Download as PDF, PPTX

































The document outlines a series of upcoming workshops focused on data modernization, analytics, and data governance, hosted by CCG. It features sessions on machine learning fundamentals, classification, and clustering methods, aiming to provide insights into the applications and advantages of machine learning in various business contexts. Additionally, it mentions the importance of aligning people, processes, technology, and data for effective machine learning implementation.
Workshops on Data Modernization, Analytics with Synapse, and Data Governance, hosted by CCG.
Housekeeping information for participants regarding session recording and questions.
Introduction to the role of machine learning in analytics and data processing.
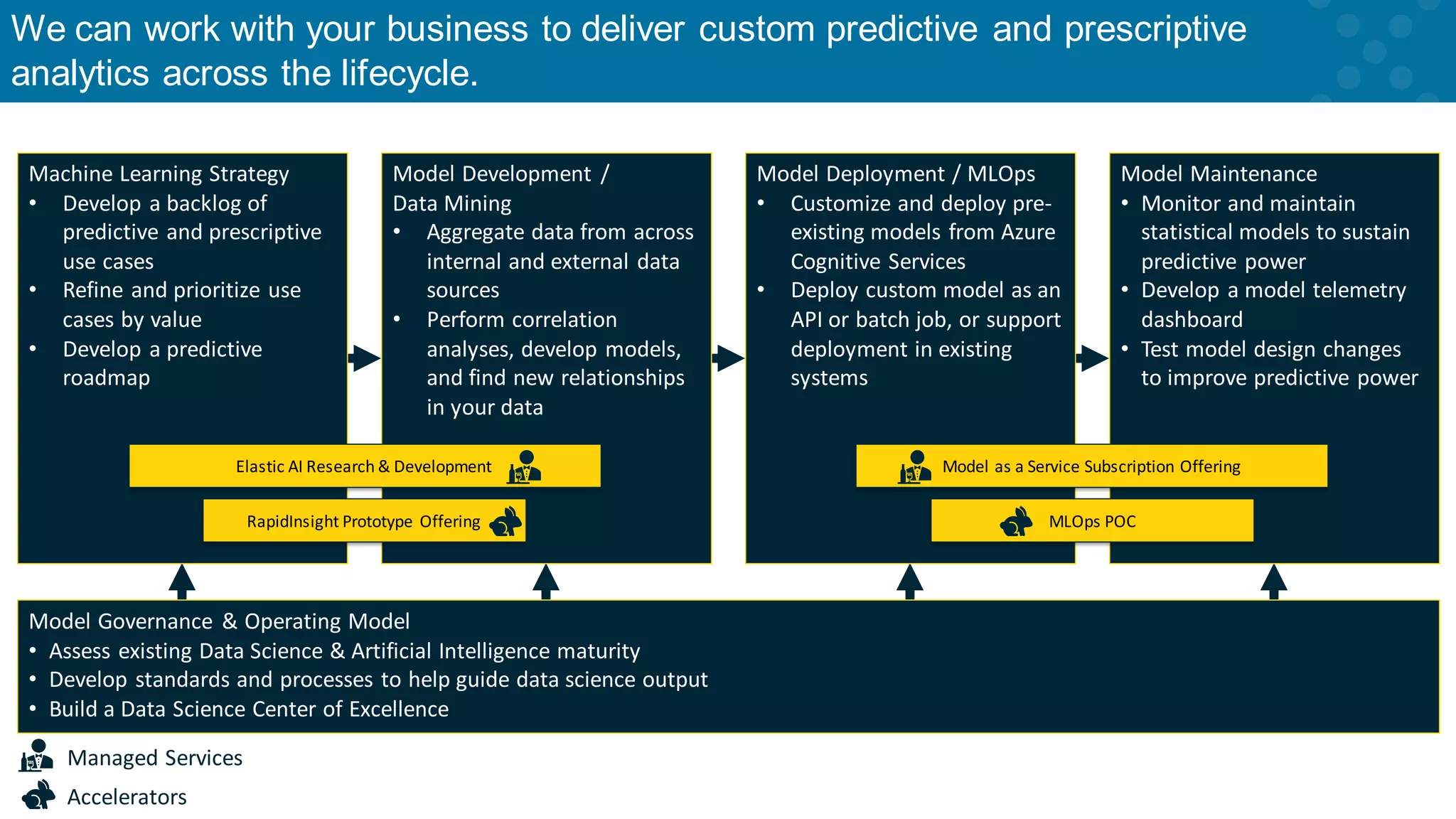
Overview of CCG's cloud analytics services including Data Governance and AI solutions.
Introduction of Brian Beesley, Data Science Practice Director at CCG, and his experience.
Agenda for workshops including topics like Azure Machine Learning and Databricks.
Basic concepts and applications of machine learning in business contexts.
Overview of the agenda for the machine learning discussion including key questions.
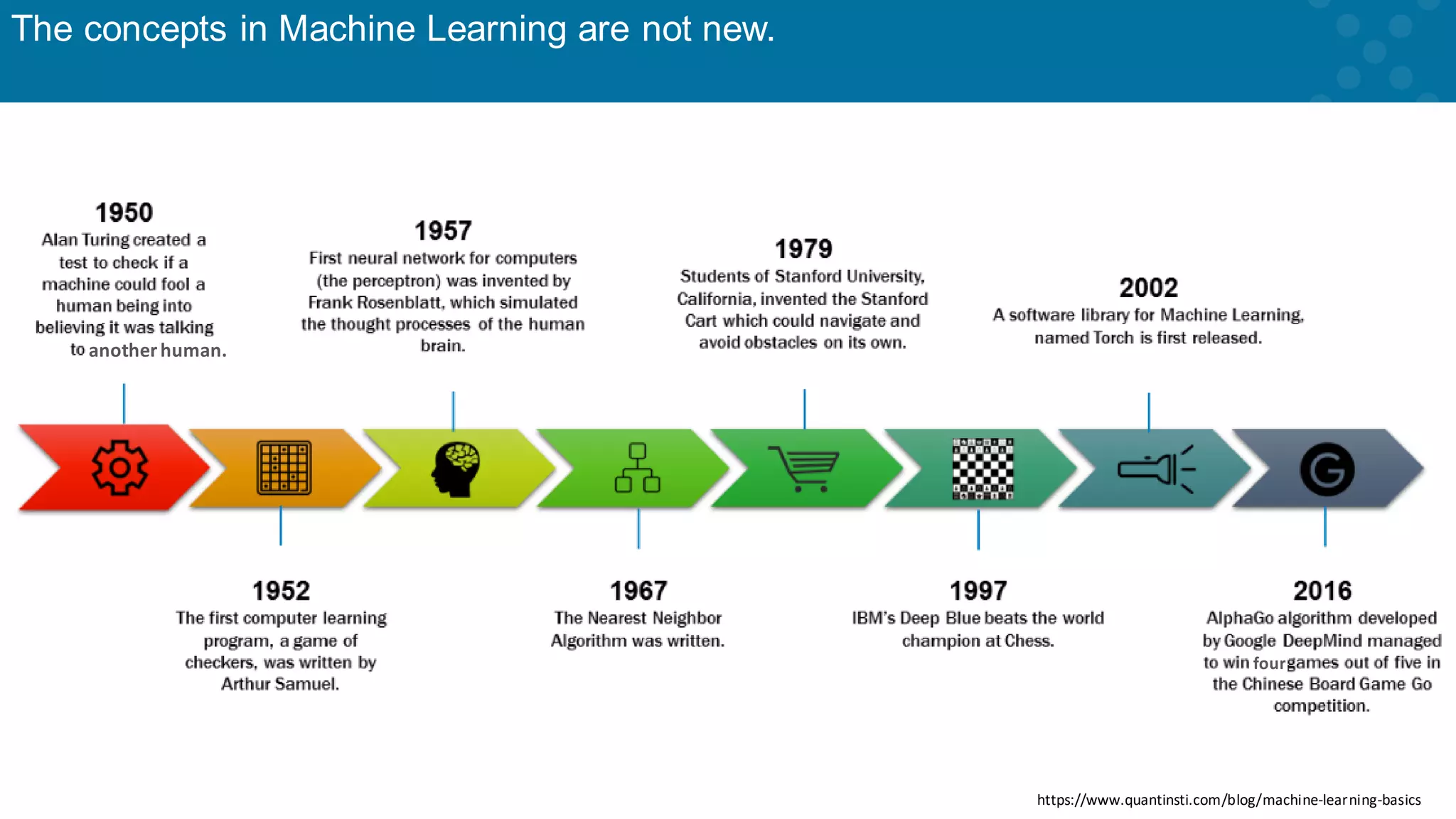
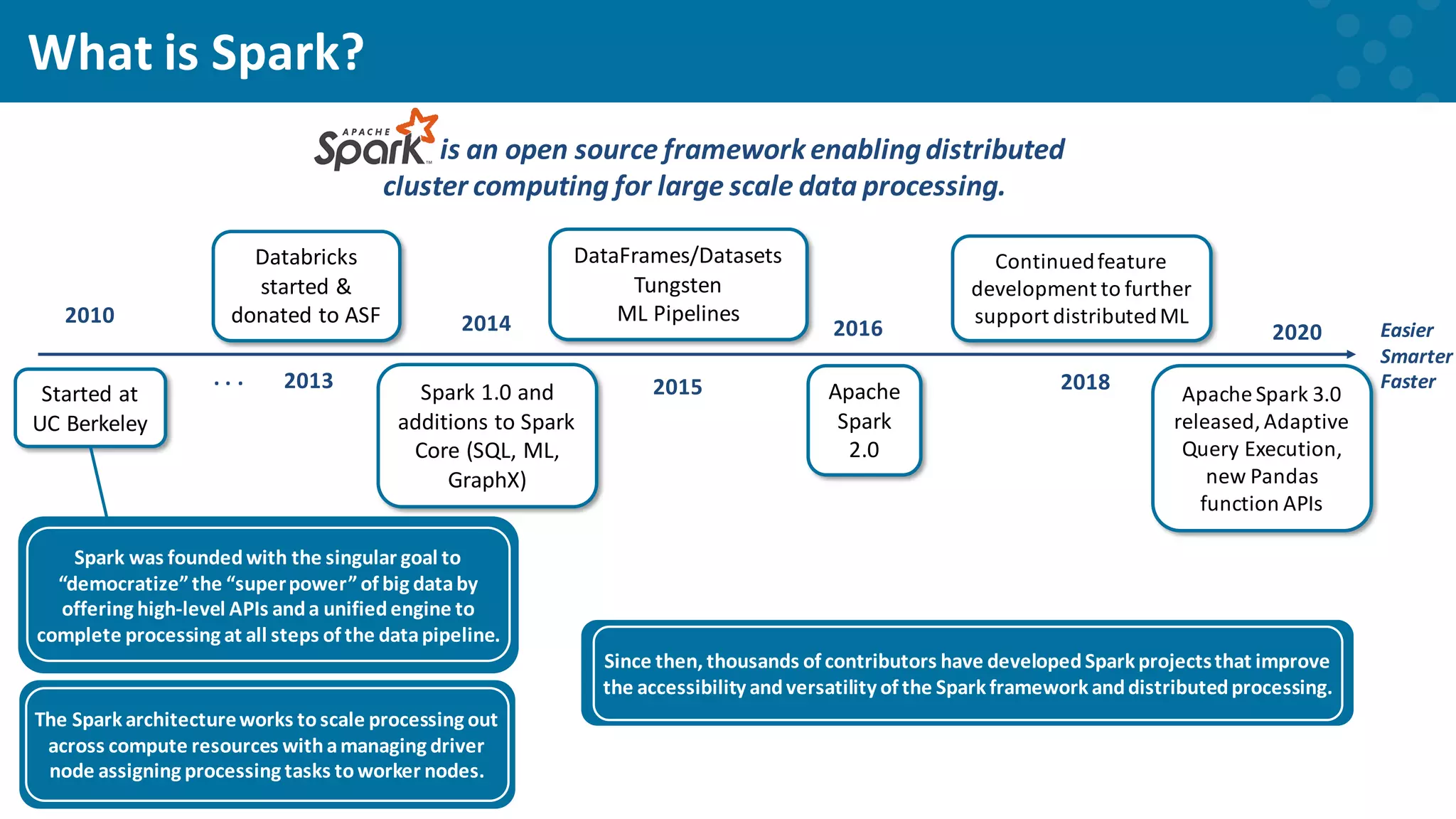
Notes on the enduring concepts of machine learning and its increasing relevance.
Factors like data availability and technological advancements that boost machine learning.
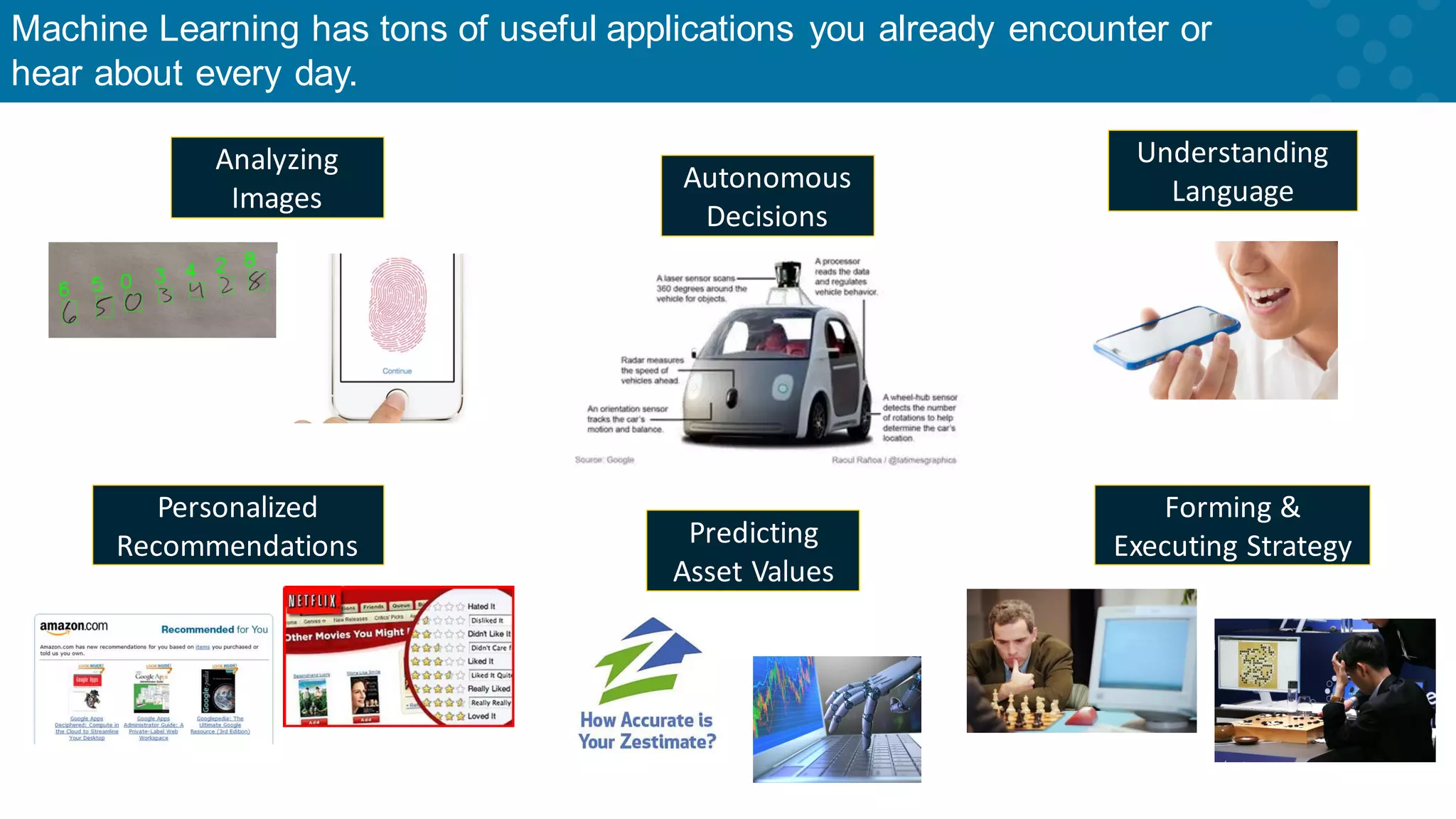
Common ML applications include image analysis, language processing, and decision-making.
Examples of ML applications in sales, finance, operations, and service sectors.
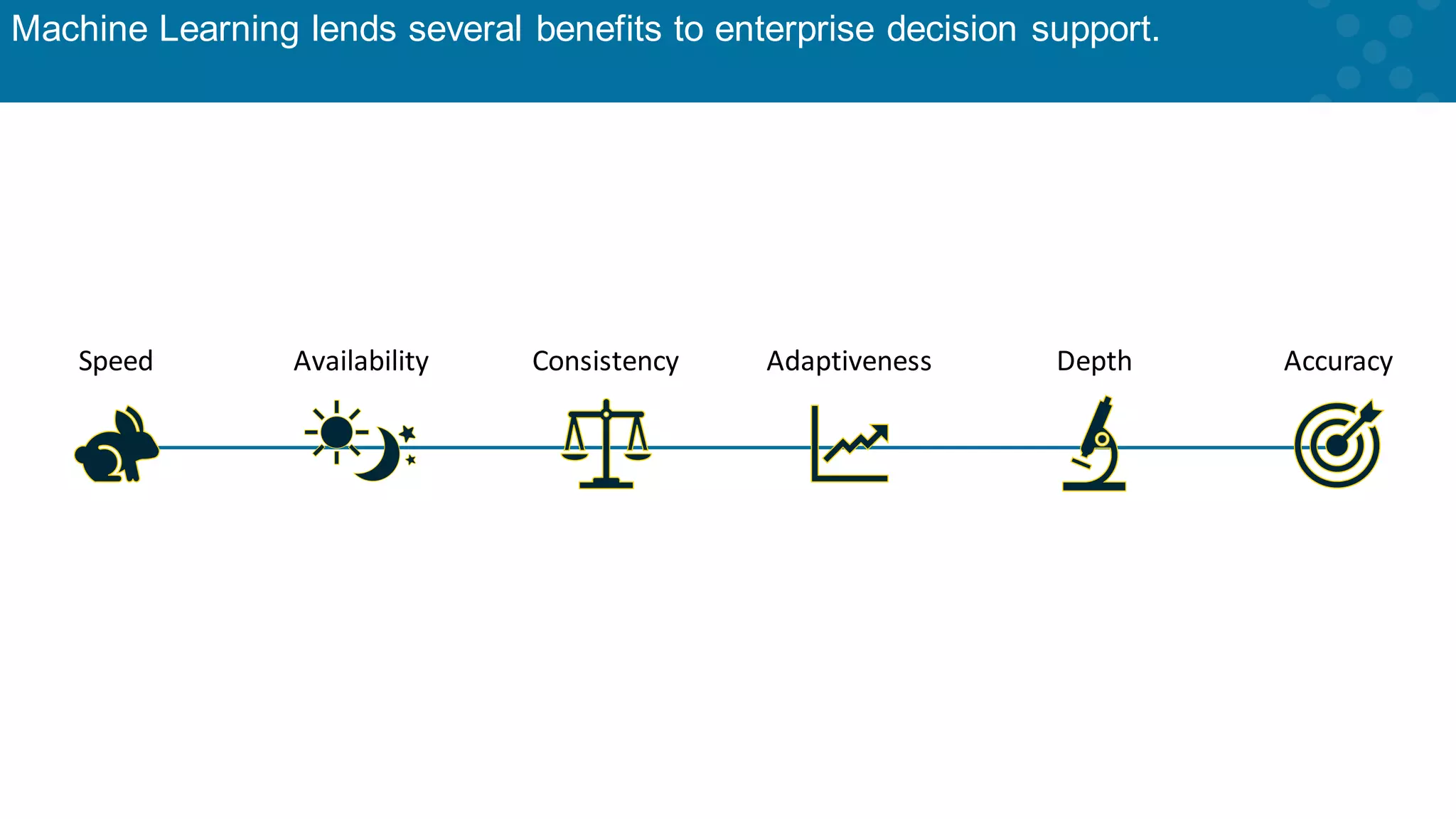
Machine learning enhances enterprise decision support through predictive insights.
Recap of the machine learning agenda with key questions regarding its implementation.
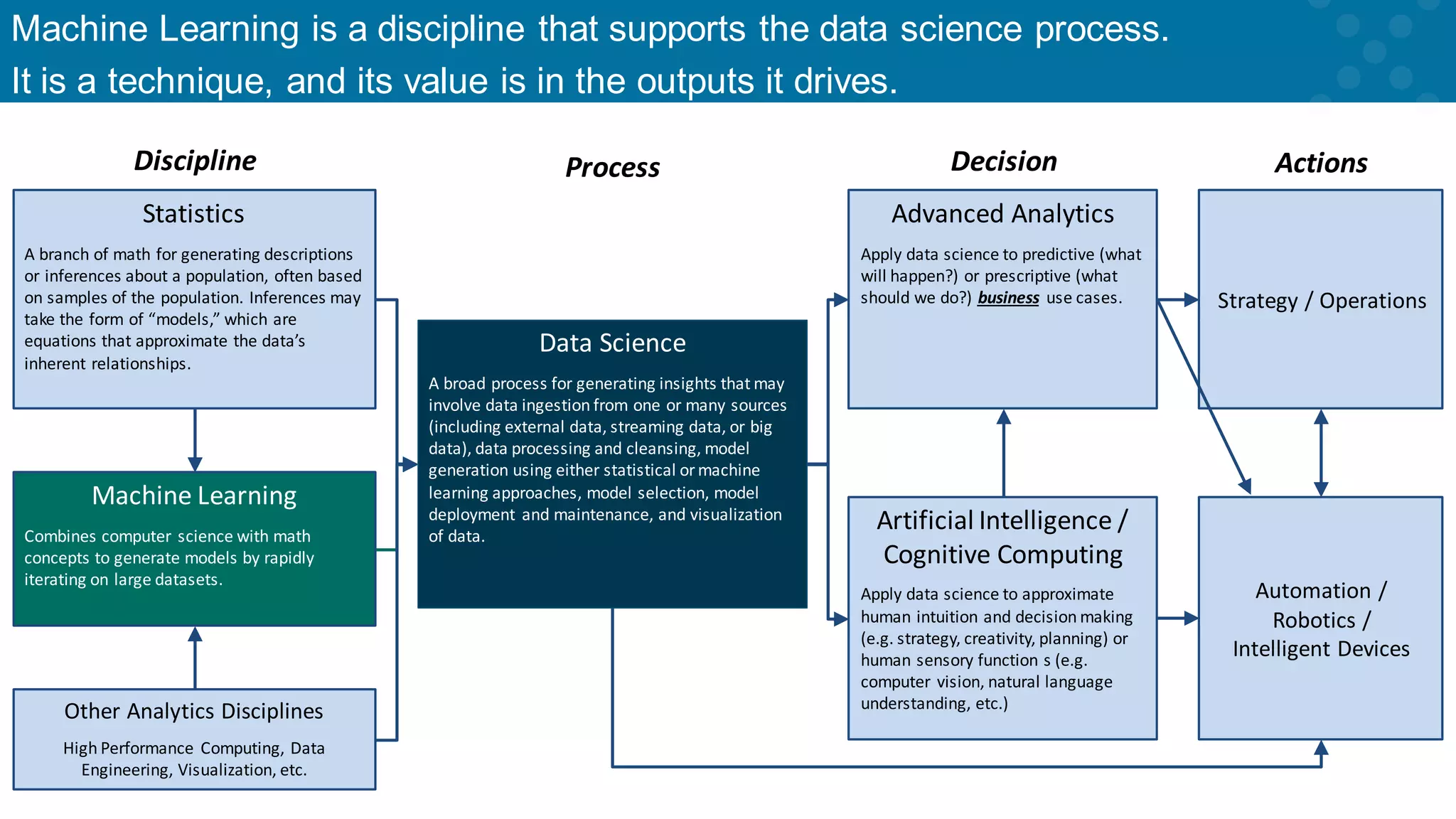
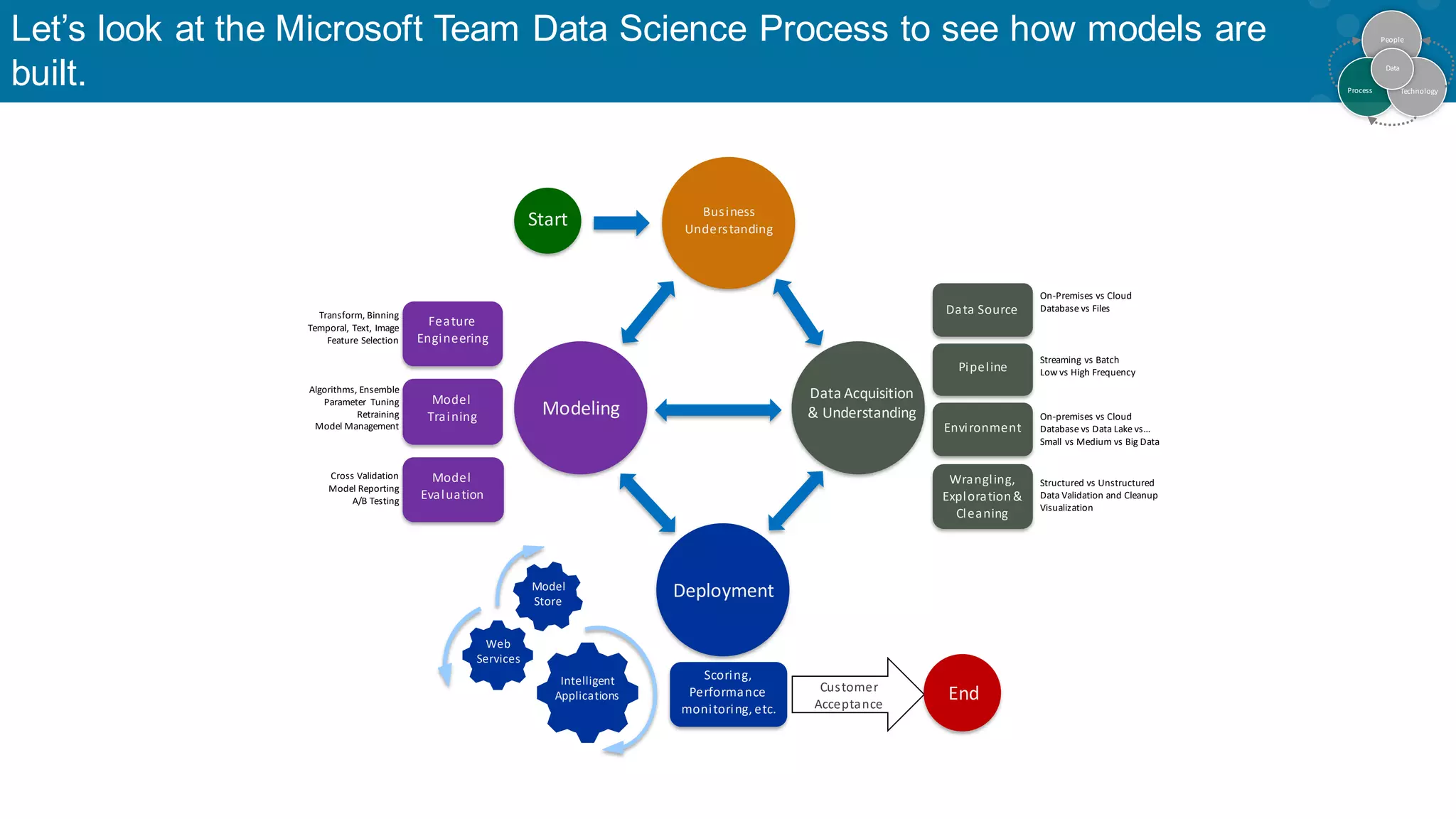
Machine learning is part of a broader data science process impacting decision-making.
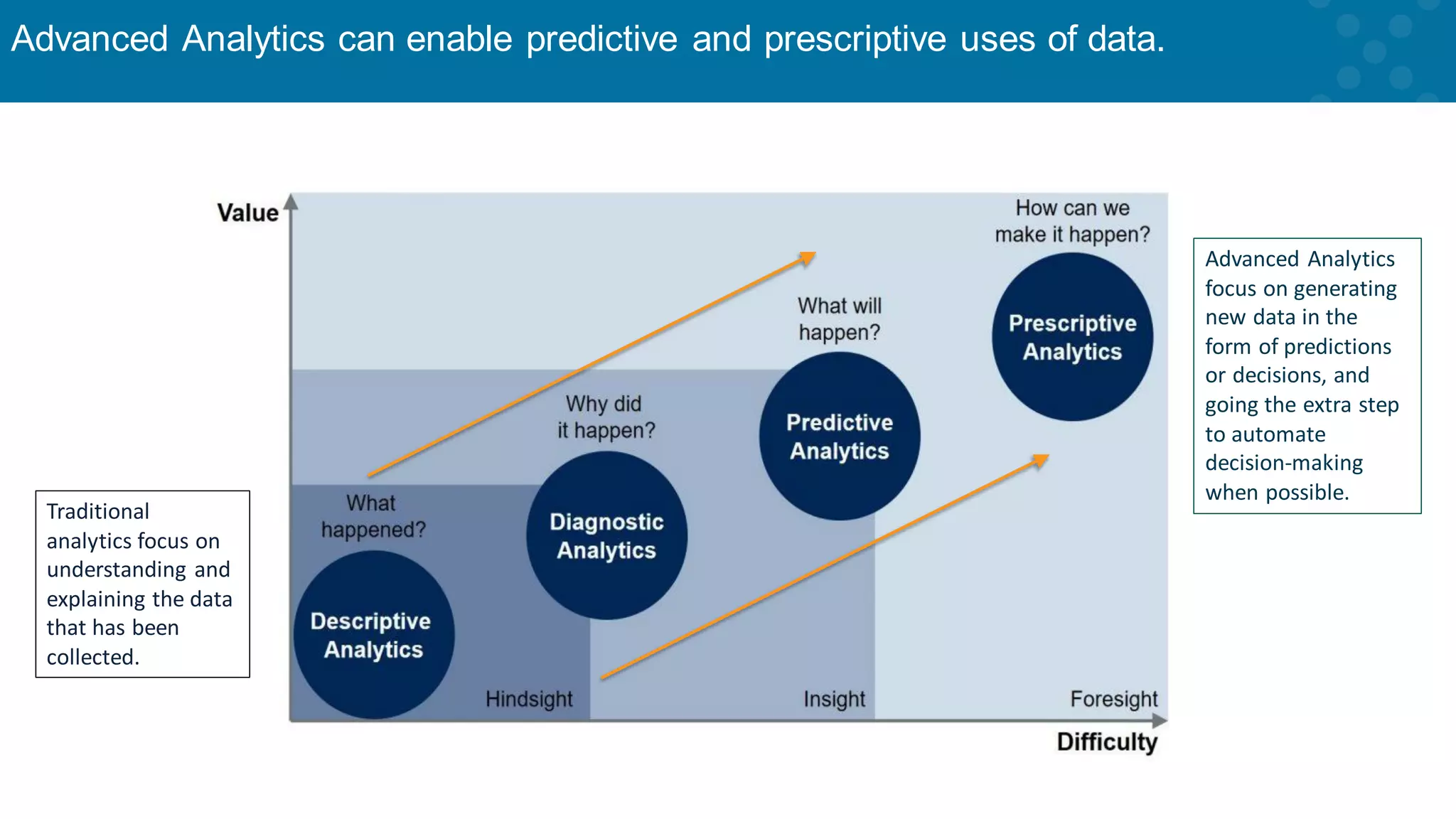
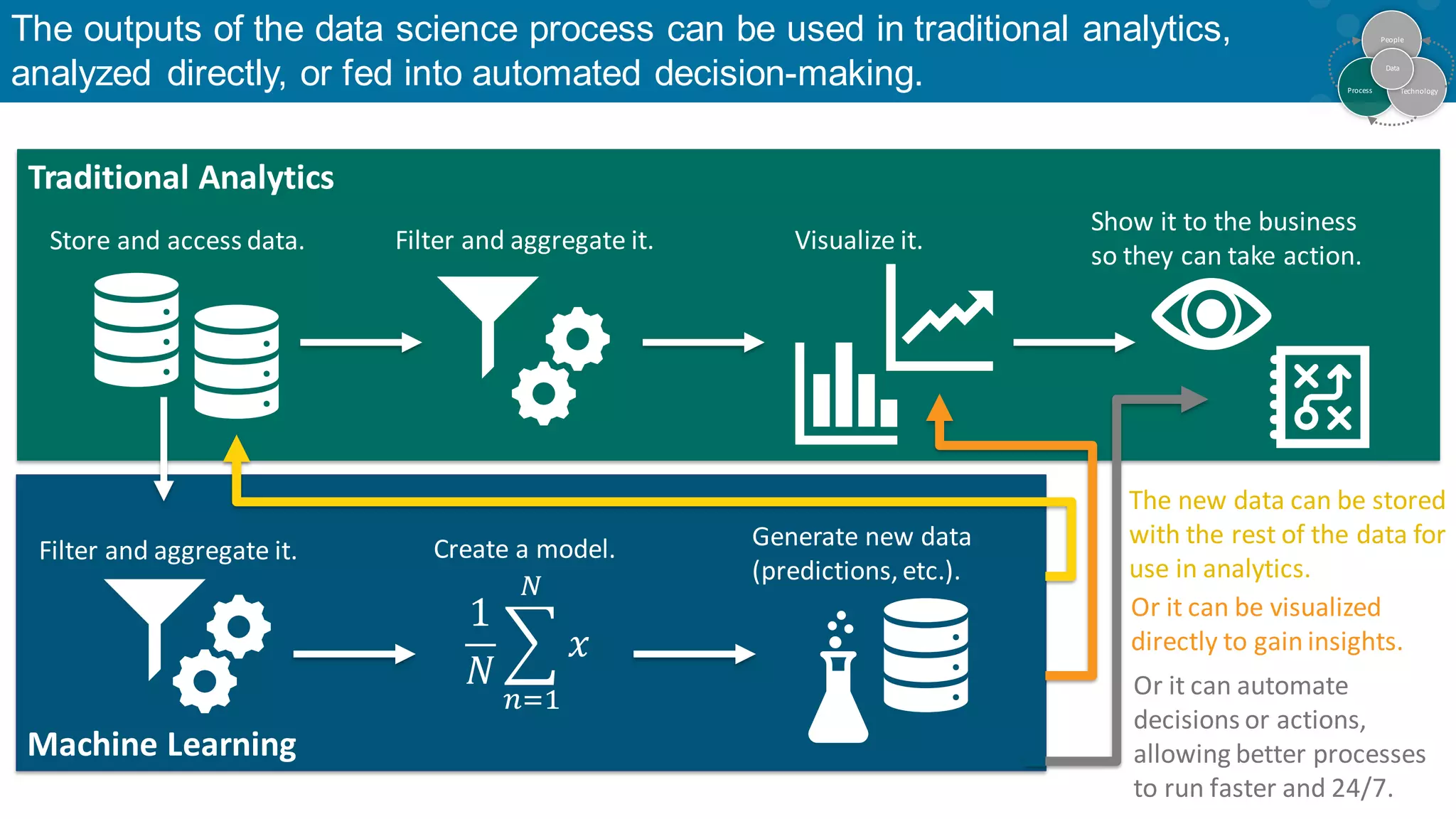
Distinction between traditional analytics and advanced analytics for predictive insights.
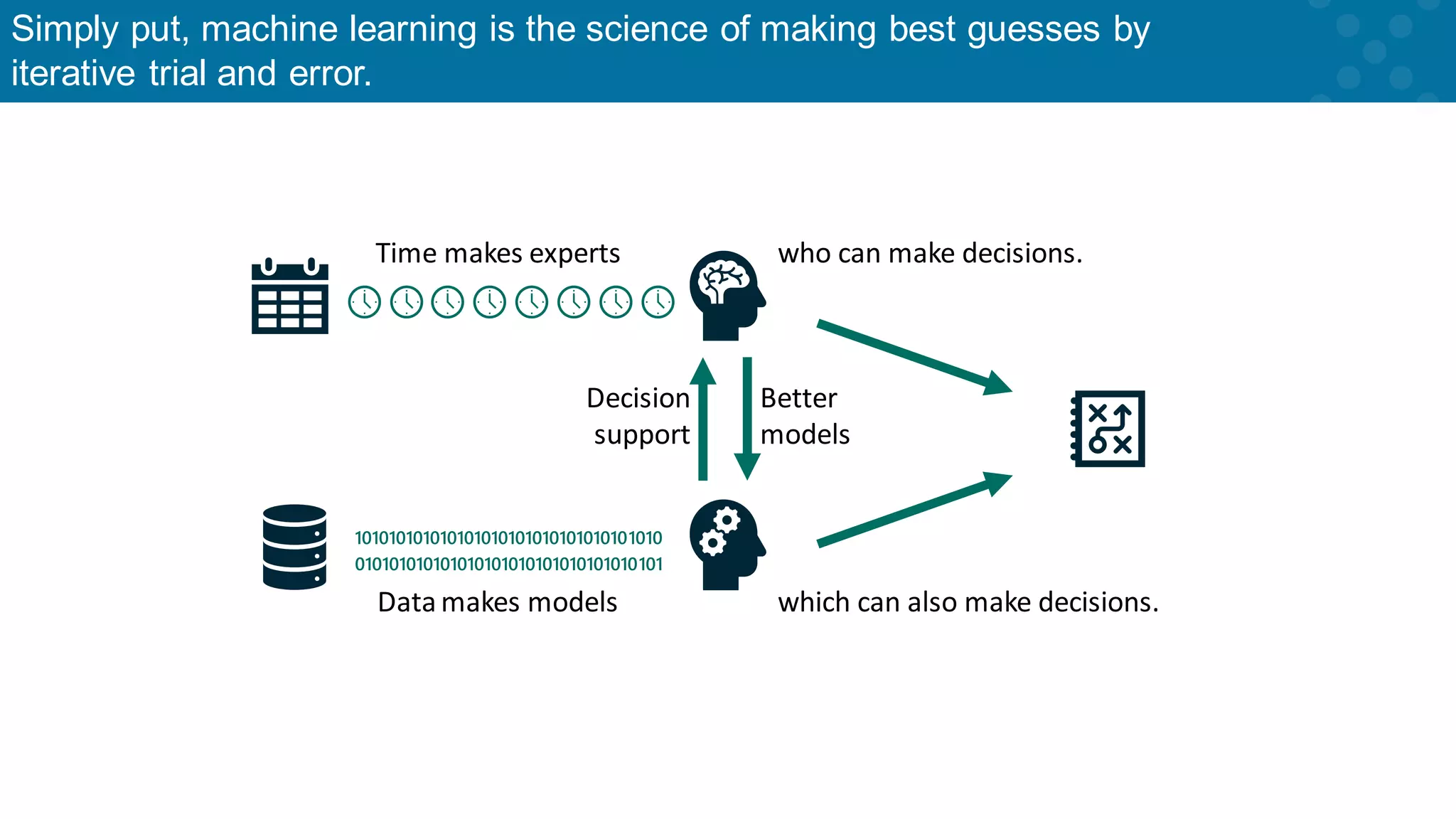
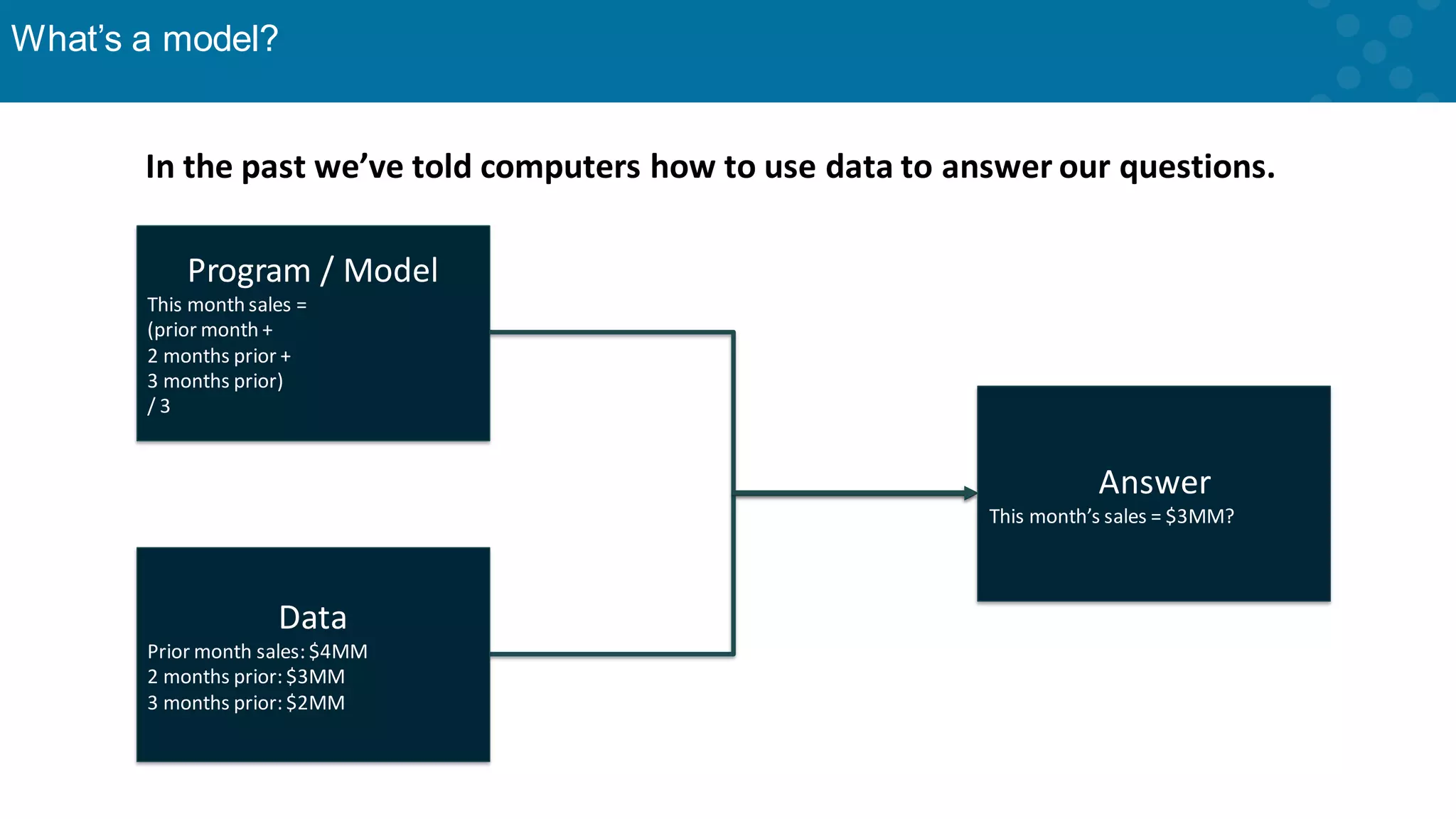
Basic definition of machine learning as a science of making predictions through iteration.
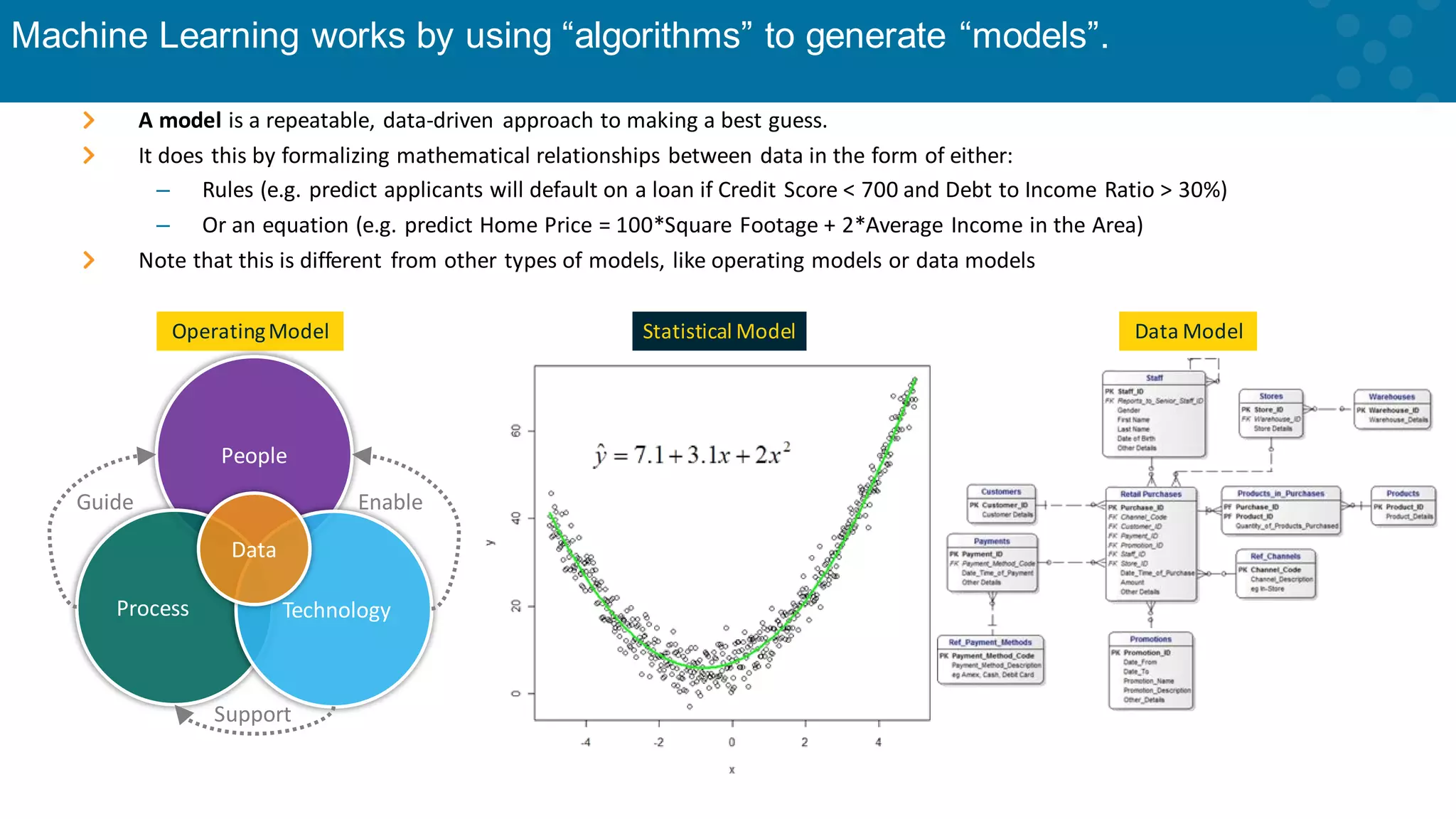
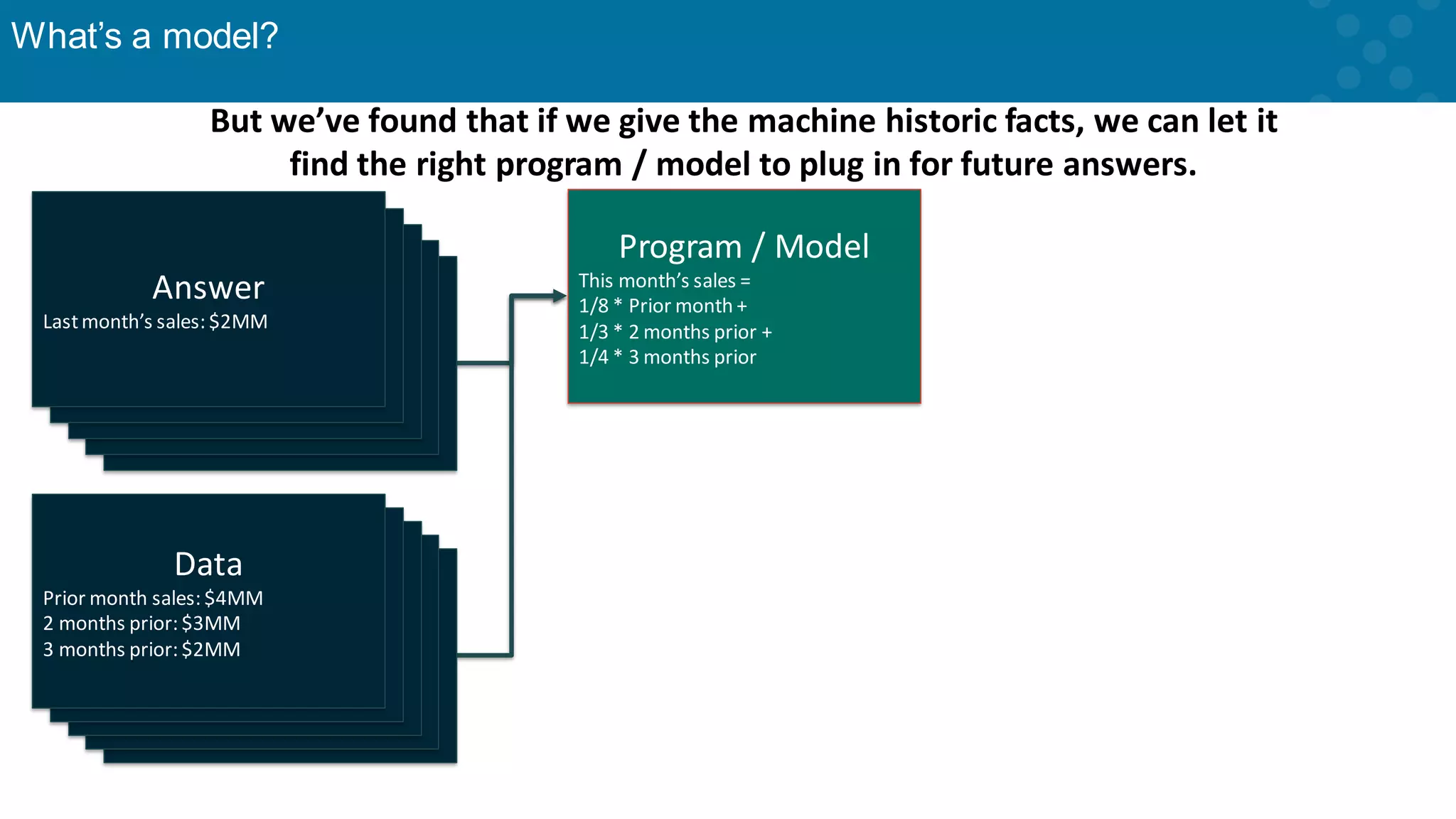
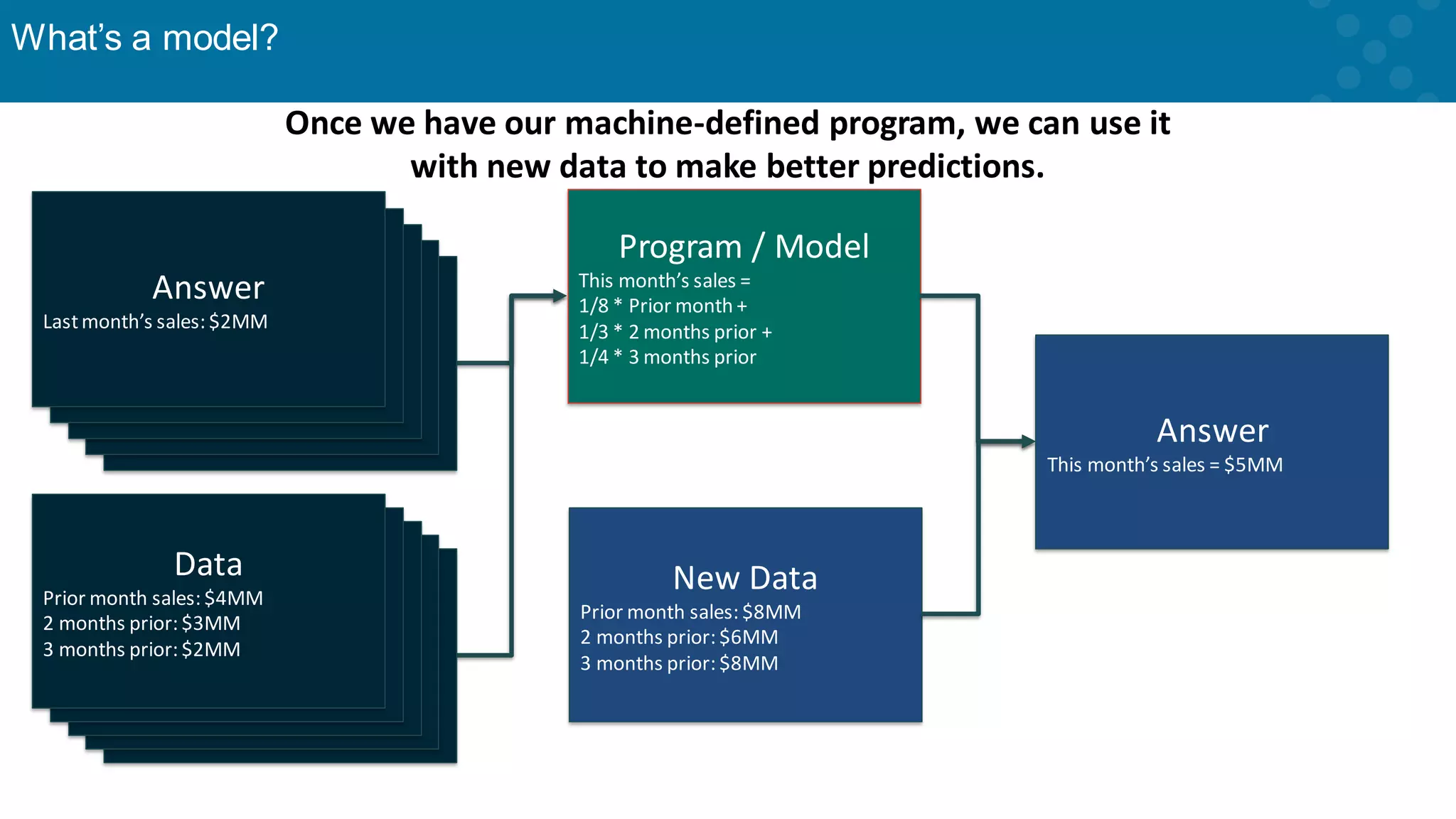
Explanation of how models are created using algorithms based on data relationships.
Sample data-driven predictions with practical examples of modeling techniques.
Further elaboration on how historical data informs predictive models.
An algorithm is systematic steps for problem-solving which may involve iterations.
Cycle of creating and evaluating hypotheses in typical machine learning algorithms.
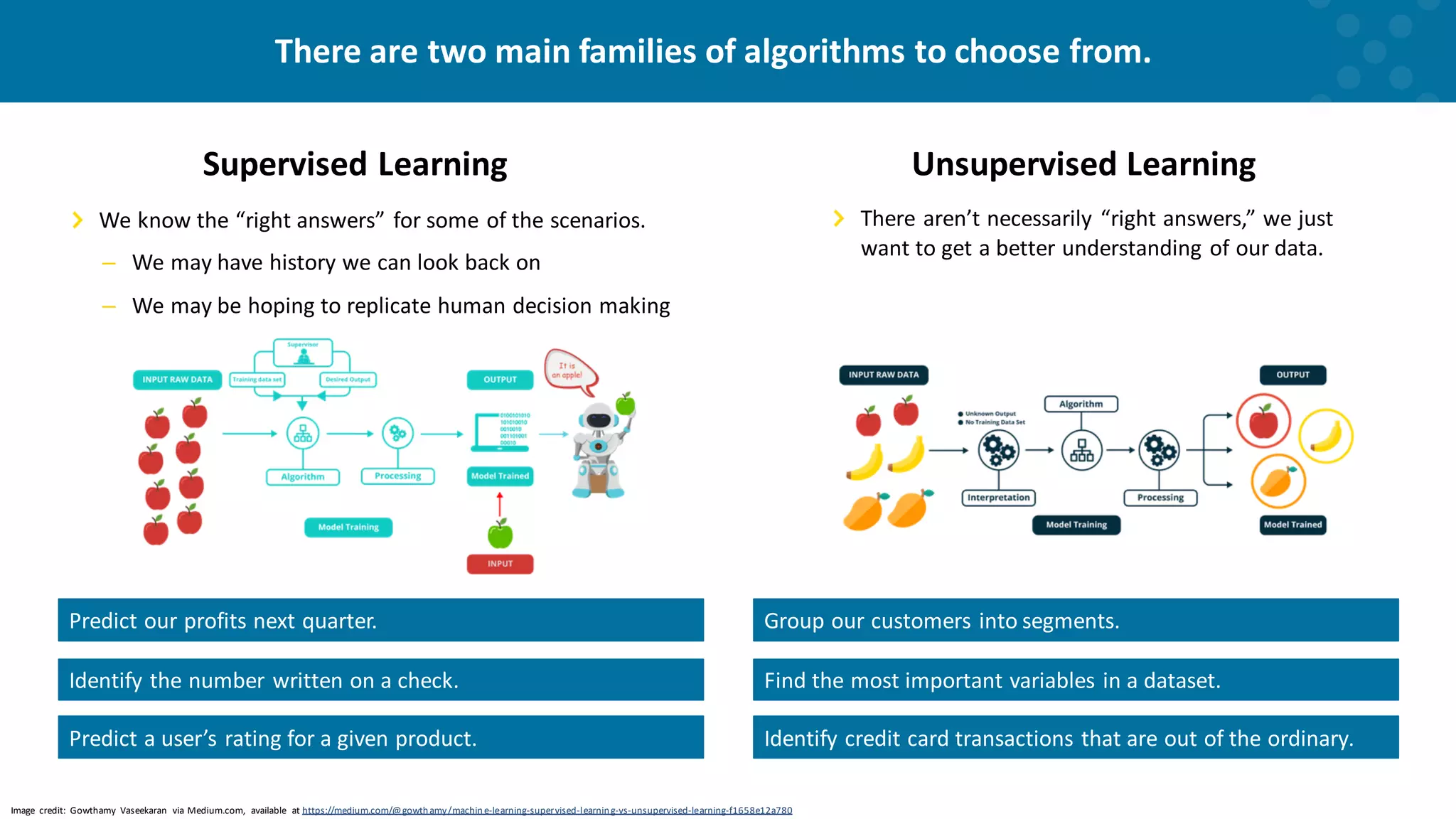
Comparison of supervised and unsupervised learning strategies and their applications.
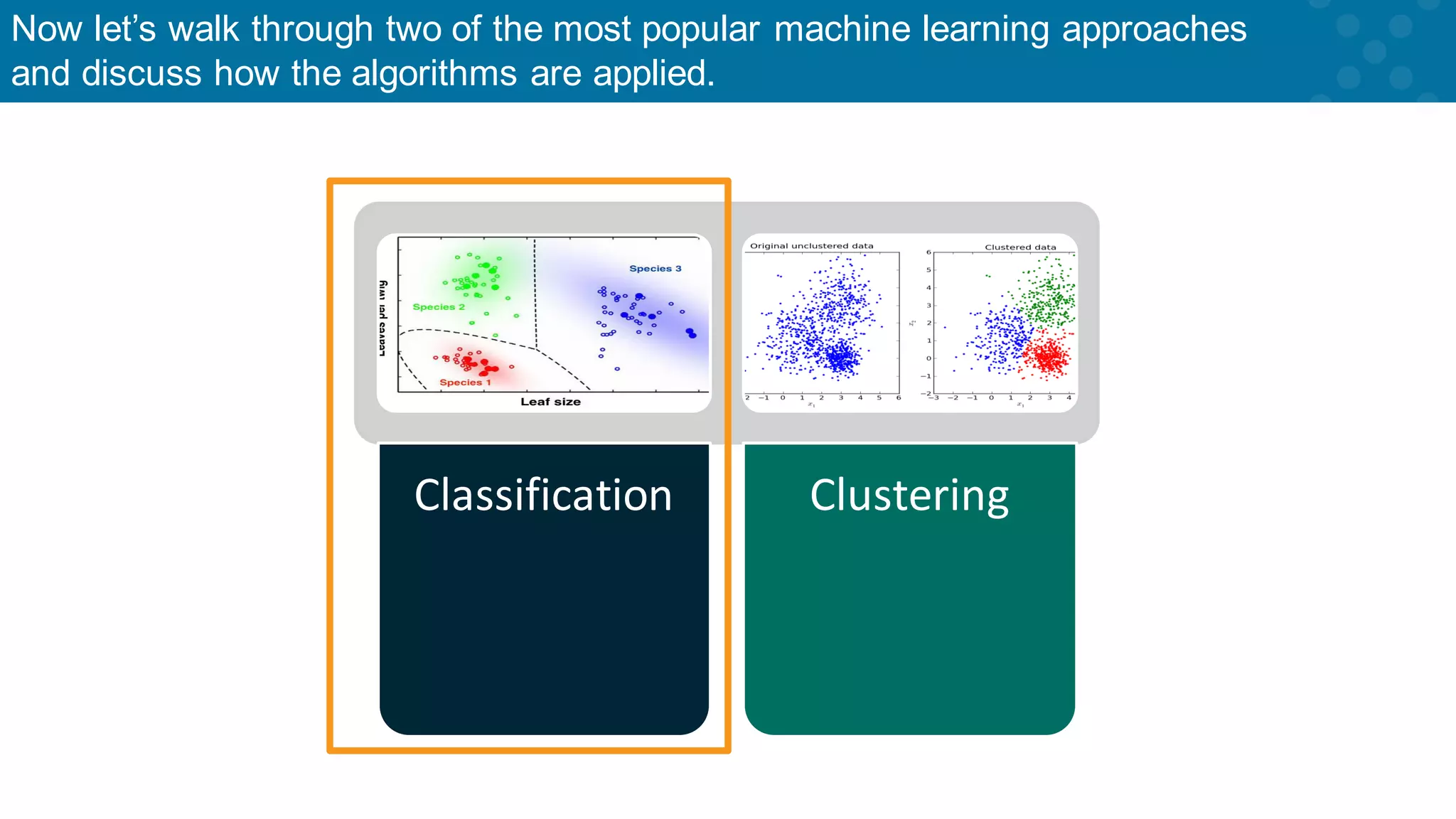
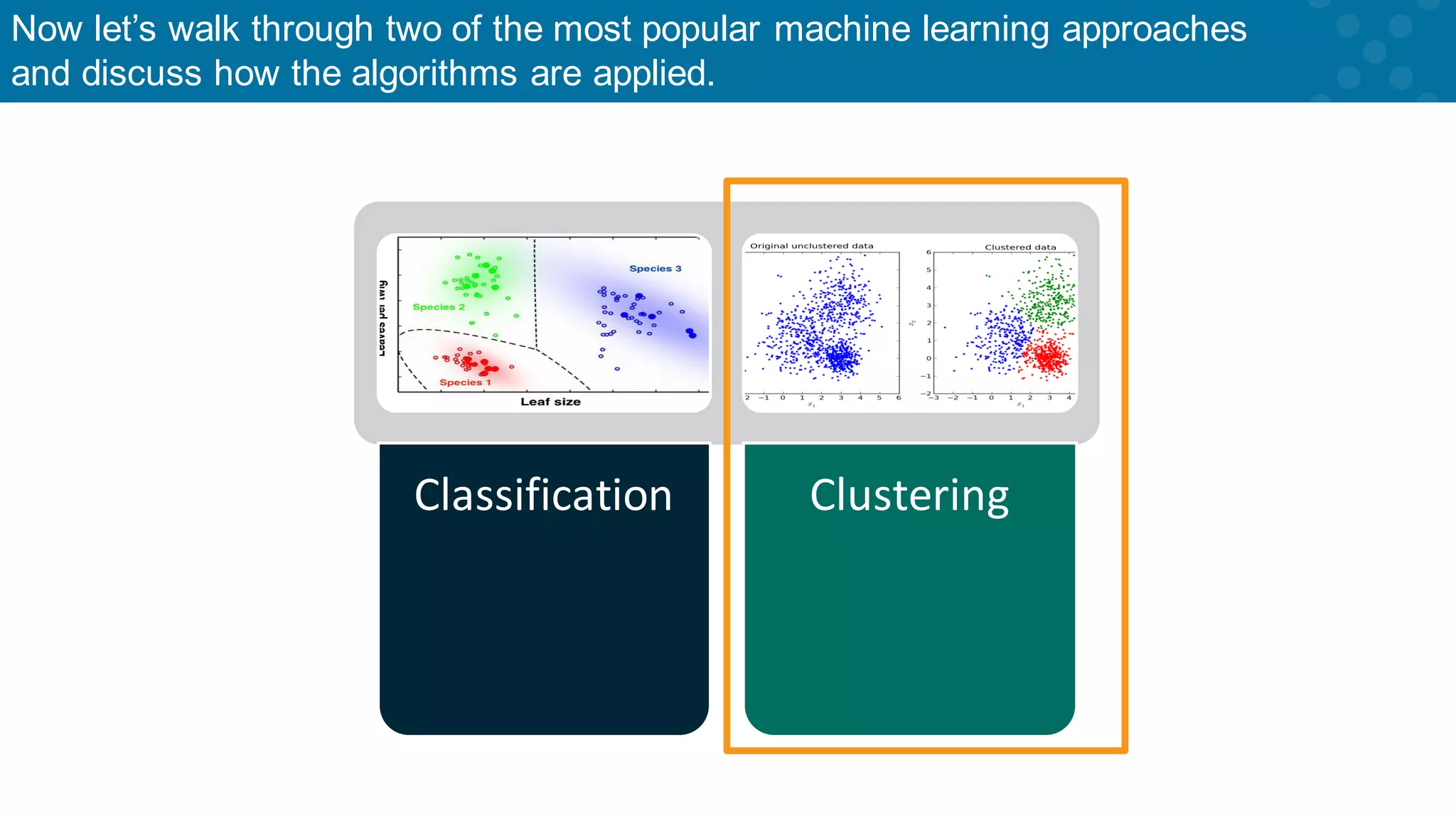
Introduction to classification and clustering as primary ML algorithm types.
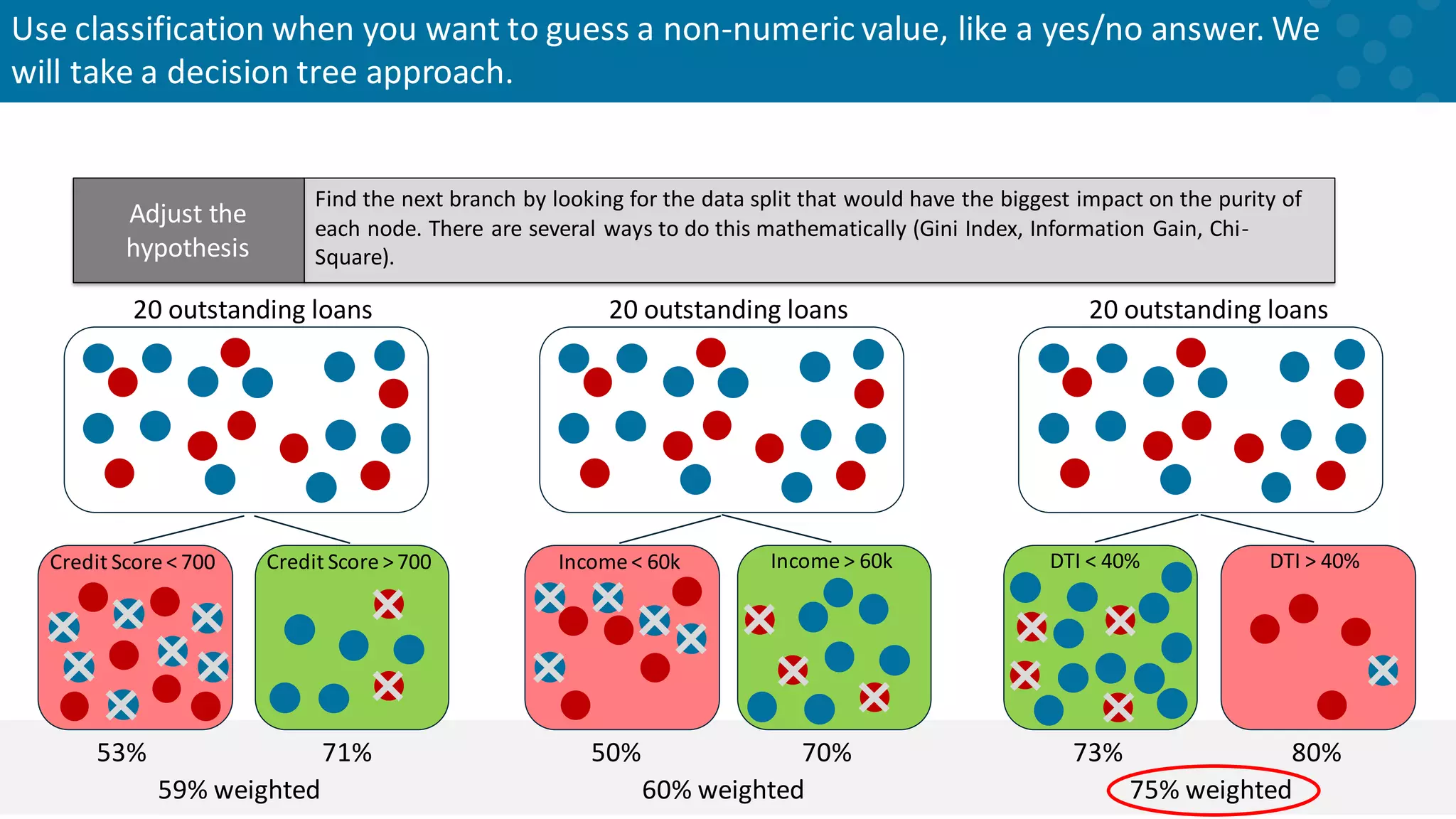
Concept of using decision trees for classification problems in predictions.
Process of calculating the accuracy of predictions in model evaluation.
Method for identifying impactful data splits in decision tree classification.
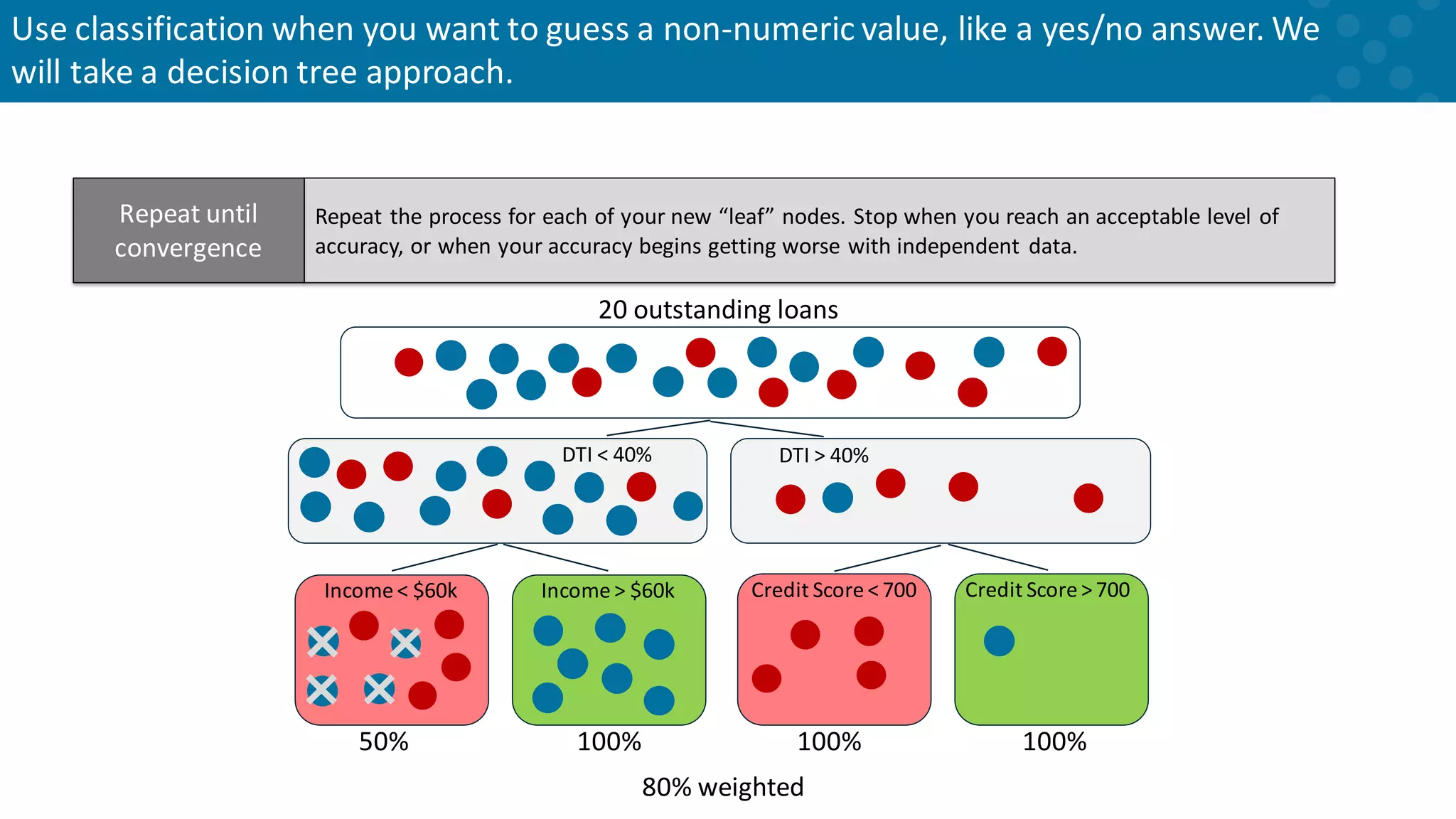
Repeatable process until an acceptable prediction accuracy is reached.
Synergy between human classification techniques and their machine learning counterparts.
Introduction again to classification vs. clustering in machine learning.
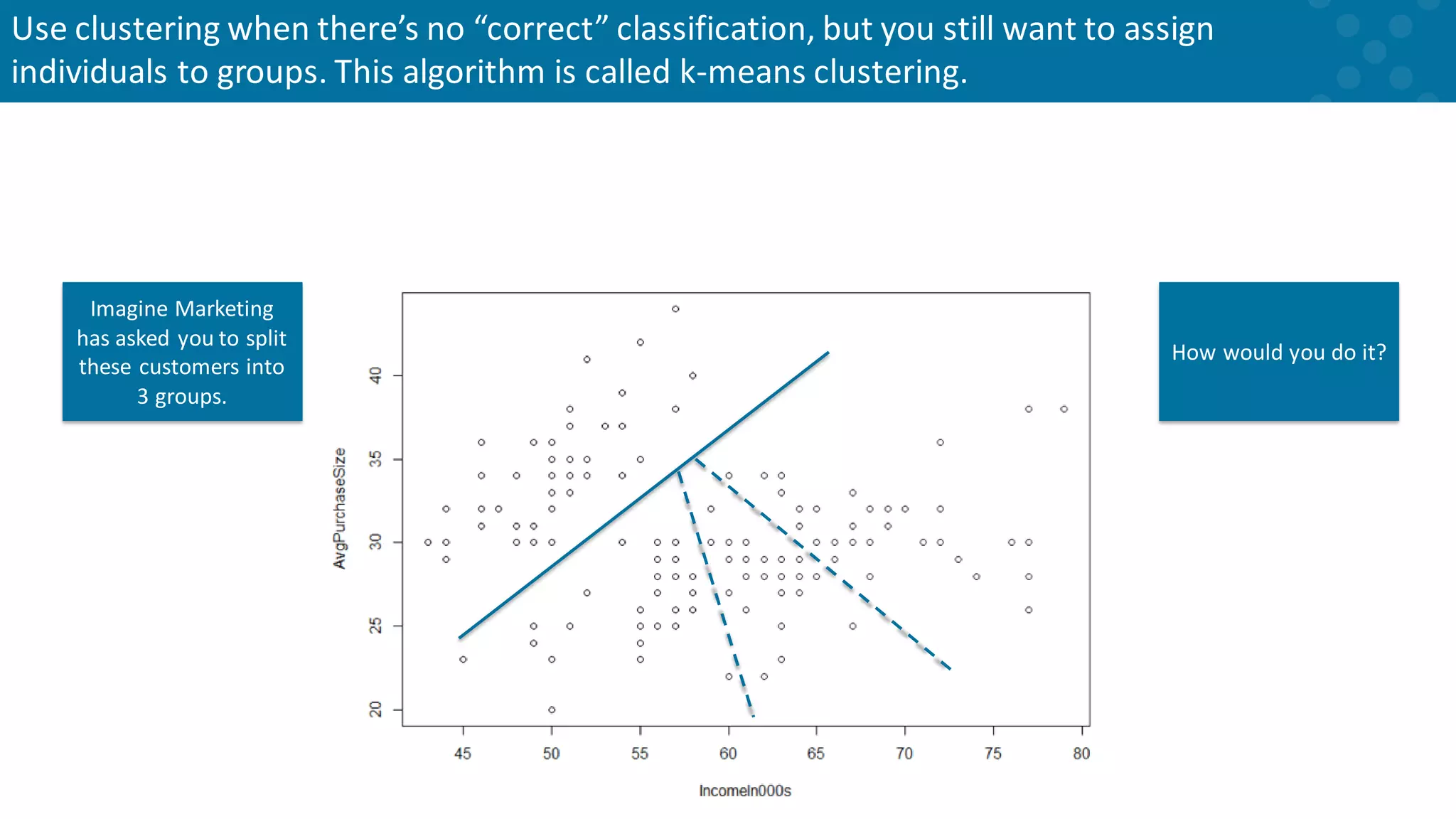
Hypothetical case study on customer segmentation using clustering techniques.
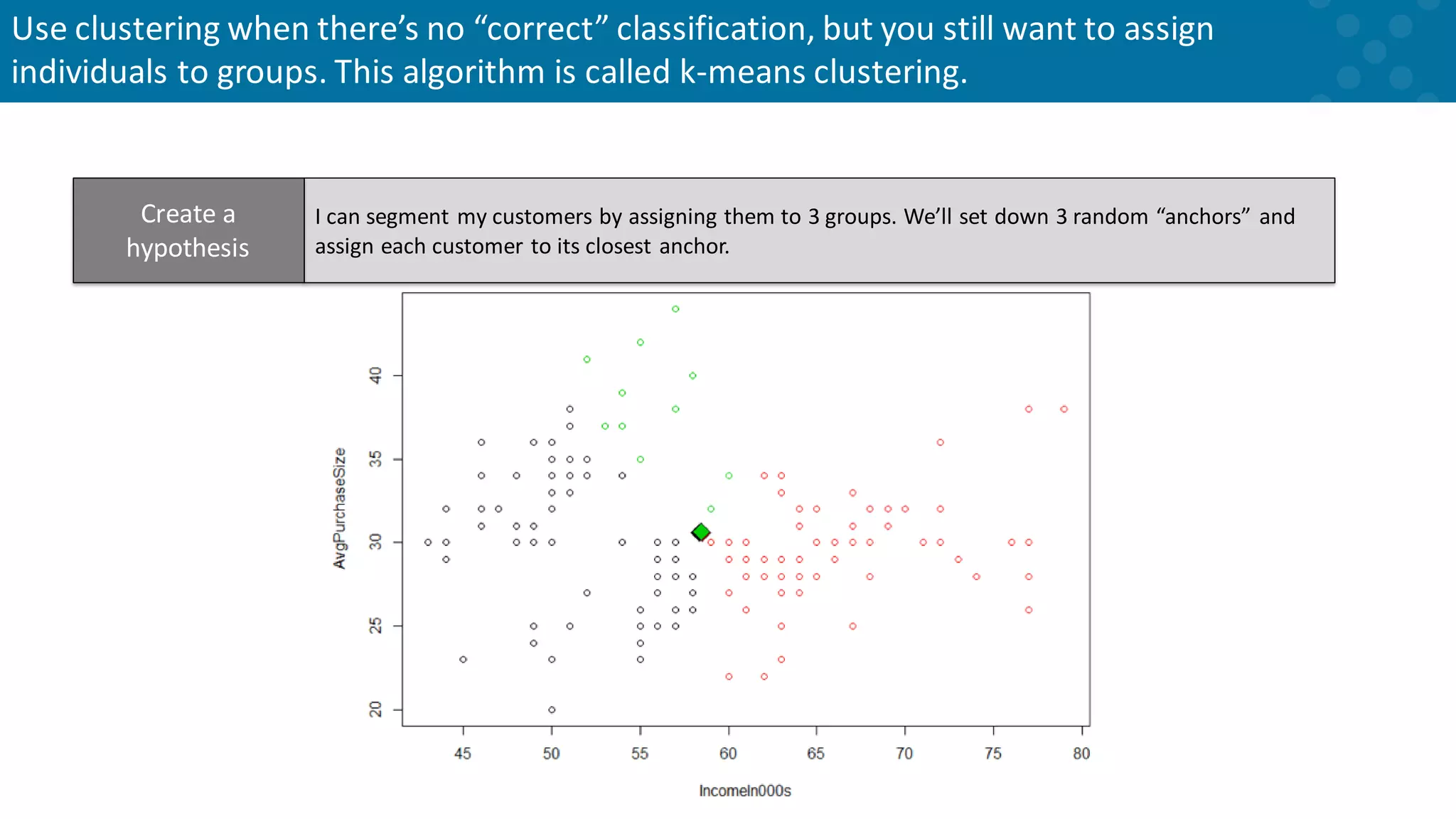
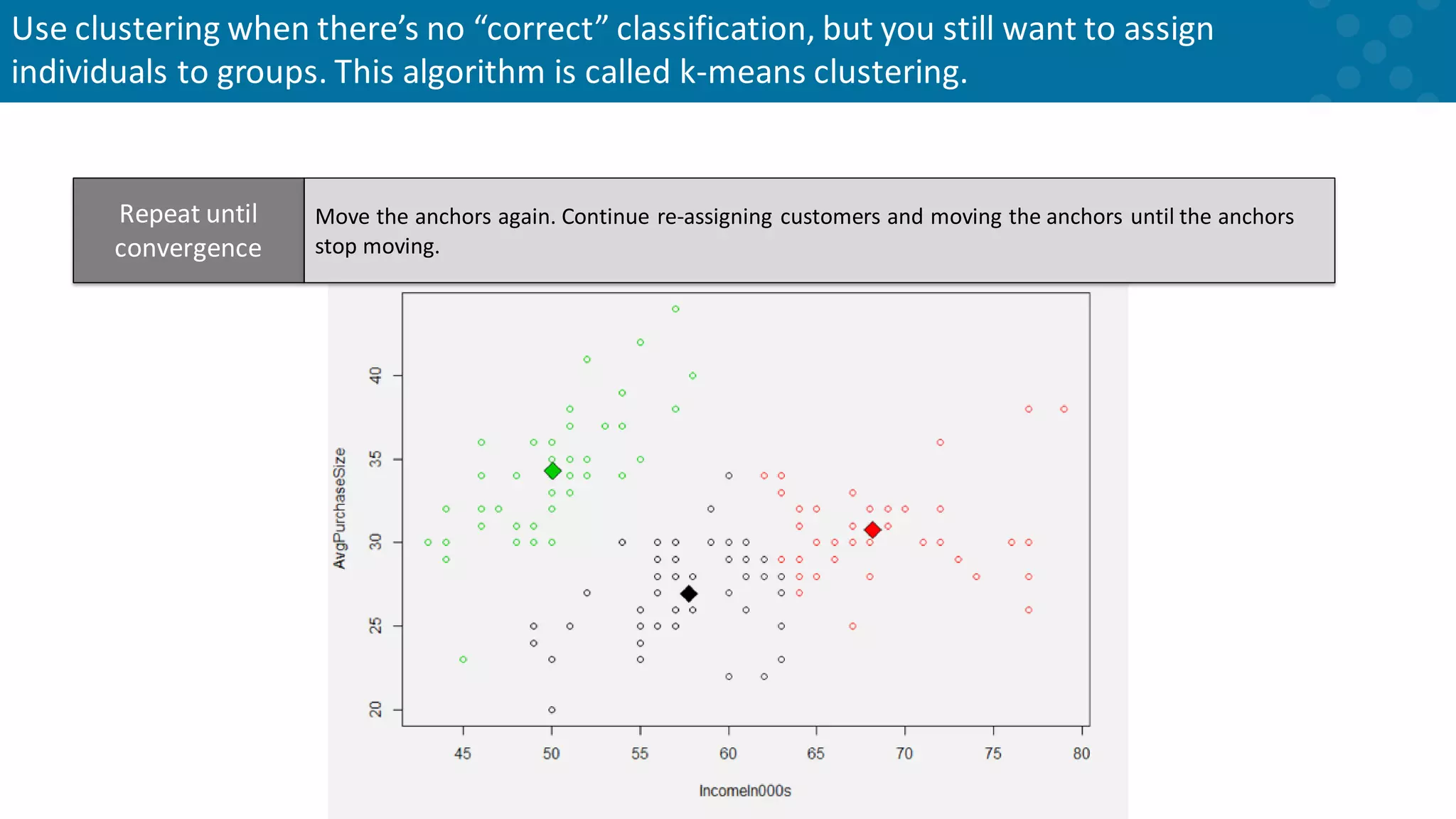
Methodology for clustering including anchor adjustment for group assignments.
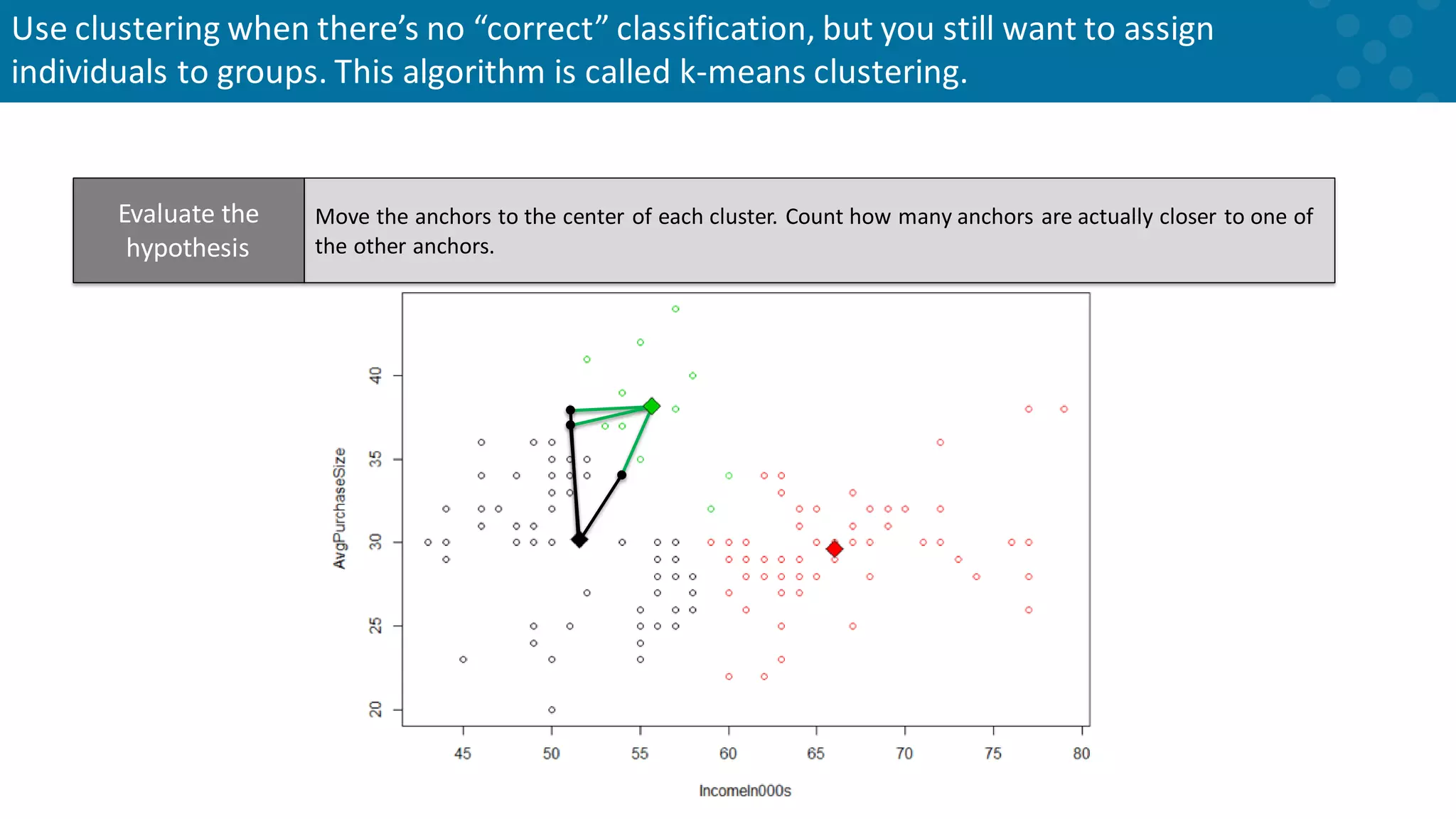
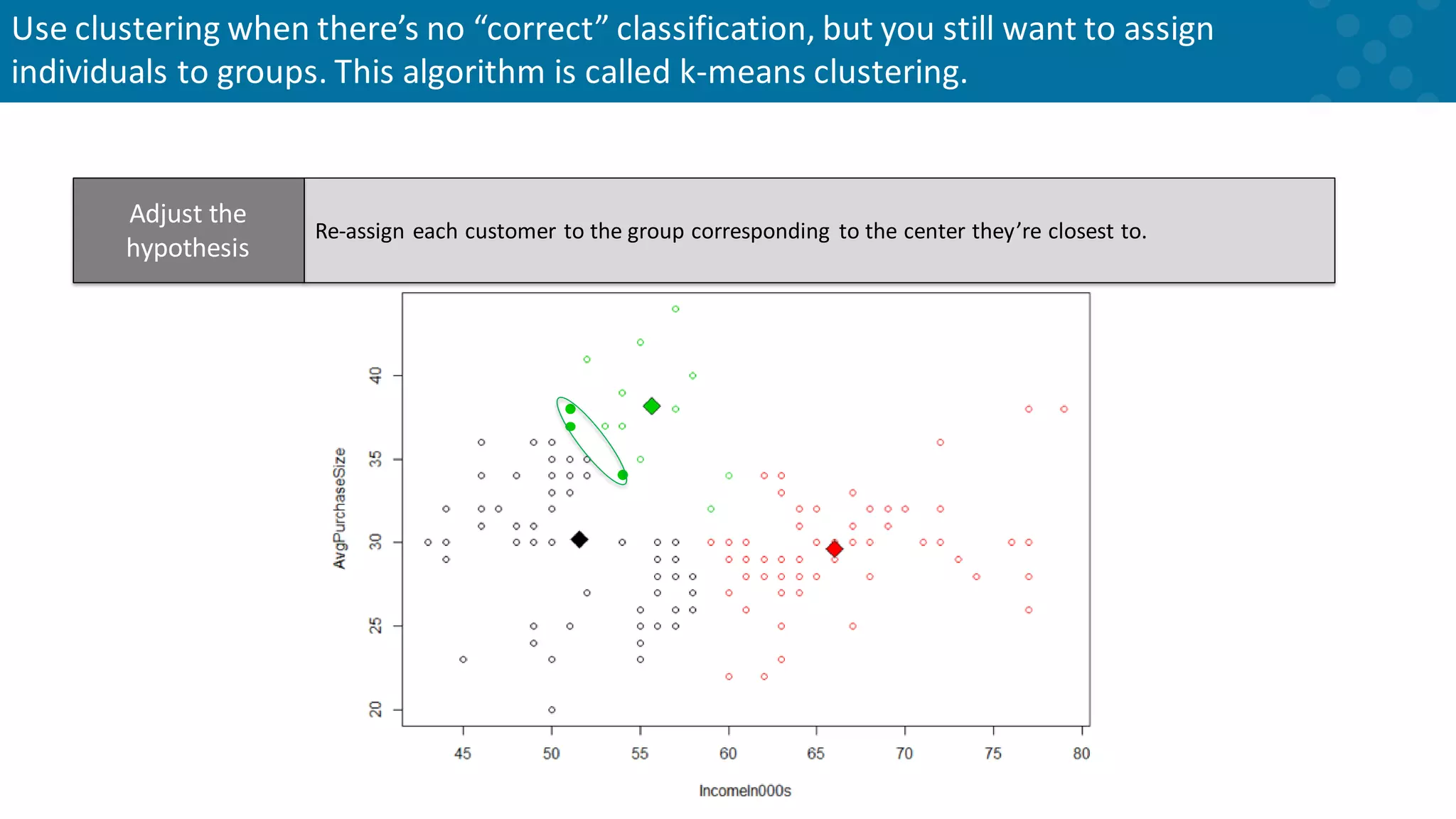
Iterative adjustments in clustering anchor points until stability is achieved.
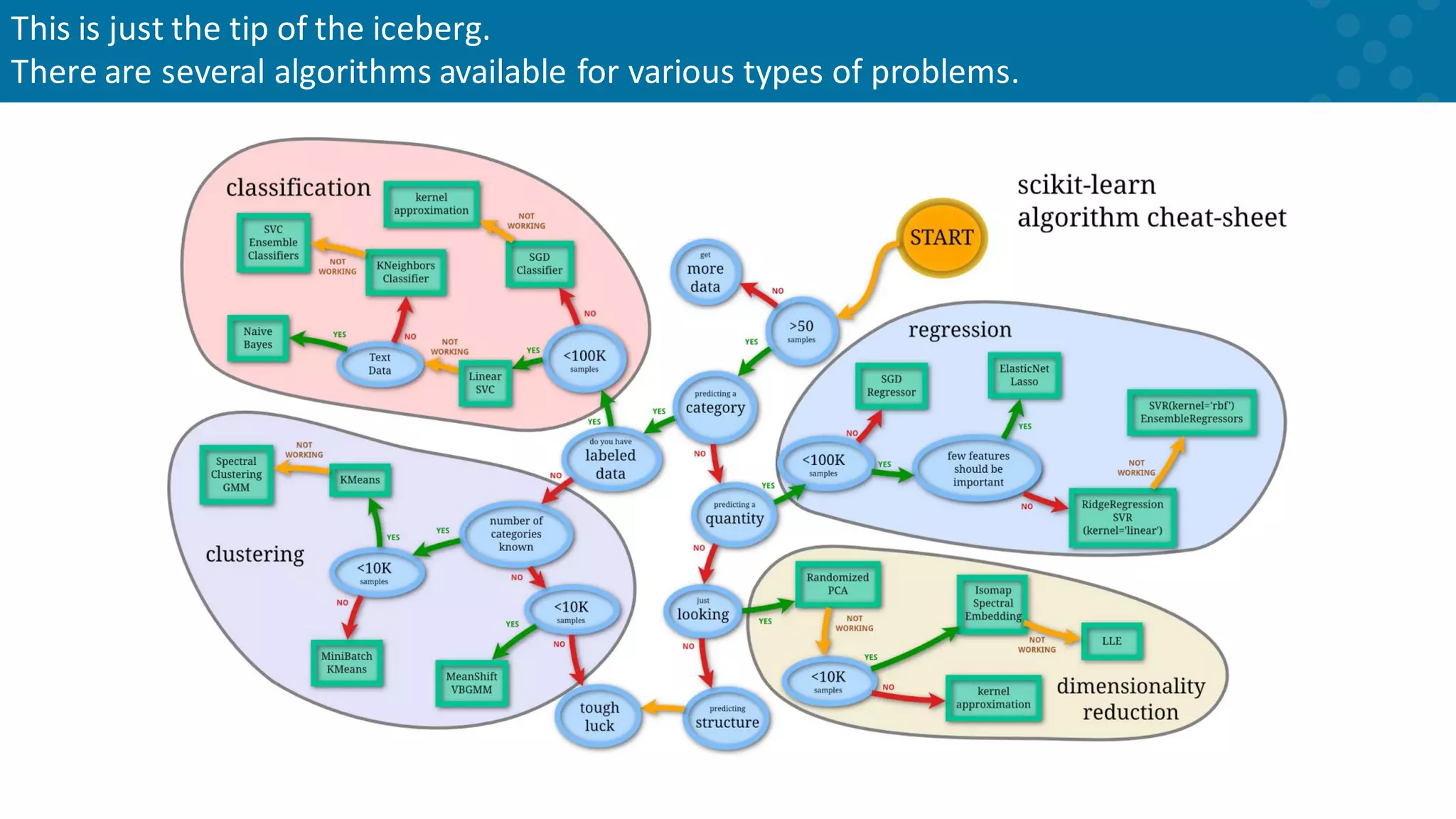
Overview of the array of machine learning algorithms available for various tasks.
Recap of agenda focusing on machine learning relevance and organizational strategy.
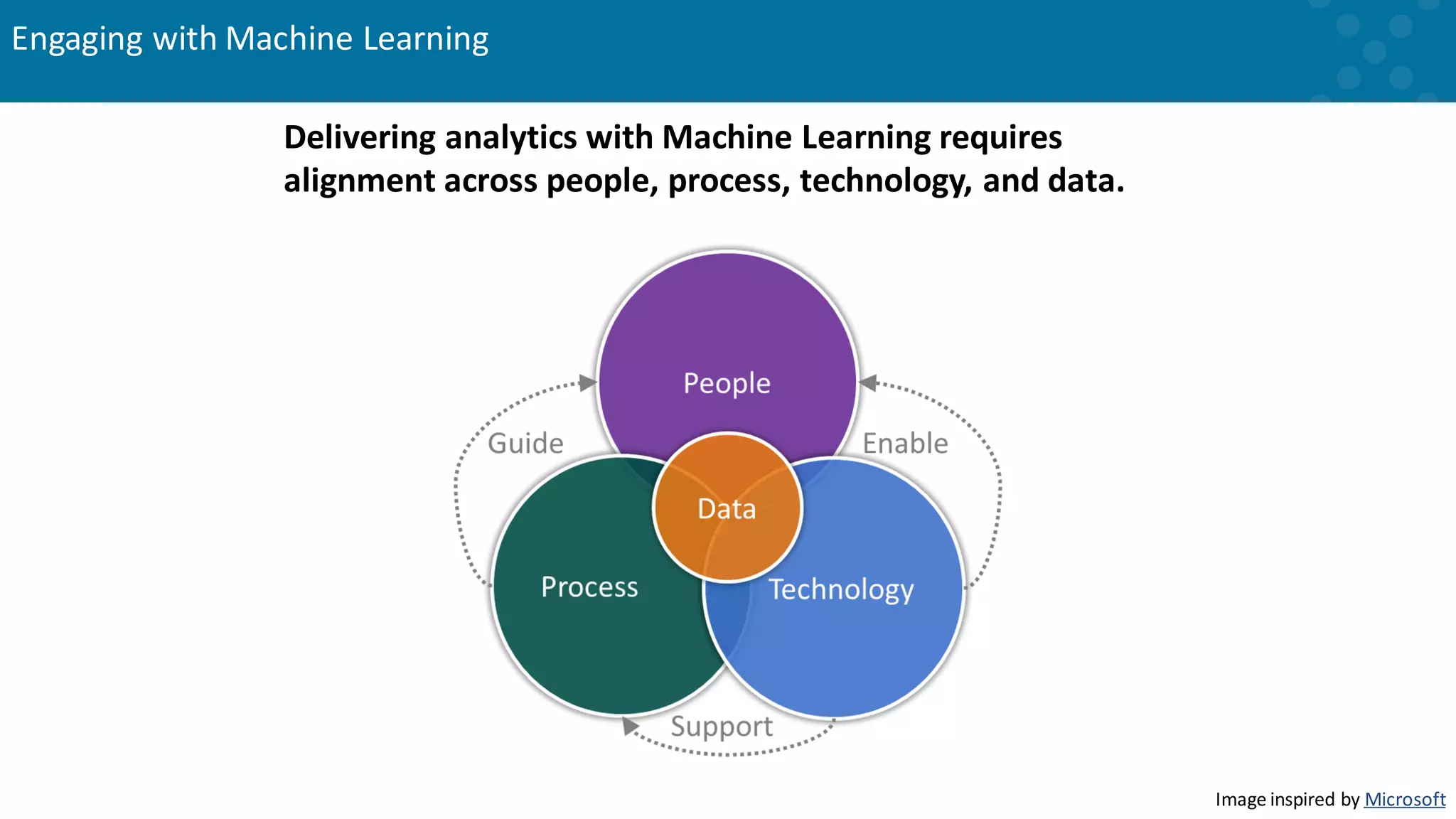
Need for alignment across data, people, processes, and technology in ML deployment.
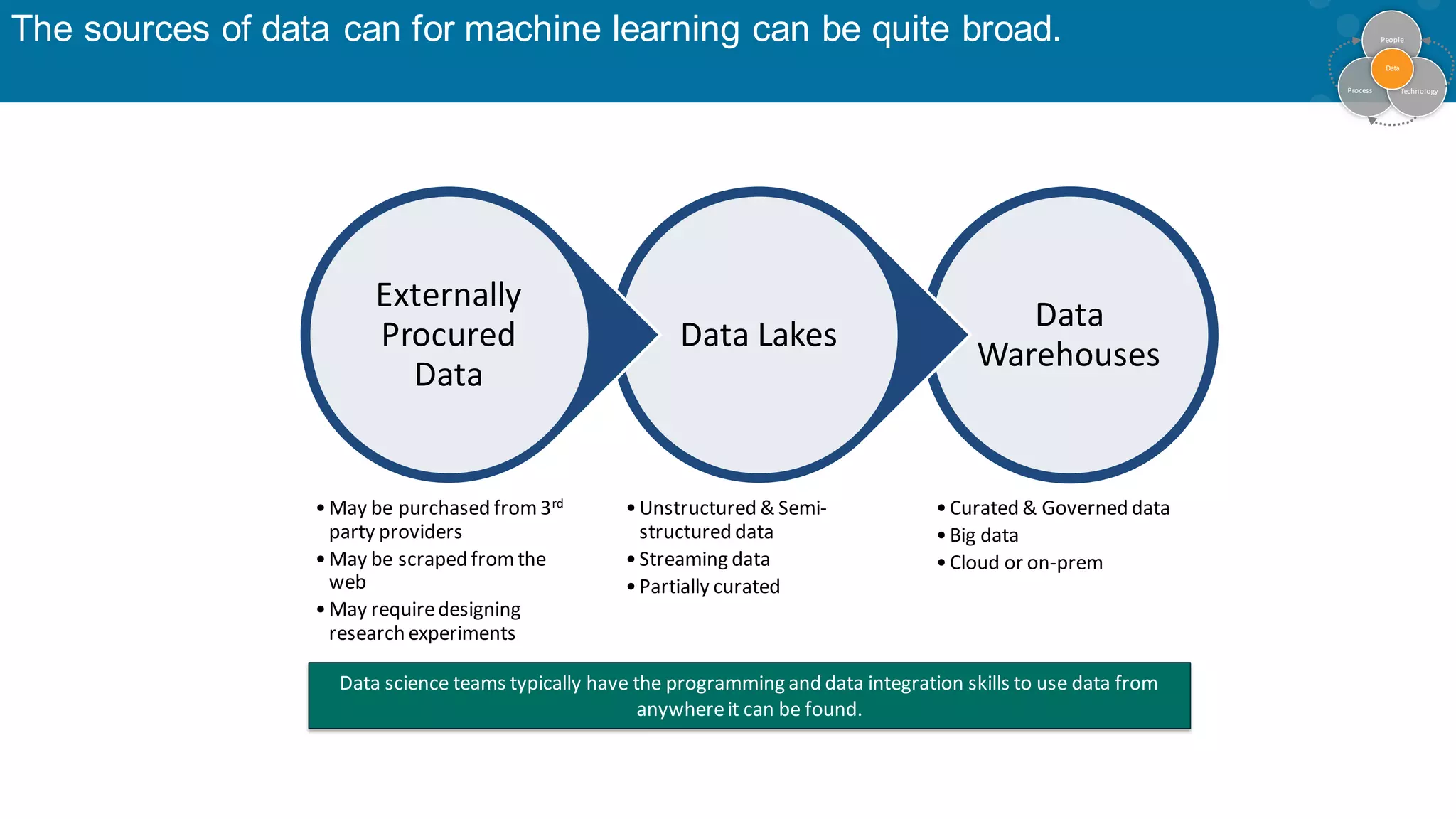
Diverse data sources including warehouses and lakes, for effective ML implementation.
Integration of skills required by data scientists for building business value.
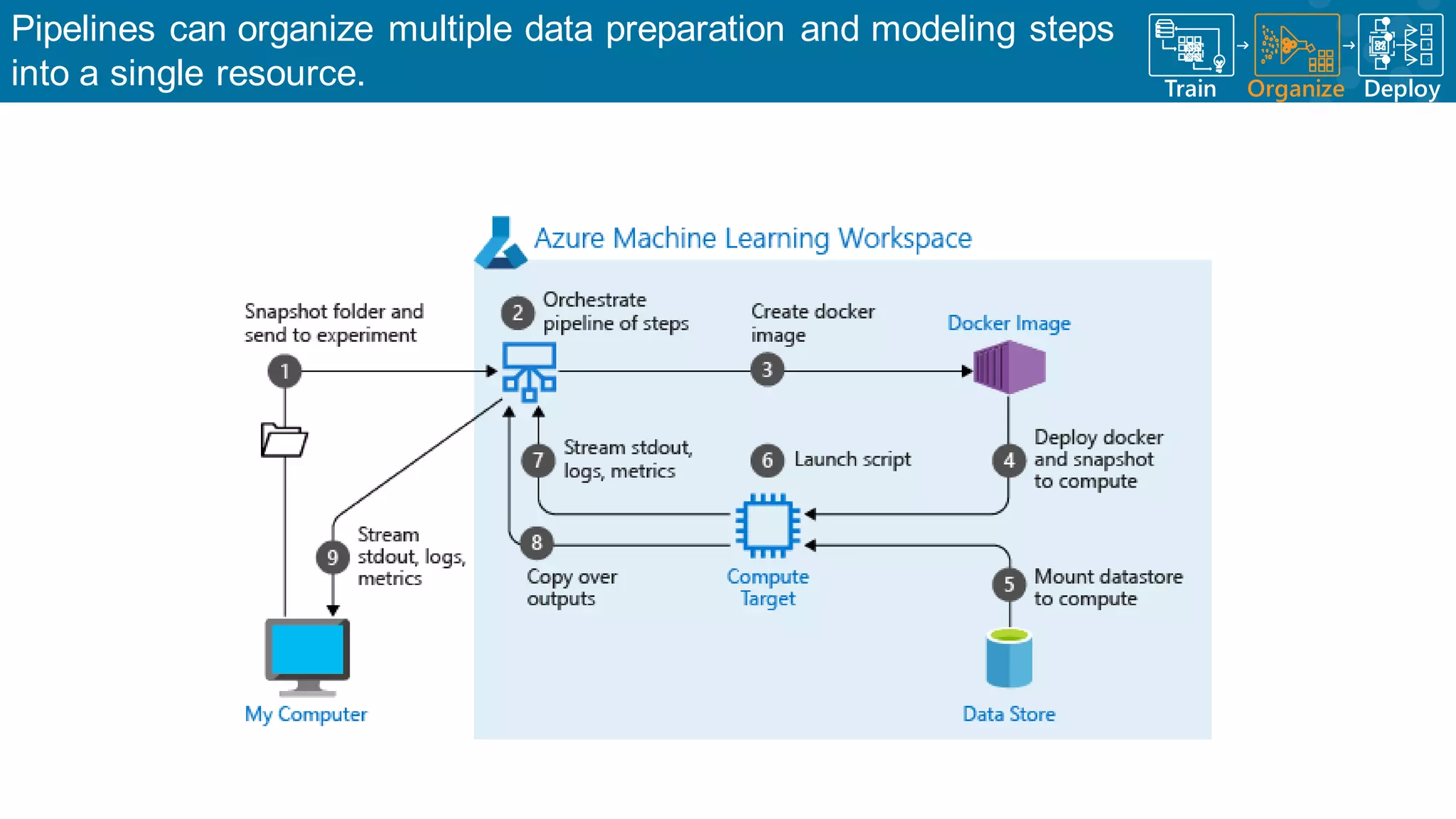
Workflow of data acquisition, model training, evaluation, and deployment.
Comparative effectiveness of traditional analytics vs machine learning outputs.
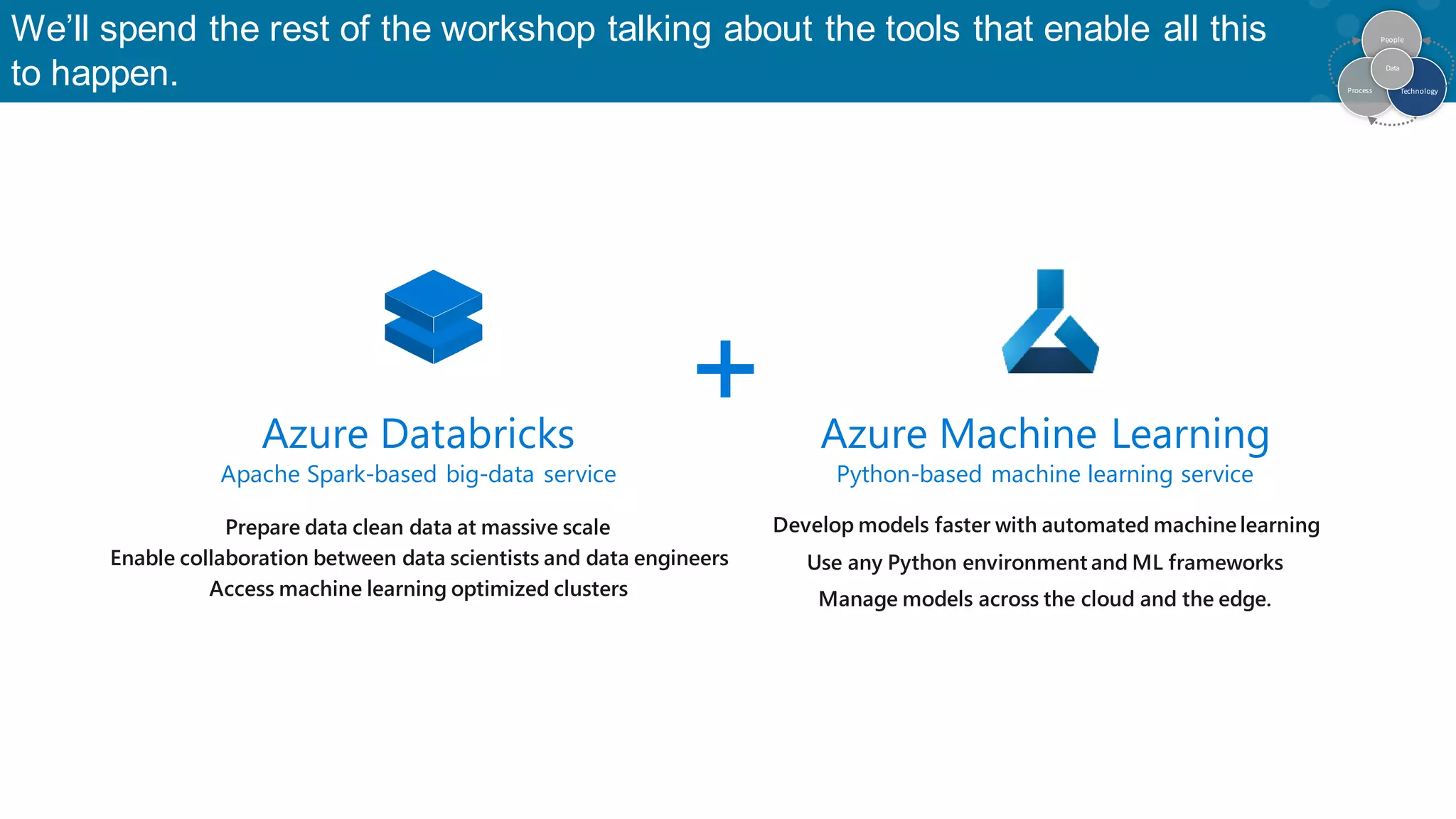
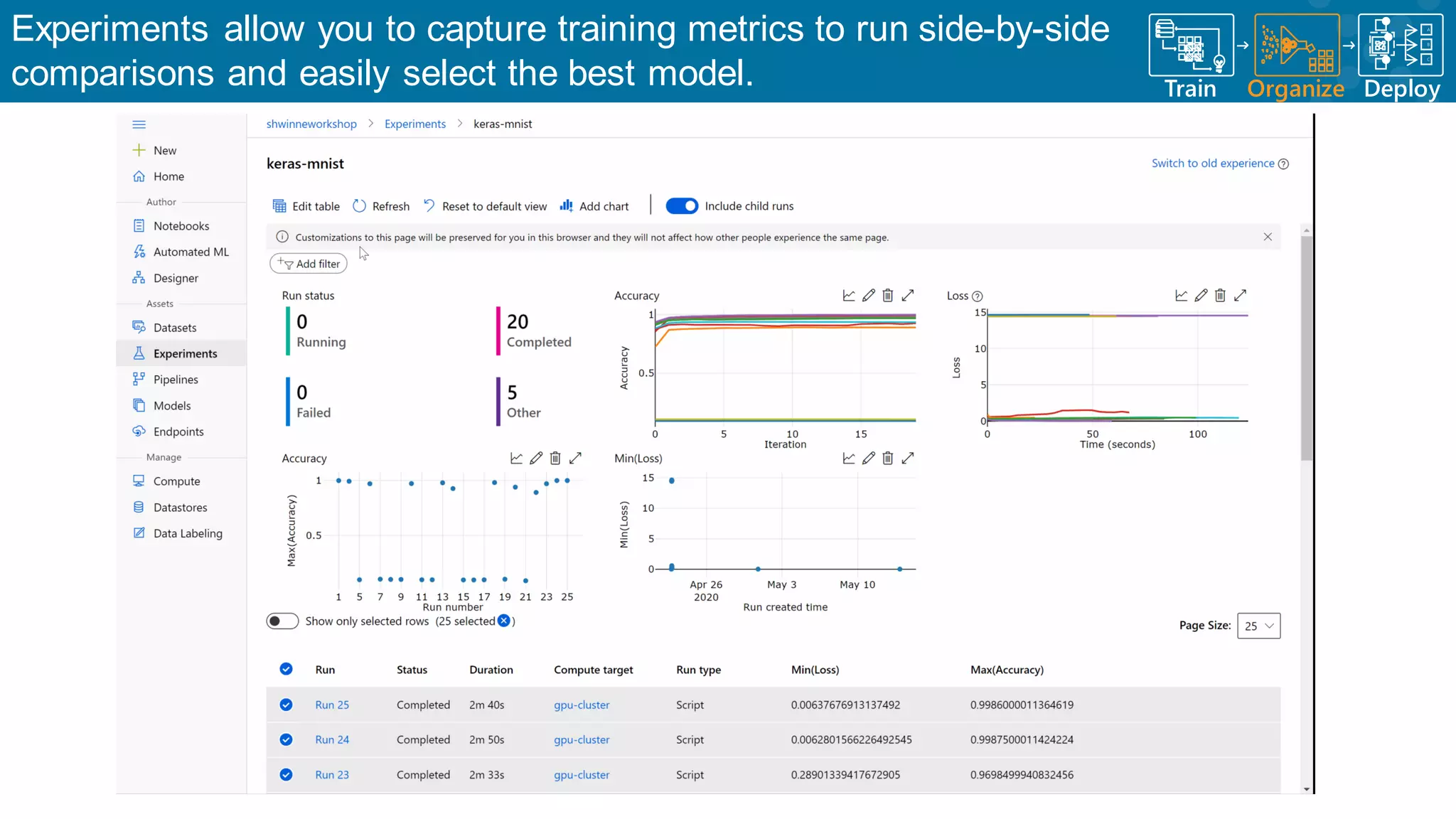
Exploration of tools for automating model development, data preparation, and collaboration.
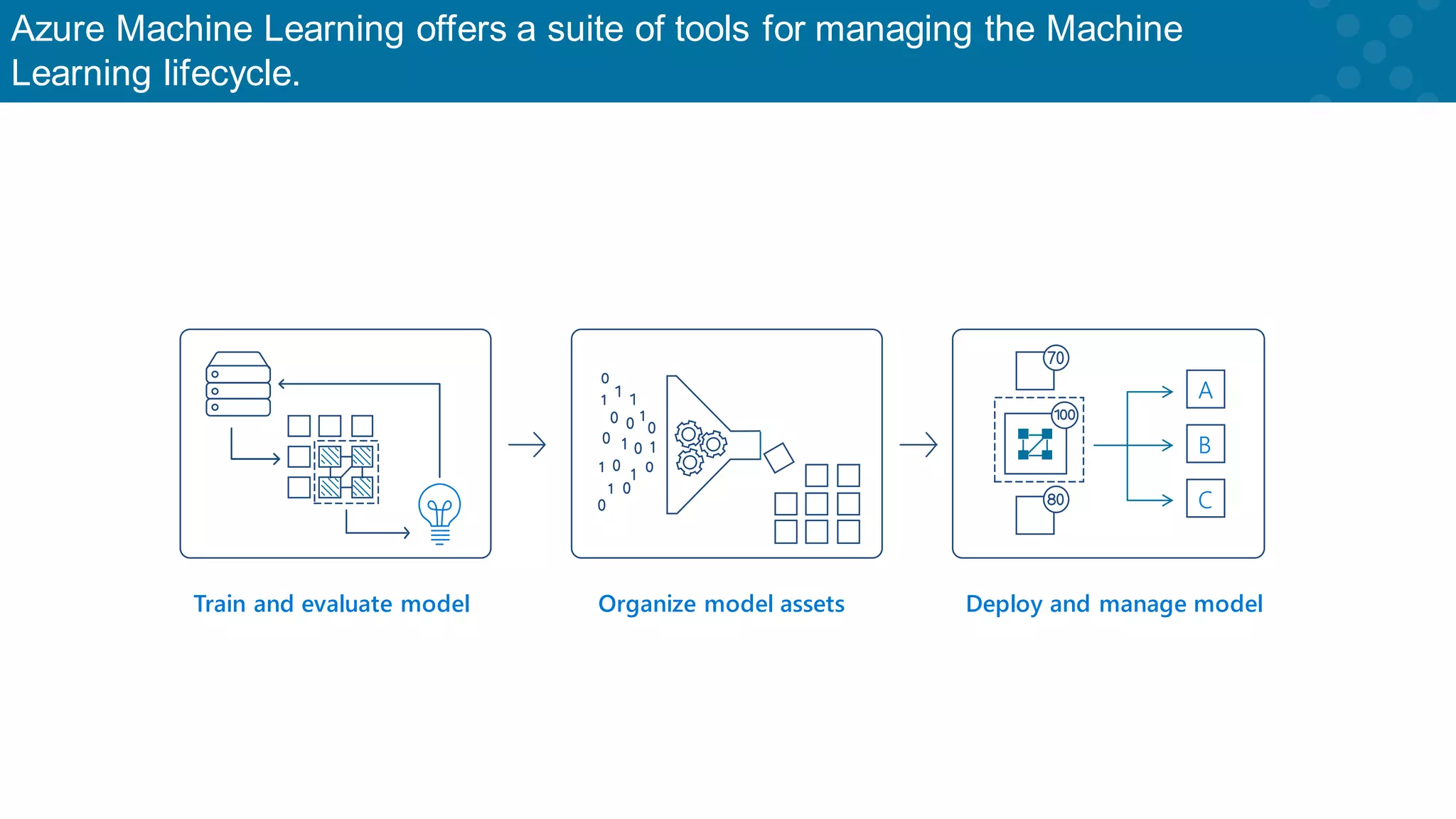
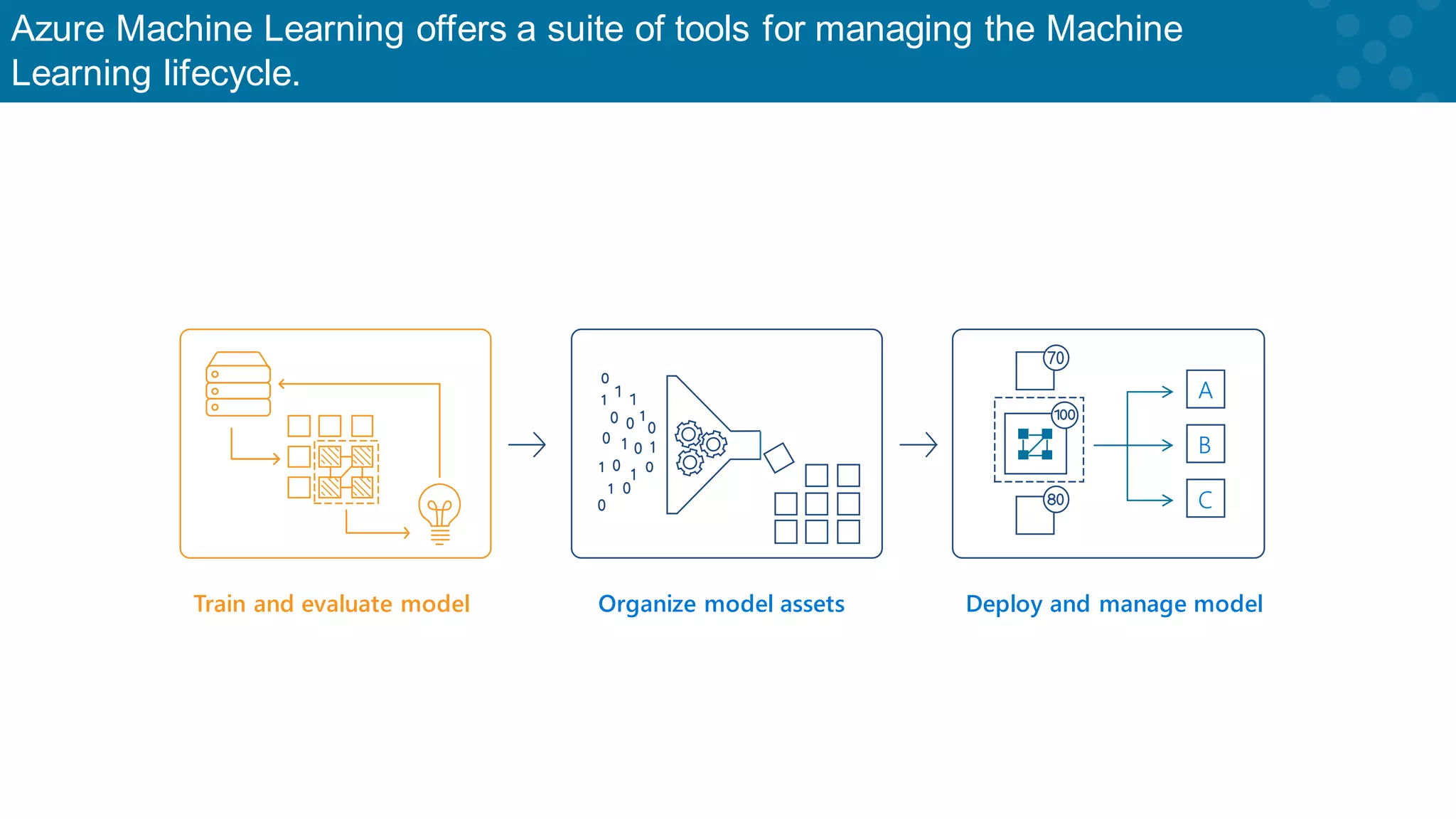
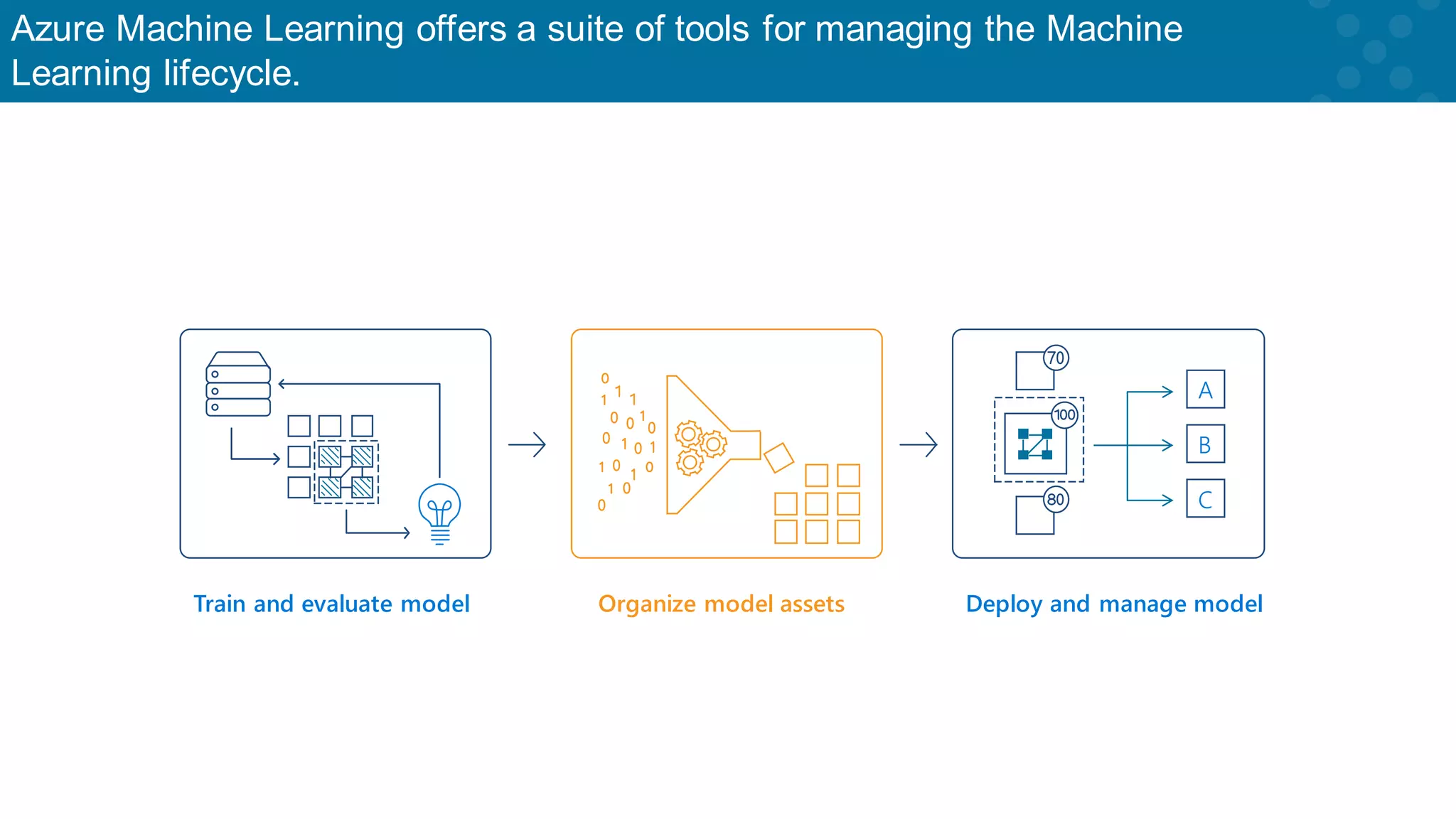
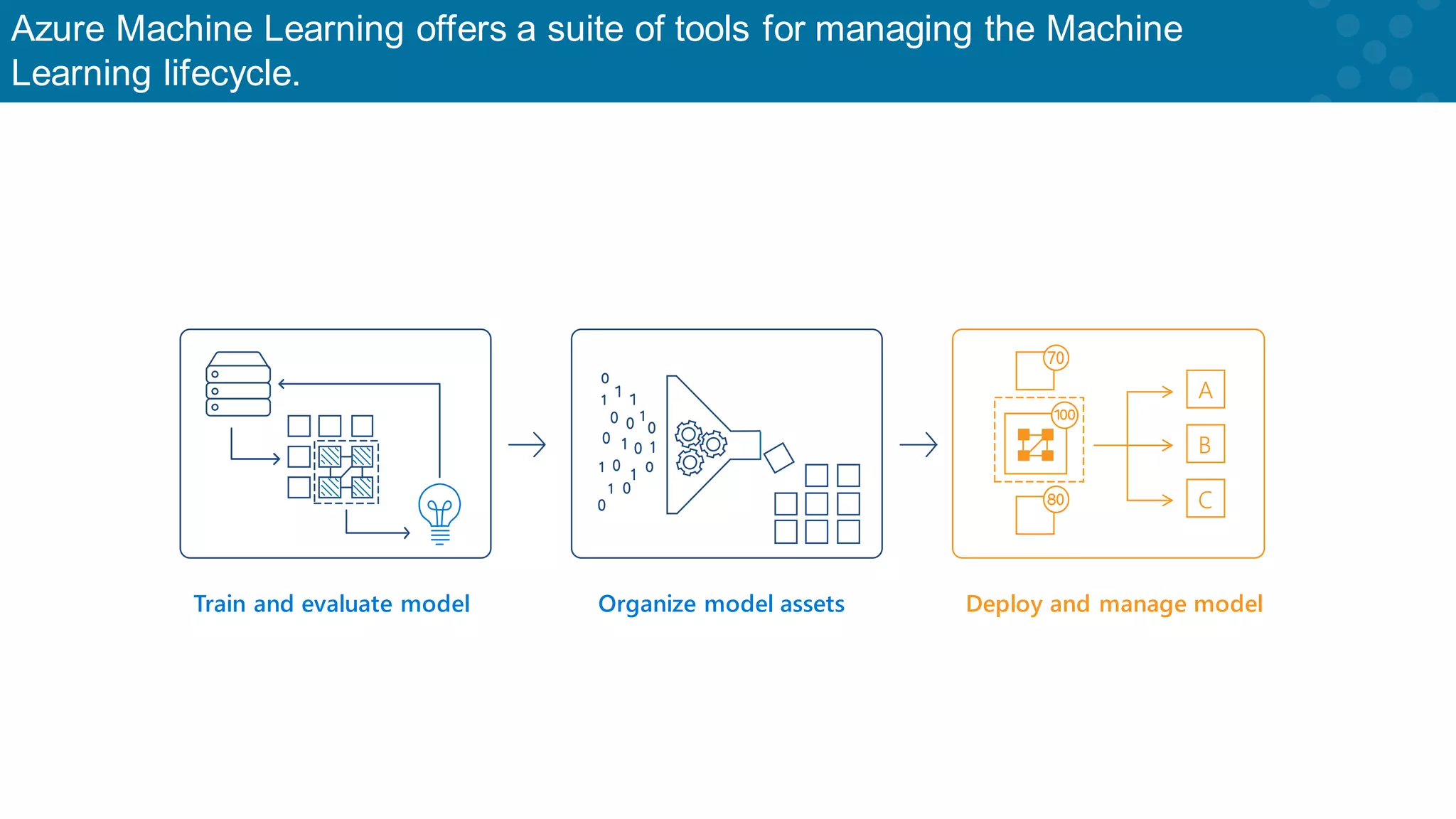
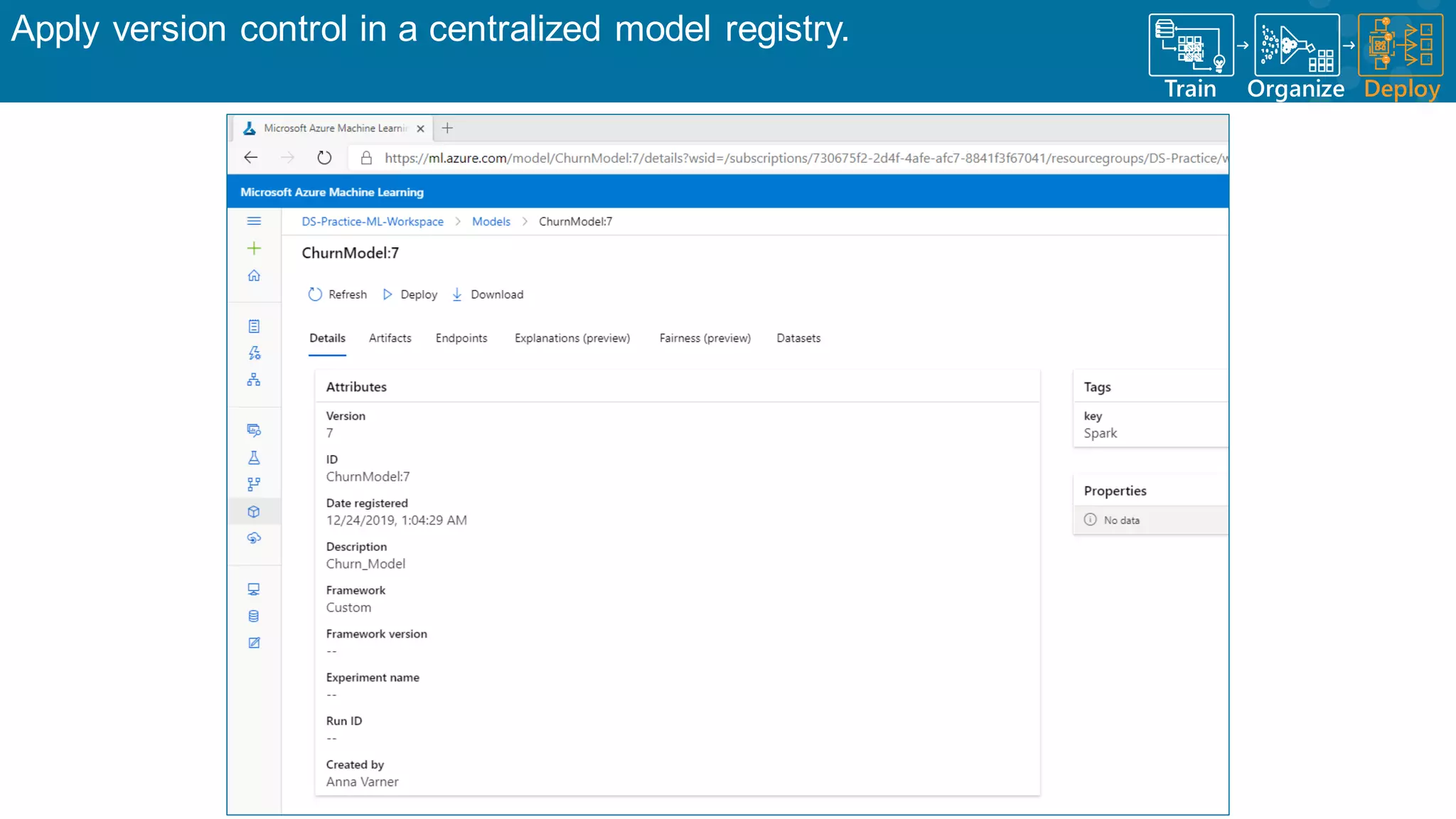
Overview of Azure ML tools for managing the machine learning lifecycle effectively.
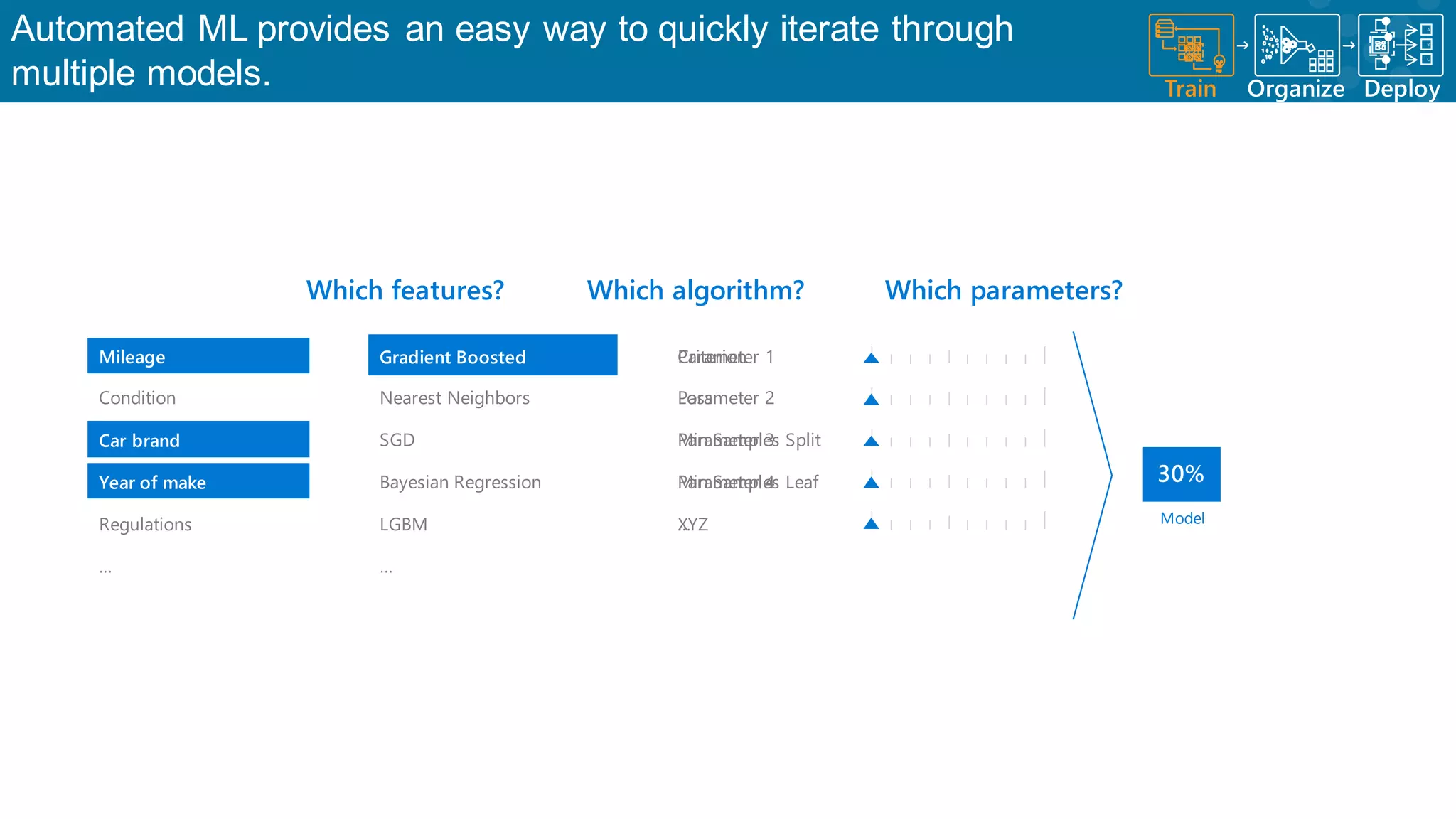
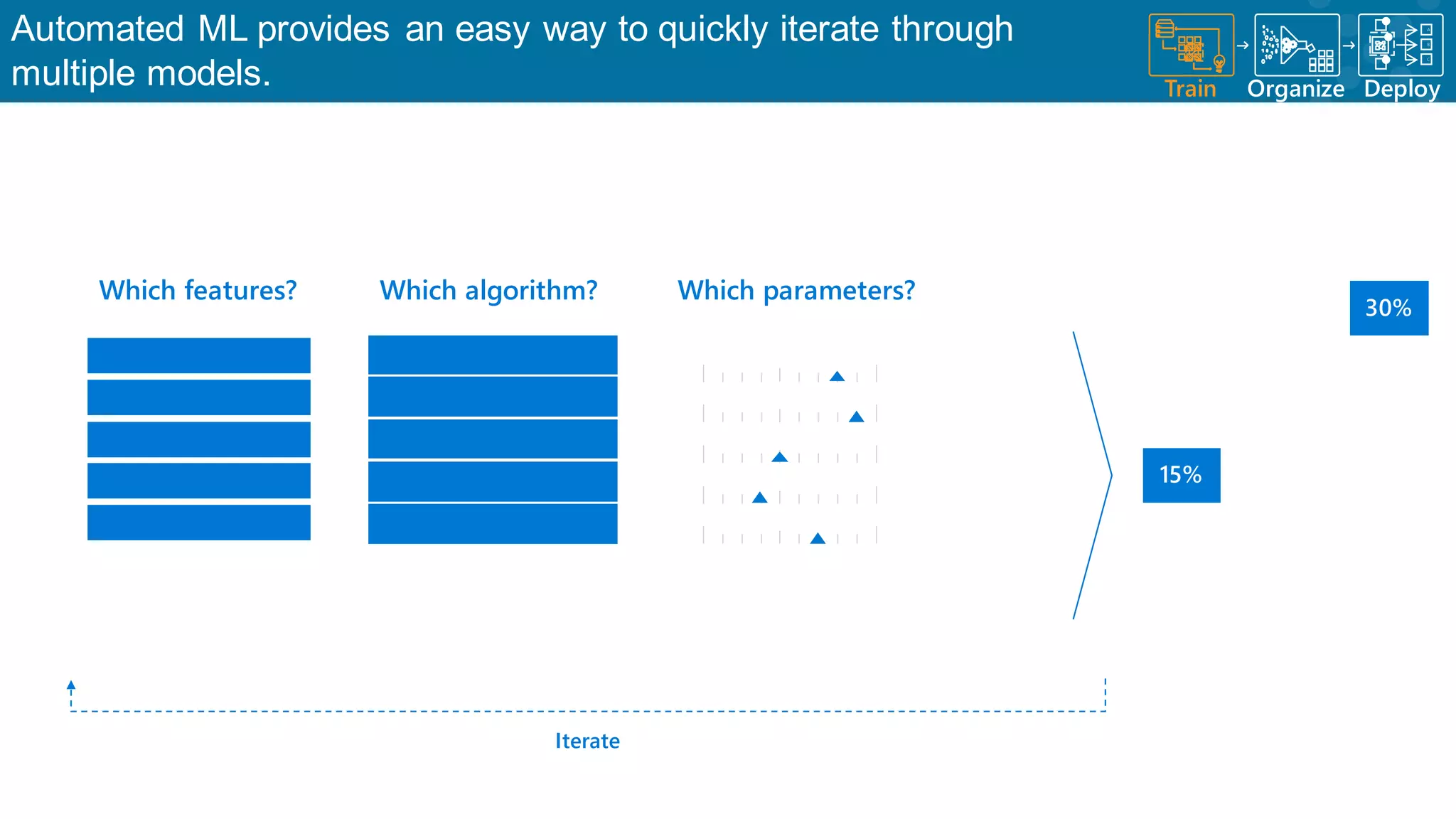
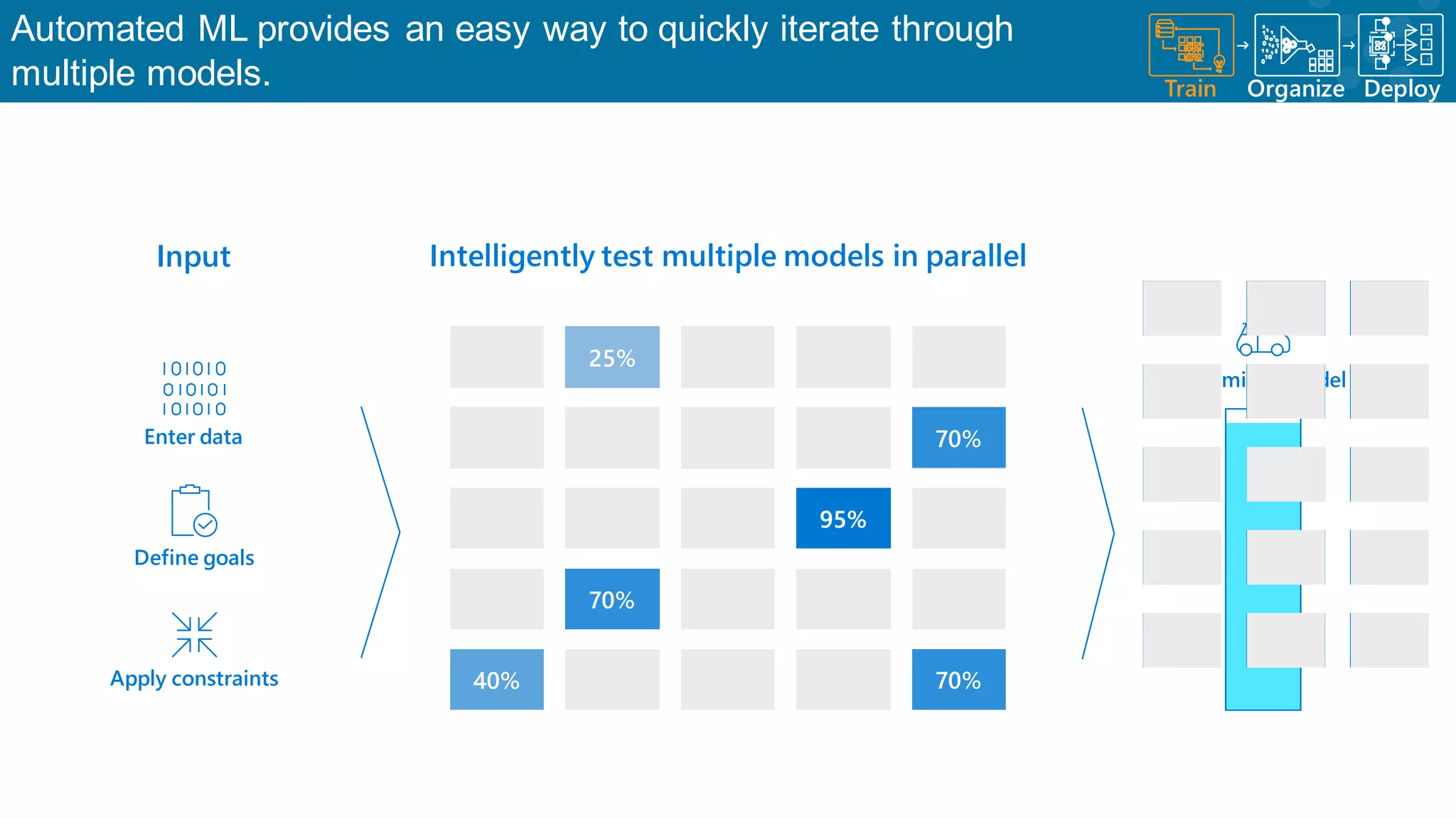
Discussion on automated ML for model iterations and parameter optimizations.
Identifying key parameters that influence the effectiveness of machine learning models.
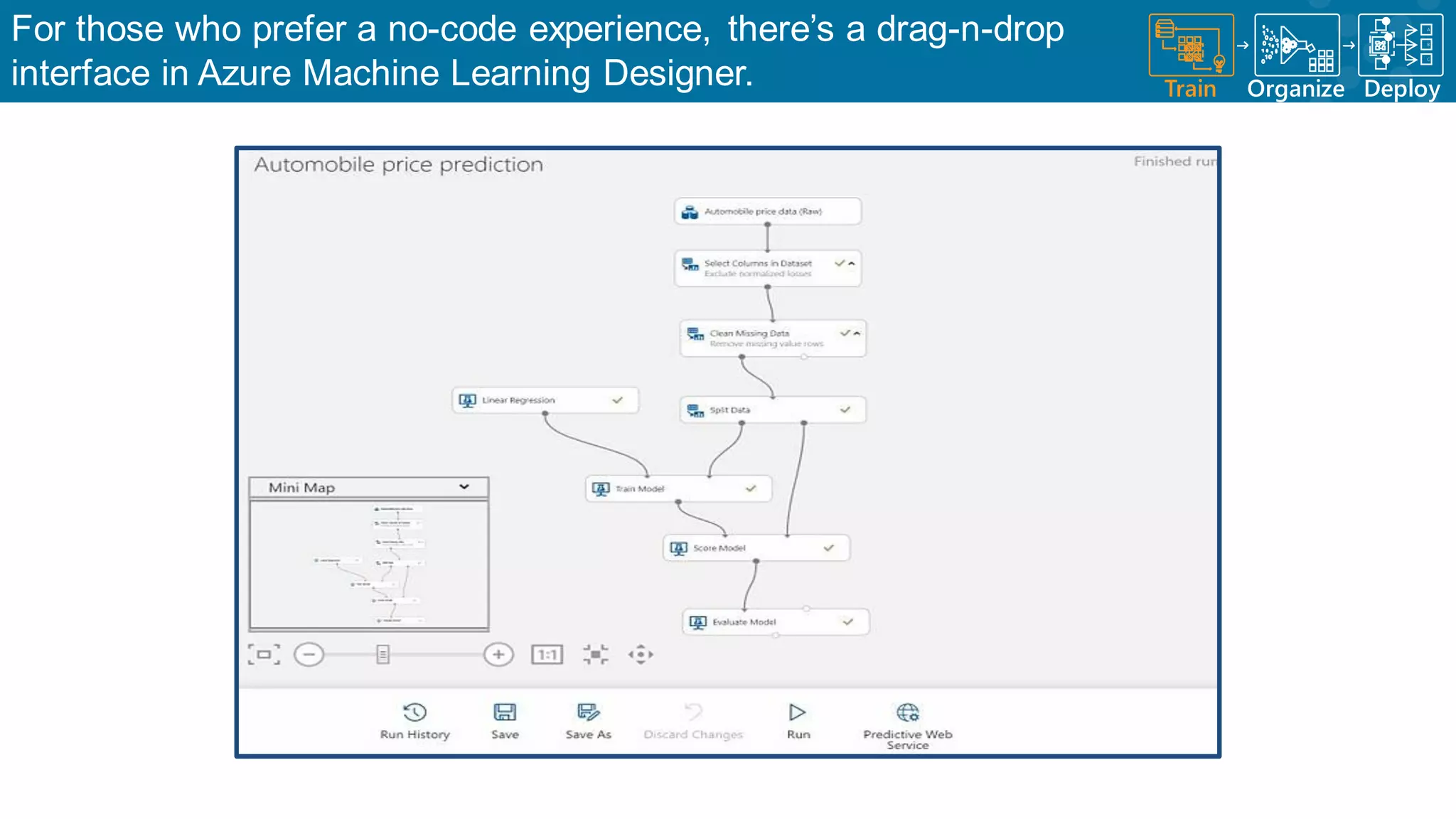
Introduction of no-code tools in Azure ML for ease of use in model creation.
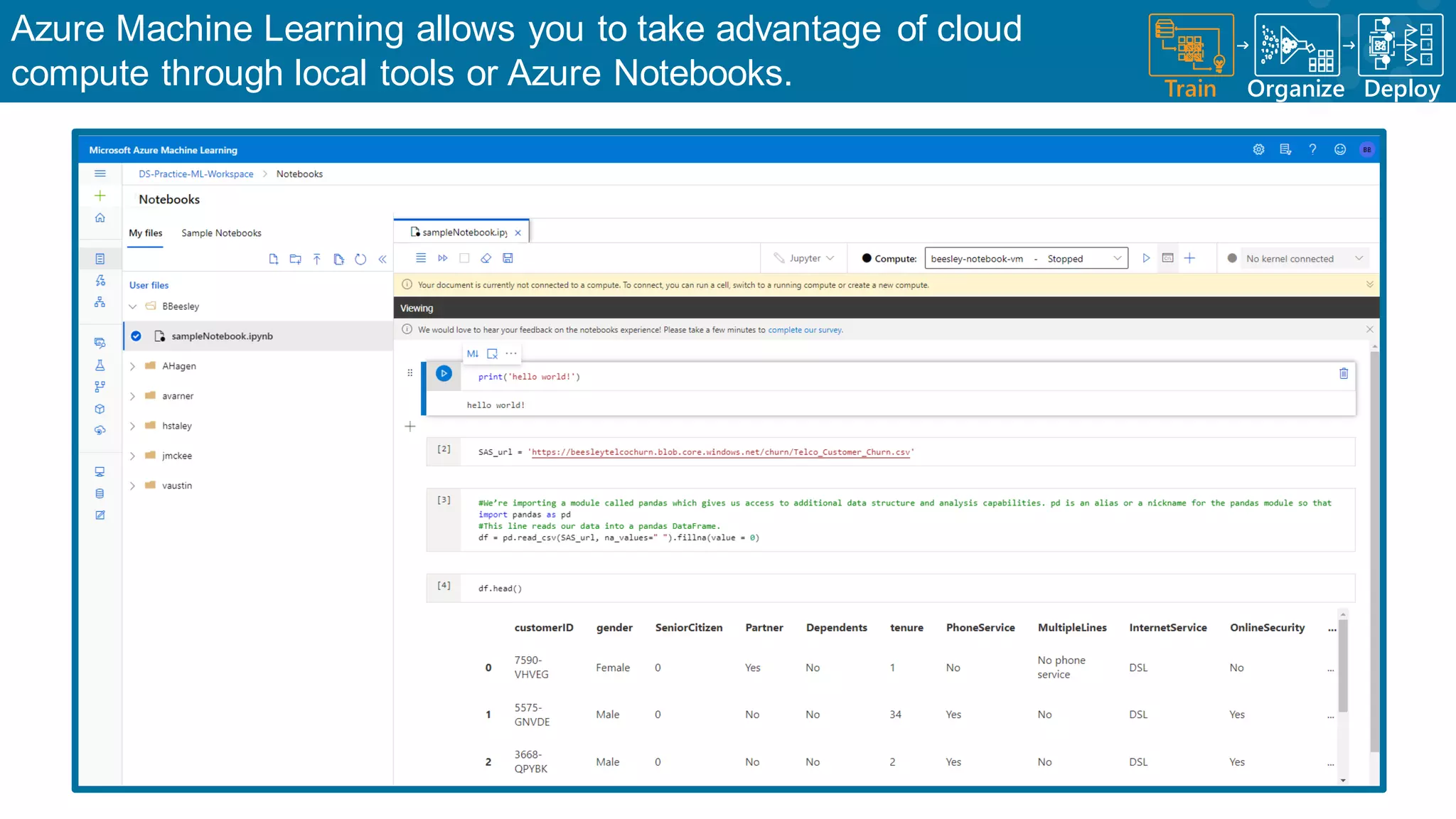
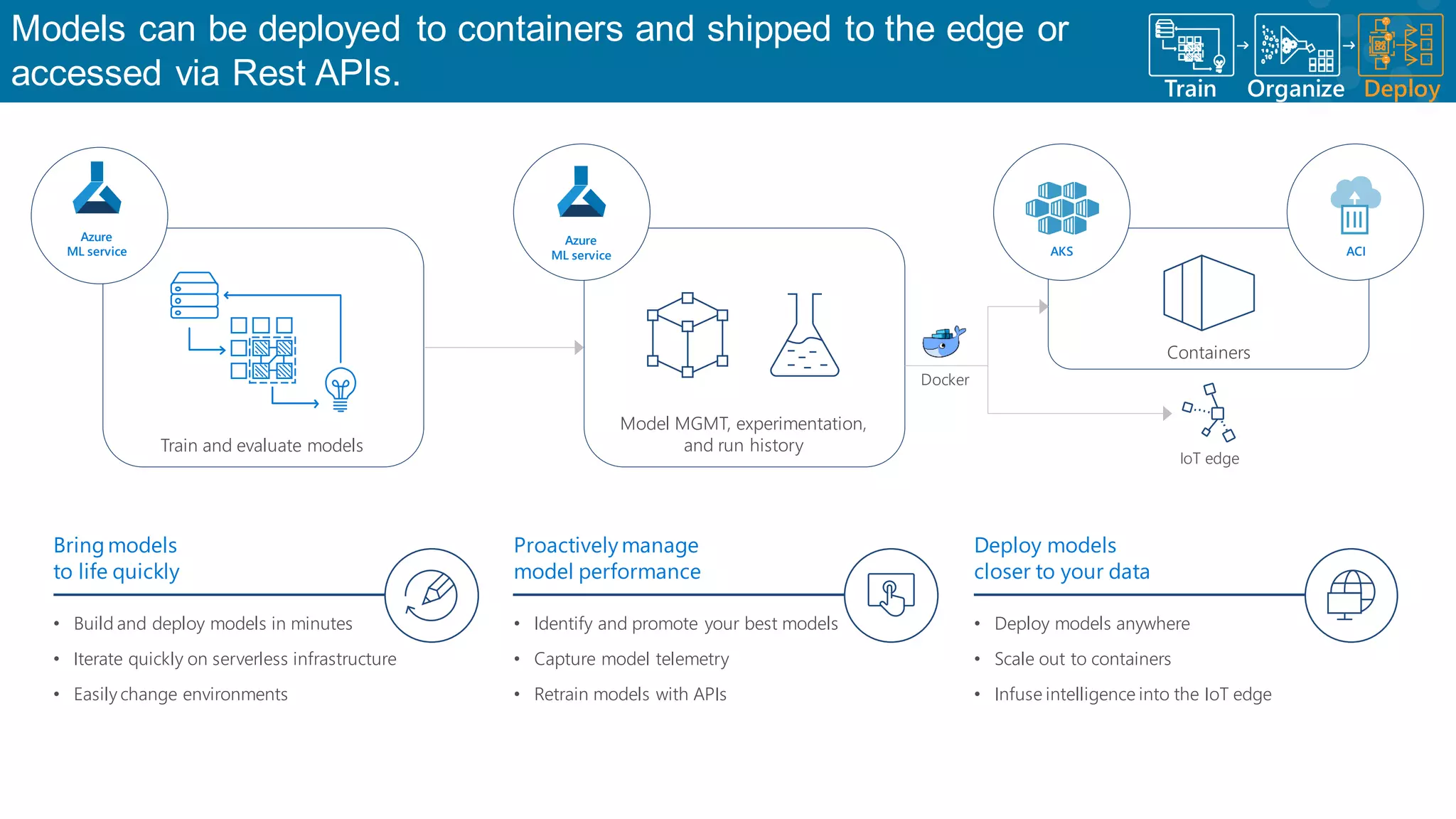
Utilization of Azure tools for ML processes to leverage cloud computing advantages.
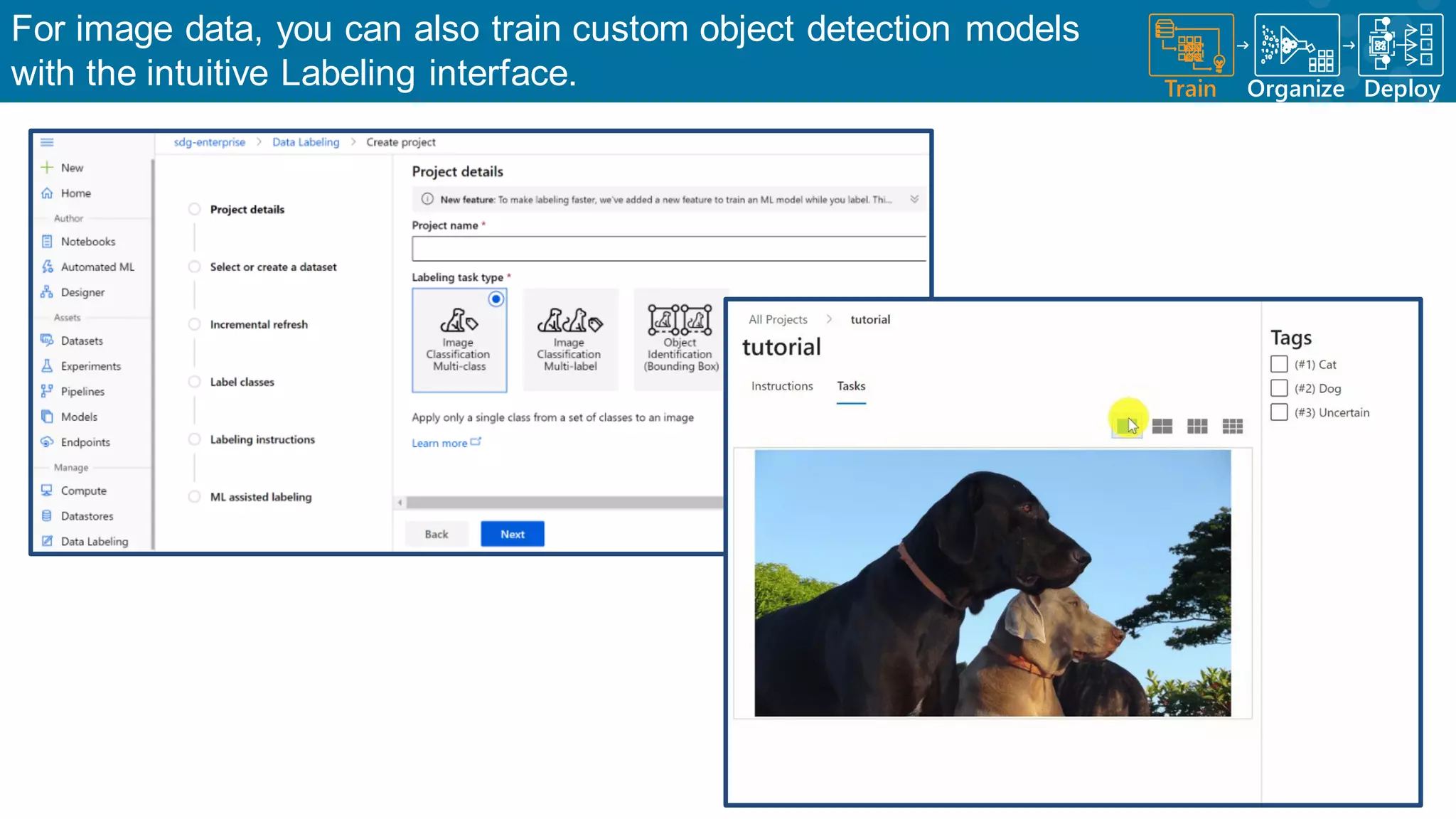
Customized model training for image data through user-friendly interfaces.
Flexibility in managing the machine learning lifecycle through Azure services.
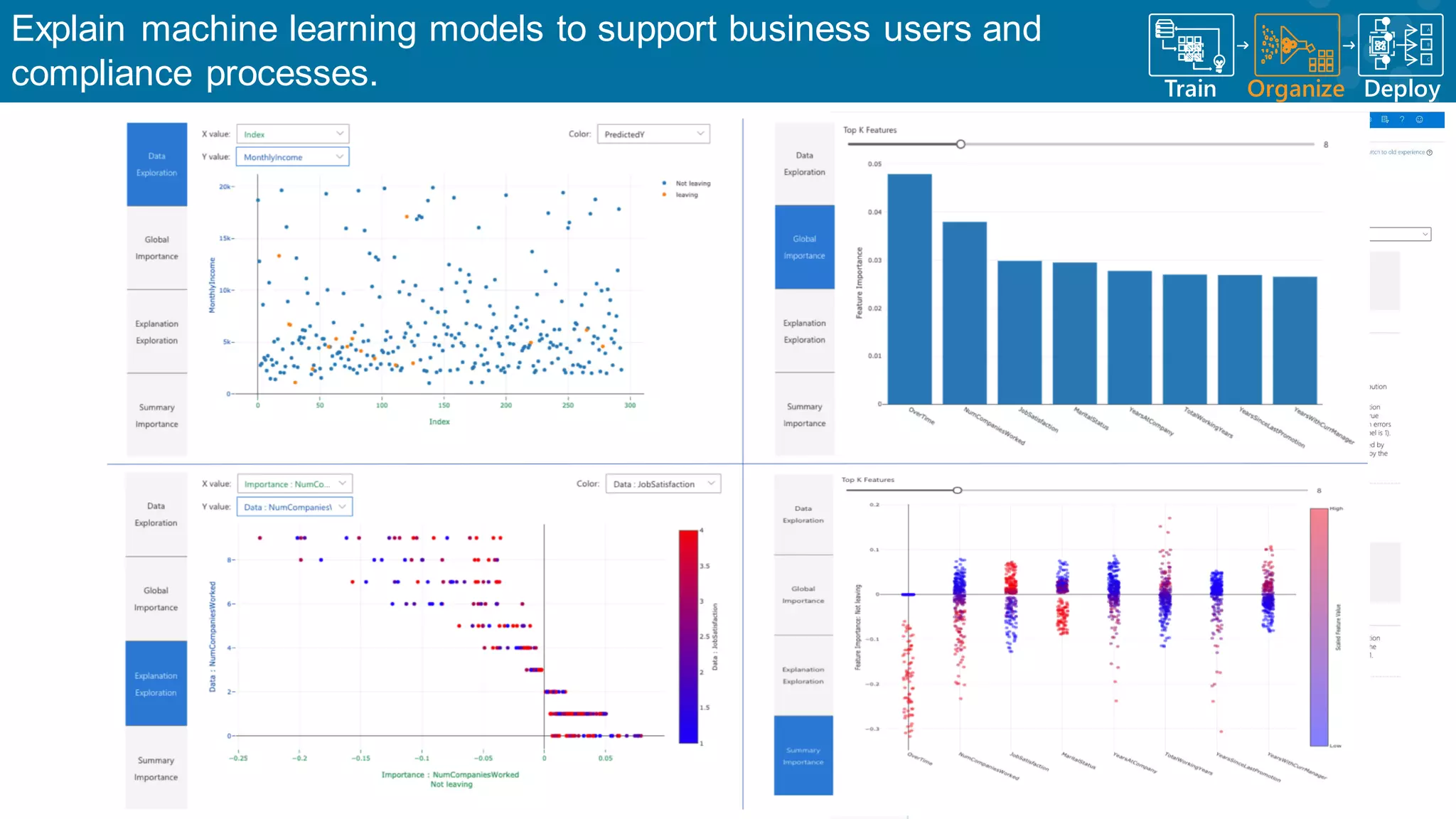
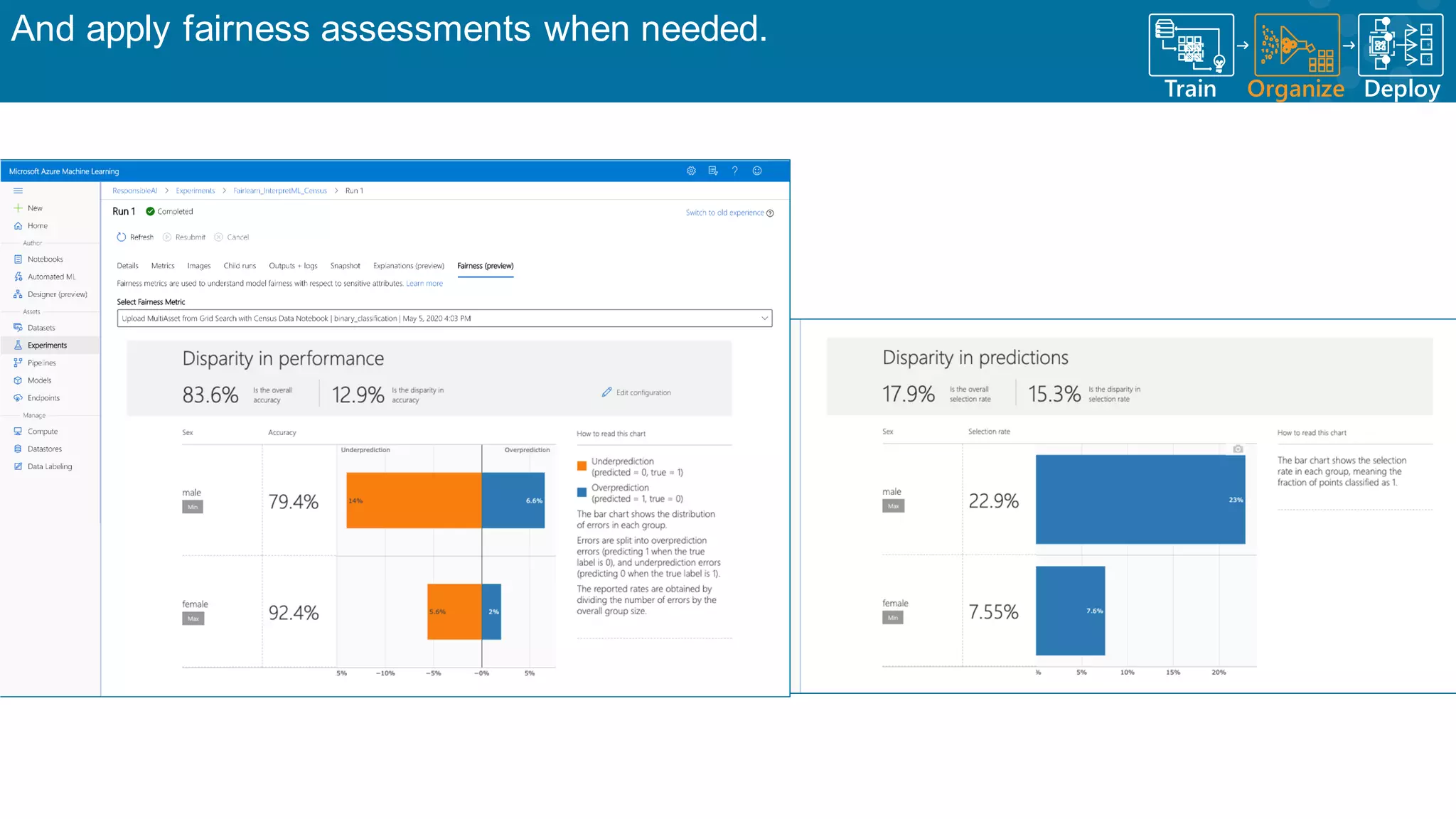
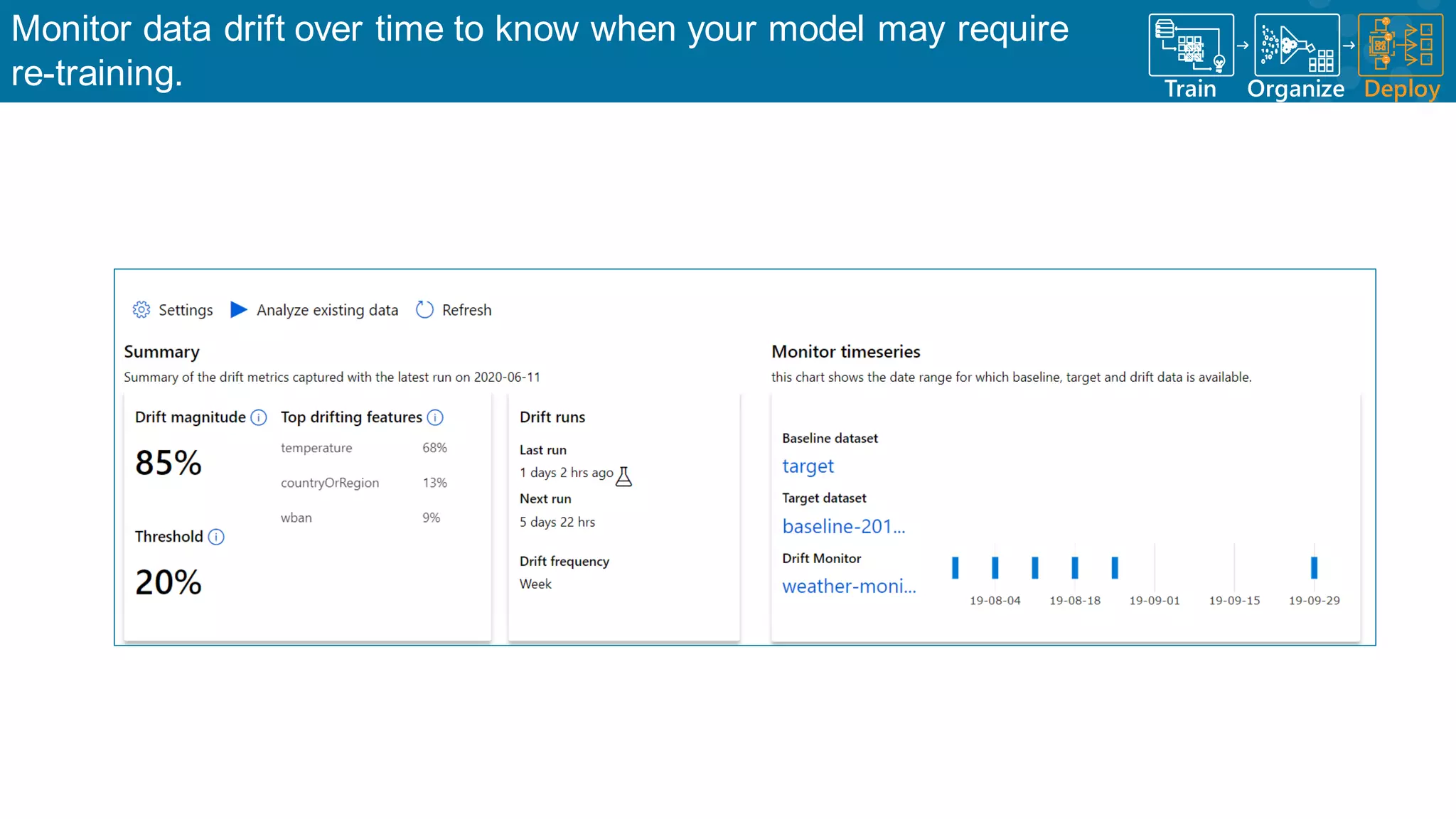
Continuous monitoring of model performance and data drift for timely interventions.
Summary of tools explored for facilitating effective machine learning practices.
Introduction to Databricks as a unified platform enhancing data processing and ML.
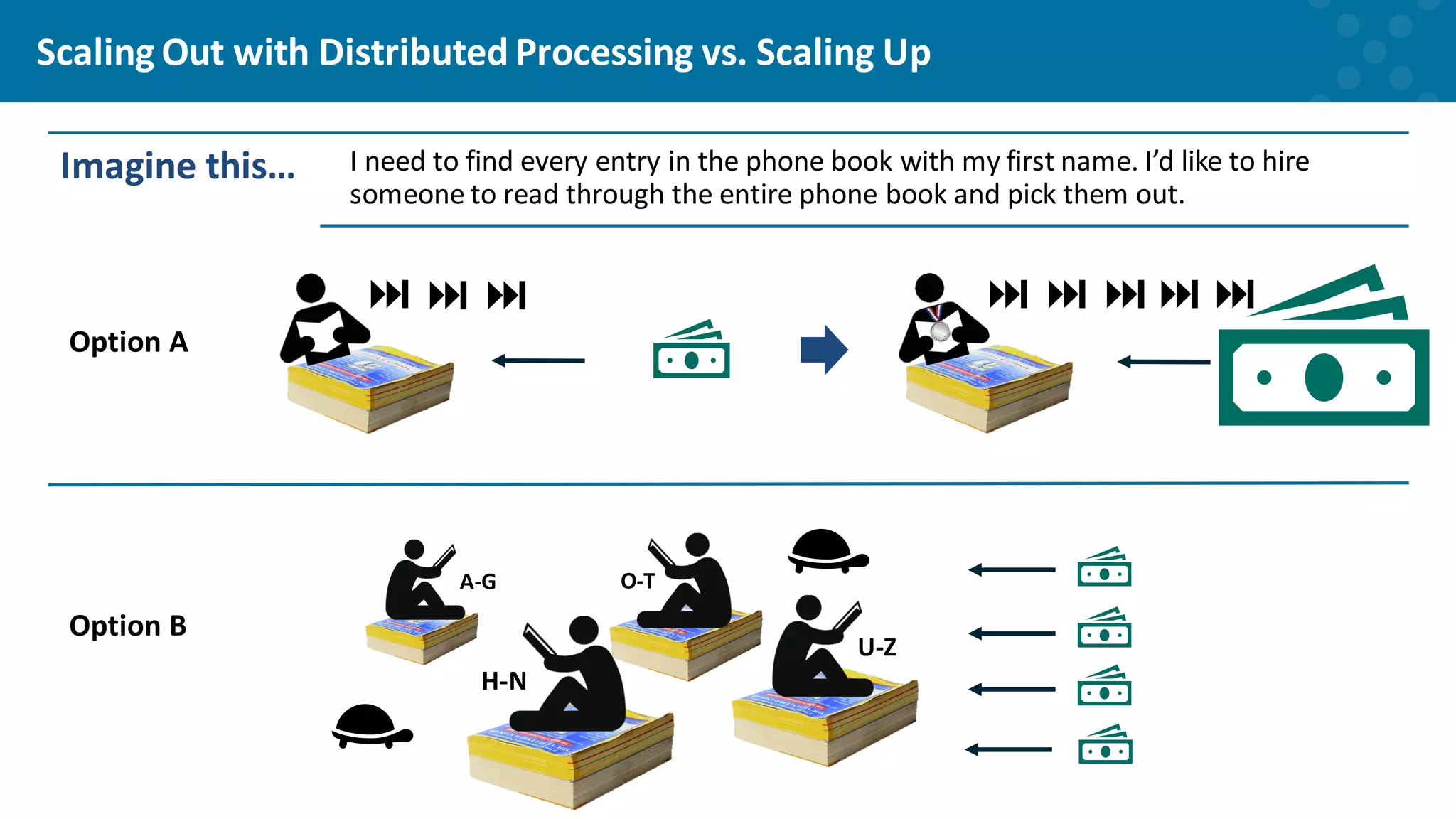
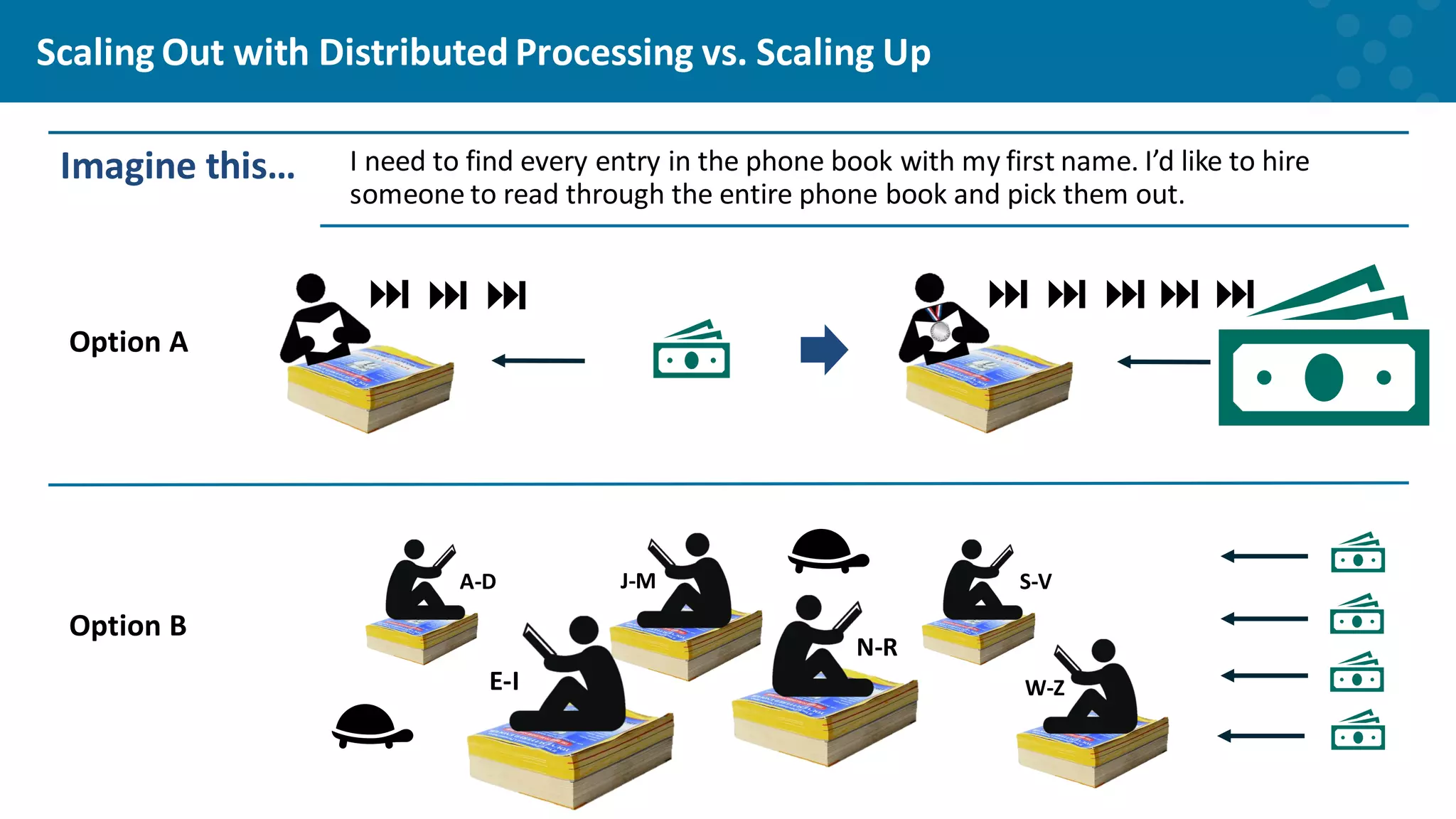
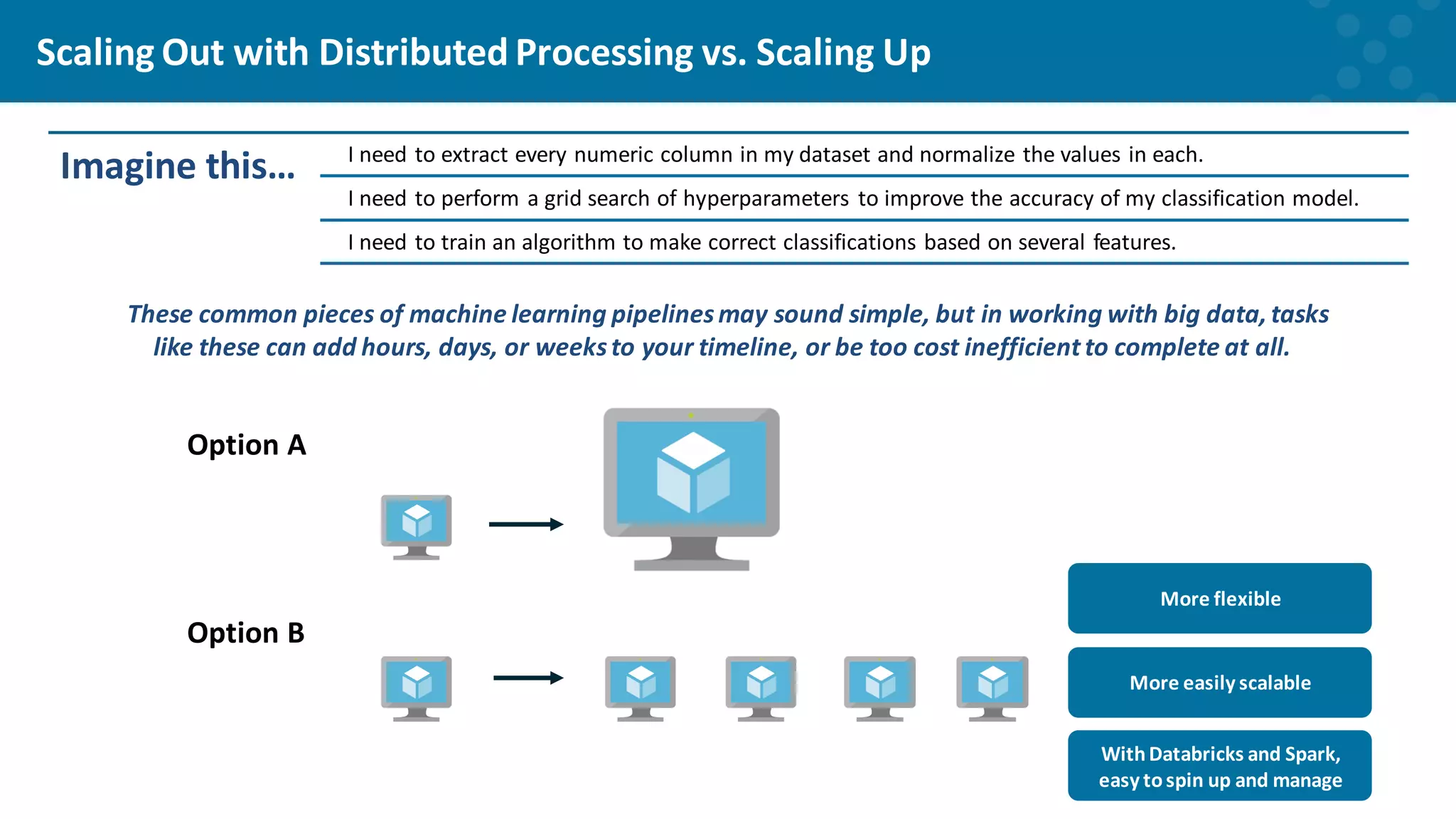
Explaining the efficiency of distributed processing for managing large datasets.
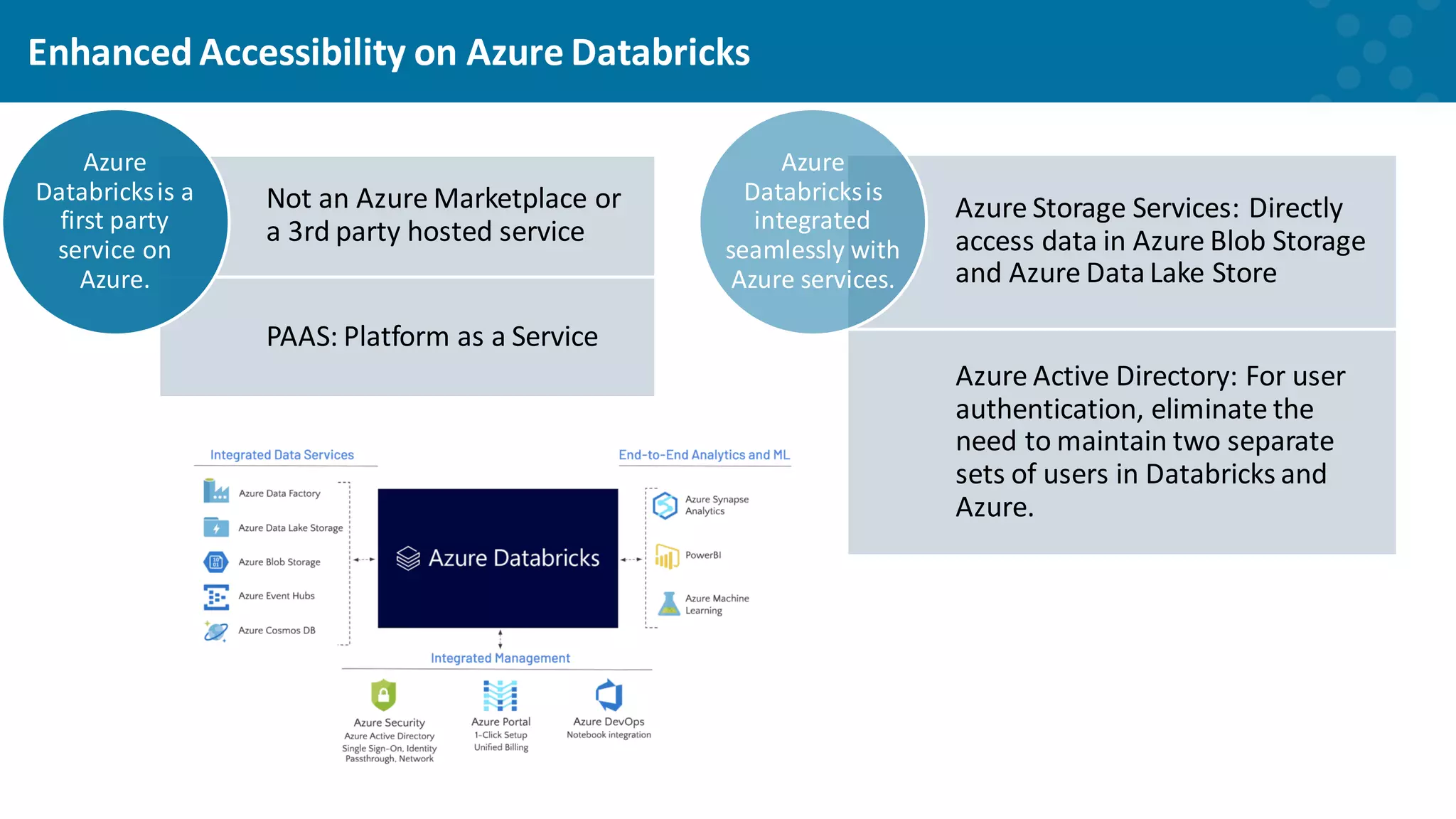
Benefits of using Databricks for improved accessibility and integration with Azure.
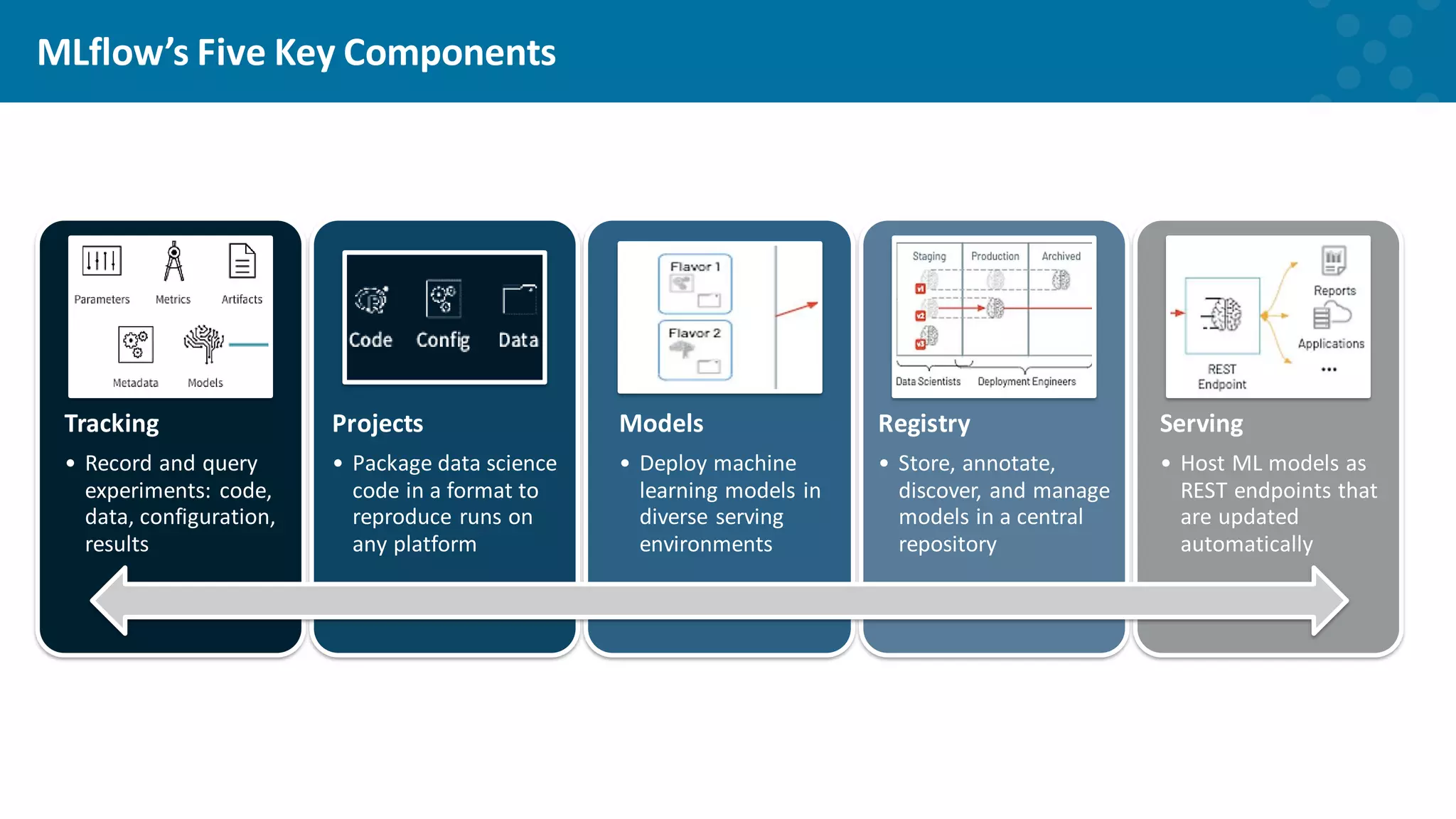
Introduction to MLflow for tracking and managing machine learning projects.
Detailed look at the five key components of the MLflow framework.
Final summary of the workshop topics regarding machine learning and its applications.
Closing remarks with contact details for further inquiries about analytics services.