Downloaded 25 times

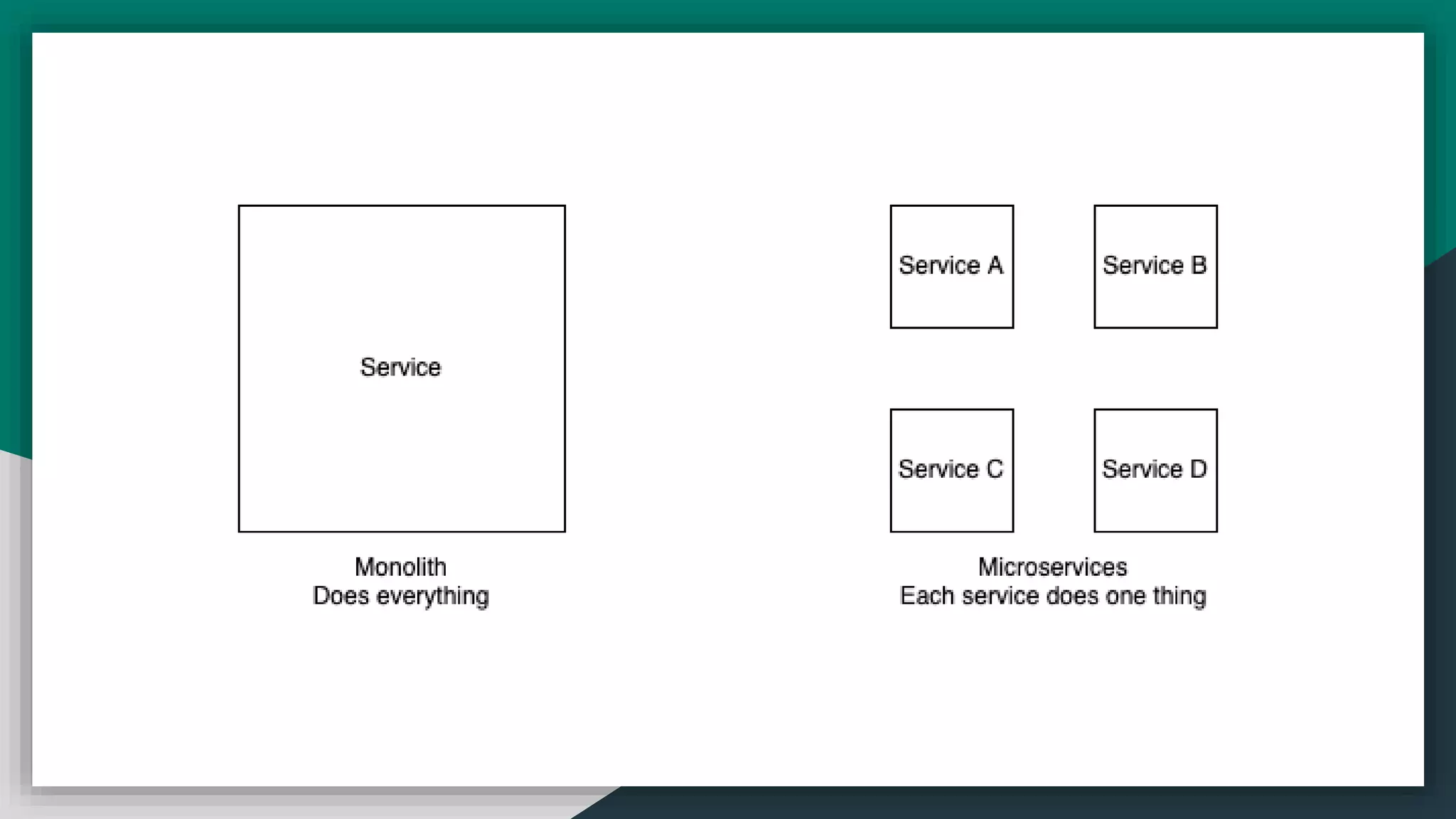


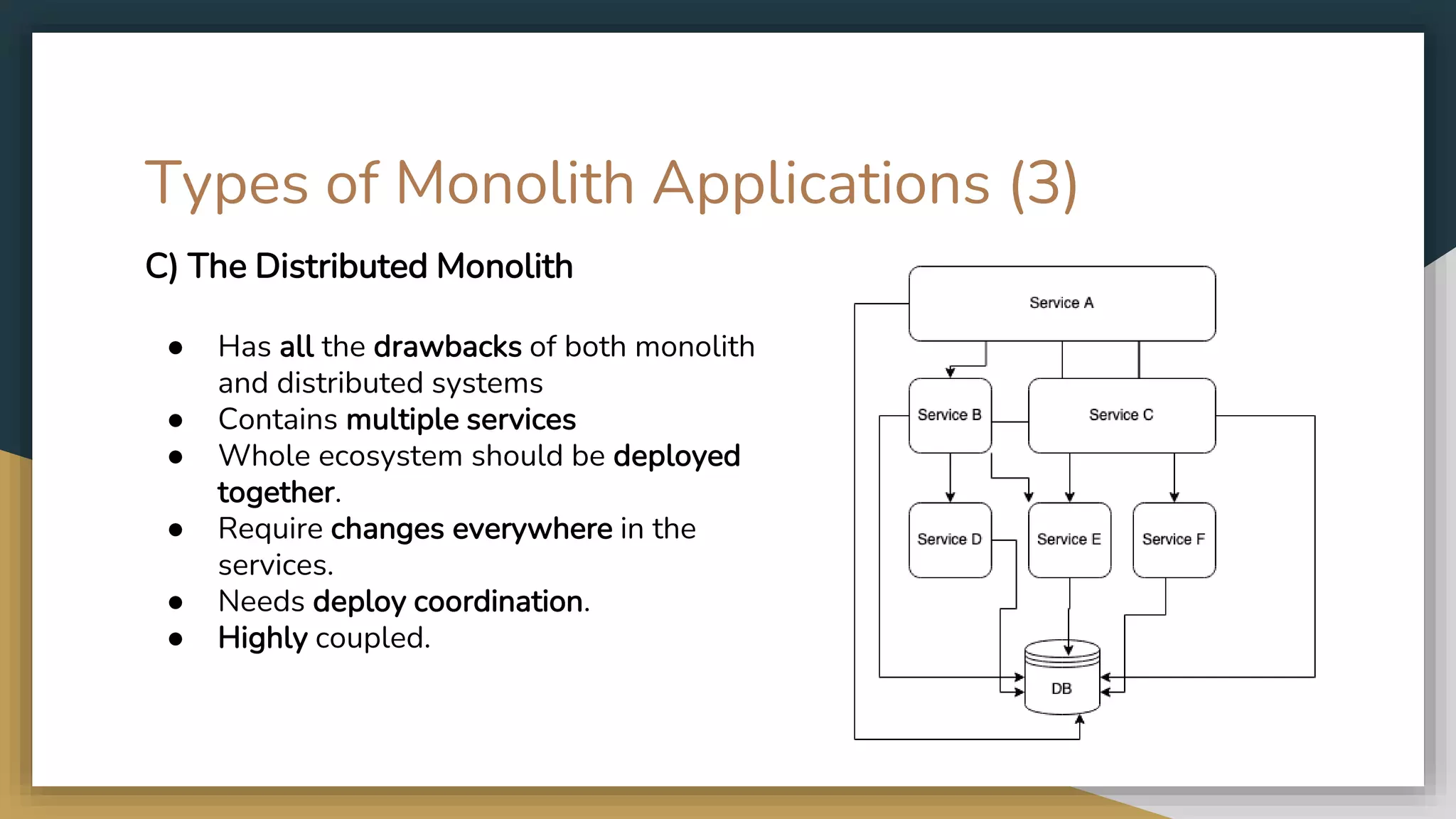

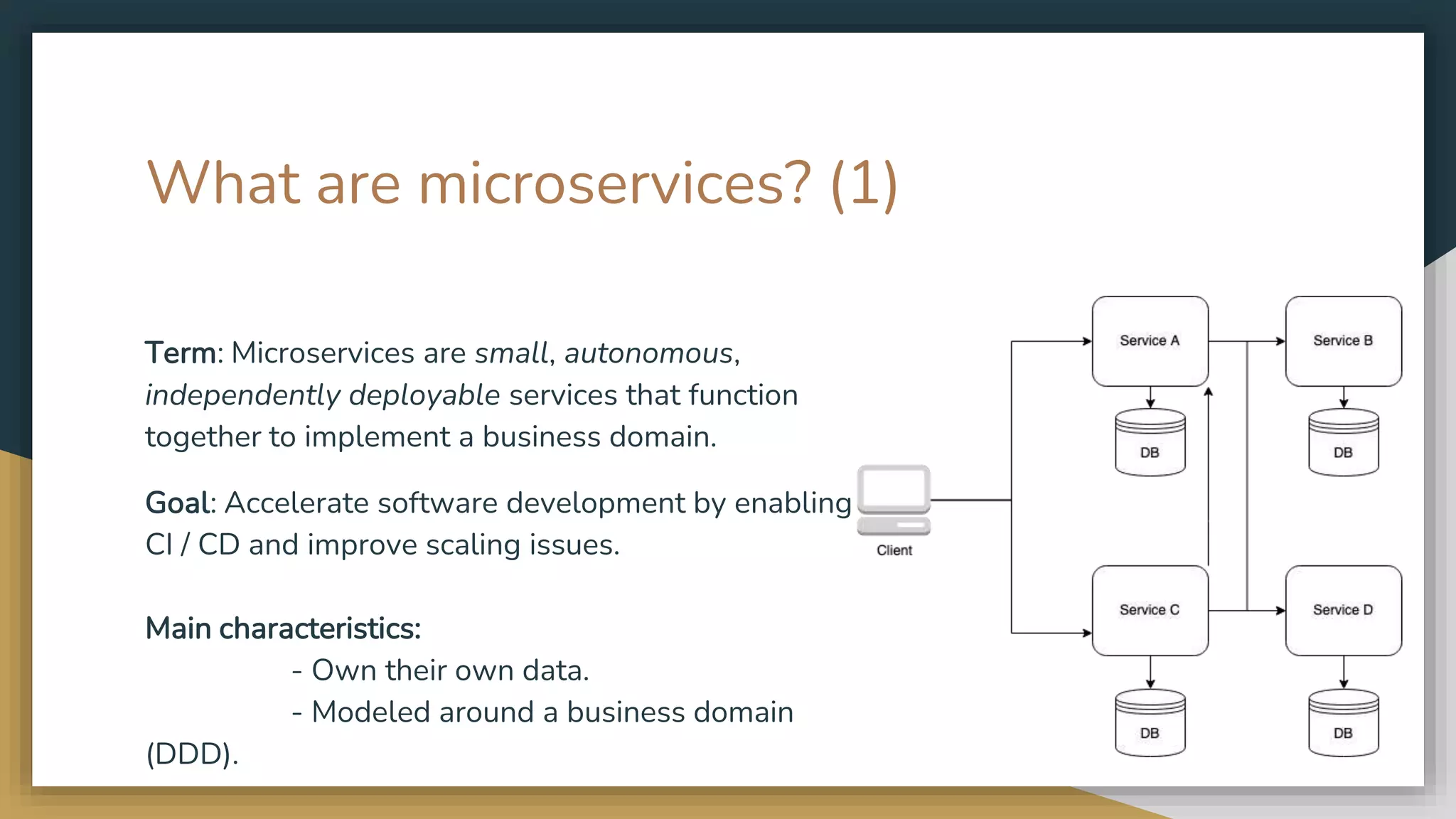


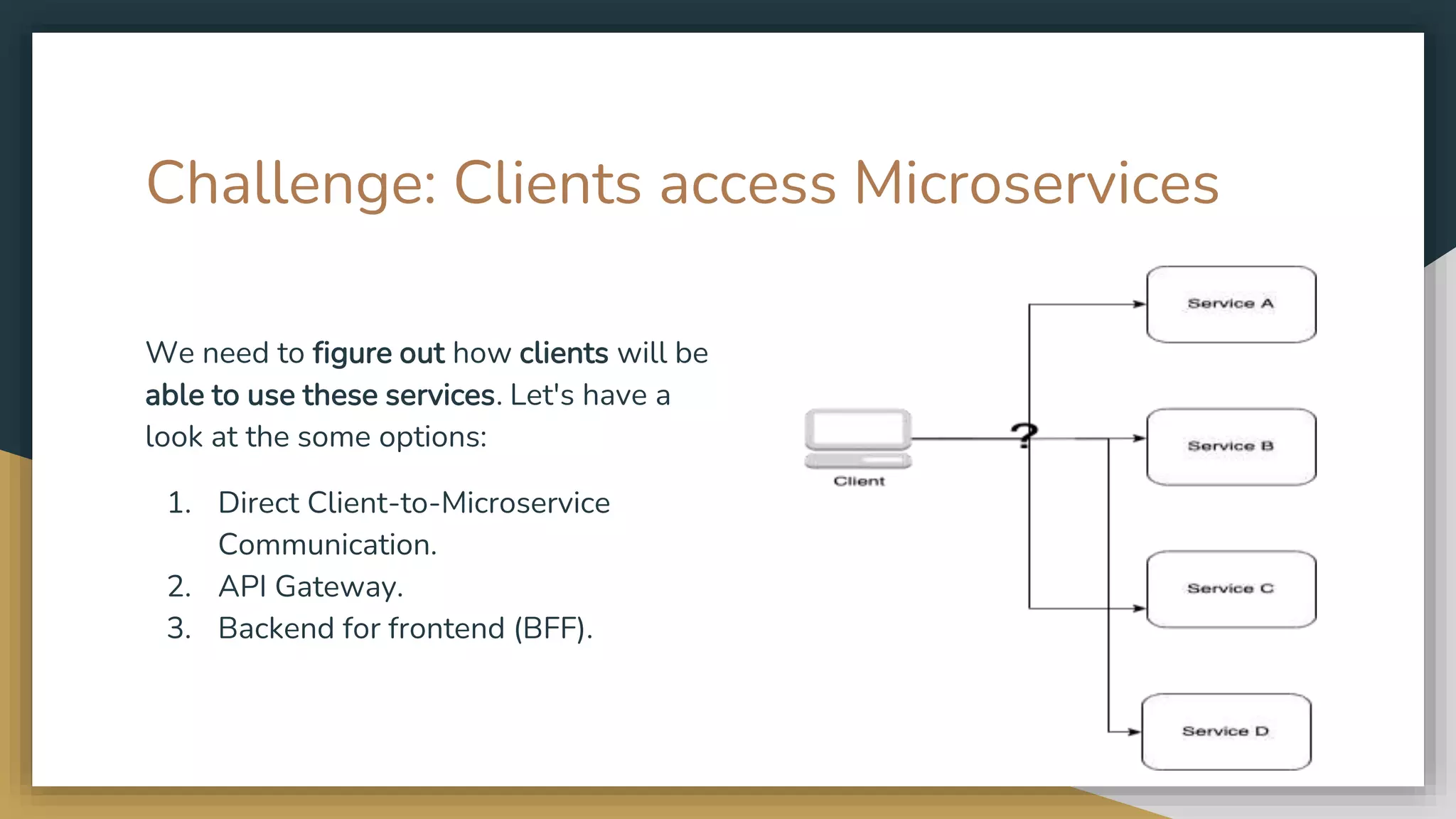

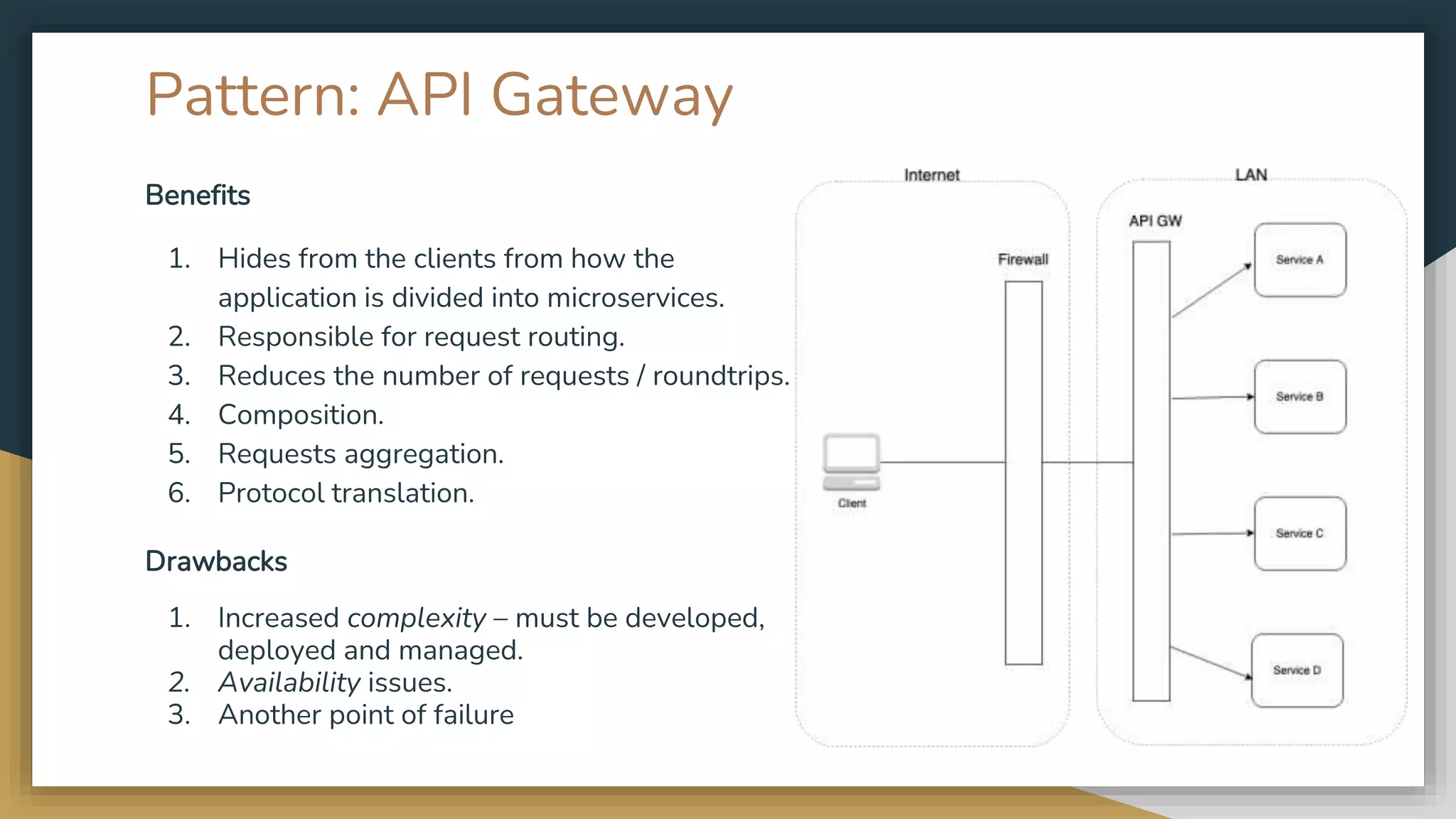

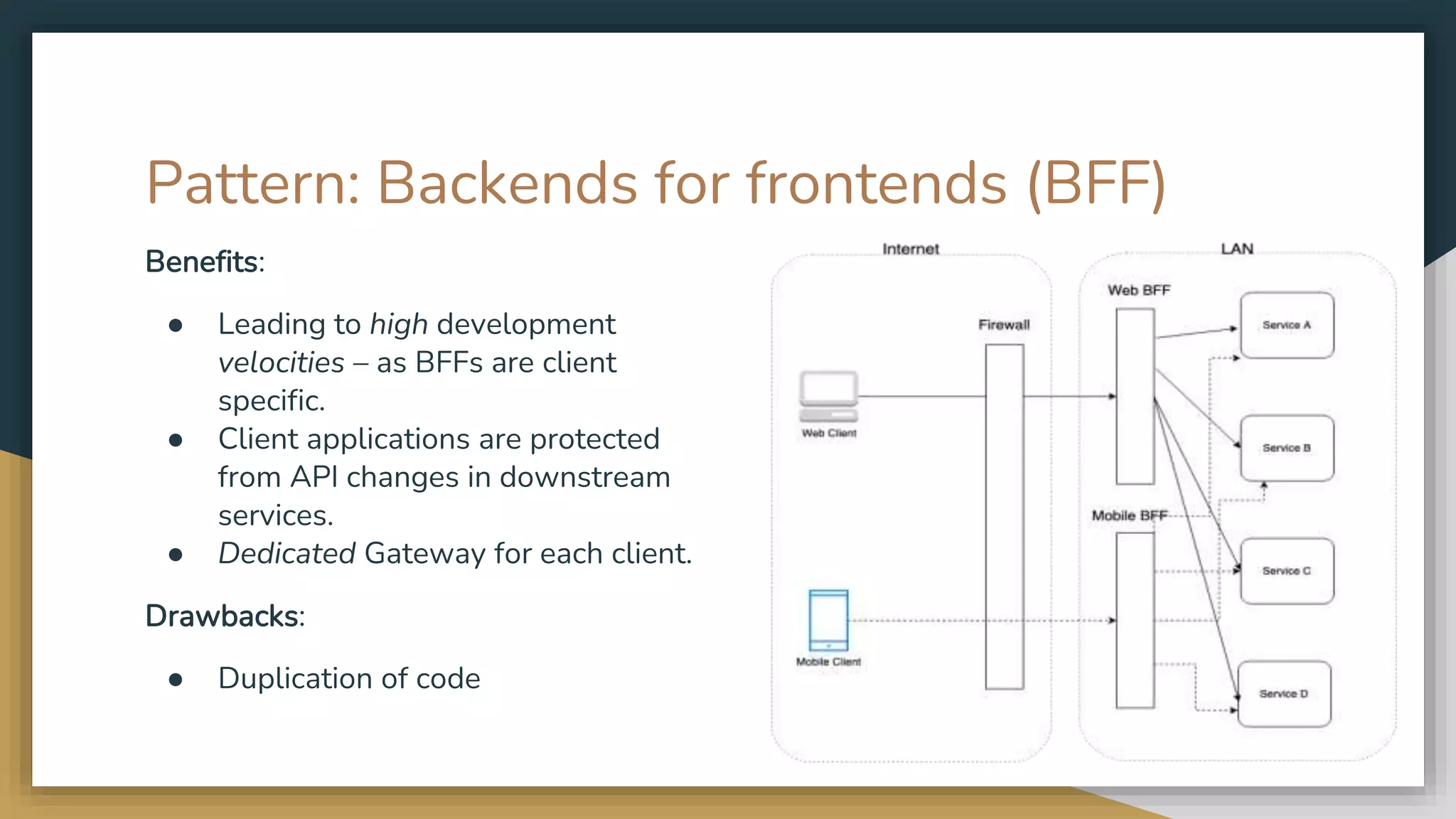

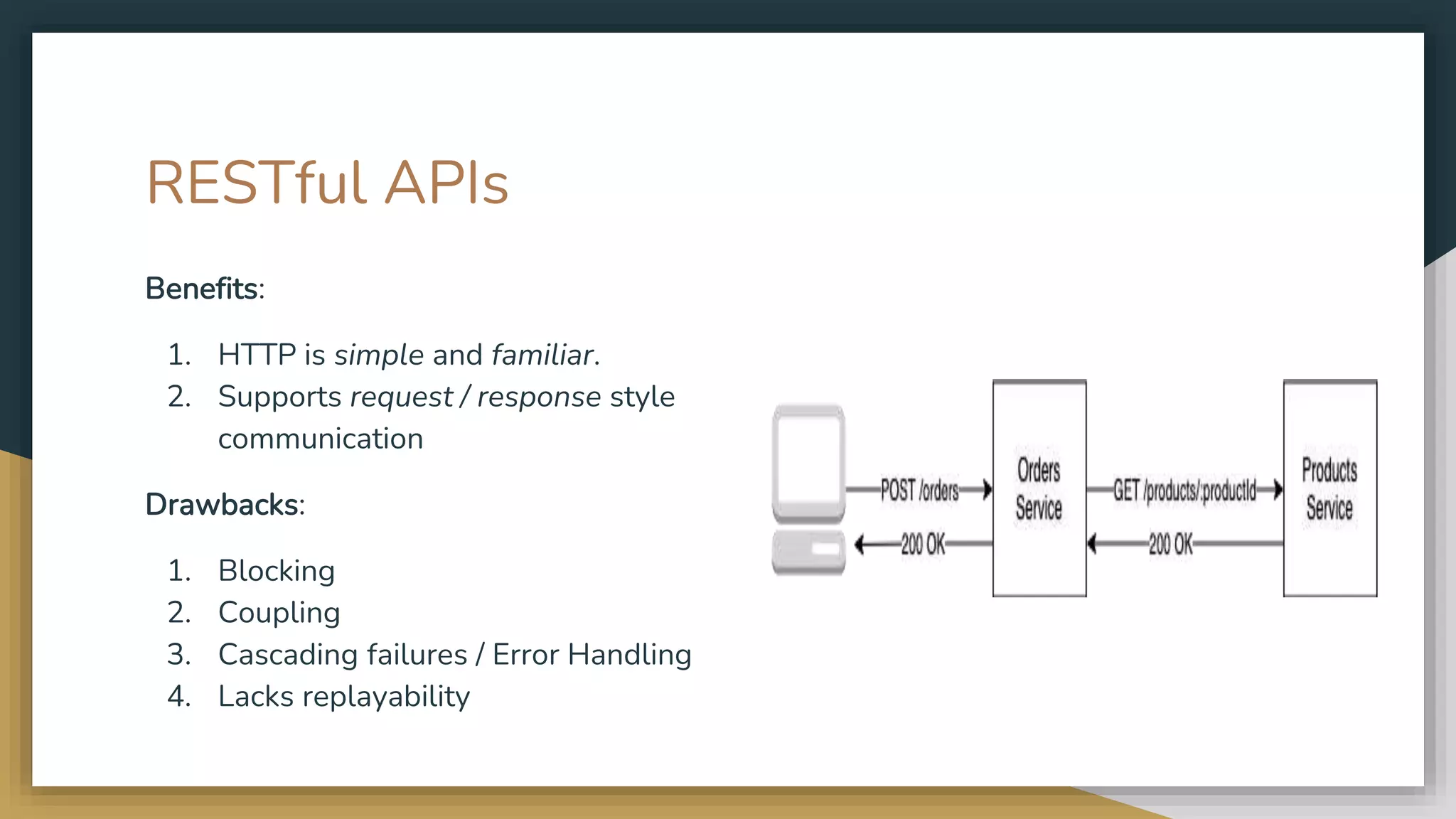
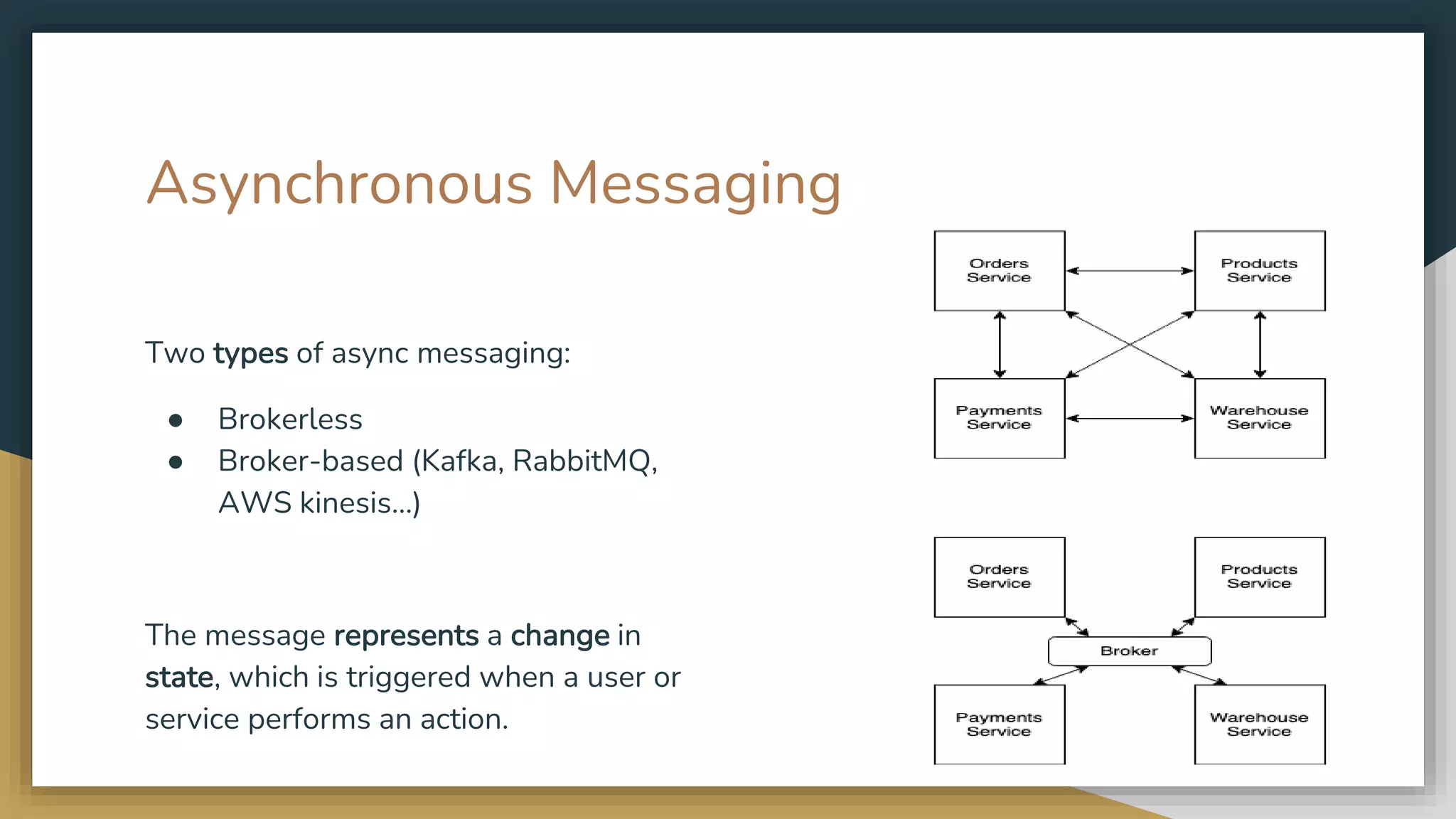
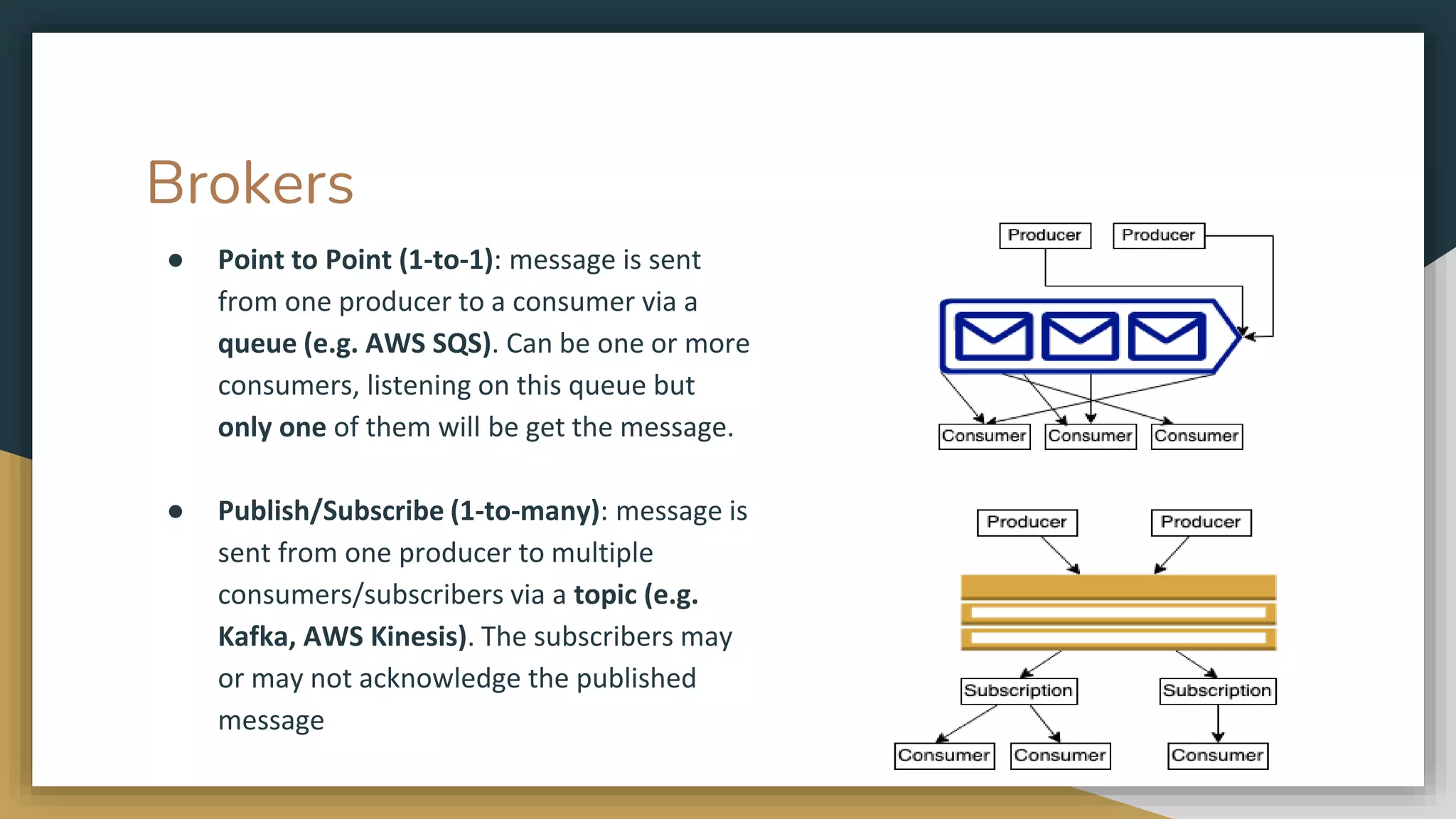


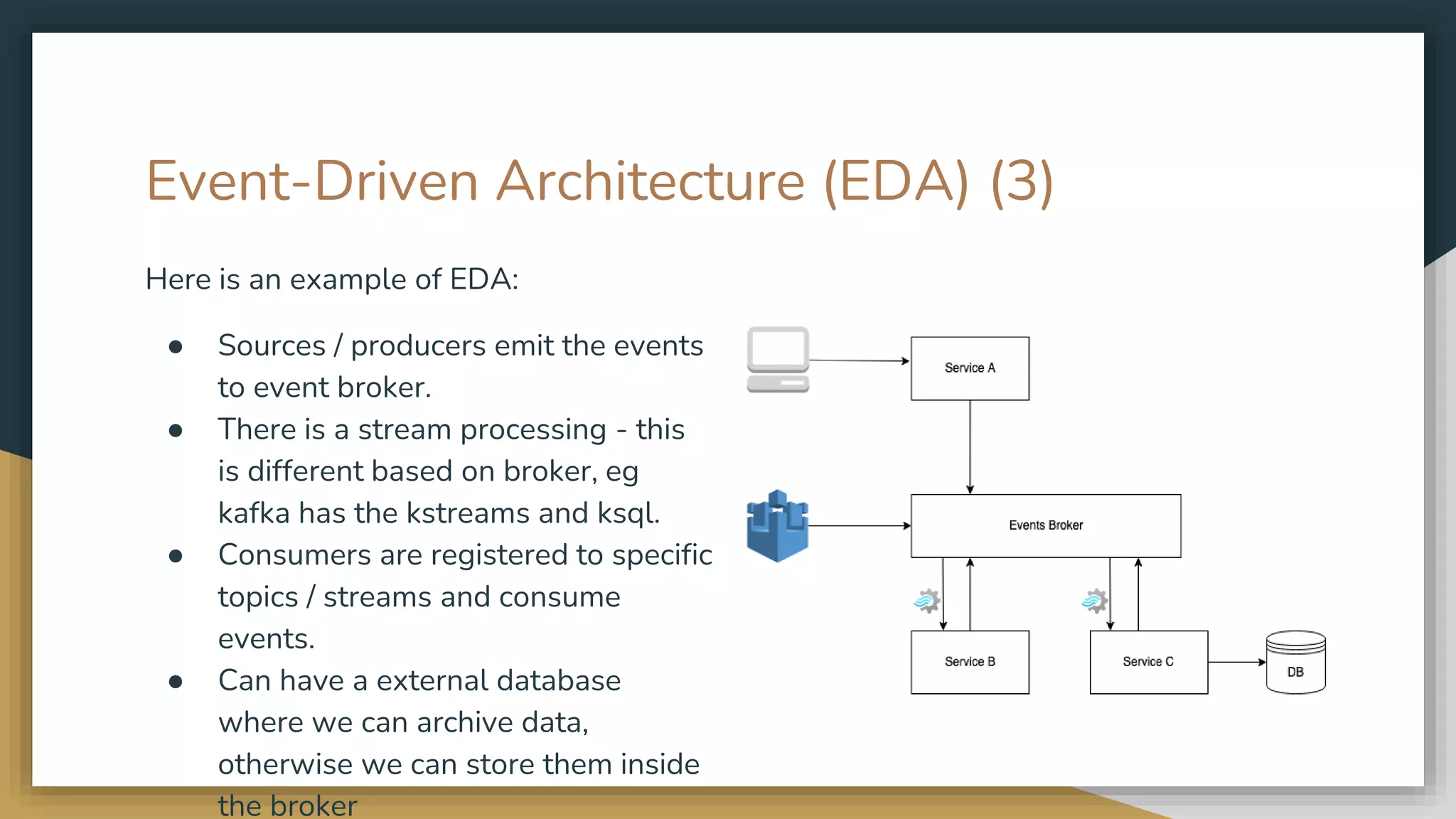
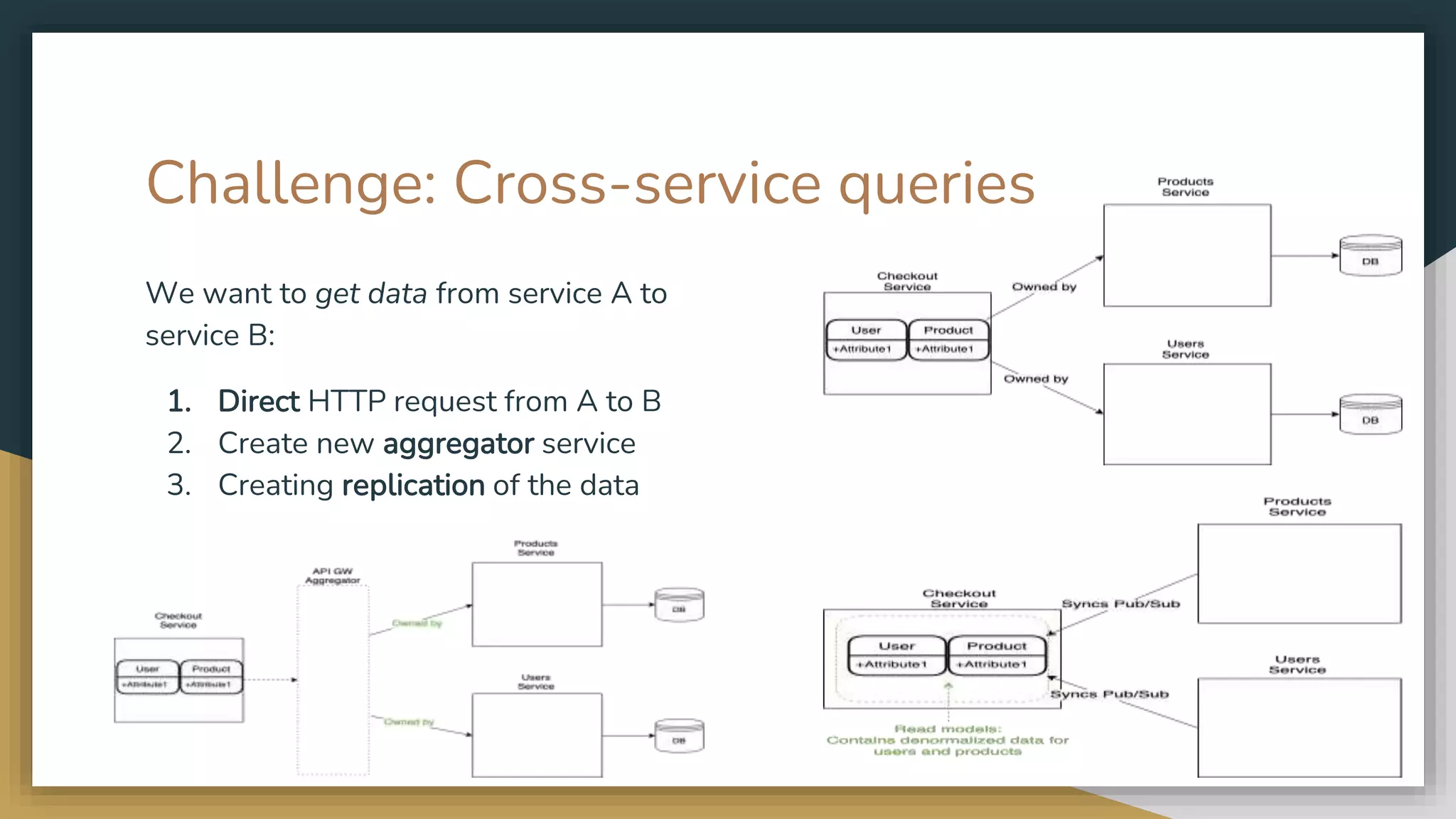
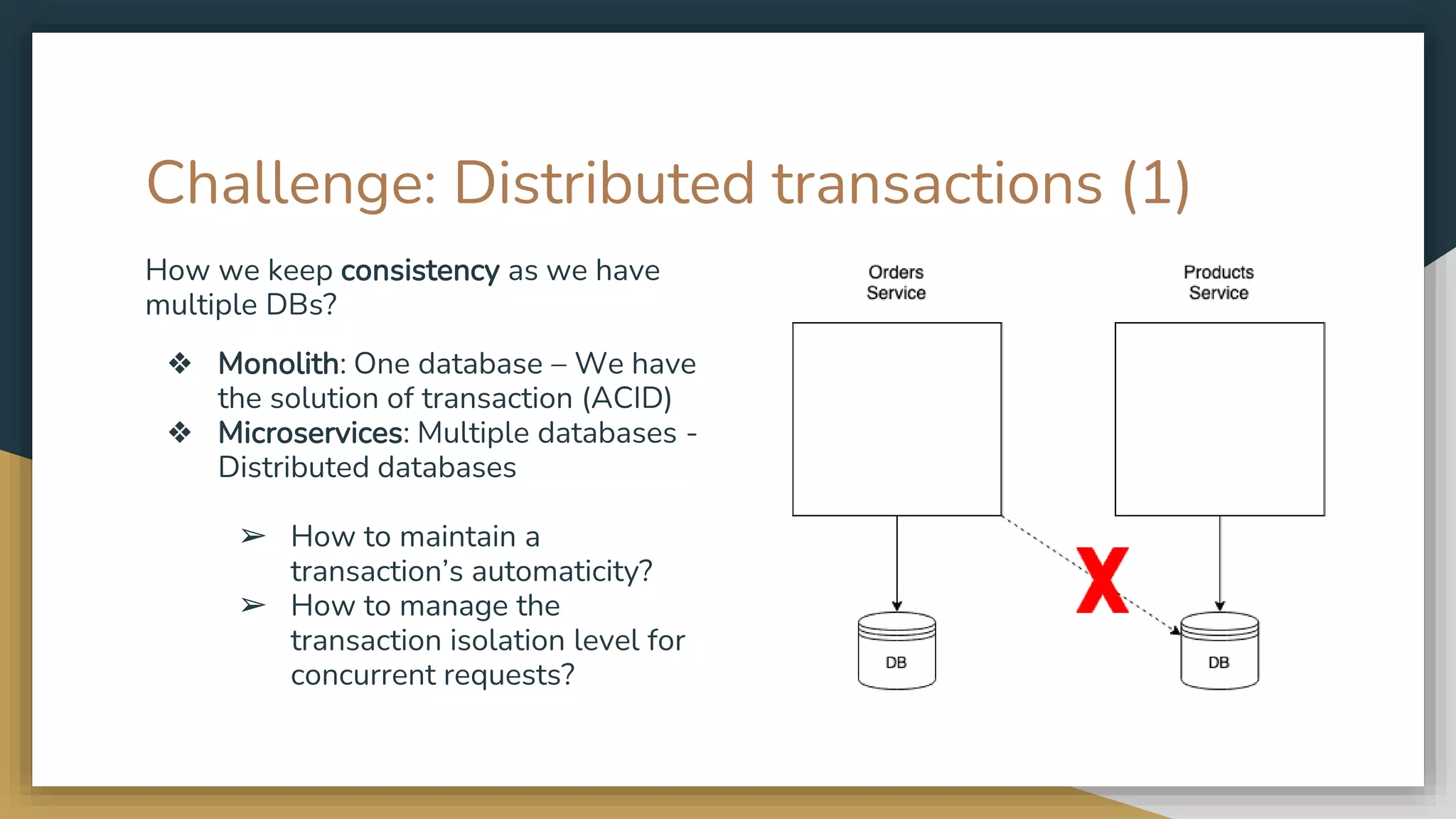

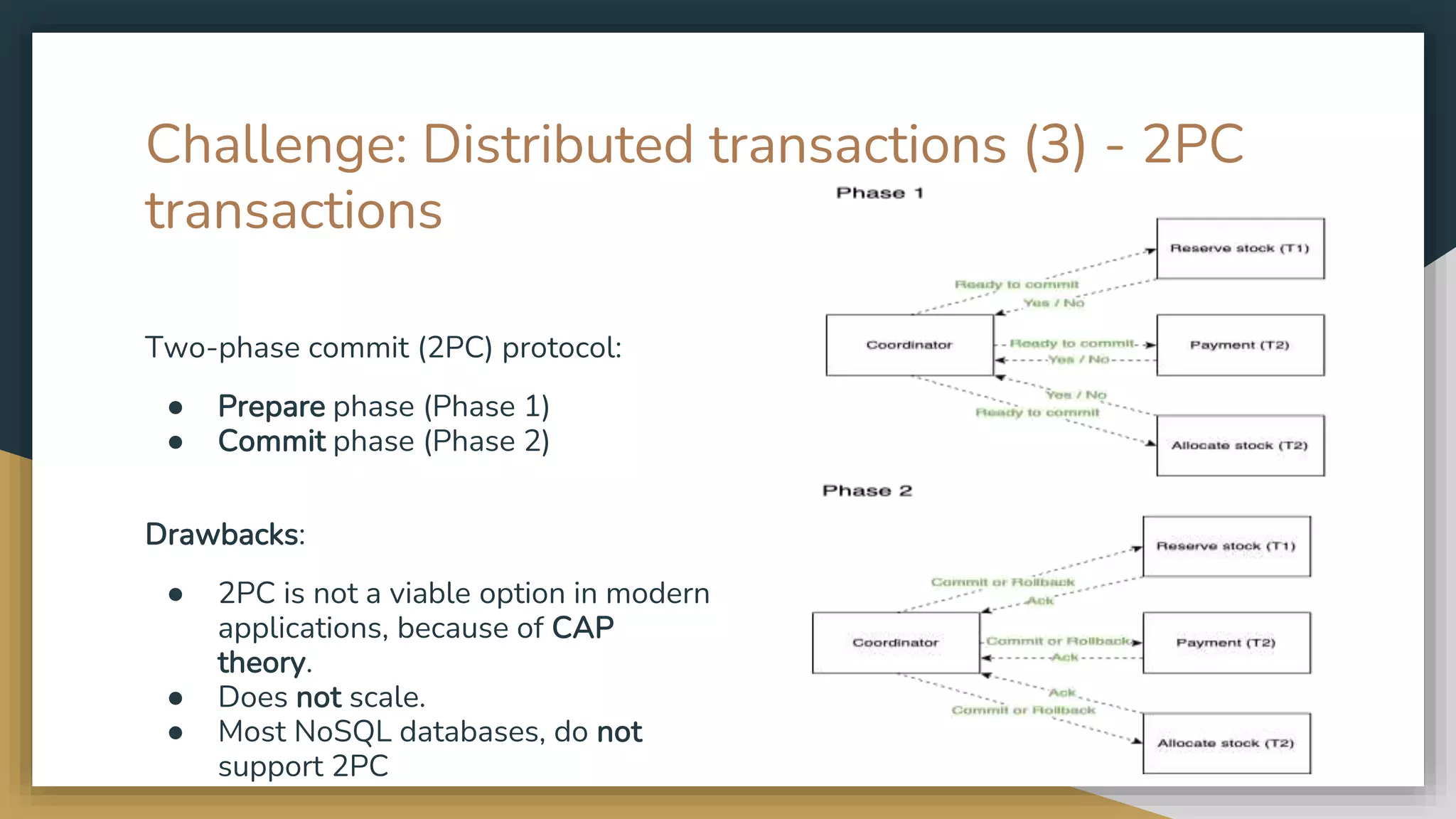
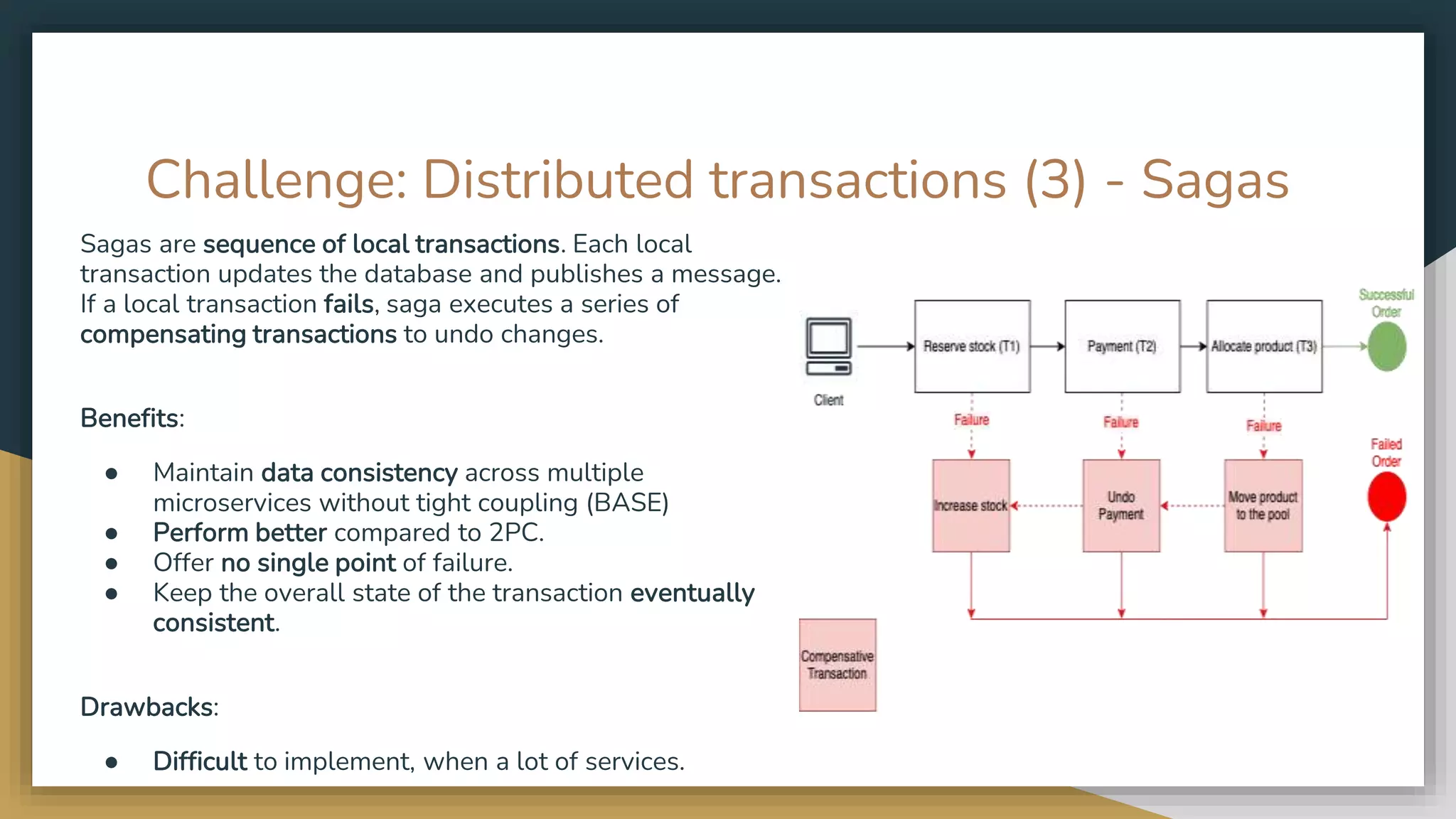

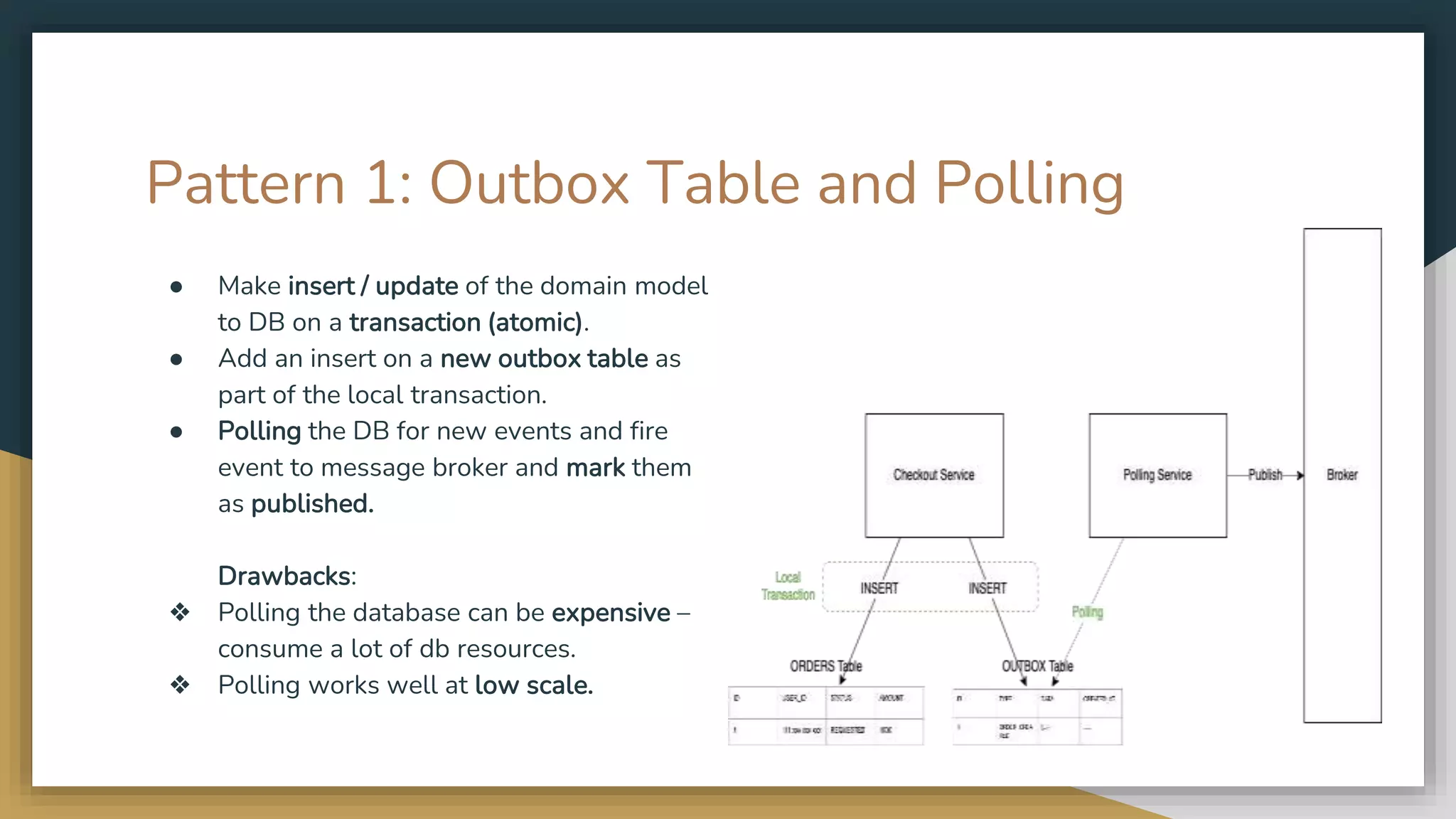
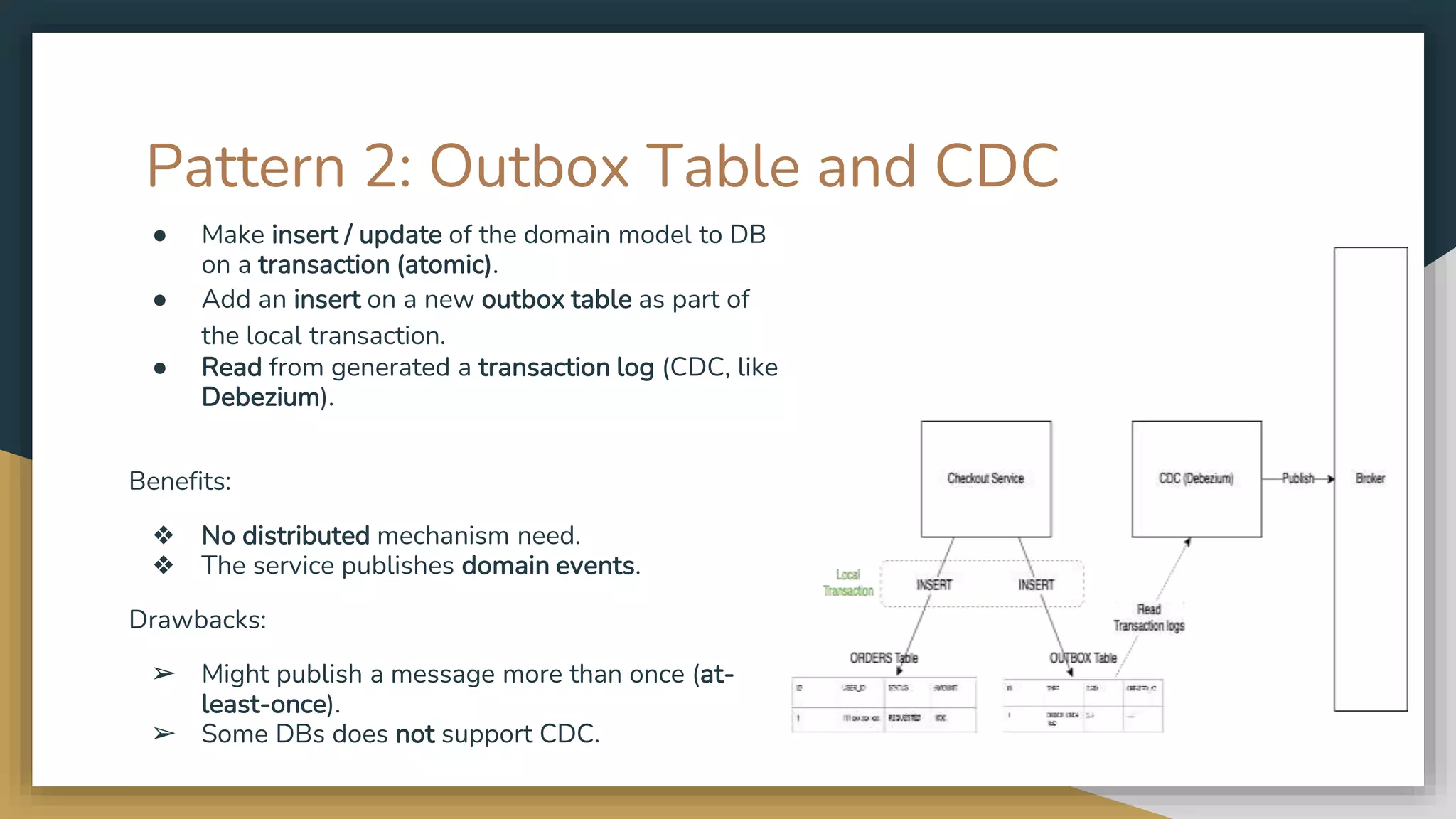
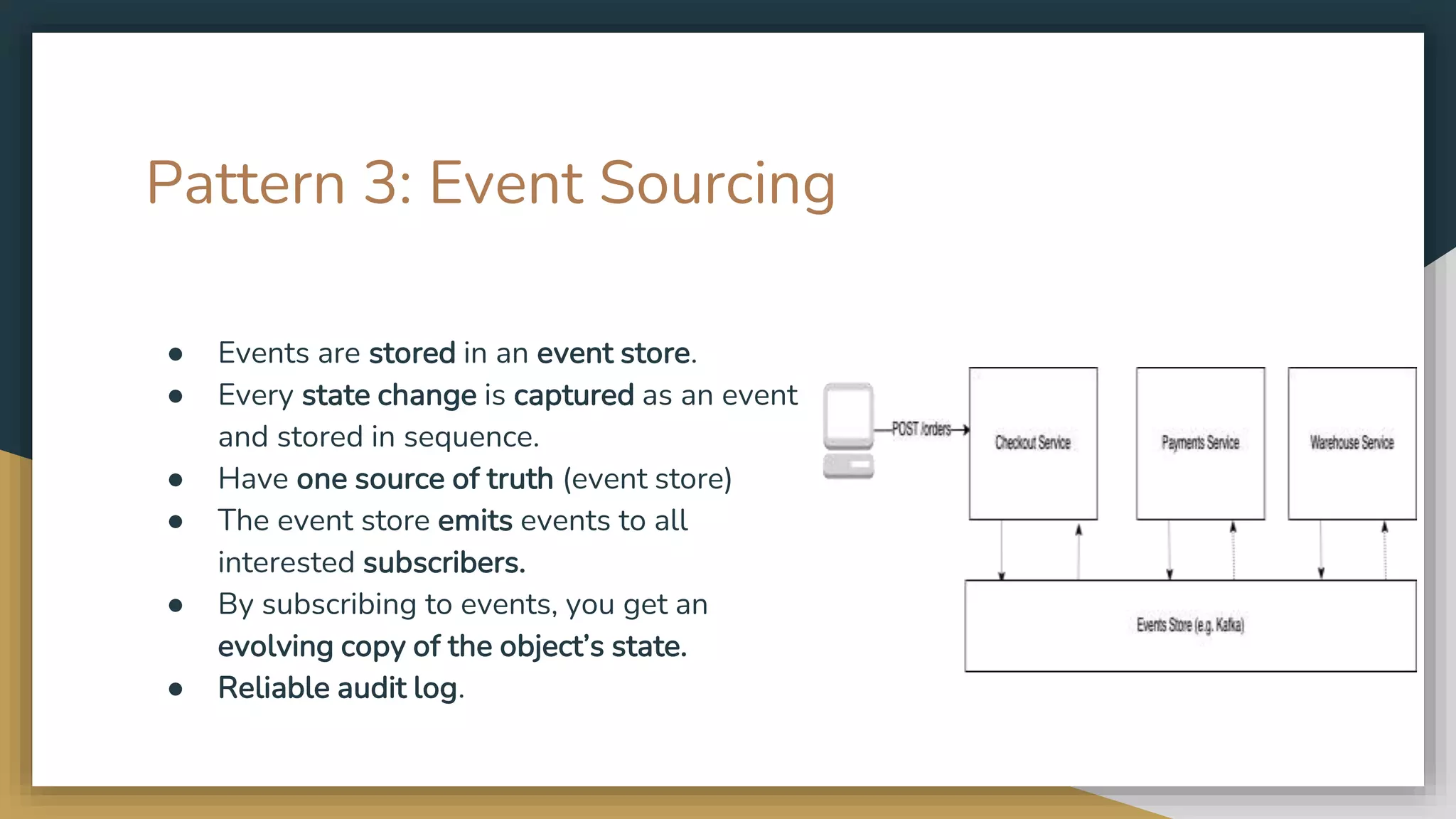





The document provides an overview of microservices and monolithic application architectures, detailing their types, advantages, and disadvantages. It discusses challenges associated with microservices, such as data ownership, inter-process communication, and ensuring data consistency in distributed systems. It also covers various patterns for implementing microservices, including API gateways, event-driven architectures, and transaction management strategies like sagas and the outbox pattern.