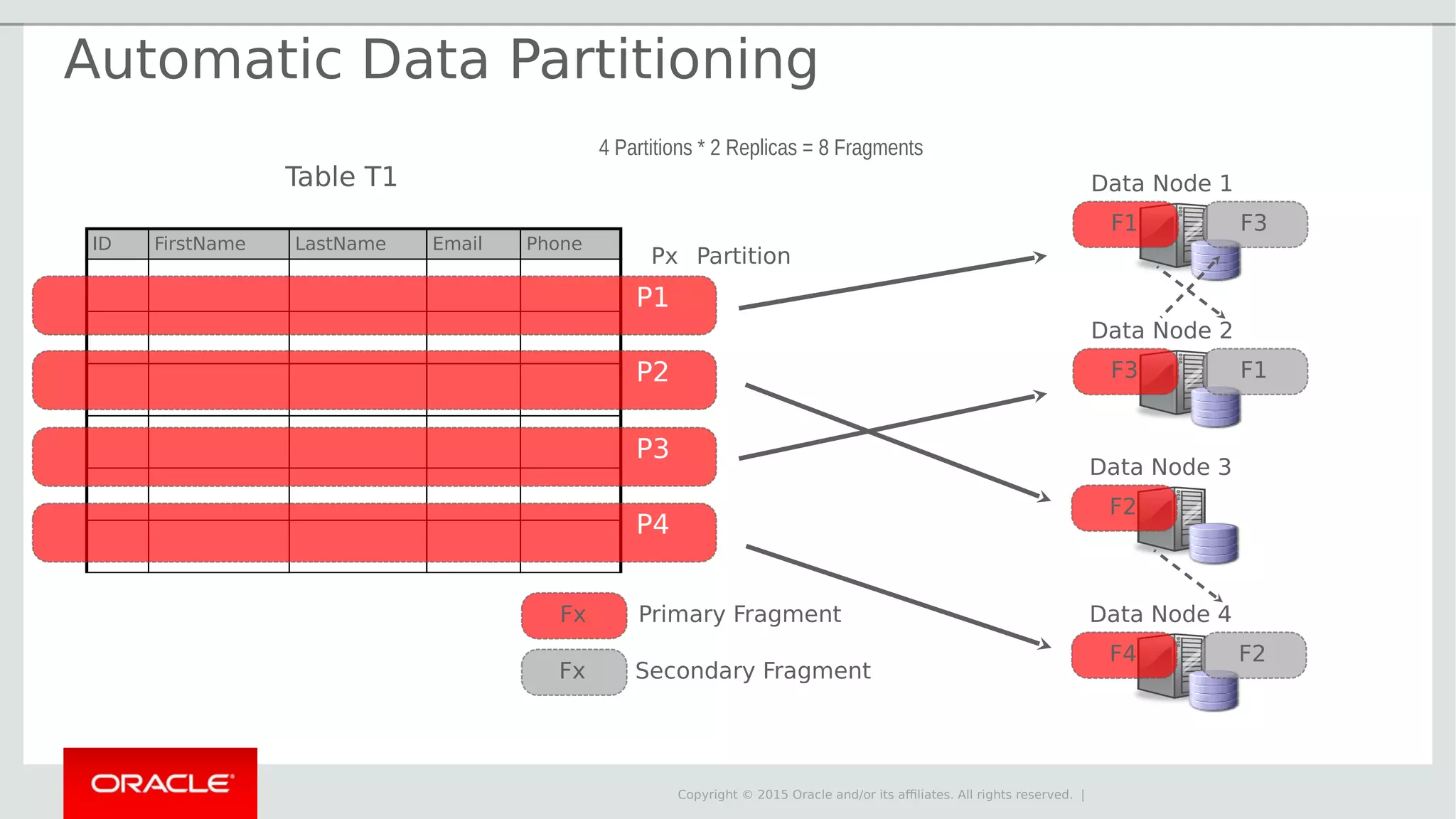
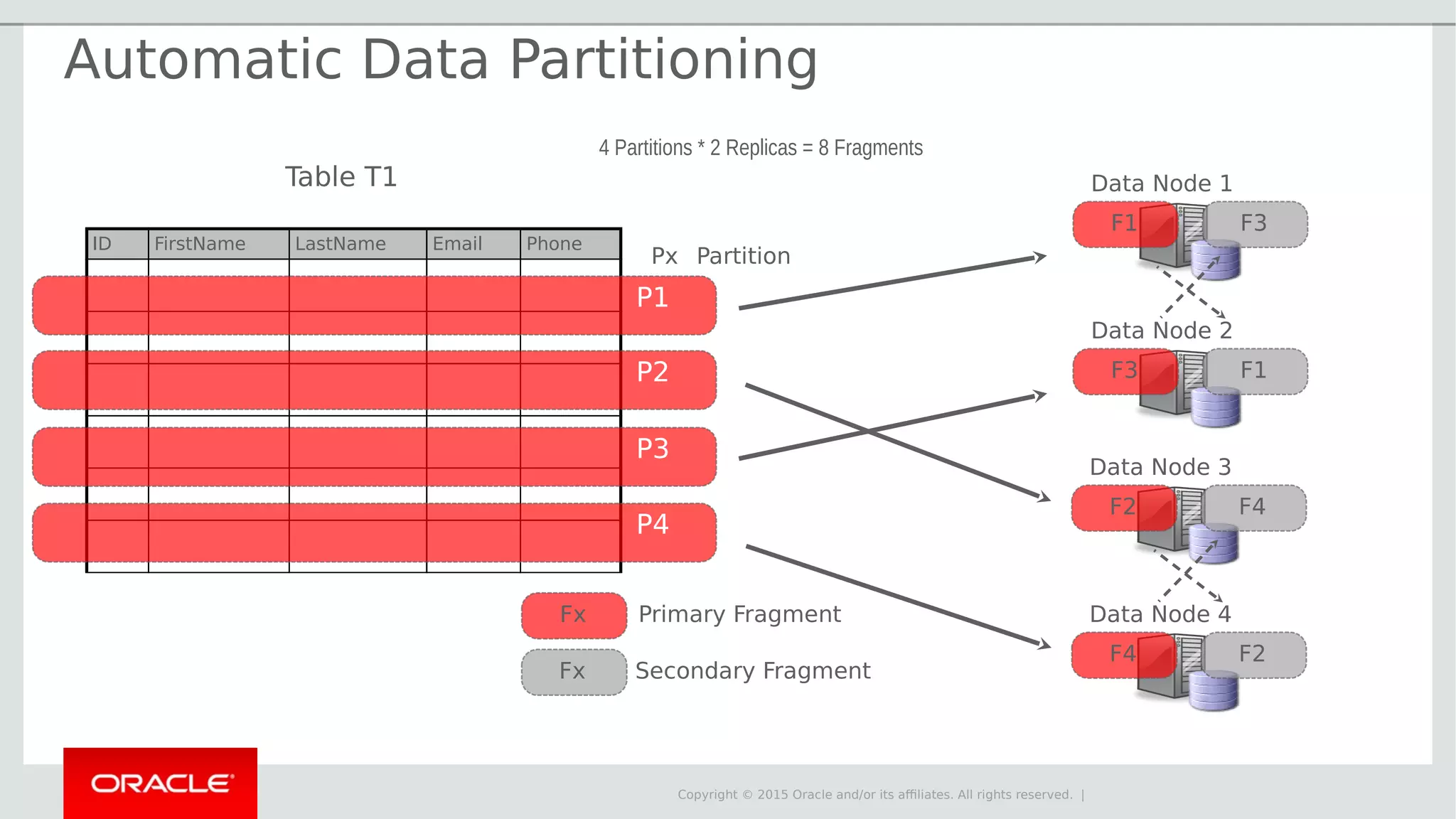
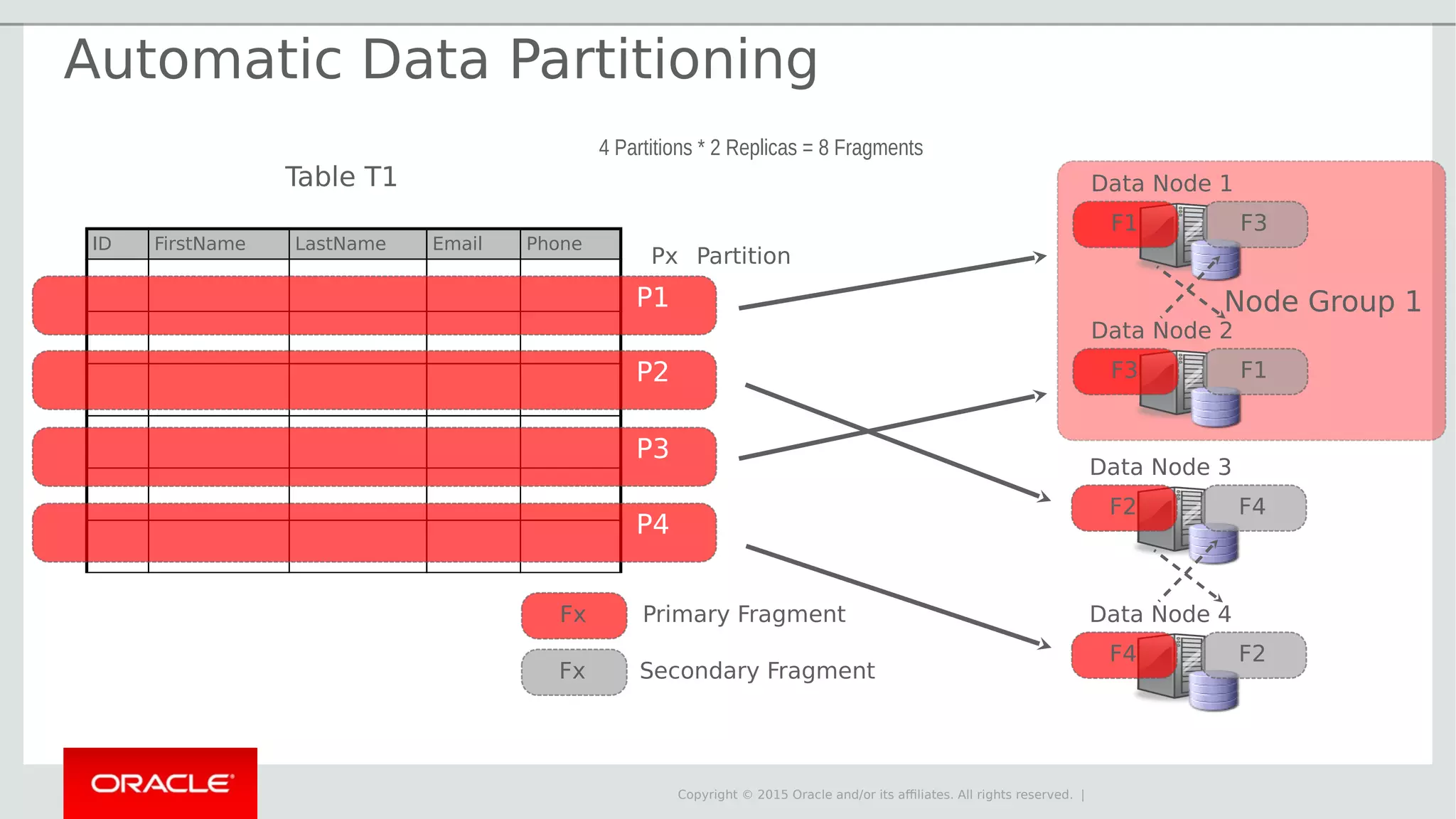
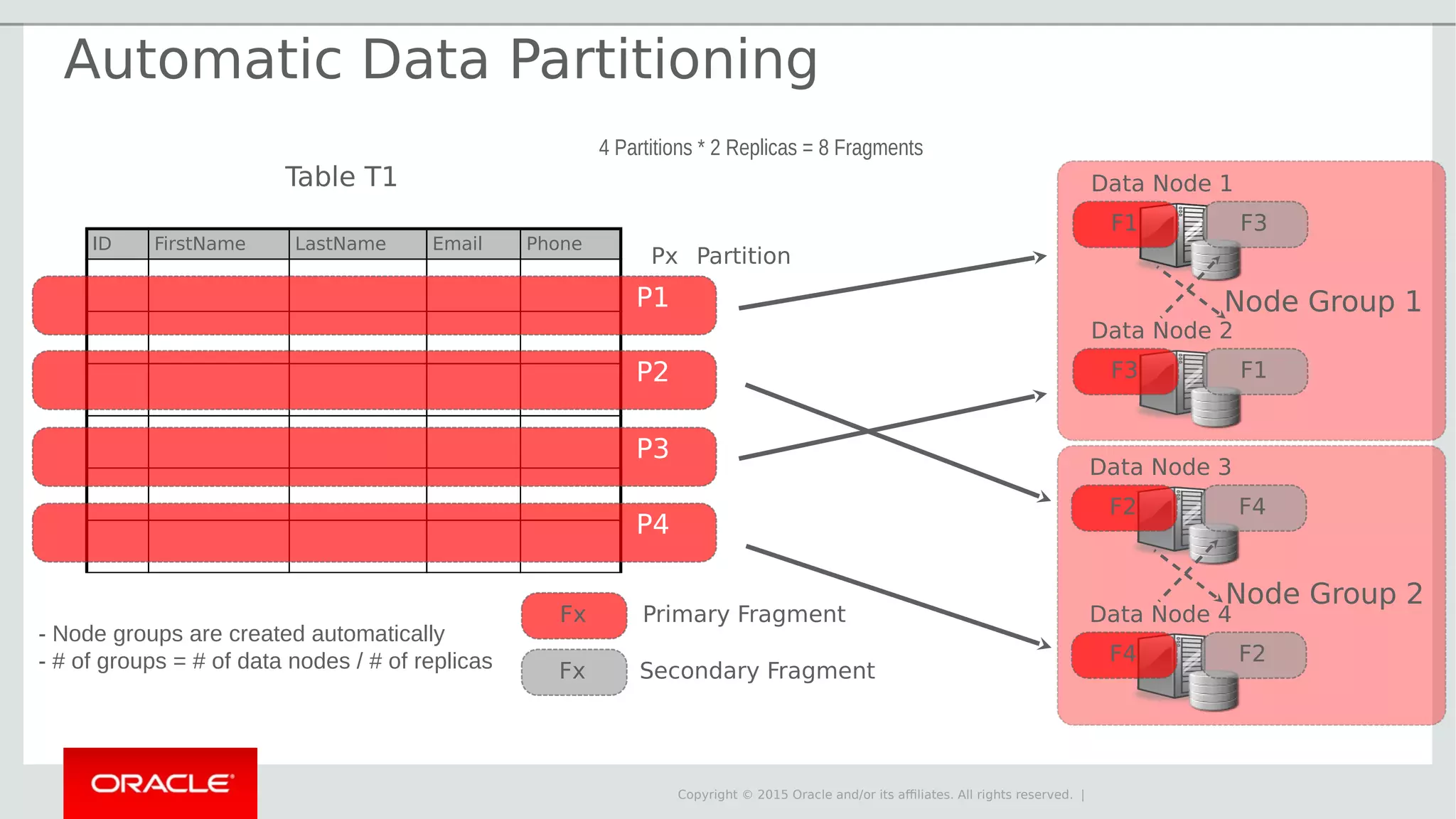
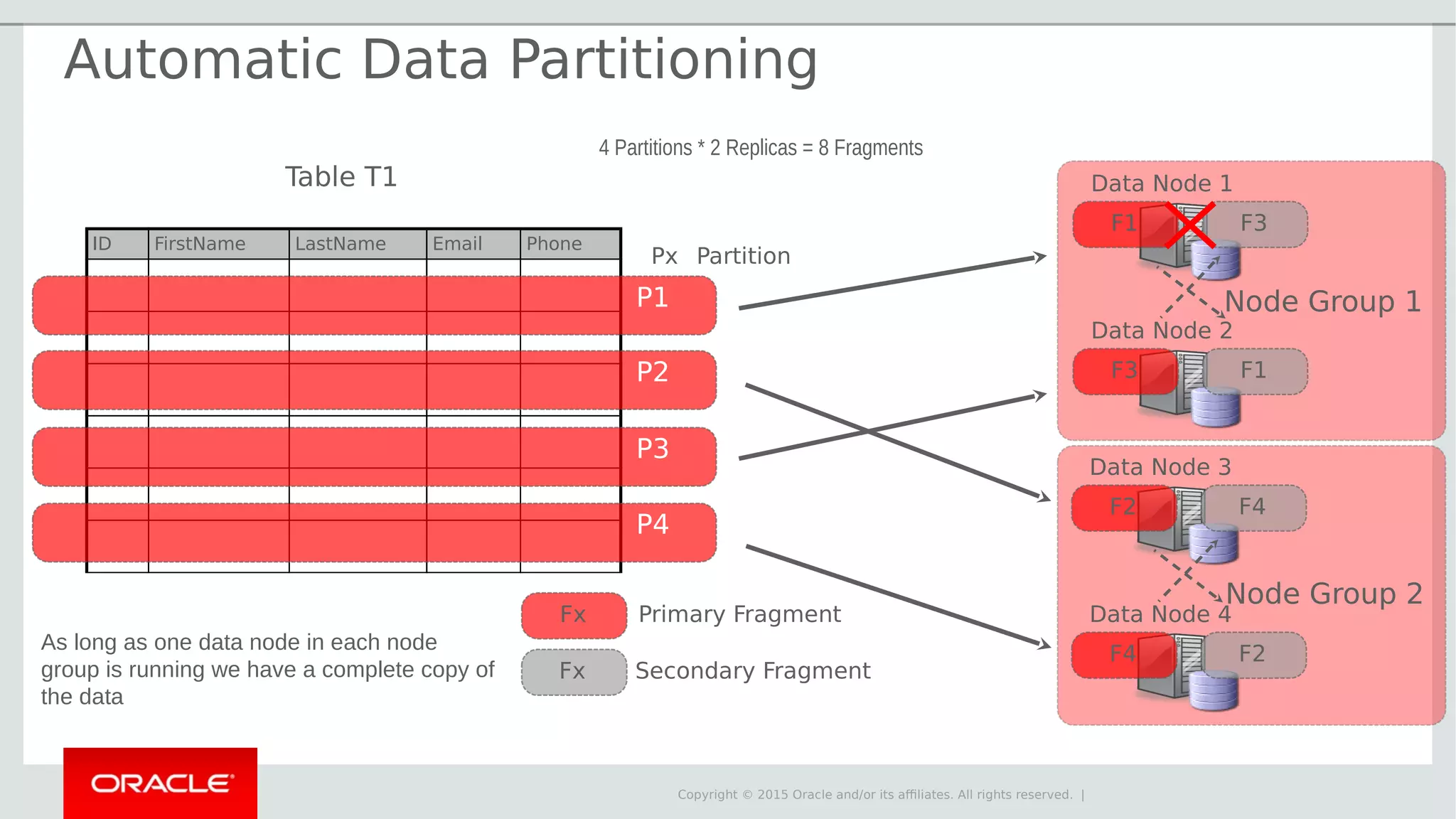
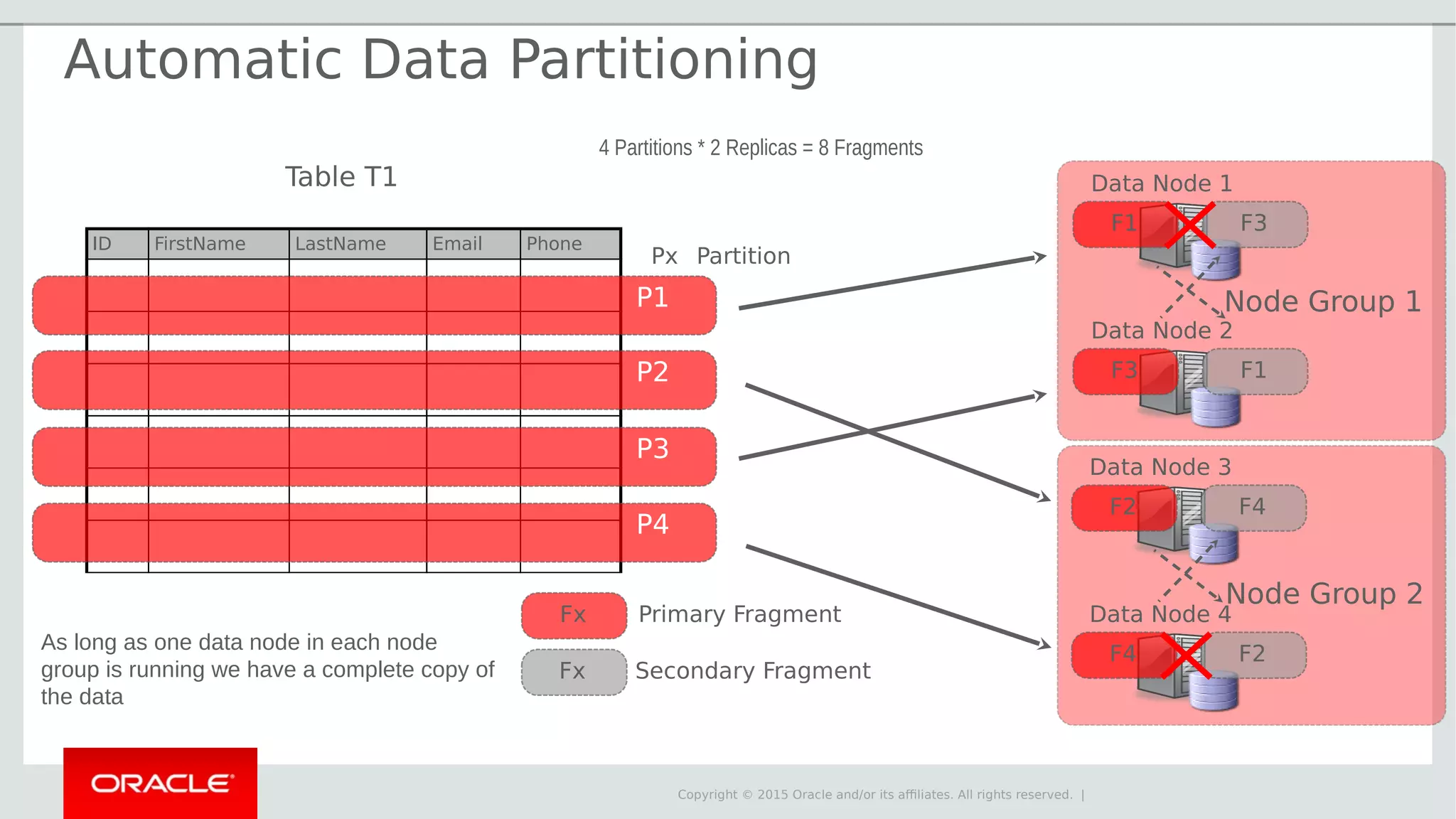
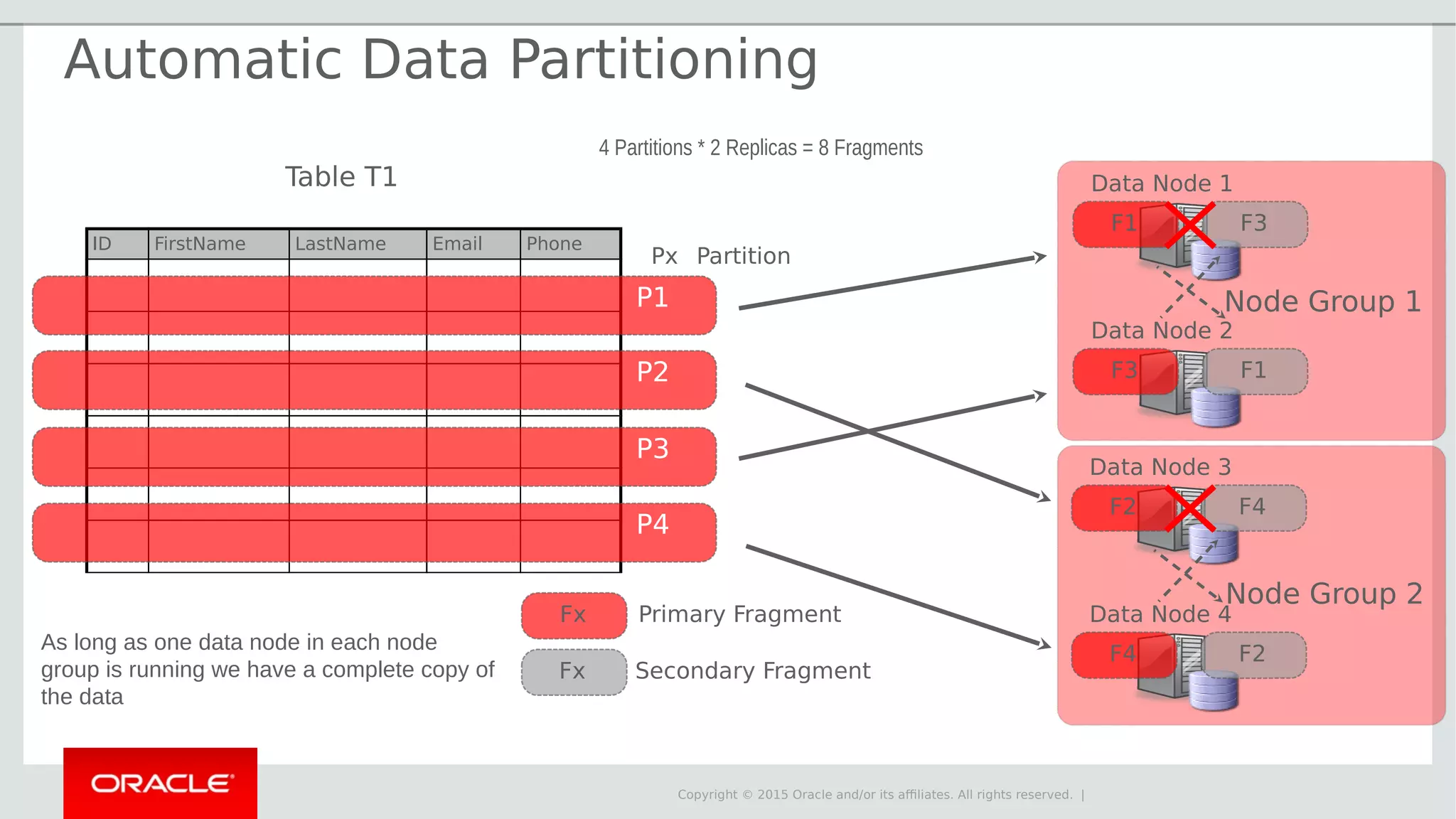
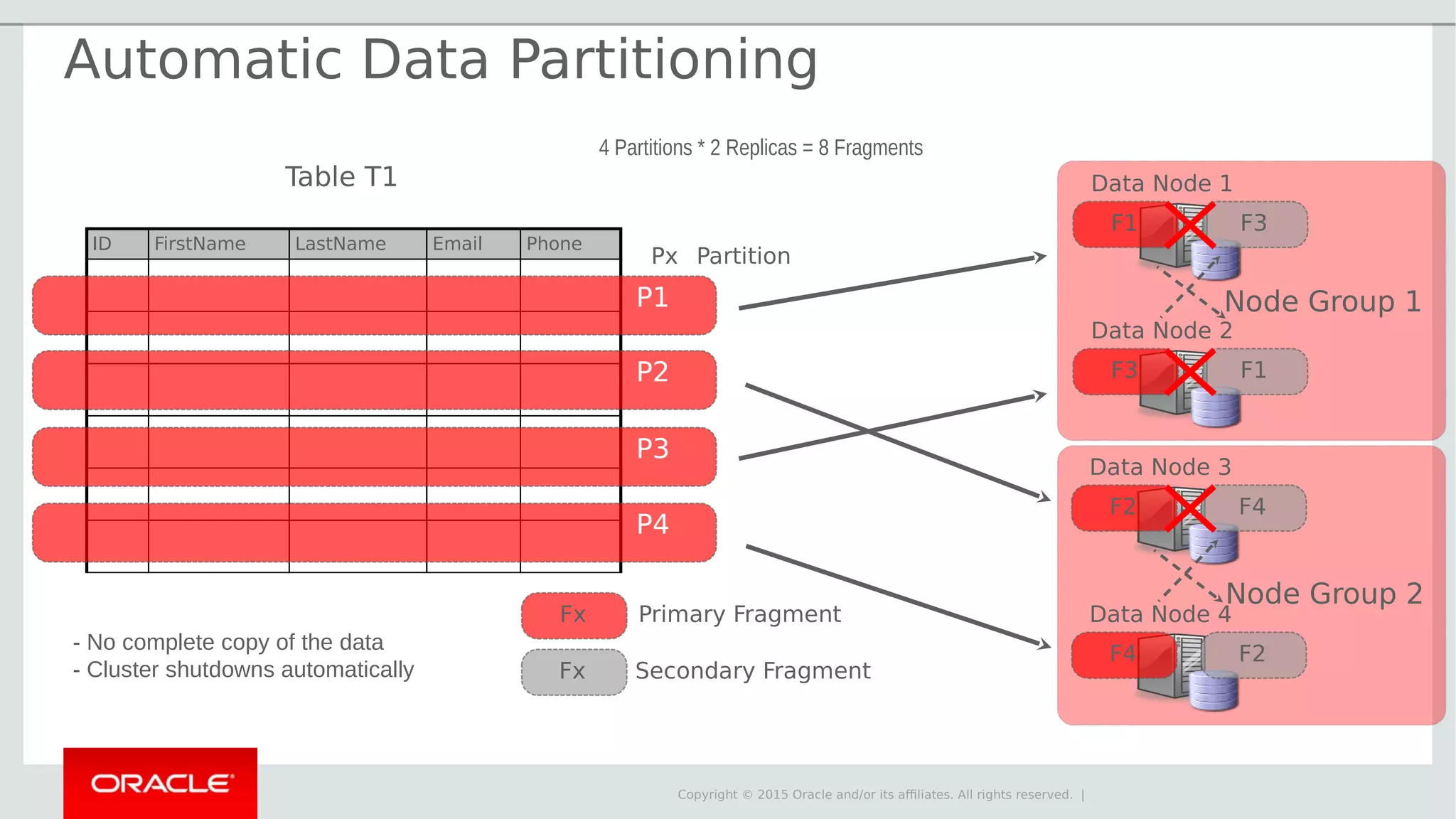

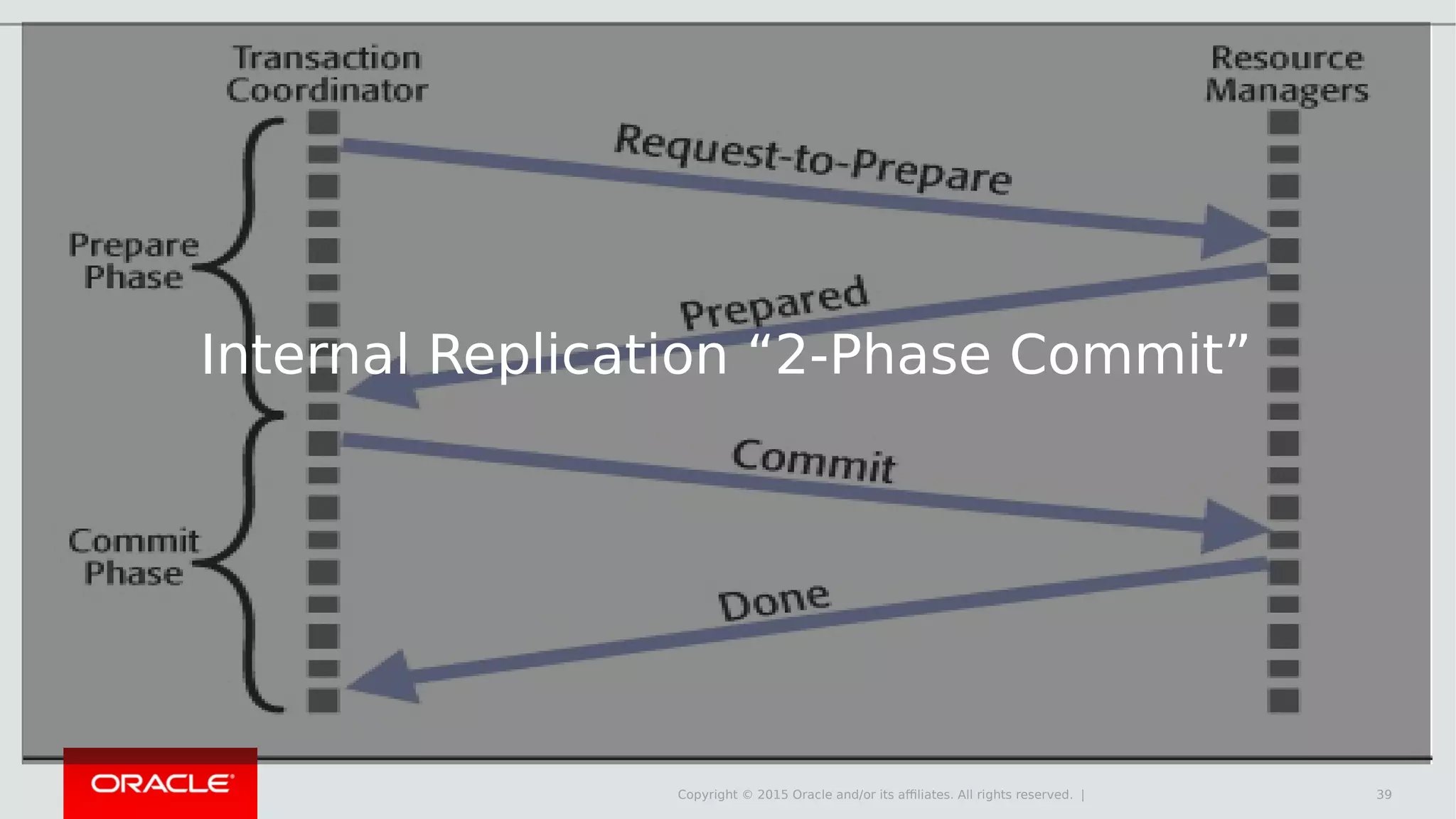
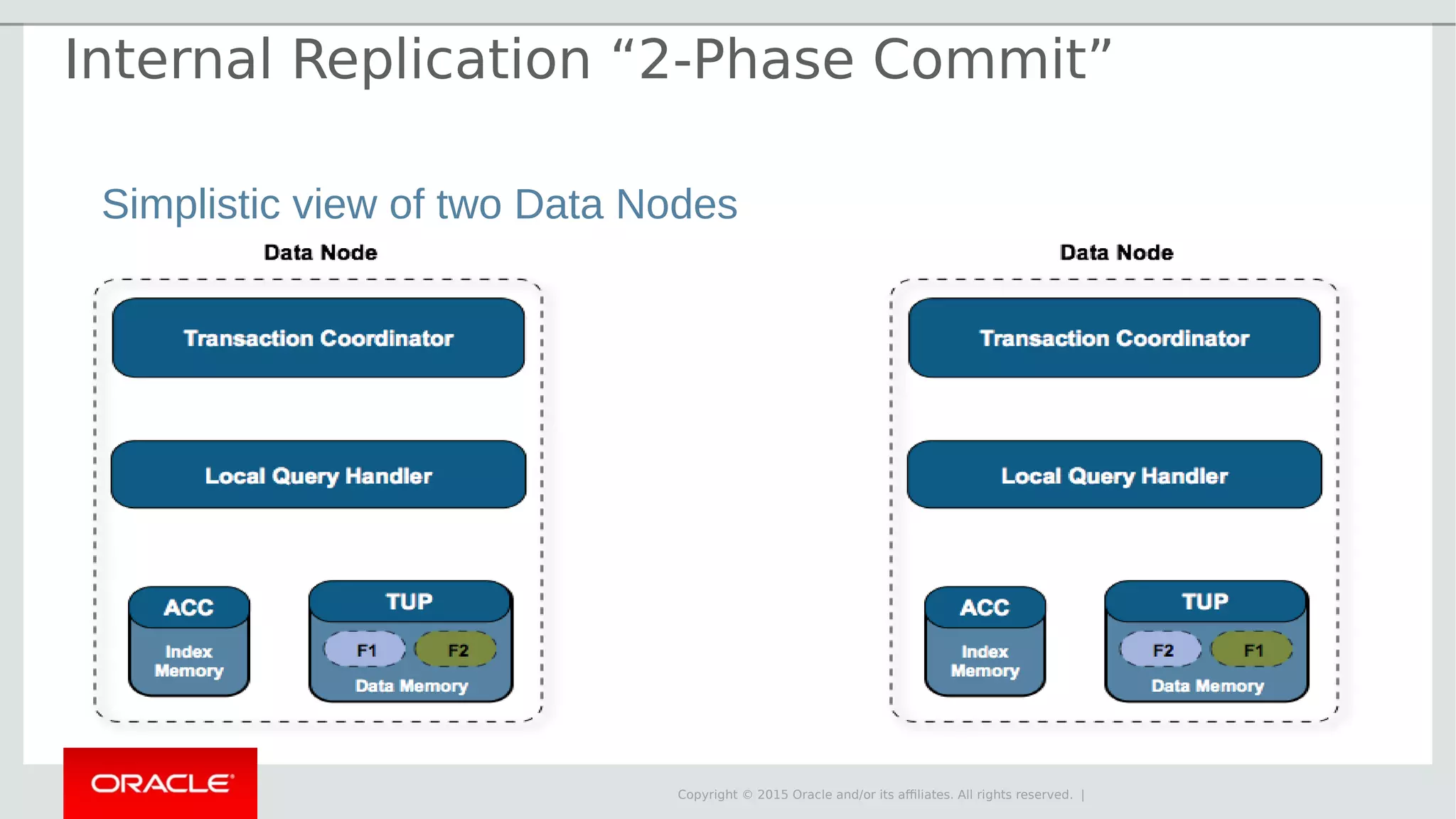
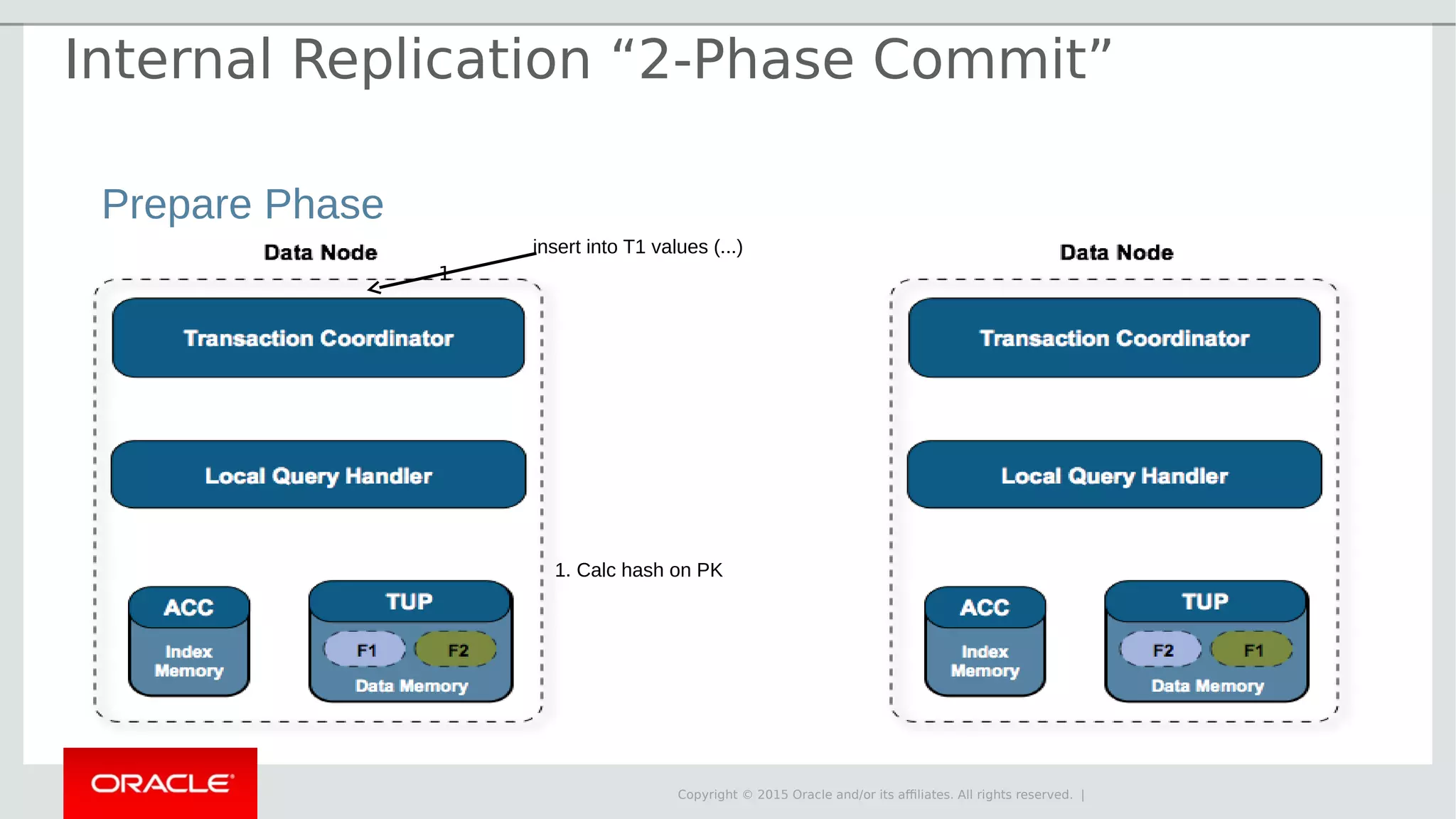
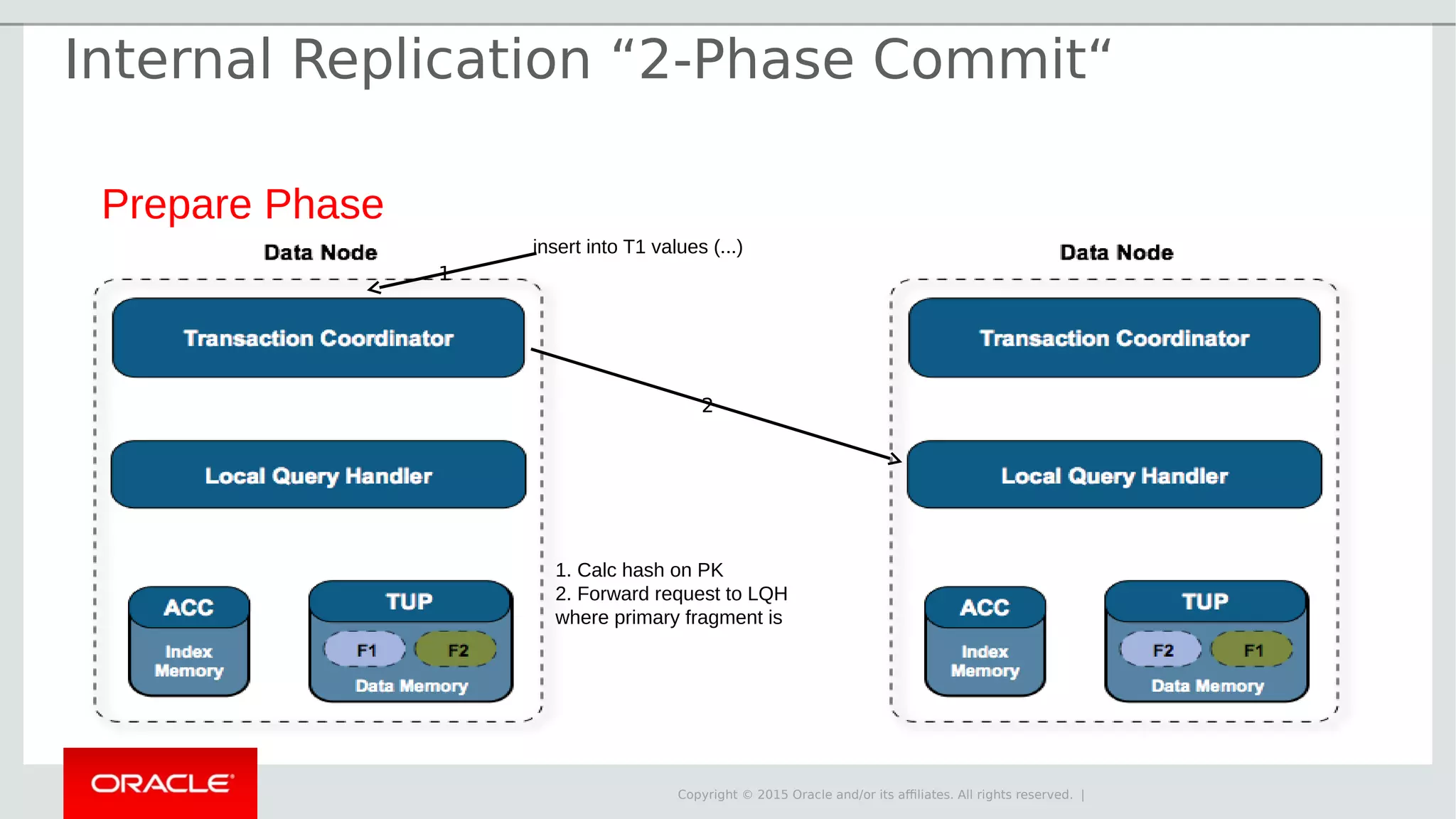
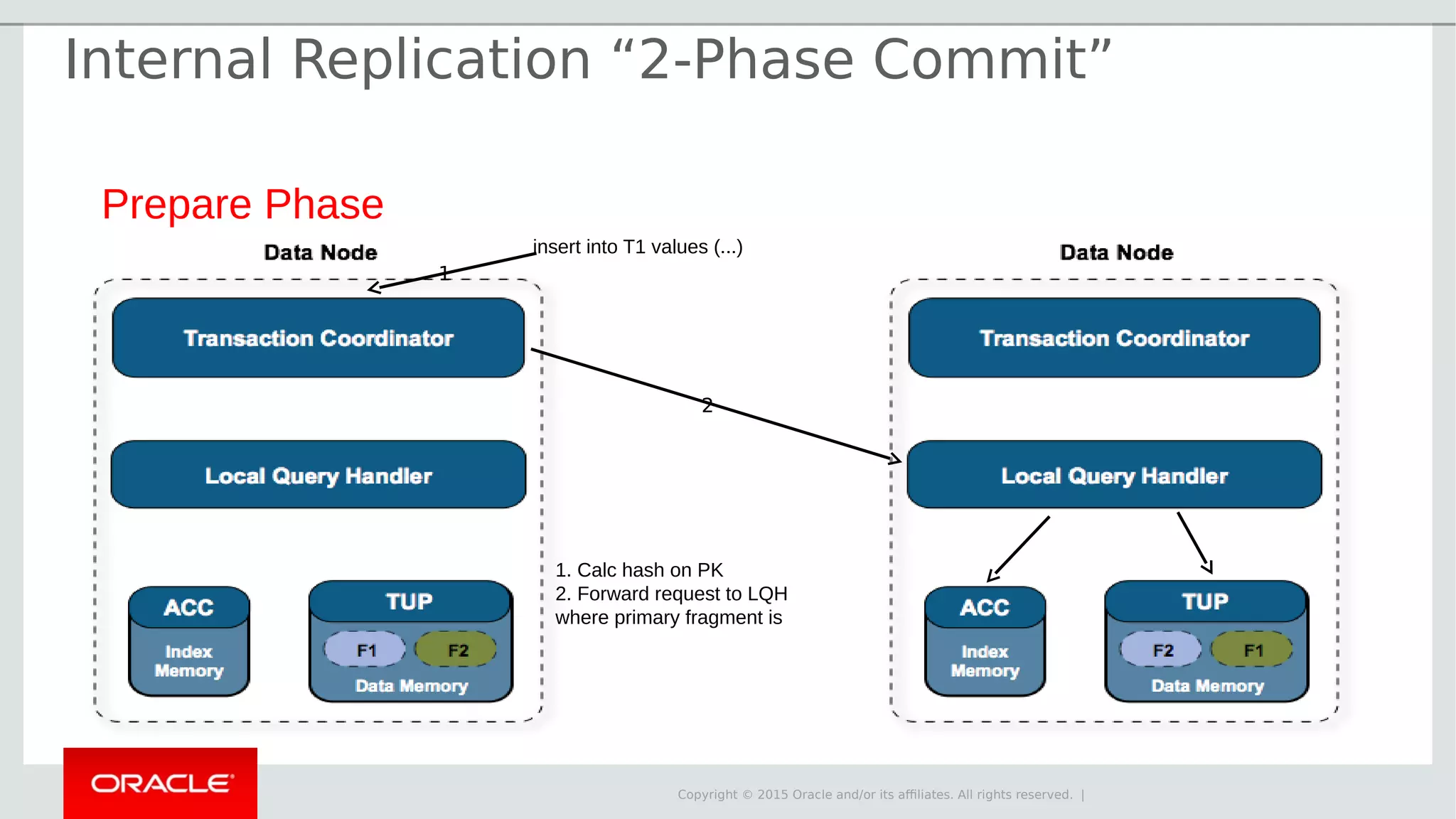
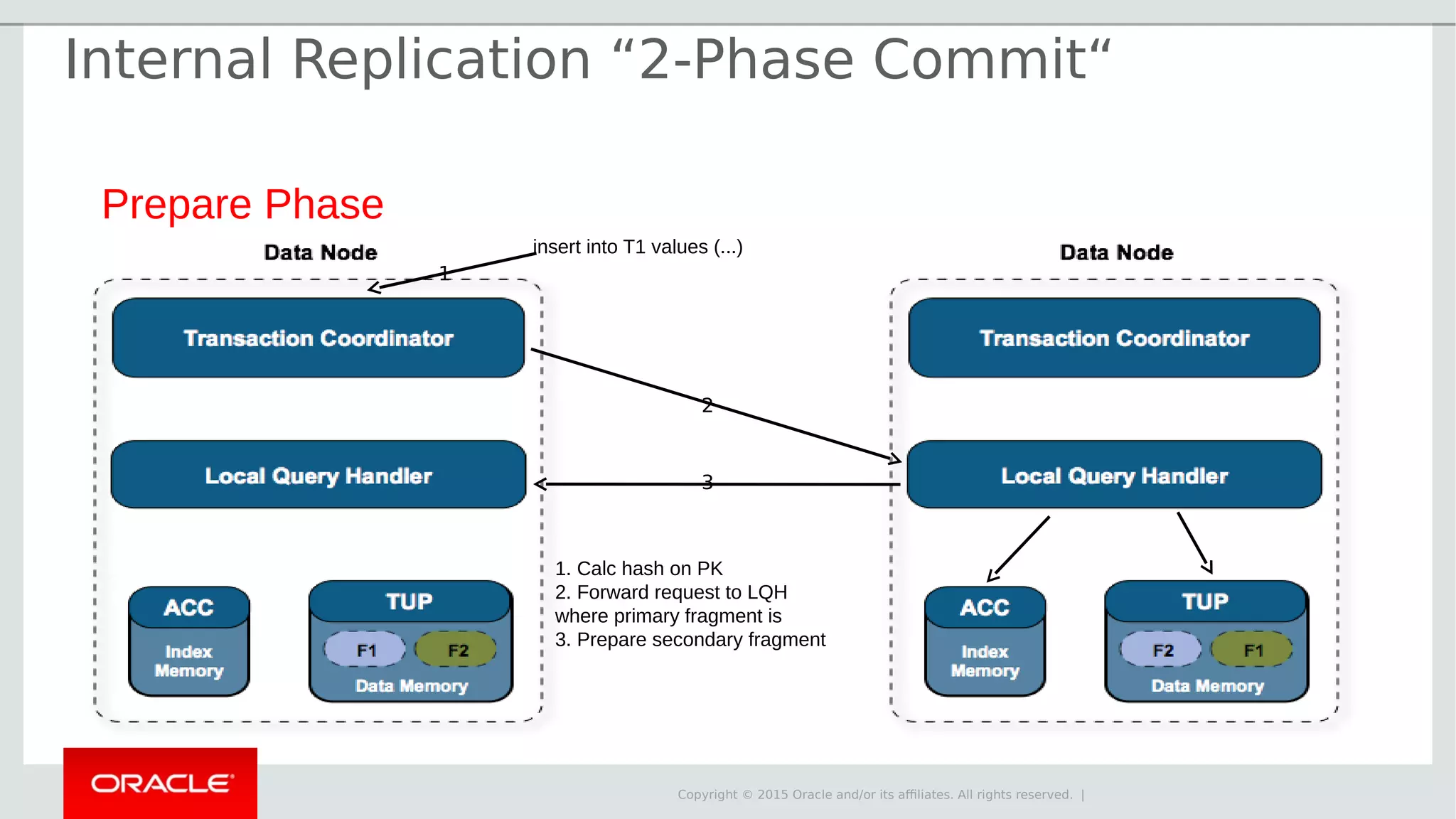
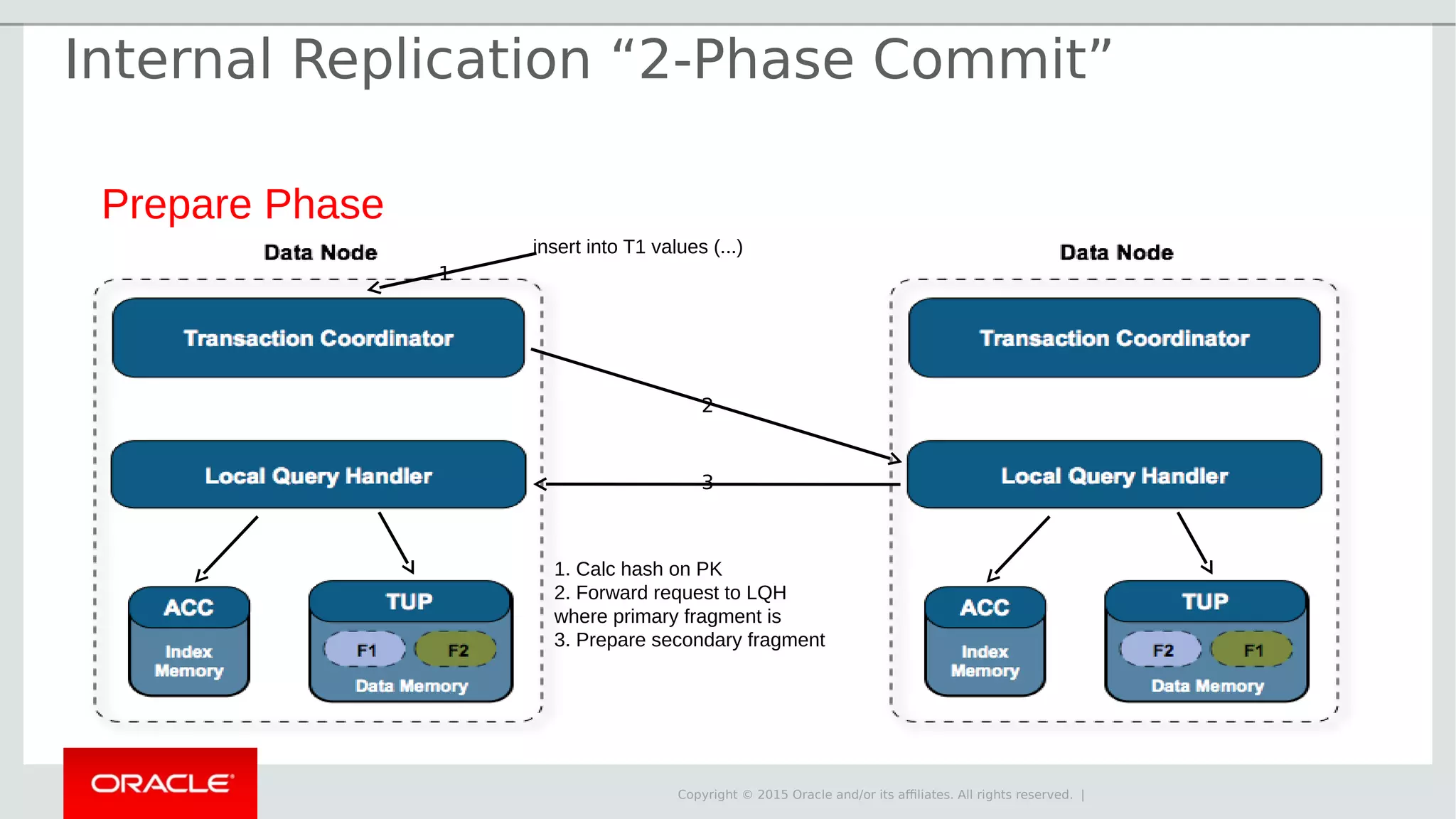
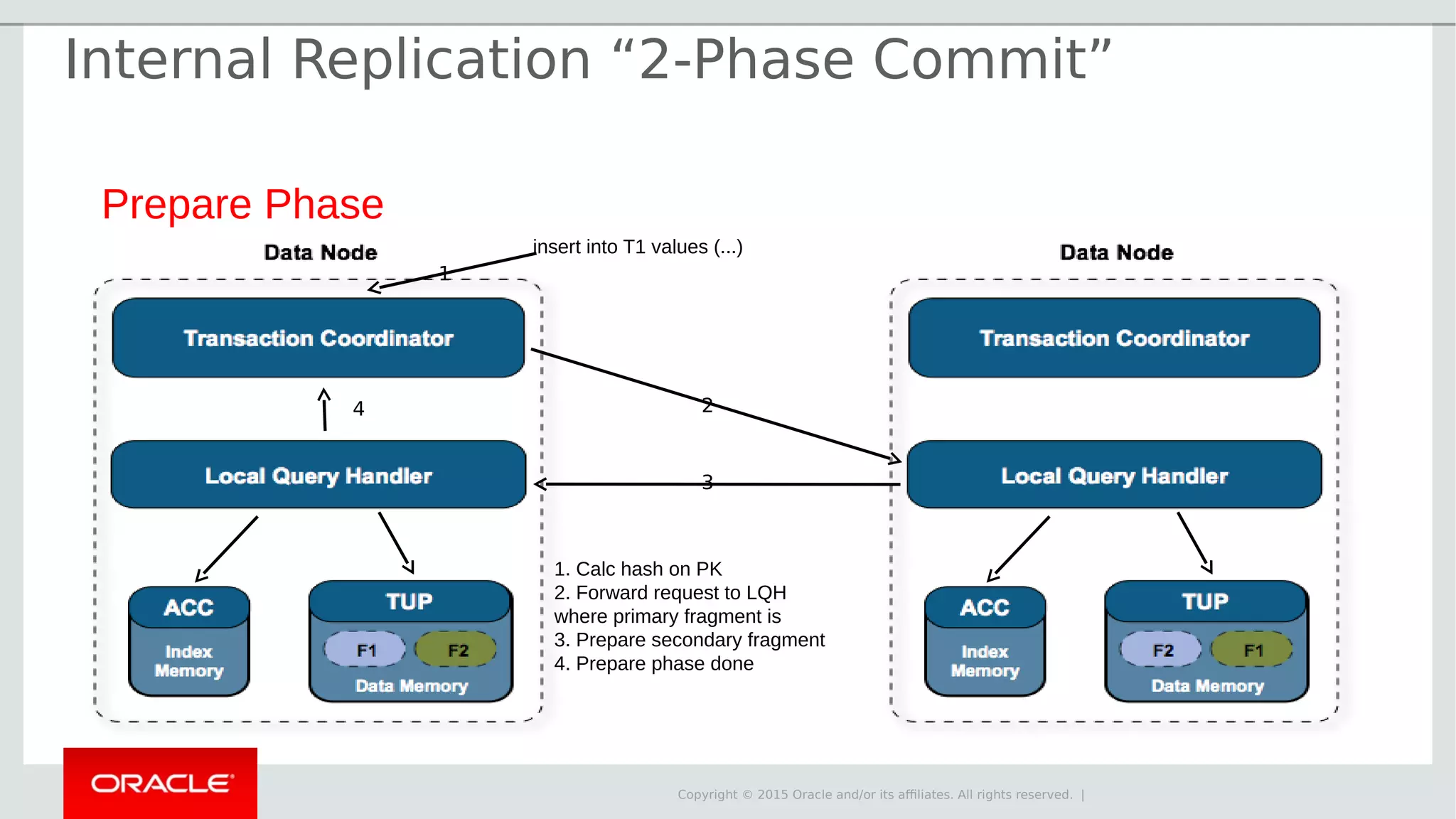
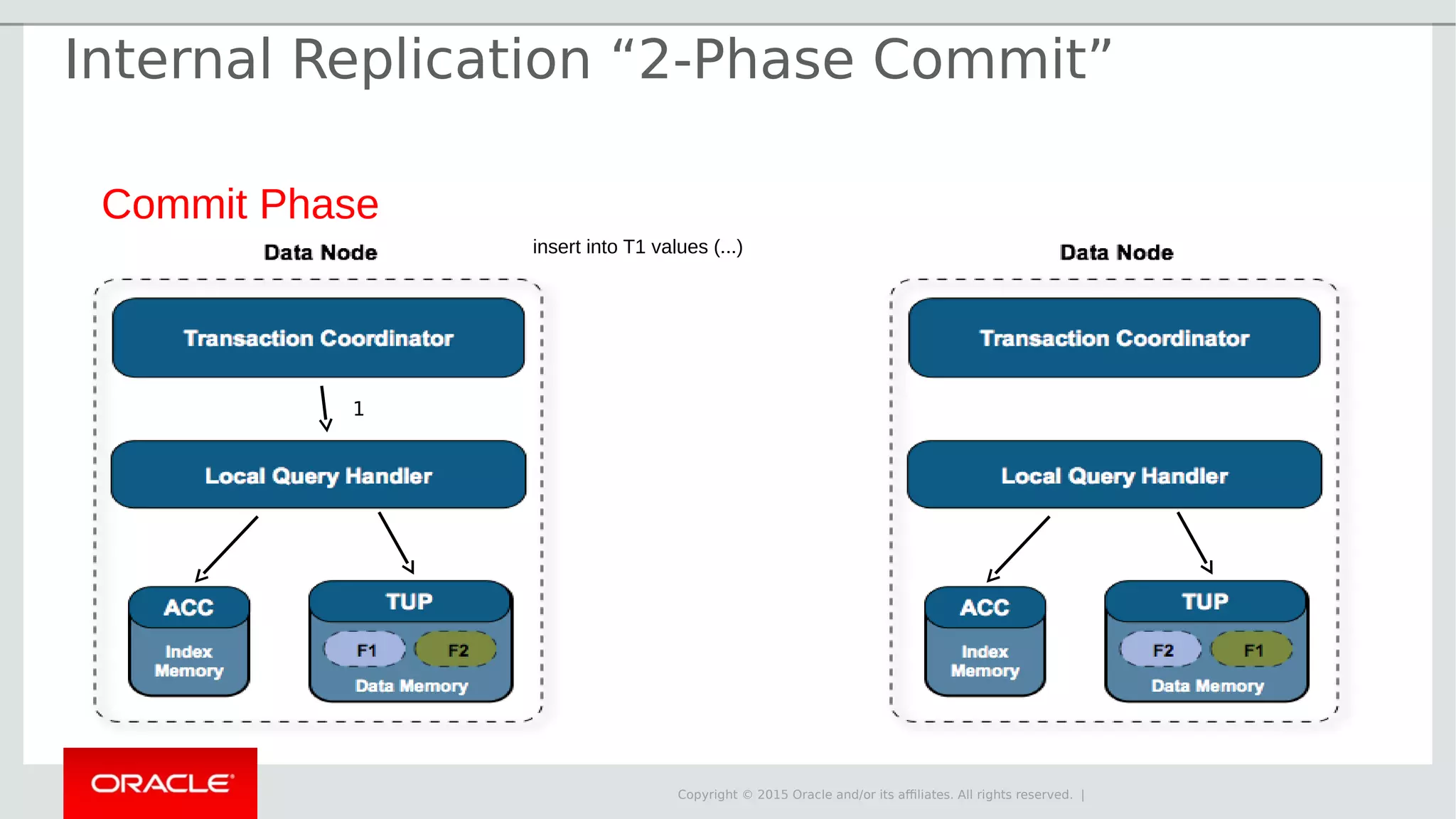
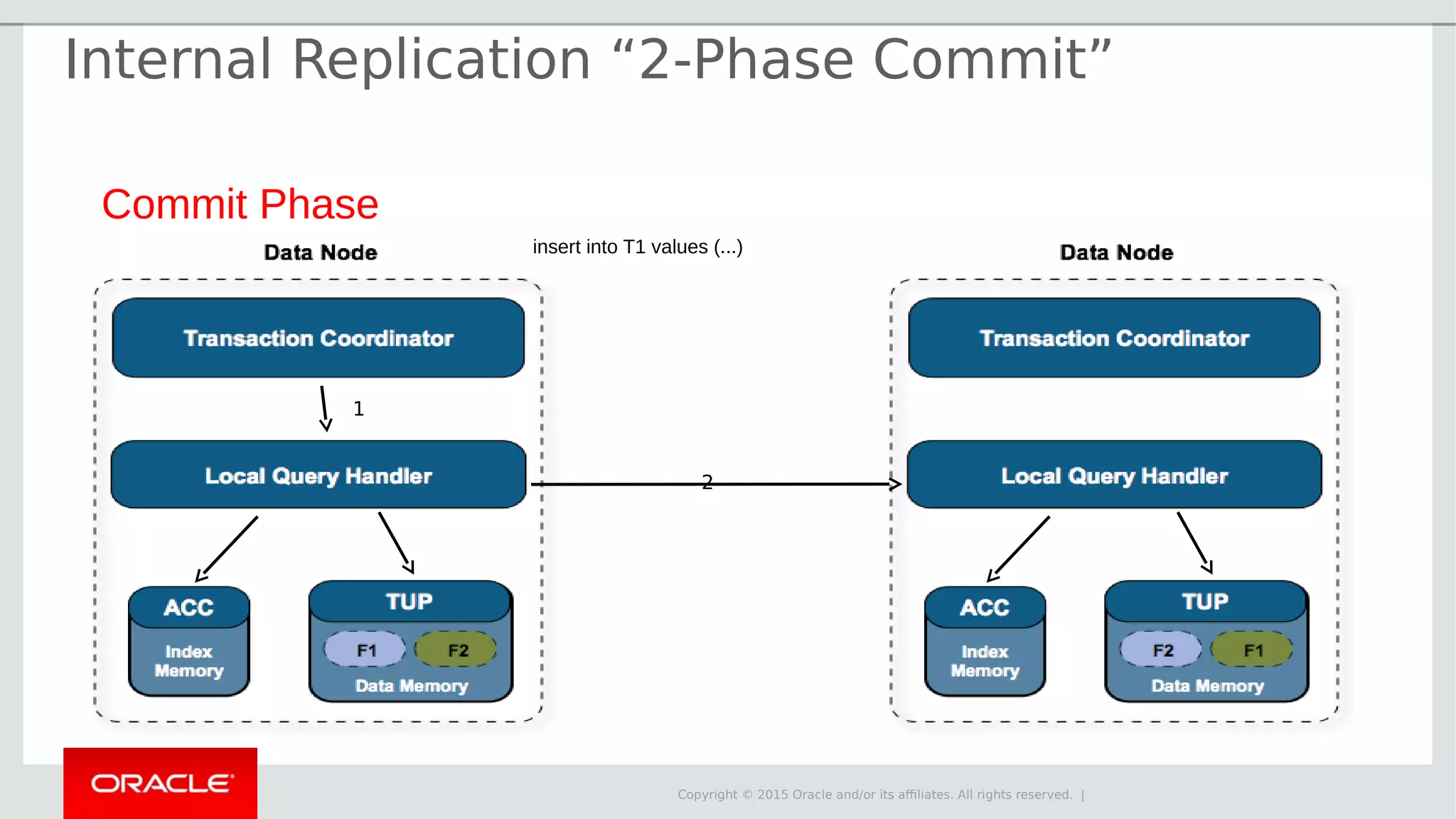
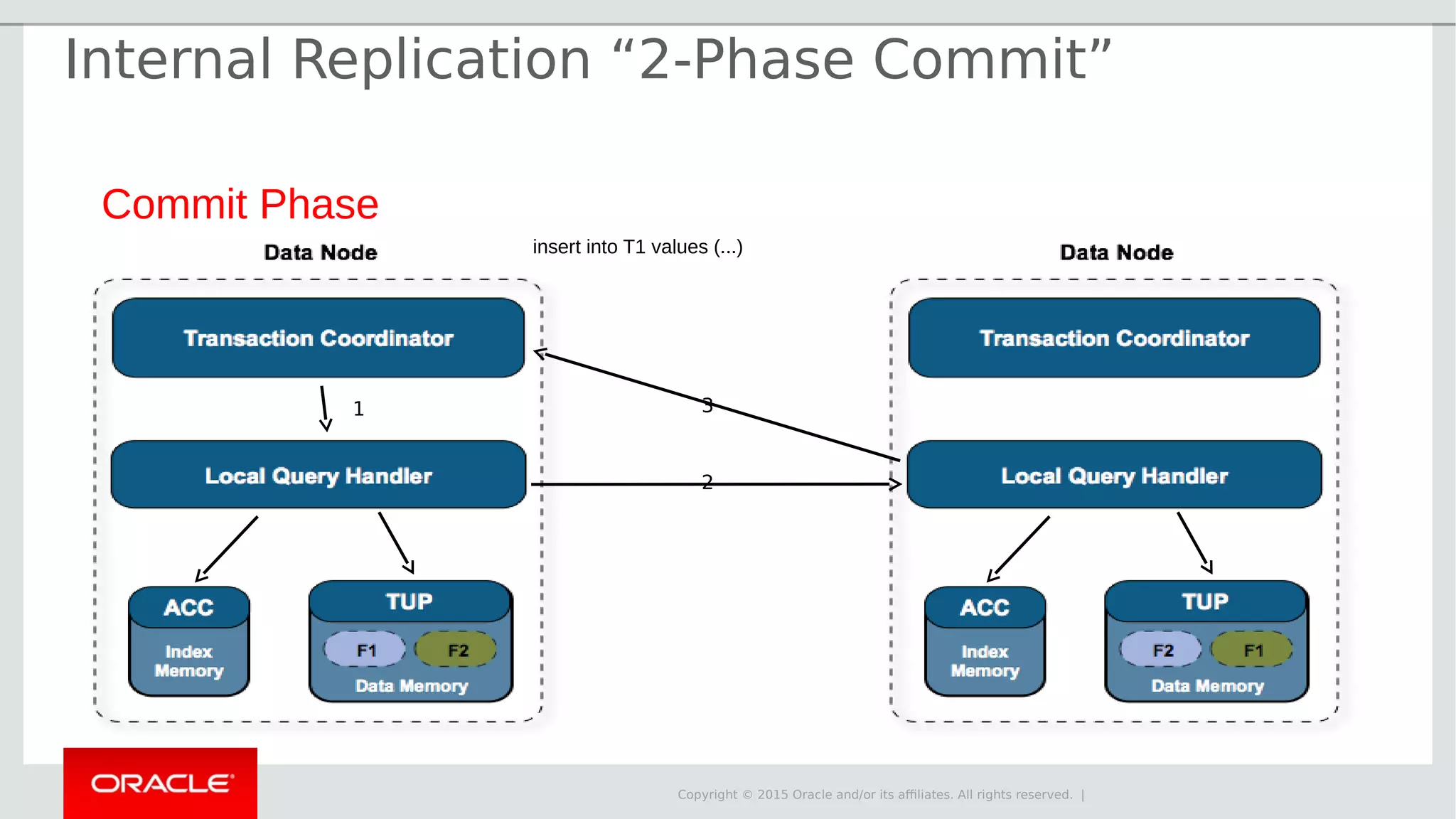
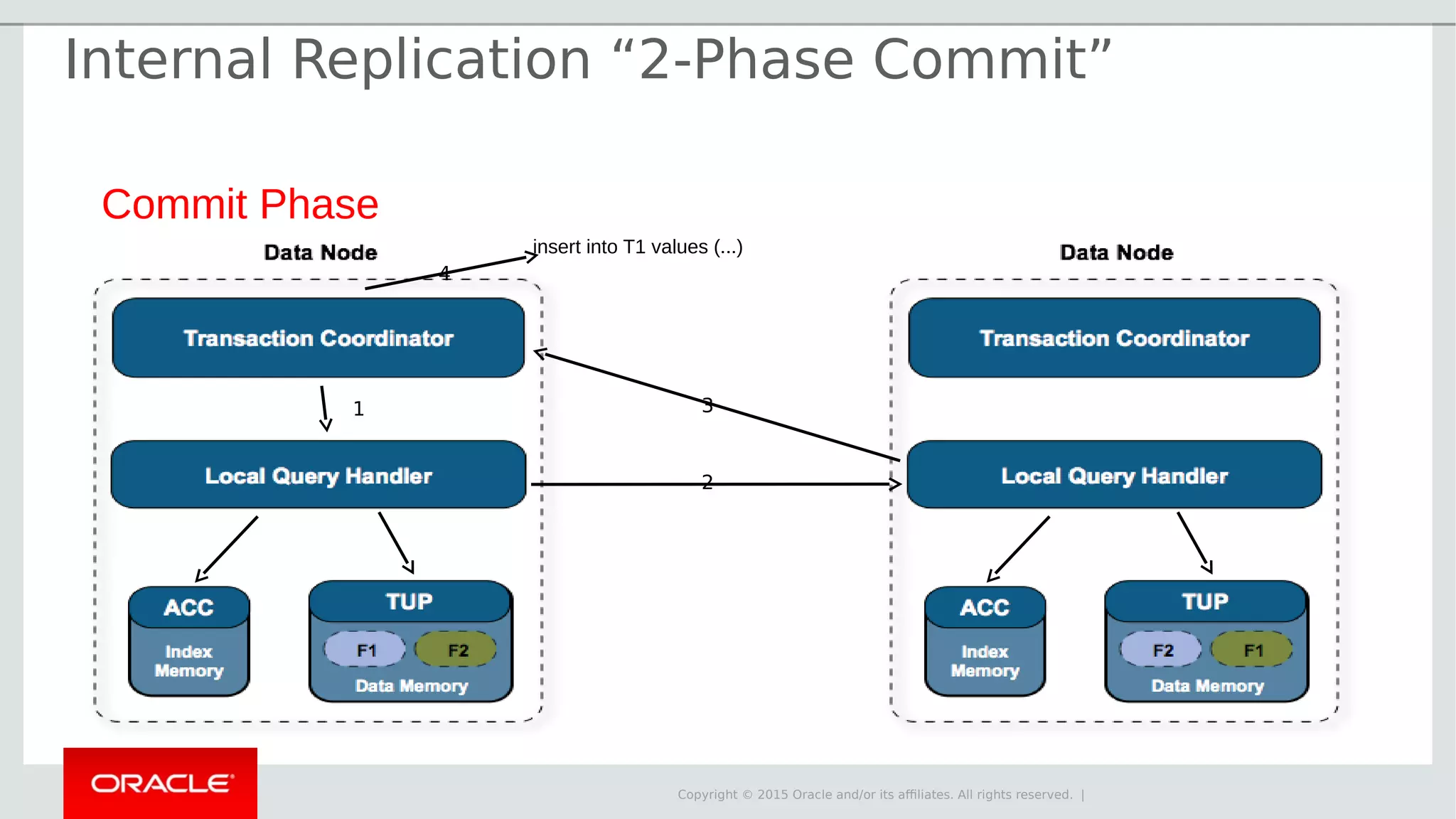

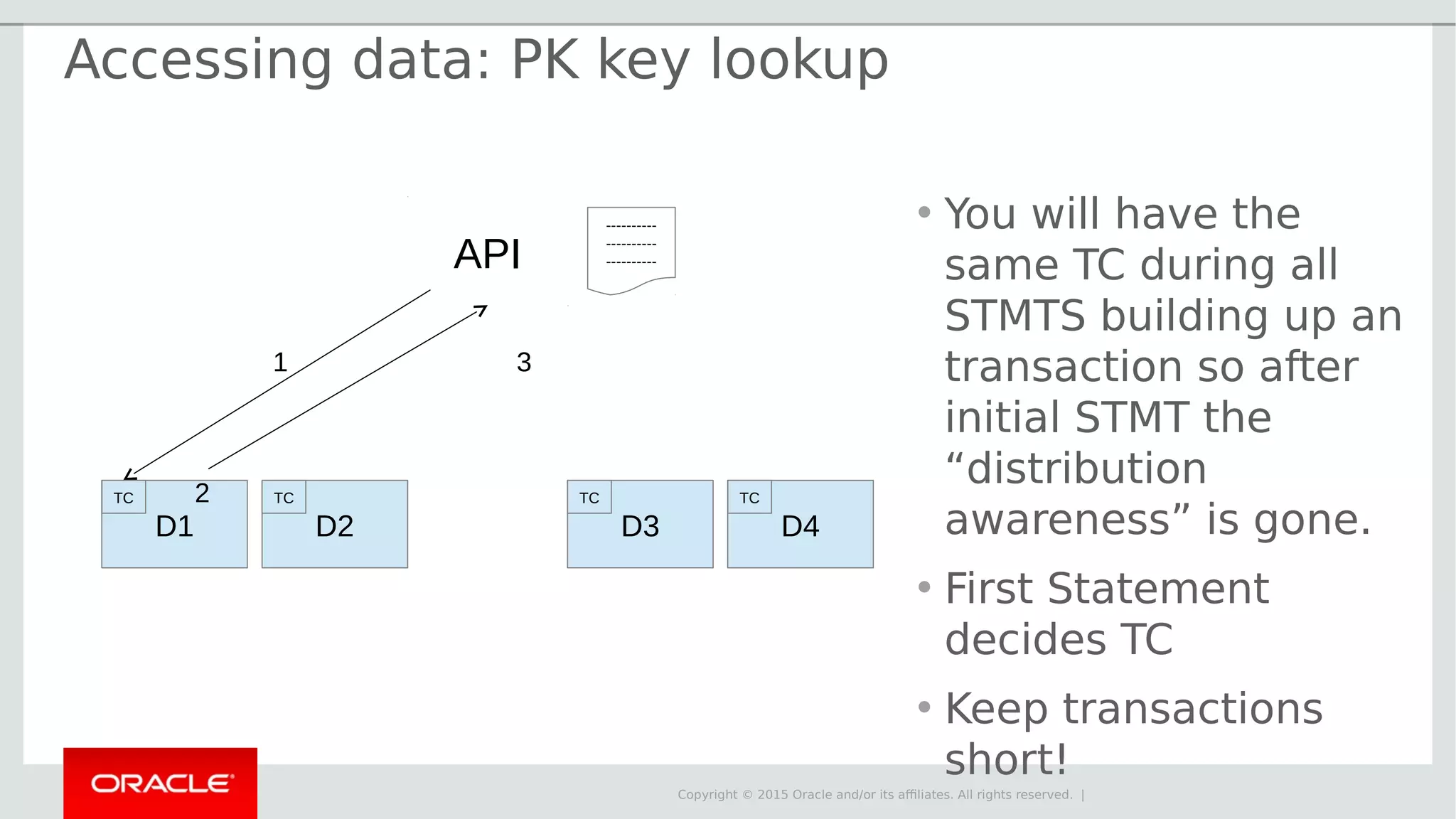
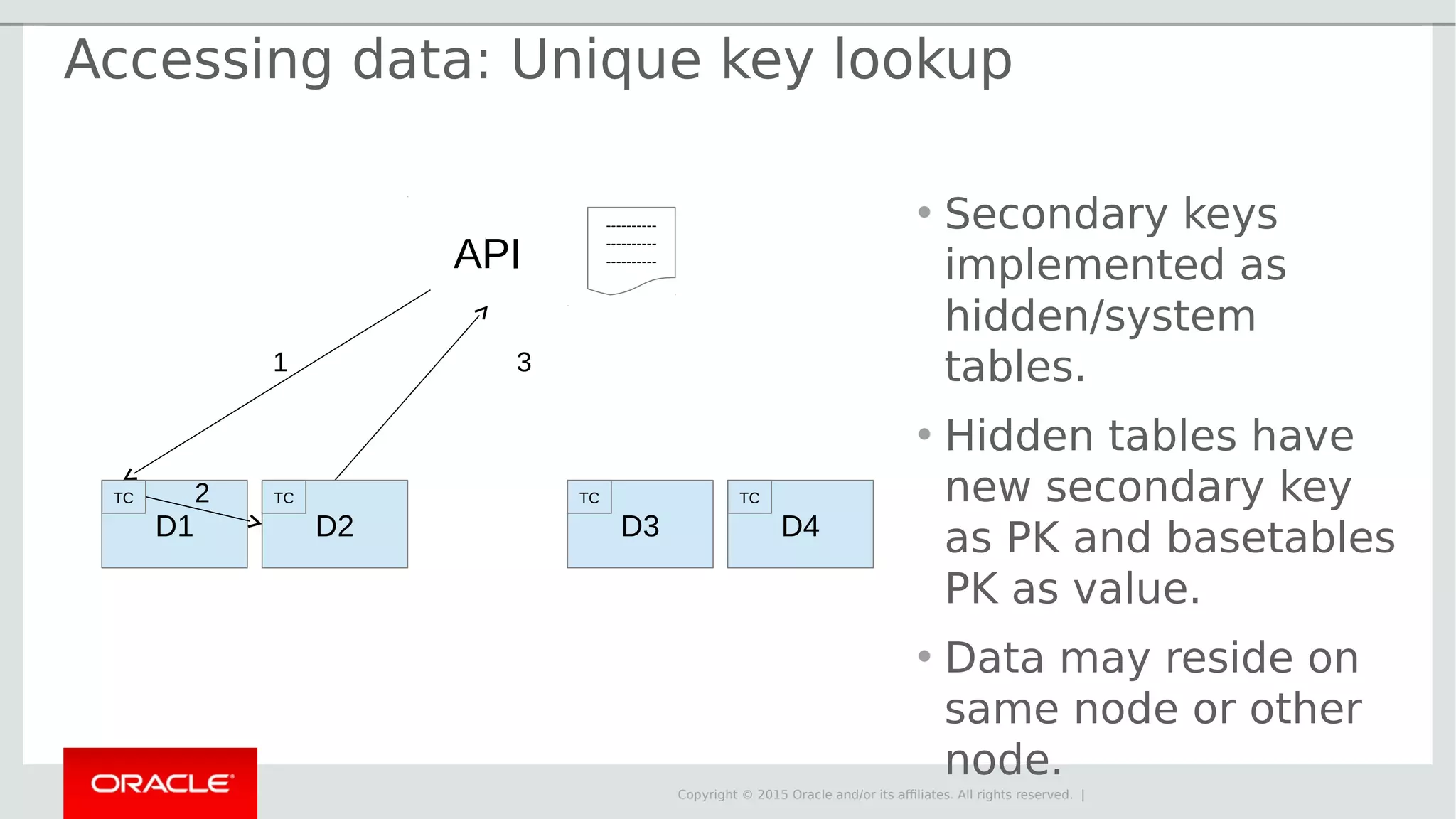
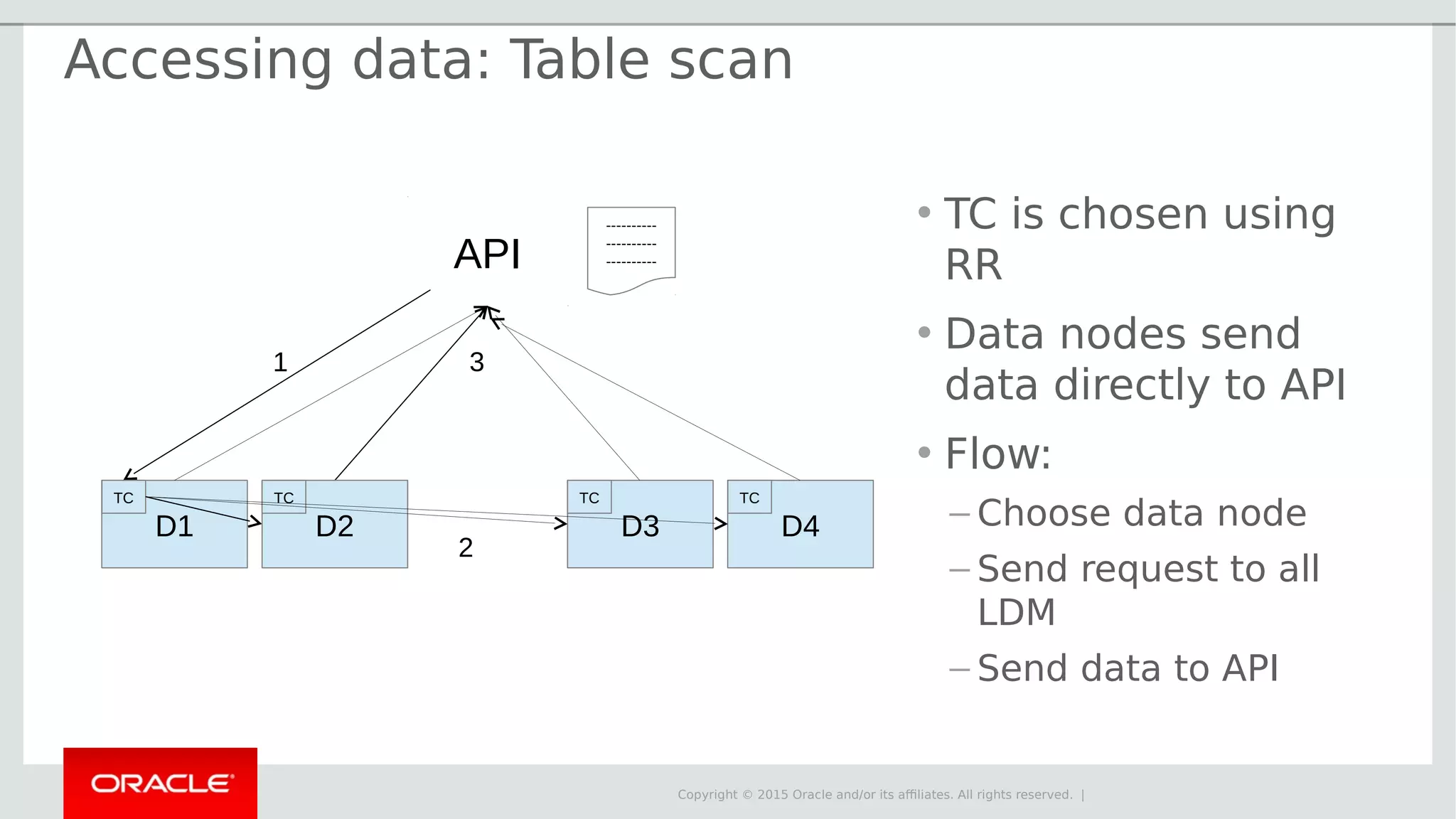



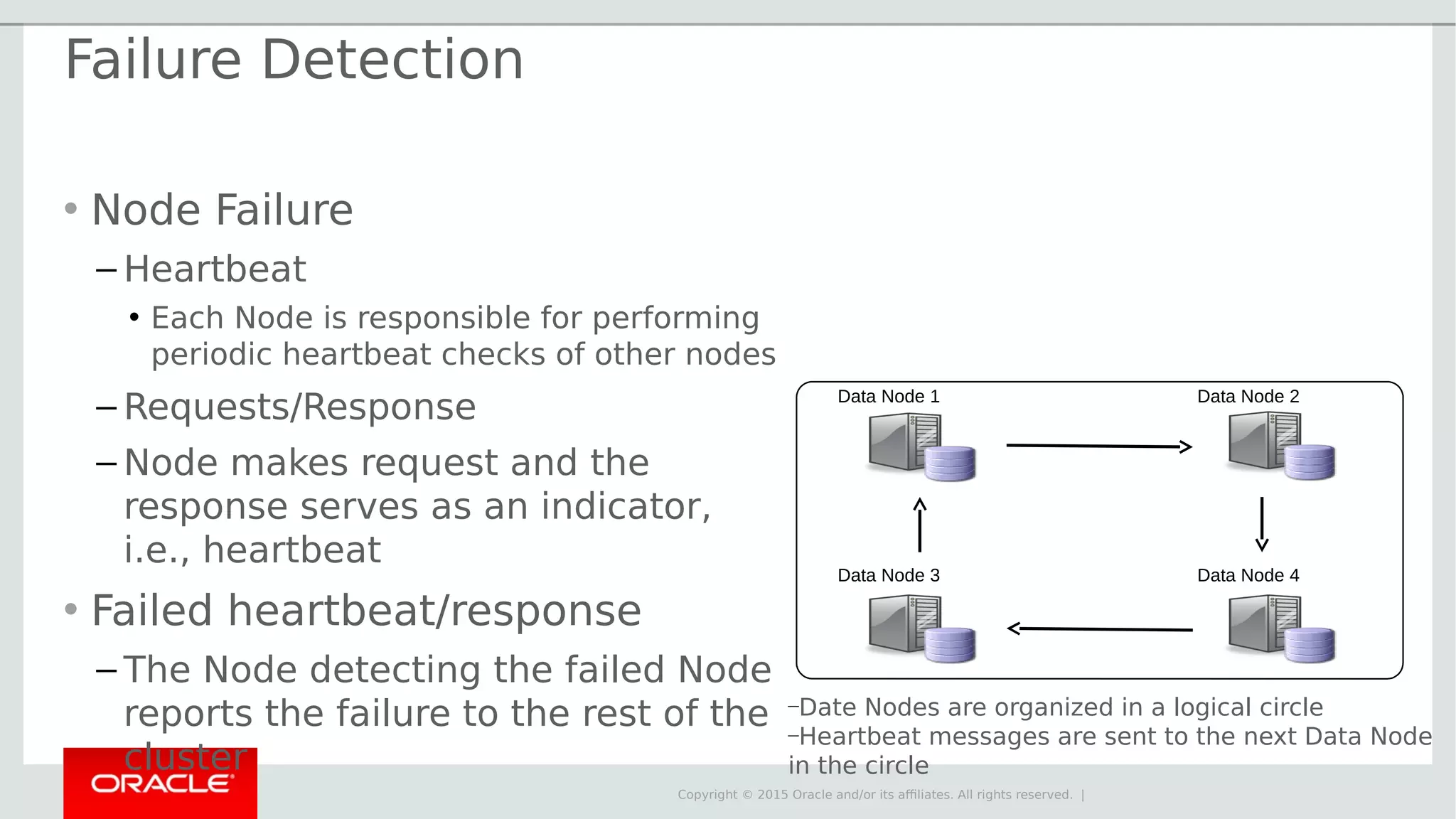
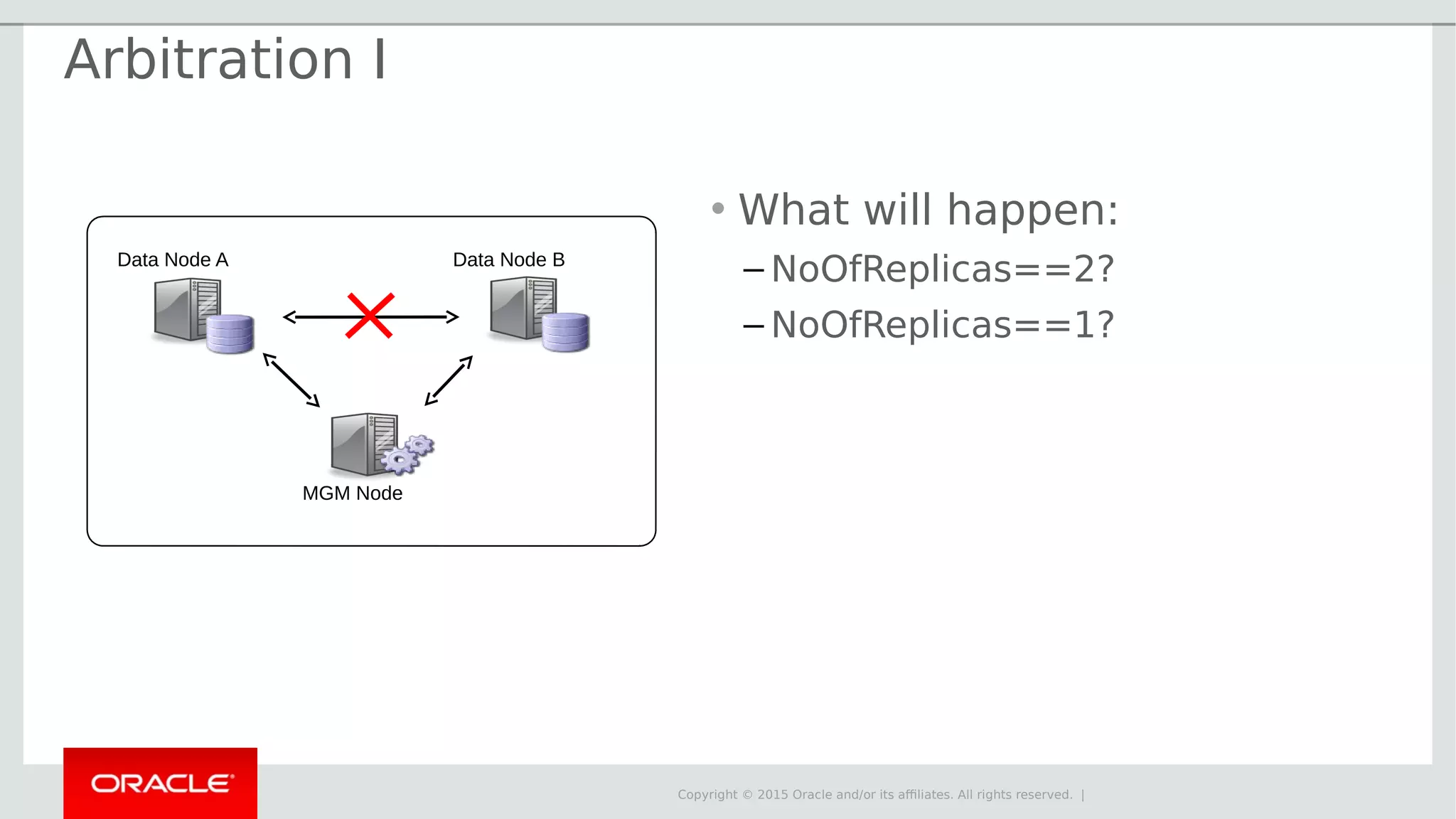
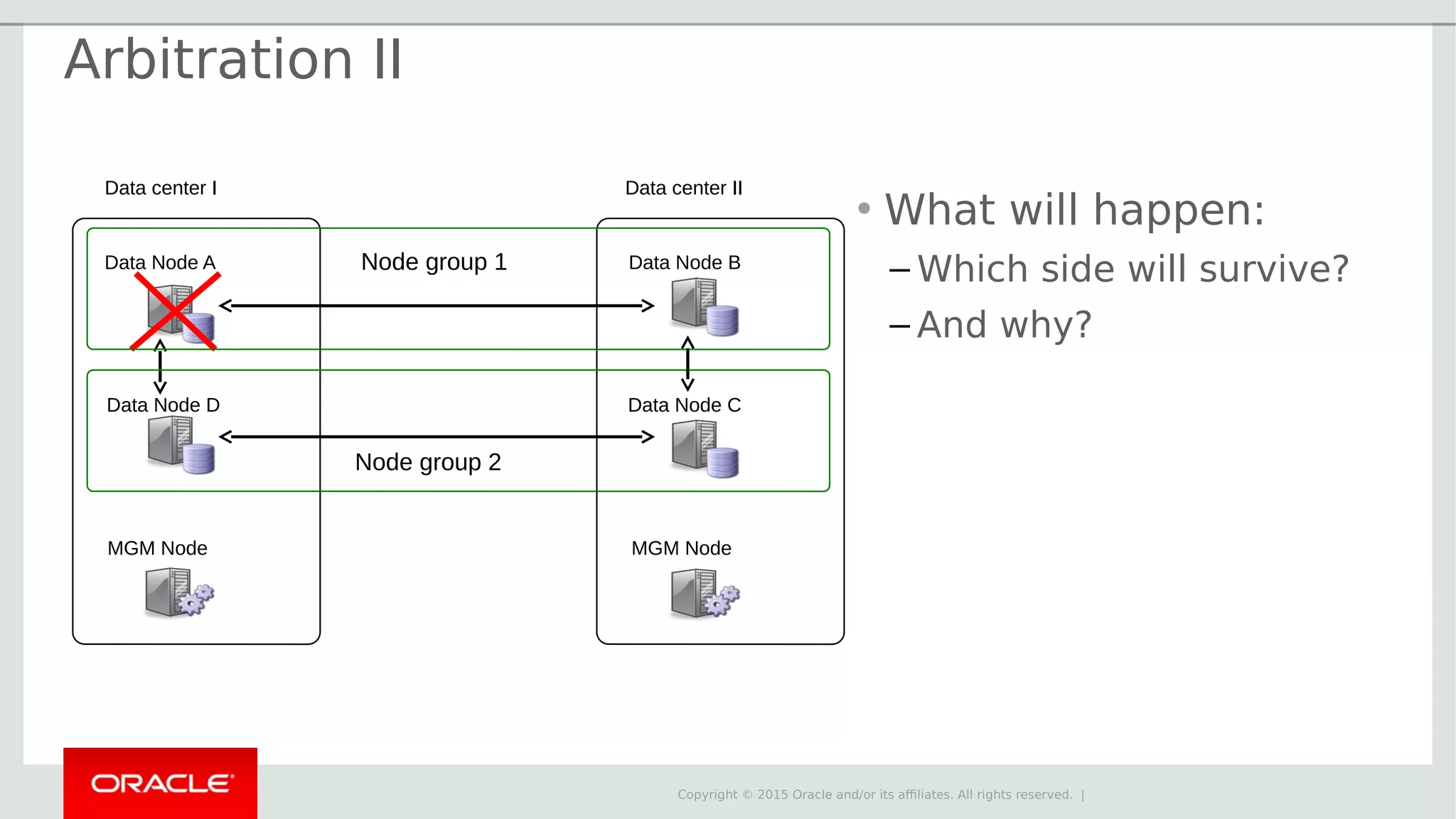
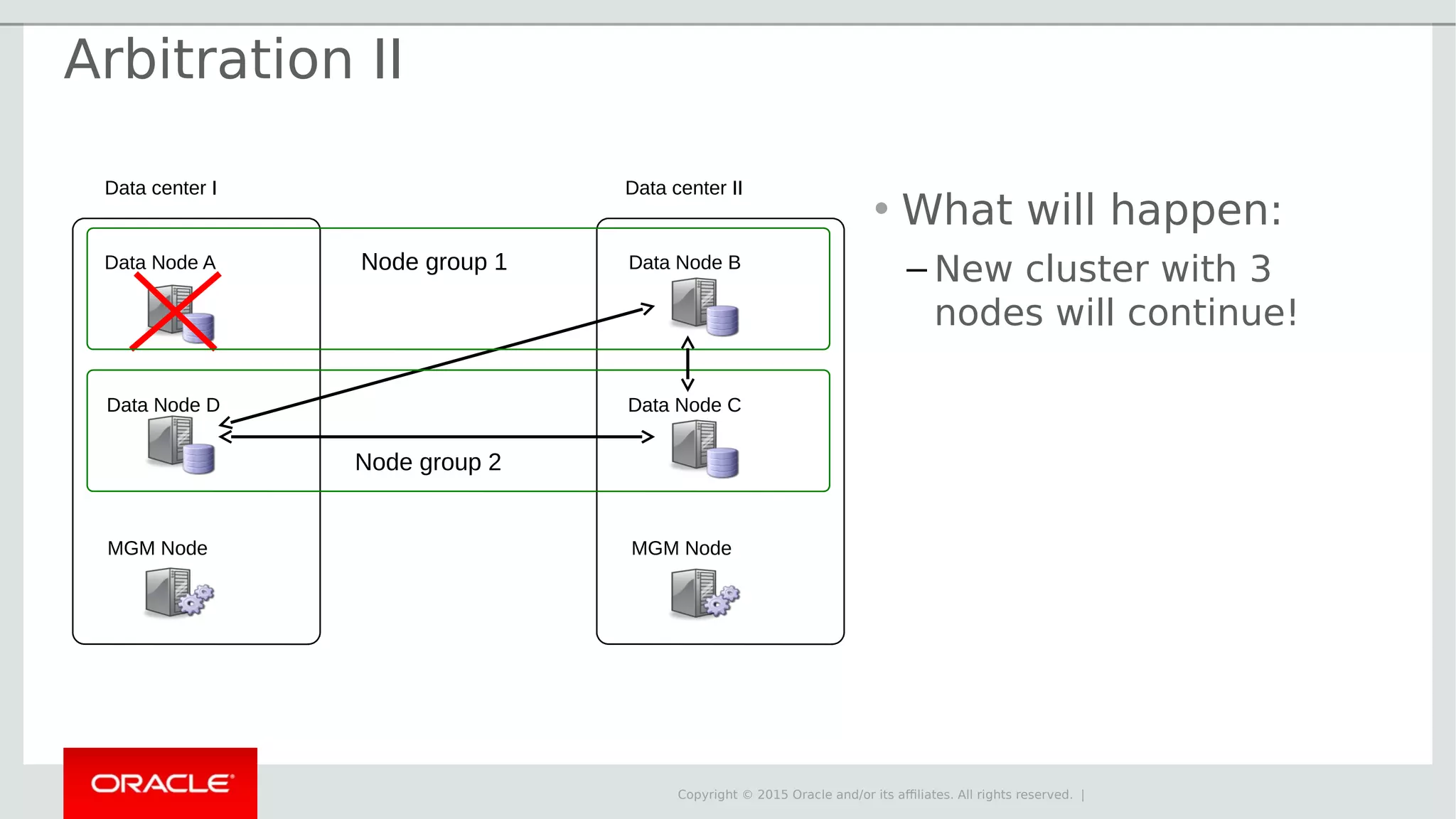
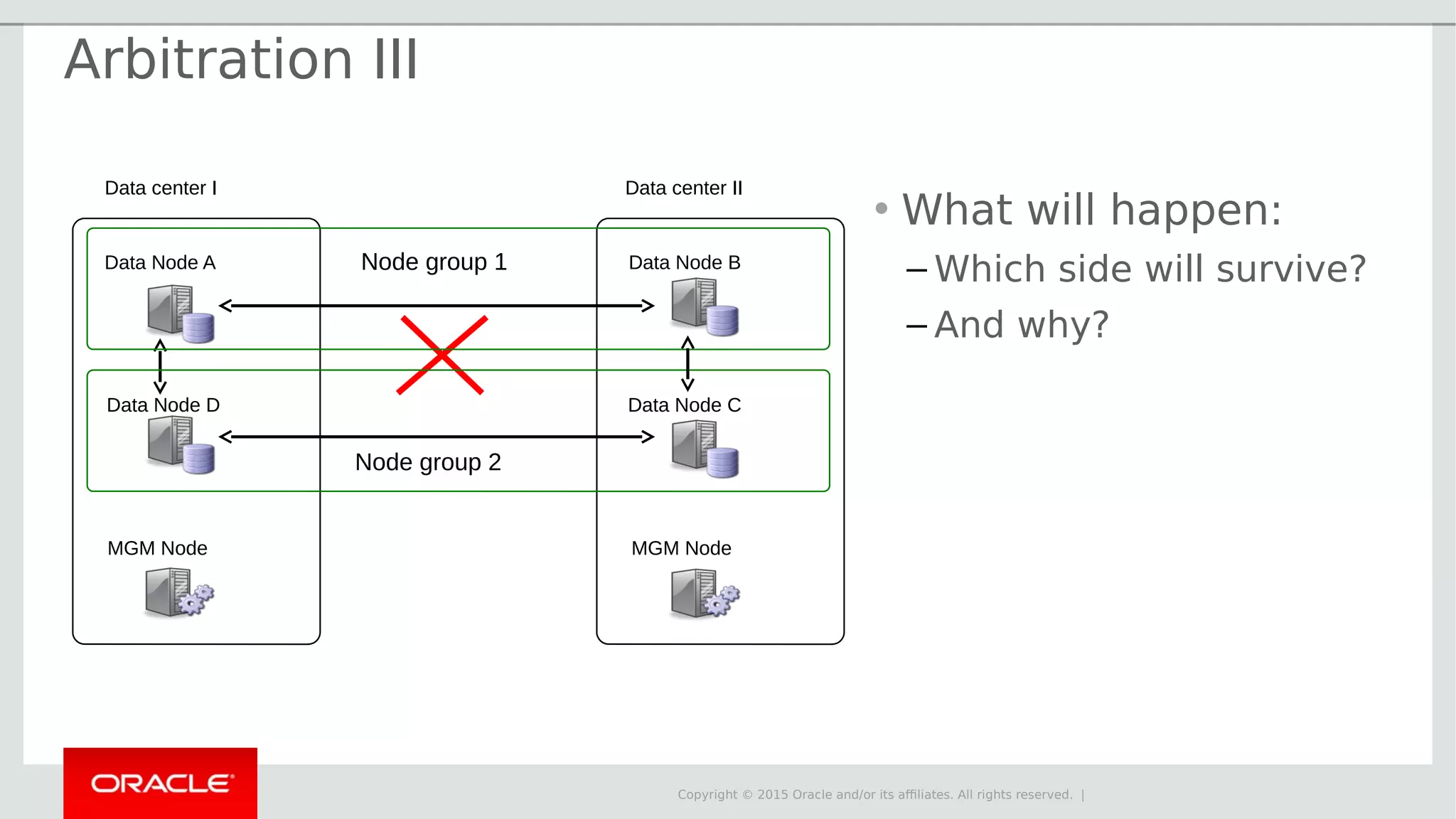
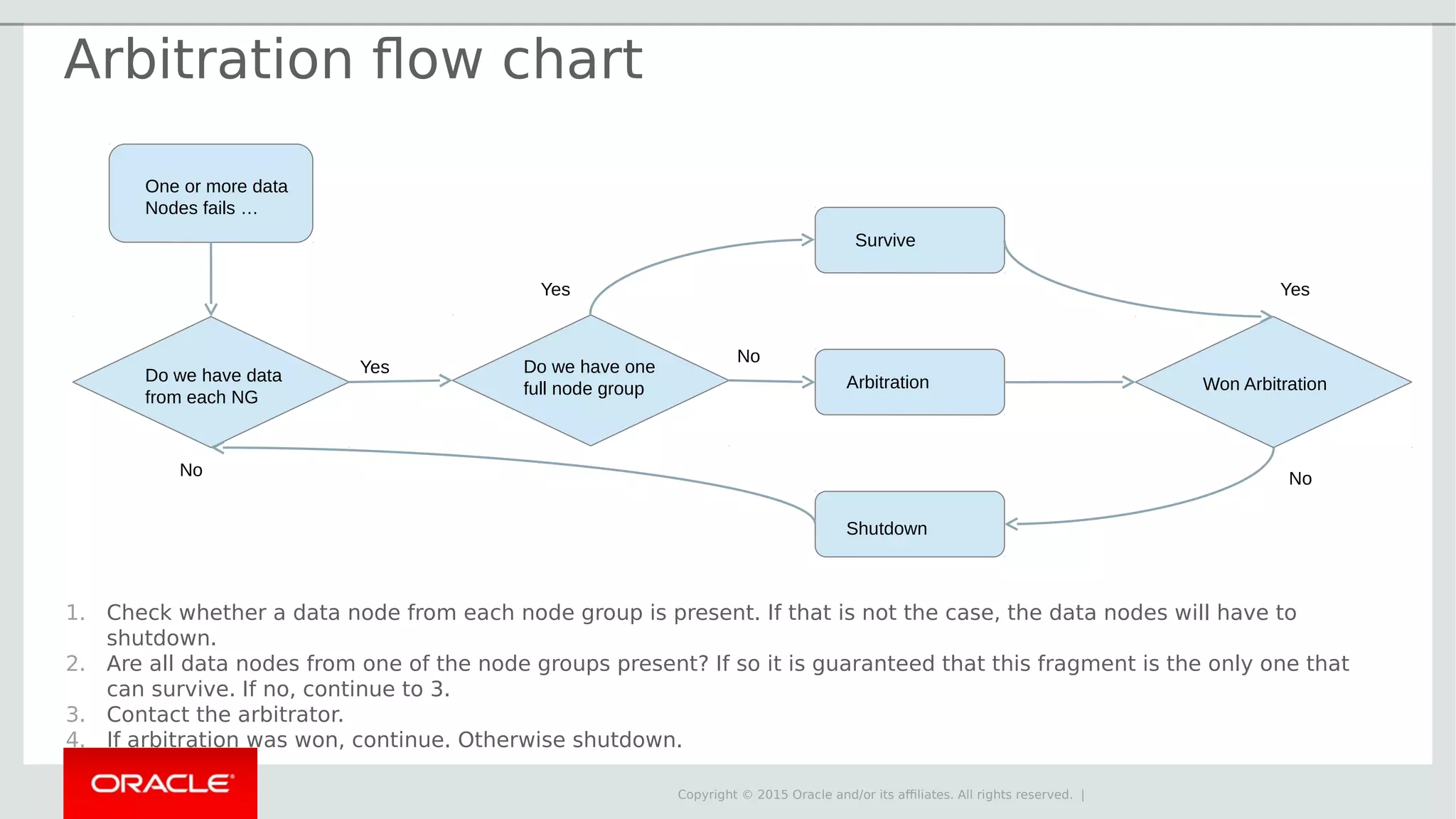



The document provides an overview of MySQL Cluster, its history, architecture, features, and use cases. It emphasizes the design goals of high reliability, performance, and real-time capabilities, primarily for telecom applications. Additionally, it outlines conditions for employing MySQL Cluster and structural components including data nodes, management nodes, and various partitioning methods.